
Towards the 4th population census in Ethiopia: Some insights into the feasibility of the Post-Enumeration Survey
Abstract
While national registry systems are evolving worldwide and, in some cases, replacing reliance on censuses, in countries where well-established population registers are lacking, the population and housing census remains the primary source of detailed data on the number of people, their spatial distribution, age and gender structure, living conditions, and other key socio-economic characteristics. The quality of the census findings is crucial for several reasons, including building public trust in the national statistical system. In many developing countries, conducting a Post-Enumeration Survey appears to be the only feasible way to evaluate the census results. Indeed, the lack or incompleteness of reliable demographic data from alternative sources precludes the use of other methods. This paper discusses some aspects of the feasibility of a Post-Enumeration Survey in Ethiopia. In particular, the paper reports on the main critical issues that emerged from the pilot surveys carried out in the framework of a cooperation project – funded by the Italian Agency for Development Cooperation – aimed at providing methodological support and technical assistance for the preparation of the 4th Ethiopian Population and Housing Census.
1.Introduction
A population and housing census is an enumeration of the total population of a country and provides data on the number of people, their spatial distribution, age and gender structure, living conditions and other key socio-economic characteristics. Such data, inter alia, are crucial for formulating national and sub-national policies, planning development and monitoring progress towards the Sustainable Development Goals (SDGs). While national registry systems are evolving worldwide and, in some cases, replacing reliance on censuses, for several countries the population and housing census still remains the primary source of detailed demographic data and provides the sampling frame for targeted national surveys on households.
A population census is not perfect and errors can occur at all stages of the data production process. The quality of the census results is crucial for many reasons, including building public trust in the national statistical system. Therefore, it is important to assess type and amount of the errors introduced during the survey. The presence of inaccuracies in the data does not diminish the importance of the census as long as the users are aware of the limitations behind the findings and the errors do not heavily affect the main uses of the final statistics.
The errors in the census results fall into two general categories:
• Coverage errors;
• Content errors.
Coverage errors are due to the omission and/or erroneous inclusion of individuals and/or housing units in the census, while content errors occur when the information on the characteristics of the enumerated individuals and/or housing units is incorrectly reported, recorded, or processed (e.g., information on Gender, Age, Marital Status). Both types of error can bias the population counts by demographic characteristics.
A number of methods for assessing coverage and content errors in census data have been developed [7, 8]. These methods include the demographic analysis, the comparison of census totals with figures from other sources, and the matching of responses provided at the census with those from the Post-Enumeration Survey (PES).
Following the United Nations (UN) [13], the PES is a complete re-enumeration of a representative sample of the census population. The results of the comparison (via case-by-case matching or record linkage) of the PES microdata with those from the census make it possible to evaluate the incidence of coverage and/or content errors generated during the census enumeration.
In addition to estimating coverage and/or content errors, a PES can be used for other purposes. These include:
• Uncovering inadequate census methods or operations; for example, the omission of whole housing units may reveal problems in the definition of the Enumeration Areas (EAs) or mistakes made by some interviewers during the fieldwork;
• Providing a statistical basis for adjusting census results; using a carefully designed survey, under-counts (or over-counts) can be converted into adjustment factors and the census population increased or decreased based on them.
In many developing countries, where an advanced registry system is lacking and population surveys are not carried out on a regular basis, conducting a PES seems to be the only feasible way to assess the quality of the census results. Indeed, the lack or incompleteness of reliable demographic data from alternative sources precludes the use of other methods. According to a survey on the implementation of the 2020 round of censuses in the UN Member States [15], Europe, Latin America, and the Caribbean rely more than any other region in the world on administrative data to verify census records, while the use of the PES is predominant in Africa and Asia.
However, the apparent simplicity of the PES is deceptive. Many countries that carried out a PES never published the results or only provided estimates of national coverage [6]. Referring to some experiences in Africa, Angola published a national estimate of under-coverage of 6 percent for the 2014 census, but no methodological report or detailed breakdown of the results [11]. In Ethiopia, the only attempt at PES took place two months after the 1994 census, but the findings were not released [1]. On the other hand, South Africa carried out a comprehensive analysis of its 2022 PES but found higher coverage errors than expected [10].
To produce reliable final estimates, a PES has to function within a number of operational and methodological constraints [12, 16]. In particular, the survey should be independent of the census, while sharing its definitions and concepts, and it should be conducted with the utmost care at each stage. Other crucial aspects for the success of a PES are the use of well-trained human resources and the error-free identification of the statistical units already enumerated in the census.
This paper discusses some aspects of the feasibility of a PES to evaluate census results in Ethiopia. In particular, the paper reports on the main critical issues that emerged from the pilot surveys carried out in the framework of a cooperation project funded by the Italian government through the Italian Agency for Development Cooperation (AICS). Under this project, the Italian National Statistical Institute (Istat) contributed to the strengthening of the Central Statistical Agency (CSA) by providing technical and methodological support for the preparation of the 4th Ethiopian Population and Housing Census11 (EPHC). In this context, given the limited experience with the PES in Ethiopia, the CSA considered specific technical support from the international community to be essential.
The paper is organised as follows. After a summary of the support provided by Istat (Subsection 2.1) and a brief country profile (Subsection 2.2), some aspects related to the strategy and feasibility of a PES in Ethiopia are discussed with reference to the following topics:22 objectives, sampling design and data collection (Section 3); data processing and coverage error estimation method (Section 4). The main results from the pilot surveys are reported in Section 5. Finally, some concluding remarks are drawn (Section 6).
