
Neuro-distributed cognitive adaptive optimization for training neural networks in a parallel and asynchronous manner
Abstract
Distributed Machine learning has delivered considerable advances in training neural networks by leveraging parallel processing, scalability, and fault tolerance to accelerate the process and improve model performance. However, training of large-size models has exhibited numerous challenges, due to the gradient dependence that conventional approaches integrate. To improve the training efficiency of such models, gradient-free distributed methodologies have emerged fostering the gradient-independent parallel processing and efficient utilization of resources across multiple devices or nodes. However, such approaches, are usually restricted to specific applications, due to their conceptual limitations: computational and communicational requirements between partitions, limited partitioning solely into layers, limited sequential learning between the different layers, as well as training a potential model in solely synchronous mode. In this paper, we propose and evaluate, the Neuro-Distributed Cognitive Adaptive Optimization (ND-CAO) methodology, a novel gradient-free algorithm that enables the efficient distributed training of arbitrary types of neural networks, in both synchronous and asynchronous manner. Contrary to the majority of existing methodologies, ND-CAO is applicable to any possible splitting of a potential neural network, into blocks (partitions), with each of the blocks allowed to update its parameters fully asynchronously and independently of the rest of the blocks. Most importantly, no data exchange is required between the different blocks during training with the only information each block requires is the global performance of the model. Convergence of ND-CAO is mathematically established for generic neural network architectures, independently of the particular choices made, while four comprehensive experimental cases, considering different model architectures and image classification tasks, validate the algorithms’ robustness and effectiveness in both synchronous and asynchronous training modes. Moreover, by conducting a thorough comparison between synchronous and asynchronous ND-CAO training, the algorithm is identified as an efficient scheme to train neural networks in a novel gradient-independent, distributed, and asynchronous manner, delivering similar – or even improved results in Loss and Accuracy measures.
1.Introduction
1.1General
Highly advanced Artificial Intelligence (AI), along with its associated sub-disciplines like machine learning (ML), paved the way for a wide range of real-world applications in sectors such as visual recognition systems, language understanding, automated translation techniques, and robotic innovations [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]. In recent years, the most prominent sub-field of machine learning (ML), Artificial Neural Networks (ANNs), have been widely and effectively utilized to transform technological advancements and elevate both businesses and daily life towards a new stage of AI sophistication [19, 20, 21, 22, 23, 24, 25].
ANNs are layered mathematical models capable of extracting semantic meaning and patterns from complex data. By simulating the biological nervous system through algorithmic training, these computational structures excel at learning, identifying hidden patterns, detecting interrelations, clustering, classifying, and uncovering anomalies. DNNs, a type of ANN, handle intricate, high-dimensional information using interconnected layers of nodes. They address more challenging problems by providing increased depth and complexity of data processing compared to traditional ANN structures. DNNs have rapidly revolutionized problem-solving and our interaction with technology [26]. Some important groundbreaking DNN implementations concern healthcare [27, 28, 29] structural safety [30, 31], traffic incident detection [32, 33], facial recognition [25, 34], predictive analytics [35, 36], and personalized medical diagnosis [37, 38, 39, 40, 41].
Deep neural networks (DNNs) however require a more challenging training procedure, than traditional artificial neural networks (ANNs) because of the increased depth and complexity of the network architecture. To this end, novel distributed machine learning approaches have been utilized in order to enable the distributed computation of different parts of the model on separate devices, reducing memory requirements and enabling scalability to handle complex models with limited resources. The conventional approach to effectively train such sophisticated models was the utilization of gradient-based distributed algorithms [42]. However, despite the huge success and the wide applicability of gradient-based methodologies, their efficiency is prohibited by their gradient dependency, especially in cases where deep and scaled-up ANN architectures are considered. Such challenges most commonly arise from the following factors:
• Dependency among layers and Difficulty for parallelism: Gradient-based approaches typically utilize back-propagation for updating the parameters of the ANN which prohibits the parallel calculation of the gradients that belong to different layers: the gradient computations of the layer parameters strongly depend on the computations of the previous layers, prohibiting the parallel updating of the parameters. To this end, the computational process needs to take place in a sequential mode where the calculation of parameters of one layer starts only when the calculations of the previous layer have been finalized, prohibiting a more computationally and timely efficient parallel/distributed learning process. This dependency may lead to slow training and convergence rates, especially in large ANNs, as well as memory and computational inefficiencies, especially when training large datasets are involved [43].
• Computational and Communicational Requirements: In ANN applications, memory limitations, and communication constraints can arise when handling activation values, derivatives, and weight adjustments across the neural network. To maintain weights and compute errors efficiently, a significant storage capacity is required, often in the range of hundreds of megabytes or even gigabytes. This necessitates using multiple CPU and GPU devices in pipelined ANNs, as on-chip memory alone may be insufficient [44]. Transferring data between different hardware devices becomes necessary, even in custom accelerators that solely focus on feed-forward execution. Such accelerators rely on external memory for loading weights and storing intermediate activation functions [45, 46, 47, 48]. Furthermore, the increasing scale of datasets and ANN parameters in machine learning and deep learning applications call for high-performance specialized equipment like powerful GPUs. Training large-scale frameworks and optimizing hyperparameters require substantial effort, time, and energy, which can be expensive. Gradient-based methodologies, given their distribution of information across computational machines and optimization of non-convex objectives, reinforce the need for specific and costly hardware resources [49]. Overall, the challenges posed by memory limitations, data transfer, and the demands of large-scale frameworks emphasize the requirement for specialized and high-performance equipment in ANN training.
• Topological Distribution: Stretching across the entire edge-to-cloud continuum, including the cloud, the edge (fog), and ultimately reaching the end-devices, suggestions have been put forth for ANNs utilizing distributed architectures recently [50]. Such architectures may even result in an actual geographical distribution where parts of the ANN are located in different geographic locations [51]. In this case, the conventional Gradient-based approaches that utilize the back-propagation algorithm, obviously preserve limitations, since updating the parameters requires a part-by-part (or location-by-location) approach following the layer dependency limitation.
• Non-analytic Scenarios: In general, gradient-based methodologies are applicable when an analytic formula of the cost function and its gradient are available. There are certain applications such as sensor networks [52], neural network control [53, 54], adaptive fine-tuning of large-scale control systems [55, 56] or embedding autonomy in large-scale IoT ecosystems [57] where analytic forms of the cost function and its gradient are not available and, thus the implementation of gradient-based methodologies is not possible. In these situations, traditional methods of gradient-based optimization, such as gradient descent, cannot be directly applied. Instead, alternative approaches need to be considered to estimate or approximate the gradient
To overcome the above shortcomings, distributed, gradient-free training methods have been proposed, widely analyzed, and evaluated in literature [42, 31, 58, 59]. Such frameworks enable efficient, robust, and large-scale training of deep neural networks adding improved computational scalability. By utilizing parallelism across multiple devices, scientists increased robustness to noisy data, and enhanced their ability to escape local minima, aiming towards global optimization solutions. This paper concerns the introduction and evaluation of the Neuro-Distributed Cognitive Adaptive Optimization Methodology (ND-CAO) for Training Artificial Neural Networks (ANN). Acting as a proof-of-concept current research work introducing the algorithm to literature and indicating its unique attributes towards the gradient-independent and asynchronous distributed training of Neural Networks. Apart from introducing the algorithm and its novelty, the current work integrates a detailed experimental section of 3 simulation cases – 15 simulation scenarios overall – for the evaluation of ND-CAO in asynchronous mode. The algorithm has been put to a test under various neural network architectures considering different datasets that concerned image classification applications (FNN/MNIST, FNN/Fashion MNST, CNN/MNIST, CNN/CIFAR10). ND-CAO exhibited its adequacy in every case scenario – even in cases where a substantial number of network blocks – nodes and parameters – acted asynchronously.
1.2Paper architecture
The paper may be summarized as follows: Section 1 concerns the description of the current status of distributed training of neural networks, along with the challenges arising from the gradient dependence that conventional approaches integrate. In Section 2 a detailed Literature work, considering the novel distributed gradient-free methodologies is illustrated, along with their limitations arising from the current implementations found in the literature. Next, in Section 3, the Novelty of ND-CAO is assessed illustrating the unique attributes of the examined scheme. This section integrates also the potential applications that ND-CAO methodology may serve, based on its novel attributes. Section 4 considers the description of each experiment case setup along with the evaluation of the algorithm’s training adequacy. Comparison between synchronous and asynchronous scenarios for every case is being assessed and followingly, the primary verdicts are being illustrated. Section 5 concerns the final conclusions and also the future potential arising from ND-CAO creation toward challenging deep learning applications.
2.Literature work
According to the literature, two primary classes of methodologies are thoroughly examined in order to provide both gradient-free as well as distributed machine learning in Neural Networks: BCD-Block coordinates descent variants and ADMM-Alternating Direction Method of Multipliers variants.
2.1Gradient-Free Block Coordinate Descent (GF-BCD)
According to Gradient Free BCD methodology, the neural network is divided into segments in non-convex optimization strategies, which serve as an example of a straightforward iterative algorithmic approach. By maintaining the other coordinates fixed, the algorithm sequentially strives to minimize the objective function within each block coordinate.; see e.g. [60]. Many different GF-BCD methodologies have been proposed for training ANNs, see e.g. [61, 62, 63, 64, 65, 66]. The convergence of GF-BDC algorithms, when applied to different types of ANNs, has been extensively studied. For instance, a GF-BCD methodology concerning Tikhonov regularized deep neural network by [63] that employs ReLU activation functions can be established using the results of [67]. As concerns other activation functions, [64] and [65] manage to improve the lifting trick – originally introduced in [63] towards multiple reversible activation functions but the aforementioned practices haven’t presented convergence guarantees for any of their schemes. As concerns as other efforts, the GF-BCD-based algorithm utilized in [68] converges to stationary points globally. Another GF-BCD-based algorithm, suitable for distributed optimization, namely Parallel Successive Convex Approximation (PSCA), was suggested in [69], exhibiting adequate convergence as well. Similarly, in more recent research, GF-BCD utilized for training Tikhonov Regularized ANNs, exhibited its global convergence to stationary points using R-linear convergence [63].
2.2Gradient-Free Alternating Direction Method of Multipliers (GF-ADMM)
Developed in the 1970s, the ADMM methodology represents a proximal-point optimization framework that has been recently popularized by Boyd et al. [70] for distributed machine learning applications. During its operation, the algorithm separates the problem into loosely-coupled sub-problems and since some of them may be addressed separately, it establishes parallelization. Gradient-free versions of the ADMM algorithm achieve linear convergence for solely convex problems, and can also address specific non-convex optimization problems [71, 72]. So far though, there is no mathematical proof or evidence that ANN training is one of these non-convex optimization problems. Thus, even if it has been experimentally utilized towards ANN training [49, 73], there is still a lack of concern about its convergence guarantee. As concerns the latest distributed machine learning implementations regarding GF-ADMM, they are following two tendencies deepened by synchronicity [74]: a) Synchronous problems: this approach commonly demands computational machines to optimize the ANN parameters timely, before the global update of the consensus variable: researchers in [75] suggested the application of distributed GF-ADMM in order to address the congestion control issue; while in [76] integrates an analysis concerning the convergence characteristics of the distributed GF-ADMM in relation to network communication challenges. Another research effort considering synchronous problems addressed by the distributed GF-ADMM is referred in [77, 78, 79, 80, 81]; b) Partly asynchronous problems: in this approach, a number of computational machines are allowed to hold the update of the parameters of the ANN. Additionally, the convergence of distributed GF-ADMM was successfully evaluated towards asynchronous problems in [82, 83, 84]. Another recent important research concerns Kumar et al. where distributed GF-ADMM addressed multi-agent problems over heterogeneous networks [85]. We might say that the majority of the potential research efforts are utilizing distributed GF-ADMM toward synchronous problems. Nevertheless, there is still a lack of a generalized scheme for GF-ADMM for training ANN in a distributed fashion [74].
