
On the relation between keys and link keys for data interlinking
Abstract
Both keys and their generalisation, link keys, may be used to perform data interlinking, i.e. finding identical resources in different RDF datasets. However, the precise relationship between keys and link keys has not been fully determined yet. A common formal framework encompassing both keys and link keys is necessary to ensure the correctness of data interlinking tools based on them, and to determine their scope and possible overlapping. In this paper, we provide a semantics for keys and link keys within description logics. We determine under which conditions they are legitimate to generate links. We provide conditions under which link keys are logically equivalent to keys. In particular, we show that data interlinking with keys and ontology alignments can be reduced to data interlinking with link keys, but not the other way around.
1.Introduction
There are large amounts of RDF data available on the Web, in the form of knowledge graphs or as part of linked open data. Interoperability between RDF datasets largely relies on links between resources from different RDF datasets and especially links asserting the identity of resources bearing different IRIs, specified using the owl:sameAs property [20]. Since RDF datasets tend to be large, the automatic discovery of owl:sameAs links between RDF datasets is an important and challenging task. This task is usually referred to as data interlinking and different algorithms and tools for data interlinking have been proposed [18,25].
Among the state-of-the-art approaches to data interlinking, some are based on finding keys [2,9,17,31] or link keys [7,8] across RDF datasets. Both keys and link keys are devices characterising what makes two resources to be identical. Hence, it is natural to exploit them for discovering links across datasets. Even though both techniques have been proven to be effective in data interlinking scenarios, their relationship has not been formally established yet.
The objective of this paper is to clarify the relationship between keys and link keys. For this, we first provide the semantics of (RDF) keys and link keys. More specifically, we formalise how a key, in its different versions, can be combined with an alignment between ontologies for data interlinking. Then, we define the semantics of six kinds of link keys – weak, plain and strong link keys, and their in- and eq-variants – and we logically ground the usage of link keys for data interlinking. Finally, we establish the conditions under which link keys are equivalent to keys and show that data interlinking with keys and ontology alignments can be reduced to data interlinking with link keys, but not the other way around.
The contribution of this paper focuses on the specific features of keys and link keys. It does it, to the extent possible, independently from the underlying ontological schema and the logical constructors used for describing or constraining class and property expressions. This is the reason why computational issues are left for further interesting research.
In the remainder, Section 2 presents the context and related work of the paper. Section 3 introduces the notations used throughout the paper. Section 4 recalls two different semantics of keys and Section 5 logically justifies their use for data interlinking. Section 6 defines link keys. Section 7 logically grounds the use of link keys for data interlinking. The relations between keys and link keys are established in Section 8, both with respect to their logical entailment and the links they produce. Section 9 concludes the paper and discusses future work.
All definitions are illustrated with concrete examples taken from real-world datasets.
2.Context and related work
Data interlinking refers to the process of finding pairs of IRIs of different RDF datasets representing the same entity [18,25]. The result of this process is a set of same-as links to be specified by the owl:sameAs property. To decide whether two IRIs represent the same entity or not is mainly based on comparing their values for selected properties. Data interlinking is reminiscent of the task of record linkage in databases [14], but it is applied to RDF data described with RDFS/OWL ontologies.
Link discovery platforms such as SILK [22,33] and LIMES [26] enable users to process link specifications to generate links. Link specifications express the properties to be used for generating owl:sameAs links between two RDF datasets. They also specify the similarity measures to be used for comparing datatype property values, the aggregation functions for combining similarity values, and the similarity thresholds beyond which two values are considered equal. Link specifications may be directly set by users or they may be built (semi-)automatically, for example, using machine learning techniques [27,29].
A key is a set of (datatype or object) properties that uniquely identify the instances of a class within a dataset. For example,
Key-based approaches to data interlinking first extract key candidates from RDF datasets and then select the most accurate candidates according to different quality measures [2,9,17,31]. When the data of two RDF datasets are described using the same ontology, then keys, if available, can be directly used for interlinking the datasets, but if the data are described using different ontologies, then they need to be combined with ontology alignments [16] relating the properties and classes of the data. For example, the previous key could be combined with the alignment correspondences
Keys can be used to build link specifications or can be translated into logical rules to perform data interlinking. The latter allows to take advantage of logical reasoning [3,4,21]. Key extraction algorithms discover either S-keys [2,17,31] or F-keys [9,30]. There are two kinds of keys since RDF properties are multivalued, contrary to relational attributes, which are monovalued. If a set of properties form an S-key for a class, it is enough that two instances of the class share one value for each of the properties of the key to infer that they are the same (e.g. email property for the AssistantProfessor class). But if the properties form an F-key then the instances must share all values (e.g. hasPoem property for the PoemAnthology class because two different poem anthologies may have a poem in common but will unlikely contain exactly the same poems).
When datasets are described with different ontologies, alignments must be used, either during the key extraction process or later when performing data interlinking. For example, the approach proposed in [31] searches in a source dataset for S-keys over classes which are equivalent to classes in a target dataset and then selects among the discovered S-keys those composed of properties which are equivalent to properties of the target dataset.
Link keys generalise the combination of keys and ontology alignments for data interlinking [7,16]. A link key is a set of pairs of properties that uniquely identify the instances of two classes of two RDF datasets. For example,
Unlike [31], the key-based approaches to data interlinking proposed in [2,17] aim to discover S-keys that hold not only in the source dataset, but in both source and target datasets. It is assumed that the datasets are described using the same vocabulary, possibly resulting from merging different ontologies with an alignment, again composed of equivalence correspondences only. Link keys do not require the properties that compose them to be equal or semantically aligned. In addition, as we will show in this paper, the kind of keys discovered in [2,17] correspond to strong link keys, although data interlinking may be possible with weak link keys (the kind of link keys considered in [7,16]) when strong link keys do not exist.
The formal semantics of S-keys and F-keys have been given in [6] using rules, but the combination of S-keys and F-keys with ontology alignments for data interlinking is not formally addressed. In this paper, we address it using description logics.
Different approaches to incorporate keys and functional dependencies to description logics have been proposed. Keys may be treated as a new concept constructor [11,32] or as global constraints in a separate key box (KBox) [12,13,23,24], which is the option that we follow in this paper. The goal of these approaches is to study the decidability of reasoning with keys or functional dependencies in specific description logics. Here, we do not address automated reasoning with link keys. Instead, we use the formalism of description logics to provide the semantics of keys and link keys. This allows us to ground their legitimacy in generating links across RDF datasets. In addition, it gives us the means to compare keys and link keys on the basis of their entailments and the links they generate.
3.Preliminaries
This section introduces minimal notions and notations used throughout the entire paper. We assume that the reader is familiar with the basics of description logics (DLs) [28].
In this paper, ontologies will be the combination of a schema and a dataset, and they will be modelled as DL knowledge bases.
