
TermIt: Managing normative thesauri
Abstract
Thesauri are popular, as they represent a manageable compromise – they are well-understood by domain experts, yet formal enough to boost use cases like semantic search. Still, as the thesauri size and complexity grow in a domain, proper tracking of the concept references to their definitions in normative documents, interlinking concepts defined in different documents, and keeping all the concepts semantically consistent and ready for subsequent conceptual modeling, is difficult and requires adequate tool support. We present TermIt, a web-based thesauri manager aimed at supporting the creation of thesauri based on decrees, directives, standards, and other normative documents. In addition to common editing capabilities, TermIt offers term extraction from documents, including a web document annotation browser plug-in, tracking term definitions in documents, term quality and ontological correctness checking, community discussions over term meanings, and seamless interlinking of concepts across different thesauri. We also show that TermIt features better fit the E-government scenarios in the Czech Republic than other tools. Additionally, we present the feasibility of TermIt for these scenarios by preliminary user experience evaluation.
1.Introduction
Terminological ambiguities across normative documents cause misunderstandings and misinterpretations. For example, according to the Prague Building Regulations11 (PBR), a building is “a construction both above and below ground, spatially concentrated and mostly enclosed by perimeter walls and a roof structure”, while according to the draft of the Metropolitan plan of Prague22 (MPP), a building is “a construction above ground with solid foundations spatially concentrated and mostly enclosed by perimeter walls and a roof structure”. In related documents, the term “construction” can denote an event (of construction works), or its outcome (the actual object).
Both MPP and PBR were published by the Institute of Planning and Development of Prague33 (IPR). While PBR is an obligatory Prague directive, MPP is still under preparation and its draft is public.44 Yet, its terminological ambiguities contributed to the lengthy public discussions and revisions.
Both the MPP document and the web application use common-sense terminology, as well as normative terminology referring to existing documents, like the Building Act No. 183/2006 Coll., Decree No. 501/2006 Coll, or Decree No. 268/2009 Coll. However, a closer look at some of the key concepts reveals that it is not just the term “building” with conflicting definitions55 across MPP, PBR, and other related normative documents, as exemplified in Fig. 1.
Fig. 1.
Terminology ambiguities – mentioned concepts lack explicit definitions in the document, while defined concepts have one. For example, the concept “building” in Decree 268/2009 Coll. has an explicit definition which refers to a concept “construction” being indirectly assumed (not explicitely mentioned) to comply with the concept “construction” from the Building Act No.183/2006 Coll.
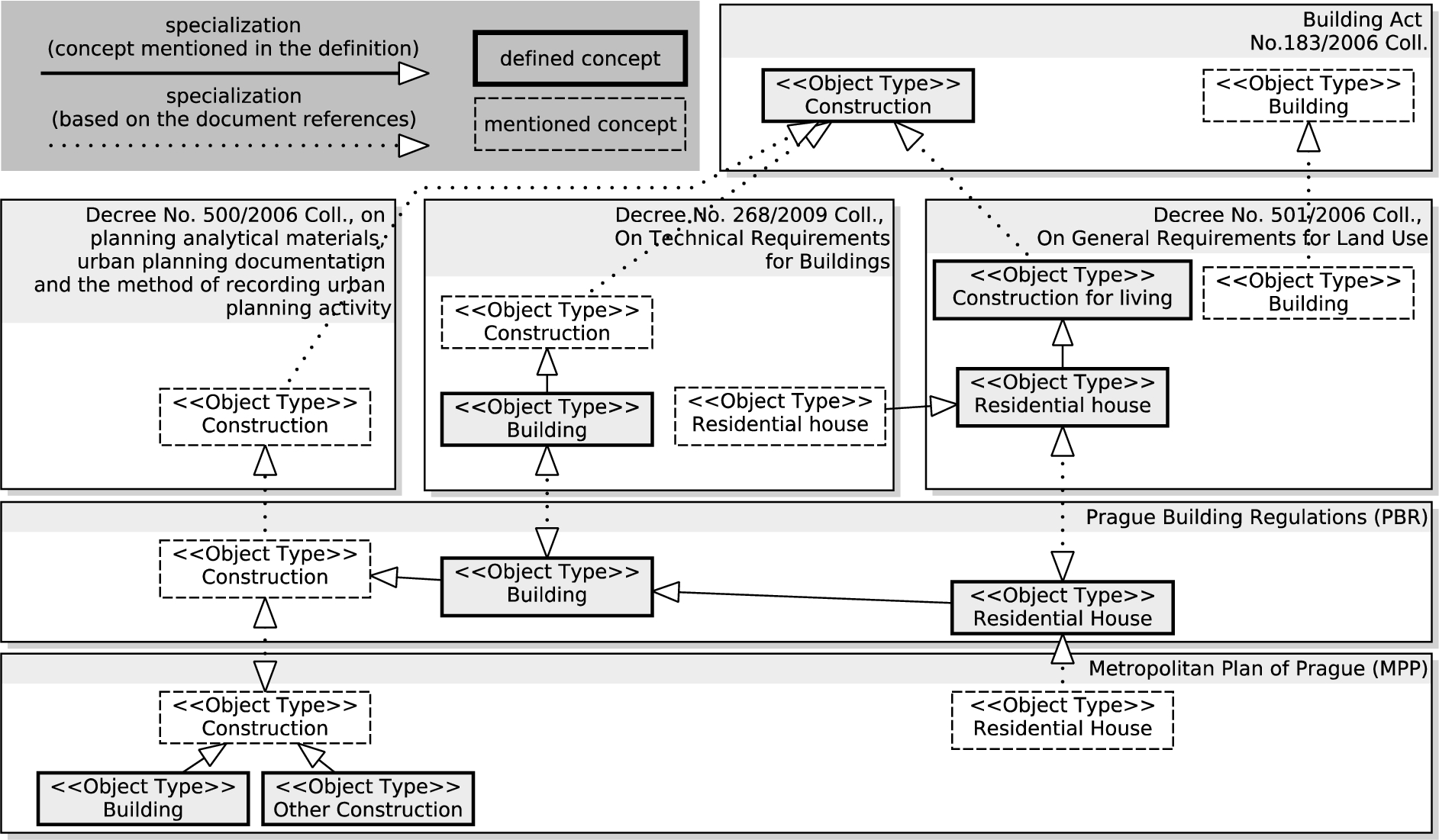
These problems deteriorate understandability of both MPP and PBR. MPP drafts have been facing many objections by individuals, professional associations as well as municipalities from the beginning in the year 2013 – many of them related to ambiguous terminology.66 Thesauri offer a solution here – they are well-understood by domain experts, yet formal enough to support word sense disambiguation, and other NLP techniques for semantic search.
