
Knowledge Graph OLAP
Abstract
A knowledge graph (KG) represents real-world entities and their relationships. The represented knowledge is often context-dependent, leading to the construction of contextualized KGs. The multidimensional and hierarchical nature of context invites comparison with the OLAP cube model from multidimensional data analysis. Traditional systems for online analytical processing (OLAP) employ multidimensional models to represent numeric values for further analysis using dedicated query operations. In this paper, along with an adaptation of the OLAP cube model for KGs, we introduce an adaptation of the traditional OLAP query operations for the purposes of performing analysis over KGs. In particular, we decompose the roll-up operation from traditional OLAP into a merge and an abstraction operation. The merge operation corresponds to the selection of knowledge from different contexts whereas abstraction replaces entities with more general entities. The result of such a query is a more abstract, high-level view – a management summary – of the knowledge.
1.Introduction
A knowledge graph (KG) represents real-world entities and their relationships. KGs have been described as “large networks of entities, their semantic types, properties, and relationships” [49], as consisting of “a set of interconnected typed entities and their attributes” [31] with possibly arbitrary relationships [64]. The majority of a KG’s contents are instance-level facts, or assertional knowledge (ABox) [64], although KGs may also include terminological and ontological knowledge (TBox) representing “the vocabulary used in the knowledge graph” [31] in order to allow for “ontological reasoning and query answering” [5] over the facts. Furthermore, a KG typically covers a variety of topics rather than focusing exclusively on a single aspect of the real world such as geographic terms [64]. For the representation of KGs, the Resource Description Framework (RDF) [23] often serves as the data model.
KGs present a wide range of potential applications, e.g., (web) search [35] and question-answering [81], intra-company knowledge management [65] and investment analysis [68]. Among the most popular examples of KGs are proprietary ones such as Google’s Knowledge Graph [32] and Microsoft’s Satori [66] as well as community-driven efforts such as DBpedia [52] and Wikidata [87]. More and more organizations follow suit with the development of KGs for their own purposes, necessitating the development of appropriate knowledge graph management systems (KGMS) [5] that facilitate exploitation of the knowledge contained in a KG, e.g., by providing mechanisms for KG summarization [90].
In order to facilitate KG management, KGs are increasingly subject to contextualization, i.e., the enrichment of facts with context metadata such as time and location. For example, in the aeronautics domain, the relevant knowledge for air traffic management is inherently context-dependent [71], especially with respect to time and location but also other context dimensions, e.g., importance or topic. In particular, knowledge about airport infrastructure and airspace such as operational status of runways and closure of airspace varies over time. Frameworks such as the Contextualized Knowledge Repository (CKR) [75] serve to organize knowledge within hierarchically ordered contexts along multiple context dimensions.
The multidimensional nature of context invites comparison with the multidimensional modeling approach as employed by online analytical processing (OLAP) systems for data analysis. In traditional OLAP systems, hierarchically ordered dimensions span a multidimensional space – also referred to as OLAP cube – where each point (or cell) represents an event of interest quantified by numeric measures. Similarly, context dimensions span a multidimensional space where each cell represents a context that comprises facts of a KG. OLAP systems employ multidimensional models to perform analytical queries over datasets using operations such as slice-and-dice and roll-up (see [83] for further information). In this regard, slice-and-dice refers to the selection of relevant data for the analysis whereas roll-up refers to the aggregation of the selected data in order to obtain a more abstract view on the underlying business situation.
In this paper, we introduce Knowledge Graph OLAP (KG-OLAP), a conceptual approach that consists of a multidimensional model and corresponding query operations for performing analysis over KGs. Extending the CKR framework [12,75], KG-OLAP cubes collect knowledge into hierarchically ordered contexts: Each cell of a KG-OLAP cube corresponds to a context, with knowledge encoded as triples replacing numeric measures as the contents of the cells. In KG-OLAP cubes, knowledge from the more general contexts propagates to the more specific contexts. Typically, the more general contexts establish the common terminological knowledge whereas the more specific contexts contain assertional knowledge. Regarding query operations, the KG-OLAP framework distinguishes two categories: contextual and graph operations. The central types of operation in each category are merge and abstraction, respectively. In particular, a merge operation combines the knowledge from different contexts whereas an abstraction operation replaces individual entities within a context with more abstract entities; different variants for each of those types of operation exist.
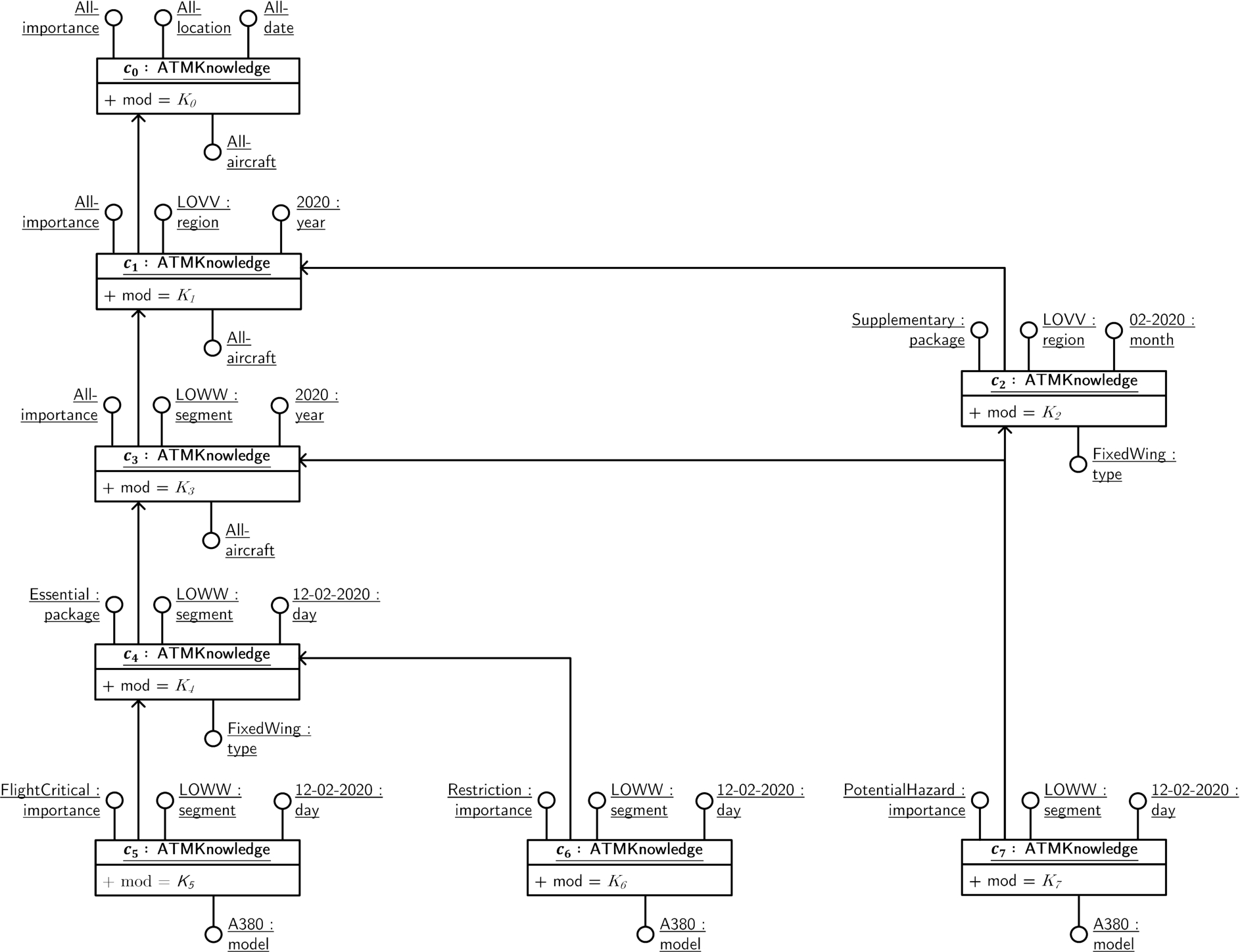
Fig. 1.
Traditional OLAP operates on numeric measures whereas KG-OLAP operates on knowledge graphs.
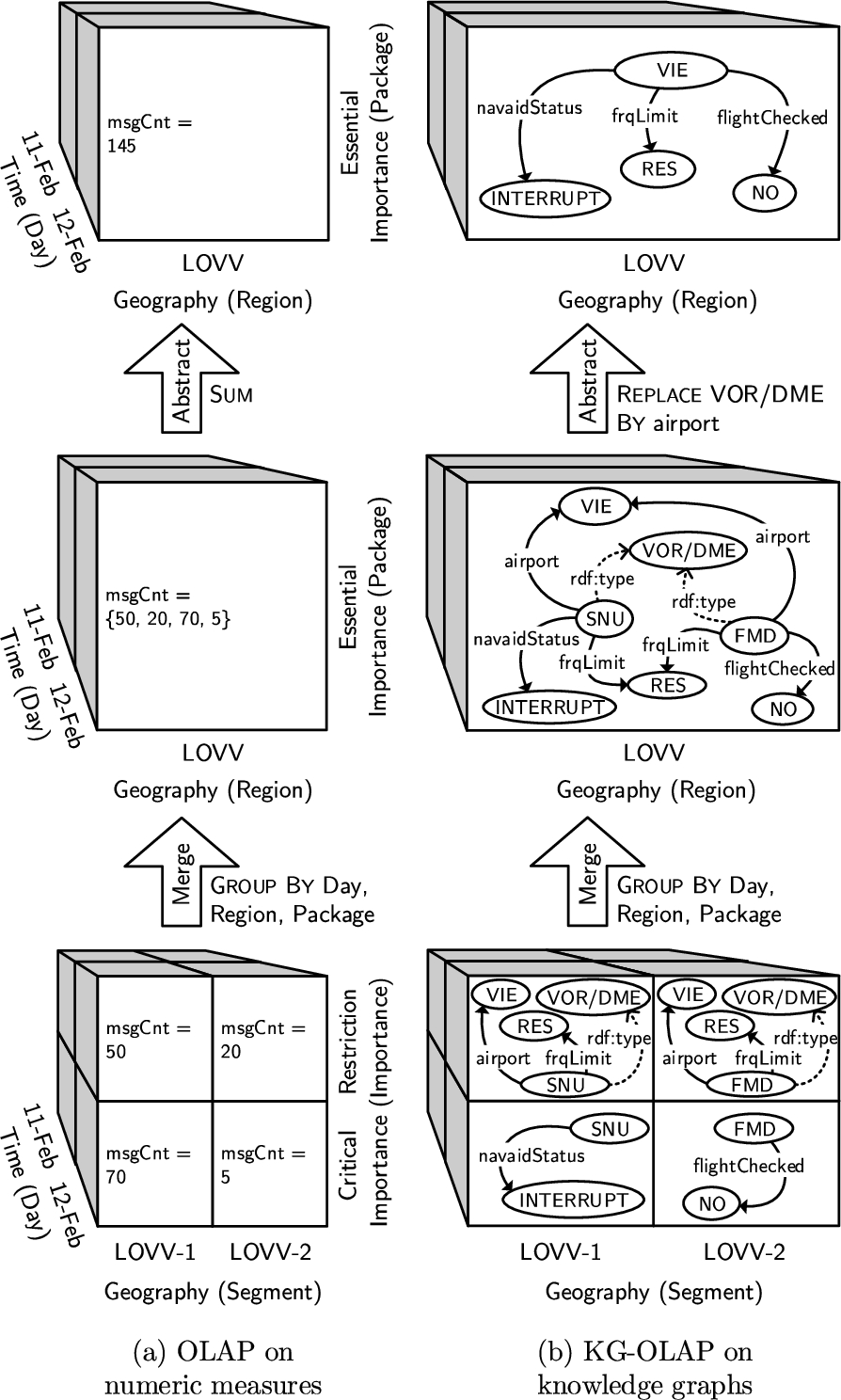
Fig. 1 draws an analogy between (a) the roll-up operation in traditional OLAP on numeric measures and (b) merge and abstraction in KG-OLAP on KGs. First, the example emphasizes the fact that traditional OLAP and KG-OLAP work on distinct types of data. The example’s general setting is air traffic management, where messages dispatched by air traffic control notify of temporary changes in infrastructure. In traditional OLAP, the description of real-world events is condensed into numeric measures: In this example, the OLAP cube captures the daily number of messages dispatched by air traffic control per geographic segment and message importance. In KG-OLAP, each cell of the cube contains knowledge, encoded as triples, valid and relevant in the context that the cell represents: In this example, knowledge about navigation aids of varying importance, valid on a particular day, and relevant for a specific geographic segment. In particular, the KG-OLAP cube comprises knowledge about navigation aids used for approaching Vienna airport (VIE): the VOR/DME (i.e., a type of radio beacon) in Sollenau (SNU) and the VOR/DME in Fischamend (FMD), which are located in different geographic segments. On the one hand, that knowledge concerns restrictions, namely limitations of frequency (frqLimit), indicating usability of the navigation aid’s frequency to be restricted (RES) to certain sectors (not shown in the example). On the other hand, there is the flight critical knowledge about a temporary change in SNU’s operational status to INTERRUPT and the fact that FMD is currently not “flight checked”, i.e., has not undergone mandatory, periodic security checks. To illustrate the idea of merge and abstraction – the main types of operations in KG-OLAP – the roll-up operation in traditional OLAP can be considered a sequence of merge and abstraction. In traditional OLAP, the merge operation obtains a collection of numeric values for each grouping of cells by day, flight information region, and importance package; each geographic segment belongs to a region, each importance to an importance package. Then, the abstraction operation applies the Sum aggregation operator on the collection of numeric values to obtain an aggregate numeric value. In KG-OLAP, the merge operation first combines triples from the more specific contexts into a more general context. Then, the abstraction operation replaces each VOR/DME entity by the target of its airport property to obtain a more abstract representation of the knowledge about navigation aids at Vienna airport. Just like there are different aggregation functions for numeric values, there are different variants of the abstraction operation for KGs. In addition, in case of KG-OLAP, there are different variants of the merge operation. In KG-OLAP, merge and abstraction may also be conducted repeatedly and in an arbitrary order.
We illustrate KG-OLAP following use cases of (contextualized) knowledge graphs for air traffic management (ATM) [41,71]; we draw from experience in collaborative research projects on the use of semantic technologies in ATM (see [34,61,79]). ATM KGs potentially comprise a wide variety of topics: events, weather, flight plans, infrastructure, equipment, organizations, companies, and personnel. The running example focuses on the representation of events such as runway closures and surface contamination which affect the operational status of airport infrastructure and thus alter general ATM knowledge. Merge and abstraction then serve to obtain a management summary of the represented knowledge for pilot briefings or post-operational analysis, providing a more abstract view on the KG which contains relevant ATM knowledge in the suitable form for a particular situation. Another potential application of KG-OLAP is the analysis of business reports formalized using KGs and business model ontologies [74], which we do not elaborate further in this paper.
Previous work [72,73] introduced the concept of ATM information cubes, presenting a use case for KG-OLAP in pilot briefings to an ATM audience, without the conceptual and technological fundamentals of KGs in general or KG-OLAP in particular. The KG-OLAP framework may serve to realize ATM information cubes, which can be considered a simplified version of KG-OLAP cubes. ATM information cubes organize messages, the contents thus being considerably less complex and comprehensive than (contextualized) KGs, lacking ontological knowledge and the knowledge propagation mechanism of KG-OLAP, among other things. The work on ATM information cubes also omits the formal definition of abstraction query operations while lacking other graph operations altogether.
The contributions of this paper are:
(i) the identification of requirements for a model and query operations for performing analysis over KGs;
(ii) the formalization of a model for KGs with hierarchical contexts and knowledge propagation suitable for performing analysis;
(iii) the definition of a set of query operations for performing analysis over KGs;
(iv) an experimental analysis of run time performance for working with contextualized KGs.
The remainder of this paper is organized as follows. In Section 2, we present the use cases that serve to illustrate KG-OLAP and motivate the approach. In Section 3, we introduce the formalization for the multi-dimensional model of KG-OLAP cubes. In Section 4, we present query operations for KG-OLAP cubes. In Section 5, we discuss implementation of the approach. In Section 6, we review related work. We conclude with a discussion and an outlook on future work.
Further details about used language, reasoning methods, implementation, and experimental evaluation are provided in the separate Appendix [70].
2.Use cases in air traffic management
In this section, we give relevant background information on air traffic management (ATM) before discussing the use of (contextualized) KGs for aeronautical information management. We then describe two potential use cases of KG-OLAP in the ATM domain, from which we derive functional requirements.
2.1.Background
Modern ATM aims to ensure safe flight operations through careful management, analysis, and advance planning of air traffic flow as well as timely provisioning of relevant information in the form of messages. The exchange of data/information between ATM stakeholders is of paramount importance in order to foster common situational awareness for improved efficiency, safety, and quality in planning and operations. In this regard, situational awareness refers to a “person’s knowledge of particular task-related events and phenomena” [78], i.e., knowledge about the world relevant for ATM, which must be accurately represented and conveyed to the various stakeholders. To this end, ATM relies on a multitude of standardized data/information (exchange) models, e.g., the Aeronautical Information Exchange Model (AIXM), the Flight Information Exchange Model (FIXM), the ICAO Meteorological Information Exchange Model (IWXXM), and the ATM Information Reference Model (AIRM).
Listing 1.
