
PRSC: From PG to RDF and back, using schemas
Abstract
Property graphs (PG) and RDF graphs are two popular database graph models, but they are not interoperable: data modeled in PG cannot be directly integrated with other data modeled in RDF. This lack of interoperability also impedes the use of the tools of one model when data are modeled in the other.
In this paper, we propose PRSC, a configurable conversion to transform a PG into an RDF graph. This conversion relies on PG schemas and user-defined mappings called PRSC contexts. We also formally prove that a subset of PRSC contexts, called well-behaved contexts, can be used to reverse back to the original PG, and provide the related algorithm. Algorithms for conversion and reversion are available as open-source implementations.
1.Introduction
Graphs are a popular data model in which knowledge is represented through objects and links between these objects. Today, there are two mainly used models of graphs: Property Graphs and RDF.
Property Graphs (PGs) are a family of implementations, in which data are represented with nodes and edges, and labels and properties (key-value pairs) can be attached to these nodes and edges. Property Graphs are not a uniform model: some implementations like Neo4j 11 only allow exactly one label for each edge. Most PG engines offer easy-to-use graph query languages like Cypher [16] and Gremlin [28] that rely on graph traversal. While no uniform standard has been settled yet, the Property Graph needs a Schema Working Group 22 is working towards defining a schema language for PG, and a unified formalization of the PG model. In the rest of this paper, following other authors [2], the variability of implementations is neglected and PGs are considered as a uniform model.
Another popular graph model is the Resource Description Framework (RDF) model [34]. In this model, data are represented with triples that represent links between resources. The resources and the links between them are identified through Internationalized Resource Identifiers (IRI). This data model is a W3C standard, and has been studied through a large quantity of works, like RDFS [9] and OWL [24] for inference, or SHACL [22] for data validation. This model has been extended by RDF-star [20] that helps writing properties on triple terms in a more concise manner, but does not provide exactly the same modeling capabilities as PGs. For example, multiple links with the same predicate between two resources are still not supported and requires using extra constructs, like the occurrence pattern described in the “Triples and occurrences” section of the RDF-star community group final report [19].
While PG and RDF are both based on the idea of using graph data, the choice of one removes the ability to use the tools developed for the other. The maintainers of Amazon Neptune, a graph database service that can support both models independently, report that their users choose the solution that best suits their current use case, then struggle because they are stuck with the tools of this model even if the tools of the other model would better answer the new business problem they have [23]. Generally speaking, this diversity of graph models, and more precisely the lack of interoperability, hinders graph database adoption.
Numerous authors [14,29] highlight the benefits of interoperable systems, and in particular of interoperability between PGs and RDF graphs [15,32,35]. We can distinguish two levels of interoperability: syntactic interoperability and semantic interoperability. The former consists in having common data formats, for example JSON or CSV. The latter consists in having data not only in a common data format, but also that use shared vocabularies. Tim Berners-Lee theorized the 5-star Open-data model.33 In this model, datasets are given a number of stars depending on how interoperable they are. RDF graphs are by design the best candidate to elevate the ranking of data in the 5-star data-model, in particular through the use of shared vocabularies. So, while internally developers may choose RDF or PG databases based on their preferences and the convenience of associated tools, RDF is better suited as a pivot model for interoperable exchange of data.
Among the many questions risen by the interoperability between PGs and RDF graphs, the scenario we want to support is the conversion from PGs to RDF (syntactic interoperability) without information loss, and while promoting the use of existing shared vocabularies (semantic interoperability). The requirement of using of existing shared vocabularies requires a converter to be highly customizable, in particular in terms of how the produced triples are structured. On the other hand, the requirement of not losing information, i.e. producing reversible conversions, requires to formally study the possible conversions.
In a previous paper [10], we introduced the motivations behind PREC (PG to RDF Experimental Converter), a user-configured mapping from Property Graphs (PG) to RDF graphs and proposed a mapping language, specialized for the PG to RDF conversion problem, to let the user describe how to convert the node labels, the edges and the properties of the original PG to an RDF graph. By converting the data stored in PGs into RDF, users are then able to use all the tools available for RDF. In this paper, we introduce a new mapping language, named PRSC,44 driven by a schema and a description of how to convert the elements of the types in the schema to RDF. This mapping language is formally defined, and conditions under which the conversion produced by PRSC is reversible are also defined. Compared to the previous mapping language, this language contains fewer terms and concepts, and should be easier to use. The PRSC engine is available under the MIT license55 and can connect both to a Cypher endpoint and a Gremlin endpoint.
The rest of this paper is organized as follows. Section 2 gives an overview of PRSC to understand its principles. Section 3 gives generic formal definitions of PGs and RDF graphs. Section 4 gives a formal definition of a PRSC conversion, which is essentially a formal definition of Section 2. Section 5 studies reversibility, and proves that some contexts can convert PG to RDF graph without information loss. Section 6 discusses the existing works to make easier interoperability between PGs and RDF graphs relatively to PRSC. Section 7 discusses the proposed solution and describes some future works.
2.PRSC in practice
The Property Graph exposed on Fig. 1 describes the relationship between Tintin and Snowy. It is composed of two nodes. The first one holds the label Person and two properties: the first property has “name” as its key and “Tintin” as its value, the second has “job” as its key and “Reporter” as its value, or more simply its name is “Tintin” and its job is “Reporter”. The other node only has one property: the name “Snowy”. These two nodes are connected by an edge that holds one label, TravelsWith, and a property that tells that it is “since” “1978”.
A similar example represented in RDF-star is exposed on Listing 1. Most information that was in the PG is represented by the triples in lines 1–4 and 6. The information about since when Tintin travels with Snowy is represented through a nested RDF-star triple.
Fig. 1.
A small PG about Tintin that serves as a running example in this paper.
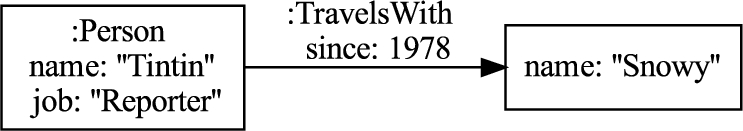
Listing 1.
An example of an RDF-star graph in Turtle Format

Using the user-defined mapping, PRSC is able to convert the PG in Fig. 1 into the RDF-star graph in Listing 1, and more generally any Property Graph with the same schema into the corresponding RDF graph. In this paper, we consider that Property Graphs with the same schema as the one in Fig. 1 are Property Graphs where all nodes have either (1) the “Person” label, a “name” property and a “job” property, (2) no label and a “name” property, (3) and where all edges have the “TravelWith” label and a “since” property. The mapping the user must provide to the PRSC engine is exposed on Listing 2 and is in Turtle-star format [27]. Rules are split in two parts:
– The target part that describes which elements of the Property Graph are targeted. The target is described depending on three criteria: (1) whether the element must be an edge or a node, (2) the labels and (3) the properties of the element.
– The production part that describes the triples to produce with a list of template triples. Values in the
Listing 2.
The PRSC context that maps the PG running example to the RDF graph running example

The mapping, named PRSC context, exposed on Listing 2 reads as follows:
– The first rule is named _:PersonRule (line 1)
∗ The rule is used for all PG nodes (line 3) that only have the node label “Person” (line 4) and have the properties “name” and “job” (line 5). In our example, the node corresponding to Tintin matches this description, but Snowy does not as it misses the Person label and the job property.
∗ It will produce three triples:
⋆ One triple with a blank node as its subject, rdf:type as its predicate and ex:Person as its object (line 8). Each node from the Property Graph is identified by a distinct blank node. In this example, _:n1 rdf:type ex:Person will be produced.
⋆ Another triple with the same blank node as its subject, foaf:name as its predicate and a literal that matches the value of the name property in the PG (line 9). The PRSC engine converts all literals whose datatype is prec:valueOf into the value of the corresponding property in the PG. In this example, _:n1 rdf:type "Tintin" will be produced.
