
Background knowledge in ontology matching: A survey
Abstract
Ontology matching is an integral part for establishing semantic interoperability. One of the main challenges within the ontology matching operation is semantic heterogeneity, i.e. modeling differences between the two ontologies that are to be integrated. The semantics within most ontologies or schemas are, however, typically incomplete because they are designed within a certain context which is not explicitly modeled. Therefore, external background knowledge plays a major role in the task of (semi-) automated ontology and schema matching.
In this survey, we introduce the reader to the general ontology matching problem. We review the background knowledge sources as well as the approaches applied to make use of external knowledge. Our survey covers all ontology matching systems that have been presented within the years 2004–2021 at a well-known ontology matching competition together with systematically selected publications in the research field. We present a classification system for external background knowledge, concept linking strategies, as well as for background knowledge exploitation approaches. We provide extensive examples and classify all ontology matching systems under review in a resource/strategy matrix obtained by coalescing the two classification systems. Lastly, we outline interesting and yet underexplored research directions of applying external knowledge within the ontology matching process.
1.Introduction
Ontology matching is the non-trivial task of finding correspondences between entities of two or more given ontologies or schemas. It is an integral part to ensure semantic interoperability. The matching can be performed manually or through the use of an automated matching system. Ontology matching is a problem for Open Data (e.g. matching publicly available domain ontologies or interlinking concepts in the Linked Open Data Cloud11) as well as for private companies which need to integrate disparate data stores for transactional or analytical purposes.
A major challenge for matching ontologies is the fact that they are typically designed within a given context and deep background knowledge that is not explicitly expressed in the schema definition [73]. In order to automatize the ontology matching process, external background knowledge is therefore required so that the automated matching system can interpret for example textual labels and descriptions of the elements within the schemas that are to be matched.
Current surveys in the ontology matching [14,19,223,238] and schema matching [12,318] domain classify matching systems according to their matching technique (strongly influenced by Euzenat and Shvaiko [74,290] as well as Rahm and Bernstein [265]) with minor or no emphasis at all on the background knowledge used.
In the area of context-based matching, i.e. matching with intermediate resources, Locoro et al. [213] present an abstract seven-step process for context-based matching together with an experimental evaluation of different parameter configurations. The proposed framework is flexible but experimentally focused on ontologies as background knowledge and a path- and logic-based exploitation approach. The survey at hand takes a broader look at the types of background sources and different exploitation strategies used in research including, for instance, unstructured data and statistical or neural approaches.
A recent survey by Trojahn et al. [334] provides a detailed perspective into foundational ontologies in ontology matching which includes, among other use cases, the exploitation of those for the task of matching domain ontologies. The survey presented here is broader in the sense that foundational ontologies are considered only as one kind of external background knowledge; it is narrower in the sense that it focuses purely on the use case of finding equivalence relations between schemas with additional background knowledge automatically.
Thiéblin et al. [327] review complex matching systems, i.e. systems that are capable of generating correspondences involving multiple entities, transformation functions, and logical constructors. The matching systems covered in their survey use different knowledge representation models (including table-based or document-based schemas, for instance). The systems are characterized based on the correspondence output and the underlying process type which generated the complex alignment. Background knowledge is not discussed and does not play a major role in the current implementations of complex matching systems. The survey at hand is complementary in the sense that it focuses on systems producing simple equivalence correspondences through the use of background knowledge.
This comprehensive survey reviews an extensive set of ontology matching and integration systems published in the last two decades in terms of the background knowledge used and in terms of the strategy that is applied to exploit the external background knowledge. It further covers the approaches used to link schema concepts to background knowledge. Based on the extensive collection of reviewed systems, we provide a comprehensive overview of background knowledge sources and strategies used in the past. Furthermore, this survey reveals a number of blind spots that have not yet been thoroughly explored.
In the following, the selection method for publications used in this survey is presented (Section 2.1). Afterwards, the core theoretic concepts are introduced in Section 3, namely schema matching and ontology matching (OM). In Section 4, background knowledge is defined, its usage in ontology matching system is analyzed, and the most used resources are presented. Thereupon, classification systems for background knowledge sources (Section 5), concept linking approaches (Section 6), and exploitation approaches (Section 7) are presented together with examples. In Section 8, we outline interesting directions for future work in the research field.
2.About this survey
2.1.Selection of publications
Search parameters For this survey, we defined three search parameters: (Q1) “ontology matching”, (Q2) “ontology alignment”, and (Q3) “ontology mapping”. We queried publications via the dblp computer science bibliography (DBLP)22 without further filters. The search criteria have been intentionally chosen to be very broad since the usage of background knowledge is very often not indicated in the title or abstract of a paper.
We further manually added all matching systems that participated in the schema matching tracks of the ontology alignment evaluation initiative (OAEI, see Section 3.4) from its inception in 200433 until 2021 [20,292–307,317].
The number of retrieved papers for each search parameter can be found in Table 1. The bibtex files can be found in the GitHub repository of this survey.44
Table 1
Search parameters and the associated number of papers
| Q1 “ontology matching” on DBLP | 589 |
| Q2 “ontology alignment” on DBLP | 514 |
| Q3 “ontology mapping” on DBLP | 570 |
| OAEI system papers | 242 |
| De-duplicated papers | 1,814 |
| Included papers | 341 |
De-duplication The bibtex files of all publications were gathered and loaded via the Zotero55 bibliographic management tool. The latter was used to detect duplicate publications based on the metadata of the papers. All scientific artifacts were exported as a CSV file including the metadata (title, authors, publication venue, date, etc.) for manual de-duplication.
The resulting set of papers constitutes the final set of publications used for identifying relevant works for this survey. In total, 1,814 papers were considered in this study.
Selection process In order to identify papers which are relevant for this survey, inclusion criteria (IC) and exclusion criteria (EC) were defined. The set of all papers was manually scanned in order to filter out publications not relevant for this survey. The complete list of inclusion and exclusion criteria is shown in Table 2. Every paper that is considered in this survey has to match all inclusion criteria.
Table 2
Inclusion and exclusion criteria for the papers in this survey
| Criteria | Inclusion criteria (IC) | Exclusion criteria (EC) | |
| C1 | Language | The paper is written in English. | The paper is not written in English; the paper is written in English but heavily ungrammatical. |
| C2 | Accessibility | The paper can be accessed through the infrastructure of the University of Mannheim without additional payment. | The paper cannot be accessed through the infrastructure of the University of Mannheim without additional payment. |
| C3 | Duplication | Included are papers whose content is unique. This explicitly includes papers on the same matching system; for example, all OAEI LogMap papers are included in this survey rather than only the latest publication in order to carry out a thorough time analysis. | Excluded are papers with identical content such as preprints which are identical in content with their peer-reviewed publications or identical papers published in multiple venues. |
| C4 | Ontology Matching System | The paper presents a matching system, i.e. a system which accepts two ontologies and returns an alignment. The matching system must be able to match ontologies (T-box). Papers which align schema and instances are also included. | The paper does not present a matching system which is able to match ontologies such as pure entity-linking or pure instance matching approaches. |
| C5 | Simple Correspondences | The matching system produces simple correspondences. | The paper presents a matching system for complex matching. |
| C6 | Background Knowledge | The matching system exploits some form of external knowledge. | The matching system presented does not use any external knowledge. |
| C7 | Application/Evaluation | The paper presents a matching system which is evaluated on the task of ontology matching. | The paper merely describes a framework or a theoretical idea but lacks a concrete implementation regarding ontology matching. |
| C8 | Level of Detail | The paper describes the use of background knowledge with an appropriate level of detail. | The usage of background knowledge is mentioned but it is unclear which knowledge source is used or how it is used. |
Papers considered in this survey had to be written in English language (C1), had to be accessible through the infrastructure of a large German research university (C2), and had not to be a duplicate of another paper (C3). It is important to note that multiple publications on the same topic (such as a matching system) do not qualify as duplicates despite their potentially large content overlap. This is rooted in the observation that there are often multiple versions and papers of a single matching system which evolves over time (for example AML [90] or LogMap [151]); in such cases, we always refer to the specific matching paper we mean in order to be precise rather than referencing the most current or most extensive paper published for the system in question.
We explicitly exclude works limited solely to instance matching or entity linking (C4). We further focus on matching systems that produce simple correspondences rather than complex ones (C5). Lastly, we only cover papers that present an actual system, i.e. a background knowledge-based (C6) ontology matching system implementation (C7) for which an evaluation is presented. The usage of the background knowledge must be appropriately documented (C8). In total, 341 papers fulfilled the inclusion criteria of this survey.
All matching systems were systematically evaluated in terms of (i) the background knowledge sources used, (ii) the strategy deployed to link ontology concepts to the background knowledge source, and (iii) the strategies the matching systems apply to exploit the background knowledge sources.
3.Schema matching and ontology matching
3.1.The schema matching problem within the data integration process
Data integration Data integration (DI) describes the process to obtain uniform access over a set of heterogeneous and autonomous sources of data [117]. The process can be divided in four main parts [344] as depicted in Fig. 1: (i) Schema Matching, (ii) Schema Translation, (iii) Record Linkage, and (iv) Data Fusion.
Schema matching Schema matching is an important and time consuming part within the data integration process. Out of the actions to carry out in order to integrate two given schemas (depicted in Fig. 1), schema matching is the first step. Schema matching describes the process of finding the relations that hold between the elements of the schemas that are to be matched. The most important relation here is the equivalence relation. In this step, structural as well as semantic heterogeneity between the two schemas are bridged.
Schema translation Schema translation describes the process of deriving the translation function from one schema to the other schema.
Record linkage Record linkage describes the process of linking the records of instances of two schemas, i.e. finding equivalent records in disparate datasets.
Data fusion Data fusion describes the process of resolving conflicting information concerning individual instances.
![Process for integrating two schemas, compiled from [344].](https://content.iospress.com:443/media/sw-prepress/sw--1--1-sw223085/sw--1-sw223085-g001.jpg)
3.2.Schemas and ontologies
The focus of this paper is a special case of the first step of the DI process, schema matching. It is important to note that a schema is not bound to a technology stack. It is, for example, possible that the same schema is implemented on different technology stacks such as different database types. Many formalization notations for schemas have evolved over time – for example in the area of (conceptual) entity relationship models Barker’s notation [21], IDEF1X [31] by the National Institute of Standards and Technology, or MERISE [324]. In semantic data modelling, data representation paradigms such as controlled vocabularies, taxonomies, knowledge graphs, among others, are used [11], all of which have been subsumed under the umbrella term of ontologies in different publications [70,192,242,268,335]. Hence, we conclude that most of the methods described for ontology matching can be more broadly understood as methods for matching semantic models in general [75].
3.3.The ontology matching problem
Ontology The term ontology has roots in philosophy and describes the study of being. In the computer science domain, an ontology is a “formal, explicit specification of a shared conceptualization”,77 i.e. an abstract model of real-world concepts that is represented in a computer-readable way and is shared by a group of stakeholders. The definition is technology-independent; conceptually, even an XML Schema could be interpreted as an ontology [49]. While multiple ontology languages are available, most ontologies are typically defined in the W3C Web Ontology Language (OWL). An OWL ontology consists of different element types: classes/concepts (C), individuals/instances (I), relations (R), data types (
Ontology matching Given two ontologies
A matching system can be seen as a function
Ontology integration Multiple interpretations exist to the terms ontology integration and ontology merging. We follow the proposal from Osman et al. [237] in this survey and regard ontology merging as a special case of ontology integration:
Ontology integration (also referred to as ontology enrichment, ontology inclusion, or ontology extension) describes the process of extending a given target ontology
1. Pre-processing Phase
2. Matching Phase
3. Merging Phase
4. Post-processing Phase
In this article, we also cover papers and systems which address the ontology integration problem where background knowledge plays a significant role in the matching phase. In figures and tables, those systems are notated with a subscript I such as
3.4.The ontology evaluation initiative since 2004
About the OAEI Schema matching can be performed manually, through an automated matching system, or in a hybrid environment. For systematically evaluating the latter two cases, the Ontology Alignment Evaluation Initiative (OAEI)99 is running campaigns every year since 2004. Unlike other evaluation campaigns where researchers submit datasets as solutions to report their results (such as Kaggle1010), the OAEI requires participants to submit a matching system, i.e. an implemented and packaged matching system, which is then executed on-site.1111 In order to do so, multiple frameworks and platforms for standardized matcher development, packaging, and evaluation have been developed and are used by OAEI participants, namely the Alignment API [54] format and framework, the SEALS [103,353] and HOBBIT [232] packaging and evaluation platforms as well as MELT [131,132,251], a framework for matcher development, packaging, and evaluation which also integrates with the aforementioned frameworks. After the evaluation, the results are publicly reported. The individual matching tasks are referred to as test cases which are bundled in tracks. Originally, the OAEI started with plain ontology matching tracks focused on simple alignments with an equality relation, i.e. a correspondence which contains only one entity from the source ontology and one ontology from the target ontology and where
OAEI tracks Figure 2 summarizes all OAEI schema matching tracks since the inception of the initiative. As visible in the figure, some older tracks have been discontinued1313 while new tracks have also been introduced. All current schema matching tracks that were evaluated in the OAEI 2020 and 2021 are listed in Table 3 together with a quick description and the best performing system of the corresponding year.
Fig. 2.
OAEI schema matching tracks since the inception of the initiative. Explicitly excluded are complex matching tracks and instance matching tracks. The knowledge graph track is not a pure schema matching task but a combined one where schemas and instances have to be matched simultaneously. The library track has been organized multiple times with completely different datasets and by different researchers using the same track name. Therefore, the track streams have been divided in three groups (A, B, C).
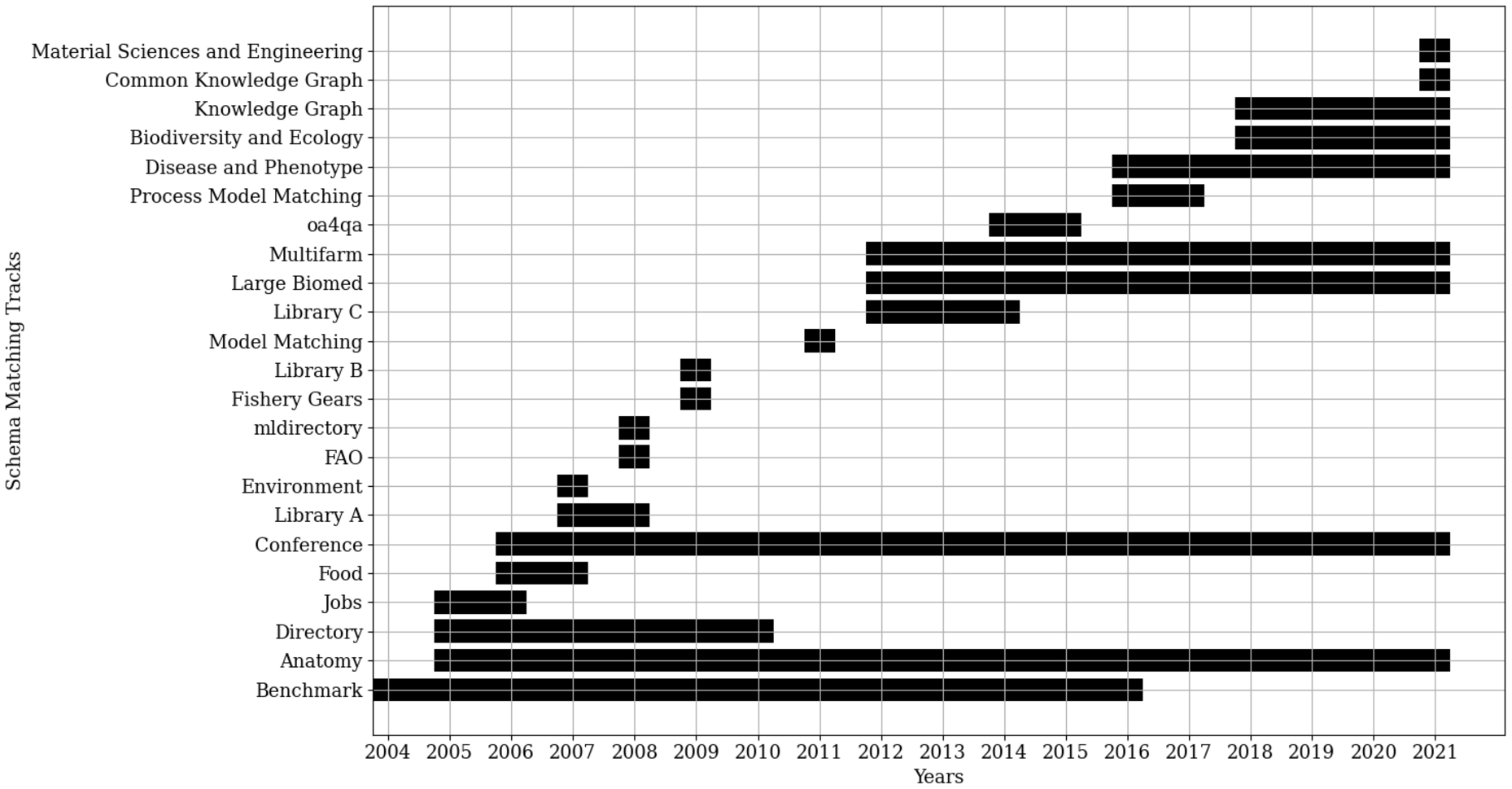
Table 3
Depicted are all schema matching tasks of the OAEI 2020 and 2021 together with the best performing systems in terms of
| Track | Track description | Best performing system in the OAEI 2020 | Best performing system in the OAEI 2021 |
| Anatomy [27] | An alignment between the Adult Mouse Anatomy and a part of the NCI Thesaurus is to be found. | AML [203] (Uberon, DOID, MeSh, WordNet, Microsoft Translator, OBO logical definitions) | AML [84] (Uberon, DOID, MeSh, WordNet, Microsoft Translator, OBO logical definitions) |
| Conference [42] | 16 ontologies from the conference domain have to be matched. | VeeAlign [140] (Google Universal Sentence Encoder) | AML [84] (see above) |
| Multifarm [218] | 7 conference ontologies translated into 8 languages (+ English) have to be matched. | AML [203] (see above) | AML [84] (see above) |
| LargeBio | An alignment between 3 large bio ontologies is to be found. | AML [203] (see above) | AML [84] (see above) |
| Phenotype [120] | An alignment between two disease and two phenotype ontologies is to be found. | LogMapBio [149] (Bioportal) | LogMap [150] (SPECIALIST, Microsoft Translator) LogMapBio [150] (Bioportal) AML [84] (see above) |
| Biodiversity and Ecology [168] | 4 matching tasks from the biodiversity and ecology domains. | AML [203] (see above) | AML [84] (see above) |
| Knowledge Graph [128] | 5 matching tasks consisting of knowledge graphs extracted from fandom.com. | Wiktionary Matcher [257] (Wiktionary/DBnary) | Wiktionary Matcher [258] (Wiktionary/DBnary) |
| Common Knowledge Graph [80] | An alignment between the classes of two large, automatically constructed knowledge graphs is to be found. | – | KGMatcher [81] (BERT, Google language model) |
OAEI matching systems Since 2004, many matching systems have been submitted and evaluated. Figures 3 and 4 list all matching systems that have been evaluated in OAEI schema matching campaigns1414 since its inception on the y-axis; the x-axis represents a time line and the black bars represent the time frame in which the systems have participated in the campaigns. As visible in the figures, many systems have been evaluated in multiple campaigns. For this survey, all of the listed matching systems that are used for schema matching have been examined in terms of what background knowledge source is used if any, how a connection between the ontologies and the background knowledge source is established, and how the background knowledge source is exploited.