2.The context
2.1Capacity building support to the Ethiopian Central Statistical Agency
Capacity building and institutional strengthening are integral parts of the technical support that Istat provides to local partner institutions in the framework of its cooperation projects. They represent the link between project outputs and sustainability and ensure that the improvements made are absorbed and maintained beyond the life of the project. As regards concrete implementation, these results are achieved with a strong emphasis on working together through coaching and advisory activities aimed at transferring the know-how of Istat experts to their counterpart, introducing innovations in the partner institution’s processes and supporting the local staff with the overall goal of developing the targeted areas. Comparative analysis is part of the coaching activity, both to present methodologies and practices that guarantee compliance with international standards and to identify specific strengths and weaknesses of the current systems. The process of developing and strengthening institutional capacity takes place not only through the transfer of methodologies and techniques appropriate to the national context, but also through the introduction of relevant tools and the enhancement of the training component. This general approach was also adopted to support the CSA in preparing for the 4th EPHC.
At the time of the project definition, the CSA was facing a number of difficulties mainly related to:
• Inadequate staff resulting from high turnover (due to low salaries and lack of career paths);
• Insufficient funds allocated to the statistical function, which made it difficult to develop processes in a holistic manner and to modernise the infrastructure supporting data production.
In particular, it was found that none of the managers of the EPHC process had been involved in the implementation of the previous census due to the high turnover of the CSA staff. This made the need for specific training extremely urgent, especially in the areas most directly affected by the introduction of process innovations. On the other hand, the lack of government funding to cover the entire budget for the EPHC and, in particular, to acquire the tablets and associated power banks for data collection made the need for technical and financial support from the international donor community and partners even more evident.
The Italian support to the CSA was part of the complex and multi-faceted preparatory activities for the 4th EPHC, to which various donors and international partners – including the World Bank, DFID (UK Department for International Development), UNFPA (UN Population Fund) and USCB (United States Census Bureau) – contributed in different ways. The complexity of the intervention in Ethiopia also stemmed from the introduction of methodological and technological innovations that, in line with international guidelines, mainly concerned the following aspects:
• The transition to fully digital maps, using mobile Geographic Information System (GIS) technology;
• The use of Computer-Assisted Personal Interviewing (CAPI) for data collection.
The Italian project took place over two years (from June 2016 to June 2018) and had two main strands: one to build the Information Technology (IT) infrastructure for the EPHC and the other to develop expertise in methodology and data analysis. The technical assistance in the IT area focused on the development of a generalised metadata-driven survey monitoring system integrated with the Census and Survey Processing (CSPro) data collection system (implemented by the USCB [2]) On the other hand, the methodological component mainly concerned the design of the PES and the development of software tools for record linkage, as discussed in the following Sections.
Figure 1.
Regions of Ethiopia (as of 2021). Source: https://en.wikipedia.org/wiki/Regions_of_Ethiopia.
2.2Country profile
Ethiopia is a federal parliamentary republic comprising eleven politically autonomous regions and the two administrative cities of Addis Ababa and Dire Dawa (Fig. 1). The regions are divided into zones, which are further divided into districts. The districts roughly correspond to territorial units called wereda. The wereda are made up of kebele, neighbourhood associations, and are the smallest administrative units. A kebele comprises approximately 500 households or the equivalent of 3,500–4,000 individuals. Any town of two thousand inhabitants includes at least one kebele. Census EAs are drawn within each kebele (on average there are three or four EAs per kebele). The boundaries of wereda and kebele are decided by the local governments and are subject to frequent changes in relation to socio-demographic, housing and environmental conditions.
From a demographic point of view, Ethiopia is the second most populous country in sub-Saharan Africa. According to CSA estimates, the population of Ethiopia was around 86 million in 2013, with an annual growth rate of 2.6 percent (one of the highest in the world). In addition to significant internal migration flows driven by economic, climatic, and political factors (droughts, wars, poverty, unrest and riots, forced resettlement processes), Ethiopia has the highest number of refugees on the entire African continent. This is linked to the strategic location of the country, which is at the same time an area of origin and transit for migrants heading to the main European destinations, but also to the Gulf, the Middle East, and South Africa.
It is worth pointing out that Ethiopia is characterised by considerable religious pluralism, with Orthodoxy remaining the most practiced faith, followed by Islam and, at a greater distance, by other minorities. Besides, the ethnic fragmentation is very high (more than 80 groups), as is the rural prevalence. According to the last population census in 2007, Ethiopia was one of the least urbanised countries in the world, with 83.6 percent of the population living in rural areas.
Regarding the state of development of the system of Civil Registration and Vital Statistics (CRVS) the country has one of the lowest birth registration rates in Africa. In 2016 only 3 percent of the births of children under the age of five were registered by civil authorities [3, 18].
3.Objectives, sampling design and data collection: some issues
3.1Objectives and sampling design
In the Ethiopian context, also in relation to the structural characteristics of the population and the peculiarities of the administrative geography, the possible objectives of a PES should be limited to:
• Assessing the coverage error at the national level and, at most, for the major sub-national domains, such as regions and administrative cities;
• Gaining experience to improve the design and implementation of future censuses and large-scale surveys on households.
Other objectives, such as assessing content errors or adjusting census results, are difficult to achieve in the national context and with the available resources.
With regard to the sampling design, the main directions provided in the framework of the cooperation project focused on the need to:
• Adopt a probabilistic approach to the sample selection rather than a non-probabilistic one;
• Consider the variety of the geographic domains;
• Draw up the sampling list of the territorial units by specifying some characteristics useful for their stratification such as:
– Typology (e.g., “Urban”, “Rural”, “Extreme”);
– Size in terms of population;
– Predominant type of dwelling;
– Presence/absence of significant population flows;
• Take the EAs as the final sampling units and enumerate all the households in the selected EAs.
The implementation of these directions led to the definition of the sampling design used to carry out the first pilot surveys for both the census and the PES. According to this design, the territorial units (wereda and kebele) were selected using a three-stage sampling design in which, within each domain (region/administrative city), the relevant wereda were stratified into three groups (“Urban”, “Rural”, “Extreme”).
Specifically, the final sample of EAs was obtained according to the following scheme:
Stage 1: for each domain, a sample of wereda was drawn from each stratum; Stage 2: a sample of kebele was drawn from each wereda selected in Stage 1; Stage 3: a sample of EAs was drawn from each kebele selected in Stage 2.