An example DNOTAM in XML notifying of a taxiway closure in Vienna due to snow removal

Among the most common types of messages exchanged in ATM are Notices to Airmen. A Notice to Airmen (NOTAM) – or Digital NOTAM (DNOTAM) when in electronic form using AIXM format – is a message that conveys important information about temporary changes in flight conditions to aircraft pilots [39], e.g., closures of aerodromes, runways, and taxiways, surface conditions, and construction activities (see [28] for a list of airport event scenarios) but also airspace restrictions. Messages shape the knowledge about the world as relevant for ATM. For example, a DNOTAM (Listing 1) may change the knowledge about the taxiways of a particular airport by announcing the temporary closure of a taxiway due to snow removal. To this end, a DNOTAM employs different time slices. A baseline timeslice defines the regular (baseline) knowledge whereas a tempdelta timeslice announces temporary changes of the baseline knowledge. Instead of the baseline, a DNOTAM typically employs snapshot timeslices, i.e., baseline blended with tempdelta knowledge. In the example DNOTAM in Listing 1, the encoded snapshot/baseline knowledge consists of the definition of the designator of Vienna airport (Lines 5–13) and the definition of various attributes of a taxiway at Vienna airport (Lines 17–27) per 12 February 2018 at 8:00 am. The tempdelta knowledge consists of the notification of a taxiway closure due to snow removal (Lines 29–50) on 12 February 2018 from 8:00 am to 10:00 am.
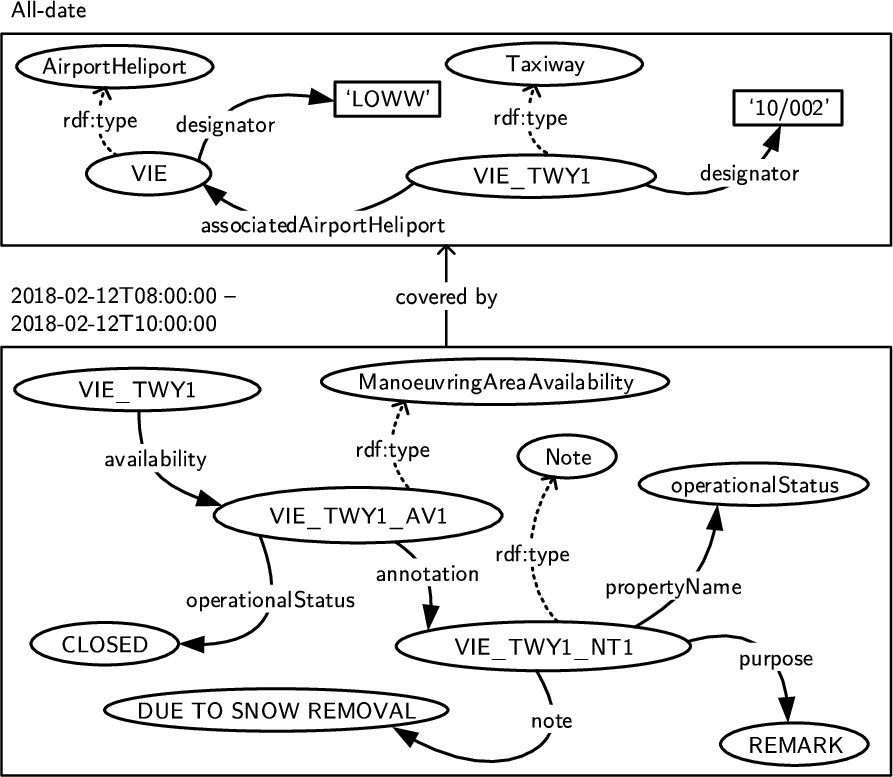
2.2.(Contextualized) ATM knowledge graphs
The knowledge encoded in DNOTAMs is more naturally represented using contextualized KGs [71]. Fig. 2 illustrates the contextualized representation of the knowledge encoded in the DNOTAM from Listing 1 along a temporal dimension. The all-date context defines general knowledge about various infrastructure elements, which hardly changes. The temporal context for the timespan from 8:00–10:00 am on 12 February 2018, on the other hand, defines knowledge about a temporarily reduced availability – a closed operational status – due to snow removal. Other context dimensions may also serve to organize ATM knowledge into contextualized KGs [71], e.g., geography, topic, and importance. Besides the knowledge derived from DNOTAMs according to the AIXM, an ATM KG may comprise knowledge from data items according to other ATM information (exchange) models, e.g., IWXXM for weather or FIXM for flight plans.
In our scenario, RDF serves as the common representation language for ATM knowledge even though XML is the native serialization format of DNOTAMs in the AIXM standard. AIXM, however, builds on the Geography Markup Language (GML), the initial proposal of which was based directly on RDF, with subsequent editions continuing to “borrow many ideas from RDF” [50, p. 20], including the GML’s object-property model [50, p. 16]. Similarly, other ATM information (exchange) models are easily translated into RDF.
In fact, ATM research has shown growing interest in the use of semantic technologies (see [40] for an overview), leading to the development of domain ontologies [33,85], e.g., the NASA ATM Ontology (ATMONTO) [42] and the AIRM Ontology [86]. NASA’s ATMGRAPH [41,43], in turn, is a KG for the ATM domain that builds on ATMONTO and comprises knowledge about infrastructure, flights, and operating conditions. The rationale behind ATMGRAPH lies in the integration of heterogeneous data from various sources for analysis purposes. Compared to a data lake solution storing raw files from various data sources [25], which shifts the burden of data integration largely to analysts, ATMGRAPH facilitates querying across sources [44, p. 2]. Using semantic technologies was also deemed preferable over a relational implementation due to increased flexibility regarding modifications, possibility of inferencing, and reusability of the knowledge [44, p. 3]. In summary, employing (contextualized) KGs for aeronautical information management seems promising.
In the remainder of this paper, we use example KGs for illustration purposes largely following the AIXM conceptual models [1] and the FAA’s airport operations scenarios [28]. In the following, we present two use cases for contextualized KGs in the ATM domain, which serve to motivate the KG-OLAP approach.
2.3.Use case 1: Pilot briefings
Prior to a flight, pilots receive a pre-flight information bulletin (PIB), which comprises all DNOTAMs, but also METARs, i.e., messages about weather conditions, that are even remotely relevant for the upcoming flight. Pilots then have to manually sift through an abundance of messages and decide upon the priority of each message. Among other things, the priority of a message depends on the current flight phase. For example, during take-off, a taxiway closure at the destination airport has low priority for a pilot.
Automated rule-based filtering and prioritization of DNOTAMs reduces information overload in pilot briefings [79]. Pilots formulate an interest specification [14], which comprises spatial, temporal, and aircraft interests [15]. The SemNOTAM system then matches DNOTAMs against the interest specification and assigns an importance, e.g., flight critical or operational restriction, to each DNOTAM. DNOTAMs are also classifed according to geographic scope and flight phase (spatio-temporal) as well as event scenario. The general approach is also applicable to other types of ATM information, e.g., METARs, provided appropriate filtering and prioritization rules are available.
The result of DNOTAM filtering and prioritization may be packaged into a semantic container [61]. A semantic container collects data items into a package that comprises all the data items satisfying a certain membership condition, formulated in terms of an ATM domain ontology. A membership condition may have multiple facets, e.g., geography, time, aircraft, and importance. Semantic containers foster reuse of previously compiled packages of ATM information, thus reducing processing effort, and allow for replication in order to increase availability and conserve bandwidth. Raw data items, not knowledge triples, constitute the contents of a semantic container. For example, a semantic container may comprise the relevant DNOTAMs for a flight from Dubai to Vienna on a particular day, along with additional information about the importance of each individual DNOTAM.
Automated rule-based filtering and prioritization in combination with semantic containers may serve to construct ATM information cubes [72,73]. Fine-grained semantic containers comprising data items of different geographic and temporal scopes as well as importance levels may be arranged in a multidimensional space. A pilot could then select the appropriate containers at the right moment without being overloaded with information. Individual messages could be combined into a more abstract representation in order to obtain a management summary of relevant events. Runway closures at the destination airport, for example, may be flight critical and pilots should be aware of the fact that there are closures in effect at the destination also in the early phases of a flight, possibly with a general indication of the reason for closure, e.g., due to snow. In detail, however, the runway closures concern the pilot only upon approach of the destination, e.g., which runway directions are closed, which types of snow are found on the runways.
In this paper, rather than considering ATM information cubes with messages collected into semantic containers, we consider cubes of ATM knowledge. More general contexts establish a common schema and business term vocabulary, which is inherited and extended by the more specific contexts. The messages represent a source of knowledge about the state of the world with limited spatial, temporal, and content scope. The information contained in the messages translates into knowledge triples that are collected into contexts based on the scope of the messages.
2.4.Use case 2: Post-operational analysis
Air traffic flow and capacity management (ATFCM), which represents one of the core activities in ATM, has post-operations teams analyzing operational events in order to identify valuable lessons learned for the benefit of future operations and produces an overview of occurred incidents [62, p. 131]. A data warehouse provides the post-operations team with statistical data about past flight operations [62, p. 130].
Post-operational analytical tasks in ATFCM may also leverage contextualized ATM knowledge. The rationale is similar to ATMGRAPH’s [44], a KG having richer semantics while being more flexible and versatile than simple statistical data organized in a data warehouse. In addition to the data warehouse, the post-operations team may employ a KG-OLAP cube of contextualized ATM knowledge extracted from DNOTAMs and other types of messages, organized by temporal relevance, route or ground segment, aircraft model, and importance. By analyzing such ATM knowledge, an air traffic flow post-operations team may gain a more comprehensive picture of past air traffic operations. Using the merge operation, the post-operations team may combine ATM knowledge from different contexts. For example, the relevant ATM knowledge per day and geographic segment could be combined to obtain the ATM knowledge per month and geographic region and month. Various incarnations of the abstraction operation then serve to obtain a more abstract representation of the ATM knowledge. For example, instead of indicating specific closures of individual runways or taxiways, the abstract ATM knowledge would indicate closures of runways and taxiways in general for aircraft with certain characteristics. Besides DNOTAMs, other types of aeronautical information relevant to ATFCM, e.g., flight data in FIXM and meteorological messages in IWXXM, could similarly serve to populate the cube of ATM knowledge.
In the remainder of this paper, we employ contextualized KGs for the ATM domain to illustrate the KG-OLAP approach. In particular, we focus mainly on ATM knowledge derived from DNOTAMs. The example contextualized KGs are plausible for both pilot briefings and post-operational analysis.
2.5.Functional requirements
Based on the presented use cases from the ATM domain, we identify functional requirements that a system for performing data analysis over KGs must fulfill. Although derived from use cases in ATM, the requirements also apply to other use cases, e.g., the analysis of business situations formalized using business model ontologies [74].
Requirement 1
Requirement 1(Heterogeneity).
The system must cope with heterogeneity in the knowledge representation. Heterogeneity is inherent to KGs, which are not simple graphs. In particular, heterogeneity in KGs manifests itself as follows:
(a) Multiple types of entities. In the ATM domain, for example, a KG comprises knowledge about various kinds of infrastructure but also flight plans, airspace, weather events, and more.
(b) Multiple types of relationships. Unlike simple graphs, the entities in a KG are connected via various relationships. For example, one type of relationship serves to indicate the airport that a runway is situated at while another associates a runway with a usage restriction.
(c) Schema variability, i.e., entities of the same type may have different properties and relationships. For example, runway availability may warn of inspection adjacent to a runway. But, runway availability may also announce runway closure, e.g., due to snow, or mention the characteristics of aircraft that are prohibited to land, which in turn may depend on weight, wingspan, etc.
Requirement 2
Requirement 2(Ontological knowledge).
The system must handle ontological knowledge that describes relationships between classes and employs logic for the definition of domain-specific terms. ATM information (exchange) models, for example, comprise a multitude of generalization/specialization relationships and define associations between classes, which potentially translate into domain and range constraints. ATM technical language is rife with domain-specific terms, e.g., heavy wake-turbulence aircraft, the meaning of which can be defined using an ontology, which facilitates use of business terms in queries [14].
Requirement 3
Requirement 3(Self-describing data).
The system must store metadata along with the instance data in order to facilitate interpretation. As a general trait of semantic systems, definitions of classes and properties are a flexible part of the data, not encoded in the system’s physical schema. The RDF data format, for example, serves for the representation of instance data and class-level data alike. Changes in the data model do not culminate in a refactoring of the database schema in the same way as in relational databases. Furthermore, query operations may directly operate on the metadata. A query operation may, for example, obtain an overview of relationships where individual entities are replaced by their classes.
Requirement 4
Requirement 4(Modularization).
The system must allow for the modularization of knowledge according to different criteria. Knowledge that belongs together can be represented together. Separate knowledge with different scopes can be split into multiple modules. For example, some knowledge, e.g., a particular runway closure, may be relevant for LOWW airport while other knowledge, e.g., reduced quality of a specific navigation aid, may be relevant for LOWL airport.
Requirement 5
Requirement 5(General and specific knowledge).
The system must support both modules with more general scope and modules with more specific scope. For example, in some cases, associating particular knowledge with individual geographic segments is impossible. Instead, the knowledge could be relevant for the entire LOVV region and not only LOWW airport. When selecting relevant knowledge for the LOWW airport, however, relevant knowledge for the entire region should also be included.
Requirement 6
Requirement 6(Knowledge selection and combination).
The system must provide query operations for selecting and combining knowledge from different modules. For example, in a pilot briefing, depending on the flight phase, knowledge with a specific geographic applicability is relevant, which must be selected from multiple modules.
Requirement 7
Requirement 7(Knowledge abstraction).
The system must provide query operations that allow to obtain a more abstract view on the represented knowledge. For example, in some situations, the knowledge about various layers of dry snow, compact snow, etc. on different runways of an airport, may be accurately summarized by the fact that the runways at LOWW airport have snow contamination.
In the following, we formulate the KG-OLAP cube model and query operations guided by the identified functional requirements.
3.Multidimensional model
In this section, we introduce the KG-OLAP cube model for the representation of contextualized KGs. We first introduce the model informally before providing a formal definition. We define the model as an extension of the Contextualized Knowledge Repository (CKR) framework [12,75].
3.1.KG-OLAP cube model
KG-OLAP adapts the multidimensional modeling paradigm from data warehousing (see [83]) in order to organize multidimensional KGs. Hence, the KG-OLAP cube is the central modeling element. Following the basic structure of the CKR framework, the KG-OLAP cube consists of two distinct layers: an upper and a lower layer. The upper layer describes the structure and properties of a cube’s cells; the lower layer specifies the contents of the cells. The two layers employ distinct and possibly disjoint languages.
A KG-OLAP cube’s upper layer defines the multidimensional structure of a cube and associates specific knowledge modules with individual cube cells. Intuitively, the cube’s dimensions (e.g., time, location) span a multidimensional space, the points of which are referred to as cells.11 The dimensions are hierarchically organized into levels. The definition of a cube’s dimensions and their hierarchical organization – the cube’s multidimensional structure – into levels is referred to as KG-OLAP cube schema.
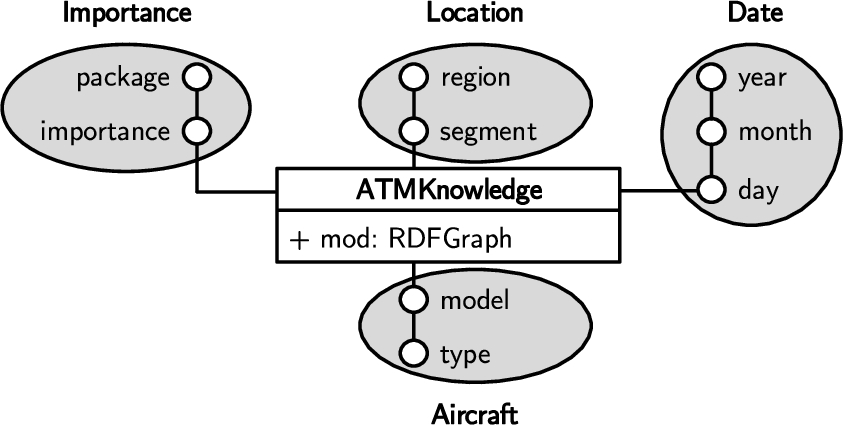
Example 1
Example 1(KG-OLAP cube schema).
Fig. 3 illustrates, in Dimensional Fact Model (DFM) notation [30], a KG-OLAP cube’s schema with its dimensions and levels. The presented KG-OLAP cube organizes relevant knowledge for air traffic management (ATM). The box in the center represents the cells of the cube: each cell contains an RDF graph that encodes the contextualized ATM knowledge – the cell’s knowledge module. The cube has four context dimensions that characterize the cells: importance, location, date, and aircraft. Hence, the ATM knowledge graph is partitioned by importance of the knowledge for a particular aircraft model on a certain day within a geographic segment. The importance dimension has the levels importance and package, the location dimension has segment and region, the date dimension has day, month, and year, the aircraft dimension has model and type.
Fig. 3.
A KG-OLAP cube with its dimensions and levels in DFM notation for the organization of KGs in air traffic management.
The dimension members (e.g., February 2020, Vienna) of a KG-OLAP cube are organized in a complete linear order, which is referred to as roll-up relationship. For example, the month February 2020 rolls up to the year 2020 and Vienna rolls up to Austria. Dimension members belong to levels, which define the granularity of the dimension members (e.g. month and year, country and city). The levels serve to aggregate individual cells of a cube (see Section 4). Levels are likewise organized in a complete linear order, which is similarly referred to as roll-up relationship. For example, month rolls up to year and city rolls up to country.
