
The number of tries required to win in international rugby sevens
Abstract
Data from the pool rounds of three HSBC World Rugby Sevens competitions (2016–17, 2017–18, and 2018–19) are used to investigate the number of tries required to win in international rugby sevens. The data consist of 4,391 tries scored in 720 matches (1,440 team performances) and are used to calculate the probability of winning a match given that T tries are scored (P[W|T]). The distribution of the number of tries scored by each team ranges from zero to nine and is shown to be well-represented by a Poisson distribution computed from the mean value of tries scored in that competition. The number of tries scored by the winning team in each match within a competition is well-described by a Gamma function evaluated at the integer number of tries scored with parameters derived from the data set. This appears to be a novel result not previously reported in the literature. Generalizing within each competition, teams scoring either zero tries or one try have less than a 2% chance of winning; those scoring two tries win 10% to 20% of the time; three tries result in nearly a 50% chance of winning; teams scoring four tries are almost sure to win (around 90%); and that for teams scoring five or more tries winning is virtually assured. Based upon the results from these three tournaments we conclude that competitive teams should strive to score three or more tries per match and that there is no winning advantage accrued by scoring more than five tries.
1Introduction
Rugby sevens is a version of rugby union played by seven players on a team in two seven minute halves rather than the full fifteen-a-side game played over two 40 minute halves. The laws governing the two games are substantially the same (Hingham et al., 2014; van Rooyen, 2015). Considerable interest and increased popularity have accompanied the game of rugby sevens since it was selected as the Olympic version of the game starting in 2016. Recent scientific investigation of rugby sevens has primarily focused on player movement patterns, physiological adaptations to the demands of the game, injury rates and modalities, and anthropometric analyses of players (Hingham et al, 2014) providing considerable reliable information regarding fundamental aspects of the game at the highest levels.
The World Rugby Sevens Series is an annual competition played by national sevens teams and sanctioned by World Rugby, the International Federation for the sport. First played in the 1999/2000 season, the competition format has evolved over the years. Currently and since 2015/2016 the series is played as ten individual tournaments around the globe spread typically from December to the following June. Two tournaments are usually played on adjacent weekends and spaced by four to six week intervals. Each tournament is two or three days in length in which 16 international teams play in a pool round – four pools of four teams each resulting in 24 matches – followed by a knock-out round involving 21 matches to determine overall standings within the tournament.
Given the interest in rugby sevens it is interesting that there is little in the literature regarding basic fundamentals of the structure of the game. In their study of rugby sevens match demands and performance, Henderson et al. (2018) lamented the dearth of research on international sevens match performance, physical activity, and skill involvement. van Rooyen (2016) has commented that data pertaining to how rugby sevens has developed are scarce. We might expand on these comments to include the dearth of research on the game’s fundamental structure to include such elementary issues as the distribution of the number of tries scored in matches or asking the question of how many tries does a team need to score to be reasonably certain of winning the match. The primary objective of this paper is to shed some light on these fundamental questions.
We begin by assuming that the number of tries scored by a team is a good surrogate value for determining the winner of a rugby sevens match. If this is true it follows that sevens teams should strive to score tries to be successful. We believe that this assumption is valid for the following reasons. In their study of the 2011–2012 Sevens World Series Hingham et al. (2014) report that the winning team in 344 of the 392 matches contested that year (88%) scored more tries than the losing team. World Rugby (2016) reports that from the 2011–2012 competition to the 2015–2016 competition the winning team scored more tries in 85% to 91% of all matches. Specifically in the 2015–2016 competition the winning team scored more tries in 397 of the 450 matches (88%). In the other 12% of matches the two teams scored an equal number of tries with 41 of the 53 matches resulting in a win and 12 in a tie score. At no time did any team win by scoring fewer tries than their opponent. Based upon these data we conclude that the number of tries scored seems to be an acceptable surrogate for winning a sevens rugby match.
The primary question being asked in this study – what is the probability of winning at sevens rugby when a team scores T tries? – is a problem in conditional probability. Bayes’ Theorem allows us to find a quantitative answer to such questions based upon observed evidence (Gelman et al., 2013). We can write Bayes’ Theorem as
P [W|T] is the probability of winning given that a team scores T tries,
P [T|W] is the probability of scoring T tries given that a team has won,
P[W] is the probability of winning a match in the tournament
and P[T] is the probability of scoring T tries in the competition.
The P [W|T] term is the value we are seeking; P [T|W] is the probability of scoring T tries among the winners (also termed the “likelihood” in the Bayesian literature); P[W] is the probability of a match having a winner in the pool round (essentially the number of matches minus the number of ties all divided by the number of matches (240) in the pool round of all 10 tournaments); and P[T] is the distribution of tries scored in the pool rounds. By calculating each term we can evaluate the probability of winning a match given the number of tries a team scores.
2Data and methods
Data used in this study are available from World Rugby and are published online at https://www.world.rugby/sevens-series. All calculations were performed with Microsoft Excel© 2010 spreadsheet software. Internal spreadsheet software was used for calculating Poisson and Gamma distributions. The confidence level for all interpretations was set a priori at the 95% level. Standard statistical tables (Rohlf & Sokal, 1969) were used in statistical tests. The p-values reported for Chi Square results were calculated using an online statistical calculator found at https://home.ubalt.edu/ntsbarsh/Business-stat/otherapplets/pvalues.htm#rkstwo.
The data were taken from the pool rounds of the ten tournaments in each of three competitions (2016–17, 2017–18, and 2018–19) yielding 240 matches (480 team performances) per competition and 720 matches (1,440 team performances) in aggregate. A total of 4,391 tries were scored in the pool rounds of the three competitions. The study was restricted to the pool rounds where each team competes against three other teams selected based upon prior tournament ranking and a random component (World Rugby, 2018). Knock-out rounds are played among the more evenly matched teams based upon pool round performance in the tournament and might tend to skew the results (future investigation can test this assumption). Additionally, tied results stand in the pool round while ties must be broken in the knock-out round. Ties are part of the game and should be considered when examining the number of tries required to win at rugby sevens.
3Results and discussion
The data used in this study are summarized in Table 1. The total number of tries scored by teams in each competition ranged from zero to nine. The mean number of tries scored was about three. This is consistent with data presented by World Rugby (2016) for the 2015–2016 Sevens World Series where the average number of tries scored in a match was 5.8 suggesting an average of 2.9 tries by each team. The mean number of tries scored by the winning team in the current study was nearly 4.5. These values – mean number of tries scored and the mean number of tries scored by the winning team – as well as the total number of tries scored and the total numbers of tries scored by the winning teams are all observed to increase throughout the three competitions. We suggest that these trends could reflect improving attacking skills and tactics or improved overall fitness through time. Ultimately, however, analysis (not detailed here) over the three competitions did not reveal any statistically significant non-zero trends. Any possible verification of these trends must wait for additional data. Also shown in Table 1 is the distribution of the average value of the data for each number of tries across the three competitions. These data are similar to those of each competition.
