
Prophy: An automated reviewer finder to improve the efficiency, diversity and quality of reviews
Abstract
Peer review is under pressure. Without fair, transparent and efficient peer review we cannot ensure the right proposals get funded and the correct manuscripts get published. In the era of Open Access, which is driving an exponential increase in the number of submitted publications, how we carry out peer review is becoming increasingly important and how we find reviewers is coming under scrutiny. The current methods are slow and produce bias pools of reviewers. As such we need an improved way. At Prophy we have developed a state-of-the-art referee finder that can find experts to review any manuscript from any scientific field in seconds. Then through post-processing filters we can find appropriate candidate referees who are most likely to review a paper, whilst highlighting important conflicts of interest through our complex citation networks. These methods can ensure fair and independent experts who can review interdisciplinary papers from any discipline. These methods are being delivered through APIs and the editorial workflow of editors ensure the right people get access to these tools. Finally, as large-language models improve, so does Prophy and as such we will be looking to drive real innovation in this area in years to come.
1.Introduction
The peer review process has been the foundation of the scientific process since its inauguration centuries ago. We as a community rely on the approval of peers to provide independent scrutiny to the scientific work carried out. This way we self-regulate what is published and in its own way, ensure the robustness and trustworthiness of that work. In order for peer review to full-fill its remit of scrutinising potentially published work it must adhere to three key pillars:
Quality and detailed - the reviewer must take enough time to scrutinise every detail of the manuscript, from introduction and literature review, through the proposed goal and idea, to methodology and ultimately the conclusions. The content from start to finish of a manuscript is designed to build, support and evidence the work of a scientist and thus each part should receive equal attention.
Fair and unbiased - Independent reviewers from a representative background are vital if we are to trust the reviews that are returned. If reviewers have invested interest in the result of the paper (for good or bad) this can impact the final published work.
Efficient and timely - Science moves quickly. With pandemics, climate change and Artificial Intelligence having immediate and continual impact on our planet, publishers need to move as fast as scientific developments. In order to do this, referees must be found quickly and reports returned in a timely fashion. If peer review is the bottle-neck in the scientific process then all progress will be stunted.
It can be argued that these three key pillars of peer review are under-pinned by a single key factor: the person carrying out the peer-review: the expert reviewer. It is this person who will define whether the manuscript meets these requirements, and hence how we find the expert reviewer will define the type of review and science we get in return. Usually publishers rely on three avenues to find reviewers: (1) Author suggestions - when the manuscript is submitted, the authors are required to submit suggested referees who are able to review their paper; (2) The editor’s network of contacts - often the editor knows the area of research well, as well as reliable referees, and as such will ask them to review the paper in question; (3) A tool based on keywords that scans the publishers’ database of known researchers - in the event the first two do not work, editors refer to simple tools to suggest referees in the journals’ network.
In the past, these three methods have proved sufficient to deliver adequate referees for each journal however, the key question here is “Do these methods lead to referees that will uphold the three pillars of peer-review?” That is, will author suggestions result in a fair and unbiased review? Will an editor’s network be sufficiently large to find experts that can return quality reviews? Finally: does a simple tool deliver experts that will accept invitations to review and thus keep the review efficient and timely?
1.1.Finding reviewers is difficult and will become even more so
Finding experts to review manuscripts is difficult. Scientists exist in a publish or perish world whereby they are required to write multiple published works each year, if they hope to achieve tenure one day.
Journals receive more manuscripts each day, with fewer scientists providing time to carry out the vital role of peer review. This creates an imbalance. In addition to this, Open Access (OA) is driving a new era in publishing. The model where the article processing charge (APC) is being pushed to the author and not the reader in a bid to provide OA reading to the world, is driving a wave in publications. The reasons for this exponential growth in publications are multiple, for which we will not go into detail in this paper, but as Fig. 1 shows, we expect a huge increase in the number of submitted manuscripts in the coming decades. In this plot we took all the published papers in PubMed1 and fitted a simple exponential model to see how the future of publications is expected to develop. We split the publications into OA and subscription-based. We found that the number of OA publications is expected to triple in the coming decade. This represents a fundamental problem in scholarly publishing: we will not have sufficient people to review papers, putting the robustness and reliability of science into question.
1.2.Reviewer pools are not representative
In addition to the problem of finding sufficient, independent experts to review manuscripts submitted to journals, we are becoming increasingly aware of the bias in the pools of reviewers that we are selecting from. A recent study showed that too few women are being invited to review [1]. They found in the Geophysical journal, 61% females who submit to the journal are being accepted for publication, yet those first authors (both male and female) who suggest authors to peer review are significantly under-recommending female reviewers. This trend is also seen when editors are required to find referees: they preferentially select male authors. In the end 27% of published articles in Geophysical journals are authored by females yet only represent 20% of the referees. Since different backgrounds will bring different reviews, it is clear that this in-balance leads to biased and unfair reviewing. This trend was seen clearly in gender, it isn’t a stretch to think this would be also seen in different minority groups.
