
States, goals and values: Revisiting practical reasoning
Abstract
In this paper11 we address some limitations with proposals concerning an argumentation scheme for practical reasoning grounded on action-based alternating transition systems augmented with values. In particular, we extend the machinery to enable the proper representation of, and ability to reason with, goals. This allows the more satisfactory representation of certain critical questions, and the means to explicitly record differences between agents as to what will count as the fulfillment of goals and the promotion of values. It also allows us to express desires in terms of values, and to make plain the relation between a change in circumstances and the promotion and demotion of values. Three detailed examples are used to illustrate the additional kinds of problem the extensions allow us to consider.
1.Introduction
Practical reasoning is concerned with deciding what to do, or justifying what one has done [28]. Agents need to use practical reasoning because they are situated in a changing world, are able to influence how the world changes, and have preferences between the states that those changes will lead to. Moreover, their ability to act is a limited resource, and so they may need to choose between several beneficial actions, actions which would improve the state from their point of view, so as to identify the best, or at least the one they most prefer. The focus of our work is on justifying reasoning about what to do and why, rather than the specifics of how to act, as is covered in planning approaches. Sequences of actions are addressed in [5].
Normally there will be aspects of the current state that the agent likes, and aspects that it does not like. So, with respect to change, the agent will have four possible motivations:
– To make something currently false true (we call this an achievement goal).
– To make something currently true false (we call this a remedy goal).
– To keep something currently true true (maintenance goal).
– To keep something currently false false (avoidance goal).
What an agent wants can be specified at several levels of abstraction. Suppose an agent enters a bar on a hot day and is asked what it wants. The agent may reply:
– I want to increase my happiness.
– I want to slake my thirst.
– I want a pint of lager.
The first reply relates to something which is almost always true, and for the sake of which other things are done. Normally there will be several things that can meet this objective. The second is a specific way of increasing happiness in the particular current situation: it is a remedy goal. There is an element of the current situation the rectification of which would increase the happiness of the agent. Again there are several ways of bringing this about. Finally the third reply identifies a specific way of remedying the situation: the agent selected a lager in preference to water, juice, etc. It is a specific condition under which the goal will be satisfied. Previous work such as [4] has used values, goals and circumstances to refer to these three levels of abstraction. In [4] these levels are related to motivate or justify a choice by instantiating the following argument scheme:
PRAS In the current circumstances R, I should perform action A, to bring about new circumstances S, which will achieve goal G and promote value V.
According to PRAS, A is an action that is performed to achieve some new situation. That situation will contain certain desirable aspects (the goal) which will promote a value (the reason why these aspects are currently desirable). In the above example: As I am in a bar and I am thirsty, I should drink a pint of lager which will slake my thirst and make me happier. Note that the same goal may promote several values in different circumstances: in a more extreme situation slaking thirst may be necessary for survival rather than happiness (although in such a case water may be a better choice). Similarly the same action may be used to achieve a variety of goals: lager may be drunk simply for pleasure, or even to get intoxicated, as well as slaking thirst. This version of the scheme has in mind achievement and remedy goals: often a similar negative version of the scheme is also used, to justify actions which avoid the demotion of a value, and so realise maintenance and avoidance goals (though previous work has not explicitly labelled goals as such).
This argument scheme, and a number of ways of challenging arguments made using it (so-called critical questions), was formalised in [4] using Action-based Alternating Transition Systems (AATS) [35]. That account had, however, a number of limitations. In this paper we will consider how some of these limitations can be addressed to give a richer account of practical reasoning.
Section 2 will give the basis of the formalisation in [4]. Section 3 will describe the limitations of the scheme proposed in [4]. Section 4 will extend the formalisation to enable some of these limitations to be addressed, and relate this to some other previous work in the literature. Section 5 will address the limitations with the new machinery, and illustrate the points with three detailed examples. Section 6 will offer some discussion and conclusions.
2.AATS with values
AATSs were originally presented in [35] as semantical structures for modelling game-like, dynamic, multi-agent systems in which the agents can perform actions in order to modify and attempt to control the system in some way. These structures are thus well suited to serve as the basis for the representation of arguments about which action to take in situations where the outcome may be affected by the actions of other agents. First we recapitulate the definition of the components of an AATS given in [35].
Definition 1
Definition 1(AATS).
An Action-based Alternating Transition System (AATS) is an
– Q is a finite, non-empty set of states;
–
–
–
–
–
– Φ is a finite, non-empty set of atomic propositions; and
–
Where
Definition 2
Definition 2(AATS+V).
Given an AATS, an AATS+V is defined by adding two additional elements as follows:
– V is a finite, non-empty set of values.
–
An Action-based Alternating Transition System with Values (AATS+V) is thus defined as a
PRAS can now be expressed using this formalism.
Definition 3
Definition 3(PRAS).
In [4], seventeen potential ways to attack arguments made by instantiating PRAS were identified:
CQ1: Are the believed circumstances true?
CQ2: Assuming the circumstances, does the action have the stated consequences?
CQ3: Assuming the circumstances and that the action has the stated consequences, will the action bring about the desired goal?
CQ4: Does the goal realise the value stated?
CQ5: Are there alternative ways of realising the same consequences?
