
Resilient edge machine learning in smart city environments
Abstract
Distributed Machine Learning (DML) has emerged as a disruptive technology that enables the execution of Machine Learning (ML) and Deep Learning (DL) algorithms in proximity to data generation, facilitating predictive analytics services in Smart City environments. However, the real-time analysis of data generated by Smart City Edge Devices (EDs) poses significant challenges. Concept drift, where the statistical properties of data streams change over time, leads to degraded prediction performance. Moreover, the reliability of each computing node directly impacts the availability of DML systems, making them vulnerable to node failures. To address these challenges, we propose a resilience framework comprising computationally lightweight maintenance strategies that ensure continuous quality of service and availability in DML applications. We conducted a comprehensive experimental evaluation using real datasets, assessing the effectiveness and efficiency of our resilience maintenance strategies across three different scenarios. Our findings demonstrate the significance and practicality of our framework in sustaining predictive performance in smart city edge learning environments. Specifically, our enhanced model exhibited increased generalizability when confronted with concept drift. Furthermore, we achieved a substantial reduction in the amount of data transmitted over the network during the maintenance of the enhanced models, while balancing the trade-off between the quality of analytics and inter-node data communication cost.
1.Introduction
In recent years, the field of Internet of Things (IoT) has seen tremendous growth and development, primarily driven by the rapid advancements in sensor technology. This has allowed physical devices to be interconnected on a massive scale, forming a vast network infrastructure [27]. The exponential growth in data generation has posed significant challenges for traditional cloud computing models. As data volumes have soared to unprecedented levels, the conventional approach of transferring all data to the cloud for processing has proved to be inadequate [30]. This has resulted in a failure to meet the critical requirements of many systems such as low latency. Consequently, demand has been raised for driving computation to the edge, shifting the data processing from the cloud closer to the user, the nodes, and introducing the computation paradigm of Edge Computing (EC).
The birth of EC aimed to enhance the quality of service of IoT applications, by fully utilizing their computational power, since data storage and transfer to the cloud would consume an excessive amount of computational space and power. Thereby, meeting the low-latency requirements of modern applications, while protecting end-users’ privacy, minimizing data transmission and network bandwidth load as well as alleviating the energy consumption of the network. Nevertheless, EC is not a panacea for the incapabilities of cloud computing. The limited computing resources and storage of the distributed Edge Nodes (ENs) make them vulnerable to attacks introducing security issues and widening the available spectrum for the attackers.
Nowadays, EC applications have proliferated across diverse sectors, spanning an array of domains including healthcare [1], agriculture monitoring [4], energy prediction systems [18] and bike-demand forecasting [29], among others. These applications collectively fall under the expansive umbrella of smart city applications. By 2012, around 143 smart cities has adopted innovative technologies in addressing urban challenges, driven by the need to accommodate urbanization demands and leverage emerging technologies, thereby establishing robust infrastructures capable of supporting novel services [21].
The predictive analytics tasks of these applications are critical aspects and play a crucial role in their success. A majority of these applications are designed to operate in real-time, requiring rapid data processing and providing accurate results. This highlights the importance of EC in various fields and its potential to revolutionize how data is processed and analyzed. Given the intricate and ever-changing characteristics of contemporary applications, it is vital to establish a DML infrastructure to effectively monitor the system and execute predictive operations. The integration of ML with distributed EDs is motivated by several key factors, including the computational and storage limitations of these devices and the associated data privacy and security concerns that arise as a result. These challenges are driving the need for a new paradigm in which ML algorithms are executed and trained locally on EDs, rather than in centralized data centers. DML systems allow for local data processing, reducing inter-node data transmission and mitigating privacy and security risks. Subsequently, they enable real-time processing of data and the deployment of ML algorithms closer to the source of the data, leading to improved response times and increased reliability, making it an increasingly attractive solution for a wide range of applications.
Nonetheless, the proliferation of IoT applications as previously mentioned has led to a significant increase in their attractiveness as targets for malicious attacks [5]. As a result, these systems are highly vulnerable to the consequences of node failures, which can severely impact their performance, reliability and availability. Furthermore, the requirements for real-time data analysis and prediction services in dynamic environments pose a significant maintainability challenge due to the occurrence of concept drift [26]. Concept drift refers to the alternations in the distribution of the incoming data as a result of shifts in trends and patterns over time. This presents a significant obstacle in ensuring the accuracy and consistency of predictions made by the ML models. With ML models designed to learn the concept of a stationary dataset, over time, the distribution of the new incoming data can deviate from that of the original training data, adversely impacting the performance of the models. To effectively address this issue, it is crucial to first detect the concept drift, comprehend its characteristics and then adapt the models accordingly. With our focus lying specifically on the maintainability and adaption of the ML models in the presence of concept drifts, we seek to address these challenges and facilitate the successful deployment of DML systems, while enhancing their security and reliability.
The spatial and temporal variations observed among the nodes in a DML system give rise to diverse statistical characteristics in their respective data. Consequently, the local ML model implemented at each node, trained exclusively on local data, fails to provide adequate support in the event of an attack on the node. This limitation arises due to the local ML model’s performance being optimized solely for high predictability services when applied to its own local data, rendering it insufficiently generalized for data originating from other nodes. Consequently, the accuracy of a node’s local model may vary depending on the specific data it is employed on. To overcome this challenge and account for the heterogeneity of data across nodes, we propose the development of enhanced models on each edge component that are sufficiently generalized. These models are trained using data influenced by both the local and adjacent ENs. Our approach incorporates the principles of federated compressed learning, which encompasses techniques such as model and data compression, joint learning, communication efficiency and secure data exchange.
This research proposes a resilience framework for DML environments that addresses node failures and concept drifts. In order to account for the heterogeneity of data across nodes, the framework proposes the development of generalized enhanced models on each edge component. These enhanced models are trained on data influenced by the local and adjacent ENs, and are designed to enhance the availability and quality of service in the event of node failure. To further enhance model resilience in the face of concept drift, the proposed framework introduces several maintenance strategies. These strategies aim to reduce the cost of model maintenance by minimizing inter-node data transmission. Our findings demonstrate that these maintenance strategies help sustain the availability and quality of service in DML environments during node failure and concept drift. Furthermore, the proposed framework achieves comparable or superior predictability performance compared to the baseline solution, offering significant cost savings in model maintenance.
To the best of our knowledge, we are among the first to investigate the interactions between enhanced models and concept drifts fusing the principles of DML to achieve efficient yet effective and secure data transmission across ENs. We summarize our contributions as follows:
A novel and systematic approach that expands the generalizability and predictability capabilities of our models, facilitating collaborative learning.
Novel and lightweight (computation and communication efficient) strategies for the construction of the enhanced models suitable for regression, multivariate and image classification predictive tasks.
We provide a theoretical analysis of different concept drift types and their applications on real-world datasets and examine their effects on the performances of our models.
We perform a comprehensive evaluation and comparative assessment of our proposed strategies against baseline models using three real datasets.
The remainder of the paper is structured as follows: Section 2 reports on the related work, Section 3 elaborates on the problem formulation, Section 4 introduces our maintenance strategies, Section 5 reports on the performance evaluation and comparative assessment of our paradigm under three experimental scenarios using real datasets and Section 6 concludes the paper with a summary and our future research agenda.
2.Related work
Firstly introduced by [22], concept drift has been initially investigated as a means to highlight how current noisy data could become helpful information in future instances. Since then, the field has undergone significant development and can be categorized into three primary stages: detection, understanding and adaption [16].
As the first step in the pipeline, detecting concept drift is a crucial component in ensuring that predictive models remain accurate and reliable over time. Concept drift detection can be categorized based on the test statistics they utilize into three main categories. The largest category, error rate-based drift detection, measures changes in the performance of predictive models over time. Proposed by [10], the Drift Detection Method (DDM), is one of the earliest and simplest concept drift detection algorithms. DDM evaluates new data instances and determines the error rate of the predictive model over a specified time window compared to the previous timeframe. The algorithm operates at two levels of detection: warning and drift. Once the warning level is reached, new predictive models are built. When the confidence level reaches the drift level, the existing models are replaced with the models trained over the warning level. Several extensions of the DDM algorithm have been proposed such as Learning with Local Drift Detection (LLDD) [9], Heoffing’s inequality-based Drift Detection Method (HDDM) [8] and Dynamic Extreme Learning Machine (DELM) [28]. LLDD uses a plurality of node-based decision trees for concept drift detection; HDDM extends the hypothesis testing part of the algorithm by using Hoeffding’s inequality to determine the drift region and DELM incorporates a hidden layer neural network base learner, targeting the enhancement of the adaption phase.