Furthermore, subsequent ontology-based conceptual modeling [9] to integrate different data sets requires clearly defined concepts too, to avoid ambiguous information system APIs or table/column names of (open) data. Although ontology creation is out of the scope of this paper, distinguishing the basic semantic types of concepts (e.g. a construction as an object and a construction as an event) not only helps to keep the hierarchy coherent but also provides a solid basis for subsequent ontology modeling [19]. In summary, the following problems were identified:
P1 The normative documents, as well as the derived artifacts (web application/open data sets) do not provide the user with the explicit context of the concepts, their definition, and relation to other concepts,
P2 A term denotes different concepts (meanings). While sometimes a concept definition is just a more restricted variant of another (building with/without subterranean parts), sometimes a term denotes two fundamentally different concepts (construction as an object vs. construction as an event). The two different meanings often come from different contexts (documents/thesauri).
P3 The connection between a concept and the place where it occurs or is defined is not maintained.
To address these issues, as a part of our research collaboration with IPR, we designed and implemented TermIt [14], a tool for managing interconnected thesauri extracted from decrees, directives, standards, and other normative documents. TermIt offers a scenario additionally supporting linking the identified concepts to their referential occurrences and definitions in normative documents, interlinking concepts coming from different thesauri, community discussions over concept meaning, as well as concept quality validation.
An overview of TermIt has been already given in [14]. The current paper focuses on the practical impact of TermIt and presents the following contributions:
1. concept validation and quality checking using the Unified Foundational Ontology [9] (Section 3.3),
2. browser plug-in for web document annotation (Section 3.2),
3. comparison of TermIt features to state-of-the-art systems and evaluation of its usability (Section 5),
4. a report of the impact of TermIt and its practical use cases (Section 6).
In Section 2, we present key models used in TermIt. Section 3 shows the architecture and features of the system. Section 4 presents existing tools which are in Section 5 compared to TermIt, together with a user study on TermIt usability. The impact of TermIt is discussed in Section 6 and the paper is concluded in Section 7.
2.Key notions
In [13] a structure of interlinked Semantic Government Vocabularies based on legal acts is proposed, without offering software support for their creation and management. Each vocabulary consists of a thesaurus represented in the Simple Knowledge Organization System (SKOS) [15] and an ontological model expressed in the Unified Foundational Ontology (UFO) [9]. To align with the proposed architecture used in the Czech eGovernment, TermIt is designed to be compliant with SKOS. Furthermore, to ensure semantic coherency of the concepts and to prepare them for the subsequent conceptual modeling, it allows classifying concepts into UFO categories.
