
Different data futures: An experiment in citizen data
Abstract
Big data and citizens are inseparable: from smartphones, meters, fridges and cars to internet platforms, the data of most digital technologies is the data of citizens. In addition to raising political and ethical issues of privacy, confidentiality and data protection, the repurposing of big data calls for rethinking relations to citizens in the production of official statistics if they are to be trusted. I argue for relations that involve co-producing data – or ‘citizen data’ – where citizens are engaged in statistical production, from the design of a data production platform to the interpretation and analysis of data. While raising issues such as data quality, I suggest that in a time of ‘alternative facts’, what constitutes legitimate knowledge and expertise are major political sites of contention and struggle and require going beyond defending existing practices towards inventing new ones. In this light, the future of official statistics not only depends on inventing new data sources and methods but also mobilizing the possibilities of digital technologies to establish new relations with citizens.
1.Introduction
Facebook data breaches and election influencing of Cambridge Analytica along with claims about alternative facts make it a challenging time to engage in a research experiment that involves designing an app for citizen data. Of course it is a challenge that extends to governments and organizations that are experimenting with apps and platforms for producing data. But such moments also afford an opportunity or opening to imagine different data futures.
How Facebook data was allegedly used to interfere in the US election and UK referendum was joined by the disclosure that the personal information of up to 87 million users was harvested without their permission by an app designed by a Cambridge academic. A main lesson to draw is not that an academic, an internet platform, and a data company are culpable. Rather it is that data and politics are inseparable such that academics, statisticians or app developers cannot be naïve but must be reflexive about how they may be implicated in the ways data is part of emerging forms of power relations. For data is not only shaping social relations but democratic politics.
That the proliferation of digital technologies and data have contributed to competing knowledge has fueled similar reactions about the threat of alternative facts. While some reactions are that this represents a democratization of knowledge and the erosion of the domination of experts, the separation between true and false is never straightforward. Such a dichotomy belies how all facts are produced and mediated by complex practices and technologies and are full of uncertainties [1]. The division between the real and fictitious is vexed – there are no truths and falsehoods independent of the knowledge regimes that produce them. For this reason, the politics of alternative facts does not herald a new era of post-truth; rather, it signals the emergence of new regimes of truth better characterized as ‘post-trust’ [2].
Yet, a prominent reaction has been the proliferation of expert practices to now authenticate facts in order to restore authority. For example, Open Europe’s Fact Check blog is where European experts distinguish ‘EU fact from EU fiction’. This has led to numerous challenges such as who will fact check the fact checkers. However, rather than restoring authority, these efforts only amplify the binary and truth making as a struggle between different gatekeepers, intermediaries and validators. It treats citizens as needing experts to validate facts for them.
These reactions are openings for thinking about different data futures through what I call an experiment in citizen data. With a focus on data about individuals and populations, it is an experiment that reconsiders relations between states, citizens and digital technologies in the production of data for statistics by imagining a new political subjectivity, that of the data citizen. Before elaborating on these openings, in the first part of this article I reflect on how these struggles are driven by imaginaries of big data that conceive of subjects as passive actors and individual privacy regulators. No doubt anyone who engages with digital technologies in the EU has experienced the call to be an individual privacy regulator through the implementation of the General Data Protection Regulation or GDPR. People are now given ever more fine-grained ways of regulating what, when and how data can be produced about them. While important, and satisfying to not opt for future communications, data rights are confined to consenting to the collection of data and the sending of emails. But how people might participate in the production and interpretation of data to which they agree or consent is not at a matter of concern. This is an issue I take up in the second part of the article where I describe an experiment that imagines subjects as data citizens with the right to shape how data is made about them and the societies of which they are a part.
The arguments in this article are based on research on the practical and political implications of methods for knowing the European population and, amongst other things, experiments with new digital technologies such as smart phones, tablets and web platforms to produce official statistics from big data such as that from mobile phones, search engine queries and social media.11 It draws on a number of working papers and articles that informed the experiment on citizen data discussed here [3, 4, 5].
