
A computational perspective on neural-symbolic integration
Abstract
Neural-Symbolic Integration (NSI) aims to marry the principles of symbolic AI techniques, such as logical reasoning, with the learning capabilities of neural networks. In recent years, many systems have been proposed to address this integration in a seemingly efficient manner. However, from the computational perspective, this is in principle impossible to do. Specifically, some of the core symbolic problems are provably hard, hence a general NSI system necessarily needs to adopt this computational complexity, too. Many NSI methods try to circumvent this downside by inconspicuously dropping parts of the symbolic capabilities while mapping the problems into static tensor representations in exchange for efficient deep learning acceleration.
In this paper, we argue that the aim for a general NSI system, properly covering both the neural and symbolic paradigms, has important computational implications on the learning representations, the structure of the resulting computation graphs, and the underlying hardware and software stacks. Particularly, we explain how the currently prominent, tensor-based deep learning with static computation graphs is conceptually insufficient as a foundation for such general NSI, which we discuss in a wider context of established (statistical) relational and structured deep learning methods. Finally, we delve into the underlying hardware acceleration aspects and outline some promising computational directions toward fully expressive and efficient NSI.
1.Introduction
During the past decade, deep learning (DL) has taken over the wider domain of artificial intelligence (AI) so rapidly that many people now commonly confuse the fields as equivalent, expecting neural networks to eventually solve all AI problems at hand. This has only been accentuated with the recent rise of foundation (neural) models [6], which exhibit many AI capabilities that have previously been though as out of reach for DL. Indeed, the dramatic progress in difficult, symbolic reasoning benchmarks has left a lot of people wondering whether there are even any limits to the current strategy of scaling large Transformers [52].
However, from the computational perspective, one thing remains striking – these neural models arrive at the answer to every possible input after a fixed number of the same computation steps, which is clearly suboptimal. For simple inputs, this is a waste of computation, and for complex inputs, there will always be a limit where this is insufficient. Particularly, many (symbolic) AI capabilities, such as reasoning or planning, are provably NP-hard (or worse) and thus require a number of computation steps exponential in the size of the input. Hence, this static DL strategy is clearly not universal. However, such a fixed form of computation is the core characteristic of DL that perpetuates the whole domain, as it is crucially required to make use of the underlying hardware-specific, data-parallel acceleration, particularly with the Graphics Processing Units (GPUs).
Researchers often like to think of their models and algorithms independently of the underlying hardware (HW) and software (SW). However, the resurrection of modern DL has been a very clear demonstration that these worlds are deeply intertwined. And while the recent computing evolution in the direction of specialized HW accelerators has been transformational for the success of DL, it unfortunately started to further deepen the gap between DL and the, more general, symbolic AI compute, making the exploration of novel neural-symbolic methods aimed at their integration increasingly more difficult. On the one hand, we have the symbolic, logic-based approaches to AI working in the regime of (hard) discrete optimization, with long historical roots reaching all the way back to the origins of AI and computing itself. These make heavy use of stateful computation with conditional branching, leading to very sparse and irregularly structured computation graphs that change dynamically from input to input. This form of compute builds on the universal capabilities of the Central Processing Unit (CPU) architecture, which dominated computing throughout history. On the other hand, we have the more recent, static, tensor-based neural approaches, working in the simpler regime of continuous optimization, now depending crucially on the GPU architecture that, however, lacks the universal support required for the (dynamic) symbolic compute. This underlying dichotomy is then heavily reflected on the SW layer, too, with largely incompatible learning representations and models.
In this paper, we argue that the current trend of shifting to the static tensor-based (neural) methods is principally limiting the expressiveness of the resulting NSI systems. To clarify the position, we overview evolution of the NSI approaches to AI, with a particular focus on relational logic representations that lie at the core of the dichotomy between the (static) neural and (dynamic) symbolic computation. We then discuss the limitations through insights into so-called “lifted models” [31] from the associated field of (statistical) relational learning [36]. Finally, we link these to the computing structures of the, increasingly popular, (deep) graph representation learning models [54], and conclude the paper with a vision of how the field of NSI might benefit from the associated HW evolution [30].
2.A brief history of neural-symbolic computation
Historically, the mainstream vision for AI has been fluctuating from the almost purely symbolic approaches in the early days to the almost purely neural approaches we see today. However, history teaches us that whenever there are two streams of very opposing schools of thought, the resolution is typically somewhere in the middle.
2.1.From neurons to symbols
Perhaps surprisingly, the correspondence between the neural and logical calculus has been well-established throughout history. Dating all the way back to the introduction of the first computational neuron by McCulloch and Pitts in their 1943’s paper “A logical calculus of the ideas immanent in nervous activity” [38], we can see that it was actually thought to emulate logic gates over binary propositions. The idea was based on the, now commonly exemplified, fact that logical connectives of conjunction and disjunction can be easily encoded by binary threshold units with weights (Fig. 1) – i.e., the perceptron, a learning algorithm for which was introduced shortly after.
While stacking these on top of each other was a clear path towards representation of more complex, nested logical functions, it took until the 1980’s to reintroduce the chain rule for differentiation of nested functions as the “backpropagation” method to calculate gradients in such “neural networks” which, in turn, could be efficiently trained with gradient descent. For that, however, researchers had to replace the original binary threshold units with differentiable activation functions, such as the logistic sigmoid, which started digging a gap between the neural networks and their crisp logical interpretations.