Definition 1
Definition 1(Ontology).
An ontology is a knowledge base
Thus, a schema is modelled as a set of terminological axioms, i.e. a set of subsumption, equivalence and disjointness axioms between classes and properties:
Alignments relate entities – classes, properties, individuals – that belong to different ontologies [16]. Alignment relations between classes and properties are subsumption, equivalence and disjointness. In the case of individuals, they are related by equality. Alignment statements between classes and properties are referred to as correspondences, whereas equality statements in alignments will be called links.
We will also model alignments as knowledge bases. The difference with ontologies is that, in the case of an alignment, the TBox and ABox use two ontologies’ vocabularies. In addition, the ABox contains equality statements (links) only.
Definition 2
Definition 2(Alignment).
Let
Different semantics for alignments may be found in the literature [10,34]. Here, though, we will consider the axioms of two ontologies and the correspondences and links of an alignment between them to be part of one single global ontology. Without loss of generality, we can assume that the vocabularies of
In what follows, given an ontology
4.Two kinds of keys in description logics
In order to compare keys and link keys, we start by reformulating the semantics of keys [6] as description logic axioms. We distinguish between several types of keys which apply in this context. Instead of S-keys and F-keys, we will speak of in-keys and eq-keys, respectively. The prefixes in- and eq- are shortened forms of intersection and equality. These notations are related to the conditions (1) and (2) in Definitions 3 and 4.
4.1.Semantics of keys
In what follows, given a DL interpretation
Definition 3
Definition 3(in-key).
An in-key assertion, or simply an in-key, has the form
An interpretation
Definition 4
Definition 4(eq-key).
An eq-key assertion, or simply an eq-key, has the form
An interpretation
According to Definition 3, if two instances of a class share at least one value for each of the properties of an in-key for the class, then we can infer that they are the same instance. This is formalised in Proposition 1.
Proposition 1.
The following holds:
Proof.
This is a direct consequence of Definition 3: for any interpretation
Similarly, according to Definition 4, given an eq-key for a class and two instances of the class, we can infer that they are the same instance if they share all values (and at least one) for each of the properties of the key. However, we need to be sure that all known values indeed are all values that the instances may have. This is stated in Proposition 2.
Proposition 2.
The following holds:
Proof.
Let
Thus, unlike in-keys, eq-keys require a local closed world assumption – represented in Proposition 2 by the axioms
Notice that Proposition 2 requires the logic to be able to express nominals and value restrictions. All our results are agnostic of the used logical language but those referring to the use of eq-keys and eq-link keys for data interlinking.
The semantics of owl:hasKey in OWL2 corresponds to the semantics of in-keys but restricted to being applied to named instances only (thus excluding blank nodes).
Although in-keys and eq-keys have been introduced separately, it is also possible to consider a hybrid notion of key.
Definition 5
Definition 5(Hybrid key).
A key assertion, or simply a key, has the form
An interpretation
From here on, an ontology
Example 1 below provides examples of in-keys and eq-keys in real RDF datasets.
Example 1
Example 1(Insee).
Insee is the French institution in charge of collecting and publishing information about French economy and society. Part of the Insee data is available in the form of RDF triples and can be downloaded as an RDF dump or queried through a SPARQL endpoint.33 Insee ontologies are available too. We only consider the Insee data related to administrative districts (COG dataset).
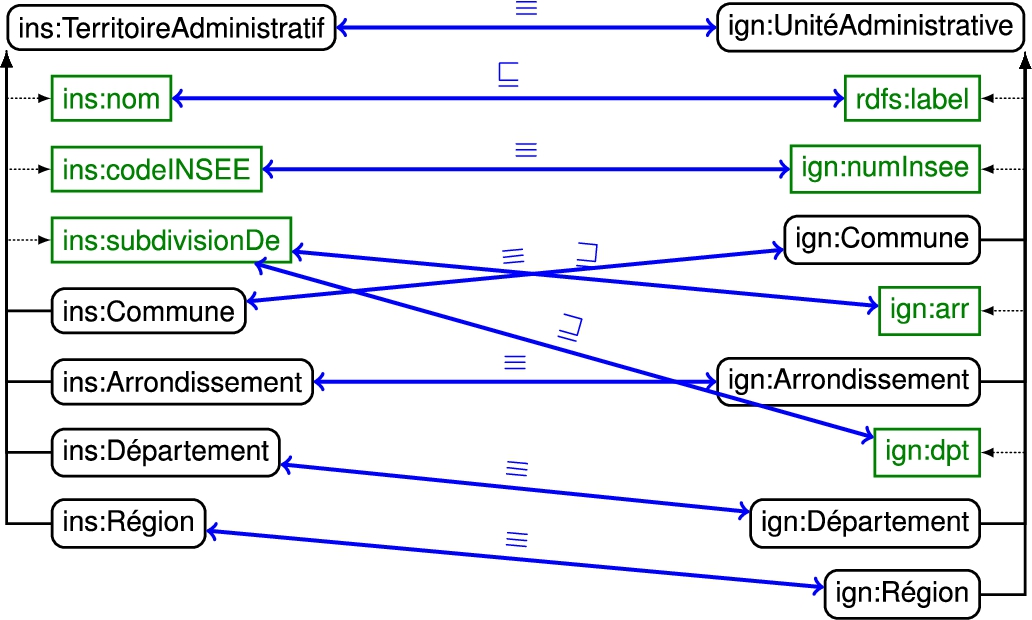
The Insee vocabulary comprises four class names for describing the main administrative divisions in France: Commune, Arrondissement, Département and Région. Among the properties of these classes, we find the datatype property nom (used to specify the name of an administrative division), the object property subdivisionDe (to specify that an administrative division is subdivision of another one, e.g. that the commune of Grenoble is a subdivision of the Isère department) and the datatype property codeINSEE (which is an identifier for territories, including administrative divisions, and can be thought of as the key in the Insee database). The property subdivisionDe is declared to be transitive in the Insee ontology. This fragment of the Insee ontology is depicted in Fig. 2.
No owl:hasKey axiom is declared in the Insee ontology. Nevertheless, we have checked the in-key and eq-key conditions for the properties and classes mentioned before. We have done so in the RDF graph of Insee extended with the transitivity of subdivisionDe. This generalises to the fully inferred graph as no other axiom of the Insee ontology may have an impact on the satisfiability of the examined key axioms.
As expected, the codeINSEE property is an in-key for Commune, Arrondissement, Département and Région. Formally:
Concerning the property nom, it turns out to be an in-key for Département and Région, but neither for Commune nor Arrondissement. Indeed, there exist different communes (and arrondissements) sharing the same name. For instance, Bully may refer to three different communes: Bully in the department of Loire, Bully in Rhône and Bully in Seine-Maritime. However, there is no pair of communes of the same department sharing the same name. In fact, nom and subdivisionDe, when put together, form a key for the class Commune. The property subdivisionDe, though, must be treated in the sense of eq-keys. This is because, since subdivisionDe is a transitive property, all French communes share (at least) a value for subdivisionDe, namely, the Insee entity representing the country France. The same holds for the class Arrondissement. Formally (note that we use hybrid keys):
From here on, we will use the shortcuts Reg, Dep, Arr and Com for the corresponding Insee classes.