2.Sociotechnical imaginaries of big data
What does it mean to reimagine relations between states and citizens in the production of data for official statistics? Philosophers and social and political theorists have argued that to understand what holds societies together requires understanding its institutions and the imaginaries they require to function. Benedict Anderson, for example, engaged with the force of imaginaries in his well-known definition of a nation as ‘an imagined political community’ [6]. He elaborated how shared imaginaries of technologies such as the census, the map, and the museum were organized historically and came to shape how colonial states governed their subjects and territories. Others have expanded on this to argue that in modernity, science and technology have played a significant role and for this reason they refer to ‘sociotechnical imaginaries’ [7]. For our present time, some of the most forceful sociotechnical imaginaries concern those about digital technologies and big data. From the internet as both liberating and enslaving to autonomous yet murderous cars, one that persists is that of a ‘big data revolution.’ What exactly is big data remains a matter of some debate and it can include everything from that generated by social media, browsers and digital transactions to that from mobile phones, emails, text messages, electricity meters, sensors and travel cards. My use of it here is not to accept the way it is being defined but to consider its imaginary force which is very much shaped by the predominant definition referred to as the ‘3Vs’: volume, velocity and variety. It is one of the most oft-cited, debated and vague and yet accepted definitions whose take up demonstrates two things.
First, what each of the ‘Vs’ means is so variable that the force of big data imaginaries is not in its definition but how its functioning provokes valuations of qualities of data such as speed, real-time, quantity, granularity, flexibility, scalability, extensity and reach. Second, the focus on these qualities obscures the practices through which data is being produced and analyzed by numerous organizations, corporations, institutions, and so on that have fueled imaginaries of it as a revolutionary force. That is, the force of big data imaginaries is to be found in the adoption of new mindsets and paradigms that take cues from how data is imagined and produced by private technology corporations and analyzed data scientists. It is to be found in how such imaginaries are simultaneously reconfiguring cultures and practices of data production within both universities and governments.
To speak of dominant imaginaries then is to underscore that they not only shape what is thinkable but also the practices through which actors perform them. So, while some commentators declare big data as hype, these pronouncements underestimate the material and political effects of imaginaries as they are taken up in practices through which new ways of thinking are propagated. One effect is what sociologist Pierre Bourdieu refers to as the power to ‘make things’ or in other words the authority over the making of statistics on economies or populations, or what comes to be legitimized as collective knowledge and truth [8]. However, it is the other side of this power that is the concern of this article, that is, the power to produce subjects. Who then are the subjects of big data?
All methods are configured in ways that imagine who are their subjects and how they should, can and will likely perform. For example, the dominant method of statistical institutes – the modern paradigm of the census or survey questionnaire – typically imagines and engages with people as respondents and data subjects. While not without problems and not wanting to idealize questionnaires, they involve direct relations with subjects who are called upon to participate in their identification but who can thereby also exercise the capacity to not answer, subvert questions, challenge categories and so on. Historically, there are many examples of how people have variously influenced, interfered, or intervened in the ways questionnaires have imagined them as respondents and data subjects by, for example, challenging social categories such as on race, ethnicity, and gender [9].
Critical citizenship studies offers a way to interpret these as ‘acts of citizenship’ where being a citizen is understood as a political subjectivity that includes not only the possession of rights but the right to make rights claims [10]. With this conception subjects who perform in ways not anticipated by a method and who demand identifications that are not recognized can be understood as performing as ‘data citizens’ [11] by claiming the right to shape how data is made about them and the populations of which they are being constituted as a part.
Methods of data production such as questionnaires have enabled such contestations in part because of how they are technically and socially organized. From open text fields enabling the insertion of elective categories to skipping or refusing to respond to questions, the method, has variously enabled such contestations and reinterpretations. One condition of this possibility is that they involve more-or-less direct and explicit relations between statistical institutes and subjects. But it is also through such relations that citizens’ trust has also been secured about how data is generated and used for official statistics. This includes practices such as focus groups, the pilot testing of questions, and consultations with civic organizations about issues of consent, data protection, privacy, impartiality and professional standards. Through these and other means NSIs have sought to secure the trust of citizens [4]. Understood in this way, trust is not the result of one but myriad practices through which the trustworthiness of official statistics is accomplished.
How then does big data transform relations between subjects and methods of data production? Subjects are imagined as passive actors where technologies are one-way tools for extracting data about them. Through subjects’ digital interactions and transactions with platforms and devices such as social media, mobile phones and browsers, data is produced without their knowledge and through processes that work in the background. Furthermore, while that data is used for purposes such as the functioning and performance of a technology such as a platform, it can also be repurposed. This is one of the valuations promoted in big data imaginaries: the possibility of the circulation and reuse of data for purposes beyond that which they were originally generated. Data are imagined as independent of the relations of production that brought them into being and interpreted as simple reflections of who subjects are, what they think, and what they do.
The many exploitive consequences of the repurposing of big data in relation to the commercial agendas of technology corporations are now well documented. As noted in the introduction, it is the repurposing of Facebook data by an academic to do psychological profiling and by a corporation to intervene in democratic elections that have fueled current struggles. Much critical attention is being paid to what this means for data protection, ownership, privacy and consent and effects such as profiling, the filtering of choices and influencing of opinions, and so on. However, what such criticisms underestimate are the implications of separating data from their conditions of production. Instead, the deleterious effects of repurposing are resolved by reducing subjects to the role of individual privacy regulators in ways such as those being instituted by the GDPR.
