
Palm Vein Recognition Based on Convolutional Neural Network
Abstract
Convolutional neural networks (CNNs) were popular in ImageNet large scale visual recognition competition (ILSVRC 2012) because of their identification ability and computational efficiency. This paper proposes a palm vein recognition method based on CNN. The four main steps of palm vein recognition are image acquisition, image preprocessing, feature extraction, and matching. To reduce the processing steps in the recognition of palm vein images, a palm vein recognition method using a CNN is proposed. CNN is a deep learning network. Palm vein images are acquired using near-infrared light, under which the veins in the palm of the hand are relatively prominent. To obtain a good vein image, many previous methods used preprocessing to further enhance the image before using feature extraction to find feature matches for further comparison. In recent years, CNNs have been shown to have great advantages and have performed well in image classification. To reduce early-stage image processing, a CNN is used to classify and recognize palm vein images. The networks AlexNet and VGG depth CNN were trained to extract image features. The palm vein recognition rates by VGG-19, VGG-16, and AlexNet were 98.5%, 97.5%, and 96%, respectively.
1Introduction
User authentication identification methods include passwords, cards, and biometrics (O’Gorman, 2003). With the increase in financial activities and safety awareness, followed by the development of science, technology, and societal progress, traditional identity authentication, such as passwords, personal identification numbers, and smart cards are largely unable to meet today’s convenience and reliability needs. Biometrics technologies classify authentication identification into physiological features, such as the user’s face, fingerprint, iris, and veins, or personal behaviour features, such as signature, gait, and voice (Jain et al., 2006). Among these features, internal biometrics (e.g. veins) are more secure than external biometrics (e.g. fingerprint, face). Facial recognition is very popular and identifies individuals by their unique facial features. However, facial recognition may be degraded due to external factors, such as hair, wearable objects, and injuries. Fingerprint recognition is also a widely used identification technology, but it may be considered unsanitary due to the need for contact and result in user resistance. In addition, under environmental conditions, such as dirt and injuries, fingerprint recognition may be insufficient and performance may be reduced. Moreover, handwriting or signatures can be easily forged. In contrast, internal biometrics are difficult to counterfeit, but acquisition is more challenging, less environmentally friendly, and must effectively prevent external damage. Vein recognition stands out as a promising recognition technology. In 1992, Shimizu first considered the application of the hand blood vessel method of authentication (Shimizu, 1992).
The process of recognizing palm veins is complicated by image preprocessing, feature extraction, and matching methods. The process is shown in Fig. 1. First, a palm vein image is preprocessed to make the image features more obvious. Second, a method must be found to extract the features of the image. Finally, feature matching must be performed via distance measures to identify the user. To reduce the manual selection process, deep learning is proposed, and target features can be automatically selected through model training. Deep learning excels in issues related to visual recognition, voice recognition, natural language, and time series. Convolutional neural networks (CNNs) were further studied by LeCun et al. in the 1990s, and their structure has been proposed (Lécun et al., 1998).
The major contributions of this paper are as follows:
• We propose a palm vein recognition method based on a CNN that uses palm vein features to identify users.
• CNNs reduce the labourious manual selection process and simplifies authentication.
Fig. 1
Palm vein recognition process.

• Finally, we test the performance metrics of CNN, such as the False Acceptance Rate (FAR) and the False Rejection Rate (FRR).
1.1Related Work
Vein recognition includes palm veins (Kang and Wu, 2014; Lu and Yuan, 2017; Raut and Humbe, 2015), finger veins (Huang et al., 2017), hand dorsal veins (Khan et al., 2009; Raghavendra et al., 2015), wrist veins (Mohamed et al., 2017; Pascual et al., 2010), forearm veins (Choras, 2017), and sclera veins (Lin et al., 2014; Suganya and Sivitha, 2014). Of these, we use palm vein images for recognition. The literature includes many relevant palm vein recognition algorithms (Kong et al., 2009), such as:
• Structure-based methods use line features and point features. This information is highly dependent on the selected coordinates and very sensitive to spatial occlusion; thus, the region of interest (ROI) must be carefully selected. Usually, when poorly performing images and feature points are used in feature extraction, difficulty in matching occurs. This method is also relatively sensitive to scaling, rotation, and displacement (Akinsowon and Alese, 2013; Xu, 2015).
• Appearance-based (subspace-based) methods use features to reduce dimensionality from high-dimensional space to low-dimensional space and retain the required information. Common methods include PCA, LDA, ICA, and subspace clustering (SSC) (Liu and Zhang, 2011; Raut and Humbe, 2015).
• Statistical-based methods use local statistics, such as the mean and variance of each small area, which are calculated and considered as characteristics. Gabor, wavelet, and Fourier transforms have been applied, including local binary patterns (LBP) or local derivative patterns (LDP) (Aglio-Caballero et al., 2017; Kang and Wu, 2014).
• Local invariant-based methods use an image pyramid that is constructed to form a three-dimensional image space. The local maxima of each layer are obtained using a Hessian matrix, and a neighbourhood corresponding to the scale is selected at the feature point to find the main direction. With the main direction as the axis, coordinates can be established at each feature point with methods including scale invariant feature transform (SIFT) and speeded up robust features (SURF) (Gurunathan et al., 2016).
• Fusion, also a very popular method, can improve the accuracy and security of the system, but the relative amount of data required is large. There are many fusion methods, including the use of palm, finger, vein, and face and many fusion rules, including algorithms, SVM, and neural networks (Garg et al., 2016; Kim et al., 2010).
• Deep learning. In recent years, the prevalence of neural networks has made CNNs the most popular image classification method; the recognition rate is not inferior to previous methods (Huang et al., 2017).
1.2Our Work
With the many research topics discussed above, because of the convenience and practicality of CNNs, we propose a palm vein recognition method based on CNN. The main contributions of our work are as follows. The vein pattern of the palm of the hand was photographed with a near-infrared camera using a pretrained CNN model called AlexNet (Krizhevsky et al., 2012). VGG (Simonyan and Zisserman, 2014) was trained and the result was identified. Although the size of the training set is very different from that of the competition, good performance is still achieved. The simplified steps required for the overall palm vein recognition are shown in Fig. 2. The first layer is the input layer, followed by the interaction of the convolution layer, pooling layer, and activation function, and finally, classification by the fully connected layer and the classifier.
2Preliminaries
Fig. 2
Using the CNN framework for palm vein recognition.
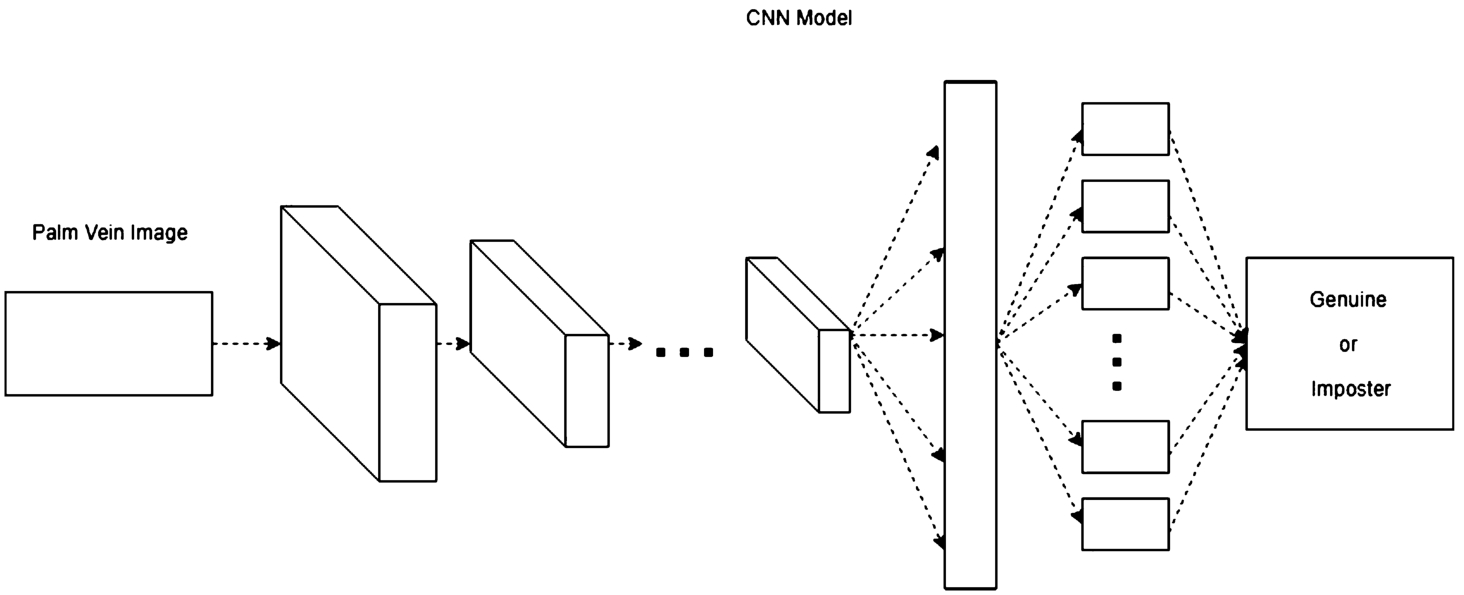
In this section, we introduce the CNN model and the network architecture. In the proposed scheme, the model is trained and used for identification. A CNN has advantages in image recognition. According to the pioneering work of Lenet (Lécun et al., 1998), CNNs have the following three characteristics: local perception, downsampling, and weight sharing. Since 2010, ImageNet has held the Large-Scale Visual Recognition (ILSVR) Competition annually. In ILSVR 2012, the appearance of AlexNet stood out, and it became the future of CNNs. It was followed by the appearance of famous models, such as ZFNet, VGG, GoogLeNet, ResNet, and SENet. Here, we use AlexNet and VGG.