4.2.Relations between the different types of keys
Compared to the semantics of S-keys and F-keys defined in [6], the semantics of in-keys corresponds directly to the semantics of S-keys. This is not the case for eq-keys and F-keys. Every eq-key is an F-key but not the other way around. The equivalence would hold if condition (2) in Definition 4 were replaced by
The prerequisite that the sets of property values must be non-empty enables to consider in-keys as a subset of eq-keys (which does not hold between S-keys and F-keys). This result is stated in Proposition 3.
Proposition 3.
The following holds:
Proof.
Let
The converse of Proposition 3 is not true, i.e. there are eq-keys that are not in-keys. Indeed, consider the interpretation defined by
Proposition 4.
If
Proof.
Let
Proposition 5 shows basic properties of in-keys and eq-keys that will be later used in the proofs of other theorems. In certain occasions, we will write
Proposition 5.
The following holds:
Proof.
Properties (5) and (6) follow directly from Definitions 3 and 4, and Properties (7) and (8) are direct consequences of property (6).
Let us prove (9). Let
Property (10) can be proven analogously. □
In the following section, we establish when it is legitimate to combine in-keys and eq-keys with alignments for data interlinking.
5.Data interlinking with keys and alignments
So far, we have considered keys independently from their use for data interlinking. Keys are able to identify duplicate resources within the same dataset and links between resources from different datasets described using the same ontologies. But as soon as the datasets do not share the same schema, keys alone are not enough for performing data interlinking, and alignments are required.
In this section, we uncover the implicit role of alignments in the process of data interlinking with keys. We show that data interlinking can be expressed as a direct logical consequence of the semantics of keys and alignments. We also highlight the need for completion when interlinking data with eq-keys.
Data interlinking can be formulated as an inference problem: for two given ontologies
In the following, we give conditions on the schemas
Theorem 1.
Let
–
–
–
–
–
Proof.
Notice that
Theorem 1 logically grounds data interlinking with in-keys and ontology alignments: if we know that the properties
Theorem 2 provides the logical basis of data interlinking with eq-keys and alignments. Note that unlike Theorem 1,
Theorem 2.
Let
–
–
–
–
–
–
–
Proof.
Notice that
Notice that in both theorems we only address the case when property values are individuals, i.e. when keys are composed of object properties only. The case when property values are literals, i.e. keys with datatype properties, does not make a difference for our purpose (although, in this case, the comparison of property values is based on equality and not on an initial set of known same-as links
Another remark on Theorems 1 and 2 is that only one key of
Even though Theorems 1 and 2 are not difficult to prove, they highlight some peculiarities of data interlinking with keys and alignments that have not received attention in the literature: the fact that equivalence of properties is not required for interlinking with in-keys, and that local completeness is necessary for interlinking with eq-keys.
It is possible to provide semantic versions of Theorems 1 and 2 in which the antecedent axioms are not asserted in the ontologies and alignments but inferred from them (e.g.
We finish this section with the definition of the link set generated by a key.
Definition 6
Definition 6(Link set generated by a key).
Let
In the following sections, we will introduce link keys and formalise data interlinking with link keys in the same manner. We will then show that data interlinking with link keys is more general than data interlinking with keys and alignments.
6.Link keys
We define three different types of link keys: weak, plain and strong link keys. They all allow to find links between two datasets, but they differ on whether they allow the existence of different resources (duplicates) satisfying the key conditions within each of the datasets: weak link keys allow them; plain link keys allow them only among the non-linked resources; strong link keys disallow them all.
This distinction provides us with the right framework in which to compare link keys and keys and alignments: keys and alignments correspond to strong link keys (Theorem 5), though data interlinking may be possible with weak link keys when strong link keys do not exist (Theorem 6). Plain link keys fill the gap between weak and strong link keys.
The distinction between weak, plain and strong link keys is important in practice too: weak link keys can be used for data interlinking; strong link keys can be used for both data interlinking and duplicate detection, i.e. for discovering same-as statements between individuals of the same dataset; plain link keys lie between weak and plain link keys, as they can be used for data interlinking and for finding duplicates among the linked individuals.
6.1.Semantics of link keys
The semantics of link keys considered in [19] is reproduced in Definition 7. It is natural to extend this semantics to eq-keys too, and we do so in Definition 8. These kinds of link keys will be referred to as weak link keys.
Definition 7
Definition 7(Weak in-link key).
A weak in-link key assertion, or simply a weak in-link key, has the form
An interpretation
Note that the above definition does not specify to which ontology vocabulary the classes and properties of a link key belong. In practice, though, the classes C and D, and the properties
Weak eq-link keys are defined below.
Definition 8
Definition 8(Weak eq-link key).
A weak eq-link key assertion, or simply a weak eq-link key, has the form
An interpretation
It is worth noting that every key can be expressed as a link key. Indeed,
Weak link keys are called weak because they are not necessarily composed of keys. Instead, strong link keys, introduced below, always embed two keys. For this reason, they are closely related to keys and alignments, as we formally state in Theorem 5. We only give the definition of strong in-link keys, as strong eq-link keys can be defined analogously.
Definition 9
Definition 9(Strong in-link key).
A strong in-link key assertion, or simply a strong in-link key, has the form
An interpretation
1.
2.
3.
Both strong and weak link keys enable to find links between two different datasets, but strong link keys do more. Indeed, since the properties of a strong link key are keys for the classes separately then they can be used for finding same-as statements between individuals of the same dataset, i.e. for identifying duplicates.
Fig. 1.
Two datasets and links generated depending on the type of link keys (double = weak, dashed = plain, waved = strong).