CQ6: Are there alternative ways of realising the same goal?
CQ7: Are there alternative ways of promoting the same value?
CQ8: Does doing the action have a side effect which demotes the value?
CQ9: Does doing the action have a side effect which demotes some other value?
CQ10: Does doing the action promote some other value?
CQ11: Does doing the action preclude some other action which would promote some other value?
CQ12: Are the circumstances as described possible?
CQ13: Is the action possible?
CQ14: Are the consequences as described possible?
CQ15: Can the desired goal be realised?
CQ16: Is the value indeed a legitimate value?
CQ17: Is the other agent guaranteed to execute its part of the desired joint action?
These critical questions were divided into three groups, each appropriate to a different stage in the reasoning:
– problem formulation: deciding what the propositions and values relevant to the particular situation are, and constructing the AATS. There are eight such CQs: CQs 2–4 and CQs 12–16.
– epistemic reasoning: determining the initial state in the structure formed at the previous stage. There are two such CQs: CQ1 and CQ17.
– choice of action: developing the appropriate arguments and counter arguments, in terms of instantiations of the argument scheme and critical questions, and determining the status of the arguments with respect to other arguments and the value orderings. These are the remaining seven CQs, CQs 5–11.
3.Limitations of PRAS
PRAS has been used in a variety of contexts, including simple puzzle solving (e.g. [4]), law (e.g. [9,33]), medicine (e.g. [6]) and e-participation (e.g. [11]). It has also formed the starting point for the extensive investigation of reasoning with values in the work of van der Weide and his colleagues (e.g. [31]). None the less PRAS as formalised in [4] has some distinct limitations, including the treatment of goals, consideration of the effect of actions only on the next state, and the fact that many differences between agents are implicit in the formulation of the AATS. Perhaps the most important of these is the absence of a proper notion of goal from the AATS, and the consequent inability to explain the promotion of values in terms of goals. Problems relating to look ahead were considered in [5].
Whereas the informal version of the scheme links future circumstances, goals and values, the formal version does not, in that there is no clean separation of circumstances and goals. Goals even disappear altogether in some applications (e.g. [36]). Also in the formalisation of [4] values are simply labels on transitions, without any justification in terms of the change in circumstances resulting from the new state.
The problem with goals in the AATS is that states can only be described as assignments to the set of atomic propositions, Φ. This means that a goal can be no more than a subset of assignments to elements of Φ. Thus a goal can be satisfied in only one way, whereas the original intention was that a goal could potentially be satisfied in a variety of ways. Also, given the state, the conjunction specifying the goal is unarguably true or false, removing the possibility of arguing as to whether the goal is satisfied in a given state, and so losing much of the point of considering goals.
Four of the critical questions, CQ3, CQ4, CQ6 and CQ15 concern goals, and so the absence of goals from the AATS formalisation of [4] does not allow these to be properly expressed, goals there being treated only as subsets of Φ. And in relation to the values promoted by realising goals, in [4] differences in value promotion were considered to be expressed by different agents having different AATSs, without any explanation of the differences, or how they might be represented. This is a further limitation we will address in this paper.
Aside from the issues with goals described above, there is also the limitation of there being only a single step of look ahead. This means that actions performed in order to enable particular things to happen, or prevent things from happening, in the future, cannot be justified cleanly with PRAS. This limitation was addressed in [5]. The remainder of this paper is concerned with providing a means to specify goals, and link them to values, which will allow the proper expression of the critical questions mentioned above. In the next section we start to tackle this by extending the AATS formalism.
4.Extending the formalism
To allow us to express goals as more than simple assignments to atomic propositions in Φ, we introduce a set of intensional definitions, Θ, which can be regarded as a set of clauses, as defined below.
Definition 4
Definition 4(Clauses).
Let Θ be a set of clauses of the form
Definition 5
Definition 5(Defined terms).
Let
Definition 6
Definition 6(Goals).
A goal of an agent
As we saw in Section 1, goals require us to consider two states: the current state
1. If γ is an achievement goal for
2. If γ is a remedy goal for
3. If γ is a maintenance goal for
4. If γ is an avoidance goal for
The above can form the basis of necessary conditions for γ to be a goal for
Therefore what we need to do is to link goals to values. Recall that in the formalism of [4], values are used to label transitions between states. Recall also the δ function which returns one of
Definition 7
Definition 7(Goals and value promotion).
Let Δ be a logic program with clauses of the form:
Thus, for example, an achievement goal will be of the form
In our previous work [4] we indicated that differences in value promotion were considered to be expressed by different agents having different AATSs. The set up we have presented above will make the promotion of values an objective matter, the same for all agents. If we wish to make what counts as promoting a value a subjective matter this can be done in several ways, depending on whether we wish to allow disagreement as to what counts as a value, what counts as promotion, or both. To allow agents to disagree on what counts as a value, each agent will have its own set of values,
Note that we could also allow agents to have their own versions of the definitions in Θ, so that each agent had its own program
4.1.Relation to other work
Now that we have spelled out the details of our approach, before we demonstrate it through application to different scenarios we compare and relate the approach to other work on practical reasoning in multi-agent systems. Argumentation has been used as a basis for a number of different proposals for how to handle practical reasoning and decision-making in agent systems, for example, [2,15,18,26,32]. For our discussion here we compare our work with a general model for agent reasoning (the BDI model), given in textbooks such as [34] and another approach [26] that is specifically grounded in argumentation.