Table 1
Data used in this study. Columns are the count of the total number of tries scored in the pool rounds of each competition and the number of tries scored by the winning team in each match. Each competition contributed 480 team performances. Tied games do not produce a winner hence the number of winners in each competition is less than 240. Also provided are the total numbers of tries scored in each competition and by the winners in the pool round. The final columns are the averaged data taken over all three years. The lower part of the Table shows the mean, variance, and standard deviation of the total number of tries and of the winning team’s tries in each competition and in the average
| Tries | 2016–2017 | 2017–2018 | 2018–2019 | Average | ||||
| Total | Winners | Total | Winners | Total | Winners | Total | Winners | |
| 0 | 36 | 0 | 33 | 0 | 30 | 0 | 33.000 | 0.000 |
| 1 | 71 | 0 | 65 | 1 | 63 | 2 | 66.333 | 1.000 |
| 2 | 106 | 20 | 94 | 9 | 101 | 8 | 100.333 | 12.333 |
| 3 | 107 | 56 | 100 | 43 | 103 | 51 | 103.333 | 50.000 |
| 4 | 73 | 68 | 88 | 80 | 80 | 72 | 80.333 | 73.333 |
| 5 | 50 | 50 | 49 | 49 | 46 | 46 | 48.333 | 48.333 |
| 6 | 18 | 18 | 28 | 28 | 31 | 31 | 25.667 | 25.667 |
| 7 | 10 | 10 | 14 | 14 | 16 | 16 | 13.333 | 13.333 |
| 8 | 8 | 8 | 7 | 7 | 8 | 8 | 7.667 | 7.667 |
| 9 | 1 | 1 | 2 | 2 | 2 | 2 | 1.667 | 1.667 |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0.000 | 0.000 |
| Sum = | 480 | 231 | 480 | 233 | 480 | 236 | 480 | 233.333 |
| Tries = | 1397 | 981 | 1490 | 1053 | 1504 | 1069 | 1463.667 | 1034.333 |
| Summary Statistics: | ||||||||
| Mean = | 2.910 | 4.247 | 3.104 | 4.519 | 3.133 | 4.530 | 3.049 | 4.433 |
| Var. = | 3.217 | 2.117 | 3.451 | 2.044 | 3.519 | 2.242 | 3.401 | 2.146 |
| S.D. = | 1.794 | 1.455 | 1.858 | 1.430 | 1.876 | 1.497 | 1.844 | 1.465 |
In each case the variance of the total number of tries scored exceeded the mean value (the ratio was typically 1.1) evidencing what has been termed “overdispersion” (Gelman et al. 2013:p.437). Overdispersion can result from several mechanisms including (Payne et al., 2018): 1) excess numbers of zero observations (which might be caused by including the results of several weaker teams in the data set); 2) the presence of outliers (perhaps caused by stronger teams “running up the score” against weaker opponents); 3) violations of the assumption of independence (where weaker teams consistently score fewer tries and stronger teams consistently score more tries); and 4) the possibility that the rate of try scoring changes through time (see also Dean & Lundy, 2016). Payne et al (2018) suggest that the adverse effects of overdispersion on statistical methods are not severe when the ratio of the computed Chi Square value of the data divided by the number of degrees of freedom under the Poisson assumption is less than 1.2. The data sets from the three competitions used in this study all have values of this ratio of less than 1.13 (details not shown). We conclude that any effects from overdispersion are minor.
The modal number of tries scored – the number of tries expected to be scored by a team – remained steady at three in each competition and the modal number of tries scored by the winners was constant at four. Interestingly, in each competition no team lost when scoring five or more tries.
3.1Evaluating P[T]
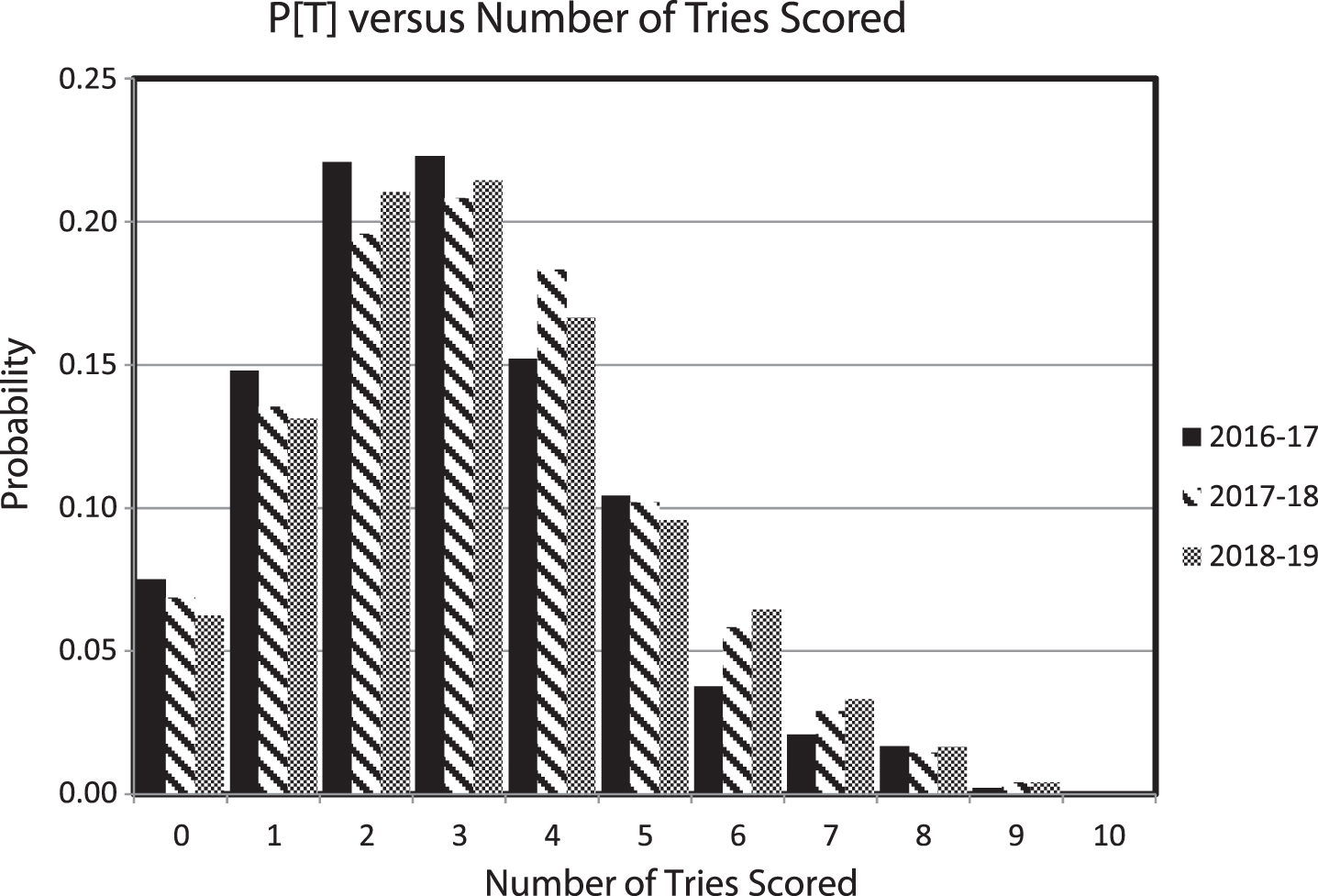
P is the probability of scoring T tries in the competition. Data from Table 1 are used to calculate P[T] for each competition and the average of all three competitions by taking the value in the Total column for try values in each year and dividing by the total number of team performances in that year. The results are shown in Table 2 and plotted in Fig. 1. The distributions are quite similar with, perhaps, a slight shifting to the right (an increased number of higher scoring tries were scored) through time. Data from the 2016–17 competition may have exhibited too few six and seven try performances relative to the other two years. The shape of the distributions suggests a Poisson process may be at work despite the slight over-dispersion seen in the data.