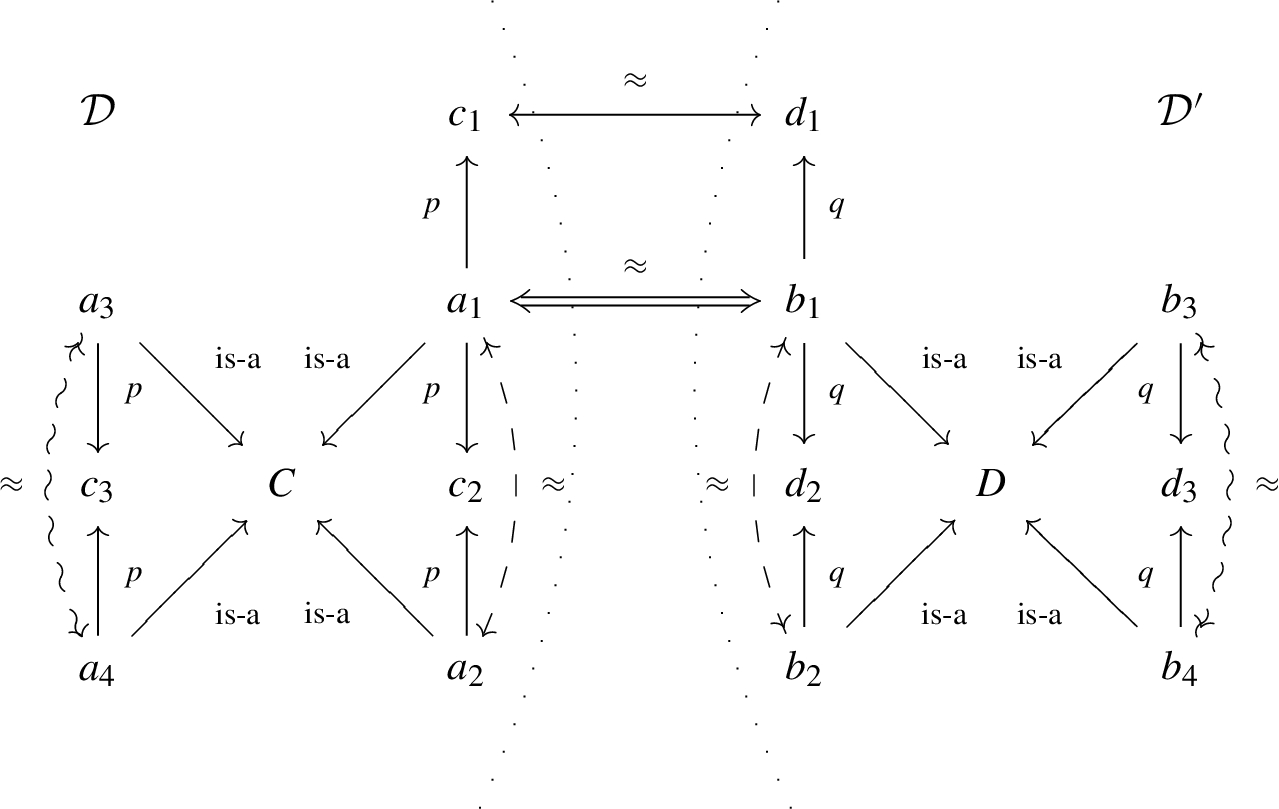
Finally, we introduce plain link keys, which are intermediate between weak and strong link keys. Plain link keys allow to find links and to identify duplicates of the instances that are linked. As before, we only give the definition of a plain in-link key, since plain eq-link keys are defined analogously.
Definition 10
Definition 10(Plain in-link key).
A plain in-link key assertion, or simply a plain in-link key, has the form
An interpretation
1.
2. for any
3. for any
Figure 1 shows the differences between weak, plain and strong link keys on two datasets
weak: | |
plain: | plus |
strong: | plus |
The question may be raised whether it is justified to link resources by key-like conditions when these conditions are not considered as keys (as in weak and plain link keys). This is for the same reason that in some context it may be enough to call people by their first name (e.g. in a nuclear family), in some another to call them by their last name (e.g. in a student class), and yet in other contexts, first name and last name may not be sufficient and birth date and birth place have to be used too (e.g. in a country). Here, the context is provided by what belongs to both datasets. It is not necessary that such a link key exists (there may be two students with the same last name in a class), but sometimes it does. In such cases, there would be no reason to prevent using it.
Fig. 2.
Fragments of the Insee and IGN ontologies and their alignment.
As it was done for keys in Definition 5, it is possible to define hybrid weak, plain and strong link keys by bringing together the in- and eq-conditions:
Alignments may be naturally extended to include a set of link keys. From here on, given two ontologies
Below we give examples of link keys in real datasets.
Example 2
Example 2(Insee-IGN).
The Insee dataset includes links to the IGN dataset (French National Geographic Institute).55 There exist owl:sameAs links between the resources representing the French communes, arrondissements, departments and regions, gathered together in the two datasets using the same class names. These links can be found by comparing the Insee codes, which are declared in both datasets – using the ins:codeINSEE property in the Insee dataset and ign:numInsee in the IGN dataset.66 The considered fragment of the IGN ontology is depicted in Fig. 2.
We have checked the different link key conditions for the property pair
Let us consider the other properties of Example 1. The property rdfs:label is used in the IGN dataset in the same way as ins:nom is used in the Insee dataset. Instead of ins:subdivisionDe, however, IGN uses the three properties ign:arr, ign:dpt and ign:region to declare the arrondissement, department and region an administrative unit belongs to. We have checked the different link key conditions for the combinations of these properties in the scope of the class pairs
Obviously, the above link keys could be used for rediscovering the links.
At present, there exist tools for discovering weak in-link keys [7] and hybrid weak link keys [8].
6.2.Relations between different link keys
Below, we provide theoretical results stating the relations between the different kinds of link keys. Propositions 6 and 7 are the counterparts of Propositions 3 and 4 for link keys and can be proven similarly.
Proposition 6.
The following holds:
Proposition 7.
If
Proposition 8 shows the relations between weak link keys, plain link keys and strong link keys: a strong link key is always a plain link key, which is always a weak link key. Interestingly, there is no distinction between weak eq-link keys and plain eq-link keys. This is due to the transitivity of equality.
Proposition 8.
The following holds:
Proof.
The first two propositions follow directly from the definitions of link keys. We prove the validity of the third one. Let
In the following section, we establish when it is legitimate to use link keys for data interlinking.
7.Data interlinking with link keys
Theorems 3 and 4 give the logical foundations of data interlinking with weak in-link keys and eq-link keys, respectively. Their proofs follow the same ideas as the proofs of Theorems 1 and 2 and are omitted.
Theorem 3.
Let
–
–
–
–
Theorem 3 provides the logical basis of data interlinking with weak in-link keys: if we know that the property pairs
The counterpart of Theorem 3 for weak eq-link keys is Theorem 4. In this case, to generate a same-as link between a and b, we need to know all the values that a and b have for
Theorem 4.
Let
–
–
–
–
–
–
Theorems 3 and 4 show that, unlike keys, weak link keys do not need mappings between classes and properties to perform data interlinking. In addition, since, by Proposition 8, any plain or strong link key is a weak link key, Theorems 3 and 4 hold for strong and plain link keys too.
Below we give the definition of the link set generated by a link key. It applies to all types of link keys.
Definition 11
Definition 11(Link set generated by a link key).