4.1.1.BDI models
One very common way of representing agents is using the Belief-Desire-Intention (BDI) Model (e.g [27,34]). In this model agents have sets of beliefs and desires and commit to particular desires according to their current circumstances, so that these desires become intentions, which they then attempt to realise. Typically desires are filtered into candidate intentions, those that the agent can currently accomplish, and the intentions are selected from these. For simplicity we will assume here that an agent must select one and only one candidate as its intention.22
In our model we justify desires, which are particular states of affairs, and which apply in some states and not in others, by using values, which are persistent aims and aspirations. The beliefs of an agent are given by the state in which an agent believes itself to be in (i.e.
4.1.2.Rahwan and amgoud
Another approach to practical reasoning was proposed in [26]. Here the agents also have a set of desires,
Both desire generation rules and planning rules can be seen to have their equivalents in our framework. Given an agent with a set of values
4.1.3.Summary of comparison with related work
The key feature of our approach compared with the more traditional approaches is that we have used the idea of values to justify what an agent desires in particular situations. Now desires, rather than comprising a fixed set of states of affairs which the agent wishes to achieve (perhaps, as in [20], supplemented by some additional desires derived from basic desires and the current situation), are instead derived according to the nature of the agent and the particular context. This means that they can be justified by pointing towards the values promoted by moving from the existing state to a new state, rather than being unchallengeable givens for the agent.
In BDI there is often some equivocation between whether desires and intentions are states of affairs or actions: Here the relationship is clear: a desire is that a particular state of affairs be reached using a particular transition, and an intention is a commitment to act so as to enable that transition to be followed. Note that the same state of affairs may be reached by several different transitions, and the choice of action will depend on the values associated with these transitions and the individual preferences of the agent. The need for any satisfactory account to accommodate such differences is demonstrated by the degree of intercultural and intracultural variation demonstrated in empirical studies such as [14] and [16]. The mechanism developed in [5] allows this to be extended to sequences of action.
We believe that the ability to give reasons for why we find particular states of affairs desirable is important: I want it because I want it is not a satisfactory explanation, and to justify wanting it solely in terms of what is the case is not satisfactory either. In contrast justification in terms of values says more about the nature of the agent concerned and its aspirations. Justification of values themselves, and the preferences between them, is possible, but requires an additional level of machinery as found in [22] and so is not in the scope of this paper. Something must be taken as given, and we feel that beginning from values rather than desires is a useful improvement and more in line with general descriptions of practical reasoning, such as those deriving from Aristotle (who is the original source of the practical syllogism). Aristotle says that:
in each art the good is that for the sake of which other things are done … in medicine this is health, in generalship victory: in every action and decision it is the end. ([25]: 1097a18-21)
Honour, pleasure, understanding and every virtue we certainly choose because of themselves, since we would choose each of them even if it had no further result ([25]: 1097a28-b5)
We believe that the values used in our approach are a better reflection of this characterisation of practical reasoning than are the desires of the BDI approach.
5.Richer practical reasoning
Returning to the exposition of our approach, we now examine how our additional machinery allows the proper expression of the critical questions relating to goals.
In our original account in [4] a goal was simply a particular assignment to a subset of propositions, Φ,
CQ4 disputes whether a value is promoted by a goal, and hence, whereas in [4] CQ4 was a simple question of the sign returned by the δ function, we now have the rationale of the δ function explicitly available in the form of the logic program Δ, and so open to challenge. Moreover since we allow agents to have their own individual programs to ascribe their values to transitions, we can see that agents may differ, so that promotion of a given value may hold under
In [4], posing CQ6 merely required there be an alternative action which realised the desired conjunction of atomic propositions. Now we have extended the notion of goal to include intensionally defined goals, and we allow different agents to define these terms differently. Moreover, as we saw in Section 4, achieving the requisite state of affairs is only a necessary condition for achieving the goal. Thus while an alternative way to satisfy this condition does indeed allow CQ6 to be posed successfully, we also need to show that the required link to values is also realised, that there is some value for which
Finally, CQ16 in [4] concerned only whether the atomic propositions in the conjunction are co-tenable, whether they can occur in some state
We will now look at some examples illustrating the use of our extensions.
5.1.Trains and tunnels
We begin with the example used to illustrate the original AATS as introduced in [35]. There are two trains, one of which (E) is Eastbound, the other of which (W) is Westbound, each occupying their own circular track. At one point, both tracks pass through a narrow tunnel and a crash will occur if both trains are in the tunnel at the same time. Each train is an agent (i.e.
Fig. 1.
AATS for Trains scenario. AW = east away, west waiting, etc.