2.2.From deep learning to logic
These historical parallels might seem outlandish in the context of modern DL. However, interestingly, even the modern idea of DL was not originally described as bound to the neural networks, but rather universally to methods modeling hierarchical composition of useful concepts that are reused in different inference paths of target variables from the input samples [4]. And while this concept has most commonly been instantiated through “hidden layers” in DL, such hierarchical abstractions are common in logical reasoning, too. In fact, logic is the very science of deduction of useful concepts from simpler premises in a hierarchical (nested) fashion. While constructing a proof in logic, auxiliary lemmas are often created to reduce the complexity of the theory in scope, in a fashion very similar to DL. Thus, instead of hidden neural layers, these hierarchical abstractions may also be thought of as “complicated propositional formulae re-using many sub-formulae”.11
And from the NSI perspective, this is not just some metaphor, but actual systems reflecting this paradigm started to emerge throughout the ’90s, such as the popular Knowledge-Based Artificial Neural Network (KBANN) [50] (Fig. 1). However, as imagined by Bengio, such a direct neural-symbolic correspondence was insurmountably limited to the aforementioned propositional setting, popularly referred to as “propositional fixation” of neural networks [37].
Fig. 1.
An example correspondence between a neural network (left) and a propositional logic program (middle), based on conjunctive and disjunctive activations emulated by the respectively weighted neurons (right), in the spirit of KBANN [50].
![An example correspondence between a neural network (left) and a propositional logic program (middle), based on conjunctive and disjunctive activations emulated by the respectively weighted neurons (right), in the spirit of KBANN [50].](https://content.iospress.com:443/media/nai-prepress/nai--1--1-nai240672/nai--1-nai240672-g001.jpg)
2.3.Problems with relational logic
While the aforementioned computational correspondence between the propositional logic programs and neural networks was very direct, transferring the same principle to the relational22 setting has remained a major challenge [3]. The issue is that in the propositional setting, only the (binary) values of the existing input propositions are changing, while the structure of the logical program stays fixed. This is easy to think of as a boolean circuit (neural network) sitting on top of a propositional interpretation (feature vector).
However, the relational input interpretations can no longer be thought of as individual values over a fixed (bounded) number of propositions (interpretation vector), but an unbound set of related atoms that are true in a given world (a Herbrand model [18]). Consequently, also the structure of the logical inference unfolded upon this representation can no longer be represented by a fixed boolean circuit. Naturally, when proving a query in relational (first-order) logic, we do not know the number of objects that will form input into the proof, we do not know the number of auxiliary lemmas that will be created in the process, and we do not know the length of the proof nor the overall size of the computation. Hence, there is just no way of mapping that relational reasoning into a static neural computation with a fixed number of inputs, neurons in each layer, and overall depth, effectively corresponding to a finite state machine, principally incapable of capturing the unboundedness, characteristic to the relational logic.
2.4.Modern NSI systems
In the field of NSI, the issue with relational expressiveness, not present in the propositional setting, has alternatively been viewed as the problem of variable binding [23]. Indeed, it is actually the relational logic variables that effectively represent the unbound sets of objects, enabling to make general statements about different individuals, and facilitating the unbound variability in symbolic AI computing structures. This is in contrast to the bounded processing of fixed-size vector (tensor)33 representations characteristic to modern DL compute.
In recent years, a large number of new NSI systems building directly on top of popular deep learning frameworks emerged [26]. Many of these systems are designed to operate with some level of first-order expressiveness, seemingly resolving the old issue of propositional fixation [37] with the efficient, modern-day, static tensor-based deep learning [12]. However, following the aforementioned computational perspective, this is in principle impossible to do. Consequently, in one way or another, these efficient, modern neural-symbolic systems are necessarily dropping parts of the symbolic (relational-level) capabilities, often somewhat inconspicuously.44 This is because building upon the modern, GPU-accelerated, DL foundation always requires some mapping into the fixed-size tensor computation of the existing frameworks [1,40], inherently insufficient to capture the unbound structures of relational inference.
3.Relational machine learning
Mapping problems to fixed-size numeric vectors (tensors) has a long history in machine learning. This representation is highly appealing since treating each sample as an independent point in an n-dimensional space allows to directly adopt classic results from multivariate statistics [25] and the efficient computing machinery of basic linear algebra subprograms [13]. However, real-world problems are not stored in numeric vectors, but in the interlinked structures of the Internet pages, knowledge graphs, and databases, which are inherently relational representations.
3.1.Propositionalization
This representation dichotomy leads to a natural urge to turn these structures into the familiar form of the vectors, and continue with our standard ML pipelines [25], following the common cognitive bias of “If all you have is a hammer, everything looks like a nail”. In relational ML, this approach is generally referred to as “propositionalization” [32] which, similarly to the “tensorization” [10,19] in modern NSI systems (Section 2.4), is an effective strategy that often works well in practice. However, it is conceptually limited.
Firstly, it is clear that one cannot map from unbound relational structures into the fixed-size vectors or tensors without (unwanted) loss of information. This obvious limitation is commonly addressed by bounding the number of domain elements, seemingly restricting the maximum size of the resulting (neural) computation [53]. However, even if we restrict ourselves to such bounded structures, designing a suitable learning representation in the form of a numeric vector or tensor is still deeply problematic. For example, let us take even just graph structures – a restricted form of relational data. If there was a definite way to map a graph into the standard learning form of a (fixed-size) numeric vector (or tensor), it would trivially solve the graph isomorphism problem, since to test if two graphs are isomorphic or not, it would suffice to turn them into such vectors and compare these for equality instead. Of course, one can simply decide to ignore this problem and choose one of the plethora of the (NSI) approximations [16]. However, any such vector (tensor) mapping that ignores the isomorphism symmetry will naturally break the underlying logical semantics that is inherently invariant to it. Therefore, to address this problem properly, it is necessary to leave the space of fixed-size vector (tensor) transformations and revisit the original space of symbolic logic.