Let
Strong link keys generate more equality statements than plain link keys, which generate more than weak link keys. Logically speaking, it is justified by the fact that the more constraining a link key is, the less models it has, and, thus, the more logical consequences follow from it. Dually, when searching for link keys, it will be easier to search for weak link keys than plain link keys, which will be easier than searching for strong link keys. This is because, in each case, more constraints need to be satisfied.
Therefore, the manipulation of link keys is delicate: the stronger a link key is, the more difficult to extract it, but the more equality statements it will generate. Furthermore, weak link keys may exist when plain and strong link keys do not. In such cases, data interlinking will only be possible with weak link keys. In contrast, duplicate detection inside datasets is only possible with plain or strong link keys.
The generation of links from a link key based on Theorems 3 and 4 is reasonably easy. It may be achieved by using specific tools such as Linkex [1], by transforming link keys into SPARQL queries (available from the Alignment API [15]) or by expressing them as (boolean) linkage rules to be executed in specific platforms such as SILK [22,33] or LIMES [26].
However, these latter platforms do not seem to support the comparison of sets of property values, thus the direct translation of eq-link keys is not possible. The natural extension of this approach, taking into account full reasoning, will require developing specific provers.
Now that we have formally defined how to interlink data with keys and link keys independently of each other, we are in position to compare them.
8.Relation between keys and link keys
Keys and link keys are data interlinking devices that we have developed so far in a parallel manner. One then may expect that their application always results in the generation of the same links. We are now able to formally establish the relation between keys and link keys, and to show that, although there may be data interlinking scenarios in which they will return the same links, this will not always be the case.
This section starts by studying the relation between keys and link keys as description logic axioms (Section 8.1). Theorem 5 states the correspondence between strong link keys and keys and alignments. This correspondence no longer holds for weak link keys (Theorem 6). We also study the impact of these results on the generation of links (Section 8.2): Theorems 7 and 8 show that the links generated by a strong link key are the same as the links generated by its corresponding keys and proper alignments. There are cases, though, in which it is possible to generate links with weak link keys while it is not possible with keys and alignments.
8.1.Logical relations between keys and link keys
The theorems presented here are consequences of stronger results included in the Appendix. We have decided to not include the latter in this section because the former are more directly related to data interlinking with keys and link keys.
Theorem 5 states the correspondence between strong link keys and keys and alignments: (11) says that strong link keys entail keys; (12) and (13) express conditions under which the converse of (11) holds.
Theorem 5.
The following holds:
Proof.
(11) is a direct consequence of the definition of strong link keys (Definition 9). (12) and (13) are consequences of Proposition 12 in the Appendix. □
Given the symmetry of the link key definitions, (11), (12) and (13) hold for the right-hand side of the link key too (with reversed subsumption relations).
Theorem 5 states that it is possible to infer keys from strong link keys. This is not surprising because strong link keys are composed of keys by definition. We call these keys the side keys associated with a strong link key. More interestingly, Theorem 5 also states that strong link keys can be inferred from keys and proper alignments. Note that one key is enough to entail the strong link key as long as the alignment holds (these alignments are different depending on whether in-link keys or eq-link keys are considered).
The converses of (12) and (13) are only partly true: strong link keys entail keys, but strong link keys (nor plain or weak link keys) do not necessarily entail an alignment between their properties and classes. This rejects the idea that link keys embed alignments. Link keys do not assert alignments, but express conditions for identifying individuals. A link key between two classes C and D does not assert that C and D are equivalent, nor that one of the classes subsumes the other, it just specifies how to link individuals that are described as instances of C and D, but there may be individuals in both classes that do not belong to the other class. For example, there may exist a link key between the classes AdministrativeCentre and Town, although no equivalence, nor subsumption holds between them (some administrative centres are towns, others are cities; some towns are administrative centres, others not).
Is Theorem 5 still valid for weak and plain link keys? (12) and (13) do hold, but (11) does not. In other words: keys and proper alignments entail weak and plain link keys (Corollary 5.1); however, none of the side components of weak or plain link keys are necessarily keys (Theorem 6).
Fig. 3.
Two ontologies
Corollary 5.1.
The following holds:
Proof.
This is a direct consequence of Theorem 5 since, by Proposition 8, any strong link key is also a plain and a weak link key. □
Unlike strong link keys, none of the side components of weak or plain link keys are necessarily keys. The proof of Theorem 6 provides two ontologies that are consistent with a weak link key but are inconsistent with any of its side components.
Theorem 6.
There exist ontologies that are consistent with a weak link key but inconsistent with each of its side components.
Proof.
Consider the two ontologies
On the contrary, the side components of λ, i.e.
It is noteworthy that not a single useful key (i.e. a key that can be used to generate links) can be found in the ontologies of the proof of Theorem 6:
Example 3 makes it clear in the context of a real data interlinking scenario that (11) in Theorem 5 does not hold for weak link keys.
Example 3
Example 3(Insee-IGN (cont.)).
The following statement of Example 2:
Let us consider the side components of the above weak link key: If (11) of Theorem 5 were true for weak link keys, then the following two keys would be satisfied by
One may think that data interlinking is still possible with
Even though the side components of a weak link key are not necessarily keys for the ontologies separately, every weak link key entails one key in the vocabulary of the ontologies together, as stated by Proposition 9 below. Unfortunately, this link key is of very limited use in practice because the inferred key holds for the intersection of the classes that we actually want to interlink (it is not known before linking which individuals belong to both classes).
Proposition 9.
The following holds:
Proof.
This is a consequence of Proposition 10 in the Appendix. □
8.2.Relations between generated link sets
The difference between using link keys for data interlinking instead of keys and ontology alignments becomes evident when comparing Theorem 1 with Theorem 3 and Theorem 2 with Theorem 4. In both cases, knowledge about keys and alignments is replaced by knowledge about link keys. Theorem 7 shows that the generated link sets are exactly the same.
Theorem 7.
Let
Proof.
The result follows from Definitions 6 and 11 and the fact that, since
The same holds for eq-keys and eq-link keys.
Theorem 8.
Let
Proof.
The result follows from Definitions 6 and 11 and the fact that, since
The lesson from Theorems 7 and 8 is that, for interlinking two datasets, if there is a key for one dataset and a proper alignment from the key to the vocabulary of the other dataset, then using the key or the strong link key entailed by the key and the alignment is strictly equivalent.
However, as explained in the previous section, weak link keys may exist even when keys and proper alignments do not. As a conclusion, in general, link keys are more suitable than keys for data interlinking. Thus, data interlinking algorithms are justified in discovering link keys rather than keys and alignments. Below we provide a real data-interlinking scenario in which keys and alignments are not useful, but link keys are.
Example 4
Example 4(Insee-GeoNames).
GeoNames is a world-wide geographical database publicly available in RDF.77 Imagine that we are given the task of finding links between the URIs of Insee and GeoNames that represent French communes. Below we show that, for this particular task, keys and alignments are useless as they will generate no link, while link keys will generate almost all of them.
