
Shadow Minimization Boolean Function Reconstruction
Abstract
A special class of monotone Boolean functions coming from shadow minimization theory of finite set-systems – KK-MBF functions – is considered. These functions are a descriptive model for systems of compatible groups of constraints, however, the class of all functions is unambiguously complex and it is sensible to study relatively simple subclasses of functions such as KK-MBF. Zeros of KK-MBF functions correspond to initial segments of lexicographic order on hypercube layers. This property is used to simplify the recognition. Lexicographic order applies priorities over constraints which is applicable property of practices. Query-based algorithms for KK-MBF functions are investigated in terms of their complexities.
1Introduction
Many problems with monotone Boolean functions (MBFs) appear in logical and physical level design of systems (Aslanyan et al., 2019), but also in artificial intelligence (Aslanyan and Sahakyan, 2009), data science and computational learning theory (Aslanyan et al., 2023a), hypergraph theory (Sahakyan, 2023; Sahakyan and Aslanyan, 2017) and other areas (e.g. Carlet et al., 2016; Kulhandjian et al., 2019; Crawford-Kahrl et al., 2022; Kabulov and Berdimurodov, 2021; Zhang et al., 2022). MBFs are used to encode extremely important constructions in various combinatorial optimizations providing a natural way of describing compatible subsets of sets of finite constraints (see e.g. Aslanyan et al., 2023b; Tennakoon et al., 2021; Damásdi et al., 2021).
Let there be n independent constraints in an optimization problem with a target function
A number of applications (e.g. wireless sensor networks, dead-end tests of tables, data mining) (Kovalerchuk and Delizy, 2005; Kulhandjian et al., 2019; Aslanyan and Sahakyan, 2009; Aslanyan et al., 2019) use optimization with MBF, where MBFs are represented by hypercube constructions such as chains and anti-chains (Freixas, 2022; Griggs et al., 2023). Other similar applications with MBF can be added to this list (Clements, 1973; Tennakoon et al., 2021; Damásdi et al., 2021; Carlet et al., 2016).
There is a number of known effective tools and methods for analysing MBFs (Korobkov, 1965; Hansel, 1966; Tonoyan, 1979; Gainanov, 1984) and new approaches are constantly being sought, investigated, and applied (e.g. Carlet et al., 2016; Boros and Hammer, 2002; Lange and Vasilyan, 2023; Sahakyan et al., 2022; Balogh et al., 2021; Bezrukov et al., 2023). Open problems in this area include the reconstruction problem of bounded classes of Boolean functions with randomization of queries and functions, and the use of cube-splitting and chain-splitting technique of the Boolean domain (Blum, 2003; Jackson et al., 2011; O’Donnell and Servedio, 2005; Aslanyan and Sahakyan, 2017; Black et al., 2023; Boros et al., 1991).
A well-known approach concerning MBFs recognition is query-based identification – recognition of an unknown MBF of n variables using an oracle and membership queries to it. Hansel’s algorithm (Hansel, 1966), based on partitioning the binary cube into a special set of non-intersecting chains, provides optimal reconstruction in the sense of Shannon complexity for the whole class of MBFs. In practical algorithmic implementations, it is even not necessary to build and store all Hansel chains in computer memory (Tonoyan, 1979), which solves the memory limitation problem in applications. But the computational complexity remains.