What is ignored is that repurposing big data is implicated in the rationalities, assumptions, interests and norms of private sector professionals and technology corporations. Consequently, if repurposed for official statistics, this could undermine the trust that NSIs have relatively well achieved. As some statisticians have noted, ‘[o]f critical importance is the implication of any use of Big Data for the public perception of a NSI as this has a direct impact on trust in official statistics’ [12]. Additionally, if authority for the production of what is deemed as official knowledge of societies is indeed a stake in struggles over ‘alternative facts’, then repurposing big data risks delegating some authority such as decisions about the values and norms that organize data production to the private sector. It also means relegating to others relations to subjects as users, customers and data sources, which makes the capacity of subjects to perform as data citizens in the ways defined above more difficult if not impossible.
The imaginary of citizen data outlined in this article is one possible response. It is founded on the principle of citizens as co-producers of data for official statistics rather than as ever more distant subjects whose impressions and confidence need to be managed. Co-production, as defined here, not only recognizes that the data of digital technologies is the data of citizens. It also means engaging citizens in how data about their digital actions, interactions, transactions and experiences are categorised, included and excluded and interpreted for policy and research. It is also based on the premise that co-production, including models that engage governments, citizens and the private sector as collaborators in the production and/or repurposing of data, could lead to greater trust in the resulting statistics.
Of course, such issues are not entirely new or limited to big data. Former Eurostat Director General Walter Radermacher expressed this more generally as a gap between citizen experiences and official statistics which in turn calls for ‘subjective statistics’ [13]. In saying so he stressed the need for a more democratic debate between citizens and data producers and owners to achieve a ‘more subjective, differentiated understanding of our world’, instead of ‘technocrats and politicians sitting together and confronting citizens in the end.’ Digital technologies now afford the possibility of addressing such a gap, which the repurposing of big data potentially widens by detaching relations between states and citizens. This is evident in some NSI experiments that are seeking to better utilize digital technologies to enable more interactive and responsive relations to respondents such as in the design of digital censuses and surveys. For example, Statistics Netherlands has been exploring data collection designs that introduce respondent interaction with sensor data as way to reconceive questionnaire design [14]. The imaginary of citizen data extends these experiments to the yet-to-be realized interactive and inventive possibilities of digital technologies for engaging subjects as citizens rather than simply respondents. The next section describes how this imaginary was explored in practice in the form of a collaborative workshop that experimented with the design of prototypes for a ‘citizen data app’.
3.A citizen data app
Four principles informed the development of prototypes for a citizen data app, which were derived from key matters of concern statisticians have expressed about the future of official statistics: experimentalism, citizen science, smart statistics and privacy-by-design [4, 5]. While all four principles guided the development of prototypes, the following discussion focuses on that of citizen science. There are many examples of initiatives that involve citizens producing their own data on issues such as pollution, crime and urban change. Others involve citizens in various roles as co-producers with government, scientific or other organizations. In relation to statistics, these include an increasing number of government initiatives related to the implementation of the Sustainable Development Goals (SDGs) including the United Nations’ new Citizen Science Global Partnership that seeks to promote and advance citizen science for a sustainable world [15]; Eurostat’s development of a common bird index to monitor SDGs based on data generated by a consortium of individuals and organizations [16]; and, Statistics Canada’s crowdsourcing of citizen work to help fill in data gaps on geolocations [17].
Figure 1.
Design elements for the ‘How we move’ citizen data app prototype.