Example 2
Example 2(Dimensions and levels).
Fig. 4 shows an ordering of dimension members and the corresponding levels, which is used in the running example cube of ATM knowledge. Each dimension is represented as a tree. The dimension’s name is depicted above the tree. Each node represents a dimension member, the caption next to each node shows the respective dimension member’s name. An edge between two nodes represents a roll-up relationship between the respective dimension members, from bottom to top. On the left hand side of each tree are the levels of the dimension members, ordered from most general to most specific. Each dimension has an implicit all level, which is not shown in Fig. 3. For example, in the importance dimension, the FlightCritical member at the importance level rolls up to the Essential member at the package level, which rolls up to the All-importance member at the all-importance level. The hierarchical ordering of the dimension members mirrors the hierarchical ordering of the levels.
Fig. 4.
Example hierarchies for the context dimension members.
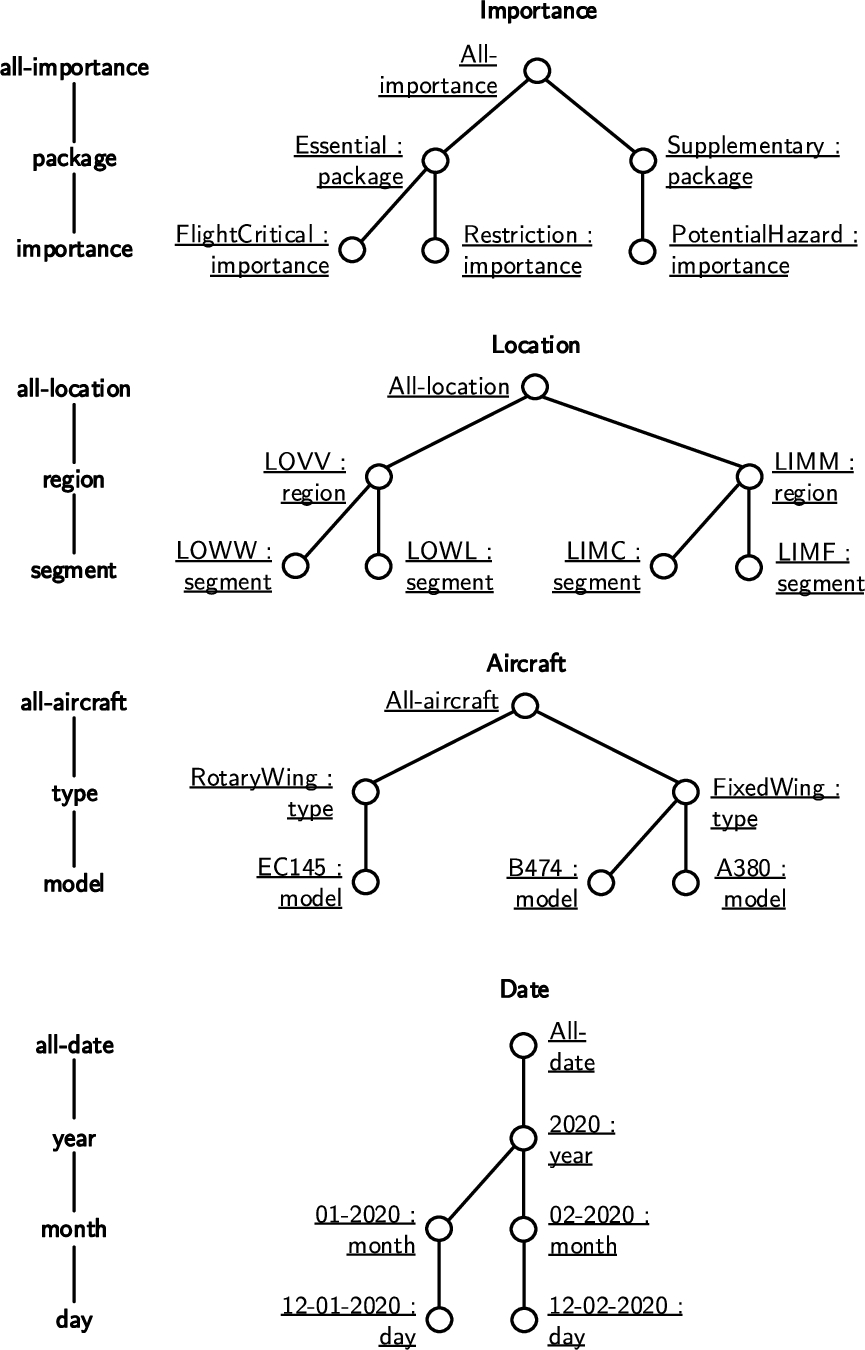
Fig. 5.
An example instance of the KG-OLAP cube schema in Fig. 3. The arrows denote coverage relationships between contexts; the covered context points to the covering. The contents of the knowledge modules
The dimension members characterize the cells of a KG-OLAP cube: each cell has a set of dimension members as identifying attributes and the dimension hierarchies organize the cells into a hierarchical structure. For example, the combination of dimension members February 2020 and Austria identifies a particular cell in a two-dimensional cube with time and location dimensions. The hierarchical order of dimension members then determines the coverage relationship, which is a partial order between cells. For example, the cell identified by the combination of dimension members February 2020 and Austria covers the cell identified by the combination of dimension members 12 February 2020 and Vienna. With each cell, a KG-OLAP cube then associates a knowledge module, which comprises facts of knowledge valid in the respective context.
Example 3
Example 3(KG-OLAP cube cells).
Fig. 5 shows a set of cells according to the KG-OLAP cube schema in Fig. 3; the contents of the knowledge modules are shown in Fig. 6 (see Example 4). The
The
The
A KG-OLAP cube’s lower layer consists of the actual knowledge modules that are associated with the individual cells. A knowledge module contains statements valid in the context of the associated cell. The knowledge inside each module is specified using an object language and expresses the facts and axioms valid in the specific context defined by the cell. Furthermore, knowledge propagates downwards along the coverage relationships, from the more general to the more specific contexts. In the examples, we employ
Example 4
Example 4(Knowledge modules).
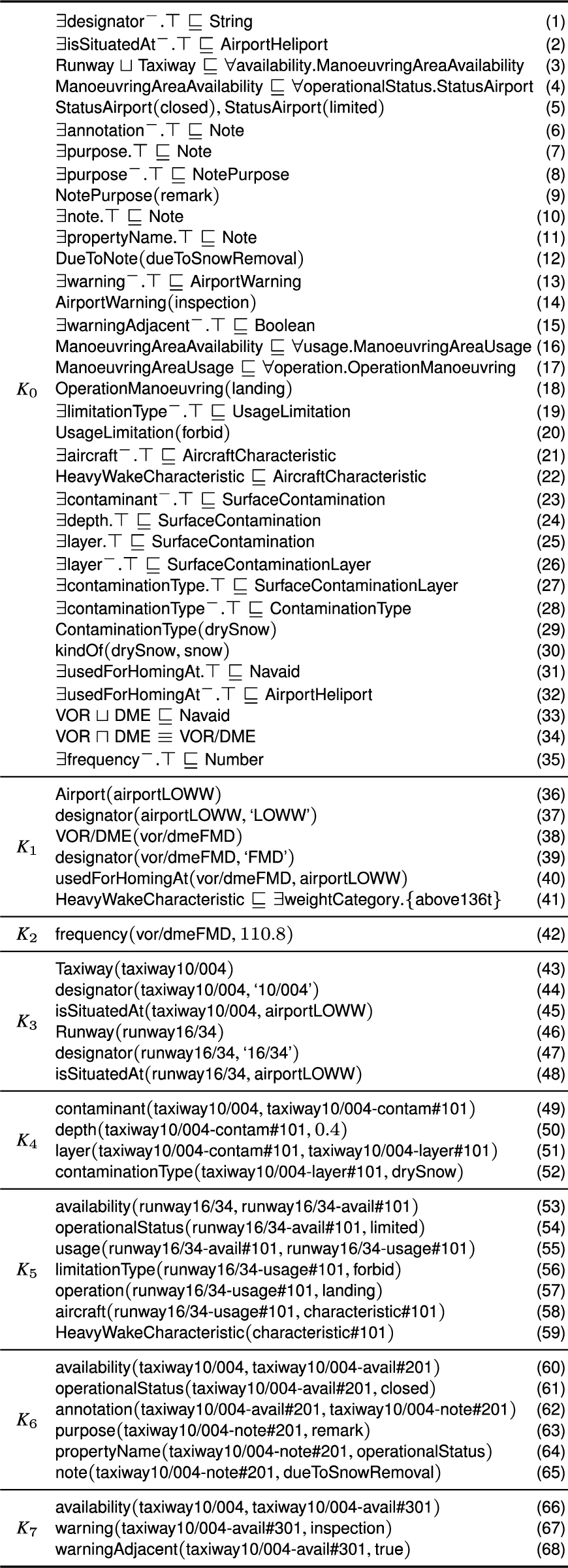
Fig. 6 defines (using DL syntax) contents for the knowledge modules
The
The availability property links a Runway or Taxiway element to a ManoeuvringAreaAvailability individual (Row 3), which typically indicates, via the operationalStatus property (Row 4), a temporal change in the runway or taxiway’s operational status, e.g., closed or limited (Row 5). A ManoeuvringAreaAvailability individual may be annotated with a Note (Row 6) for a certain purpose (Rows 7 and 8), e.g., as a remark (Row 9) that gives an additional explanation via the note property (Row 10) for the value of the property referred to by the note’s propertyName attribute (Row 11). For example, a DueToNote individual attached to the Note via the note property may indicate why the operationalStatus property assumes the value closed, e.g., dueToSnowRemoval (Row 12); this example corresponds to the DNOTAM shown in Listing 1.
In some cases, a ManoeuvringAreaAvailability individual may indicate nothing more than a warning via the warning property (Row 13), which refers to a cause for caution, e.g., inspection (Row 14). The boolean warningAdjacent property (Row 15) indicates whether or not the warning refers to an area adjacent to the infrastructure element that the ManoeuvringAreaAvailability individual belongs to.
A ManoeuvringAreaAvailability individual may also indicate a usage restriction for a runway or taxiway, which forbids certain operations, e.g., landing, possibly conditional to certain aircraft characteristics. In that case, the usage property links a ManoeuvringAreaAvailability individual to a ManoeuvringAreaUsage individual (Row 16). The operation property, in turn, links a ManoeuvringAreaUsage individual to an OperationManoeuvring individual (Row 17), e.g., landing (Row 18). The limitationType property (Row 19) then indicates the type of limitation, e.g., forbid (Row 20), imposed for the previously specified operation. The aircraft property (Row 21) specifies characteristics of aircraft which the usage restriction applies to. HeavyWakeCharacteristic is a kind of AircraftCharacteristic (Row 22), referring to aircraft with heavy wake turbulence.
The contaminant property (Row 23) indicates SurfaceContamination for an infrastructure element, e.g., a runway or taxiway. A SurfaceContamination has an overall depth (Row 24) and several contamination layers, specified via the layer property linking a SurfaceContamination to SurfaceContaminationLayer individuals (Rows 25 and 26). A SurfaceContaminationLayer has a contaminationType property (Row 27), indicating the ContaminationType (Row 28) present on the surface, e.g., drySnow (Row 29). The drySnow contamination type represents a kind of snow (Row 30); the kindOf property defines a grouping of individuals.
A navigation aid (Navaid) may be used for homing at an AirportHeliport (Rows 31 and 32). Very High Frequency Omni-Directional Range (VOR) and Distance Measureing Equipment (DME) are special types of Navaid (Row 33), with VOR/DME representing navigation aids that act both as VOR and DME (Row 34). The frequency property (Row 35) indicates the frequency which a piece of equipment, e.g., a navigation aid, operates at.
The
The
The
The
The
The
The
Example 4 illustrates how knowledge representation in KG-OLAP fulfills the functional requirements defined in the previous section. First, the represented KGs are heterogeneous (Requirement 1) regarding both the types of entities and relationships; schema variability is exemplified by the different variants of ManoeuvringAreaAvailability. The KGs comprise ontological knowledge (Requirement 2), mainly in
The knowledge from higher-level cells propagates to the covered lower-level cells; the knowledge associated with the lower-levels cells also specializes the more general knowledge inherited from the higher levels. The hierarchical organization facilitates the combination of knowledge across cells in the course of data analysis: the higher-level facts contain a shared conceptualization of business terms that may be extended by lower-level facts. The actual contents of lower-level cells are defined in terms of the shared conceptualization provided by the higher-level facts. The propagated knowledge is also available for reasoning.
Example 5
Example 5(Inference).
Consider the cells in Fig. 5 and the corresponding knowledge modules in Fig. 6. In the
3.2.Formalization
In the following, we adapt and extend the definitions of the CKR framework – building on the CKR definition [8,12] in a generic description logic (DL) language [4] – in order to fit the needs of KG-OLAP and its query operations (see Section 4).
3.2.1.Basic definitions
We first define the basic notions of a KG-OLAP cube before relating the KG-OLAP cube definitions to the CKR framework. The multidimensional structure is expressed using a cube vocabulary Ω, which is a DL signature. Ω is composed of the mutually disjoint sets
For every dimension
In order to define the hierarchical order of cells, we adapt the definition of dimensional vector and context coverage from the original CKR definition [75]. Let
Given a dimensional vector, we associate with that vector a cell name using the function
Context coverage derives from the order of the dimensional vectors associated with the contexts, which in turn derives from the individual dimension orders. Let
The knowledge represented in each cell is expressed in a DL language
3.2.2.Extending the CKR framework
We now define a KG-OLAP cube as a special kind of CKR with hierarchically-ordered dimensions and cells as well as knowledge propagation from higher to lower-level cells. In the following, in order to formalize the semantics of a KG-OLAP cube, we employ the OLAP cube vocabulary Ω as a CKR meta-knowledge vocabulary and extend the definitions of the CKR core. In particular, we extend the definitions of the CKR as presented by Bozzato and Serafini [12] – which has the advantage over the original CKR formulation [75] that it can be implemented as forward rules – to express propagation of knowledge modules along the coverage relations, and to allow contexts with empty knowledge contents. Further extending the definition of CKR in [12], we adopt the notion of the contextual structure being defined by contextual dimensions from the original CKR formulation [75], and we define knowledge propagation as inheritance of knowledge modules. We provide only basic definitions of the CKR core and refer to previous work [12,75] for an exhaustive presentation of the CKR framework.
A CKR is a two-layered structure composed of (1) the global context
The meta-knowledge of a CKR is expressed in a DL language containing the elements that define the contextual structure. A meta-vocabulary Γ is a DL vocabulary that consists of a set of context names
The meta-language
Definition 1
Definition 1(Contextualized Knowledge Repository).
A Contextualized Knowledge Repository (CKR) over a meta-vocabulary Γ and an object vocabulary Σ is a structure
–
–
In the following we call
The CKR semantics basically follows the two-layered structure of the CKR framework: a CKR interpretation is composed by a DL interpretation for the global context and a DL interpretation for every context.
Definition 2
Definition 2(CKR interpretation).
A CKR interpretation for
(i)
(ii) for every
The interpretation of ordinary DL expressions in
Definition 3
Definition 3(KG-OLAP cube model).
A CKR interpretation
(i) for
(ii) for
(iii) for
(iv) if
(v) for
(vi) if
Intuitively, while the conditions (i) and (ii) of Definition 3 impose that
Given a CKR
3.2.3.Reasoning in KG-OLAP cubes
While the definitions for KG-OLAP cube and CKR are independent of any specific DL language used at the meta and object levels, we formalize instance-level reasoning inside a KG-OLAP cube using a materialization calculus (see [47]) for cubes that employ the
Intuitively, the materialization calculus is based on a translation to Datalog. The axioms of the input cube
With respect to the calculus for
Then, the translation procedure is extended from the one presented for CKR [12] by introducing new steps in which the cell coverage relation is computed from the dimensional coverage in the global program (see Section 3.3 of the Appendix [70]).
The rules and the translation process constitute a sound and complete calculus for instance checking in KG-OLAP cubes using
Theorem 1.
Given
3.3.Extensions
The presented KG-OLAP model can be extended in several directions in order to increase flexibility. In the following, we briefly identify possible extensions.
As in the underlying model of CKR, the KG-OLAP model assumes a centralized view on the available data: The structure of the cube and the knowledge associated to each cell is assumed to be locally available in a single knowledge base for the application of reasoning and operations on the cube. Thus, a possible extension, supported by the modular nature of the cube model, concerns the distribution of the cube structure over separate knowledge bases. This would require to revise the formalization so that both the meta and object information are distributed across more local knowledge bases and knowledge is propagated also considering the topology of the distributed knowledge bases (e.g., by introducing an additional “distribution” dimension). The reasoning procedures and OLAP operations on such distributed system have to be consequently adapted to the distributed structure and the intended knowledge propagation across local knowledge bases. On the other hand, the modularization of knowledge bases can represent an advantage to limit the load of reasoning tasks and to restrict application of operations to a limited subset of cells.