In order to obtain solutions for bounded classes of MBFs, it is necessary to find a way to the structural properties of these classes (Braverman et al., 2022; Chao and Yu, 2023; Lovász, 2007). The research objective of this paper is related to the well-known Kruskal-Katona theorem (Kruskal, 1963; Katona, 1968, 1987; Sales and Schülke, 2022; Frankl and Katona, 2021), and the class of
In this research, we investigate the
The rest of the paper is organized as follows. Section 2 provides necessary definitions, preliminaries, and basic concepts. The
2Preliminaries
2.1Monotone Boolean Function Recognition
Let
The serial number of the vertex
We will also use the lexicographic order of vertices: α precedes β lexicographically (
In literature there are different, sometimes confusing definitions of lexicographic order (Schröder, 2016). Mathematical definition is set-theoretical that uses the value 1 to code the presence of an element in a subset:
Lexicographic, co-lexicographic and simplicial orders are shown in Fig. 1 on the set of vertices of
Fig. 1
Lexicographic, co-lexicographic and simplicial orders of vertices of
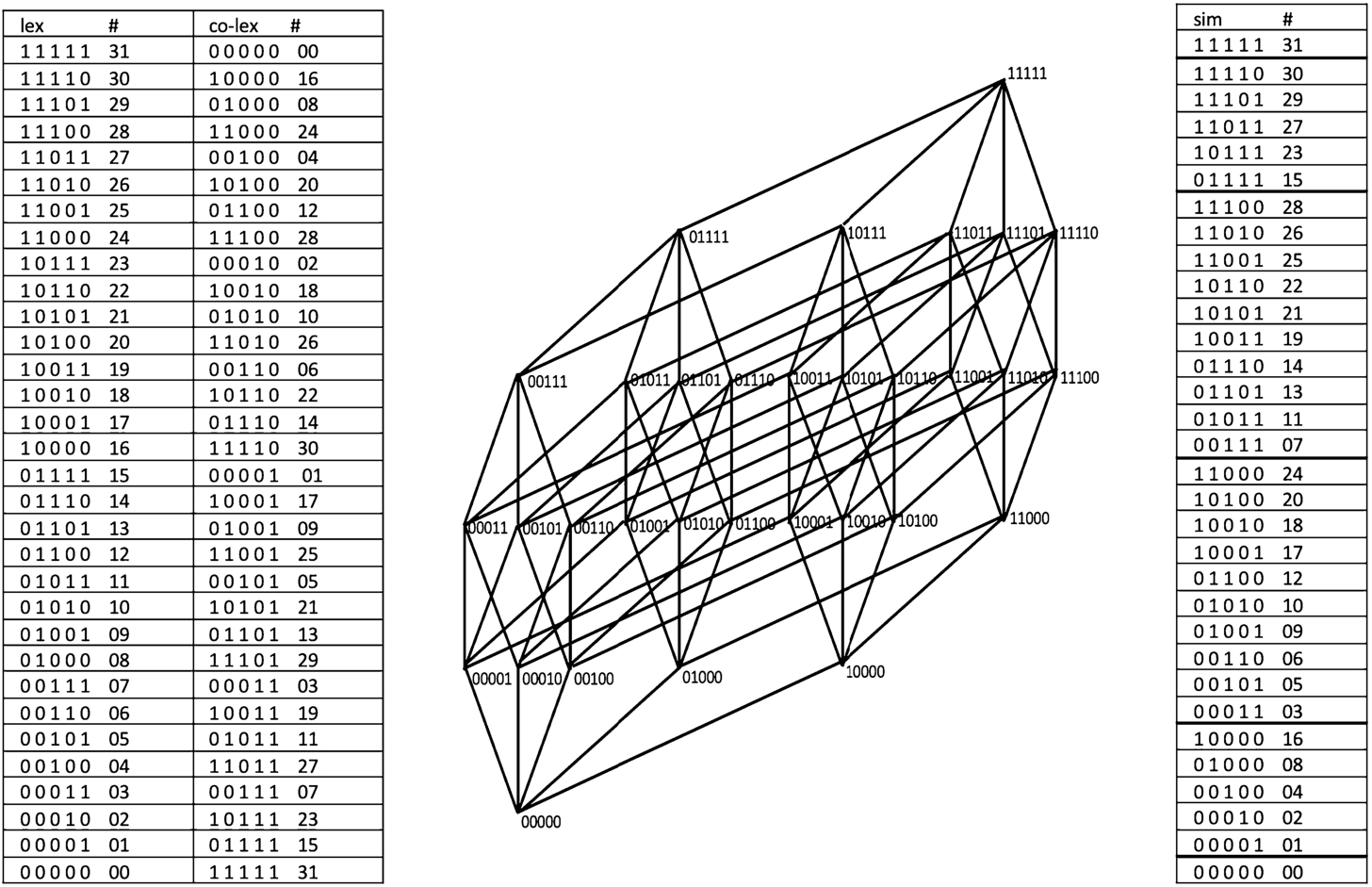
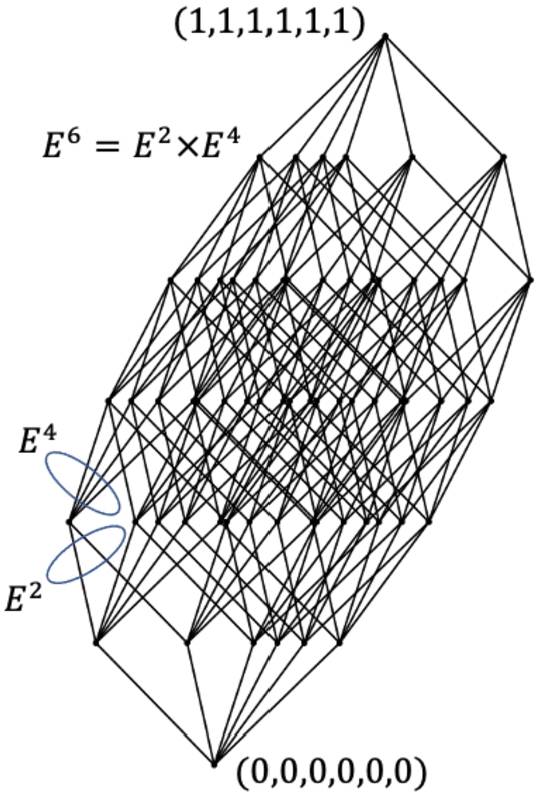
We define also partition/splitting of
Figure 2 illustrates the split of the
Fig. 2
Split of the
Let
The shadow
In case all the vertices of
Boolean function
Formally, the work with MBFs started in 1897, with the issue of counting their number (Dedekind, 1895). The first algorithmic and complexity-related considerations belong to Korobkov (1965), where, in particular, the valuable concept of resolving subsets was introduced. The final asymptotic estimate about the number of MBFs of n variables was obtained in Korshunov (1981, 2003). The technique on how to introduce and analyse MBFs, is basically presented in Hansel (1966), Korshunov (2003), Lovász (2007).