However, it is worth noting that, in the absence of cost constraints, the sample size may depend on several factors, including:
As the cluster effect, the desired accuracy (sufficiently narrow confidence intervals), and the classification detail of the final estimates increase, the required sample size increases. In particular, if the estimates are to be produced only at the national level, the sample size may be relatively small compared to that of a sample aimed at producing results for finer territorial domains.
3.2Data collection technique
With the increasing affordability, reliability, power, and user-friendliness of mobile and wireless technologies, CAPI is expected to become the standard for field data collection even in countries where access to information and communication technology infrastructure is limited, such as African countries.
Considering that the EPHC data are supposed to be collected using CAPI, the same survey technique should be used for the PES.
CAPI has several advantages over traditional Paper-And-Pencil Interviewing (PAPI). In the former mode, the enumerators also act as data entry operators. By eliminating the need to transcribe information from paper forms, automatic checks can be made at the input stage, reducing errors and processing times [14]. Besides, the CAPI technique allows for more efficient management of the interviewers, including updating their assignments and checking the completed questionnaires.
The above-mentioned features of the CAPI mode positively influence not only the accuracy of the data collected in the field but also, as a consequence, that of the record linkage results. Nevertheless, there may be situations where the PAPI technique remains the only option for both the census and the PES (i.e., in the areas where problems are more likely to occur, such as those where power supply and network connectivity are scarce or there is a shortage of tablets).
3.3Questionnaire
In general, the PES questionnaire should be designed on the basis of the census questionnaire in order to facilitate the comparison of the information useful for the identification of the statistical units – households and individuals – enumerated in both surveys. Typically, the PES questionnaire is a shorter version of the corresponding census questionnaire.
As for the information to be used for the matching in the specific context, the pilot PES questionnaire included the same questions, with the same items, as the pilot census questionnaire with regard to: i) identifiers of the EA; ii) identifiers or socio-demographic characteristics of each individual.
The variables of interest in the latter category (ii) were as follows: First name, Middle name, Third name, Relationship to the head of the household, Gender, Age, Marital status, Ethnic group, Religion, Mother tongue, and Level of education.
In addition to the listed variables, a household’s barcode sticker – i.e., a numerical code printed on adhesive support – was introduced in the 2nd pilot edition to facilitate the matching process, following the positive experience of the South African Institute of Statistics [9]. The sticker was to be placed at the main entrance of each dwelling unit during the census operations so that it could be easily found later by the PES enumerators. In this regard, the CSA staff was also urged to define precise rules for the placement of stickers by listing in the enumerators’ manual, in order of importance, all alternative places (other than the main entrance) on which stickers could be attached.
As for the individual characteristics, it was preferred to consider the variable Age rather than the date of birth. In Ethiopia, the latter information shows greater problems of accuracy, as there is not yet an established CRVS system [4]. As a result, individuals (especially the elderly) may not know their exact date of birth or tend to report it approximately.
Finally, in line with the recommendations of the UN Secretariat [12], the PES questionnaire was designed to include other questions aimed at classifying each individual as “Non-mover”, “Out-mover”, “In-mover” or “Out-of-scope” and at gathering detailed information about his/her census enumeration status (definitions are in Appendix A).
3.4Fieldwork
For a PES to be valid, a number of operational and statistical constraints should be met. Since the independence between census and PES is a key requirement for the coverage error estimation methodology, special efforts should be made to keep the two surveys as separate as possible.
At the organisational level, this objective can be achieved by assigning the technical responsibility for the PES to a team other than the one in charge of the census.
As far as fieldwork is concerned, the PES data should be collected no later than one month after the census operations in order to minimise:
• The impact of population changes – births, deaths, and migrations – between the reference dates of the census and the PES;
• Recall errors.
On the other hand, this time frame can be considered sufficient to retrieve all the material used in the field during the census, so as not to interfere with the PES operations.
Moreover, the PES enumerators and supervisors should not know the census results for the EAs to which they are assigned, to avoid the tendency to confirm what the census already recorded. Therefore, in the implementation of the pilot surveys, the PES enumerators and supervisors were selected from those who had performed best during the census and assigned to the EAs in which they had not worked.
For budgetary reasons, the CSA experts proposed to use the barcode stickers only in the wereda selected for the PES sample (Subsection 3.1). It is important to emphasise that this practice does not comply with the generally accepted ground rules for a PES and invalidates the final results. Allowing the census takers to know the PES units in advance is unacceptable. However, in the implementation of the pilot surveys, the use of barcode stickers was only considered to see if the accuracy of the matching process could be improved (Subsection 4.2).
4.Main choices for data processing and coverage error estimation
4.1Preliminary treatment of data
Once the PES microdata have been collected, the next phase is to link them with the census records. This involves comparing the corresponding fields (or matching variables) that are common to the two datasets in order to identify the individuals enumerated in both surveys. The matching variables may be subject to errors or omissions and usually have a different identifying power. For example, a field such as Gender alone is insufficient to identify a match uniquely, assuming only two value states. Conversely, a field such as First name provides much more information, but it is more likely to be reported or transcribed incorrectly [5]. Furthermore, some variables may take on different values over time for the same unit (e.g., Marital status), which makes the linkage more difficult.
To reduce the number of records to be compared, the comparisons can be limited to only those records that agree on some matching variables (blocking variables).
In this context, as the data are geographically structured, the identification code of the EA was considered a blocking variable. It is clear that the reliability and efficiency of a matching procedure depend to a large extent on how the blocking variables are chosen, since errors in them may lead to erroneous links or to the failure to identify records referring to the same unit. Therefore, a number of measures were taken after the data acquisition to improve the linkage results and, consequently, the accuracy of the final coverage error estimates. In particular, the census and PES data were checked and processed to:
• Detect and correct any errors in the identification codes of the EAs;
• Verify the existence and uniqueness of the barcode for each household;
• Detect and remove any duplicate records;
• Standardise the free-format information (i.e. the names of the individuals).