Data Distribution-based Drift Detection and Multiple Hypothesis Test Drift Detection form the last two categories of the detection phase methods. In the former category, distance metrics are used to measure the dissimilarity between the distribution of new incoming data and historical data. If the dissimilarity is statistically significant, a new concept is detected. This category provides additional information about the location of the drift, making it attractive for various distribution-based detection methods such as Information-Theoretic Approach (ITA) [13] and PCA-based change detection framework (PCA-CD) [20]. ITA uses a kdqTree partition method to cluster both the historical and new data, while Kullback–Leibler divergence is applied to determine density difference. PCA-CD, on the other hand, employs principal component analysis to facilitate density estimation, reducing computational costs. The final category of concept drift detection methods is hypotheses-based detection, which uses multiple hypotheses to determine concept drift. Hierarchical Hypothesis Testing with Attribute-wise “Goodness-of-fit” (HHT-AG) [31] is one of the most evolved methods in this category. HHT-AG is capable of handling concept drift with fewer true labels, making it more robust in the face of high verification latency.
Concept drift understanding refers to the ability of the drift detection algorithm to determine when, how and where the concept drift occurs. In addition to identifying the time of occurrence of concept drift, density-based algorithms can also provide information on its severity and drift regions with a few exceptions. As a result, all of this information will be used later in the adaptation phase to help us achieve it as easily and efficiently as possible. Firstly, by incorporating the information on the start time and the duration of the concept drift we aid the adaption process by identifying the drift type. The algorithm’s timestamp will, however, be delayed compared to the actual one due to its requirement that a minimum number of new data must be collected before evaluating the drift. Therefore, it is still unclear when the new concept emerges. The detected timestamp of the drift can be controlled by some algorithms based on the sensitivity chosen, with the warning level set a little lower than the drift level. Typically, a p-value of
The severity of the concept drift, or else, the similarity between the old and new concepts, can also be taken into consideration when selecting appropriate adaption methods. In less severe cases, incremental learning may be sufficient to adjust the model, while highly severe drifts require the retraining of the model from scratch. Although severity cannot be directly measured using error-based detection algorithms, it can be indirectly counted by comparing the rate of change of the overall accuracy
Since our work relies upon preserving the model performance in the face of concept drift, we concentrate on concept drift adaption and resilience maintenance. Drift adaptation refers to strategies aimed at updating predictive models by incorporating information gained during the detection and understanding phases. However, existing research in this domain has limitations, with approaches targeting specific models and concatenating the detection and adaptation phases, limiting the flexibility of the proposed approaches and making them problematic to apply as extensions to individual components. Proposed by [2], Paired Learners is an example of an adaption method that entails training new models from scratch. This approach uses two models, the stable learner, which is trained over all historical data, and the reactive learner, which predicts based on the latest data. Upon the presence of a new concept, the performance of the stable learner will drop indicating a concept drift, with the reactive learner taking the place of the stable learner. Another approach,
In conclusion, the current state of the literature surrounding data transmission and maintenance issues does not offer solutions that are sufficiently generalizable. This research aims to address this gap by proposing a resilience mechanism composed of several strategies for maintaining enhanced models while considering the distributed nature of the edge environment. Additionally, we investigate the trade-off between the amount of data transmission and the potential performance loss, with the goal of minimizing network data transmission costs while preserving user privacy and ensuring that the performance of enhanced models remains uncompromised.
3.Problem definition
Our study is a natural extension of the research presented in [24] by Wang et al. In particular, our work expands upon their findings by delving into the regression, multivariate classification and image classification aspects of the DML systems. We seek to evaluate the effectiveness of statistical learning, dimensionality reduction, compression, and DL techniques in enhancing the performance of our models. In addition, we also examine the impact of these techniques on the maintainability of our models in concept drift scenarios. Specifically, we aim to assess the degree to which these techniques can help to mitigate the adverse effects of concept drift and enhance the overall robustness of our models over time.
Fig. 1.
DML system diagram in a smart city edge computing environment.
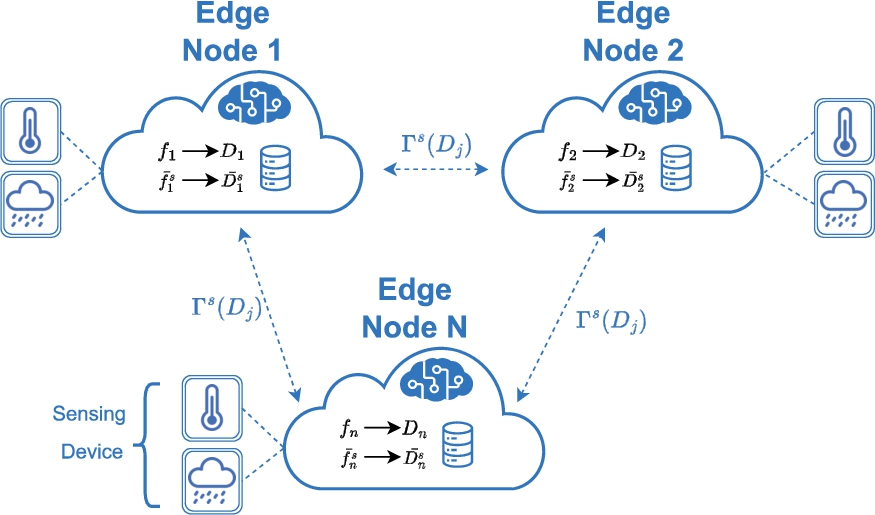
Consider a DML environment depicted in Fig. 1 that comprises n nodes, denoted as
Enhanced Models are firstly introduced in [25], that is, for each node
In the context of an enhanced predictive model
Problem 1.
We examine how the severity of concept drifts affects the performances of the enhanced models.
Specifically, we aim to assess the effectiveness of enhanced models in handling concept drifts and compare their performances against baseline and local models. Our focus lies on evaluating the impact of introducing a new concept on enhanced model performance, rather than on detecting or understanding concept drifts more generally. To this end, we will simulate abrupt concept drifts, which involve sudden changes in the underlying data distribution, making the effects of concept drift more readily observable. We have identified three distinct types of concept drift simulations, each defined by the relationship between input-output pairs from the original distribution (x and y) and those from the drifted distribution (
Virtual:
Actual:
Total:
Problem 2.
We seek maintenance strategies that can be used to extract information from novel concepts and maintain enhanced models in the event of concept drift.
Consider a DML environment with two nodes, denoted as
4.Maintenance strategies
In this research paper, we present a maintenance approach for our enhanced models, where we leverage the drifted data along a selected strategy to extract information that is used to retrain the enhanced model. We propose different maintenance strategies that can be employed depending on the dataset and predictive tasks performed by the DML system. Our framework comprises strategies that are applicable to regression, multivariate classification, and image classification predictive tasks.
For regression tasks, we adopt on statistical learning approaches, such as clustering, to extract statistics about the underlying data distribution, thereby reducing the number of instances transmitted. For multivariate classification, we primarily rely on dimensionality reduction and compression techniques to transmit the compressed form of the drifted data to the target node, which is then decompressed. Finally, for image classification tasks, we leverage a DL technique to capture the intricate characteristics of computer vision applications.
It is important to note that for all predictive tasks, a baseline (BS) approach exists that involves transmitting raw data over the network. However, this approach violates security constraints and significantly increases the network bandwidth. Our proposed maintenance strategies address these issues and aim to optimize the performance of the DML system while ensuring data security and minimizing network resource utilization. Experimental results demonstrate the effectiveness of our approach in achieving these objectives.
Centroid Guided (CG): The CG approach involves partitioning the input space
Enhanced Centroid Guided (ECG): The ECG approach builds upon CG strategy. It starts by partitioning the data space into K clusters and then transfers the resulting cluster centroids
Mock Data (MD): The MD approach is a novel strategy that avoids any data transfer to the target node
Principal Component Analysis (PCA): Our proposed approach employs PCA to reduce the dimensionality of the input space
Discrete Cosine Transformation (DCT): Widely used by JPEG as a lossy image compression technique, DCT is utilised as an efficient way of storing our data space
Our transformation technique does not reduce the number of bits required to represent the data. However, it concentrates the low-frequency coefficients, while setting the other coefficients to zero. When considering an
Conditional Variational AutoEncoder (CVAE): It is an enhanced version of the standard Variational AutoEncoder (VAE) that enables the generation of samples conditioned on supplementary input data. The architecture of the CVAE, depicted in Fig. 2, comprises an encoder network, a decoder network, and a latent space.
Fig. 2.
CVAE architecture.