3.2.Inductive logic programming
Much out of the lights of the ML mainstream, there has been a community of Inductive Logic Programming (ILP) [9], concerned with proper ways of learning (interpretable) models from exactly such relational representations. For illustration, let us see how the graph-structured learning problems can be approached with the relational logic representations of ILP. To represent a graph, we simply define a binary “edge” relation, with a set of instantiations
Fig. 2.
An example learned ILP model of a path (left), being unfolded on a labeled graph sample encoded in relational logic (middle), resulting into two different computation graphs for the same target query “path(d, a)” (right).
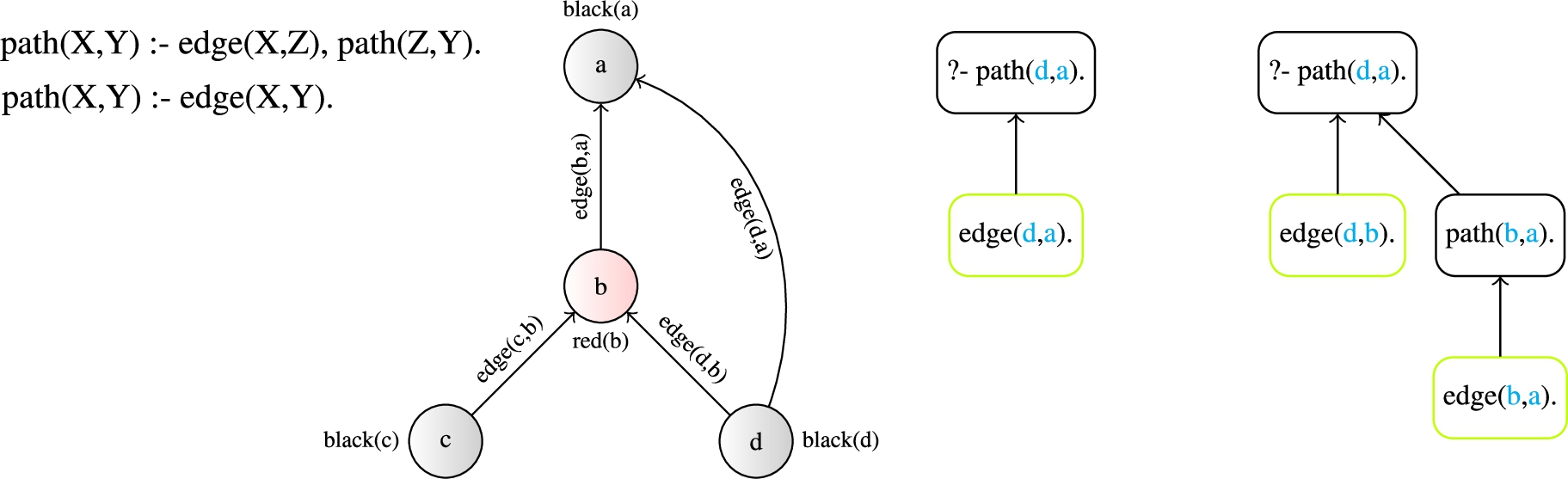
The models then take the form of relational logic rules, enabling to capture an unbound variety of structures, from characteristic motifs in molecules to paths in a network (Fig. 2). For instance, a (learned) relational model correctly capturing paths in a graph, can be easily learned with a basic ILP system from but a few examples. The simplicity of this problem within the relational representation formalism of ILP is then in direct contrast to the neural models operating on the propositional foundation of fixed-size vectors (tensors). There, in order to properly embed the same problem into the hypothesis space of a classic, fixed neural architecture, we would generally need to restrict ourselves to fixed-size graphs, design an exponentially large network to capture all the possible (inference) paths, in which it would be close to impossible for gradient descent to find the correct solution, and we would still not be able to properly generalize to different (larger) graphs. Moreover, the learning difficulties remain even if we move to theoretically expressive (Turing-complete) neural architectures, such as the (DeepMind’s) “Differentiable Neural Computer” [22], which required an extreme number of examples and additional hacking (e.g., pruning out invalid path predictions) to approximate the very same path-finding task through the (propositional) tensor representation, emulating a “differentiable memory” [21].
While ILP is able to correctly capture the expressiveness of relational logic, it is not well suited for dealing with noise and uncertainty, commonly present in real-world learning tasks. To address that issue, a number of methods arose to merge ILP with statistical learning under the notion of Statistical Relational Learning (SRL) [20], such as the “graphicalization”55 approach of [17], transforming the relational domains into graphs on top of which kernel methods were utilized. Generally, there have been two major streams of approaches in SRL – (i) probabilistic logic programs [11] and (ii) lifted graphical models [31]. While the former builds heavily on the classic, symbolic ILP formalism, the latter is much closer to standard statistical models, the expressiveness of which it “lifts” from the propositional into the relational setting, while retaining proper logical semantics. Naturally, this is highly relevant to the aforementioned problem of propositional fixation of neural networks and relational-level NSI (Section 2.3).