Regarding the need to standardise the names, it should be noted that for the same person this information may be reported or transcribed differently in the two surveys. Indeed, a name can often vary because of alternative ways of referring to a person or because of the presence of insignificant words, acronyms, abbreviations44 or trivial mistakes. In the Ethiopian context, relevant differences may also be due to the transliteration from the Amharic to the Latin script. Therefore, the standardisation of names was carried out by removing the most error-prone letters, taking into account the phonetic characteristics of the languages spoken in the country. To this end, an algorithm for the standardisation of names was developed and successfully tested during the pilot surveys (Appendix B).
4.2Record linkage
In linking census and PES records, even a few errors can affect the accuracy of the final coverage error estimates. Two types of matching errors may occur: I) records relating to the same unit are not linked; II) records relating to different units are linked.
If the perfect agreement of the values of all the matching variables is required to establish that a unit is captured by both the census and the PES, records relating to the same unit may remain unlinked. This may happen for a number of reasons, including:
• Incorrect reporting and/or recording;
• Missing values;
• Time lag between the two surveys.
However, as the matching rules are relaxed and made flexible in order to reduce the cases of type I error, the cases of type II error may increase. Besides, a fully manual matching process would be too expensive and time-consuming due to the size of the datasets involved. The use of automatic procedures is advisable as far as possible, so that only the most ambiguous cases need to be checked visually.
In this context, a strategy combining automated and manual computer-assisted operations was proposed. This strategy was implemented and applied to process the data from the pilot surveys. In particular, a prototype Web-based application (CSPro Linkage) was developed by the Istat team to standardise the names (according to the algorithm described in Appendix B) and to perform/assist the record linkage.
At its current state of development, this application – which is based on Java, Spring MVC Framework, and MySQL procedures – can process census and PES microdata in eleven stages blocking by EA. Each stage consists of two steps, one automatic and the other manual. In each stage, an automatic deterministic linkage is first performed, followed by a computer-assisted manual matching step, which can be done using appropriate interfaces and where strictly necessary, with considerable gain in terms of accuracy and reproducibility of results. Within each household in which at least one person is automatically linked, an attempt is made to manually link any remaining non-matched member using all the available information (including information not used in the automatic step). The only difference among the stages is in the set of variables (or matching key) used for the automatic operations. This set ranges from a full matching key in the first stage to a minimal key in the last stage, depending on the power and accuracy of the variables included:
Stage 1: Barcode, First name, Middle name, Third name, Relationship to the head of the household, Gender, Age, Marital status, Ethnic group, Religion, Level of education; Stage 2: all the variables of Stage 1 except Age; Stage 3: Barcode, Standardised first name, Standardised middle name, Standardised third name, Relationship to the head of the household, Gender, Age, Marital status, Ethnic group, Religion, Level of education; Stage 4: all the variables of Stage 3 except Age; Stage 5: Barcode, Standardised first name, Standardised middle name, Standardised third name, Gender; Stage 6: all the variables of Stage 5 except Standardised third name; Stage 7: all the variables of Stage 1 except Barcode and Age; Stage 8: all the variables of Stage 3 except Barcode; Stage 9: all the variables of Stage 3 except Barcode and Age; Stage 10: all the variables of Stage 5 except Barcode; Stage 11: all the variables of Stage 5 except Barcode and Standardised third name.
Figure 2.
Computer-assisted manual matching of individuals within a household enumerated at both the census and the PES. Source: developed by Istat.
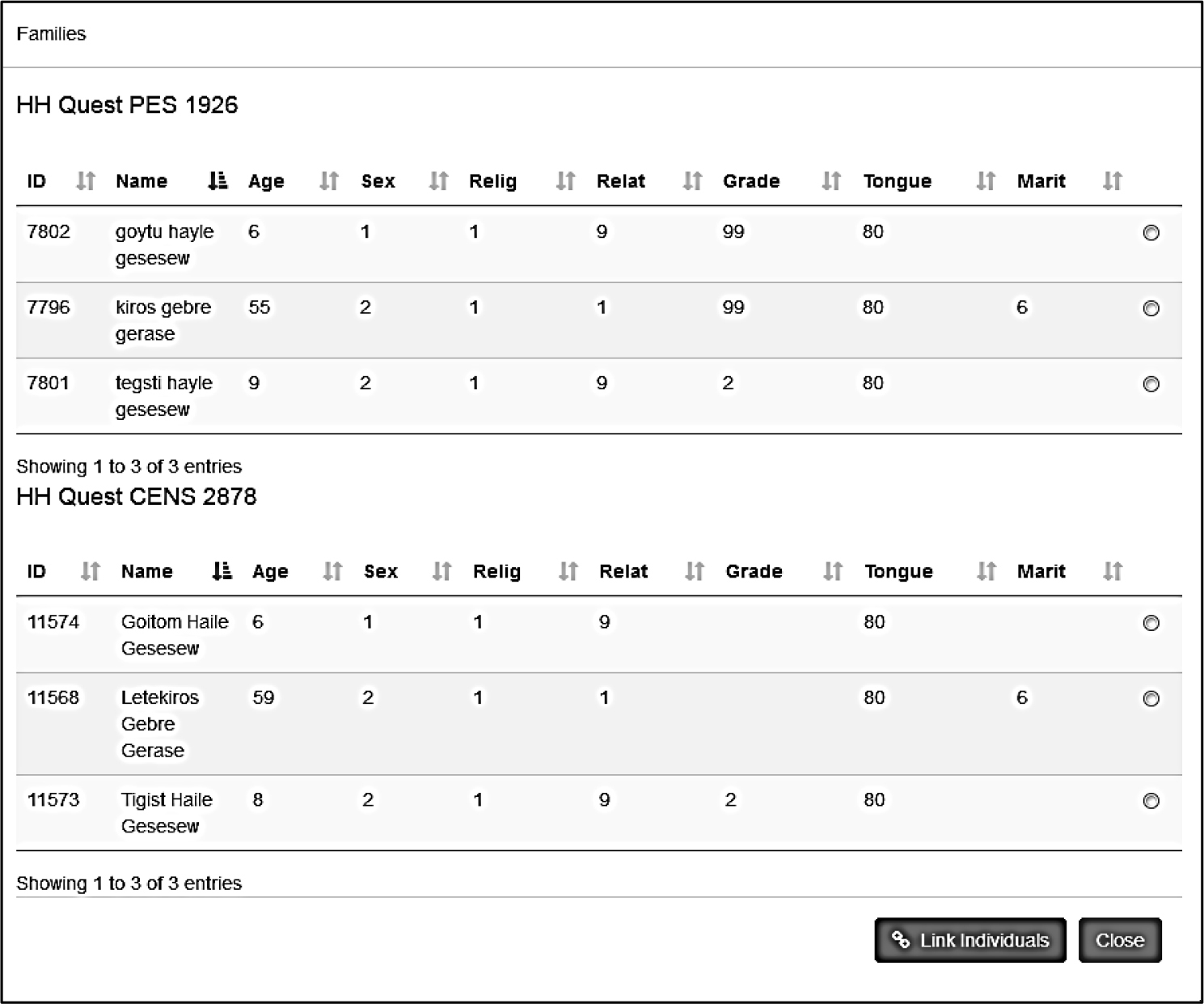
Figure 2 shows an example of the interface used for the manual matching. The figure displays, one below the other, two lists of non-matched household members as a result of the previous step, which has automatically linked at least one person in the household. For each individual, the information from the PES (Name, Age, Gender, Religion, Relationship to the head of the household, Level of education, Mother tongue, Marital status) can be compared with the corresponding information from the census. The radio buttons in the last column allow the manual selection of the records to be linked.
