
Transforming and decision-making based on probabilistic linguistic term sets with comparative linguistic expressions and incomplete assessments
Abstract
The probabilistic linguistic term sets (PLTSs) are widely used in decision-making, due to its convenience of evaluation, and allowances of probability information. However, there are still some cases where it is not convenient to give an evaluation using the PLTS gramma. Sometimes the evaluators can only give a comparative relationship between alternatives, sometimes evaluators may have difficulty understanding all the alternatives and cannot give a complete assessment. Therefore, we propose a method to transform the comparative linguistic expressions (CLEs) into PLTSs, and the comparison objects of CLEs are alternatives evaluated by PLTSs. And the probability distribution has been adjusted to make the transformation more in line with common sense. Then, a method to correct the deviation is proposed, allowing alternatives to be compared in the case of incomplete assessment. Combining the above two methods, we propose a decision-making method when both CLEs and incomplete assessments coexist. With the study in this paper, the limitations of PLTS-based evaluation and decision-making are reduced and the flexibility of using PLTS is improved.
1Introduction
In many cases, it is difficult to describe alternatives quantitatively, but the use of words or sentences can be more flexible. In recent years, methods for reasoning, calculation and decision-making on information in natural language have been continuously proposed [10, 17, 18]. And the progress of analyzing linguistic variables has led to an active research area today named computing with words (CWW) [5].
After that, in order to solve the problem of uncertainty or hesitation between options, which often encountered in applications, the hesitant fuzzy linguistic term set (HFLTS) was proposed by Rodríguez et al. [19]. At the same time, expressions such as “between good and excellent” can be processed by using the context-free grammars defined by Rodríguez [19]. Many research studied the definition [20], operation [21, 22] and comparison [23, 24] of HTLTS based on Rodríguez [19]. And some extensions of the HFLTS for different application were proposed [25– 27].
As an extension of HFLTS, Pang et al. [4] proposed the probabilistic linguistic term set (PLTS), which allows terms in HFLTS to have different probabilities, then proposed the operation and comparison methods. Owning to its usefulness and efficiency, the PLTS has attracted a lot of researchers’ attention [1]. The comparison of PLTS has been extensively studied as a part of the decision-making process. Pang et al. [4] and Wu et al. [28] proposed a comparison method based on scores and variances. And Chen [7], Bai [8] and Feng [9] proposed the comparison method based on the possibility degree of one PLE over another. However, these methods focus on the comparison between PLTSs when decision making and do not study the transformation of complex of mixed expressions. In order to explore the connection between PLTS in data analysis, scholars have focused their research on the measurement of information. Zhang [30], Lin and Xu [11], Wang [12] defined the distance between PLTS and used distance to describe the similarity and correlation between PLTS. Peng [13] and Farhadinia and Xu [14] and Liu and Teng [15] proposed the aggregation methods to aggregate evaluations, and depict the overall performance of alternatives. In addition, Wu and Liao [30] and Gao et al. [3] have studied probabilistic linguistic preference relations (PLPR), which focus on the relationship between alternatives, and investigated the decision-making with incomplete PLPR. And the consistency and consensus of PLPR are also studied. However, this method is based on the comparison relationship only, and the comparison relationships between each other need to be known.
Based on the model of PLTS, many studies aim at the problem of inherent uncertainty and ambiguity in the assessing process to obtain more realistic results. Using pairwise comparisons between two alternatives, the PL-LMAHP (probabilistic linguistic logarithm multiplicative analytic hierarchy process) is proposed by Liao et al. [44], deriving the weights of indicators more accurately. And proposed the model to derive the comprehensive life satisfaction degrees of residents. In this way, the inherent uncertainty of the evaluations on the importance of life satisfaction indicators can be reflected. In [43], the PL-TODIM (PLTS-based TODIM) method considering the DMs’ psychological factors has been proposed by Zhang et al. The proposed approach captures the uncertainties, and takes the DMs’ non-complete rationality into consideration. However, these studies mainly focus on the rational determination of weights, and cannot deal with the mixed assessment with both linguistic term and comparative relationship.
Based on the concept of CLE (comparative linguistic expression), Rodríguez et al. [19] proposed a method to translate CLE using the context-free grammars into HFLTS. Àlvaro Labella et al. [2] proposed the extended comparative linguistic expressions with symbolic translation (ELICIT), which extends the object of CLE into PLTS. Based on the two-tuple model, the comparison and decision were completed by using symbolic translation. In the process of transforming CLE, considering the inherent uncertainty and vagueness in CLE, Liu et al. [45] proposed a representation model of CLE: the type-2 fuzzy envelope of hesitant fuzzy linguistic term set. This model facilitates the calculation of CLE, greatly increasing the effective information, overcoming the shortcomings of information loss in transforming process.
However, in many cases that do not require thoughtful evaluation, evaluators prefer to use the simple comparative expression like “I can’t give the evaluation or comparison of LeBron’s physical talent with linguistic terms, but he has better physical talent than Kobe”, or “Class 1 is better than Class 2”. This kind of CLE can directly express the relationship between alternatives, and can make a more realistic assessment sometimes. For example, someone evaluates songs on a list of a music player. After evaluating more than a dozen songs, he hears a song similar to the previous one. It may be easy for him to compare the two songs, but may be difficult to give an accurate PLTS evaluation because of having forgotten the evaluation of previous one given before. For a better introduction, Table 1 shows the comparison of some research on CLE.