2.1.SKOS
Simple Knowledge Organization System (SKOS) [15] has been used for more than a decade as a standard for representing simple thesauri on the web. Its main features involve representing concepts and organizing them into hierarchies. For example it contains the generic skos:broader relationship without requiring to specify the particular specialization semantics (e.g. superclass, type, part of a whole). For example, when creating the concept of pbr:building,77 it can have the SKOS representation as shown in Listing 1.
The SKOS specification does not provide support for distinguishing between different ontological categories, like endurants (Objects) and perdurants (Events).
Listing 1.
Example SKOS representation of a building

2.2.Unified foundational ontology
Unified Foundational Ontology (UFO) [9] is a top-level ontology designed for conceptual modeling, originally expressed in modal logic [9], but with recent partial translations to OWL 2 [1].
UFO covers static properties of endurants (UFO-A) [9], dynamic properties of perdurants (UFO-B) [11], a multi-level theory for modeling types (UFO-MLT) [6], and other extensions.
The basic semantic categories of types involve events (e.g. football match, wedding), objects (e.g. Building, Person, Information system, Document), aspects (e.g. Person name,Building height), and relators (e.g. Marriage, Course enrollment). However, endurant types (the latter three) can be partitioned not only according to their meaning but also according to their rigidity and sortality – their ontological characteristics. Taking an example from [10], while the Marriage relator can be characterized as a kind (rigid sortal), Foreign Marriage is a Role (anti-rigid sortal), as it depends on a relationship to a Foreign person type (being itself a role). We developed an OWL version of UFO,88 used to augment the thesauri with UFO-based categories. To exemplify, the Listing 1 can be extended by the triple pbr:building rdf:type ufo:object-type.
3.TermIt architecture
TermIt99 is a Web application with backend written in Java1010 and front-end written in TypeScript.1111 The back-end follows a layered architectural style [4] and provides a REST API [8] supporting JSON as well as JSON-LD [18].
TermIt is backed by a GraphDB [2] repository that uses custom rules allowing inference combining selected RDFS [3] (class and property hierarchies) and OWL [16] (inverse properties) features. A linked data API can be set up on top of the repository using Pubby [7].
TermIt deployment can be done via Docker1212 as well as by running individual services directly on the underlying host. Installation as well as requirements are described on TermIt web pages.1313
TermIt1414 consists of several modules for thesauri creation, verification of their quality, and their usage for document annotation and search. Figure 2 illustrates the system architecture and the following sections provide details.
Fig. 2.
Schematic depiction of the architecture of TermIt. Annotace [17] is an external document annotation service. TermIt Annotate is a browser plugin [5] for direct web annotation. Solid edges (with labels indicating protocol and data format) represent data flow. Oval nodes within the TermIt box represent the main use cases/components with arrows indicating their interdependence.
![Schematic depiction of the architecture of TermIt. Annotace [17] is an external document annotation service. TermIt Annotate is a browser plugin [5] for direct web annotation. Solid edges (with labels indicating protocol and data format) represent data flow. Oval nodes within the TermIt box represent the main use cases/components with arrows indicating their interdependence.](https://content.iospress.com:443/media/sw-prepress/sw--1--1-sw243547/sw--1-sw243547-g003.jpg)
3.1.Thesauri management
In the thesauri management module, users can maintain domain thesauri (called vocabularies in TermIt for historical reasons), as well as categorize the concepts using the UFO [9] semantic categories (see Section 2.2). A concept hierarchy can be constructed within a single thesaurus, but also across different thesauri to support cross-document links described in Section 1. Textual attributes of concepts (e.g., label, definition) are multilingual, so the thesauri can also be used in an international environment. Concepts and thesauri can also be searched using full-text matching.
3.2.Document annotation and web annotation
Linking documents and concepts is a key feature of TermIt. Users can attach documents to thesauri, either by uploading an HTML file through TermIt UI, or by annotating a web page directly using the TermIt Annotate plug-in [5]. Then, occurrences of concepts and their definitions in the text can be linked to the thesauri concepts. In this manner, documents and web pages linked to the given concept can be listed. TermIt uses Annotace [17], a standalone text analysis service, to discover concept occurrences in documents and suggest new concepts based on their significance in the text. As the service is based on the Czech language for which a gold standard is not available yet, Annotace is only used for concept suggestions – a domain expert has to always review and confirm them.