In the development of the application, further efforts should be made to allow searching in neighbouring EAs or blocking by kebele or wereda. This may be useful when a person or household is not found in a particular EA (there may be units enumerated by the census in a given EA but subsequently reported by the PES as not living in that EA, and vice versa). However, the CSA experts were recommended to plan reconciliation visits in the field to resolve the most ambiguous cases arising from the matching process.
4.3Estimation method
In this context, the primary objective of the PES is to estimate the Under-coverage rate, which is defined as the ratio of the number of individuals not enumerated on the census date to the estimated amount of population. To estimate the under-coverage rate, the Dual System Estimation (DSE) methodology was proposed. With this methodology, the size of an unknown population can be estimated through two enumerations of the eligible units and the subsequent identification of the cases captured on the two occasions [17]. With reference to the EAs included in the PES sample, the resulting amounts can be reported in the following contingency table (Table 1) where
Table 1
Population counts from census and PES
| In PES | Out of PES | ||
|---|---|---|---|
| In census |
|
|
|
| Out of census |
| ||
|
|
|
Assuming independence between census and PES (i.e. the probability of a unit being enumerated by the PES does not depend on whether the unit is enumerated by the census or not) and no over-coverage, the Dual System estimate of the total population is:
The validity of the DSE methodology depends on other strong assumptions, including:
• The population remains unchanged between the two surveys;
• The number of linked units is determined without error;
• In each survey, all the units have the same probability of being captured.
Given the limited experience with the PES in Ethiopia and the lack of auxiliary information to be used in the estimation process, direct estimation methods can be adopted, possibly using calibrated estimators.
The coverage and under-coverage rates can be estimated as follows:
The adoption of a direct estimator requires the calculation of two factors:
• a sampling weight (given by the inverse of the probability of selecting the EAs), which is applied to all the individuals belonging to the same EA;
• a calibration factor, which adjusts the individual sampling weight to ensure consistency between some totals obtained from the census (e.g. population by Gender, Age category, Ethnic group) and the corresponding estimates calculated by using the PES data collected for the sampled EAs.
When only direct weights are used, the direct estimator for the under-coverage is:
where:
•
•
•
•
When using calibrated weights, which are given by the product of the direct weight with its own calibration factor, the calibrated estimator for the under-coverage is:
where:
•
•
•
•
The Under-coverage rate can be produced at the national level and for the regions/administrative cities. Given the sampling design that stratifies the wereda, under-coverage rates could also be estimated for the three types of wereda (“Urban”, “Rural”, and “Extreme”). However, the possibility of disseminating accurate final results related to smaller domains – sub-regions or particular sub-populations identified by specific socio-demographic characteristics (e.g., Gender, Ethnic group) – depends on the size and allocation of the sample used.
5.Results from the pilot surveys
Three pilot editions were carried out during the project implementation period. Although the Istat experts actively contributed to the design of the third pilot PES, they could not fully assess its results as the fieldwork ended shortly after the project deadline (June 2018). Therefore, most of the considerations are based on the experience gained from the first two pilots (conducted in February and September 2017, respectively).
The first pilot PES involved 38 EAs that were selected from the 256 EAs covered by the corresponding census test. In this first exercise, the PES took place three months after the census (November 2016 for the census, February 2017 for the PES). Very significant differences at the EA level were observed in the counts of individuals enumerated on the two occasions. These differences were mainly attributed to:
• Problems in the data transfer;
• Lack of trained and experienced enumerators;
• Large time gap between census and PES.
This inevitably led to a considerable number of unlinked records, which invalidated the final outcome of the experiment. Thus, the first round of pilot surveys highlighted some major technical difficulties to be addressed in the implementation of a large-scale survey in Ethiopia, particularly those related to:
• Sustainability of the IT-based data collection;
• Skills of the fieldworkers;
• Organisation and scheduling of the fieldwork.