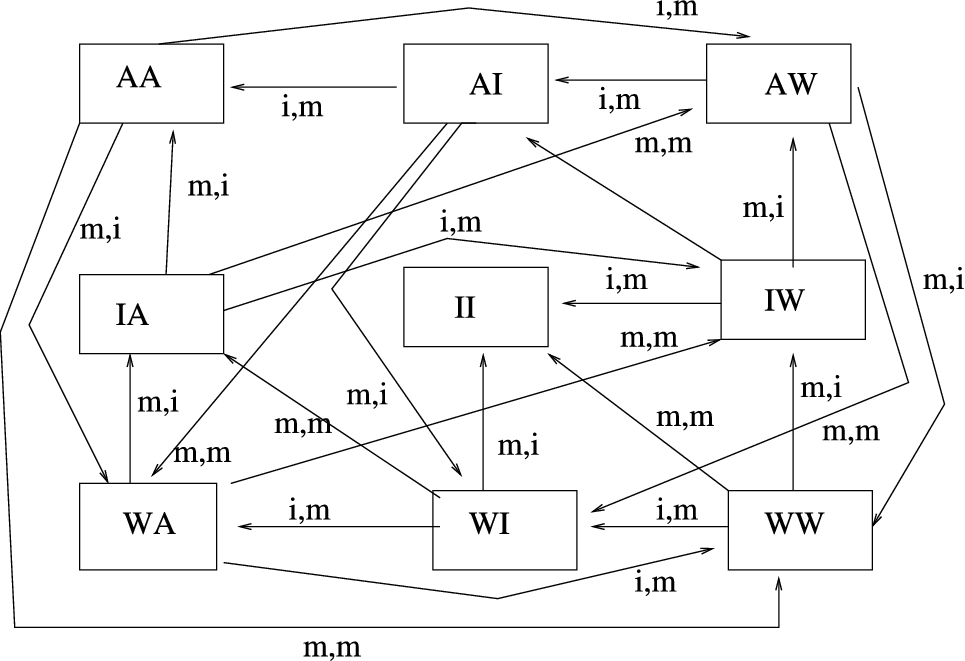
We define one term in Θ. We say that
The agents will have two values: Progress and Safety, the first promoted by moving, the second demoted by a crash. Thus the basic Δ is the same for both agents in this case:
Each agent can now form its own
Now we can see that Progress will motivate movement to the next state through an achievement goal, while Safety will motivate idling as an avoidance goal in the state where both trains are waiting. This gives rise to the arguments:33
Arg1: In a state where I am waiting I should move to promote progress.
Agr2: In a state where I am waiting I should idle to promote safety.
If we now assume that trains prefer Safety to Progress, they will both prefer Arg2 and so they will get stuck in waiting, since Arg1 will be open to an objection based on CQ9:
Obj1: In a state where I am waiting, I should not move since this may demote safety.
Suppose, however, we add a clause to Θ
Now we revise the value theory for E; instead of seeing Progress as promoted by any movement, E now believes it to be promoted only by moving when it is sure that it is safe to do so. This means that
Now this additional knowledge that Progress will not be promoted by entering the tunnel unless it is safe to do so will mean that the agent E will only have an argument to enter the tunnel when it is safe to do so. Thus E will replace Arg1 with Arg1E.
Arg1E: In a state where it is safe to enter and I am waiting I should move to promote progress.
This argument is not subject to Obj1. It will not, however, ensure deadlock is avoided. Obj1 still applies to W and a preference for Safety will mean that W will continue to wait, and so E may never know that it is safe to enter, and so will be unable to deploy Arg1E. E will thus not have an argument to move when it is waiting. So let us look at CQ9 a little further.
For the objection such as Obj1, arising from CQ9, to be effective, three things are needed. As noted, Safety has to be preferred to Progress. Thus deadlock could be avoided if W was sufficiently impatient that it came to disregard safety, and prefer progress, so that Arg1 defeats Arg2. Second, the agent must believe that the state is such that both are waiting. If W can see that E is away, then it can move with confidence, since it nows that Arg2 is not effective since it cannot in practice demote safety. Otherwise, however, it is a risk to assume that this is not the state. Finally a crash will only occur if E chooses to move rather than idle. So W can move and hope that E will choose to be idle. This is open to a further objection based on CQ17,
Obj2: Can you be sure that the other train will not move?
If, however, W knows that E is using
To summarise: this example illustrates:
– the use of goals to define non-atomic propositions, such as crash and safeToEnter.
– how the goals and the desirable transitions can be generated from the values of the agents, and how the value preferences allow a particular transition to be chosen. Both these aspects are open to debate within our framework. This movement from value to chosen action corresponds to the identification and filtering of candidate intentions in the BDI model.
– how differences between agents can be expressed using different perceptions of how values are promoted, and how these can help to resolve deadlocks, especially if the agents are themselves aware of these differences.
5.2.Should I stay or should I go?
For our second example we look at the choice between career and domestic life. We assume two agents,
For the example we will consider only what is necessary for the example: some larger system may be assumed. In this example there is no interaction between the agents, and so we can consider them separately. Accordingly the AATS will be applicable to both Mary and Jane (both agents thinking of themselves as “me”, hence suffix “m”, and their partner as “p”). The action options are move or stay. From the initial state move will reach a state in which
We now introduce some defined terms in Θ. First we define
The relevant AATS fragment is shown in Fig. 2.
Fig. 2.
AATS for Mary and Jane scenario.