The Hansel chain structure (Hansel, 1966) was invented in 1966 and played one of the central roles in MBF-related algorithmic techniques.
The next valuable step towards this was taken by Tonoyan (1979), who introduced a set of simple procedures (chain algebra) that serve all the actual queries about Hansel chains, providing a technical solution to all the problems related to algorithms with Hansel chains, without constructing and keeping them in computer memory. A slightly modified and simplified version of Sokolov (1987) is presented using tools such as: enumeration of all chains, and a procedure of finding the i-th vertex of the j-th chain.
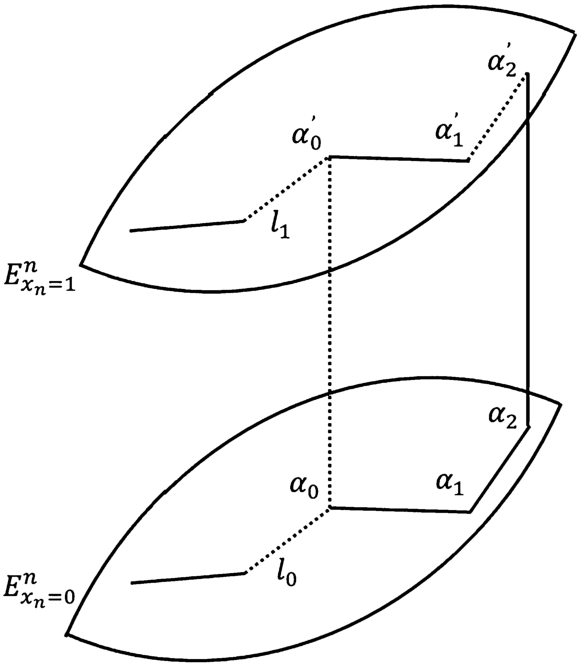
A recurrent step of constructing Hansel chains in
We aim at extending this picture of chain-split to the lexicographic order of vertices in
Fig. 3
Recurrent step of constructing Hansel chains in
In the MBF recognition problem using membership queries, the overall goal is to determine an unknown MBF of n variables using as few oracle queries (or tests) as possible. The function can be fully recognized by finding all its upper zeros (and/or lower units) (Korobkov, 1965). The Shannon complexity of finding all upper zeros (lower units) of an arbitrary monotone Boolean function of n variables is
Another recognition structure is used in Sokolov (1987) and in its extensions. For even n,
2.2Constraint Monotone Boolean Function Recognition
In general, tasks related to the recognition of MBFs may have different formulations. One objective is to recognize a particular unknown function, knowing that it belongs to the class of MBFs or to one of its subclasses. Another goal is to start with partial knowledge about the unknown function, trying to complete the information. One more case is when the number of queries is restricted by some number k and the goal is to maximize the recognized part of the function (Sahakyan et al., 2022). Similar problems can be formulated for specific classes of Boolean functions. Examples of classes are as follows:
KK-MBF Kruskal-Katona MBFs arise as a result of the shadow minimization theorem (Kruskal, 1963; Katona, 1968, 1987).
Symmetric MBF This is a trivial class of functions that takes a constant value on the cube layers. Trivial, but these functions are practically important. Examples are majority functions, parity functions, and others (Nosov, 2023).
