
“You say you want a [data] revolution”: A proposal to use unofficial statistics for the SDG Global Indicator Framework
Abstract
This paper argues that the Global Indicator Framework required to support the 2030 Agenda Sustainable Development Goals will not be successfully populated, using only existing approaches and mechanisms. Official statistical systems must adapt and consider new approaches if only partial success is to be averted. This paper presents a proposal to accredit unofficial statistics as official for the purposes of compiling sustainable development goal indicators. While there may be some reluctance, and there are certainly risks with this proposal, the arguments put forward highlight the potential for collaboration.
1.Introduction
‘We always overestimate the change that will occur in the next two years and underestimate the change that will occur in the next ten’ – Bill Gates [1].
In 2015, the United Nations (UN) launched its most audacious and ambitious development plan; The 2030 Agenda and corresponding Sustainable Development Goals (SDGs). That agenda covers sixteen separate dimensions of development ranging from eradication of extreme poverty, achieving gender equality, ensuring sustainable consumption and production to combating climate change. It also includes a seventeenth multi-dimensional goal to address implementation. This goal comprises five operational sub-dimensions: finance, technology, capacity-building; trade and systemic issues.
Unlike the previous development programme, the Millennium Development Goals (MDGs), the SDGs explicitly require statistical performance indicators to be compiled. The resulting Global Indicator Framework (GIF) was adopted by the UN General Assembly in July 2017. The broad scope of the 2030 Agenda means that (currently) 232 performance indicators are required. Many of these indicators are not produced regularly if at all. In fact, the Inter-Agency and Expert Group on Sustainable Development Goal Indicators (IAEG-SDGs) calculated in April 2019 that less than half of the selected indicators for the GIF could be populated.
Various agencies and economists have attempted to put a cost on populating the GIF. The estimates vary enormously, but all are far in excess of existing funding [2]. In an environment of faltering multilateralism, it seems unlikely that available funding will match requirements. Yet political expectations appear to be very high; perhaps irrationally so, considering the scale and complexity of the SDG targets and the resultant indicators. Historic difficulties in populating the more modest MDG indicators suggest these expectations may be very optimistic. Therefore, in order to meet expectations new, or supplementary, approaches will be required.
One supplementary approach could be the introduction of a mechanism to certify unofficial statistical indicators as official. Although the approach discussed in this paper is consistent with philosophy of the data revolution and the established trend of endorsing ‘unofficial’ scientific discovery through accreditation and validation by a recognized authority, we nevertheless make this suggestion somewhat reluctantly. Our hesitancy arises as we believe the ideal situation is one where National Statistical Offices (NSOs), National Statistical Systems (NSSs) and International Organisations (IOs) are mandated and properly funded and resourced to compile all required national and international official statistics respectively. However, as this is not the case, and it is hard to envisage a sudden and dramatic improvement, then alternative solutions must be considered. The pessimistic viewpoint sees this as the thin edge of a dangerous wedge, where funding to NSOs may be further reduced and the standing of NSSs and official statistics is further undermined. A more optimistic perspective recognizes the opportunities to develop the mandate of official statistics beyond its current role.
It is useful at this juncture to clarify what we mean by the term official statistics. An official statistic is any statistic produced by a mandated institution or system in accordance with the UN Fundamental Principles of Official Statistics [3] or internationally accepted national or international code of practice or principles, such as, Principles Governing International Statistical Activities [4].11
The idea of using unofficial data to compile official statistics, be they national or international is nothing new. NSOs use unofficial data everyday as inputs to compiling official statistics (see also Section 2.2). IOs must also resort to using unofficial data to compile global aggregates. In fact, the Committee for the Coordination of Statistical Activities (CCSA) has published guidelines Recommended Practices on the Use of Non-Official Sources in International Statistics [5] on the topic. The practice of using unofficial data is expected to grow in the coming years as NSOs and IOs are increasingly reliant on administrative data and perhaps even Big Data to compile official statistics. But what if we were to go a step further? Rather than simply using unofficial data as inputs to derive or compute official statistics, what if we could use already compiled unofficial statistics to fill some of the gaps in official statistics? In other words, use statistics that have been compiled by institutions other than those formally mandated by States to compile statistics for national or international purposes. At this point it may be useful to clarify another very important point. Data and statistics are not the same thing. While the terms are frequently (and incorrectly) used inter-changeably or synonymously, they are in fact two different things. Data are basic elements or single pieces of information. Statistics are numerical data that have been organized through mathematical operations in line with conceptual frameworks.
The idea of using unofficial statistics to compile official statistics is not a new idea either. Several papers have raised this issue before, either directly or indirectly, questioning whether there is a new role for official statistics as a certification authority [6, 7, 8, 9]. Hammer et al. [10, p. 19] summarise the issue succinctly: ‘statistical agencies could consider new tasks, such as the accreditation or certification of data sets created by third parties or public or private sectors. By widening its mandate, it would help keep control of quality and limit the risk of private big data producers and users fabricating data sets that fail the test of transparency, proper quality, and sound methodology.’
In this paper we discuss, whether such a mechanism might be useful in the specific context of compiling indicators for the 2030 Agenda. From the outset, we would like to clarify that the proposal put forward in this paper is not driven by any ideological position but rather by a desire to find a pragmatic, yet professional, solution to what we perceive as a serious problem. In making this proposal our intention is not to be subversive or iconoclastic. We have no desire to undermine or corrode official statistics. We are not setting out to promote or argue for the privatization or ‘uberfication’ of official statistics. Nor are we advocating a completely open wiki-stat approach. On the contrary – we are staunch defenders of the need for impartial, independent official statistics. But given the pace of progress, the cost of developing the SDG indicators and the weight of expectation, we feel it is necessary to ask whether there are other approaches? Specifically, we are asking whether there might be a way to collaboratively harness the intellectual power of those outside the official statistics tent to avoid needless delays, duplication and expenditure. Bordt and Nia [11, p. 1] argue that populating the GIF is an ‘adaptive challenge requiring us to go beyond any one authoritative expertise to discover and generate new capacity, new expertise, and new ways of doing things.’ We agree. We also argue that in a post-truth era, official statistics might do well to take more control of a rapidly fragmenting and complicated information environment. Our fear is that, as Gates has warned, we (the statistics community) are underestimating the changes underway in the world of data and statistics. In brief, this is a risk management strategy. The details of the proposal are outlined in Part 2 – A proposal for a system to certify unofficial statistics.
This proposal is in keeping with the inclusive spirit of the 2030 Agenda and the idea of holistic data ecosystems. To date, many of the discussions regarding the GIF have placed official national statisticians, official international statisticians and other statistical compilers as competitors. But perhaps there is a way to collaborate rather than compete? This latter aspect of collaboration and data sharing is at the heart of recent recommendations of the Bogota Declaration of The UN Global Working Group on Big Data [12].
The paper is divided into two parts. Part 1 (Background and Context) outlines some of the background issues, such as measurement difficulties and the likely costs associated with populating the GIF to help readers understand the scale of the challenge facing the global statistical community. Part 2 (A Proposal for a system to accredit unofficial statistics) outlines the proposal and argues the approach is consistent with the philosophy of the 2030 Agenda. The arguments put forward are also consistent with notions of the wider data revolution and a longer historic trend of embracing ‘unofficial’ scientific discovery through accreditation and validation by a recognized authority.
2.Part 1 – Background and context
‘The data demands arising from the SDGs are huge and cannot be realistically met by official data alone’ – M. Kituyi, UNCTAD Secretary General [13].
2.1Measuring the SDGs
From a statistical perspective the measurement challenges arising from the 2030 Agenda are huge. To assess progress, each of the 169 complex, multi-faceted targets requires a statistical indicator. In fact, many of the targets are so complex, 232 indicators have been agreed. In truth, if all aspects of the targets were covered properly, then arguably twice that number would be required [14].
The MDG requirements were modest in comparison with the SDGs. Nevertheless, at the end of the MDG lifecycle in 2015, countries could populate on average, only 68 per cent of MDG indicators [2]. In their final MDG progress report, the United Nations [15, p. 10] warned that ‘Large data gaps remain in several development areas. Poor data quality, lack of timely data and unavailability of disaggregated data on important dimensions are among the major challenges. As a result, many national and local governments continue to rely on outdated data or data of insufficient quality to make planning and decisions.’
The far reaching ambition of the 2030 Agenda has led to development targets that are well ahead of available official statistics and statistical concepts. In many cases, appropriate statistical methodologies do not yet exist from which to generate indicators. To elaborate this problem and facilitate the population of the GIF the IAEG-SDG has classified all SDG indicators in to three tiers on the basis of their conceptual development and availability of data [16]. The tiers are:
Tier 1: the indicator is conceptually clear, has an internationally established methodology, standards are available, and data are regularly produced by countries for at least 50 per cent of countries and of the population in every region where the indicator is relevant. Tier 2: the indicator is conceptually clear, has an internationally established methodology, standards are available, but data are not regularly produced by countries. Tier 3: no internationally established methodology or standards are yet available for the indicator, but methodology/standards are being (or will be) developed or tested.
Table 1
Number of SDG indicators by Tier
| Tier classification | December 2016 | December 2017 | December 2018 | April 2019 | ||||
|---|---|---|---|---|---|---|---|---|
| Number | % | Number | % | Number | % | Number | % | |
| 1 | 81 | 35 | 93 | 40 | 101 | 44 | 101 | 44 |
| 2 | 57 | 25 | 66 | 28 | 84 | 36 | 91 | 39 |
| 3 | 88 | 38 | 68 | 29 | 41 | 18 | 34 | 15 |
| Multiple | 4 | 2 | 5 | 2 | 6 | 3 | 6 | 3 |
| Total | 230 | 100 | 232 | 100 | 232 | 100 | 232 | 100 |
Source: Derived from IAEG-SDG [16]. https://unstats.un.org/sdgs/iaeg-sdgs/tier-classification/.
In April 2019, the IAEG-SDG reported that 44 per cent of the selected indicators were classified as Tier 1 (see Table 1). Furthermore, they reported that 15 per cent of the indicators remained classified as Tier 3. While Table 1 shows the not inconsiderable improvements in conceptual development and data availability that has been made since 2016, it also highlights the magnitude of the task still facing the global statistical community. The pace of transition of indicators through the tiers to reach Tier 1 is likely to slow as presumably the low hanging fruit has now been picked. Table 1 suggests this is indeed the case, as the conversion rate to Tier 1 was slower between December 2017–2018 than between December 2016–2017. There were no additional conversions between December 2018 and April 2019.