2.1Convolution Neural Network Structure
In this paper, a CNN is used to analyse the important parts of the network and the overall architecture. A CNN is a type of deep neural network. It has important advantages in image recognition processing. CNN feature extraction is different in each layer, and as the number of layers increases, feature classification improves.
Previous neural networks were still very limited when dealing with problems, such as computer vision, natural language processing and voice recognition. Due to the appearance of the convolution kernel, CNN has advantages for processing multidimensional data. The most important concepts of the CNN are the convolution layer, activation function, pooling layer, and fully connected layer.
2.2Convolution Layer
Fig. 3
Convolution operation of
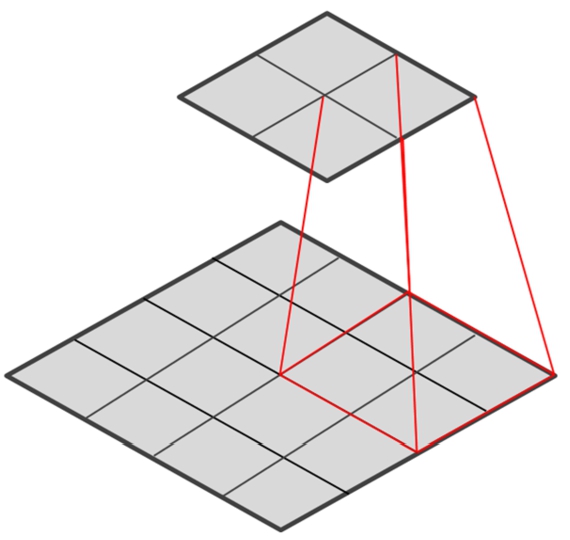
The processing performed by the convolutional layer is called the “convolutional operation”. It uses filters to process and extract features and reduce noise. As the local links and weights are shared, the training parameters are significantly reduced. In high-dimensional images, all connected neurons will need to train a large number of parameters, which causes the calculation to be time consuming and leads to severe overfitting. The characteristics of local links and weight sharing simplifies parameter training. As shown in Fig. 3, the image is
2.3Activation Function
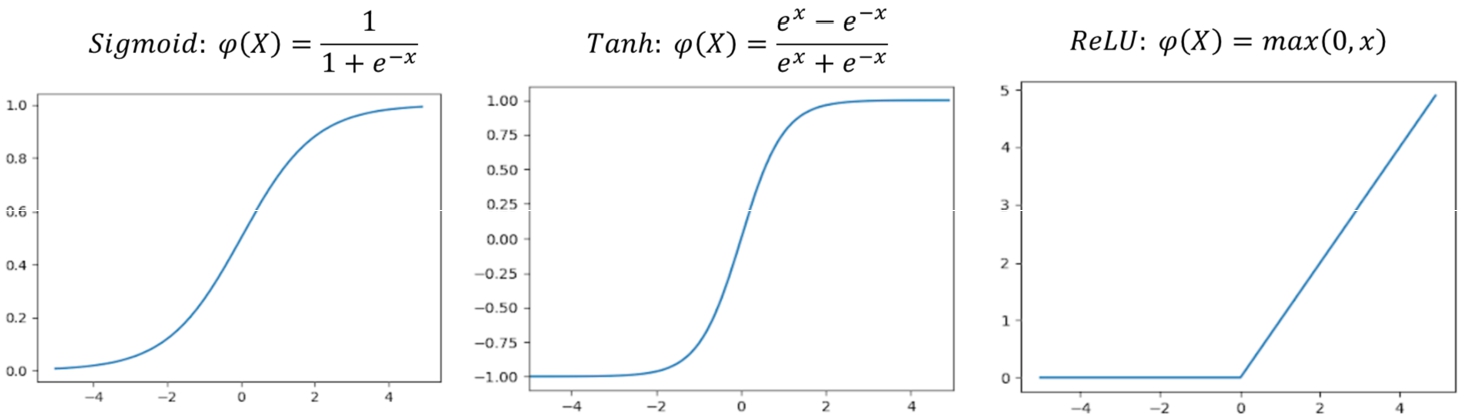
The activation function is used to add nonlinear factors. If the activation function is not used in the neural network, the output and input cannot be separated from each other using a linear relationship. Therefore, it is meaningless to make a deep neural network without the activation function. The Sigmoid and Tanh functions were previously used as the activation function, but gradient disappearance easily occurs when using these functions. When the neural network is deepened, training obstacles often occur. The ReLU function can effectively overcome gradient disappearance and requires less computation. The ReLU function gradually replaced the Sigmoid and Tanh functions.
(1)
(2)
(3)
Fig. 4
The activation functions.
2.4Pooling Layer
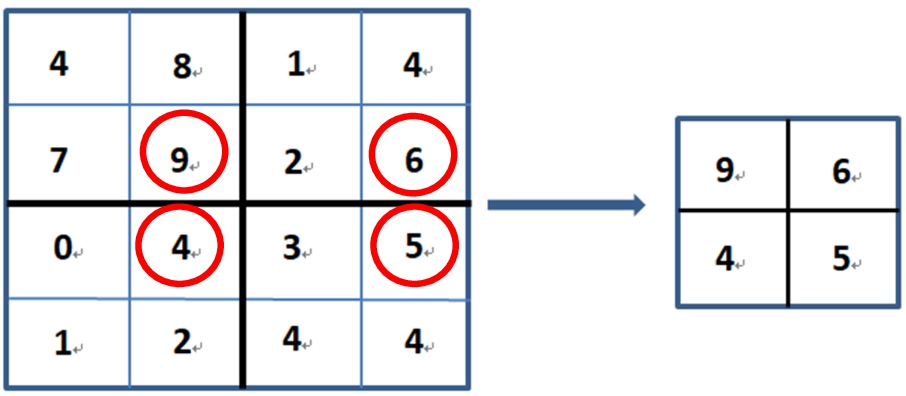
The data extracted by the convolutional layer have a high data dimension. The primary role of the pooling layer is to reduce the data dimension to avoid overfitting. The commonly used methods are max pooling and average pooling. In addition to reducing data dimensionality, pooling is resistant to image translation and slight deformation. Figure 5 shows the max pooling processing. For reducing the data dimensionality, pooling extracts the largest features with a specific window size to avoid overfitting problems.
Fig. 5
The max pooling processing.
2.5Fully Connected Layer
The entire CNN acts as a classifier. If the operations of the convolutional layer, pooling layer, and activation function map the original data to the hidden layer feature space, the fully connected layer will learn the “distributed feature representation” maps to the role of the sample tag space. Among them, the result is classified by Softmax and normalized to obtain the probability value, as shown in (4).
(4)
3Methodology
3.1Palm Vein Database
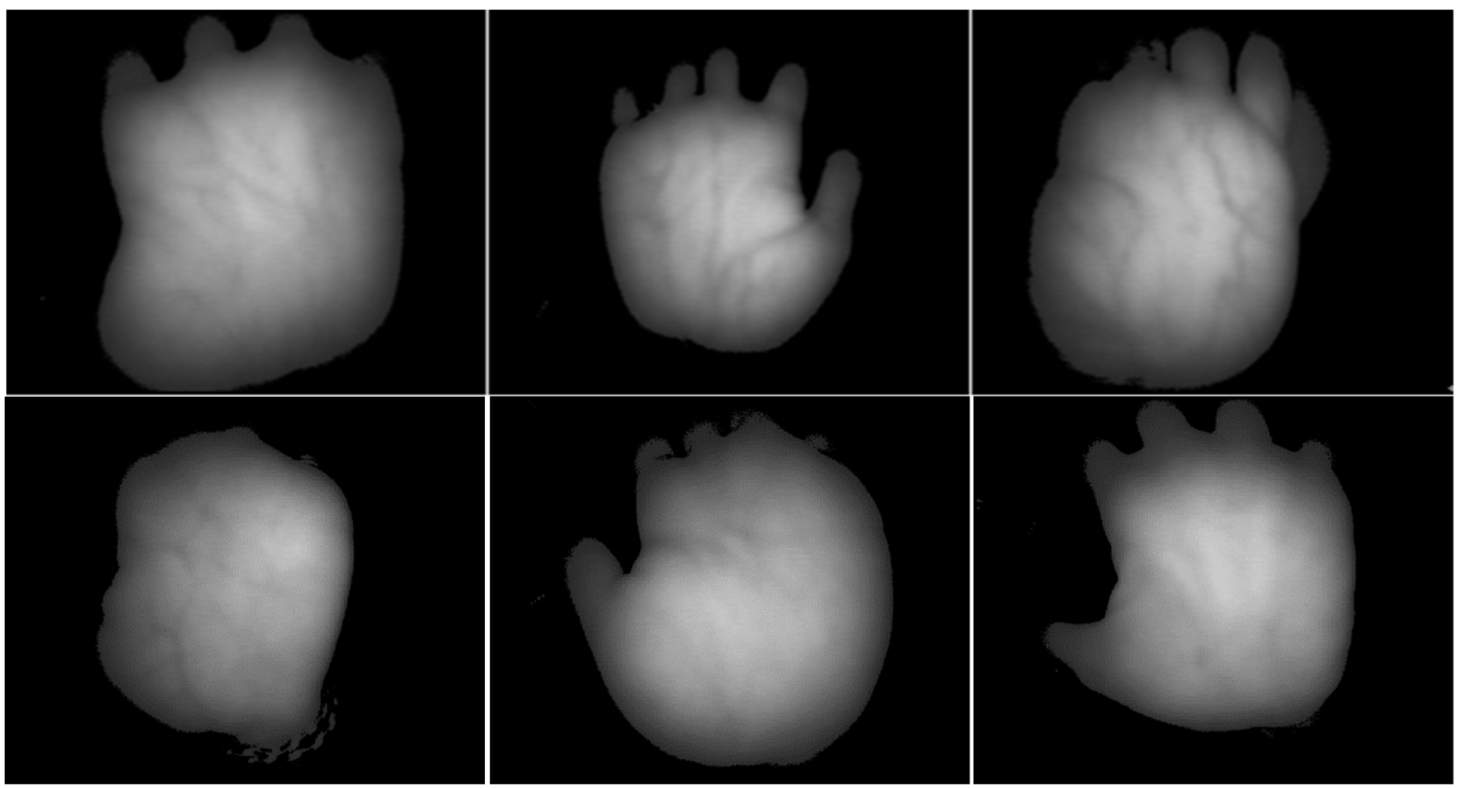
The two palm vein databases currently published have a multispectral palm vein database. The database equipment used by the Hong Kong Polytechnic University has a fixed contact type acquisition device (Zhang et al., 2010). The Chinese Academy of Sciences Institute of Automation uses five wavelengths for spectral acquisition (Hao et al., 2008), in which images with wavelengths of 850 to 940 nm are clear. The equipment used is a noncontact acquisition device. We established a database of palm veins. Twenty images from each of 50 individuals were collected, for a total of 1 000 experimental images. The size of the captured image is
Fig. 6
Original palm vein images.