Some progress was made with the subsequent round of pilot surveys. In the second exercise, the pilot PES was carried out in four EAs selected from the ten EAs of the census test. This time, more accurate data were obtained by introducing the barcode sticker,55 overcoming data transfer issues, recruiting better-trained enumerators, and conducting the PES only one month after the census (August 2017 for the census, September 2017 for the PES).
This second round of surveys, building on the previous pilot experience, revealed more subtle problems related to the recognition of the individuals who were enumerated on the two occasions. Despite the progress made, the matching results could be considered satisfactory for only one of the four EAs included in the PES sample (93 percent of the individuals were linked); for the other three EAs, the percentage of linked individuals did not exceed 80 percent.66
However, the most critical point in each round was that the type of information collected through the questionnaire proved to be insufficient to uniquely identify the individuals. Indeed, within the same EA, more than one person turned out to have the same values for all the matching variables.
Table 2
Individuals enumerated in the same EA and with the same Standardised first name and Standardised middle name
| ID | First name | Middle name | Last name | Standardised first name | Standardised middle name |
|---|---|---|---|---|---|
| 2383 | Zehara | Hamed | Bilai | ZHRX | HMDX |
| 2650 | Zehara | Hamed | Niebale | ZHRX | HMDX |
| 2818 | Zehara | Hamed | Ali | ZHRX | HMDX |
| 3577 | Zehara | Hamedu | Yaldu | ZHRX | HMDX |
| 3774 | Zehara | Hamed | Dimio | ZHRX | HMDX |
| 3805 | Zehara | Hamed | Ebrahim | ZHRX | HMDX |
Source: 2nd pilot PES (September 2017), CSA.
Table 3
Very frequent standardised components of the individuals’ name observed in four EAs
| Variable | Frequency |
|---|---|
| Standardised first name | |
| MHMD | 61 |
| FTMX | 43 |
| HSNX | 35 |
| Standardised middle name | |
| MHMD | 111 |
| HSNX | 76 |
| ALXX | 75 |
| Standardised last name | |
| MHMD | 110 |
| ALXX | 84 |
| HSNX | 66 |
Source: 2nd pilot PES (September 2017), CSA.
Some examples based on data from the second pilot PES (Tables 2 and 3) show the high frequency with which several Ethiopian names recur; therefore, their identifying power is very low.77
Regarding the variable Age, most people do not know or remember their date of birth (Subsection 3.3). It is therefore not surprising that the frequency distribution of individuals by Age indicates a clear tendency to round off the age using multiples of 5.
Figure 3.
Frequency distribution of individuals by Age. Source: First pilot census (November 2016), CSA.
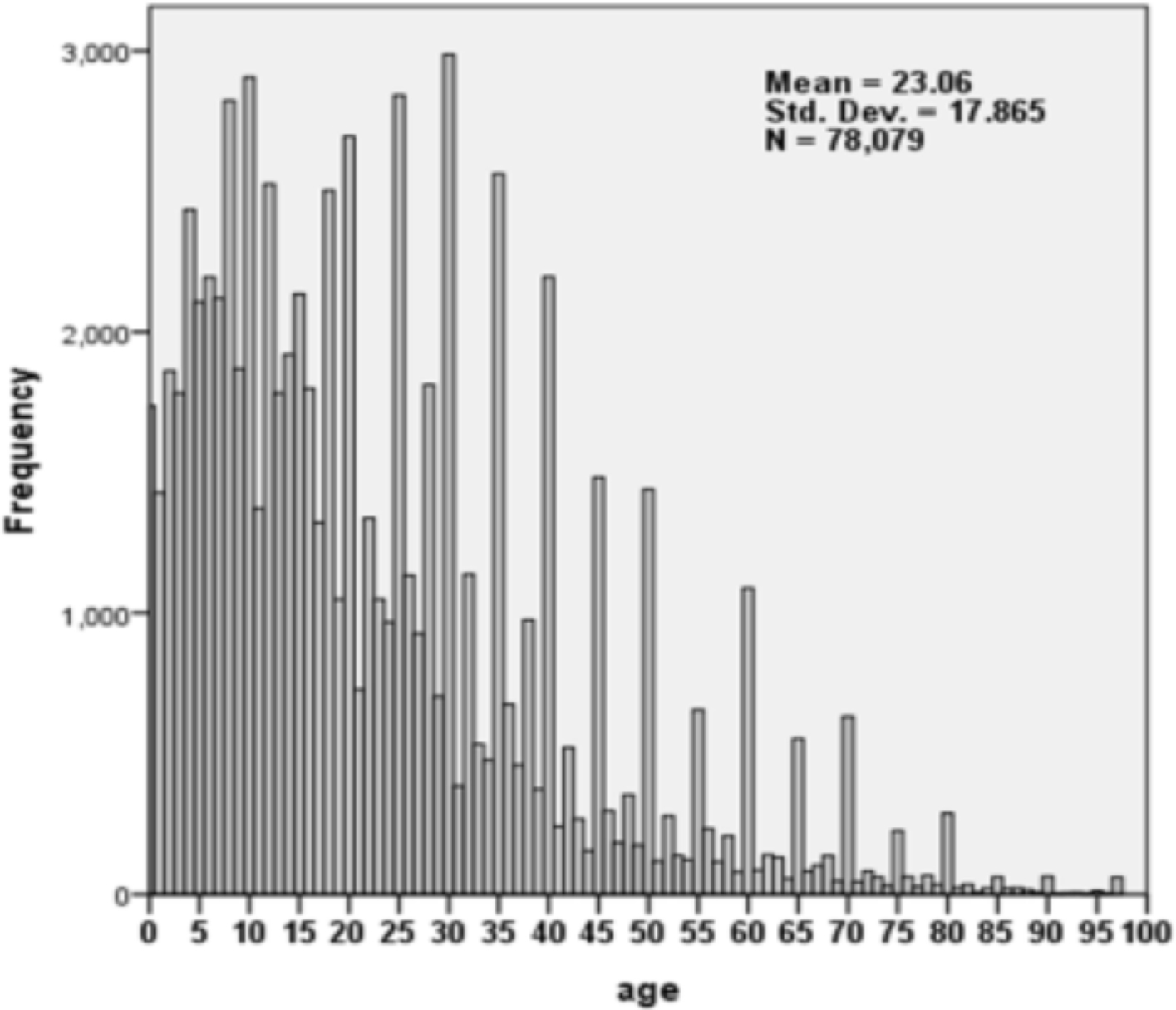
The histogram based on the data from the first pilot census (Fig. 3) shows that the rounding is more pronounced for the adult population. This obviously reduces both the accuracy and the identifying power of the variable Age.
