
A Novel T-Spherical Fuzzy REGIME Method for Managing Multiple-Criteria Choice Analysis Under Uncertain Circumstances
Abstract
The theory of T-spherical fuzzy (T-SF) sets possesses remarkable capability to manage intricate uncertain information. The REGIME method is a well-established technique concerning discrete choice analysis. This paper comes up with a multiple-criteria choice analysis approach supported by the REGIME structure for manipulating T-SF uncertainties. This paper constructs new-created measurements such as superiority identifiers and guide indices for relative attractiveness and fittingness, respectively, between T-SF characteristics. This study evolves the T-SF REGIME I and II prioritization procedures for decision support. The application and comparative studies exhibit the effectiveness and favorable features of the propounded T-SF REGIME methodology in real decisions.
1Introduction
Uncertain decisions often take place in miscellaneous kinds of multiple criteria evaluation and assessment processes, especially in coping with complicated realistic problems (Dogan, 2021; Farrokhizadeh et al., 2021). As the ever-increasing complexity of problems, uncertain decisions can be addressed by various fuzzy methods and techniques within indistinct and equivocal environments, and it can call for innovative high-order fuzzy approaches to generate interpretable solutions and efficacious decisions (Ashraf and Abdullah, 2021; Gül, 2021; Özlü and Karaaslan, 2021). In particular, the uncertain set of T-spherical fuzziness has been in a position of considerable influence for manipulating ambiguous and equivocal information in intricate real-world circumstances (Chen et al., 2021; Guleria and Bajaj, 2021; Munir et al., 2021; Özlü and Karaaslan, 2021). This section provides a concise review of high-order fuzzy approaches to multiple-criteria choice analysis. Special attention will be paid to a well-established qualitative evaluation method, named the REGIME method.
1.1T-Spherical Fuzziness with Decision-Making Applications
Realistic decision-making activities are usually highly sophisticated and poorly structured, and many classical decision models cannot directly deal with these complicated problems (Alipour et al., 2021; Garg, 2021b; Garg and Rani, 2021; Ullah et al., 2021b). Numerous classical decision models manage crisp assessment data, which means that the subjective judgment offered by the decision maker is expressed as a precise number. Nevertheless, in considerable down-to-earth situations, the decision information may be inaccurate and/or imprecise (Alipour et al., 2021; Garg, 2021a; Ullah et al., 2021a; Wang and Chen, 2021). Moreover, the decision maker may be unable to explicitly give accurate numerical values for subjective evaluations in uncertain circumstances (Gao and Deng, 2021; Garg, 2021b; Garg and Rani, 2021). In particular, certain judgment criteria are qualitative or equivocal in nature, making it difficult for the decision maker to exploit precise values to externalize subjective assessments and preferences (Alipour et al., 2021; Garg and Rani, 2021; Ullah et al., 2021b). Convoluted decision-making issues usually involve inaccuracy, ambiguity, and indefiniteness, resulting in traditional decision models and relevant canonical techniques often ineffective when manipulating subjective assessment information (Garg, 2021a, 2021b; Wang and Chen, 2021). The aforementioned difficulties and considerations make the notion of fuzzy sets flourish in decision theory (Alipour et al., 2021; Gao and Deng, 2021; Garg, 2021b).
There are different general variants of the fuzzy models that delineate an object’s membership in a fuzzy set in various formats (Smarandache, 2019; Ullah et al., 2020a, 2020b). The notion of ordinary fuzzy sets generalized classical sets and permits a gradual appraisal about an object’s membership in a set. The real world would be full of indeterminism, vagueness, and limited knowledge; thus, the complexities associated with the high-order fuzziness are dependent in a sophisticated way on their uncertainty (Chen, 2021; Donyatalab et al., 2020; Farrokhizadeh et al., 2021; Gül, 2021). In such considerations, it is evidently meaningful to constitute non-standard fuzzy configurations for modelling imprecision and murkiness in recent decades, such as advanced fuzzy models regarding intuitionistic fuzziness (Atanassov, 1986), Pythagorean fuzziness (Yager, 2013), Fermatean fuzziness (Senapati and Yager, 2019a, 2019b), q-rung orthopair fuzziness (Yager, 2017), picture fuzziness (Cuong, 2014), spherical fuzziness (Gündoğdu and Kahraman, 2019), and T-spherical fuzziness (Mahmood et al., 2019). As an efficacious means to expound ambiguous and equivocal information, the generalizations of fuzzy sets exhibit a mathematical strength to expatiate on the uncertainty in subjective thinking and cognitive processes for the reasoning behind intricate decisions in a logical and sensible way (Garg, 2021a; Senapati and Yager, 2019b; Shahzadi et al., 2021; Ullah et al., 2020a). After introducing the generalizations of fuzzy sets, the ordinary fuzzy version of decision models and techniques also began to attain full developments via these higher-order fuzzy sets. Especially, the configuration involving T-spherical fuzziness is a recent advancement in fuzzy theory and has a magnificent capability of tackling decision-making in multiple criteria choice issues (Chen et al., 2021; Garg et al., 2021; Wang and Chen, 2021; Zeng et al., 2020).
The conceptual framework of T-spherical fuzzy (T-SF) sets, initially introduced by Mahmood et al. (2019), is a significant tool for decision makers with multiple criteria evaluation and assessment problems under complicated uncertain circumstances. The uncertain sets of intuitionistic, Pythagorean, Fermatean, and q-rung orthopair fuzziness are elucidated by virtue of belonging and non-belonging functions. More precisely, a total sum of both functions takes a value in a real unit interval from 0 to 1 in the intuitionistic fuzzy model (Atanassov, 1986); the square sum of both functions is valued in
From an alternative perspective, the concept of neutrosophic sets, incipiently propounded by Smarandache (2005a, 2005b), is worthy of note as well. The conception of neutrosophic sets can be deemed to be a generalized conformation of unification toward intuitionistic fuzzy logic (Jana et al., 2021; Nabeeh et al., 2021; Pamucar et al., 2020). The primary scheme behind neutrosophic logic is to describe the features of a three-dimensional neutrosophic space (Pamucar et al., 2020; Smarandache, 2019). Specifically, three dimensions of the space characterize the grade of truth-membership, the grade of falsehood-membership, and the grade of indeterminacy-membership that are equivalent to positive, negative, and refusal memberships, respectively, under uncertainty (Chen, 2021; Qin and Wang, 2020). In particular, these grades of membership are independent of each other in essence (Karaaslan and Hunu, 2020; Şahin and Liu, 2017). Notably, the most obvious differentiation between intuitionistic fuzzy logic and neutrosophic logic lies in whether the three membership degrees are independent or dependent (Karaaslan and Hunu, 2020; Pamucar et al., 2020; Smarandache, 2019). In view of the dependent components in intuitionistic fuzzy logic, when one membership degree changes, the other membership degrees need to be changed accordingly to meet the restriction for keeping their total sum being up to 1 (Atanassov, 1986; Smarandache, 2019). On the contrary, making allowance for the independent components in neutrosophic logic, when one membership degree becomes different, the other membership degrees are unnecessary to change accordingly, wherein the summation of three membership degrees is always up to 3 (Smarandache, 2005a, 2005b, 2019). When the decision maker evaluates the choice options, there is bound to be a certain degree of relevance in the assessments of the advantages and disadvantages of the options with respect to specific judgment criteria. In other words, it is impossible for the favourable and unfavourable evaluations of the same subject matter to be unrelated. Therefore, in neutrosophic logic, the assumption that the grades of positive membership and negative membership meet independence is not appropriate for decision-making problems. More precisely, the mechanism involving independent components is not suitable for practical multiple-criteria choice problems, for the reason that the interactions surrounded by three grades of membership have objective reality included in human appraisals and judgments to a great extent (Chen, 2021). The T-SF framework provides an all-encompassing model including intuitionistic fuzzy sets along with certain non-standard fuzzy sets; thus, it would be more appropriate than the neutrosophic framework to portray assessment information for multiple-criteria choice analysis in uncertain circumstances.
Due to the comprehensiveness of T-SF sets, the T-SF configuration serves an important tool to manipulate convoluted uncertainties for formulating and solving multiple-criteria choice problems. By way of illustration, Ali et al. (2020) put forward aggregation operators in complex T-SF settings for the sake of managing multiple-criteria evaluation affairs. With the assistance of the generalized parameter contained in T-SF sets, Chen et al. (2021) carried forward certain useful geometric aggregation operators with the aim of multiple-criteria choice analysis. Garg et al. (2021) launched several beneficial T-SF power aggregation operators to make headway for multiple-criteria evaluation and appraisement. Guleria and Bajaj (2021) progressed aggregation operators for T-SF soft sets to tackle decision-making issues. Ju et al. (2021) gave impetus to a T-SF TODIM (i.e. interactive and multiple-criteria decision making in Portuguese) technique for facilitating group decision-making tasks under incomplete preference information. Khan et al. (2021b) set forth a fresh evaluation approach using the agency of T-SF Schweizer-Sklar power Heronian aggregation operators for uncertain decisions. Liu et al. (2021a) promoted new and creative Muirhead mean aggregation operations via a complex 2-tuple linguistic structure in T-SF circumstances to treat decision analysis issues. Liu et al. (2021b) brought forward Maclaurin symmetric aggregation operators with normal T-SF numbers in the support of uncertain decision making. Munir et al. (2020) evolved T-SF Einstein hybrid aggregating operations to support the determination of choice options. Munir et al. (2021) propounded a T-SF decision-aiding algorithm on grounds of interactive geometric aggregation operations along with associated immediate probabilities. Özlü and Karaaslan (2021) delivered correlation coefficients concerning T-SF type-2 hesitant information and exploited these notions for solving an issue involving clustering the choice options. Wang and Chen (2021) propounded a T-SF ELECTRE (i.e. ELimination Et Choice Translating REality) outranking model for decision analysis with multiple criteria. On account of the advancement of T-SF decision models and techniques, this paper intends to develop an innovative multiple-criteria choice analysis approach using the agency of the T-SF theory for determining the predominance ranks of choice options or alternatives.
1.2Brief Review of the REGIME Methodology
The REGIME method, incipiently propounded by Hinloopen et al. (1983a, 1983b), is a well-established technique concerning multiple-criteria choice analysis, especially for qualitative information (Alinezhad and Khalili, 2019; Oztaysi et al., 2021; Tsigdinos and Vlastos, 2021). Based on an efficient and convenient-to-use approach of paired comparisons for choice options, the REGIME method manipulates qualitative information (such as ordinal data) in a mathematically reasonable way (Oztaysi et al., 2022). Of course, the REGIME method accepts both qualitative and quantitative data, and the implementation procedure of this method is simple and easy to understand (Esangbedo et al., 2021; Kamran et al., 2017; Oztaysi et al., 2021). The characteristic of the classical REGIME framework is the formation of a REGIME matrix that collects outcomes about paired comparisons of choice options in an impact matrix (Esangbedo et al., 2021). Herein, the impact matrix elucidates the effect measurements of choice options on an amalgamation of quantitative and qualitative judgment criteria manifested in ordinal values (Alinezhad and Khalili, 2019; Tsigdinos and Vlastos, 2021). REGIME can conclusively generate a complete list of ranking for choice options via comparing the pairs with selected judgment criteria (Esangbedo et al., 2021; Kamran et al., 2017).