3.3.Quality checking and validation
To control the quality and completeness of concepts, TermIt employs constraints encoded as SHACL [12] rules that are evaluated over the SKOS [15] representation of a thesaurus. The constraints include, for example:
(g2) each concept has a skos:prefLabel in a language,
(g3) each concept has at most one skos:definition in a language,
(g4) each concept has at least one skos:definition in a language,
(g9) a concept has a skos:prefLabel which is unique in the thesaurus,
(g13) a concept should have a dc:source,
(g14) a concept should have a parent (either skos:broader, or skos:broadMatch).1515
Although the primary purpose of TermIt is thesauri management, P2 (see Section 1) requires different concepts to be properly distinguished. To support this disambiguation, TermIt supports classification of concepts using UFO. Thus, SHACL constraints are also used to check the semantic coherency of a concept typed with a UFO type, e.g.:
(m1) each concept has at least one UFO semantic category (Object, Relator, Aspect, Event, or sub-types thereof),
(m2) The above categories are pairwise disjoint.
Rule violations are presented to the user by the TermIt user interface (UI). Additionally, rules g4, g13, g14, and m1 form a quality score of the concept – failing any of these rules decreases the score of the concept by 25%, which is signalized to the user by the color of its quality badge.
4.Related work
Various tools addressing the problems P1–P3 were investigated, which we described in a survey report.1717
For P1, tools that are able to express concepts, i.e. the meaning of terms can be utilized. Terminology management tools like Vocbench 31818 often targeted to domain experts or language translators, use textual definitions and relate concepts with thesauri relations such as skos:broader and skos:related. Knowledge management tools such as Protégé 1919 typically tailored towards ontology engineers, tend to employ more precise semantic relationships (e.g., utilizing OWL properties) or logical axioms to establish meaning. Other tools like Menthor Editor2020 may also employ diagrams to specify the meaning.
For P2, various techniques are used by tools to differentiate the meaning of identical or similar terms or phrases. The quality of concept labels, textual definitions and structural properties of taxonomies is checked by tools like PoolParty Semantic Suite.2121 SKOS Shuttle2222 identifies and proposes fixes for orphaned concepts. Sketch Engine2323 identifies different concepts by analyzing a corpus and presenting contextual information for them. Lastly, tools like Menthor Editor utilize upper-level ontology theories, employing typing by stereotypes developed within those theories to differentiate the meaning of similar terms.
For P3, connecting concepts to locations within documents where they are defined or used is a challenge. Terminology management tools like PoolParty Semantic Suite or SKOS Shuttle, computer-assisted translation (CAT) tools like SDL Trados,2424 and NLP-related tools for text annotations like GATE2525 or BRAT2626 work with extracted text, not the documents themselves, so they do not keep track of those locations. Web annotating tools like Hypothesis2727 or Diigo2828 can annotate parts of the text within documents and navigate there, but they lack support for concept management or concept search within the document.
In summary, we have not found any existing tool to effectively address all three problems P1–P3. The challenge in combining existing tools is due to P3, where tools either operate solely with extracted text and do not work with actual documents or lack support for concept management and concept search within the document. This presents a significant obstacle to solving these problems simultaneously.
5.Evaluation
For evaluation, we have identified five functional features based on the use cases mentioned in Section 1
(F1) browsing and searching for thesauri and concepts,
(F2) creating/editing new thesauri and concepts, interlinking concepts,
(F3) handling documents and web resources,
(F4) thesauri quality control,
(F5) annotation of resources and their content.
5.1.Tool comparison
To compare the tools, we used the review from Section 4. After disregarding tools that do not support document/web source management (e.g. Vocbench 3) or do not consider textual content (e.g. VoCol2929), we picked four tools most relevant to our use cases – the PoolParty Semantic Suite (PP), TopBraid Enterprise Data Governance (EDG), SKOS Shuttle (SKS), and TermIt. Table 1 highlights key differences among the tools w.r.t. to features F1–F5.
F1 is well-supported in SKS and has excellent support in other tools. All the tools support hierarchical visualization of concepts, search within key metadata of concepts (like labels, synonyms, or definitions), and thesauri (like description). Search for non-label metadata can be done in SKS only using SPARQL queries. In addition, EDG and PP implement faceted search and advanced search filters.
F2 support is diverse across the tools. Although they all support multi-user access, change tracking, multilingual concepts, and their linking across thesauri, only TermIt can link a concept to the place where it is defined. PP and EDG support customizable collaboration workflows, while TermIt only supports the draft/confirmed status of a concept. PP, EDG, and TermIt provide a discussion thread about a concept.
F3 is well-supported in all tools, including managing local files or URL resources. In addition, the competitors support the web crawling of documents. PP and EDG also support full-text searches within documents.
F4 is well supported in EDG and PP, featuring customizable validation rules, metrics, and the generation of reports. F4 is also well supported in TermIt, offering validation rules and metrics for concepts and thesauri that are configured during deployment. SKS has support only for concept deorphanization.
