
Estimating excess mortality in Canada during the COVID-19 pandemic: Statistical methods adapted for rapid response in an evolving crisis
Abstract
This paper presents the approach adopted at Statistics Canada to produce timely and accurate estimates of excess mortality during the ongoing COVID-19 pandemic. It focuses primarily on the two models involved in the estimation of excess mortality: the model used to estimate the expected number of deaths in the absence of the pandemic (baseline mortality), and the model used to adjust provisional death counts for undercoverage. We describe both, including how the models were adapted to fit our specific criteria as well as the various limitations they both possess. We conclude by presenting selected results from Statistics Canada’s official release of excess mortality estimates from February 8
1.Introduction
In the face of the ongoing pandemic, it is crucial for national governments to obtain precise measures of the impact of COVID-19 on the health outcomes of their populations. In Canada, while the tracking of vital statistics is the responsibility of provincial and territorial governments, Statistics Canada is the federal agency tasked with all official dissemination of these data. As a response to the pandemic, Statistics Canada has begun producing estimates of excess mortality11 as one means of quantifying COVID-19’s effect on mortality in Canada. Defined as the number of all-cause deaths observed during a crisis above and beyond what would be expected under “normal circumstances” [1], excess mortality provides a means of measuring the full impact of the pandemic by incorporating both direct effects – i.e. deaths caused by COVID-19 – as well as indirect effects, such as deaths with COVID-19 as a contributing cause, or deaths caused by circumstances surrounding the pandemic.
Many challenges surround the estimation of excess mortality within Canada. Unlike others countries22 that had developed surveillance systems to monitor abnormalities in weekly death counts prior to the pandemic, Statistics Canada had no such network in place. Moreover, death data provided to Statistics Canada by regional offices are often subject to significant delays, impacting our ability to disseminate death estimates in a timely fashion. Long reporting delays also inhibit us from adopting existing models for excess mortality if complete coverage of death data is an underlying assumption.
This paper describes the authors’ contributions to tackling these defined challenges in order to develop a method that would allow for the monthly production of excess mortality estimates at Statistics Canada. Section 2 describes the model used to estimate baseline (expected) mortality, and Section 3 the method used to adjust provisional death counts for reporting delays. Section 4 describes the method used to produce excess mortality estimates, along with 95% confidence intervals, and presents selected results from one of Statistics Canada’s recent releases. The final section presents our conclusion.
2.Estimating baseline mortality
Baseline mortality – defined as the number of deaths that would be expected to occur within the population of interest in the absence of the COVID-19 pandemic – is the first of two components required in the computation of excess mortality. Numerous challenges surround the accurate estimation of baseline mortality, each of which impacted our selection of a method.
The largest challenge concerns the selection of a reference period. Deaths counts in Canada are frequently subject to large relative year-to-year fluctuations due to death being a statistically rare event. Moreover, changes in yearly observed death counts may reflect changes in the composition of a population – such as an evolving population age structure, for example – in addition to true changes in mortality outcomes. The selection of a reference period thus requires a balance between being long enough to capture underlying trends in the presence of large annual variance, and being short enough to ensure that large changes in the population composition over time do not result in over- or under-estimation of expected deaths.
Other challenges in estimating baseline mortality involve modelling seasonality in the death data and ensuring that periods of historically high death counts in the reference period do not result in overestimation of baseline mortality. The selection of a model was made taking these challenges into consideration.
2.1Model
The model used to compute the expected number of deaths is based on an infectious disease surveillance algorithm for Poisson count data developed by Farrington et al. [2]. The same model is used in the Centre for Disease Control’s (CDC) own computation of excess deaths in the United States [3].