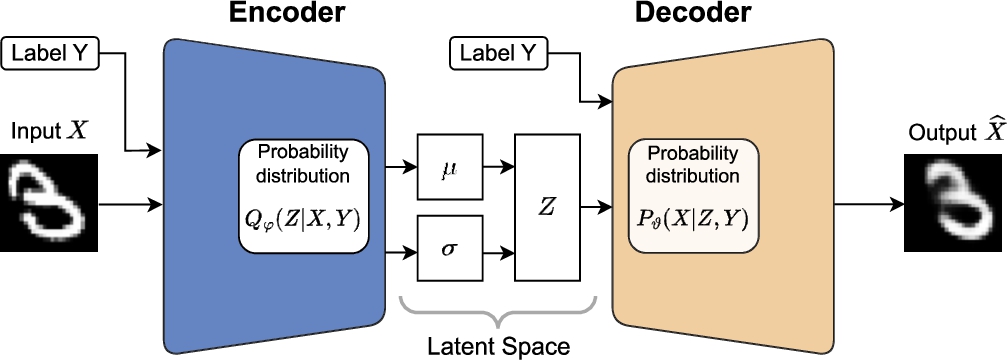
The encoder network takes an input sample X and a conditioning label Y and maps them to the latent vector Z. More specifically, the encoder maps the input data X and the condition label Y to the latent vector Z that follows Gaussian distribution with mean μ and variance σ learned from the input. To achieve this, the encoder output is split into two parts, the mean μ and the variance σ of the Gaussian distribution, which are then used to sample the latent space from the Gaussian distribution. The sampling process introduces stochasticity into the model and helps capture the variations in the data. Formally, let X be the input data and Y be the condition. The encoder maps the input
The decoder then maps the latent code Z and the condition Y to a distribution over the data space, which is also modeled as a Gaussian distribution with mean and variance:
During training, the loss function is the negative log-likelihood of the data, which is approximated using the evidence lower bound (ELBO) objective:
5.Experimental evaluation
Our objective is to investigate Problem 1 by examining varying levels of concept drifts and their impact on enhanced models’ performance, and the efficacy of the proposed maintenance strategies in addressing Problem 2. To assess our paradigm, we established three experimental scenarios using real datasets in DML environments.
5.1.Performance metrics
We assess our methods with respect to two categories of performance metrics for accuracy and network throughout. For the former, we utilize two metrics acknowledged in the literature: Accuracy and Root Mean Squared Error (RMSE) for classification and regression predictive tasks, respectively. RMSE measures the square root of the mean of the squared difference between the actual
5.2.Descriptions of the scenarios
We report on the descriptions of the experimentation scenarios, the concept drift simulation and the experimental setup to assess the performance of the proposed framework.
5.2.1.Experimental Scenario I: Regression
Dataset Description: We evaluated our regression scenario upon the real GNFUV multi-node dataset11 adopted by Harth and Anagnostopoulos [11]. The dataset consists of mobile sensors readings over four Unmanned Surface Vehicles (USVs), floating over the sea surface in a testbed in Athens, Greece. Each USV (node) records the measurements such as humidity and temperature of the sea surface, each of which represents an ED within a DML environment. For our experiments, the local data gathered by two of the USVs are employed notated by
Simulating Concept Drift: We simulated concept drift in a controlled manner to one of our nodes by employing the three drift types on
Experiment Setup: We conduct experiments by building local
Fig. 3.
Distributions of the GNFUV drifted nodes.
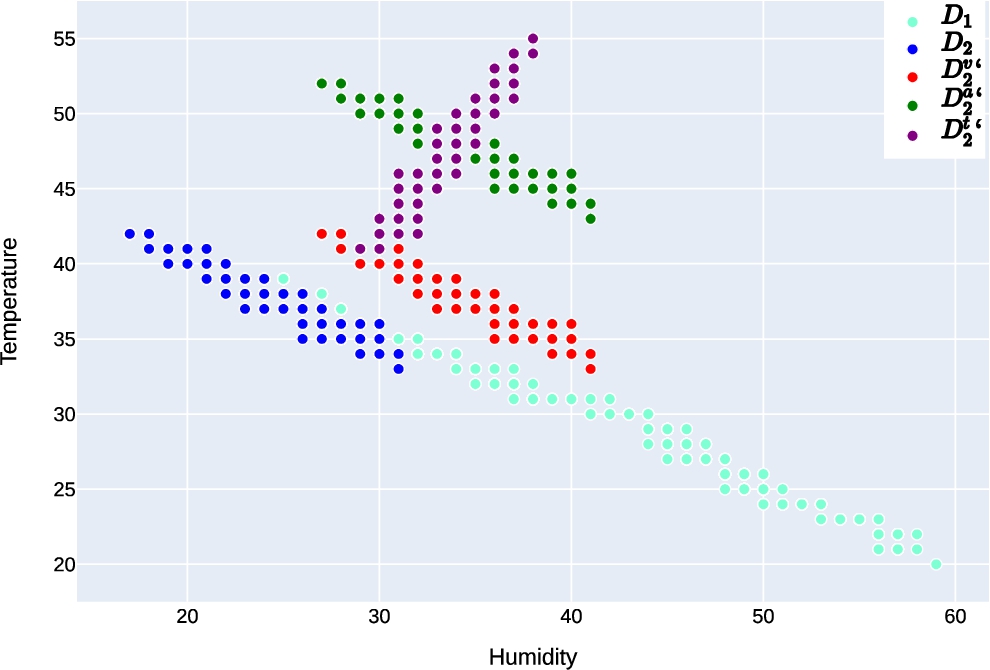
5.2.2.Experimental Scenario II: Multivariate classification
Dataset Description: We also delve into the performance of our resilience framework using the Banknote Authentication (BA) real dataset22 taken from UCI machine learning repository. The present scenario employs a binary classification dataset, consisting of 1372 instances, comprised of image-extracted data from genuine and forged banknote-like specimens. The dataset contains five attributes, with four features and one target attribute and a balanced class distribution ratio of 55:45. In contrast to the GNFUV dataset, the current dataset, lacks an inherent network-node structure. Therefore, the K-means clustering was utilized to construct two nodes. The resulting clusters were designated as
Simulating Concept Drift: We simulated concept drifts on
Experimental Setup: Our classification models are constructed using the Gaussian Naive Bayes (GaussianNB) algorithm, along with the CG, PCA, and DCT strategies. Upon investigation of the effect of the severity of the concept drift, we update our models to reflect the drifted data
Fig. 4.
Clustered BA dataset projected to 3 PCs.
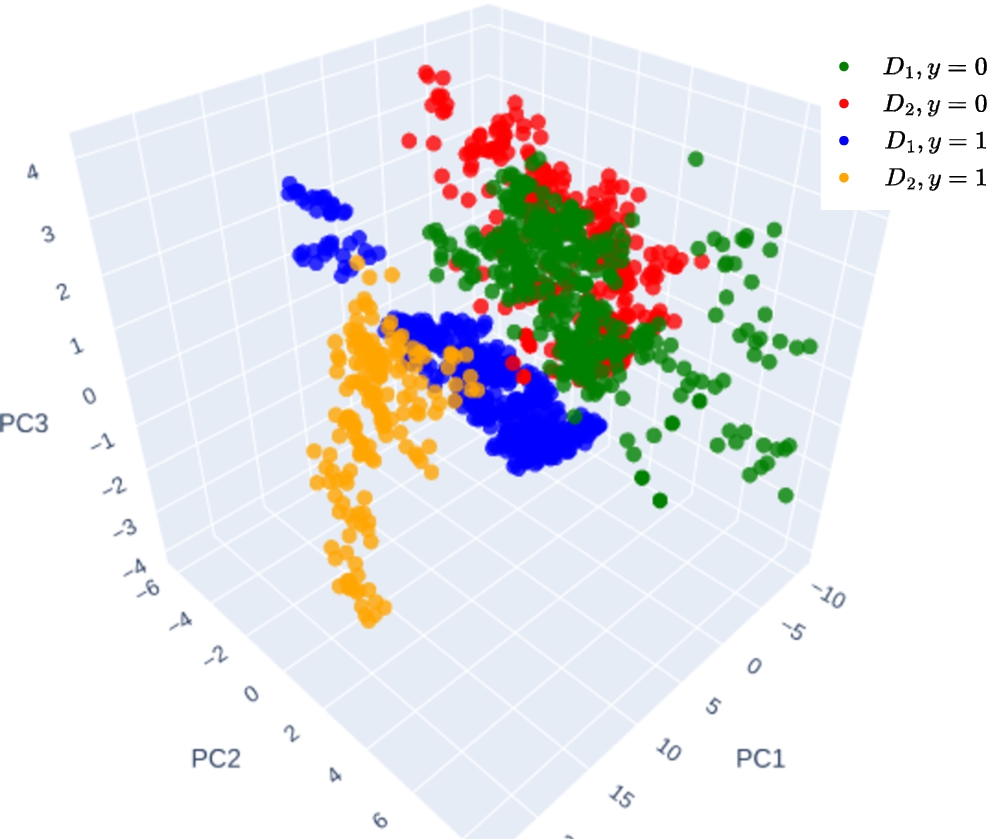
5.2.3.Experimental Scenario III: Image classification
Dataset Description: In order to investigate the applicability of our framework in more intricate tasks, we conduct an analysis on a Computer Vision classification task using the MNIST dataset33 introduced by LeCun et al. [14]. The dataset contains a set of 70,000
Simulating Concept Drift: In the current scenario, we simulated concept drift by employing the Virtual drift type to alternate
Experimental Setup: We used a Multi-Layer Perception (MLP) classifier consisting of three linear layers and ReLU activations functions. This allowed us to learn complex non-linear relationships between the input features
The experimental procedure for the training of the enhanced models consisted of four steps: (i) training a CVAE model
Fig. 5.
MNIST images with a label value of 5.