F5. TermIt competitors allow importing different content types (e.g., PDF, XLSX, HTML) but do not support manual annotations. Only PP can visualize annotated content as plain text. In contrast, TermIt allows both online annotations in the web browser and importing HTML documents supporting manual annotations. Complex HTML documents often need to be adjusted manually before import.
Table 1
Differences among the tools w.r.t. features F1–F5. Commonalities of the tools are described in Section 5.1
| PoolParty Semantic Suite | TopBraid EDG | SKOS Shuttle | TermIt | |
| F1 | - Faceted search - Advanced search filters | - Faceted search - Advanced search filters | ||
| F2 | - Discussion about concept - Customizable collaboration workflows | - Discussion about concept - Customizable collaboration workflows | - Discussion about concept - Simple concept approving workflow - Differentiate between concept use and concept definition - Navigable link to concept definition | |
| F3 | - Crawling web resources - Full-text search within documents | - Crawling web resources - Full-text search within documents | - Crawling web resources | |
| F4 | - Customizable validation rules - Customizable metrics - Generation of reports | - Customizable validation rules - Customizable metrics - Generation of reports | - Predefined validation rules - Predefined metrics | |
| F5 | - Different content types - Annotated content visualization in plain text | - Different content types | - Different content types | - HTML content type only - Annotated content visualization respecting document layout - Manual annotation support |
To sum up, EDG and PP are professional tools that provide many additional features that are more or less relevant for the presented use case. PP is intuitive and provides the best support in F1 and F4. EDG provides similar features as PP, yet, with a more complex UI. SKS is a very promising alternative to PP but lacks F4. F5 has the weakest support across the tools except TermIt. TermIt allows creating or approving suggested concepts directly from the document without the need to leave the document view. Moreover, the user can navigate from a concept to its definition within a document to get the proper context for understanding the concept.
5.2.User experience evaluation
We have set up a set of tasks for the features F1–F5, each evaluated w.r.t. the following criteria:
1. the time needed to finish the task,
2. the understanding of the task,
3. the understanding of the TermIt content,
4. the importance of tested features,
5. the difficulty of the tasks, and
6. the error detection.
These criteria reflect the user experience with TermIt – the goal is not to find out what the users are doing, but how they understand the content, the features and what is the subjective difficulty of task completion in TermIt.
Testing scenarios3030 were applied to five users with different levels of experience with TermIt. They were recruited from the people working as domain experts for urban planning, aviation, and medicine and also developers, none of which participated in the development of TermIt. The testers know normative texts regarding their domain very well and understand the meaning of words in context. The testing scenario was divided into five specific tasks.
Searching for a concept based on the label (T1) seemed easy, yet one of the testers did not succeed. According to the evaluation, most users understood what to do and how to do it, including the user who had it wrong.
Finding a concept, writing its definition, and checking its quality (T2) was completed incorrectly by one tester, again. Although the others succeeded, the concept quality didn’t seem to be well understood. Namely, how errors (e.g. missing UFO type of a concept) relate to the quality score, or even finding the errors on the concept detail page.
Creating a new thesaurus and concepts and marking new concepts in the document supported by automatic text analysis (T3). The most problematic part appeared to be marking definitions in the document. All users have described it as impossible to do but very useful. It is interesting that most of the users consider file analysis and concept detection in the documents as useful, yet for some it is not essential.
As a response to the feedback, a new web browser plugin (TermIt Annotate) has been designed, allowing testers to create the concepts directly by annotating web resources in the browser, without the need of (re-)importing web documents to TermIt and modifying their appearance. Out of five testers, three responded they would favor it over the internal TermIt annotator, one is not sure, and the last one would not. Overall usability of the web annotator plugin scored high in the evaluation (average score 4.6 out of 5). More details can be found in [5].
Improving thesaurus quality (T4) involved filling up all attributes of concepts to increase the quality score. As expected, more advanced attributes caused problems for the testers. The reason seems to be that UFO-based values of the ‘Type of concept’ field were too general to most users. Also, some of the quality checks turned out to be irrelevant – e.g. checking the length of concept definition and requiring each concept (except one) to have a parent.
Distinguishing different concepts with the same label (T5) addresses another problem in Section 1. First, we asked users for any ideas on how to solve the problem of two concepts with the same label and a different meaning. Only one of the testers had an idea. After presenting the options to link concepts, they all succeeded. Then we asked them to create relations between concepts from different thesauri. Two of the testers had minor problems, but the functionality was evaluated positively.