2.3Limitations of gradient-free distributed methodologies
However, while gradient-free distributed methods may provide useful solutions in certain situations their applicability presents multiple limitations:
• Topology restrictions: It is noticeable that the majority of the existing approaches in the literature are applicable only when each of the blocks/partitions corresponds to a specific layer of the ANN. In other words, the majority of the existing algorithms consider that each of the ANN’s layers is a separate partition, assigning a computational machine to each of the layers. This separation may be sometimes problematic since (a) machines with different computational capabilities may be available, in which case, splitting the ANN into partitions that correspond to exactly one layer maybe not be efficient and (b) there may be cases – e.g., the case of geographically distributed ANNs – where the one-to-one correspondence between blocks and layers may be not suitable.
• Limited parallelism: Both distributed approaches update parameters one block at a time, which can limit the level of parallelism that can be achieved during training. This can be particularly problematic for large-scale problems or deep neural networks that require a significant amount of computation. Most of the existing approaches in the literature illustrate sequential training for the parameters of each layer for updating their values. For instance, in many cases, a specific layer is allowed to update its parameters only if its previous block/layer has completed its update. The requirement of following a specific sequence in the updating of the layers (or partitions) leads to delays in the overall training procedure which could have been avoided if a fully asynchronous training algorithm would be available, i.e., an algorithm where each of the blocks updates their parameters independently of what is happening to the rest of the blocks.
• Communication demand: Typically the gradient-free distributed algorithms for ANN training require a significant amount of data exchange between the different layers to accomplish the update tasks. This may be a severe drawback, especially in cases where a hardware implementation of the training procedure is required.
• Computational demand: The training procedure employed in each of the blocks is quite computationally expensive which, sometimes, leads the ANN users to prefer using centralized approaches which employ less computationally expensive schemes. To this end, converge is slow, especially when dealing with non-convex loss functions. This can be a disadvantage when training large-scale or complex models, where fast convergence is critical.
• Lack of flexibility: Distributed, gradient-free me-thodologies are usually designed for specific types of problems, and may not be well-suited to problems with irregular or complex structures. It is noticeable, that the convergence of gradient-free, distributed algorithms has been mathematically established for a specific type of ANNs (e.g., ANNs with specific activation functions).
Overall, while both approaches provide useful optimization for training neural networks in certain scenarios, do not portray a one-size-fits-all solution, and their efficiency depends on the specific problem being solved. When splitting an ANN into blocks, it’s important to consider the communication and synchronization between the blocks to ensure convergence and coordination. Techniques such as parameter exchange, consensus algorithms, or periodic updates can be employed to facilitate cooperation among the blocks and minimize any negative impact on overall performance. The choice of how to split an ANN into blocks depends on the specific problem, the available computational resources, and the desired trade-offs between parallelism, coordination, and communication overhead.
3.Novelty and contribution of neuro-distributed cognitive adaptive optimization (ND-CAO)
3.1Novelty attributes
In this paper, we introduce the Neuro-Distributed Cognitive Adaptive Optimization (ND-CAO) methodology for gradient-free, distributed training of arbitrary scale ANNs. Based on an already well-evaluated distributed optimization algorithm – namely Local4Global CAO (L4GCAO) algorithm [57, 86, 56, 55, 87, 88, 89, 90, 91] for embedding autonomy in large-scale IoT ecosystems, ND-CAO application has as its primary aim to overcome several shortcomings of the already evaluated gradient-free distributed algorithms and also to provide a novel distributed framework suitable also for asynchronous training of Neural Networks. An important feature of the algorithm is grounded on the limited communicational requirements that the ND-CAO scheme requires. Contrary to distributed algorithmic schemes that demand the exchange of information between the different network blocks, ND-CAO updates its network block parameters towards global error minimization – to this end, no data exchange is required between the different blocks during training. The only information each block requires is the global performance of the model. Consequently such an attribute unlocks two primary attributes of ND-CAO operation:
3.1.1ND-CAO potential for asynchronous and distributed training of each network block
An attribute that has not been tested in literature – at least on model parallel terms. This paper is primarily focused on illustrating ND-CAO adequacy in training an ANN in asynchronous mode since such scheme evaluation is significantly limited in literature in comparison to conventional synchronous approaches. However, we prove that such an attribute is adequate to provide several benefits over synchronous training. For example, it is adequate to improve the speed of training as the network blocks can update the model weights independently and in parallel. Additionally, it can handle scenarios where the blocks need different computing capabilities or network bandwidth, as each block can work at its own pace without waiting for others. To this end, asynchronous training is potentially more scalable and efficient for large neural networks – especially when the model is too large to fit into a single processor’s memory – facts that are also being identified by concerned simulation experiments in various datasets and neural network architectures. However, it’s important to note that asynchronous training can be more challenging than conventional synchronous training since the updates from different blocks can interfere with each other and lead to sub-optimal results: it may require more careful tuning of the algorithm parameters to ensure convergence and avoid interference between nodes. However, according to the integrated results of the current simulation experiments – 15 in total – such a phenomenon does not take place when ND-CAO is applied since convergence is achieved in every case scenario.
3.1.2ND-CAO adequacy to support every neural network distribution scheme
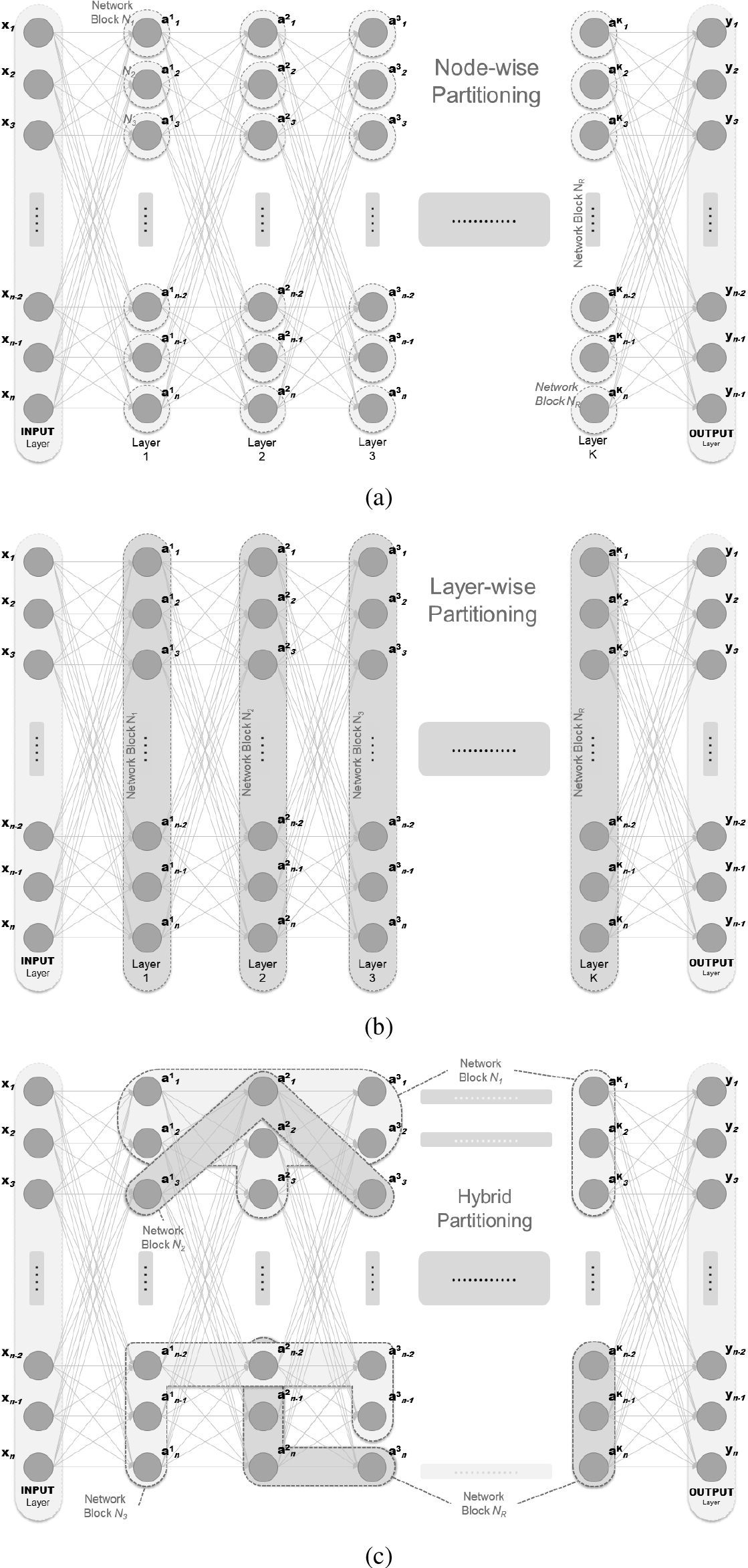
Splitting an Artificial Neural Network (ANN) into blocks or partitions can be done in different ways based on various factors such as network architecture, computational resources, and problem characteristics. To this end, the most common approach is to split the network by grouping layers into blocks (Layer-wise), or even into individual nodes or neurons (Node-wise). This approach can be useful when the computational resources are limited or when specific parts of the network require more parallelization. Each block would contain a subset of nodes and their corresponding connections would be limited to the nodes within the same block. Moreover dividing the network’s towards its parameters or weights into separate parts, each associated with a specific block or partition is another option (Parameter-wise). Such distribution may lead to improved scalability, reduced computational burden, and faster training times. However, the effectiveness of partitioning strategies depends on factors such as problem complexity, network architecture, and the communication and coordination mechanisms employed. Moreover, if the model performs multiple tasks or has multiple outputs, one may consider partitioning the network based on the tasks (Task-wise). Each block would focus on a specific task, allowing for independent training and optimization. Last but not least, a combination of the above approaches might be suitable. The model may be partitioned at multiple levels, such as layer-wise partitioning within each block and node-wise partitioning within certain layers. This can provide flexibility and customization based on the specific requirements of the problem. Based on Fig. 1 Neural Network, Fig. 2 Illustrates Node-wise, Layer-wise as well as Hybrid-wise partitioning. It should be mentioned that for simplicity reasons the number of nodes per layer has been considered the same and equal to
All and all, the novelty attributes of the proposed algorithm may be summarized as follows:
• ND-CAO is applicable to any possible splitting of ANN into blocks/partitions.
• Each of the blocks is allowed to update its parameters fully asynchronously and independently of the rest of the blocks/partitions.
• Most importantly, no data exchange is required between the different blocks during training. The only information each block requires from “outside” is the global performance of the ANN.
• The training of each block is accomplished using a computationally inexpensive least-squares algorithm.
• Convergence of the ND-CAO is mathematically established for generic ANNs architectures, independently of the particular choices made for e.g., activation functions, etc. More precisely, it is shown that ND-CAO behaves approximately the same as asynchronous gradient-based BCD which was shown to converge to the same points as the ones of conventional fully centralized back propagation.