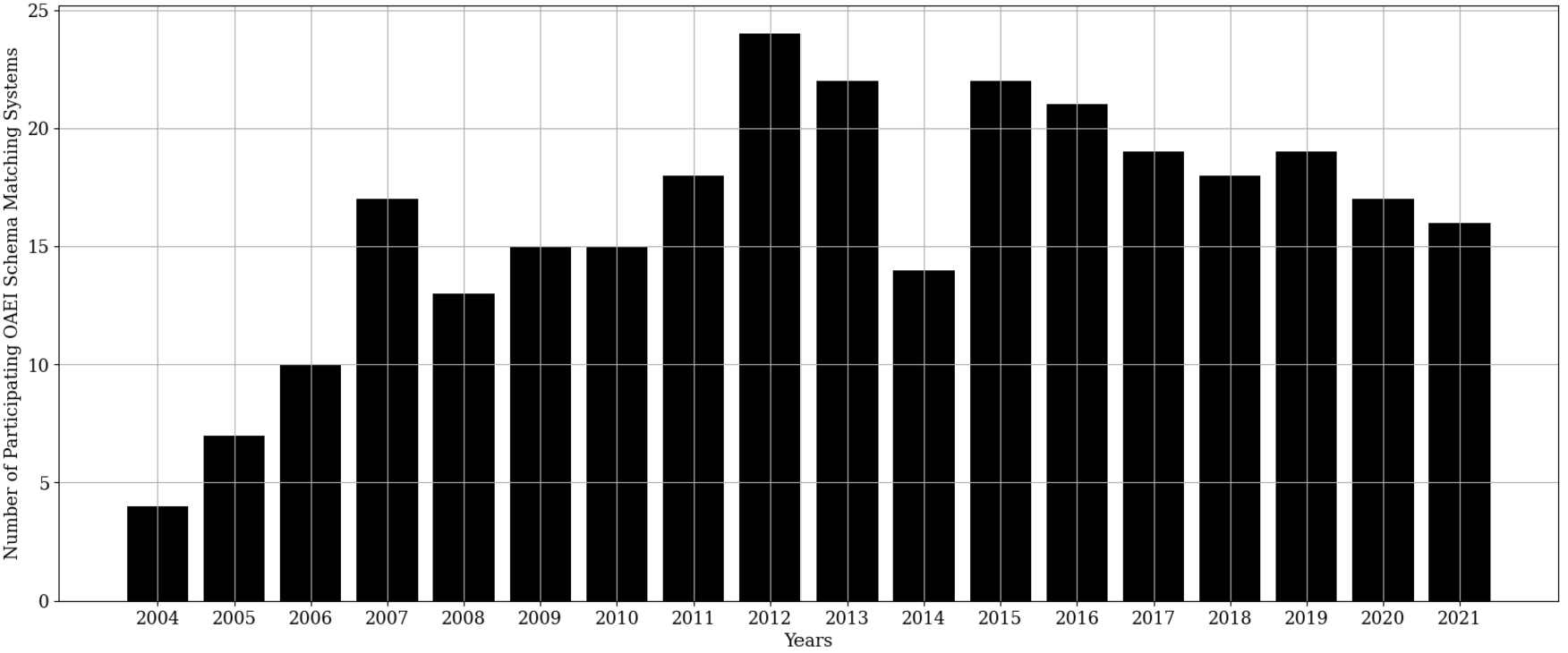
Figure 5 reveals that over the years the number of participating schema matching systems to date has slightly dropped from the peak in the year 2012 albeit the current participation total is still comparatively high compared to the early days of the initiative.1515
Table 3 lists all schema matching tracks from 2020 and 2021 together with the best performing system and the background knowledge sources used by those. As visible in the table, all those systems make use of external knowledge datasets. AML, which scores as best performing system in multiple tracks, exploits multiple external knowledge sources.
4.Background knowledge in ontology matching
4.1.Background knowledge
We define background knowledge in matching as any knowledge source that is external to the matching process and is used to obtain the final alignment. Hence, within the matching process, external knowledge can be used in the form of an existing alignment (
Fig. 3.
All OAEI schema matching systems (which participated in the tracks listed in Fig. 2) and their evaluation time frame since the inception of the OAEI; Part 1 of 2 from 2012–2021.

Fig. 4.
All OAEI schema matching systems (which participated in the tracks listed in Fig. 2) and their evaluation time frame since the inception of the OAEI; Part 2 of 2 from 2004–2021.
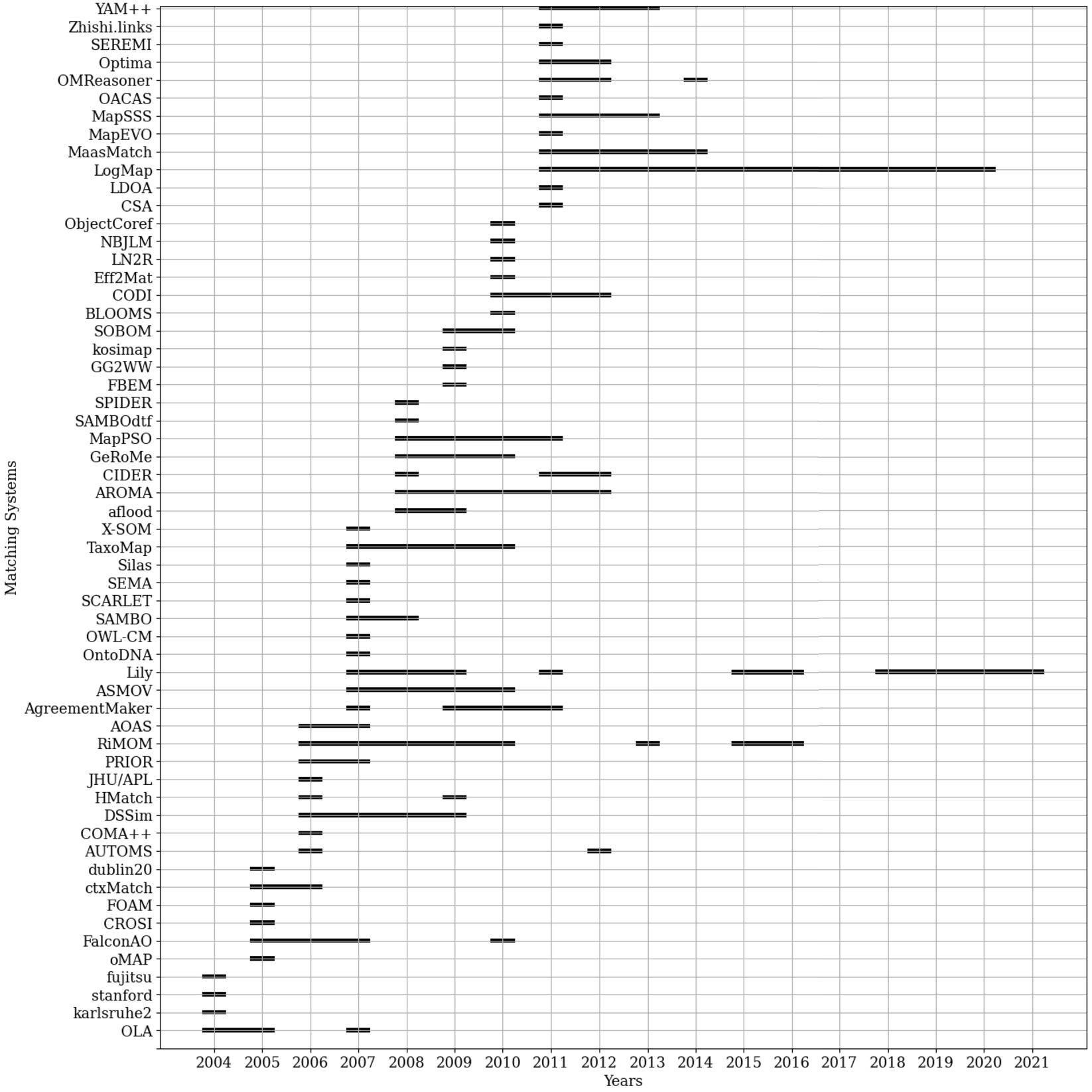
Fig. 5.
The number of ontology matching systems participating in the OAEI from inception to date.
Background knowledge can significantly improve the performance of ontology matching systems. This is clearly visible by analyzing different OAEI systems: When comparing LogMap and LogMapBio [150] in the OAEI 2021 campaign, for instance, it can be seen that the latter system scores a significantly higher recall on the OAEI Anatomy dataset. Other examples can be found through a comparison of AML [88] and Gomma1616 in the 2013 campaign: Both systems participated in two configurations – with and without background knowledge. On the Anatomy track, the background knowledge configurations significantly outperformed all other systems in terms of recall and
In [87], Faria et al. evaluate strategies for matching biomedical ontologies. The experiments show a clear performance increase when background knowledge is used. In terms of exploitation strategies, the authors recommend to use cross-references (if available) over lexical expansion.
While evaluating an approach to build a background knowledge resource for ontology matching, Annane et al. [17] also analyze the performance of the YAM++ matching system with and without background knowledge finding that the matcher configuration which uses background knowledge significantly outperforms the version without additional resources. They report that the better performance is mainly due to a higher recall.
In an extensive survey on the systems participating in the OAEI Anatomy track from 2007 to 2016, Dragisic et al. report that “[f]or the systems that participated with a version using biomedical auxiliary sources and a version not using biomedical auxiliary sources, the F-measure for the one with biomedical auxiliary sources was always higher” [68].
Missing background knowledge was named as one of the 10 challenges for ontology matching in 2008 [291]; this was re-affirmed in 2013 [73] and it is still under active research.
4.2.Background knowledge selection in ontology matching
As there are often multiple potentially beneficial sources of background knowledge available for ontology matching, some authors propose heuristics to determine the benefit of a background knowledge source in order to select one before performing the match operation. Nasser et al. [330] define four criteria to automatic background knowledge selection:
1. type independence: A selection system should be capable to handle various serialization formats.
2. domain independence: A selection system should be domain-independent and be able to select sources for any domain.
3. multilingualism: A selection system should be language-independent, i.e. support cross-lingual ontology matching.
4. optimality: A selection system should return the best background knowledge source from the corpus.
In the LogMapBio system, Chen et al. [45] apply a relatively simple lexical algorithm to identify suitable mediating ontologies from BioPortal [104,352]. In the OAEI 2020 campaign, the system achieved a significantly higher recall and
Faria et al. [89] propose a heuristic called Mapping Gain which is based on the number of additional correspondences found given a baseline alignment. Quix et al. [264] use a keyword-based vector similarity approach to identify suitable background knowledge sources. Similarly, Hartung et al. [122] introduce a metric, called effectiveness, that is based on the mapping overlap between the ontologies to be matched.