In the proposed KG-OLAP model, we assume that all the dimensions and dimensional values are known a priori and thus no context is undefined (but may have an empty module). The KG-OLAP model could be extended to consider updates of dimensions and dimensional values, which necessitate the dynamic reorganization of knowledge in the contexts that are identified by the newly introduced dimensional values. Updates of the dimensions and their dimensional values will typically be limited to extending the hierarchy with new branches rather than modifying the existing dimensional values. In this regard, however, the notion of “slowly-changing dimensions” from traditional data warehousing (see [83, pp. 139–145] for further information) may be adopted in KG-OLAP. Furthermore, in some cases, it may not be possible to determine the right dimensional value for the statements. The KG-OLAP model allows for the introduction of “unknown” or “not applicable” members in the dimensions. For example, there could be a cell containing knowledge of unknown importance, a cell containing knowledge of unknown temporal or spatial applicability. Future work may investigate the different notions and implications of such default members in the dimension hierarchies.
We note that, due to the modular structure of the model, concepts in different cells can assume different interpretations: the particular situation identified by a cell can determine the local meaning of a concept, reflecting the contextual view of the model. In this regard, we refer to the
The concepts that are propagated from the higher to the lower cells are assumed to be refined by the knowledge in the lower cells. Such refinement is necessarily monotonic, as the knowledge in the lower-level cells cannot truly “override” the concept definitions from the higher-level cells. In this direction, in the CKR model, a notion of defeasible axiom has been recently introduced: Defeasible axioms hold in general but can be “overridden” by the instances in the lower contexts of a contextual hierarchy [8,9,13]. Likewise, defeasible axioms could be introduced in KG-OLAP.
For the presented definition of the KG-OLAP model we consider a simple hierarchical organization of dimensional values, which can be divided into levels, i.e., ranked hierarchies [13]. While this provides an intuitive organization of the cube structure, such organization might be relaxed to allow for multiple relations and more general definitions of hierarchies. In this regard, an extensive body of research in data warehousing and OLAP is dedicated to investigate different kinds of hierarchies (see [83, pp. 94–106]), which could be adapted for the KG-OLAP framework. Regarding the CKR model, propagation of knowledge (with defeasible inheritance) in general contextual hierarchies has been studied by Bozzato et al. [10].
4.Query operations
In this section, we introduce a set of query operations for working with KG-OLAP cubes. We distinguish between contextual operations and graph operations. Contextual operations alter the multidimensional structure of a cube. Graph operations modify the graph structure (knowledge triples) in the knowledge modules of the cells of a cube.
4.1.Contextual operations
The contextual operations select and combine cells of a KG-OLAP cube, thus satisfying Requirement 6, using its dimensions and levels. The slice-and-dice operation allows for the selection of a set of facts whereas the merge operation combines cells at finer granularities into aggregated cells at a coarser granularity, merging the contents of the modules from the finer-grained cells.
4.1.1.Slice and dice
The slice-and-dice operation restricts a cube to a set of cells with a specific subset of dimension attribute values; the operation selects a subcube of an input KG-OLAP cube. The slice-and-dice operation selects a partition of the cube for subsequent manipulation. Note that slice-and-dice operations in data warehousing literature and practice come in various forms. The definition in this section establishes a basic notion of slice-and-dice for KG-OLAP cubes. Future work may well extend this notion to provide rich query mechanisms in order to filter contexts based on complex conditions in an expressive domain ontology.
Definition 4
Definition 4(Slice and dice).
Given a cube
–
– For each
–
–
Fig. 7(a) depicts the definition of slice-and-dice operation on a one-dimensional cube. Intuitively, the slice-and-dice operation takes as argument the coordinates of a point in the cube, i.e., a dimensional vector
Fig. 7.
Illustration of contextual operations definitions.
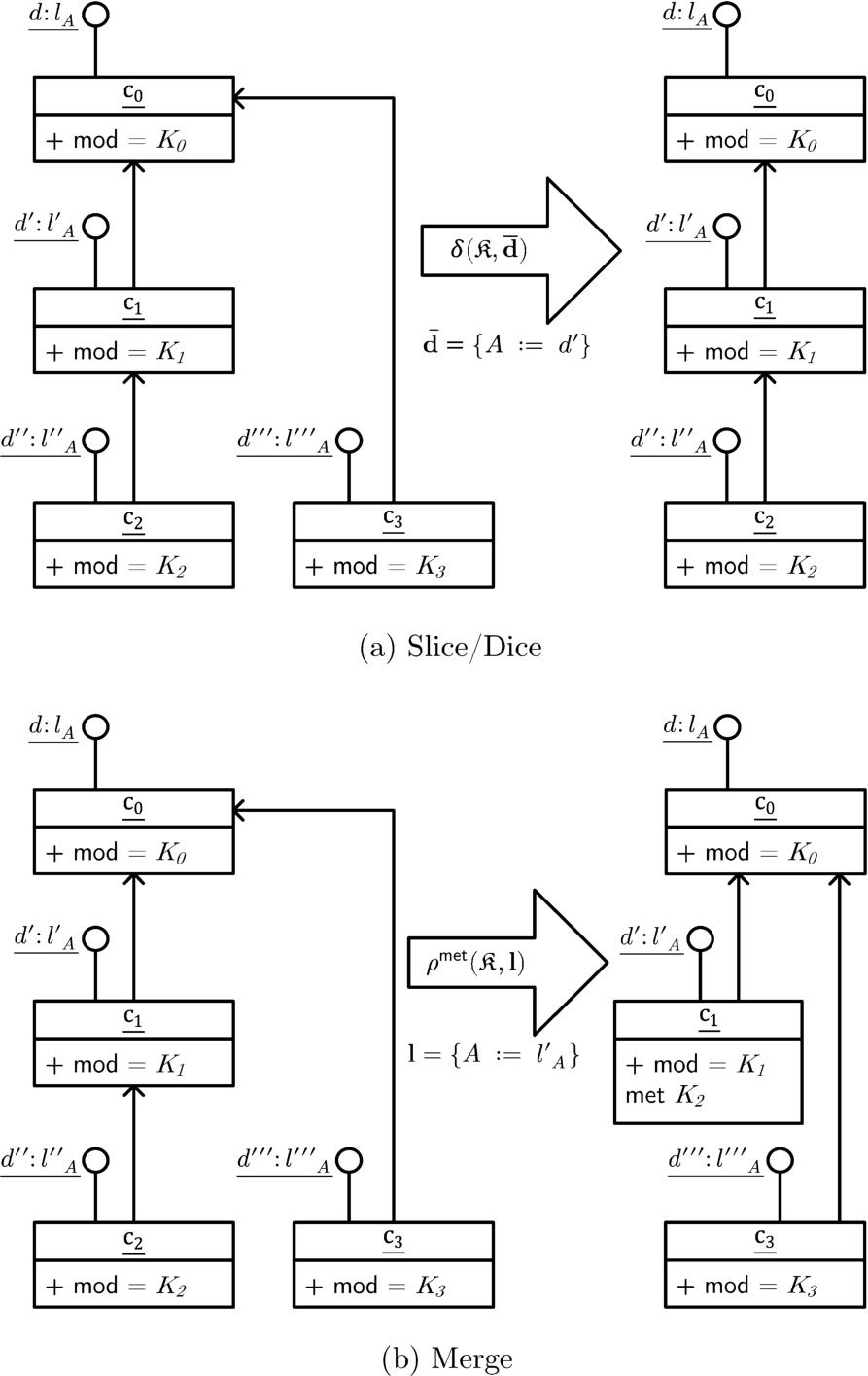
Fig. 8.
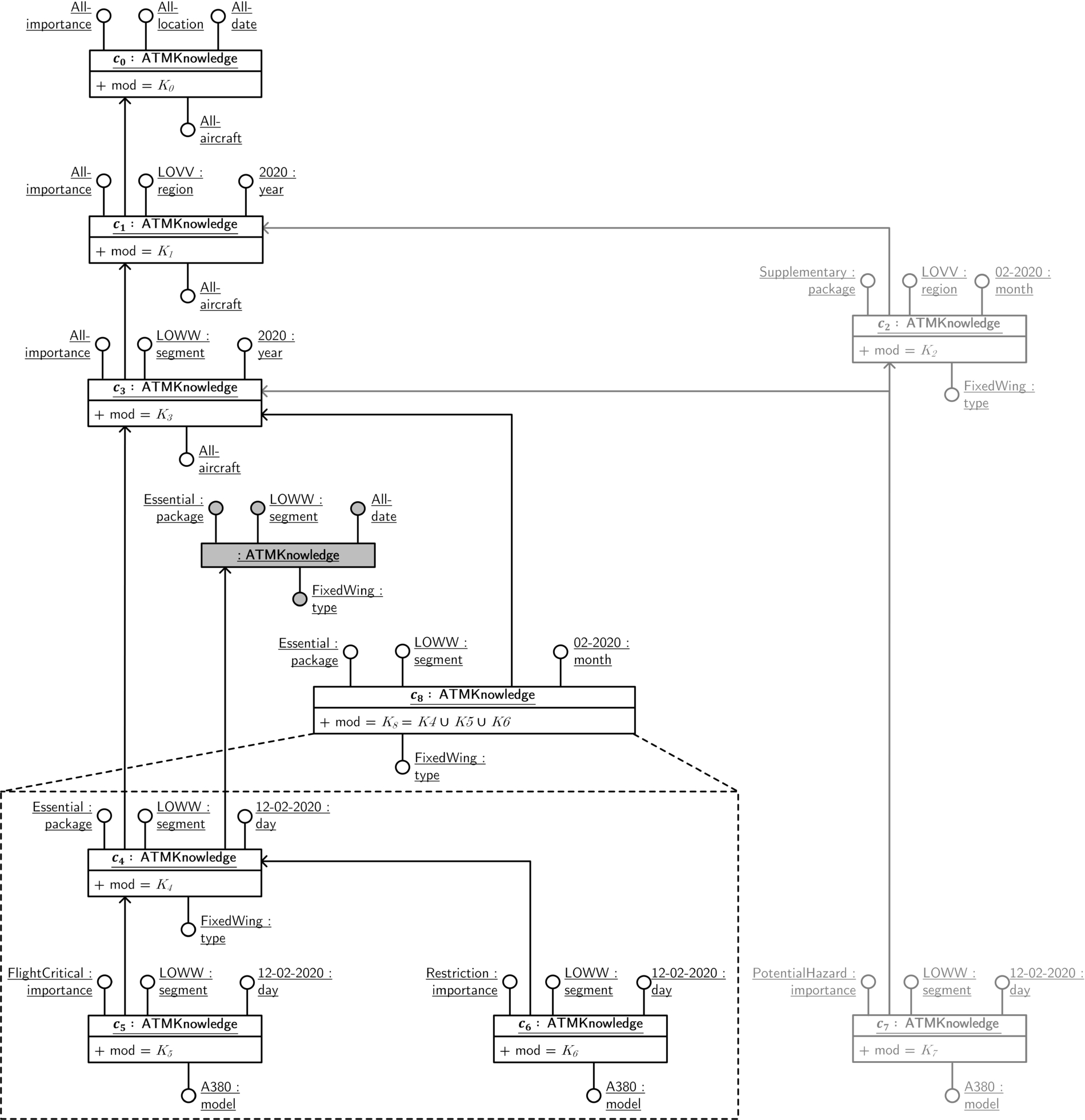
Applying slice-and-dice and merge operations on the KG-OLAP cube instance from Fig. 5. Gray lines denote contexts that are disregarded by the slice-and-dice operation
Example 6
Example 6(Slice and dice).
Fig. 8 illustrates the application of the slice-and-dice operation on the KG-OLAP cube from Fig. 5, which we denote by
In data warehousing, conceptual multidimensional models typically distinguish between dimensional attributes and non-dimensional attributes (see [30]). While the dimensional attributes identify the cell, non-dimensional attributes provide additional information that can be used for selection. Similarly, KG-OLAP cubes could be extended with non-dimensional attributes to allow for additional variants of the slice-and-dice operation.
4.1.2.Merge
The merge (or contextual roll-up) operation changes the granularity of a cube and its dimensions. Given an argument granularity specified as a vector of dimension levels l, the merge operation combines the contents of knowledge modules at granularities that are more specific than the given granularity.
Formally, we define a level vector as a set:
Let
Definition 5
Definition 5(Merge).
Given a cube
–
–
–
– For each
– For each
–
– Union merge
– Intersection merge
Fig. 7(b) illustrates the definition of the merge operation. Intuitively, the merge operation is a transformation over the original cube that combines the knowledge from lower-level cells into higher-level cells in the contextual hierarchy (by adding a new module
Example 7
Example 7(Merge).
In Fig. 8, the
In the case of general context coverage hierarchies that do not follow a clear notion of granularity level, the merge operation, which is now defined in terms of levels, requires reformulation. Moreover, the combination method in the merge operation – which in its current form simply considers either the union or intersection of the knowledge from the contexts in lower levels – can be refined to consider different methods for selection of knowledge in the newly generated module, e.g., by considering ontology merging methods that suit the use case at hand. We note that in the merge operation we do not explicitly consider the management of RDF blank nodes since we abstract from the serialization of the knowledge. We assume that blank nodes have been skolemized before the application of the merge operation; another option is to consider methods for merging RDF blank nodes in the resulting graph [36, #shared-blank-nodes-unions-and-merges].
4.2.Graph operations
Graph operations – abstraction, pivoting, and reification – alter the structure of the KGs inside the knowledge modules of a cell, thus satisfying Requirement 7. Abstraction replaces sets of entities with individual and more abstract entities. Pivoting moves metaknowledge (contextual information) inside the modules. Reification allows to represent relations as individuals.
4.2.1.Abstraction
Abstraction serves as an umbrella term for a class of graph operations that, broadly speaking, replace entities in an RDF graph with more abstract entities. This abstraction is based on various types of ontological information, e.g., class membership and grouping properties. We also refer to abstraction as ontological roll-up.
We distinguish three types of abstraction: (a) triple-generating abstraction generates new triples from existing triples, where an existing individual acts as abstraction of a set of other resources; (b) individual-generating abstraction generates a new individual that acts as abstraction of a set of resources; (c) value-generating abstraction computes a new value using some aggregation operation on a set of values.
Consider the set of asserted and inherited modules of a cell
Definition 6
Definition 6(Abstraction).
Given a cube
–
–
–
– triple generation T: for
∗ for every role assertion
∗ for every role assertion
– individual generation I: for
∗ for every
∗ for every role assertion
∗ resp. for every
– value generation
∗ add to
∗ remove every
Note that for simplicity we treat literal values as individuals and we do not distinguish roles across individuals and values in our language. We note that rdf:type may serve as a grouping property, provided that (newly introduced) grouping individuals represent the concepts employed for grouping and that the management of these grouping individuals is taken care of (cf. OWL punning [22]). Individual-generating abstraction may be extended for multiple grouping properties. Moreover, we note that the grouping role S is allowed to be a complex role expression, thus permitting to group, e.g., along role compositions.
Fig. 9.
Illustration of abstraction operations definitions.
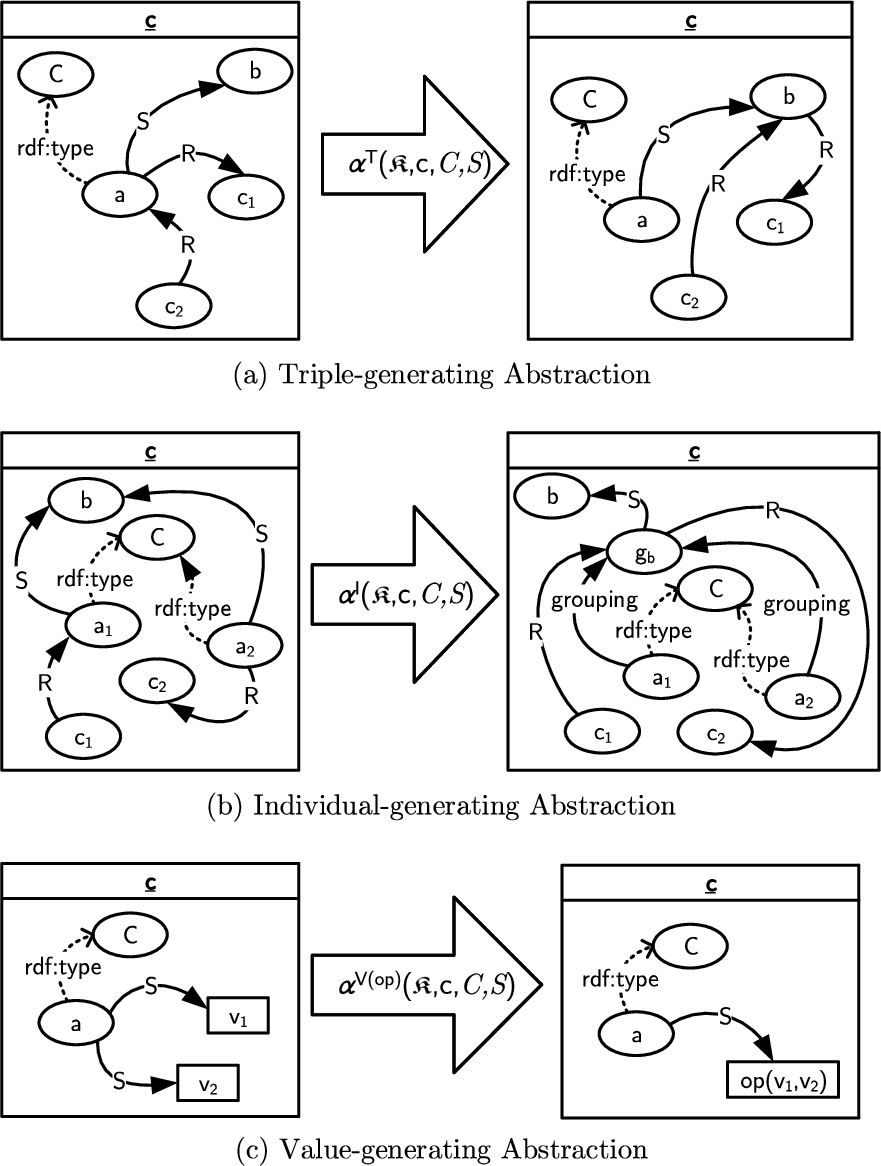
Fig. 9 shows a graphical representation for definitions of the abstraction operations. Intuitively, the abstraction operation takes as input the single cell, on the knowledge module of which the operation is applied, a class C of individuals to be abstracted, and a property S, which represents the grouping relation along which the elements have to be abstracted. The kind of manipulation on the cell’s knowledge then depends on the abstraction type: (a) in triple-generating abstraction, for every instance
The definition of individual-generating abstraction can be easily extended to allow for multiple grouping properties. For example, in individual-generating abstraction, given grouping relations
Fig. 10.