⋆ One last triple is produced with the same blank node as its subject, ex:profession as its predicate and a literal corresponding to the value of the property job (line 10). In this example, _:n1 ex:profession "Reporter" will be produced.
– The second rule is named _:NamedRule (line 12).
∗ It is applied to nodes (line 14) that have no labels and only one property: name (line 15). This is the case of the PG node used to describe Snowy but not the one that describes Tintin as it has an extra label and an extra property.
∗ These PG nodes will be converted into one triple with a blank node that identifies the PG node as its subject, foaf:name as its predicate and the literal that correspond to the value of the name property as its object (line 18). In this example, the triple _:n2 foaf:name "Snowy" is produced.
– The third rule is named _:TravelsWithRule (line 20):
∗ It is used to convert edges (line 22) whose only label is “TravelsWith” (line 23) and with one and only one property named “since” (line 24).
∗ These edges are converted by producing a triple with the identifier of the source PG node as the subject, ex:isTeammateOf as the predicate and the identifier of the destination PG node as the object (line 27). In this example, the triple _:n1 ex:isTeammateOf _:n2 is produced.
∗ A triple with a quoted triple is created by the rule on line 28: the triple that was created by the line 27 is used on the subject position of the triples created by this triple, ex:since is used as the predicate and the value of the “since” property is used as the object. In our example, the triple << _:n1 ex:isTeammateOf _:n2 >> ex:since 1978 is produced.
∗ Note that in this example, pvar:self is not used in lines 27 and 28. If it was used, it would be mapped to a blank node that identifies the edge. The consequence of not using it is a smaller RDF graph, at the cost of if several PG edges with the “TravelsWith” label were present between the two same nodes, the RDF representation of these edges would have been merged.
Note that this mechanism of using quoted triples to describe templates in a pure Turtle-star file was already presented in our previous work [10]. Compared to R2RML [14], it lets the user describe the triples to produce with a syntax closer to the triples that will actually be produced, but it is currently impossible to express templated terms in any position. For example, if the user wants to generate a named node <http://example.org/person/{name}> in subject position in which the {name} part is substituted with the value of the name property, R2RML offers it as a native feature. As PRSC is currently unable to generate arbitrary IRIs, nodes and edges from the PG are always mapped to blank nodes and minting IRIs is left for future works.
3.General definitions
This section introduces some standard definitions, mostly inspired from previous works.
3.1.Notations and conventions
Let
Definition 1
Definition 1(Domain and image of a function).
For all partial functions
–
–
Example 1.
For the partial function
Let S be a set, we recall that
3.2.Compatible functions
For all functions f, we recall that they can be seen as sets:
Example 2.
Consider the three functions
Table 1
Some functions defined both with the usual function notation and with a set notation
| Function notation | Set notation |
As
The set
On the opposite,
Remark 1.
Instead of using the notation
Definition 2
Definition 2(Functions compatibility).
Two functions f and g are compatible iff
In other words, two functions f and g are compatible iff for every common input, they share the same output i.e.
3.3.Property Graph
Definition 3
Definition 3(Property Graph).
Following the definition of Angles [2], a property graph
–
–
–
–
The set of all property graphs is denoted
In this paper, property graph nodes and edges are grouped under the term element.
In the rest of the paper, when any PG x is introduced, we allow ourselves to use the symbols
Example 3
Example 3(Running example of a Property Graph).
The PG exposed on Fig. 1 can formally be defined as the PG denoted
–
–
–
–
Definition 4
Definition 4(The empty PG).
The empty PG, which is the PG that contains no nodes and no edges, is formalized as follows:
3.3.1.Renaming Property Graphs and isomorphism
The chosen formal definition of the running example is not the only one that is possible: for example an arbitrary element named a could have been used in place of
Definition 5
Definition 5(Renaming function).
For all sets
Example 4.
Let
An example of a renaming function
Definition 6
Definition 6(Property Graph renaming).
Let
–
–
–
–
–
–
Example 5.
Let us consider back
The PG produced by
–
–
–
–
Definition 7
Definition 7(Isomorphic property graph).
Two PGs
Note that both
Existing works [16,33] on PG query languages focus on extracting the properties of some nodes and edges, and never look for the exact identity of the elements. It is therefore possible to affirm that the exact identity is not important, and that if two PGs are isomorphic, they are the same PG for practical matter.
3.4.RDF-star definition
Definition 8
Definition 8(Atomic RDF terms).
Let I be the infinite set of IRIs,
IRIs, literals and blank nodes are grouped under the name “Atomic RDF terms”.
Notation: In the examples, the IRIs, the elements of I, will be either noted as full IRIs between brackets, e.g. <http://example.org/Tintin> or by using prefixes to shorten the IRI e.g. ex:Tintin. The list of prefixes used in this paper is described in Table 2.
Literals, the elements of L, can be noted either by using the usual tuple notation, e.g.
Finally, the blank nodes, the elements of B, are denoted by blank node labels prefixed with the two symbols “
Table 2
List of prefixes used in this paper
| Prefix | IRI |
| rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| xsd | http://www.w3.org/2001/XMLSchema# |
| ex | http://example.org/ |
| prec | http://bruy.at/prec# |
| pvar | http://bruy.at/prec-var# |
Definition 9
Definition 9(RDF(-star) triples and graphs).
The set of all RDF triples6 is denoted
–
–
A subset of
Both the atomic RDF terms defined in Definition 8 and RDF triples are terms. A triple used in another triple, in subject or object position, is a quoted triple. An RDF triple can not contain itself and can not be nested infinitely.
Example 6.
1. The triple
2. The RDF graph exposed in Listing 1 is composed of 5 triples written in Turtle format. In our formalism, the second triple, _:tintin foaf:name "Tintin", is
3.
Definition 10
Definition 10(Term membership).
The ∈ operator is extended to triples to check if a term is part of a triple.
Example 7
Example 7(Term membership examples).
–
–
–
–
–
–
–
Definition 11
Definition 11(List of blank nodes used in an RDF graph).
For every RDF graph
Example 8.
Let
4.PRSC: Mapping PGs to RDF graphs
PRSC enables the user to convert any Property Graph to an RDF graph by using user-defined templates.
4.1.Property graphs with blank nodes
By default, every node and edge of the PG to convert is mapped by PRSC to an arbitrary fresh blank node. This mapping is arbitrary because blank nodes are essentially interchangeable, and because they have no global identifiers which would allow to map to a specific blank node anyway. This mapping is used throughout the transformation. For the sake of conciseness, we introduce the following modelling trick.
We note that in the respective definitions of PGs and RDF, the sets N and E of nodes and edges (in any PG) and the global set B of blank nodes (in RDF), are very loosely characterized. The only constraints are that N and E are disjoint and finite, and that B is disjoint from the sets of IRIs and literals. Theoretically, nothing prevents a property graph to take its nodes and edges in the set B, in other words, to have
Our arbitrary mapping from
Conversely, when we study the reversibility of some contexts in Section 5, we prove that the produced BPG is exactly the original one. Producing a PG with arbitrary elements, and proving that it was isomorphic to the original, would be much more complex.
Definition 12
Definition 12(Blank Node Property Graph).
Example 9.
By defining the renaming function
–
–
–
–
By construction,
This may raise the question of the meaning of two BPGs that share the same blank nodes, in particular if one blank node is used as a node in one BGP and as an edge in the other. However, this question could also be raised for all PGs: what would it mean for two PGs to have common elements in their respective sets of nodes and edges? In general, it would not hold any semantics, as PG elements are considered locally for a given PG. However, in Section 5.3.4, we will define operators for PGs, even the ones without blank nodes, that will consider PGs with shared PG elements and their possible relations.