Table 2
The probability of scoring T tries (P[T]) in a match for all three competitions and the average distribution
| Tries | 2016–2017 | 2017–2018 | 2018–2019 | Average |
| P[T] | P[T] | P[T] | P[T] | |
| 0 | 0.075 | 0.069 | 0.063 | 0.069 |
| 1 | 0.148 | 0.135 | 0.131 | 0.138 |
| 2 | 0.221 | 0.196 | 0.210 | 0.209 |
| 3 | 0.223 | 0.208 | 0.215 | 0.215 |
| 4 | 0.152 | 0.183 | 0.167 | 0.167 |
| 5 | 0.104 | 0.102 | 0.096 | 0.101 |
| 6 | 0.038 | 0.058 | 0.065 | 0.053 |
| 7 | 0.021 | 0.029 | 0.033 | 0.028 |
| 8 | 0.017 | 0.015 | 0.017 | 0.016 |
| 9 | 0.002 | 0.004 | 0.004 | 0.003 |
| 10 | 0.000 | 0.000 | 0.000 | 0.000 |
| Sum = | 1.000 | 1.000 | 1.000 | 1.000 |
Fig. 1
The proportion of the number of tries scored in each competition. The data are quite consistent year to year with equivalent modal values of 3. The mean value of the number of tries scored and the standard deviation and variance of the number of tries scored both increased slightly through time.
The number of tries scored in a rugby sevens match is an example of “count data.” The distribution of count data may be expected to be described by the Poisson distribution provided that the elements being counted occur independently and with a constant probability of occurrence at any given time (Gelman et al., 2013).
The Poisson distribution is given (in the format of this study) by the following equation (Forbes et al., 2011:p.152):
Researchers in goal scoring sports have sometimes modeled score distributions as a Poisson distribution. Maher (1982) noted that many investigations have found that the distribution of soccer scores from English domestic competitions is described by the Poisson distribution while noting that the distribution may be better described by the closely-related negative binomial distribution. His study, however, shows that the Poisson distribution gives a reasonably good fit to the data with some slight systematic differences. Croucher (2002) concluded that the negative binomial distribution yields a better fit than the Poisson but requires much more data collection and calculation. Greenhough et al. (2002) concluded from worldwide soccer scoring data that neither the Poisson nor the negative binomial distributions described the distribution in the extreme values as the observed score distribution is too “heavy-tailed” (too many high scores). They prefer extremal statistics as a better fit but note that the Poisson or negative binomial distributions are sufficient models for English soccer. Popular articles written for the sports betting industry (see Naoumis, 2019, for instance) often assume that scores are distributed according to the Poisson distribution but with little (if any) rigorous justification.
In ice hockey, Mullett (1977) showed that the distribution of the number of goals scored in the National Hockey League follows a Poisson distribution. In a fairly recent study on try scoring in rugby league, Tonkes (2016) observed that the distribution of tries scored in all 201 matches from the 2015 Australian National Rugby League competition are well represented by a Poisson distribution. Jones (2019:p.215) speculated that, while the total score in rugby may not be distributed as a Poisson due to the differing number of points for different ways of scoring, the number of tries (and other ways of scoring such as penalty goals and dropped goals) could be distributed as a Poisson distribution.
There clearly is some difference of opinion regarding how well the Poisson distribution describes soccer and other goal scoring sports. The deviations from a Poisson distribution that have been observed seem minor and from the standpoint of practicality may not be important. We can test this assumption for the current data and draw conclusions regarding the propriety of using the Poisson distribution to describe try scoring in sevens rugby.
As part of this study we test how well the observed distributions approach a Poisson distribution using a Chi Square Goodness of Fit Test (Sokal & Rohlf, 1969). The result for the 2016–2017 competition is shown as an example calculation in Table 3. In this Table the data for seven tries and greater are pooled together to ensure that there are at least five expected occurrences in each try category (Sokal & Rohlf, 1969:p.568; Healey, 2005:p.295). For six degrees of freedom, the calculated chi square value of 7.570 has a p-value of 0.271. The coefficient of determination (r2) (Healey, 2005:p.404) comparing these two distributions was found to be 0.9890 meaning that the Poisson distribution explains 98.9% of the variance in the data. We conclude that the observed distribution is not significantly different from a Poisson distribution despite the slight over-dispersion.
Table 3
Chi Square Goodness of Fit Test for 2016–17 competition data to Poisson distribution. Data for seven tries and beyond are pooled to ensure more than five expected values. The comparison is for six degrees of freedom – one is lost for ensuring the total sums to 480, and one for estimating the mean value of the distribution (2.910). The critical value at the 5% level is 12.592. The calculated Chi Square is 7.570. The difference between the observed data and the Poisson distribution is not significant. The calculated P-value is 0.271
| Tries | Count Observed | Count Poisson | Contrib. to Chi Sq. |
| 0 | 36 | 26.137 | 3.721 |
| 1 | 71 | 76.071 | 0.338 |
| 2 | 106 | 110.699 | 0.199 |
| 3 | 107 | 107.393 | 0.001 |
| 4 | 73 | 78.140 | 0.338 |
| 5 | 50 | 45.484 | 0.448 |
| 6 | 18 | 22.063 | 0.748 |
| 7 | 10 | 9.173| | |
| 8 | 8 | 3.337| | 1.775 |
| 9 | 1 | 1.079| | |
| ≥10 | 0 | 0.423| | |
| Sum = | 480 | 480 | 7.570 |
| df = | 8 – 2 = 6 | ||
| p value = | 0.271 |
The vertical lines indicate values that were pooled together.
Figure 2 compares the distribution of try data from the 2016–17 competition with a Poisson distribution with the same mean. Based upon the chi square goodness of fit analysis the differences between the two curves are attributable to sampling and are not significant. The overall agreement between the two distributions is apparent.
Fig. 2
Distribution of the count of the number of tries scored in the pool round of the 2016–2017 competition compared with a Poisson distribution with the same mean (λ= 2.9104). The p-value of the Chi Square Goodness of Fit is 0.271 and the Coefficient of Determination (r2) = 0.9890.
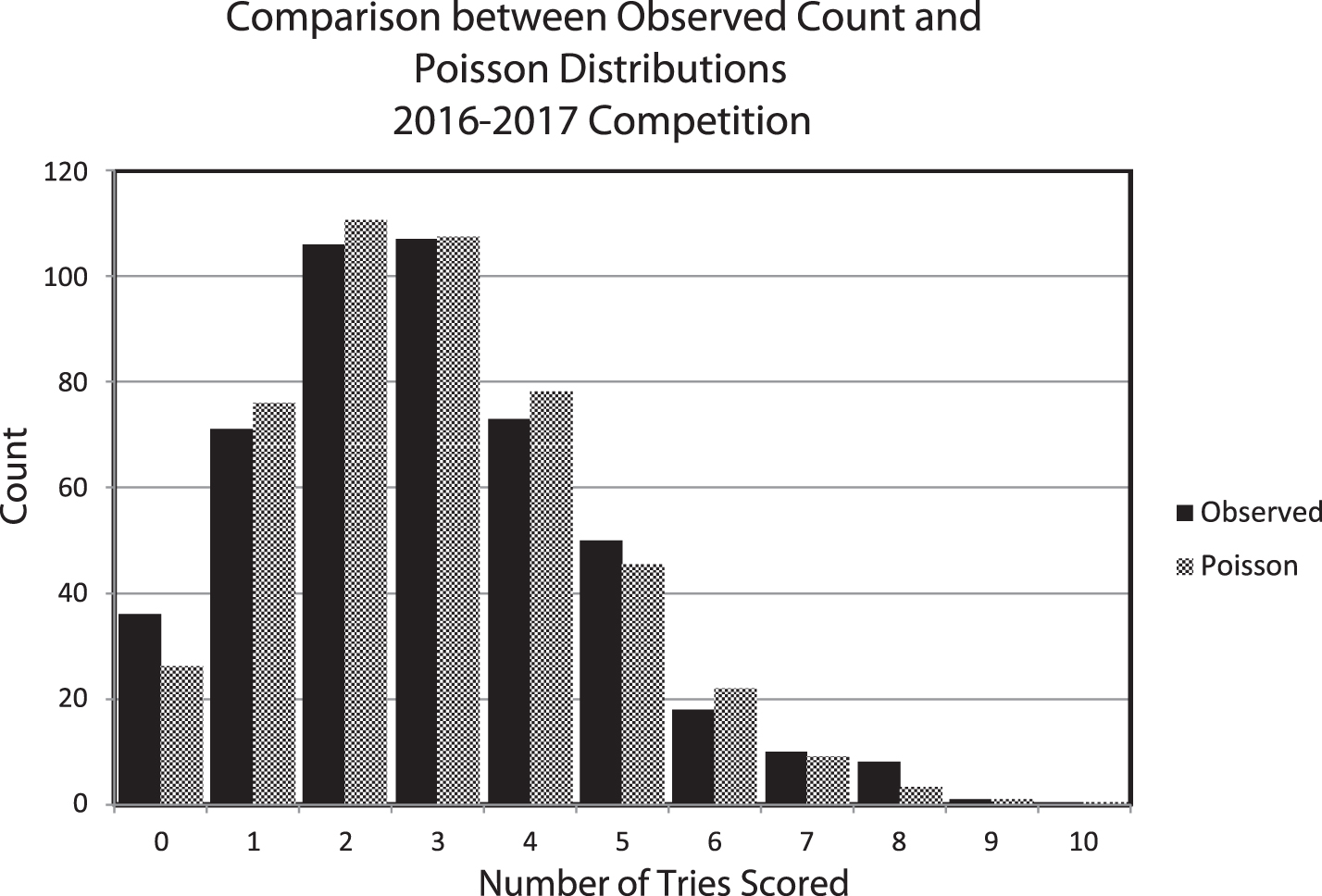
Table 4 provides a summary of the results for the Chi Square Goodness of Fit Test for all three years and the averaged data. As with the 2016–17 data, the distributions of the number of tries scored in the other two competition years do not differ significantly from a Poisson distribution – p-values are all well in excess of 0.05 and the values of r2 are all in the vicinity of 0.98 or 0.99. We conclude that we can be confident that the distributions of the number of tries scored in each year of the Sevens World Series we investigated closely follow a Poisson distribution with a mean value (λ) equal to the observed mean for the competition. Also, the distribution of the averaged data is not significantly different from a Poisson. This is to be expected as a result of the Additive Property of the Poisson distribution (Jones, 2019:p.212).