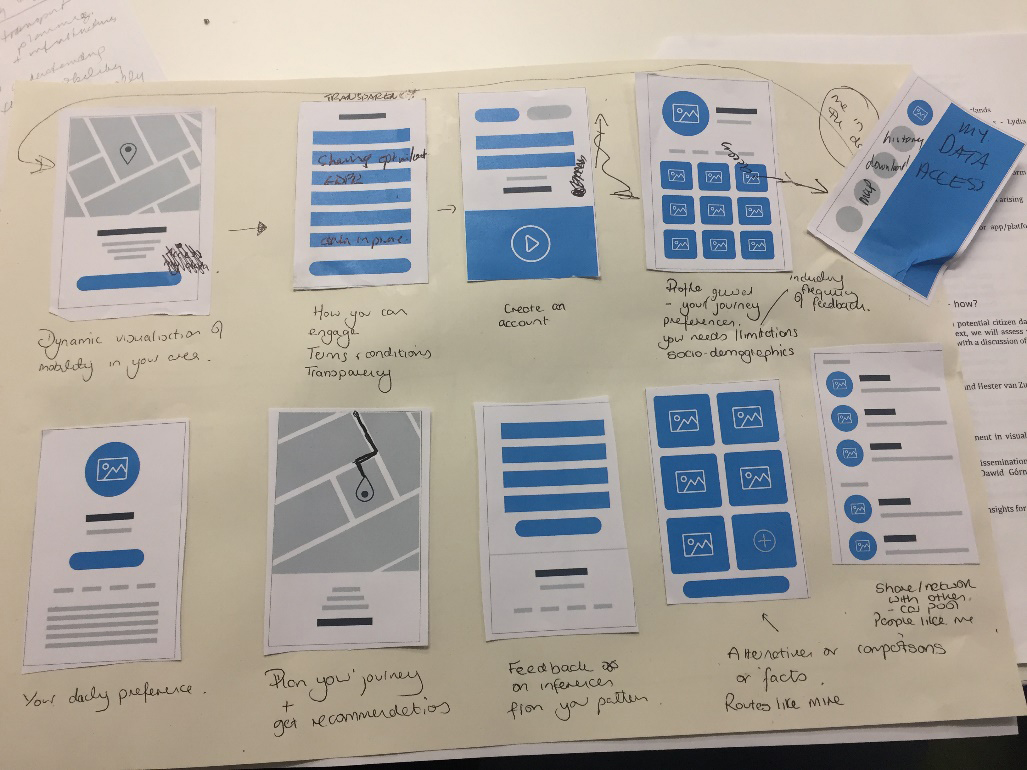
The principle of citizen science builds on these co-production models by extending them to consider how citizens might perform not simply as data collectors but as active contributors to data production. It is in relation to this principle that collaborative workshops were conducted to imagine different data futures through creative experimentation. The first took place over two days in September 2017 and involved academic researchers, national and international statisticians, information and interaction designers, and facilitators. Four groups developed principles, designed prototypes and proposed road maps for developing four different apps. Here I will reflect on a few of the outcomes that I observed.
The first to note is that there was a change in terminology by the end of the second day. Many participants started using the language of citizens rather than respondents, and co-production rather than data collection. To be sure, the meanings each participant gave to these terms was different and not settled but words shape imaginaries and through their uptake the potential for reimagining relations was then made possible. It was also relatively easy to come up with shared principles such as that co-production apply to the full life cycle of data; that an app meet collective values; that there be incentives for citizen participation; that an app be easy to use; that the software be open and the data co-owned; and that consent and privacy be built into the design of all stages of production. What was more difficult was evident in frictions that emerged when translating terminology and principles into designs. This highlights a value of experimental design work: imaginaries of citizens as co-producers when materialised in prototypes revealed frictions in meaning and understanding but was also generative of something new.
One example of friction arose in a group that designed a prototype for an app called ‘How we move’ to explore the different meanings of, and relations citizens have, to mobility that defy usual statistical categories of where people live and work. An issue discussed by the group was that existing statistical categories about what is called a subject’s usual place of residence do not capture the complexity of mobilities in contemporary societies. Amongst other issues, the group considered how these categories could be rethought through an app that mixed automatically collected GPS data along with citizens annotations, interpretations and categorizations of their and others’ mobility patterns (Fig. 1). The premise was that GPS data alone was not sufficient to understand the motivations, rationales, subjective meanings and lived experiences of mobility.