3.2AlexNet
Krizhevsky et al. (2012) proposed a CNN in the ImageNet contest and earned first place in image classification. Subsequently, this convolutional neural network became popular. The network architecture of AlexNet included five convolution layers and three fully connected layers; the network structure is shown in Fig. 7. The five convolutional layers contain the processes of the convolutional layers, pooling layers, activation function, and local normalization. Because the network uses two GTX580 GPUs, it is divided into upper and lower parts, which can be used for interaction. The fully connected layers have 4,096 neurons each. The image is classified by Softmax.
Fig. 7
Structure of AlexNet.
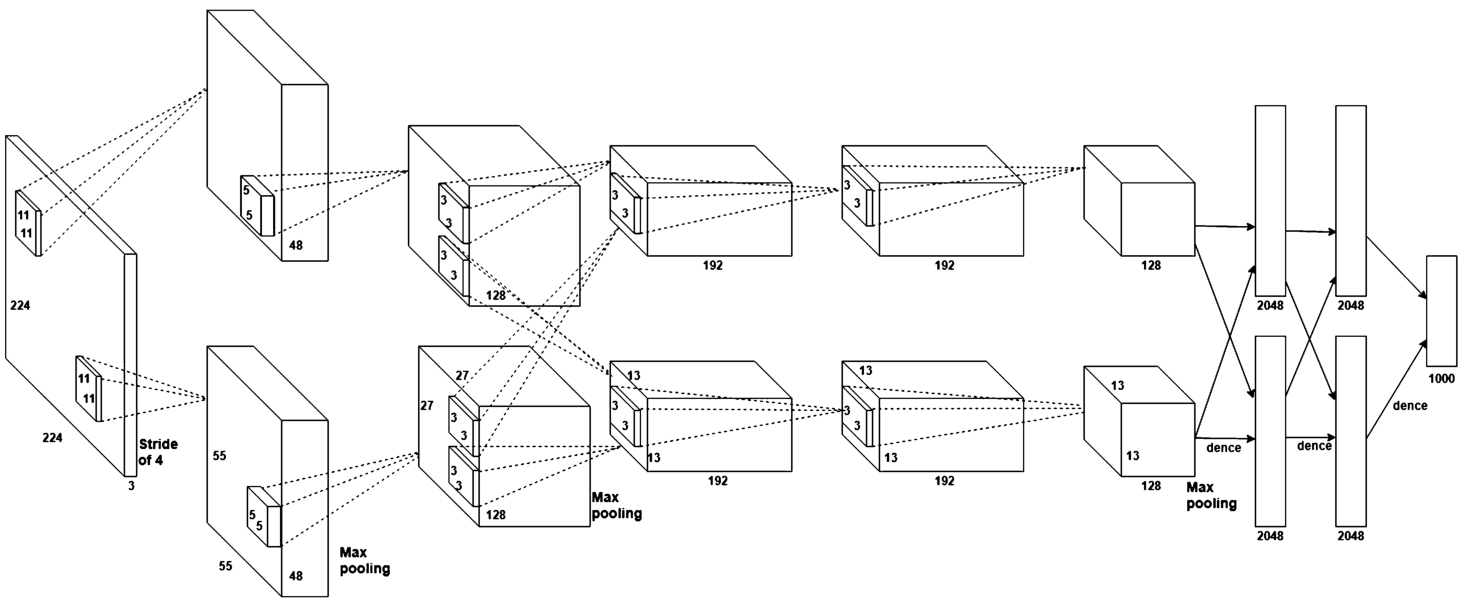
Fig. 8
Structure of VGG16 and VGG19.
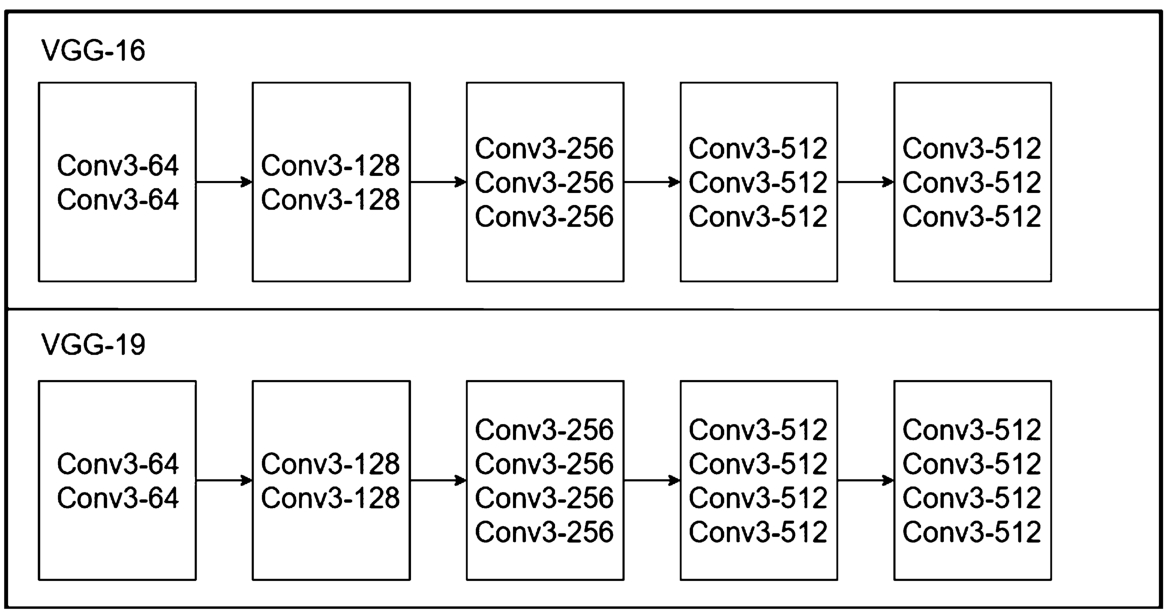
3.3VGG-16 and VGG-19
In 2014, an image recognition method based on a VGG network was developed by the University of Oxford. VGG was the first to use small
3.4Transfer Learning
In most machine learning, deep learning, and data mining tasks, we assume the training and inference use data following the same distribution and coming from the same feature space. However, in practical applications, this assumption is difficult to establish and often encounters some problems:
• The number of marked training samples is limited. For example, when dealing with the classification of the target domain, there is a lack of sufficient training samples. Additionally, there is a large number of training samples in the B (source) domain related to the A field, but the B field and the A field are in different feature spaces or their samples obey different distributions.
• The data distribution will change. The data distribution can be related to time, location or other dynamic factors. With a change in dynamic factors, the data distribution will change. Thus, the previously collected data are outdated, and so it must be recollected and the model must be rebuilt.
Transfer learning is a research issue in machine learning. The model will be trained by transferring the trained model parameters to new problems. Considering that most of the data or tasks are relevant, we can learn the model parameters (this can also be understood as model learned knowledge) through transfer learning in a way that optimizes and improves the speed of the learning efficiency of the model and does not require learning from zero, as with most networks.
We use pretrained AlexNet and VGG to move from the 1 000 classes of the original model to our palm vein categories.
Table 1 shows the network architecture of AlexNet, including the use of each layer, stride and padding in the convolution layer, following the rules to adjust the image, and the dropout in the fully connected layer. We used transfer learning to convert the last three layers into our classification, as in the AlexNet example. VGG16 and VGG19 use the same method to replace the last three layers.
