
Digital humanities projects and standards: Let’s get this conversation started!
Abstract
This article is in part about digital humanities projects and the metadata that supports them. It is also a call for project creators, publishers, aggregators, and professionals working on metadata and standards to start a conversation about how to incorporate digital humanities projects into the scholarly communications lifecycle in spaces where books and journal articles have dominated for decades. It begins this conversation by analyzing benefits and challenges of the metadata contributed to two projects - Preserve the Baltimore Uprising and The Six Degrees of Francis Bacon - and two platforms - Zooniverse and Mukurtu Content Management System. It proposes a couple of key pieces of metadata around which to build a standard for integrating digital humanities projects into publication.
1.Introduction
Metadata is amazing for a lot of reasons, but one important thing it can do is provide a future for publications and other digital projects - it makes them findable many years after they are created. Digital humanities projects are great because they can open the door to engaging communities in scholarly and public discourse beyond what is possible with traditional written forms, such as books and journal articles. Digital humanities projects are also challenging because they are usually expensive and time-consuming to create and then require maintenance to keep them accessible. Moreover, no one set of metadata standards and elements are designed specifically for digital humanities projects. No standards such as the Journal Article Tag Suite (JATS), the Book Interchange Tag Suite (BITS), or the Machine Readable Cataloging (MARC 21), and the Research Description and Access (RDA) exist to make digital humanities projects discoverable inside of aggregated platforms (neither publisher platforms nor library discovery layers or dataset aggregators). Nor are Dublin Core elements (DC), the Metadata Object Description Schema (MODS) or other controlled vocabularies with people, subjects or concepts designed around born-digital content.
These challenges aside, a growing number of born-digital humanities projects demand the same scholarly respect given to books and journal articles. One of the ways to elevate importance of digital humanities projects is for the publishing community to work with scholars to produce some of their born-digital content in a publication space rather than relegating it to websites outside of the scholarly communications lifecycle. That integration is, however, a topic for another day. In order to even begin considering how to bring this type of content into the scholarly communications lifecycle, we must begin by looking at existing projects and how they have used metadata to fuel creation of new knowledge, as well as the kinds of challenges projects face in extending their reach in scholarly and non-scholarly communities. A clearer understanding of metadata used with digital humanities projects is good first step toward integrating them more fully into scholarly publishing.
2.Digital humanities projects and their metadata needs
A growing body of projects fall under the bigger digital humanities tent [1]. A number of projects with a particularly public scholarship focus have been cataloged in the Humanities for All database, organized by the National Humanities Alliance [2]. Humanities for All provides a good entry point into different types of digital humanities projects that have been created in the United States, especially those that have some connection to “public scholarship”. And, it helps to fulfill part of the mission of the National Humanities Alliance, which includes expanding educational access to digital humanitis projects and preserving culture recorded in times of crisis and change [3]. Two projects discussed below - Preserve the Baltimore Uprising and The Six Degrees of Francis Bacon - are part of the Humanities for All database. Two additional projects are platforms that help publicly-focused digital humanities projects frame their work. All of them require some type of metadata internal to the project, often created to organize content within a given platform, but sometimes integrated from pre-existing sets of metadata. These pieces of metadata make it possible to find content inside of projects and sometimes these pieces of metadata are the key to involving experts and non-experts in a project. They represent different implementations of how flexible and malleable metadata creation and use is within the context of these projects.
2.1.Preserve the Baltimore uprising
The Preserve the Baltimore Uprising Archive Project is a digital archive that was designed originally to document first-hand experiences of the protests and calls for action in the Baltimore area following the death of Freddie Gray in 2015. In response to the protests for Black Lives Matter in 2020, the Preserve the Baltimore Uprising project has decided to expand its collection to include content for protests related to murders of Ahmaud Arbery, Breonna Taylor, George Floyd, and others [4]. This project excels at providing space for first-hand and official accounts of protest to exist side by side in the same web space. It also offers an important pedagogical space, to help train those interested in methods and theories of recording oral history [5].
