
Game learning support system based on future position
Abstract
In games with a large number of legal yet complicated moves like Shogi, the number of candidate moves that can be performed are considerably large especially for beginners; therefore, often, beginners encounter situations where they cannot select the next move to play. The hint function in the existing Shogi programs provides support by directly showing candidate moves. However, such direct hints may not only deprive the pleasure of playing the game intellectually, but also instigate players to avoid thinking about the next steps entirely. Therefore, a method to provide indirect hints is required, which retains the objective and fun of the game. Thus, in this study, a method that presents the future position in the game, which is generated by self-play of Shogi AI, is proposed. In particular, the proposed system displays the next position, position after 5 steps, or position after 9 steps in advance using the Shogi AI. Then, the learning effect based on the evaluation experiment was analyzed and discussed.
1.Introduction
In games with a large number of legal yet complicated moves like Shogi, it is difficult for beginners to estimate the moves of their opponent; in addition, they often encounter situations wherein they find it hard to select the next move they want to play. At such instances, providing appropriate hints might encourage and assist beginners in making decisions. In some existing computer Shogi programs, hint functionality is available, which shows the candidate moves and searching traces that the computer program is considering. Though this functionality is considerably helpful for beginners, such direct assistance for moves not only deprives the player of a chance for engaged thinking, but also relying on this hint function considerably might lead to abandonment of thinking and loss of game value entirely.
To address this problem, in a previous study, a method called “indirect guidance” in a learning support system was proposed (Ito and Furugori, 1996). “Indirect instruction” is a teaching method that presents indirect hints rather than directly indicating the method to obtain a solution; this method has been practiced for a considerable time in practical learning support activities, such as “cognitive counseling” (Ichikawa, 2005) as well as in mathematics education. Several case studies exist on the effect of this method on the learner’s behavior; in the case of indirect guidance, it has been observed that the learner “became tenacious in tackling the problem” and “less dependent on the tutor.”
In this study, I propose a system to encourage beginner learning by presenting a future position generated by computer self-play to the learners instead of direct candidate moves. In addition, I evaluated the learning effect of this proposed system on the learners.
2.Related works
In recent years, several studies have been conducted on computer-based learning support systems, which has seen increasing interest among researchers. In particular, Miwa et al. developed a system that presents learners with arbitrary levels of support methods for the problem-solving task of six disks of the “Tower of Hanoi”; they conducted experiments to evaluate the learning effect of each level of support (Miwa et al., 2012). As concrete support levels, they prepared four levels of support: display the state after the next move (1 move group), display the state after five moves (5 moves group), display the state after nine moves (9 moves group), and display no moves (none group). In their experiment, after explaining the use of their system to the experiment participants, in the learning phase, they divided the subjects into condition groups based on the four levels of support; then, the subjects were allowed to use the system for 40 minutes to solve the problem at hand. Subsequently, as a posttest, all the participants in the experiment were asked to solve the problem without support. Then, the solution efficiency (actual number of steps / minimum number of steps) and the time per move were analyzed. Based on their analyses, the grades during the learning phase followed the trend “1 move group > 5 moves group > 9 moves group > none group,” while the grades after learning followed the trend “9 moves group > 5 moves group > none group > 1 move group.” These results indicate that the learning effect was the least in the case of the “1 move group,” which represented the most direct support. Thus, based on this study, the problem that human motivation for learning and the learning itself are obstructed by excessive computer-based support is observed; this problem is referred to as the “assistance dilemma problem” (Koedinger and Aleven, 2007).
Considering the effect of computer-based support in the case of human learning, it will be useful to investigate the increase in the performance of a person without computer-based support and clarify the level of computer-based support useful for human learning. In the cases where it is difficult for humans to solve problems on their own, it is necessary to provide appropriate levels of support; however, it is better to restrict assistance as these problems become solvable with subsequent steps; in particular, balancing computer-based support is an important problem. In the experiment conducted by Miwa et al., it was observed that support in the case of the “9 moves group” was most appropriate among the abovementioned four levels of support.