There was something unique about the theory of the REGIME methodology, which constitutes a distinctive outranking-based model for multiple-criteria evaluation and choice analysis. As is well known, the ELECTRE and the PROMETHEE (i.e. Preference Ranking Organization METHod for Enrichment of Evaluations) are widely employed outranking-based models. Compared with these two outranking-based models, the REGIME method exploits a mixed approach with combining the logit analysis and Kendall’s paired comparisons based on ordinal data (Asgharizadeh et al., 2014; Aspen et al., 2015; Hinloopen et al., 1983a). In this regard, a favourable feature possessed by the REGIME is its ability to utilize hybrid qualitative and quantitative data without requiring to convert the qualitative information into quantitative values (Esangbedo et al., 2021; Kamran et al., 2017; Oztaysi et al., 2022). Moreover, the REGIME is capable of conducting an adaptive analysis (Kamran et al., 2017) because it can render a complete predominance ranking for choice options or alternatives supported by paired comparisons with selected criteria in miscellaneous decision scenarios (Briamonte et al., 2021; Wątróbski et al., 2019). Especially, utilizing the REGIME method can generate undisputed consequences, so the dominant choice will be identified for the most cases (Hinloopen and Nijkamp, 1990; Wątróbski et al., 2019). Over and above that, the REGIME method has been proved as an efficacious technique to resolve various evaluation and decision-making affairs (Frank, 2014; Oztaysi et al., 2021; Tsigdinos and Vlastos, 2021). For these reasons, this research makes an effort at choosing the REGIME as the basic framework for extending to T-SF decision environments and conducting specialized decision-making tasks.
The REGIME has been smoothly exploited in the treatment of multiple-criteria evaluation problems (Hinloopen and Nijkamp, 1990), such as assessment and prioritization of coastal areas (Hinloopen et al., 1983b), regional sustainable resource policy (Akgün et al., 2012), assessment of alternative wind park locations (Stratigea and Grammatikogiannis, 2012), environmental management on wastewater from agriculture (Massei et al., 2014), economic-ecological sustainability for rural development (Akgün et al., 2015), sawability related to ornamental and building stones (Kamran et al., 2017), and strategic road network of a metropolitan region (Tsigdinos and Vlastos, 2021). On the flip-side, the REGIME framework has been generalized to fuzzy environments, such as the directly extended REGIME methods involving Pythagorean fuzziness (Oztaysi et al., 2021) and spherical fuzziness (Oztaysi et al., 2022). These fuzzy extensions of the REGIME method would form a basis for further advancement under T-SF uncertainties. Even though the usefulness and effectiveness of the REGIME technique have been demonstrated in the aforesaid literature, the advancement of the REGIME methodology has not been investigated yet in T-SF decision contexts. In view of this, it is critically important in the establishment of a T-SF REGIME approach as the increasing complexity and high-order fuzziness in realistic decision-making processes.
1.3Research Gaps and Motivations
In terms of fuzzy community, the theory of T-spherical fuzziness contains a very comprehensive account of several non-standard fuzzy configurations. The advancements in the study of the fuzzy decision-making field are crucial for the subject of multiple-criteria choice analysis because of the necessity of managing uncertain information in real decisions. According to the investigations regarding the aforementioned literature, the research gaps and motivations for this paper are threefold:
1. With the increasing usage of the T-SF theory in decision analysis, developing an appropriate multiple-criteria choice technique for resolving preference predominance rankings has become more critical under remarkably complicated uncertainties. This generates the first motivation in order to span the gap in such research topics. Namely, there would be generally high demand for exploiting the T-SF theory in multiple-criteria choice analysis, which has been echoed by numerous decision-making models and methods in T-SF circumstances.
2. As uncertainties in real decisions are common, the classical REGIME method would be criticized for its ignorance of ambiguous and equivocal information and lack of proper manipulation. On account of this technical gap, as technology requirements in realistic uncertain contexts increases, so does demand for more precise modelling of uncertainties and efficient manipulation of subjective assessments, which brings about the second motivation.
3. There are now a mushrooming number of studies that shed some light on the subject of decision models predicated on T-SF sets; however, little research has been done on adapting the classic REGIME methodology to a T-SF uncertain context. The existing multiple criteria evaluation and choice methods involving T-spherical fuzziness displayed an utter lack of interest in the extension of the REGIME technique to T-SF environments, which gives rise to the third motivation.
From this basis, this paper attempts to making the REGIME accommodate to the realities of intricate uncertain circumstances. Moreover, this paper contrives of a novel T-SF REGIME method using several beneficial notions for conducting multiple-criteria choice analysis under T-SF uncertainty.
1.4Originality and Contributions
The primary purpose of this study is to specify a suitable measurement system for complex T-SF information and launch an innovative T-SF REGIME method for addressing multiple criteria evaluation and choice issues. It is worth mentioning that this paper intends to exploit the main structure of REGIME to adapt to T-SF decision environments. Because this paper desires to manipulate complex T-SF uncertain information, the evolved REGIME method should have differing adaptive notions corresponding to the differing phases of the core REGIME procedure. First, this paper constitutes a T-SF multiple-criteria choice problem involving judgment criteria and choice options, along with relevant T-SF evaluation values embedded in each T-SF characteristic. Next, in order to differentiate such T-SF assessment information, this study exploits a beneficial score function that signifies grades of satisfaction, neutral satisfaction, dissatisfaction, and refusal membership for utilizing T-SF uncertain information adequately. In accordance with score functions and accuracy values, this study identifies the superiority criteria supported by paired predominance relationships. Soon afterward, this study amalgamates the discrepancy between score functions with the total weights of superiority criteria for enriching the notion of superiority indices. Then, this paper originates an efficacious superiority identifier capable of measuring the relative attractiveness between T-SF characteristics. And following the superiority identifier, this paper presents the notions of REGIME identifiers and REGIME vectors to lay the foundations of a REGIME matrix and establish a guide index capable of measuring the relative fittingness for T-SF characteristics. This study conceives two beneficial procedures for the T-SF REGIME I and II prioritization to yield the eventual partial- and complete-preference rankings, respectively, for available options. By way of the Boolean matrices based on superiority identifiers and guide indices, this paper confirms valuable outranking relationships for generating the T-SF REGIME I predominance ranks for choice options. Moreover, this paper evolves the T-SF REGIME II predominance ranks of options on the basis of the net superiority identifier and the net guide index. To demonstrate the conceivability and advantages of the evolved T-SF REGIME methodology in pragmatic decisions, this paper explores a realistic problem concerning the company selection for plant-building. The effectiveness and constructiveness of the developed techniques can be illustrated through the agency of a comparative analysis.
1.5Structure of This Research
The remainder of this research paper is exhibited systematically along these lines. Section 2 provides an introductory description of some rudimental notions about T-SF sets. Section 3 puts forward a novel T-SF REGIME method through the utility of the score function-based superiority identifiers and guide indices. Section 4 executes the initiated technique to handle the selection problem of companies for setting up food processing plants and then carry out a comparative analysis with the T-SF versions of other decision-making methods. Section 5 concludes this research work with certain concluding remarks, academic contributions, limitations, and future research directions.
2Notion of T-SF Sets: Preliminaries
T-SF sets contribute a magnificent model to comprehensively manage the equivocation and indefiniteness accompanied by multiple criteria evaluation and assessment activities. Herein, this section intends to describe preliminary notations related to T-SF sets. Throughout this work, the notations μ, η, ν, and γ represent grades of positive membership, neutral membership (i.e. abstinence), negative membership, and refusal membership, respectively, in the unit interval
Definition 1
Definition 1(Cuong, 2014).
Let a finite nonempty set U represent the domain of discourse containing an element u. A picture fuzzy set P in U is stated precisely like this:
(1)
Definition 2
Definition 2(Gündoğdu and Kahraman, 2019).
A spherical fuzzy set S in U is listed below:
(2)
Definition 3
Definition 3(Mahmood et al., 2019).
A T-SF set T in U is delineated as shown:
(3)
If
Definition 4
Definition 4(Mahmood et al., 2019).
The score value
(4)
(5)
The notions of
1. If
2. If
a) If
b) If
However, the grades of neutral membership
Definition 5
Definition 5(Zeng et al., 2019).
The score function
(6)
3Proposed T-SF REGIME Methodology
This section makes an effort to develop a novel T-SF REGIME method for managing multiple-criteria choice issues under intricate uncertain circumstances. This section designs some beneficial concepts to plan an approach for determining predominance relationships among the T-SF evaluation values of given alternatives. An efficacious T-SF REGIME procedure is evolved to help decision makers arrive at a choice.