Table 2 shows average and limit times needed to finish the tasks. T2 was misinterpreted by the testers, making the time measure irrelevant. T5 focused on understanding the concept rather than efficiency of the relevant actions.
Table 2
Times needed to finish particular tasks in minutes
| T1 | T3 | T4 | |
| Average time | 4.5 | 35 | 20 |
| Fastest time | 2 | 15 | 5 |
| Longest time | 6 | 74 | 47 |
In summary, less experienced users needed more time to finish the tasks. Also, users found it difficult to create definitions from the text. With the browser plugin, however, the testing showed its feasibility. Another feature difficult to understand was concept quality. On the other hand, it took only very little explanation for the users to finally understand it – in T2, users did not understand what it meant, but in T4, everyone was able to fix the errors. Interlinking and recognition of concepts raised some minor issues caused by the UI.
6.Impact
While TermIt has been designed and tested in the Metropolitan plan scenario introduced in Section 1, it has been actively developed since then and used in other setups. Several projects in the aviation3131 and healthcare industry3232 used TermIt for research purposes, two other TermIt uses then go beyond the academic sphere.3333
The mentioned scenarios have common characteristics that show the expected setup for further deployments:
– Each of the scenarios is backed by a professional community responsible for maintaining/publishing data that historically suffer from terminological ambiguities and misinterpretations.
– Each community uses a dedicated TermIt instance to maintain a set of interlinked thesauri, where each thesaurus represents a normative document that the community maintains, or refers to.
– Each community opens the final terminology to the public, to help interpret produced documents and data.
6.1.Digital technical map of the Czech Republic
IPR uses TermIt on a commercial basis to systematize the terminology of the Digital Technical Maps across the Czech Republic, based on Decree No.393/2020 Coll, with technical support provided by the Czech Technical University in Prague. The community of contributors who are using TermIt to create or comment on the terminology has been steadily growing (approx. 80 as of July 2022). Within the past two years, we organized several online webinars for the community (public administration and commercial professionals in urban planning, architects, and civil engineering) to become familiar with TermIt and the basics of knowledge modeling. The released thesauri versions are then used by a terminology viewer developed at IPR to present the resulting uniform terminology of the Digital Technical Maps to the general public.3434
6.2.eGovernment
The second usage of TermIt goes beyond the Czech Technical University in Prague. TermIt has been adopted by the Department of the eGovernment Chief Architect of the Ministry of Interior of the Czech Republic (MI) within the EU-funded project No. CZ.03.4.74/0.0/0.0/15_025/0013983. It has been used here as a part of the Assembly line3535 – a larger ecosystem of tools supporting the creation of conceptual models of public administration agendas. For example, TermIt has been used for managing the terminology of the eGovernment thesaurus,3636 a set of concepts used for modeling the information architecture of the eGovernment of the Czech Republic, covering information architecture standards, like The Open Group Architecture Framework,3737 or various Czech eGovernment-related laws, and decrees. Over the past two years, four training sessions for more than 150 attendees in total were organized, each including a dedicated session on TermIt usage and applicability.
7.Conclusions
We presented TermIt, an open-source (GPL 3.0) tool for managing contextual (typically document-based) thesauri, interlinking their concepts, and connecting the concepts to their occurrences and definitions in documents. Especially the latter seems to be rather neglected in the existing open-source solutions, which is however crucial to maintaining the link between a normative document and a thesauri concept.
The usability testing proved the suitability of our approach, yet revealed problems that made some tasks difficult to complete for non-trained TermIt users – e.g. the concept quality scenario (T2) revealed that concept identification (e.g. unique concept definition/label) was not understood well by our users. On the other hand, linking a concept to its defining occurrence in the document was well understood and doable using the web annotation TermIt plugin.
In the future, we plan to test TermIt in the eGovernment domain for the specific task of managing interlinked thesauri related to core Czech legislation and governmental data management as well as to standards and other normative documents. TermIt’s focus is narrow, primarily targeting P1–P3 challenges. However, we also foresee the potential to integrate features from existing tools (like role-based governance) and assess TermIt applicability in broader terminology management contexts. Furthermore, we plan to extend support for validation constraint management and extraction of formal concept definitions from the textual ones.
Notes
1 https://iprpraha.cz/uploads/assets/dokumenty/psp/psp_2018_web.pdf, cit. 2024-02-15, a Prague norm codifying construction rules, 2018.
2 https://www.pocernice.cz/app/uploads/2018/06/TZ_00_Textova_cast_Metropolitniho_planu.pdf, cit. 2024-02-15, a key urban planning document containing a long-term vision of Prague urban development, 2018.
3 https://iprpraha.cz/en/, cit. 2024-02-15.