Mizuno and colleague that took over this study, conducted two experiments on assistance dilemmas using a game of Othello (Mizuno et al., 2017). In the first experiment, they investigated the relationship between degree of support and learning effect in short-term learning. In this experiment, they prepared three support conditions such as “no support” which do not support, “best move” to suggest the best move generated by computer and “three candidates” to suggest two random legal moves and a best move generated by computer. They made the subjects to play 12 matches, and examined the results of the competition (learning phase) and the grades of the post test after the competition. For the grade evaluation, they analyzed with average response time per a move and dominance rate on board (number of player’s stone/total number of stones). As the result, in the learning phase, in the “best move”, the average time per move was the shortest and the dominance rate was the highest, whereas between the “no support” and the “three candidates” there was no significant difference. In the post test, no significant difference was found between the three conditions.
In their second experiment, the learning period was extended to 2 weeks and the support levels were limited to two: “no support” and “best move.” Based on the results of the second experiment, in the learning phase, the “best move” group had the shortest average time per move among the two with a high dominance rate on the board. However, in the posttest, the “no support” group showed a higher dominance rate than the “best move” group. Thus, the results of these experiments suggest that direct assistance by providing the best move may inhibit learning.
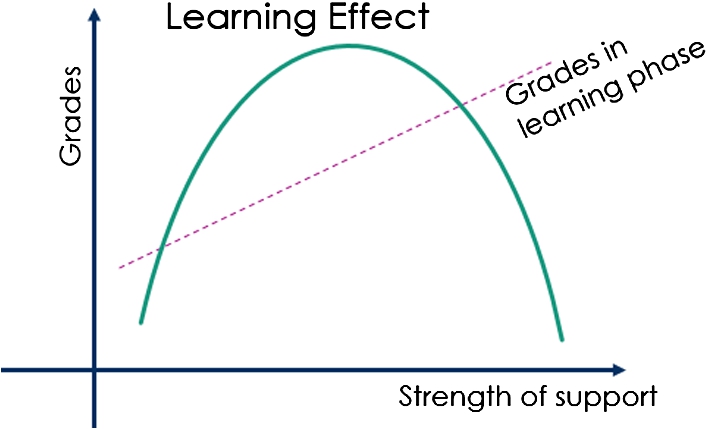
This type of assistance dilemma is graphically represented in Fig. 1. In the figure, the stronger the strength of support, the higher the grades in the learning phase; however, a considerably strong support hinders learning, nevertheless if the support is too weak, it makes learning difficult. Therefore, it can be deduced that moderate support encourages learning.
However, experiments based on games like Othello do not indicate learning differences in the case of detailed support; in addition, they cannot be used to obtain new findings on better support levels. Therefore, in this study, a method of adjusting the support level based on the future steps in the case of Shogi is proposed. Furthermore, the effect of the support levels on learning is verified.
Fig. 1.
Relationship between strength of support and learning effect.
3.Proposed system
3.1.Design policy
In this study, the game of Shogi is considered because of a more extensive problem-solving space than in the cases of Tower of Hanoi and Othello. In Shogi, Ito et al. observed that “read-ahead” is important from the perspective of cognitive science (Ito et al., 2004; Takahashi et al., 2011). “Read-ahead” means thinking the positions after several moves. Therefore, to support learning in the case of Shogi, I believe that it is important to support the ability of read-ahead. In this study, the use of computer-based support showing future phases of several moves as in the previously introduced research for “Towers of Hanoi” is proposed.
However, in Shogi, because there is no unique procedure for the next appropriate step (i.e., shortest procedure) like in the case of games like the Towers of Hanoi, it is possible to only present one computer-generated virtual future position by a computer that is stronger than the players. Nevertheless, for beginners, I believe this would be helpful to support learning.
In particular, a system was developed that presents future positions after 1 move, after 5 moves, and after 9 moves, which were generated by allowing the computer to play against itself. In all, programs for four conditions were prepared including a condition with no move presentation.
3.2.Outline
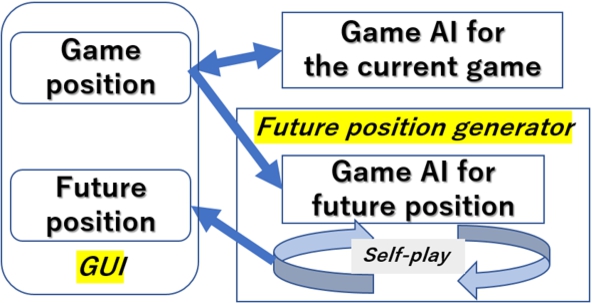
Figure 2 shows the outline of the proposed system. In the GUI of the proposed, both the game and future positions are displayed. The game is played with an independent game artificial intelligence (AI). As a hint, the future position is presented in the game, which is generated by sending the current position to another AI, then, implementing self-play between the AIs.