In cases where concept drift is detected, a new CVAE model
5.3.Comparative assessment
5.3.1.Concept drift effects on enhanced models
We first analyze the effect of concept drift on the efficacy of enhanced models, as well as its correlation with local models. Furthermore, we seek to delve deeper into this impact and its relationship with the strategies employed in constructing the enhanced models. Through this analysis, we aim to provide valuable insights into the nuances of concept drift and its implications for model performance.
Scenario I: To examine the impact of concept drifts on the performance of the enhanced model, we conducted experiments by combining the original
The outcomes of the study in Scenario I reveal the mean RMSE performance of the local and enhanced models for each concept drift type, as indicated in Table 1. Additionally, Fig. 6 showcases the performances of
Table 1
Scenario I mean models’ performance by drift
| RMSE | ||||
| Model | ||||
Fig. 6.
Performance of
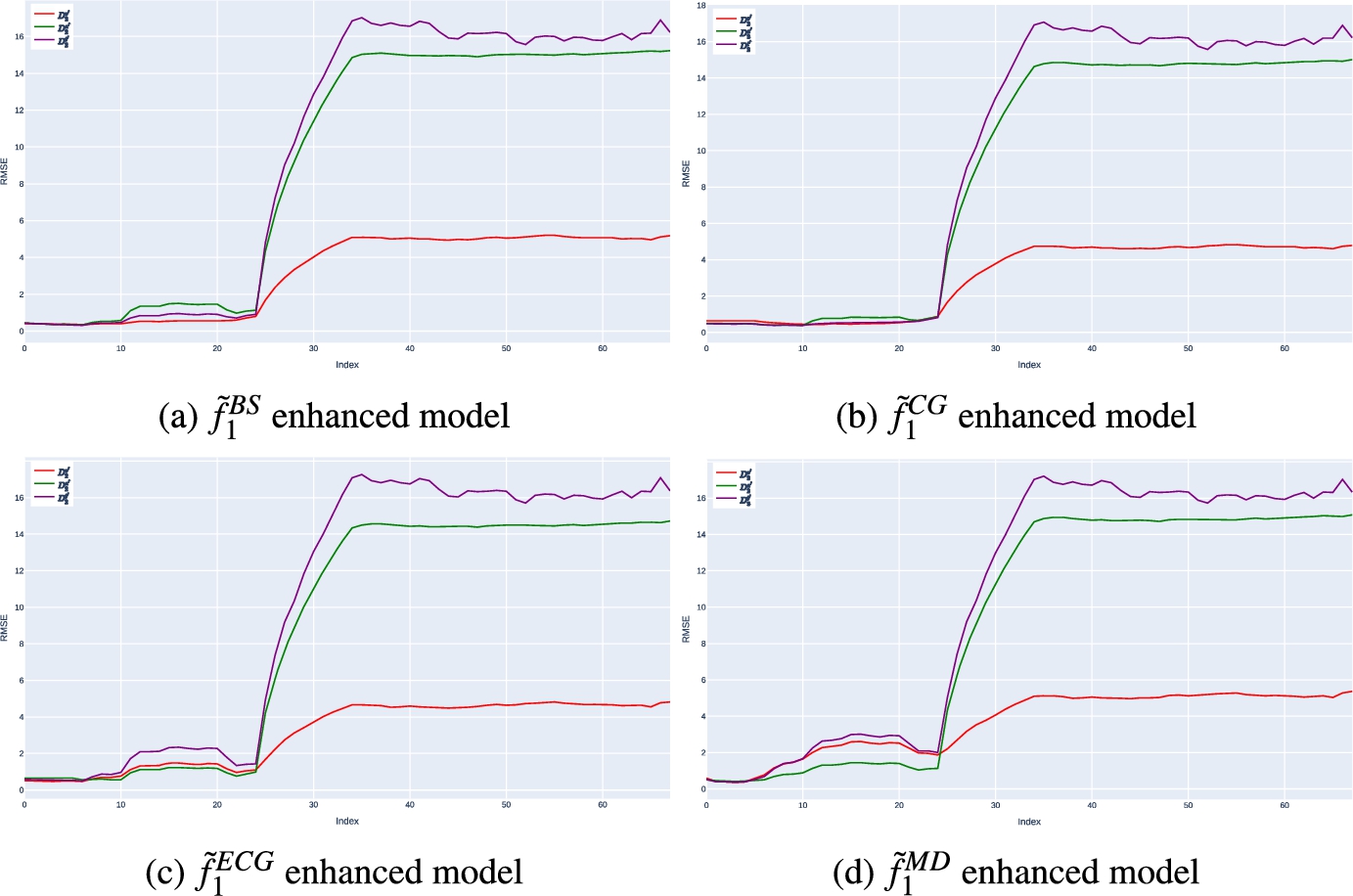
The analysis of the results presented in Table 1 reveals that the local model
Furthermore, it is worth noting that the strategies employed to construct the enhanced models do not appear to have a significant impact on the effect of concept drift, as evidenced in Fig. 6, where all the enhanced models exhibit similar trends and patterns. Moreover, the experimental findings indicate that
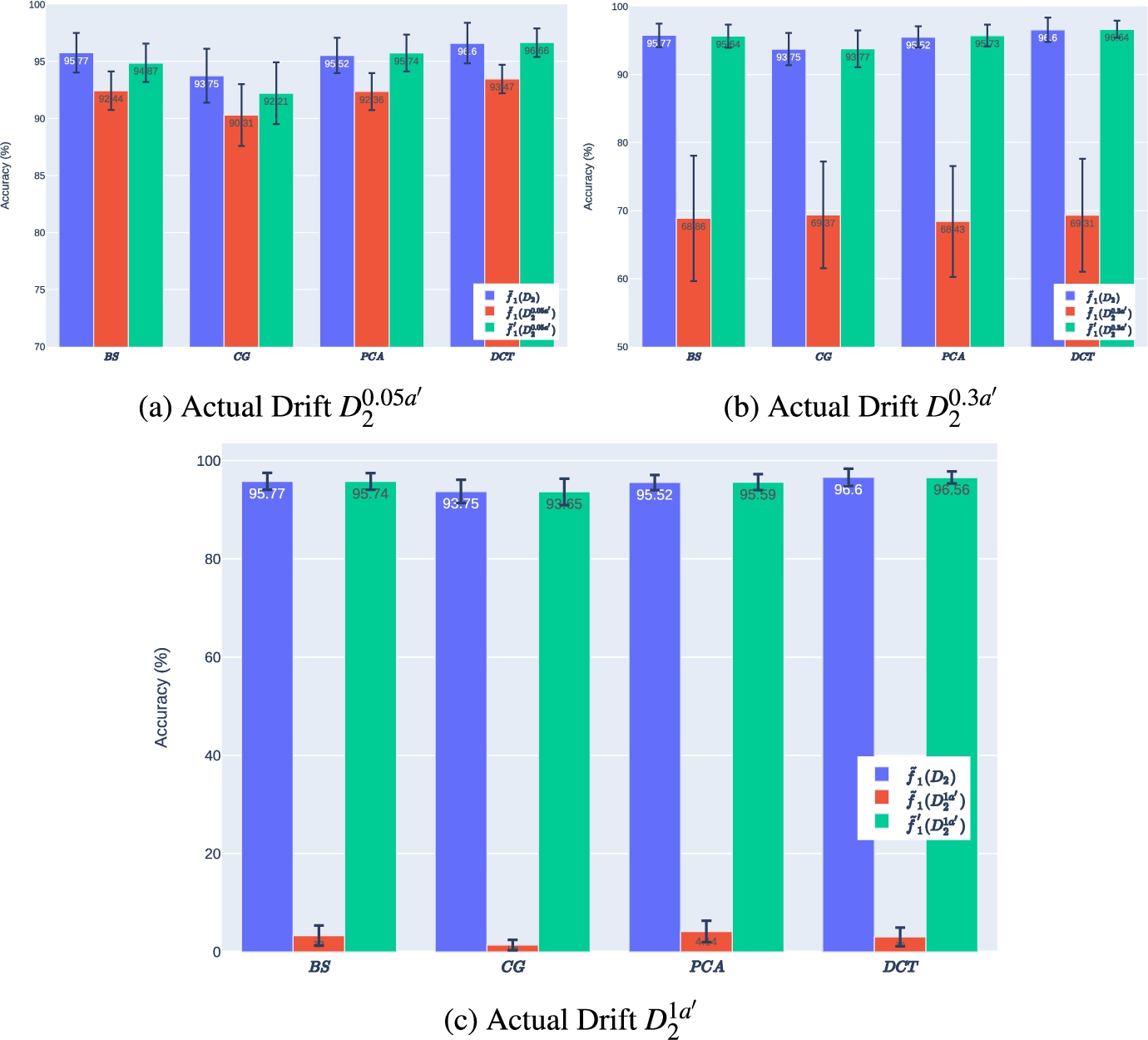
Scenario II: In this study, we conducted multivariate classification using the distribution
Table 2
Scenario II mean models’ performance by drift
| Accuracy (%) | ||||
| Model | ||||
Fig. 7.