4 https://plan.praha.eu, cit. 2024-02-15.
5 Note that we consider here only explicit definitions. Although legal acts are at the top of both MPP and PBR, the community authoring these documents consists mainly of urban planning professionals (not lawyers), who focus only on the terminological consistency of the documentation and derived data.
6 An overview of the first round of objections in 2013, that refers to many terminology-related problems can be found at https://iprpraha.cz/uploads/assets/dokumenty/mup/pripominky_zadani_mp.pdf, cit. 2024-02-15.
7 Prefixes pbr and skos correspond to the namespaces https://onto.fel.cvut.cz/ontologies/pbr and http://www.w3.org/2004/02/skos/core# respectively.
8 http://onto.fel.cvut.cz/ontologies/ufo, cit. 2024-02-15. The ontology has a prefix ufo denoting the namespace http://onto.fel.cvut.cz/ontologies/ufo/.
9 This paper refers to the current version – 2.16.3
10 sources at https://github.com/kbss-cvut/termit, cit. 2024-02-15.
11 https://github.com/kbss-cvut/termit-ui, cit. 2024-02-15.
12 An application containerization service – https://www.docker.com/, cit. 2024-02-15.
13 https://kbss-cvut.github.io/termit-web, cit. 2024-02-15.
14 To access a demo instance, install the Google Chrome Extension from https://chrome.google.com/webstore/detail/termit-annotate-semantic/penpnbbgbibnedeecnkbnemoilfdjlbh and use username/password: demo. TermIt UI can be accessed through https://kbss.felk.cvut.cz/termit-ann, see the tutorial at https://kbss-cvut.github.io/termit-web/tutorial.
15 This rule motivates users to properly ground the concepts in the foundational ontology UFO. The only element for which this rule would fail would be the top-level Entity element from UFO. Since UFO is never directly managed by TermIt, we do not consider it a problem.
16 https://github.com/kbss-cvut/sgov-validator, cit. 2024-02-15.
17 https://zenodo.org/record/8357127, cit. 2024-02-15.
18 http://vocbench.uniroma2.it/doc/, cit. 2024-02-15.
19 https://protege.stanford.edu/, cit. 2024-02-15.
20 https://github.com/MenthorTools/menthor-editor, cit. 2024-02-15.
21 https://www.poolparty.biz/, cit. 2024-02-15.
22 https://semweb.solutions/skosshuttle, cit. 2024-02-15.
23 https://www.sketchengine.eu/, cit. 2024-02-15.
24 https://www.trados.com/, cit. 2024-02-15.
25 https://gate.ac.uk/, cit. 2024-02-15.
26 https://brat.nlplab.org/, cit. 2024-02-15.
27 https://web.hypothes.is/, cit. 2024-02-15.
28 https://www.diigo.com/, cit. 2024-02-15.
29 https://github.com/vocol/vocol, cit. 2024-02-15.
30 An English version available at https://forms.gle/JSDhFb5PNfAgbvdw5, cit. 2024-02-15.
31 Improving effectiveness of aircraft maintenance planning and execution (CK01000204, https://starfos.tacr.cz/en/projekty/CK01000204) and Ontology engineering utilization in reliability and quality knowledge management systems in the aviation (LTACH19032, https://starfos.tacr.cz/en/projekty/LTACH19032), cit. 2024-02-15.
32 Strategic management of the development of electronic healthcare in the Ministry of Health (CZ.03.4.74/0.0/0.0/15_025/0006212, https://ncez.mzcr.cz/cs/projekty/strategicke-rizeni-rozvoje-elektronickeho-zdravotnictvi-v-rezortu-mz), cit. 2024-02-15.
33 Details on the list of use-cases can be found at https://kbss-cvut.github.io/termit-web/about, cit. 2024-02-15.
34 For example, the concept ‘Building’ can be seen in https://app.iprpraha.cz/apl/app/prohlizecka_slovniku/?pojem=plocha-budovy, in Czech, cit. 2024-02-15.
35 https://github.com/opendata-mvcr/sgov-assembly-line, in Czech only, cit. 2024-02-15.
36 draft version of the terminology is published at https://archi.gov.cz/playgroud:tezaurus, cit. 2024-02-15.
37 https://www.opengroup.org/togaf, cit. 2024-02-15.
Acknowledgements
The work was supported by grant No. SGS19/110/OHK3/2T/13 Efficient Vocabularies Management Using Ontologies of the Czech Technical University in Prague.