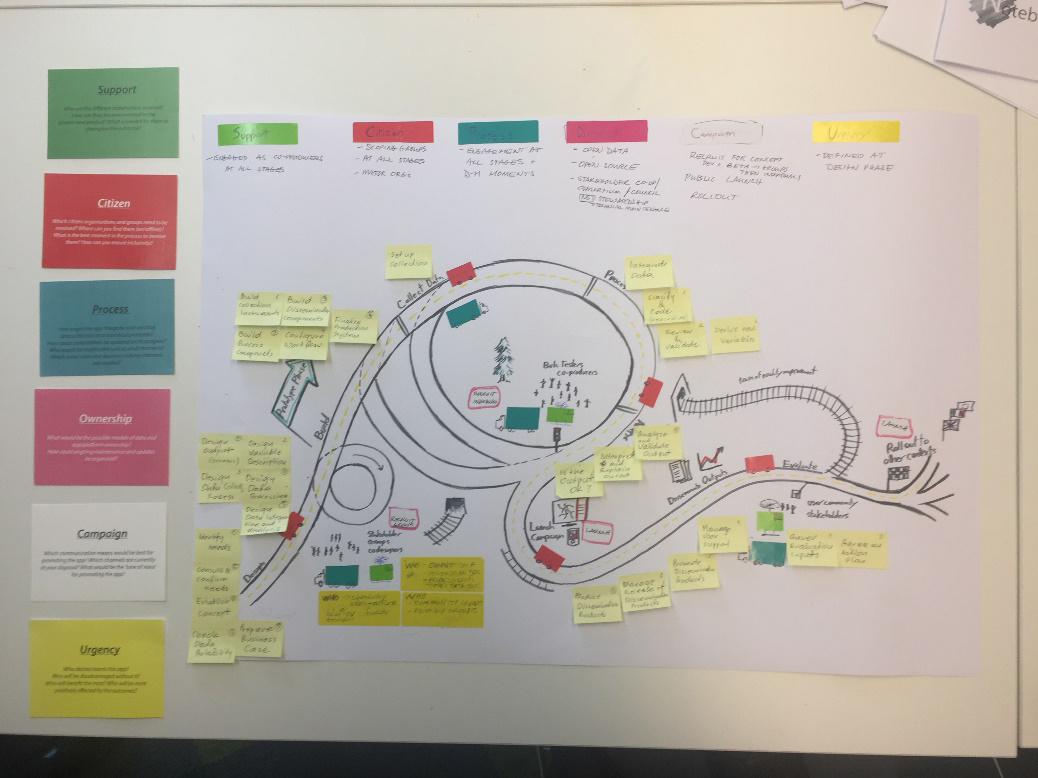
Figure 2.
Roadmap for ‘How we move’ citizen data app prototype.
A tension though existed between the introduction of design elements that created possibilities for citizens to engage with data in these interpretive and meaning-making ways versus those that aimed to control data collection, standardization and quality. Not a surprising dynamic perhaps but rather than resolving the tension one solution offered was that co-produced data could be treated as a hybrid form. It could be based on different quality standards yet generative of unique and perhaps previously unimagined kinds of statistics. In subsequent conversations, statisticians spoke of co-produced data as complementary rather than a replacement of existing data, a term often called forth when a new and unsanctioned form of data is innovated. That is, relegating co-produced data to a special status was a strategy of accepting it while at the same time retaining the authority of existing methods of data production.
However, it also signified another potential. It signified that there is not one set of standards through which data can be produced and made official. Arguably, in practice, such variability is a condition of all methods from how surveys are conducted to how administrative registers are organized. Adherence to standards, norms, conventions, rules and principles varies to the extent that what can become official is not settled or measurable by any single standard, but something that is collectively negotiated, instituted and maintained.
To note this is to underscore that the practices of different collectives may involve forms of reasoning that adhere to different principles and standards. Researchers have documented, for example, that standards such as measurement accuracy are not the only criteria for evaluating environmental data gathered through, for example, citizen sensing practices [18]. A rough measurement to identify a pollution event when it is happening or when it has happened might be sufficient and ‘good-enough’. In other words, methods can be evaluated according to different norms, objectives and standards, and, in the case of this experiment, the relations of production between citizens and governments that bring data into being rather than their truth claims. To imagine complementary data then is to offer a different way of accomplishing what counts as official. However, and critically, this interpretation does not mean according complementary data the status of alternative facts. As argued in the introduction, at issue is not a competition between facts and which experts win the authority to legitimize what counts as official data and statistics. Rather, it is the norms and values on which public facts are produced, including the relations through which they are instituted and negotiated. Rather than truth claims, public facts can perhaps be evaluated in terms of the extent to which citizens have the capacity to directly participate in their making and through processes that are democratically organised and accountable.
A second friction concerned the design of a roadmap for taking design principles forward by identifying all of the stages and co-production relations that would be required to develop a prototype. One statistician recommended applying the procedures of the ‘General Statistical Business Process Model’ (GSBPM) – an international standard developed by the UNECE for statistical offices to map the steps and processes involved in generating data [19]. The GPSBM describes and defines the business processes that are needed to produce official statistics such as identifying needs, testing production systems and reviewing and validating data. It provides a standard framework and harmonized terminology intended to help statistical organizations modernize their statistical production processes. It is a management approach to standardising not simply the procedures but the various steps for statistics to become official.