Performance of
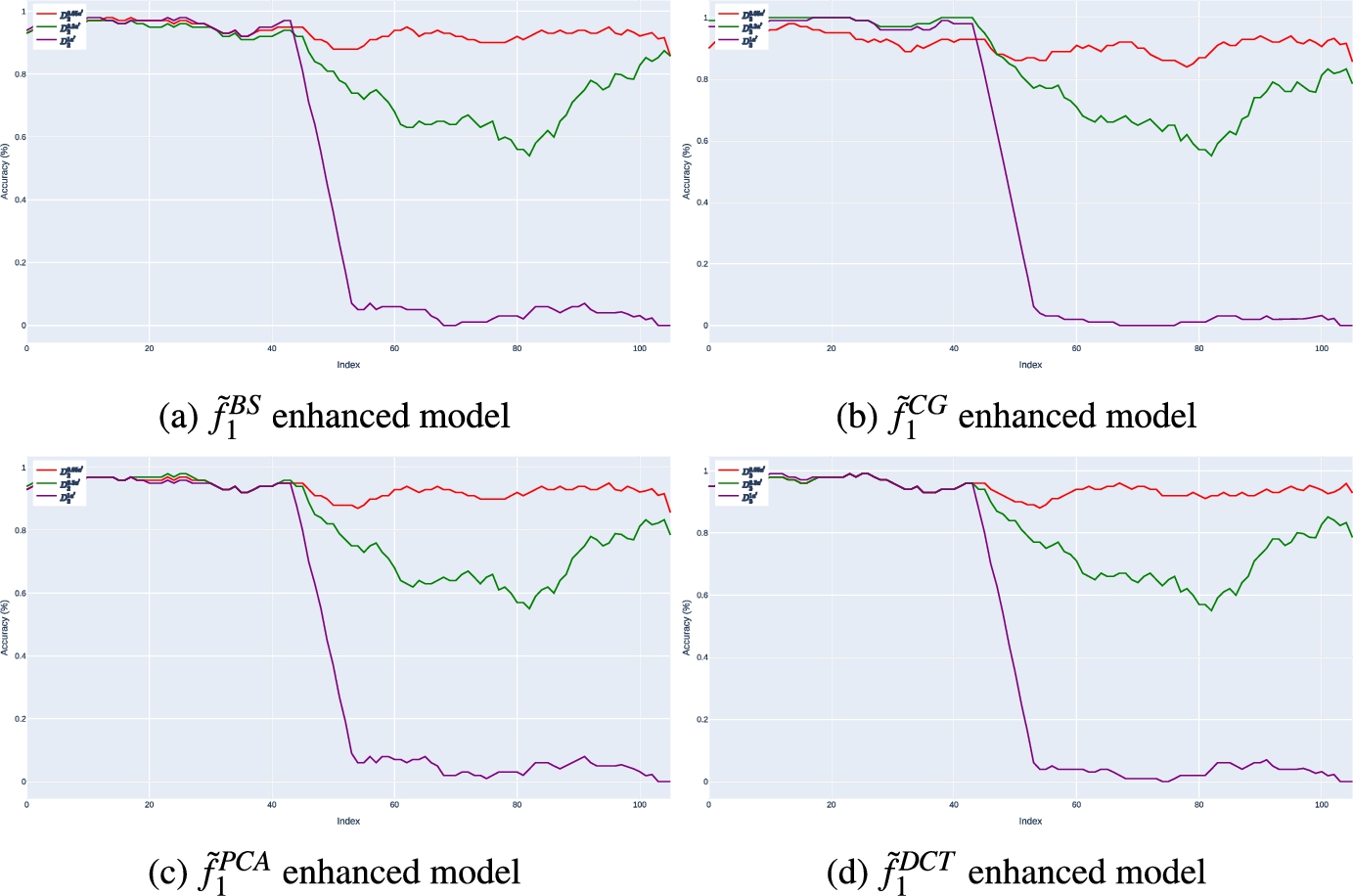
Our results indicate that similar to Scenario I, the local model outperforms the enhanced models by a small margin of approximately
We also found that the parameter α, which was introduced to the formula of the Actual Drift, is correlated with the performance drop of the model. When α was set to 5%, we observed a corresponding drop in accuracy of approximately 5%, which was consistent across all drift cases. Finally, by analyzing the accuracy of the enhanced models over batches of incoming data in Fig. 7, we reveal a consistent trend, indicating that the strategies employed to construct the enhanced models are independent of the performance drop.
Scenario III: In this scenario, we conducted an evaluation of the image classification predictive task. To ensure consistency with our previous evaluation procedures, we followed the same methodology for this scenario. Specifically, we concatenated the original dataset
Table 3
Scenario III mean model’s performance by drift
| Accuracy (%) | |||
| Model | |||
Fig. 8.
Models performances against
Upon observing
On the other hand, the experimental results reveal that the performance of
5.3.2.Enhanced models maintenance
In this phase of our evaluation, we employ all types of drifted data
Fig. 9.
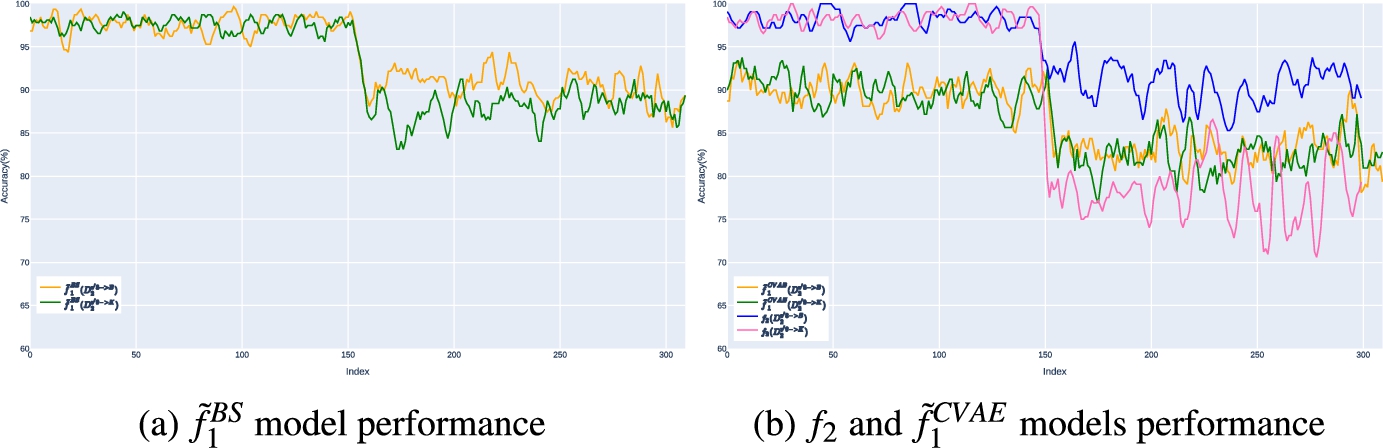
Average performance of
Scenario I: Fig. 9 showcases the outcomes of our analysis. The plot displays the performance of the initial enhanced model over the original
Upon examining the performances of the enhanced models before and after the occurrence of concept drift, it is apparent that superior performance of
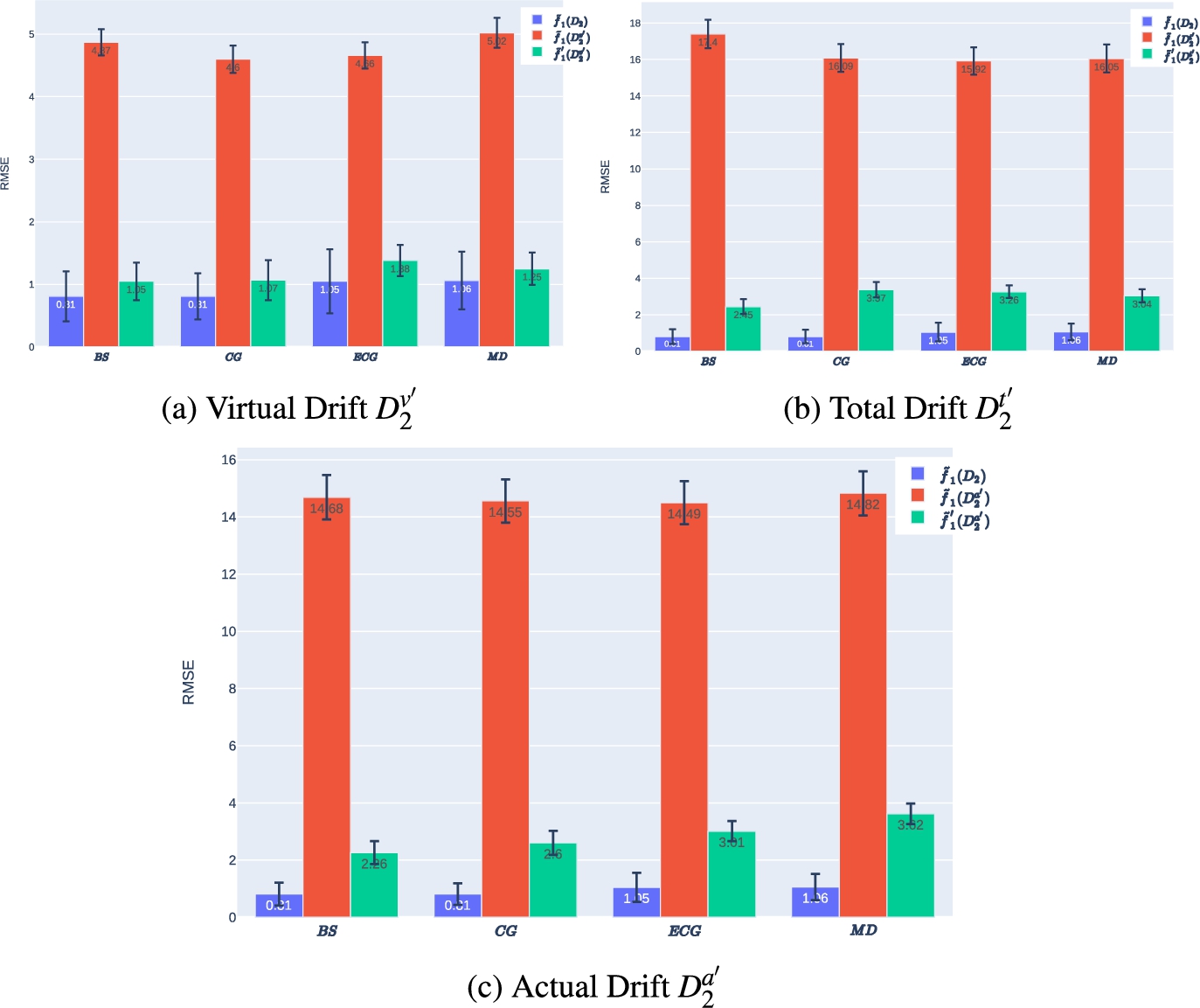
Fig. 10.