1.3.Science is becoming more interdisciplinary leading to longer referee assignment times
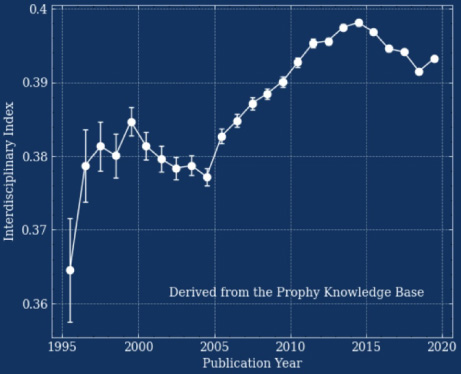
A final complication in peer review is that science is becoming increasingly interdisciplinary. Figure 2 shows the average interdisciplinary index over over the last 25 years, where the index is defined by the variance in scientific concepts per paper, is increasing (albeit to slight recent downward trend). This is mainly attributed to computer science which is leaking into many areas of science. The problem with interdisciplinary sciences is that finding individuals to review a multi- faceted proposal is difficult, and often one person does not have the skills to review the entire manuscript. This results in a long delay in finding an appropriate reviewer (due to simply finding someone and an increase in the rate at which referees reject invitations to review).
Fig. 1.
(LEFT): The potential impact of the huge increase in Open Access (OA) publications on the current peer-review system. Publication rates in PubMed is predicted to dramatically rise (driven by OA) in the coming decade. If we are to be ready for this we need a new, more efficient way of finding referees.
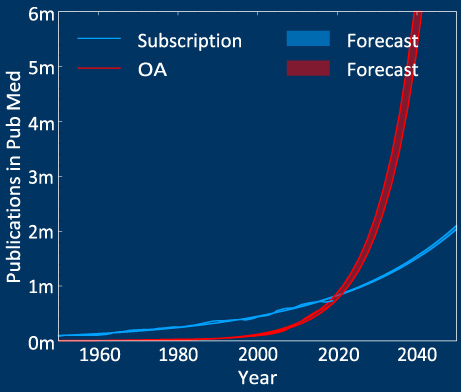
Fig. 2.
(RIGHT): The average interdisciplinary index of papers (variance in scientific concepts for a given paper) is increasing over time, making it more difficult to find experts who can review entire scientific manuscripts.
The path to finding reviewers that bring fair, detailed and efficient reviews is difficult and is getting more difficult. As we gather more data we find that our methods are becoming increasingly biased, and as a result this will impact publications and science. To this end, Prophy has attempted to bring the first automated referee finder, based on machine learning, to solve all these issues at once.
2.The Prophy Knowledge Base
Everyday, thousands of manuscripts are published online containing the work of scientists from all over the world. These works are published in pre-print servers, OA journals and other free-to-access repositories. These papers are normally managed and organised through a series of keywords. That is, when an author writes the manuscript, they assign pre-defined keywords that describe the content of that paper. The problem with keywords are two fold - (1) They are ambiguous. In a large scientific space of many thousand keywords, they can overlap with no context, as such, one keyword can mean many different things. In the context of explaining a paper, these keywords become useless. (2) They are overly specific. Two key-words that are extremely close, have as much relative meaning as two keywords that are completely irrelevant. This is because they stand alone with no relative meaning. By moving to a semantic space where we use an ontology of scientific concepts, we can move beyond keywords and use more useful descriptors.
2.1.A bag of concepts
A scientific concept can exist as a single word or a collection of words. They have no predefined limit and can often be extremely explicit or very general. By extracting all of the scientific concepts directly from the raw text (and not reliant on authors predefining keywords) we can generate hundreds of descriptors of a manuscript. At Prophy we have carried out this exercise over our entire database of manuscripts (amounting to over 150 million articles at time of writing). This creates a large collection or “Bag of Concepts”. We can then use word embedding to relate all of these scientific concepts together.
Word embedding refers to the method of creating relevant meaning to strings using neural networks [2]. They nominally use a single layered Neural Net and by encoding each word as a vector, the Neural Net is optimised to guess the missing word from a sentence with a word extracted. By training the weights in the net to guess the missing word, it builds up a relational network of each scientific concept. The result is that we are able to relate all the concepts in the bag to each other. This means that we cannot only give things meaning, knowing how close (or far apart) two concepts are, but it can also disambiguate scientific concepts within manuscripts.