2.2Who measures?
Countries understandably guard and protect their reputations preciously. Consequently, countries can be quite sensitive about what is measured and who does the measurement. This sensitivity has often led to tensions between official national statistics compilers and external compliers. For example, IOs may from time to time, alter national statistics to ensure they align with international standards to facilitate international comparisons – the main purpose of international statistics. Understandably this can lead to disagreements and tensions. Tensions can also arise between governments and Non-Governmental Organisations (NGOs), universities or other countries for a variety of reasons. In the context of the 2030 Agenda, this has led to some tensions as to whose data should be used in the compilation of the SDG indicators.
Countries, perhaps not unreasonably, are anxious that only official national data are used to populate the SDG indicators. Equally, IOs are anxious that national statistics are internationally comparable and have therefore put forward arguments as to why their data should be used. Kapto [17, p. 135] notes, ‘A tense debate is taking place on data flows from national to regional to global levels, and on custodian agencies’ role in harmonizing national data for global comparability, as countries assert their sovereignty over national data.’ What he describes as a ‘cease-fire’ between countries and IOs; an agreement on data flows has been brokered by the IAEG-SDG [18]. But there are some circumstances where this approach may be sub-optimal. In thinking about this, it is useful to remember that the primary purpose of the GIF is to produce global and internationally comparable indicators.
The first reason to query the ‘country data’ approach is where specific national official statistics do not exist. Unfortunately, this is not an uncommon problem. It makes perfect sense to use good quality national official statistics when they exist but if they don’t, and there is insufficient data to populate global indicators (see Tier 2 – Table 1), then other approaches must be found. The demand for SDG indicators has exacerbated this problem as many of the targets (and consequent indicators) fall far outside the scope of traditional official statistics and thus are not guided by agreed international measurement standards (see Tier 3 – Table 1).
A second problem with the ‘country data’ approach is where problems with the national official statistics exist. Problems could mean anything from incompleteness, errors or inaccuracies, non-adherence to international standards, inconsistencies over time, or imbalances. A good example of where this might arise is the asymmetries that frequently exist between bilateral trade datasets. From a global perspective, unbalanced trade data are not especially useful, and so steps are taken by IOs to remove these asymmetries. This may lead to a mismatch between official national statistics and official international statistics. This issue is not unique to international trade, problems with national data exist across all statistical domains. Despite the best efforts of NSOs and IOs, internationally comparable data will be a real challenge for the GIF.
A third and more delicate issue is that of impartiality. Targets, such as for example, 16.5 or 16.6 which deal with corruption, bribery and institutional accountability provide perfect examples of why it might make sense to use external data sources other than official statistics provided by a NSS. There have clearly been cases where official national statistics could not be trusted to provide an independent or impartial picture. This is not to say, that all national data are untrustworthy. On the contrary – most national official statistics are trustworthy. But there are cases (either indicator or country specific) where arguments can be made that more independent and trustworthy data may exist.
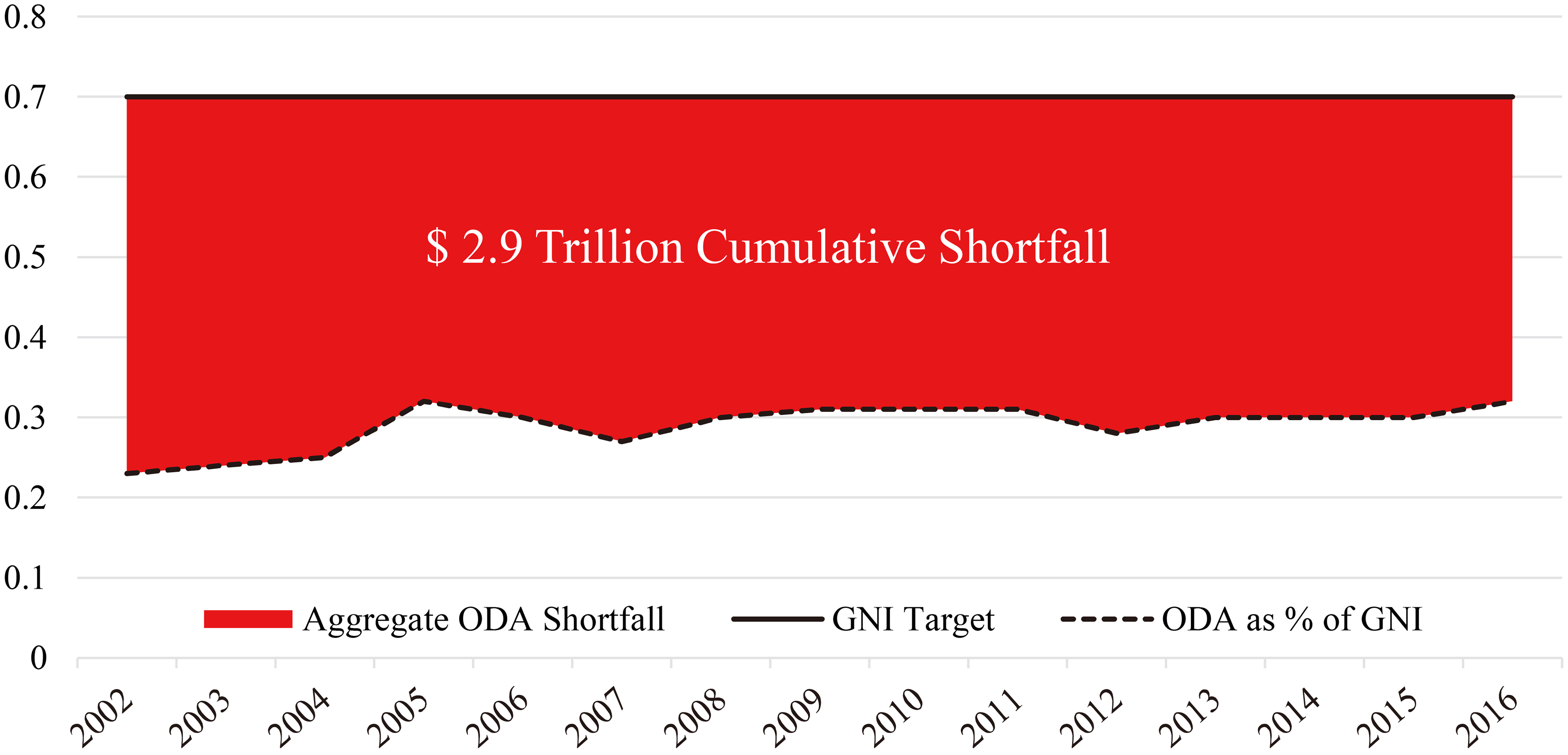
Figure 1.
Net official development assistance (total) as a % of gross national income, 2002–2016. Source: OECD DAC: https://data.oecd.org/ oda/net-oda.htm and authors own calculations.
Another exception to the ‘country data’ approach arises from what can be termed the data revolution. Today our day-to-day dependence on technology is leaving a bewildering array of ‘digital footprints’. This in turn has created a deluge of digital data. Some of these new digital datasets are global in scope offering the possibility of compiling genuinely harmonised global statistics. In such cases, where a single data source might provide more consistent and timely data than the amalgamation of multiple individual country datasets, it would seem insensible to discount their use for the purpose of global reporting. This might be applicable to targets such as 15.1 that deal with forest, drylands, wetlands and mountain regions governed by international agreements. Arguably superior quality and internationally comparable data could be derived from satellite imagery than from multiple national datasets of which many will be based on irregular sample surveys of varying quality. For other examples, see the mapping of projects in the UN Big Data Inventory and the UN Global Pulse to SDG goals undertaken by MacFeely [9].
2.3The cost of measurement
Unlike the MDGS, the SDGs are universal. The SDGs are also much broader in scope, far beyond simply reducing extreme poverty, to encompass the survival of our planet, improving equity and freedom in our societies and trying to develop a more stable and sustainable economic model. One of the implications of such a broad and ambitious development agenda is the price tag. Estimates vary, but Ambassador Macharia Kamau of Kenya, who co-chaired the SDG intergovernmental consultative process, anticipates that implementing the 2030 Agenda could cost somewhere between $3.5 and $5 trillion per year [19]. Ibrahim Thiaw [20], United Nations Assistant Secretary-General and Deputy Executive Director of the United Nations Environment Programme, estimates it will cost at least an additional US$1.5 trillion annually over the Millennium Development Goals. The intergovernmental committee of experts on sustainable development financing [21] estimated the value of investment in infrastructure required to achieve the eradication of poverty alone at between $5 and $7 trillion annually.
To put these numbers in perspective, total Official Development Assistance (ODA) contributions from the OECD Development Assistance Committee members’, averages about $113 billion per year (in current prices).22 Since Monterrey in 2002, when the wealthier nations of the world, promised to contribute 0.7% of their Gross National Income to ODA [22], the cumulative shortfall in ODA (2002–2016) has risen to $2.4 trillion (current prices) or $2.9 trillion in 2016 constant prices. Since 2015, and the commencement of Agenda 2030, the average country effort hasn’t changed appreciably (see Fig. 1) and remains well short of the 0.7% target.
Developing the statistical concepts and collecting the data required for the GIF will not be inexpensive either. The Global Partnership for Sustainable Development Data estimates around $650 million per year is needed to collect data to support the 2030 Agenda, of which only $250 million is currently funded [23]. PARIS21 [24, p. 11] has estimated that ‘funding for statistics needs to be increased from current commitments of between US$300 million and 500 million to between US$1 billion and 1.25 billion by 2020’. The PARIS21 estimates cover a wider remit than just SDG indicators, and presumably this explains some of the difference in scale between the two estimates. But irrespective of which estimate of costs is used; all estimates clearly exceed existing funding. More recently PARIS21 [25] has estimated that ODA devoted to data and statistics ($591 million in 2015 and $623 million in 2016) is only one third of 1% of ODA.
2.4Summary of challenges
Part 1 has provided some of the background and context that are relevant to the proposals put forward in Part 2. The universal and broad scope of the 2030 Agenda present real measurement challenges for the global statistical community. Populating the GIF will be a challenging and complex task with enormous resource implications, even for developed countries with sophisticated statistical systems. History suggests that it is highly unlikely that by 2030 all of the 232 indicators will be populated. Today, only 44% of the SDG indicators can be populated. One of the risks with the Tier system is that it has created a vacuum, and as the saying goes: ‘nature abhors a vacuum’. Who will fill that vacuum and how? At a time when multilateralism is faltering, when funding is not matching ambition, and where the ‘data revolution’ has brought new competition, we see countries clinging to an anachronistic view, prioritising ‘country data’ or even abandoning the use of statistics as a policy support instrument, and international organisations jealously laying claim to indicators to attract or safeguard funding. If the development and statistical communities are serious about populating the GIF then it is time to consider alternative approaches.