4.2.Type of a PG element and PG schemas
We define the type of a PG element and PG schemas as follows. Let
Definition 13
Definition 13(Property keys of an element).
We recall that in Section 2 and in Definition 3, properties are described as key-value pairs.
Definition 14
Definition 14(Type of a PG element).
A type is a triple composed of 1) the kind of the PG element, i.e. if it is a node or an edge, 2) a set of labels and 3) a set of property keys. The set of all types is denoted
The type of an element
A set of PG types is named a schema.
The functions
Example 10.
Table 3 shows the types of the PG elements in the running example.
Table 3
The types of the elements in the PG
| m | |
Remark 2.
If two PGs
Indeed, by definition, there exists a renaming function ϕ from the elements of
4.3.Template triples
PRSC resorts to a mechanism of templating: to produce an RDF graph from a PG, we use tuples of three elements, named template triples, that will be mapped to proper RDF triples.
Definition 15
Definition 15(Placeholders).
There are four distinct elements, not included in either of the previously defined sets, named
Let
Let
Definition 16
Definition 16(Template triples).
A template triple is a member of
–
–
Note that unlike RDF triples, the elements of
Any subset of
Example 11.
The triple
The triple
The triple
Definition 17
Definition 17(Placeholders and template triple membership).
The ∈ operator, which we extended in Definition 10, is further extended to placeholders and template triples:
4.4.PRSC context
In this paper, the notion of PRSC context is the keystone to let the user drive the conversion from a PG to an RDF graph. It maps PG types to template graphs. The
Definition 18
Definition 18(PRSC Context).
A PRSC context
All template graphs must be valid, i.e. for all types, the placeholders used in the associated template graph must be consistent with the type: (1) for any given property key, its associated placeholder may only be used in template graphs associated with types that contain the property key, for example the placeholder
Formally, all template graphs used by a context
1.
2.
The set of all context functions is denoted
Definition 19
Definition 19(Complete PRSC contexts for a given PG).
A PRSC context is said complete for a property graph
Remark 3.
Note that the type system described in Definition 14 is trivial to resolve as the type of a PG element m, denoted by
Example 12.
Table 4 exposes an example of a complete
Table 4
An example of a complete context for the Tintin Property Graph
Example 13.
The function
Table 5
An incomplete context for the Tintin PG
Example 14.
The function
Table 6
A function that is not a context
4.5.Application of a PRSC context on a PG
We now define formally the conversion operated by PRSC. A PRSC conversion of a PG depends on a chosen context
Definition 20
Definition 20(Property value conversion).
For the conversion of property values to literals, we consider that we have a fixed total injective function
Definition 21
Definition 21(The prsc
The operation that produces an RDF graph from the application of a PRSC context
As said previously, the result of
Example 15.
Table 7 exposes the resolution of
Table 7
Application of a PRSC context on the running example
| m | |||
The resolution of
Algorithm 1 gives an algorithmic view of the
Algorithm 1:
The

4.6.Complexity analysis
In this section, we discuss the different metrics that can be used to evaluate the complexity and evaluate the complexity of the
4.6.1.Functions considered constant
For a given PG
The complexity of the functions
Evaluating if something is a member of a given set, for example if an entity is part of the set
4.6.2.Considered metrics
For a given PG
– The number of nodes and edges in
– The size of the biggest template graph, denoted
– The complexity of the types in the context, denoted
– The number of types supported by the context
In RDF-star, quoted triples can be used as subject or object of other triples, without limit on how deeply triples can be nested. In practice, however, it is rare to have more than one level of nesting. Usually, users are expected to use atomic RDF triples like _:tintin :travelsWith _:haddock or to use RDF-star triples with a depth of one like << _:tintin :travelsWith _:haddock >> :since 1978. We therefore consider the depth of any triple to be bound by a constant. As a consequence, in all functions processing terms and triples recursively (such as β in Algorithm 1), we can ignore the recursion depth in the complexity analysis.
In all complexity analyses, all metrics are considered non null. Indeed, if there are no elements or if the biggest template graph is empty, the produced RDF graph will be empty so this case is not interesting. As we add one to the number of labels and properties, the type complexity can never be zero, even if the context only supports nodes and edges with no labels and no properties.
4.6.3.Complexity of ctx prsc
For each given PG element m, the complexity of a call to
– The type of m in the PG
∗ Evaluating if m is a node or an edge is constant as checking if an element is a member of a set is constant.
∗ Calls to
– In the complexity analysis, we consider that
4.6.4.Complexity of prsc
Given a PG
– Calls to
– Calls to the β function in line 7 are constant, as it has been assumed that the depth of the most nested triple is low enough to be ignored and the operations it performs are in constant time.
– There are two for loops, one iterating on all PG elements (
The
5.PRSC reversibility
When PGs are converted into RDF graphs, an often desired property is to not have any information loss. To determine whenever or not a conversion induces information loss is to check if the conversion is reversible, i.e. if from the output, it is possible to compute back the input. The reversion is studied relatively to the used PRSC contexts: the PRSC context is used as both an input of both the PRSC algorithm and the reversion algorithm. In other words, we consider that the information stored in the PRSC context do not need to be stored in the produced RDF graph to produce a reversible conversion.
This section first shows that not all PRSC contexts are reversible. Then, properties are exhibited about PRSC contexts, leading to a description of a subset of reversible PRSC contexts, i.e. contexts that we prove do not induce information loss.
5.1.Reversibility in this paper
In this paper, we call a function f reversible if we can find back x in practice from
– The function f must be injective. Indeed, if two different values x and
– The inverse function
We say that a context
More formally, when studying reversibility, we want to check if for a given
Example 16
Example 16(A trivially non-reversible context).
Consider the context
Example 17
Example 17(A more realistic example of a non-reversible context).
Another example of a non-reversible context is the context exposed in Table 4: while this context can be applied on PGs in which edges have the “since” property, the value of this property will never appear in the produced RDF graph.
As not all contexts are reversible, the next sections focus on characterizing some contexts that produce reversible conversions.
5.2.Well-behaved contexts
5.2.1.Characterization function
To be able to reverse back to the original PG, we need a way to distinguish the triples that may have been produced by a given member of
Definition 22
Definition 22(Characterization function).
The κ function maps:
– All template triples to a super set of triples that it is able to generate.
– All RDF triples t to a super-set of the RDF triples that a template triple that may generate the triple t may also generate. For example, a literal may be generated by any element of P. An element of P may generate any literal. Therefore, the κ function maps all literals to the set of all literals.
The κ function is extended to all template graphs and RDF graphs
Example 18
Example 18(κ applied to the running example from Fig. 1).
–
–
–
–
–
– Note that
∗
∗
–
–
Table 8 provides an example of applying κ on the running example context of Table 4.
Table 8
The running example context with the corresponding values through κ
Remark 4
Remark 4(κ on terms and triples is, as expected, a super-set of the possible generated values).
When comparing the definition of the κ function with the β functions defined in Section 4.5, it appears that:
– For elements in B,
– For elements in I, the image of κ is equal to a singleton containing that element; β maps any IRI to itself.
– If the given term is a triple, the image of κ is the cross product of the application of the κ function to the terms that compose the RDF triple. As β on triples recursively applies itself to the three terms in the triple, we can see that
Therefore, if x is a term or an RDF triple, for any β function,
Remark 5
Remark 5(The result of build
The
From Remark 4, it can be deduced that if
Remark 6
Remark 6(A template and its produced values share the same image through κ).
When using the κ function, elements in B and
When using the β function:
– Elements in
– Elements in P map to elements in
– Elements in L and I are mapped to themselves.
– Elements in
Therefore,
As mentioned previously, the role of κ is to allow us to determine whether two template triples with placeholders may produce the same triple. It maps all placeholders to a super-set 9 of all elements they can generate with the
Lemma 1.
If a triple is generated by a template graph, then there exists a template triple with the same image through κ.