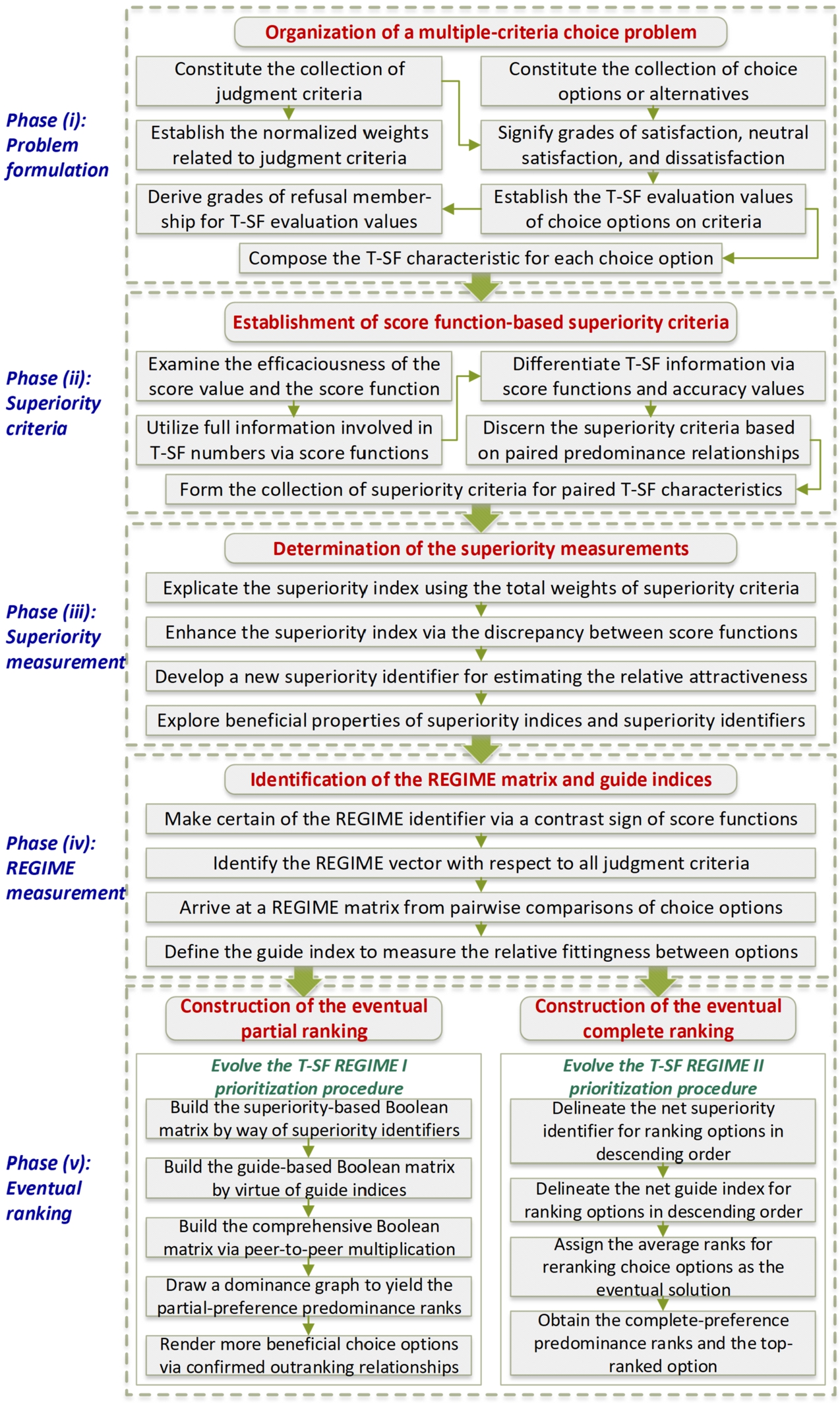
The proposed T-SF REGIME method consists of five phases: (i) organization of a multiple-criteria choice problem, (ii) establishment of score function-based superiority criteria, (iii) determination of the superiority measurements, (iv) identification of the REGIME matrix and guide indices, and (v) construction of the eventual partial/complete ranking. The research focuses in the five phases are depicted in the T-SF REGIME framework of the evolved methodology. The analytical framework of the advanced T-SF REGIME is portrayed in Fig. 1. In the first phase, this paper constitutes a multiple-criteria choice issue under complicated T-SF uncertainty. In the second phase, this paper utilizes a beneficial score function to differentiate T-SF information for pinpointing the superiority criteria. In the third phase, the developed approach aims to exploit the score function-based collection of superiority criteria to delineate the notions of a superiority index and a superiority identifier. In the fourth phase, this paper utilizes the sign of the contrast between score functions to form a REGIME matrix and then generate a guide index. In the final phase, this study produces the T-SF REGIME I and II prioritization mechanisms in the expectation of yielding partial-preference and complete-preference predominance rankings, respectively, for choice options. To draw as a logical conclusion about the T-SF REGIME I eventual predominance ranks, this study launches the conception of a superiority-based Boolean matrix and a guide-based Boolean matrix. This paper unfolds the notions of net superiority identifiers and net guide indices for deducing the T-SF REGIME II ranking among choice options. At the beginning, a multiple-criteria choice task would be constituted in T-SF decision circumstances.
Fig. 1
The framework of the evolved T-SF REGIME methodology.
Consider the mathematical description of a multiple-criteria choice analysis task in the first phase. Let
(7)
The REGIME mechanism exploits a comparison of any two choice options in pairs. Next, an eventual predominance ranking of all available options is co-ascertained through the mutual comparisons of alternatives. With the purpose of building a new mechanism of the proposed T-SF REGIME method, this paper would first launch an identification approach of a regime. There is usually no obvious single dominant choice option in practical decision-making affairs. Therefore, one needs a better way to proceed with T-SF evaluation values in pairwise comparisons that focus on differences between choice options with respect to the judgment criteria. The score function exhibited by Zeng et al. (2019) can fully utilize the information about grades of positive, neutral, negative, and refusal memberships that quantify belongingness of a judgment criterion in the domain of discourse to a T-SF characteristic. Let us examine the effectiveness of the score function
Example 1.
Consider that two T-SF evaluation values
The research focus in the second phase is the differentiation of T-SF evaluation values for discerning the superiority criteria. For the most part, one can determine a predominance relationship portrayed by the rationale of “the higher, the better”. A T-SF evaluation value is considered to be superior to another T-SF evaluation value in case that the corresponding score function is more significant. When two T-SF evaluation values have an identical score function value, the corresponding accuracy values would be exploited to examine the superiority of these T-SF evaluations. That is, a T-SF evaluation value is regarded to be more significant to another T-SF evaluation value if its accuracy value is larger. Considering two T-SF evaluation values of choice options
1. If
2. If
a) If
b) If
Definition 6.
Consider two T-SF characteristics
(8)
Theorem 1.
The complement of
(9)
(T1.1)
(T1.2)
(T1.3)
(T1.4)
Proof.
Because two equalities
Example 2.
Consider a collection of judgment criteria
Consider the third phase of the superiority measurements in the evolved T-SF REGIME methodology. A significant concept in the classical REGIME mechanism would be the superiority index. This index manifests an extent to which a choice option
Definition 7.
Consider the normalized weight
(10)
(11)
Theorem 2.
The superiority index
(T2.1)
(T2.2)
Proof.
Based on (T1.2), it can be recognized that
Next, consider the fourth phase of the REGIME matrix formation and the determination of guide indices in the current methodology. In particular, the guide index is employed to measure the relative fittingness between choice options. In accordance with the score functions of T-SF evaluation values, this paper builds the REGIME identifier and the REGIME vector for arriving at a REGIME matrix from paired juxtapositions of choice options in conjunction with judgment criteria, as described below.
Definition 8.
Consider the T-SF evaluation values
(12)
(13)
(14)
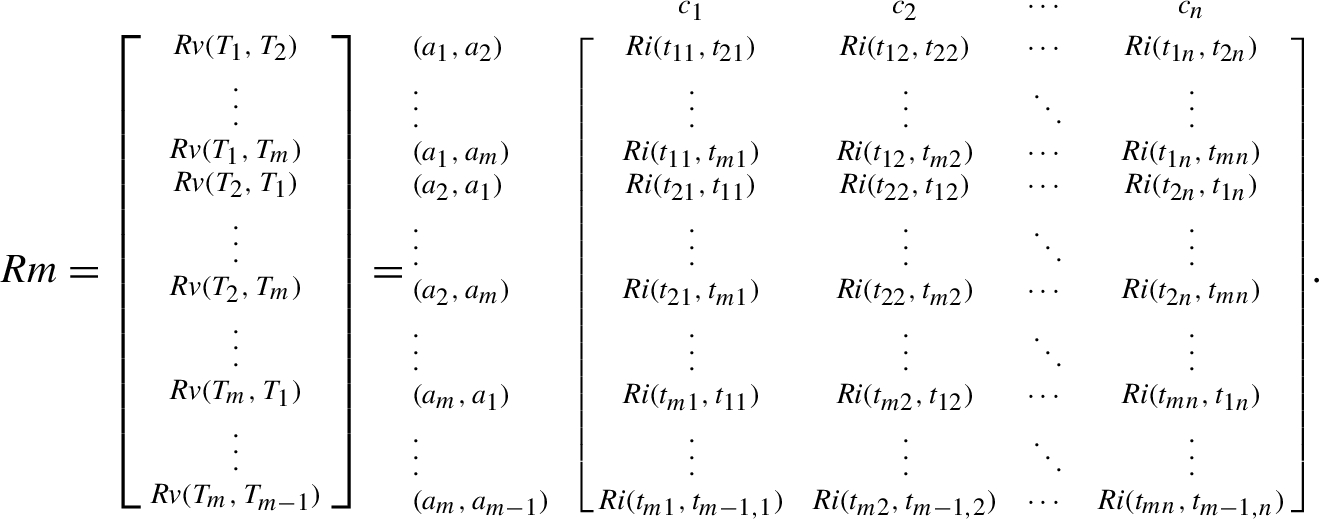
Theorem 3.
The REGIME identifier
Proof.
Based on Eq. (12), it readily draws as a logical conclusion that
Definition 9.
Considering the normalized weight
(15)
Theorem 4.
The guide index
(T4.1)
(T4.2)
(T4.3)
Proof.
As per the fact that
In the final phase, this paper first establishes the T-SF REGIME I prioritization procedure as a means of achieving partial-preference predominance ranks for choice options. Specifically, this paper attempts to constitute two Boolean matrices on the grounds of superiority identifiers and guide indices separately for generating eventual predominance ranks of all available options. First, on the basis of the superiority identifiers
Definition 10.
Given the superiority identifier
(16)
(17)
Theorem 5.
For all
(T5.1)
(T5.2)
(T5.3)
Proof.
When
Definition 11.
Given a guide index
(18)
(19)
Theorem 6.
For all
(T6.1)
(T6.2)
(T6.3)
Proof.
The proving process would be analogous to the proof in Theorem 5. □
By applying a peer-to-peer multiplication operation in conjunction with the entries in
(20)
(21)
The unit entries in the comprehensive Boolean matrix
However, the use of the Boolean matrices
The proposed T-SF REGIME II approach delineates the net superiority identifier
(22)
(23)
Obviously, a choice option
The initiated T-SF REGIME I and II methods for manipulating a multiple-criteria choice problem in uncertain contexts with T-spherical fuzziness are devised systematically as Algorithms I and II, respectively, described below. The two algorithms consist of five phases, including formulating a multiple-criteria choice problem in Phase (i), constructing score function-based superiority criteria in Phase (ii), ascertaining the superiority measurements in Phase (iii), pinpointing the REGIME matrix and guide indices in Phase (iv), and generating the eventual partial/complete ranking in Phase (v).
Algorithm I: T-SF REGIME I method
Step I.1. Designate the collection of choice options
Step I.2. Signify the normalized weight
Step I.3. Compose the T-SF characteristic
Step I.4. Utilize Eqs. (6) and (5) to compute the score function
Step I.5. Obtain the superiority criteria in which
Step I.6. Compute the discrepancy between
Step I.7. Make use of the normalized weight
Step I.8. Apply Eq. (12) to generate the REGIME identifier
Step I.9. Fuse the normalized weight
Step I.10. Exploit Eq. (16) to gain an entry
Step I.11. Use Eq. (18) to acquire an entry
Step I.12. Employ Eq. (20) to derive an entry
Step I.13. Confirm the partial-preference predominance rank regarding
Algorithm II: T-SF REGIME II method
Steps II.1–II.9. See Steps I.1–I.9 in Algorithm I.
Step II.10. Derive the net superiority identifier
Step II.11. Delineate the net guide index
Step II.12. Select the top-ranked option as the eventual solution if it enjoys the maximal net superiority identifier and the maximal net guide index, otherwise select an option having the highest average rank. The complete-preference predominance ranks are yielded by reranking options based on the average ranks.