Threshold MBF Functions are defined by a linear inequality of weighted sums of variables.
Matroid MBF Monotone Boolean function f is called a matroid function if for each
The combinatorial complexity of reconstruction in these and other subclasses of MBFs is not well studied. For example, monotone Boolean functions, with zeros and units separated by two middle layers of the cube, are the most difficult functions for query-based reconstruction when only the monotonicity of the function is given. But if it is known that the function belongs to the class of symmetric functions, the reconstruction of this function can be done by n queries. The same function also belongs to the
3KK-MBF Recognition
In this section, we consider a special class of monotone Boolean functions, related to the well-known Kruskal-Katona theorem, which describes the exact optimal monotone constructions of shadow minimization (constraint minimization) problem, and the existence problem of Sperner systems for a given set of parameters. Although the reconstruction problem for general MBFs is intractable, the problem itself is extremely important in system design and implementation. The reconstruction problem for such subsets of MBFs is insufficiently investigated, and in this paper, for the first time in our knowledge, the problem of recognition of functions of class
3.1Introduction to KK-MBF Type Functions
Definition 1.
Let f be a monotone Boolean function on
The initial formulations of the shadow theorem in Kruskal (1963), Katona (1968, 1987) are given in terms of co-lexicographic order, but this framework was later simplified to the simple lexicographic ordering (Aslanyan, 1979). The basic result was obtained for two neighbour layers of the cube. The name
Fig. 4
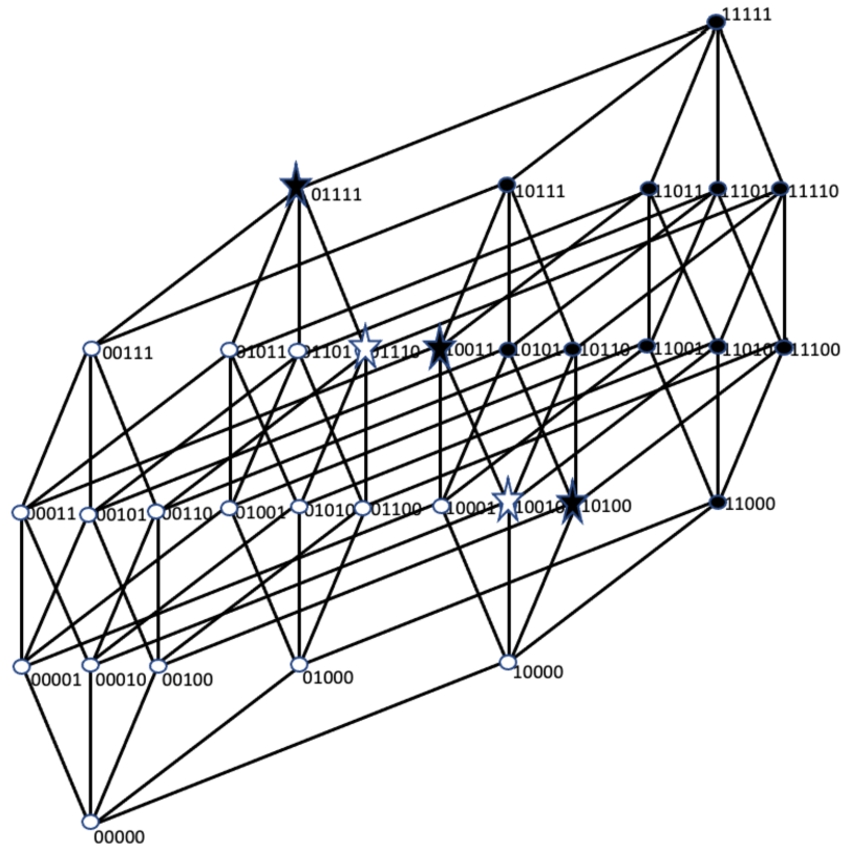
3.2Resolving Sets for KK-MBF
First, let us introduce some general concepts from the field of reconstruction of Boolean functions (Korobkov, 1965). Suppose we are given a certain class
Definition 2.
A set of vertices
a) a function g belongs to
b)
It follows from the definition that to reconstruct a function it is sufficient to determine its values on some of its resolving sets.
A resolving set
When
It should be noted that this is not true for other Boolean functions and classes, for example, for the class of symmetric Boolean functions there are no unique deadlock resolving sets.
In this section, we investigate the existence of a deadlock resolving set for
We formulate two simple properties for
Cond-h:
(1) if
(2) if
(1) if
(2) if
These conditions, applied recursively, define a domain for each vertex
Proposition 1.