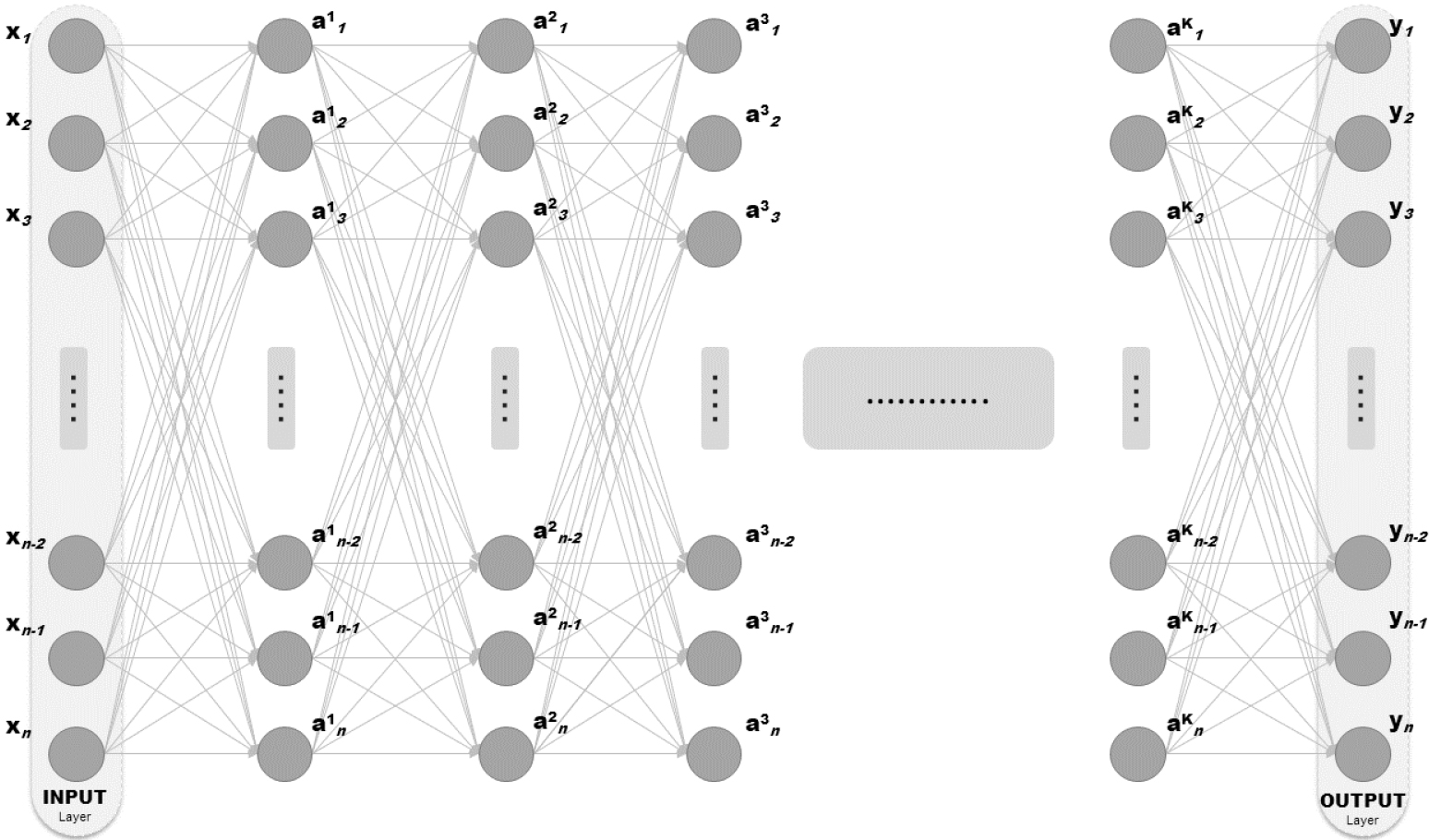
Figure 1.
Feed-forward ANN architecture.
ND-CAO aim represents the first approach that supports a distributed and also asynchronous training of Neural Networks. Except from illustrating a novel concept and mathematic methodology, this work illustrates also the adequacy of the algorithm for efficient distributed asynchronous training and indicates that such training scheme may be significantly beneficial in comparison to the conventional synchronous training scheme, using simulation results – at least as concerns the ND-CAO training scheme.
3.2Potential applications
Grounded on its unique novelty attributes ND-CAO training may prove a beneficial approach towards distributed model parallel training of large-scale models in image classification, natural language processing, financial forecasting applications, and more. However, ND-CAO scheme integrates a gradient-independent distributed and asynchronous training scheme, a unique attribute suitable to overcome the challenges of data exchange between geographically distributed models. Such particular frameworks require training each partition independently and updating its local model parameters based on local or global data or processing capabilities. It is envisaged that ND-CAO Asynchronous training is adequate to offer advantages in terms of scalability, privacy, and performance by reducing the reliance on continuous and synchronous data exchange between distributed locations. Such real-life frameworks may concern: a) Distributed IoT applications: where Neural networks are deployed on interconnected devices in various locations. ND-CAO asynchronous training enables efficient local model training without continuous data exchange between the sub-models; b) Multi-Cloud applications: Partitioned neural networks trained across diverse cloud environments across different geographical locations. ND-CAO asynchronous training allows independent updates limiting considering network latency and data transfer costs; c) Collaborative Research Applications: Multiple institutions contribute to a shared neural network model. ND-CAO Asynchronous training allows independent updates without constant real-time synchronization between the Network Blocks of the shared neural network; d) Federated Learning applications: Decentralized training on devices or servers in different locations. Local models are trained and aggregated to create a global model. ND-CAO distributed asynchronous updates may accommodate varying network conditions; e) Distributed Data Centers applications: Neural networks distributed across multiple data centers in different regions. ND-CAO Asynchronous training also independent updates considering network latency and limited bandwidth; f) Privacy-Preserving Learning applications: Data partitioned across geographic locations to ensure privacy. ND-CAO Asynchronous training enables local model updates without sharing raw data between different locations; g) Edge Computing applications: Neural networks on edge devices closer to a data source. ND-CAO asynchronous training is adequate to enable independent updates considering limited resources and intermittent connectivity.
Figure 2.
Examples of splitting an ANN into Neural Blocks (NBs). (a) Node-wise Partitioning: presents the partition of the NN that every NB corresponds to a node of the model; (b) Layer-wise Partitioning: presents the partition of the NN that every NB corresponds to a Layer of the model (K
4.The ND-CAO algorithm
4.1The set-up
We consider a quite standard ANN supervised learning setup. The ANN architecture is shown in Fig. 1 (for simplicity, we assume that the ANN has only feed-forward connections; the extension to the case where feedback connections are also present, is straightforward). Also, for simplicity the ANN shown in Fig. 1 is assumed to have equal number of nodes at each layer; the extension to the case of layers with different number of nodes is straightforward. The ANN of Fig. 1 has
(1)
where
with
4.2ANN “break-down” into Neural Blocks (Asynchronous Agents)
Let us now assume that the overall ANN of Fig. 1 is “broken-down” into
• A synaptic weight
• There is no synaptic weight that does not belong to one of the NBs
The above two properties for splitting the ANN into
• from the extreme case where we have as many NBs as neurons, i.e., the case where each neuron is an NB, see e.g., Fig. 2(a);
• the case where each layer is an NB, see e.g., Figure 2(b);
• the cases where each NB consists of two or more layers;
• down to cases each NBs may be constructed by randomly picking synaptic weights across the ANN, see e.g., Fig. 2(c);
• and, many other configurations.
Given the above definition of NBs, let us define
4.3The learning algorithm
Consider each of the NB’s
The first key element of our approach is that each of the NBs is associated with an estimator which attempts – using only information available at the NB-level – to estimate the error (or, equivalently, the output) of the overall ANN.
More precisely, let
(2)
where
The purpose of the estimator (2) is to estimate the value of the global cost function
For this reason, the choice of
• The vector
(3)
where
Problem (3) is a standard linear-least squares problem and can be solved using computationally inexpensive realizations of its least-squares solution:
(4)
where
As it was shown in [92], it is sufficient for learning algorithms like NDCAO that employ estimators of the form (2), to approximate locally the global cost function. As this global cost function is a quadratic one, it is sufficient to use linear and second-order terms for its local approximation. For this reason, the nonlinear vector function comprises
The second key element in our approach is to employ – at its NB level and totally asynchronously with respect to the rest of the NBs – the estimator (2) to test different perturbations of the current value of the synaptic weights and pick the one that produces the “best” estimate/prediction for the global cost function. The overall methodology combining the two key elements of the methodology is summarized in Algorithm 1.
We proceed with the convergence analysis of the algorithm. We have the following theorem.
Theorem 1. At each time-instant
Remark 1. In simple words, Theorem 4.3 establishes that the ND-CAO algorithm behaves similarly to asynchronous gradient-based BCD “disturbed” by the term
Remark 2. As it has been established in many different papers – see e.g. [93] and the references therein – asynchronous gradient-based BCD converges to the same points as the ones of conventional fully-centralized backpropagation. Therefore, Theorem 4.3 establishes convergence of the ND-CAO algorithm the same points as the ones of conventional fully-centralized back propagation:
| Algorithm 1: Asynchronous ND-CAO Algorithm |
|---|
| Definitions/Initializations: |
|
|
|
| |
• for any possible splitting of ANN into Neural Blocks (NBs), including even blocks elements may be totally disconnected;
• with each of the NBs allowed to update their parameters fully asynchronously and independently of the rest of the NBs;
• no data exchange is required between the different blocks during training with the only information each block requires from “outside” is the global performance of the ANN;
• The training of each NB is accomplished using a computationally inexpensive least-squares algorithm.
Proof of Theorem 1: A brief outline of the proof is given, as its derivation closely mirrors the proof process of Theorem 2 of [57], by simply performing the following “time-transformation”: consider a sufficiently small
for some nonlinear function
Combining the two above equations, we establish the proof.