Fig. 2.
Outline of the proposed system.
3.3.Game AI for the current game
As game AI for the current game, Bonanza 6.0 was used (Takahashi et al., 2011). Because the proposed support system is intended for amateur players, the strength of AI was adjusted by limiting the search depth to 1. Aside from limiting the depth, in order to avoid the selection of the same move at all instances, the opening book is used.
3.4.Future position generator
In this study, the future positions after 1 move, 5 moves, and 9 moves were shown to the players. In the game, the search depth for generating the future positions was set to 5 to ensure thinking time not requiring much time to display while being sufficiently strong.
In the case of the future position generator, a hint command was developed that allows the Bonanza system to self-play and output the position after N moves. With the hint command, for example, by entering an arbitrary numerical value as in the case of “Hint 5,” the moves after the input numerical value, and the Nth move and the future position are output to the user. After outputting the future position, the future position generator reads the game record for the position before proceeding, so that it can return to the original position.
3.5.GUI
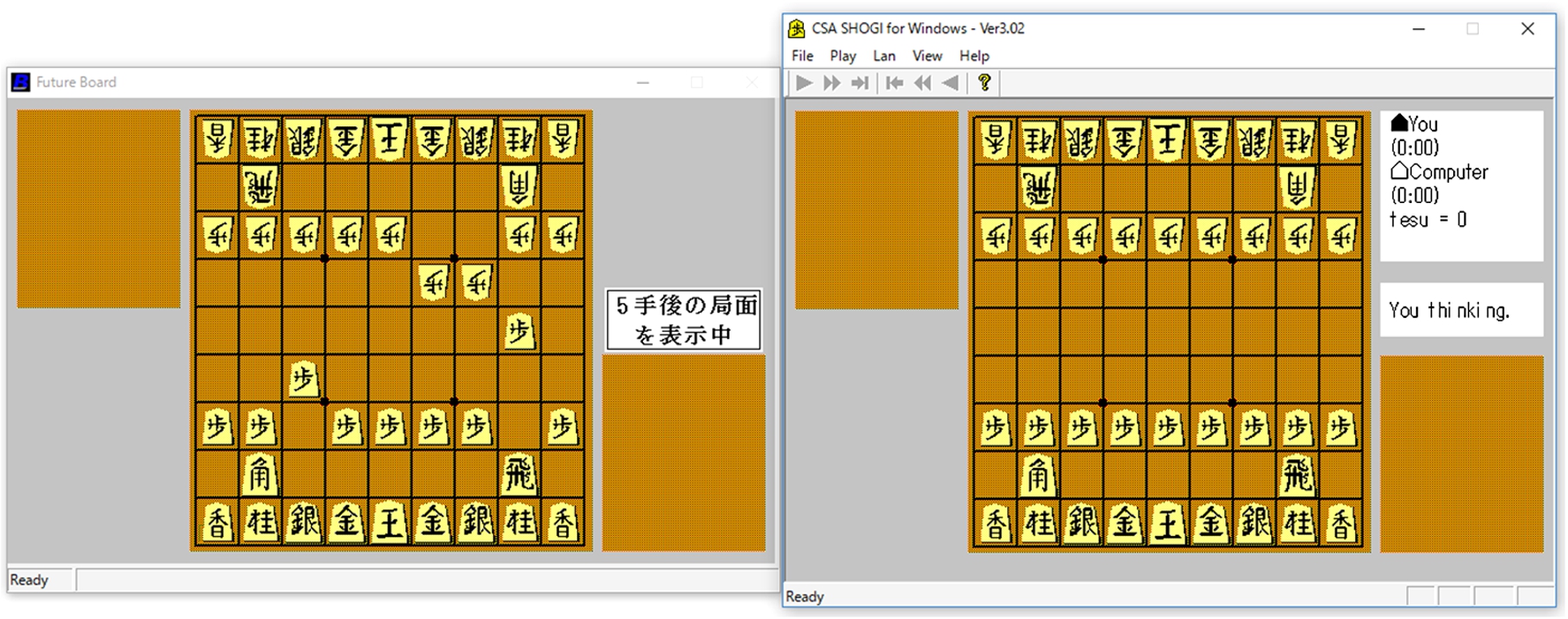
For the GUI, aside from the displayed normal game screen, parts for inputting the hint command to “sikou.dll” associated with Bonanza as well as for “Future Board” generated using “sikou.dll” are included; the latter displays the image of the future position output by Bonanza. For example, as shown in Fig. 3, it is possible to obtain the position after 9 moves after the current position by entering hint 9.