In comparison with the prevailing decision-making methods predicated on a variety of aggregation operators, such as various multiple-criteria evaluation approaches in Ali et al. (2020), Chen et al. (2021), Garg et al. (2021), Guleria and Bajaj (2021), Khan et al. (2021b), Liu et al. (2021a), Liu et al. (2021b), Munir et al. (2020), and Munir et al. (2021), the T-SF REGIME architecture and techniques propounded by this research are simpler, easier to use, and more efficacious. The initiated T-SF REGIME methodology in this study possesses a comprehensive theoretical basis; but in terms of execution procedures, it is quite simple and conforms to human intuitive judgments. For analysts or decision makers, the principles of the REGIME method are easy to understand and accept. Moreover, abstract theoretical foundations can be realized through the developed notions and measurements, such as the superiority index, superiority identifier, REGIME identifier, and guide index. The decision maker can exploit systematic algorithms, i.e. T-SF REGIME I and II, to manage real-world multiple-criteria choice problems in highly complex and uncertain environments. In a nutshell, the most significant advantage of the propounded algorithms is highly intellectual but still easily understandable to use. The advanced methodology is designed to be easy for an untrained decision maker to manipulate, and it will facilitate the determination of eventual partial- and complete-preference predominance rankings of choice options in an uncomplicated and effectual manner.
4Real-World Application and Comparisons
This section endeavors to study a real-life choice issue to demonstrate the technical practicality and strengths of using the T-SF REGIME methodology for multiple-criteria evaluations. Comparative discussions are also held under different score values for understanding the effectiveness and value of the initiated methods. Furthermore, this section makes more comparisons with the T-SF versions of other multiple-criteria evaluation methods to give substance to the superiority of the T-SF REGIME methodology. Consider that the TOPSIS (i.e. Technique for Order Preference by Similarity to Ideal Solutions) and the VIKOR (i.e. VIseKriterijumska Optimizacija I Kompromisno Resenje) are widely employed and reliable in resolving issues for multiple-criteria choice analysis. This section institutes certain comparisons of the propounded method with the T-SF TOPSIS and the T-SF VIKOR for stating the merits.
4.1Realistic Application and Discussions
The investigated selection problem of companies for erecting food processing plants was originated from the case study in Garg et al. (2018), as outlined in Fig. 2. The Jharkhand government in India attempts to establish essential agricultural-focused industries in rural regions. The authorities constituted the global investor summit and encouraged companies and enterprises for the investment in the surrounding countryside. Moreover, the authorities made a formal public statement about adequate facilities that were exploitable to construct food processing plants in the countryside.
Fig. 2
The selection problem of companies for erecting food processing plants.
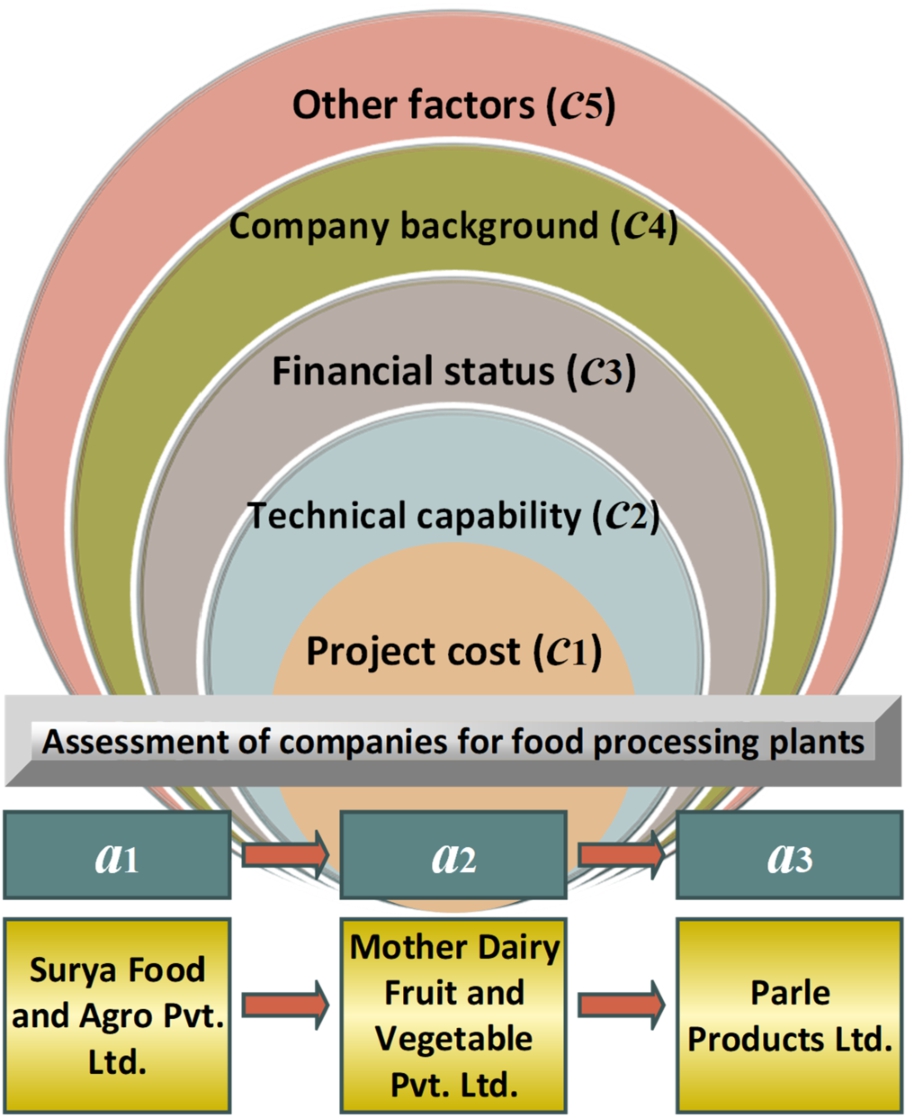
To begin with, the T-SF REGIME I method in Algorithm I would be illustrated with the realistic selection problem of companies for building food processing plants. As disclosed in Fig. 2, there are five judgment criteria (i.e.
Table 1
Decision information pertaining to each choice option.
| Choice option | Choice option | Choice option | |||||
| 0.1117 | 0.6811 | 0.8411 | 0.9750 | ||||
| 0.2365 | 0.4344 | 0.8536 | 0.9322 | ||||
| 0.3036 | 0.9750 | 0.8582 | 0.9565 | ||||
| 0.2365 | 0.9221 | 0.8959 | 0.9158 | ||||
| 0.1117 | 0.8411 | 0.9295 | 0.8698 | ||||
Table 2
Results of score functions, accuracy values, and collections of superiority criteria.
| Choice option | Choice option | Choice option | ||||
| 0.2128 | 0.6840 | 0.2207 | 0.4050 | 0.6842 | 0.0730 | |
| 0.6035 | 0.9180 | 0.7629 | 0.3780 | 0.6107 | 0.1900 | |
| 0.6842 | 0.0730 | 0.2864 | 0.3680 | 0.4335 | 0.1250 | |
| 0.5626 | 0.2160 | 0.3013 | 0.2810 | 0.7449 | 0.2320 | |
| 0.4272 | 0.4050 | 0.5977 | 0.1970 | 0.5416 | 0.3420 | |
Consider Phase (ii) as an illustration. In Step I.4, the calculation consequences of the score function
Concerning Step I.6 in Phase (iii), the discrepancy between
Table 3
Outcomes relevant to the score function-based superiority identifiers.
| – | – | 0.0079 | – | 0.4714 | 0.4636 | |
| – | – | 0.1594 | 0.1522 | 0.0072 | – | |
| 0.3978 | 0.2507 | – | – | – | 0.1471 | |
| 0.2613 | – | – | – | 0.1824 | 0.4436 | |
| – | – | 0.1705 | 0.0561 | 0.1144 | – | |
| 0.1826 | 0.0761 | 0.0576 | 0.0423 | 0.1103 | 0.2014 |
Relating to Step I.8 in Phase (iv), the REGIME identifier
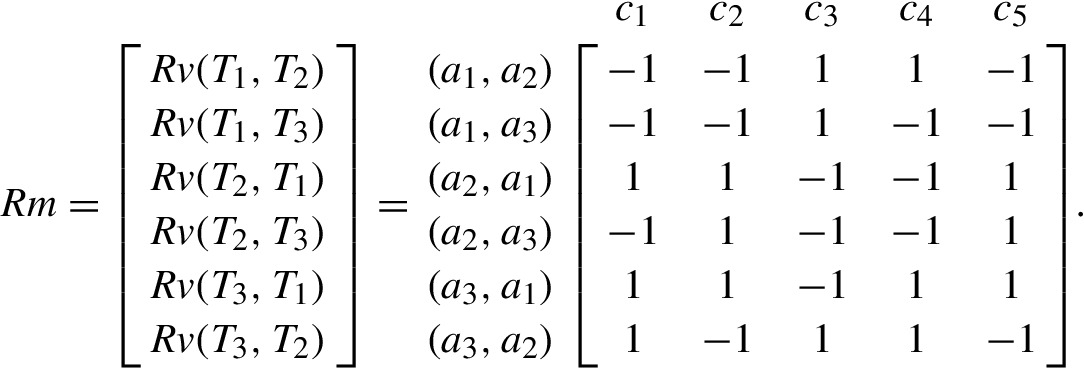
Concerning Step I.9, this study exploited Eq. (15) to synthesize the normalized weight
Considering Steps I.10 and I.11 in Phase (v), this paper made use of Eqs. (16) and (18) to acquire the entries
In Step I.13, the partial-preference predominance rankings
Fig. 3
The dominance graph yielded by the T-SF REGIME I prioritization procedure.