Table 4
Knowledge sources and matching systems that use them part 1 of 4. Referenced is the first documented usage by the matching system. Systems that did not participate in the OAEI are italicized. Named systems are referred to using their system name
| Knowledge source | Source description | Resource available | Used by system |
| Apertium [96] | A free open-source platform for machine translation. | yes | Bella et al. (2017) [22] |
| BabelNet [228] | Multilingual, large knowledge graph derived through the integration of multiple knowledge sources such as WordNet and Wikipedia. | yes | LYAM++ (2015) [329] Helou et al. (2016) [125] Biniz et al. (2017) [24] EVOCROS (2018) [56] Kolyvakis et al. (2018) [183] |
| BERT [57] | A transformer-based language model. | yes | Neutel et al. (2021) [229] KGMatcher (2021) [81] Fine-TOM (2021) [181] TOM (2021) [184] |
| Big Huge Thesaurus | Web API for synonyms and antonyms. | yes | SOCOM++ (2012) [101] HotMatch (2012) [52] |
| Bing Search Engine API | Cloud API for the Microsoft Bing Web search engine. | yes | Fu et al. (2011) [100] WeSeE Match (2012) [243] SOCOM++ (2012) [101] SYNTHESIS (2013) [188] |
| Bing Translator / Microsoft Translator | Cloud API for the Microsoft Bing translation service. | yes | SOCOM (2010) [99] Spohr et al. (2011) [312] WeSeE Match (2012) [243] YAM++ (2012) [230] Koukourikos et al. (2013) [187] AML (2014) [85] XMap (2014) [60] Kachroudi et al. (2014) [165] LogMap (2015) [155] CLONA (2015) [1] KEPLER (2017) [162] Kachroudi & Yahia (2018) [164] |
| BioBERT [194] | A language model pre-trained on medical text. | yes | MEDTO (2021) [119] |
| BioPortal [104,352] | A repository of interlinked biomedical ontologies. | yes | LogMapBio (2014) [156] Annane et al. (2016) [16] Zaveri & Dumontier (2016) [375] Lily (2018) [323] Annane et al. (2018) [17] |
| ConceptNet [310] | A freely-available word graph collected from multiple sources. | yes | Kolyvakis et al. (2018) [183] |
| Cooking Dictionary | A collection of term definitions in the cooking domain. | yes | van Hage et al. (2005) [337] |
| DBpedia [195] | A knowledge graph extracted from Wikipedia info boxes. | yes | BLOOMS (2010) [142] LDOA (2011) [163] Grütze et al. (2012) [113] |
| DOID [283] | The Human Disease Ontology (DOID). | yes | AML (2014) [85] Ochieng & Kyanda (2018) [236] Annane et al. (2018) [17] |
| DOLCE [102] | The descriptive ontology for lingusitic and cognitive engineering (DOLCE) is an upper ontology. | yes | Mascardi et al. (2010) [217] Davarpanah et al. (2015) [53] |
| FAROO Web Search | A framework for Web search. | yes | WeSeE Match (2013) [245] |
| fastText model | A model trained with facebook’s AI reserach (FAIR) fastText [28] framework. | yes | OntoConnect (2020) [38] Neutel et al. (2021) [229] |
Table 5
Knowledge sources and matching systems that use them from part 2 of 4. Referenced is the first documented usage by the matching system. Systems that did not participate in the OAEI are italicized. Named systems are referred to using their system name
| Knowledge source | Source description | Resource available | Used by system |
| FIBO | The Financial Industry Business Ontology (FIBO). | yes | DESKMatcher (2020) [221] |
| FMA | The Foundational Model of Anatomy (FMA). | yes | AOAS (2007) [380] Groß et al. (2011) [110] GOMMA (2012) [111] Petrov et al. (2013) [247] |
| Google NNLM | A neural text embedding model available through TensorFlow Hub by Google. | yes | KGMatcher (2021) [81] |
| Freelang | A translation API (available as offline and as online version). | yes | Medley (2012) [123] |
| Google Search API | Cloud API for the Google Web search engine. | yes | Pan et al. (2005) [239] van Hage et al. (2005) [337] PROMPT-V (2007) [159] X-SOM (2007) [50] Gligorov et al. (2007) [107] KMSS (2009) [376] Mao et al. (2011) [216] MapSSS (2013) [41] Jiang et al. (2014) [148] |
| Google Translation API | A translation Web API by Google. | yes | SOCOM (2010) [98] Fu et al. (2011) [100] SOCOM++ (2012) [101] RiMom (2013) [384] LogMap (2014) [156] Helou et al. (2016) [125] NuSM (2017) [22] Destro et al. (2017) [55] |
| Google Universal Sentence Encoder [36,374] | Pre-trained encoder by Google (monolingual [36] and multilingual [374]). | yes | VeeAlign (2020) [140] |
| Google Word2Vec Vectors | Word2vec models by Google. | yes | Bulygin (2018) [32] Bulygin & Stupnikov (2019) [33] |
| HowNet [61] | An online sememe knowledge base in Chinese and English. | yes | Li et al. (2006) [199] Wang et al. (2008) [349] |
| ImageNet | A large database of images. | yes | Doulaverakis et al. (2015) [67] |
| iTranslate4 | API for machine translation. | no | Koukourikos et al. (2013) [187] |
| KGvec2go [254] | Pre-trained RDF2Vec embeddings. | yes | ALOD2Vec (2020) [255] |
| Lanes API | Language Analysis Essentials (LANES) API. Does not seem to be online anymore. | no | HotMatch (2012) [52] |
| Medical Subject Headings (MeSH) [314] | The Medical Subject Headings (MeSH) are a controlled vocabulary thesaurus. | yes | AML (2014) [85] Ochieng & Kyanda (2018) [236] Real et al. (2020) [267] Annane et al. (2018) [17] |
| Medline | Bibliographic database of the National Library of Medicine. Medline is a subset of PubMed. | yes | DisMatch (2016) [275] OntoEmma (2018) [342] |
| MyMemory API | A translation REST API provided by translated.com. | yes | GOMMA (2012) [111] |
| Ontology Lookup Service (OLS) | Repository and Web APIs for biomedical ontologies. | yes | PAXO (2020) [121] |
| OpenCyc [196] | Open-source version of the Cyc knowledge base by Cycorp. No longer available. | no | Mascardi et al. (2010) [217] Davarpanah et al. (2015) [53] |
| Paraphrase DB (PPDB) [246] | A very large collection of paraphrases. | yes | DeepAlignment (2018) [182] |
| PubMed | Bibliographic database maintained by the National Library of Medicine. | yes | Fang et al. (2013) [82] Li (2020) [198] |
Table 6
Knowledge sources and matching systems that use them from part 3 of 4. Referenced is the first documented usage by the matching system. Systems that did not participate in the OAEI are italicized. Named systems are referred to using their system name
| Knowledge source | Source description | Resource available | Used by system |
| RadLex | A radiology lexicon. | yes | Groß et al. (2011) [110] |
| SAP Term | Definitions of terms in SAP software. | not publicly | DESKMatcher (2020) [221] |
| SBERT [270] | A BERT modification so that similarity can be determined via cosine distance. | yes | MEDTO (2021) [119] |
| SDL FreeTranslation | An online translation service. | no | SOCOM (2010) [98] |
| SPECIALIST Lexicon | Contains common English words as well as biomedial vocabulary. | yes | FCA-Map (2016) [383] LogMap (2018) [153] Real et al. (2020) [267] |
| SUMO [235] | The suggested upper merged ontology (SUMO), an upper ontology. | yes | Mascardi et al. (2010) [217] |
| Swoogle [58] | A search engine for the Semantic Web. No longer available. | no | SCARLET (2007) [276,278] Vazquez & Swoboda (2007) [338] Spider (2008) [277] |
| synonyms-fr.com | A Web service to retrieve French synonyms and antonyms. | yes | Fu et al. (2011) [100] |
| UBERON [116,224] | A cross-species anatomical ontology. | yes | Groß et al. (2011) [110] AgreementMaker (2011) [48] GOMMA (2012) [111] AML (2013) [88] LYAM++ (2016) [331] CroMatcher (2016) [115] POMap (2017) [190] Lily (2020) [136] |
| UMLS [208] | The unified medical language system is a compendium of vocabularies in the biomedical domain. | yes | NLM (2006) [379] AOAS (2007) [380] ASMOV (2007) [146] RiMom (2007) [201] SAMBO (2007) [319] AgreementMaker (2009) [47] LogMap (2011) [158] Groß et al. (2011) [110] GOMMA (2012) [111] Fernández et al. (2012) [93] AML (2013) [88] Amin et al. (2014) [13] LILY (2018) [323] FCA-Map (2018) [44] OntoEmma (2018) [342] |
| Universal Knowledge Core (UKC) | A multilingual lexical resource. | yes | NuSM (2017) [22] |
| WebIsALOD [127,284] | Web-extracted hypernymy relations provided as an RDF knowledge graph. | yes | ALOD2Vec Matcher (2018) [256] |
| Webtranslator API | A Java translation API. | yes | AUTOMS (2012) [185] WeSeE Match (2013) [245] |
| Wikipedia Corpus | Text corpus of the online encyclopedia Wikipedia. | yes | CIDER-CL (2013) [108] Zhang et al. (2014) [382] Todorov et al. (2014) [332] DisMatch (2016) [275] Li (2020) [198] |
Table 7
Knowledge sources and matching systems that use them from part 4 of 4. Referenced is the first documented usage by the matching system. Systems that did not participate in the OAEI are italicized. Named systems are referred to using their system name
| Knowledge source | Source description | Resource available | Used by system |
| Wikipedia MediaWiki API | Web API of the online encyclopedia Wikipedia. | yes | BLOOMS (2010) [142,143] SOCOM (2010) [99] Fu et al. (2011) [100] WikiMatch (2012) [126] OntoEmma (2018) [342] |
| Wikisynonyms | Semantic lexicon built from Wikipedia redirects. | yes | Kolyvakis et al. (2018) [183] DeepAlignment (2018) [182] |
| Wiktionary | A community-built dictionary; an RDF version [287] is also available. | yes | Lin & Krizhanovsky (2011) [205] Wiktionary Matcher (2019) [252] |
| WordNet [92] | A well-known database of English synsets. | yes | see Tables 8 and 9 |
| WordsAPI | A Web API for (English) word definitions, multiple word relations, and more. | yes | Hnatkowska et al. (2021) [134] |
| YAGO [316] | A large knowledge base extracted from multiple sources. | yes | Todorov et al. (2014) [332] |
| Yahoo Image Search | A search engine for images on the Web. | yes | Doulaverakis et al. (2015) [67] |
| Yahoo Search | A search engine for the Web. | yes | Vazquez & Swoboda (2007) [338] |
| Yandex Translation API | A translation Web API by the Yandex search engine. | yes | CroLOM (2016) [172] SimCat (2016) [176] Ibrahim et al. (2020) [137] |
4.3.Background knowledge in ontology matching over time
Tables 4 to 7 list all background knowledge sources that have been used by the systems evaluated in this survey together with the actual systems that use the corresponding knowledge source. As multiple papers exist for some systems, the first documented usage of the knowledge source by the matching system is referenced. Consequently, there is no guarantee that the latest system still uses the specified sources. WeSeE Match, for example, used the Microsoft Bing search engine in its 2012 version [243] but switched to the FARO Web Search framework in 2013 [245]. Therefore, different papers are referenced for the system. For each knowledge source, the systems in column Used by System are ordered according to publication year. Since this survey covers a large time period, not all resources used in the past are still available; therefore, column Resource Available indicates whether the resource is still available to researchers. Due to the frequent usage of WordNet [92], systems that use this source are listed in Tables 8 and 9 which are organized according to the same methodology as Tables 4 to 7. Tables 4 to 9 also include some non-OAEI matching systems (indicated by italics).
Fig. 6.
Cumulative usage of a particular knowledge source of all systems in this survey within the years 2000 to 2021.
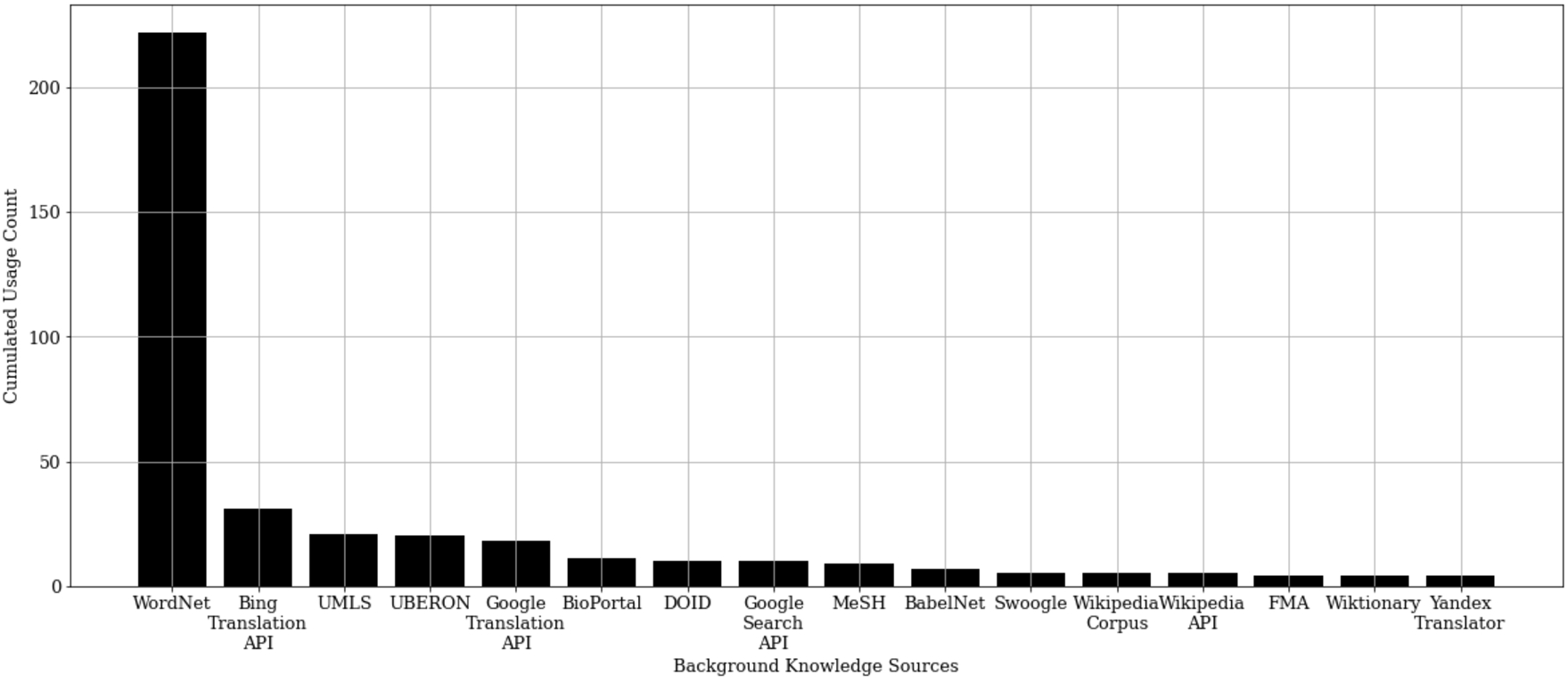
Figure 6 shows the cumulative usage of background knowledge sources that have been referenced in at least four different publications. The by far most often used external knowledge resource is WordNet [92]. Further often used resources are the Unified Medical Language System (UMLS) [208] as well as the Microsoft Bing Translation API. When looking at the distribution of the usage counts in Fig. 6, a power-law distribution can be recognized: Most systems use the same knowledge source; although many knowledge sources exist, most are used only by very few systems. It is important to note that the long-tail in the distribution is actually much longer as shown in the figure because the latter only lists sources used by at least four different matching system publications.
In Fig. 7, background knowledge source usage is plotted over time. As in the figure before, only sources are depicted which are used at least four times by the papers included in this survey. What is visible from the figure (and also from Tables 4, 5, 6, 7, 8, and 9) is that background knowledge has been used from very early on. In the first OAEI in 2004, for example, the OWL-Lite Alignment (OLA) [72] matching system already uses WordNet to retrieve synonym sets. A look at the usage over time (Fig. 7) reveals that only few sources have been used in the early days of ontology matching. With a progression of time, more and more resources are evaluated. However, only few sources show a consistently high application, in particular WordNet, the Microsoft Translation API, UBERON, and UMLS. We can also observe spikes of usage, i.e. a resource has been used within a short time-frame in multiple papers but not afterwards: Examples here are Swoogle [58], a Semantic Web search engine,1717 or the Google Search API.
Fig. 7.
Number of publications of this survey using a particular knowledge source over time.