3.3.Lifted graphical models
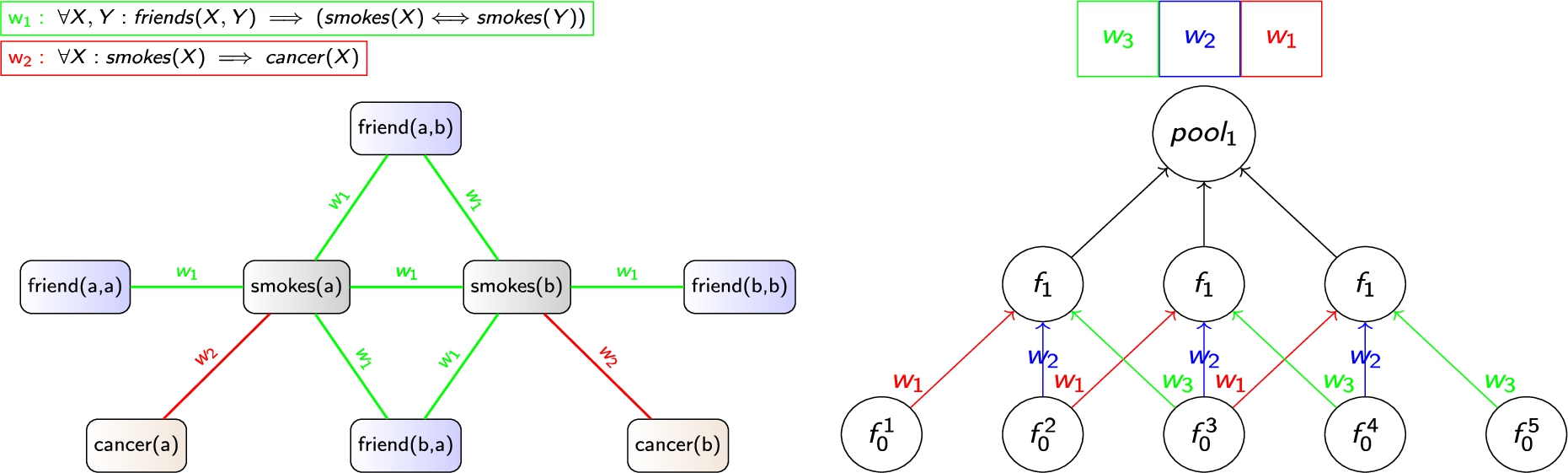
As opposed to standard (“ground”) machine learning models, such as neural networks, lifted models do not specify a particular computation structure, but rather a logical “template” from which the standard models are being unfolded as part of the inference (evaluation) process, given the varying context of the relational input data. For instance, the (arguably) most popular lifted model – a Markov Logic Network (MLN) [42] may be seen as such a template for the classic Markov networks. For example, such an MLN template may express a general prior that “friends of smokers tend to be smokers” and “smoking may lead to cancer”. The learning data may then describe a social network of people with a subset of smokers labeled as such. The lifted modeling paradigm of MLNs then allows to induce the smoking probabilities of all the other people based on their social relationships, as if modeled by a regular Markov network, yet correctly generalizing over social networks of diverse structures and sizes, overcoming the propositional fixation of the base Markov model (Fig. 3).
The crucial ability to capture the unbound variability of the relational computation structures with a bounded computation template necessarily induces some form of repeated regularities, i.e. symmetries, within any such unfolded computation. In relational logic, these symmetries stem from the use of logical variables within the relations, i.e. subsets of the Cartesian products defined over the respective sets of objects. That is, unless the computation is effectively propositional as a corner case, one should be able to observe these repeated computational substructures, including shared parameterization, in the unfolded computation of the (ground) model. And while the, relational logic-based, lifted graphical models make this observation very explicit, we can actually observe the same principle being effectively exploited in many successful DL architectures, too, such as the popular CNNs, exploiting the symmetry of translational equivariance.66 From this computational view, the CNNs can thus be seen as a particular instance of an (implicit) relational modeling template (Fig. 3).
Fig. 3.
Illustration of two forms of relational expressiveness, with CNNs (right) capturing a spatial pattern of a 3-neighborhood, and an MLN (left) capturing a social pattern of smoking habits amongst friends, both reflected by the symmetries in the respective ground model computations.
The proper logical semantics of the lifted graphical models is, however, redeemed by computational difficulties. Due to the explicit treatment of the logic variable binding, these models are commonly viewed as computationally expensive. Nevertheless, from the perspective of a general NSI system, this view is somewhat misleading since the computation is exactly as complex as necessary to properly capture the respective relational (logic) expressiveness.77 However, the problematic factor is the structure of the resulting computation.
4.Structured computation graphs
For the sake of delving deeper into the (relational) computing structures in NSI, let us now define, a bit more formally, the common DL abstraction of a computation graph. A computation graph
4.1.Basic deep learning
By far the most common computation paradigm in deep learning is to structure the computation graphs regularly into homogeneous “layers”, which are used to refer to the sets of neurons
4.2.Relational neural models
The regular, dense, and homogeneous structure of the computation graph G, mapping to the basic matrix (tensor) operations, is a salient feature of the basic neural models. Note that from the aforementioned perspective of the lifted (graphical) models from SRL (Section 3.3) such computation, lacking any symmetries, is effectively propositional. However, there are also neural models designed to operate with some forms of relational data structures, such as sequences, trees, and graphs, which necessarily need to reflect some level of relational expressiveness. As a consequence, following the SRL reasoning from Section 3.3, their computations will, in contrast to the basic neural models, need to reflect some type of sparsity, heterogeneity, or irregularity, within the scope of the necessary symmetries reflected by some form of regular weight-sharing patterns within their computation graphs. Let us now inspect some common representatives of these neural models.
Fig. 4.
The symmetric weight-sharing patterns in the structured computation graphs of recurrent (left) and recursive (right) neural models.