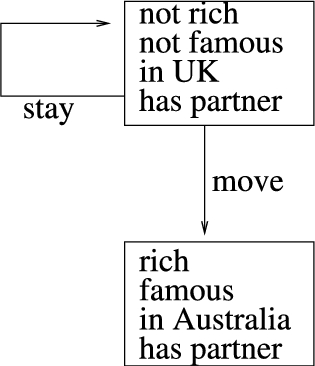
Now we define Δ. Both Mary and Jane have the values of Money, promoted by being rich, Relationship, promoted by
Note that here the current value of successful does not matter: if it is currently true it is a maintenance goal and if false it is an achievement goal. Mary, on the other hand, is more interested in her relationship than success, so that
If hasPartner holds, separated is an avoidance goal if it is currently false and a remedy goal if it is currently true. If hasPartner is currently false, finding a partner in the right country becomes an achievement goal.
Now consider the choice that Mary and Jane must make. We can now see that Money will be promoted for both by move. The value Relationships will be neither promoted nor demoted since
Now suppose that Mary wanted to challenge Jane’s decision. Although both are entirely agreed on the problem formulation, share the same values, and have used the AATS correctly in accordance with their own preferences, they disagree on whether Happiness will be promoted or demoted (CQ4 from [4]) and so label the move transition differently. Now, however, we can debate which labelling is correct since their Δs contain a justification for their different labellings. Mary can suggest her own Happiness rules to Jane – will you really be happy in a long distance relationship? Alternatively Jane may urge her own views on Happiness to Mary – will you not be made unhappy by giving up the prospect of success? Note, however, that even if they do succeed in convincing one another that both success and separation are relevant to happiness, they may still make different decisions. If we consider the program
So far we have, like previous work such as [4], used an ordering on values to adjudicate conflicts between arguments. Our new machinery for considering goals, however, offers an opportunity for a different basis for choice. If we just consider the program
We have used this example to illustrate in particular:
– The effect of agents having different ways of promoting their values;
– The possibility of using a general principle such as loss aversion to rank arguments, to complement or even replace value orderings.
Our third example will illustrate the distinction used in [10] between values which have no effect after they have reached a certain threshold (satisficers) and those which are always considered beneficial (maximisers). Whilst there are other approaches in the argumentation literature that capture reasoning about preferences between goals (e.g. [15]), we show through the example how reasoning about preferences may play a secondary role to the need to attain satisfactory levels for the various motivating values involved in the scenario.
5.3.Enough is enough
This example concerns an agent trying to strike an appropriate balance between work and leisure. Employees often have some say over how many hours they will work, and may choose the extra leisure or the extra money according to their individual preferences. We model this situation in the AATS fragment of Fig. 3. The propositions of interest are hoursWorked, freeTime and hourlyRate.
Fig. 3.
AATS for Working Hours scenario.
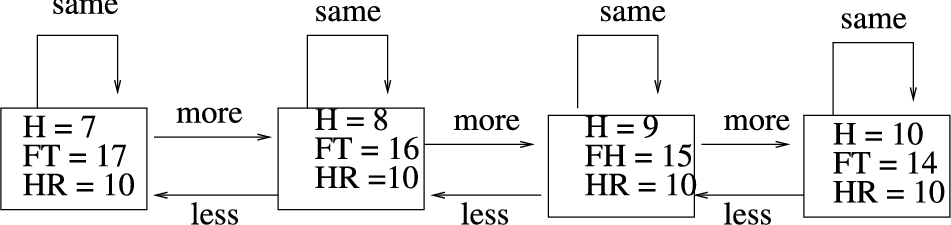
In Θ we define income as the product of hoursWorked and hourlyRate. Agents can increase their hours, which increases hoursWorked (and hence income), but decreases freeTime. Of course, whether the agent is free to choose its hours depends on the employer. The more traditional situation is for overtime to be offered, but not a reduction in standard hours (although currently so-called flexible working is becoming increasingly available). For this reason when we consider the joint actions with the employer the option to work less may not always be available.
Often economics assumes that when people make decisions they always prefer more of a good. Empirical work, however, suggests they can been seen as maximisers or satificers (e.g. [30]), and can also adopt different attitudes towards different values. While maximisers always seek to maximise their criteria, satificers set a threshold for particular criteria, and once the threshold is reached that criterion ceases to have any effect. In practice, as the notion of diminishing marginal returns suggests, for most goods the additional utility of a given amount decreases as more of that good is acquired; satisficing can be seen as an extreme application of this principle: at a certain point more adds no additional utility at all. When combined with the notion of loss aversion [17] discussed in the previous example, we can see that choice may be a good deal more complicated than a simple application of preferences.
Now consider possible rules for Δ. We have two values, Money and Leisure. Because income and freeTime are continuous variables rather than Booleans, the third term in the body clauses will here be an integer rather than one of
But for satisficers, the rules will be:
Agents may mix and match these rules: they may be maximisers for both values (M1–M4), satisficers for both values (S1–S4), money maximisers and leisure satisficers (M1, M2, S3 and S4), or money satisficers and leisure maximisers (S1, S2, M3 and M4). We will term the agents MMLM (i.e. money maximiser and leisure maximiser), MSLS, MMLS and MSLM respectively. Loss aversion can be effected by giving the demotion rules priority over the promotion rules. Where they are maximisers of one value and satificers of another they may tend to prefer satisficing to maximising. Thus a money satisficer and leisure maximiser will order the rules M4, M3, S2 and S1. Alternatively the agent may express its preferences in terms of values rather than the general principles. We will represent this value preference by the order of the values and qualifiers: thus in the case of the double maximiser, MMLM prefers money to leisure and LMMM prefers leisure to money.