Examples of triple-, individual-, and value-generating abstraction.
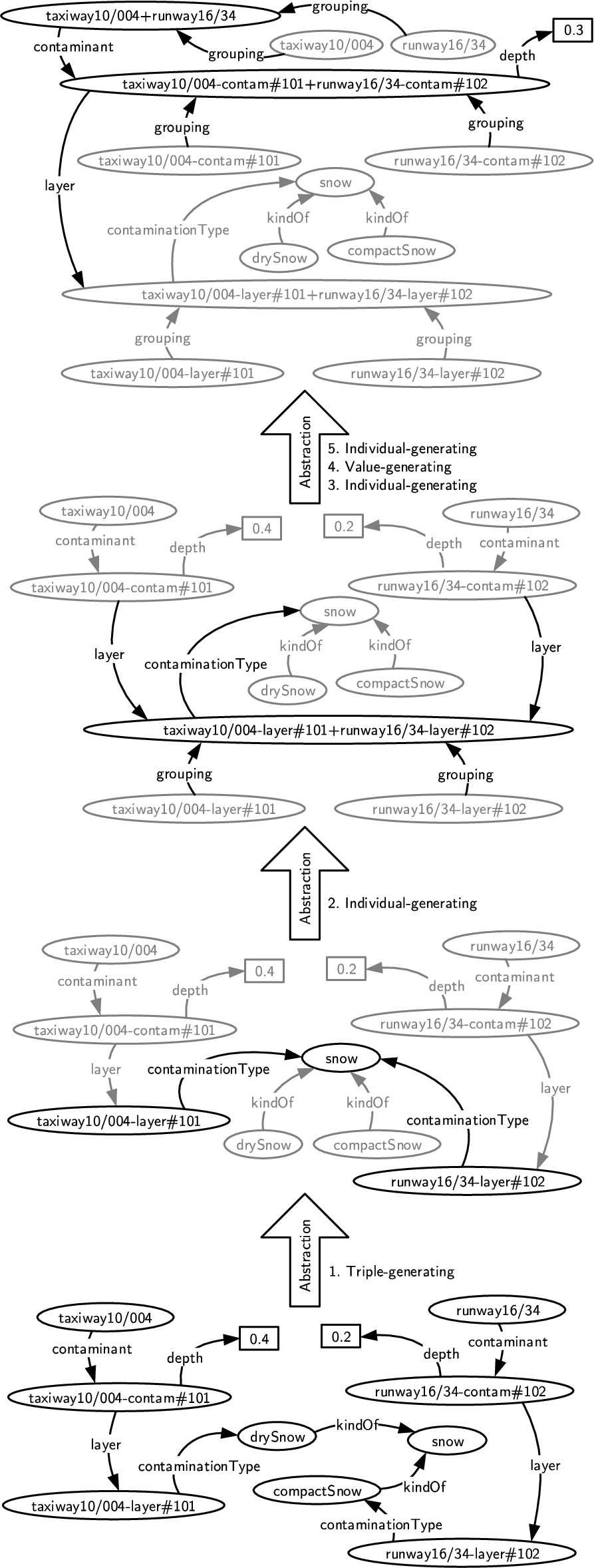
Example 8
Example 8(Abstraction).
Fig. 10 illustrates the different variants of abstraction on the running example of ATM knowledge graphs. Take the
The grouping role S can be an inverse role as well as a composite (complex) role. For example, in order to perform an individual-generating abstraction that groups SurfaceContaminationLayer individuals by the infrastructure element they belong to, the composite role
Additional variants of the abstraction operation can be defined in order to adapt the concept of abstraction to the structure of the object knowledge. For example, in individual-generating abstraction, we consider an explicit grouping relation to be introduced between grouped individuals and the newly introduced group individual. The grouping may also be realized with the introduction of a new class representing the abstraction, with class membership assuming the role of the grouping relation.
We note that KG-OLAP, in general, aims at being independent from the specific ontology language chosen for the representation of local axioms and assertions. If an ontology language were employed that could express the semantics of the abstraction operations (or some variant), that ontology language, in conjunction with an automated reasoner, could serve to implement the abstraction operations. Regardless, in the case of OWL, reasoning alone cannot serve to implement the abstraction operations. For example, in case of individual-generating abstraction, since OWL does not support grouping of individuals by property value when that value is a variable, extralogical steps must be followed in addition to reasoning. In Example 8, membership reasoning for the complex concept
4.2.2.Pivoting
The pivoting operation attaches dimensional properties (dimension attribute values) of a cell to a specified set of individuals inside the cell’s object knowledge. Pivoting allows for the preservation of contextual knowledge in case of a merge operation.
Definition 7
Definition 7(Pivoting).
Given a cube
–
–
–
– for every
Note that we have to admit that
Fig. 11.
Illustration of the pivoting operation definition.
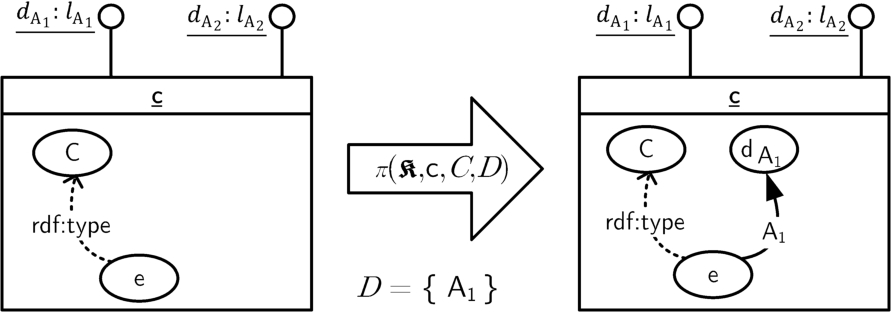
Example 9
Example 9(Pivoting).
Consider the
4.2.3.Reification
The reification operation takes “triples” (instance-level assertions) in the object knowledge of a cell and creates individuals that represent such triples. Reification allows for the preservation of duplicates in case of a union merge, which facilitates subsequent counting of occurrences in the course of the analysis. Furthermore, in combination with pivoting, the reification operation allows for attaching contextual information to context-dependent knowledge, preserving information about the context of a triple in case of a merge union, which would otherwise be lost.
Consider the set of asserted modules of cell
Definition 8
Definition 8(Reification).
Given a cube
– a module name
Fig. 12.
Illustration of the reification operation definition.
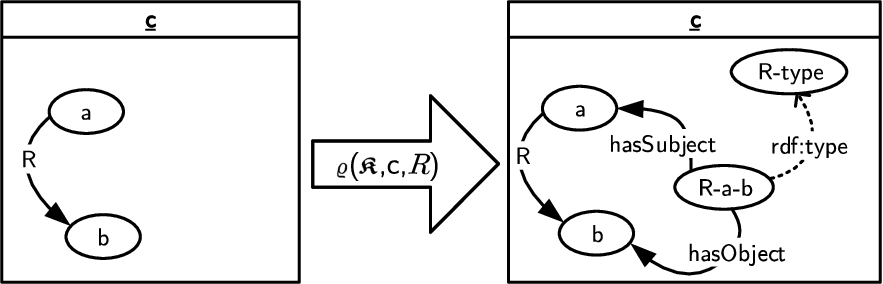
– a concept
– for every
Fig. 12 shows an illustration of the reification operation definition. Intuitively, the reification operation considers a single cell
Example 10
Example 10(Reification).
Consider the
5.Proof-of-concept prototype
In this section we sketch the foundations of a proof-of-concept prototype of a KG-OLAP system implemented on top of off-the-shelf quad stores. We evaluate the prototype’s performance in order to grasp the complexity of KG-OLAP cube maintenance and query operations as basis for future optimization efforts; performance optimization is not a goal of this paper. We refer to Section 4 and Section 5 of the Appendix [70] for additional information on implementation and performance evaluation, respectively. Source code and logs from the experiments are available in an online repository.33
5.1.Design and implementation
A mapping of the formal language to an actual RDF representation allows for the storage of KG-OLAP cubes in off-the-shelf quad stores with SPARQL realizations of the query operations. Context-aware rules serve to materialize roll-up relationships for levels and cells as well as inference and propagation of knowledge. Details about logical model, reasoning and queries are provided in Section 4 of the Appendix [70].
Architecture For each KG-OLAP cube, a base repository in a quad store comprises the cube knowledge (structure) and object knowledge (contents) for the cube. Using the slice-and-dice operation, the user selects a subset of the base data into a temporary repository, which then contains a working copy of the original data that can be modified using merge and abstraction.
Logical model The definition of the KG-OLAP model primitives (e.g., cell/fact, dimension, dimension members) can be easily defined in terms of RDF/OWL classes and properties. The two-layered structure of the KG-OLAP system with a global context and multiple local contexts – as in the CKR core [12] – is realized in RDF using different RDF graphs – one graph for the global knowledge and one graph for each knowledge module as well as a graph for the materialized inferred knowledge of each module.
Reasoning The reasoning procedure presented in Section 3.2.3, analogously to the CKR core [12], can be implemented using SPARQL-based forward rules that materialize the inferences, including coverage relationships between contexts. The KG-OLAP implementation employs the RDFpro framework [21] for rule execution. RDFpro supports the specification of SPARQL-based rules over multiple graphs, a feature required for reasoning inside individual cells as well as across different cells.
Queries The query operations introduced in Section 4 can be implemented using SPARQL queries. In particular, the query operations translate into SPARQL SELECT statements that return “delta” tables which consist of quads along with an indication of the operation (insert or delete). The delta tables can then be applied to the temporary repository.
5.2.Performance evaluation
In the following, we analyze performance of the core set of KG-OLAP cube operations – i.e., slice-and-dice, merge union, and abstraction. Specifically, we look at median run times for the computation of the query operations’ delta statements, i.e., the statements that must be inserted or deleted in order to perform the respective query operation, measured over multiple iterations, relative to repository size (number of statements), context size (number of contexts), and delta size (number of computed delta statements). We do not include the duration of actual insertions or deletions of the delta statements in the run times since these are not specific to contextualized KGs.
The performance experiments employed synthetic datasets based on the ATM scenario used throughout the paper, which allowed us to vary the number of dimensions, contexts, and statements while keeping the graphs similar. The generated contexts contain knowledge about airports, runways and taxiways, warnings, temporary closures of runways and taxiways for different aircraft characteristics based on weight or wingspan, layers of surface contamination with the depth of each layer, and navigation aids with their frequencies. Query operations ran on three-dimensional and four-dimensional datasets with 1365, 2501, and 3906 contexts, respectively. The contexts were not all on the same granularity but distributed over five different granularity levels (not including the root context), where the number of contexts per granularity level gradually increased with the depth; the majority of the contexts were on the most specific granularity level (see Section 5.2 of the Appendix [70] for details). Some entities were shared between contexts at different granularities to accurately study the effect of knowledge propagation. Context size was varied by adding/removing branches in the context hierarchy. In turn, for each dimensionality and context size there were three different repository sizes. In order to make for more realistic datasets, repository size was varied by increasing the number of airports, runways and taxiways, warnings, etc. per context, dependent on the granularity level, not by randomly distributing statements across contexts, which due to the structure of the context hierarchy results in differences in the repository sizes between context sizes. Additional “baseline” datasets were used in the experiments involving abstraction operations, which consisted of a single context, in order to investigate the impact of contextualization on query processing.
We remark that designing performance experiments after existing benchmarks for traditional OLAP, e.g., TCP-DS,44 would not give an accurate idea of the inherent complexity of KG-OLAP cube maintenance and query operations due to the different nature of the involved data and the queries. Traditional OLAP operates on numeric data, and does not fulfill Requirements 1–3 as well as Requirement 5 described in Section 2.5. While it would be possible to model numeric data using RDF and analyze those data using SPARQL, it would be beside the point to measure performance of atypical uses of KG-OLAP. Furthermore, related work on OLAP and information networks that aims at performance optimization, e.g., [88,89,91], does not (wholly) fulfill the requirements described in Section 2.5 (see also Section 6.3), rendering those approaches incomparable to KG-OLAP in terms of performance. Related work on ATM KGs conducting performance evaluation [44] runs general SPARQL queries over large RDF datasets but does not feature modularization (Requirement 4). Those SPARQL queries cannot be reasonably adapted to queries over multiple modules, and running SPARQL queries over a single context would only serve to replicate the results of related work, which depend on the experimental setting and require the same datasets to be used, which are not public. Finally, in this paper, we do not aim at performance optimization. Rather, we investigate complexity of KG-OLAP cube maintenance and query operations to inform future optimization efforts.
Fig. 13.
Performance of contextual operations.
The performance experiments were conducted on a virtual CentOS 6.8 machine with four cores of an Intel Xeon CPU E5-2640 v4 with 2.4 GHz, hosting a GraphDB55 8.9 instance. The Java Virtual Machine (JVM) of the GraphDB instance ran with 100 GB heap space. The JVM running the KG-OLAP system, which conducts rule evaluation, prepares queries, and caches query results, ran with 20 GB heap space.
The GraphDB instance comprised two repositories – base and temporary – with the following configuration (see [63] for further information). The entity index size was 30000000 and the entity identifier size was 32 bits. Context index, predicate list, and literal index were enabled. Reasoning and inconsistency checks were disabled; the KG-OLAP implementation takes care of reasoning via RDFpro rule evaluation.
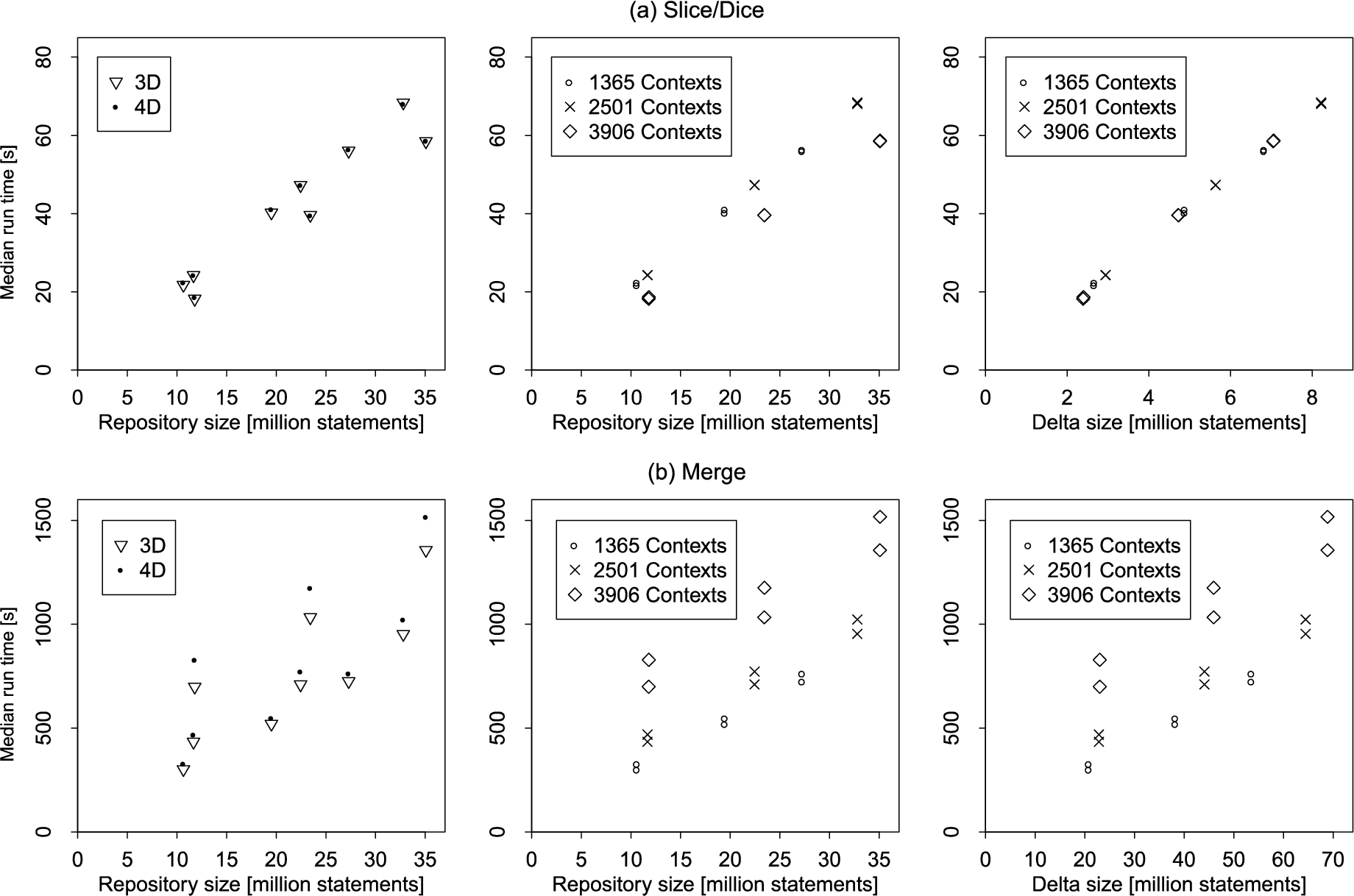
Fig. 13(a) shows run times of the slice-and-dice operation. The plot on the left shows run time relative to repository size per dimensionality. The plot in the middle shows run time relative to repository size per context size. The plot on the right shows run time relative to the size of the delta table computed by the query operation. Hence, performance of the slice-and-dice operation primarily depends on the number of delta statements in the query result, i.e., the number of selected cells/statements from the base repository. In fact, in this example, the slice-and-dice operation performs better on the large context size (3906 contexts) due to fewer delta statements being computed because of the distribution of the statements across the contexts. Dimensionality does not play a role here. In summary, slice and dice does not involve any complex computations, consisting only of the selection of relevant contexts and their contents.