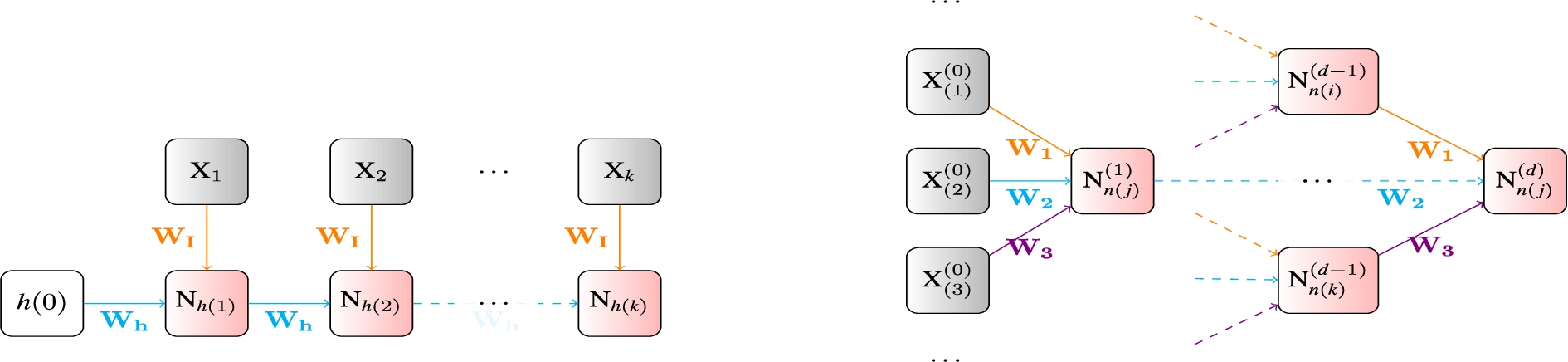
A Recursive Neural Network (RecNN) [41,46] is a neural architecture the computation graphs
Note that the basic form of the more common Recurrent Neural Networks (RNNs) [34] can then be seen as a restriction of the RecNN computation to sequential structures
The most popular recent addition in this category are then Graph Neural Networks (GNN) [5,43] which, in contrast to the RNNs, can be seen as an extension of RecNNs to completely irregular graph data
![Compressing a typical GNN model computation (up) based on the contained computation graph symmetries, resulting into a much smaller yet functionally equivalent computation (down), in the spirit of (symbolic) lifted inference [49], as implemented in LRNNs (Section 4.3).](https://content.iospress.com:443/media/nai-prepress/nai--1--1-nai240672/nai--1-nai240672-g005.jpg)
4.3.Lifted relational neural networks
Lifted Relational Neural Networks [47] can be seen as a further generalization of the GNNs to arbitrary relational structures, covering all the previous models as special cases [48]. For that, they transfer the strategy of lifted modeling (Section 3.3) into a deep learning setting, effectively extrapolating the original, direct neuro-symbolic correspondence between deep learning and propositional logic (Section 2.2) straight into fully expressive relational setting.
Similarly to the lifted graphical models (Section 3.3), they adopt the language of weighted relational logic as their foundation, endowing them with explicit variable binding and symbolic reasoning capabilities, as found in the ILP systems (Section 3.2). This covers the sought-after ability to manipulate unbound structures
5.Hardware and software lottery
It is instructive to note again the RecNNs architecture, which can be seen as a strict generalization of the common RNNs, adding significant flexibility by exploiting also the sentence structure in NLP, while retaining comparable computation complexity.99 Moreover, in contrast to the RNNs, the RecNNs can, in principle, be parallelized, thanks to the recursive decomposition. Nevertheless, they have never reached anywhere near the popularity of the simpler RNNs, as they were notoriously difficult to effectively implement in the mainstream, fixed-size tensor-based deep learning frameworks.1010 A similar story then followed with the subsequent replacement of the RNNs with Transformers [52], the core “attention” concept of which can be seen simply as a restriction of the GNN computation to fixed-size, fully connected graphs. This hardwired restriction removes the relational flexibility w.r.t. the GNNs and restricts the length of the input sequence w.r.t. the RNNs, while also substantially increasing the computation complexity from linear to quadratic. Nevertheless, it is exactly these apparent drawbacks that provide the architecture one crucial advantage – it is perfectly aligned with the current HW stack, particularly the GPUs.
The GPU architecture is inherently based on the “single instruction, multiple data” (SIMD)1111 concept [15], enabling for high-throughput data-parallel processing of dynamic values through static operations. With neural networks, this generally means static, regular, and dense structure of the computation graph, which maps perfectly to the homogeneous, fixed-size tensor processing underlying the mainstream deep learning architectures and frameworks. On the contrary, the dynamic, sparse, irregular, and heterogeneous nature of the discussed (lifted) neural models, reflecting some level of relational expressiveness, is highly problematic to this mainstream regime of compute. And the situation is further considerably worse with the symbolic (logic) computation (Section 3.2), commonly relying on conditional branching and looping (recursion).
5.1.Accelerating symbolic computation
The maturity of the existing HW&SW DL ecosystem naturally incentivizes NSI researchers away from the expressive symbolic computation towards further “tensorization” of their systems [19], even in cases where such a choice would otherwise be conceptually inappropriate, which has a self-reinforcing side-effect of regressing to the same models [27]. This is becoming noticeable with more and more NSI methods operating simply as modules on top of existing tensor-based frameworks [2]. However, the symbolic computation, as exploited in the classic (relational) AI tasks, is often inherently sequential, stateful, and conditional, leading to dynamically sized and structured computation graphs, the forms of which are just impossible to properly embed into the common fixed-size tensor processing on GPUs.
For instance, the computation of a relational (lifted) model (Section 3.3) may completely change from sample to sample, making it principally incompatible with the SIMD philosophy of the GPU architecture. Importantly, this does not mean that the relational (symbolic) compute strategy would itself be somehow inferior or impossible to accelerate. On the contrary, akin to batching in DL, one can always naively parallelize in the data dimension across multiple CPU threads, utilizing its “multiple instructions, multiple data” (MIMD) capabilities. Consequently, should the evolution of CPU parallelism have reflected its GPU counterpart, i.e. chips with (hundreds of) thousands of CPU threads be readily available, there would be no need to sacrifice the symbolic capabilities in NSI systems. Moreover, the symbolic model representation also offers a much broader range of interesting acceleration strategies, such as lifted inference [51], in contrast to the comparatively brute-force approach of the GPU-based DL.