5.Experimental evaluation of ND-CAO asynchronous training
Table 1
Use case description and setup features
| Case | Dataset | Input shape | Model type | Model architecture | Weights | Partitioning scheme | Asynchronous agents | Epochs |
|---|---|---|---|---|---|---|---|---|
| I | MNIST | 28 | FNN | 32 | 320 | Node-wise: 1 Agent/Node | 0, 10, 20, 30, 40 | 5000 |
| II | Fashion MNIST | 28 | FNN | 32 | 672 | Parameter-wise: 1 Agent/Node | 0, 10, 20, 30, 40, 50, 55 | 1000 |
| III | MNIST | 28 | CNN | 32 | 25258 | Parameter-wise: 1 Agent/1000 Weights | 0, 10, 20, 30, 40 | 2500 |
| IV | CIFAR10 | 32 | CNN | 32 | 25258 | Parameter-wise: 1 Agent/1000 Weights | 0, 10, 20, 30, 40 | 2500 |
In this section, we examine ND-CAO adequacy in training neural networks of different architectures, towards image classification problems, giving also emphasis on asynchronous mode training. Asynchronous training can provide several benefits over synchronous training, especially towards a distributed model. For example, it can improve the speed of training as the blocks can update the model weights independently and in parallel. Additionally, it can handle scenarios where the blocks need different computing capabilities or network bandwidth, as each block can work at its own pace without waiting. Before proceeding to the detailed description of the four experimental Cases and their integrated simulations, it is appropriate to describe some initial conditions and frameworks that served equally the procedures in order to implement the experiments. Table 1 describes at a high level the four experimental Cases:
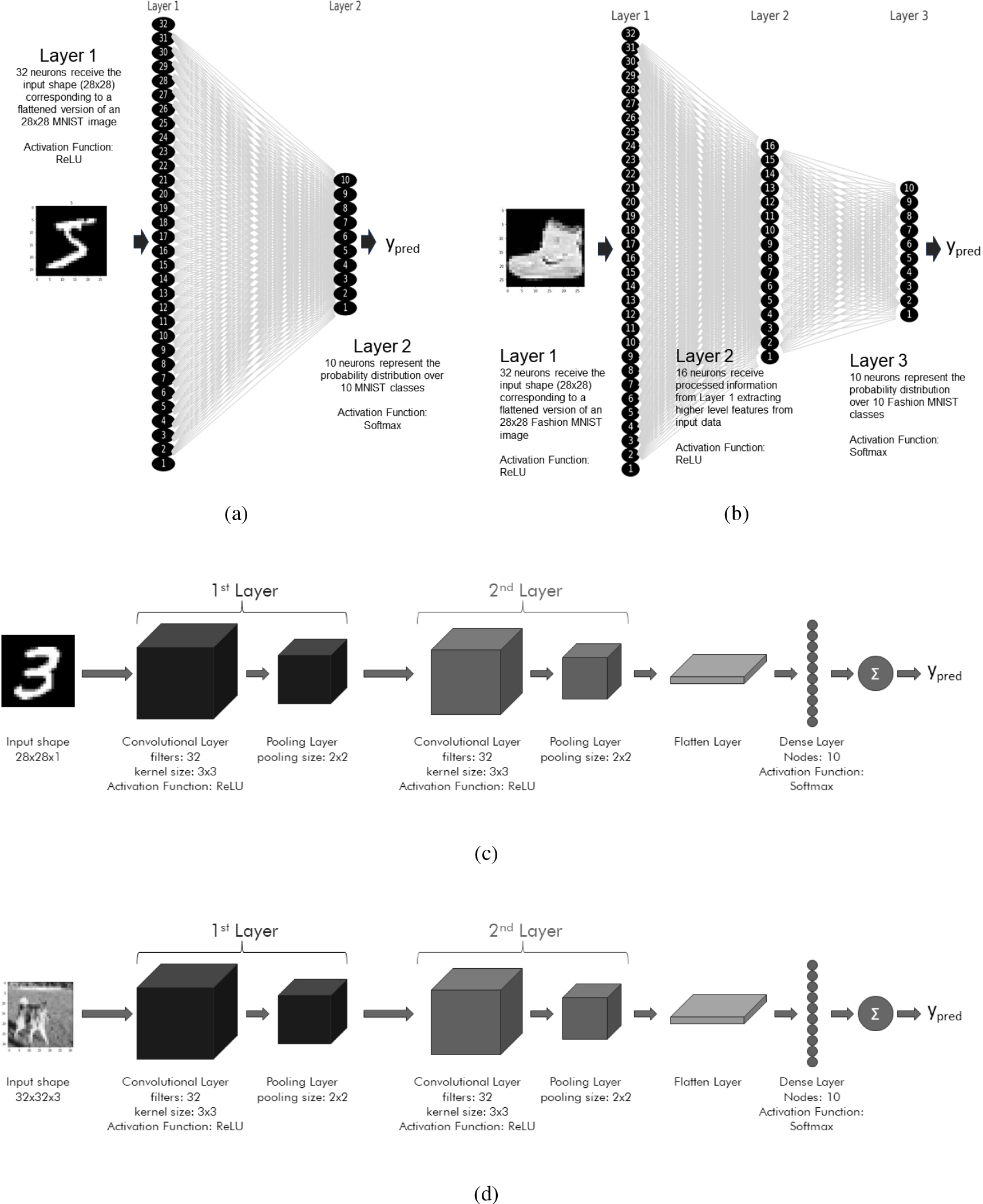
Datasets, model type, architecture, and number of training epochs: Case I concerns an FNN model for addressing the MNIST image classification problem in 5000 epochs, Case II concerns a more demanding FNN model for addressing the Fashion MNIST image classification problem in 1000 epochs, Case III concerns a CNN model for addressing the MNIST image classification problem in 2500 epochs, and Case IV concerns a CNN model for addressing the CIFAR10 image classification problem in 2500 epochs. In Fig. 3 the (a), (b), (c) and (d) subfigures, illustrate the architecture of Case I, Case II, Case III, and Case IV models respectively.
Asynchronous agents: Additionally. we have considered the same following asynchronous training scenarios: at each time instant,
Partitioning scheme: It should be also underlined that in Case I and Case II, the Network Blocks (NBs) have been elected to act as Asynchronous Agents/Nodes (AA) in order to implement a Node-wise Partitioning scheme while in Case III and Case IV, the agents of ND-CAO concern a certain amount of parameters (1000 weights per agent – 42 agents overall) in order to implement a more sophisticated Parameter-wise partitioning scheme. Last but not least, It should be mentioned, that in our work the selection of the asynchronous agents per epoch is taking place in a random manner in order to exhibit the adequacy of our approach to training the networks under totally stochastic conditions. The primary conclusions of the comparison between ND-CAO synchronous and ND-CAO asynchronous training exhibit the adequacy and efficiency of the algorithm.
Hardware and software: As regards the hardware and software equipment it acted equally for all four Cases (4
• Hardware: The computational machine that all experiments took place considered a conventional x64 – based PC setup holding the following characteristics CPU: AMD Ryzen 7 5800X / 8 cores, 3801 Mhz; GPU: NVIDIA GeForce RTX 3060 Ti / 8 GB; RAM: Corsair Vengeance RGB Pro / 32GB;
• Software: The concerned PC was operating Windows 11 Pro. Python 3.8 Code Framework was enabled and acted as the ground for constructing the algorithm and executing all four experimental simulations for ND-CAO evaluation. The Primary Python Machine Learning Libraries that were utilized concerned: numpy, scipy, multiprocessing (mp) module, keras, scikit-learn, pandas and openpyexcel.
Figure 3.
Detailed architecture of the examined Neural Network cases: (a) Case I: Feed-forward NN over MNIST; (b) Case II: Feed-forward NN over Fashion MNIST; (c) Case III: Convolutional NN over MNIST, and (d) Case IV: Convolutional NN over CIFAR10.
The following subsections of the paper describe the Setup of each experimental Case in detail, providing the dataset information, the deployed network architecture, the elected distribution scheme that took place, and the settings of the five experimental scenarios for each Case. Next, after illustrating the training results in Figs 4, 5, and Fig. 6 for Case I, Case II, Case III, and Case IV respectively, a brief Evaluation is conducted for every respective case. The last subsection of the Results Section concerns the final Verdict where fruitful conclusive notes are drawn, considering the training of ND-CAO efficiency in synchronous and asynchronous modes.
5.1Case I: ND-CAO asynchronous training evaluation on FNN – MNIST
The first set of experiments took place, concerning a typical Feedforward ANN of 42 NBs being trained over the MNIST dataset in synchronous and asynchronous modes. The summary of the Use case Description setup may be found under Table 1 – Case I.
5.1.1Setup – Case I
Dataset information: It should be mentioned that the MNIST dataset contains a total of 70,000 data items. These items are split into two main subsets: a training set and a test set. The training set consists of 60,000 handwritten digits from 0 to 9, while the test set contains 10,000 handwritten digits. Each data item in the MNIST dataset represents a 28
Neural Network Architecture: In this case, each NB (Network Block) or ND-CAO agent considers a single ANN neuron. The ANN architecture consists of two dense (fully connected) layers: The first layer is a dense layer with 32 neurons, using the ReLU activation function. This layer takes the input of shape (28
Distribution type and features: This initial scenario concerns a Node-wise Partitioning scheme since Network Blocks (NBs)/Asynchronous ND-CAO Agents (AA) have been elected to act as Asynchronous Nodes. The choice
Experimental scenarios: We have considered the following asynchronous training scenarios, at each time instant, where
5.1.2Evaluation – Case I
Figure 4.
Asynchronous ND-CAO for training FNN towards MNIST: (a) Loss per Epoch, (b) Accuracy per Epoch.
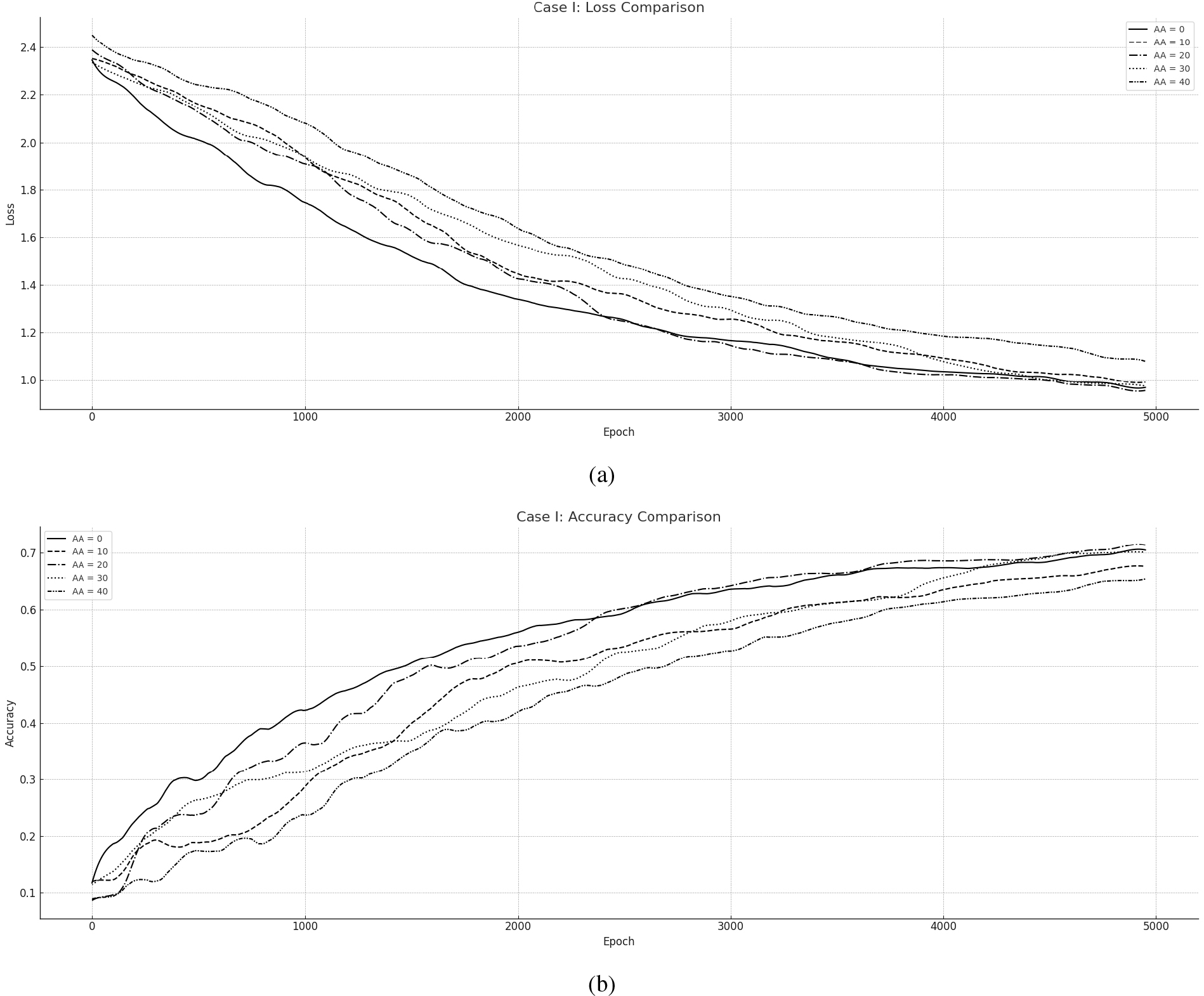
The results overall are presented in Loss and Accuracy measures in Fig. 4: (a) presents the overall Loss during training while (b) Illustrates the Accuracy of the Network. The course of all the training simulations is potentially the same and convergence is guaranteed for each case scenario. The Asynchronous cases (
5.2Case II: ND-CAO asynchronous training evaluation on FNN – Fashion MNIST
The second set of experiments took place, concerning a similar Feedforward NN being trained over the Fashion MNIST dataset in synchronous and asynchronous modes under 1000 Epochs. While the implementation concerns similarly a Node-wise partitioning to Case I, the FNN architecture is more deep and serves a relatively more demanding image classification task by utilizing 58 ND-CAO agents. The primary aim of this implementation is to illustrate the adequacy of ND-CAO training in synchronous and asynchronous modes over a potentially more complicated network, under a more demanding dataset. The summary of the Use case Description setup may be found under Table – Case II.