Performance of
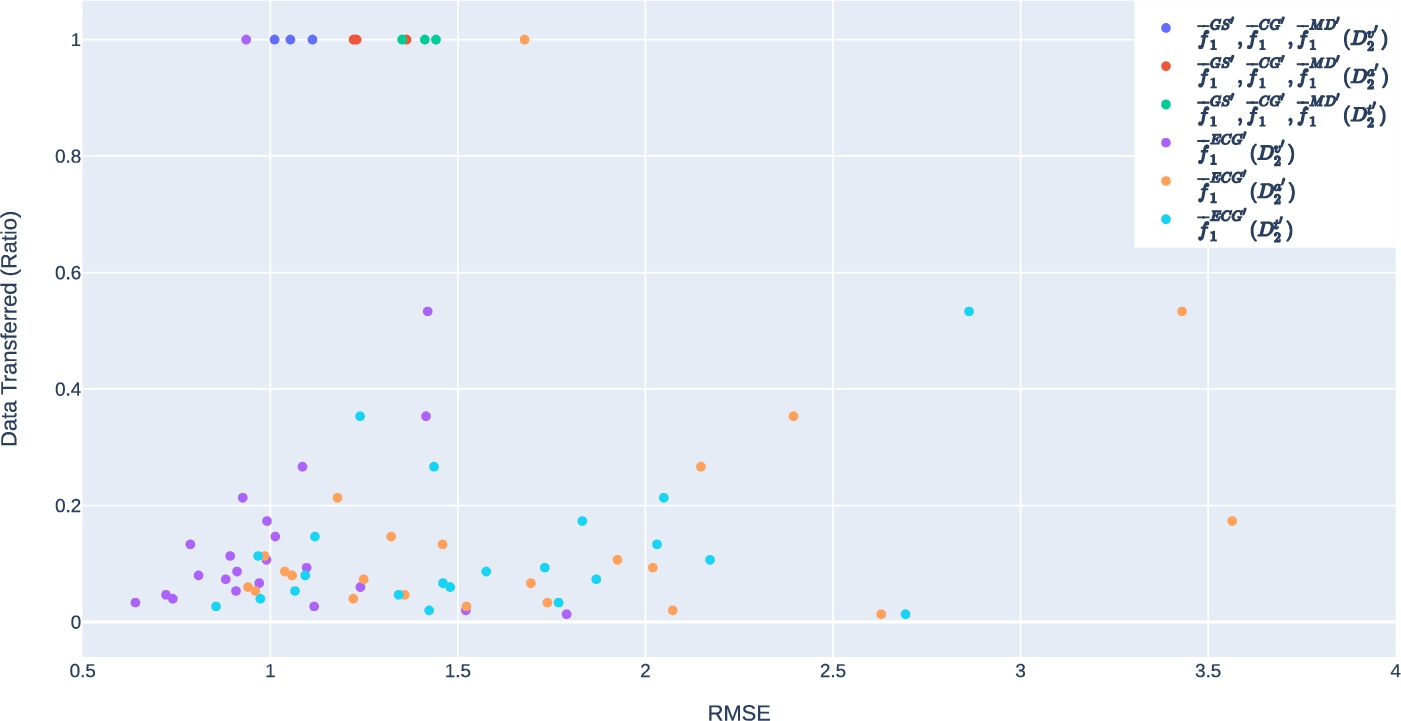
Figure 10 illustrates the RMSE performance of the
Scenario II: This section presents the experimental results of our analysis on a multivariate classification scenario over the BA dataset, obtained after the maintenance of the enhanced models. Figure 11 presents the maintained performance of the models for
Fig. 11.
Average performance of
It can be observed that the slight deterioration in the performance of the maintained enhanced models, as witnessed in Scenario I, is no longer evident. This is due to the fact that certain enhanced models after maintenance
In this section, we focus on the trade-off plot presented in Fig. 12, which provides insights into the relationship between model performance and inter-node data transmission. Specifically, we examine the right-bottom corner of the plot where models achieve superior performance with less inter-node data transmission. To identify the optimal parameters for each maintenance strategy, we explore several parameters that push the boundaries of the models while avoiding those with poor performance. Our experimentation begins with
Fig. 12.
Performance of
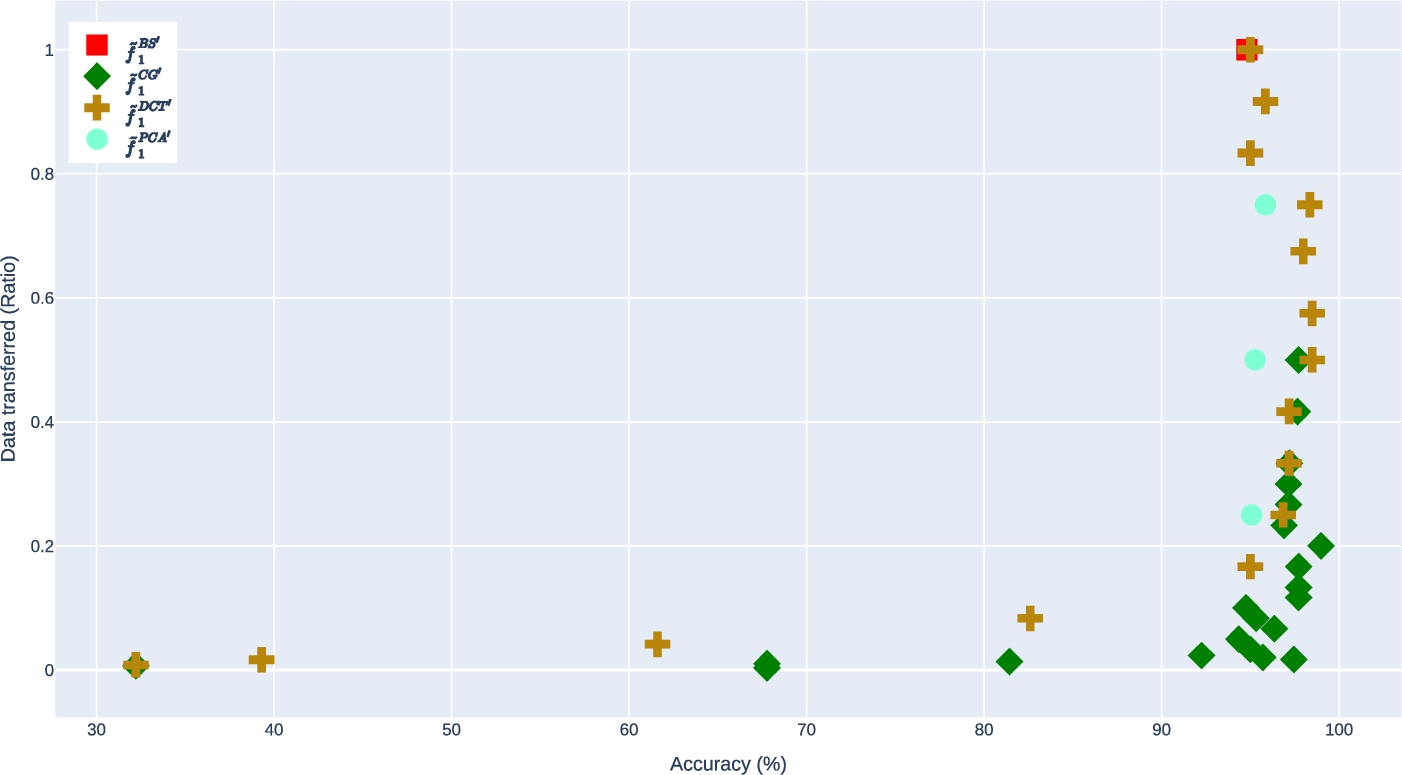
Upon careful examination of the performance of the
Our analysis revealed that all the strategies we tested achieved a substantial reduction in the amount of data required to be transmitted over the network during the maintenance of our enhanced models. We observed instances where our strategies transferred significantly less data compared to the baseline. Notably, the CG strategy stood out as the most effective strategy in terms of data transfer ratio and accuracy performance of the enhanced model. This strategy reduced data transmission by up to 50 times while achieving better accuracy than the baseline.