Now consider that AATS fragment in Fig. 3, where the hourly rate is fixed at 10. Agents may choose to increase their hours, or stay the same (we assume that the employer is not making the reduced hours option available: the symmetry means that we can make this simplification without loss of generality). Suppose working eight hours is the initial state. Let us now consider our various agents in turn. We will assume that agents are not loss adverse in general, but will not wish to fall below a satisfied threshold for one value for the sake of improving the other, even where that other value is preferred.
The satisficers will have different choices according to their thresholds. There are four situations: both thresholds are satisfied,
Table 1
Choices of maximising and satisficing agents with various preferences. Bold indicates that the choice is based on the value preference
| Thresholds currently satisfied | Thresholds satisfied if move | MMLM | LMMM | MSLS | LSMS | MMLS | LSMM | MSLM | LMMS |
| Increased hours offered | |||||||||
| M and L | M and L | more | same | same | same | more | more | same | same |
| M and L | M | more | same | same | same | same | same | same | same |
| M | M | more | same | same | same | more | same | same | same |
| L | M and L | more | same | more | more | more | more | more | more |
| L | L | more | same | more | more | more | more | more | same |
| L | Neither | more | same | same | same | same | same | more | same |
| Neither | M | more | same | more | more | more | same | more | more |
| Neither | Neither | more | same | more | same | more | same | more | same |
| Hourly rate cut, but increased hours offered | |||||||||
| M and L | L | more | same | more | more | more | more | more | more |
| M and L | Neither | more | same | more | same | same | same | more | same |
The double maximiser will have an achievement goal based on money to increase its hours, but an avoidance goal based on leisure to refuse the extra hours. Since thresholds are not applicable to these agents, the choice will be based on value preferences: MMLM will increase its hours and LMMM will keep them the same.
The double satisficer will only have arguments to increase its hours when the money threshold is not already satisfied, and will only have arguments against increasing its hours where the leisure threshold will cease to be satisfied as a result. Only where neither threshold is satisfied in both states will the preference between the values determine the action.
The money maximiser and leisure satisficer will always have a reason to increase its hours but will only have a reason not to increase its hours if this would take it below its leisure threshold. Here the value preference makes a difference only if the leisure threshold is unsatisfied in neither state. Similarly the value preference makes a difference to the money satisficer and leisure maximiser only where the money threshold is satisfied in neither state.
What this shows is that we can get a variety of behaviour, even when agents share value orderings. Whereas maximisers will always act in accordance with the pure value preference, the influence of this preference decreases when the agents are satisficing values.
This also has implications for an employer who wishes to encourage staff to work overtime. The obvious course would be to increase wages. But suppose we assume that all staff currently satisfy their thresholds. Now an increase in hourly rate will only attract money maximisers, and, where the additional hours would take the agent below their leisure threshold, not even these. Note that in this case, where both thresholds are satisfied initially, the value preferences of the workers do not make a difference at all: money maximisers will accept the extra hours only if it does not jeopardise their leisure threshold, and money satisfiers will not be interested. Worse for the employer is that the increase in wages may enable leisure maximisers to reduce their hours while keeping above their money threshold, and so the increased wage will result in fewer hours worked by such agents. It is probably for this reason that overtime hours are often offered at a premium rate, not applicable to the basic hours. But the effect may still cause problems with staff with no standard hours, for example, casual bar staff.
Perversely, the employers may be able to attract more employees to overtime by cutting pay, since this may bring the money satisficers below their thresholds, as illustrated by the last two rows of Table 1. Here the wage cut may cause the money threshold to cease to be satisfied: the leisure threshold can be satisfied by keeping the same hours, and may or may not cease to be satisfied if hours are increased. Now all agents (except the double maximisers with a preference for leisure) will accept the overtime provided that they will remain above the leisure threshold, so as to restore, or approach their money threshold. All agents who value money more than leisure will accept the overtime, even if this takes them below the leisure threshold (effectively, if neither threshold can be satisfied, all agents become double maximisers). This phenomenon is similar to that of the Giffen Good in economics (see, e.g., [19]), where raising the price of a good increases demand (whereas the normal expectation is the demand falls when price rises). The classic example given by Marshall [19] is of less desirable foods, whose demand is driven by poverty. People will satisfy their hunger with a combination of basics, such as bread, and luxury foods, such as ham. If the price of bread rises, they must buy less ham to afford sufficient bread to maintain the calorie level, and bread consumption will need to rise to replace the ham they can no longer afford. Such people are, in our terms, bread satisficers and ham maximisers.
To summarise this example, it illustrates:
– The idea that the motivation offered by promoting a value may change according to the current situation.
– The distinction between motivating values, which are always prized, and values which agents require up to a sufficient level, but which they do not value beyond that.
– That value preferences may play a secondary role to the need to attain satisfactory levels for the various values.