For
• vertices of
• vertices of
Proof.
• Suppose that
1)
2)
• Consideration of the case
Note that not all vertices of
We also define the notion of corner points for
Definition 3.
A zero vertex α of a function f is called a zero-corner point if:
(1)
(2)
(1)
(2)
Let
Summarizing all the above reasoning, we formulate the following statement.
Proposition 2.
Every monotone Boolean function f of class
Proof.
First note that any zero-corner point α, as a point of
For a general MBF, it is well-known that
Proposition 3.
For monotone Boolean functions f of class
Proof.
According to the condition Cond-h, on each layer of
It is still a question if the value
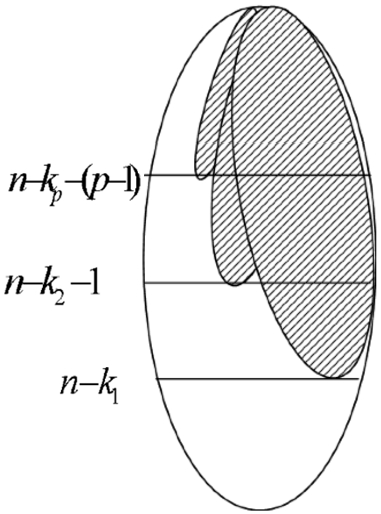
Concerning the issue about the size of deadlock resolving sets we may refer to the Theorem 1 of Daykin et al. (1974) and to Clements (1973). Here, parametrized subsets of MBF are considered. Let us suppose that there are given numbers
Similar theorems could be formulated for
On the other hand, let us consider a series of
Define corner points on layers as follows:
On the 1st layer we take two corner points: 1-corner point is the vertex
On the 2nd layer we construct two corner points as follows: 1-corner point is
This process is continued until one of the constructed subcubes becomes small and we reach a corner point defined by a 0-size subcube, i.e. a vertex.
Let us explain again the construction. Vertex
Starting from the first layer, we reach the last possible corner point on the:
In both cases, we get
3.3Identification of KK-MBF Type Functions: Main Procedures
Hansel chain based MBF recognition methods are global tools and can be applied to recognize any class of monotone Boolean functions, including
A useful step and exercise in recognitions is to determine the first and last nontrivial layers (trivial layers are those with all-zeros or with all units of the function). This can be done considering the following two chains of length n:
On the other hand, if the vertices on each layer of
In this manner, a
Proposition 4.
Time complexity of reconstruction of monotone Boolean functions of class
For
To find a way to reduce the memory complexity we continue to address algorithmic questions on layers from an additional perspective. In order to apply bisections on layers, we need to keep all
One way to avoid this situation is using sub-cube structures on layers when partitioning the cube. This is easily applicable to find the 0–1 border on layers, although it will require more than logarithmic queries on layers.
We will use
Let
Instead of taking the arithmetical middle vertex of
If
In general, in
In this way, after each query, we continue in a smaller sub-cube, and hence, the number of queries in each layer can be at most
Proposition 5.
Reconstruction of monotone Boolean functions of class
As an example, consider the function given in Fig. 4, and suppose that
This way, we found the corner points
So far, when recognizing
Suppose that
For the given example in Fig. 4,
But to calculate the length of the interval
Here as well, one can use sub-cube structures, but the benefit is only in the case when
We conclude the section with the following general note. It addresses an alternative partial order of vertices to the traditional monotony based order, where
4Cardinality of KK-MBF Class
Another important issue is the size of the whole class of
In general,
Note that among
Thus, constraints on
Let C denote a particular subclass of
To construct this subclass we take an arbitrary point
5Special Cases
In this section, we address another particular subclass of
Let
Fig. 5
Structure of
Let
It is known (Sahakyan, 2013, 2015) that
Numbers of lower units of
Equivalently,
Consider again the binary representation of t:
Suppose that the first positive summand is
By constructing the same function in this manner, we know the numbers of lower units in layers, depending on t.