3.Part 2 – A proposal for a system to certify unofficial statistics
‘One of the greatest tasks of our era may be figuring out how to unlock and harness the value of [private and civil sector] data to provide actionable insights for positive social and economic impacts’ Stefaan Verhulst [26].
As outlined in Part 1, the data demands arising from the 2030 Agenda are enormous. If the history of MDG data is any indication of future outcomes, then it suggests that a large portion of the GIF could remain empty for much of the remaining time between now and 2030. Addressing the data gaps using only traditional approaches will realistically not achieve success. For this reason, we propose, not only using existing unofficial data as inputs to derive SDG indictors but also using already compiled unofficial indicators or statistics.
The rationale behind this proposal is straight- forward. The demand for data to populate the SDG GIF far outstrips supply from traditional sources. Yet there are no shortage of data and indicators in existence; if anything, the opposite is true, we are awash with both. The statistical and information landscape has changed utterly over the past decade. Today there are an unimaginable range of statistical indicators being compiled by a wide variety of producers: civil society; academia; NGOs; and the private sector. For the purposes of the GIF many of these indicators have not been considered to date. Bearing in mind the scale of challenge facing the statistical community, we argue, it is time to rethink this approach.
3.1A proposal
An agreed recognized and mandated body, with the authority and competence to certify statistics as ‘fit for purpose’, would review unofficial statistics to see whether they can be certified as ‘official’ for the purposes of populating the SDG GIF. Statistics certified ‘fit for purpose’ could be accredited and used as official statistics. For the purposes of this discussion ‘Fit for purpose’ means that an indicator or statistic meets pre-defined quality and metadata standards and has been compiled in an impartial and independent manner. Those pre-defined standards and criterion must be open and transparent to all. The term quality can be interpreted in the broadest sense, encompassing all aspects of how well statistical processes and outputs fulfil expectations as a SDG indicator. In more concrete terms, ‘fit for purpose’ would mean that any statistic must be relevant, accurate, reliable, coherent, timely, accessible, and interpretable. The statistic must be produced using sound methodologies, concepts and reliable systems. The statistic must also be compiled within an institutional environment that recognises the need for objectivity, impartiality and transparency. This last point is important. For a statistic to be designated official, neither the input data nor the methodologies can be proprietary but must be available to all and open to scrutiny (subject to obvious confidentiality constraints).
Figure 2.
A proposed future: Using unofficial data and statistics to compile SDG indictors.
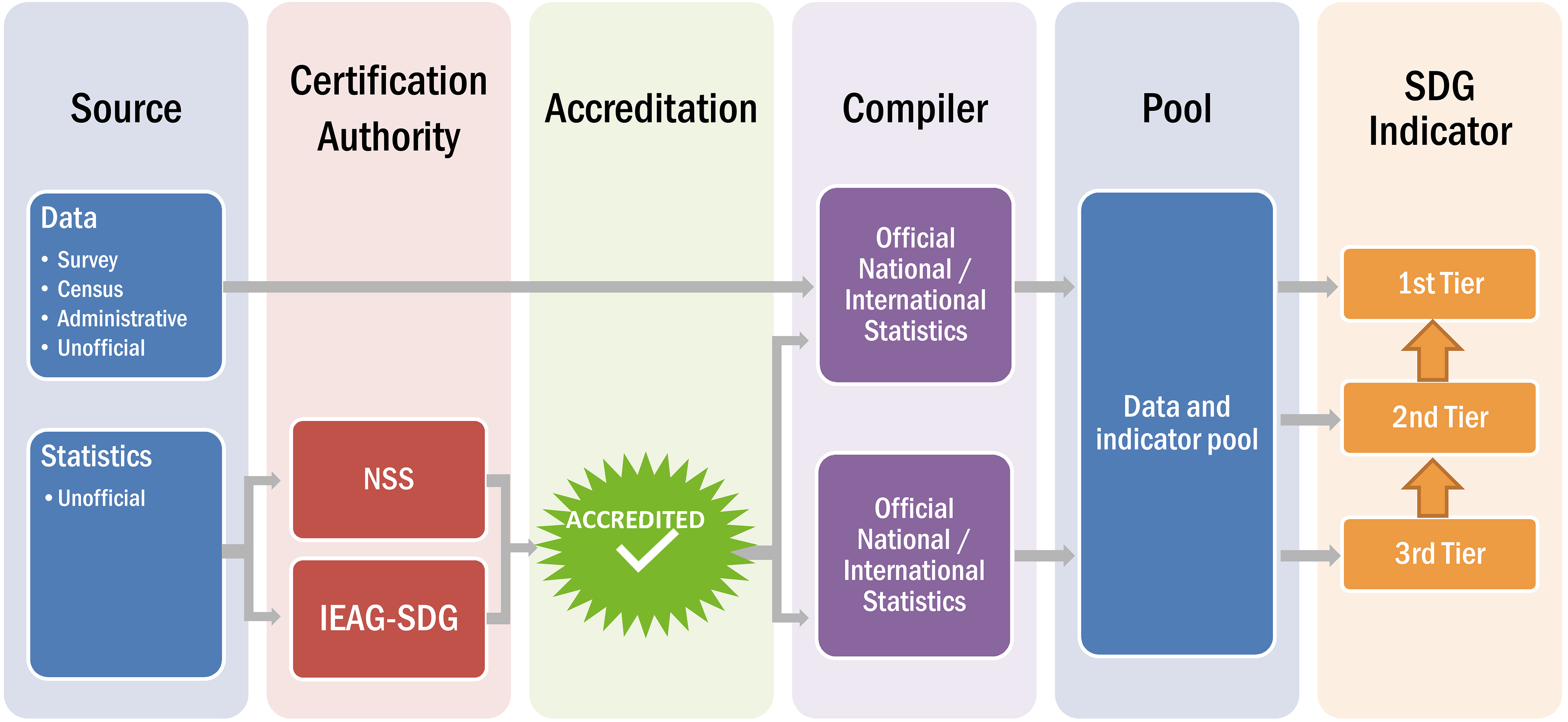
This proposal envisages the SDG GIF being populated from a combination of official statistics and unofficial (but certified as official) statistics. By pooling all available indicators an improved completion rate will be achieved. To ensure a level playing field and maintain quality standards a formal accreditation system is required. By combining official and accredited unofficial sources into a single high-quality ‘pool’ the chances of successfully populating the GIF will increase (See Fig. 2).
In this new regime the indicator pool would comprise of:
1. Official national statistics. These are statistics produced by the NSO in accordance with the UN Fundamental Principles of Official Statistics [3] and other national codes of practice, other than those explicitly stated by the NSO not to be official; and all statistics produced by the NSS in accordance with the UN Fundamental Principles of Official Statistics and national codes of practice i.e. by other national organisations that have been mandated by national government or certified by the head of the NSS to compile statistics for their specific domain.
2. Unofficial national statistics that are accredited as ‘official national statistics’ by the NSS for the purposes of supplying statistics to populate the SDG – MGF.
3. Official international statistics. These are statistics, indicators or aggregates produced by a UN agency or other IO in accordance with the Principles Governing International Statistical Activities [4] and other institutional codes of practice. It is often necessary for a UN agency, or other international organisation, to modify official national statistics that have been provided by an NSO or another organisation of a NSS, in order to harmonise statistics across countries, to correct evidently erroneous values or to reconcile with international standards. Furthermore, in the absence of an official national statistic, a UN agency or other international organisation may compile estimates. Thus, it is not sufficient to define official international statistics as simply the reproduction of official national statistics.
4. Unofficial international unofficial statistics that are accredited as ‘official international statistics’ by the body mandated by the UN Statistics Commission for the purposes of supplying statistics to populate the SDG GIF.
This supplementary approach would only be used when particular conditions apply. Firstly, it should be a measure of last resort, and only considered when all other official options have been exhausted. Specifically, when:
1. Tier 3 indicators (i.e. indicators with no internationally established methodology or standards are available) remain unpopulated and when realistically, no methodology or standards will be developed in time. The concept of ‘in time’ will need to be specified – perhaps by 2025 would be a reasonable cut-off.
Or
2. when Tier 2 indicators (i.e. where the indicator is conceptually clear, has an internationally established methodology and standards are available) remain unpopulated and data are not being systematically produced. Here too, a cut-off date will be needed. Again 2025 might be sensible.
Secondly, compilers of unofficial indicators hoping to secure accreditation must demonstrate their adherence to the principles of official statistics. For national accreditation this means observance of the UN Fundamental Principles of Official Statistics [3]. In particular, principles 1 (impartiality), 2 (professionalism), 3 (scientific standards), 6 (confidentiality), 9 (international classifications) are of special relevance and should be rigorously tested. Principle 5 (quality and other aspects of data) is also extremely important. For global accreditation it would mean adherence to the Principles Governing International Statistical Activities [4].
Thirdly, unofficial indicators will be required to meet a defined set of quality standards. For national accreditation, the indicator would be required to meet the same standards and conditions as set out in the national code of practice or national statistical quality framework. For international accreditation, the indicator will be expected to meet the quality standards as defined in the UN Statistical Quality Assurance Framework [27]. Furthermore, clear metadata standards should be set for accreditation. In cases where standards don’t yet exist, the UNECE Common Metadata Framework [28] sets out suitable generic standards that could be used as criteria for accreditation.
Finally, prospective compilers of official SDG indicators must be able to guarantee that they can supply those indicators for, at least, the lifetime of Agenda 2030. In practical terms, this means being able to supply, at a minimum, the statistic on an annual basis for the years 2010–2030. While sufficient funding is important, in line with the UN Fundamental Principles of Official Statistics [3], funding must be free of any political or ideological conditions or influence. Access to the indicator itself must also be open and constraint free.