5.2.1Setup – Case II
Dataset information: Fashion MNIST is a dataset commonly used for image classification tasks. It consists of 60,000 grayscale images of 10 different clothing categories, with each image having a size of 28
Neural network architecture: Similarly to Case I, each NB (Network Block) or ND-CAO agent considers a single NN neuron. The NN architecture consists of three dense (fully connected) layers: The first hidden layer is a dense layer with 32 neurons, using the ReLU activation function. This layer takes the input of shape (28
Distribution type and features: Case II concerns a relatively more demanding Node-wise Partitioning scheme considering 58 nodes overall being updated by 58 Asynchronous ND-CAO Agents (AA). The choice
Experimental scenarios: Similarly the training scenarios have considered the same number of asynchronous agents and one additional of 50 AA (Tirquise line): at each time instant,
5.2.2Evaluation – Case II
Figure 5.
Asynchronous ND-CAO for training CNN towards MNIST: (a) Loss per Epoch, (b) Accuracy per Epoch.
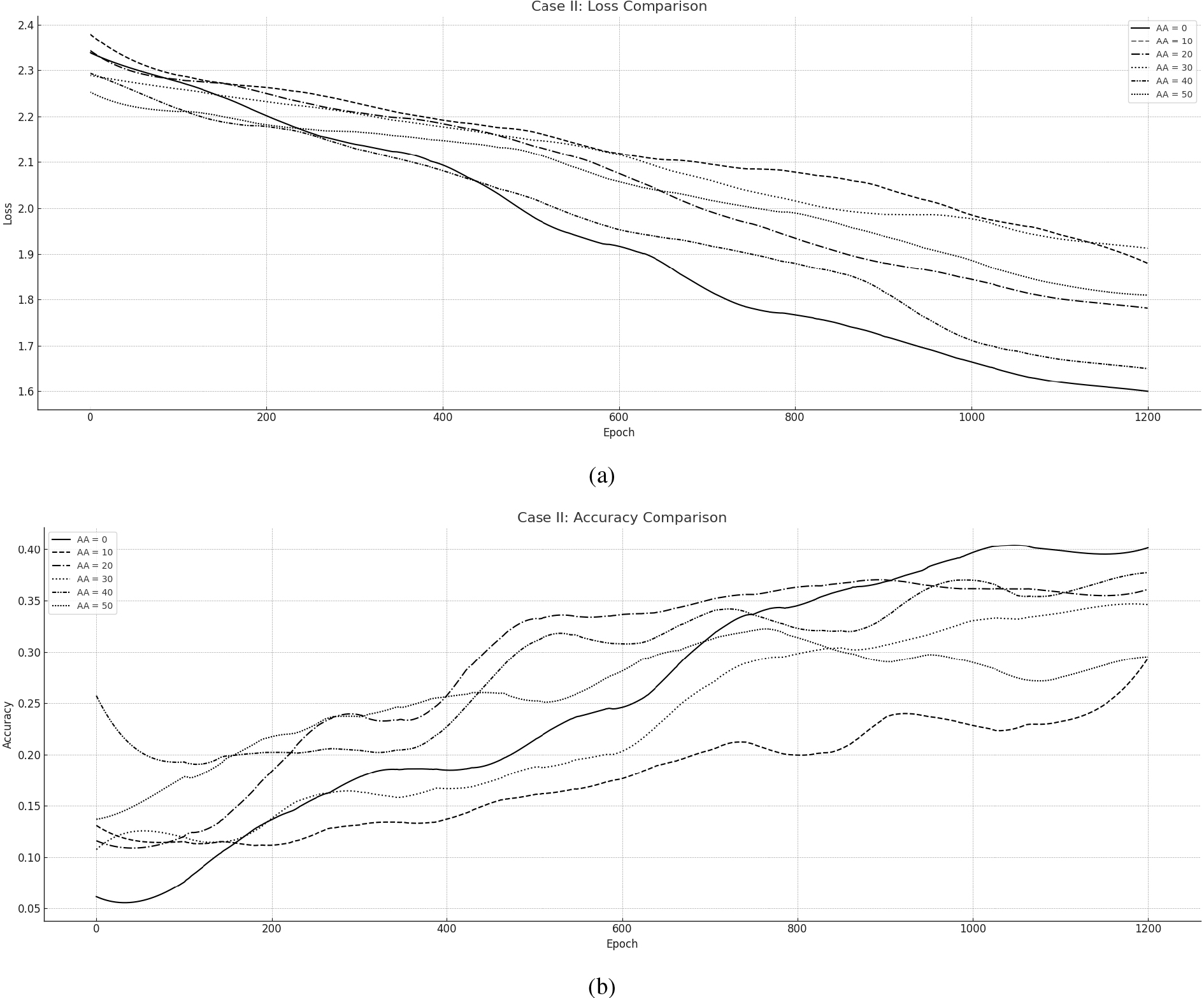
This particular experiment was executed for 1000 epochs revealing also the efficiency of ND-CAO in both synchronous and Asynchronous manner in Fig. 5. Scenario
5.3Case II: ND-CAO asynchronous training evaluation on FNN – Fashion MNIST
The third set of experiments took place, concerning a Convolutional Neural Network (CNN) (32
5.3.1Setup – Case III
Dataset information: The dataset information of MNIST has already give in Case I. However, the architecture and design principles of a CNN portray a potentially well-suited model for image classification tasks like MNIST, allowing to capture spatial information, exploit parameter sharing, handle translation invariance, and learn hierarchical representations, resulting in improved prediction performance.
Neural network architecture: The model portrays a convolutional neural network (CNN) designed for image classification tasks taking as input grayscale images of MNIST (size 28
• Convolutional Layer 1: Number of filters: 32, Kernel size: 3
• Max Pooling Layer 1: Pooling size: 2
• Convolutional Layer 2: Number of filters: 32 (Kernel size: 3
• Max Pooling Layer 2: Pooling size: 2
• Flatten Layer: Converts the output from the previous layer into a 1D vector for input to the dense layers
• Dense Layer: The number of neurons is 10, producing a probability distribution over the 10 possible classes (Activation function: Softmax)
The full Architecture of the FNN is illustrated in Fig. 3(b).
Distribution type and features: In this distribution scheme we have elected to dedicate one ND-CAO agent towards 1000 weights of the neural network. Such Parameter-wise partitioning involves dividing the network’s parameters or weights into separate parts, each associated with a specific block or partition. This partitioning allows different parts of the network to be trained or updated independently while still working towards the common goal of minimizing the overall error.
Experimental scenarios: Similarly to Case I, we have considered the following asynchronous training scenarios, at each time instant,
5.3.2Evaluation – Case III
The results overall are presented in Loss and Accuracy measures in Fig. 6: (a) presents the overall Loss during training while (b) Illustrates the Accuracy of the Network. The course of all the training simulations is potentially the same and convergence is guaranteed for each case scenario. The Asynchronous cases (
Figure 6.
Asynchronous ND-CAO for training CNN towards MNIST: (a) Loss per Epoch, (b) Accuracy per Epoch.
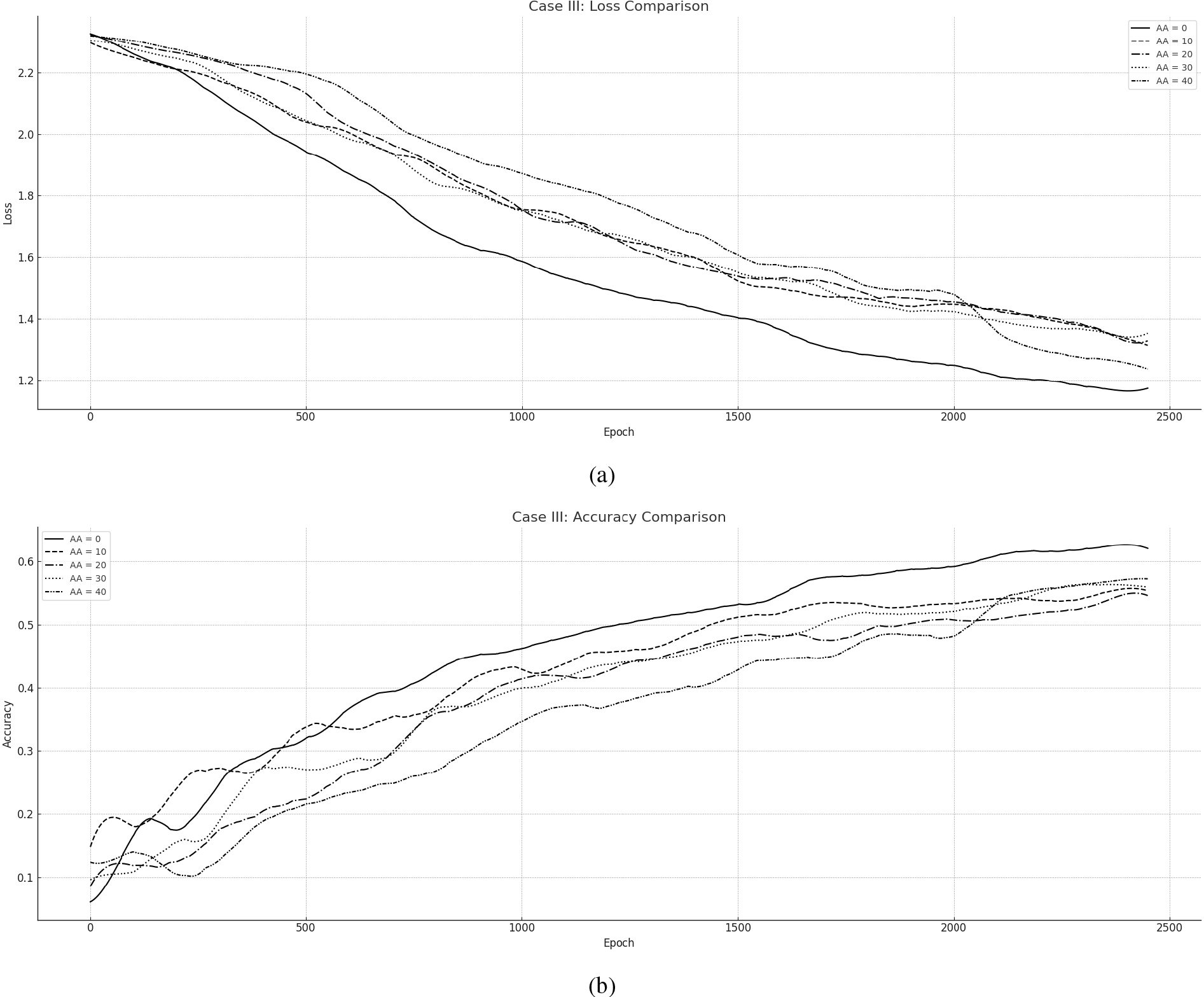
However, the asynchronous cases – and especially the
5.4Case IV: ND-CAO asynchronous training evaluation on CNN – CIFAR10
The fourth set of experiments took place, concerning the same Convolutional Neural Network (CNN) being trained over the more challenging CIFAR10 dataset, in synchronous and asynchronous scenarios. The summary of the second Use case description setup may be found under Table – Case IV.