The model is implemented in R with the use of the Surveillance package [4]. The method is described as follows. An overdispersed Poisson GLM with linear time trend and seasonal adjustment factors is fit to all-cause weekly death based on a rolling reference period spanning 2016 to 2020.33 Models are fit for the total population and for the population disaggregated by age group (0–44, 45–64, 65–84, and 85
Mathematically, the model can be expressed using the following log-linear configuration:
where:
•
•
•
•
Seasonality is modelled by dividing the fifty-two weeks of the year into ten distinct periods – one seven-week period corresponding to the current week
Noufaily et al. [7] propose certain adjustments to the original Farrington algorithm in order to minimize the effect of historical periods of increased mortality on estimates of expected deaths, and to prevent periods of increased mortality leading up to the week being estimated, i.e. an ongoing outbreak, from impacting estimates. In the case of the former, once a model is fit to the data, residuals77 for each estimate in the reference period are computed. Any week with its residual,
where
With regard to accounting for ongoing outbreaks, they suggest omitting the twenty-six weeks preceding the current week,
95% confidence intervals88 are then computed for the estimates by assuming that the death count in week
Where
As of August 2020, this model has been used to produce estimates of expected deaths monthly for every week1010 of 2020 beginning with the week ending January 4
2.2Limitations
This model possesses three primary limitations. First, the method used to compute confidence bounds, developed by Noufaily et al. [7], incorporates neither parameter uncertainty nor estimation uncertainty. Using the estimated
The second limitation is more a consequence of reporting delays present in the provisional death data. Since only the twenty-six weeks preceding each week are omitted from the reference period, 2020 death data are used in the estimation of counts for every week after the week of July 4
A final limitation is the lack of an available means to evaluate the model’s overall performance. The algorithm is intended to detect aberrancies in count data, implying that fitting the model to an alternative reference period or assessing the model’s accuracy in estimating historical counts is of little value. Weeks with historical death counts above expected values may be due to external factors (such as a particularly severe flu season) and is thus not necessarily indicative of poor model performance. Regardless, the models were used to estimate counts in historical years (2018–2019), and it was found that they did reasonably well at predicting the overall trend in death counts. Results were also validated by comparing the sums of the disaggregated models to the models fit to the total counts.
3.Adjusting provisional death counts
The period of time between the date of a death and the date the death is received by Statistics Canada is referred to as the delay. In some provinces and territories, recent death data may not be complete – i.e. all of the deaths have not yet been received – until months after the date of death. Exceptional circumstances brought on by the COVID-19 pandemic may also put additional strain on local health care systems, leading to further delays. Our selection of a model was thus motivated by the need for a method that could handle delays of widely varying length that may change rapidly over time.
3.1Model
The method we adopt is a nowcasting approach that adjusts for incompleteness by evaluating the distribution of reporting delays observed within a set period of time, defined
To evaluate the distribution of delays (measured in weeks), observed deaths, denoted
For a death occurring within the reference period, the estimated probability that the reporting delay equals
Thus, the estimated probability that, for a death occurring during the reference period and received within
The adjusted number of deaths occurring in week
3.2Limitations
The described approach does possess some limitations. The first relates to the assumption of a completion rate of 100% at
Moreover, the model assumes there is no change in the reception rate within the reference period. However, experiments using alternative reference periods did show changes in the distribution of reporting delay for certain provinces in 2020, likely attributable to the pandemic. To account for this, the reference period was divided into two based on observed shifts in reporting delays: the pre-pandemic period, beginning the first week of 2020, and the pandemic period, beginning on the 12
Figure 1.
Observed death counts and adjusted estimates for Canada, January 2020 to September 2020. Source: Statistics Canada’s monthly release on excess deaths. Available here: https://www150.statcan.gc.ca/n1/daily-quotidien/201028/dq201028b-eng.htm.