Fig. 3.
Example of future board after 9 moves from the initial position.

4.Evaluation experiment
4.1.Purpose
In my experiment, based on the concept of assistance dilemma, the appropriate support balance using the future position in the case of Shogi is examined. To this end, experimental participants used the proposed system, which, as previously mentioned, presents three support cases, including “1 move,” “5 moves,” and “9 moves,” as well as those with the “no support” case for the future position; the difference in learning effects between these conditions is then analyzed.
It is believed that the “1 move” case will provide lesser support in the order of excessive support, followed by “5 moves,” “9 moves,” and “no support.” As a hypothesis, it is assumed that the “1 move” case provides excessive support, and therefore, the learning effect declines; in contrast, appropriate learning effects are observed in the case of “5 moves” or “9 moves”; furthermore, in the case of “no support,” learning among participants is hampered. To verify this hypothesis, I planned the experiment as follows.
4.2.Subjects
Before my experiment, a total of 35 people, including 32 university students who are not skilled in Shogi and 3 people from the general public, participated in the pre-questionnaire. Of these, a total of 16 people were selected to participate in the experiment. People who participated in the experiment till the end are treated as subjects in the study.
4.3.Procedure
This procedure for my experiment was as follows.
1. Pre-questionnaire before the experiment.
2. Pre-test before learning.
3. Learning phase lasting 3 days.
4. Questionnaire.
5. Posttest after learning.
4.4.Pre-questionnaire
The preliminary survey guidance was sent to individuals who were interested in the experiment via email before the experiment was conducted; the survey was a form that was to be filled online.
Through the pre-questionnaire, not only was the intention of participating in this experiment confirmed for individuals, but also knowledge of Shogi was measured by including questions regarding piece movements, Shogi rule details, and typical formations for attack or defense. The individuals who did not know about piece movements were judged as not suitable for this experiment and did not participate in the experiment. In contrast, individuals with the amateur kyu-level were allowed to participate.
4.5.Pre-test before learning
After the pre-questionnaire, individuals who wished to participate in the experiment were emailed a guide of pre-test before learning. Before answering the pretest, the participants were asked to play “Ham Shogi” for beginners on a game website, and were asked to note their ability using the “Ham Shogi level” and declare it (Shogi, 2018). This was done to acclimatize the participants to playing the game before playing the computer-based Shogi game. The self-declaration varied between “I can win mostly with a handicap of two pieces” and “There is a time when I cannot win against the bare king.” Based on these declarations, even the strongest participant was judged as an amateur kyu-level player.
Then, the correct answer rate was evaluated by asking the participants to answer 20 problems online; these next move problems included six choices for amateur beginners. This test was scored with 100 points per 5 points per question. In addition, all problems were supported by a sufficiently strong computer Shogi program. It was confirmed that there is a sufficient evaluation value difference between performing the best move of each problem and the other candidate moves, i.e., that is, the best move is the problem of becoming almost the only one answer.
In addition to the abovementioned six choices, an option of “cannot solve” was included for the next move problems; thus, in all, there were 7 choices. Because the subjects in my experiment are beginners, they are not only presented with the direction of the moves, but also the choices with arrows on the board. Furthermore, though the subjects were instructed to respond within 1 or 2 minutes for each problem, but no restriction was placed on the response time.
4.6.Learning phase
The participating candidates who responded to the pretest were provided the Shogi software with support of “1 move,” “5 moves,” “9 moves,” as well as “no support. The participants were instructed to play the game for about two hours per day. Based on the results of the pre-questionnaire and pre-test, the participants were allocated to each condition so that the obtained grades were not biased. Along with the Shogi software, instruction manuals describing the experimental procedure and steps to use the system were distributed, which the participants were instructed to read. After playing the game for 2 hours a day, the participants were asked to report the game time of the day, and number of games played, including the wins and losses; this game record was to be sent via e-mail. All subjects had to perform these steps for a total of 3 days.