Others instead were trying to literally draw a road and a map as a journey towards a goal but with cul-de-sacs, dead-ends, tunnels, shortcuts and roundabouts. These aspects were critically about co-production as processual – that is, not simply involving data extraction but the multiple activities that a mode of coproduction would demand, from negotiating an initial conception to ownership and long term maintenance, for example. The roadmap ended up containing all those features with the statistician overlaying the steps of the process model along the top and post-its specifying the fit of locations on the map to that process. In other words it became a hybrid form that again, through design, imagined a space between the processual and managerial. Remarkably, each part of the GSBPM was successfully allocated to a location along the roadmap (Fig. 2).
What the designs of citizen data app prototypes and roadmaps made visible is that new digital technologies and sources of data call for more than minor adjustments to existing methods and processes of statistical production. Rather, they brought to the fore what many statisticians argue is necessary: the fundamental rethinking of existing methodological paradigms. Examples of how such rethinking might be stimulated are often drawn from the private sector as evident in the adoption of practices such as data boot camps, hackathons, innovation labs, method experiments, and sandboxes [20]. The same could be said of the experiment in citizen data, which adopted the technology of the app. However, by starting with different principles and values such as citizen co-production, the experiment in citizen data demonstrated how technologies such as apps can be mobilised to forge different futures. That is, digital technologies are not inevitably exploitive but can be reimagined to achieve public values and goods.
A second workshop addressed the necessity of such rethinking in relation to both statistical definitions and methods. It involved further exploring the ‘How we move’ app as it is connected to an issue that not only arose in the first workshop but also came up regularly during our fieldwork. Since the inception of modern national censuses some 200 hundred years ago, a fundamental basis of population statistics has been determining who constitutes a resident. Determining a single residence for each person has been the foundation of allocating people to locations, and knowing who to count. In contemporary times, the internationally agreed to definition is called the 12 month rule for determining who makes up the ‘usually resident population’ of a country: it is ‘composed of those persons who have their place of usual residence in the country at the census reference time and have lived, or intend to live, there for a continuous period of time of at least 12 months. A “continuous period of time” means that absences (from the country of usual residence) whose durations are shorter than 12 months do not affect the country of usual residence’ [21]. However, a recurring problem, beyond technical difficulties, are people who cannot be placed in a usual residence for which there are numerous ‘exceptions’ or ‘particular cases’ such as higher education students, nomads, homeless people, diplomats, illegal, irregular or undocumented migrants, asylum seekers, refugees and so on. Additionally, there are many people whose lives involve different forms of mobility within a twelve-month period and varied relations to residence such as circular migrants, living apart together, reconstructed families, weekenders, weekly commuters, and FIFOs (FlyIn/FlyOut workers). For EU citizens who exercise their mobility rights, this can mean multiple residences and familial relations that are divided between two or more places or countries, which is sometimes referred to as ‘multilocal living’ [22]. In relation to labour, three forms of mobility were reported in 2017 in the Annual report on intra-EU labour mobility [23]. Long term ‘movers’ are people who lived in an EU country other than their country of citizenship and made up approximately 4% of the EU population (17 million EU citizens up from 11.8 in 2016) A second is cross-border mobile workers: citizens who reside in one country but are employed or self-employed in another and who, for this purpose, move across borders regularly. Based on the EU-LFS, there were approximately 1.4 million cross-border workers in 2017. And finally, approximately 2.8 million mobile citizens were reported as ‘posted’ workers, people regularly employed in one member state but sent to another by the same employer for a limited period of time. These are but some of the recognized categories of mobile citizens that variously bring into question the relevance of the category of usual residence.
At a 2014 meeting of the British Society for Population Studies, these various modes of mobility were discussed in relation to the question of whether the concept of usual residence has reached its ‘sell-by date’ [24]. Some of the issues raised included whether usual residence is a good measure of demand for services, given that demand varies according to the time, day, month and season; that if usual residence is used to allocate resources, plan service demand, and compare locations then might there be better or different measures? and, that usual residence is not just about the amount of time spent in a place, but also about attachment to a place and the intensity of use.
In light of these issues, the second collaborative workshop, which involved university researchers, speculated on imagining populations differently. Rather than beginning with usual residents and identifying rules for addressing exceptions, the workshop experimented with how residence might be reimagined or perhaps replaced with a category or other kind of metric that accords with the multiplicity of ‘modes of living’. That is, exceptions were taken as the rule. To that end, the workshop imagined different relations to locations based on family, work, registration, social and political rights, biographies, administrative requirements, and citizenship, and how movement creates transborder obligations and relations. Some participants speculated on how understanding these relations and obligations might be more relevant than usual residence. On that note, an idea that emerged was to think of mobility not as a category but as a network and how measures of different relations to locations and their intensities might be innovated. How might networks register, for example, intensities of relations people have to locations along various forms of attachment such as work, recreation, family, etc. and meaning such as intentions and biography? How might new registers of mobility be innovated by combining the automated and interactive possibilities of digital technologies? What these questions exemplify is that thinking anew requires rethinking fundamental assumptions and imagining other possibilities that better accord with the lived experiences of contemporary societies.