One could view the conditions outlined above as overly rigid and with too many criteria. The counter argument might be to just let compilers bid against each other and whichever indicator or statistic can be demonstrated to have the best quality (however defined) would be selected. While such an egalitarian approach might be intuitively logical and attractive, it might be seen as contravening the spirit of the ‘country first’ principle agreed by the IAEG-SDG in 2019 [16]. Hence, for the purposes of this paper, a set of reasonable, albeit conservative, conditions are envisaged. It also means that the results of the homologation would be binary i.e. only two possible outcomes are envisaged – a statistic is either accredited or it is not. One could also make the argument that such a binary result is itself too rigid, and one could perhaps envisage a wider set of choices, for example, an intermediate or experimental certification might be possible. If the scope of the discussion were broadened to official statistics more generally, this indeed would be a worthwhile consideration. However, in the context of the SDGs, which already have the complication of Tiers, an experimental category might muddy the waters too much.
3.2How does this differ from the current situation?
Unofficial or ‘non-official’ data sources are already being used as inputs in the compilation of official statistics all around the world, both at national level and international level. At national level, for example, unofficial data are frequently used to supplement official survey data in the derivation of consumer price index expenditure weights, retail sales index trading day weights, and in many aspects of compiling national accounts. Typically, at national level, there are no official guidelines or accreditation systems used in these processes. Depending on the quality and detail of the metadata, the reliance of an individual statistic on unofficial data may or may not be clear. As noted above, NSOs will be guided by their own national codes of practice and the UN Fundamental Principles of Official Statistics [3], in particular, principle 5 which states that ‘Data for statistical purposes may be drawn from all types of sources, be they statistical surveys or administrative records…’
The same is true at international level, except that IOs are directed by the Committee for the Coordination of Statistical Activities guidelines on the use of unofficial data. Those guidelines, Recommended Practices on the use of Non-Official Sources in International Statistics [5], provide direction on the use of unofficial source data. No formal accreditation system is necessary when using unofficial data as they are effectively subsumed into official aggregates and thus are covered by the formal ‘official’ label applied to the derived indicator. In other words, accreditation of unofficial data is implicit. The guidelines however stay silent on the use of fully developed indicators.
Both NSOs and IOs already regularly use unofficial source data to compile official statistics. This practice is expected to grow as statistical agencies are now looking beyond survey data and administrative records to investigate whether big data is a useful source of data for compiling official statistics. In 2018, 34 NSSs from around the world had registered 109 separate big data projects on the Big Data Project Inventory33 compiled by the UN Global Working Group on Big Data. IOs had logged a further 91 projects [9]. NSOs and IOs are investigating a wide range of big data sources, from satellite imagery to mobile phone CDR records to augment or supplant existing data sources or generate completely new statistics. The question now is how all of this activity will be integrated with the compilation of official statistics more generally.
This proposal goes a step further than existing practices and frameworks, in that it anticipates using, in the specific cases outlined in Section 2.1, unofficial statistics to create a larger ‘pool’ from which SDG indicators can be selected. This pool would comprise of not only unofficial source data to derive official statistics, but also using already developed unofficial indicators or statistics (but reclassified as official) – see Fig. 2. Now compilers of statistics (official and unofficial) would submit bids (proposals) to the IAEG-SDG for consideration. Bids would only be considered if they adhere to agreed quality and metadata standards and broader principles of official statistics.
3.3Risks associated with adopting this proposal
No doubt persuasive counter-arguments can be made against implementing this proposal. After all such a move will introduce risks. But not adapting to the modern data world runs the risk of achieving only a partially populated GIF, which in turn risks tarnishing the reputation of the global statistical community. A business as usual approach also puts NSSs, particularly those in developing countries, under unnecessary pressure to compile a range of new statistics.
This section outlines some of the most obvious risks in adopting this proposal. There are legal concerns, reputational risks and practical implementation issues, such as costs, to be considered. Some of these issues are discussed briefly.
3.3.1Legal issues
In theory accreditation could be done at national level or at global level. At national level, it will be important that compilers of unofficial indicators can demonstrate that they adhere to the same standards as compilers of national official statistics. In most countries, the national accrediting body will most likely be (but not necessarily) the head of the NSS, or if a formal system does not exist, then the head of the NSO. In some countries this may be the same person. Here some legal hurdles might need to be jumped. For example, not only might the unofficial statistic itself need to be accredited as an official statistic, but the compiling agency might also need to be certified as a public body or a recognized statistical agency or authority in order to comply with national statistical legislation and/or national codes of practice. For example, in some countries official statistics are defined as statistics compiled by the NSO or other public institutions.44 Such a broad accreditation might be seen as a bridge too far. However, this caveat might be circumvented by outsourcing the actual compilation of the statistic (under license) to a third party but the statistic itself would be disseminated by a recognized body of the NSS or the NSO itself. This approach would also satisfy the UN Fundamental Principles of Official Statistics [3].
At global level, as no head of the global statistical system exists, an accreditation body would need to be mandated. However, as the UN Statistical Commission (UNSC) has been mandated to compile the SDG indicators, the UNSC would seem to be the obvious and appropriate body to mandate such an accreditation board. One could imagine that they might ask the IAEG-SDG to take on this additional task. Assuming the IAEG-SDG is mandated as the statistical accreditation body, they would most likely need additional statistical support (as the indicators in question will most likely fall outside the expertise of traditional NSO statisticians), in particular from IOs who can provide both technical, professional and secretarial support.
Equally, at the global level there is no statistical law to impose constraints. The UN Fundamental Principles of Official Statistics [3] discussed above apply only to official national statistics, and so, do not have anything to say regarding the compilation of official international statistics. The Principles Governing International Statistical Activities [4], which are the equivalent of the fundamental principles for compilers of official international statistics, are also silent on who exactly can compile international statistics or who is a member of the international statistical community. As the CCSA has expanded considerably over recent years, there is clearly some flexibility regarding the interpretation of how ‘international statistical community’ can be interpreted.55 There is also some ambiguity as to what an official international statistic is. The UN Statistics Quality Assurance Framework [27, p. 9] defines official International statistics as ‘statistics, indicators or aggregates produced by a UN agency or other international organisation in accordance with the Principles Governing International Statistical Activities [4] formulated by the Committee for the Coordination of Statistical Activities’. But this quality assurance framework applies only to UN agencies and thus does not prescribe the activities of other non-UN IOs.
There is no doubt more to be said on this matter. Nevertheless, a preliminary assessment suggests that there are no absolute legal barriers sufficient to prevent either national or global accreditation mechanisms being put in place, should that be desired. Nor would such mechanisms, if done carefully, breach the letter or the spirit of the UN Fundamental Principles of Official Statistics [3] or the Principles Governing International Statistical Activities [4].
3.3.2Reputational risks
Whether certifying unofficial statistics will undermine or enhance the reputation of the official statistics brand is difficult to predict. But there will naturally be concerns that certifying unofficial statistics as official may ultimately undermine or tarnish the official statistics brand. A valid argument can be made that by using unofficial statistics, the line between official and unofficial statistics may become blurred and the reputation of official statistics will be damaged or put at risk. Such a risk must be anticipated and mitigated as official statistics have many unique qualities and enjoys a reputation worth preserving and delineating. Consequently, it will be very important that the protection of the official statistics brand is carefully considered.
There may also be concerns that in allowing some unofficial sources to be designated as official, this may be the thin end of a dangerous wedge, whereby the compilation of official statistics is slowly outsourced or privatized and incrementally taken away from NSOs and NSSs. Some may fear also that this is somehow an admission of failure – that official statisticians cannot deliver. There may be concerns too that in an era of data revolution, but reduced funding for official statistics, that official statistics is already surrendering ground to other information providers and this proposal will only add fuel to the fire. In other words, effectively outsourcing the production of official statistics may further drain funding from NSSs and IOs. Perhaps so, but a (cold) data war is already underway. There is a growing asymmetry in the resources available for the compilation of public/official and private/unofficial statistics and indicators. In a world where official estimates are increasingly being challenged by alternate facts it may be unwise to take the future of official statistics for granted. This may sound alarmist, but developments in Greece [29, 30]; Canada [31]; Norway [32]; and most recently in Tanzania [33, 34]; South Korea [35]; or Russia [36] provide sobering reminders that the impartiality and independence of official statistics can be surprisingly fragile.
The reputational risks outlined in this section are not trivial and must be carefully considered and mitigated. Official statistics must adapt in a way that allows official national and international mechanisms to take some control (or at least exert more influence) over a rapidly fragmenting information landscape. Reputation is a double-edged sword. If there are risks of reputational damage arising from certification of unofficial statistics must be balanced against the risk of reputational damage to official statistics failing to deliver on the expectations arising from Agenda 2030. Of course, a counter argument could be made that by being proactive and showing leadership, the official statistics brand might enjoy a heightened reputation.
3.3.3Double standards
To certify unofficial indicators as official, a level playing field will be essential. Careful thought must to be given to ensuring that quality standards are comparable, so that neither unofficial nor official compilers are placed at a disadvantage. It will be very important that unofficial statistics don’t enjoy light touch regulation vis-a-vis their official counterparts or vice-versa. If unofficial statistics are to be used, then they must adhere to the same high-quality standards as official statistics. The dimensions of those quality standards, for the purposes of compiling UN statistics, are defined by the UN Statistics Quality Assurance Framework [27, p. 22] as: relevance; accuracy; reliability; coherence; timeliness; punctuality; accessibility; and interpretability.
Adherence to the principles of official statistics must also be a condition for accreditation. Although the principles themselves are not overly specific in technical terms, their importance cannot be overstated. In particular: principles 1 (impartiality); 2 (professionalism); and 6 (confidentiality) are of paramount importance. More technical in nature but no less important are principles 9 and 5 which deal with use of international classifications and quality standards respectively. Thus, adherence to the UN Fundamental Principles of Official Statistics [3] must apply to all compilers. In particular, unofficial statistics must adopt the same standards of openness and transparency of metadata.
In order to accredit unofficial statistics as official, these quality dimensions and principles must be assessed and judged ‘fit for purpose’ for SDG indicators. Indicators must also be available for the entire duration of the 2030 agenda. Ideally this means from 2010–2030. Any indicator selected as an SDG indicator must provide certainty on this issue. As noted in Section 2.1 this proposal only allows for a binary outcome – pass or fail. If this debate were expanded beyond the SDGs to official statistics more broadly, then a more nuanced set of options that allows for experimental statistics might be necessary. But this is beyond the scope of the discussion in this paper.