Metadata created for Preserve the Baltimore Uprising reflects a grassroots approach to collecting and preserving content. Contributors submitting content create descriptive metadata for images, interviews, or written content (the content is vetted based upon a collection policy that focuses on relevancy to events of protest and unrest) [6]. The metadata is structured using the Dublin Core schema, which offers a great deal of flexibility for users to choose the specific fields that they need to accommodate a project. Dublin Core is flexible enough and accessible enough that even inexperienced metadata creators can contribute meaningful and important contextual information to describe and catalog content. The relatively open metadata creation policy is both a strength and a weakness of this platform. The collection is small enough that end users can find specific content inside of the platform without using the search box, but overall, the searching infrastructure under Search Items is not designed for discovery searching (known-item searching is easier, especially if the user knows the ID#). Unfortunately, no explanation is offered to help users effectively use the search under Search Items menu. The search menu is built around the underlying metadata element sets chosen from Dublin Core, Item Metadata, and Zotero, but it feels overlaid rather than growing organically out of user experience [7]. The two best ways to find content are to use the Browse by Tag menu or the Browse Collections menu. A quick look at the tags used in the Browse Tags menu reveals that these labels are likely a folksonomy rather than a controlled vocabulary imported from existing practices and standards developed previously [8]. The collections menu is organized by individual contributors who contributed the content [9].
Fig. 1.
Francis Bacon’s ISNI record, complete with names of people who are known or supposed to have a connection with him.

Fig. 1 (Continued).

Fig. 2.
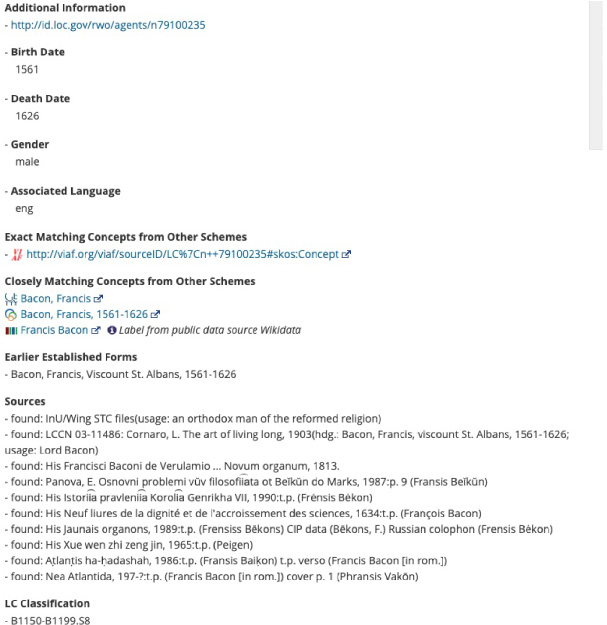
Francis Bacon’s Library of Congress Name Authority record, complete with links to authoritative forms of his name in other schemas.

Fig. 2 (Continued).
2.2.Six degrees of Francis Bacon
The Six Degrees of Francis Bacon is directed specifically to an academic audience, but open to community contributions. It is “a digital reconstruction of the early modern social network that scholars and students from all over the world can collaboratively expand, revise, curate, and critique” [10]. The graph that represents the entire network reflects who was connected to whom and what types of people were connected (e.g. lawyers, composers, philosophers) in early modern Britain.
From a user perspective, this platform is intended for historians who study early modern Britain. From a metadata perspective, however, this network is an excellent example of how choosing well-developed sets of metadata can make a project interoperable with others. The directors of the project created crosswalks between the names recorded in the Francis Bacon database and authoritative name sets in the Wikidata database [11]. The name authorities imported included the Virtual Integrated Authority File (VIAF), the German Integrated Authority File (GND), the International Standard Name Identifier file (ISNI), and the Library of Congress Name Authority file (LCNAF). The project partners have also linked the Oxford Dictionary of National Biography [12].
These discrete data points from controlled vocabularlies, enhanced with human intervention, work together in the Six Degrees of Francis Bacon to create a visual representation of the social world active in early modern England. The controlled vocabularies (e.g., VIAF, GND, ISNI, LCNAF) make the project interoperable with other projects and collections that use these same authority files. In addition to the officially recorded version of a person’s name, the controlled vocabularies provide other important information about Francis Bacon's birth and death dates, occupations, aliases and alternate name spellings (see for example Francis Bacon’s ISNI (Fig. 1) and LC Name Authority Records (Fig. 2)). The bibliographical notes in the ISNI and LCNAF are then complimented by the biographical entries in the Oxford Dictionary of National Biography, thus fleshing out a fuller narrative of a person’s life. Dates, occupations, and biographical information provide the data points to buildout the timelines and group networks. All of this metadata, once ingested, can create networks automatically with the help of a Python script. Humans further enhance it based on expertise and supplemental knowledge.
Fig. 3.
South Sudan Diversity Cam Image with controlled vocabulary of animals listed on the right side of the screen.