Table 1
The comparison of researches on CLE
| Evaluation model | Compare with | Transforming method/method | Transform into | |
| Rodríguez et al. [19] | HFLTS | Linguistic terms | Transformation function for context-free grammar | HFLTS |
| Àlvaro Labella et al. [2] | 2-tuple linguistic representation | Linguistic terms | Extended comparative linguistic expressions with symbolic translation | Fuzzy envelope |
| Liu et al. [45] | PLTS | Linguistic terms | Type-2 fuzzy envelope of hesitant fuzzy linguistic term set | Fuzzy envelope |
| Our study | PLTS | Alternatives | Transformation function for context-free grammar | PLTS |
The above literature solves theoretical and practical problems and promoter the research on PLTS, but there are still some aspects that need further discuss:
(1) Lack of transforming methods for commonly used expressions. Many commonly used expressions are not only convenient to express, but may have rich meanings in different situations. We need to think about the information in the semantics deeply and transform it in reasonable way [32].
(2) Most of the researches focus on using same models for assessment and decision-making, and there are few methods for decision-making evaluation using mixed model of expressions.
(3) Existing methods place excessive demands on evaluators. The original CWW was proposed to improve the convenience and flexibility of evaluation and decision-making. Nowadays many methods require evaluators to provide some specific numbers or have a comprehensive understanding of alternatives, which deviates from the original intention of semantic evaluation to some extent.
(4) Score functions may fail to capture the true meaning of linguistic assessments because of the different standards. For example, “good” may mean diverse scores for different people, which may lead to deviation in decision making [1].
In order to overcome the problems mentioned above, this paper aim to address the situation where CLEs may be mixed in the evaluation, and the situation where incomplete assessments are caused by a lack of comprehensive understanding of alternatives, proposed transforming and decision-making methods. The main contributions of this paper are as follows:
(1) The transforming method when the comparison linguistic expressions are mixed in the evaluation based on PLTS is proposed. And according to different situations, the result of the transforming was modified to make it more consistent with the common sense of expression.
(2) The method for correcting deviations caused by incomplete assessments is proposed.
(3) The decision-making process is proposed in the presence of both comparison linguistic expressions and incomplete assessments.
(4) The restrictions and requirements for evaluators have been reduced to some extent, and the flexibility of using PLTS has been improved.
The rest of this paper is arranged as follows: Section 2 reviews the basic research related to this paper; In Section 3, we introduce the method of transforming CLE into PLTSs, then revise the transformed result; Section 4 introduce the comparison when the incomplete assessments exist in evaluation; The process of decision making when both CLEs and incomplete assessments coexist is presented in Section 5; Section 6 shows an example that illustrates the content of this research. Finally, Section 7 summarizes the full paper and presents future work.
2Preliminaries
In recent years, scholars have done a lot of research on related issues. In this section, we will briefly review what is used or related in this paper.
2.1The linguistic term sets
Definition 2.1. Let a linguistic term set be S ={ st|t =-τ, …, -1, 0, 1, …, τ }, with odd cardinality where the midterm represents the assessment of “approximately 0.5” or “indifference”, and the rest linguistic labels are placed symmetrically around it. Furthermore, [35] extended the discrete LTS to a continuous version:
A commonly used LTS is the additive LTS, which has the following properties:
And the negation operator is
Definition 2.2. [36] Let sα1, sα2 ... , sαN be N linguistic terms, λ1, λ2, ... , λN ⩾ 0, then the combined operational is
2.2The probabilistic linguistic term sets
(1) The Concept of PLTS
Definition 2.3. [4] Let S ={ st|t =-τ, …, -1, 0, 1, …, τ } be a LTS. Then a PLTS is defined as:
(2) The Basic Operation of LTS.
Definition 2.4. [4] Let
(3) The Normalization of PLTS
In the case of
Definition 2.5. [4] Given a PLTS L (p) with
Example 1. Let L1 (p) ={ s1 (0.3) , s2 (0.5) }. According to Definition 2.3, it can be obtained:
Therefore, after normalization,
For ease of expression, the PLTS in the following sections of the text defaults to PLTS after normalized.
(4) The Probabilistic Linguistic Weighted Averaging (PLWA) Operator
In order to aggregation the information of PLTSs with different weights, [41] proposed the PLWA operator.
Definition 2.6. [4] Let
In addition, some different aggregation operators such as PLA operator, PLG operator, PLWG operator [4] are defined to aggregate information of PLTSs. And DAWA operator, DAOWA operator [37] are proposed to aggregate distribution assessments based on LTSs.
2.3The Comparison between PLTSs
With reference to mathematical expectations and deviation, Pang et al. [4] defined the score and the deviation degree of the PLTS to compare PLTSs for decision making.
Definition 2.7. [4]. Let L (p) defined as Definition 2.3. The score of L (p) is
The deviation degree of L (p) is
The rules of comparison are as follows:
At the same time, with reference to the approaches to ranking fuzzy numbers [38, 39], Bai et al. [8] proposed the possibility degree formula for compare PLTSs, to conquer the limitation of the loss of information.
Definition 2.8. [8] Let L (p) defined as Definition 2.3. Let L- = min(r(k)) be the lower bound of L (p) and L+ = max(r(k)) be the upper bound of L (p). The possibility degree formula for comparing L1 (p) and L2 (p) is
Where a (L(k)) is the area of L(k) in the two-dimensional orthogonal space, where the horizontal axis is r(k) and the vertical axis is p(k), and a (L1 ∩ L2) is the area of the intersection between L1 (p) and L2 (p). And a (L) - and a (L) + is the lower area and upper area of L (p), respectively. a (L) is defined as the area in the orthogonal region formed by p(k) (the probability of L(k)) and r(k) (the subscript of L(k)).
And the method to cpmpare PLTSs is
The detailed and intuitive definition of the area can be found in [8].