Table 1
Architecture network of AlexNet.
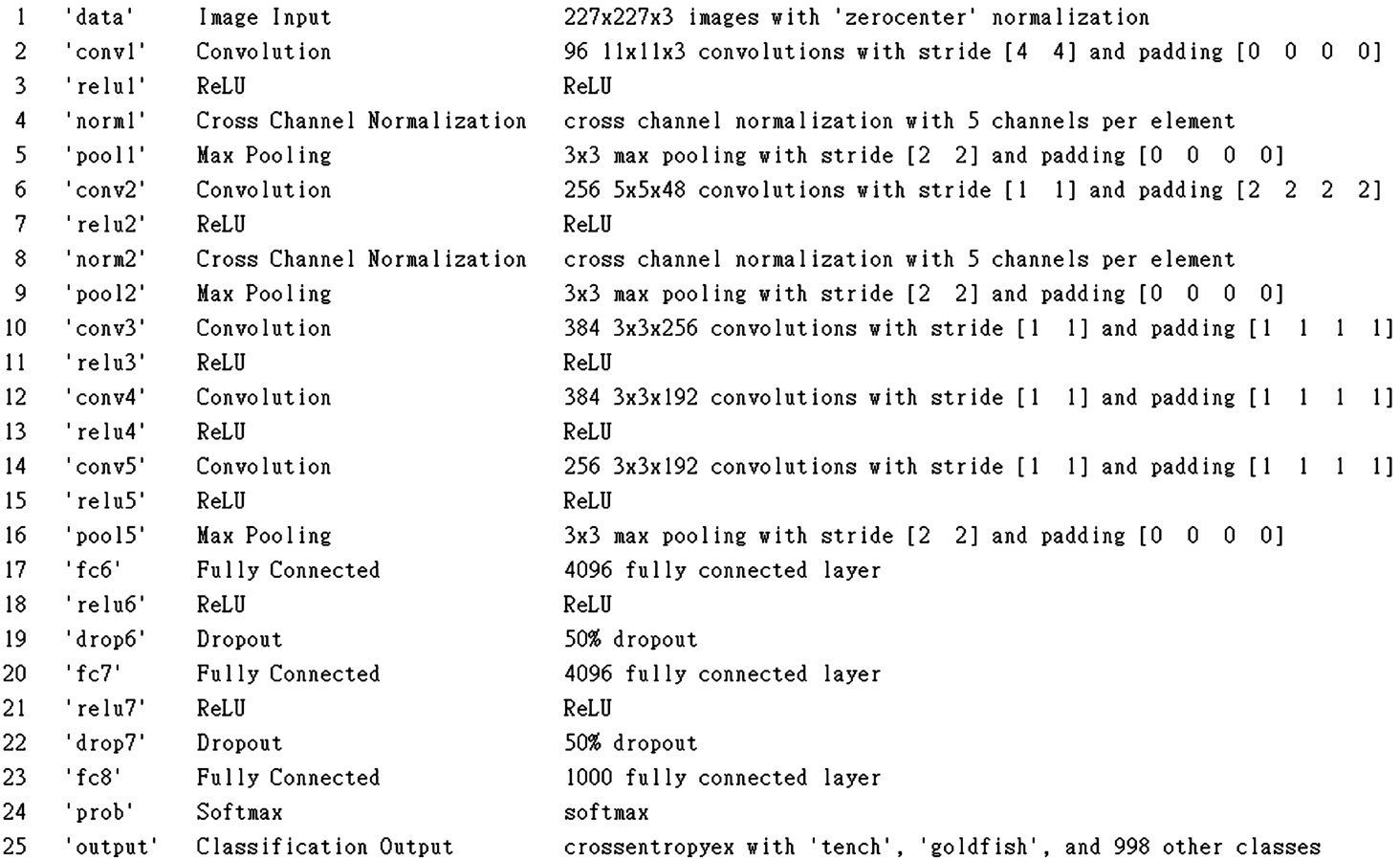
Table 1 is the initial network architecture. The last three layers are initially set to 1 000 categories, and we adjust for the new categories in Table 2.
Table 2
Fully connected layer and output layer adjustment.

In Table 2, we adjust the final fully connected layer, Softmax layer, and output layer to our experimental classification.
4Experiment and Result Analysis
In this section we discuss the results of the CNN palm vein recognition experiments and analysis. We constructed AlexNet and VGG using MATLAB and the deep learning convolutional neural network framework. The main process includes the following: image acquisition, model training, parameter adjustment, and result identification.
4.1Dataset
We established two set of datasets of palm veins. The first dataset contains twenty images from each of 50 individuals, for a total of 1 000 experimental images. The second dataset contains twenty images from each of 63 individuals, for a total of 1 260 experimental images. The size of a captured image is
Table 3
Equipment of the first dataset.
| Equipment | Device configuration |
| System | Windows 10 64-bit |
| CPU | Intel(R)Core(TM)i7-6500 CPU @ 2.50 GHz |
| RAM | 8 GB |
| GPU | GTX940MX |
| Framework | MATLAB |
Table 4
Equipment of the second dataset.
| Equipment | Device configuration |
| System | Windows 10 64-bit |
| CPU | Intel(R)Core(TM)i7-8700 CPU @ 3.20 GHz |
| RAM | 32 GB |
| GPU | GTX1080 |
| Framework | MATLAB |
4.2Equipment
The experimental environment for our equipment of the first dataset is shown in Table 3. We use a Windows 10 64-bit system, and 8 G memory, NVIDIA GTX940MX; the framework is MATLAB. The equipment of the second dataset is shown in Table 4. We use a Windows 10 64-bit system, and 32 G memory, NVIDIA GTX1080; the framework is MATLAB.
Fig. 9
Training process of AlexNet.
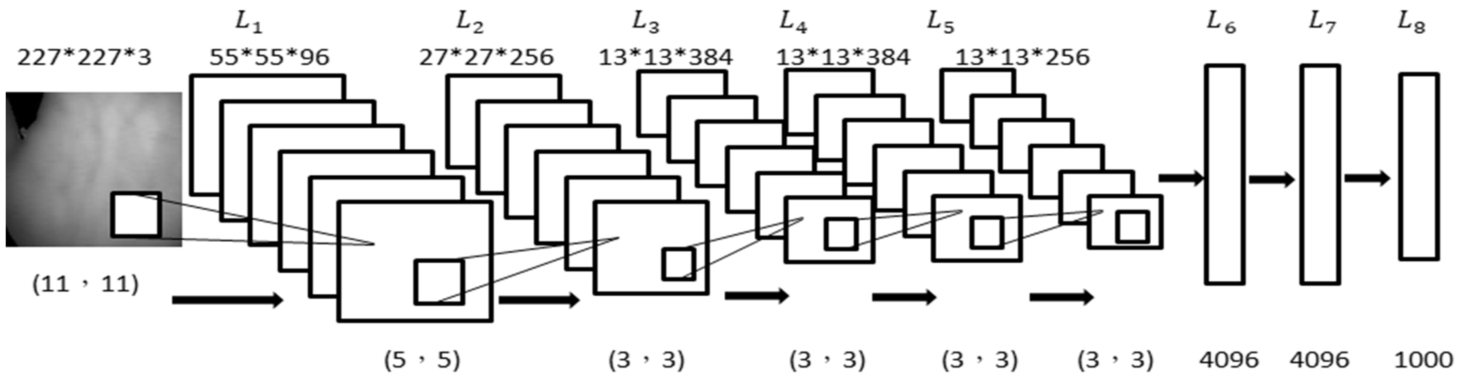
4.3Training Process
The training of CNN is to optimize various parameters. Different parameters, as well as the network structure and usage, will affect the effectiveness and training speed of CNN recognition. The AlexNet neural network model is used as an example to illustrate the training process of palm vein recognition, whose network structure is shown in Fig. 9. The input image size of the first layer is 227*227*3, where 3 represents the colour of the image (RGB). The equation for the convolution and pooling layers is
(5)
The first convolution layer (
4.4Experimental Results
4.4.1Experimental Results of the First Dataset
Table 5
Training iterations results of the first dataset.