Proof.
Per the Definition 21 of
Definition 23
Definition 23(unique
A template triple
It is defined as follows with
Combined with Remark 6, what
Theorem 1
Theorem 1(Triples produced by a unique
In the result of the
Proof.
We prove the theorem by contradiction.
Let us suppose that:
– (A)
– (B1)
– (B2)
– (C)
Theorem 1 allows us to link an RDF triple to the unique template triple that produced it. Then by comparing the terms of the RDF triple to the corresponding placeholders in the template triple, we will be able to reconstruct the original PG.
5.2.2.Well-behaved PRSC context
In this section, we define a subset of contexts that we call well-behaved PRSC contexts. In the next section, we will prove that these contexts are reversible.
Definition 24
Definition 24(Well-behaved contexts).
A PRSC context
1. Element provenance: all generated triples must contain the blank node that identifies the node or the edge it comes from. This is achieved by using the
–
2. Signature template triple:
–
3. No value loss: for all elements in the PG, we do not want to lose information stored in properties, nor for edges, the source and destination node. Each of these pieces of information must be present in an unambiguously recognizable triple pattern.
–
–
–
The set of all well-behaved contexts is
Remark 7
Remark 7(Handling multiple sig n ctx
In the case where there are multiple template triples candidates to become the signature template triple, the choice of the signature template triple among the candidates is generally not important.
To make the choice deterministic, it could be considered that the chosen signature template triple is the first in lexicographic order. In the case of the presented algorithms, the choice of the signature template triple is not important, and will lead to the same output.
Remark 8
Remark 8(The template graphs used in well-behaved contexts are not empty).
A well-behaved context cannot map a type to an empty template graph: the signature template triple criterion ensures that every template graph contains at least one template triple:
Remark 9
Remark 9(Inside a well-behaved context, all template graphs are different from all others).
For any well-behaved context
Example 19.
Table 8 studies the context used in our running example, exposed in Example 12.
– The type
∗ All triples contain
∗ At least one template triple is a signature: the image through κ of
∗ The properties
– The type
– The type
For all these reasons, this context is not well-behaved.
Example 20
Example 20(A well-behaved context for the running example).
Let
This context is well-behaved:
Table 9
An example of a complete and well-behaved context for the Tintin Property Graph
–
– Template triples that are signature are marked with a ⋆. At least one signature triple appears for each type,
– All property keys have a unique template triple.
Listing 3.
The RDF graph produced by the application of the well-behaved context

Listing 3 is the RDF graph produced by the application of the context
Remark 10
Remark 10(Relationship between the empty PG and the empty RDF graph with well-behaved PRSC context).
For all well-behaved PRSC contexts, the only PG that can produce the empty RDF graph is the empty PG:
Indeed, Remark 8 ensures that the template graphs are non-empty. So any application of the
5.2.3.Complexity analysis and implementation
PRSC well-behaved contexts will be proved to be reversible in Section 5.3, meaning that producing an RDF graph from them will preserve all information stored in the PG. It is therefore important to be able to determine if in practice, it is possible to compute if a PRSC context is well-behaved.
Lemma 2.
The values through κ of two given terms are either disjoint or equal:
Proof.
Consider any atomic RDF term t:
– If
– If
– If
As L, I and B are pairwise disjoint, for two given atomic RDF terms, the value through κ is either disjoint or equal.
For two given RDF triples composed of atomic terms, their value through κ are equals to the Cartesian product of the value through κ of the components. As the values through κ of their components are either equals or disjoints, the values through κ of the triples are also either equals or disjoints. By induction, this is true for any two RDF triples, even if their subject or object are also triples. □
Remark 11
Remark 11(Implementing κ and complexity analysis).
The function κ is defined to return sets, some of them being infinite sets. While this definition is useful to prove different theorems in this paper, it is not practical from an implementation perspective.
Let λ and δ be two distinct values that are not members of the set I. We propose below an alternative function
Compared to Definition 22, we replaced:
– the singleton
– the sets L and B with two constants λ and δ that are not elements of I,
– the cross product with a simple triple of the values returned for each element of x when x is a triple.
The complexity of the
– For any x that is not a triple nor a graph, calls to this function can be done in constant time, by simply checking the type of x.
– When x is a triple, calls to this function involves recursive calls up to the depth of x, which we consider to be bounded by a constant (see Section 4.6.2). So it is also done in constant time.
– When x is a graph, calls to this function involves calling
Note that:
– For two triples, checking if their value through
– Thanks to Lemma 2, checking if the value through
Remark 12
Remark 12(Complexity of checking if a PRSC context is a well-behaved).
The first task to check if a context
After the value through κ of all template triples have been computed, for each type, we need to check if the type complies with the three criterion exposed in the Definition 24.
– The element provenance criterion consists in checking if
– The signature template triple consists in checking if there is at least one signature template triple in the template graph of all types, i.e. checking if the value through κ of one of the template triples of each type is not contained in the set of the value through κ of the other types template graph. As hash sets make the membership check constant, this task has an
– For a given type, checking the no value loss criterion consists in checking if a
The final complexity of checking if a context is a well-behaved PRSC context is:
5.3.Reversion algorithm
Algorithm 2 aims to convert an RDF graph, that was produced from a PG and a known well-behaved context, into the original PG.
It is a four steps algorithm: 1) it finds the elements of the PG, by assuming they are the same as the blank node in the RDF graph, 2) it gives a type to all PG elements with the
Algorithm 2:
The main algorithm to convert back an RDF graph into a PG by using a context

Algorithm 3:
Associate the elements of the future PG with their types

Algorithm 4:
Associate each triple to the element that has produced it

Algorithm 5:
Produce a PG from the previous analysis of the elements and triples

Further subsections prove that for all
5.3.1.Finding the elements of the PG
The first step of the algorithm relies on the assumption that the blank nodes of the RDF graph and the elements of the original PG are the same.
Theorem 2
Theorem 2(Equality between the elements of a PG and the blank nodes of the RDF graph).
If the RDF graph
Proof.
– The
– From Remark 8, we know that
Theorem 2 proves the correctness of the
5.3.2.Finding the type related to each element
In this part of the proof, we show that the
Lemma 3.
If a data triple shares the same value through κ as one of the signature triples of a type (Definition 24-2), then the element from which the data triple was produced must be of this type:
Proof.
Definition 25
Definition 25(Formalizing candtypes
For a given blank node/PG element b,
They give the set of all node types and edge types, respectively, for which one of their signature triple could have produced a triple with b.
Theorem 3
Theorem 3(candtypes
Even though the
–
–
Table 10 provides an overview of the cardinality of the different
Proof.
Per Definition 25,
We are going to restrict the portion of the graph
– We see that all triples
– If
– If
The reasoning for
Finally, a blank node
Remark 13.
Theorem 3 not only shows that the
Remark 14
Remark 14(Using different signatures to determine the types).
As mentioned previously, the choice of the signature template triple
5.3.3.Finding the generated triples for each PG element
For each PG element, given the produced RDF graph and the type of this PG element, we are able to compute the list of RDF triples produced from this PG element. In other words, Algorithm 4 correctly partitions the RDF graph into sub-graphs describing each element of the original PG.
Theorem 4.
In Algorithm 4, assuming that the passed value of
Proof.
As
The algorithm associates each triple
– Let’s first recall that blank nodes in
– If
– If
∗ Node template graphs can contain only one placeholder from
∗ Edge template graphs can contain several placeholders from
– Error(No element provenance) will never be raised if
As each triple in
5.3.4.Building the PG element
Projecting Property Graphs As an RDF graph is defined as a set of RDF triples, any subset of that set, as well as the union of two RDF graphs, are formally defined and are also RDF graphs. Algorithm 5 constructs back the original PG in an iterative manner. To prove its correctness, we need operators similar to ⊂ and ∪ for RDF graphs, but for our formalization of PGs.