Fig. 14.
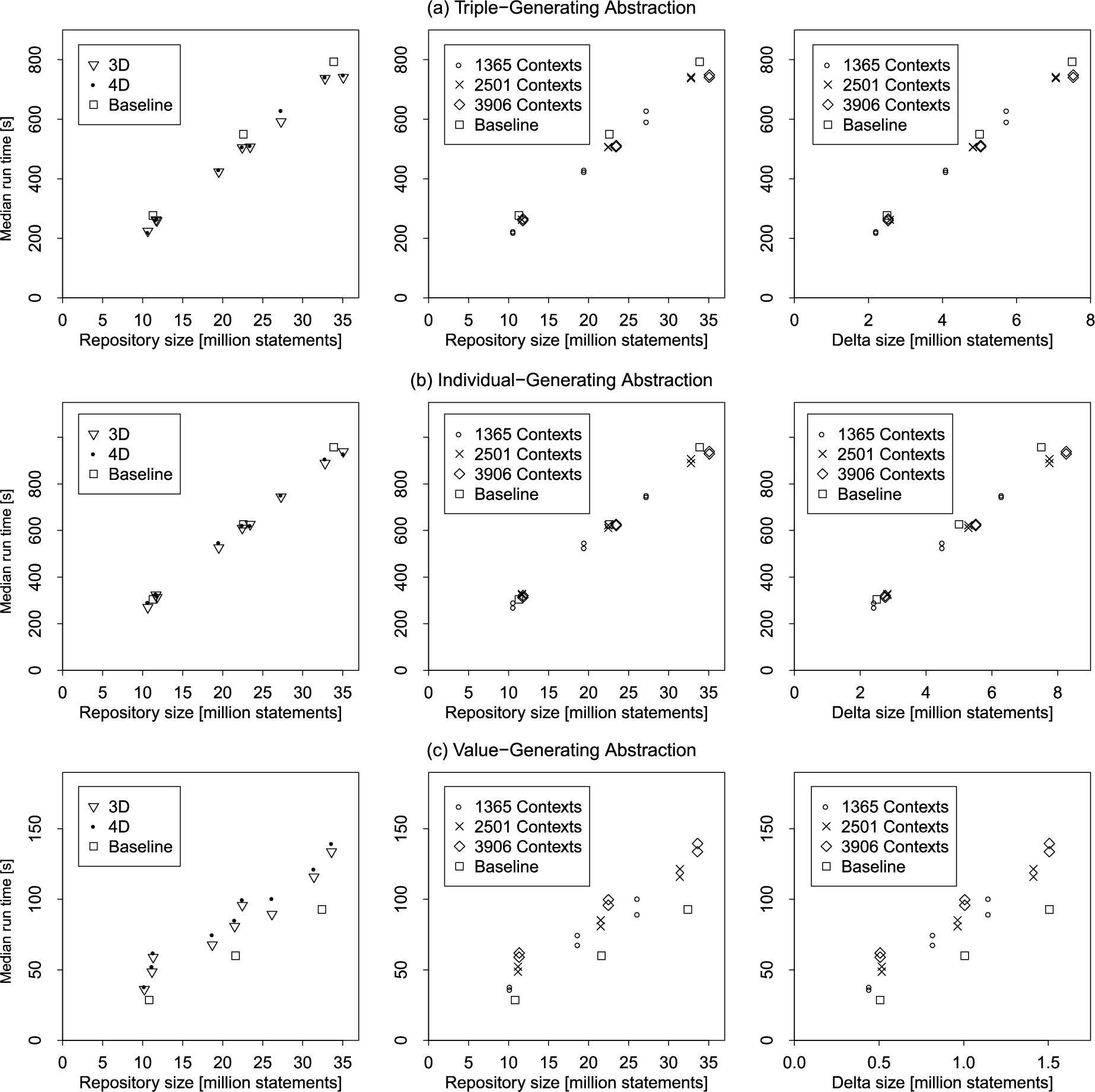
Performance of abstraction operations.
In case of the merge operation, in order to study worst-case performance, we deliberately chose dataset and formulation of the merge operation such that the result would be an almost complete reorganization of the contexts in the KG-OLAP cube. The lower-level cells contain the majority of statements, which are all affected by the merge operation. The complexity of the chosen operation is evidenced by the delta size, which is about twice the repository size: the merge operation first removes the statements from the merged cells only to insert those statements again into higher-level cells. The run time of the merge union operation, as shown in Fig. 13(b), primarily depends on the number of contexts. For each context size, we observe a linear increase in run time with respect to the repository size. For the large context size (3906 contexts) there is also a marked influence of dimensionality on run time.
Fig. 15.
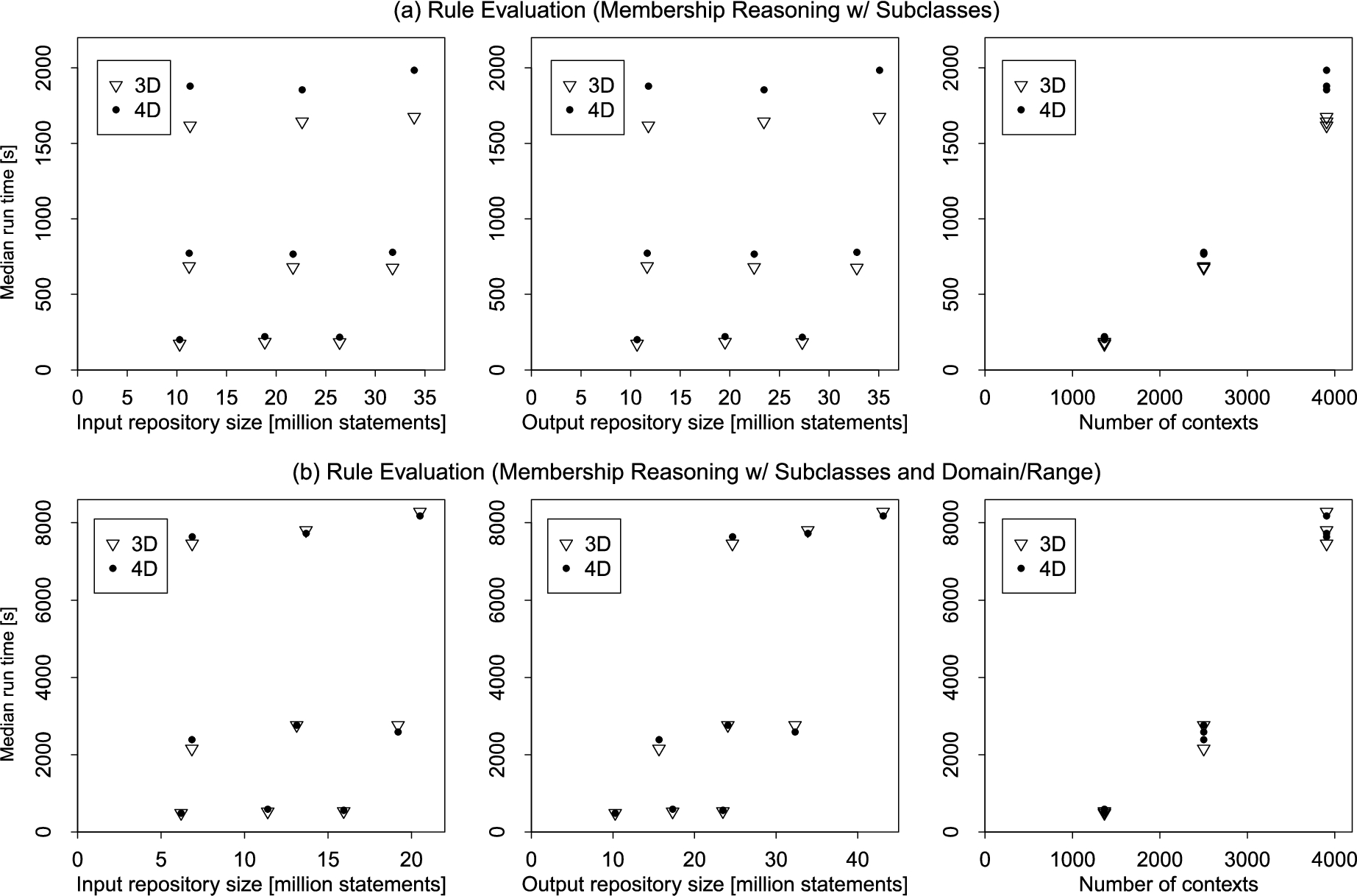
Performance of rule evaluation.
For performance evaluation of the abstraction operations, we employ, on the one hand, baseline datasets which consist of a single context comprising all statements in order to gain an understanding of the inherent complexity of these operations regardless of contextualization. Such abstraction operations on a single context correspond to the formalization. On the other hand, we perform abstraction operations in a variant that performs the abstraction to each cell at a particular granularity level. Similar to the merge operation, we deliberately choose a setting where the query operations affect a large number of statements in order to study worst-case performance.
Fig. 14(a) shows run times of triple-generating abstraction. Run time grows linearly with repository size. Run times for individual-generating abstraction with a single grouping property are similar, as shown in Fig. 14(b). For triple-generating abstraction, the baseline datasets had significantly higher run times. The difference was less pronounced for individual-generating abstraction.
For value-generating abstraction, the queries resulted in smaller sizes of the computed delta tables. Fig. 14(c) shows that the run time of value-generating abstraction grows about linearly with respect to repository size with a small influence of context size and little influence of dimensionality. Run times for the baseline datasets were smaller. We note that the run times of value-generating abstraction were in general quite low.
For results of reification and pivoting operations we refer to Section 4.5.6 and Section 4.5.7, respectively, of the Appendix [70]. In summary, the reification operation grows linearly with the repository size. For the pivoting operation we observe context size as the main factor influencing run time.
The proof-of-concept implementation relies on materialization of coverage relationships and inferences, which requires evaluation of a set of rules over the base repository in order to initialize the KG-OLAP cube. Fig. 15 shows run times for the evaluation of different rulesets relative to the repository sizes before and after reasoning – input and output repository size, respectively – as well as number of contexts for three-dimensional and four-dimensional KG-OLAP cubes. Reasoning in the performance experiments was conducted with the entire repository loaded into main memory first. Performance of two different rulesets was evaluated. The first ruleset, at the local level, i.e., within each context, performs membership reasoning under consideration of subclass relationships. For example, if Runway is a subclass of RunwayTaxiway and the fact
5.3.Discussion
The purpose of the implementation was to get an idea of the complexity of KG-OLAP cube maintenance and query operations. Even though optimization was not a main goal of this paper, performance is already more than satisfactory for certain use cases. In order to handle big KGs, however, future work will consider a distributed, parallelized implementation. Nevertheless, optimization requires a thorough definition of the framework’s fundamental concepts, which we provide in this work.
In the following, we briefly discuss the implications of the results of the performance evaluation regarding the use cases presented in Section 2.
Use Case 1
Use Case 1(Pilot briefings).
Performance of the proof-of-concept prototype is more than satisfactory for use in pilot briefings. In that case, a KG-OLAP cube would cover the pilot briefing for a particular flight. Knowledge would consist, on the one hand, of relevant baseline information, e.g., available runways and taxiways, route of the flight, and navigation aids. On the other hand, temporary knowledge would be extracted from DNOTAMs and METARs. A typical short-distance flight has fewer than 200 relevant DNOTAMs [79, p. 6B2-10]. Assuming that it takes 10 triples to represent a single DNOTAM, the knowledge extracted from DNOTAMs amounts to 2000 triples for a short-distance flight. Even when accounting for other potentially relevant knowledge, and assuming a long-distance flight, the KG for a pilot briefing for a single flight will be in the range of at most 100000 triples, which is well within the capabilities of the proof-of-concept prototype and would also allow for more sophisticated reasoning. The expected number of contexts for a single flight, even with hourly or half-hourly granularity of contextualization, assuming tens of geographic segments, is within the capabilities of the prototype implementation.
Use Case 2
Use Case 2(Post-operational analysis).
Maintaining a large KG-OLAP cube for post-operational analysis in Europe or the United States, or even in a single region within one of those areas, with possibly tens of thousands of contexts and billions of triples, would require a different implementation strategy. Taking the figures regarding ATMGRAPH’s size as reference, the volume of knowledge for only the New York area generated within a single month amounts to 260 million triples [44]. An alternative to maintaining a single KG-OLAP cube would be the adoption of a federated approach, maintaining multiple cubes within a metacube [73], i.e., a cube of cubes. A drill-across operation would then serve to combine knowledge from different cubes. Processing would have to be distributed and parallelized on multiple worker nodes.
6.Related work
In this section we review related work on contextualization in KGs, on OLAP and semantic web technologies, on OLAP and information networks, and on (knowledge) graph summarization.
6.1.Contextualized knowledge graphs
The choice of CKR as base formalism for the definition of the KG-OLAP cube model was motivated by the explicit representation of dimensions and the organization of dimensions into levels which, as discussed in the previous sections, is compatible with the multidimensional perspective of OLAP. The idea of associating contexts with dimensions traces back to the theoretical works of Lenat [53] and the “context as a box” paradigm from Benerecetti et al. [7] for representation of contexts in knowledge representation.
The problem of annotation and contextualization of knowledge in KGs has been present since the early years of semantic web technologies. Different ways of introducing a notion of modularization in the RDF data model or KG implementations have been proposed [16,38,45]. Such approaches, however, often do not provide a formal (logic-based) definition of the resulting contextual model, which goes against Requirement 2 (ontological knowledge).
The need for formalization of the notion of context in KGs led to the proposal of several (description) logic-based approaches for the contextualization of knowledge bases: apart from the CKR [12,75], we can cite [46,80,82,92], for example. While these models explicitly introduce contexts as a primitive in knowledge bases, these proposals do not always take into account an explicit representation of the notion of dimensions and/or level hierarchies, which is important – as of Requirement 4 for modularization and Requirement 5 for hierarchical decomposition of KGs into more general and more specific knowledge along with knowledge propagation – to qualify the different situations represented by contexts, and to have a clear separation of knowledge bases associated with each context.
Krötzsch et al. [48] propose an approach for adding annotations in a logic-based reading of KGs. While that model formally introduces annotations to local description logic axioms and assertions, it does not provide definite criteria for knowledge propagation across contextual structures as in the KG-OLAP coverage hierarchy (cf. Requirement 5, general and specific knowledge).
6.2.OLAP and semantic web technologies
Semantic technologies have been used for a variety of tasks in the context of OLAP (see [3] for an overview). Related to KG-OLAP are techniques for data analysis over RDF data. The RDF data cube vocabulary (QB) [24] and its extension, QB4OLAP [26], provide an RDF representation format for publishing traditional OLAP cubes with numeric measures on the Semantic Web, with often SPARQL-based operators that emulate traditional OLAP queries for analyzing multidimensional data in QB [57] and QB4OLAP [27,84]. Such statistical linked data are just different serialization and publication formats of traditional OLAP cubes. Other work has suggested “lenses” over RDF data [20] for the purpose of RDF data analysis, i.e., analytical schemas which can be used for OLAP queries on RDF data. Similarly, superimposed multidimensional schemas [37] define a mapping between a multidimensional model and a KG in order to allow for the formulation of OLAP queries. Contrary to these approaches, KG-OLAP focuses on RDF graphs as the “measures” of OLAP cubes rather than numeric measures that are aggregated using aggregation operators such as Sum and Avg.
Fusion cubes [2] supplement traditional OLAP cubes with external data in RDF format, particularly linked open data where typically the data are not owned by the analyst. Fusion cubes are traditional OLAP cubes with numeric measures that can be populated dynamically with statistical data from RDF sources. Fusion cubes store contextual information about provenance and data quality of the external sources. Other similar work [59] extracts traditional OLAP cubes with numeric measures from RDF data sources and ontologies, which analysts may then query using a traditional OLAP language, namely MDX. The Semantic Cockpit project [60] employed ontologies for the definition of a shared understanding of business terms and analysis situations among business analysts. With respect to these approaches, KG-OLAP cubes may have some similarities to a structured data lake (see [69] for more information on data lakes), which stores the data of interest in a semantically richer format than plain numeric measures, but unlike conventional data lakes, which store raw data, provides a certain degree of integration and cleaning as well as dedicated query operations.