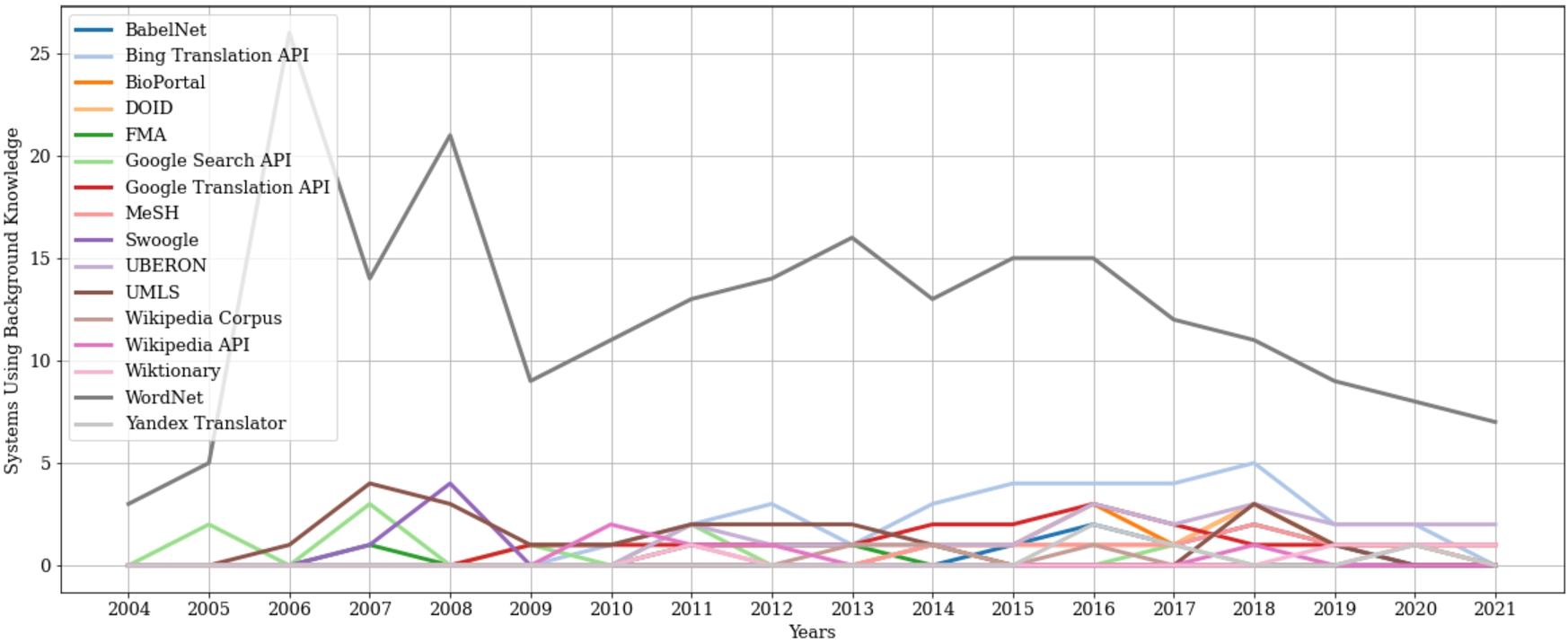
Table 8
Matching systems using WordNet; Part 1 of 2. Referenced is the first documented usage by the matching system. Systems that did not participate in the OAEI at some point in time are italicized. Ontology integration systems are indicated by a subscript I. Named systems are referred to using their system name
| Knowledge source | Used by system | |
| WordNet | OLA (2004) [72] | Cardoso et al. (2008) [34] |
| ASCO (2004) [193] | Zhang et al. (2008) [378] | |
| RiMOM (2004) [322] | OMIE (2008) [30] | |
| Fatemi et al. (2008) [91] | ||
| oMap (2005) [313] | Wang et al. (2008) [349] | |
| CROSI (2005) [166] | SECCO (2008) [248] | |
| Mongiello & Totaro (2005) [220] | Lera et al. (2008) [197] | |
| Aleksovski & Klein (2005) [8] | Agreement Maker (2009) [47] | |
| OWL-Ctx (2006) [234] | Eckert et al. (2009) [69] | |
| AUTOMS (2006) [186] | Zhong et al. (2009) [385] | |
| DSSim (2006) [226] | Xia et al. (2009) [356] | |
| HMatch (2006) [35] | Fernández et al. (2009) [94] | |
| Aleksovski et al. (2006) [9,10] | Eff2Match (2010) [46] | |
| Park et al. (2006) [240,241] | Mascardi et al. (2010) [217] | |
| Alasoud et al. (2006) [6] | NBJLM (2010) [343] | |
| Sen et al. (2006) [286] | ontoMATCH (2010) [214] | |
| Reynaud & Safar (2006) [272] | IROM (2010) [288] | |
| Abolhassani et al. (2006) [2] | Cheatham (2010) [40] | |
| Chen et al. (2006) [43] | Wang et al. (2010) [348] | |
| iMapper (2006) [315] | SOCOM (2010) [99] | |
| ontoDNA (2006) [180] | CSA (2011) [333] | |
| Nagy et al. (2006) [227] | LogMap (2011) [158] | |
| ACAOM (2006) [346,347] | MaasMatch (2011) [279] | |
| Trojahn et al. (2006) [62] | OMReasoner (2011) [289] | |
| Wang et al. (2006) [351] | Optima (2011) [325] | |
| Kim et al (2006) [178] | YAM++ (2011) [231] | |
| Wang et al. (2006) [350] | Lin & Krizhanovsky (2011) [205] | |
| ASMOV (2007) [146] | Sadaqat et al. (2011) [145] | |
| SEMA (2007) [311] | Thayasivam & Doshi (2011) [326] | |
| X-SOM (2007) [50] | MAMA (2011) [39] | |
| iG-Match (2007) [133] | Vaccari et al. (2012) [336] | |
| Tan & Lambrix (2007) [320] | Liu et al. (2012) [210] | |
| Trojahn et al. (2007) [64] | Acampora et al. (2012) [4] | |
| PROMPT-V (2007) [159] | OARS (2012) [144] | |
| Jin et al. (2007) [160] | Fernández et al. (2012) [93] | |
| IAOM (2007) [354] | FuzzyAlign (2012) [95] | |
| Sen et al. (2007) [285] | OACLAI (2012) [202] | |
| UFOme (2007) [249] | Song et al. (2012) [309] | |
| MapPSO (2008) [26] | Schadd & Roos (2012) [280] | |
| Alasoud et al. (2008) [7] | Gulic et al. (2013) [114] | |
| Jeong-Woo et al. (2008) [308] | MAPSOM (2013) [161] | |
| e-CMS (2008) [191] | Acampora et al. (2013) [3,5] | |
| Kaza & Chen (2008) [169] | AML (2013) [88] | |
| Trojahn et al. (2008) [63,65,66] | XMap (2013) [59] | |
| Ichise (2008) [138] | SPHeRe (2013) [170] | |
Table 9
Matching systems using WordNet; Part 2 of 2. Referenced is the first documented usage by the matching system. Systems that did not participate in the OAEI at some point in time are italicized. Ontology integration systems are indicated by a subscript I. Named systems are referred to using their system name
| Knowledge source | Used by system | |
| WordNet | ServOMap (2013) [167] | Vennesland et al. (2018) [339,340] |
| Kumar & Harding (2013) [189] | Refoufi & Benarab (2018) [269] | |
| SMILE (2013) [18] | Kolyvakis et al. (2018) [182] | |
| Petrov et al. (2013) [247] | Bulygin et al. (2018) [32] | |
| Lin et al. (2013) [207] | Kachroudi & Yahia (2018) [164] | |
| Fang et al. (2013) [82] | ONTMAT1 (2019) [106] | |
| UFOM (2014) [381] | Lily (2020) [136] | |
| Todorov et al. (2014) [332] | WeGO++ (2019) [266] | |
| Xue et al. (2014) [368,370,371] | Bulygin & Stupnikov (2019) [33] | |
| Jaiboonlue et al. (2014) [141] | Biniz & Fakir (2019) [25] | |
| AOT/AOTL (2014) [173] | Xue & Chen (2019) [360] | |
| InsMT/InsMTL (2014) [174] | WeGo++ (2019) [266] | |
| Chaker et al. (2014) [37] | Yang (2019) [373] | |
| Schadd & Roos (2014) [281] | Ibrahim et al. (2020) [137] | |
| ServOMBI (2015) [171] | Real et al. (2020) [267] | |
| DKP-AOM (2015) [78] | Xue & Chen (2020) [361] | |
| Kiren & Shoaib (2015) [179] | Lv et al. (2021) [215] | |
| Nguyen & Conrad (2015) [233] | Zhu et al. (2021) [386] | |
| Wang (2015) [345] | Xue et al. (2021) [372] | |
| Xue et al. (2015) [358,363,366,367,369] | ||
| Benaissa et al. (2015) [23] | ||
| Schadd & Roos (2015) [282] | ||
| ALIN (2016) [51] | ||
| CroLOM (2016) [172] | ||
| CroMatcher (2016) [115] | ||
| OMI-DL (2016) [211] | ||
| Anam et al. (2016) [15] | ||
| Xie et al. (2016) [357] | ||
| Mountasser et al. (2016) [222] | ||
| Idoudi et al. (2016) [139] | ||
| Xue et al. (2016) [365] | ||
| ALINSyn (2017) [365] | ||
| Liu et al. (2016) [209] | ||
| HSOMap (2016) [97] | ||
| FCA-Map (2016) [383] | ||
| KEPLER (2017) [162] | ||
| ONTMAT (2017) [105] | ||
| Xue et al. (2017) [359,362,364] | ||
| He et al. (2017) [124] | ||
| OIM- | ||
| SANOM (2018) [219] | ||
| EVOCROS (2018) [56] | ||
| FCA-MapX (2018) [44] | ||
| Ochieng & Kyanda (2018) [236] | ||
| Roussille et al. (2018) [274] | ||
4.4.Most used background knowledge resources
In the following, the ten most used external resources in ontology matching (see Fig. 6) are shortly introduced.
WordNet WordNet is a database of English words grouped in sets which represent a particular meaning, so called synsets; further semantic relationships, such as hypernymy1818 and hyponymy,1919 also exist in the database. The resource is publicly available.2020 In fact, WordNet is so heavily used that there exists a dedicated survey paper titled “A survey of exploiting WordNet in ontology matching” [206]. The resource is under a permissive license can also be used for commercial purposes.2121
Bing/Microsoft translation API The Microsoft Translation API,2222 formerly known as Bing Translation API, allows, among other functions such as language detection, for translating a text string from a source language to a target language. The cloud API can be accessed through any programming language. Since the service is provided in a cloud infrastructure, the translation service is continuously improved. These changes impede reproducibility of matching systems using the API. The service is not free, but as of 2021, 2 million characters of translation/detection per month are not charged.2323
UMLS The Unified Medical Language Sytem (UMLS) is a manually-built compendium of vocabularies in the biomedical domain. The UMLS is maintained by the United States National Library of Medicine (NLM). UMLS can be used without charge but a download2424 requires a registration at the NLM.
UBERON In the anatomy domain, the Uber-anatomy ontology (UBERON) [116,224] is an ontology for multiple species comprising of more than 13,000 classes (as of 2021). Since UBERON defines a canonical model, it can be used as a “hub ontology” to solve various integration problems in the anatomy domain. The ontology can be used on its own but also in combination with other anatomical ontologies such as the Foundational Model of Anatomy (FMA). Particularly the bridging ontologies which connect UBERON to other ontologies (such as UBERON to FMA) make the resource interesting for the task of ontology matching in this domain. UBERON is publicly available and can be directly downloaded2525 without any registration.
Google Translation API The Google Translation API 2626 is very similar to the Microsoft Translation API: It is also a continuously improved cloud service. The Google Translation API is not free, but as of 2021, a translation of 500,000 characters per month are free of charge.2727
BioPortal The National Center for Biomedical Ontology (NCBO) developed and maintains BioPortal2828 [104,352], a Web repository of interlinked biomedical ontologies. The portal grants access to biomedical ontologies and terminologies developed in various Semantic Web formats. Via REST services, users can query (among other things) for ontologies, their metadata, and also for individual ontology terms. Registered users can also submit ontology mappings. This allows for community-created integration content. Particularly interesting in the area of ontology matching are the mapping services provided: Mappings can be easily obtained for a term or for a given ontology. The BioPortal services and data can be used free of charge.
DOID The Human Disease Ontology (DO, very often also abbreviated with DOID) [283] contains, as of 2021, more than 10,800 human diseases which are described through an ontology; its identifiers start with the prefix DOID. The resource is built by a community of experts. The disease ontology contains mappings to other vocabularies such as MeSH (see below), ICD,2929 or SNOMED-CT3030 concepts. It is publicly available3131 under a very permissive license (CC0).
Google Search API The Google Search API3232 allows to perform Web searches programmatically. Like the Google Translation API, it is not free, but as of 2021, 100 search queries per day are free of charge.
Medical Subject Headings (MeSH) The Medical Subject Headings (MeSH) [314] form the controlled vocabulary thresaurus which is used to index medical articles. It is built by experts and maintained by the US National Library of Medicine (NLM). The data is freely available online for download in multiple formats (including RDF).3333 The dataset is available under a permissive license.
BabelNet BabelNet3434 [228] is a large multilingual knowledge graph that integrates (originally) Wikipedia and WordNet. Later, additional resources such as Wiktionary were added. The integration between the resources is performed in an automated manner. The dataset does not just contain lemma-based knowledge but also instance data (named entities) such as the singer and songwriter Trent Reznor. For BabelNet 3.6, an RDF version exists [71]. The dataset can be queried via a UI, SPARQL, and an HTTP API (a Java and a Python client are also available). The dataset is under a restrictive license and the number of free queries is limited. However, researchers can request access to the indices for non-commercial research projects.
5.Categorization of background knowledge in ontology matching
5.1.Classification system
Multiple approaches for categorizing general matching techniques have been proposed [74,265,290]. The matching techniques further studied in this survey can be broadly categorized as context-based approaches according to Euzenat and Shvaiko [74,290] or as schema-only based approaches according to Rahm and Bernstein [265].3535 Rahm et al. do not group background knowledge sources while Euzenat et al. distinguish formal resources, i.e. those on which reasoning can be applied, and informal resources, i.e. those on which reasoning cannot be applied. The latter authors further name the dimensions breadth, formality, and status [77]. In this survey, we propose a more fine-grained categorization with a clear distinction between the background knowledge source that is used and the strategy that is applied to exploit the given knowledge source.
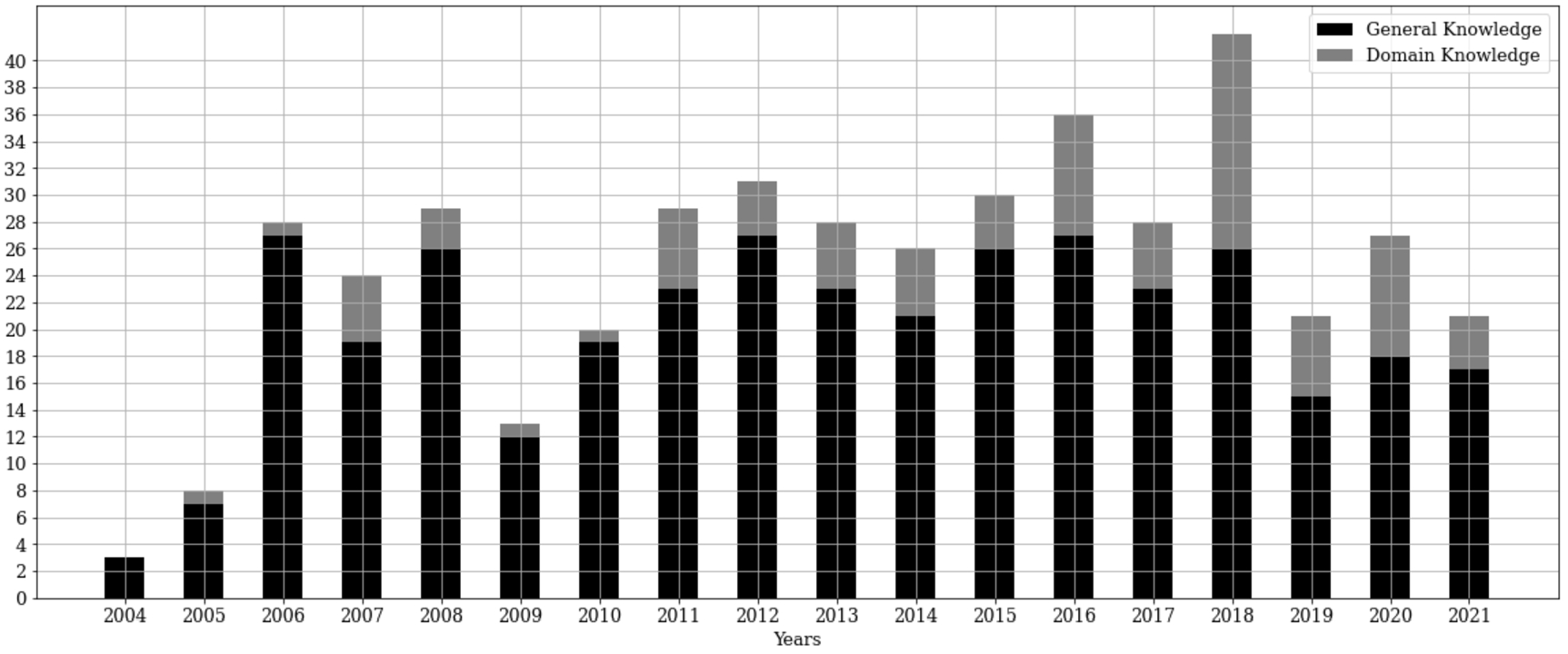
Target domain Background knowledge sources for matching can be grouped by their target domain or target purpose. Here, it can be differentiated between domain-specific assets and general-purpose assets. While general-purpose background knowledge is intended to improve the overall matching quality on any task, domain-specific background knowledge is intended to improve the matching performance within a specific domain or even for a specific matching task. An example for a widely used general-purpose knowledge source is WordNet; a point in case for a popular domain-specific knowledge source is the Unified Medical Language System (UMLS). The distinction between domain-specific and domain-independent (lexical and grammatical) sources is also made by Real et al. [267] who show in a recent publication that the inclusion of domain specific lexical- and grammatical knowledge can significantly improve matching systems in domain-specific tasks. In Fig. 8, the aggregated usage of background knowledge in schema matching systems is plotted per year. It is visible that – up to date – general-purpose knowledge sources are used more often than domain-specific knowledge sources. This finding is intuitive, since general-purpose datasets are easier to find and their application makes sense for any matcher whereas domain-specific datasets may be harder to find (depending on the matching task) and require a concrete, domain-bound matching problem. It is also visible that the research community initially started with general-purpose background knowledge and explored domain-specific sources at a later stage. Most publications using external background knowledge sources (general and domain-specific) were published in 2018. It is important to note that this survey does not cover the full year of 2021.
Fig. 8.
Aggregated number of publications of this survey using external background knowledge in ontology matching. Domain-specific background knowledge sources are colored in light gray, general-purpose background knowledge sources are colored in black.
Structuredness Independent of the domain, the knowledge sources can be split in structured sources and unstructured sources. Structured data is organized according to a known data schema whereas unstructured data is not. An example for a structured external data source in ontology matching is WordNet; an example for a general-purpose unstructured data source in ontology matching is the entirety of Wikipedia texts whereas SAP Term, a set of definitions of terms in SAP software, is an example of a domain-specific unstructured resource. Unstructured external resources are rarely used in ontology matching. We, therefore, only classify into textual and non-textual unstructured resources whereby we did observe merely one publication [67] using non-textual, unstructured sources (i.e., images).
Fig. 9.
Classification of background knowledge sources that are used for matching.