| Models | Iterations | Result |
| AlexNet | 800 | 96% |
| VGG-16 | 800 | 97.5% |
| VGG-19 | 1000 | 98.5% |
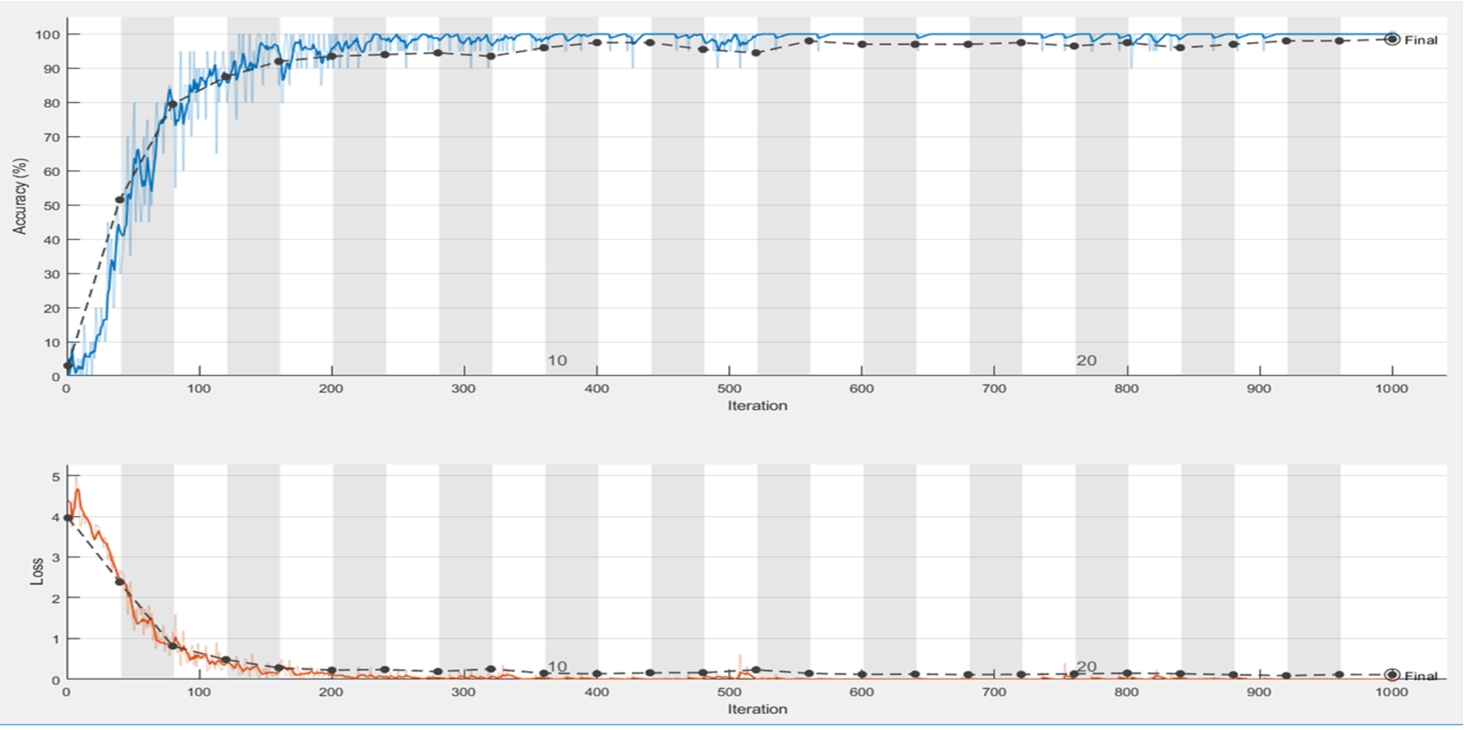
In this paper, the experimental process includes the following: randomly selecting the training image and validation sets, adjusting the batch value according to the performance of the hardware, and adjusting the learning rate. The hyperparameter adjustment on the model will affect the experimental results. In this process, the final numbers of iterations were 800, 800, and 1 000 in AlexNet, VGG-16 and VGG-19, respectively, as shown in Table 5, and the accuracy rates were 96%, 97.5%, and 98.5%, respectively. Experimental process diagrams are shown in Figs. 10, 11 and 12. The loss function was used to evaluate the degree of inconsistency between the predicted value and the true value of the model. It is a nonnegative real-valued function; the smaller the loss function, the better the robustness of the model. The loss function is as follows:
(6)
The number of iterations in Table 5 is either 800 or 1 000, and the recognition rate is as high as 98.5%.
Fig. 10
Accuracy, iterations and loss for iterations of AlexNet of the first dataset.
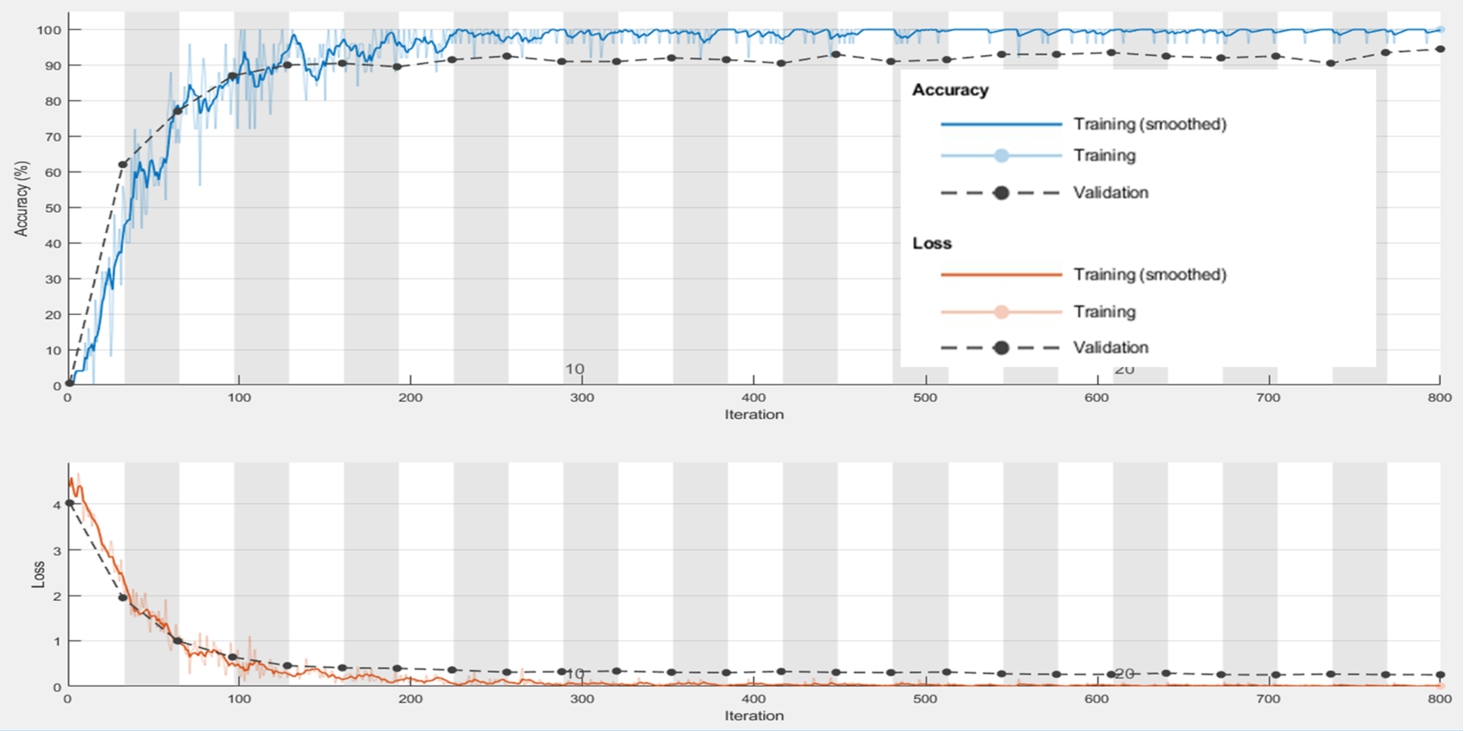
Fig. 11
Accuracy, iterations and loss for iterations of VGG-16 of the first dataset.
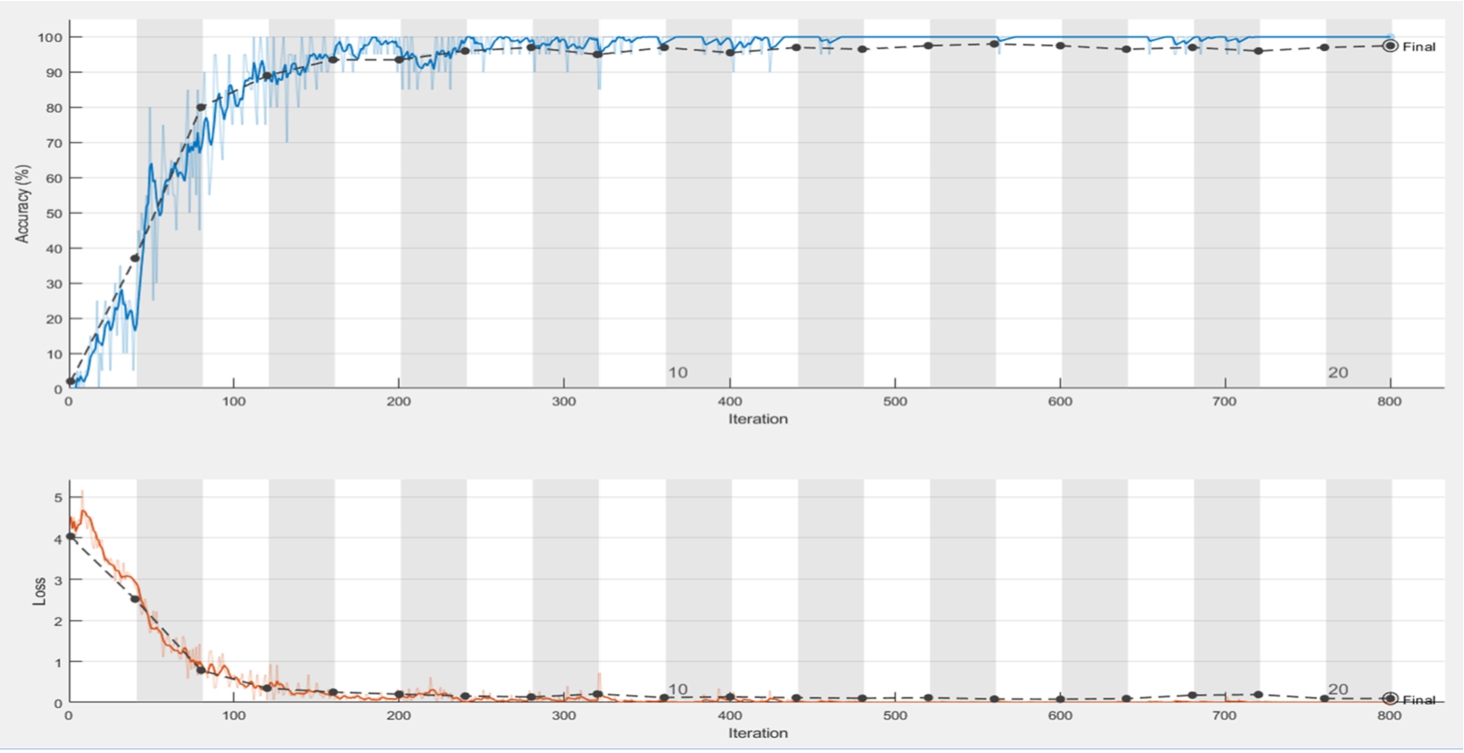
Fig. 12
Accuracy, iterations and loss for iterations of VGG-19 of the first dataset.