Figure 7.
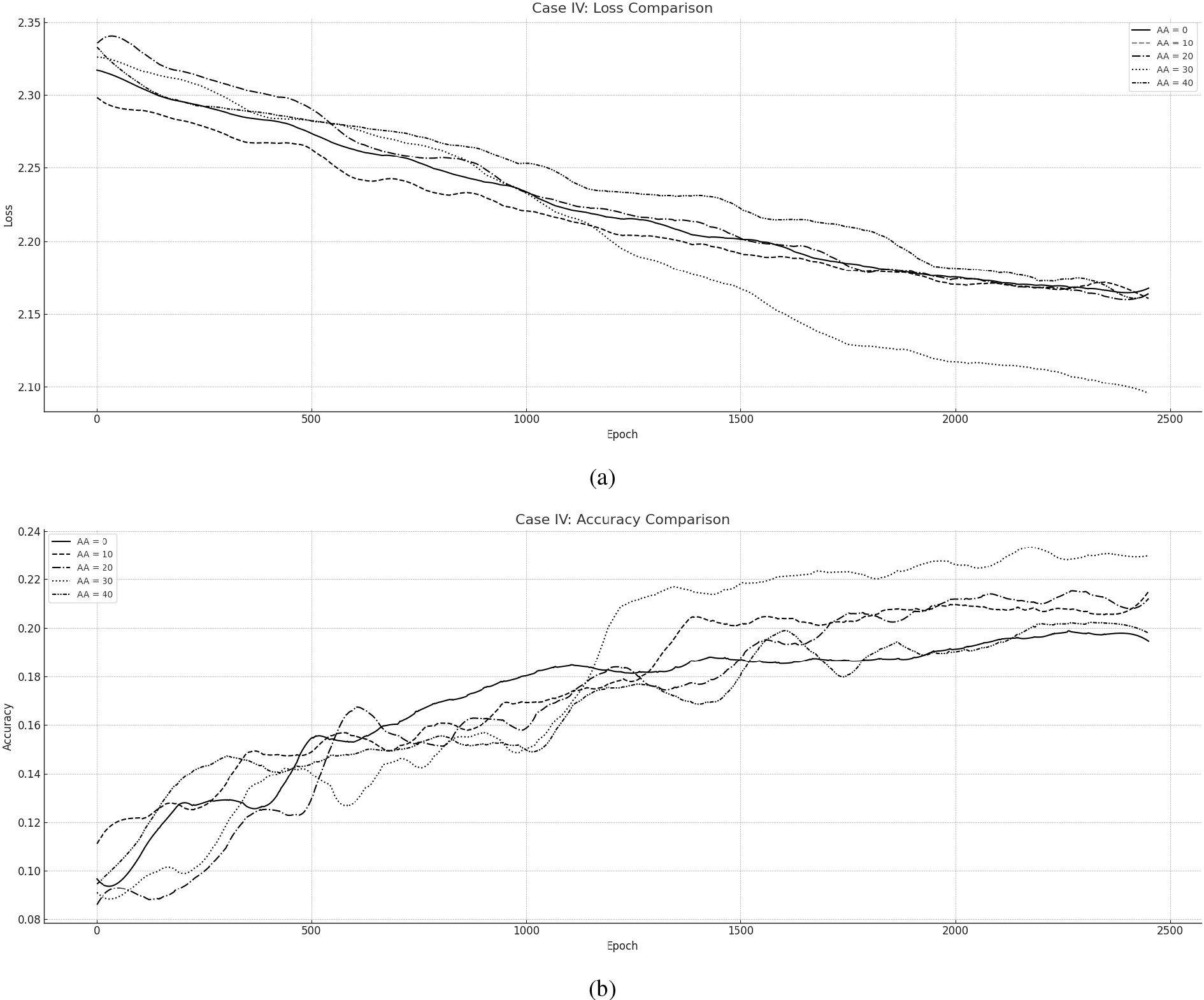
Asynchronous ND-CAO for training CNN towards CIFAR10: (a) Loss per Epoch, (b) Accuracy per Epoch.
5.4.1Setup – Case IV
Dataset information: The CIFAR10 represents a widely used benchmark dataset in the field of computer vision and machine learning. It consists of 60,000 32
Neural network architecture: The CNN model portrays a convolutional neural network (CNN) designed for image classification tasks taking as input RGB images of CIFAR10 (size 32
• Convolutional Layer 1: Number of filters: 32, Kernel size: 3
• Max Pooling Layer 1: Pooling size: 2
• Convolutional Layer 2: Number of filters: 32 (Kernel size: 3
• Max Pooling Layer 2: Pooling size: 2
• Flatten Layer: Converts the output from the previous layer into a 1D vector for input to the dense layers
• Dense Layer: The number of neurons is 10, producing a probability distribution over the 10 possible classes (Activation function: Softmax)
The full Architecture of the CNN is illustrated in Fig. 3(d).
Distribution type and features: Similarly to Case III, the distribution scheme considers Parameter-wise partitioning where one ND-CAO agent updates 1000 weights of the model. This partitioning allows different parts of the network to be trained or updated independently while still working towards the common goal of minimizing the overall error.
Experimental scenarios: Similarly to Case I and Case III, Case IV integrates a set of five simulations which have been implemented considering the following asynchronous training scenarios, at each time instant,
5.4.2Evaluation – Case IV
The results overall are presented in Loss and Accuracy measures in Fig. 7: (a) presents the overall Loss during training while (b) Illustrates the Accuracy of the Network. The course of all the training simulations is perfectly identical however, convergence is guaranteed for each case scenario. The Asynchronous cases (
To this end, and similarly to Case I Case II, and Case III, Case IV asynchronous scenarios converge towards the synchronous case as Fig. 7 illustrates. However, the synchronous case does not portray the best potential training setting, since the
5.5Verdict
The primary verdict of the Evaluated comparison between ND-CAO synchronous and ND-CAO asynchronous training arising from Figs 4, 5, 6 and 7 exhibits the adequacy of the algorithm to training neural networks in a gradient-free and distributed manner in both synchronous and asynchronous modes under different model architectures. The primary attributes of ND-CAO evaluation may be summarized as follows:
• Note 1 – ND-CAO training efficiency: One important attribute observed in all of the synchronous and asynchronous training cases is that ND-CAO achieved both Loss and Accuracy convergence close to the Synchronous ND-CAO reference case: by the examination of two FNNs and two CNNs case scenarios concerning different image classification problems (MNIST, Fashion MNIST, CIFAR10), ND-CAO exhibited its robustness and efficiency for training in both synchronous and asynchronous modes in an adequate manner.
• Note 2 – ND-CAO Asynchronous training capability: ND-CAO was operational even in cases where a substantial number of neurons or parameters were potentially deactivated (e.g. the scenarios of
• Note 3 – Parameters Optimization requirement: It is noticeable that there is a critical number of deactivated nodes that results in the best possible outcome of each potential model. That number is potentially different for every model and is being affected by diverse parameters that are resulting in the best possible outcome in Loss and Accuracy measures: model architecture, training epochs, dataset characteristics, etc. To this end, before deploying an asynchronous training mode, it is beneficial to determine the potential features that suit the model and its potential characteristics. Such type of optimization is not an easy task, however, and thus, it paves the way for more essential research work that may be generated in the future.
• Note 4 – ND-CAO distribution adequacy: Last but not least, ND-CAO achieved to adequately respond to synchronous or asynchronous training challenges towards different distribution schemes. While Case I and Case II concerned a Node-wise distributing scheme, Case III and Case IV which preserved a significantly larger number of parameters, considered a more sophisticated Parameter-wise distributing scheme. Such attribute indicates the novelty of the algorithm to support gradient-free distributed training of ANNs in a wide range of applications that demand multifunctional distribution schemes e.g. Task-wise or Hybrid-wise partitioning schemes that have never been illustrated in the literature as concern gradient-free distributed methodologies.
6.Conclusions and future work
ND-CAO methodology, portrays a novel gradient-free and distributed algorithmic scheme, capable to support synchronous and asynchronous training. Grounded on its conceptual background, the algorithm proved adequate to support any potential partitioning scheme – in a model parallel manner and eliminate the data exchange between the network blocks during training. Contrary to conventional approaches, ND-CAO proved sufficient to update the parameters of each network block fully independently and asynchronously, towards global error minimization: ND-CAO proved adequate to train each scenario efficiently without requiring a definition of discrimination areas – in local areas – for a given network configuration. Moreover, interesting results have arisen from the comparison between the synchronous training – which acted as the baseline – and the asynchronous settings in each case scenario. As the comparison indicates for Case I, Case II, Case III, and Case IV, ND-CAO asynchronous approach proved quite beneficial in numerous scenarios evaluations – in terms of Loss and Accuracy measures over a certain number of epochs. Taking in mind that asynchronous training is additionally advantageous in training time, computational, and communicational demand, such benefits are extended even further.
Such properties deliver a quite optimistic perspective for the future utilization of the algorithm and potentially contribute to the challenging training of large-scale neural networks that require gradient-free distributed and asynchronous training that is prohibited by the limitations of conventional approaches. It should be mentioned that this work portrays the first literature work that a gradient-free distributed algorithmic framework has been successfully utilized for asynchronous training – in a model parallel terms and thus, it paves the way for addressing challenging distributed deep learning problems that haven’t been satisfied – or have merely satisfied. Moreover, the current work portrays the first gradient-free and distributed scheme that is being evaluated for Node-wise and Parameter-wise partitioning, since the literature integrates applications that have solely concerned Layer-wise partitioning applications.