Thus, for a given t, we constructed a
On the other hand, if given characteristics
In general, it is possible to impose restrictions on the numbers/layers of the lower units of
6Concluding Remarks
Boolean functions are not only a means of computing functional dependencies, but also represent a suitable mathematical apparatus for modelling data science systems. The limitations of models and the structure of their joint collections are reduced to considering Boolean functions that have the property of monotonicity. However, decoding monotone Boolean functions is a multifaceted problem, and there remain many unsolved or inefficiently solved problems in this context. Combinatorial constructions have been considered in some detail, but they are complex and often reduced to enumeration (brute-force). A possible new approach is to bring in a new resource, namely that of artificial intelligence (Valiant, 1984; Sahakyan et al., 2022; Zhuravlev et al., 2019, 2020). In this formulation, the emphasis is placed on solving a large number of problems of the class under consideration, accumulating the results of solutions in the form of a database, training on them, and not solving but recognizing the solution of the problem under consideration by analysing the parameters of the problem and the database information. The problem in this formulation is already becoming popular, and our first results related to it refer to decoding arbitrary monotone Boolean functions and are presented in Sahakyan et al. (2022).
Another possible approach continues the first one and seeks ways of refining, and reconstructing the problem constraints, with subtypes of monotone Boolean functions appearing, the decoding of which requires refined approaches, and the associated algorithms, whether combinatorial or based on machine learning, that can be practically implemented. There is a list of practical problems in big data analytics that reduce to the diverse classes of monotone Boolean functions. We begin the study of one of the classes of such functions – shadow minimized Boolean functions, for subsets of finite sets. We proceeded from the well-known solution of the problem for layers, formulated in the form of the Kruskal-Katona theorem, and on the extension of this fact to all layers of the cube, when the existence conditions for Sperner systems are obtained. We were able to show that the class of these functions has the structure of a generating set, which is not a necessary property of arbitrary classes of functions. Basic structures of data analysis of the problem of identification of these functions, details of memory organization in the optimal mode are also given, but we consider the beginning of these investigations as the main step, and we think that subsequent investigations will give acceptable complexity results for solving these problems, both in this and in other systems of functions with constraints.
Acknowledgements
The work is partially supported by grant No. 21T-1B314 of the Science Committee of MESCS RA.
References
1 | Aslanyan, L.H. ((1979) ). The discrete isoperimetry problem and related extremal problems for discrete spaces. Problemy Kibernetiki, 36: , 85–128. |
2 | Aslanyan, L., Sahakyan, H. ((2009) ). Chain split and computations in practical rule mining. In: Intenational Book Series Information Science and Computing, Book 8, Classification, Forecasting, Data Mining. Institute of Information Theories and Applications, FOI ITHEA, Bulgaria, pp. 132–135. |
3 | Aslanyan, L., Sahakyan, H. ((2017) ). The splitting technique in monotone recognition. Discrete Applied Mathematics, 216: , 502–512. |
4 | Aslanyan, L., Sahakyan, H., Romanov, V., Da Costa, G., Kacimi, R. ((2019) ). Large network target coverage protocols. In: 2019 Computer Science and Information Technologies (CSIT), Yerevan, Armenia, 2019, pp. 57–64. https://doi.org/10.1109/CSITechnol.2019.8895058. |
5 | Aslanyan, L., Gishyan, K., Sahakyan, H. ((2023) a). Target class classification recursion preliminaries. Baltic Journal of Modern Computing, 11: (3), 398–410. |
6 | Aslanyan, L., Katona, G., Sahakyan, H. ((2023) b). Notes on reconstruction of shadow minimization Boolean functions. In: 2023 Computer Science and Information Technologies (CSIT), Yerevan, Armenia, 2023, September 25–30, pp. 119–123. |