In this section, the projection of a Property Graph is defined by focusing only on a single PG element, node or edge. The concept of merging PGs, which is the inverse of the projection, is also defined.
Let
Definition 26
Definition 26(π projection of a Property Graph on an element).
The π projection of a PG on a node is equal to the PG with only the node itself. The π projection of a PG on an edge is the edge, and its source and destination nodes without the labels and properties of these nodes.
– If
– If
–
–
Definition 27
Definition 27(Property Graph merge operator ⊕).
The merge operator ⊕ is the inverse of the projection operator π. It can only be used on two PGs that are compatible, i.e. (1) a PG element defined as a node is not defined as an edge in the other, (2) an edge defined in both PGs have the same source and destination in both, and (3) if in both PGs, the value of a property key on the same PG element is defined, the values should be the same. The ⊕ operator builds a PG with the PG elements, labels and properties of both PGs.
We now define the ⊕ merge operator on property graphs.
–
–
–
Its value is
–
–
–
–
–
–
Lemma 4.
⊕ is commutative, associative, and the neutral element is the empty PG
Proof. (Sketch).
⊕ is defined by using the ∪ operator, which is commutative, associative and whose neutral element is ∅. The equivalent of ∅ for PGs is
Theorem 5.
The ⊕ merge of the π projection of a PG on all its PG elements is equal to the PG itself:
Proof.
The proof is provided in Appendix A. □
While the ⊕ operator has been primarily designed as the inverse operation of the projection operator π, it can only merge two PG that are consistent between themselves. If a PG defines an entity as a node, the other PG can not define it as an edge. If a PG has a given source and destination for a given edge, the other one can not define another source or destination. Properties must also be consistent in both PGs. The presented version of the merge operator can only add information, and in the case merging two PGs would lead to an inconsistent PG, the merge operator is undefined.
Relationship between the
The RDF graph built by
The
– m itself.
– Its labels, i.e.
– Its property values, i.e.
– If m is an edge, its source and destination nodes, i.e.
– The template graph
Therefore the following equality can be asserted,
Completing the proof of the reversion algorithm We are now back to proving that for all well-behaved contexts
To prove the correctness of the
Lemma 5
Lemma 5(Merging the projection of one PG element to the reconstructed PG).
In Algorithm 5, assuming that the
Proof.
The PG
Table 11
Description of the PG projection that is built in Algorithm 5
| ∅ | ||
In the following, we want to check that
The
Theorem 1 ensures that the built set
After the loop, because only
The last instructions differ for
As all values of
Remark 15
Remark 15(Completeness of buildpg
In the case where
Theorem 6
Theorem 6(Merging the projection of all PG elements to the reconstructed PG).
Under the same assumptions as Lemma 5, the PG returned by Algorithm 5 is the original
Proof.
The PG g in the algorithm is initialized to
As
5.3.5.Complexity analysis
Let us now discuss the complexity of the
Extracting the list of blank nodes of an RDF graph on line 2 has a linear complexity of
The
Trivially, Algorithm 4 has a complexity of
In Algorithm 5:
– Calls to
In the context of the∗ It loops all triples in the template graph
∗ Inside the loop, building the
– The
∗ Notice that while
∗ There are at most
∗ The complexity of each iteration is
– The overall complexity of the
The overall complexity of the
The
5.4.Edge-unique extension
In many cases, there is only one edge of certain types between two nodes, like the “TravelWith” edge in our running example or for relationships like knowing someone, a parental relationship… For this type of edges, it is more intuitive to represent them with a simple RDF triple, and get rid of the blank node corresponding to the edge. However, Well-Behaved PRSC contexts require
Table 12
A context for the Tintin PG with the “since” property
Consider the Tintin PG exposed in Fig. 1 and the context exposed in Table 12, which uses RDF-star to convert the “since” property. The output of PRSC from those two inputs is exposed in Listing 4. By looking at the produced RDF graph, it appears that the RDF graph captures all the information of the PG. More generally, RDF graphs produced by this context would always be reversible as long as the source PG does not contain multiple “TravelsWith” edges between two given nodes.

Definition 28
Definition 28(Edge-unique extension).
a) In a context
–
– For all template triples
∗
∗
∗
Theorem 7 shows that
Theorem 7.
Let
– For every two BPGs,
– There is an algorithm such that for all BPGs
Proof. (Sketch).
The context
Denote W the set of all types in the well-behaved part and U the types in the edge-unique part. Let
It is also possible to split
From all the theorems on well-behaved contexts, there is a bijection between
All template triples used in the template graph of edge-unique types are both signature and unique: from any triple in
By using a fresh blank node for u, it is possible to build a PG isomorphic to
5.5.Discussion about the constraints on well-behaved PRSC contexts
In this section, we discuss the acceptability of the different constraints posed by PRSC well-behaved contexts in terms of usability. In other words, to what extent do they limit what can be achieved with PRSC?
The no value loss criterion on well-behaved contexts ensures that the data are still present and can be found unambiguously: as its name implies, this constraint is obviously required to avoid information loss. Therefore, it should not be perceived as overly constraining when building PRSC contexts.
The signature template triple is a method to force the user to type the resources, which is usually considered to be good practice. The type can either be explicit, through a triple with
The element provenance constraint may hinder the integration of RDF data coming from a PG with regular RDF data: it forces the user to keep the structure exposed in the PG, with blank nodes representing the underlying structure of the PG. The edge-unique extension enables to leverage this constraint, by avoiding representing PG edges as RDF nodes.
6.Related works
Many works already exist to address the interoperability between PGs and RDF.
A common pivot for PGs and RDF To achieve interoperability, some authors propose to store the data into another data model, and then expose the data through usual PG and RDF APIs. Angles et al. propose multilayered graphs [4], for which the OneGraph vision from Lassila et al. [23] is a more concrete version. These works propose to describe the data with a list of edges, with the source of the edge, a label and the destination of the edge. All edges are associated with an identifier, that can be used as the source or the destination of other edges. However, authors note that several challenges are raised about the way to implement the interoperability between the OneGraph model and the existing PG and RDF APIs.
In a Unified Relational Storage Scheme [35], Zhang et al. propose to store the data in relational databases. While they specify how to store both models in a similar relational database structure, they do not mention how they align the data that come from one model with the data that come from another, for example to match the PG label “Person” with the RDF type foaf:Person.
The Singleton Property Graph model proposed by Nguyen et al. [25] is an abstract graph model that uses the RDF Singleton Property pattern that can be implemented both with a PG and an RDF graph. They also describe how to convert a regular RDF graph or a regular PG into a Singleton Property Graph. But the use of the Singleton Property pattern induces the creation of many different predicates, which hinders the performance of many RDF database systems as shown by Orlandi et al. [26].
From PGs to RDF In terms of PG to RDF conversion, the most impactful work is probably RDF-star [17–20], an extension of the RDF model originally proposed by Olaf Hartig and Bryan Thompson to bridge the gap between PGs and RDF by allowing the use of triples in the composition of other triples. Indeed, the most blatant difficulty when converting PG to RDF is converting the edge properties. However, most PG engines support multi-edges, i.e. two edges of the same type between the two same nodes. On the other hand, the naive approach consisting in using the source node, the type of the edge and the destination node as respectively the subject, the predicate and the object of an RDF triple would collapse the multi-edges. Converting each edge property to an RDF-star triple that uses the former triple as its subject would lead to the properties of each multi-edge to be merged. Khayatbashi et al. [21] study on a larger scale the different mappings described by Hartig and benchmark them. By allowing triples to be used as the subject and the object of other triples, it is possible to emulate the edge properties of PGs. While these mappings allow some kind of user customization, by letting them choosing the used IRIs, they never consider using different model structures for different PG types during the same conversion. For example, consider a PG with two types of edges: one edge type with the “knows” label and one with the “marriedTo” label. The mappings described in this paper do not enable the user to model edges with the “knows” label as a predicate and edges with the “marriedTo” label as a proper RDF resource. To tackle the edge property problem, Das et al. study how to use already existing reification techniques to represent properties [12]: the modelings that do not rely on quads can be used when writing a PRSC context.