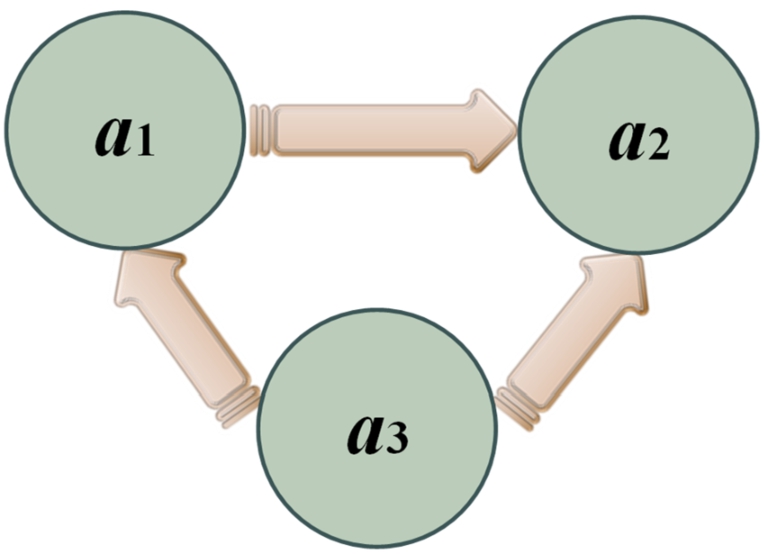
On the flip-side, the T-SF REGIME II method in Algorithm II would be utilized to tackle the identical selection problem of companies for food processing plants. As mentioned previously, Steps II.1–II.9 are the same as Steps I.1–I.9. Concerning Step II.10 in Phase (v), this paper employed Eq. (22) to identify the net superiority identifiers in this manner:
Finally, in Step II.12, the complete-preference predominance ranking
In an attempt to validate the methodological advantages, this paper implements a comparative approach to different score values in the initiated T-SF REGIME methods and techniques. Based on Definition 4, the score value
Table 4
Summary outcomes in the comparative analysis on grounds of score values.
| 0.1270 | 0.6650 | 0.0630 | 0.0610 | 0.0910 | |
| −0.0910 | 0.3160 | −0.0910 | −0.1520 | 0.0610 | |
| 0.0560 | 0.1240 | −0.1250 | 0.2080 | 0.0910 |
| 0.2074 | 0.1930 | 0.0000 | 0.0557 | 0.0348 | 0.1049 | |
| 1 | 1 | 0 | 0 | 0 | 1 | |
| 1.0000 | 0.4153 | −1.0000 | 0.0802 | −0.4153 | −0.0802 | |
| 1 | 1 | 0 | 0 | 0 | 1 | |
| 1 | 1 | 0 | 0 | 0 | 1 |
| 0.3656 | −0.2565 | −0.1090 | |
| 2.8306 | −1.8396 | −0.9910 |
First, let us examine the results using the score value-based T-SF REGIME I method. As attested by the entry
The evolved T-SF REGIME methodology possesses an exceptional ability to make more accurate decisions by using a more suitable and efficacious measurement system concerning the characteristics of T-SF information. In particular, the initiated T-SF REGIME I and II prioritization procedures can make more precise decisions. Results are presented in the format of the partial-and complete-preference predominance ranks and can be utilized for the further applications in decision-making support systems.
4.2Comparisons with T-SF Versions of TOPSIS and VIKOR
This subsection attempts to make comparisons with other decision-making approaches carefully and objectively to verify the performance of the evolved T-SF REGIME methodology. As is well known, the TOPSIS and VIKOR have been widely used throughout the compromise decision-making processes and have been renowned as anchor dependent models in multiple criteria analysis. From this basis, this subsection exploits the T-SF versions of TOPSIS and VIKOR to facilitate comparisons.
Choice options that come nearer to the positive-ideal option in separation measures are more favourable than those that come farther away. In contrast, choice options that keep away from the negative-ideal option via separation measures are more favourable than those that come near. The rationale of human choice is to simultaneously come near to the positive-ideal option and keep away from the negative-ideal option to the most possible extent. Such axioms of choice have explicitly assumed that there exist sharply bipolar anchor values of reference. Two types of bipolar anchor values were utilized in the comparative analysis with the T-SF TOPSIS and the T-SF VIKOR: fixed ideals and displaced ideals.
Take into consideration the selection problem of companies for erecting food processing plants. Place the fixed positive-ideal option
Place the displaced positive-ideal option
(24)
The closeness coefficients
(25)
(26)
Table 5
Results of the closeness coefficients yielded by the T-SF TOPSIS approach.
| Outcomes based on bipolar anchor values of the fixed ideals | |||||||||||
| 0.7259 | 0.7750 | 0.7873 | 0.7915 | 0.7931 | 0.7939 | 0.7943 | 0.7945 | 0.7946 | 0.7946 | 0.7946 | |
| 0.7448 | 0.7978 | 0.8131 | 0.8197 | 0.8231 | 0.8249 | 0.8260 | 0.8267 | 0.8271 | 0.8274 | 0.8279 | |
| 0.8270 | 0.8761 | 0.8884 | 0.8932 | 0.8955 | 0.8968 | 0.8976 | 0.8981 | 0.8985 | 0.8987 | 0.8997 | |
| Outcomes based on bipolar anchor values of the displaced ideals | |||||||||||
| 0.2328 | 0.2685 | 0.2823 | 0.2886 | 0.2918 | 0.2935 | 0.2945 | 0.2951 | 0.2954 | 0.2956 | 0.2960 | |
| 0.3412 | 0.3806 | 0.3968 | 0.4051 | 0.4098 | 0.4125 | 0.4142 | 0.4152 | 0.4159 | 0.4163 | 0.4171 | |
| 0.6449 | 0.6902 | 0.7041 | 0.7096 | 0.7122 | 0.7137 | 0.7146 | 0.7153 | 0.7158 | 0.7162 | 0.7179 | |
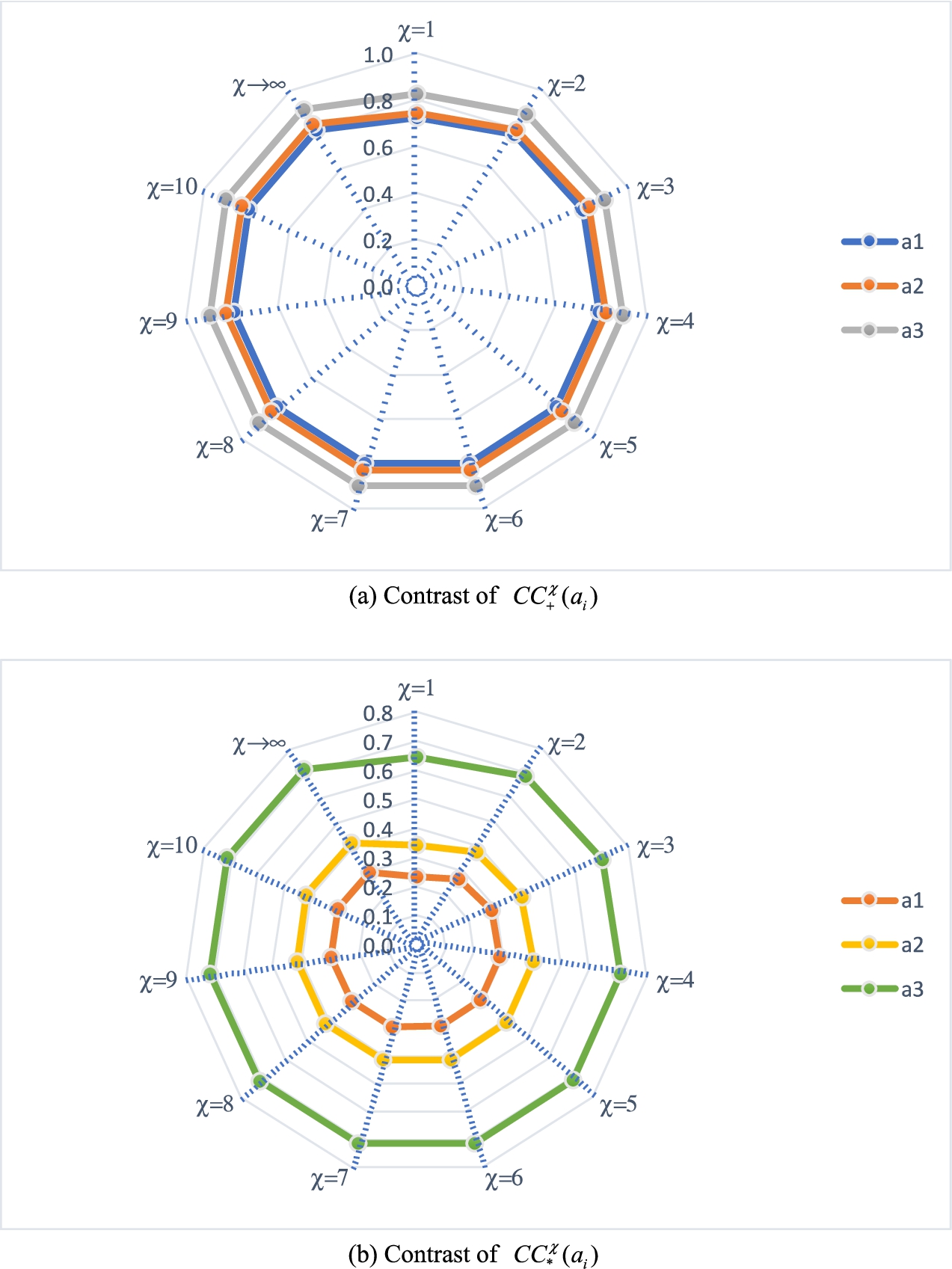
Based around the data in the selection problem of companies, the computation outcomes of the closeness coefficients
Fig. 4
The contrasting effect of the obtained closeness coefficients in different χ values.
Next, consider the determination outcomes produced by the T-SF VIKOR method. Place any two T-SF evaluation values
(27)
By incorporating the normalized weight
(28)
(29)
In an analogous way, the measures
(30)
(31)
By virtue of a VIKOR parameter
(32)
(33)
Table 6
Results of the measurements related to the T-SF VIKOR approach.