7 | Balogh, J., Katona, G.O., Linz, W., Tuza, Z. ((2021) ). The domination number of the graph defined by two levels of the n-cube, II. European Journal of Combinatorics, 91: , 103201. |
8 | Bezrukov, S., Kuzmanovski, N., Lim, J. ((2023) ). Pull-push method: a new approach to edge-isoperimetric problems. Discrete Mathematics, 346: (12), 113632. |
9 | BFA (2023). Ninth Dedekind number discovered: scientists solve long-known problem in mathematics. In: The 8th International Workshop on Boolean Functions and their Applications (BFA), in memory of Kai-Uwe Schmidt, September 3–8, 2023, Voss, Norway. |
10 | Black, H., Chakrabarty, D., Seshadhri, C. (2023). Directed isoperimetric theorems for Boolean functions on the hypergrid and an |
11 | Blum, A. ((2003) ). Learning a function of r relevant variables. In: Learning Theory and Kernel Machines, 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT, Kernel 2003, Washington, DC, USA, August 24–27, 2003. Springer, Berlin, Heidelberg, pp. 731–733. |
12 | Boros, E., Hammer, P. ((2002) ). Pseudo-Boolean optimization. Discrete Applied Mathematics, 123: (1–3), 155–225. |
13 | Boros, E., Hammer, P., Ibaraki, T., Kawakami, K. ((1991) ). Identifying 2-monotonic positive Boolean functions in polynomial time. In: ISA’91 Algorithms: 2nd International Symposium on Algorithms Taipei, Republic of China, December 16–18, 1991. Springer, Berlin, Heidelberg, pp. 104–115. |
14 | Braverman, M., Khot, S., Kindler, G., Minzer, D. (2022). Improved monotonicity testers via hypercube embeddings. Preprint: arXiv:2211.09229v1. |
15 | Carlet, C., Joyner, D., Stănică, P., Tang, D. ((2016) ). Cryptographic properties of monotone Boolean functions. Journal of Mathematical Cryptology, 10: (1), 1–14. |
16 | Chao, T.-W., Yu, H.-H.H. (2023). Kruskal–Katona-type problems via entropy method. Preprint: arXiv:2307.15379. |
17 | Clements, G.F. ((1973) ). A minimization problem concerning subsets of a finite set. Discrete Mathematics, 4: (2), 123–128. |
18 | Crawford-Kahrl, P., Cummins, B., Gedeon, T. ((2022) ). Joint realizability of monotone Boolean functions. Theoretical Computer Science, 922: , 447–474. |
19 | Damásdi, G., Gerbner, D., Katona, G.O., Keszegh, B., Lenger, D., Methuku, A., Nagy, D.T., Pálvölgyi, D., Patkós, B., Vizer, M., Wiener, G., ((2021) ). Adaptive majority problems for restricted query graphs and for weighted sets. Discrete Applied Mathematics, 288: , 235–245. |
20 | Daykin, D.E., Godfrey, J., Hilton, A.J.W. ((1974) ). Existence theorems for Sperner families. Journal of Combinatorial Theory, Series A, 17: (2), 245–251. |
21 | Dedekind, R. (1895). Uber die Begründung der Idealtheorie. Gött. Nachr, 106–113. |
22 | Frankl, P., Katona, G.O. ((2021) ). On strengthenings of the intersecting shadow theorem. Journal of Combinatorial Theory, Series A, 184: , 105510. |
23 | Freixas, J. (2022). On the enumeration of some inequivalent monotone Boolean functions. Optimization, https://doi.org/10.1080/02331934.2022.2154126. |
24 | Gainanov, D.N. ((1984) ). On one criterion of the optimality of an algorithm for evaluating monotonic Boolean functions. Zhurnal Vychislitel’noi Matematiki i Matematicheskoi Fiziki, 24: (8), 1250–1257. |
25 | Griggs, J.R., Kalinowski, T., Leck, U., Roberts, I.T., Schmitz, M. ((2023) ). The saturation spectrum for antichains of subsets. Order, 40: , 537–574. https://doi.org/10.1007/s11083-022-09622-6. |
26 | Hansel, G. ((1966) ). Sur le nombre des fonctions Booléennes monotones de n variables. Comptes Rendus de l’Académie des Sciences, 262: (20), 1088–1090. |
27 | Jackson, J.C., Lee, H.K., Servedio, R.A., Wan, A. ((2011) ). Learning random monotone DNF. Discrete Applied Mathematics, 159: (5), 259–271. |
28 | Jung, A. ((2023) ). Shadow ratio of hypergraphs with bounded degree. Graphs and Combinatorics, 39: (3), 40. |
29 | Kabulov, A., Berdimurodov, M. ((2021) ). Parametric algorithm for searching the minimum lower unity of monotone Boolean functions in the process synthesis of control automates. In: 2021 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 2021, pp. 1–4. https://doi.org/10.1109/ICISCT52966.2021.9670370. |
30 | Katona, G. ((1968) ). A theorem of finite sets. In: Theory of Graphs (Proceedings of the Colloquim held at Tihany). Academic Press, New York. |
31 | Katona, G. (1987). A theorem of finite sets. In: Classic Papers in Combinatorics, pp. 381–401. |
32 | Korobkov, V.K. ((1965) ). On monotone functions of the algebra of logic. Problemy Kibernetiki, 13: , 5–28. |