3.3.4Data neutrality
Conflict of interest is always a risk when consumers of data become compilers. The reasons should be obvious. Rosling et al. [37, p. 236] explains it with a simple analogy – ‘a long jumper is not allowed to measure her own jumps.’ Advocacy or ideology may encourage compilers to achieve a certain result or outcome. The impartiality or agnosticism of official statisticians is one of its key strengths. The European Statistics Code of Practice [38], the draft Statistics Quality Assurance Framework for the African Statistics System [39], the Caricom Data Quality Assurance Framework [40] and the UN’s Fundamental Principles of Official Statistics [3] all stress the need for official statistics compiled free from political and external interference.
The counter argument is that there is no such thing as neutral information [41] and that consumers probably know the context better and so can compile better, more nuanced, statistics. These are not invalid arguments. Behind every statistic there were people who made decisions and these decisions are often unstated and undocumented [42, 43]. They may even be unconscious. The translation from words to numbers, involves assumptions and theories which may be obscured behind a veil of a technocratic objectivity [44]. As the title of Gitleman’s book [45] eloquently puts it “‘Raw Data” Is an Oxymoron.’ The choice of indicator may inadvertently reflect a political ideology, but it may also be a deliberate attempt to control a narrative. Mahajan [46, p. 110] sums up the situation well – ‘measurement is never an innocent matter where as it were, the facts speak for themselves. What is measured, who finances and does the measuring, how data are collated, interpreted, and disbursed, how they are harnessed to decision-making and program implementation, and how other measures and ways of collecting information are displaced – all these are contested matters because they are linked with the specific orientation of institutions and policies, the outcomes that they aspire to, and the forms of knowledge that they privilege.’
Every statistic comprises several conscious and subconscious decisions – how to treat outliers, how to impute for missing values or what level of aggregation should be chosen? The list of decisions is almost endless. So, no statistic is strictly neutral in the sense that choices have unavoidably been made during compilation. But perhaps the more relevant question is whether the statistics were compiled with the intention of providing impartial information or to advocate for a specific objective? Not always an easy question to answer. The purpose of official statistics is the former – to provide statistics and information, that in as far as is possible are free from any political agenda. The argument as to whether other agents can compile better statistics than official statisticians is at the heart of the debate as to whether centralised or decentralised statistical systems are better. There are strengths and weaknesses with either approach. Centralised statistical systems are typically seen as strong on independence and impartiality but sometimes struggle with relevancy, owing to their remoteness from policy debate. Decentralised statistical units often produce highly relevant statistics but are more susceptible to political interference and pressure to present statistics relating to ministerial policies and outcomes in a favourable light, or to schedule publications to suit political considerations, thus compromising the credibility of the statistics [47, 48]. From the perspective of accrediting unofficial statistics, all compilers must be able to demonstrate adherence to principle 1 of the UN Fundamental Principles of Official Statistics [3].
The risks associated with users compiling statistics already exist. These risks can arguably be mitigated through implementation of codes of practice, quality standards, transparent metadata, open data standards and peer reviews.
3.4The risks associated with not adopting the proposal
Some of the risks associated with implementing the proposed approach have been outlined above. But there are also risks in not considering such an approach. It is also important to carefully consider these. The main risks would appear to be those arising from unaddressed competition.
3.4.1Competition
We live in a world where development funding is not exclusively provided by States. Philanthropic funding is now increasingly important, with funds, such as, the Gates, Ford, Hilton and Rockefeller foundations making enormous sums of money available. Unfortunately, relatively little is known about these philanthropic funds, what they fund or how they decide what gets funded. Salazar [49] estimated that in 2009, the top 10 philanthropic foundations made US$5.6 billion available, of which, US$3.6 billion was given to ‘global development’. In 2016, Viergever and Hendriks [50] estimated that the 10 largest philanthropic funders of health research together funded research costing $37.1 billion, constituting 40% of all public and philanthropic health research spending globally. They note the need for increased transparency about who the main funders are globally.
The danger for official statistics is philanthropically funded projects may inadvertently be counterproductive; competing with official statistics and the SDG GIF. See Mahajan [46, p. 110] for a graphic example in the health sector, where she argues that the Institute for Health Metrics and Evaluation funded by the Gates Foundation has led to the ‘relative sidelining of international agencies and especially the World Health Organization.’ In the growing world of online collaboration, competition to the SDG GIF could emerge at any time. If other data compilers in civil society or the private sector feel disenfranchised or frustrated with the official approach they may develop competing frameworks. Arguably this has begun already. The Sustainable Development Solutions Network (SDSN),66 the Global Partnership for Sustainable Development Data (GPSDD)77 and the United Nations Global Pulse88 are all, in one way or another, competing with the UN Statistical Commission. They are all competing for funding and other resources to improve data and statistics for development. Take the GPSDD for example – reportedly a network of more than 280 members, including governments, the private sector, civil society, international organizations, academic institutions, foundations, statistics agencies, and other data communities, it was established to fully harness the data revolution for sustainable development. Their ambition is to, among other things: strengthen inclusive data ecosystems; drive data collaborations; drive global collaboration to improve production and use of data; develop global data principles and protocols for sharing and leveraging privately held data; Bring together data communities at global and national level to spur innovation and collaboration; harmonize data specifications and architectures; and ensure the interoperability of technology platforms for assembling, accessing, and using data. These all seems like sensible ambitions. The risk of course is that, in doing so, it may undermine the global structure established by countries to do exactly this – the United Nations. The risk also, is that, several of the organisations who have joined the network, may have done so under duress, as they can’t risk being excluded or being seen to be irrelevant. The distinction between voluntary collaboration and forced cooptation is often blurred.
In terms of addressing the threat of competition, arguably it is better that official statistics takes control and propagates statistical standards, rather than building a wall in an attempt to shelter or safeguard official statistics from other compilers. Proactive cooperation could mitigate the detrimental risks of involuntary cooptation. In the rapidly changing data environment that we live in today, not adapting may be the bigger risk.
3.5Ideological arguments
It is clear there is resistance in many countries to governments collecting more data. The argument underlying this resistance is supposedly fears of a Big Brother state [51, 52]. Despite statistical legislation and the UN fundamental principles, respondents, but most particularly firms, don’t always trust NSOs to safeguard their data from other arms of government or not to use their data for non-statistical purposes. As an aside, MacFeely [9] notes the incongruity of these concerns and the lack of concern regarding the emergence of a corporate or private sector Big Brother. But there is ideology at play here. The neo-liberal agenda aims to minimise the role of the public sector. Landefeld [7] warns, even in the data sphere, there will be resistance by industry to expanded government oversight.
Thus, one can anticipate ideological arguments against accreditation, along the lines that this is an expansion of the role of government. But as Reich [53, p. 5] correctly points out ‘Government doesn’t “intrud” on the “free market”. It creates the market.’ Polanyi [54, p. 61] too notes the importance of the ‘deus ex machina of state intervention’ for the formation of markets. The UN or national government must set normative standards, whether, defining post codes, tax numbers, personal identification numbers or statistical classifications – these are all part of a nations data infrastructure [55] and essential to the efficient functioning of a market. Even Hayak [56], the godfather of modern liberal economics, understood this, explaining that in line with liberal principles, the State should exercise control of weights, measures and statistics.
In any event, challenging the establishment of national or global accreditation mechanisms on the grounds of such ideology is a specious argument. An accreditation system will facilitate wider participation of the private sector, along with academia, NGOs and civil society in the 2030 Agenda. It opens a doorway, for indicators that have traditionally been excluded from consideration, to compete for recognition as official SDG indicators.
3.6Consistent philosophy
The 2030 Agenda emerged from a globally inclusive, open and democratic process. In line with this philosophy, contributions on the compilation of SDG indicators could also be open and inclusive. To an extent they already are, in that anyone can propose indicators, or comment on existing proposals. But to date, it has been envisaged that compilation will be the exclusive permit of official statisticians (either national or international). But what if the power and knowledge of unofficial data and unofficial statisticians could be harnessed? This indeed would be a data revolution.
The idea of an accreditation system is not inconsistent with the philosophy underlying the UN Fundamental Principles of Official Statistics [3]. In particular principle 5 which states:
‘Data for statistical purposes may be drawn from all types of sources, be they statistical surveys or administrative records. Statistical agencies are to choose the source with regard to quality, timeliness, costs and the burden on respondents’.99
In other words, statistical agencies should in principle use the widest variety of data sources possible to compile official statistics provided the quality of those data are sufficiently good and the costs are not prohibitive. Why not go one step further, and argue that statistical agencies should in principle use, not only the widest variety of data, but also the widest variety of statistics for the purposes of providing official statistics to feed the SDG GIF?
The idea is also broadly consistent with the spirit of the 2030 Agenda itself, which states ‘Data and information from existing reporting mechanisms should be used where possible’ [57, p. 48]. So, like the fundamental principles, the 2030 Agenda recognises the importance of reusing existing data and information from other official systems. Again, one could argue that what we are proposing is simply an extension or relaxation of this condition – in particular, a relaxation of the term ‘existing reporting mechanisms.’ The 2030 Agenda also noted that any ‘global review will be primarily based on national official data sources’ (our emphasis) [57, p. 74a]. Thus, it was recognized from the start the GIF might require data from outside national official sources. The document wisely didn’t set any conditions or limitations on what these sources might be.
This proposal is also consistent with the broad philosophy or vision put forward by the Independent Expert Advisory Group on a Data Revolution for Sustainable Development in their report ‘A World That Counts’. In this report, they state ‘New institutions, new actors, new ideas and new partnerships are needed, and all have something to offer the data revolution. National statistical offices, the traditional guardians of public data for the public good, will remain central to the whole of government efforts to harness the data revolution for sustainable development. To fill this role, however, they will need to change…and strong collaboration between public institutions and the private sector’ [58, p. 9]. The report stresses the need to create incentives for private sector participation and comes tantalizingly close a number of times to proposing something quite radical, but it never quite does1010 – it highlights the importance of data sharing but never statistics. In short, they advocate a vibrant ‘global data ecosystem’ [58, p. 17] and an extended concept of statistical systems. We interpret (global or national) data ecosystems as something much broader than (global or national) statistical systems – See Fig. 3.
Figure 3.
(National/Global) statistical and data ecosystems.