With regard to the primary objective of the PES(Subsection 4.3), the under-coverage rates for the first exercise were not calculated due to the high number of matching errors.
For the second pilot PES, an attempt was made to estimate an undercoverage rate despite the aforementioned problems and the limitations arising from the small number of EAs. Due to the lack of a large and representative dataset it was not possible to apply the formulas of the direct and calibrated estimators (Subsection 4.3). Instead, hypothetical weighting systems were used, giving equal weight to the statistical units in the same EA. In this way, the estimate of the overall under-coverage rate with different weighting systems ranged from 15.94 to 22.41 percent, depending on whether a more or less favourable88 weighting system was adopted.
6.Concluding remarks
The support to the CSA was part of the complex and multi-faceted preparatory activities for the 4th EPHC to which various donors and international partners contributed in different ways. In the framework of the Italian project, Istat provided technical assistance for the design of the PES.
Given the limited experience with this survey in Ethiopia, the possible objectives of the PES should be limited to assessing the coverage error at the national level and, at most, for the major sub-national domains. The findings would contribute to a more informed interpretation and use of the census data and would improve the design and implementation of future censuses and large-scale surveys on households. The national context – characterised by a lack of infrastructure, a not yet established CRVS system, and the presence of strong internal migration flows – highlights several critical issues that require the study and adoption of appropriate solutions in the survey practice.
Some methodological and operational solutions for a possible PES were implemented during the various pilot surveys conducted throughout the project implementation period.
As for the sampling design, the main directions focused on the need to consider the variety of the geographic domains, proposing a three-stage stratified scheme in which the EAs are taken as final sampling units.
For the data collection phase, the CAPI technique was recommended, with PAPI limited only to “extreme” areas where power supply and network connectivity are scarce or there is a shortage of tablets.
Particular attention was paid to the collection of the information to be used for the matching process and to the need to adhere as closely as possible to the assumptions underlying the coverage error estimation methodology.
Some measures taken during the second round of pilot surveys – introducing the barcode sticker, improving the data transfer, recruiting well-trained enumerators, and conducting the PES only one month after the census – resulted in appreciable progress in terms of data accuracy compared to the first round. However, it is important to point out that the use of barcode stickers only in the wereda selected for the PES sample does not comply with the generally accepted ground rules for a PES and invalidates the survey results. The barcode stickers can only be justified if they are used to tag all the households in the country during the census operations.
To link census and PES records, a strategy combining automated and manual operations was adopted. In this regard, a specially developed prototype Web application was used in the pilot surveys to standardise the names and to perform/assist the matching. A desirable refinement for the application concerns the possibility of linking records from blocks larger than those identified by the EAs.
The results of the pilot surveys – especially the coverage assessments obtained by applying weighting systems that correspond to more or less favourable scenarios – revealed serious critical points that may preclude the success of a PES. In particular, the structural issues that characterise the Ethiopian context, especially those arising from the mobility of the pastoralists and from the weakness of the information available for the matching, may cause problems in both fieldwork and data processing, introducing a non-negligible bias in the estimates of the coverage rates. To mitigate such effects, each phase of the PES should be improved, from the sample design to the estimation process.
There is still some way to go before a PES can be successfully implemented in Ethiopia. In this regard, it is important to emphasise the key role that a well-functioning CRVS system would play, providing an essential service in facilitating the unique identification of individuals and, more generally, leading to substantial progress in the production of more accurate population data on a continuous basis.
Notes
1 At the time of writing, the EPHC – originally planned for 2017 – has not yet been carried out, having undergone several postponements due to the complex political and social situation in the country.
2 More comprehensive directions for the design and implementation of a PES can be found in [12].
3 The cluster effect, due to the correlation induced by individuals living in the same EA, can increase the variance of the estimates.
4 The list of abbreviations or words that can be disregarded is long and includes, for instance, H. (standing for Hayile) and G. (standing for Gebre or Gebru). In particular, Gebre is a common Ethiopian masculine name (meaning “servant”) often used in some compound names such as Gebre Meskel (“Servant of the Cross”) or Gebre Mariam (“Servant of Mary”), while Gebru is a typical variant from the Tigray region.
5 No issues were encountered with the use of barcode stickers during the fieldwork. However, it is not possible to draw conclusions on their effectiveness throughout the country due to the limited number and low representativeness of the EAs considered in the second round of pilot surveys.
6 In countries with a low census coverage error, the percentage of linked individuals is typically very high (above 98 percent).
7 In Ethiopia, it is common to give names that coincide with those of close relatives (father, mother, grandfather, etc.).
8 A favourable weighting system means a system that gives more weight to the EAs for which the percentage of links is higher.
Acknowledgments
The support for the preparation of the 4th EPHC was granted by AICS through Project #XM-DAC-6-4-010649-01-5 (implementation period: June 2016–June 2018). The views and opinions expressed in this paper are those of the authors and do not necessarily reflect the official policy or position of Istat.
The authors would like to thank all the CSA colleagues involved in the preparation of the EPHC. Special thanks go to Ginevra Letizia – director of the AICS headquarters in Addis Ababa during the project implementation period – and to Simona Leali – coordinator of the AICS programme “Child Protection and Gender” in Ethiopia – who constantly encouraged and supported the work of the Istat team.