6.3.OLAP and information networks
KG-OLAP is related to applications of OLAP technology for analysis of information networks. Among the first, and arguably the most prominent, of these approaches was Graph OLAP (also known as InfoNetOLAP) [18,19], which through its informational and topological OLAP queries provides rich query facilities suitable for graph analysis. In Graph OLAP, graphs are associated with dimensional attributes, which yields a graph cube, i.e., the contents of the cube cells are graphs. The edges of the graphs themselves are weighted; the weights represent the measures to be analyzed. Typical applications of Graph OLAP are analysis of co-author and similar social graphs from different time periods, geographic locations, and so on. Graph OLAP distinguishes between informational roll-up and topological roll-up, which corresponds to the distinction between contextual and graph operations in KG-OLAP. The focus of Graph OLAP are weighted directed graphs with highly structured and homogeneous data. Hence, Graph OLAP does not consider heterogeneity (Requirement 1) and ontological knowledge (Requirement 2). Schema information, e.g., about roll-up hierarchies, are external to the data, i.e., graphs in Graph OLAP are not self-describing (Requirement 3), resulting in rigid, inflexible graph schema and queries. Graph OLAP also does not consider the systematic propagation of knowledge from more general to more specific contexts (Requirement 5); graph data are only associated with the most specific granularity in the cube.
Since the original proposal of Graph OLAP, other approaches that apply OLAP to information networks have been proposed, which can be compared along different criteria, most notably the type of network, i.e., homogeneous or heterogeneous [67]. KGs have been likened to “schema-rich” heterogeneous information networks [77] and, therefore, only approaches applying OLAP to heterogeneous networks can be accurately compared to KG-OLAP. Yet, even approaches applying OLAP technology to heterogeneous information networks, e.g., [29,55,88,89,91], do not consider schema variability, i.e., Requirement 1(c), or ontological knowledge (Requirement 2). Furthermore, unlike KG-OLAP, approaches to OLAP on information networks also lack a systematic way of structuring large bodies of knowledge, which comes with the decomposition of large knowledge graphs into hierarchically structured modules, from more general to more specific, in conjunction with knowledge propagation (Requirement 5). Schema and instance data are also firmly separated, i.e., the data are not self-describing (Requirement 3), reducing flexibility of the query operations. Another approach [56] aims to reconcile statistical/multidimensional linked data in QB and QB4OLAP with the informational/topological view of OLAP on information networks. Regarding the requirements, that approach does not consider schema variability, i.e., Requirement 1(c), ontological knowledge (Requirement 2), distinction between more general and more specific knowledge in conjunction with knowledge propagation (Requirement 5), and knowledge abstraction (Requirement 7). Some approaches, e.g., [88], offer abstraction operations that are similar to the KG-OLAP operations, but less flexible due to lack of self-describing data (Requirement 3), which allow for a more flexible formulation of roll-up paths within the graph structure. Furthermore, KG-OLAP allows for the use of complex concepts and roles in abstraction (in line with Requirement 2, ontological knowledge), allowing for flexible query formulation. For example, individual-generating abstraction with complex concepts such as
Techniques for optimization of OLAP on information networks may inform the optimization of KG-OLAP. Precomputation and materialization of aggregate views [88,89] is the most prevalent optimization technique for OLAP on information networks, which may not be applicable directly to KG-OLAP due to the heterogeneous data and highly flexible query formulation in KG-OLAP. Adopting a MapReduce-based implementation like Pagrol’s [89] or Process OLAP’s [6] is an interesting perspective for KG-OLAP as well.
Work on the analysis (or mining) of heterogeneous information networks [76] and Semantic Web databases [51] is orthogonal to KG-OLAP. Such approaches calculate, for example, degree distribution or PageRank, but may also serve to predict links and as the basis for recommender systems. Just like data mining may use OLAP cubes, information network mining may use KG-OLAP cubes.
6.4.(Knowledge) graph summarization
The KG-OLAP query operations also invite comparison with (knowledge) graph summarization techniques [17,54], which aim at making KGs more accessible to end users and applications by providing a condensed view on the represented knowledge. Use cases for KG summarization include visualization and exploration of KGs as well as facilitating query formulation and processing. Broadly speaking, KG (or RDF) summarization techniques may be divided into structural summarization, mining-based, and statistical summarization [17]. Statistical summarization computes quantitative measures that characterize a graph whereas mining-based (or pattern-based) summarization employs graph mining to extract frequent patterns that act as a summary. Structural summarization aims at finding a summary graph that preserves characteristics of the original graph while considerably reducing the size of the graph, making the graph easier to handle and comprehend.
Among the structural summarization approaches for RDF graphs, quotient RDF summaries represent a type of summaries that produce an RDF graph where multiple nodes from the source graph are replaced by a single summary node in the RDF summary. Accordingly, the results of abstraction operations in KG-OLAP may be considered structural quotient RDF summaries [17]. Unlike most structural approaches towards RDF summarization, KG-OLAP allows for ad hoc summarization based on user-specified, application-specific summarization criteria.
Unlike KG-OLAP, existing work on graph and KG summarization largely ignores modularization and contextuality in KGs (Requirement 4). In fact, existing work on KG summarization is orthogonal to the KG-OLAP approach. Consequently, future work may adapt summarization algorithms to serve as graph operators in KG-OLAP.
7.Conclusion
In this paper, we presented KG-OLAP for the analysis of knowledge represented in KGs. We extended the multidimensional modeling paradigm from OLAP to the representation of contextualized KGs. Each cell (or context) in a KG-OLAP cube contains knowledge triples. We introduced specific query operations for KG-OLAP cubes. On the one hand, contextual operations allow for selecting and merging contexts. On the other hand, graph operations allow for summarizing knowledge triples within individual contexts. We illustrated KG-OLAP with use cases in air traffic management [72,73]. A proof-of-concept prototype using off-the-shelf quad stores and SPARQL queries demonstrates feasibility. Using the prototype, we conducted experimental performance evaluation, which may inform future optimization efforts. Even though optimization was not a goal, we conclude that there is a class of use cases for which the proof-of-concept implementation’s performance is more than satisfactory.
Different directions can be investigated for future work. We aim at extending the formalism for a distributed approach with federated KG-OLAP cubes. We sketch a first version of a distributed, parallelized KG-OLAP framework in [11]. Regarding implementation, we aim at realizing a distributed, parallelized implementation of a KG-OLAP system including the concept of metacube and the drill-across operation [73], in order to support big KGs. We are interested in extending the KG-OLAP model with defeasible axioms similar to previous work on CKR [8,13]. Regarding the KG-OLAP operations, different variants can be studied to meet the needs of the use cases at hand and the extensions of the underlying model (e.g. by distribution). Moreover, we may extend the proposed definitions of query operations with common RDF summarization techniques.
Notes
1 Alternatively, data warehouse literature refers to those points as facts – a term which in order to avoid confusion we reserve to designate the statements in a KG.
2 In the definition of operations, for simplicity of notation, we assume that components of the cube
References
[1] | AIXM 5.1.1 – Data Model (UML), Accessed: 20 October 2020, http://aixm.aero/document/aixm-511-data-model-uml. |
[2] | A. Abelló, J. Darmont, L. Etcheverry, M. Golfarelli, J. Mazón, F. Naumann, T.B. Pedersen, S. Rizzi, J. Trujillo, P. Vassiliadis and G. Vossen, Fusion cubes: Towards self-service business intelligence, International Journal of Data Warehousing and Mining 9: (2) ((2013) ), 66–88. doi:10.4018/jdwm.2013040104. |
[3] | A. Abello, O. Romero, T.B. Pedersen, R. Berlanga, V. Nebot, M.J. Aramburu and A. Simitsis, Using semantic web technologies for exploratory OLAP: A survey, IEEE Transactions on Knowledge and Data Engineering 27: (2) ((2015) ), 571–588. doi:10.1109/TKDE.2014.2330822. |
[4] | F. Baader, D. Calvanese, D. McGuinness, D. Nardi and P. Patel-Schneider (eds), The Description Logic Handbook, Cambridge University Press, (2003) . |
[5] | L. Bellomarini, G. Gottlob, A. Pieris and E. Sallinger, Swift logic for big data and knowledge graphs, in: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), C. Sierra, ed., (2017) , pp. 2–10. doi:10.24963/ijcai.2017/1. |
[6] | B. Benatallah, H.R. Motahari-Nezhad et al., Scalable graph-based OLAP analytics over process execution data, Distributed and Parallel Databases 34: (3) ((2016) ), 379–423. doi:10.1007/s10619-014-7171-9. |
[7] | M. Benerecetti, P. Bouquet and C. Ghidini, On the dimensions of context dependence: Partiality, approximation, and perspective, in: Modeling and Using Context. CONTEXT 2001, V. Akman, P. Bouquet, R.H. Thomason and R.A. Young, eds, Lecture Notes in Computer Science, Vol. 2116: , Springer, Berlin, Heidelberg, (2001) , pp. 59–72. doi:10.1007/3-540-44607-9_5. |
[8] | L. Bozzato, T. Eiter and L. Serafini, Enhancing context knowledge repositories with justifiable exceptions, Artificial Intelligence 257: ((2018) ), 72–126. doi:10.1016/j.artint.2017.12.005. |
[9] | L. Bozzato, T. Eiter and L. Serafini, Reasoning with justifiable exceptions in |
[10] | L. Bozzato, T. Eiter and L. Serafini, Justifiable exceptions in general contextual hierarchies, in: Modeling and Using Context. CONTEXT 2019, G. Bella and P. Bouquet, eds, Lecture Notes in Computer Science, Vol. 11939: , Springer, Cham, (2019) , pp. 26–39. doi:10.1007/978-3-030-34974-5_3. |
[11] | L. Bozzato and C.G. Schuetz, Towards distributed contextualized knowledge repositories for analysis of large-scale knowledge graphs, in: Proceedings of the 35th Italian Conference on Computational Logic (CILC 2020), F. Calimeri, S. Perri and E. Zumpano, eds, CEUR Workshop Proceedings, Vol. 2710: , CEUR-WS.org, (2020) . http://ceur-ws.org/Vol-2710/short1.pdf. |
[12] | L. Bozzato and L. Serafini, Materialization calculus for contexts in the Semantic Web, in: DL 2013, T. Eiter, B. Glimm, Y. Kazakov and M. Krötzsch, eds, CEUR Workshop Proceedings, Vol. 1014: , CEUR-WS.org, (2013) . http://ceur-ws.org/Vol-1014/paper_51.pdf. |
[13] | L. Bozzato, L. Serafini and T. Eiter, Reasoning with justifiable exceptions in contextual hierarchies, in: Principles of Knowledge Representation and Reasoning: Proceedings of the Sixteenth International Conference (KR 2018), M. Thielscher, F. Toni and F. Wolter, eds, AAAI Press, (2018) , pp. 329–338. https://aaai.org/ocs/index.php/KR/KR18/paper/view/18032. |
[14] | F. Burgstaller, D. Steiner, B. Neumayr, M. Schrefl and E. Gringinger, Using a model-driven, knowledge-based approach to cope with complexity in filtering of notices to airmen, in: Proceedings of the Australasian Computer Science Week Multiconference, (2016) , p. 46. doi:10.1145/2843043.2843044. |
[15] | F. Burgstaller, D. Steiner, M. Schrefl, E. Gringinger, S. Wilson and S. van der Stricht, AIRM-based, fine-grained semantic filtering of notices to airmen, in: Proccedings of the 15th Integrated Communication, Navigation and Surveillance Conference (ICNS) Conference, (2015) . doi:10.1109/ICNSURV.2015.7121222. |
[16] | J.J. Carroll, C. Bizer, P.J. Hayes and P. Stickler, Named graphs, provenance and trust, in: Proceedings of the 14th International Conference on World Wide Web (WWW 2005), A. Ellis and T. Hagino, eds, ACM, (2005) , pp. 613–622. doi:10.1145/1060745.1060835. |
[17] | Š. Čebirić, F. Goasdoué, H. Kondylakis, D. Kotzinos, I. Manolescu, G. Troullinou and M. Zneika, Summarizing semantic graphs: A survey, The VLDB Journal 28: (3) ((2019) ), 295–327. doi:10.1007/s00778-018-0528-3. |
[18] | C. Chen, X. Yan, F. Zhu, J. Han and P.S. Yu, Graph OLAP: a multi-dimensional framework for graph data analysis, Knowledge and Information Systems 21: (1) ((2009) ), 41–63. doi:10.1007/s10115-009-0228-9. |
[19] | C. Chen, F. Zhu, X. Yan, J. Han, P. Yu and R. Ramakrishnan, InfoNetOLAP: OLAP and mining of information networks, in: Link Mining: Models, Algorithms, and Applications, P.S. Yu, J. Han and C. Faloutsos, eds, Springer, New York, (2010) , pp. 411–438. doi:10.1007/978-1-4419-6515-8_16. |
[20] | D. Colazzo, F. Goasdoué, I. Manolescu and A. Roatiş, RDF analytics: Lenses over semantic graphs, in: Proceedings of the 23rd International Conference on World Wide Web, C. Chung, A.Z. Broder, K. Shim and T. Suel, eds, (2014) , pp. 467–478. doi:10.1145/2566486.2567982. |
[21] | F. Corcoglioniti, M. Rospocher, M. Mostarda and M. Amadori, Processing billions of RDF triples on a single machine using streaming and sorting, in: Proceedings of the 30th Annual ACM Symposium on Applied Computing (SAC 2015), R.L. Wainwright, J.M. Corchado, A. Bechini and J. Hong, eds, (2015) , pp. 368–375. doi:10.1145/2695664.2695720. |
[22] | B. Cuenca Grau, I. Horrocks, B. Motik, B. Parsia, P.F. Patel-Schneider and U. Sattler, OWL 2: The next step for OWL, Journal of Web Semantics 6: (4) ((2008) ), 309–322. doi:10.1016/j.websem.2008.05.001. |
[23] | R. Cyganiak, J.J. Carroll and B. McBride, RDF 1.1 Concepts and Abstract Syntax – W3C Recommendation 25 February 2014, Technical Report, W3C, 2014. https://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/. |
[24] | R. Cyganiak and D. Reynolds, The RDF Data Cube Vocabulary – W3C Recommendation 16 January 2014, Technical Report, W3C, 2014, https://www.w3.org/TR/2014/REC-vocab-data-cube-20140116/. |
[25] | M.M. Eshow, M. Lui and S. Ranjan, Architecture and capabilities of a data warehouse for ATM research, in: 2014 IEEE/AIAA 33rd Digital Avionics Systems Conference (DASC), (2014) . doi:10.1109/DASC.2014.6979418. |
[26] | L. Etcheverry and A.A. Vaisman, QB4OLAP: A vocabulary for OLAP cubes on the Semantic Web, in: COLD 2012, CEUR Workshop Proceedings, Vol. 905: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-905/EtcheverryAndVaisman_COLD2012.pdf. |
[27] | L. Etcheverry, A.A. Vaisman and E. Zimányi, Modeling and querying data warehouses on the Semantic Web using QB4OLAP, in: Data Warehousing and Knowledge Discovery. DaWaK 2014, L. Bellatreche and M.K. Mohania, eds, Lecture Notes in Computer Science, Vol. 8646: , Springer, Cham, (2014) , pp. 45–56. doi:10.1007/978-3-319-10160-6_5. |
[28] | Federal Aviation Administration, Federal NOTAM system airport operations scenarios, 2010, Accessed: 20 October 2020. https://notams.aim.faa.gov/FNSAirportOpsScenarios.pdf. |
[29] | A. Ghrab, O. Romero, S. Skhiri and E. Zimányi, TopoGraph: An End-To-End Framework to Build and Analyze Graph Cubes, Information Systems Frontiers (2020), 1–24. doi:10.1007/s10796-020-10000-z. |