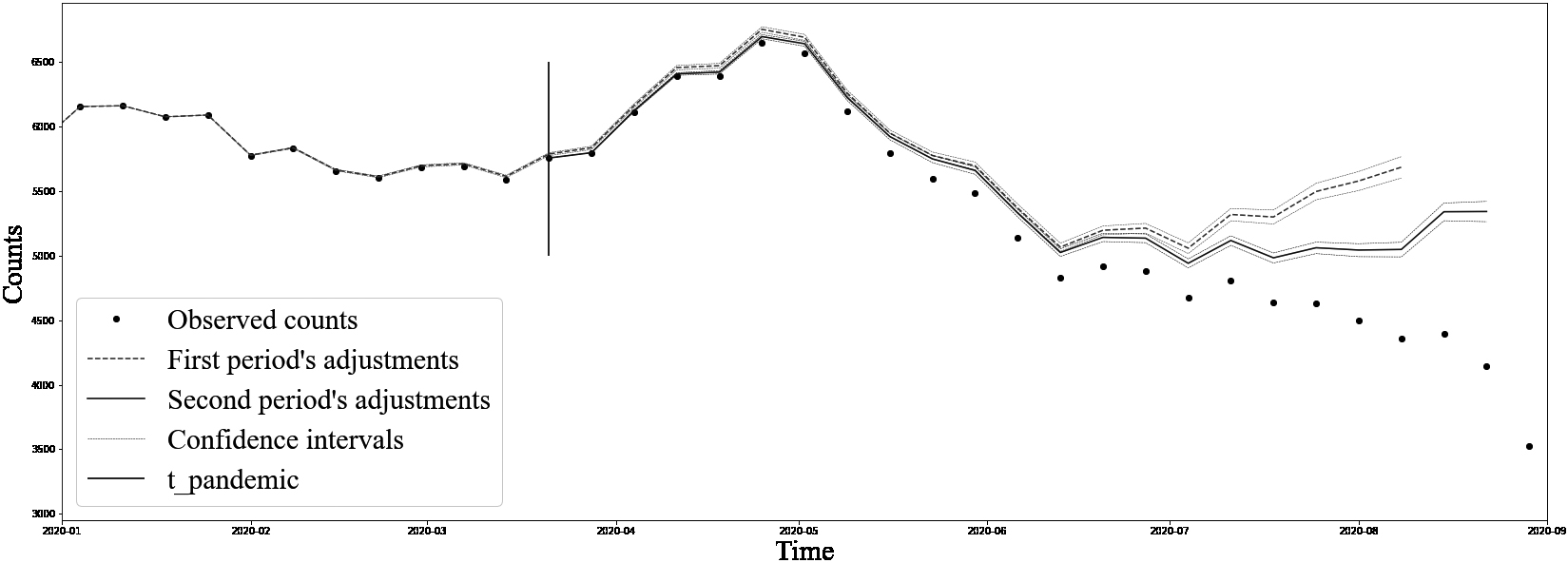
To minimize the impact of changes in the rate of reception, we use results obtained from the pre-pandemic period,
To ensure continuity, adjusted counts for deaths occurring during the pandemic period are increased by a multiplicative factor
Thus:
One final issue relates to the quality of adjustments for deaths occurring at the very end of the reference period. A large degree of adjustment implies that very few observed deaths are available, and the model is thus more sensitive to variations in observed counts. We thus impose a minimum coverage threshold,
For all of Statistics Canada’s releases between August 2020 and February 2021, a threshold of
Based on this methodology, adjusted death counts were produced for each of the provinces and territories. Validation of the adjustments disaggregated by age group, sex, and age group and sex was done by ensuring that they were similar to those obtained from regional aggregate models. The relevance of the adjustments can be validated a posteriori with future releases, as shown in Fig. 3. Figure 2 displays final adjusted counts produced at the Canada-level from Statistics Canada’s October 2020 release. A divergence in trends between adjustments resulting from the two different periods can be observed, signifying substantial change in the distribution of delays.
Figure 2.
Comparison of adjusted death counts from the first and second periods, Canada, January 2020 to September 2020. Source: Statistics Canada’s monthly release on excess deaths. Available here: https://www150.statcan.gc.ca/n1/daily-quotidien/201028/dq201028b-eng.htm.