33 | Korshunov, A.D. ((1981) ). On the number of monotone Boolean menge. Problemy Kibernetiki, 38: , 5–109. |
34 | Korshunov, A.D. ((2003) ). Monotone Boolean functions. Russian Mathematical Surveys, 58: (5), 929. |
35 | Kovalerchuk, B., Delizy, F. ((2005) ). Visual data mining using monotone Boolean functions. In: Visual and Spatial Analysis: Advances in Data Mining, Reasoning, and Problem Solving. Springer, Dordrecht, pp. 387–406. |
36 | Kruskal, J.B. ((1963) ). The number of simplices in a complex. Mathematical Optimization Techniques, 10: , 251–278. |
37 | Kulhandjian, M., Aslanyan, L., Sahakyan, H., Kulhandjian, H., D’Amours, C. ((2019) ). Multidisciplinary discussion on 5G from the viewpoint of algebraic combinatorics. In: 2019 Computer Science and Information Technologies (CSIT), Yerevan, Armenia, 2019, pp. 69–76, https://doi.org/10.1109/CSITechnol.2019.8895166. |
38 | Lange, J., Vasilyan, A. (2023). Agnostic proper learning of monotone functions: beyond the black-box correction barrier. Preprint: arXiv:2304.02700. |
39 | Lovász, L. ((2007) ). Combinatorial Problems and Exercises, 3nd edition. American Mathematical Society. |
40 | Madden, G.N. (2023). Shadows of Colored Complexes and Cycle Decompositions of Equipartite Hypergraphs. PhD thesis, Illinois State University. |
41 | Nosov, M.V. ((2023) ). Estimates of the degrees of separating polynomials for monotone and self-dual functions. Intelligent Systems. Theory and Applications, 27: (2), 79–82. |
42 | O’Donnell, R., Servedio, R. (2005). Learning monotone functions from random examples in polynomial time. CMU School of Computer Science. Citeseer. |
43 | Sahakyan, H. ((2013) ). (0, 1)-matrices with different rows. In: Ninth International Conference on Computer Science and Information Technologies Revised Selected Papers, Yerevan, Armenia, 2013, pp. 1–7. https://doi.org/10.1109/CSITechnol.2013.6710342. |
44 | Sahakyan, H. ((2015) ). On the set of simple hypergraph degree sequences. Applied Mathematical Sciences, 9: (5), 243–253. |
45 | Sahakyan, H. ((2023) ). On nonconvexity of the set of hypergraphic sequences. In: 2023 Computer Science and Information Technologies (CSIT). NAS RA, pp. 47–52. |
46 | Sahakyan, H., Aslanyan, L. ((2017) ). Discrete tomography with distinct rows: relaxation. In: 2017 Computer Science and Information Technologies (CSIT). Yerevan, Armenia, 2017, pp. 117–120. https://doi.org/10.1109/CSITechnol.2017.8312153. |
47 | Sahakyan, H., Aslanyan, L., Katona, G. ((2022) ). Notes on identification of monotone Boolean functions with machine learning methods. In: Proceedings of “Middle-European Conference on Applied Theoretical Computer Science” Conference. Koper, Slovenia, 13–14 October 2022. |
48 | Sales, M., Schülke, B. (2022). A local version of Katona’s intersection theorem. Preprint: arXiv:2206.04278. |
49 | Schröder, B. ((2016) ). Ordered Sets: An Introduction with Connections from Combinatorics to Topology. Birkhäuser. |
50 | Sokolov, N.A. ((1987) ). Optimal reconstruction of monotone Boolean functions. Computational Mathematics and Mathematical Physics, 27: (6), 181–187. |
51 | Tennakoon, R., Suter, D., Zhang, E., Chin, T.-J., Bab-Hadiashar, A. ((2021) ). Consensus maximisation using influences of monotone Boolean functions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2866–2875. |
52 | Tonoyan, G.P. ((1979) ). Chain partitioning of n-cube vertices and deciphering of monotone Boolean functions. Journal of Computational Mathematics and Mathematical Physics, 19: (6), 1532–1542. |
53 | Valiant, L.G. ((1984) ). A theory of the learnable. Communications of the ACM, 27: (11), 1134–1142. |
54 | Zhang, E., Suter, D., Tennakoon, R., Chin, T.-J., Bab-Hadiashar, A., Truong, G., Gilani, S.Z. ((2022) ). Maximum consensus by weighted influences of monotone Boolean functions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 2022, pp. 8964–8972. https://doi.org/10.1109/CVPR52688.2022.00876. |
55 | Zhuravlev, Y.I., Ryazanov, V.V., Aslanyan, L.H., Sahakyan, H.A. ((2019) ). On a classification method for a large number of classes. Pattern Recognition and Image Analysis, 29: , 366–376. |
56 | Zhuravlev, Y.I., Ryazanov, V.V., Ryazanov, V.V., Aslanyan, L.H., Sahakyan, H.A. ((2020) ). Comparison of different dichotomous classification algorithms. Pattern Recognition and Image Analysis, 30: , 303–314. |