5.2.Accelerating graph neural networks
An interesting borderline example between these two, largely separate, worlds of symbolic and neural compute are the aforementioned GNN models, which can be seen as an instance of deep learning evolving in the direction of relational learning. Since the GNNs are able to (partially) capture graph-structured data, they necessarily reflect some level of (symbolic) relational logic expressiveness. Particularly, their expressive power corresponds to a guarded fragment of C2 logic [24,48].1212 Similarly to the other relational models, this increased, albeit still relatively limited (e.g., compared to the LRNNs [48]), expressiveness already takes its toll in their compute structure. Particularly, the variability of the input graph data, reflected in the irregularly sparse interconnection patterns within the GNN layers requiring random access to the underlying tensor indices (through respective gather/scatter operations [14]), is highly detrimental to the classic GPU acceleration.
However, the significant rise in popularity of the GNN-like architectures, driven by the omnipresence of the graph data structures in real-world problems, has come with an interesting paradigm shift in which the SW and HW developers started to actively reflect back on these alternative computing concepts in AI, too. Consequently, there have been new SW frameworks emerging [14,29], and most of the latest GPU cards support some levels of sparsity [8]. This is an interesting step in a direction beneficial for NSI [33], however, it is still far from a proper foundation for the full NSI compute, which can never fully fit the SIMD design of the GPUs. The corresponding low-level optimizations here are still largely incremental, building heavily on the legacy of the matrix-multiplication-based architectural design. Moreover, they tend to be increasingly specific, e.g., enforcing particular, fixed sparsity patterns [8], or even containing hardwired acceleration for particular models, such as the Transformers [7].
In contrast, the high-level, HW-independent, symbolic acceleration techniques are much more principled and reusable. For instance, in the spirit of NSI, the symbolic techniques of lifted inference (Section 3.3) can be transferred into deep learning to effectively accelerate relational neural models, such as the GNNs, by exploiting the inherent symmetries contained in their computation graphs. This results into explicitly smaller neural computation that effectively performs the exact same function (Fig. 5), which was unprecedented in deep learning [49]. Consequently, using this symbolic technique, even a naive CPU implementation of a GNN model can become faster than a specialized GPU-accelerated implementation [49].1313 However, should we completely fixate on the GPU-based deep learning as the foundation for NSI, our possibilities for such a beneficial transfer of symbolic techniques into deep learning (and vice-versa) might gradually become extinct.
6.Conclusion – a call for neuro-symbolic HW
In the past, AI researchers used to design their algorithms independently of the underlying HW, relying on the universal capabilities of the CPU architecture, and its all-encompassing acceleration through the Moore’s law [44]. However, in this new era of AI compute, an inadequate alignment with the existing specialized HW can easily turn conceptually strong ideas upside down. The prospect of the GPU acceleration, together with the mature DL SW ecosystem built upon that foundation, naturally incentivizes researchers to adjust their ideas to this mainstream regime of compute in order to reap its benefits. However, as argued throughout this paper, this choice has important consequences, especially for NSI.
While the SIMD architecture of the GPUs is a perfect fit for the current, tensor-based neural models, the principles of the symbolic methods are closely connected to the universal flexibility of the CPUs. The vision of a proper, fully expressive and efficient NSI computation thus calls for a much tighter integration between the CPU and GPU features than currently present. Instead of incremental improvements of the, principally limited, SIMD approach, for NSI it would be much more meaningful to transfer the MIMD principles from CPUs onto a significantly more parallel, high-throughput, low-latency foundation.
While the AI industry is currently dominated by the GPU-based applications of DL with largely predictable business potential, it is highly unlikely that we will see the same amount of interest in acceleration of the, more demanding, symbolic computing. The NSI community is just too small of a niche to attract the astronomical investments needed for development of such a new HW architecture. However, with the rapid growth in popularity of the GNN models, reflecting some of the computing demands of the symbolic methods, we start to see first signs of the needed HW convergence with newly emerging architectures, such as the Intelligence Processing Unit (IPU) [30], finally breaking beyond the SIMD legacy of the GPUs, and currently leading the GNN performance benchmarks [28]. While still far from meeting all the compute demands of a general NSI system, it might be very interesting for researchers to watch this emerging stream of novel computing architectures, bearing promise to enable exploring truly novel and expressive neural-symbolic systems.
Notes
1 quotation from the abstract of “Learning Deep Architectures for AI” by Y. Bengio [4].
2 We use the common term “relational logic” to refer to first-order logic without function symbols, which would unnecessarily complicate the computational perspective taken in this paper by leading further to infinite interpretations.
3 We do not make much differences between vectors and tensors since, from the representation expressiveness point of view, they are the same.
4 or opting for merely compositional (unintegrated) approaches, such as those explained in Section 3.3 and Section 5.2.
5 which can be seen as a lossless alternative to the discussed propositionalization.
6 or invariance with the use of the pooling operator.
7 For instance, there are many useful relational templates (patterns) the computational complexity of which is simply linear, such as the CNNs and almost all other weight-sharing neural models.
8 which can also be seen as graphs with completely regular grid topologies.
9 depending on the specific parse/dependency tree representation, but generally
10 A notable, yet largely unsuccessful, attempt to improve this situation was, e.g., Tensorflow Fold [35].
11 A bit more precise term with modern GPUs is SIMT, combining SIMD with multi-threading which, however, shares the same limitation as all the threads effectively execute the same logic.
12 Relational logic with neighbor “guards”, counting quantifiers, and at most 2 variables [24].
13 Particularly in relational domains with highly symmetric graph structures, such as molecular chemistry.
Acknowledgements
The author of this work acknowledges support from the European Union’s Horizon Europe Research and Innovation program under the grant agreement TUPLES No 101070149, and funding from the Czech Science Foundation grant. no. 24-11664S.