4.7.System display
The example of my game display is shown in Fig. 4. In the figure, the display for “5 move” support at the start of the game is displayed. The image on the right-hand side is the game window, whereas the image on the left-hand side is the support window. The users proceed with the game taking reference from the left-hand side window.
Fig. 4.
Example of display for “5 move” support at the start of a game.
4.8.Questionnaire and posttest
On the third day, a questionnaire and posttest invitation was sent to those subjects who completed the requirements of the study.
In the questionnaire, subjects with support had questions on the “Future Board,” whereas subjects without support were asked questions regarding the support they would have liked to receive to assist them in learning.
After answering the questionnaire form, to the participants then answered the online posttest form. The posttest included the same 20 problems that were part of the pre-test; however, the problem presentation order was randomly changed. The subjects were instructed to answer the problems in about one minute or two per problem in the same manner as in the pretest.
4.9.Results
From the results obtained from the 16 people, the results of 3 people (who answered 20 questions in less than 3 minutes) with considerably short pre-test and posttest response times could not be trusted and were excluded. Thus, the results of the remaining 13 people were considered.
There were 20 subjects who participated in the pre-test; however, there were 7 participants who did not complete the experiment until the end or did not provide reliable results in the posttest.
Thus, as listed in Table 1, considering the average score of the test only in the case of the pretest there were slight variations among the conditions.
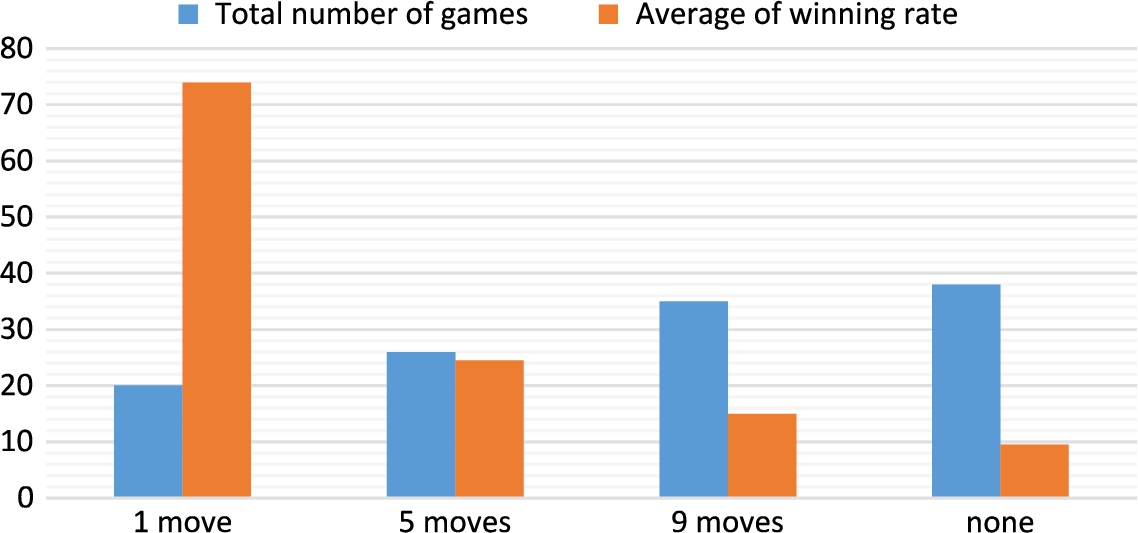
Figure 5 shows the total number of games and winning rate for the 3 days in the learning phase. From the figure, it can be seen that the “1 move” support has the highest winning rate and the winning rate decreases in the order of “5 moves” > “9 moves” > “no support.” In contrast, the total number of games increased in the order of “1 move” < “5 moves < “9 moves” < “no support.”