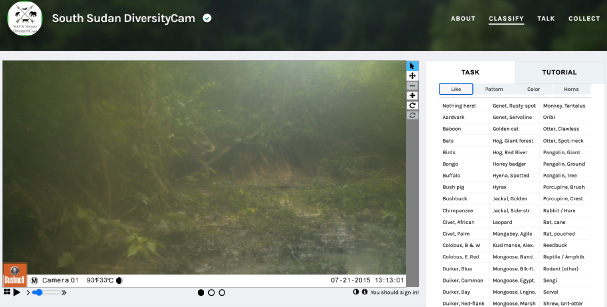
Fig. 4.
Image of Fishing at the Sunnyside Dam.

Fig. 4 (Continued).
Washington State University Metadata for Image of Fishing at the Sunnyside Dam.
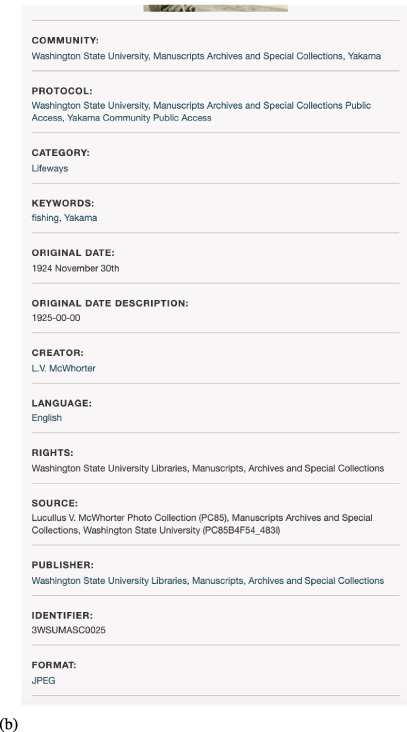
Fig. 4 (Continued).
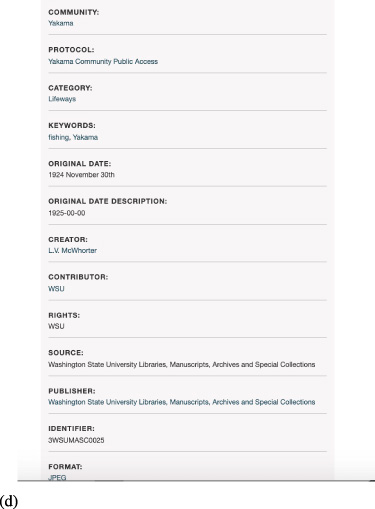
Yakama metadata, with Description, Cultural Narrative, and Traditional Knowledge for the Image Fishing at the Sunnyside Dam.

Fig. 4 (Continued).
Yakama metadata, with Description, Cultural Narrative, and Traditional Knowledge for the Image Fishing at the Sunnyside Dam.
2.3.Zooniverse
All projects discussed in this paper have a crowd sourcing component that shares the labor of creating content and metadata. Zooniverse is, however, the project that is most active with recruiting and training volunteers to participate in citizen science projects: “At the Zooniverse, anyone can be a researcher” [13]. Most of the projects include work whereby participants add or clarify information depicted in an image or video. A particular strength of this project, in addition to the crowd-sourced metadata created in individual projects, consists of articles documenting the challenges and effective execution of citizen science projects [14].
So what about the metadata for projects indexed in Zooniverse? Each project has produced or is producing a plethora of associated descriptive metadata, to help researchers identify and study large content-rich, non-machine readable data points, including images of space, illustrated manuscripts, letters, and other handwritten documents. For many projects, the project directors provide the metadata to attach to an image, text, or video, which helps to control the vocabulary and descriptive terms internal to the project. For example, in a project measuring animal diversity in the South Sudan, volunteers select animals from a defined list based on what they see in the image. From a metadata creation perspective, this helps the research directors use a particular spelling of each animal and also defines which animals to observe in the camera (South Sudan DiversityCam, Fig. 3). Content description of these types of materials is cost prohibitive for most institutions or research groups, which is why Zooniverse offers such a great opportunity to help researchers conduct otherwise difficult visual and textual analysis while giving volunteers a meaningful way to contribute to a project or study a topic about which they are passionate [15].
While the descriptive enhancement provided through the Zooniverse project model is robust, the submission policies for the platform do not require specific sets of metadata to be deposited into the platform. Some projects come with pieces of metadata that are required in many publishing platforms, including date of creation, author, or DOI/persistent URLs; other projects do not and may also lack distinct subjects, topics, names or other pieces of metadata associated with the objects before volunteers work with them. The metadata designed for each project grows out of the project needs rather than being drawn from standardized vocabulary. From a large-scale indexing standpoint, this means that the best way to facilitate connections between projects in the Zooniverse platform is to rely on the hashtags created by the tagging volunteers or by the discipline tags assigned by the platform managers (the current tags are: arts, biology, climate, history, language, literature, medicine, nature, physics, social science and space).