The comparison with other authors’ research results are shown in Table 6. Fronitasari and Gunawan (2017) proposed using DCLBP, which is a LBP, average LBP, median LBP and LBP original corrections, and feature matching process using PNN. (Badrinath et al., 2013) proposed using the geometric hash of the SURF keypoint to index and perform a fractional fusion of the voting strategy. Lee (2012) proposed using the 2-D Gabor filter to represent a palm vein image using its texture features and the hamming distance. In addition, the author proposed a direction coding to code the palm vein features in two-bit representation. (Pratiwi et al., 2016) proposed using the LBPROT feature extraction as a palm vein image matching process by using the Cosine Distance. Among the three models we used, the highest accuracy rate was 98.5%. Compared with other papers, we simplified the entire palm vein recognition process, and the preprocessing part only adjusted the image size. The experimental results in Table 5 show that, in the previous research methods, the steps taken are too complex. Compared with the previous CNN-based palm vein recognition methods, the only pretreatment we have done is image size reduction and step reduction; the entire process obtained excellent results.
Table 6
Test results for various algorithms of the first dataset.
| Algorithm | Result |
| LBP+PNN (Fronitasari and Gunawan, 2017) | 98% |
| SURF (Badrinath et al., 2013) | 96.7% |
| Gabor (Lee, 2012) | 96.37% |
| LBPROT (Pratiwi et al., 2016) | 96% |
| AlexNet (ours) | 96% |
| VGG-16 (ours) | 97.5% |
| VGG-19 (ours) | 98.5% |
Based on the performance of biometrics-based verification systems (Seshikala et al., 2012; Vaid and Mishra, 2015), the false acceptance rate (FAR) and the false rejection rate (FRR) are the primary metrics used to evaluate the performance of the model in this paper. Among them, there are the four categories of True Positive (TP), False Positive (FP), False Negative (FN) and True Negative (TN) used in these two metrics. If the test is positive and classified as positive, it is TP. If the test is positive and classified as negative, it is FP. If the test is negative and classified as positive, it is FN. If the test is negative and classified as negative, it is TN. Our performance metrics used in this paper are FAR and FRR. FAR and FRR can be measured with the following formulas:
(7)
(8)
Table 7
Performance metrics of the first dataset.
| Performance metrics | |||
| No. | Models | FAR (%) | FRR (%) |
| 1 | AlexNet | 0 | 0.77 |
| 2 | VGG-16 | 0 | 0.65 |
| 3 | VGG-19 | 0 | 0.6 |
From Table 7, it can be seen that performance of CNN is quite remarkable among the unprocessed images.
4.4.2Experimental Results of the Second Dataset
In this study, we divided the image dataset into two sets, namely a training set and a validation set. For the training and validation of the three models AlexNet, VGG-16, and VGG-19, we set the number of iterations to be 1000 times.
The palm vein images in the database were collected by using a near-infrared light camera. Since these were contactless shots, each image had a different resolution and needed to be preprocessed. To obtain the best result of image contrast enhancement while avoiding noise amplification, we used a new technique for contactless palm vein recognition. To preprocess the input image, our design uses contrast limited adaptive histogram equalization (CLAHE) to enhance the image quality and thus the feature distinguishability. Figure 13(a) shows a raw image, and Fig. 12(b) shows the enhanced image.
Fig. 13
(a) Original image; (b) Enhanced image.
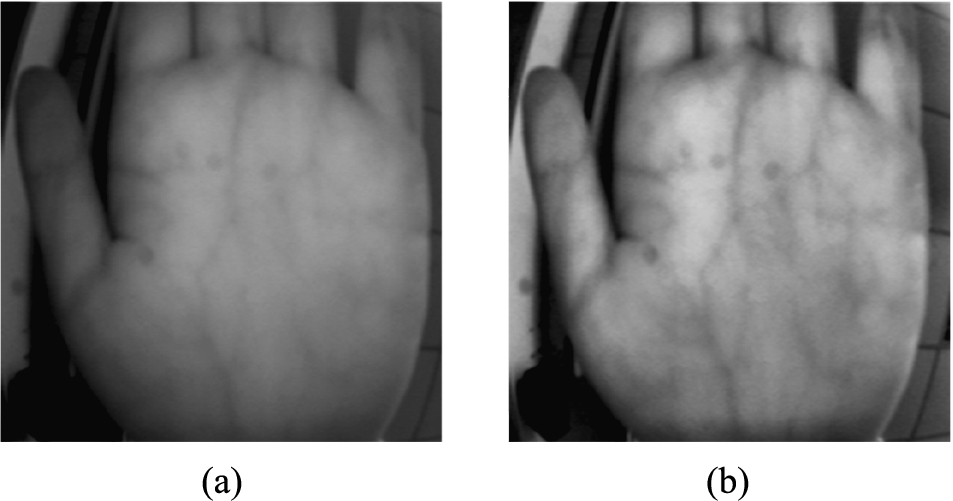
Fig. 14
Training processes and accuracy of the models of the second dataset.
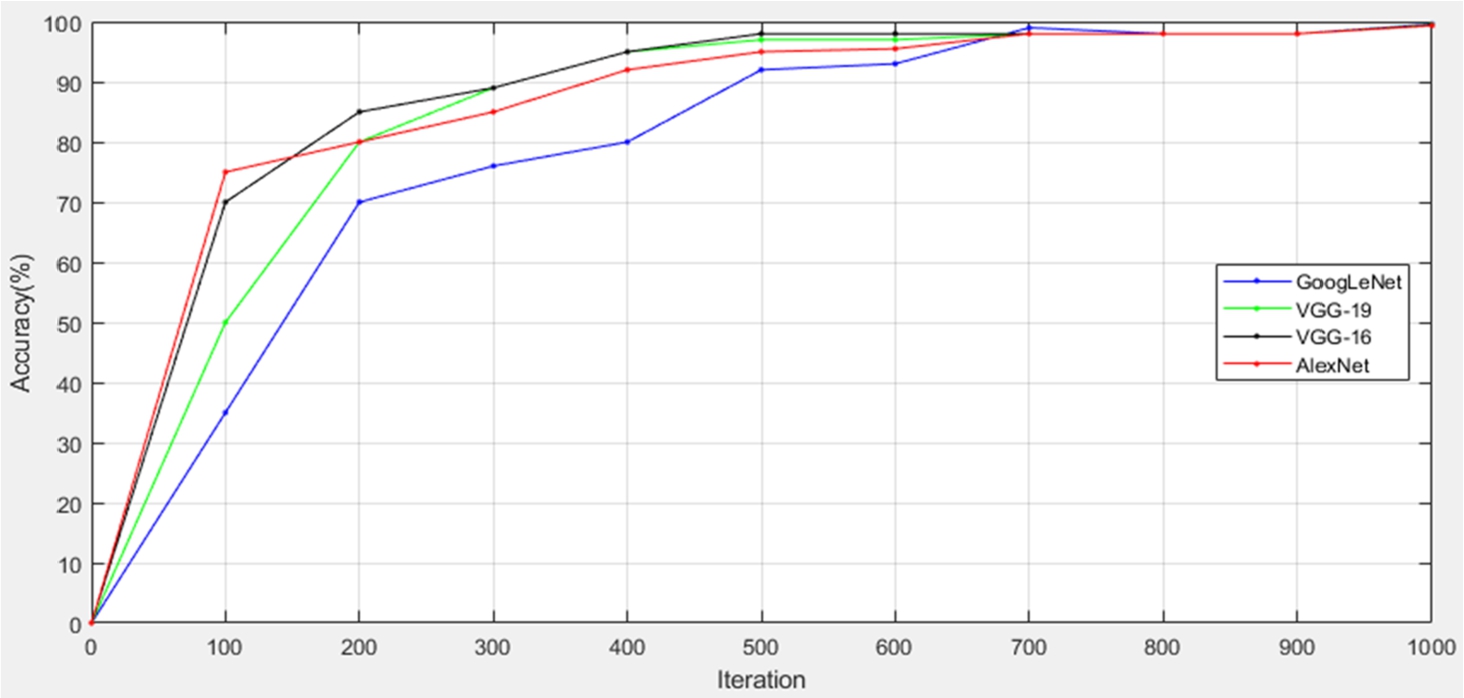
The training processes of the three models are shown in Fig. 14. In Table 8, we present the final results of accuracy of the three models. All three models gave excellent results with the accuracy rate of AlexNet being 99.35%, the accuracy rate of VGG-16 being 99.45%, and the accuracy rate of VGG-19 being 99.5%.