Table 4
Results of Chi Square Goodness of Fit Test for observed data by competition year and for the average distribution versus Poisson distribution with the same mean. Columns are for competition year, the number of degrees of freedom for the chi square test, the coefficient of determination, the chi square critical value at the 95% level, the observed chi square of the comparison between the observed data and the Poisson distribution, the calculated p-value, and the result of the test. NS = observed distribution is not significantly different from a Poisson distribution at the 95% confidence level
| Year | Critical | Observed | ||||
| df | r2 | Chi Sq. | Chi Sq. | p-value | Result | |
| 2016–17 | 6 | 0.9890 | 12.592 | 7.570 | 0.271 | NS |
| 2017–18 | 7 | 0.9850 | 14.067 | 9.084 | 0.247 | NS |
| 2018–19 | 7 | 0.9911 | 14.067 | 7.891 | 0.342 | NS |
| Average | 7 | 0.9930 | 14.067 | 7.277 | 0.401 | NS |
These results suggest that the distribution of the number of tries scored within each competition conform to a Poisson distribution. This result may be disconcerting to some. Panditt (2016) argues that the conformance of any real distribution to a Poisson distribution could be interpreted as evidence that the occurrence of each event is random and not the result of intent or design. Such a conclusion might trouble us – despite the consistency of the Laws under which the game is played; despite the consistent application of these Laws by Referees; despite the time spent by coaches training and developing their teams; despite the decisions and actions of the players – scoring tries in rugby sevens would seem to be as random as Prussian cavalry officers dying from horse kicks or the location of the impacts of V-1 flying bombs during World War Two.
In reality, the apparent randomness is due to our focus on the collective probability of the number of tries scored in sevens rugby. Each individual try has an identifiable set of predisposing factors illuminated by the studies of performance analysis in sevens rugby. Each try is scored in a more deterministic manner that we can observe and possibly predict given the opponents or the status of the game. It is only when we look at all of the matches and all of tries scored within a competition that the random nature appears (Panditt, 2016).
3.2Evaluation of P[W]
We can calculate the probability of winning a match P[W] for each competition directly from the data in Table 1. This probability equals the total number of winning performances divided by the total number of matches (240). In each competition the value of P[W] is less than 0.5 due to the existence of tied scores in the pool rounds. The values of P[W] by competition year and the average are given in Table 5. The number of ties per competition is seen to decrease through time and P[W] increased slightly. The probability of winning was fairly stable equaling between 0.48 and 0.49 in each competition and in the overall average value.
Table 5
The number of ties and winning probability (P[W]) in each competition year pool round and the average distribution. P[W] is less than 0.5 due to the occurrences of tied matches
| Year | Ties | P[W] |
| 2016–17 | 9 | 0.481 |
| 2017–18 | 7 | 0.485 |
| 2018–19 | 4 | 0.492 |
| Average | 20 | 0.486 |
3.3Evaluation of P[T|W]
The likelihood function given by P[T|W] – the probability of scoring T tries given that a team has won – is the third value we compute from the observed data. The likelihood provides all of the information contained in the data regarding the relationship between try scoring by the winning teams (Box & Tiao, 1973:p.10). The distributions of P [T|W] for all three of the competitions are given in Table 6 and shown in Fig. 3. This figure shows that very few winning teams scored fewer than two tries. The most likely number of tries scored by the winning team was 4. The distributions show that the range of tries scored by winning teams still spans the range of zero to nine tries – the same as for the number of tries scored in the competitions as a whole. The distributions of P [T|W] and P[T] have different shapes with different means and variance. The P [T|W] distribution is more peaked than the P[T] distribution and the means and the modes of the distributions have been shifted to the right to higher values. While still resembling a Poisson distribution, detailed analysis of the P [T|W] distributions has revealed that the true form of the observed distributions is better described by the related Gamma distribution. Jones (2019:pp.224-226) illustrates how the Poisson distribution and the Gamma distribution are complementary functions.
Table 6
The likelihood function (P[T|W]) for three competitions and the average distribution
| 2016–17 | 2017–18 | 2018–19 | Average | |
| Tries | P[T|W] | P[T|W] | P[T|W] | P[T|W] |
| 0 | 0.000 | 0.000 | 0.000 | 0.000 |
| 1 | 0.000 | 0.004 | 0.008 | 0.004 |
| 2 | 0.087 | 0.039 | 0.034 | 0.053 |
| 3 | 0.242 | 0.185 | 0.216 | 0.214 |
| 4 | 0.294 | 0.343 | 0.305 | 0.314 |
| 5 | 0.216 | 0.210 | 0.195 | 0.207 |
| 6 | 0.078 | 0.120 | 0.131 | 0.110 |
| 7 | 0.043 | 0.060 | 0.068 | 0.057 |
| 8 | 0.035 | 0.030 | 0.034 | 0.033 |
| 9 | 0.004 | 0.009 | 0.008 | 0.007 |
| 10 | 0.000 | 0.000 | 0.000 | 0.000 |
| Sum = | 1.000 | 1.000 | 1.000 | 1.000 |
Fig. 3
The proportion of the number of tries scored by the winning team in each competition (P[T|W]). Note the failure of any team scoring zero tries to win. In the 2016–2017 competition no team won when scoring one try. The mean value of the number for tries scored by the winning team and the standard deviation and variance of tries scored by the winning team both increase slightly through time. The modal value in each competition was 4.