Insee’s ontology is very different from GeoNames’ ontology.88 It is not surprising as Insee’s scope is France and GeoNames’ is world-wide. GeoNames’ ontology basically contains only one class, gn:Feature, of which all geographical features (countries, cities, mountains, lakes, etc.) are direct instances. There is no named class equivalent to ins:Com, ins:Arr, ins:Dép or ins:Rég, but the following complex alignment holds:
From here on, the complex classes of the right-hand sides of the above equivalences will be denoted by gn:Com, gn:Arr, gn:Dep and gn:Reg.
Fig. 4.
Fragments of the Insee and GeoNames ontologies and their alignment.
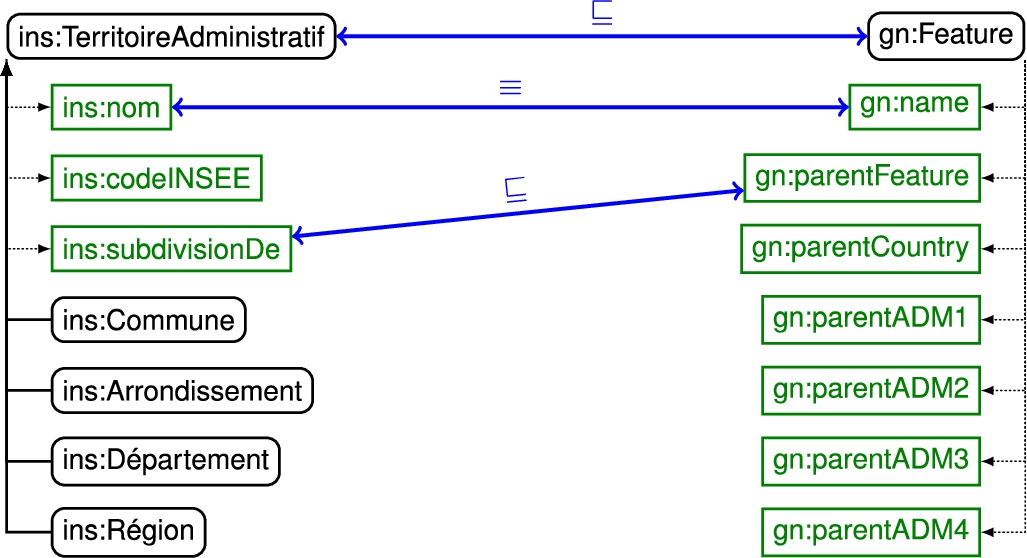
In Insee, apart from rdf:type and owl:sameAs, communes only have the following properties: ins:nom, ins:subdivisionDe, ins:codeCommune and ins:codeInsee. Neither ins:codeCommune nor ins:codeInsee has any counterpart in GeoNames’ ontology, but ins:nom and ins:subdivisionDe are aligned in the following way:
Besides ins:subdivisionDe, one could also consider the GeoNames properties gn:parentCountry and gn:parentADMN – where gn:parentADMN refers to a level N administrative parent,
The following are the minimal keys that can be formed with the properties of the alignment made up of (16) and (17):
From the above paragraph, we can conclude that keys and alignments are not useful for interlinking communes of Insee and GeoNames. Nevertheless, link keys are. More specifically, the following link keys can be used:
To conclude, let us stress that, even though (19) is not true, (22) and (23) hold and are useful for interlinking. This confirms once again that the properties of a link key are not necessarily semantically related via subsumption or equivalence.
9.Conclusions and further work
The relation between keys and link keys is much more subtle than may be thought of at first sight, and one may not be replaced by the other without care. In particular, we have shown that data interlinking with keys requires (a) a proper alignment (Theorems 1 and 2), and (b) completion in the case of eq-keys (Theorem 2). Data interlinking with link keys, in turn, does not need alignments (Theorems 3 and 4) but still needs completion in the case of eq-link keys (Theorem 4).
Strong link keys entail keys by definition, and keys with proper alignments entail strong link keys (Theorem 5). In this case, the links generated by a strong link key are the same as those generated by their associated side keys and alignments (Theorems 7 and 8).
Nonetheless, in addition to not needing an alignment, weak link keys may exist independently from the existence of any key of the individual ontologies (Theorem 6; if they are, then they are strong link keys), and yet they may be useful for interlinking datasets.
These results provide a clear picture of the relationships between key-inspired devices available for data interlinking. They can be easily transferred to the hybrid keys and link keys.
The work presented in this paper contributes grounding data interlinking methods based on keys and link keys. In particular, it justifies the work for directly extracting weak link keys [7] instead of searching for keys with matching alignments. Link key extraction directly focuses on what may be used for data interlinking instead of generating keys and alignments that may not be possible to exploit. Also, when no strong link key exists, link key extraction may find a suitable weak link key, though key extraction will not return any useful key.
The clarification of the semantics of link keys tackled in this paper should lead to complement data interlinking methods with inference methods. One approach consists in designing rules, inspired by the statements found in propositions of this paper, to infer (link) keys from (link) keys in the same way as Armstrong’s axioms [5] allow to derive functional dependencies. However, this approach is highly dependent on the actual schema language used. Another approach extends description logic reasoners to include keys [23] and link keys as axioms. In both cases, entailed link keys could be exploited by extended versions of reasoning-based data interlinking tools. This should also enable breaking the extraction + interlinking process by reasoning on link keys before interlinking in order to provide more accurate links, eventually more efficiently.
Notes
1 Notice that “≈” is a symbol of the language, which is interpreted as equality. More specifically, for any DL interpretation
2 By
4 More specifically, this is the interpretation whose domain is made up of all IRIs and literals of the Insee graph (there are no blank nodes), it interprets domain individuals as themselves, and classes and properties as their extensions in the graph.
6 ign is bound to the namespace http://data.ign.fr/def/geofla#.
Acknowledgements
This work has been partially supported by the ANR project Elker (ANR-17-CE23-0007).
The authors acknowledge the numerous discussions they had with Michel Chein, Madalina Croitoru, Chan Le Duc, Michel Leclère, Nathalie Pernelle, Fatiha Saïs, François Scharffe and Danai Symeonidou on the various definitions of keys that may apply in logical formalisms.
Appendices
Appendix
AppendixProofs of Section 8.1
This appendix describes the relations between keys and link keys in a more precise way than it was done in Section 8.1. Some of the results of Section 8.1 are synthetic consequences of the ones presented here.
Proposition 10.
The following holds:
Proof.
Let us prove the first entailment. Let
Let us prove the third entailment. Let
Proposition 11 is the counterpart of Proposition 10 for strong link keys. Notice that this time the consequent is a key in the union of classes, and not only in the intersection.
Proposition 11.
The following holds:
Proof.