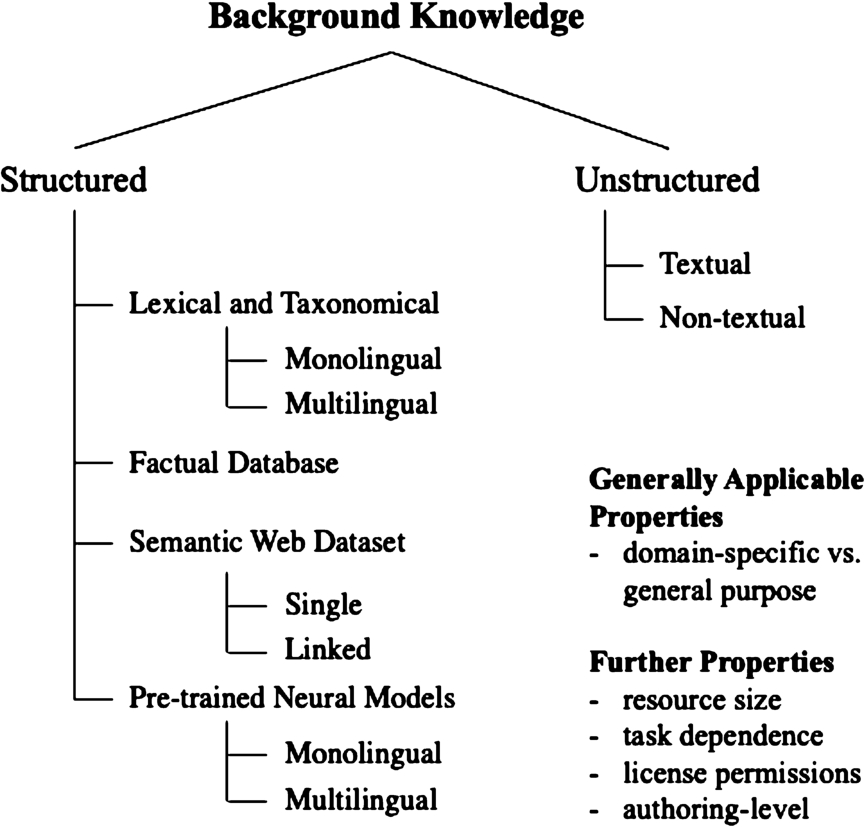
Structured sources appear in different variations (type): (i) Lexical and taxonomic resources, (ii) factual databases, (iii) Semantic Web datasets, and (iv) pre-trained neural models. Lexical and taxonomic resources as well as pre-trained neural models can again be subdivided into monolingual and multilingual resources.3636 Semantic Web datasets can be subdivided into single datasets and interlinked datasets.
An overview of the proposed classification system is presented in Fig. 9; in Table 10, all resources covered in this survey are categorized according to the presented classification system. In the following, we will further define each structured resource and provide examples for all fine-grained categories.
Lexical and taxonomical knowledge Lexical and taxonomical knowledge is the most exploited external type of knowledge in ontology matching. The most commonly used resource in this class in our study is WordNet. The resource is monolingual, this means it is available in only one language, i.e. English. Similar resources exist in other languages such as the German thesaurus GermaNet [118] – however, since most ontology matching benchmark datasets are provided in English, our study is consequently also skewed towards English resources. Concerning multilingual lexical knowledge, dictionaries and dictionary-like resources, such as APIs, are heavily used for multilingual ontology matching. In our study, we found substantial usage of the Microsoft Bing Translation API but also of other general-purpose translation APIs. Although not appearing in the tables, domain-specific multilingual resources exist, for example the Fachwörterbuch Versicherungswirtschaft und -recht3737 [260].
Factual databases A factual database provides (non-lexical) facts that can be included into the matching process. An example here might be a database of postal codes and cities. We did not find any significant usage of such a resource despite imaginable use case scenarios. An example for a domain-specific database would be MEDLINE, the bibliographic database of the National Library of Medicine which is used by the DisMatch [275] and OntoEmma [342] matching systems.
Table 10
Background knowledge sources sorted according to their type
| Background knowledge type | Background knowledge source | |||
| Domain-specific | Structured | Lexical and Taxonomical | Monolingual | RadLex SPECIALIST Lexicon |
| Multilingual | – | |||
| Factual Database | Medline PubMed | |||
| Semantic Web Dataset | Single | DOID FMA FIBO Medical Subject Headings (MeSH) UBERON | ||
| Linked | BioPortal Ontology Lookup Service (OLS) UMLS | |||
| Pre-trained Neural Model | Monolingual | BioBERT | ||
| Multilingual | – | |||
| Unstructured | Textual | Cooking Dictionary SAP Term | ||
| Non-Textual | – | |||
| General-purpose | Structured | Lexical and Taxonomical | Monolingual | Big Huge Thesaurus Paraphrase DB (PPDB) synonyms-fr.com Universal Knowledge Core (UKC) Wikipedia MediaWiki API (non-text serach) Wikisynonyms WordNet WordsAPI |
| Multilingual | Apertium Bing/Microsoft Translator Freelang Google Translation API HowNet iTranslate4 Lanes API MyMemory API SDL FreeTranslation Webtranslator API Yandex Translation API | |||
| Factual Database | – | |||
| Semantic Web Dataset | Single | BabelNet DBnary DBpedia ConceptNet DOLCE OpenCyc SUMO Swoogle WebIsALOD YAGO | ||
| Linked | – | |||
| Pre-trained Neural Model | Monolingual | BERT fastText model Google Word2Vec Vectors KGvec2go SBERT | ||
| Multilingual | Google Universal Sentence Encoder | |||
| Unstructured | Textual | Bing Search Engine API FARO Web Search Google Search API Wikipedia Corpus Wikipedia MediaWiki API (for text search) Yahoo Search | ||
| Non-Textual | ImageNet Yahoo Image Search | |||
Semantic web dataset A Semantic Web (SW) dataset is a knowledge base developed with technologies from the Semantic Web technology stack, such as RDF or OWL files. The category includes knowledge graphs with or without instance data where we define a knowledge graph slightly broader than in its original sense [244] and also count domain-specific graphs. We also consider SPARQL endpoints as SW datasets in this survey as well as plain ontologies.
We further differentiate between (i) single and (ii) linked SW datasets. A single dataset is in this case an individual knowledge graph or ontology.
An example for a general-purpose single SW dataset would be DBpedia [195] (used e.g. by LDOA [163]), WebIsALOD [127,284] (used e.g. by ALOD2Vec Matcher [256]), or Wikidata. An example for a domain-specific single SW dataset would be the Financial Industry Business Ontology (FIBO) used for instance in [221].
An example for domain-specific linked SW dataset in this sense would be some or all BioPortal [352] ontologies together with their mappings while an example for general-purpose linked SW dataset would be any two linked general-purpose knowledge graphs.
Pre-trained neural models A recent development is the application of deep learning in a multitude of applications. A pre-trained neural model in this classification system may be an API exposing latent representations of concepts, such as KGvec2go3838 [254], or a pre-trained model such as the Google Universal Sentence Encoder3939 [36,374] used by VeeAlign [140].
5.2.Further relevant properties
Further properties of background knowledge sources that are not used here for the proposed classification are (i) resource size, (ii) task dependence, (iii) license permissions, and (iv) authoring level. Those properties are important in particular when it comes to the strategies that are applied to exploit the background knowledge.
The resource size may limit the utility provided by the source – a small general knowledge thesaurus, for example, may only be of limited use – but may at the same time also limit the exploitation strategy that can be used; the RDF2Vec [273] embedding approach (a comparatively scalable embedding approach) is very hard to apply to the BabelNet (RDF) knowledge graph [71] due to its sheer size. Surprisingly, the most used general-purpose background knowledge source, WordNet, is relatively small compared to community-built resources such as BabelNet, Wiktionary, or Wikidata.
The task-dependency also limits the options to exploit the source (see Section 7). A very specific Web-API providing only a very specific service may limit the strategy to the simple call of the service.
While license permissions are not of utmost concern to the research community, they are very important in the enterprise world when it comes to the actual application of matching systems in the real world for commercial purposes.
The level of authoring or trust of a knowledge source is affecting the exploitation strategy as well. Generally, four main categories can be observed: (1) expert-built resources such as WordNet, (2) community-built resources such as Wiktionary, (3) semi-automatically built resources such as BabelNet, and (4) automatically built resources such as WebIsALOD. It can be assumed that the amount of trust decreases from (1) to (4): A deeply reviewed, expert built dictionary such as WordNet may be used with less caution than a community built online dictionary like Wiktionary or a heuristically extracted dataset such as WebIsALOD. The quality of the matching results is likely not in every case proportional to the level of trust since it depends on the exploitation strategy used and the concrete resource. Automatically-trained neural language models, for instance, have a low authoring level but may produce very good results.
6.Categorization of linking approaches
In order to exploit an external knowledge source, the concepts in one or both of the ontologies to be matched need to be linked to the knowledge source. The linking process is also known as anchoring or contextualization [77]. For example, to determine whether the classes http://mouse.owl#MA_0002390 and http://human.owl#NCI_C33743 of the OAEI Anatomy track [27] are similar using Wiktionary, the URIs have to be first linked to one or more Wiktionary entries. In this case, the label of the first can be used to link it to the entry of “temporalis” and the label of the latter can be used to link it to the entry of “temporal muscle”. Within the knowledge source, we can then find a synonymy relation between the two entries and derive a degree of similarity.
While many publications address the concrete application of a background source for ontology matching, few discuss the actual linking problem. However, since linking is the first step in exploiting a knowledge source, it significantly determines the quality of the outcome. In a visionary paper by Sabou et al. [278], online ontologies obtained with a Semantic Web search engine have been used for ontology matching. Out of the 1,000 correspondences checked manually, 217 false ones have been identified. The authors find that out of those, 53% are due to anchoring errors. This emphasizes the need for a solid anchoring strategy.
The linking process is typically dependent on the knowledge source used and can be as simple as forwarding a label (e.g. when using the Google search API) or as complicated as the ontology matching problem itself (e.g. when another knowledge graph shall be used).
For linking, we distinguish two goals: (i) finding at most one link for each concept in an ontology and (ii) finding up to many links for each concept in an ontology. Multiple links can be sensible in the case of partial linking; for example, a concept with label “derivatives exchange” may be linked to “derivatives” and “exchange” in cases where there is no match for the complete concept. Other reasons for multi-linking are datasets with homonyms4040 or knowledge sources that explicitly provide multiple senses for strings. For the latter two cases, a Word Sense Disambiguation (WSD) approach may help to decide on a smaller set of links.
In terms of classifying linking approaches, we propose a classification system consisting of four categories: (i) given links, (ii) direct label linking, (iii) fuzzy linking, (iv) Word Sense Disambiguation (WSD). The proposed classification system is summarized in Fig. 10. In the following, we will introduce each category in detail and provide examples. It is important to note that not every linking strategy can be applied on each dataset; WSD, for instance, can only be applied if there are multiple senses available in the background dataset.
Fig. 10.
Categorization of linking approaches.
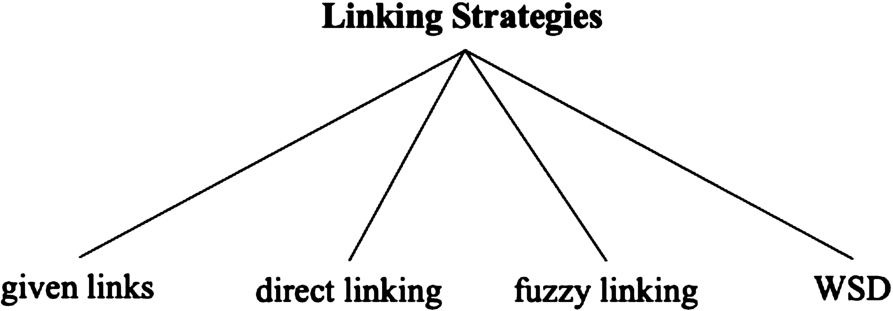
Given links In few cases, linking can be omitted if the external knowledge source already contains links, e.g., in the form of owl:sameAs or owl:equivalentClass statements. A case in point is Wikidata where multiple identifiers are typically specified; the concept pneumonia (Q121924141), for instance, lists more than 30 identifiers for other datasets – among them IDs for MeSH, BabelNet, the Disease Ontology, Freebase, or UMLS.
Direct label linking Given the sparse information provided in publications concerning the linking strategy, it can be assumed that in most cases linking is performed by directly looking up a potentially normalized label. This works particularly well if the external dataset has a very large coverage of concepts or even provides synonyms such as lexical and large taxonomical background knowledge datasets. Recent matching systems that apply this kind of linking are for example FCA-MapX [44], ONTMAT1 [106], or Wiktionary Matcher [252,257].
Fuzzy linking The linking process can also be based on only parts of a label, n-grams within a label, or expanded labels. Such linking approaches fall under the fuzzy linking category. The underlying goal of this strategy is to find more links than through direct label linking. Naturally, this strategy is attractive if the background dataset is small and/or the concepts in it are described by a single label (without stating alternative names, abbreviations, synonyms etc.). Mascardi et al. [217], for instance, match two ontologies to an upper ontology and then use the obtained two alignments to derive a final alignment; they perform an involved (upper ontology) matching/linking operation including synonymy expansion and substring-based approaches.
Word Sense Disambiguation (WSD) We did not find matching systems that try to actually disambiguate the sense of a label through Word Sense Disambiguation (i.e. which try to settle with one correct sense) – despite the heavy usage of WordNet (which is built around senses).4242 Instead, similarity approaches that can handle multiple senses are typically used. The NBJLM [343] matching system narrows down the number of WordNet synsets – but only to reduce the computational complexity.
7.Categorization of background knowledge exploitation approaches
In Section 5, the background knowledge resources used in ontology matching have been presented and categorized. The second main dimension of this survey is the exploitation strategy of the background resource. In many cases, there are multiple options to beneficially use an external knowledge source.
We classify exploitation strategies into four groups: (i) factual queries, (ii) structure-based approaches, (iii) statistical/neural approaches, and (iv) logic-based approaches. A factual query is the request for one or more data records contained in the background resource. Structure-based approaches exploit structural elements in the background knowledge source. Statistical or neural approaches apply statistics or deep learning on the background knowledge source or consume an existing pre-trained model. Lastly, logic based approaches employ reasoning with the externally provided resource. In the following, the categories are further described and extensive examples are provided. An overview of the proposed classification system is provided in Fig. 11.
Fig. 11.
Overview of the types of background knowledge exploitation strategies.
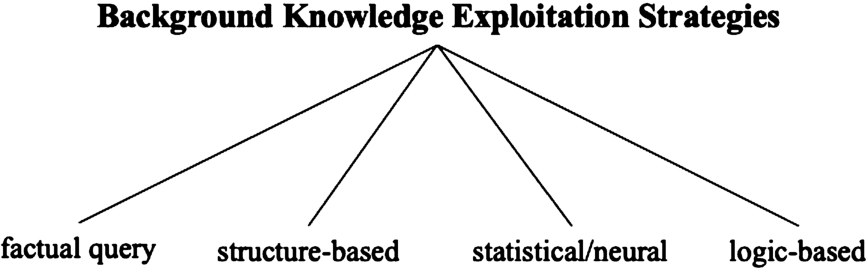
Factual queries A factual query is the extraction of an existing record from the knowledge source. This type of exploitation strategy is the most common one and used since the early days of (semi-) automated ontology matching. An example for retrieving factual information would be retrieving synonyms from WordNet (applied by many matching systems e.g. RiMom [200], AgreementMaker [47], or FCA-Map [44]) or from DBnary [287] (e.g. by Wiktionary Matcher [252,257]).
Structure-based approaches Structure-based methods require a structural dimension in the background resource such as a tree or graph structure. Elements to be compared are typically projected into the background source and the structure is used to derive a new fact between the projected elements such as equivalence or subsumption. Structure-based approaches are often applied on WordNet to determine similarity such as the path-based approaches by Wu and Palmer [355] or Jian and Conrath [147] (both used for example by the YAM++ matching system [231]) or the information-based approach proposed by Lin [204] (used for example by the RiMom [321] matching system).4343 Many more WordNet-based approaches that fall into the structure-based category of this survey paper have been proposed and used in ontology matching; we direct the interested reader to the survey by Lin et al. [206]. Structure-based approaches have not only been used together with WordNet but have also been applied on other datasets such as overlap-based metrics based on WebIsALOD [259]. A structural approach on Wikipedia categories is applied by BLOOMS [142] where concepts are linked into the Wikipedia taxonomy and an overlap measure on taxonomy sub-trees is defined to determine similarity. Given a repository of ontologies together with correspondences, Annane et al. [16] apply a structure-based strategy, where they first form a so called global mapping graph. Source and target ontology are linked into the latter and a path-based strategy is applied so that the correspondences with the highest confidence can be extracted.
Due to their nature, structure-based approaches are not (obviously) applicable to factual databases, or pre-trained neural models.