Table 1
Average score of the pre-test and number of participants for each condition
| Support | Average | Number of subjects |
| 1 move | 40 | 4 |
| 5 moves | 41.67 | 3 |
| 9 moves | 43.33 | 3 |
| none | 37.5 | 3 |
The average scores of the pre-test and post-test are shown in Fig. 6. Because the number of subjects is small, there was no significant difference between the average scores of the pretest and posttest, but improvements in grades were observed in order of “9 moves” > “no support” > “5 moves” > “1 move.”
Fig. 5.
Total number of games and average wining rate in the learning phase.
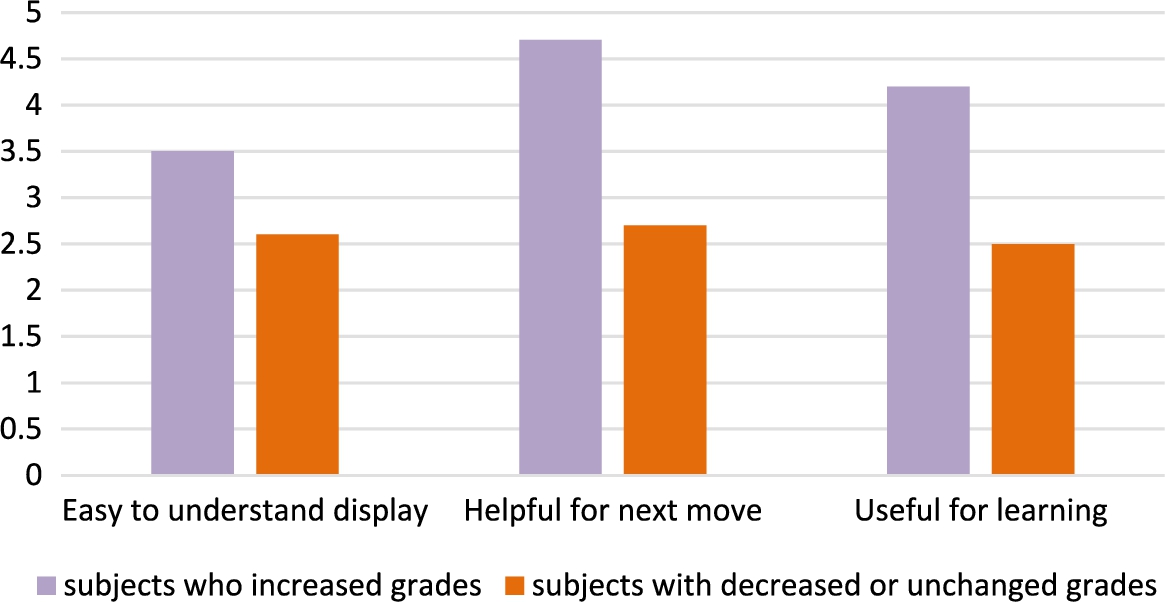
In the questionnaire administered to the subjects with support, the result of the 5-step evaluation of the question concerning the feeling on using the “Future Board” was divided into “subjects who increased grades” and “subjects with decreased or unchanged grades” These results are shown in Fig. 7. The subjects who had increased grades selected “Easy to understand display,” “Helpful for next move,” and “Useful for learning” in their evaluations.
Fig. 6.
Average scores before and after learning for support and difference.
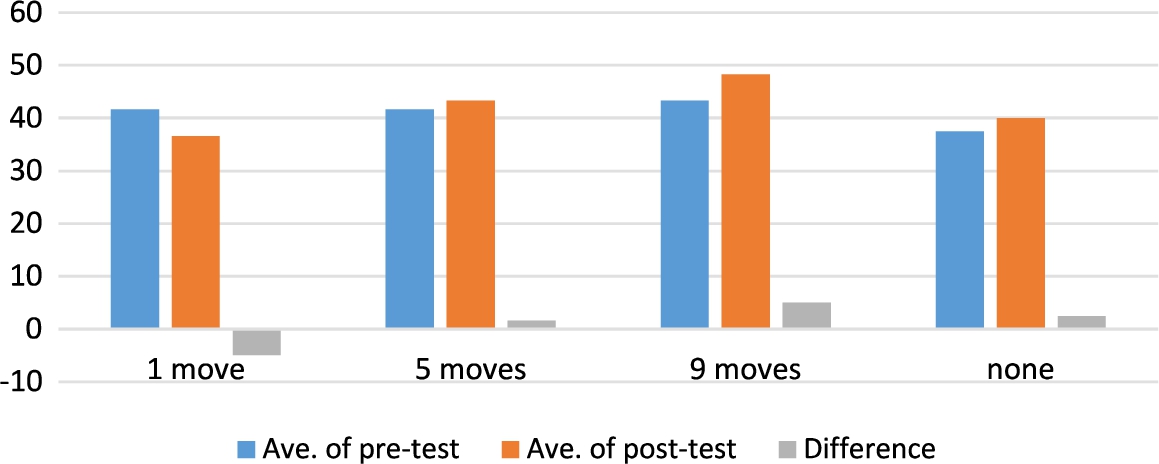
Fig. 7.