[30] | M. Golfarelli, D. Maio and S. Rizzi, The dimensional fact model: A conceptual model for data warehouses, International Journal of Cooperative Information Systems 7: (2–3) ((1998) ), 215–247. doi:10.1142/S0218843098000118. |
[31] | J.M. Gomez-Perez, J.Z. Pan, G. Vetere and H. Wu, Enterprise knowledge graph: An introduction, in: Exploiting Linked Data and Knowledge Graphs in Large Organisations, J.Z. Pan, G. Vetere, J.M. Gomez-Perez and H. Wu, eds, Springer, Cham, (2017) , pp. 1–14. doi:10.1007/978-3-319-45654-6. |
[32] | Google, Introducing the Knowledge Graph: Things, not strings, 2012. https://search.googleblog.com/2012/05/introducing-knowledge-graph-things-not.html (Accessed: 20 October 2020). |
[33] | E. Gringinger, R.M. Keller, A. Vennesland, C.G. Schuetz and B. Neumayr, A comparative study of two complex ontologies in air traffic management, in: 2019 IEEE/AIAA 38th Digital Avionics Systems Conference (DASC), (2019) . doi:10.1109/DASC43569.2019.9081790. |
[34] | E. Gringinger, C. Schuetz, B. Neumayr, M. Schrefl and S. Wilson, Towards a value-added information layer for SWIM: The semantic container approach, in: Proceedings of the 18th Integrated Communications Navigation and Surveillance (ICNS) Conference, (2018) , pp. 3–113114. doi:10.1109/ICNSURV.2018.8384870. |
[35] | A.Y. Halevy, F. Korn, N.F. Noy, C. Olston, N. Polyzotis, S. Roy and S.E. Whang, Managing Google’s data lake: An overview of the Goods system, IEEE Data Engineering Bulletin 39: (3) ((2016) ), 5–14. http://sites.computer.org/debull/A16sept/p5.pdf. |
[36] | P.J. Hayes and P.F. Patel-Schneider, RDF 1.1 Semantics – W3C Recommendation 25 February 2014, Technical Report, W3C, 2014. https://www.w3.org/TR/2014/REC-rdf11-mt-20140225/. |
[37] | M. Hilal, C.G. Schuetz and M. Schrefl, Using superimposed multidimensional schemas and OLAP patterns for RDF data analysis, Open Computer Science 8: (1) ((2018) ), 18–37. doi:10.1515/comp-2018-0003. |
[38] | J. Hoffart, F.M. Suchanek, K. Berberich and G. Weikum, YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia, Artificial Intelligence 194: ((2013) ), 28–61. doi:10.1016/j.artint.2012.06.001. |
[39] | International Civil Aviation Organization, Annex 15 to the Convention on International Civil Aviation: Aeronautical information services, 14 edn, 2013, Accessed: 29 October 2020, https://www.icao.int/NACC/Documents/Meetings/2014/ECARAIM/REF05-Annex15.pdf. |
[40] | R.M. Keller, Ontologies for aviation data management, in: Proceedings of the IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), (2016) . doi:10.1109/DASC.2016.7777971. |
[41] | R.M. Keller, Building a knowledge graph for the air traffic management community, in: Companion Proceedings of the 2019 World Wide Web Conference, (2019) , pp. 700–704. doi:10.1145/3308560.3317706. |
[42] | R.M. Keller, The NASA Air Traffic Management Ontology (atmonto) – Release dated March, 2018, Technical Report, National Aeronautics and Space Administration, 2018, Accessed: 20 October 2020. https://data.nasa.gov/ontologies/atmonto/. |
[43] | R.M. Keller, The NASA Air Traffic Management Ontology (atmontoPlus) – Release dated March, 2018, Technical Report, National Aeronautics and Space Administration, 2018, Accessed: 20 October 2020. https://data.nasa.gov/ontologies/atmontoPlus/. |
[44] | R.M. Keller, S. Ranjan, M.Y. Wei and M.M. Eshow, Semantic representation and scale-up of integrated air traffic management data, in: Proceedings of the International Workshop on Semantic Big Data, S. Groppe and L. Gruenwald, eds, (2016) . doi:10.1145/2928294.2928296. |
[45] | O. Khriyenko and V. Terziyan, A framework for context sensitive metadata description, International Journal on Metadata, Semantics and Ontologies 1: (2) ((2006) ), 154–164, ISSN 1744-2621. doi:10.1504/IJMSO.2006.011011. |
[46] | S. Klarman, Reasoning with Contexts in Description Logics, PhD thesis, Free University of Amsterdam, 2013. |
[47] | M. Krötzsch, Efficient inferencing for OWL EL, in: JELIA 2010, Lecture Notes in Computer Science, Vol. 6341: , Springer, (2010) , pp. 234–246. doi:10.1007/978-3-642-15675-5_21. |
[48] | M. Krötzsch, M. Marx, A. Ozaki and V. Thost, Attributed description logics: Reasoning on knowledge graphs, in: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI 2018), J. Lang, ed., (2018) , pp. 5309–5313. doi:10.24963/ijcai.2018/743. |
[49] | M. Krötzsch and G. Weikum, Editorial for special section on knowledge graphs, Journal of Web Semantics 37–38: ((2016) ), 53–54. doi:10.1016/j.websem.2016.04.002. |
[50] | R. Lake, D.S. Burggraf, M. Trninić and L. Rae, Geography Mark-up Language: Foundation for the Geo-Web, Wiley, Hoboken, (2004) . |
[51] | S. Lee, S.R. Sukumar, S. Hong and S.-H. Lim, Enabling graph mining in RDF triplestores using SPARQL for holistic in-situ graph analysis, Expert Systems with Applications 48: ((2016) ), 9–25. doi:10.1016/j.eswa.2015.11.010. |
[52] | J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P.N. Mendes, S. Hellmann, M. Morsey, P. Van Kleef, S. Auer and C. Bizer, DBpedia – a large-scale, multilingual knowledge base extracted from Wikipedia, Semantic Web 6: (2) ((2015) ), 167–195. doi:10.3233/SW-140134. |
[53] | D. Lenat, The Dimensions of Context-Space, Technical Report, CYCorp, 1998, Accessed: 28 October 2020. https://www.researchgate.net/publication/243530490_The_dimensions_of_context-space. |
[54] | Y. Liu, T. Safavi, A. Dighe and D. Koutra, Graph summarization methods and applications: A survey, ACM Computing Surveys 51: (3) ((2018) ), 62–63. doi:10.1145/3186727. |
[55] | S. Loudcher, W. Jakawat, E.P.S. Morales and C. Favre, Combining OLAP and information networks for bibliographic data analysis: A survey, Scientometrics 103: (2) ((2015) ), 471–487. doi:10.1007/s11192-015-1539-0. |
[56] | A. Matei, K.-M. Chao and N. Godwin, OLAP for multidimensional Semantic Web databases, in: Enabling Real-Time Business Intelligence. BIRTE 2014, BIRTE 2013, M. Castellanos, U. Dayal, T.B. Pedersen and N. Tatbul, eds, Lecture Notes in Business Information Processing, Vol. 206: , Springer, Berlin, Heidelberg, (2015) , pp. 81–96. doi:10.1007/978-3-662-46839-5_6. |
[57] | M. Meimaris, G. Papastefanatos, P. Vassiliadis and I. Anagnostopoulos, Efficient computation of containment and complementarity in RDF data cubes, in: Proceedings of the 19th Conference on Extending Database Technology (EDBT 2016), E. Pitoura, S. Maabout, G. Koutrika, A. Marian, L. Tanca, I. Manolescu and K. Stefanidis, eds, (2016) , pp. 281–292. doi:10.5441/002/edbt.2016.27. |
[58] | B. Motik, B. Cuenca Grau, I. Horrocks, Z. Wu, A. Fokoue and C. Lutz, OWL 2 Web Ontology Language Profiles, 2nd edn, 2009, W3C Recommendation 11 December 2012, Technical Report, W3C, https://www.w3.org/TR/2012/REC-owl2-profiles-20121211/. |
[59] | V. Nebot and R. Berlanga Llavori, Building data warehouses with semantic web data, Decision Support Systems 52: (4) ((2012) ), 853–868. doi:10.1016/j.dss.2011.11.009. |
[60] | T. Neuböck, B. Neumayr, M. Schrefl and C. Schütz, Ontology-driven business intelligence for comparative data analysis, in: Business Intelligence. EBISS 2013, E. Zimányi, ed., Lecture Notes in Business Information Processing, Vol. 172: , Springer, Cham, (2014) , pp. 77–120. doi:10.1007/978-3-319-05461-2_3. |
[61] | B. Neumayr, E. Gringinger, C.G. Schuetz, M. Schrefl, S. Wilson and A. Vennesland, Semantic data containers for realizing the full potential of system wide information management, in: Proceedings of the 36th IEEE/AIAA Digital Avionics Systems Conference (DASC), (2017) , pp. 1–10. doi:10.1109/DASC.2017.8102002. |
[62] | S. Niarchakou and J.S. Selva, ATFCM operations manual – network operations handbook, 21.0 edn, 2017, Accessed: 20 October 2020. http://www.eurocontrol.int/sites/default/files/content/documents/nm/network-operations/HANDBOOK/ATFCM-Operations-Manual-next.pdf. |
[63] | Ontotext, Configuring a repository, http://graphdb.ontotext.com/documentation/8.9/free/configuring-a-repository.html (Accessed: 20 October 2020). |
[64] | H. Paulheim, Knowledge graph refinement: A survey of approaches and evaluation methods, Semantic Web 8: (3) ((2017) ), 489–508. doi:10.3233/SW-160218. |
[65] | V. Penela, G. Álvaro, C. Ruiz, C. Córdoba, F. Carbone, M. Castagnone, J.M. Gómez-Pérez and J. Contreras, miKrow: Semantic intra-enterprise micro-knowledge management system, in: The Semanic Web: Research and Applications. ESWC 2011, G. Antoniou, M. Grobelnik, E. Simperl, B. Parsia, D. Plexousakis, P. De Leenheer and J. Pan, eds, Lecture Notes in Computer Science, Vol. 9981: , Springer, Berlin, Heidelberg, (2011) , pp. 154–168. doi:10.1007/978-3-642-21064-8_11. |
[66] | R. Qian, Understand your world with Bing, 2013, https://blogs.bing.com/search/2013/03/21/understand-your-world-with-bing/ (Accessed: 20 October 2020). |
[67] | P.O. Queiroz-Sousa and A.C. Salgado, A review on OLAP technologies applied to information networks, ACM Transactions on Knowledge Discovery from Data 14: (1) ((2019) ), 8. doi:10.1145/3370912. |
[68] | T. Ruan, L. Xue, H. Wang, F. Hu, L. Zhao and J. Ding, Building and exploring an enterprise knowledge graph for investment analysis, in: The Semantic Web – ISWC 2016. ISWC 2016, P. Groth, E. Simperl, A. Gray, M. Sabou, M. Krötzsch, F. Lecue, F. Flöck and Y. Gil, eds, Lecture Notes in Computer Science, Vol. 9982: , Springer, Cham, (2016) , pp. 418–436. doi:10.1007/978-3-319-46547-0_35. |
[69] | P. Russom, Data Lakes: Purposes, Practices, Patterns, and Platforms, 2017, Accessed: 20 October 2020, https://tdwi.org/research/2017/03/best-practices-report-data-lakes. |
[70] | C.G. Schuetz, L. Bozzato, B. Neumayr, M. Schrefl and L. Serafini, Knowledge Graph OLAP: Appendix, Technical Report, 2020. http://kg-olap.dke.uni-linz.ac.at/appendix. |
[71] | C.G. Schuetz, B. Neumayr, M. Schrefl, E. Gringinger, A. Vennesland and S. Wilson, The case for contextualized knowledge graphs in air traffic management, in: Joint Proceedings of the International Workshops on Contextualized Knowledge Graphs, and Semantic Statistics, S. Capadisli, F. Cotton, J.M. Giménez-García, A. Haller, E. Kalampokis, V. Nguyen, A.P. Sheth and R. Troncy, eds, CEUR Workshop Proceedings, Vol. 2317: , CEUR-WS.org, (2018) . http://ceur-ws.org/Vol-2317/article-10.pdf. |
[72] | C.G. Schuetz, B. Neumayr, M. Schrefl, E. Gringinger and S. Wilson, Semantics-based summarization of ATM data to manage information overload in pilot briefings, in: Proceedings of the 31st Congress of the International Council of the Aeronautical Sciences, (2018) . http://www.icas.org/ICAS_ARCHIVE/ICAS2018/data/papers/ICAS2018_0763_paper.pdf. |
[73] | C.G. Schuetz, B. Neumayr, M. Schrefl, E. Gringinger and S. Wilson, Semantics-based summarisation of ATM information: Managing information overload in pilot briefings using semantic data containers, The Aeronautical Journal 123: (1268) ((2019) ), 1639–1665. doi:10.1017/aer.2019.74. |
[74] | C.G. Schütz, B. Neumayr and M. Schrefl, Business model ontologies in OLAP cubes, in: CAiSE 2013, C. Salinesi, M.C. Norrie and O. Pastor, eds, Lecture Notes in Computer Science, Vol. 7908: , Springer, (2013) , pp. 514–529. doi:10.1007/978-3-642-38709-8. |
[75] | L. Serafini and M. Homola, Contextualized knowledge repositories for the Semantic Web, Journal of Web Semantics 12: ((2012) ), 64–87. doi:10.1016/j.websem.2011.12.003. |
[76] | C. Shi, Y. Li, J. Zhang, Y. Sun and P.S. Yu, A survey of heterogeneous information network analysis, IEEE Transactions on Knowledge and Data Engineering 29: (1) ((2017) ), 17–37. doi:10.1109/TKDE.2016.2598561. |
[77] | C. Shi and P.S. Yu, Schema-rich heterogeneous network mining, in: Heterogeneous Information Network Analysis and Applications, Springer, Cham, (2017) , pp. 181–199. doi:10.1007/978-3-319-56212-4_7. |
[78] | Skybrary, Situational Awareness, https://www.skybrary.aero/index.php/Situational_Awareness (Accessed: 20 October 2020). |
[79] | D. Steiner, I. Kovacic, F. Burgstaller, M. Schrefl, T. Friesacher and E. Gringinger, Semantic enrichment of DNOTAMs to reduce information overload in pilot briefings, in: Proceedings of the 16th Integrated Communications Navigation and Surveillance (ICNS) Conference, (2016) . doi:10.1109/ICNSURV.2016.7486359. |
[80] | U. Straccia, N. Lopes, G. Lukácsy and A. Polleres, A general framework for representing and reasoning with annotated Semantic Web data, in: Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2010), M. Fox and D. Poole, eds, (2010) , http://www.aaai.org/ocs/index.php/AAAI/AAAI10/paper/view/1590. |
[81] | W. Tunstall-Pedoe, True Knowledge: Open-domain question answering using structured knowledge and inference, AI Magazine 31: (3) ((2010) ), 80–92. doi:10.1609/aimag.v31i3.2298. |
[82] | O. Udrea, D. Recupero and V.S. Subrahmanian, Annotated RDF, ACM Transactions on Computational Logic 11: (2) ((2010) ), 10–11041, ISSN 1529-3785. doi:10.1145/1656242.1656245. |
[83] | A. Vaisman and E. Zimányi, Data Warehouse Systems – Design and Implementation, Springer, Berlin Heidelberg, (2014) . doi:10.1007/978-3-642-54655-6. |
[84] | J. Varga, L. Etcheverry, A.A. Vaisman, O. Romero, T.B. Pedersen and C. Thomsen, QB2OLAP: Enabling OLAP on statistical linked open data, in: Proceedings of the 32nd IEEE International Conference on Data Engineering (ICDE 2016), (2016) , pp. 1346–1349. doi:10.1109/ICDE.2016.7498341. |
[85] | A. Vennesland, R.M. Keller, C.G. Schuetz, E. Gringinger and B. Neumayr, Matching ontologies for air traffic management: A comparison and reference alignment of the AIRM and NASA ATM ontologies, in: Proceedings of the 14th International Workshop on Ontology Matching, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2536: , CEUR-WS.org, (2019) . http://ceur-ws.org/Vol-2536/om2019_LTpaper1.pdf. |
[86] | A. Vennesland, B. Neumayr, C. Schuetz, A. Savulov, S. Wilson, E. Gringinger and J. Gorman, AIRM-O – ATM Information Reference Model Ontology, 2017, https://w3id.org/airm-o/ontology. |
[87] | D. Vrandečić and M. Krötzsch, Wikidata: A free collaborative knowledgebase, Communications of the ACM 57: (10) ((2014) ), 78–85. doi:10.1145/2629489. |
[88] | P. Wang, B. Wu, B. Wang and T.S.M.H. Graph, Cube: A novel framework for large scale multi-dimensional network analysis, in: Proceedings of the 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA 2015), (2015) . doi:10.1109/DSAA.2015.7344826. |
[89] | Z. Wang, Q. Fan, H. Wang, K. Tan, D. Agrawal and A. El Abbadi, Pagrol: Parallel graph OLAP over large-scale attributed graphs, in: Proceedings of the IEEE 30th International Conference on Data Engineering, I.F. Cruz, E. Ferrari, Y. Tao, E. Bertino and G. Trajcevski, eds, (2014) , pp. 496–507. doi:10.1109/ICDE.2014.6816676. |
[90] | H. Wu, R. Denaux, P. Alexopoulos, Y. Ren and J.Z. Pan, Understanding knowledge graphs, in: Exploiting Linked Data and Knowledge Graphs in Large Organisations, J.Z. Pan, G. Vetere, J.M. Gomez-Perez and H. Wu, eds, Springer, Cham, (2017) , pp. 147–180. doi:10.1007/978-3-319-45654-6_6. |
[91] | P. Zhao, X. Li, D. Xin and J. Han, Graph cube: On warehousing and OLAP multidimensional networks, in: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, T.K. Sellis, R.J. Miller, A. Kementsietsidis and Y. Velegrakis, eds, (2011) , pp. 853–864. doi:10.1145/1989323.1989413. |
[92] | A. Zimmermann and J.M. Giménez-García, Contextualizing DL axioms: Formalization, a new approach, and its properties, in: Joint Proceedings of the Web Stream Processing Workshop (WSP 2017) and the 2nd International Workshop on Ontology Modularity, Contextuality, and Evolution (WOMoCoE 2017), D. Dell’Aglio, D. Anicic, P.M. Barnaghi, E.D. Valle, D.L. McGuinness, L. Bozzato, T. Eiter, M. Homola and D. Porello, eds, CEUR Workshop Proceedings, Vol. 1936: , CEUR-WS.org, (2017) , pp. 74–85, http://ceur-ws.org/Vol-1936/paper-07.pdf. |