![The proportion of the number of tries scored by the winning team in each competition (P[T|W]). Note the failure of any team scoring zero tries to win. In the 2016–2017 competition no team won when scoring one try. The mean value of the number for tries scored by the winning team and the standard deviation and variance of tries scored by the winning team both increase slightly through time. The modal value in each competition was 4.](https://content.iospress.com:443/media/jsa/2021/7-1/jsa-7-1-jsa200437/jsa-7-jsa200437-g003.jpg)
The equation for the Gamma distribution is given by (Gelman et al., 2013:p.578) as (written in the format of this study):
T = the number of tries scored by the winning teams,
and Γ (α) is the Gamma function of the value α (Artin, 1964).
The Gamma function is a complicated expression equal to (in the format of this study):
We note that the Gamma distribution is a continuous distribution while P [T|W] is a discrete distribution. We find that if we evaluate the values of the Gamma distribution only at the discrete integer values of T in computing P [T|W] we observe that the values of P [T|W] sum to 1 as required of a true probability. Hence, in this study the Gamma distribution reported is actually a discrete distribution represented by the integer values of the continuous Gamma distribution. There is, of course, a risk of this approach as we would expect that the change from a continuous to a discrete function should add another source of variance. In the end the data will tell us of this discrete approach is satisfactory or not.
We also note that if α > 1 (i.e. – the square of the mean exceeds the variance) the value of the Gamma distribution equals zero when T = 0. This requires that any team scoring zero tries cannot win if the distribution of P [T|W] is truly a Gamma distribution. While it is possible for a team to win by scoring only penalty goals or dropped goals in rugby, scoring in these ways is highly unusual in the seven-a-side game. The data used in this study show that teams did not win without scoring at least one try.
The three distributions of P [T|W] (Table 6 and Fig. 3) are quite similar in appearance. There is evidence that the data from the 2016–2017 competition tend towards smaller values of T and the data for the 2018–2019 competition tends towards higher values of T. The mean values of T shown in Table 1 confirm that the average number of tries scored by the winning teams was not stationary through time and increased in each competition. In all three competitions no team won when scoring zero tries and any team scoring one try is unlikely to win.
We can perform a Chi Square Goodness of Fit Test between P [T|W] and the Gamma distribution with parameters computed from the observed mean and variance within the data set of one competition. An example calculation is provided for the 2016–17 competition in Table 7 and plotted in Fig. 4 showing that the distribution of tries scored by the winning team essentially follows a Gamma distribution. Here the p-value was 0.390 and the r2 value between the data and the Gamma distribution was 0.9875. The comparison between the two distributions provided in Fig. 4 shows that the agreement is striking.
Table 7
Chi Square Goodness of Fit Test for 2016–2017 P[T|W] to Gamma distribution. Data for zero to two tries and for eight tries and beyond are pooled to ensure more than five expected values. Comparison is for four degrees of freedom – one is lost for ensuring the total sums to 231, one for estimating the value of α (8.51865) and one for estimating the value of β (0.49852). The critical value at the 5% level is 9.488. The calculated Chi Square is 4.122. The difference between the observed data and the Gamma distribution is not significant. The calculated P-value is 0.390
| Count | Count | Contrib. | Gamma Data | ||
| Tries | Winners | Gamma | to Chi Sq. | ||
| 0 | 0 | 0.000| | Mean = | 4.247 | |
| 1 | 0 | 0.801| | 0.016 | Var. = | 2.117 |
| 2 | 20 | 19.764| | S.D. = | 1.455 | |
| 3 | 56 | 56.065 | 0.000 | alpha = | 8.51865 |
| 4 | 68 | 65.600 | 0.088 | beta = | 0.49852 |
| 5 | 50 | 47.247 | 0.160 | ||
| 6 | 18 | 25.035 | 1.977 | ||
| 7 | 10 | 10.733 | 0.050 | ||
| 8 | 8 | 3.941| | |||
| 9 | 1 | 1.285| | 1.832 | ||
| >10 | 0 | 0.527| | |||
| Sum = | 231 | 231 | 4.122 | ||
| df = | 7–3 = 4 | ||||
| p-value = | 0.390 |
The vertical lines indicate the values pooled.
Fig. 4
Comparison between P[T|W] and a Gamma distribution for the 2016–17 competition with parameters computed from the data in Table 1 and given in Table 7. The p-value of the Chi Square Goodness of Fit is 0.390 and r2 is 0.9875.
![Comparison between P[T|W] and a Gamma distribution for the 2016–17 competition with parameters computed from the data in Table 1 and given in Table 7. The p-value of the Chi Square Goodness of Fit is 0.390 and r2 is 0.9875.](https://content.iospress.com:443/media/jsa/2021/7-1/jsa-7-1-jsa200437/jsa-7-jsa200437-g004.jpg)
Table 8 summarizes the Chi Square Goodness of Fit Tests for all three competitions and the averaged data. For the three competitions the p-values were in excess of 0.390 and the r2 values ranged from about 0.97 to 0.99. For each competition year the values of P [T|W] are consistent with a Gamma distribution. Table 9 is a summary of the parameters used in computing the Gamma distributions. For these three years, the values of α range from 8.519 to 9.993 and β values range from 0.452 to 0.499. Additional research is needed to test any universality associated with these values of α and β but their relative consistency over three years’ of Sevens World Series competition suggests there may be a common process at work.
Table 8
Results of Chi Square Goodness of Fit Test for observed P[T|W] by competition year versus Gamma distribution calculated from the observed mean and variance. Columns are for competition year, n = number of winners, the number of degrees of freedom for the chi square test, the coefficient of determination, the chi square critical value at the 95% level, the observed chi square of the comparison between the observed P[T|W] and the Gamma distribution, the calculated P-value, and the result of the test. NS = observed distribution is not significantly different from a Gamma distribution
| Year | Critical | Observed | |||||
| n | df | r2 | Chi Sq. | Chi Sq. | p-value | Result | |
| 2016–17 | 231 | 4 | 0.9875 | 9.488 | 4.122 | 0.390 | NS |
| 2017–18 | 233 | 4 | 0.9687 | 9.488 | 4.142 | 0.387 | NS |
| 2018–19 | 236 | 4 | 0.9763 | 9.488 | 3.201 | 0.525 | NS |
| Average | 233.33 | 4 | 0.9868 | 9.488 | 2.205 | 0.698 | NS |
Table 9
Values computed from the data in Table 1 to compute the parameters for the Gamma distributions for P[T|W] – alpha and beta
| Year | Gamma alpha | Gamma beta | Observed Mean | Observed S.D. |
| 2016–17 | 8.51865 | 0.49852 | 4.247 | 1.455 |
| 2017–18 | 9.99321 | 0.45224 | 4.519 | 1.430 |
| 2018–19 | 9.15292 | 0.49489 | 4.530 | 1.497 |
| Average | 9.15795 | 0.48404 | 4.433 | 1.465 |
As a check on the veracity of this result a Monte Carlo-type experiment was performed using 5,000 paired samples from a Poisson distribution with mean of 3. As shown in the Appendix to this study, the 10,000 variates are found, as expected, to be distributed as a Poisson distribution, and the distribution of the 4,208 “winners” of the comparisons between the samples were seen to be well described by the Gamma distribution with parameters computed from the winners of the sample pairs. The theoretical number of equal-try matches in this example is found to result in 16.7% ties and the sample of 5,000 “winners” during this experiment resulted in 15.8% ties (792 values). These compare well to the previously mentioned World Rugby (2016) data for the 2015–16 competition where the winning team scored more tries in 88% of the matches and in the remaining 12% of the matches the number of tries scored was equal. The difference between the theoretical value for the number of equal-try matches and the observed value are not significant at the 95% level.
We conclude that the distributions of P [T|W] in these data are consistent with a discrete distribution represented by the integer values of a continuous Gamma distribution. We believe that this is a novel point that has not been demonstrated previously in the literature. We note that there is no compelling a priori reason for this to occur. Gamma distributions are typically used to describe such phenomena as the time of the n-th occurrence of several events distributed as a Poisson process; amounts of rainfall over an area; the size of loan defaults and insurance claims; the flow of items through manufacturing or distribution facilities and processes; the demand on web servers; the timing of disk drive failures; and the demand on telecommunications centers (Jones, 2019, p. 227). The distribution of the number of tries scored by the winning team in a pairwise competition where the number of tries scored is a Poisson process is not similar to any of these processes.