| Outcomes based on bipolar anchor values of the fixed ideals | |||||||||||
| 0.4222 | 0.5172 | 0.5712 | 0.6031 | 0.6237 | 0.6381 | 0.6487 | 0.6567 | 0.6631 | 0.6682 | 0.7162 | |
| 0.5053 | 0.6048 | 0.6672 | 0.7050 | 0.7295 | 0.7465 | 0.7589 | 0.7683 | 0.7758 | 0.7818 | 0.8379 | |
| 0.4801 | 0.6308 | 0.7051 | 0.7468 | 0.7731 | 0.7912 | 0.8044 | 0.8144 | 0.8222 | 0.8286 | 0.8881 | |
| 0.1435 | 0.2009 | 0.2255 | 0.2390 | 0.2474 | 0.2532 | 0.2574 | 0.2606 | 0.2631 | 0.2651 | 0.2842 | |
| 0.1697 | 0.1936 | 0.2119 | 0.2236 | 0.2313 | 0.2367 | 0.2406 | 0.2436 | 0.2460 | 0.2479 | 0.2657 | |
| 0.1708 | 0.2163 | 0.2411 | 0.2553 | 0.2643 | 0.2705 | 0.2750 | 0.2784 | 0.2811 | 0.2833 | 0.3036 | |
| 0.0000 | 0.1619 | 0.2335 | 0.2422 | 0.2437 | 0.2439 | 0.2440 | 0.2440 | 0.2440 | 0.2440 | 0.2440 | |
| 0.9806 | 0.3857 | 0.3584 | 0.3545 | 0.3540 | 0.3539 | 0.3540 | 0.3540 | 0.3540 | 0.3540 | 0.3540 | |
| 0.8487 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| Outcomes based on bipolar anchor values of the displaced ideals | |||||||||||
| 0.5669 | 0.5595 | 0.5596 | 0.5604 | 0.5612 | 0.5618 | 0.5623 | 0.5626 | 0.5629 | 0.5630 | 0.5634 | |
| 0.6008 | 0.6084 | 0.6141 | 0.6177 | 0.6198 | 0.6211 | 0.6219 | 0.6224 | 0.6227 | 0.6229 | 0.6234 | |
| 0.4185 | 0.4212 | 0.4203 | 0.4199 | 0.4199 | 0.4200 | 0.4201 | 0.4202 | 0.4203 | 0.4203 | 0.4204 | |
| 0.2365 | 0.2365 | 0.2365 | 0.2365 | 0.2365 | 0.2365 | 0.2365 | 0.2365 | 0.2365 | 0.2365 | 0.2365 | |
| 0.3036 | 0.3036 | 0.3036 | 0.3036 | 0.3036 | 0.3036 | 0.3036 | 0.3036 | 0.3036 | 0.3036 | 0.3036 | |
| 0.2017 | 0.1892 | 0.1814 | 0.1778 | 0.1763 | 0.1756 | 0.1753 | 0.1752 | 0.1751 | 0.1751 | 0.1751 | |
| 0.5777 | 0.5763 | 0.5848 | 0.5885 | 0.5899 | 0.5905 | 0.5907 | 0.5908 | 0.5909 | 0.5910 | 0.5911 | |
| 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
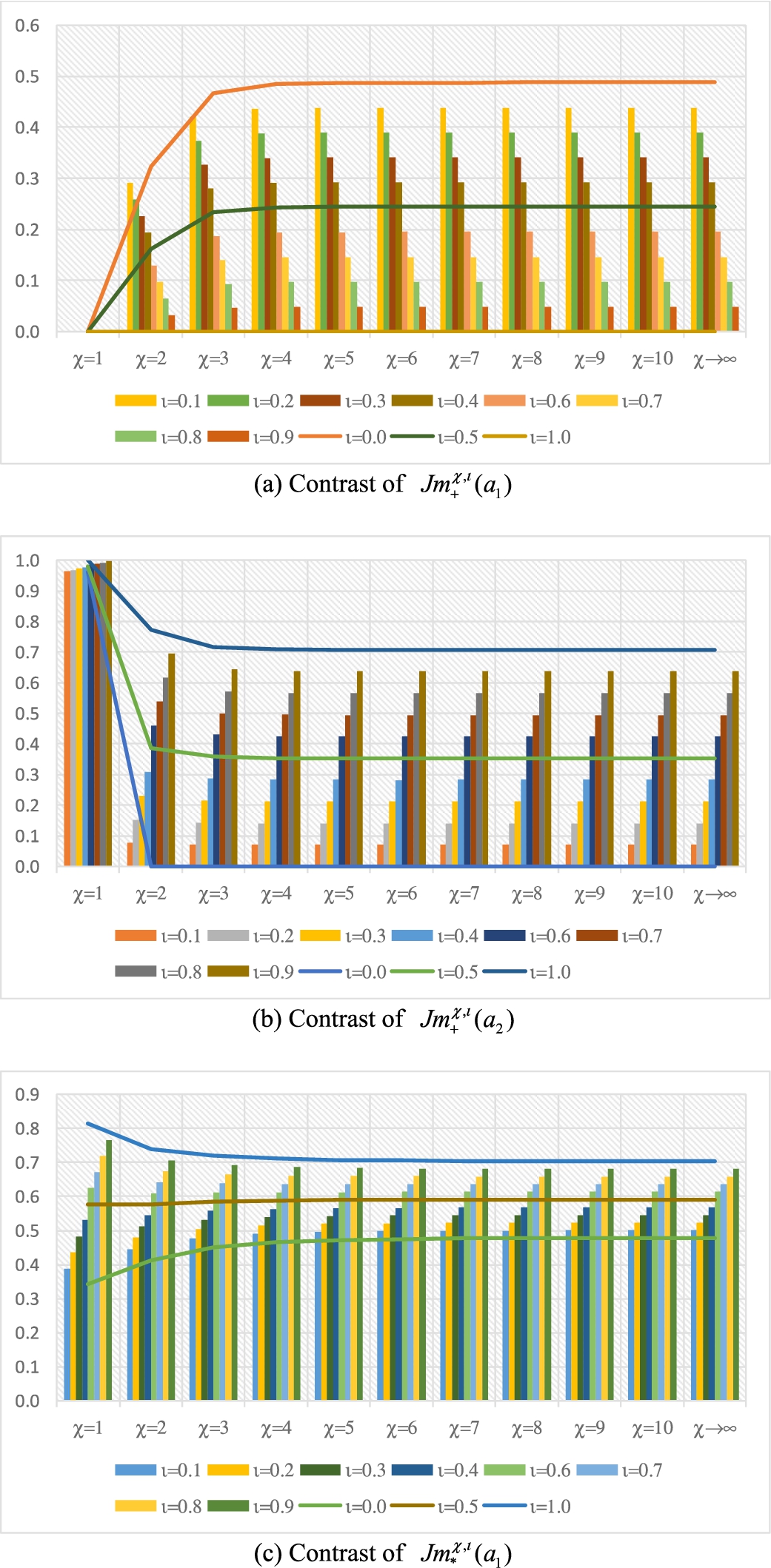
Giving consideration to the selection problem of companies, the determined outcomes of the measures
In order to observe the changes of the joint measures
Fig. 5
Selected comparisons of the joint measures in every combination of parameters ι and χ.
5Conclusions
The T-SF theory has the productive competence and technological capability to manipulate ambiguous and equivocal decision information in a complex real-world environment. In particular, on the subject of fuzzy community, the T-SF model contains a comprehensive account of several beneficial non-standard fuzzy configurations, such as intuitionistic fuzziness, Pythagorean fuzziness, Fermatean fuzziness, q-rung orthopair fuzziness, picture fuzziness, and spherical fuzziness. The three motivations were the major driving forces to propound the T-SF REGIME methodology, consisting of: (1) high demand for utilizing the T-SF theory in specialized decision analysis, (2) technical gap of the current REGIME methods and techniques, and (3) lack of T-SF versions of the REGIME framework.
This study has made some noteworthy academic contributions to decision-making practice under complicated uncertainties, including the advancement of the REGIME-based technique, the beneficial measurement system in T-SF settings, superiority indices and identifiers for relative attractiveness, REGIME identifiers and guide indices for relative fittingness, and the efficacious T-SF REGIME I and II procedures for decision support. Consider that the REGIME method is a well-established approach to a multiple-criteria evaluation process and choice analysis; however, fresh enrichments of REGIME-based techniques have not been discussed in T-SF decision situations. In this regard, this paper has unfolded a novel and creative T-SF REGIME methodology through the utility of an advisable measurement system in T-SF uncertain circumstances. This paper has utilized an efficacious score function to differentiate T-SF information in a thorough manner. Moreover, the superiority criteria have been recognized judging by score functions and accuracy values; the resulting outcomes have been used to determine the superiority index and the superiority identifier for ascertaining the relative attractiveness between the T-SF characteristics. Furthermore, this paper has identified the REGIME identifier and the REGIME vector to constitute the REGIME matrix and the guide index for ascertaining the relative fittingness between T-SF characteristics. Two effectual prioritization procedures have been inaugurated to generate the T-SF REGIME I and II predominance rankings regarding all choice options. The core notions in the T-SF REGIME I mechanism contain the superiority-based Boolean matrix, guide-based Boolean matrix, and comprehensive Boolean matrix. The core notions in the T-SF REGIME II mechanism involve the net superiority identifier and net guide index. The investigation toward the selection problem of companies for constructing food processing plants has exhibited the usefulness and superior points of employing the advanced T-SF REGIME methodology in tackling pragmatic decision issues.
However, the proposed T-SF REGIME methodology is subject to one major theoretical limitation. This paper has made an important contribution by strengthening the REGIME method aiming to empower it to manipulate T-FS uncertain information. The initiated T-FS version of the REGIME method has been validated to be an advantageous approach to multiple-criteria choice analysis within intricate equivocal environments. The technological applicability has been also illustrated in the selection problem of companies for erecting food processing plants. Nevertheless, decision makers or analysts might recognize some of the research limitations on the propounded methodology. The major limitation of the developed techniques is the early defuzzification of T-SF evaluation values by way of the score function advanced by Zeng et al. (2019). After constructing T-SF characteristics in the first phase of the T-SF REGIME framework, the T-SF evaluation values are then converted to the scalar value using the score function; moreover, the sequential phases are performed by the agency of the exploitation of such crisp forms. The specification of score functions can exploit enough information contained in T-SF evaluation values because of the utilization of grades of positive, neutral, negative, and refusal memberships. However, the T-SF evaluation values are defuzzied in a very early stage, which might make the T-SF REGIME method questionable in the process of evaluation, because perhaps certain information might be lost in practicality. In this regard, the initiated Algorithms I and II might result in a small amount of information not being considered in addressing a multiple-criteria choice problem in uncertain contexts, which is the main research limitation faced by the T-SF REGIME methodology.
Another consideration should be mentioned concerning the application of T-SF sets, namely, the data collection issue. The T-SF theory has been progressively concerned owing to its great ability for treating much complicated and obscure decision situation. However, a critical challenge for the T-SF theory to put into practice is how to collect evaluations from the decision maker and convert them into T-SF information. In most cases, the decision maker may be not familiar with the notion of T-SF sets. Thus, the decision maker may not know what T-SF evaluation values mean. Accordingly, the data collection process would be very challenging in case an analyst would like to collect evaluations from the decision maker. Therefore, how to reasonably produce T-SF evaluation values originating out of the decision maker’s discernments and appraisals is an issue worthy of mention. This study suggests an approach to generating T-SF evaluation values by employing a linguistic rating system, i.e. using the scale for the linguistic variables. For example, Mathew et al. (2020) presented two nine-point rating scales and an eleven-point rating scale that can be exploited by decision makers to quantify their subjective judgments and assessments. By the same token, Farrokhizadeh et al. (2021) and Jin et al. (2021) also provided useful nine-point rating scales for facilitating data collection. These linguistic variables can be easily converted into spherical fuzzy or T-SF numbers. With the advent of linguistic rating scales involving spherical fuzziness, linguistic terms can be quantified by transforming them to spherical fuzzy numbers, which leads to convenient construction of T-SF evaluation values.
Furthermore, this paper proposes some future research work directions that are promising and appropriate. First, the proposed notions and measurements (e.g. the superiority index, superiority identifier, REGIME identifier, and guide index) can furnish theoretical bases to create other decision-making models and support mechanisms. For example, by expanding Garg and Rani’s (2021) intuitionistic fuzzy MULTIMOORA (i.e. MULTIplicative form for Multiple Objective Optimization based on a Ratio Analysis) technique, our proposals can be incorporated into the MULTIMOORA scheme to adapt to T-SF decision contexts. By the same token, the proposed measurements can be exploited in the procedure of the ORESTE (i.e. Organisation, Rangement Et Synthèse de données relaTionnElles) approach for facilitating an advancement of ORESTE in T-SF circumstances. Secondly, in addition to multiple-criteria choice analysis, the procedures for the T-SF REGIME I and II prioritization can be recognized as a significant enhancement tool for exploring group decision analyses, sorting approaches, design and evaluation strategies, etc. By way of illustration, the sine-trigonometric operations presented by Garg (2021b) can be generalized to T-SF environments and then combined in the T-SF REGIME mechanism for group decision-making processes. Finally, the evolved T-SF REGIME methodology can be continuously modified and developed for adapting to different decision circumstances. To give an instance, Garg’s (2021a) initiated possibility degree measure derived from the q-rung orthopair fuzzy model is suggested to be exploited and extended in the evolved T-SF REGIME methodology. These improvements and modifications can offer the most appropriate and functional approaches regarding the exact engineering, management science, economics, and business problem.