References
[1] | M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard et al., Tensorflow: A system for large-scale machine learning, in: 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), (2016) . |
[2] | K. Ahmed, T. Li, T. Ton, Q. Guo, K.-W. Chang, P. Kordjamshidi, V. Srikumar, G. Van den Broeck and S. Singh, PYLON: A PyTorch framework for learning with constraints, in: NeurIPS 2021 Competitions and Demonstrations Track, PMLR, (2022) , pp. 319–324. |
[3] | S. Bader and P. Hitzler, Dimensions of neural-symbolic integration – a structured survey, (2005) , arXiv preprint. |
[4] | Y. Bengio, Learning deep architectures for AI, Foundations and Trends in Machine Learning 2: (1) ((2009) ), 1–127. ISBN 2200000006. doi:10.1561/2200000006. |
[5] | M.M. Bronstein, J. Bruna, Y. LeCun, A. Szlam and P. Vandergheynst, Geometric deep learning: Going beyond Euclidean data, IEEE Signal Processing Magazine 34: (4) ((2017) ), 18–42. doi:10.1109/MSP.2017.2693418. |
[6] | T. Brown, B. Mann, N. Ryder, M. Subbiah, J.D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., Language models are few-shot learners, Advances in neural information processing systems 33: ((2020) ), 1877–1901. |
[7] | J. Choquette, Nvidia Hopper h100 gpu: Scaling performance, IEEE Micro ((2023) ). |
[8] | J. Choquette, W. Gandhi, O. Giroux, N. Stam and R. Krashinsky, NVIDIA A100 tensor core GPU: Performance and innovation, IEEE Micro 41: (2) ((2021) ), 29–35. doi:10.1109/MM.2021.3061394. |
[9] | A. Cropper, S. Dumančić and S.H. Muggleton, Turning 30: New ideas in inductive logic programming, (2020) , arXiv preprint arXiv:2002.11002. |
[10] | L. De Raedt, S. Dumančić, R. Manhaeve and G. Marra, From statistical relational to neuro-symbolic artificial intelligence, (2020) , arXiv preprint arXiv:2003.08316. |
[11] | L. De Raedt and A. Kimmig, Probabilistic (logic) programming concepts, Machine Learning 100: ((2015) ), 5–47. doi:10.1007/s10994-015-5494-z. |
[12] | I. Donadello, L. Serafini and A.D. Garcez, Logic tensor networks for semantic image interpretation, (2017) , arXiv preprint arXiv:1705.08968. |
[13] | J.J. Dongarra, J. Du Croz, S. Hammarling and I.S. Duff, A set of level 3 basic linear algebra subprograms, ACM Transactions on Mathematical Software (TOMS) 16: (1) ((1990) ), 1–17. doi:10.1145/77626.79170. |
[14] | M. Fey and J.E. Lenssen, Fast graph representation learning with PyTorch geometric, (2019) , arXiv preprint arXiv:1903.02428. |
[15] | M.J. Flynn, Very high-speed computing systems, Proceedings of the IEEE 54: (12) ((1966) ), 1901–1909. doi:10.1109/PROC.1966.5273. |
[16] | M.V. Franca, G. Zaverucha and A. Garcez, Fast relational learning using bottom clause propositionalization with artificial neural networks, Machine learning 94: (1) ((2014) ), 81–104. doi:10.1007/s10994-013-5392-1. |
[17] | P. Frasconi, F. Costa, L. De Raedt and K. De Grave, klog: A language for logical and relational learning with kernels, Artificial Intelligence 217: ((2014) ), 117–143. doi:10.1016/j.artint.2014.08.003. |
[18] | J.H. Gallier, Logic for Computer Science: Foundations of Automatic Theorem Proving, Courier Dover Publications, (2015) . |
[19] | A. Garcez, M. Gori, L. Lamb, L. Serafini, M. Spranger and S. Tran, Neural-symbolic computing: An effective methodology for principled integration of machine learning and reasoning, Journal of Applied Logics 6: (4) ((2019) ), 611–631. |
[20] | L. Getoor and B. Taskar, Introduction to Statistical Relational Learning, (2007) , p. 586. ISBN 0262072882. |
[21] | A. Graves, G. Wayne and I. Danihelka, Neural turing machines, (2014) , arXiv preprint arXiv:1410.5401. |
[22] | A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwińska, S.G. Colmenarejo, E. Grefenstette, T. Ramalho, J. Agapiou et al., Hybrid computing using a neural network with dynamic external memory, Nature 538: (7626) ((2016) ), 471–476. doi:10.1038/nature20101. |
[23] | K. Greff, S. Van Steenkiste and J. Schmidhuber, On the binding problem in artificial neural networks, (2020) , arXiv preprint arXiv:2012.05208. |
[24] | M. Grohe, The logic of graph neural networks, in: 2021 36th Annual ACM/IEEE Symposium on Logic in Computer Science (LICS), IEEE, (2021) , pp. 1–17. |
[25] | D. Haussler and M. Warmuth, The Probably Approximately Correct (PAC) and Other Learning Models, Springer, (1993) . |
[26] | P. Hitzler and M.K. Sarker, Neuro-Symbolic Artificial Intelligence: The State of the Art, (2022) . |
[27] | S. Hooker, The hardware lottery, Communications of the ACM 64: (12) ((2021) ), 58–65. doi:10.1145/3467017. |
[28] | W. Hu, M. Fey, H. Ren, M. Nakata, Y. Dong and J. Leskovec, Ogb-lsc: A large-scale challenge for machine learning on graphs, (2021) , arXiv preprint arXiv:2103.09430. |
[29] | M. Innes, Flux: Elegant machine learning with Julia, Journal of Open Source Software ((2018) ). doi:10.21105/joss.00602. |