Table 8
Training iteration results of the second dataset.
| Models | Iterations | Result |
| AlexNet | 1000 | 99.35% |
| VGG-16 | 1000 | 99.45% |
| VGG-19 | 1000 | 99.5% |
The smaller the loss function, the better the stability. The loss function is the core part of the empirical risk function and an important part of the structural risk function. The common loss function includes the following factors:
• Hinge Loss: Mainly used in support vector machines (SVM).
• Cross Entropy Loss; Softmax Loss: Used in Logistic Regression and Softmax Classification.
• Square Loss: Mainly in Ordinary Least Squares (OLS).
• Exponential Loss: Mainly used in the Adaboost integrated learning algorithm.
• Other loss (such as 0–1 loss, absolute value loss)
Fig. 15
Training process and loss of the models of the second dataset.
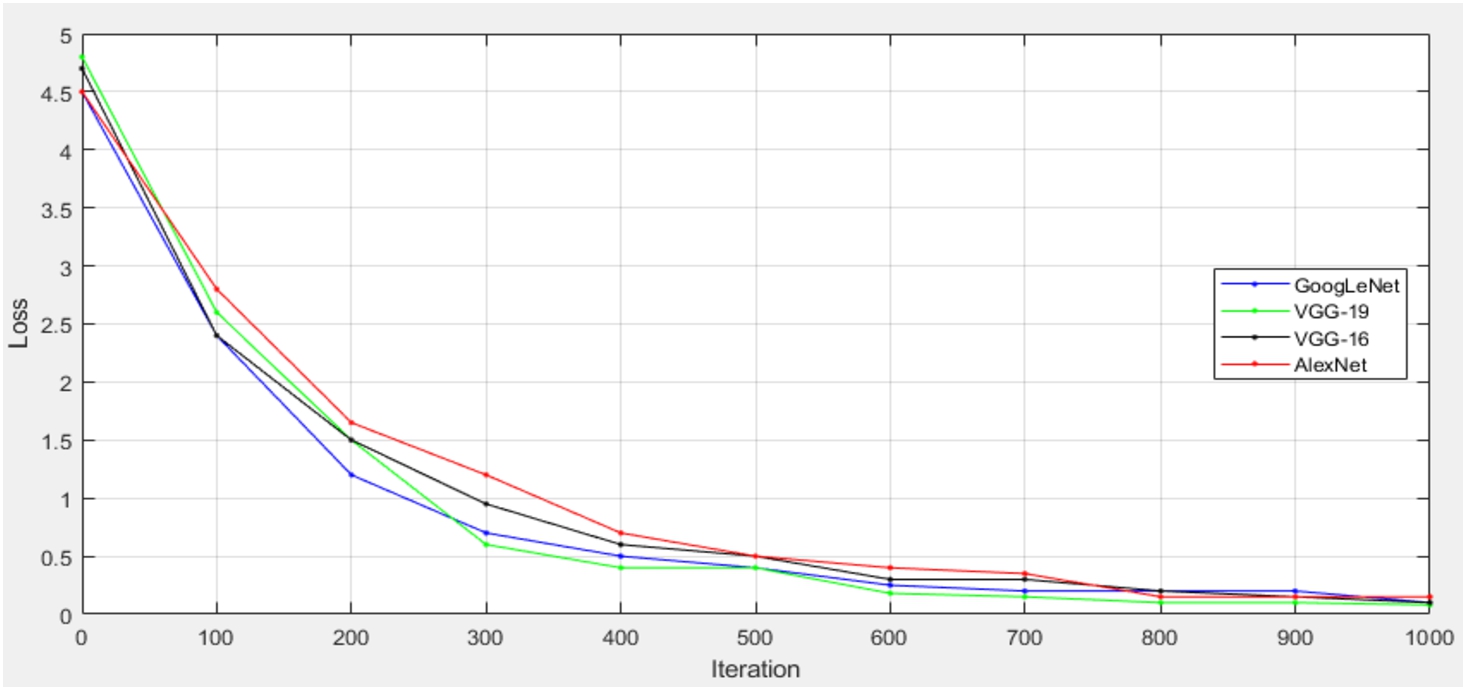
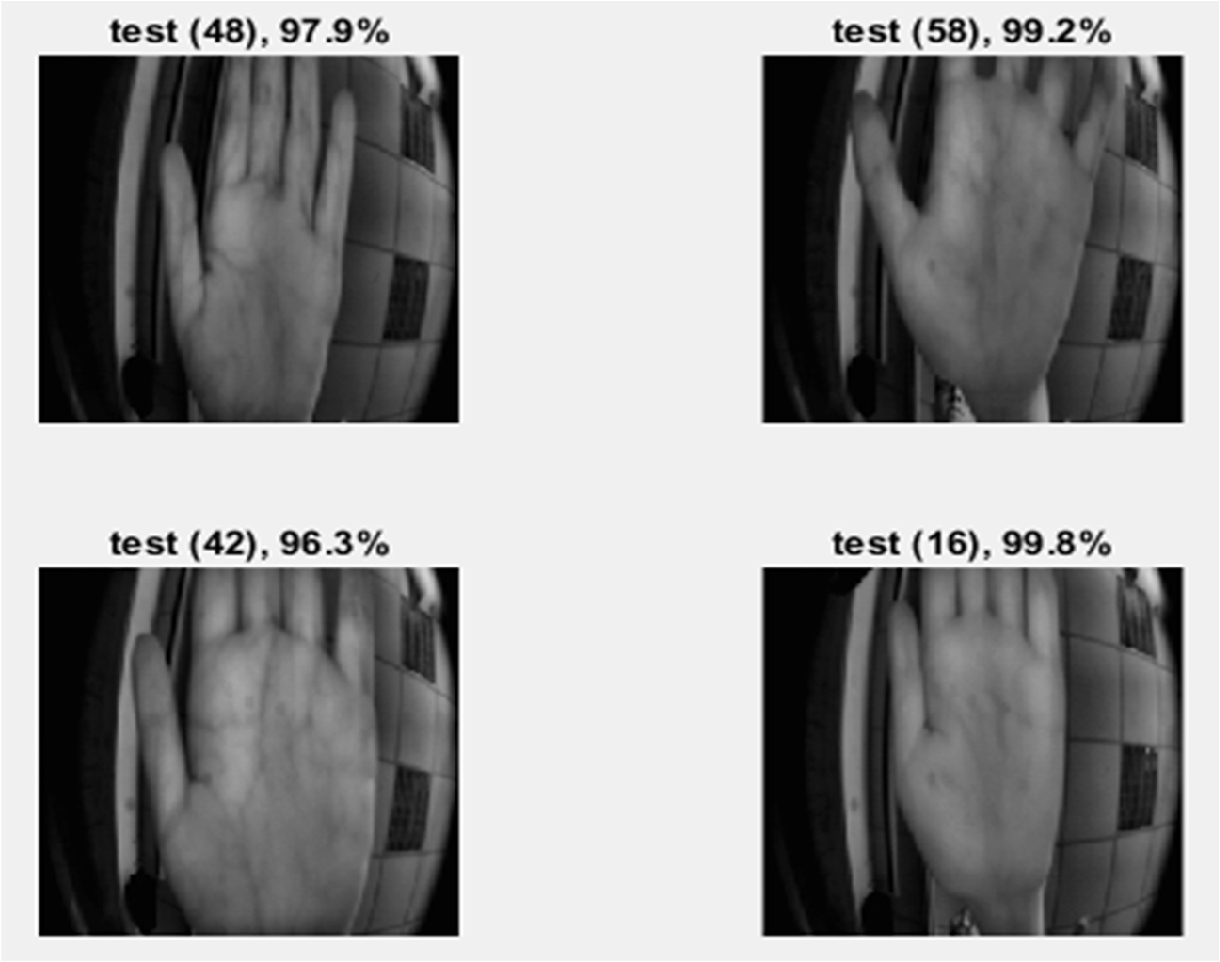
Fig. 16
Training results of four random users.
In addition, we also tested the models with two different graphics cards, and the training time and accuracy differed accordingly. The results are shown in Table 9. Please note that in this part of our experiment, the test image had not been preprocessed.
Table 9
Performance comparison among models when using different graphics cards.
| Models | GTX940 | GTX1080 | ||
| Training time | Accuracy | Training time | Accuracy | |
| AlexNet | 695 s | 96% | 83 s | 97% |
| VGG-16 | 757 s | 97.5% | 515 s | 98% |
| VGG-19 | 832 s | 98.5% | 560 s | 98.5% |
The statistics of our performance metrics for the three models of the second dataset are shown in Table 10.