Acknowledgements
The author acknowledges the assistance of the respected editor and the anonymous referees for their insightful and constructive comments, which helped to improve the overall quality of the paper.
References
1 | Akgün, A.A., Baycan, T., Nijkamp, P. ((2015) ). Rethinking on sustainable rural development. European Planning Studies, 23: (4), 678–692. https://doi.org/10.1080/09654313.2014.945813. |
2 | Akgün, A.A., van Leeuwen, E., Nijkamp, P. ((2012) ). A multi-actor multi-criteria scenario analysis of regional sustainable resource policy. Ecological Economics, 78: (June), 19–28. https://doi.org/10.1016/j.ecolecon.2012.02.026. |
3 | Akram, M., Naz, S., Shahzadi, S., Ziaa, F. ((2021) a). Geometric-arithmetic energy and atom bond connectivity energy of dual hesitant q-rung orthopair fuzzy graphs. Journal of Intelligent & Fuzzy Systems, 40: (1), 1287–1307. https://doi.org/10.3233/JIFS-201605. |
4 | Akram, M., Shahzadi, G., Shahzadi, S. ((2021) b). Protraction of Einstein operators for decision-making under q-rung orthopair fuzzy model. Journal of Intelligent & Fuzzy Systems, 40: (3), 4779–4798. https://doi.org/10.3233/JIFS-201611. |
5 | Ali, Z., Mahmood, T., Yang, M.-S. ((2020) ). Complex T-spherical fuzzy aggregation operators with application to multi-attribute decision making. Symmetry, 12: (8), 1311. https://doi.org/10.3390/sym12081311. |
6 | Alinezhad, A., Khalili, J. ((2019) ). New methods and applications in multiple attribute decision making (MADM). International Series in Operations Research & Management Science: Vol. 277: . Springer, Berlin. https://doi.org/10.1007/978-3-030-15009-9. |
7 | Alipour, M., Hafezi, R., Rani, P., Hafezi, M., Mardani, A. (2021). A new Pythagorean fuzzy-based decision-making method through entropy measure for fuel cell and hydrogen components supplier selection. Energy, 234(November). Article ID 121208, 14 pp. https://doi.org/10.1016/j.energy.2021.121208. |
8 | Ashraf, S., Abdullah, S. ((2021) ). Decision aid modeling based on sine trigonometric spherical fuzzy aggregation information. Soft Computing, 25: (13), 8549–8572. https://doi.org/10.1007/s00500-021-05712-6. |
9 | Asgharizadeh, E., Safari, H., Faraji, Z., Majidian, S. ((2014) ). Supply chain performance measurement by combining criterions of SCOR, Gunasekaran and BSC models with REGIME technique. Journal of Basic Applied Scientific Research, 4: (3), 309–320. |
10 | Aspen, D.M., Sparrevik, M., Fet, A.M. ((2015) ). Review of methods for sustainability appraisals in ship acquisition. Environment Systems and Decisions, 35: (3), 323–333. https://doi.org/10.1007/s10669-015-9561-6. |
11 | Atanassov, K.T. ((1986) ). Intuitionistic fuzzy sets. Fuzzy Sets and Systems, 20: (1), 87–96. https://doi.org/10.1016/S0165-0114(86)80034-3. |
12 | Briamonte, L., Pergamo, R., Arru, B., Furesi, R., Pulina, P., Madau, F.A. (2021). Sustainability goals and firm behaviours: a multi-criteria approach on Italian agro-food sector. Sustainability (Switzerland), 13(10). Article ID 5589, 16 pp. https://doi.org/10.3390/su13105589. |
13 | Chen, T.-Y. (2021). A likelihood-based preference ranking organization method using dual point operators for multiple criteria decision analysis in Pythagorean fuzzy uncertain contexts. Expert Systems with Applications, 176(August). Article ID 114881, 32 pp. https://doi.org/10.1016/j.eswa.2021.114881. |
14 | Chen, Y., Munir, M., Mahmood, T., Hussain, A., Zeng, S. (2021). Some generalized T-spherical and group-generalized fuzzy geometric aggregation operators with application in MADM problems. Journal of Mathematics, 2021(April). Article ID 5578797, 17 pp. https://doi.org/10.1155/2021/5578797. |
15 | Cuong, B.C. ((2014) ). Picture fuzzy sets. Journal of Computer Science and Cybernetics, 30: (4), 409–420. https://doi.org/10.15625/1813-9663/30/4/5032. |
16 | Dogan, O. (2021). Process mining technology selection with spherical fuzzy AHP and sensitivity analysis. Expert Systems with Applications, 178(September). Article ID 114999, 10 pp. https://doi.org/10.1016/j.eswa.2021.114999. |
17 | Donyatalab, Y., Seyfi-Shishavan, S.A., Farrokhizadeh, E., Gundogdu, F.K., Kahraman, C. ((2020) ). Spherical fuzzy linear assignment method for multiple criteria group decision-making problems. Informatica, 31: (4), 707–722. https://doi.org/10.15388/20-INFOR433. |
18 | Esangbedo, M.O., Bai, S., Mirjalili, S., Wang, Z. (2021). Evaluation of human resource information systems using grey ordinal pairwise comparison MCDM methods. Expert Systems with Applications, 182(November). Article ID 115151, 17 pp. https://doi.org/10.1016/j.eswa.2021.115151. |
19 | Farrokhizadeh, E., Seyfi-Shishavan, S.A., Gündoğdu, F.K., Donyatalab, Y., Kahraman, C., Seifi, S.H. (2021). A spherical fuzzy methodology integrating maximizing deviation and TOPSIS methods. Engineering Applications of Artificial Intelligence, 101(May). Article ID 104212, 14 pp. https://doi.org/10.1016/j.engappai.2021.104212. |
20 | Frank, D. ((2014) ). Biodiversity, conservation biology, and rational choice. Studies in History and Philosophy of Biological and Biomedical Sciences, 45: (1), 101–104. https://doi.org/10.1016/j.shpsc.2013.10.005. |
21 | Gao, X., Deng, Y. (2021). Generating method of Pythagorean fuzzy sets from the negation of probability. Engineering Applications of Artificial Intelligence, 105(October). Article ID 104403, 11 pp. https://doi.org/10.1016/j.engappai.2021.104403. |
22 | Garg, H. ((2021) a). CN-q-ROFS: connection number-based q-rung orthopair fuzzy set and their application to decision-making process. International Journal of Intelligent Systems, 36: (7), 3106–3143. https://doi.org/10.1002/int.22406. |
23 | Garg, H. ((2021) b). Sine trigonometric operational laws and its based Pythagorean fuzzy aggregation operators for group decision-making process. Artificial Intelligence Review, 54: (6), 4421–4447. https://doi-org.proxy.lib.cgu.edu.tw:2443/10.1007/s10462-021-10002-6. |
24 | Garg, H., Rani, D. ((2021) ). An efficient intuitionistic fuzzy MULTIMOORA approach based on novel aggregation operators for the assessment of solid waste management techniques. Applied Intelligence. https://doi.org/10.1007/s10489-021-02541-w. in press. |
25 | Garg, H., Munir, M., Ullah, K., Mahmood, T., Jan, N. (2018). Algorithm for T-spherical fuzzy multi-attribute decision making based on improved interactive aggregation operators. Symmetry, 10(12). Article ID 670, 23 pp. https://doi.org/10.3390/sym10120670. |
26 | Garg, H., Ullah, K., Mahmood, T., Hassan, N., Jan, N. ((2021) ). T-spherical fuzzy power aggregation operators and their applications in multi-attribute decision making. Journal of Ambient Intelligence and Humanized Computing, 12: (10), 9067–9080. https://doi.org/10.1007/s12652-020-02600-z. |
27 | Gül, S. ((2021) ). Extending ARAS with integration of objective attribute weighting under spherical fuzzy environment. International Journal of Information Technology and Decision Making, 20: (3), 1011–1036. https://doi.org/10.1142/S0219622021500267. |
28 | Guleria, A., Bajaj, R.K. ((2021) ). T-spherical fuzzy soft sets and its aggregation operators with application in decision-making. Scientia Iranica, 28: (2), 1014–1029. https://doi.org/10.24200/SCI.2019.53027.3018. |
29 | Gündoğdu, F.K., Kahraman, C. ((2019) ). Spherical fuzzy sets and spherical fuzzy TOPSIS method. Journal of Intelligent & Fuzzy Systems, 36: (1), 337–352. https://doi.org/10.3233/JIFS-181401. |
30 | Hinloopen, E., Nijkamp, P. ((1990) ). Qualitative multiple criteria choice analysis. Quality & Quantity, 24: (1), 37–56. https://doi.org/10.1007/BF00221383. |
31 | Hinloopen, E., Nijkamp, P., Rietveld, P. ((1983) a). Qualitative discrete multiple criteria choice models in regional planning. Regional Science and Urban Economics, 13: (1), 77–102. https://doi.org/10.1016/0166-0462(83)90006-6. |
32 | Hinloopen, E., Nijkamp, P., Rietveld, P. ((1983) b). The REGIME Method: A New Multicriteria Technique. Essays and Surveys on Multiple Criteria Decision Making. Springer, Berlin, Heidelberg, pp. 146–155. |
33 | Jana, C., Muhiuddin, G., Pal, M. ((2021) ). Multi-criteria decision making approach based on SVTrN Dombi aggregation functions. Artificial Intelligence Review, 54: (June), 3685–3723. https://doi.org/10.1007/s10462-020-09936-0. |
34 | Jin, C., Ran, Y., Wang, Z., Zhang, G. (2021). Prioritization of key quality characteristics with the three-dimensional HoQ model-based interval-valued spherical fuzzy-ORESTE method. Engineering Applications of Artificial Intelligence, 104(September). Article ID 104271, 18 pp. https://doi.org/10.1016/j.engappai.2021.104271. |
35 | Ju, Y., Liang, Y., Luo, C., Dong, P., Santibanez Gonzalez, E.D.R., Wang, A. ((2021) ). T-spherical fuzzy TODIM method for multi-criteria group decision-making problem with incomplete weight information. Soft Computing, 25: (4), 2981–3001. https://doi.org/10.1007/s00500-020-05357-x. |
36 | Kamran, M.A., Khoshsirat, M., Mikaeil, R., Nikkhoo, F. ((2017) ). Ranking the sawability of ornamental and building stones using different MCDM methods. Journal of Engineering Research, 5: (3), 125–149. |
37 | Karaaslan, F., Hunu, F. ((2020) ). Type-2 single-valued neutrosophic sets and their applications in multi-criteria group decision making based on TOPSIS method. Journal of Ambient Intelligence and Humanized Computing, 11: (10), 4113–4132. https://doi.org/10.1007/s12652-020-01686-9. |
38 | Khan, M.J., Ali, M.I., Kumam, P. ((2021) a). A new ranking technique for q-rung orthopair fuzzy values. International Journal of Intelligent Systems, 36: (1), 558–592. https://doi.org/10.1002/int.22311. |