4.Final reflections
Through design, imaginaries of different data futures involving relations between citizens, states and technologies were performed. That is, beyond words, design made things present and made them open to change and speculation. Importantly, design began with words – that of citizens and co-production – that in turn opened up the possibility of reimagining relations. In these ways, the workshops contribute to numerous initiatives beyond those of citizen science mentioned previously and which imagine different data futures. For example, DataCommons is a Dutch association of citizens that seeks the right to self-determination over their own data [25]. The DECODE European project is working to provide tools that put citizens in control of their data and, if desired, share it for the public good [26]. The experiment in citizen data is to imagine yet another approach for citizens to co-produce and contribute data for public benefit.
The imaginary of citizen data has in part been recognized in the Bucharest Memorandum on Official Statistics in a Datafied Society adopted by the Director Generals of National Statistical Institutes (DGINS) in October 2018. It acknowledges citizens as partners and stakeholders rather than merely subjects of data and statistics [27]. The subsequent European Statistical System Committee (ESSC) implementation document further specifies this in a section called ‘citizen science data’ that acknowledges the successful development of citizen science collaborations and their potential for creating ‘citizen statistics’ [28]. Echoing some of the issues explored in the collaborative workshop, the section notes that digital technologies not only enable the continuous collection of ‘objective’ data from sensors, but also new modes of interaction with citizens and the production of ‘subjective’ data. In this way, the document also recognises the possibilities of digital technologies as not simply data extraction devices but also enablers of interaction and co-production.
The concept of citizen data and co-production raise practical and political questions including what the propositions set out in this article could mean for future work and plans of statistical institutes [4]. Amongst other things, this article has suggested the production of roadmaps as one way to rethink existing methodological paradigms. This could involve imagining different roadmaps for engaging with citizens at different stages of the statistical production process, from the co-design of prototypes for data generation platforms and apps to the establishment of co-operative forms of data ownership. In other words, citizen data calls for rethinking statistical production processes and some of their fundamental premises.
In sum, the experiment in citizen data posits that the authority and expertise to make statistics official are not founded in a single institution, but in processes of co-production and direct relations to citizens. In that regard, citizen data approaches claims of alternative facts as not matters of accuracy and standards but of the relations to citizens through which data and in turn statistics are made official. In this regard, it entails a move from ‘data driven’ to ‘democratically driven’ data for official statistics.
Notes
1 The project is ARITHMUS (Peopling Europe: How data make a people) and was funded by a European Research Council grant. I studied these issues along with five researchers through what we describe as a multi-sited and multi-method collaborative ethnography of the data practices of EU national and international statistical institutes.
Acknowledgments
The project, Peopling Europe: How data make a people (ARITHMUS) was funded by the European Research Council under the European Union’s Seventh Framework Programme (FP/2007–2013)/ERC Grant Agreement no. 615588, PI Evelyn Ruppert. Postdoctoral researchers were Baki Cakici, Francisca Grommé, Stephan Scheel, and Funda Ustek-Spilda and Doctoral researcher Ville Takala. I am grateful for the support and contributions of statisticians at seven field sites who made this research possible: UK Office for National Statistics, Statistics Netherlands, Statistics Estonia, Turkish Statistical Institute, Statistics Finland, Eurostat and UNECE. I am also grateful for the feedback and suggestions from two reviewers and the organisers of this special section.