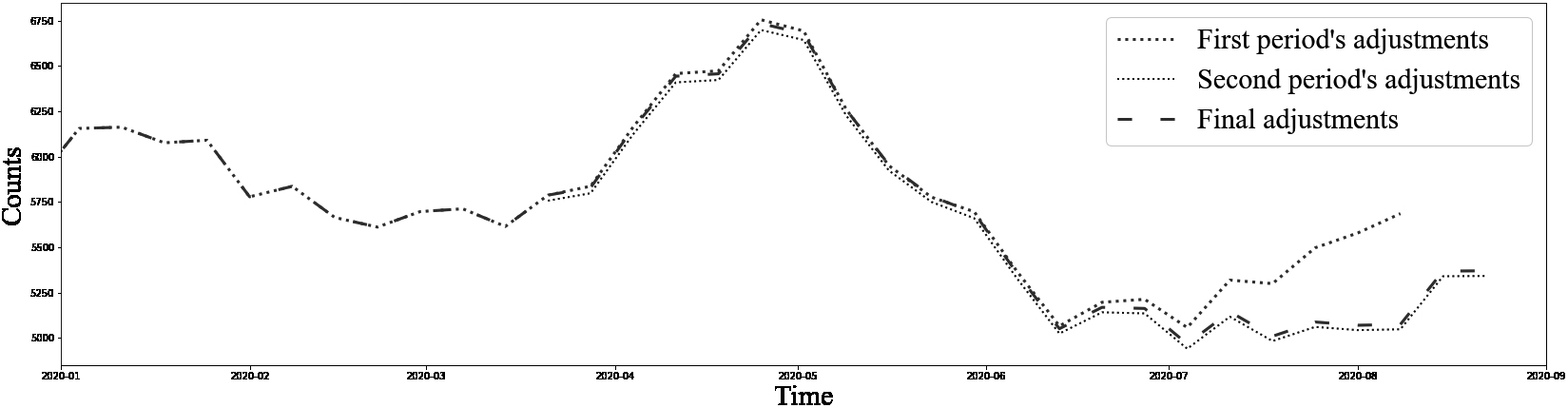
Figure 3.
Comparison of estimated adjustments for Canada based on Statistics Canada’s October 28th, 2020 release and February 8th, 2021 release. Source: Statistics Canada’s monthly releases on excess deaths. Available here: https://www150.statcan.gc.ca/n1/daily-quotidien/201028/ dq201028b-eng.htm.
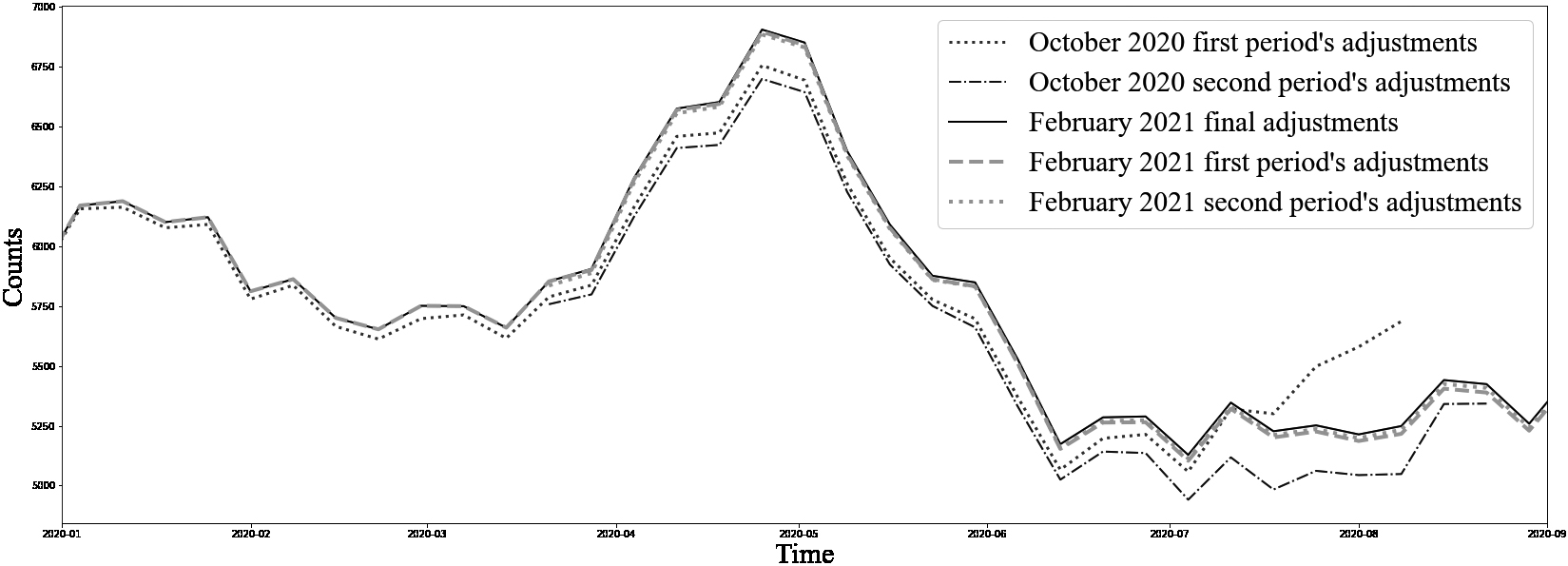
A posteriori validation demonstrated that adjustments are generally slightly underestimated, partially because the true distribution of the delays over the course of the entire pandemic is unknown and constantly evolving. As shown in Fig. 3, the difference in the distribution of delays over time provides justification for the use of a second reference period, which has a higher capacity to capture recent trends than the first period.
4.Excess mortality
Excess deaths for a given week are computed simply as the difference between the adjusted observed count and the expected count. In order to compute an estimate of variance, an assumption about the dependence between the processes used to generate adjusted and expected death counts must be made. We choose to assume independence between the two in order to simplify computations. While it may be possible that the distribution of reporting delays is correlated with the number of expected deaths, obtaining an accurate estimate of correlation is made difficult by a number of factors. One issue is that expected