We only prove the first entailment. Let
(1) Assume that
(2) Assume that
(3) Finally, assume that
The other two statements can be proven similarly. □
Proposition 12 is the converse of Proposition 11. Notice, however, that, in the case of in-link keys, the subsumptions are inverted, i.e. they are the subsuming and not the subsumed properties the ones that must form an in-key in the union of classes.
Proposition 12.
The following holds:
Proof.
We only prove the first entailment. Let
Since
Now, we prove
The second entailment can be proven analogously. The third entailment can be proven analogously too, but will use (10) of Proposition 5. □
References
[1] | N. Abbas, J. David and A. Napoli, Linkex: A tool for link key discovery based on pattern structures, in: Supplementary Proceedings of ICFCA 2019 Conference and Workshops, Frankfurt, Germany, June 25–28, 2019, D. Cristea, F.L. Ber, R. Missaoui, L. Kwuida and B. Sertkaya, eds, CEUR Workshop Proceedings, Vol. 2378: , CEUR-WS.org, (2019) , pp. 33–38. |
[2] | M. Achichi, M.B. Ellefi, D. Symeonidou and K. Todorov, Automatic key selection for data linking, in: Knowledge Engineering and Knowledge Management – 20th International Conference, EKAW 2016, Bologna, Italy, November 19–23, 2016, Proceedings, E. Blomqvist, P. Ciancarini, F. Poggi and F. Vitali, eds, Lecture Notes in Computer Science, Vol. 10024: , Springer, (2016) , pp. 3–18. doi:10.1007/978-3-319-49004-5_1. |
[3] | M. Al-Bakri, M. Atencia, J. David, S. Lalande and M. Rousset, Uncertainty-sensitive reasoning for inferring sameAs facts in linked data, in: ECAI 2016 – 22nd European Conference on Artificial Intelligence – Including Prestigious Applications of Artificial Intelligence (PAIS 2016), The Hague, the Netherlands, 29 August–2 September 2016, G.A. Kaminka, M. Fox, P. Bouquet, E. Hüllermeier, V. Dignum, F. Dignum and F. van Harmelen, eds, Frontiers in Artificial Intelligence and Applications, Vol. 285: , IOS Press, (2016) , pp. 698–706. doi:10.3233/978-1-61499-672-9-698. |
[4] | M. Al-Bakri, M. Atencia, S. Lalande and M. Rousset, Inferring same-as facts from linked data: An iterative import-by-query approach, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, January 25–30, 2015, B. Bonet and S. Koenig, eds, AAAI Press, (2015) , pp. 9–15. |
[5] | W.W. Armstrong, Dependency structures of data base relationships, in: Information Processing, Proceedings of the 6th IFIP Congress 1974, Stockholm, Sweden, August 5–10, 1974, J.L. Rosenfeld, ed., North-Holland, (1974) , pp. 580–583. |
[6] | M. Atencia, M. Chein, M. Croitoru, J. David, M. Leclère, N. Pernelle, F. Saïs, F. Scharffe and D. Symeonidou, Defining key semantics for the RDF datasets: Experiments and evaluations, in: Graph-Based Representation and Reasoning – 21st International Conference on Conceptual Structures, ICCS 2014, Iaşi, Romania, July 27–30, 2014, Proceedings, N. Hernandez, R. Jäschke and M. Croitoru, eds, Lecture Notes in Computer Science, Vol. 8577: , Springer, (2014) , pp. 65–78. doi:10.1007/978-3-319-08389-6_7. |
[7] | M. Atencia, J. David and J. Euzenat, Data interlinking through robust linkkey extraction, in: ECAI 2014 – 21st European Conference on Artificial Intelligence – Including Prestigious Applications of Intelligent Systems (PAIS 2014), Prague, Czech Republic, 18–22 August 2014, T. Schaub, G. Friedrich and B. O’Sullivan, eds, Frontiers in Artificial Intelligence and Applications, Vol. 263: , IOS Press, (2014) , pp. 15–20. doi:10.3233/978-1-61499-419-0-15. |
[8] | M. Atencia, J. David, J. Euzenat, A. Napoli and J. Vizzini, Link key candidate extraction with relational concept analysis, Discrete Applied Mathematics 273: ((2020) ), 2–20. doi:10.1016/j.dam.2019.02.012. |
[9] | M. Atencia, J. David and F. Scharffe, Keys and pseudo-keys detection for web datasets cleansing and interlinking, in: Knowledge Engineering and Knowledge Management – 18th International Conference, EKAW 2012, Galway City, Ireland, October 8–12, 2012, Proceedings, A. ten Teije, J. Völker, S. Handschuh, H. Stuckenschmidt, M. d’Aquin, A. Nikolov, N. Aussenac-Gilles and N. Hernandez, eds, Lecture Notes in Computer Science, Vol. 7603: , Springer, (2012) , pp. 144–153. doi:10.1007/978-3-642-33876-2_14. |
[10] | A. Borgida and L. Serafini, Distributed description logics: Assimilating information from peer sources, Journal on Data Semantics 1: ((2003) ), 153–184. doi:10.1007/978-3-540-39733-5_7. |
[11] | A. Borgida and G. Weddell, Adding uniqueness constraints to description logics (preliminary report), in: Deductive and Object-Oriented Databases, 5th International Conference, DOOD ’97, Montreux, Switzerland, December 8–12, 1997, Proceedings, F. Bry, R. Ramakrishnan and K. Ramamohanarao, eds, Lecture Notes in Computer Science, Vol. 1341: , Springer, (1997) , pp. 85–102. doi:10.1007/3-540-63792-3_10. |
[12] | D. Calvanese, G. De Giacomo and M. Lenzerini, Keys for free in description logics, in: Proceedings of the 2000 International Workshop on Description Logics (DL2000), Aachen, Germany, August 17–19, 2000, F. Baader and U. Sattler, eds, CEUR Workshop Proceedings, Vol. 33: , CEUR-WS.org, (2000) , pp. 79–88. |
[13] | D. Calvanese, G. De Giacomo and M. Lenzerini, Identification constraints and functional dependencies in description logics, in: Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence, IJCAI 2001, Seattle, Washington, USA, August 4–10, 2001, B. Nebel, ed., Morgan Kaufmann, (2001) , pp. 155–160. |
[14] | P. Christen, Data Matching – Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection, Data-Centric Systems and Applications, Springer, (2012) . doi:10.1007/978-3-642-31164-2. |
[15] | J. David, J. Euzenat, F. Scharffe and C. Trojahn dos Santos, The alignment API 4.0, Semantic Web Journal 2: (1) ((2011) ), 3–10. doi:10.3233/SW-2011-0028. |