6.Discussion and concluding remarks
In this paper we have revisited an account of practical reasoning using arguments and values to consider its limitations and provide mechanisms to overcome these. In the account of Action-based Alternating Transition System with Values, as given in [4], goals were not represented as explicit entities. In this paper we have extended the formal machinery described in [4] to provide the ability to reason about goals and promotion of values in an explicit and transparent manner, allowing the subjective preferences representing the different aspirations of different agents to be expressed. This provides the explanation facilities associated with argumentation in general and value based argumentation in particular, which are harder to obtain if a black box set up such as is more common in utility based approaches is used. In some domains, such as law and politics, transparent explanation is essential. A legal verdict without reasons for that decision is of no practical use. Indeed, a number of important legal AI systems such as HYPO [3] and CATO [1] do not offer any decisions, but merely supply arguments for and against so that the users can choose which to adopt, so that their preferences can be satisfied. Moreover the subjectivity has been extended in this paper beyond values, as in [4], to include which goals are adopted by an agent, and what counts as value promotion for particular agents, extending the possibilities for rational disagreement and persuasive debate. In utility based theories, in contrast, the utility functions are often simply taken as givens and not open to challenge.
Moreover, as we have seen from the examples, we can use this machinery to model aspects affecting choice other than value preference, to allow us to model some quite sophisticated reasoning, such a loss aversion and the difference between values the agent wishes to maximise and those it wishes to satisfice. The examples we have provided in Section 5 are intended to motivate the need for our refinements and demonstrate how they work in different applied reasoning scenarios that have different features of interest which necessitate the ability to make these distinctions.
The new notions in our account as presented in this paper form part of a larger body of work intended to increase the expressiveness and improve our account of practical reasoning. In [4] the argumentation considered only the next state, and so was unable to express arguments based on the need to reach a state from which a particular value could be promoted, or to avoid states in which the demotion of values became inevitable. This was addressed in [5].
We further envisage our new work on practical reasoning as being expressed using appropriate argumentation schemes that can themselves be formalised in a suitable framework, such as ASPIC+ [24], so that desirable properties, such as the satisfaction of rationality postulates, e.g. [13], can be shown to hold. Furthermore, we intend to look at proofs of correspondences between our approach and others, such as the BDI approach. The work set out in this paper provides the essential basis which will enable us to tackle all these issues.
Notes
2 Here we discuss only the basic BDI systems as presented in e.g. [34]. There are, of course many variants on BDI (e.g. [12] and [29]), but here we can consider only the core idea.
3 For simplicity we express arguments only in terms of current state, supported action and value.
Acknowledgements
We are grateful to Sanjay Modgil and Adam Wyner for fruitful discussions on some of the issues contained in this paper, and to the anonymous reviewers of ArgMas 2014.
References
[1] | V. Aleven, Teaching case-based argumentation through a model and examples, PhD thesis, University of Pittsburgh, 1997. |
[2] | L. Amgoud and H. Prade, Using arguments for making and explaining decisions, Artif. Intell. 173: (3–4) ((2009) ), 413–436. doi:10.1016/j.artint.2008.11.006. |
[3] | K. Ashley, Modelling Legal Argument: Reasoning with Cases and Hypotheticals, Bradford Books/MIT Press, Cambridge, MA, (1990) . |
[4] | K. Atkinson and T. Bench-Capon, Practical reasoning as presumptive argumentation using action based alternating transition systems, Artif. Intell. 171: (10–15) ((2007) ), 855–874. doi:10.1016/j.artint.2007.04.009. |
[5] | K. Atkinson and T. Bench-Capon, Taking the long view: Looking ahead in practical reasoning, in: Proceedings of COMMA 2014, (2014) , pp. 109–120. |
[6] | K. Atkinson, T. Bench-Capon and S. Modgil, Argumentation for decision support, in: 17th International DEXA Conference, (2006) , pp. 822–831. |
[7] | N. Bardsley, Dictator game giving: Altruism or artefact?, Experimental Economics 11: (2) ((2008) ), 122–133. doi:10.1007/s10683-007-9172-2. |
[8] | T. Bench-Capon, Persuasion in practical argument using value-based argumentation frameworks, J. Log. Comput. 13: (3) ((2003) ), 429–448. doi:10.1093/logcom/13.3.429. |
[9] | T. Bench-Capon, K. Atkinson and A. Chorley, Persuasion and value in legal argument, J. Log. Comput. 15: (6) ((2005) ), 1075–1097. doi:10.1093/logcom/exi058. |