2.4Transforming CLE into PLTSs
When using heterogeneous grammar for expression, all the expression should be transformed into one model. Rodríguez et al. [19] pointed out that all the linguistic expressions should be transformed into the HFLEs before the aggregation and comparison when heterogeneous methods based on HFLTS are used for expression. And in [19] Rodríguez et al. defined a context-free grammar that generates simple but rich linguistic expressions that can be easily represented by means of HFLTS.
Definition 2.9. [19] Let EGH be a function that can transform linguistic expressions ll, which are obtained by GH, into HFLTS HS. Where GH is the context-free grammar, HS is a complement of HFLTS, S is the linguistic term set that is used by GH.
And function EGH is defined as follows:
(1) EGH (si) ={ si|si ∈ S }
(2) EGH (lessthansi) ={ sj|sj ∈ Sandsj ⩽ si }
(3) EGH (greaterthansi) ={ sj|sj ∈ Sandsj ⩾ si }
(4) EGH (betweensiandsj) ={ sk|sk ∈ Sandsi ⩽ sk ⩽ sj }
In this way, expressions with context-free grammar can be transformed into HFLTS.
Example 2. Let S = { none, verylow, low, medium, high, veryhigh, perfect } be a linguistic term set.
(1) EGH (verylow) ={ verylow }
(2) EGH (lowerthanhigh) ={ none, verylow, low, medium, high }
(3) EGH (greaterthanhigh) ={ high, veryhigh, perfect }
(4) EGH (betweenmediumandperfect) ={ medium, high, veryhigh, perfect }
3Transformation for the CLE
In some cases, due to incomplete information, or limited by the subjectivity, it may be difficult to give accurately evaluations using standard PLTS gramma. However, CLEs, such as “His performance is better than good”, or “He is taller than his brother”, is more flexible, and it is convenient for evaluators to give their own access [32].
For this situation, in this section, two main issues are considered:
(1) When the comparison object is a linguistic item, such as “His performance is better than good”, we can use the method introduced in 2.4 to get the corresponding HFLTS. But if the comparison object is another alternative, such as “He is taller than his brother”, and the height of his brother is assessed by PLTS, how could the comparison linguistic expression be transformed at this time.
(2) In some cases, although the transformed results are consistent with the original meaning of the expression to some extent, it is difficult to meet the common sense in the expression.
3.1Transforming CLEs into PLTS
Definition 3.1. Let GP be the gramma which combines PLTSs and CLEs in order to help the experts to express with more flexibility, and the CLEs given by evaluators is denoted by cl. Forms of cl are as follows:
(1) cl1 = lowerthan L1
(2) cl2 = greaterthan L1
(3) cl3 = lowerthan L1 and L2
(4) cl4 = greaterthan L1 and L2
(5) cl5 = between L1 and L2
Where L1 and L2 are the linguistic terms represented by PLTSs.
According to the CLEs given by the evaluators, the method to transform to PLTSs is proposed as follows:
Definition 3.2. Let PS be the gramma using standard PLTSs. And let EGP be the function that can transform CLEs cl, which are obtained by GP, into PLTSs PS, i.e.: p[
According to the meaning of the comparison linguistic expression, the function EGP is set as follows:
Where
Example 3. Two experts M1 and M2 need to assess alternative A1, A2 and A3, using PLTSs combine with CLEs. And S ={ s-3, s-2, s-1, s0, s1, s2, s3 }. The evaluations are shown in Table 2. Since M1 uses a CLE in the evaluation, it is necessary to determine the PLTS corresponding to cl according to other evaluations of M1.
Table 2
The evaluations using PLTSs combines with CLEs
| A1 | A2 | A3 | |
| M1 | {s-2 (0.4) , s-1 (0.6)} | {s1 (0.5) , s2 (0.5)} | cl |
| M2 | {s-1 (1)} | {s1 (0.2) , s2 (0.8)} | {s0 (0.9) , s1 (0.1)} |
There are five cases of forms according to the different forms of cl given by M1, and the possible PLTS-based evaluations transformed of A3 are as follows:
Remark.
(1) Using the function EGH defined by Rodríguez [19] introduced in Section 2.4, we can get the corresponding HFLTS rather than PLTS. But the HFLTS can be regarded as a PLTS, which the probability of each item is equal [4]. Therefore, we can directly represent the HFTLTs obtained by the function EGH as PLTSs with each term has equal probability.
(2) When two PLTS have the same term, the linguistic set between the two PLTS maybe ∅. For example, L3 ={ s0 (0.4) , s1 (0.6) }, L4 ={ s1 (0.2) , s2 (0.8) }.
In the transformed PLTS,
At this time, the method of Definition 2.4. [Pang] in Section 2.2 is needed for normalization after transformation.
(3) When using CLEs, L1 or L2 in the comparison linguistic expression is the evaluation of alternatives 1 or 2 by the same evaluator.
(4) When the object to be compared is also a CLE, the transformation can be performed sequentially. For example, L1 is a PLTS, and L2 is better than L1, and L3 is better than L2. Then, the PLTS of L2 can be determined firstly, and then the PLTS of L3. If the results of the comparison are contradictory, these evaluations are deemed to be invalid evaluations.
3.2Adjustment the Probability in PLTSs
After the above process, the CLEs can be transformed into PLTSs. But this process only satisfies the basic semantics, there are still problems that are not consistent with the actual common sense. For example, in Example 4. If the CLE of cl is “greaterthanL1”, then the obtained PLTS is
The above transforming process only determines the interval of PLTS and structure probability information. It still lacks specific probability information that matches the actual situation. So, in this case, the following principles should be met:
(1) Respect the clear message given by evaluator in the evaluation, i.e., strictly adhere to the intervals identified in the evaluation given by evaluator, and the calculated structural probability information.