2.4.Mukurtu CMS
Like Zooniverse, the Mukurtu Content Management System (CMS) is a software tool and not a specific project, but at least two major projects use this CMS to digitally archive sacred and historically-significant tribal collections [16]. The history of Mukurtu and the metadata management provided within the platform are bound together. Mukurtu was conceived as a tool to “manage, circulate, and narrate the Warumungu Aboriginal community’s digital materials using their own cultural protocols” [17]. The materials retained digitally in the original Mukurtu platform, the Mukurtu Wumpurrarni-kari Archive, are culturally-sensitive objects that were originally collected and archived without following Warumungu tribal protocols. Mukurtu is helping to fix the problematic archival practices of the local, state, and national archives that appropriated these materials from the Warumungu people. The second major installation of Mukurtu was the Plateau Peoples’ CMS, which “sought to extend the alpha version of Mukurtu to incorporate existing library digital collections (with Dublin Core metadata), in a web-based platform including multiple tribes across several states who share common histories, but also unique tribal vales, languages, and collections” [17].
The metadata fields for the Warumungu and Plateau People’s instances of Mukurtu are tribe-specific. Among the most important features of Mukurtu’s metadata schemas are the self-defined fields, that give communities the power to categorize and name in culturally-appropriate ways, and flexible rights access, which allows platform designers to control rights access to archival content based upon a user’s relationship to the content owners [18]. The customization features of Mukurtu are one of its strengths and force users to engage with collections in a particular cultural, social, and historical context driven by content owners. It supports what founder Kimberley Christen calls “digital heritage stewardship”, which shifts management of collections from “collecting to stewarding [undoing] the colonial model and [inscribing] a relational model built on obligations that one has to care for, maintain, and preserve a variety of belongings” [19]. In other words, Mukurtu makes it possible for collections to be curated and maintained in a collaborative way. In the Plateau People’s Portal, for example, images can have multiple sets of metadata that allows a rich and layered history of a given object to come through (e.g., see Fig. 4a an image of fishing at the Sunnyside dam (Fig. 4b with Washington State University Metadata and Fig. 4c with Yakama Metadata)).
3.Lack of community wide standards for DH projects
It might be self-evident from the variety of elements, controlled and uncontrolled vocabularies, and different strategies for community engagement in each of the projects that no one standard, element set or crowd sourced workflow exists that encompasses all projects. Metadata internal to a project usually grows organically out of specific project needs. It may be harvested from existing data sets (e.g. ISNIs or LCNAFs), but it is more likely created in order to support community needs or to facilitate involvement from a larger group of contributors. Ideally, whatever metadata vocabularies are used, the element sets and schema could be more standardized.
The metadata for several of these projects was provided to Humanities for All, which itself is a home-grown set of elements that identify the project partners, affiliated institutions, community partners, locations, disciplines, funding, thematic tags, and websites. These pieces of metadata help users to find the projects inside of Humanities for All’s web space, but what is the functional reach of the Humanities for All database? How likely is serendipitous discovery of either Humanities for All or the projects collected therein?
4.Where do we go from here?
I propose that the publishing industry take a closer look at how to incorporate digital humanities projects into the scholarly communications lifecycle and that standards groups such as NISO work with project creators, publishers, and librarians to develop official Best Practices for assigning metadata to these projects.
Ideal places to begin developing standard access and discovery points for a project include: creating or using existing standard vocabularies, element sets and schema that are interoperable with current platforms. Even two elements such as a title and DOI would make project discovery easier and indexable in multiple repositories. One option could be adopting the XML schema defined at re3data.org to capture the elements in an interoperable way for easy inclusion in a database such as re3data or other platforms [20].
Now that we have studied how several digital humanities projects create and use metadata and now that I have proposed a couple of options about what pieces of metadata could be used to support access and discovery of digital humanities projects, it is time to consider this discussion open!
What can the scholarly communications industry do to assist in the discovery of digital humanities projects? How can digital humanities projects be better integrated into publishing workflows? Let’s get this conversation started now.
Acknowledgements
Thank you to Daniel Fisher and Gregory Grazevich for participating in the lifecycle of this paper by presenting this work originally for a session at the NISO Plus Conference (February 2020) and to Alice Meadows for proposing the idea of this session. Many thanks to: Samantha Blickhan, the IMLS Postdoctoral Fellow and Humanities Lead for Zooniverse, for providing supplemental information about Zooniverse metadata; Michael Wynne, Digital Applications Librarian at the Center for Digital Scholarship and Curation at Washington State University Libraries, for providing supplemental information about Mukurtu’s metadata schema; and Christopher Warren, Associate Professor of English at Carnegie Mellon University and Project Director and Co-Principle Investigator, for providing supplemental information about the Six Degrees of Francis Bacon: reassembling the early modern social network.