Statistical/neural approaches Statistical approaches apply a statistical process on the data derived from the external knowledge source. The WeSeE-Match system [243,245], for instance, builds virtual documents from search engine results and derives a similarity estimate by applying a strategy that is based on the term frequency-inverse document frequency (TF-IDF) vectors of the documents.
Neural approaches employ artificial neural networks either directly on the background knowledge source or re-use existing pre-trained models. For example, the background knowledge source may be transformed into a vector space [256] or the background knowledge source is already a vector space that may be used directly to link the schemas to be matched [140] in a vector space. We also count neural APIs into this category; ALOD2Vec Matcher [255], for example, uses in its most recent version the API of KGvec2go [254] to obtain vectors for concepts. While this could be seen as a factual query, we still consider this strategy to be a neural one due to the nature of the approach. It is important to note that we focus only on strategies applied to the background knowledge – a matching system that uses neural networks to configure weights of various features (e.g. the 2011 version of CIDER [109]) does not fall in this category and neither does a matching system that applies a neural model to the ontologies that are to be matched such as DOME [129]; the reason for this decision is that the latter two system types do not actually use external background knowledge for their matching strategy. Systems that apply statistical approaches are not novel – however, systems that apply neural methods are relatively recent (the oldest ones of this survey being from 2018, e.g. [256]), not plentiful in numbers, and achieve mixed results. This is most likely due to the novelty of this exploitation strategy. Notable in this category is the VeeAlign [140] matching system which uses a sentence encoder as external knowledge and achieved the best results on the Conference [42] track in the OAEI 2020.
Logic-based approaches Logic-based approaches apply reasoning on or together with the external resources. This class of approach is also referred to as context-based matching [213] or indirect matching.4444 Typical external resources are upper ontologies, domain-ontologies, knowledge graphs, or linked data. We differentiate reasoning from the factual queries in that a reasoning operation goes beyond querying a graph with an ASK query for equivalence or any other relation between two concepts. Logic-based approaches are already envisioned in the earlier days of ontology matching. An archetypal setup of such an approach is presented in Fig. 12 which was first presented by Sabou et al. [276] and slightly adapted for this survey: Elements of the ontologies to be matched are linked to the external ontology (Sabou et al. call this step anchoring, Euzenat et al. refer to this step as contextualization, see Section 6) and reasoning is applied to derive correspondences. It is important to note that reasoning can also be applied across multiple ontologies: Locoro et al. [213] generalize and significantly extend the approach by Sabou et al.; they perform reasoning also across more than one intermediate ontology. Their proposed generalized framework consisting of seven logical steps4545 is particularly applicable for logic-based approaches.
However, we did not find broad usage of logic-based exploitation approaches in past and current (OAEI and non-OAEI) ontology matching systems that go beyond singled out experiments. Approaches that fall into this category are Sabou et al. who use Swoogle to retrieve ontologies from the Web. BLOOMS+ [143] does not strictly reason on the external resource but applies a context similarity measure which is based on overlap of superclasses which could be seen as such. Mascardi et al. [217] perform experiments on multiple upper ontologies (DOLCE [102], SUMO [235], OpenCyc [196])4646 following a similar approach of exploiting the transitivity of equivalence relations. Strictly speaking, Mascardi et al. are also not performing a real reasoning operation as defined in the beginning of this paragraph. Despite the clear vision of the latter two publications, upper ontology approaches that exploit actual reasoning have not gained traction so far.
Fig. 12.
A logic-based exploitation strategy on an external ontology, initially presented by Sabou et al. [276], adapted. A and B represent concepts from the ontologies to be matched that are linked to
![A logic-based exploitation strategy on an external ontology, initially presented by Sabou et al. [276], adapted. A and B represent concepts from the ontologies to be matched that are linked to A′ and B′ in the external ontology.](https://content.iospress.com:443/media/sw-prepress/sw--1--1-sw223085/sw--1-sw223085-g012.jpg)
8.Directions for future work
In Section 5, we proposed a classification system for background knowledge sources and in Section 7 we presented a classification system for exploitation approaches. In this section, we will overlap those to a matrix and will position the systems evaluated in this survey in there. We will use this matrix as a starting point for discussions of white-spots in the area of background knowledge-based ontology matching. We further outline interesting observations, shortfalls and biases found in the ontology matching domain.
Table 11
Systems in the background knowledge type / exploitation method type matrix (domain-specific background knowledge)
| Background knowledge (domain-specific) | Strategy | ||||||
| Factual queries | Structure-based | Logic-based | Statistical/Neural | ||||
| Domain-specific | Structured | Lexical and Taxonomical | Monolingual | Groß et al. (2011) [110] AML (2014) [85] FCA-Map (2016) [383] Ochieng & Kyanda (2018) [236] LogMap (2018) [153] Real et al. (2020) [267] | – | Fang et al. (2013) [82] | |
| Multilingual | – | ||||||
| Factual Database | – | – | DisMatch (2016) [275] OntoEmma (2018) [342] Li (2020) [198] | ||||
| Semantic Web Dataset | Single | AOAS (2007) [380] GOMMA (2012) [111] AML (2014) [85] LAYM++ (2016) [331] CroMatcher (2016) [115] POMap (2017) [190] Ochieng & Kyanda (2018) [236] Lily (2020) [136] | Petrov et al. (2013) [247] Annane et al. (2018) [17] | DESKMatcher (2020) [221] | |||
| Linked | NLM (2006) [379] AOAS (2007) [380] ASMOV (2007) [146] SAMBO (2007) [319] LogMap (2011) [158] Fernández et al. (2012) [93] GOMMA (2012) [111] AML (2013) [88] Amin et al. (2014) [13] LogMapBio (2014) [156] Zaveri & Dumontier (2016) [375] Lily (2018) [323] FCA-Map (2018) [44] PAXO (2020) [121] | Petrov et al. (2013) [247] Annane et al. (2016) [16] Annane et al. (2018) [17] | RiMom (2007) [201] OntoEmma (2018) [342] | ||||
| Pre-trained Neural Models | Monolingual | – | – | MEDTO (2021) [119] | |||
| Multilingual | – | – | |||||
| Unstructured | Textual | – | – | – | van Hage et al. (2005) [337] DESKMatcher (2020) [221] | ||
| Non-Textual | – | – | – | ||||
Table 12
Systems in the background knowledge-type / exploitation method type matrix (general-purpose background knowledge)
| Background knowledge (general purpose) | Strategy | ||||||
| Factual queries | Structure-based | Logic-based | Statistical/Neural | ||||
| General-purpose | Structured | Lexical and Taxonomical | Monolingual | HotMatch (2012) [52] SOCOM++ (2012) [101] [many WordNet systems, see Tables 8 and 9] Mao et al. (2011) [216] Hnatkowska et al. (2021) [134] | BLOOMS (2010) [142] [many WordNet systems, see Tables 8 and 9] | – | DeepAlignment (2018) [182] |
| Multilingual | Li et al. (2006) [199] Wang et al. (2008) [349] SOCOM (2010) [98,99] / SOCOM++ (2012) [101] Spohr et al. (2011) [312] Fu et al. (2011) [100] AUTOMS (2012) [185] WeSeE Match (2012) [243] YAM++ (2012) [230] Medley (2012) [123] RiMom (2013) [384] Koukourikos et al. (2013) [187] GOMMA (2012) [111] AML (2014) [85] Kachroudi et al. (2014) [165] XMap (2014) [60] LogMap (2015) [155] CLONA (2015) [1] CroLOM (2016) [172] SimCat (2016) [176] Helou et al. (2016) [125] Destro et al. (2017) [55] KEPLER (2017) [162] Bella et al. (2017) [22] NuSM (2017) [22] Kachroudi & Yahia (2018) [164] Wiktionary Matcher (2019) [252] Ibrahim et al. (2020) [137] | – | Kolyvakis et al. (2018) [183] | ||||
| Factual Database | – | – | |||||
| Semantic Web Dataset | Single | Vazquez & Swoboda (2007) [338] Spider (2008) [277] LDOA (2011) [163] Davarpanah et al. (2015) [53] EVOCROS (2018) [56] | BLOOMS (2010) [142] Grütze et al. (2012) [113] Todorov et al. (2014) [332] | SCARLET (2007) [276,278] | LYAM++ (2015) [329] ALOD2Vec (2018) [256,259] Kolyvakis et al. (2018) [183] | ||
| Linked | |||||||
| Pre-trained Neural Models | Monolingual | – | – | Bulygin (2018) [32] Bulygin & Stupnikov (2019) [33] VeeAlign (2020) [140] ALOD2Vec (2020) [255] KGMatcher (2021) [81] Fine-TOM (2021) [181] TOM (2021) [184] MEDTO (2021) [119] Neutel et al. (2021) [229] | |||
| Multilingual | – | – | VeeAlign (2020) [140] | ||||
| Unstructured | Textual | – | – | – | van Hage et al. (2005) [337] Pan et al. (2005) [239] Vazquez & Swoboda (2007) [338] Gligorov et al. (2007) [107] PROMPT-V (2007) [159] X-SOM (2007) [50] KMSS (2009) [376] Mao et al. (2011) [216] WeSeE Match (2012) [243] WikiMatch (2012) [126] CIDER-CL (2013) [108] MapSSS (2013) [41] DisMatch (2016) [275] OntoConnect (2020) [38] Neutel et al. (2021) [229] | ||
| Non-Textual | – | – | – | Doulaverakis et al. (2015) [67] | |||
8.1.White spots
Tables 11 (domain knowledge) and 12 (general knowledge) present the systems evaluated in this study in a source/strategy matrix. The exploitation strategy (columns) in the table follows the proposed classification which is summarized in Fig. 11. The rows represent the background knowledge type and follow the proposed classification which is summarized in Fig. 9. Irrelevant combinations of source and strategy are marked in the tables with a hyphen. Empty or rarely filled cells hint at yet underexplored and potentially interesting research directions in the area of background knowledge-based ontology matching.
From the tables we see that general purpose background knowledge is used more often than domain-specific background knowledge.4747 The most often used background knowledge type are lexcial and taxonomical resources with WordNet being the clear winner. Clearly not often used are unstructured, non-textual data, pre-trained neural models, and general-purpose Semantic Web datasets.4848 It is important to note that the heavy usage of linked data in Table 11 is mainly due to UMLS falling in that category – almost all systems listed use this single resource. Hence, the general application of linked data is not yet common, too. Interestingly, the application of general-purpose textual data has been explored in multiple publications whereas there is merely a single application of domain-specific free text.
It is quickly visible that factual queries are most often used regarding the strategy. When it comes to yet underexplored research directions of background knowledge usage, we see that in terms of the approaches used, logic-based and neural-based strategies are an interesting and promising research direction. Pre-trained embedding-models and architectures, for instance, are up to 2020 rarely used but may be very promising given breakthroughs in other scientific communities. An increase in publications in 2021 in this category may indicate that scientific interest is already moving in this direction. Structural approaches are almost completely limited to the English WordNet. The exploration of structural methods on multilingual datasets as well as on Semantic Web datasets may yield interesting results given good results on the English WordNet and given that this class of approaches is typically intuitive to understand and can be comprehended by humans (unlike neural models).
8.2.It’s a biomedical world
If we take a closer look at the domain-specific knowledge sources used, it is striking that almost all datasets are from the biomedical domain. This may be due to a particularly prolific bioinformatics community that holds open standards and open data high – however, the skewness of ontology matching publications towards the biomedical domain must be pointed out. In Fig. 6 (cumulative background knowledge usage), it is striking that all domain-specific datasets are from the biomedical domain. This domain-focus also visible when looking at OAEI tracks where almost all domain-specific problems are from this domain. This fact is likely self-enforcing: New researchers use existing evaluation datasets and existing background knowledge and quickly find themselves in this domain area.
Nonetheless, ontology matching is a problem in all domains that are concerned with data management which makes it ubiquitous. Enterprise schema matching and integration challenges in the business world, for example, are not reflected at all in OAEI tracks.4949 In addition, there are indications that top-performing OAEI schema matching systems perform comparatively bad on real world business integration tasks [253]. More insights on the generalization of current matching methods, properties of matching problems in other domains, or further well-performing domain-specific or general-purpose datasets are desirable.
An interesting research direction is, therefore, also to broaden the domain-focus of the ontology matching problem and to evaluate which background datasets and exploitation strategies are applicable in other domains. Therefore, new and publicly available benchmark datasets from more domains are required to support research efforts in this area. New challenges may come to light such as missing domain-specific knowledge sources not being broadly available [250]. The provisioning of further evaluation datasets in other domains is a clear desideratum.
8.3.Multilinguality
A further bias besides a domain-focus is the focus on monolingual ontology matching. At the OAEI, there is currently only one multilingual matching task with few participants. The techniques currently applied are purely lookup-based despite advances in machine translation.
Multilingual ontology matching requires the addition of external resources; hence, we can find many multilingual background sources in Tables 4 to 7. However, when we compare the resource/strategy matrix in Tables 11 and 12, we quickly see that there are many systems that use general-purpose multilingual resources but there is not a single system that uses domain-specific multilingual resources. This may be due to the fact that there are at the moment no benchmark datasets for more advanced multilingual matching tasks available – despite this being a relevant problem in the real world. The current multilingual evaluation datasets are all from the conference domain with a rather low level of domain-complexity.
It could be further observed that, although many diverse multilingual resources such as Wikidata or EuroVoc5050 exist, most multi-lingual matchers use translation APIs with a simple factual query strategy. This setup limits reproducibility and transparency.
Interesting research directions are the exploration of new multilingual matching methods and datasets as well as the exploration of multilingual matching challenges in domain-specific settings. The provisioning of further evaluation datasets is also for the aspect of multilinguality a desideratum. Given well-performing and publicly available deep-learning models from the NLP domain, their application should also be considered for the ontology matching task.
8.4.The English bias
Another language-based bias is the focus on aligning schemas that are semantically described in the English language. The research community currently mainly solves English–English alignment problems.5151 This bias can already be seen when reviewing the most common evaluation datasets – but this bias is also found in the background knowledge used: The majority of background knowledge sources listed in Tables 4 to 7 are available in English as main language (with the exception of some translation-oriented datasets such as translation APIs). It is unlikely that this setting reflects the real-world situation.
An interesting research direction is, therefore, the exploration of non-English rooted ontology matching problems with non-English background knowledge sources. As with the multilingual bias, the community would greatly benefit from the provisioning of more evaluation datasets.
8.5.Manual background knowledge selection
While multiple automatic background knowledge selection approaches have been proposed (see Section 4.2), we did not find significant usage of documented automated selection processes in the publications reviewed for this survey. Up to date, the majority of background knowledge sources in ontology matching is either bound to one predefined source or uses few hand-picked resources. With the exception of LogMapBio, most matching systems which apply an automated selection approach are presented in the context of background knowledge selection. Hence, self-configuring matching systems that select their own background resources based on a particular matching problem are still an interesting area of research. Very recent approaches, such as the usage of pre-trained language models that are fine-tuned on the matching task, do not solve this task (but instead emphasize the importance since the pre-trained model also needs to be selected).
8.6.Linking
Our analysis on how concepts are linked into the background knowledge source revealed that most matching systems do not perform elaborated linking approaches but use a direct string lookup. While this may be sufficient for some background datasets, there is indication that in some cases linking is a significant component in the performance of background knowledge-based matching systems [277,278].
A reason for the negligence when it comes to linking might be that Word Sense Disambiguation is perceived as too hard. Another reason might be due to the fact that schemas to be integrated are often derived from the same domain which significantly reduces the amount of concept and definiens and concept mismatches [341] induced by homonyms since words will often refer to the same senses. For example, when two ontologies from the financial services domain use the term “bank”, they likely both refer to the sense of a financial institution – an elaborated WSD approach would not provide any value here. Existing evaluation datasets are all more or less from the same domain and do not reflect this problem appropriately.
However, when large external knowledge bases are to be matched or when the schemas to be matched are large and diverse such as in the case of knowledge graph matching, WSD may significantly improve the results obtained with external background knowledge. This finding is in line with a recent publication on knowledge graph matching by Hertling and Paulheim [130] who show that state-of-the-art matching systems perform badly when it comes to matching non-related or weakly-related knowledge graphs due to non-disambiguated homonyms.
An interesting research direction is consequently the development, evaluation, and comparison of multiple linking approaches and their effect on the performance of automated matching systems. We also see a need for the provisioning of additional matching gold standards in the area of knowledge graph matching as well as matching of weakly related schemas.
9.Conclusion
Since the early 2000’s, the understanding of the (automated) ontology matching problem as well as the development of advanced matching systems have greatly improved. Nonetheless, the ontology matching problem is not solved and will stay an interesting research area for the years to come. One key to coming closer to the solution is the deeper integration of background knowledge within the ontology matching process.