Scenario III: This study presents an experimental analysis of the performance of enhanced models before and after maintenance in the image classification scenario. The performance of the enhanced models over
Through a comparative analysis of the performance of
Fig. 13.
Average performance of
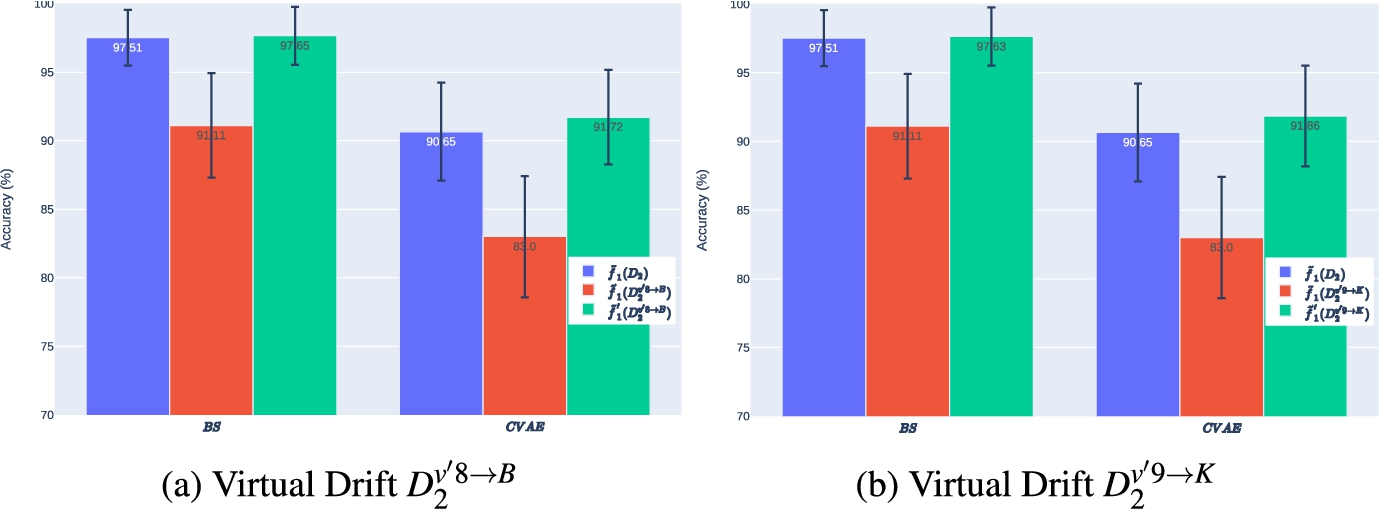
The construction and maintenance of
However, for the construction and maintenance of
Table 4
Byte-wise data requirements for the construction and maintenance of
| Strategy | Z dimensions | Parameters θ | Bytes |
| BS | – | – | 15,860,000 |
| CVAE | 30 | 326,784 | 1,307,136 |
| CVAE | 20 | 322,784 | 1,291,136 |
| CVAE | 10 | 318,784 | 1,275,136 |
| CVAE | 5 | 316,784 | 1,267,136 |
| CVAE | 3 | 315,984 | 1,263,936 |
| CVAE | 2 | 315,584 | 1,262,336 |
| CVAE | 1 | 315,184 | 1,260,736 |
Fig. 14.
Performance of
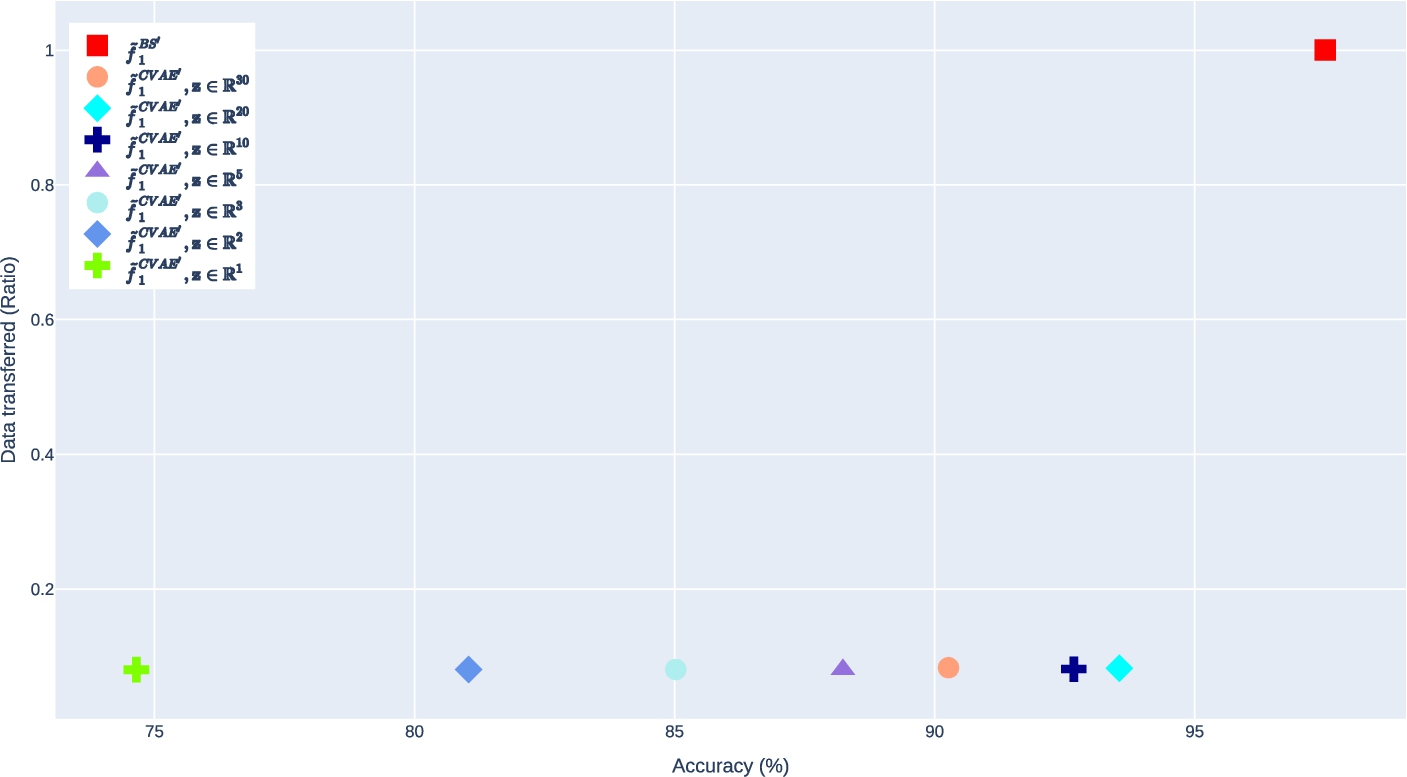
Based on the results presented in Table 4 and Fig. 14, it can be concluded that the dimensionality of the latent space Z does not have a significant impact on the inter-node data transmission. However, it does play a critical role in the performance of the enhanced models. Among the enhanced models constructed using the CVAE strategy, it was observed that
These findings demonstrate the practical implications of using CVAE over the traditional baseline approach, as the byte-wise data requirements for transferring latent space Z are substantially lower than those for transferring raw images. This is an important consideration when designing systems that must operate efficiently and with minimal network utilization.
6.Conclusion
In this research, we addressed the problem of model maintenance in a DML environment, where models must adapt to changes in the data distribution over time. Specifically, we proposed a framework that constructs enhanced models to aid failed nodes in their predictive analytics services and introduced maintenance strategies to sustain the quality of service of the enhanced models in the presence of concept drifts, in a lightweight yet effective manner. Our method can work together with federated learning, especially for making federated learning resilient and robust when it comes to node failures and concept drifts.
To evaluate the effectiveness of our proposed framework and maintenance strategies, we conducted three experimental scenarios over three real datasets with different predictive analytics tasks, including regression, multivariate classification, and image classification. For each scenario, we proposed maintenance strategies that are applicable to each task and simulated different types of concept drifts in a controlled manner.