(2) Supplement missing probability information based on other known information.i
In order to define the degree of influence on one probability, then adjust the probability, the probability adjustment operator (PA operator) is proposed:
Definition 3.3. Let
And the probability adjusted PLTS is
The adjusted PLTS
At this point, the probability-adjusted PLTS LAP (p) can be obtained.
Remark.
(1) The function
Fig. 1
Image of function μ (a) Image of
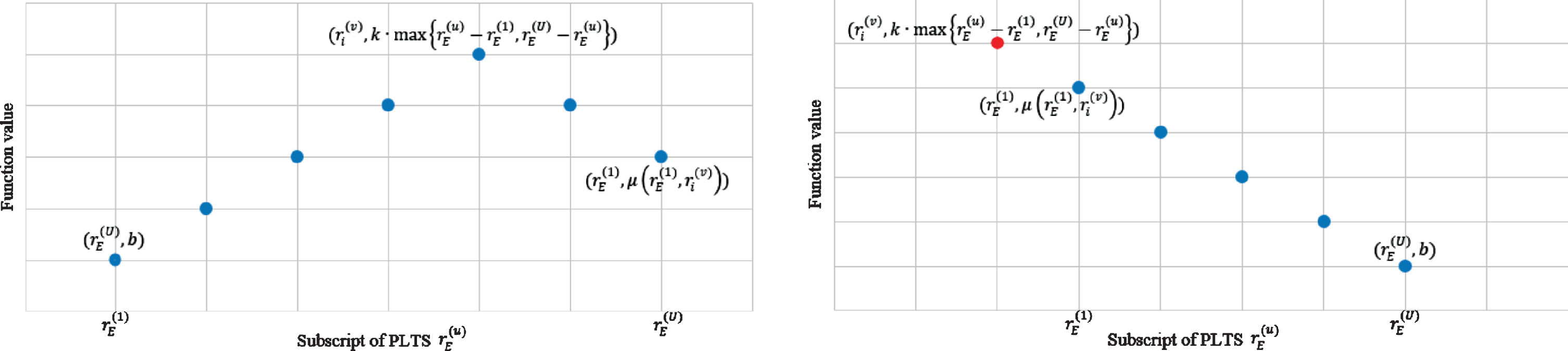
(2) The known evaluations of the same object L(i) (p) should not be ∅. Although many methods, such as [40], can determine feasible spaces based on multiple comparisons. However, in this study, PLTS-based evaluation methods were used, and a large number of evaluations were not performed according to grammar, indicating that the evaluators had limited cognition of the subject, or that the selected evaluation method needed to be corrected. So this situation will not be discussed.
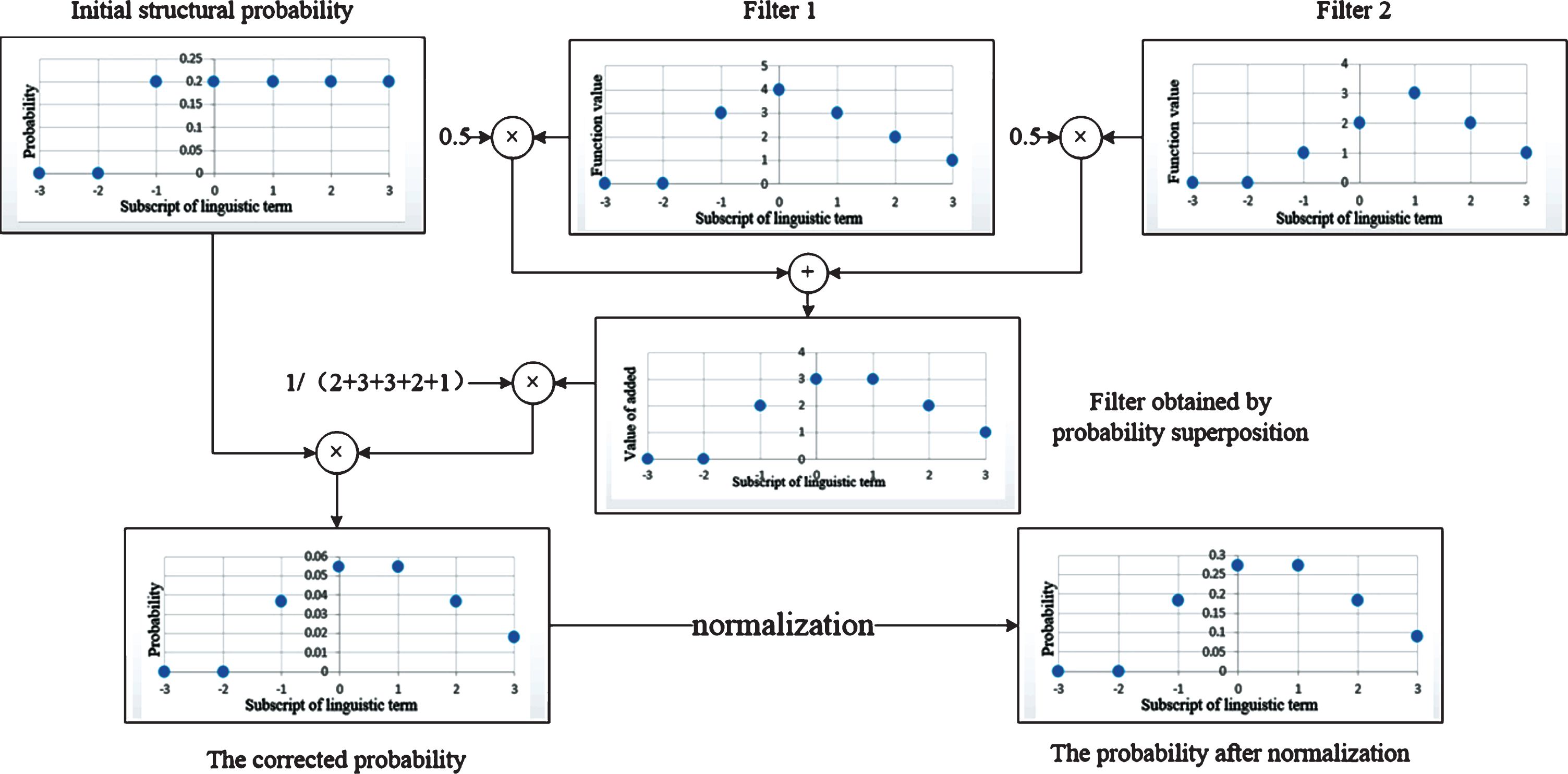
(3) Intuitively, the process of probability correction is similar to signal filtering. Each known evaluation can be seen as a filter, which can be superimposed into a total filter according to probability weights. An example of the process of probability correction is shown in Fig. 2.