[16] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, (2013) . |
[17] | H. Farah, D. Symeonidou and K. Todorov, KeyRanker: Automatic RDF key ranking for data linking, in: Proceedings of the Knowledge Capture Conference, K-CAP 2017, Austin, TX, USA, December 4–6, 2017, Ó. Corcho, K. Janowicz, G. Rizzo, I. Tiddi and D. Garijo, eds, ACM, New York, NY, USA, (2017) , pp. 7–178. doi:10.1145/3148011.3148023. |
[18] | A. Ferrara, A. Nikolov and F. Scharffe, Data linking for the semantic web, International Journal of Semantic Web and Information Systems 7: (3) ((2011) ), 46–76. doi:10.4018/jswis.2011070103. |
[19] | M. Gmati, M. Atencia and J. Euzenat, Tableau extensions for reasoning with link keys, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 37–48. |
[20] | T. Heath and C. Bizer, Linked Data: Evolving the Web into a Global Data Space, Morgan and Claypool, (2011) . doi:10.2200/S00334ED1V01Y201102WBE001. |
[21] | A. Hogan, A. Zimmermann, J. Umbrich, A. Polleres and S. Decker, Scalable and distributed methods for entity matching, consolidation and disambiguation over linked data corpora, Journal of Web Semantics 10: ((2012) ), 76–110. doi:10.1016/j.websem.2011.11.002. |
[22] | R. Isele, A. Jentzsch and C. Bizer, Efficient multidimensional blocking for link discovery without losing recall, in: Proceedings of the 14th International Workshop on the Web and Databases 2011, WebDB 2011, Athens, Greece, June 12, 2011, A. Marian and V. Vassalos, eds, (2011) . |
[23] | C. Lutz, C. Areces, I. Horrocks and U. Sattler, Keys, nominals, and concrete domains, Journal of Artificial Intelligence Research 23: ((2005) ), 667–726. doi:10.1613/jair.1542. |
[24] | C. Lutz and M. Milicic, Description logics with concrete domains and functional dependencies, in: Proceedings of the 16th Eureopean Conference on Artificial Intelligence, ECAI ’2004, Including Prestigious Applicants of Intelligent Systems, PAIS 2004, Valencia, Spain, August 22–27, 2004, R.L. de Mántaras and L. Saitta, eds, IOS Press, (2004) , pp. 378–382. |
[25] | M. Nentwig, M. Hartung, A.-C. Ngonga Ngomo and E. Rahm, A survey of current link discovery frameworks, Semantic Web 8: (3) ((2017) ), 419–436. doi:10.3233/SW-150210. |
[26] | A.-C. Ngonga Ngomo and S. Auer, LIMES – A time-efficient approach for large-scale link discovery on the web of data, in: IJCAI 2011, Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, July 16–22, 2011, T. Walsh, ed., IJCAI/AAAI, (2011) , pp. 2312–2317. doi:10.5591/978-1-57735-516-8/IJCAI11-385. |
[27] | A.-C. Ngonga Ngomo and K. Lyko, EAGLE: Efficient active learning of link specifications using genetic programming, in: The Semantic Web: Research and Applications – 9th Extended Semantic Web Conference, ESWC 2012, Heraklion, Crete, Greece, May 27–31, 2012, Proceedings, E. Simperl, P. Cimiano, A. Polleres, Ó. Corcho and V. Presutti, eds, Lecture Notes in Computer Science, Vol. 7295: , Springer, (2012) , pp. 149–163. doi:10.1007/978-3-642-30284-8_17. |
[28] | S. Rudolph, Foundations of description logics, in: Reasoning Web. Semantic Technologies for the Web of Data – 7th International Summer School 2011, Galway, Ireland, August 23–27, 2011, Tutorial Lectures, A. Polleres, C. d’Amato, M. Arenas, S. Handschuh, P. Kroner, S. Ossowski and P.F. Patel-Schneider, eds, Lecture Notes in Computer Science, Vol. 6848: , Springer, (2011) , pp. 76–136. doi:10.1007/978-3-642-23032-5_2. |
[29] | M.A. Sherif, A.-C. Ngonga Ngomo and J. Lehmann, Wombat – A generalization approach for automatic link discovery, in: The Semantic Web – 14th International Conference, ESWC 2017, Portorož, Slovenia, May 28–June 1, 2017, Proceedings, Part I, E. Blomqvist, D. Maynard, A. Gangemi, R. Hoekstra, P. Hitzler and O. Hartig, eds, Lecture Notes in Computer Science, Vol. 10249: , Springer, (2017) , pp. 103–119. doi:10.1007/978-3-319-58068-5_7. |
[30] | T. Soru, E. Marx and A.-C. Ngonga Ngomo, ROCKER – A refinement operator for key discovery, in: Proceedings of the 24th International Conference on World Wide Web, WWW 2015, Florence, Italy, May 18–22, 2015, A. Gangemi, S. Leonardi and A. Panconesi, eds, ACM, New York, NY, USA, (2015) , pp. 1025–1033. doi:10.1145/2736277.2741642. |
[31] | D. Symeonidou, V. Armant, N. Pernelle and F. Saïs, SAKey: Scalable almost key discovery in RDF data, in: The Semantic Web – ISWC 2014 – 13th International Semantic Web Conference, P. Mika, T. Tudorache, A. Bernstein, C. Welty, C.A. Knoblock, D. Vrandecic, P. Groth, N.F. Noy, K. Janowicz and C.A. Goble, eds, Lecture Notes in Computer Science, Vol. 8796: , Springer, (2014) , pp. 33–49. doi:10.1007/978-3-319-11964-9_3. |
[32] | D. Toman and G. Weddell, On keys and functional dependencies as first-class citizens in description logics, Journal of Automated Reasoning 40: (2–3) ((2008) ), 117–132. doi:10.1007/s10817-007-9092-z. |
[33] | J. Volz, C. Bizer, M. Gaedke and G. Kobilarov, Discovering and maintaining links on the web of data, in: The Semantic Web – ISWC 2009, 8th International Semantic Web Conference, ISWC 2009, Chantilly, VA, USA, October 25–29, 2009, Proceedings, A. Bernstein, D.R. Karger, T. Heath, L. Feigenbaum, D. Maynard, E. Motta and K. Thirunarayan, eds, Lecture Notes in Computer Science, Vol. 5823: , Springer, (2009) , pp. 650–665. doi:10.1007/978-3-642-04930-9_41. |
[34] | A. Zimmermann and J. Euzenat, Three semantics for distributed systems and their relations with alignment composition, in: The Semantic Web – ISWC 2006, 5th International Semantic Web Conference, ISWC 2006, Athens, GA, USA, November 5–9, 2006, Proceedings, I.F. Cruz, S. Decker, D. Allemang, C. Preist, D. Schwabe, P. Mika, M. Uschold and L. Aroyo, eds, Lecture Notes in Computer Science, Vol. 4273: , Springer, (2006) , pp. 16–29. doi:10.1007/11926078_2. |