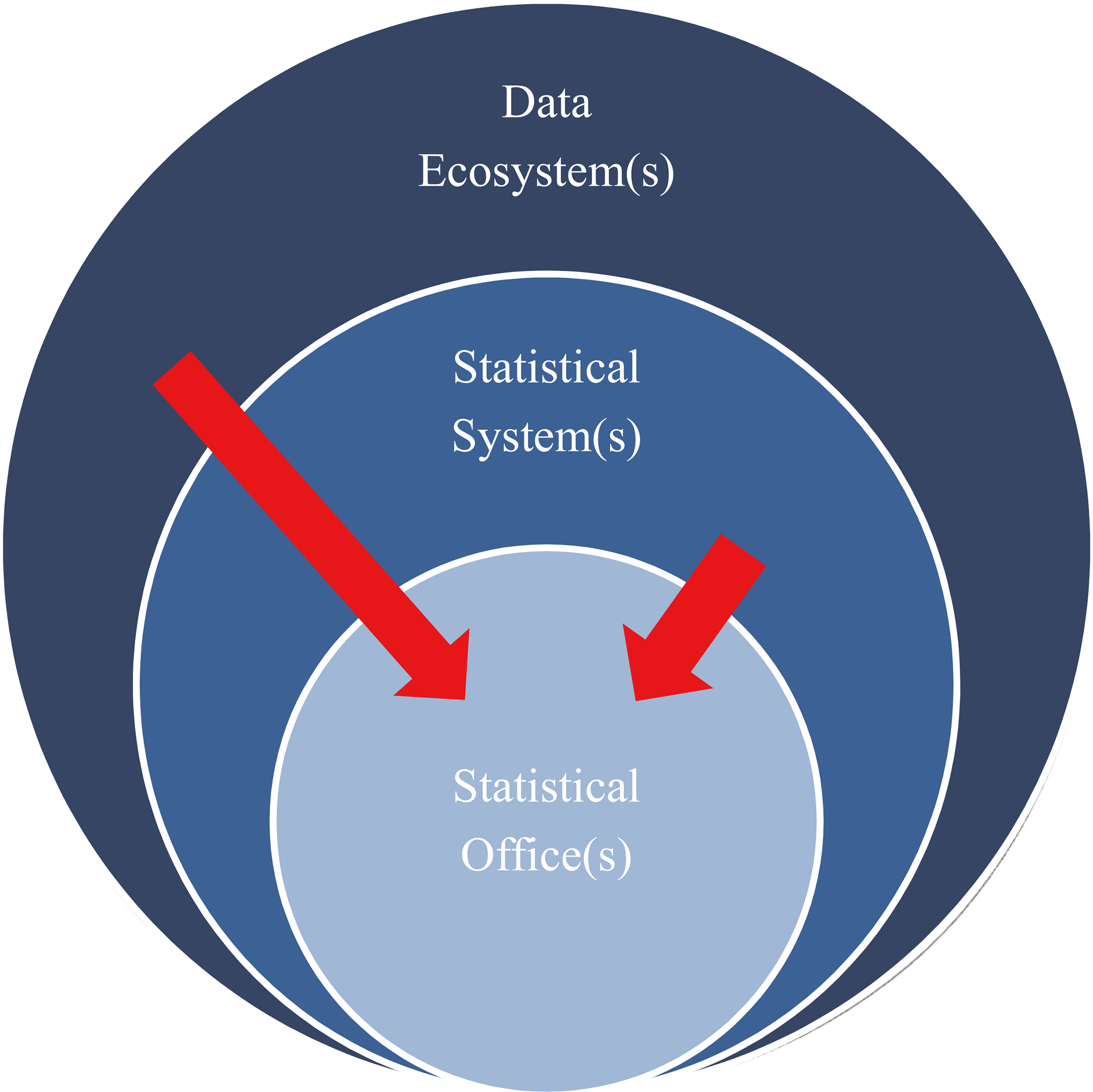
The NSOs mapped in Fig. 3 don’t require any explanation. A NSS is the collection of statistical institutions or units within a country that collects, compiles and disseminates official statistics on behalf of national government. For the purposes of this argument, we understand a data ecosystem to be the amalgam of all data and statistical actors in a country, including official statistics and holders of public sector or administrative data, private and commercial sector data holdings and indicators, research data, civil society and non-governmental data holdings. We acknowledge that in an era of globalising data imposing a distinction between a national and a global data ecosystem is perhaps somewhat archaic. The idea of constraining global digital data to a ‘country’ or that data will respect national borders is anachronistic. Thus, we acknowledge that data ecosystems may need to be international or global by default. The important point is that data ecosystems are much broader than official statistical systems.
The official statistical system, whether national, regional or global, should retain control of the process for standards and certification. Thereafter, there is no reason why NSOs or NSSs could not accredit unofficial statistics or indicators for the purposes of compiling SDG indicators. Furthermore, with the evolution of modern, globalised data sources, there is no reason why IOs or the UN could not establish regional or global accreditation systems to facilitate the use of good quality unofficial statistics.
3.7Lessons from history
Scientific discovery has always relied on amateur inventors or scientists. Many important contributions were made ‘by men with minimal scientific education’ [59, p. 201]. John Harrison, a clock maker, invented the famous
There are lessons we can learn from this approach. Just as professional scientists did not have the monopoly on scientific wisdom in the past, official statisticians do not have the monopoly on information today. In fact, when it comes to mining new forms of digital data, official statisticians are for the most part far behind their unofficial counterparts. Today, many unofficial statistics are produced by a wide variety of compilers, ranging from: journalists; researchers; social media outlets; civil society; academia; commercial enterprises; lobby groups; and NGOs. The quality of these statistics varies enormously, from one end of the quality spectrum to the other. In many cases the quality is hard to determine, as the underlying data and methodologies are proprietary and shrouded in mystery. In other situations, the statistics are clearly of good quality and are accompanied by supporting metadata. It seems unwise therefore to tar all unofficial statistics and indicators with the same brush.
Is there a way to sift and sort this effort in such a way as to harness it? Could NSOs (at country level) or the UN (at the global level) provide mechanisms that could test and validate unofficial statistics and accredit them for the purposes of the SDG GIF? That is the question posed in this paper. Without such a system, new statistics will emerge daily, leaving the public unclear as to their quality and utility. But by providing a quality assurance stamp, NSOs at country level and the UN at the global level could say which statistics are ‘facts’. The UN could become today, what the Académie des Sciences was to the Victorian era, in terms of validation. Winning such recognition might provide the necessary incentive for many compilers to become less proprietary with their data, methodologies and algorithms.
3.8Lessons from the data ecosystem
Official statisticians are not the only experts grappling with the challenges of homologation. Across the wider data ecosystem, data scientists and researchers too have been developing their own principles,1111 certification standards and accreditation procedures. Some examples include: The Network of Expertise in long-term Storage and Accessibility of Digital Resources (NESTOR) seal;1212 the Trusted Digital Repository checklist (ISO standard 16363) https:// www.crl.edu/archiving-preservation/digital-archives/ metrics-assessing-and-certifying/iso16363; and most recently (2016) the CoreTrustSeal or Core Trustworthy Data Repositories Requirements,1313 launched jointly by the International Council for Science World Data System (ICSU-WDS) and the Data Seal of Approval. While the focus of these standards has been primarily the certification of digital data repositories rather than on the compilation of statistics, they nevertheless offer examples of how communities have developed governance structures and certification standards to ensure that data can be trusted. No doubt there are lessons to be learned from these scientific communities.
The fact that certification standards and accreditation procedures are being developed by communities in the wider data ecosystem suggests that perhaps, our concerns and thinking inside the national and global statistical system are not so different from those outside. In other words, official statisticians, data scientists, researchers, and other scientists are all concerned with the quality of data, statistics and analyses. Perhaps optimistically, it suggests, that compilers of unofficial statistics will not find adherence to accreditation standards an alien or overly challenging concept.
4.Conclusion
The demands made by the SDG GIF are colossal with enormous implications for NSSs. In April 2019, the IAEG-SDG stated that at best only 44 per cent of the selected indicators for the SDG GIF could be populated. The costs of populating the GIF exceed existing funding. It seems unlikely that funding will increase sufficiently to match requirements. Yet the global statistical system is expected to deliver a fully populated GIF to support the 2030 Agenda. Although these expectations are probably not realistic, failure to deliver could nevertheless result in significant reputational damage to that system, with far reaching repercussions.1414
It is time to consider new approaches to populating the SDG GIF. Experience from the MDGs tells us that by 2030 many of the SDG indicators will not be populated. Without considerable investment, most Tier 2 and 3 indicators, are unlikely to become Tier 1 indicators. Few countries will be capable of producing the country level data required for the foreseeable future. While it is very important that countries feel ownership of the SDG process, the insistence on prioritising country statistics may ultimately be self-defeating; the focus should be on the best available statistics. There is a risk that in taking a rigid position on the source of statistics, countries are simply trying to hold back the tide. The data deluge will overcome them eventually.
Hence the proposal for a supplementary approach. To recap – an agreed recognized and mandated body, with the authority and competence to certify statistics as ‘fit for purpose’, would review unofficial statistics to see whether they can be certified as ‘official’ for the purposes of populating the SDG GIF. Statistics certified ‘fit for purpose’ could be accredited and used as official statistics. In other words, the SDG GIF would be populated from a combination of official statistics and unofficial (but certified official) statistics. There will naturally be concerns that the proposal outlined in this paper may contribute to a wider corrosion of official statistics, multilateral systems and public goods. There may be fears that this is the vanguard for the privatization of official statistics. There will be concerns too regarding the quality of any ‘outsourced’ indicators, and even whether they have been compiled free of political or advocacy pressures. These are all valid concerns that must be addressed if an accreditation system is to be introduced. But as already stated, this is not an argument for the privatisation or ‘uberfication’ of official statistics, nor is it an attempt to subvert NSOs or NSSs. Quite the contrary, the argument is that in order to protect official statistics and NSSs, those systems must evolve and adapt.
The approach proposed here is consistent with the open philosophy adopted during the consultation and negotiation phase of the 2030 Agenda. One could think of it as democratizing the SDG GIF but in a controlled way with clear rules. It would harness the intellectual power of NGOs, civil society and the private sector, giving them an incentive to share their data. In a world of ‘alternative facts’ it might also allow NSOs and the UN to assert their mandate and protect their legitimate role as custodians of knowledge and protectors of deliberative public spaces.