Table 10
Performance metrics of the second dataset.
| Performance metrics | |||
| No. | Models | FAR (%) | FRR (%) |
| 1 | AlexNet | 0 | 0.5 |
| 2 | VGG-16 | 0 | 0.35 |
| 3 | VGG-19 | 0 | 0.3 |
The performance comparison between our approaches with others are shown in Table 11. Cancian et al. (2017) proposed a method that was the combination of the Gabor filter and histogram calculations to create a biometric template. Zheng et al. (2017) proposed a LeNet structure to process palm veins, and the method achieved an accuracy rate of 99.1%. Zheng and Han (2018) proposed an AlexNet design to do palm vein image ROI extraction. We compared our approaches with the three similar methods above in terms of FAR, FRR, as well as accuracy rate, and the results are shown in Table 11. As the results show, all the models of ours had lower error rates and higher accuracy rates, demonstrating the superiority of our approached over the others.
5Conclusion
This paper proposed a palm vein recognition method based on a convolutional neural network. Through AlexNet and VGG, the entire palm vein recognition process is simplified, and image processing, feature extraction, and matching methods are no longer as complicated. The unique advantages of CNNs compared to other methods include greater convenience and excellent accuracy rates; there are also good results for the performance metrics. In our first palm vein dataset, 1000 images from 50 individuals were adopted for testing, and an FRR of 0.6% was achieved. The above three models provide a new research method for palm vein recognition and prove the advantages of deep learning in the image field. The second dataset, including 1260 images from 63 individuals, was adopted for testing, and an FRR of 0.3% was achieved. We tried to preprocess the palm vein image, use the CLAHE method to increase the contrast of the image, highlight its feature, and improve the accuracy of the three types of CNN to 99%. When using different graphics cards, the training time will have an enormous impact, and the accuracy will be slightly affected.
In the future, this study can be improved in two directions. First, the palm vein images used in our method need to be clear and uncontaminated files, and the effect on shadows is not very good. In the future, we can further improve the pre-processing method of CLAHE proposed in this paper to remove some noise and shadows, which should improve the recognition rate. The second one is towards the finger vein recognition so that it can be applied to the security system control of handheld mobile devices.
References
1 | Aglio-Caballero, A., Ríos-Sánchez, B., Sánchez-Ávila, C., de Giles, M.J.M. ((2017) ). Analysis of local binary patterns and uniform local binary patterns for palm vein biometric recognition. In: International Carnahan Conference on Security Technology (ICCST), pp. 1–6. |
2 | Akinsowon, O.A., Alese, B.K. ((2013) ). Edge detection methods in palm-print identification. In: 8th International Conference for Internet Technology and Secured Transactions (ICITST-2013), pp. 422–426. |
3 | Badrinath, G.S., Gupta, P., Mehrotra, H. ((2013) ). Score level fusion of voting strategy of geometric hashing and SURF for an efficient palmprint-based identification. Journal of Real-Time Image Processing, 8: (3), 265–284. |
4 | Cancian, P., Donato, G.W.D., Rana, V., Santambrogio, M.D. ((2017) ). An embedded Gabor-based palm vein recognition system. In: IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), pp. 405–408. |
5 | Choras, R.S. ((2017) ). Personal identification using forearm vein patterns. In: International Conference and Workshop on Bioinspired Intelligence (IWOBI), pp. 1–5. |
6 | Fronitasari, D., Gunawan, D. ((2017) ). Palm vein recognition by using modified of local binary pattern (LBP) for extraction feature. In: 15th International Conference on Quality in Research (QiR): International Symposium on Electrical and Computer Engineering, pp. 18–22. |
7 | Garg, S.N., Vig, R., Gupta, S. ((2016) ). Multimodal biometric system based on decision level fusion. In: International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), pp. 753–758. |
8 | Gurunathan, V., Sathiyapriya, T., Sudhakar, R. ((2016) ). Multimodal biometric recognition system using SURF algorithm. In: 10th International Conference on Intelligent Systems and Control (ISCO), pp. 1–5. |
9 | Hao, Y., Sun, Z., Tan, T., Ren, C. ((2008) ). Multispectral palm image fusion for accurate contact-free palmprint recognition. In: 15th IEEE International Conference on Image Processing, pp. 281–284. |
10 | Huang, H., Liu, S., Zheng, H., Ni, L., Zhang, Y., Li, W. ((2017) ). DeepVein: novel finger vein verification methods based on deep convolutional neural networks. In: IEEE International Conference on Identity, Security and Behavior Analysis (ISBA), pp. 1–8. |
11 | Jain, A.K., Bolle, R., Pankanti, S. (2006). Biometrics: Personal Identification in networked Society. Springer Science & Business Media, Vol. 479. |
12 | Kang, W., Wu, Q. ((2014) ). Contactless palm vein recognition using a mutual foreground-based local binary pattern. IEEE Transactions on Information Forensics and Security, 9: (11), 1974–1985. |
13 | Khan, M.H.-M., Subramanian, R.K., Khan, Ali Mamode, N. ((2009) ). Representation of hand dorsal vein features using a low dimensional representation integrating cholesky decomposition. In: 2nd International Congress on Image and Signal Processing, pp. 1–6. |
14 | Kim, Y., Toh, K.A., Teoh, A.B.J. ((2010) ). An online learning algorithm for biometric scores fusion. In: Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), pp. 1–6. |
15 | Kong, A., Zhang, D., Kamel, M. ((2009) ). A survey of palmprint recognition. Pattern Recognition, 42: (7), 1408–1418. |
16 | Krizhevsky, A., Sutskever, I., Hinton, G.E. ((2012) ). ImageNet classification with deep convolutional neural networks. In: International Conference on Neural Information Processing Systems, pp. 1097–1105. |
17 | Lécun, Y., Bottou, L., Bengio, Y., Haffner, P. ((1998) ). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86: (11), 2278–2324. |
18 | Lee, J.C. ((2012) ). A novel biometric system based on palm vein image. Pattern Recognition Letters, 33: (12), 1520–1528. |
19 | Lin, Y., Du, E.Y., Zhou, Z., Thomas, N.L. ((2014) ). An efficient parallel approach for sclera vein recognition. IEEE Transactions on Information Forensics and Security, 9: (2), 147–157. |
20 | Liu, J., Zhang, Y. ((2011) ). Palm-dorsa vein recognition based on two-dimensional fisher linear discriminant. In: International Conference on Image Analysis and Signal Processing, pp. 550–552. |
21 | Lu, W., Yuan, W.Q. ((2017) ). Comparison of four local invariant characteristics based on palm vein. In: IEEE International Conference on Computational Science and Engineering (CSE) and Embedded and Ubiquitous Computing (EUC), pp. 850–853. |
22 | Mohamed, C., Akhtar, Z., Eddine, B.N., Falk, T.H. ((2017) ). Combining left and right wrist vein images for personal verification. In: Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), pp. 1–6. |
23 | O’Gorman, L. ((2003) ). Comparing passwords, tokens, and biometrics for user authentication. Proceedings of the IEEE 91: (12), 2021–2040. |
24 | Pan, S.J., Yang, Q. ((2010) ). A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 22: (10), 1345–1359. |
25 | Pascual, J.E.S., Uriarte-Antonio, J., Sanchez-Reillo, R., Lorenz, M.G. ((2010) ). Capturing hand or wrist vein images for biometric authentication using low-cost devices. In: Sixth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, pp. 318–322. |
26 | Pratiwi, A.Y., Budi, W.T.A., Ramadhani, K.N. ((2016) ). Identity recognition with palm vein feature using local binary pattern rotation Invariant. In: 4th International Conference on Information and Communication Technology (ICoICT), pp. 1–6. |
27 | Raghavendra, R., Surbiryala, J., Busch, C. ((2015) ). Hand dorsal vein recognition: sensor, algorithms and evaluation. In: IEEE International Conference on Imaging Systems and Techniques (IST), pp. 1–6. |
28 | Raut, S.D., Humbe, V.T. ((2015) ). Palm vein recognition system based on corner point detection. In: IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), pp. 499–502. |
29 | Seshikala, G., Kulkarni, U., Giriprasad, M.N. ((2012) ). Biometric parameters & palm print recognition. International Journal of Computer Applications, 46: (21), 31–34. |
30 | Shimizu, K. ((1992) ). Optical trans-body imaging feasibility of optical CT and functional imaging of living body. Medicina Philosophica, 11: , 620–629. |
31 | Suganya, A., Sivitha, M. ((2014) ). A new biometric using sclera vein recognition for human identification. In: IEEE International Conference on Computational Intelligence and Computing Research, pp. 1–4. |
32 | Simonyan, K., Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556. |
33 | Vaid, S., Mishra, D. ((2015) ). Comparative analysis of palm-vein recognition system using basic transforms. In: IEEE International Advance Computing Conference (IACC), pp. 1105–1110. |
34 | Xu, J. ((2015) ). Palm vein identification based on partial least square. In: 2015 8th International Congress on Image and Signal Processing (CISP), pp. 670–674. |
35 | Zhang, D., Guo, Z., Lu, G., Zhang, L., Zuo, W. ((2010) ). An online system of multispectral palmprint verification. IEEE Transactions on Instrumentation and Measurement, 59: (2), 480–490. |
36 | Zheng, S.W., Han, J.G. ((2018) ). Deep learning for contact-less palmprint recognition. Microelectronics & Computer, 35: (4), 98–102. |
37 | Zheng, S.W., Han, J.G., Wang, Y.F., Jing, J.D. ((2017) ). Convolutional neural network for palmprint recognition. Science Technology and Engineering, 17: (35), 1–7. |