About the Author
Michelle Urberg currently consults in the library and publishing industry, including working with Maverick Publishing Specialists. She was previously a Metadata Librarian at Proquest. She has a PhD in Music History and an MS in Library and Information Science and is passionate about metadata workflows and improving the scholarly communications life cycle. More can be found at the Humanities Commons: https://hcommons.org/members/murberg/ and at ORCID: https://orcid.org/0000-0002-2748-8. E-mail: [email protected].
References
[1] | P. Svensson, Big Digital Humanities: Imagining a Meeting Place for the Humanities and the Digital. University of Michigan Press, Ann Arbor, MI, (2016) , Available at: 10.3998/dh.13607060.0001.001, accessed August 1, 2020. |
[2] | National Humanities Alliance. Humanities for All. 2017; updated regularly, available at: https://humanitiesforall.org/, accessed August 1, 2020. |
[3] | D. Fisher, Goals of the Publicly Engaged Humanities [Internet]. [unknown date], available at: https://humanitiesforall.org/features/goals-of-the-publicly-engaged-humanities, accessed August 1, 2020. |
[4] | Preserve the Baltimore Uprising [Internet], available at: https://baltimoreuprising2015.org/home, accessed August 1, 2020. |
[5] | Preserve the Baltimore Uprising [Internet]. Record and Remember: Gather Stories of Protest Unrest, and Community Action, available at: https://baltimoreuprising2015.org/oralhistorytraining/, accessed August 1, 2020. |
[6] | Preserve the Baltimore Uprising [Internet]. About this project, available at: https://baltimoreuprising2015.org/about, accessed August 1, 2020. |
[7] | Preserve Baltimore Uprising [Internet]. Search Items, available at: https://baltimoreuprising2015.org/items/search, accessed August 1, 2020. |
[8] | Preserve the Baltimore Uprising [Internet]. Browse Items, available at: https://baltimoreuprising2015.org/items/tags, accessed August 1, 2020. |
[9] | Preserve the Baltimore Uprising [Internet]. Browse Collections, available at: https://baltimoreuprising2015.org/collections/browse, accessed August 1, 2020. |
[10] | The Six Degrees of Francis Bacon [Internet], About Six Degrees of Francis Bacon, available at: http://www.sixdegreesoffrancisbacon.com/about, accessed August 1, 2020. |
[11] | Welcome to Wikidata [Internet], available at: https://www.wikidata.org/wiki/Wikidata:Main_Page, accessed August 1, 2020. |
[12] | Six Degrees of Francis Bacon: reassembling the early modern social network [Internet]. Introducing: Six Degrees on Wikidata, available at: https://6dfb.tumblr.com/, accessed August 1, 2020. |
[13] | Zooniverse [Internet]. What is the Zooniverse? Available at: https://www.zooniverse.org/about, accessed August 1, 2020. |
[14] | Zooniverse [Internet]. Publications, available at: https://www.zooniverse.org/about/publications, accessed August 1, 2020. |
[15] | The National Archives [Internet]. Engaging Crowds: Citizen research and heritage data at scale, available at: https://www.nationalarchives.gov.uk/about/our-research-and-academic-collaboration/our-research-and-people/engaging-crowds-citizen-research-and-heritage-data-at-scale/, accessed August 1, 2020. |
[16] | Mukurtu [Internet], The Mukurtu Community, available at: https://mukurtu.org/showcase/, accessed August 1, 2020. |
[17] | K. Christen, A. Merrill and M. Wynne, A Community of Relations: Mukurtu Hubs and Spokes, D-Lib Magazine [Internet], 2017 May/June, Volume 23 available at: 10.1045/may2017-christen, accessed August 1, 2020. |
[18] | Mukurtu [Internet], Digital Heritage Metadata Fields (2.1), available at: https://mukurtu.org/support/digital-heritage-metadata-fields-2-1/, last updated April 16, 2020, accessed August 13, 2020. |
[19] | K. Christen, Relationships not records: Digital heritage and ethics of sharing indigenous knowledge online. in: Routledge Companion to Media Studies and Digital Humanities. Taylor and Francis, Routledge, (2018) , pp. 403–412. |
[20] | Re3data [Internet], Schema, available at: https://www.re3data.org/schema, accessed August 1, 2020. |