It is time for a data revolution. The Dubai Declaration, drafted at the conclusion of the 2018 UN World Data Forum acknowledges ‘that the data demands for the 2030 Agenda require urgent new solutions that leverage the power of new data sources and technologies through partnerships between national statistical authorities and the private sector, civil society, and the academia and other research institutions.’ [61, p. 7]. The UN Statistics Division, summarizing the debate of a special session at the 50
The information environment is changing. Official statisticians must remain vigilant – complacency will create vulnerabilities. The proposal outlined here brings risks, but it may be necessary to open up and surrender a position of dominance or monopoly today in order to survive tomorrow. With every bold initiative there are risks. It is essential that such a system not be adopted blindly but only after careful consideration, and if adopted, known risks must be mitigated. As Diamond [63, p. 433] points out, all ‘decisions involve gambles, because one often can’t be certain that clinging to core values will be fatal, or (conversely) that abandoning them will ensure survival.’ For better or worse, the Tier 2 and Tier 3 indicators have created a vacuum and if this vacuum is not filled by official statistics, then it will be exploited by someone else. In a rapidly changing and increasingly competitive data world, official statisticians may need to collaborate with a variety of actors from the wider data ecosystems or perish. In doing so it may not be easy to decide what core values or principles to discard and which to cling on to. But given the experience with the MDG indicators, it is highly improbable that by 2030, the majority of the SDG indicators will be populated. The question for official statisticians is whether it is time to try something different or just keep doing the same thing over and over again, hoping for a different result; a practice Einstein purportedly defined as insanity.
The proposal here is that official statistics switch from a purely production or manufacturing based model to a mixed business model: one combining the manufacture of official statistics with the franchising of production under license. One could think of this approach as a decentralized supply chain model. This is not a wiki approach but rather a spoke – hub, or HQ – subsidiary model. This proposal envisages the creation of a regulated market place, where compilers bid to populate SDG indicators. NSOs at national level and the UN at international level, as independent brokers of information, would be the quality controllers. The benefits of such an approach would be the enormous human and organizational capital that could be harnessed from all around the world. It would allow official statistics to tap into and avail of immense creativity and innovation, possibly accelerating change and reducing duplication, but in a controlled way. This approach positions NSOs and IOs as the guardians of public trust, the data stewards for the 21
This proposal is not a panacea. Myriad problems will remain, new and unforeseen ones will arise. But it may unleash the untapped productivity and creativity of a wider data ecosystem. It should be stressed that this proposal is specific to addressing gaps in the SDG GIF, and consequently the scope is limited to populating SDG indicators. The approach discussed in this paper, is scalable beyond the SDGs. The same, or similar, approach could be applied to official statistics more broadly. Although this wider debate falls outside the scope of this paper, one could nevertheless consider the SDGs a petri dish where a limited or confined experiment could be trialed. The danger of course, is that by 2030, as Gates warned in the opening quote, we will have underestimated the changes that will occur over the next 10 years and the data landscape may have changed dramatically, and official statisticians may look back wistfully and wish they had been braver and more proactive. Furthermore, in this paper we limit our discussion to the homologation of statistics. One could have a parallel debate about the certification of institutions to be inducted into a formal official data ecosystem. Again, this is a related, but different, discussion and that also falls outside our immediate scope.
Notes
1 These terms are defined and discussed more detail in Section 2.1 – A Proposal.
2 Authors own calculations based on OECD Development Assistance Committee Statistics (Table 1: Net Official Development Assistance) 2002–2014.
3 https://unstats.un.org/bigdata/inventory/ [examined on 27 April, 2018]. These numbers are a best estimate. Projects are not always well defined or explained on the inventory. Some projects seem to incorporate several projects or big data sources.
4 A similar approach is adopted by the European Union where European official statistics are by definition and law (Regulation 223/2009) those, and only those, that are disseminated by Eurostat.
5 Membership of the CCSA comprises international and supranational organizations, whose mandate includes the provision of international official statistics in the context of the Principles Governing International Statistical Activities [4], and which have a permanent embedded statistical service in their organization and regular contacts with countries. At the inaugural meeting in 2003, there were 25 agencies. By 2017, the CCSA had expanded to 45 member agencies.
9 ‘Data for statistical purposes may be drawn from all types of sources, be they statistical surveys or administrative records’ is a curious sentence, as ‘all types’ is presented as a choice between survey or administrative data. This we think was simply a reflection of the reality at the time. Today a much greater variety of potential data sources exist. One imagines the next update of the Fundamental Principles will need to adopt more generic terms, such as, primary and secondary data to reflect this abundance. See MacFeely and Barnat [48] for a more developed discussion on this point.
10 No doubt this was deliberate. But it is nevertheless ironic in a report discussing revolution.
11 For example, the FAIR (Findable, Accessible, Interoperable, and Reusable) principles for scientific data management and stewardship were published in 2016. See https://www.go-fair.org/fair-principles/.
12 See German Institute for Standardization (DIN) standard 31644 https://www.prestocentre.org/resources/nestor.
14 This of course presupposes that 232 is the optimal number of indicators. It is possible of course that by 2030 the UNSC and the IAEG-SDG may have concluded that there were too many metrics rather than too few. Therefore, to assess partial completion as failure is to uncritically accept that 232 was in fact the correct number of indicators to begin with. One could make the argument that a more select set of indicators would be better – just as one could also argue that more would have been better.
References
[1] | Gates, W.H. ((1995) ). The Road Ahead. Penguin Books Ltd. London. |
[2] | United Nations Conference on Trade and Development ((2016) ). Development and Globalization: Facts and Figures 2016. Available at: http://stats.unctad.org/Dgff2016/index.html [last accessed October 21, 2018]. |
[3] | United Nations ((2014) ). Fundamental Principles of Official Statistics. Resolution 68/261 adopted by the General Assembly on January 29, 2014. A/RES/68/261. Available from: https://unstats.un.org/unsd/dnss/gp/FP-New-E.pdf [last accessed October 21, 2018]. |
[4] | Committee for the Coordination of Statistical Activities ((2014) ). Principles Governing International Statistical Activities. Available at: https://unstats.un.org/unsd/accsub-public/principles_stat_activities.htm [last accessed October 21, 2018]. |
[5] | Committee for the Coordination of Statistical Activities ((2013) ). Recommended Practices on the Use of Non-Official Sources in International Statistics. Available at: https://unstats.un.org/unsd/accsub-public/practices.pdf [last accessed May 31, 2018]. |
[6] | Cervera, J.L., et al. ((2014) ). Big Data in Official Statistics. Eurostat ESS Big Data Event Rome 2014 – Technical Event Report. Available at: https://ec.europa.eu/eurostat/cros/system/files/Big%20Data%20Event%202014%20-%20Technical%20Final%20Report%20-finalV01_0.pdf [last accessed January 18, 2018]. |
[7] | Landefeld, S. ((2014) ). Uses of Big Data for Official Statistics: Privacy, Incentives, Statistical Challenges, and Other Issues. Discussion paper presented at the United Nations Global Working Group on Big Data for Official Statistics, Beijing, China October 31, 2014. Available at: https://unstats.un.org/unsd/trade/events/2014/beijing/Steve%20Landefeld%20-%20Uses%20of%20Big%20Data%20for%20official%20statistics.pdf [last accessed January 18, 2018]. |
[8] | MacFeely, S. ((2016) ). The continuing evolution of official statistics: Some challenges and opportunities. Journal of Official Statistics, 32: (4), 789–810. |
[9] | MacFeely, S. (January (2019) ). The big (data) bang: Opportunities and challenges for compiling SDG indicators. Global Policy, 10: (1), 121–133. |
[10] | Hammer, C.L., Kostroch, D.C., Quiros, G. ((2017) ). Big Data: Potential, Challenges, and Statistical Implications. IMF Staff Discussion Note, September 2017 SDN/17/06. Available at: https://www.imf.org/en/Publications/Staff-Discussion-Notes/Issues/2017/09/13/Big-Data-Potential-Challenges-and-Statistical-Implications-45106 [last accessed October 21, 2018]. |
[11] | Bordt, M., Nia, A.B. ((2018) ). SDG Implementation – what to do when it’s not clear what to do? ESCAP Stats Brief, Issue No. 6, August 2018. Available from: https://www.unescap.org/sites/default/files/Stats_Brief_Issue16_Aug2018_SDG_implementation.pdf [last accessed September 3, 2018]. |
[12] | United Nations Global Working Group on Big Data ((2017) ). Bogota Declaration. 4th Global Conference on Big Data for Official Statistics in Bogota, Colombia, November 8–10, 2017. Available at: https://unstats.un.org/unsd/bigdata/conferences/2017/Bogota%20declaration%20-%20Final%20version.pdf [last accessed September 5, 2018]. |
[13] | Kituyi, M. ((2016) ). Development and Globalization: Facts and Figures 2016. Available at: http://stats.unctad.org/Dgff2016/index.html [last accessed October 21, 2018]. |
[14] | MacFeely, S. ((2018) ). The 2030 Agenda: An Unprecedented Statistical Challenge. International Policy Analysis, Friedrich Ebert Stiftung. November 2018. |
[15] | United Nations ((2015) ). The Millennium Development Goals Report 2015 – Summary. Available at: http://www.un.org/millenniumgoals/2015_MDG_Report/pdf/MDG%202015%20Summary%20web_english.pdf [last accessed October 26, 2017]. |
[16] | Inter-Agency and Expert Group on Sustainable Development Goal Indicators ((2018) ). Tier Classification for Global SDG Indicators. Available at: https://unstats.un.org/sdgs/iaeg-sdgs/ [last accessed May 1, 2019]. |