Fig. 2
Process of probability correction. When the PLTS given by another evaluator is known to be {s0 (0.5) , s1 (0.5)}, and the transformed PLTS is {s-3 (0) , s-2 (0) , s-1 (0.2) , s0 (0.2) , s1 (0.2) , s2 (0.2) , s3 (0.2)}, k, b = 1.
Example 5. In the context of Example 4. When the CLE of cl is “greater than L1”, then the obtained PLTS after probability adjustment is:
Borrowing the results in Example 4., the PLTS before probability adjustment is
There is only one known evaluation of the same object,
According to Definition 3.3. we can first calculate the PA operators. In this example, we set k, b = 1 in function μ.
Then calculate the adjusted probability:
After normalization, the probability-adjusted PLTS can be obtained.
It can be seen from the results that the adjusted PLTS not only completely conforms to the semantics of “greater than L1”, but also the probability distribution is concentrated around s-1, s0, s1, which is more in line with common sense.
4Comparison for the incomplete assessment
In previous research, when making decisions, evaluators is often required to evaluate all alternatives [1]. But in some cases, it is difficult for evaluators to have a comprehensive understanding of all alternatives, preventing evaluators from evaluating some of alternatives. Some deviations due to the subjective factors of the evaluator will have an impact on the evaluation. For example, one evaluator assesses the alternatives honestly, but his standard was obviously stricter than others. At this point, alternatives not evaluated by him will inadvertently benefit.
In the fields of management and medicine, it is often necessary to modify various subjective evaluations [42, 43], but the methods seem not to be directly applied to the PLTS evaluation system. For this reason, a scoring correction function (SC function) is proposed in this section, which is used to correct the impact caused by the different subjective standard of the evaluator.
Definition 4.1. Evaluators M1, M2, ... , MN use PLTSs to assess alternatives A1, A2, ... , AM. And S ={ st|t =-τ, …, -1, 0, 1, …, τ }.
Select the evaluation of some of alternatives by some of evaluators as the reference domain D. It is required that any alternative in the reference domain is evaluated by more than γ of the evaluators. And the evaluator should evaluate more than δ of the alternatives, where γ, δ ∈ [0, 1]. At the same time, expressions with PLTSs must be provided in the reference domain, without any CLEs. In this paper, we consider that the average score of an evaluator in the reference domain can reflect the evaluator’s scoring standard.
Then, for
Subject to
where α is defined in Definition 2.7..
Then, the corrected PLTS
Remark.
(1) The value ofγandδ should be determined based on the amount of data. Intuitively, the reference domain responds to the evaluator’s scoring difference by comparing evaluations of common alternatives. When the number of evaluators and alternatives is large, the value can be set relatively low. Because when the number increases, the evaluation will gradually converge to the true value. And when the amount of data is small, the value of γandδ should be set higher.
(2) When comparing the revised evaluations, the method in Definition 2.7. [4] is used, because this method is simpler to operate and conforms to the semantics of most PLTS expressions. However, the variance is focused on the degree of stability, so we do not use the part that compares variance when the scores are the same, i.e. we think that there is no difference for PLTSs with the same score.
(3) If there is (are) term(s) in the corrected PLTS exceed the LTS interval, this (these) item(s) is (are) modified as the largest item in LTS.
Then, we use an example to illustrate the main idea of our method for readers’ easy understanding.
Example 6. Three experts M1, M2 and M3 need to assess alternative A1, A2, A3, A4 and A5. And S ={ s-3, s-2, s-1, s0, s1, s2, s3 }. The evaluations are shown in Table 3. Where “-” indicates that the evaluation is not provided.
Table 3
The evaluations using PLTSs combines with incomplete assessment
| A1 | A2 | A3 | A4 | A5 | |
| M1 | {s-2 (1)} | {s-2 (0.3) , s-1 (0.7)} | {s0 (1)} | {s1 (0.8) , s2 (0.2)} | – |
| M2 | – | {s0 (1)} | {s1 (1)} | {s1 (0.4) , s2 (0.6)} | {s3 (1)} |
| M3 | {s-2 (1)} | {s-1 (1)} | {s0 (1)} | {s1 (1)} | {s2 (1)} |
Due to the small number of reviewers and alternatives, both γandδ are required to be 1. So the evaluations of A2, A3 and A4 given by M1, M2 and M3, are set to be the reference domain.
Then, it can be calculated that
Subject to
And
Similarly, other PLTSs can be corrected, and the evaluations after scoring correction is shown in Table 4.