In this survey, we reviewed all ontology matching systems that participated in the OAEI from 2004 until today, as well as systematically selected ontology matching systems in terms of what background knowledge sources they use, which linking approach they employ, and how they use the external knowledge. We classify background knowledge in multiple structured and unstructured classes according to their purpose (domain-specific or general-purpose). The main structured knowledge source types are (i) lexical and taxonomical resources, (ii) factual databases, (iii) Semantic Web datasets, and (iv) pre-trained neural models. The main unstructured resource types are (i) textual and (ii) non-textual. In our review we found that mostly general-purpose structured knowledge is used in ontology matching. Most systems to date make use of simple lexical and taxonomical sources. Yet underexplored sources of background knowledge are unstructured resources, pre-trained neural models, general purpose knowledge graphs, and linked data.
We further presented a classification system for linking strategies consisting of four categories: (i) given links, (ii) direct linking, (iii) fuzzy linking, and (iv) Word Sense Disambiguation. Although linking is important when it comes to exploiting external knowledge sources, we found that most systems use direct label linking.
Concerning the strategy that is used to exploit knowledge sources, we presented a classification system consisting of four categories: (i) factual queries, (ii) structure-based approaches, (iii) logic-based approaches, and (iv) statistical/neural approaches. We found that a look-up strategy of facts is most commonly used. Structure-based strategies are almost exclusively applied on WordNet. Despite a clear vision, logic-based approaches did not gain much traction in recent years. A novel research area in terms of exploitation strategies are neural approaches which are currently barely used but showed very good results in other domains.
In our survey, we found multiple biases when it comes to ontology matching with background knowledge: (i) A focus on biomedical matching tasks, (ii) a focus on monolingual matching, and (iii) a focus on matching schemas rooted in the English language. In particular the business world where integration problems are plentiful and multi-faceted, is hardly considered in current research efforts. Although the focus of this survey is the usage of external knowledge within the ontology matching process, we consider the identified biases to be generally applicable.
Notes
1 See https://lod-cloud.net/.
2 See https://dblp.org/.
3 Back then the competition was actually referred to as EON Ontology Alignment Contest.
5 See https://www.zotero.org/.
8 Originally called r but renamed for better clarity here.
10 See https://www.kaggle.com/.
11 Prior to 2010, participants submitted resulting alignments directly. The submission of packaged tools (at first in the form of URLs of Web services running on the participants’ site) instead of results was started in 2010. Since 2012, the submission of packaged tools is the standard evaluation procedure at the OAEI.
13 The discontinuation of tracks is often due to missing track organizers. Reasons may be the high effort connected to evaluating other researchers’ matching systems and writing summarizing reports or a change in the research focus. However, most track data is still available for download and for further usage.
14 The tracks which were considered are listed in Fig. 2. Figures 3 and 4 do not include other evaluation tracks such as team participations in the SemTab [157] track. Due to very high similarity, the following matching systems have been merged in the figure: NLM [379] and AOAS [380], Agreement Maker and AMExt (both described in [47]), as well as GeRoMe [262,263] and GeRoMe SMB [261].
15 Figure 5 has been compiled from Figs 3 and 4, hence the concrete number of schema matching systems is counted each year excluding pure instance matching systems. The OAEI does not calculate this statistic. In addition, we found that over the years the OAEI counted inconsistently with regards to participation (for example counting participating teams in 2012 but matching systems in 2013 on their results Web page).
16 There is no results paper for the OAEI 2013 participation of Gomma. However, the system is described in the paper of the 2012 campaign [111].
17 The search engine is not online anymore.
18 A hypernym or hyperonym is a concept which is superordinate to another one. In computer science, it is often represented as an IS-A relationship. For example, animal is a hypernym of cat [225].
19 A hyponym is a concept which is subordinate to another one. In computer science, it is often represented as an IS-A relationship. For example, cat is a hyponym of animal [225].
25 See http://uberon.org.
29 ICD stands for “International Classification of Diseases”.
30 SNOMED-CT stands for “Systematized Nomenclature of Medicine Clinical Terms”.
31 See https://disease-ontology.org/.
34 See https://babelnet.org/.
35 This is naturally not precise. WordNet and other lexical resources, for example, are not classified as formal/informal resource-based but instead as language-based according to Euzenat and Shvaiko.
36 Theoretically, the other structured resources can also be mono- or multilingual – however, the focus of the knowledge provided there is rather factual and the language is typically not the core property of the knowledge resource. Therefore, we decided against a subdivision here in favor of clarity.
37 German book title, translates to dictionary of insurance and insurance law.
38 See http://www.kgvec2go.org/.
40 Homonyms are words that have the same writing (homographs) or the same pronunciation (homophones) but different senses [212]. An example would be the word “bank” in two different contexts: It may refer to the financial institution in one case and to a seating-accommodation in the other case. To be precise, for the linking problem at hand only homographs are challenging.
42 Some authors consider WordNet metrics such as the Resnik word similarity [271] or WuPalmer [355] as WSD (e.g. [24]) – however, we regard averaging synset similarity scores or picking the maximum score across multiple synset comparisons not as real Word Sense Disambiguation; the obtained similarity through such approaches is a word similarity rather than a disambiguated sense similarity.
43 There is in some cases no clear boundary between structure-based and statistical approaches since structure-based approaches typically apply statistics. We classify an approach to be structure-based if the focus is the exploitation of the structure of the knowledge source.
44 The term indirect matching may also refer to structure-based approaches such as the works by Annane et al. [16,17]. This is due to the fact that in this survey, we differentiate in structure-based approaches (such as a path-based algorithm) and logic-based approaches – a distinction that other authors do not make.
45 The steps are namely: (i) ontology arrangement, (ii) contextualization, (iii) ontology selection, (iv) local inference, (v) global inference, (vi) composition, and (vii) aggregation.
46 SUMO stands for “suggested upper merge ontology”, DOLCE stands for “descriptive ontology for linguistic and cognitive engineering”, and OpenCyc is a subset of the Cyc knowledge base by Cycorp that is not available anymore.
47 Note that systems that use WordNet (see Tables 8 and 9) are not explicitly listed for better clarity in Table 12.
48 The low usage of factual databases may be due to the fact that the community prefers knowledge presented in a graph.
49 In the years 2016 and 2017, there was a Process Model Matching Track at the OAEI. While the topic of process model matching is relevant for the industry, the dataset was limited to the domains of university admissions in 2016 and additionally birth registrations in 2017. At the OAEI, the overall participation in the track was rather low with only four systems in two years: AML [83,86], DKP [79], LogMap [152,154], and I-Match [175].
50 EuroVoc is a multilingual thesaurus by the Publications Office of the European Union. See https://op.europa.eu/en/web/eu-vocabularies.
51 It has to be mentioned here that this survey only considers publications published in English (see C1 in Table 2) which may skew the observations. However, given that English is the lingua franca in the ontology matching community, we assume that this skew is small.
Acknowledgement
The publication of this article was funded by the University of Mannheim.
References
[1] | M.E. Abdi, H. Souid, M. Kachroudi and S.B. Yahia, CLONA results for OAEI 2015, in: Proceedings of the 10th International Workshop on Ontology Matching Collocated with the 14th International Semantic Web Conference (ISWC 2015), Bethlehem, PA, USA, October 12, 2015, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 1545: , CEUR-WS.org, (2015) , pp. 124–129. http://ceur-ws.org/Vol-1545/oaei15_paper2.pdf. |
[2] | H. Abolhassani, B.B. Hariri and S.H. Haeri, On ontology alignment experiments, Webology 3: (3) ((2006) ). http://www.webology.org/2006/v3n3/a28.html. |
[3] | G. Acampora, U. Kaymak, V. Loia and A. Vitiello, A FML-based fuzzy tuning for a memetic ontology alignment system, in: FUZZ-IEEE 2013, IEEE International Conference on Fuzzy Systems, Hyderabad, India, 7–10 July, 2013, Proceedings, IEEE, (2013) , pp. 1–8. doi:10.1109/FUZZ-IEEE.2013.6622490. |
[4] | G. Acampora, V. Loia, S. Salerno and A. Vitiello, A hybrid evolutionary approach for solving the ontology alignment problem, Int. J. Intell. Syst. 27: (3) ((2012) ), 189–216. doi:10.1002/int.20517. |
[5] | G. Acampora, V. Loia and A. Vitiello, Enhancing ontology alignment through a memetic aggregation of similarity measures, Inf. Sci. 250: ((2013) ), 1–20. doi:10.1016/j.ins.2013.06.052. |
[6] | A. Alasoud, V. Haarslev and N. Shiri, A multi-level matching algorithm for combining similarity measures in ontology integration, in: Ontologies-Based Databases and Information Systems, First and Second VLDB Workshops, ODBIS 2005/2006, Trondheim, Norway, September 2–3, 2005, Seoul, Korea, September 11, 2006, Revised Papers, M. Collard, ed., Lecture Notes in Computer Science, Vol. 4623: , Springer, (2006) , pp. 1–17. doi:10.1007/978-3-540-75474-9_1. |
[7] | A. Alasoud, V. Haarslev and N. Shiri, An effective ontology matching technique, in: Foundations of Intelligent Systems, 17th International Symposium, ISMIS 2008, Toronto, Canada, May 20–23, 2008, Proceedings, A. An, S. Matwin, Z.W. Ras and D. Slezak, eds, Lecture Notes in Computer Science, Vol. 4994: , Springer, (2008) , pp. 585–590. doi:10.1007/978-3-540-68123-6_63. |
[8] | Z. Aleksovski and M.C.A. Klein, Ontology mapping using background knowledge, in: Proceedings of the 3rd International Conference on Knowledge Capture (K-CAP 2005), Banff, Alberta, Canada, October 2–5, 2005, P. Clark and G. Schreiber, eds, ACM, (2005) , pp. 175–176. doi:10.1145/1088622.1088655. |
[9] | Z. Aleksovski, M.C.A. Klein, W. ten Kate and F. van Harmelen, Matching unstructured vocabularies using a background ontology, in: Managing Knowledge in a World of Networks, 15th International Conference, EKAW 2006, Podebrady, Czech Republic, October 2–6, 2006, Proceedings, S. Staab and V. Svátek, eds, Lecture Notes in Computer Science, Vol. 4248: , Springer, (2006) , pp. 182–197. doi:10.1007/11891451_18. |
[10] | Z. Aleksovski, W. ten Kate and F. van Harmelen, Exploiting the structure of background knowledge used in ontology matching, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper2.pdf. |
[11] | P. Alexopoulos, Semantic Modeling for Data, O’Reilly Media, (2020) . |
[12] | A.A. Alwan, A. Nordin, M. Alzeber and A.Z. Abualkishik, A survey of schema matching research using database schemas and instances, International Journal of Advanced Computer Science and Applications 8: (10) ((2017) ). |
[13] | M.B. Amin, M. Ahmad, W.A. Khan and S. Lee, Biomedical ontology matching as a service, in: Smart Homes and Health Telematics – 12th International Conference, ICOST 2014, Denver, CO, USA, June 25–27, 2014, Revised Papers, C. Bodine, S. Helal, T. Gu and M. Mokhtari, eds, Lecture Notes in Computer Science, Vol. 8456: , Springer, (2014) , pp. 195–203. doi:10.1007/978-3-319-14424-5_21. |
[14] | S. Anam, Y.S. Kim, B.H. Kang and Q. Liu, Review of ontology matching approaches and challenges, International journal of Computer Science and Network Solutions 3: (3) ((2015) ), 1–27. |
[15] | S. Anam, Y.S. Kim, B.H. Kang and Q. Liu, Adapting a knowledge-based schema matching system for ontology mapping, in: Proceedings of the Australasian Computer Science Week Multiconference, Canberra, Australia, February 2–5, 2016, ACM, (2016) , p. 27. doi:10.1145/2843043.2843048. |
[16] | A. Annane, Z. Bellahsene, F. Azouaou and C. Jonquet, Selection and combination of heterogeneous mappings to enhance biomedical ontology matching, in: Knowledge Engineering and Knowledge Management – 20th International Conference, EKAW 2016, Bologna, Italy, November 19–23, 2016, Proceedings, E. Blomqvist, P. Ciancarini, F. Poggi and F. Vitali, eds, Lecture Notes in Computer Science, Vol. 10024: , (2016) , pp. 19–33. doi:10.1007/978-3-319-49004-5_2. |
[17] | A. Annane, Z. Bellahsene, F. Azouaou and C. Jonquet, Building an effective and efficient background knowledge resource to enhance ontology matching, J. Web Semant. 51: ((2018) ), 51–68. doi:10.1016/j.websem.2018.04.001. |
[18] | N. Arch-int and S. Arch-int, Semantic ontology mapping for interoperability of learning resource systems using a rule-based reasoning approach, Expert Syst. Appl. 40: (18) ((2013) ), 7428–7443. doi:10.1016/j.eswa.2013.07.027. |
[19] | F. Ardjani, D. Bouchiha and M. Malki, Ontology-alignment techniques: Survey and analysis, International Journal of Modern Education & Computer Science 7: (11) ((2015) ). doi:10.5815/ijmecs.2015.11.08. |
[20] | B. Ashpole, M. Ehrig, J. Euzenat and H. Stuckenschmidt (eds), Integrating Ontologies ’05, Proceedings of the K-CAP 2005 Workshop on Integrating Ontologies, Banff, Canada, October 2, 2005, CEUR Workshop Proceedings, Vol. 156: , CEUR-WS.org, (2005) . http://ceur-ws.org/Vol-156. |
[21] | R. Barker, CASE Method – Entity Relationship Modelling, Computer Aided Systems Engineering, Addison-Wesley, (1990) . ISBN 978-0-201-41696-1. |
[22] | G. Bella, F. Giunchiglia and F. McNeill, Language and domain aware lightweight ontology matching, J. Web Semant. 43: ((2017) ), 1–17. doi:10.1016/j.websem.2017.03.003. |
[23] | M. Benaissa and A. Khiat, A new approach for combining the similarity values in ontology alignment, in: Computer Science and Its Applications – 5th IFIP TC 5 International Conference, CIIA 2015, Saida, Algeria, May 20–21, 2015, Proceedings, A. Amine, L. Bellatreche, Z. Elberrichi, E.J. Neuhold and R. Wrembel, eds, IFIP Advances in Information and Communication Technology, Vol. 456: , Springer, (2015) , pp. 343–354. doi:10.1007/978-3-319-19578-0_28. |
[24] | M. Biniz, R. El Ayachi and M. Fakir, Ontology matching using BabelNet dictionary and word sense disambiguation algorithms, Indonesian Journal of Electrical Engineering and Computer Science 5: (1) ((2017) ), 196–205. doi:10.11591/ijeecs.v5.i1.pp196-205. |
[25] | M. Biniz and M. Fakir, An ontology alignment hybrid method based on decision rules, Int. Arab J. Inf. Technol. 16: (6) ((2019) ), 1114–1120. https://iajit.org/index.php?option=com_content&task=blogcategory&id=143&Itemid=483. |
[26] | J. Bock and J. Hettenhausen, MapPSO Results for OAEI 2008, in: Proceedings of the 3rd International Workshop on Ontology Matching (OM-2008) Collocated with the 7th International Semantic Web Conference (ISWC-2008), Karlsruhe, Germany, October 26, 2008, P. Shvaiko, J. Euzenat, F. Giunchiglia and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 431: , CEUR-WS.org, (2008) . http://ceur-ws.org/Vol-431/oaei08_paper8.pdf. |