[10] | T. Bench-Capon, K. Atkinson and P. McBurney, Using argumentation to model agent decision making in economic experiments, Autonomous Agents and Multi-Agent Systems 25: (1) ((2012) ), 183–208. doi:10.1007/s10458-011-9173-6. |
[11] | T. Bench-Capon, K. Atkinson and A. Wyner, Using argumentation to structure e-participation in policy making, in: Transactions on Large-Scale Data- and Knowledge-Centered Systems XVIII, Springer, (2015) , pp. 1–29. |
[12] | J. Broersen, M. Dastani, J. Hulstijn, Z. Huang and L. van der Torre, The BOID architecture: Conflicts between beliefs, obligations, intentions and desires, in: Proceedings of the Fifth International Conference on Autonomous Agents, ACM, (2001) , pp. 9–16. doi:10.1145/375735.375766. |
[13] | M. Caminada and L. Amgoud, On the evaluation of argumentation formalisms, Artif. Intell. 171: (5–6) ((2007) ), 286–310. doi:10.1016/j.artint.2007.02.003. |
[14] | C. Engel, Dictator games: A meta study, Experimental Economics 14: (4) ((2011) ), 583–610. doi:10.1007/s10683-011-9283-7. |
[15] | X. Fan, R. Craven, R. Singer, F. Toni and M. Williams, Assumption-based argumentation for decision-making with preferences: A medical case study, in: Proceedings of Computational Logic in Multi-Agent Systems, 14th International Workshop, CLIMA XIV, J. Leite, T.C. Son, P. Torroni, L. van der Torre and S. Woltran, eds, Lecture Notes in Computer Science, Vol. 8143: , Springer, (2013) , pp. 374–390. doi:10.1007/978-3-642-40624-9_23. |
[16] | J. Henrich, R. Boyd, S. Bowles, C. Camerer, E. Fehr, H. Gintis and R. McElreath, In search of homo economicus: Behavioral experiments in 15 small-scale societies, The American Economic Review 91: (2) ((2001) ), 73–78. doi:10.1257/aer.91.2.73. |
[17] | D. Kahneman and A. Tversky, Choices, values, and frames, American Psychologist 39: (4) ((1984) ), 341–350. doi:10.1037/0003-066X.39.4.341. |
[18] | A.C. Kakas and P. Moraitis, Argumentation based decision making for autonomous agents, in: Proc. of 2nd AAMAS Conference, (2003) , pp. 883–890. |
[19] | A. Marshall, Principles of Economics, Macmillan, (1890) . |
[20] | P. McBurney, I. Rahwan and S. Parsons (eds), Argumentation in Multi-Agent Systems, 7th International Workshop, ArgMAS 2010, Toronto, ON, Canada, May 10, 2010, Lecture Notes in Computer Science, Vol. 6614: , Springer, (2011) , Revised Selected and Invited Papers. |
[21] | S. Modgil, Reasoning about preferences in argumentation frameworks, Artificial Intelligence 173: (9) ((2009) ), 901–934. doi:10.1016/j.artint.2009.02.001. |
[22] | S. Modgil and T.J. Bench-Capon, Metalevel argumentation, Journal of Logic and Computation ((2010) ), 959–1004. |
[23] | S. Modgil and H. Prakken, A general account of argumentation with preferences, Artif. Intell. 195: ((2013) ), 361–397. doi:10.1016/j.artint.2012.10.008. |
[24] | H. Prakken, An abstract framework for argumentation with structured arguments, Argument and Computation 1: (2) ((2010) ), 93–124. doi:10.1080/19462160903564592. |
[25] | H. Rackham et al., The Nicomachean Ethics, W. Heinemann, (1926) . |
[26] | I. Rahwan and L. Amgoud, An argumentation-based approach for practical reasoning, in: ArgMAS, N. Maudet, S. Parsons and I. Rahwan, eds, Lecture Notes in Computer Science, Vol. 4766: , Springer, (2006) , pp. 74–90. |
[27] | A.S. Rao and M.P. Georgeff, Bdi agents: From theory to practice, in: ICMAS, V.R. Lesser and L. Gasser, eds, The MIT Press, (1995) , pp. 312–319. |
[28] | J. Raz, Practical Reasoning, Oxford University Press, Oxford, (1979) . |
[29] | S.V. Rueda, A.J. García and G.R. Simari, Argument-based negotiation among bdi agents, Journal of Computer Science & Technology 2: ((2002) ). |
[30] | B. Schwartz, A. Ward, J. Monterosso, S. Lyubomirsky, K. White and D.R. Lehman, Maximizing versus satisficing: Happiness is a matter of choice, Journal of Personality and Social Psychology 83: (5) ((2002) ), 1178–1197. doi:10.1037/0022-3514.83.5.1178. |
[31] | T. van der Weide, F. Dignum, J.-J. Meyer, H. Prakken and G. Vreeswijk, Practical reasoning using values, in: Argumentation in Multi-Agent Systems, 6th International Workshop, (2009) , pp. 79–93. |
[32] | T.L. van der Weide, F. Dignum, J.-J.C. Meyer, H. Prakken and G. Vreeswijk, Arguing about preferences and decisions, in: Argumentation in Multi-Agent Systems, 7th International Workshop, (2010) , pp. 68–85. |
[33] | M. Wardeh, A. Wyner, K. Atkinson and T. Bench-Capon, Argumentation based tools for policy-making, in: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Law, ACM, (2013) , pp. 249–250. |
[34] | M. Wooldridge, An Introduction to MultiAgent Systems, 2nd edn, Wiley, (2009) . |
[35] | M. Wooldridge and W. van der Hoek, On obligations and normative ability: Towards a logical analysis of the social contract, J. Applied Logic 3: (3–4) ((2005) ), 396–420. doi:10.1016/j.jal.2005.04.006. |
[36] | A. Wyner, K. Atkinson and T. Bench-Capon, Model based critique of policy proposals, in: Electronic Participation, 4th Int. Conf, (2012) , pp. 120–131. doi:10.1007/978-3-642-33250-0_11. |