2.2.Digital fingerprints
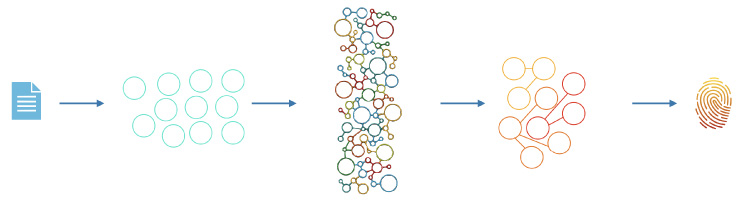
Now armed with an ontology that is able to represent scientific concepts as vectors of 100 dimensions, we are able to carry out mathematical operations on them. For example, we can extract all the scientific concepts from a manuscript, and then simply find the mean vector. This becomes the digital fingerprint of that paper. If we find the angle between two vectors, we know what the similarity is between those two papers, enabling us to find papers that are truly close to another. And since authors, in this context, could be considered as collections of papers, we are able to generate digital fingerprints of authors. Hence by comparing the digital fingerprint we can find those authors that are close or “expert” in that manuscript. Figure 3 shows an overview of this process.
Fig. 3.
The Prophy Solution to referee finding: We extract scientific concepts from the raw text of a manuscript and generate digital fingerprints of the paper.
2.3.Author profiles
A key aspect of this is the clustering of articles into authors. This is a non-trivial task and requires sophisticated neural nets to understand how two articles are related to each other. How well one can cluster articles into authors ultimately defines how well these automated methods can work. At Prophy we spend a lot of time improving our algorithms to do just this. Especially for countries in which specific family names are very common.
Once we have our curated clusters of articles we can generate additional meta-information. This includes not only bibliometrics (for example the h-index and citation counts) but most used concepts, affiliations (current and past), contact details and other aspects of a published researcher profile. Primarily, this enables Prophy to carry out a thorough and complete Conflict of Interest report. Ensuring that any reviewer is real and independent of the manuscript in question. This collection of meta-information also enables us to filter out experts. For example, it is known that established professors might not have the time to review many papers, therefore you might want to focus on early career researchers. By filtering out the people with high citation counts or those who began their academic career over a decade ago, Prophy can filter out those less likely to accept an invitation to review.
We can take these filters further to include geographical locations where you might want to include or focus on improving the diversity of your selected referees, or select articles that have been published in the last five years to ensure that the candidate referees are relevant. There are infact endless filters one can place post-process in order to find exactly who you are looking for. We at Prophy continue to analyse our data and provide filters where they are useful and appropriate.
2.4.Bringing referees to your door-step
The selection of referees is a thank-less task. It is vital in the peer-review process but can be time consuming. Therefore making it easy and accessible is almost equally as important. As such bringing these tools to the finger-tips of editors so they can be used seamlessly has been a focus of Prophy in the last year. We have worked with organisations such as Editorial Manager2 and eJournalPress3 to bring Prophy into the editorial workflow. Now using our in-house application programming interface (API) we can provide our referee suggestions trivially to the desktop of an editor or user, making our platform both revolutionary and simple to use.
3.Conclusions
Peer review is being pushed to it limits. Without fair, transparent and detailed peer review we can not ensure the right proposals get funded and the right manuscripts get published. We are already seeing biases in the reviews we write, and in the era of Open Access where we are seeing an explosion of publications, these biases are only getting worse. How the scholarly publishing community responds to this demand will ultimately determine the fate of science.
If we as a community are to act on these demands we need a new way of finding referees. We need a new way to manage the scientific content out there such in order to identify experts to review manuscripts. At Prophy we are doing this.
We have a self-curated database of over 150 million articles, from which we have trained a state-of-the-art algorithm that can match any person to any manuscript from any scientific discipline. With post-process filters we are able to find diverse, interdisciplinary referees at the click of a button. Finally our APIs can integrate Prophy in to the editorial workflow, bringing these tools to those who need it the most and delivering those experts to the manuscripts that need them.
Acknowledgements
We would like to thank the Berlin Institute of Scholarly Publishing for all of their help in supporting Prophy. We would also like to thank Digital Science in recognising the work of the Prophy CTO, Vsevolod Soloyvov, as he won the inaugural award for Innovation in Publishing.
References
[1] | J. Lerback and B. Hanson, Journals invite too few women to referee, Nature 541: (7638) ((2017) ), 455–457. |
[2] | S. Selva Birunda and R. Kanniga Devi, A review on word embedding techniques for text classification. in: Innovative Data Communication Technologies and Application, J.S. Raj, A.M. Iliyasu, R. Bestak and Z.A. Baig (eds), Singapore, (2021) , pp. 267–281. |