39 | Khan, Q., Gwak, J., Shahzad, M., Alam, M.K. (2021b). A novel approached based on T-spherical fuzzy Schweizer-Sklar power Heronian mean operator for evaluating water reuse applications under uncertainty. Sustainability (Switzerland), 13(13). Article ID 7108, 35 pp. https://doi.org/10.3390/su13137108. |
40 | Liu, P., Ali, Z., Mahmood, T. ((2021) a). Novel complex T-spherical fuzzy 2-tuple linguistic Muirhead mean aggregation operators and their application to multi-attribute decision-making. International Journal of Computational Intelligence Systems, 14: (1), 295–331. https://doi.org/10.2991/ijcis.d.201207.003. |
41 | Liu, P., Wang, D., Zhang, H., Yan, L., Li, Y., Rong, L. ((2021) b). Multi-attribute decision-making method based on normal T-spherical fuzzy aggregation operator. Journal of Intelligent and Fuzzy Systems, 40: (5), 9543–9565. https://doi.org/10.3233/JIFS-202000. |
42 | Mahmood, T., Ullah, K., Khan, Q., Jan, N. ((2019) ). An approach toward decision-making and medical diagnosis problems using the concept of spherical fuzzy sets. Neural Computing and Applications, 31: (11), 7041–7053. https://doi.org/10.1007/s00521-018-3521-2. |
43 | Massei, G., Rocchi, L., Paolotti, L., Greco, S., Boggia, A. ((2014) ). Decision support systems for environmental management: a case study on wastewater from agriculture. Journal of Environmental Management, 146: (December), 491–504. https://doi.org/10.1016/j.jenvman.2014.08.012. |
44 | Mathew, M., Chakrabortty, R.K., Ryan, M.J. (2020). A novel approach integrating AHP and TOPSIS under spherical fuzzy sets for advanced manufacturing system selection. Engineering Applications of Artificial Intelligence, 96(November). Article ID 103988, 13 pp. https://doi.org/10.1016/j.engappai.2020.103988. |
45 | Munir, M., Kalsoom, H., Ullah, K., Mahmood, T., Chu, Y.-M. (2020). T-spherical fuzzy Einstein hybrid aggregation operators and their applications in multi-attribute decision making problems. Symmetry, 12(3). Article ID 365, 24 pp. https://doi.org/10.3390/sym12030365. |
46 | Munir, M., Mahmood, T., Hussain, A. ((2021) ). Algorithm for T-spherical fuzzy MADM based on associated immediate probability interactive geometric aggregation operators. Artificial Intelligence Review, 54: (December), 6033–6061. https://doi.org/10.1007/s10462-021-09959-1. |
47 | Nabeeh, N.A., Abdel-Basset, M., Soliman, G. (2021). A model for evaluating green credit rating and its impact on sustainability performance. Journal of Cleaner Production, 280(1). Article ID 124299, 16 pp. https://doi.org/10.1016/j.jclepro.2020.124299. |
48 | Özlü, Ş., Karaaslan, F. ((2021) ). Correlation coefficient of T-spherical type-2 hesitant fuzzy sets and their applications in clustering analysis. Journal of Ambient Intelligence and Humanized Computing. https://doi.org/10.1007/s12652-021-02904-8. In press. |
49 | Oztaysi, B., Onar, S.C., Kahraman, C. ((2021) ). Waste disposal location selection by using Pythagorean fuzzy REGIME method. Journal of Intelligent & Fuzzy Systems. https://doi.org/10.3233/JIFS-219199. In press. |
50 | Oztaysi, B., Kahraman, C., Onar, S.C. ((2022) ). Spherical fuzzy REGIME method waste disposal location selection. In: Kahraman, C., Cebi, S., Onar, S.C., Oztaysi, B., Tolga, A.C., Sari, I.U. (Eds.), Intelligent and Fuzzy Techniques for Emerging Conditions and Digital Transformation. INFUS 2021, Lecture Notes in Networks and Systems, Vol. 308: . Springer, Cham. https://doi.org/10.1007/978-3-030-85577-2_84. |
51 | Pamucar, D., Yazdani, M., Obradovic, R., Kumar, A., Torres-Jiménez, M. ((2020) ). A novel fuzzy hybrid neutrosophic decision-making approach for the resilient supplier selection problem. International Journal of Intelligent Systems, 35: (12), 1934–1986. https://doi.org/10.1002/int.22279. |
52 | Qin, K., Wang, L. ((2020) ). New similarity and entropy measures of single-valued neutrosophic sets with applications in multi-attribute decision making. Soft Computing, 24: (21), 16165–16176. https://doi.org/10.1007/s00500-020-04930-8. |
53 | Şahin, R., Liu, P. ((2017) ). Correlation coefficient of single-valued neutrosophic hesitant fuzzy sets and its applications in decision making. Neural Computing and Applications, 28: (6), 1387–1395. https://doi.org/10.1007/s00521-015-2163-x. |
54 | Senapati, T., Yager, R.R. ((2019) a). Fermatean fuzzy weighted averaging/geometric operators and its application in multi-criteria decision-making methods. Engineering Applications of Artificial Intelligence, 85: (October), 112–121. https://doi.org/10.1016/j.engappai.2019.05.012. |
55 | Senapati, T., Yager, R.R. ((2019) b). Some new operations over Fermatean fuzzy numbers and application of Fermatean fuzzy WPM in multiple criteria decision making. Informatica, 30: (2), 391–412. https://doi.org/10.15388/Informatica.2019.211. |
56 | Shahzadi, G., Zafar, F., Alghamdi, M.A. (2021). Multiple-attribute decision-making using Fermatean fuzzy Hamacher interactive geometric operators. Mathematical Problems in Engineering, 2021(June). Article ID 5150933, 20 pp. https://doi.org/10.1155/2021/5150933. |
57 | Smarandache, F. ((2005) a). A unifying field in logics: Neutrosophic logic. Neutrosophy, neutrosophic set, neutrosophic probability and statistics, fourth ed. American Research Press, Rehoboth. |
58 | Smarandache, F. ((2005) b). Neutrosophic set–a generalization of the intuitionistic fuzzy set. International Journal of Pure and Applied Mathematics, 24: (3), 287–297. https://ijpam.eu/contents/2005-24-3/1/1.pdf. |
59 | Smarandache, F. ((2019) ). Neutrosophic set is a generalization of intuitionistic fuzzy set, inconsistent intuitionistic fuzzy set (picture fuzzy set, ternary fuzzy set), Pythagorean fuzzy set, spherical fuzzy set, and q-rung orthopair fuzzy set, while neutrosophication is a generalization of regret theory, grey system theory, and three-ways decision (revisited). Journal of New Theory, 29: (December), 1–32. https://dergipark.org.tr/tr/pub/jnt/issue/51172/666629. |
60 | Stratigea, A., Grammatikogiannis, E. ((2012) ). A multicriteria decision support framework for assessing alternative wind park locations: the case of Tanagra – Boiotia. Regional Science Inquiry, 4: (1), 105–120. |
61 | Tsigdinos, S., Vlastos, T. ((2021) ). Exploring ways to determine an alternative strategic road network in a metropolitan city: a multi-criteria analysis approach. IATSS Research, 45: (1), 102–115. https://doi.org/10.1016/j.iatssr.2020.06.002. |
62 | Ullah, K., Garg, H., Mahmood, T., Jan, N., Ali, Z. ((2020) a). Correlation coefficients for T-spherical fuzzy sets and their applications in clustering and multi-attribute decision making. Soft Computing, 24: (3), 1647–1659. https://doi.org/10.1007/s00500-019-03993-6. |
63 | Ullah, K., Mahmood, T., Garg, H. ((2020) b). Evaluation of the performance of search and rescue robots using T-spherical fuzzy Hamacher aggregation operators. International Journal of Fuzzy Systems, 22: (2), 570–582. https://doi.org/10.1007/s40815-020-00803-2. |
64 | Ullah, K., Ali, Z., Mahmood, T., Garg, H., Chinram, R. ((2021) a). Methods for multi-attribute decision making, pattern recognition and clustering based on T-spherical fuzzy information measures. Journal of Intelligent & Fuzzy Systems. https://doi.org/10.3233/JIFS-210402. In press. |
65 | Ullah, K., Garg, H., Gul, Z., Mahmood, T., Khan, Q., Ali, Z. (2021b). Interval valued T-spherical fuzzy information aggregation based on Dombi t-norm and Dombi t-conorm for multi-attribute decision making problems. Symmetry, 13(6). Article ID 1053, 26 pp. https://doi.org/10.3390/sym13061053. |
66 | Wang, J.-C., Chen, T.-Y. ((2021) ). A T-spherical fuzzy ELECTRE approach for multiple criteria assessment problem from a comparative perspective of score functions. Journal of Intelligent & Fuzzy Systems, 41: (2), 3751–3770. https://doi.org/10.3233/JIFS-211431. |
67 | Wątróbski, J., Jankowski, J., Ziemba, P., Karczmarczyk, A., Zioło, M. ((2019) ). Generalised framework for multi-criteria method selection. Omega (United Kingdom), 86: (July), 107–124. https://doi.org/10.1016/j.omega.2018.07.004. |
68 | Xu, Z.S. ((2005) ). An overview of methods for determining OWA weights. International Journal of Intelligent Systems, 20: (8), 843–865. https://doi.org/10.1002/int.20097. |
69 | Yager, R.R. ((2013) ). Pythagorean fuzzy subsets. In: Proceedings of the 2013 Joint IFSA World Congress and NAFIPS Annual Meeting, Edmonton, Canada, June 24–28, 2013, pp. 57–61. https://doi.org/10.1109/IFSA-NAFIPS.2013.6608375. |
70 | Yager, R.R. ((2017) ). Generalized orthopair fuzzy sets. IEEE Transactions on Fuzzy Systems, 25: (5), 1222–1230. https://doi.org/10.1109/TFUZZ.2016.2604005. |
71 | Yager, R.R., Abbasov, A.M. ((2013) ). Pythagorean membership grades, complex numbers, and decision making. International Journal of Intelligent Systems, 28: (5), 436–452. https://doi.org/10.1002/int.21584. |
72 | Zeng, S., Garg, H., Munir, M., Mahmood, T., Hussain, A. (2019). A multi-attribute decision making process with immediate probabilistic interactive averaging aggregation operators of T-spherical fuzzy sets and its application in the selection of solar cells. Energies, 12(23). Article ID 4436, 26 pp. https://doi.org/10.3390/en12234436. |
73 | Zeng, S., Munir, M., Mahmood, T., Naeem, M. (2020). Some T-spherical fuzzy Einstein interactive aggregation operators and their application to selection of photovoltaic cells. Mathematical Problems in Engineering, 2020(June). Article ID 1904362, 16 pp. https://doi.org/10.1155/2020/1904362. |