References
[1] | Abelti G. Data evaluation methods used in the previous census. Post enumeration and demographic analysis. Presentation ESA/STAT/AC.200/15 for the United Nations Regional Workshop on the 2010 World programme on population and housing census: census evaluation and post enumeration surveys, for English-speaking African countries, Addis Ababa, 14–18 September 2009. https//unstats.un.org/unsd/demographic/ meetings/wshops/Ethiopia_14_Sept_09/list_of_docs.htm. |
[2] | Bruno M, Grassia F, Handley J, Abate AA, Mamo DD, Girma A. Census metadata driven data collection monitoring: the Ethiopian experience. Statistical Journal of the IAOS. (2020) ; 36: (1): 67-76. |
[3] | Central Statistical Agency, ICF. Ethiopia. Demographic and health survey 2016. Addis Ababa, Ethiopia, and Rockville, Maryland, USA: Central Statistical Agency and ICF; (2016) ; https//dhsprogram.com/pubs/pdf/FR328/FR328.pdf. |
[4] | Economic Commission for Africa. Report on the status of civil registration and vital statistics in Africa: outcome of the Africa programme on accelerated improvement of civil registration and vital statistics systems monitoring framework. Addis Ababa, Ethiopia: United Nations Economic Commission for Africa; (2017) . https//repository.uneca.org/handle/10855/24047. |
[5] | Jaro MA. Advances in record linkage methodology as applied to matching the 1985 census of Tampa, Florida, Journal of the American Statistical Association. (1989) ; 84: (406): 414-420. |
[6] | Kiregyera B. Censuses of population and housing in Africa: some issues and problems, Journal of Official Statistics. (1986) ; 2: (4): 481-499. |
[7] | Kordos J. The challenges of the population census round of 2020. Outline of the methods of quality assessment of population census data. Statistics in Transition – New Series. (2017) ; 18: (1): 115-138. |
[8] | Newell R, Smallwood S. A cross country review of the validation and/or adjustment of census data. Population Trends. (2010) ; 141: : 115-126. |
[9] | Statistics South Africa. Post-enumeration survey (PES). Results and methodology. Report n. 03-01-46, Pretoria, South Africa: Statistics South Africa; (2012) . https//www.statssa.gov.za/census/census_2011/census_products/Census_2011_PES.pdf. |
[10] | Statistics South Africa. Post-enumeration Survey (PES) 2022. Statistical Release P0301.5, Pretoria, South Africa: Statistics South Africa; (2023) . https//www.statssa.gov.za/publications/P03015/P030152022.pdf. |
[11] | United Nations Population Fund, Inter-divisional Working Group on Census. Technical guidance: post enumeration surveys in population and housing censuses. Technical Brief, (2019) . https//www.unfpa.org/sites/default/files/resource-pdf/Technical_Brief_PES.pdf. |
[12] | United Nations Statistics Division. Post enumeration surveys: operational guidelines. Technical Report, New York, NY, USA: United Nations; (2010) . https//unstats.un.org/unsd/demographic/standmeth/handbooks/manual_pesen.pdf. |
[13] | United Nations Statistics Division. Principles and recommendations for population and housing censuses. Revision 3. New York, NY, USA: United Nations, (2017) . |
[14] | United Nations Statistics Division. Guidelines on the use of electronic data collection technologies in population and housing censuses. New York, NY, USA: United Nations, (2019) . |
[15] | United Nations Statistics Division. Report on the results of the UNSD survey on 2020 round population and housing censuses. 51 session of the United Nations Statistical Commission, 3–6 March 2020. https//unstats.un.org/unsd/statcom/51st-session/documents/BG-Item3j-Survey-E.pdf. |
[16] | Whitford DC, Banda JP. Post-enumerations surveys (PES’s): are they worth it? Symposium on global review of 2000 round of population and housing censuses: mid-decade assessment and future prospects. Statistics Division, Department of Economics and Social Affairs, United Nations Secretariat. New York, 7–10 August 2001. https//unstats.un.org/unsd/demographic/meetings/egm/symposium2001/docs/symposium_10.htm. |
[17] | Wolter KM. Some coverage error models for census data. Journal of the American Statistical Association. (1986) ; 81: (394): 338-346. |
[18] | Zewoldi Y. Snapshot of civil registration and vital statistics systems of Ethiopia. Centre of Excellence for Civil Registration and Vital Statistics (CRVS) Systems in partnership with the United Nations Economic Commission for Africa (UNECA), Ottawa, ON, Canada: International Development Research Centre, (2019) . https//crvssystems.ca/sites/default/files/assets/files/CRVS_EthiopiaSnapshot_e.pdf. |
Appendices
Appendix A: some definitions
“Non-mover”: an individual who resided in a particular household on the census date and still belongs to that household on the PES date.
“Out-mover”: an individual who resided in a household on the census date but does not belong to that household on the PES date.
“In-mover”: an individual who resides in a household on the PES date but did not belong to that household on the census date.
“Out-of-scope”: an individual who does not belong to the target population (e.g., a child born after the census date).
Appendix B: algorithm for the standardisation of names
The algorithm produces a standardised four-character form for each name component – First Name, Middle Name, Third Name – according to the following steps:
1. Any titles, insignificant words, punctuation, blanks, and special characters are removed from the original name component;
2. The initial letter – vowel or consonant – of the name component resulting from step 1 becomes the first letter of the standardised form; however,
– If the initial letter is “I” or “E”, this is replaced with “1”;
– If the initial letter is “O” or “U”, this is replaced with “2”;
3. the next two consonants and the last consonant of the name component resulting from step 1 are included in the standardised form in the same order as they appear, but repeated consecutive consonants are considered only once;
4. if the total number of digits and/or letters in the standardised form resulting from step 3 is less than four, the form is completed by adding as many “X”s as necessary until the length of four characters is reached.