[17] | Kapto, S. ((2019) ). Layers of politics and power in the SDG indicators process. Global Policy, 10: (1), 134–136. |
[18] | IAEG-SDGs ((2019) ). Best Practices in Data Flows and Global Data Reporting for the Sustainable Development Goals. Report prepared by the Inter-Agency and Expert Group on Sustainable Development Goal Indicators (IAEG-SDGs). Item 3(a)of the provisional agenda – UN Statistical Commission, 50 |
[19] | Deen, T. ((2016) ). UN targets trillions of dollars to implement sustainable development agenda; Available at: http://www.ipsnews.net/2015/08/u-ntargets-trillions-of-dollars-to-implement-sustainable-development-agenda/ [last accessed October 31, 2016]. |
[20] | Thiaw, I. ((2016) ). Environment and the Implementation of the SDGs and the 2030 Agenda: A Policy Perspective. IISD – SDG Knowledge Hub. March 29, 2016. Available at: http://sdg.iisd.org/commentary/guest-articles/environment-and-the-implementation-of-the-sdgs-and-the-2030-agenda-a-policy-perspective/ [last accessed October 26, 2018]. |
[21] | Intergovernmental Committee of Experts on Sustainable Financing ((2014) ). Report of the Intergovernmental Committee Experts on Sustainable Development Financing. UN General Assembly A/69/315*, August 15, 2014. Available at: http://www.un.org/ga/search/view_doc.asp?symbol=A/69/315&Lang=E [last accessed October 26, 2018]. |
[22] | United Nations ((2003) ). Monterrey consensus of the International Conference on Financing for Development; available at: http://www.un.org/esa/ffd/monterrey/MonterreyConsensus.pdf [last accessed October 31, 2016]. |
[23] | Runde, D. ((2017) ). The Data Revolution in Developing Countries Has a Long Way to Go. Forbes, February 25, 2017. Available at: https://www.forbes.com/sites/danielrunde/2017/02/25/the-data-revolution-in-developing-countries-has-a-long-way-to-go/#620717201bfc [last accessed September 4, 2018]. |
[24] | PARIS21 ((2015) ). A road map for a country-led data revolution. Available at: https://read.oecd-ilibrary.org/development/a-road-map-for-a-country-led-data-revolution_9789264234703-en#page1 [last accessed March 20, 2019]. |
[25] | PARIS21 ((2018) ). Partner Report on Support to Statistics – Press 2018. Available at: http://www.paris21.org/sites/default/files/inline-files/PRESS2018_V3_PRINT_sans%20repres_OK_0.pdf [last accessed November 17, 2018]. |
[26] | Verhulst, S.G. ((2018) ). How to harness private data towards meeting the SDGs? The need for data stewards. Blog, July 3, 2018. Available at: https://undataforum.org/ [last accessed August 15, 2018]. |
[27] | Committee of the Chief Statisticians of the United Nations System ((2018) ). United Nations Statistics Quality Assurance Framework. Available at: https://unstats.un.org/unsd/unsystem/documents/UNSQAF-2018.pdf [last accessed April 25, 2018]. |
[28] | United Nations Economic Commission for Europe ((2009) ). Common Metadata Framework – Part A – Statistical Metadata in a Corporate Context: A guide for managers. Available at: http://www.unece.org/fileadmin/DAM/stats/publications/CMF_PartA.pdf [last accessed October 24, 2018]. |
[29] | European Statistical Governance Advisory Board ((2017) ). Opinion of the European Statistical Governance Advisory Board (ESGAB), concerning professional statistical independence and staffing resources in the Hellenic Statistical Authority (ELSTAT)’, ESGAB/2017/10. Issued from Helsinki, May 11, 2017. Available at: http://ec.europa.eu/eurostat/documents/34693/344453/ESGAB+doc.++2017_10_ESGAB+Opinion+on+Greek+developments_11.05.2017.pdf/e684a082-caf4-4c27-a38f-ee9717a09772 [last accessed January 5, 2018]. |
[30] | Greene, M. ((2017) ). By convicting an honest statistician, Greece condemns itself. Politico, March 8, 2017. Available at: https://www.politico.eu/article/greece-andreas-georgiou-elstat-by-convicting-an-honest-statistician-greece-condemns-itself/ [last accessed January 5, 2018]. |
[31] | Zimonjic, P., Kupfer, M. ((2016) ). Chief statistician resigns over government’s failure to ‘protect the independence’ of StatsCan. CBC News, Sep 16, 2016 and Updated: September 17, 2016. Available at: https://www.cbc.ca/news/politics/statscan-wayne-smith-resigns-1.3765765 [last accessed September 3, 2018]. |
[32] | The Local ((2017) ). Norway statistics bureau head leaves post over conflict. November 13, 2017. Available at: https://www.thelocal.no/20171113/norway-statistics-bureau-chief-resigns-over-conflict [last accessed January 5, 2018]. |
[33] | World Bank ((2018) ). World Bank Statement on Amendments to Tanzania’s 2015 Statistics Act. Statement, October 2, 2018. Available at: https://www.worldbank.org/en/news/statement/2018/10/02/world-bank-statement-on-amendments-to-tanzanias-2015-statistics-act [last accessed October 21, 2018]. |
[34] | Reuters ((2018) ). Tanzania law punishing critics of statistics “deeply concerning”: World Bank, October 3, 2018. Available at: https://af.reuters.com/article/idAFKCN1MD16H-OZATP [last accessed October 21, 2018]. |
[35] | Yoon, J. ((2018) ). Dismissal of statistics chief draws criticism. The Korea Times, August 27, 2018. Available at: http://www.koreatimes.co.kr/www/nation/2018/09/356_254533.html [last accessed March 4, 2019]. |
[36] | Kramer, A. ((2019) ). Russia Changes Economic Reporting. The Results Improve. The New York Times, March 20, 2019. Available at: https://www.nytimes.com/2019/03/20/world/europe/russia-income-statistics.html [last accessed March 22, 2019]. |
[37] | Rosling, H., Rosling, O., Rosling-Ronnlund, A. ((2018) ). Factfulness: Ten Reasons We’re Wrong About the World – and Why Things Are Better Than You Think. Flatiron Books, New York. |
[38] | European Commission ((2017) ). European Statistics Code of Practice – For the National Statistical Authorities and Eurostat (EU Statistical Authority). Adopted by the European Statistical System Committee. November 16, 2017. Available at: https://ec.europa.eu/eurostat/documents/4031688/8971242/KS-02-18-142-EN-N.pdf/e7f85f07-91db-4312-8118-f729c75878c7 [last accessed September 5, 2018]. |
[39] | African Union ((2015) ). Statistics Quality Assurance Framework for the African Statistics System. Statistics Division, Economic Affairs Department. Available at: https://au.int/sites/default/files/documents/32850-doc-quality_framework_for_the_ass_en_2016-03-17.pdf [last accessed March 5, 2019]. |
[40] | Caricom ((2009) ). Caricom Data Quality Assurance Framework. Available at: https://caricom.org/documents/13410-caricom_statistics_code_of_practice.pdf [last accessed March 5, 2019]. |
[41] | Luce, E. ((2017) ). The retreat of Western Liberalism. Little, Brown Books, London. |
[42] | Borgman, C.L. ((2015) ). Big Data, Little Data, No Data – Scholarship in the Networked World. Cambridge, MA: MIT Press. |
[43] | Rudder, C. ((2014) ). Dataclysm: What our online lives tell us about our offline selves. 4 |
[44] | Fukuda-Parr, S., McNeill, D. ((2019) ). Knowledge and politics in setting and measuring the SDGs: Introduction to special issue. Global Policy, 10: (1), 5–15. |
[45] | Gitelman, L. (Ed) ((2013) ). ‘Raw Data’ is an Oxymoron MIT Press, Cambridge, MA. |
[46] | Mahajan, M. ((2019) ). The IHME in the shifting landscape of global health metrics. Global Policy, 10: (1), 110–120. |
[47] | PARIS21 ((2005) ). Models of Statistical Systems, Document Series No. 6. 2005. Available at: https://www.paris21.org/sites/default/files/2101.pdf [last accessed October 22, 2018]. |
[48] | MacFeely, S., Barnat, N. ((2017) ). Statistical capacity building for sustainable development: Developing the fundamental pillars necessary for modern national statistical systems. Statistical Journal of the IAOS, 33: (4), 895–909. |
[49] | Salazar, N. ((2011) ). Top 10 philanthropic foundations: A primer. DEVEX, August 1, 2011. Available at: https://www.devex.com/news/top-10-philanthropic-foundations-a-primer-75508 [last accessed January 4, 2018]. |
[50] | Viergever, R.F., Hendriks, T.C.C. ((2016) ). The 10 largest public and philanthropic funders of health research in the world: What they fund and how they distribute their funds. Health Research Policy and Systems, 14: (1), 1–15. |
[51] | Noyes, K. ((2015) ). Scott McNealy on privacy: You still don’t have any. PC World, IDG News Service, June 25, 2015. Available at: https://www.pcworld.com/article/2941052/scott-mcnealy-on-privacy-you-still-dont-have-any.html [last accessed January 29, 2018]. |
[52] | Taplin, J. ((2017) ). Move Fast and Break things – How Facebook, Google and Amazon cornered culture and undermined democracy. Little, Brown and Company, New York. |
[53] | Reich, R. ((2015) ). Saving Capitalism: For the Many, Not the Few. London: Icon Books Ltd. |
[54] | Polanyi, K. ((1944) ). The Great Transformation – The political and economic origins of our time. Beacon Press, Boston. |
[55] | MacFeely, S., Dunne, J. ((2014) ). Joining up public service information: The rationale for a national data infrastructure. Administration, 61: (4), 93–107. |
[56] | Hayak, F.A. ((1944) ). The Road to Serfdom. The University of Chicago Press, Chicago. |
[57] | United Nations General Assembly ((2015) ). Transforming our world: the 2030 Agenda for Sustainable Development. Resolution A/RES/70/1 adopted by the General Assembly on 25 September 2015, 21 October 2015. Available at: http://www.un.org/ga/search/view_doc.asp?symbol=A/RES/70/1&Lang=E [last accessed October 22, 2018]. |
[58] | Independent Expert Advisory Group on a Data Revolution for Sustainable Development ((2014) ). A World That Counts: Mobilising the Data Revolution for Sustainable Development. Report prepared at the request of the United Nations Secretary-General. Available from: http://www.undatarevolution.org/report/ [last accessed October 22, 2018]. |
[59] | Ferguson, N. ((2011) ). Civilization – The West and the Rest. The Penguin Press, New York. |
[60] | Weinberger, D. ((2014) ). Too Big to Know. Basic Books, New York. |
[61] | United Nations ((2018) ). The Dubai Declaration: Supporting the Implementation of the Cape Town Global Action Plan for Sustainable Development Data. October 24, 2018. Available at: https://undataforum.org/WorldDataForum/wp-content/uploads/2018/10/Dubai-Declaration-on-2030-Agenda_Draft-22-October-2018.pdf [last accessed October 24, 2018]. |
[62] | United Nations Statistics Division ((2019) ). Summary on the Update of the System of Economic Statistics. Friday Seminar on Emerging Issues – The Future of Economic Statistics. 1 March 2019, United Nations Headquarters, New York. Available at: https://unstats.un.org/unsd/statcom/50th-session/side-events/documents/20190301-1M-Summary_Friday-Seminar-The-Future-of-Economic-Statistics.pdf [last accessed March 26, 2019]. |
[63] | Diamond, J. ((2005) ). Collapse – How societies choose to fail or succeed. Viking, Penguin Group, New York. |