References
[1] | Jasanoff S, Simmet HR. No funeral bells: Public reason in a ‘post-truth’ age. Social Studies of Science. (2017) ; 47: : 751-770. |
[2] | Lynch M. Post-truth, alt-facts, and asymmetric controversies. (2017) . Available at: https://bit.ly/2IPjgep. |
[3] | Ruppert E. Sociotechnical imaginaries of different data futures: An experiment in citizen data. 3e Van Doornlezing. Rotterdam: Erasmus University Rotterdam School of Behavioural and Social Sciences. (2018) . |
[4] | Ruppert E, Grommé F, Ustek-Spilda F, Cakici B. Citizen data and trust in official statistics. Economie Et Statistique/Economics and Statistics. (2018) ; 505-506: : 179-193. |
[5] | Grommé F, Ustek-Spilda F, Ruppert E, Cakici B. Citizen data and official statistics: Background document to a collaborative workshop. ARITHMUS Working Paper Series, Paper No. 2. (2017) . Avaliable at: www.artihmus.eu. |
[6] | Anderson B. Imagined communities: Reflections on the origin and spread of nationalism. London: Verso. (1991) . |
[7] | Jasanoff S. Future imperfect: Science, technology and the imaginations of modernity. in: Dreamscapes of Modernity: Sociotechnical Imaginaries and the Fabrication of Power. Jasanoff S, Kim S-H, eds. Chicago: University of Chicago Press. (2015) . 1-33. |
[8] | Bourdieu P. Social space and symbolic power. Sociological Theory. (1989) ; 7: : 14-25. |
[9] | Kertzer DI, Arel D. Censuses, identity formation, and the struggle for political power. in: Census and Identity: The Politics of Race, Ethnicity, and Language in National Censuses. Kertzer DI, Arel D, Eds, Cambridge: Cambridge University Press. (2002) ; 1-42. |
[10] | Isin E, Ruppert E. Being digital citizens. London: Rowman & Littlefield International. (2015) . |
[11] | Gabrys J. Data citizens: How to reinvent rights. in: Data Politics: Worlds, Subjects, Rights. Bigo D, Isin E, Ruppert E, eds. Milton Park, Abingdon and New York: Routledge. (2019) ; 248-56. |
[12] | Struijs P, Braaksma B, Daas PJH. Official statistics and big data. Big Data & Society. Apr-June (2014) ; 1-6. |
[13] | Rademacher W. Presentation at the Eurostat conference: Towards more agile social statistics. Luxembourg. 28-30 November (2016) . |
[14] | Mussmann BO, Bakker J, Schouten B, Warmerdam R. Dissolving questionnaire borders with technology: The paradigm shift in data collection. Paper Presented to the UNECE Workshop on Statistical Data Collection. 10-12 October (2017) . Ottawa: Statistics Canada. |
[15] | Edmunds SC. Citizen Smith goes to Nairobi. Taking Citizen Science to the UN. Citizenscience. Asia Journal [Internet]. (2018) Jan 26; Available from: https://bit.ly/2NB44Vc. |
[16] | Eurostat. Common bird index by type of species – EU aggregate dataset. Available from: http://bit.ly/2FMFUFh. (2019) . Accessed 04/07/2019. |
[17] | Statistics Canada. Open Building Data: an exploratory initiative. Available from: http://bit.ly/2XlNj4o. (2019) . Accessed 04/07/2019. |
[18] | Gabrys J, Pritchard H. Just good enough data and environmental sensing: Moving beyond regulatory benchmarks toward citizen action. International Journal of Spatial Data Infrastructures Research. (2018) ; 13: : 4-14. |
[19] | UNECE. Generic Statistical Business Process Model (Version 5.1). UNECE Statswiki. (2019) . Available at: https://statswiki.unece.org/. Accessed 05/05/19. |
[20] | Grommé F, Ruppert E, Cakici B. Data scientists: A new faction of the transnational field of statistics. in: Ethnography for a Data Saturated World. Knox H, Nafus D, Eds, Manchester: Manchester University Press. (2018) ; 33-61. |
[21] | UNECE. Conference of European Statisticians Recommendations for the 2020 Censuses of Population and Housing. Report No. ECE/CES/41. United Nations. (2015) ; 74. Available at: https://www.unece.org/. Accessed 09/07/2019. |
[22] | Duchêne-Lacroix C. Multilocal living arrangements in Switzerland. British Society for Population Studies Meeting on Usual Residence. (2014) . London School of Economics and Political Science. Available from: https://bit.ly/2EtLcEa. |
[23] | Fries-Tersch E, Tugran T, Markowska A, Jones M. Annual report on intra-EU labour mobility. Brussels: European Commission Directorate General for Employment, Social Affairs and Inclusion. (2018) . |
[24] | Potter R, Champion T. The concept of usual residence: Has it reached its sell-by date? Report on a BSPS Day Meeting, Friday 24th October 2014. LSE: British Population Studies Association. (2014) . |
[25] | DataCommons. Available at http://datacommons.nl/. Access-ed 09/07/2019. |
[26] | DECODE. Available at https://decodeproject.eu/what-decode. Accessed 09/07/2019. |
[27] | DGINS (Director Generals of National Statistical Institutes). Bucharest Memorandum on Official Statistics in a Datafied Society. 104th DGINS Conference: The European Path towards Trusted Smart Statistics. Bucharest: Eurostat; (2018) . |
[28] | ESSC. (European Statistical System Committee). Implementation of the Bucharest Memorandum on Official Statistics in a Datafied Society. 40 |