Table 4
The evaluations after scoring correction
| A1 | A2 | A3 u A4 | A5 | ||
| M1 | {s-2 (0.622) , s-1 (0.378)} | {s-1 (0.922) , s0 (0.078)} | {s0 (0.622) , s1 (0.378)} | {s1 (0.422) , s2 (0.578)} | – |
| M2 | – | {s-1 (U0.589) , s0 (0.411)} | {s0 (0.589) , s1 (0.411)} | {s1 (0.989) , s2 (0.011)} | {s2 (0.589) , s3 (0.411)} |
| M3 | {s-2 (0.722) , s-1 (0.278)} | {s-1 (0.722) , s0 (0.278)} | {s0 (0.722) , s1 (0.278)} | {s1 (0.722) , s2 (0.278)} | {s2 (0.722) , s3 (0.278)} |
5Decision-making with CLEs and incomplete assessments
When making decisions based on PLTS, if there are CLEs and incomplete assessments in evaluation, the following steps can be used to make decisions.
Step 1. Set the value of γandδ according to the number of evaluators and alternatives, and the nature of the problem, and then determine the reference domain. After that, adjust the evaluation using the method of Definition 4.1.
Step 2. When there are CLEs in the evaluation results, we can use the method in Definition 3.2. to transform them to PLTSs, and then use the method in Definition 3.3. to modify it.
Step 3. Use the method in Definition 2.7. to compare PLTSs and make optimal decisions.
6A case study
In this section, we use a concrete example to show the decision-making process based on PLTSs with CLEs and incomplete assessments.
Example 7. A movie website allows the client to use PLTS to evaluate the quality of movies after watching. And set 50 popular movies as the reference domain. After the user has evaluated 40 of them (using PLTS), set this client as a potential reviewer. Movies outside the reference domain can be evaluated in two ways: using PLTS or comparing with evaluated movies. Now the website is assessing 4 science fiction movies released in 2019, and refer to the evaluations of 4 potential reviewers. Let S ={ st|t = -3, - 2, - 1, 0, 1, 2, 3 }be the LTS. It is known that the average evaluation of all potential reviewers’ for the movies in reference domain is 1.29, i.e.
Table 5
The original evaluation given by the reviewers
| A1 | A2 | A3 | A4 | |
| I1 | {s-1 (0.3) , s0 (0.7)} | {s2 (0.2) , s3 (0.8)} | between L*1 and L11 | {s-2 (1)} |
| M2 | {s-2 (1)} | {s2 (0.5) , s3 (0.5)} | {s0 (0.8) , s1 (0.2)} | – |
| M3 | – | {s3 (1)} | – | {s-1 (0.8) , s0 (0.2)} |
| M4 | {s-1 (0.3) , s0 (0.7)} | {s2 (0.2) , s3 (0.8)} | {s1 (1)} | lower than L41 |
Step 1. According to the situation given, it can be calculated that
Subject to
So,
Similarly, other corrected evaluations can be calculated, the corrected evaluations are shown in Table 6.
Table 6
The corrected evaluation
| A1 | A2 | A3 | A4 | |
| M1 | {s-1 (0.51) , s0 (0.49)} | {s2 (0.41) , s3 (0.59)} | between L*1 and L11 | {s-3 (0.21) , s-2 (0.79)} |
| M2 | {s-2 (0.21) , s-1 (0.79)} | {s3 (1)} | {s0 (0.01) , s1 (0.99)} | – |
| M3 | – | {s2 (0.38) , s3 (0.62)} | – | {s-2 (0.18) , s-1 (0.82)} |
| M4 | {s-1 (0.51) , s0 (0.49)} | {s2 (0.41) , s3 (0.59)} | {s0 (0.21) , s1 (0.79)} | lower than L41 |
Step 2. Translate CLEs in evaluations into PLTSs.
According to Definition 3.3. we can calculate the PA operators. In this example, we set k, b = 1 in function μ.
Similarly,
Then, the transformed evaluation is shown in Table 7.
Table 7
The transformed evaluation
| A1 | A2 | A3 | A4 | |
| M1 | {s-1 (0.51) , s0 (0.49)} | {s2 (0.41) , s3 (0.59)} | {s-1 (0.081) , s0 (0.391) , s1 (0.528)} | {s-3 (0.21) , s-2 (0.79)} |
| M2 | {s-2 (0.21) , s-1 (0.79)}. | {s3 (1)} | {s0 (0.01) , s1 (0.99)} | |
| M3 | – | {s2 (0.38) , s3 (0.62)} | – | |
| M4 | {s-1 (0.51) , s0 (0.49)} | {s2 (0.41) , s3 (0.59)} | {s0 (0.21) , s1 (0.79)} | {s-3 (0.24) , s-2 (0.35) , s-1 (0.33) , s0 (0.08)} |
Step 3. Compare alternatives using Definition 2.7. [4].
So,
We rank the films in descending order: A2, A3, A1, A4.
In the above process, the decision-making based on PLTSs with CLEs and incomplete assessments is solved. In this example, it takes several hours to watch and understand a movie, and people tend to evaluate after watching it shortly. The interval between the evaluations of two movies to be evaluated may be weeks, months, or even years. The reviewer may not remember the specific evaluation (PLTS given before) given to a movie before, but it is relatively easy to give a comparative relationship (〈〈The godfather II〉〉 is better than 〈〈The godfather III〉〉) with each other. At the same time, it is very impractical to require reviewers to watch all movies and give reviews. Therefore, in the case of supporting comparison linguistic expressions and incomplete assessment, it is very convenient to use PLTS for evaluation. This process can relax the requirements for evaluators, making evaluation and decision-making more accurate and flexible.