deaths are estimated based on a historical reference period of four years, while the distribution of reporting delays is based on only a 2020 reference period. Defining the covariance between the two processes when only one of them (i.e. expected deaths) accounts for annual seasonal patterns would likely lead to a misrepresentation of the true relationship.
Figure 4.
Aggregate excess mortality estimates from Statistics Canada’s February 8th, 2021 release. Source: Statistics Canada’s monthly releases on excess deaths. Available here: https://www150.statcan.gc.ca/n1/daily-quotidien/201028/dq201028b-eng.htm.
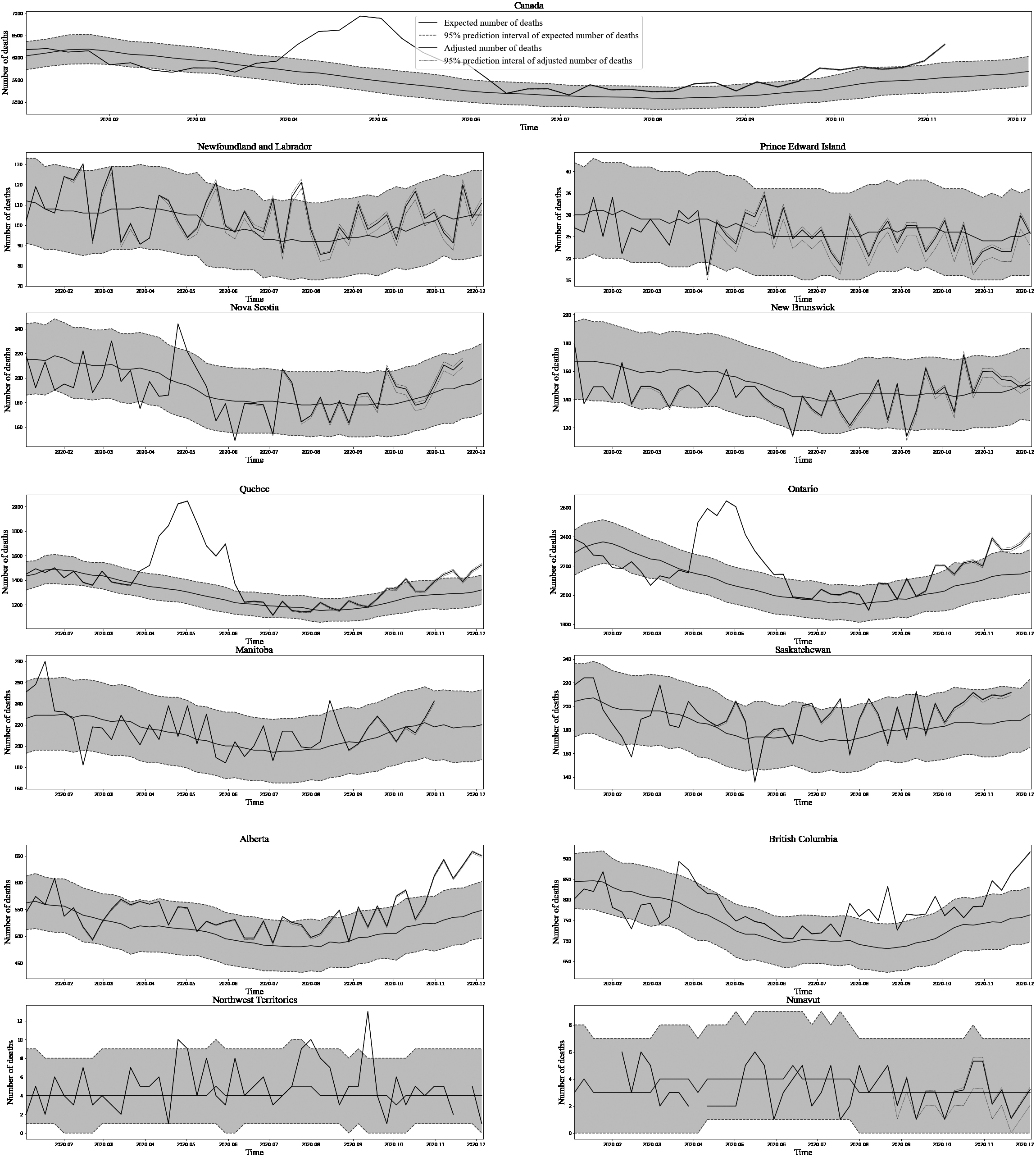
To estimate variance, one possibility we considered was to use the Normal approximation to the distribution of expected counts (negative binomial) and to the distribution of adjusted counts (Poisson), so that the resulting distribution of excess deaths would be Normal. While this approximation was fairly accurate when it came to the distribution of expected counts on the provincial aggregate level, it became increasingly worse the further counts were disaggregated. Given this finding, we decided to adopt an empirical approach that made minimal additional assumptions. The method is described as follows.
1) 10,000 bootstrap samples1515 of adjusted counts for each week in 2020 were generated for each of the models;
2) 10,000 samples1616 from the distribution of expected counts were generated for each of the corresponding weeks and for each model;
3) Each of the 10,000 samples of adjusted counts was paired with the 10,000 samples of expected counts in the sampling order (i.e. they were not paired randomly), and 10,000 estimates of excess mortality were obtained by subtracting the two;
4) A 95% confidence interval was obtained by taking the 0.025 and 0.0975 quantiles of the empirical distribution of these excess mortality estimates.
Figure 4 below displays aggregate estimates of excess deaths along with corresponding 95% confidence intervals for each of the provinces and territories from Statistics Canada’s release covering deaths from the period January 1
5.Conclusion
The statistical methods presented in this paper were intended to help minimize estimation uncertainty arising from incompleteness in reported death counts and in baseline mortality in order to produce timely and accurate estimates of excess mortality. The estimates produced by our methods have been widely used externally as a means of both measuring the impact of COVID-19 in Canada and as a means of placing the situation in Canada within a global context. It is the authors’ goal to improve our current methods by adapting them as the pandemic evolves, and by developing long-term solutions to the limitations outlined in this
paper. We hope that our contribution will eventually lead to the implementation of an up-to-date mortality surveillance system in Canada.