The results of this study, including the Monte Carlo simulation, strongly suggest that the distribution of P [T|W] truly follows the Gamma distribution. Further research is necessary to discern why this is so.
3.4Evaluating P [W|T]
We are now in a position to use Bayes’ Theorem to calculate P [W|T] – the probability of winning a match in the World Rugby Sevens World Series given the number of tries scored by a team. We note that while P [W|T] can be computed accurately in this manner, it turns out that there is a simpler and mathematically equivalent way to get there (Stone, 2013:p.70). P [W|T] can be computed directly from the count data given in Table 1. Within any given competition, P [W|T] is equal to the number of times the winning team scored T tries divided by the total number of times that T tries were scored.
Table 10 shows the values of P [W|T] for each competition and these are plotted in Fig. 5. We see that the distribution is a step-like pattern rising from a probability of zero when no tries are scored to a probability of 1.00 when five tries are scored and is constant at 1.00 thereafter to the maximum observed number of tries. The winning probability from scoring only one try is quite bleak, reaching an average value of fewer than two wins in each 100 matches. Scoring two tries raises the winning probability from 10% to 20%. With three tries a team is close to winning 50% of its matches (43% to 52%). Four tries resulted in a fairly high certainty of a win, ranging from 91% to 93% of the time. Five or more tries resulted in certain victory in these competitions.
Table 10
P[W|T] for each competition and the average distribution computed from the data in Table 1
| Tries | 2016–17 | 2017–18 | 2018–19 | Average |
| P[W|T] | P[W|T] | P[W|T] | P[W|T] | |
| 0 | 0.000 | 0.000 | 0.000 | 0.000 |
| 1 | 0.000 | 0.015 | 0.032 | 0.015 |
| 2 | 0.189 | 0.096 | 0.079 | 0.123 |
| 3 | 0.523 | 0.430 | 0.495 | 0.484 |
| 4 | 0.932 | 0.909 | 0.900 | 0.913 |
| 5 | 1.000 | 1.000 | 1.000 | 1.000 |
| 6 | 1.000 | 1.000 | 1.000 | 1.000 |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 |
| 8 | 1.000 | 1.000 | 1.000 | 1.000 |
| 9 | 1.000 | 1.000 | 1.000 | 1.000 |
Fig. 5
The probability of winning given that a team scores T tries (P[W|T]) for three competitions. Teams that scored one try or did not score a try had essentially no chance of winning. The 50–50 point for winning was about 3 tries, and teams scoring five or more tries were certain to win in these competitions.
![The probability of winning given that a team scores T tries (P[W|T]) for three competitions. Teams that scored one try or did not score a try had essentially no chance of winning. The 50–50 point for winning was about 3 tries, and teams scoring five or more tries were certain to win in these competitions.](https://content.iospress.com:443/media/jsa/2021/7-1/jsa-7-1-jsa200437/jsa-7-jsa200437-g005.jpg)
These results might inform coaching decisions regarding teams in the Sevens World Series. To remain competitive teams evidently must have the consistent ability to score three or more tries per match. Without this there is no pathway towards success in these competitions (van Rooyen, 2015). Even with three tries per match and the resultant 50% winning probability it is unlikely that a team will consistently finish in the top two places in pool play. If a team fails to finish in the top two of their pool and they eventually win the Challenge Trophy (the knock-out round for the third and fourth place finishers in each pool) the maximum number of points they can acquire is only 36% of the points the tournament champion receives (van Rooyen, 2015). Competitive teams must routinely finish in the top two of their pool which, according to the values of P [W|T] developed in this study, requires routinely scoring more than three tries per match.
Teams can be quite certain of winning by scoring four tries in a match and virtually certain of winning by scoring five or more tries. There is no additional benefit to be accrued (based on the data used in this study) from scoring more than five tries. While the observed distribution of P accounts for the probability of scoring up to nine tries in a match – and there have been 145 occurrences of six or more tries in a match in 1,440 team performances (an observed probability of 0.10) – from a practical perspective the effort required to score more than five tries is essentially wasted. We strongly suspect that in some future Sevens World Series matches a team will score five or more tries and lose the match but this has not been observed in the last three years. At present there is no evidence that “running-up the score” provides tangible benefits in terms of winning matches in exchange for the additional effort. There may, however, be real psychological benefits over future opponents from scoring more than five tries in a match. Coaches must weigh the costs and benefits.
Finally, we believe that most experienced rugby sevens coaches sense much of the results of this study intuitively. It should surprise no high level sevens rugby coach that their team needs to score three or more tries in a match to be competitive, provided that the team’s technical and tactical abilities (particularly in defense) are good enough. The benefit of this study is that we can now address this issue more quantitatively. Two tries does not just result in losing a rugby sevens match, two tries loses the match for a team approximately 80% of the time. Four tries do not just generally ensure a victory, four tries is sufficient to win 90% of the time. This quantification of the game and the education of coaches who can articulate and interpret the probabilities will allow them to make better decisions on how they should prepare their teams.
4Conclusions
Analysis of the number of tries scored by teams in the pool round in three years of the World Rugby Sevens World Series and the number of tries scored by the winning teams in those competitions has allowed us to determine the probability of winning given the number of tries scored (P[W|T]) in these competitions. We also can formulate some generalizations regarding the distributions of the number of tries scored (P[T]) and the number of tries scored by the winning teams (P[T|W]).
The distribution of the number of tries scored by teams (P[T]) in the pool rounds ranged from 0 to 9. The distribution in each competition was well-defined by a Poisson distribution with the Poisson parameter λ equal to the observed mean number of tries scored. The number of tries scored by the winning teams (P[T|W]) in the pool rounds was well-approximated by a Gamma distribution with parameters computed from the observed mean and variance of the distributions. The Gamma distribution holds through all three competition years and is supported by a Monte Carlo experiment on pairwise samples from a Poisson distribution with the mean number of tries scored equal to three. We believe that this is a new observation not previously reported in the literature.
The probability of winning a match (P[W]) in each competition was seen to approach but be less than 0.5 due to the number of tied games in the pool rounds. The observed winning percentages in each of the three competitions ranged from about 0.48 to 0.49.
Using data on P[T|W], P[T] and P[W] for each competition we computed the probability of winning given the number of tries scored (P[W|T]) using Bayes’ Theorem. The results for each competition show that teams cannot expect to win if they score zero or one try per match and the chances of winning with scoring two tries is no better than 20%. Three tries results in about a 50–50 chance of winning. Four tries result in an approximately 90% surety of winning, and winning was guaranteed by scoring five or more tries.
We finish by opining that more quantitative studies of sevens rugby are needed. The results of studies that provide quantitative data and information to sevens rugby coaches allow them to make better informed decisions about how their teams should play the game.
Appendices
5
5Appendix - Monte Carlo Simulation of P[T|W]
We seek to verify that the likelihood function (P[T|W]) in sevens rugby is distributed as a Gamma distribution. Consistent with observations of sevens rugby we assume that: 1) the number of tries scored is distributed as a Poisson variable, and 2) the number of tries scored is a good surrogate for the number of points scored (data – not presented here – from the pool rounds of two tournaments (Dubai and Los Angeles) from the 2018–19 HSBC Sevens show the correlation between number of tries scored and the number of points scored is about 0.98). The match is won by the team that scores more tries.