Questionnaire results for “Future Board”.
4.10.Discussion
From Fig. 5, it is clear that the winning rate was in the order of “1 move” > “5 moves” > “9 moves” > “no support.” so it indicated to express the original thickness of support as planned. In particular, because the winning rate of “1 move” was considerably high, it indicates that the “1 move” support is quite profound.
Furthermore, based on Fig. 6, owing to the small number of participants, although a significant difference is not observed, there is a tendency that the score decrease in the case of the “1 move” support; it is believed that the attenuation of the learning effect may have occurred due to excessive assistance. Moreover, because the growth of the results was the largest in the case of the “9 moves” support, it was suggested that there is a possibility of obtaining a high learning effect by presenting a suitable level for the future position.
From Fig. 7, it is clear that the experiment participants who had improved scores showed more favorable evaluation of the support provided by my system. Therefore, it might be assumed that the appropriate understanding of the support contents may be related to the increase in the scores.
5.Conclusion
In this study, a new learning support method called “Future Position” with participants playing Shogi is proposed. As in the previous works, the attenuation of the learning effect with excessive support was observed. In addition, my analysis results showed the possibility of obtaining a high learning effect by providing an appropriate level of support using my method.
In my verification experiment, the number of subjects was not sufficient to observe significant differences. Therefore, as future work, I will continue quantitative analysis of the proposed system by increasing the number of subjects and conducting experiments.
Acknowledgements
I would like to thank Kobayashi Hiroki for assisting me in the development of the system and the conducting the experiments in this research. In addition, I would like to thank everyone who participated in the experiment.
References
1 | Bonanza – The Computer Shogi Program. Available at: http://www.geocities.jp/bonanza_shogi/ (last accessed date: May 31, 2018). |
2 | Hamu Shogi. Available at: http://www.hozo.biz/shogi/ (last accessed date: May 31, 2018). |
3 | Ichikawa, S. ((2005) ). Cognitive counseling to improve students’ metacognition and cognitive skills. In Applied Developmental Psychology: Theory, Practice, and Research from Japan (Chapter 4, pp. 67–88). |
4 | Ito, T. & Furugori, T. ((1996) ). An effect of self-monitoring on learning process. In A CAI System for Independent Learning, IPSJ-CIG-CE, 93-CE-041 (pp. 49–56). (In Japanese.) |
5 | Ito, T., Matsubara, H. & Grimbergen, R. ((2004) ). Cognitive science approach to Shogi playing processes (2) – Some results on next move test experiments. Journal of Information Processing Society of Japan, 45: (5), 1481–1492. |
6 | Koedinger, K. & Aleven, V. ((2007) ). Exploring the assistance dilemma in experiments with cognitive tutors. Educational Psychology Review, 19: , 239–264. doi:10.1007/s10648-007-9049-0. |
7 | Miwa, K., Terai, H. & Nakaike, R. ((2012) ). Tradeoff between problem-solving and learning goals, two experiments for demonstrating assistance dilemma. In Proceedings of the 34th Annual Conference of the Cognitive Science Society (pp. 2008–2013). |
8 | Mizuno, Y., Miwa, K., Kojima, K. & Terai, H. ((2017) ). Experimental investigation on learning activities affected by cognitive loads. In The Japan Society for Artificial Intelligence, SIG-ALST-B506-20 (pp. 103–108). (In Japanese.) |
9 | Takahashi, K., Ito, T., Muramatsu, M. & Matsubara, H. ((2011) ). Analysis on go players’ recognition when they are thinking next moves. IPSJ Journal, 52: (12), 3796–3805. (In Japanese.) |