Notes
1 Excess deaths and excess mortality are used interchangeably throughout this paper.
2 Such as those participating in the European Mortality Monitoring Project (EuroMOMO). See: euromomo.eu.
3 A four year reference period was selected after conducting various tests with periods of alternating length.
4 There are certain exceptions. Too few death counts resulted in unreliable disaggregated estimates in Prince Edward Island, Nunavut, and the Northwest Territories. Only totals were released for these regions. No estimates were produced for Yukon, due to lack of available data.
5 The Canadian Vital Statistics Death Database is an administrative database that collects monthly and annual information on deaths from the provincial and territorial vital statistical offices in Canada [5].
6 The National Routing System is a real-time birth and death record collection system that facilitates the transfer of information between regional vital statistics offices and Statistics Canada [6].
7 The residuals used are the scaled Anscombe residuals. Refer to Section 3.6 in Farrington et al. [2] for further details.
8 In the context of the original method, it is not confidence intervals that are estimated, but an upper bound (threshold) to detect abnormally high counts.
9 In the event that
10 The epidemiological week is defined as beginning on Sunday.
11 Estimates released in a given month typically include all deaths occurring up until two months prior to release day and received by Statistics Canada at least three weeks prior.
12 See Section 3.
13 The reason being that deaths occurring before March 28
14 The original R code was kindly provided to Statistics Canada by the authors and adapted to our needs.
15 See Brookmeyer and Damiano [8] for a description of the method.
16 Generated using the approach described at the end of Section 2.2.
References
[1] | Checchi F, Roberts L. Interpreting and using mortality data in humanitarian emergencies. Humanitarian Practice Network. (2005) ; 52. Available from: https://odihpn.org/wp-content/uploads/2005/09/networkpaper052.pdf. |
[2] | Farrington CP, Andrews NJ, Beale AD, Catchpole MA. A statistical algorithm for the early detection of outbreaks of infectious disease. Journal of the Royal Statistical Society: Series A (Statistics in Society). (1996) ; 159: : 547–563. doi: 10.2307/2983331. |
[3] | Centers for Disease Control and Prevention. Excess Deaths Associated with COVID-19 [Internet]. (2020) [updated 2021 January 21; cited 2021 February 10]. Available from: https://www.cdc.gov/nchs/nvss/vsrr/covid19/excess_deaths.htm#techNotes. |
[4] | Salmon M, Schumacher D, Höhle M. Monitoring count time series in R: Aberration detection in public health surveillance. Journal of Statistical Software. (2016) ; 70: (10): 1–35. doi: 10.18637/jss.v070.i10. |
[5] | Statistics Canada. Statistics Canada, Canadian Vital Statistics – Death database (CVSD) [Internet]. [date unknown] [updated 2021 June 4; cited 2021 July 7]. Available from: https://www23.statcan.gc.ca/imdb/p2SV.pl?Function=getSurvey&SDDS=3233. |
[6] | Statistics Canada. The National Routing System: Administrative data collection in real-time [Internet]. (2009) [updated 2021 July 30; cited 2021 July 30]. Available from: https://www150.statcan.gc.ca/n1/en/catalogue/11-522-X200800011009. |
[7] | Noufaily A, Enki DG, Farrington P, Garthwaite P, Andrews N, Charlett A. An improved algorithm for outbreak detection in multiple surveillance systems. Statistics in Medicine. (2013) ; 32: : 1206–1222. doi: 10.1002/sim.5595. |
[8] | Brookmeyer R, Damiano A. Statistical methods for short-term projection of AIDS incidence. Statistics in Medicine. (1989) ; 8: (1): 23–34. |
[9] | Seaman S, De Angelis D. Challenges in Estimating the Distribution of Delay from COVID-19 Death to Report of Death. Medical Research Council Biostatistics Unit; 2020 [cited 2021 February 10]. Available from: https://www.mrc-bsu.cam.ac.uk/wp-content/uploads/2020/05/Challenges-in-estimating-the-distribution-of-delay-from-COVID-19-death-to-report-of-death-1.pdf. |