Future work is already planned to investigate the behavior of ND-CAO in broader contexts, such as the utilization of the algorithm towards challenging asynchronous training of neural networks regarding the Internet of Things (IoT), Multi-Cloud Environments, Federated Learning, Distributed Data Centers, Privacy-Preserving Learning, Collaborative Research and more where challenges of data exchange between geographically distributed partitions limiting the application potential of conventional methodologies. Future work will additionally focus on newer supervised machine learning/classification algorithms as part of a potential extension of ND-CAO, such as Neural Dynamic Classification algorithm, Dynamic Ensemble Learning Algorithm, Finite Element Machine for fast learning, and self-supervised learning [94, 95, 96]. More specifically, ND-CAO asynchronous methodology performance is expected to be enhanced, by adopting different policies for selectively updating partitions of the NN in order to further upgrade its efficiency. Additionally, ND-CAO is planned to act as a training framework for asynchronous learning on large-scale NNs and be compared with the already evaluated gradient-based asynchronous approaches. Last but not least, the novel algorithm is planned to generate a hybrid framework between ND-CAO and gradient-based methodologies, in order to embrace both advantages and create a fruitful ecosystem of algorithmic CAO-based tools, targeting to address specific challenging machine learning problems.
Notes
1 Throughout this paper, the terms “Neural Blocks (NBs)” and “Asynchronous Agents (AAs)” is used interchangeably.
Acknowledgments
We acknowledge support of this work by the project “Study, Design, Development and Implementation of a Holistic System for Upgrading the Quality of Life and Activity of the Elderly” (MIS 5047294) which is implemented under the Action “Support for Regional Excellence”, funded by the Operational Programme “Competitiveness, Entrepreneurship and Innovation” (NSRF 2014-2020) and co-financed by Greece and the European Union (European Regional Development Fund).
References
[1] | Liapis S, Christantonis K, Chazan-Pantzalis V, Manos A, Elizabeth Filippidou D, Tjortjis C. A methodology using classification for traffic prediction: Featuring the impact of COVID-19. Integrated Computer-Aided Engineering. (2021) ; 28: (4): 417-35. |
[2] | Islam S, Abba A, Ismail U, Mouratidis H, Papastergiou S. Vulnerability prediction for secure healthcare supply chain service delivery. Integrated Computer-Aided Engineering. (2022) ; (Preprint): 1-21. |
[3] | Fernández-Rodríguez JD, Palomo EJ, Ortiz-de Lazcano-Lobato JM, Ramos-Jiménez G, López-Rubio E. Dynamic learning rates for continual unsupervised learning. Integrated Computer-Aided Engineering. (2023) ; (Preprint): 1-17. |
[4] | Melgani F, Serpico SB, Vernazza G. Fusion of multitemporal contextual information by neural networks for multisensor remote sensing image classification. Integrated Computer-Aided Engineering. (2003) ; 10: (1): 81-90. |
[5] | Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems. (2012) ; 25: . |
[6] | Hinton G, Deng L, Yu D, Dahl GE, Mohamed AR, Jaitly N, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal processing magazine. (2012) ; 29: (6): 82-97. |
[7] | Li Y, Jiang Y. Real-time control of robot manipulators by neural networks. Integrated Computer-Aided Engineering. (1995) ; 2: (3): 241-8. |
[8] | Arciniegas JI, Eltimsahy AH, Cios KJ. Identification of flexible robotic manipulators using neural networks. Integrated Computer-Aided Engineering. (1994) ; 1: (3): 195-208. |
[9] | Devlin J, Kamali M, Subramanian K, Prasad R, Natarajan P. Statistical machine translation as a language model for handwriting recognition. In: 2012 International Conference on Frontiers in Handwriting Recognition. IEEE; (2012) . pp. 291-6. |
[10] | Keroglou C, Kansizoglou I, Michailidis P, Oikonomou KM, Papapetros IT, Dragkola P, et al. A Survey on Technical Challenges of Assistive Robotics for Elder People in Domestic Environments: The ASPiDA Concept. IEEE Transactions on Medical Robotics and Bionics. (2023) . |
[11] | Karatzinis GD, Michailidis P, Michailidis IT, Kapoutsis AC, Kosmatopoulos EB, Boutalis YS. Coordinating heterogeneous mobile sensing platforms for effectively monitoring a dispersed gas plume. Integrated Computer-Aided Engineering. (2022) ; (Preprint): 1-19. |
[12] | Salavasidis G, Kapoutsis AC, Chatzichristofis SA, Michailidis P, Kosmatopoulos EB. Autonomous trajectory design system for mapping of unknown sea-floors using a team of AUVs. In: 2018 Eiuropeam Control Conference (ECC). IEEE; (2018) . pp. 1080-7. |
[13] | Kotis K, Dimara A, Angelis S, Michailidis P, Michailidis I, Anagnostopoulos CN, et al. Towards Optimal Planning for Green, Smart, and Semantically Enriched Cultural Tours. Smart Cities. (2022) ; 6: (1): 123-36. |
[14] | Vamvakas D, Michailidis P, Korkas C, Kosmatopoulos E. Review and Evaluation of Reinforcement Learning Frameworks on Smart Grid Applications. Energies. (2023) ; 16: (14): 5326. |
[15] | García E, Villar JR, Tan Q, Sedano J, Chira C. An efficient multi-robot path planning solution using A* and coevolutionary algorithms. Integrated Computer-Aided Engineering. (2023) ; 30: (1): 41-52. |
[16] | Grosset J, Ndao A, Fougeres AJ, Djoko-Kouam M, Couturier C, Bonnin JM. A cooperative approach to avoiding obstacles and collisions between autonomous industrial vehicles in a simulation platform. Integrated Computer-Aided Engineering. (2023) ; (Preprint): 1-22. |
[17] | Hernandez-Barragan J, Lopez-Franco C, Arana-Daniel N, Alanis AY, Lopez-Franco A. A modified firefly algorithm for the inverse kinematics solutions of robotic manipulators. Integrated Computer-Aided Engineering. (2021) ; 28: (3): 257-75. |
[18] | Roda-Sanchez L, Olivares T, Garrido-Hidalgo C, de la Vara JL, Fernandez-Caballero A. Human-robot interaction in Industry 40 based on an Internet of Things real-time gesture control system. Integrated Computer-Aided Engineering. (2021) ; 28: (2): 159-75. |
[19] | Vera-Olmos FJ, Pardo E, Melero H, Malpica N. DeepEye: Deep convolutional network for pupil detection in real environments. Integrated Computer-Aided Engineering. (2019) ; 26: (1): 85-95. |
[20] | Rodriguez Lera FJ, Rico FM, Olivera VM. Neural networks for recognizing human activities in home-like environments. Integrated Computer-Aided Engineering. (2019) ; 26: (1): 37-47. |
[21] | Sørensen RA, Nielsen M, Karstoft H. Routing in congested baggage handling systems using deep reinforcement learning. Integrated Computer-Aided Engineering. (2020) ; 27: (2): 139-52. |
[22] | Thurnhofer-Hemsi K, Lopez-Rubio E, Roe-Vellve N, Molina-Cabello MA. Multiobjective optimization of deep neural networks with combinations of Lp-norm cost functions for 3D medical image super-resolution. Integrated Computer-Aided Engineering. (2020) ; 27: (3): 233-51. |
[23] | Ruiz L, Díaz S, González JM, Cavas F. Improving the competitiveness of aircraft manufacturing automated processes by a deep neural network. Integrated Computer-Aided Engineering. (2023) ; (Preprint): 1-12. |
[24] | Urdiales J, Martín D, Armingol JM. An improved deep learning architecture for multi-object tracking systems. Integrated Computer-Aided Engineering. (2023) ; (Preprint): 1-14. |
[25] | Benamara NK, Val-Calvo M, Alvarez-Sanchez JR, Diaz-Morcillo A, Ferrandez-Vicente JM, Fernandez-Jover E, et al. Real-time facial expression recognition using smoothed deep neural network ensemble. Integrated Computer-Aided Engineering. (2021) ; 28: (1): 97-111. |
[26] | Cheng B, Titterington DM. Neural networks: A review from a statistical perspective. Statistical Science. (1994) ; 2-30. |
[27] | Jin J, Fang H, Daly I, Xiao R, Miao Y, Wang X, et al. Optimization of model training based on iterative minimum covariance determinant in motor-imagery BCI. International Journal of Neural Systems. (2021) ; 31: (7): 2150030. |
[28] | Adeli H, Hung SL. An adaptive conjugate gradient learning algorithm for efficient training of neural networks. Applied Mathematics and Computation. (1994) ; 62: (1): 81-102. |
[29] | Rafiei MH, Gauthier LV, Adeli H, Takabi D. Self-Supervised Learning for Electroencephalography. IEEE Transactions on Neural Networks and Learning Systems. (2022) . |
[30] | Perez-Ramirez CA, Amezquita-Sanchez JP, Valtierra-Rodriguez M, Adeli H, Dominguez-Gonzalez A, Romero-Troncoso RJ. Recurrent neural network model with Bayesian training and mutual information for response prediction of large buildings. Engineering Structures. (2019) ; 178: : 603-15. |
[31] | Adeli H, Park HS. Optimization of space structures by neural dynamics. Neural Networks. (1995) ; 8: (5): 769-81. |
[32] | Adeli H, Samant A. An adaptive conjugate gradient neural network–wavelet model for traffic incident detection. Computer-Aided Civil and Infrastructure Engineering. (2000) ; 15: (4): 251-60. |
[33] | Molina-Cabello MA, Luque-Baena RM, Lopez-Rubio E, Thurnhofer-Hemsi K. Vehicle type detection by ensembles of convolutional neural networks operating on super resolved images. Integrated Computer-Aided Engineering. (2018) ; 25: (4): 321-33. |
[34] | Koziarski M, Cyganek B. Image recognition with deep neural networks in presence of noise – dealing with and taking advantage of distortions. Integrated Computer-Aided Engineering. (2017) ; 24: (4): 337-49. |
[35] | Wang R, Zhang Y, Zhang L. An adaptive neural network approach for operator functional state prediction using psychophysiological data. Integrated Computer-Aided Engineering. (2016) ; 23: (1): 81-97. |
[36] | Gérard O, Patillon JN, D’Alché-Buc F. Discharge prediction of rechargeable batteries with neural networks. Integrated Computer-Aided Engineering. (1999) ; 6: (1): 41-52. |
[37] | Ghosh-Dastidar S, Adeli H. Improved spiking neural networks for EEG classification and epilepsy and seizure detection. Integrated Computer-Aided Engineering. (2007) ; 14: (3): 187-212. |
[38] | Adeli H, Ghosh-Dastidar S. Automated EEG-based diagnosis of neurological disorders: Inventing the future of neurology. CRC press; (2010) . |
[39] | Adeli H, Ghosh-Dastidar S, Dadmehr N. A wavelet-chaos methodology for analysis of EEGs and EEG subbands to detect seizure and epilepsy. IEEE Transactions on Biomedical Engineering. (2007) ; 54: (2): 205-11. |
[40] | Hirschauer TJ, Adeli H, Buford JA. Computer-aided diagnosis of Parkinson’s disease using enhanced probabilistic neural network. Journal of Medical Systems. (2015) ; 39: : 1-12. |
[41] | Acharya UR, Sudarshan VK, Adeli H, Santhosh J, Koh JE, Adeli A. Computer-aided diagnosis of depression using EEG signals. European Neurology. (2015) ; 73: (5-6): 329-36. |