Consider a pairwise sampling of 5,000 pairs of Poisson-distributed variates. We compare the samples (simulated tries) and determine the “winner” of the match to be the variate with a greater value. If the values are the same we borrow from tic-tac-toe and declare it to be a “cat’s game” – the tie stands without a winner but the variates are still included in the total number of values sampled from the original distribution. This provides us with 10,000 variates and up to (but probably fewer than) 5,000 winners.
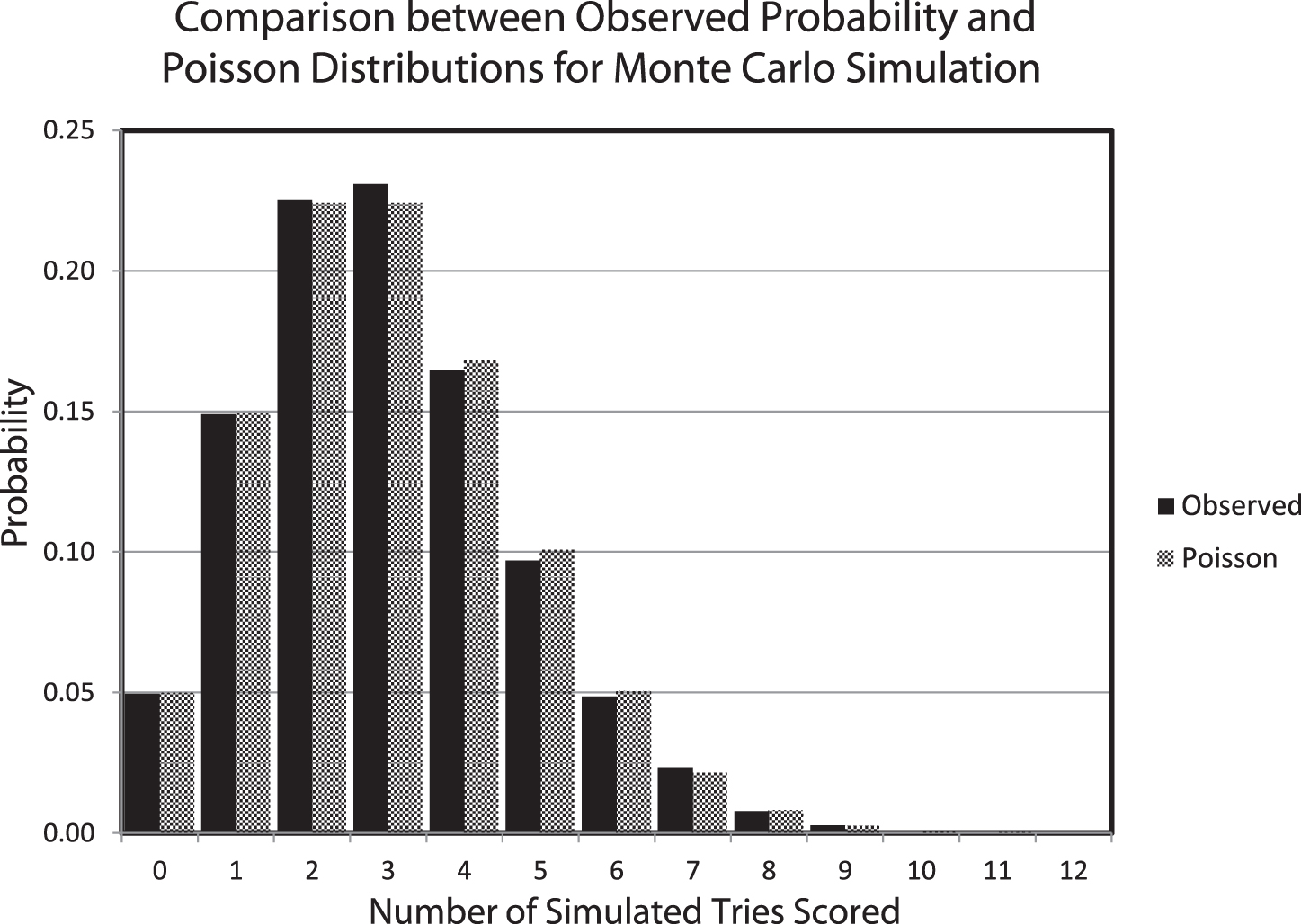
For this simulation we sample from a Poisson distribution with a parameter λ equal to 3 which is a reasonable approximation to the average number of tries a team scores in a sevens rugby match. The Poisson distribution was generated by a Microsoft Excel© 2010 Random Data generator. Table A1 provides the distribution of the Monte Carlo simulation and the Poisson distribution while Fig. A1 shows a comparison between the distributions. The plot shows that the fit between the sampled Poisson distribution and the theoretical distribution is excellent. The coefficient of determination (r2) between the two cumulative distributions is 0.9990. There is a slight surplus of 3 try observations, but this is not deemed critical. We conclude that the simulation data are demonstrated to be defined by the Poisson distribution.
Table A1
Cumulative proportion of simulated tries scored in simulation of 10,000 Poisson variables and a Poisson distribution (λ= 3). The coefficient of determination (r2) between the distributions is 0.9990
| Tries | Observed | Poisson | ||
| P[T] | p[T] | Poisson Distribution: | ||
| 0 | 0.050 | 0.050 | Mean = | 3.000 |
| 1 | 0.149 | 0.149 | Var. = | 3.000 |
| 2 | 0.225 | 0.224 | ||
| 3 | 0.231 | 0.224 | Observed Distribution: | |
| 4 | 0.165 | 0.168 | Mean = | 2.990 |
| 5 | 0.097 | 0.101 | Var. = | 2.990 |
| 6 | 0.049 | 0.050 | ||
| 7 | 0.023 | 0.022 | ||
| 8 | 0.008 | 0.008 | ||
| 9 | 0.003 | 0.003 | ||
| 10 | 0.001 | 0.001 | ||
| 11 | 0.000 | 0.000 | ||
| 12 | 0.000 | 0.000 | ||
| Sum= | 1.000 | 1.000 | ||
Fig. A1
Comparison between the distribution of 10,000 samples drawn from a Poisson distribution and the theoretical cumulative Poisson distribution (λ= 3). The coefficient of determination (r2) between the two distributions is 0.9990.
The pairwise sampling of the Poisson distribution produced 4,208 “winners.” The distribution of the winners was modeled as a Gamma distribution ∼Γ(α, β) with α and β computed from the data (Forbes et al., 201:p.111). The Gamma distribution referred-to here is a discrete distribution represented by the integer values of a continuous Gamma distribution. The computed values of α and β from the Poisson winners are 7.0794 and 0.5897. As these values are computed from the sample data they are subject to variation – other samples would yield different but similar values. Table A2 and figure A2 show a comparison between the computed likelihood (P [T|W]) from the winners and the theoretical Gamma distribution. The fit between the data and the Gamma distribution is quite close with the coefficient of determination equal to 0.9987. There are slight deviations between the two distributions at try values of 1 and 7, but the overall fit is striking.