Tomaszuk et al. propose the Property Graph Ontology (PGO) [32], an ontology to describe PGs in RDF. As this solution only describes the structure of the PG in RDF, the produced data is forced to use this ontology, with the exception of other already existing RDF ontologies without further transformations. Thanks to the Neosemantics1212 plugin developed by Barrasa, Neo4j is able to benefit from RDF related tools like ontologies, and performs a 2-way conversion from and to RDF-star data. However, the PG to RDF conversion performed by Barrasa tends to affirm all triples it can, even for PG edges that may describe facts with a probability or that are time restricted: if the marriage between Alice and Bob has ended in 2017, the triple :Alice :marriedto :Bob should probably not be produced.
Gremlinator [31] allows users to query a PG and an RDF database by using the SPARQL language. This is a first step towards federated queries. However, it supposes that data stored in the PG and data stored in the RDF graph have a similar modeling, and it does not support RDF-star.
Instead of having a fixed mapping, our work on PREC [10] propose a mapping language named PREC to drive the conversion from PG to RDF. Delva propose RML-star [13], an extension of RML [14] and R2RML [30] that introduces new RML directives to generate RDF-star triples. As discussed in Section 2, the format in which the template triples are described in this work is closer to the produced triples, at the cost of reducing the ability to produce templated IRIs or terms.
To leverage the requirement for users to manually write the mapping, Fathy et al. proposed ProGoMap [15], an engine that first generates a putative ontology for the terms in a PG, aligns this ontology with a real world ontology, and finally converts the PG to an RDF graph with an RML mapping generated from the alignment. The authors motivate the choice of automating the ontology alignment process by mentioning that writing mapping manually can be time-consuming. While this may be true, we do not think that this hinders PRSC usefulness as 1) the schema part of a PRSC context may be generated automatically, and nothing prevents a tool from generating the template triples automatically, 2) a PG schema for which writing template triples is time-consuming may be an indicator that the schema is too complex, and therefore that the structure of the data stored in the PG should be cleaned, not only to make the conversion to RDF easier, but also as a benefit for the PG itself, and 3) while the process of aligning terms of the putative ontologies to terms of real ontologies indeed increase data interoperability, it still relies on the idea that the structure of the PG is somewhat close to the structure of the desired RDF graph. However, in this paper, we advocate that it may not be the case, and that the desired method to model each edge type depends on the semantics of held by each edge type.
In general, to the best of our knowledge, most existing works only tackle the syntactic aspect of converting PG to RDF data. While this level of interoperability is appreciated, it is not enough to be able to properly use the converted data in any existing RDF application without further modification of the RDF graph. Other existing works provide a level of semantic interoperability. However, they tend to choose one of the many syntactic representations of edges that exist, despite RDF ontologies having a great variety of patterns to model knowledge. PRSC gives full control to the user, by letting them choosing both the syntactic representation and use shared vocabularies in the produced RDF graph. The use of PG schemas in PRSC contexts guides users in the process of writing the context. The study on PRSC well-behaved contexts, and the related discussion on their constraints in Section 5.5, provide information on if the PRSC context written by the user leads to a reversible conversion or not, and by consequence, if any information is lost in the process of converting the data stored in the PG into RDF.
From RDF to PGs Abuoda et al. [1] study the different RDF-star to PG approaches and identified two classes: the RDF-topology preserving transformation which converts each term into a PG node, and the PG transformation that converts literals into property values. They also evaluate the performance of these different approaches. The PRSC reversion algorithm, and the general philosophy of this work clearly falls under the latter category. The former can be considered as using a PG database to store RDF data.
Angles et al. [5] discuss different methods to transform an RDF graph into a PG. They propose different mappings, including an RDF-topology preserving one and a PG transformation. Atemezing and Hyunh [6] propose to use a mapping similar to the former to publish and explore RDF data with PG tools, namely Neo4j. However, these works offer little customization for the user.
With G2GML [11], Chiba et al. propose to convert RDF data by using queries: the output of the query is transformed into a PG by describing a template PG, similar to a Cypher insert query. This approach can be considered to be a counterpart of PRSC, but to convert RDF into PG.
PG schemas Finally, the “Property Graph needs a Schema” Working Group propose a formal definition of PG schemas [3]. Some PG engines, like TigerGraph, are based on the use of schemas. For PG engines that do not enforce a schema at creation, like Neo4j or Amazon Neptune, the schema may be extracted from the data, as proposed by Bonifati et al. [8] or Beereen [7]. As PRSC uses schemas for mapping between PGs and RDF graphs, these approaches may be used to automatically list the types existing in the PG to convert i.e. the target of the rule part in Listing 2. Then the user would only have to provide the way to convert these types into RDF, i.e. the template graph part.
7.Conclusion
This work improves interoperability between the two worlds of Property Graphs and RDF graphs. We have presented PRSC, a mapping language to convert PGs into RDF graphs. A mapping, named PRSC context, is written by the user and is driven by a schema: PG elements are converted according to their type. By letting the user configure the conversion, we aim to better integrate PG data into already existing RDF graphs: the produced RDF graphs can be made to use a specific vocabulary, or comply with specific shapes.
We have also proved that some PRSC contexts, named well-behaved PRSC contexts, are reversible: they do not induce any information loss, and therefore it is possible to reverse back to the original PG from the produced RDF graph. Finally, we broaden the realm of reversible contexts with the edge-unique extension. Other existing works focus either on describing a syntactic construction, or providing a semantic construction that relies on a specific syntactic pattern. PRSC lets the user specify the semantics, and proved the reversibility for the two most popular methods to model edges: as an RDF resource in PRSC well-behaved contexts, and as a predicate through the edge-unique extension.
For big PGs, fully converting them into RDF may not scale. For this reason, future works include studying how to use PRSC context not only for PG conversion but also to convert SPARQL queries into the usual PG query languages Cypher and Gremlin. This would not only address the scalability issues, but also avoid data duplication and help for federated queries.
The expressiveness of PRSC contexts could also be extended. As it is currently presented, PRSC contexts are unable to reproduce RDF graphs complying with some ontologies, for example the PG ontology [32]. To solve this issue, PRSC contexts should be able to introduce new blank nodes, and not be limited to the ones in the original PG. This would lead to new challenges, as the presented reversion algorithm relies on the fact that all blank nodes are PG elements.
Other extensions on expressiveness may also be interesting. For examples, types in PRSC contexts are closed, in the sense that a complying element must have exactly the properties of the type, barring any other. Allowing extra properties in elements of the PGs would be useful, but raises the challenge of converting properties that are not known in advance.
To let PG data further benefit from the tools that have been developed around RDF, PRSC could also be explored in two directions. The use of blank nodes for the PG elements may not be suitable in all cases, especially in a linked data context. PRSC could be extended to mint IRIs for nodes and edges of the PG, but this would require to extend the mapping language to be able to express these template IRIs. It would also require an adaptation of the reversion algorithm to be able to differentiate the minted IRIs from the “static” IRIs of the template, which would require additional precautions on well-behaved contexts.
The provided reversion algorithm does not only work for RDF graphs that were produced by PRSC, but can work on any compatible RDF graph. One way to use it would be to use PRSC to convert a PG to an RDF graph, modify the produced RDF graph with RDF-specific tools, e.g. by using a reasoner designed for RDF graphs, and then transform back the RDF graph into a PG, which could be considered as equivalent as using a reasoner on a PG. However, this requires to formally characterize the modifications that can be performed on the RDF triples while maintaining the ability to convert it back to a PG.