[42] | Adeli H, Kumar S. Distributed computer-aided engineering. vol. 2: . CRC Press; (1998) . |
[43] | Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks. (1994) ; 5: (2): 157-66. |
[44] | Alzubaidi L, Zhang J, Humaidi AJ, Al-Dujaili A, Duan Y, Al-Shamma O, et al. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. Journal of Big Data. (2021) ; 8: : 1-74. |
[45] | Mostafa H, Ramesh V, Cauwenberghs G. Deep supervised learning using local errors. arXiv. arXiv preprint arXiv: 171106756; (2017) ; 10: . |
[46] | Cavigelli L, Gschwend D, Mayer C, Willi S, Muheim B, Benini L. Origami: A convolutional network accelerator. In: Proceedings of the 25th edition on Great Lakes Symposium on VLSI; (2015) . pp. 199-204. |
[47] | Ardakani A, Leduc-Primeau F, Onizawa N, Hanyu T, Gross WJ. VLSI implementation of deep neural network using integral stochastic computing. IEEE Transactions on Very Large Scale Integration (VLSI) Systems. (2017) ; 25: (10): 2688-99. |
[48] | Jouppi NP, Young C, Patil N, Patterson D, Agrawal G, Bajwa R, et al. In-datacenter performance analysis of a tensor processing unit. In: Proceedings of the 44th annual international symposium on computer architecture; (2017) . pp. 1-12. |
[49] | Taylor G, Burmeister R, Xu Z, Singh B, Patel A, Goldstein T. Training neural networks without gradients: A scalable admm approach. In: International conference on machine learning. PMLR (2016) ; pp. 2722-31. |
[50] | Teerapittayanon S, McDanel B, Kung HT. Distributed deep neural networks over the cloud, the edge and end devices. In: 2017 IEEE 37th international conference on distributed computing systems (ICDCS). IEEE; (2017) . pp. 328-39. |
[51] | Serb A, Corna A, George R, Khiat A, Rocchi F, Reato M, et al. A geographically distributed bio-hybrid neural network with memristive plasticity. arXiv preprint arXiv:170904179; (2017) . |
[52] | Long Wang JCS. Multilevel Data Integration with Application in Sensor Networks. 2020 American Control Conference (ACC). (2020) . |
[53] | Long Wang JCS, Zhu J. Model-Free Optimal Control using SPSA with Complex Variables. 55th Annual Conference on Information Sciences and Systems (CISS). (2021) . |
[54] | Song SJC Q, Soh YC. Robust Neural Network Tracking Controller Using Simultaneous Perturbation Stochastic Approximation. IEEE Transactions on Neural Networks. (2008) ; 19: (5): 817-35. |
[55] | Michailidis IT, Manolis D, Michailidis P, Diakaki C, Kosmatopoulos EB. A decentralized optimization approach employing cooperative cycle-regulation in an intersection-centric manner: a complex urban simulative case study. Transportation Research Interdisciplinary Perspectives. (2020) ; 8: : 100232. |
[56] | Michailidis IT, Sangi R, Michailidis P, Schild T, Fuetterer J, Mueller D, et al. Balancing energy efficiency with indoor comfort using smart control agents: a simulative case study. Energies. (2020) ; 13: (23): 6228. |
[57] | Michailidis IT, Kapoutsis AC, Korkas CD, Michailidis PT, Alexandridou KA, Ravanis C, et al. Embedding autonomy in large-scale IoT ecosystems using CAO and L4G-CAO. Discover Internet of Things. (2021) ; 1: (1): 1-22. |
[58] | Park HS, Adeli H. Distributed neural dynamics algorithms for optimization of large steel structures. Journal of Structural Engineering. (1997) ; 123: (7): 880-8. |
[59] | Adeli H, Kim H. Cost optimization of composite floors using neural dynamics model. Communications in Numerical Methods in Engineering. (2001) ; 17: (11): 771-87. |
[60] | Lyu H. Convergence and complexity of block coordinate descent with diminishing radius for nonconvex optimization. arXiv preprint arXiv:201203503. (2020) . |
[61] | Zeng J, Lau TTK, Lin S, Yao Y. Global convergence of block coordinate descent in deep learning. In: International conference on machine learning. PMLR; (2019) ; pp. 7313-23. |
[62] | Carreira-Perpinan M, Wang W. Distributed optimization of deeply nested systems. In: Artificial Intelligence and Statistics. PMLR; (2014) ; pp. 10-9. |
[63] | Zhang Z, Brand M. Convergent block coordinate descent for training tikhonov regularized deep neural networks. Advances in Neural Information Processing Systems. (2017) ; 30. |
[64] | Askari A, Negiar G, Sambharya R, Ghaoui LE. Lifted neural networks. arXiv preprint arXiv:180501532; (2018) . |
[65] | Gu F, Askari A, El Ghaoui L. Fenchel lifted networks: A lagrange relaxation of neural network training. In: International Conference on Artificial Intelligence and Statistics. PMLR; (2020) ; pp. 3362-71. |
[66] | Lau TTK, Zeng J, Wu B, Yao Y. A proximal block coordinate descent algorithm for deep neural network training. arXiv preprint arXiv:180309082; (2018) . |
[67] | Xu Y, Yin W. A block coordinate descent method for regularized multiconvex optimization with applications to nonnegative tensor factorization and completion. SIAM Journal on Imaging Sciences. (2013) ; 6: (3): 1758-89. |
[68] | Xu Y, Yin W. A globally convergent algorithm for nonconvex optimization based on block coordinate update. Journal of Scientific Computing. (2017) ; 72: (2): 700-34. |
[69] | Razaviyayn M, Hong M, Luo ZQ, Pang JS. Parallel successive convex approximation for nonsmooth nonconvex optimization. Advances in Neural Information Processing Systems. (2014) ; 27: . |
[70] | Boyd S, Parikh N, Chu E. Distributed optimization and statistical learning via the alternating direction method of multipliers. Now Publishers Inc; (2011) . |
[71] | Nishihara R, Lessard L, Recht B, Packard A, Jordan M. A general analysis of the convergence of ADMM. In: International Conference on Machine Learning. PMLR; (2015) ; pp. 343-52. |
[72] | Wang Y, Yin W, Zeng J. Global convergence of ADMM in nonconvex nonsmooth optimization. Journal of Scientific Computing. (2019) ; 78: (1): 29-63. |
[73] | Zhang Z, Chen Y, Saligrama V. Efficient training of very deep neural networks for supervised hashing. In: Proceedings of the IEEE conference on computer vision and pattern recognition; (2016) ; pp. 1487-95. |
[74] | Wang J, Chai Z, Cheng Y, Zhao L. Toward model parallelism for deep neural network based on gradient-free ADMM framework. In: 2020 IEEE International Conference on Data Mining (ICDM). IEEE; (2020) . pp. 591-600. |
[75] | Mota JF, Xavier JM, Aguiar PM, Püschel M. Distributed ADMM for model predictive control and congestion control. In: 2012 IEEE 51st IEEE Conference on Decision and Control (CDC). IEEE; (2012) . pp. 5110-5. |
[76] | Makhdoumi A, Ozdaglar A. Convergence rate of distributed ADMM over networks. IEEE Transactions on Automatic Control. (2017) ; 62: (10): 5082-95. |
[77] | Chang TH. A proximal dual consensus ADMM method for multi-agent constrained optimization. IEEE Transactions on Signal Processing. (2016) ; 64: (14): 3719-34. |
[78] | Chang TH, Hong M, Wang X. Multi-agent distributed optimization via inexact consensus ADMM. IEEE Transactions on Signal Processing. (2014) ; 63: (2): 482-97. |
[79] | Shi W, Ling Q, Yuan K, Wu G, Yin W. On the linear convergence of the ADMM in decentralized consensus optimization. IEEE Transactions on Signal Processing. (2014) ; 62: (7): 1750-61. |
[80] | Xu Z, Taylor G, Li H, Figueiredo MA, Yuan X, Goldstein T. Adaptive consensus ADMM for distributed optimization. In: International Conference on Machine Learning. PMLR; (2017) ; pp. 3841-50. |
[81] | Zhu S, Hong M, Chen B. Quantized consensus ADMM for multi-agent distributed optimization. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE; (2016) . pp. 4134-8. |
[82] | Zhang R, Kwok J. Asynchronous distributed ADMM for consensus optimization. In: International conference on machine learning. PMLR; (2014) ; pp. 1701-9. |
[83] | Wei E, Ozdaglar A. Distributed alternating direction method of multipliers. In: 2012 IEEE 51st IEEE Conference on Decision and Control (CDC). IEEE; (2012) . pp. 5445-50. |
[84] | Chang TH, Hong M, Liao WC, Wang X. Asynchronous distributed ADMM for large-scale optimization – Part I: Algorithm and convergence analysis. IEEE Transactions on Signal Processing. (2016) ; 64: (12): 3118-30. |
[85] | Kumar S, Jain R, Rajawat K. Asynchronous optimization over heterogeneous networks via consensus admm. IEEE Transactions on Signal and Information Processing over Networks. (2016) ; 3: (1): 114-29. |
[86] | Michailidis P, Pelitaris P, Korkas C, Michailidis I, Baldi S, Kosmatopoulos E. Enabling optimal energy management with minimal IoT requirements: A legacy A/C case study. Energies. (2021) ; 14: (23): 7910. |
[87] | Michailidis IT, Manolis D, Michailidis P, Diakaki C, Kosmatopoulos EB. Autonomous self-regulating intersections in large-scale urban traffic networks: a Chania City case study. In: 2018 5th international conference on control, decision and information technologies (CoDIT). IEEE; (2018) . pp. 853-8. |
[88] | Michailidis IT, Michailidis P, Alexandridou K, Brewick PT, Masri SF, Kosmatopoulos EB, et al. Seismic Active Control under Uncertain Ground Excitation: an Efficient Cognitive Adaptive Optimization Approach. In: 2018 5th International Conference on Control, Decision and Information Technologies (CoDIT). IEEE; (2018) . pp. 847-52. |
[89] | Michailidis IT, Schild T, Sangi R, Michailidis P, Korkas C, Fütterer J, et al. Energy-efficient HVAC management using cooperative, self-trained, control agents: A real-life German building case study. Applied Energy. (2018) ; 211: : 113-25. |
[90] | Michailidis IT, Michailidis P, Rizos A, Korkas C, Kosmatopoulos EB. Automatically fine-tuned speed control system for fuel and travel-time efficiency: A microscopic simulation case study. In: 2017 25th Mediterranean Conference on Control and Automation (MED). IEEE; (2017) . pp. 915-20. |
[91] | Korkas CD, Baldi S, Michailidis P, Kosmatopoulos EB. A cognitive stochastic approximation approach to optimal charging schedule in electric vehicle stations. In: 2017 25th Mediterranean Conference on Control and Automation (MED). IEEE; (2017) . pp. 484-9. |
[92] | Kosmatopoulos E. An adaptive optimization scheme with satisfactory transient performance. Automatica. (2009) ; 45: (3): 716-723835. |
[93] | Sun T, Hannah R, Yin W. Asynchronous Coordinate Descent under More Realistic Assumptions; (2017) . |
[94] | Rafiei MH, Adeli H. A new neural dynamic classification algorithm. IEEE Transactions on Neural Networks and Learning Systems. (2017) ; 28: (12): 3074-83. |
[95] | Pereira DR, Piteri MA, Souza AN, Papa JP, Adeli H. FEMa: A finite element machine for fast learning. Neural Computing and Applications. (2020) ; 32: : 6393-404. |
[96] | Alam KMR, Siddique N, Adeli H. A dynamic ensemble learning algorithm for neural networks. Neural Computing and Applications. (2020) ; 32: : 8675-90. |