[30] | Z. Jia, B. Tillman, M. Maggioni and D.P. Scarpazza, Dissecting the graphcore ipu architecture via microbenchmarking, (2019) , arXiv preprint arXiv:1912.03413. |
[31] | A. Kimmig, L. Mihalkova and L. Getoor, Lifted graphical models: A survey, Machine Learning 99: (1) ((2015) ), 1–45. doi:10.1007/s10994-014-5443-2. |
[32] | M.-A. Krogel, S. Rawles, F. Železný, P.A. Flach, N. Lavrač and S. Wrobel, Comparative Evaluation of Approaches to Propositionalization, Springer, (2003) . |
[33] | L.C. Lamb, A.S. d’Avila Garcez, M. Gori, M.O.R. Prates, P.H.C. Avelar and M.Y. Vardi, Graph neural networks meet neural-symbolic computing: A survey and perspective, in: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, C. Bessiere, ed., ijcai.org, (2020) , pp. 4877–4884. |
[34] | Z.C. Lipton, J. Berkowitz and C. Elkan, A critical review of recurrent neural networks for sequence learning, (2015) , arXiv preprint arXiv:1506.00019. |
[35] | M. Looks, M. Herreshoff, D. Hutchins and P. Norvig, Deep learning with dynamic computation graphs, (2017) , arXiv preprint arXiv:1702.02181. |
[36] | G. Marra, S. Dumančić, R. Manhaeve and L. De Raedt, From statistical relational to neurosymbolic artificial intelligence: A survey, Artificial Intelligence ((2024) ), 104062. doi:10.1016/j.artint.2023.104062. |
[37] | J. McCarthy, Epistemological challenges for connectionism, Behavioral and Brain Sciences 11: (1) ((1988) ), 1–74. doi:10.1017/S0140525X0005264X. |
[38] | W.S. McCulloch and W. Pitts, A logical calculus of the ideas immanent in nervous activity, The Bulletin of Mathematical Biophysics 5: (4) ((1943) ), 115–133. ISBN 0007-4985. doi:10.1007/BF02478259. |
[39] | G. Neubig, C. Dyer, Y. Goldberg, A. Matthews, W. Ammar, A. Anastasopoulos, M. Ballesteros, D. Chiang, D. Clothiaux, T. Cohn et al., Dynet: The dynamic neural network toolkit, (2017) , arXiv preprint arXiv:1701.03980. |
[40] | A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga and A. Lerer, (2017) , Automatic differentiation in pytorch. |
[41] | J.B. Pollack, Recursive distributed representations, Artificial Intelligence 46: (1) ((1990) ), 77–105. doi:10.1016/0004-3702(90)90005-K. |
[42] | M. Richardson and P. Domingos, Markov logic networks, Machine learning ((2006) ). |
[43] | F. Scarselli, M. Gori, A.C. Tsoi, M. Hagenbuchner and G. Monfardini, The graph neural network model, IEEE transactions on neural networks / a publication of the IEEE Neural Networks Council 20: (1) ((2009) ), 61–80. doi:10.1109/TNN.2008.2005605. |
[44] | R.R. Schaller, Moore’s law: Past, present and future, IEEE spectrum 34: (6) ((1997) ), 52–59. doi:10.1109/6.591665. |
[45] | R. Socher, D. Chen, C.D. Manning and A. Ng, Reasoning with neural tensor networks for knowledge base completion, in: Advances in Neural Information Processing Systems, (2013) . |
[46] | R. Socher, A. Perelygin, J.Y. Wu, J. Chuang, C.D. Manning, A.Y. Ng, C. Potts et al., Recursive deep models for semantic compositionality over a sentiment treebank, in: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Vol. 1631: , Citeseer, (2013) , p. 1642. |
[47] | G. Šourek, V. Aschenbrenner, F. Železný, S. Schockaert and O. Kuželka, Lifted relational neural networks: Efficient learning of latent relational structures, Journal of Artificial Intelligence Research 62: ((2018) ), 69–100. doi:10.1613/jair.1.11203. |
[48] | G. Šourek, F. Železný and O. Kuželka, Beyond graph neural networks with lifted relational neural networks, Machine Learning 110: (7) ((2021) ), 1695–1738. doi:10.1007/s10994-021-06017-3. |
[49] | G. Šourek, F. Železný and O. Kuželka, Lossless Compression of Structured Convolutional Models via Lifting, International Conference on Learning Representations, (2021) . |
[50] | G.G. Towell, J.W. Shavlik and M.O. Noordewier, Refinement of approximate domain theories by knowledge-based neural networks, in: Proceedings of the Eighth National Conference on Artificial Intelligence, Boston, MA, (1990) , pp. 861–866. |
[51] | G. Van den Broeck, N. Taghipour, W. Meert, J. Davis and L. De Raedt, Lifted probabilistic inference by first-order knowledge compilation, in: Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, AAAI Press/International Joint Conferences on Artificial Intelligence, Menlo, (2011) , pp. 2178–2185. |
[52] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser and I. Polosukhin, Attention Is All You Need, Neural Information Processing Systems, (2017) . |
[53] | M. Vitor, M.V.M. França and A.S. d’Avila Garcez, Neural relational learning through semi-propositionalization of bottom clauses, in: 2015 AAAI Spring Symposium in Knowledge Representation and Reasoning: Integrating Symbolic and Neural Approaches, (2015) , pp. 53–56. ISBN 1412920388. |
[54] | Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang and S.Y. Philip, A comprehensive survey on graph neural networks, IEEE Transactions on Neural Networks and Learning Systems ((2020) ). |