Notes
4 PG to RDF: Schema-driven Converter, pronounced “presque”.
6 For the sake of readability, although RDF-star is not yet part of the official RDF recommendation [34], we conflate RDF-star and RDF in this paper. When we mention an RDF triple or an RDF graph, we allow them to contain quoted triples.
7 In practice, our implementation of this paper maps
8 Inserting and searching in a hash map is not strictly speaking a constant time operation but has an amortized constant complexity, and is linear in the worst case.
9 Note that as κ maps to a super set, it may catch false positives. For example, P can only generate elements in
10 To help the comprehension of Algorithm 3, we recall that for a given set A, the mathematical notation
11 Note that if
Appendices
Appendix A.
Appendix A.Proof of projecting and merging back a Property Graph
In this section, we expose the proof for Theorem 5
A.1.Extra mathematical elements
Definition 29
Definition 29(Restriction).
For all functions f, for all sets X,
Remark 16.
The restriction of a function to its domain is equal to the function itself:
Remark 17.
A functional definition of Definition 29 would be, for all functions f,
Lemma 6.
For all functions f, for all sets
Proof.
□
Remark 18.
For all function f, for all sets
Theorem 8.
If the union of the sets
Proof.
□
A.2.Redefinition of the projection
Remark 19.
–
–
–
Proof.
For nodes,
For edges,
The same reasoning applies for
The new definition of
A.3.Proof of Theorem 5
Remark 20.
The property graphs used in the following proof are described with formula. To help readability, for a given PG x, we allow ourselves to use the notation
Proof.
We first need to check if we can apply the ⊕ operator, i.e. if the three conditions of Definition 27 are met:
– When the π function is applied, nodes remain nodes and edges remain edges. The ⊕ operator also conserves this property. As
– The definition of π (restriction of the original function), the definition of ⊕ (union of the functions) and the Lemma 6 (the union of two restriction is a restriction) imply that the
As ⊕ is commutative and associative, we can write the following decomposition:
To prove the theorem, we are going to check if it is true for all functions related to
Edges (
Nodes (
To prove that the last expression above is equal to
Source of the edges (
Destination of the edges (
Properties (
Noticing that:
–
–
Labels (
The value of this function is
From the definition of π applied on
– For
– For all other
It can be concluded that
Conclusion We have demonstrated that
References
[1] | G. Abuoda, D. Dell’Aglio, A. Keen and K. Hose, Transforming RDF-star to Property Graphs: A preliminary analysis of transformation approaches, in: Proceedings of the QuWeDa 2022: 6th Workshop on Storing, Querying and Benchmarking Knowledge Graphs Co-Located with 21st International Semantic Web Conference (ISWC 2022), Hangzhou, China, 23–27 October 2022, M. Saleem and A.N. Ngomo, eds, CEUR Workshop Proceedings, Vol. 3279: , CEUR-WS.org, (2022) , pp. 17–32, https://ceur-ws.org/Vol-3279/paper2.pdf. |
[2] | R. Angles, The property graph database model, in: Proceedings of the 12th Alberto Mendelzon International Workshop on Foundations of Data Management, Cali, Colombia, May 21–25, 2018, D. Olteanu and B. Poblete, eds, CEUR Workshop Proceedings, Vol. 2100: , CEUR-WS.org, (2018) , https://ceur-ws.org/Vol-2100/paper26.pdf. |
[3] | R. Angles, A. Bonifati, S. Dumbrava, G. Fletcher, A. Green, J. Hidders, B. Li, L. Libkin, V. Marsault, W. Martens, F. Murlak, S. Plantikow, O. Savkovic, M. Schmidt, J. Sequeda, S. Staworko, D. Tomaszuk, H. Voigt, D. Vrgoc, M. Wu and D. Zivkovic, PG-schema: Schemas for Property Graphs, Proc. ACM Manag. Data 1: (2) ((2023) ), 198:1–198:25. doi:10.1145/3589778. |
[4] | R. Angles, A. Hogan, O. Lassila, C. Rojas, D. Schwabe, P. Szekely and D. Vrgoč, Multilayer graphs: A unified data model for graph databases, in: Proceedings of the 5th ACM SIGMOD Joint International Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA), GRADES-NDA ’22, Association for Computing Machinery, New York, NY, USA, (2022) . ISBN 9781450393843. doi:10.1145/3534540.3534696. |
[5] | R. Angles, H. Thakkar and D. Tomaszuk, Mapping RDF databases to property graph databases, IEEE Access 8: ((2020) ), 86091–86110. doi:10.1109/ACCESS.2020.2993117. |
[6] | G.A. Atemezing and A. Huynh, Knowledge Graph publication and browsing using Neo4J, in: 1st Workshop on Squaring the Circles on Graphs, SEMANTiCS, Amsterdam, Netherlands, (2021) . |
[7] | N. Beeren, Designing a Visual Tool for Property Graph Schema Extraction and Refinement: An Expert Study, CoRR, (2022) , arXiv:2201.03643. |
[8] | A. Bonifati, S. Dumbrava, E. Martinez, F. Ghasemi, M. Jaffré, P. Luton and T. Pickles, DiscoPG: Property Graph schema discovery and exploration, Proc. VLDB Endow. 15: (12) ((2022) ), 3654–3657, https://www.vldb.org/pvldb/vol15/p3654-bonifati.pdf. doi:10.14778/3554821.3554867. |
[9] | D. Brickley and R. Guha, RDF Schema 1.1, W3C Recommendation, W3C, (2014) , https://www.w3.org/TR/2014/REC-rdf-schema-20140225/. |
[10] | J. Bruyat, P.-A. Champin, L. Médini and F. Laforest, PREC: Semantic translation of property graphs, in: 1st Workshop on Squaring the Circles on Graphs, SEMANTiCS, Amsterdam, Netherlands, (2021) , https://hal.archives-ouvertes.fr/hal-03407785. |
[11] | H. Chiba, R. Yamanaka and S. Matsumoto, G2GML: Graph to graph mapping language for bridging RDF and Property Graphs, in: Proceedings of the ISWC 2020 Demos and Industry Tracks: From Novel Ideas to Industrial Practice Co-Located with 19th International Semantic Web Conference (ISWC 2020), Globally Online, November 1–6, 2020 (UTC), K.L. Taylor, R.S. Gonçalves, F. Lécué and J. Yan, eds, CEUR Workshop Proceedings, Vol. 2721: , CEUR-WS.org, (2020) , pp. 363–368, https://ceur-ws.org/Vol-2721/paper591.pdf. |
[12] | S. Das, J. Srinivasan, M. Perry, E.I. Chong and J. Banerjee, A tale of two graphs: Property Graphs as RDF in Oracle, in: Proceedings of the 17th International Conference on Extending Database Technology, EDBT 2014, Athens, Greece, March 24–28, 2014, S. Amer-Yahia, V. Christophides, A. Kementsietsidis, M.N. Garofalakis, S. Idreos and V. Leroy, eds, OpenProceedings.org, (2014) , pp. 762–773. doi:10.5441/002/EDBT.2014.82. |
[13] | T. Delva, J. Arenas-Guerrero, A. Iglesias-Molina, Ó. Corcho, D. Chaves-Fraga and A. Dimou, RML-star: A declarative mapping language for RDF-star generation, in: Proceedings of the ISWC 2021 Posters, Demos and Industry Tracks: From Novel Ideas to Industrial Practice Co-Located with 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 24–28, 2021, O. Seneviratne, C. Pesquita, J. Sequeda and L. Etcheverry, eds, CEUR Workshop Proceedings, Vol. 2980: , CEUR-WS.org, (2021) , https://ceur-ws.org/Vol-2980/paper374.pdf. |