Table A2
Cumulative probability of winning given the number of simulated tries scored in 4,208 paired Poisson samples P[T|W] and the Gamma Distribution with α= 7.07940 and β= 0.58966. The coefficient of determination (r2) between the two distribution is equal to 0.9987
| Tries | Observed | Gamma | ||
| P[T|W] | P[T|W] | Gamma Function: | ||
| 0 | 0.000 | 0.000 | Mean = | 4.174 |
| 1 | 0.016 | 0.009 | Var. = | 2.461 |
| 2 | 0.109 | 0.115 | ||
| 3 | 0.245 | 0.247 | alpha = | 7.07940 |
| 4 | 0.254 | 0.261 | beta = | 0.58966 |
| 5 | 0.188 | 0.186 | ||
| 6 | 0.107 | 0.103 | ||
| 7 | 0.053 | 0.048 | ||
| 8 | 0.019 | 0.020 | ||
| 9 | 0.007 | 0.007 | ||
| 10 | 0.002 | 0.003 | ||
| 11 | 0.000 | 0.001 | ||
| 12 | 0.000 | 0.000 | ||
| Sum= | 1.000 | 1.000 | ||
Finally, the number of cat’s games observed from our Poisson sample is 792 out of 5,000 (15.8%). The theoretical number of ties using the pairwise Poisson test can be calculated from the expected P[T] for each value of T and summed over all values of T. The probability of scoring T tries and the opponent scoring T tries is equal to (P[T])2. Summing these over T values of zero to 12 yields an expected percentage of equal try games as 16.7%. The observed number of equal-try performances from the 2018–2019 Sevens World Series as part of this study was 34 out of 240 (14.2%). These values are all of similar magnitude. We can compare the probabilities of equal number of tries from the 2018–19 competition (0.142) with the theoretical probability of equal tries (0.167) via a Z-test for a single sample proportion (Healey, 2005:p.213):
p1 and p2 are the probability values derived from theory and the competition, respectively, and
n is the number of matches in the competition (240).
We find that the computed Z-value for this test is 1.038. The two-tailed critical value at the 95% level is 1.96. The p-value is 0.299, and we conclude that the observed value of the proportion of equal-try matches (0.142) is not significantly different from the theoretical value (0.167). We also see that the observed probability computed from our samples of 10,000 Poisson distributed variates (0.158) falls between the theoretical value and the value computed for the 2018–2019 Sevens World Series and it, too, would not be significantly different.
We can confirm this result by performing an arcsine t-test (Sokal & Rohlf, 1969):
p1 and p2 are the probability values derived from theory and the competition, respectively, with the arcsine expressed in degrees, and
n = number of matches in the competition (240).
The factor 820.8 is a “constant representing the parametric variance of a distribution of arcsine transformations of proportions or percentages” (Sokal & Rohlf, 1969:p.607).
We find that the t-value of this comparison is 1.072 with a p-value is 0.284. The critical t-value at the 95% level is 1.96. We conclude again that the observed number of equal-try matches does not deviate significantly from the theoretical value.
Fig. A2
Comparison between the theoretical Gamma distribution (α= 7.0794, β= 0.5897) and the distribution of P[T|W] derived from 4,208 winners. The coefficient of determination (r2) between the two distributions is 0.9987.
![Comparison between the theoretical Gamma distribution (α= 7.0794, β= 0.5897) and the distribution of P[T|W] derived from 4,208 winners. The coefficient of determination (r2) between the two distributions is 0.9987.](https://content.iospress.com:443/media/jsa/2021/7-1/jsa-7-1-jsa200437/jsa-7-jsa200437-g007.jpg)
We conclude, therefore, that the likelihood function for the simulated data conforms well to the discrete distribution represented by the integer values of a continuous Gamma distribution with parameters drawn from the observed distribution of winners in our Poisson pairwise sample.
References
1 | Artin E. & Mineola NY , (1964) , The Gamma Function. Mineola, NY, Dover Publications. |
2 | Box G.E.P. & Tiao G.C. , (1972) , Bayesian Inference in Statistical Analysis. Reading, MA, Addison-Wesley. |
3 | Clarke R.D. , (1946) , An application of the Poisson distribution. Journal of the Institute of Actuaries, 72: (3), 481. |
4 | Croucher J.S. , (2002) , Analysing scores in English premier league soccer. In: Cohen, G. & Langtry, T. (eds.). Proceedings of the 6th Australian Conference on Mathematics and Computers in Sport, 1 – 3 July, 2002. Queensland. pp 119-126. |
5 | Dean C.B. & Lundy E.R. , (2016) , Overdispersion. Wiley StatsRef: Statistical Reference Online. Available from: https://doi.org/10.1002/9781118445112.stat06788.pub2. |
6 | Forbes C. , Evans M. , Hastings N. , Peacock B. & Hoboken NJ , (2011) , Statistical Distributions. Fourth Edition. Hoboken, NJ, Wiley. |
7 | Gelman A. , Carlin J.B. , Stern H.S. , Dunson D.B. , Vehtari A. , Rubin D. & Boca Raton FL , (2013) , Bayesian Data Analysis: Third Edition. Boca Raton, FL, CRC Press. |
8 | Greenough J. , Birch P.C. , Chapman S.C. & Rowlands G. , (2002) , Football goal distributions and extremal statistics. Physica A, 316, 615-624. |
9 | Healey J.J. , (2005) , Statistics: A tool for Social Science Research, 7th ed. Belmont, CA, Thompson/Wadsworth. |
10 | Henderson M.J. , Harries S.K. , Poulos N. , Fransen J. & Coutts A.J. , (2018) , Rugby sevens match demands and measurement of performance: A review, Kinesiology, 50: (Supplement 1), 49–59. |
11 | Hingham D.G. , Hopkins W.G. , Pyne D.B. & Anson J.M. , (2014) , Patterns of play associated with success in international rugby sevens, International Journal of Performance Analysis in Sport, 14: , 111–122. |
12 | Jones A.R , (2019) , Probability, Statistics, and Other Frightening Stuff. London, Routledge. |
13 | Maher M.J. , (1982) , Modelling association football scores, Statistica Neerlandica, 36: , 109–118. |
14 | Mullet G.M. , (1977) , Simeon Poisson and the National Hockey League, The American Statistician, 31: (1), 8–12. |
15 | Naoumis G. , (2019) , Using the Poisson distribution to predict rugby league (NRL) matches. Available from: https://www.linkedin.com/pulse/using-poisson-distributionpredict-rugby-league-nrl-matches-naoumis [Accessed 5th September 2019]. |
16 | Panditt J.J. , (2016) , Deaths by horsekick in the Prussian army – and other ‘Never Events’ in large organizations, Anaesthesia, 71: , 7–11. |
17 | Payne E.H. , Gebregziabher M. , Hardin J.W. , Ramakrishnan V. & Egede L.E. , (2018) , ,, An empirical approach to determine a threshold for assessing overdispersion in Poisson and negative binomial models for count data, Communication in Statistics – Simulation and Computation, 47: (6), 1722–1738. |
18 | Peeters A. , Carling C. , Piscione J. & Lacome M. , (2019) , In-match physical performance fluctuations in international rugby sevens competition, Journal of Sports Science and Medicine, 18: , 419–426. |
19 | Rohlf F.J. & Sokal R.R. , (1969) , Statistical Tables. San Francisco, W.H. Freeman. |
20 | Sokal R.R. & Rohlf F.J. , (1969) , Biometry. San Francisco, W.H. Freeman. |
21 | Stone J.V. , (2013) , Bayes’ Rule: A Tutorial Introduction to Bayesian Analysis. Middletown, DE, Sebtel Press. |
22 | Tonkes E. , (2016) , On the distribution of winning margins in rugby league. In: Stefani, R. & Schembri, A. (eds). Proceedings of the 13th Australasian Conference on Mathematics and Computers in Sports. 11-13 July, 2016, Melbourne. ANZIAM MathSport. pp. 150-155. |
23 | van Rooyen M. , (2015) , Early success is key to winning an IRB sevens world series, International Journal of Sport Science and Coaching, 10: (6), 1129–1138. |
24 | van Rooyen K.M. , (2016) , Seasonal variations in the winning scores of matches in the sevens world series, International Journal of Performance Analysis in Sport, 16: , 290–304. |
25 | World Rugby 2016, 2015-2016 Series Game Analysis Report, World Rugby Game Analysis. Available from: https://www.world.rugby/game-analysis?lang=en. [Accessed 5th September 2019]. |
26 | World Rugby 2018, HSBC World Rugby Sevens Series 2018 – Tournament Rules. Available from https://www.world.rugby/sevens-series/series-info?lang=en. [Accessed 5th September 2019]. |