We divided our experimental evaluation into two phases. In the first phase, we investigated how the performance of the enhanced model is affected under different severities of concept drift and how this correlates with the performance effects of local models. We found that the enhanced model exhibited increased generalizability, resulting in less impact on predictability performance when facing a concept drift as compared to local models. Moreover, the severity of concept drift correlated with the performance drop of the enhanced models. Importantly, we also found that the strategies adopted to construct the enhanced model did not significantly impact its performance, as all of them exhibit similar trends and patterns.
In the second phase of our experimental evaluation, we validated the applicability of our proposed maintenance strategies by retraining the models with the novel trends encountered after a concept drift. Our findings suggest that the trade-off between the inter-node data transmission volume and performance loss can be effectively managed by selecting a suitable maintenance strategy that balances the need for data reduction with the preservation of model performance. Different scenarios yielded different optimal strategies, but all performed similarly or even better than the baseline, achieving a substantial reduction in the amount of data required to be transmitted over the network during the maintenance of the enhanced models.
Our future agenda includes exploring several areas to improve upon our framework and extend its applicability to a wider range of DML scenarios. One important direction is to expand the scope of our experimental evaluation beyond the limited two-EN setting, and explore the applicability of the enhanced model to aid multiple failed nodes in more complex DML environments. This would provide a more comprehensive understanding of the framework’s effectiveness and limitations, and enable us to further optimize the maintenance strategies for the enhanced models in such scenarios. Another promising direction is to investigate the applicability of other conditional generative models, such as Conditional Generative Adversarial Network (cGAN) and Conditional PixelCNN, which could help improve the framework’s capabilities in generating high-quality images, and thereby improve the predictability performance of the enhanced models. While our study has focused on VAE-based conditional generative models, cGANs and Conditional PixelCNN have been shown to have high-quality image generation capabilities, and could be explored for image-based predictive analytics tasks.
Conflict of interest
None to report.
Notes
References
[1] | A.A. Abdellatif, A. Mohamed, C.F. Chiasserini, M. Tlili and A. Erbad, Edge computing for smart health: Context-aware approaches, opportunities, and challenges, IEEE Network 33: (3) ((2019) ), 196–203. doi:10.1109/MNET.2019.1800083. |
[2] | S.H. Bach and M.A. Maloof, Paired learners for concept drift, in: 2008 Eighth IEEE International Conference on Data Mining, IEEE, (2008) , pp. 23–32. doi:10.1109/ICDM.2008.119. |
[3] | M. Baena-Garcıa, J. del Campo-Ávila, R. Fidalgo, A. Bifet, R. Gavalda and R. Morales-Bueno, Early drift detection method, in: Fourth International Workshop on Knowledge Discovery from Data Streams, Vol. 6: , (2006) , pp. 77–86. |
[4] | S. Bouarourou, A. Zannou, A. Boulaalam and E.H. Nfaoui, Iot based smart agriculture monitoring system with predictive analysis, in: 2022 2nd International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), (2022) , pp. 1–5. |
[5] | J. Deogirikar and A. Vidhate, Security attacks in iot: A survey, in: 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), IEEE, (2017) , pp. 32–37. doi:10.1109/I-SMAC.2017.8058363. |
[6] | P. Domingos and G. Hulten, Mining high-speed data streams, in: Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2000) , pp. 71–80. doi:10.1145/347090.347107. |
[7] | R. Elwell and R. Polikar, Incremental learning of concept drift in nonstationary environments, IEEE Transactions on Neural Networks 22: (10) ((2011) ), 1517–1531. doi:10.1109/TNN.2011.2160459. |
[8] | I. Frías-Blanco, J.d. Campo-Ávila, G. Ramos-Jiménez, R. Morales-Bueno, A. Ortiz-Díaz and Y. Caballero-Mota, Online and non-parametric drift detection methods based on Hoeffding’s bounds, IEEE Transactions on Knowledge and Data Engineering 27: (3) ((2015) ), 810–823. doi:10.1109/TKDE.2014.2345382. |
[9] | J. Gama and G. Castillo, Learning with local drift detection, in: Advanced Data Mining and Applications, X. Li, O.R. Zaïane and Z. Li, eds, Springer, Berlin Heidelberg, (2006) , pp. 42–55. |
[10] | J. Gama, P. Medas, G. Castillo and P. Rodrigues, Learning with drift detection, in: Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 3171: , (2004) , pp. 286–295. |
[11] | N. Harth and C. Anagnostopoulos, Edge-centric efficient regression analytics, in: 2018 IEEE International Conference on Edge Computing (EDGE), (2018) , pp. 93–100. |
[12] | G. Hulten, L. Spencer and P. Domingos, Mining time-changing data streams lau ries @ innovation-next.corn, 2001. |
[13] | S. Krishnan, S. Venkatasubramanian, T. Dasu and K. Yi, An information-theoretic approach to detecting changes in multidimensional data streams an information-theoretic approach to detecting changes in multi-dimensional data streams, 2014. |
[14] | Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE 86: (11) ((1998) ), 2278–2324. doi:10.1109/5.726791. |
[15] | A. Liu, Y. Song, G. Zhang and J. Lu, Regional concept drift detection and density synchronized drift adaptation, in: IJCAI International Joint Conference on Artificial Intelligence, (2017) . |
[16] | J. Lu, A. Liu, F. Dong, F. Gu, J. Gama and G. Zhang, Learning under concept drift: A review, IEEE Transactions on Knowledge and Data Engineering 31: ((2019) ), 2346–2363. |
[17] | N. Lu, G. Zhang and J. Lu, Concept drift detection via competence models, Artificial Intelligence 209: ((2014) ), 11–28. doi:10.1016/j.artint.2014.01.001. |
[18] | H. Luo, H. Cai, H. Yu, Y. Sun, Z. Bi and L. Jiang, A short-term energy prediction system based on edge computing for smart city, Future Generation Computer Systems 101: ((2019) ), 444–457. doi:10.1016/j.future.2019.06.030. |
[19] | K. Nishida and K. Yamauchi, Detecting concept drift using statistical testing, in: International Conference on Discovery Science, Springer, (2007) , pp. 264–269. |
[20] | A. Qahtan, B. Alharbi, S. Wang and X. Zhang, A pca-based change detection framework for multidimensional data streams, in: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2015-August, Vol. 8: , (2015) , pp. 935–944. |
[21] | N.P. Rana, S. Luthra, S.K. Mangla, R. Islam, S. Roderick and Y.K. Dwivedi, Barriers to the development of smart cities in Indian context, Information Systems Frontiers 21: ((2019) ), 503–525. doi:10.1007/s10796-018-9873-4. |
[22] | J.C. Schlimmer and R.H. Granger, Incremental learning from noisy data, Machine Learning 1: (3) ((1986) ), 317–354. |
[23] | A. Tsymbal, M. Pechenizkiy, P. Cunningham and S. Puuronen, Dynamic integration of classifiers for handling concept drift, Information fusion 9: (1) ((2008) ), 56–68. doi:10.1016/j.inffus.2006.11.002. |
[24] | M.Q. Wang, D.C. Anagnostopoulos, J. Fornes, D.K. Kolomvatsos and M.A. Vrachimis, Maintenance of model resilience in distributed edge learning environments, in: 19th IEEE International Conference on Intelligent Environments (IE’23), (2023) . |
[25] | Q. Wang, J.M. Fornes, C. Anagnostopoulos and K. Kolomvatsos, Predictive model resilience in edge computing, 2022. |
[26] | G.I. Webb, R. Hyde, H. Cao, H.L. Nguyen and F. Petitjean, Characterizing concept drift, Data Mining and Knowledge Discovery 30: ((2016) ), 964–994. doi:10.1007/s10618-015-0448-4. |
[27] | E. Welbourne, L. Battle, G. Cole, K. Gould, K. Rector, S. Raymer, M. Balazinska and G. Borriello, Building the internet of things using rfid: The rfid ecosystem experience, IEEE Internet computing 13: (3) ((2009) ), 48–55. doi:10.1109/MIC.2009.52. |
[28] | S. Xu and J. Wang, Dynamic extreme learning machine for data stream classification, Neurocomputing 238: ((2017) ), 433–449. doi:10.1016/j.neucom.2016.12.078. |
[29] | T. Xu, G. Han, X. Qi, J. Du, C. Lin and L. Shu, A hybrid machine learning model for demand prediction of edge-computing-based bike-sharing system using internet of things, IEEE Internet of Things Journal 7: (8) ((2020) ), 7345–7356. doi:10.1109/JIOT.2020.2983089. |
[30] | E.P. Yadav, E.A. Mittal and H. Yadav, Iot: Challenges and issues in indian perspective, in: 2018 3rd International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), IEEE, (2018) , pp. 1–5. |
[31] | S. Yu, X. Wang and J.C. Principe, Request-and-reverify: Hierarchical hypothesis testing for concept drift detection with expensive labels, in: IJCAI International Joint Conference on Artificial Intelligence 2018-July, Vol. 6: , (2018) , pp. 3033–3039. |