[14] | A. Dimou, M.V. Sande, P. Colpaert, R. Verborgh, E. Mannens and R.V. de Walle, RML: A generic language for integrated RDF mappings of heterogeneous data, in: Proceedings of the Workshop on Linked Data on the Web Co-Located with the 23rd International World Wide Web Conference (WWW 2014), Seoul, Korea, April 8, 2014, C. Bizer, T. Heath, S. Auer and T. Berners-Lee, eds, CEUR Workshop Proceedings, Vol. 1184: , CEUR-WS.org, (2014) , https://ceur-ws.org/Vol-1184/ldow2014_paper_01.pdf. |
[15] | N. Fathy, W. Gad, N. Badr and M. Hashem, ProGOMap: Automatic generation of mappings from Property Graphs to ontologies, IEEE Access 9: ((2021) ), 113100–113116. doi:10.1109/ACCESS.2021.3104293. |
[16] | N. Francis, A. Green, P. Guagliardo, L. Libkin, T. Lindaaker, V. Marsault, S. Plantikow, M. Rydberg, P. Selmer and A. Taylor, Cypher: An evolving query language for Property Graphs, in: Proceedings of the 2018 International Conference on Management of Data, SIGMOD ’18, Association for Computing Machinery, New York, NY, USA, (2018) , pp. 1433–1445. ISBN 9781450347037. doi:10.1145/3183713.3190657. |
[17] | O. Hartig, Foundations of RDF⋆ and SPARQL⋆ (an alternative approach to statement-level metadata in RDF), in: Proceedings of the 11th Alberto Mendelzon International Workshop on Foundations of Data Management and the Web, Montevideo, Uruguay, June 7–9, 2017, J.L. Reutter and D. Srivastava, eds, CEUR Workshop Proceedings, Vol. 1912: , CEUR-WS.org, (2017) , https://ceur-ws.org/Vol-1912/paper12.pdf. |
[18] | O. Hartig, Foundations to query labeled Property Graphs using SPARQL, in: Joint Proceedings of the 1st International Workshop on Semantics for Transport and the 1st International Workshop on Approaches for Making Data Interoperable Co-Located with 15th Semantics Conference (SEMANTiCS 2019), Karlsruhe, Germany, September 9, 2019, L. Kaffee, K.M. Endris, M. Vidal, M. Comerio, M. Sadeghi, D. Chaves-Fraga and P. Colpaert, eds, CEUR Workshop Proceedings, Vol. 2447: , CEUR-WS.org, (2019) , https://ceur-ws.org/Vol-2447/paper3.pdf. |
[19] | O. Hartig, P.-A. Champin, G. Kellogg and A. Seaborne, RDF-star and SPARQL-star, W3C Community Group Report, (2021) , https://www.w3.org/2021/12/rdf-star.html. |
[20] | O. Hartig and B. Thompson, Foundations of an alternative approach to reification in RDF, (2014) , arXiv preprint arXiv:1406.3399. |
[21] | S. Khayatbashi, S. Ferrada and O. Hartig, Converting property graphs to RDF: A preliminary study of the practical impact of different mappings, in: GRADES-NDA ’22: Proceedings of the 5th ACM SIGMOD Joint International Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA), Philadelphia, Pennsylvania, USA, 12 June 2022, V. Kalavri and S. Salihoglu, eds, ACM, (2022) , pp. 10:1–10:9. doi:10.1145/3534540.3534695. |
[22] | D. Kontokostas and H. Knublauch, Shapes Constraint Language (SHACL), W3C Recommendation, W3C, (2017) , https://www.w3.org/TR/2017/REC-shacl-20170720/. |
[23] | O. Lassila, M. Schmidt, O. Hartig, B. Bebee, D. Bechberger, W. Broekema, A. Khandelwal, K. Lawrence, C. López-Enríquez, R. Sharda and B.B. Thompson, The OneGraph vision: Challenges of breaking the graph model lock-in, Semantic Web 14: (1) ((2023) ), 125–134. doi:10.3233/SW-223273. |
[24] | D.L. McGuinness, F. Van Harmelen et al., OWL web ontology language overview, W3C recommendation 10: (10), (2004) , 2004. |
[25] | V. Nguyen, H.Y. Yip, H. Thakkar, Q. Li, E. Bolton and O. Bodenreider, Singleton Property Graph: Adding a Semantic Web abstraction layer to graph databases, in: Proceedings of the Blockchain Enabled Semantic Web Workshop (BlockSW) and Contextualized Knowledge Graphs (CKG) Workshop Co-Located with the 18th International Semantic Web Conference, BlockSW/CKG@ISWC 2019, Auckland, New Zealand, October 27, 2019, R. Samavi, M.P. Consens, S. Khatchadourian, V. Nguyen, A.P. Sheth, J.M. Giménez-García and H. Thakkar, eds, CEUR Workshop Proceedings, Vol. 2599: , CEUR-WS.org, (2019) , https://ceur-ws.org/Vol-2599/CKG2019_paper_4.pdf. |
[26] | F. Orlandi, D. Graux and D. O’Sullivan, Benchmarking RDF metadata representations: Reification, singleton property and RDF, in: 15th IEEE International Conference on Semantic Computing, ICSC 2021, Laguna Hills, CA, USA, January 27–29, 2021, IEEE, (2021) , pp. 233–240. doi:10.1109/ICSC50631.2021.00049. |
[27] | E. Prud’hommeaux and G. Carothers, RDF 1.1 Turtle, W3C Recommendation, W3C, (2014) , https://www.w3.org/TR/2014/REC-turtle-20140225/. |
[28] | M.A. Rodriguez, The Gremlin graph traversal machine and language (invited talk), in: Proceedings of the 15th Symposium on Database Programming Languages, DBPL 2015, Association for Computing Machinery, New York, NY, USA, (2015) , pp. 1–10. ISBN 9781450339025. doi:10.1145/2815072.2815073. |
[29] | M. Sporny, G. Kellogg and M. Lanthaler, JSON-LD 1.0, W3C Recommendation, W3C, (2014) , https://www.w3.org/TR/2014/REC-json-ld-20140116/. |
[30] | S. Sundara, S. Das and R. Cyganiak, R2RML: RDB to RDF Mapping Language, W3C Recommendation, W3C, (2012) , https://www.w3.org/TR/2012/REC-r2rml-20120927/. |
[31] | H. Thakkar, D. Punjani, J. Lehmann and S. Auer, Two for one: Querying property graph databases using SPARQL via gremlinator, in: Proceedings of the 1st ACM SIGMOD Joint International Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA), Houston, TX, USA, June 10, 2018, A. Arora, A. Bhattacharya, G.H.L. Fletcher, J.L. Larriba-Pey, S. Roy and R. West, eds, ACM, (2018) , pp. 12:1–12:5. doi:10.1145/3210259.3210271. |
[32] | D. Tomaszuk, R. Angles and H. Thakkar, PGO: Describing property graphs in RDF, IEEE Access 8: ((2020) ), 118355–118369. doi:10.1109/ACCESS.2020.3002018. |
[33] | O. van Rest, S. Hong, J. Kim, X. Meng and H. Chafi, PGQL: A property graph query language, in: Proceedings of the Fourth International Workshop on Graph Data Management Experiences and Systems, GRADES ’16, Association for Computing Machinery, New York, NY, USA, (2016) . ISBN 9781450347808. doi:10.1145/2960414.2960421. |
[34] | D. Wood, M. Lanthaler and R. Cyganiak, RDF 1.1 Concepts and Abstract Syntax, W3C Recommendation, W3C, (2014) , https://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/. |
[35] | R. Zhang, P. Liu, X. Guo, S. Li and X. Wang, A unified relational storage scheme for RDF and Property Graphs, in: Web Information Systems and Applications, W. Ni, X. Wang, W. Song and Y. Li, eds, Springer International Publishing, Cham, (2019) , pp. 418–429. ISBN 978-3-030-30952-7. doi:10.1007/978-3-030-30952-7_41. |