7Conclusion
This paper designs solutions to the problems often encountered in the evaluation process: The first is when the evaluator cannot provide an accurate evaluation, but can provide a comparison relationship between alternatives, a method for transforming CLEs into PLTSs is proposed; At the same time, according to the information provided by other evaluators, the transformed PLTSs were adjusted to make them more in line with common sense, improving the flexibility and practicability of the evaluation. Then, a method of correcting deviations when the evaluator has difficulty evaluating all alternatives is proposed. This method corrects deviations that may occur when the number of evaluations is not equal, and reduces the requirements for evaluators and makes it easier to evaluate. A decision-making method is proposed for situations where there are both CLEs and incomplete assessments. This study can relax the requirements for evaluators, making evaluation and decision-making more accurate and flexible, and expand the range of use of the PLTS.
Although the method proposed in this paper relaxes the requirements for evaluation, the many necessary requirements still remain. When certain conditions are not met, large deviations or unreasonable decision may be brought. And the range of influence of inaccurate evaluation will increase to some extent. An unreasonable evaluation may not only affect its own evaluation, but also affect other reasonable evaluations.
In future work, we need to further understand the deep meaning of human expression. Understand the exact semantics expressed in different situations. And further study the methods of fusion and comparison for the various heterogeneous data in the context of big data application. On the basis of this study, we can use the model of fuzzy sets to take uncertainty into account, such as the type-2 fuzzy envelope of hesitant fuzzy linguistic term set proposed in [45]. In addition to the differences in the strictness of the standards proposed in this paper, there are many evaluation biases due to subjective limitations. In the future, we can combine the characteristics of consistency and consensus to further improve the rationality and fairness of decision-making and assessment.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (Grant No.41775039, and 41775165).
References
[1] | Liao H. , Mi X. and Xu Z. , A survey of decision-making methods with probabilistic linguistic information: bibliometrics, preliminaries, methodologies, applications and future directions, Fuzzy Optimization and Decision Making 19: ((2020) ), 81–134. |
[2] | Labella Á. , Rodríguez R.M. and Martínez L. , Computing with Comparative Linguistic Expressions and Symbolic Translation for Decision Making: ELICIT Information, IEEE Transactions on Fuzzy Systems (Early Access). |
[3] | Xu Z. , He Y. and Wang X. , An overview of probabilistic-based expressions for qualitative decision-making: techniques, comparisons and developments, International Journal of Machine Learning and Cybernetics 10: ((2019) ), 1513–1528. |
[4] | Pang Q. , Wang H. and Xu Z.S. , Probabilistic linguistic term sets in multi-attribute group decision making, Information Sciences 369: ((2016) ), 128–143. |
[5] | Mendel J.M. , Zadeh L.A. , Trillas E. , Yager R. , Lawry J. , Hagras H. and Guadarrama S. , What computing with words means to me [discussion forum, IEEE Computational Intelligence Magazine 5: ((2010) ), 20–26. |
[6] | Wu X.L. and Liao H.C. , A consensus-based probabilistic linguistic gained and lost dominance score method, European Journal of Operational Research 272: ((2019) ), 1017–1027. |
[7] | Chen Z.S. , Chin K.S. , Li Y.L. and Yang Y. , Proportional hesitant fuzzy linguistic term set for multiple criteria group decision making, Information Sciences 357: ((2016) ), 61–87. |
[8] | Bai C.Z. , Zhang R. , Qian L.X. and Wu Y.N. , Comparisons of probabilistic linguistic term sets for multi-criteria decision making, Knowledge-Based Systems 119: ((2017) ), 284–291. |
[9] | Feng X.Q. , Liu Q. and Wei C.P. , Probabilistic linguistic QUALIFLEX approach with possibility degree comparison, Journal of Intelligent & Fuzzy Systems 36: ((2019) ), 710–730. |
[10] | Pedrycz W. and Song M. , A granulation of linguistic information in ahp decision-making problems, Information Fusion 17: ((2014) ), 93–101. |
[11] | Zhang X.F. , Xu Z.S. and Ren P.J. , A novel hybrid correlation measure for probabilistic linguistic term sets and crisp numbers and its application in customer relationship management, International Journal of Information Technology & Decision Making 18: ((2019) ), 673–694. |
[12] | Wang X.K. , Wang J.Q. and Zhang H.Y. , Distance-based multicriteria group decision-making approach with probabilistic linguistic term sets, Expert Systems 36: ((2019) ), e12352. |
[13] | Peng H.G. , Zhang H.Y. and Wang J.Q. , Cloud decision support model for selecting hotels on TripAdvisor.com with probabilistic linguistic information, International Journal of Hospitality Management 68: ((2018) ), 124–138. |
[14] | Farhadinia B. and Xu Z.S. , Ordered weighted hesitant fuzzy information fusion-based approach to multiple attribute decision making with probabilistic linguistic term sets, Fundamenta Informaticae 159: ((2018) ), 361–383. |
[15] | Liu P.D. and Teng F. , Some Muirhead mean operators for probabilistic linguistic term sets and their applications to multiple attribute decision-making, Applied Soft Computing 68: ((2018) ), 396–431. |
[16] | Xu Z.S. , Incomplete linguistic preference relations and their fusion, Information Fusion 7: ((2006) ), 331–337. |