References
[1] | A. Benevides, J.-R. Bourguet, G. Guizzardi, R. Peñaloza and J. Almeida, Representing a reference foundational ontology of events in SROIQ, Applied Ontology 14: ((2019) ), 1–42. doi:10.3233/AO-190214. |
[2] | B. Bishop, A. Kiryakov, D. Ognyanoff, I. Peikov, Z. Tashev and R. Velkov, OWLIM: A family of scalable semantic repositories, Semantic Web – Interoperability, Usability, Applicability ((2010) ). |
[3] | D. Brickley and R.V. Guha, RDF schema 1.1, W3C Recommendation, W3C, (2014) , https://www.w3.org/TR/rdf-schema/, cit. 2024-02-15. |
[4] | F. Buschman, R. Meunier, H. Rohnert, P. Sommerlad and M. Stal, Pattern-Oriented Software Architecture: A System of Patterns, Vol. 1: , Wiley, Hoboken, New Jersey, (1996) . |
[5] | A. Buzek, Web browser plug-in for semantic vocabulary creation, Bachelor thesis, Czech Technical University in Prague, 2022, http://hdl.handle.net/10467/100959, cit. 2024-02-15. |
[6] | V.A.D. Carvalho, J.P.A. Almeida, C.M. Fonseca and G. Guizzardi, Extending the foundations of ontology-based conceptual modeling with a multi-level theory, in: ER 2015, LNCS, Springer, (2015) , pp. 119–133. doi:10.1007/978-3-319-25264-3_9. |
[7] | R. Cyganiak and C. Bizer, Pubby – a linked data frontend for SPARQL endpoints, (2007) , http://wifo5-03.informatik.uni-mannheim.de/pubby/, cit. 2024-02-15. |
[8] | R.T. Fielding, Architectural styles and the design of network-based software architectures, PhD thesis, University of California, (2000) . |
[9] | G. Guizzardi, Ontological foundations for structural conceptual models, PhD thesis, University of Twente, (2005) . |
[10] | G. Guizzardi, C.M. Fonseca, A.B. Benevides, J.P.A. Almeida, D. Porello and T.P. Sales, Endurant types in ontology-driven conceptual modeling: Towards OntoUML 2.0, in: ER 2018, LNCS, Vol. 11157: , Springer, (2018) , pp. 136–150. doi:10.1007/978-3-030-00847-5_12. |
[11] | G. Guizzardi, G. Wagner, R. De Almeida Falbo, R.S.S. Guizzardi and J.P.A. Almeida, Towards ontological foundations for the conceptual modeling of events, in: LNCS, Vol. 8217: , (2013) , pp. 327–341, ISSN 03029743. ISBN 9783642419232. doi:10.1007/978-3-642-41924-9_27. |
[12] | H. Knublauch and D. Kontokostas, Shapes Constraint Language (SHACL), W3C Recommendation, W3C, (2017) , https://www.w3.org/TR/2017/REC-shacl-20170720/. |
[13] | P. Křemen and M. Nečaský, Improving discoverability of open government data with rich metadata descriptions using semantic government vocabulary, Journal of Web Semantics 55: ((2019) ), 1–20. doi:10.1016/j.websem.2018.12.009. |
[14] | M. Ledvinka, P. Křemen, L. Saeeda and M. Blaško, TermIt: A practical semantic vocabulary manager, in: ICEIS, SCITEPRESS, (2020) , pp. 759–766. doi:10.5220/0009563707590766. |
[15] | A. Miles and S. Bechhofer, SKOS Simple Knowledge Organization System reference, W3C Recommendation, W3C, (2009) . |
[16] | B. Motik, P.F. Patel-Schneider and B. Parsia, OWL 2 Web Ontology Language structural specification and functional-style syntax (second edition), W3C Recommendation, W3C, (2012) , https://www.w3.org/TR/owl2-syntax/, cit. 2024-02-15. |
[17] | L. Saeeda, M. Med, M. Ledvinka, M. Blaško and P. Křemen, Entity linking and lexico-semantic patterns for ontology learning, in: The Semantic Web, Springer, Cham, (2020) , pp. 138–153. ISBN 978-3-030-49461-2. doi:10.1007/978-3-030-49461-2_9. |
[18] | M. Sporny, D. Longley, G. Kellogg, M. Lanthaler, P.-A. Champin and N. Lindström, JSON-LD 1.1 A JSON-based serialization for linked data, W3C Recommendation, W3C, (2020) , https://www.w3.org/TR/json-ld11/, cit. 2024-02-15. |
[19] | M. Verdonck, F. Gailly, R. Pergl, G. Guizzardi, B. Martins and O. Pastor, Comparing traditional conceptual modeling with ontology-driven conceptual modeling: An empirical study, Information Systems ((2019) ). doi:10.1016/j.is.2018.11.009. |