[17] | Li C.C. , Dong Y. , Herrera F. , Herrera-Viedma E. and Martínez L. , Personalized individual semantics in computing with words for supporting linguistic group decision making. An application on consensus reaching, Information Fusion 33: ((2017) ), 29–40. |
[18] | Rodríguez R.M. , Labella A. and Martínez L. , An overview on fuzzy modelling of complex linguistic preferences in decision making, International Journal of Computational Intelligence Systems 9: ((2016) ), 81–94. |
[19] | Rodriguez R.M. , Martinez L. and Herrera F. , Hesitant fuzzy linguistic term sets for decision making, IEEE Transactions on Fuzzy Systems 20: ((2012) ), 109–119. |
[20] | Liao H.C. , Xu Z.S. , Zeng X.J. and Merigó J.M. , Qualitative decision making with correlation coefficients of hesitant fuzzy linguistic term sets, Knowledge Based Systems 76: ((2015) ), 127–138. |
[21] | Gou X.J. , Liao H.C. , Xu Z.S. and Herrera F. , Double hierarchy hesitant fuzzy linguistic term set and multimoora method: a case of study to evaluate the implementation status of haze controlling measures, Information Fusion 38: ((2017) ), 22–34. |
[22] | Liao H.C. , Xu Z.S. and Xia M.M. , Multiplicative consistency of hesitant fuzzy preference relation and its application in group decision making, International Journal of Information Technology & Decision Making 13: ((2014) ), 47–76. |
[23] | Liao H.C. , Xu Z.S. and Zeng X.J. , Hesitant fuzzy linguistic vikor method and its application in qualitative multiple criteria decision making, IEEE Transactions on Fuzzy Systems 23: ((2015) ), 1343–1355. |
[24] | Wei C.P. , Ren Z.L. and Rodríguez R.M. , A hesitant fuzzy linguistic todim method based on a score function, International Journal of Computational Intelligence Systems 8: ((2015) ), 701–712. |
[25] | Liao H.C. , Wu X.L. , Liang X.D. , Yang J.B. and Xu D.L. , Continuous interval-valued linguistic ORESTE method for multi-criteria group decision making in mobile design, Knowledge Based Systems 153: ((2017) ), 65–77. |
[26] | Chen Z.S. , Chin K.S. , Mu N.Y. , Xiong S.H. , Chang J.P. and Yang Y. , Generating hflts possibility distribution with an embedded assessing attitude, Information Science 394: ((2017) ), 141–166. |
[27] | Wu Z.B. and Xu J.P. , Possibility distribution-based approach for magdm with hesitant fuzzy linguistic information, IEEE Transactions on Cybernetics 46: ((2016) ), 694–705. |
[28] | Wu X.L. , Liao H.C. , Xu Z.S. , Hafezalkotob A. and Herrera F. , Probabilistic linguistic MULTIMOORA: Multi-criteria decision making method based on the probabilistic linguistic expectation function and the improved Borda rule, IEEE Transactions on Fuzzy Systems 26: ((2018) ), 3688–3702. |
[29] | Zhang Y.X. , Xu Z.S. , Wang H. and Liao H.C. , Consistency-based risk assessment with probabilistic linguistic preference relation, Applied Soft Computing 49: ((2016) ), 817–833. |
[30] | Gao J. , Xu Z.S. , Liang Z.L. and Liao H.C. , Expected consistency-based emergency decision-making with incomplete probabilistic linguistic preference relations, Knowledge-Based Systems 176: ((2019) ), 15–28. |
[31] | Liao H. , Xu Z. , Herrera-Viedma E. et al., Hesitant Fuzzy Linguistic Term Set and Its Application in Decision Making: A State-of-the-Art Survey, International Journal of Fuzzy Systems 20: ((2018) ), 2084–2110. |
[32] | Yager R.R. , An approach to ordinal decision making, International Journal of Approximate Reasoning 12: ((1995) ), 237–261. |
[33] | Xu Z. , Deviation measures of linguistic preference relations in group decision making, Omega 33: ((2005) ), 249–254. |
[34] | Xu Z.S. , Linguistic decision making: theory and methods (Springer Publishing Company, Incorporated, 2013) |
[35] | Xu Z.S. and Wang H. , On the syntax and semantics of virtual linguistic terms for information fusion in decision making, Information Fusion 34: ((2016) ), 43–48. |
[36] | Zhang G. , Dong Y. and Xu Y. , Consistency and consensus measures for linguistic preference relations based on distribution assessments, Information Fusion 17: ((2014) ), 46–55. |
[37] | Chu T.C. and Tsao C.T. , Ranking fuzzy numbers with an area between the centroid point and original point, Computers & Mathematics with Applications 43: ((2002) ), 111–117. |
[38] | Hao M. and Kang L. , A method for ranking fuzzy numbers based on possibility degree, Mathematics in Practice and Theory 21: ((2011) ), 209–213. |
[39] | Xu Z. , A method for multiple attribute decision making with incomplete weight information in linguistic setting, Knowledge-Based Systems 20: ((2007) ), 719–725. |
[40] | Gou X. and Xu Z. , Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets, Information Science 372: ((2016) ), 407–427. |
[41] | Alkemade N. , Bowden S.C. and Salzman L. , Scoring Correction for MMPI-2 Hs Scale with Patients Experiencing a Traumatic Brain Injury: A Test of Measurement Invariance, Archives of Clinical Neuropsychology 30: ((2015) ), 39–48. |
[42] | Olerud C. and Molander H. , A scoring scale for symptom evaluation after ankle fracture, Archives of orthopaedic and traumatic surgery 103: ((1984) ), 190–194. |
[43] | Water security evaluation based on the TODIM method with probabilistic linguistic term sets, Soft Computing 23: ((2019) ), 6215–6230. |
[44] | Life satisfaction evaluation in earthquake-hit area by the probabilistic linguistic GLDS method integrated with the logarithm-multiplicative analytic hierarchy process, International Journal of Disaster Risk Reduction 38: ((2019) ), 101–190. |
[45] | Liu Y. , Rodríguez R.M. , Hagras H. et al., Type-2 fuzzy envelope of hesitant fuzzy linguistic term set: a new representation model of comparative linguistic expression, IEEE Transactions on Fuzzy Systems 27: ((2019) ), 2312–2326. |