[27] | O. Bodenreider, T.F. Hayamizu, M. Ringwald, S. de Coronado and S. Zhang, Of mice and men: Aligning mouse and human anatomies, in: AMIA 2005, American Medical Informatics Association Annual Symposium, Washington, DC, USA, October 22–26, 2005, AMIA, (2005) . https://knowledge.amia.org/amia-55142-a2005a-1.613296/t-001-1.616182/f-001-1.616183/a-012-1.616655/a-013-1.616652. |
[28] | P. Bojanowski, E. Grave, A. Joulin and T. Mikolov, Enriching word vectors with subword information, Trans. Assoc. Comput. Linguistics 5: ((2017) ), 135–146, https://transacl.org/ojs/index.php/tacl/article/view/999. doi:10.1162/tacl_a_00051. |
[29] | W.N. Borst, Construction of engineering ontologies for knowledge sharing and reuse, PhD thesis, University of Twente, Enschede, Netherlands, 1997. http://purl.utwente.nl/publications/17864. |
[30] | A. Bouzeghoub, A. Elbyed and F. Tahi, OMIE: Ontology mapping within an interactive and extensible environment, in: Data Integration in the Life Sciences, 5th International Workshop, DILS 2008, Evry, France, June 25–27, 2008, Proceedings, A. Bairoch, S.C. Boulakia and C. Froidevaux, eds, Lecture Notes in Computer Science, Vol. 5109: , Springer, (2008) , pp. 161–168. doi:10.1007/978-3-540-69828-9_16. |
[31] | R. Brown, Integration Definition for Information Modelling (IDEF1X), National Institute of Standards and Technology (NIST), viewed Jan 24 (1993), 2011. https://web.archive.org/web/20131203223034/http://www.itl.nist.gov/fipspubs/idef1x.doc. |
[32] | L. Bulygin, Combining lexical and semantic similarity measures with machine learning approach for ontology matching problem, in: Selected Papers of the XX International Conference on Data Analytics and Management in Data Intensive Domains (DAMDID/RCDL 2018), Moscow, Russia, October 9–12, 2018, L.A. Kalinichenko, Y. Manolopoulos, S.A. Stupnikov, N.A. Skvortsov and V. Sukhomlin, eds, CEUR Workshop Proceedings, Vol. 2277: , CEUR-WS.org, (2018) , pp. 245–249. http://ceur-ws.org/Vol-2277/paper42.pdf. |
[33] | L. Bulygin and S.A. Stupnikov, Applying of machine learning techniques to combine string-based, language-based and structure-based similarity measures for ontology matching, in: Selected Papers of the XXI International Conference on Data Analytics and Management in Data Intensive Domains (DAMDID/RCDL 2019), Kazan, Russia, October 15–18, 2019, A.M. Elizarov, B. Novikov and S.A. Stupnikov, eds, CEUR Workshop Proceedings, Vol. 2523: , CEUR-WS.org, (2019) , pp. 129–147. http://ceur-ws.org/Vol-2523/paper14.pdf. |
[34] | H.L. Cardoso, D.D. Teixeira and E. Oliveira, Enhancing interoperability: Ontology-mapping in an electronic institution, in: Agent-Based Technologies and Applications for Enterprise Interoperability – International Workshops, ATOP@AAMAS 2005, Utrecht, The Netherlands, July 25–26, 2005, and ATOP@AAMAS 2008, Estoril, Portugal, May 12–13, 2008, Revised Selected Papers, K. Fischer, J.P. Müller, J. Odell and A. Berre, eds, Lecture Notes in Business Information Processing, Vol. 25: , Springer, (2008) , pp. 47–62. doi:10.1007/978-3-642-01668-4_3. |
[35] | S. Castano, A. Ferrara and G. Messa, Results of the HMatch ontology matchmaker in OAEI 2006, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper12.pdf. |
[36] | D. Cer, Y. Yang, S. Kong, N. Hua, N. Limtiaco, R.S. John, N. Constant, M. Guajardo-Cespedes, S. Yuan, C. Tar, Y. Sung, B. Strope and R. Kurzweil, Universal sentence encoder, CoRR (2018). arXiv:1803.11175. |
[37] | J. Chaker, M. Khaldi and S. Aammou, Enhancing the interoperability of multimedia learning objects based on the ontology mapping, iJET 9: (5) ((2014) ), 40–44, https://www.online-journals.org/index.php/i-jet/article/view/3934. |
[38] | J. Chakraborty, S.K. Bansal, L. Virgili, K. Konar and B. Yaman, OntoConnect: Unsupervised ontology alignment with recursive neural network, in: SAC ’21: The 36th ACM/SIGAPP Symposium on Applied Computing, Virtual Event, Republic of Korea, March 22–26, 2021, C. Hung, J. Hong, A. Bechini and E. Song, eds, ACM, (2021) , pp. 1874–1882. doi:10.1145/3412841.3442059. |
[39] | S. Chang, F. Colace, M.D. Santo, E. Zegarra and Y. Qie, MAMA: A novel approach to ontology mapping, in: Proceedings of the 17th International Conference on Distributed Multimedia Systems, DMS 2011, Convitto della Calza, Florence, Italy, October 18–20, 2011, Knowledge Systems Institute, (2011) , pp. 34–41. |
[40] | M. Cheatham, Targeted ontology mapping, in: 2010 International Symposium on Collaborative Technologies and Systems, CTS 2010, Chicago, Illinois, USA, May 17–21, 2010, W.W. Smari and W.K. McQuay, eds, IEEE, (2010) , pp. 123–132. doi:10.1109/CTS.2010.5478518. |
[41] | M. Cheatham and P. Hitzler, StringsAuto and MapSSS results for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 146–152. http://ceur-ws.org/Vol-1111/oaei13_paper7.pdf. |
[42] | M. Cheatham and P. Hitzler, Conference v2.0: An uncertain version of the OAEI conference benchmark, in: The Semantic Web – ISWC 2014 – 13th International Semantic Web Conference, Riva del Garda, Italy, October 19–23, Proceedings, Part II, P. Mika, T. Tudorache, A. Bernstein, C. Welty, C.A. Knoblock, D. Vrandecic, P. Groth, N.F. Noy, K. Janowicz and C.A. Goble, eds, Lecture Notes in Computer Science, Vol. 8797: , Springer, (2014) , pp. 33–48. doi:10.1007/978-3-319-11915-1_3. |
[43] | B. Chen, H. Tan and P. Lambrix, Structure-based filtering for ontology alignment, in: 15th IEEE International Workshops on Enabling Technologies: Infrastructures for Collaborative Enterprises (WETICE 2006), Manchester, United Kingdom, 26–28 June 2006, IEEE Computer Society, (2006) , pp. 364–369. doi:10.1109/WETICE.2006.64. |
[44] | G. Chen and S. Zhang, FCAMapX results for OAEI 2018, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 160–166. http://ceur-ws.org/Vol-2288/oaei18_paper7.pdf. |
[45] | X. Chen, W. Xia, E. Jiménez-Ruiz and V.V. Cross, Extending an ontology alignment system with BioPortal: A preliminary analysis, in: Proceedings of the ISWC 2014 Posters & Demonstrations Track a Track Within the 13th International Semantic Web Conference, ISWC 2014, Riva del Garda, Italy, October 21, 2014, M. Horridge, M. Rospocher and J. van Ossenbruggen, eds, CEUR Workshop Proceedings, Vol. 1272: , CEUR-WS.org, (2014) , pp. 313–316. http://ceur-ws.org/Vol-1272/paper_67.pdf. |
[46] | W.W.K. Chua and J. Kim, Eff2Match results for OAEI 2010, in: Proceedings of the 5th International Workshop on Ontology Matching (OM-2010), Shanghai, China, November 7, 2010, P. Shvaiko, J. Euzenat, F. Giunchiglia, H. Stuckenschmidt, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 689: , CEUR-WS.org, (2010) . http://ceur-ws.org/Vol-689/oaei10_paper5.pdf. |
[47] | I.F. Cruz, F.P. Antonelli, C. Stroe, U.C. Keles and A. Maduko, Using AgreementMaker to align ontologies for OAEI 2009: Overview, results, and outlook, in: Proceedings of the 4th International Workshop on Ontology Matching (OM-2009) Collocated with the 8th International Semantic Web Conference (ISWC-2009), Chantilly, USA, October 25, 2009, P. Shvaiko, J. Euzenat, F. Giunchiglia, H. Stuckenschmidt, N.F. Noy and A. Rosenthal, eds, CEUR Workshop Proceedings, Vol. 551: , CEUR-WS.org, (2009) . http://ceur-ws.org/Vol-551/oaei09_paper2.pdf. |
[48] | I.F. Cruz, C. Stroe, F. Caimi, A. Fabiani, C. Pesquita, F.M. Couto and M. Palmonari, Using AgreementMaker to align ontologies for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper1.pdf. |
[49] | I.F. Cruz, H. Xiao et al., The role of ontologies in data integration, Engineering Intelligent Systems for Electrical Engineering and Communications 13: (4) ((2005) ), 245. |
[50] | C. Curino, G. Orsi and L. Tanca, X-SOM results for OAEI 2007, in: Proceedings of the 2nd International Workshop on Ontology Matching (OM-2007) Collocated with the 6th International Semantic Web Conference (ISWC-2007) and the 2nd Asian Semantic Web Conference (ASWC-2007), Busan, Korea, November 11, 2007, P. Shvaiko, J. Euzenat, F. Giunchiglia and B. He, eds, CEUR Workshop Proceedings, Vol. 304: , CEUR-WS.org, (2007) . http://ceur-ws.org/Vol-304/paper26.pdf. |
[51] | J. da Silva, F.A. Baião and K. Revoredo, ALIN results for OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 130–137. http://ceur-ws.org/Vol-1766/oaei16_paper1.pdf. |
[52] | T. Dang, A. Gabriel, S. Hertling, P. Roskosch, M. Wlotzka, J.R. Zilke, F. Janssen and H. Paulheim, HotMatch results for OEAI 2012, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/oaei12_paper5.pdf. |
[53] | S.H. Davarpanah, A. Algergawy and S. Babalou, Fuzzy inference-based ontology matching using upper ontology, in: New Trends in Databases and Information Systems – ADBIS 2015 Short Papers and Workshops, BigDap, DCSA, GID, MEBIS, OAIS, SW4CH, WISARD, Poitiers, France, September 8–11, 2015, Proceedings, T. Morzy, P. Valduriez and L. Bellatreche, eds, Communications in Computer and Information Science, Vol. 539: , Springer, (2015) , pp. 392–402. doi:10.1007/978-3-319-23201-0_40. |
[54] | J. David, J. Euzenat, F. Scharffe and C.T. dos Santos, The Alignment API 4.0, Semantic Web 2: (1) ((2011) ), 3–10. doi:10.3233/SW-2011-0028. |
[55] | J.M. Destro, J.C. dos Reis, A.M.B.R. Carvalho and I.L.M. Ricarte, Influence of semantic similarity measures on ontology cross-language mappings, in: Proceedings of the Symposium on Applied Computing, SAC 2017, Marrakech, Morocco, April 3–7, 2017, A. Seffah, B. Penzenstadler, C. Alves and X. Peng, eds, ACM, (2017) , pp. 323–329. doi:10.1145/3019612.3019836. |
[56] | J.M. Destro, G.O. dos Santos, J.C. dos Reis, R. da Silva Torres, A.M.B.R. Carvalho and I.L.M. Ricarte, EVOCROS: Results for OAEI 2018, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 152–159. http://ceur-ws.org/Vol-2288/oaei18_paper6.pdf. |
[57] | J. Devlin, M. Chang, K. Lee and K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2–7, 2019, Volume 1 (Long and Short Papers), J. Burstein, C. Doran and T. Solorio, eds, Association for Computational Linguistics, (2019) , pp. 4171–4186. doi:10.18653/v1/n19-1423. |
[58] | L. Ding, T.W. Finin, A. Joshi, R. Pan, R.S. Cost, Y. Peng, P. Reddivari, V. Doshi and J. Sachs, Swoogle: A search and metadata engine for the semantic web, in: Proceedings of the 2004 ACM CIKM International Conference on Information and Knowledge Management, Washington, DC, USA, November 8–13, 2004, D.A. Grossman, L. Gravano, C. Zhai, O. Herzog and D.A. Evans, eds, ACM, (2004) , pp. 652–659. doi:10.1145/1031171.1031289. |
[59] | W.E. Djeddi and M.T. Khadir, XMapGen and XMapSiG results for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 203–210. http://ceur-ws.org/Vol-1111/oaei13_paper15.pdf. |
[60] | W.E. Djeddi and M.T. Khadir, XMap++: Results for OAEI 2014, in: Proceedings of the 9th International Workshop on Ontology Matching Collocated with the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Trentino, Italy, October 20, 2014, P. Shvaiko, J. Euzenat, M. Mao, E. Jiménez-Ruiz, J. Li and A. Ngonga, eds, CEUR Workshop Proceedings, Vol. 1317: , CEUR-WS.org, (2014) , pp. 163–169. http://ceur-ws.org/Vol-1317/oaei14_paper9.pdf. |
[61] | Z. Dong and Q. Dong, HowNet-a hybrid language and knowledge resource, in: International Conference on Natural Language Processing and Knowledge Engineering, 2003, Proceedings, 2003, IEEE, (2003) , pp. 820–824. doi:10.1109/NLPKE.2003.1276017. |
[62] | C.T. dos Santos, M.C. Moraes, P. Quaresma and R. Vieira, Using cooperative agent negotiation for ontology mapping, in: Proceedings of the 4th European Workshop on Multi-Agent Systems EUMAS’06, Lisbon, Portugal, December 14–15, 2006, B. Dunin-Keplicz, A. Omicini and J.A. Padget, eds, CEUR Workshop Proceedings, Vol. 223: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-223/47.pdf. |
[63] | C.T. dos Santos, M.C. Moraes, P. Quaresma and R. Vieira, A cooperative approach for composite ontology mapping, J. Data Semant. 10: ((2008) ), 237–263. doi:10.1007/978-3-540-77688-8_8. |
[64] | C.T. dos Santos, P. Quaresma and R. Vieira, An extended value-based argumentation framework for ontology mapping with confidence degrees, in: Argumentation in Multi-Agent Systems, 4th International Workshop, ArgMAS 2007, Honolulu, HI, USA, May 15, 2007, Revised Selected and Invited Papers, I. Rahwan, S. Parsons and C. Reed, eds, Lecture Notes in Computer Science, Vol. 4946: , Springer, (2007) , pp. 132–144. doi:10.1007/978-3-540-78915-4_9. |
[65] | C.T. dos Santos, P. Quaresma and R. Vieira, An argumentation framework based on confidence degrees to combine ontology mapping approaches, Int. J. Metadata Semant. Ontologies 3: (2) ((2008) ), 142–150. doi:10.1504/IJMSO.2008.021892. |
[66] | C.T. dos Santos, P. Quaresma and R. Vieira, An argumentation framework based on strength for ontology mapping, in: Argumentation in Multi-Agent Systems, Fifth International Workshop, ArgMAS 2008, Estoril, Portugal, May 12, 2008, Revised Selected and Invited Papers, I. Rahwan and P. Moraitis, eds, Lecture Notes in Computer Science, Vol. 5384: , Springer, (2008) , pp. 57–71. doi:10.1007/978-3-642-00207-6_4. |
[67] | C. Doulaverakis, S. Vrochidis and I. Kompatsiaris, Exploiting visual similarities for ontology alignment, in: KEOD 2015 – Proceedings of the International Conference on Knowledge Engineering and Ontology Development, Part of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015), Vol. 2: , Lisbon, Portugal, November 12–14, 2015, A.L.N. Fred, J.L.G. Dietz, D. Aveiro, K. Liu and J. Filipe, eds, SciTePress, (2015) , pp. 29–37. doi:10.5220/0005588200290037. |
[68] | Z. Dragisic, V. Ivanova, H. Li and P. Lambrix, Experiences from the anatomy track in the ontology alignment evaluation initiative, J. Biomed. Semant. 8: (1) ((2017) ), 56:1–56:28. doi:10.1186/s13326-017-0166-5. |
[69] | K. Eckert, C. Meilicke and H. Stuckenschmidt, Improving ontology matching using meta-level learning, in: The Semantic Web: Research and Applications, 6th European Semantic Web Conference, ESWC 2009, Heraklion, Crete, Greece, May 31–June 4, 2009, Proceedings, L. Aroyo, P. Traverso, F. Ciravegna, P. Cimiano, T. Heath, E. Hyvönen, R. Mizoguchi, E. Oren, M. Sabou and E.P.B. Simperl, eds, Lecture Notes in Computer Science, Vol. 5554: , Springer, (2009) , pp. 158–172. doi:10.1007/978-3-642-02121-3_15. |
[70] | L. Ehrlinger and W. Wöß, Towards a definition of knowledge graphs, in: Joint Proceedings of the Posters and Demos Track of the 12th International Conference on Semantic Systems – SEMANTiCS2016 and the 1st International Workshop on Semantic Change & Evolving Semantics (SuCCESS’16) Co-Located with the 12th International Conference on Semantic Systems (SEMANTiCS 2016), Leipzig, Germany, September 12–15, 2016, M. Martin, M. Cuquet and E. Folmer, eds, CEUR Workshop Proceedings, Vol. 1695: , CEUR-WS.org, (2016) . http://ceur-ws.org/Vol-1695/paper4.pdf. |
[71] | M. Ehrmann, F. Cecconi, D. Vannella, J.P. McCrae, P. Cimiano and R. Navigli, Representing multilingual data as linked data: The case of BabelNet 2.0, in: Proceedings of the Ninth International Conference on Language Resources and Evaluation, LREC 2014, Reykjavik, Iceland, May 26–31, 2014, N. Calzolari, K. Choukri, T. Declerck, H. Loftsson, B. Maegaard, J. Mariani, A. Moreno, J. Odijk and S. Piperidis, eds, European Language Resources Association (ELRA), (2014) , pp. 401–408. http://www.lrec-conf.org/proceedings/lrec2014/summaries/810.html. |
[72] | J. Euzenat, D. Loup, M. Touzani and P. Valtchev, Ontology alignment with OLA, in: EON 2004, Evaluation of Ontology-Based Tools, Proceedings of the 3rd International Workshop on Evaluation of Ontology-Based Tools Held at the 3rd International Semantic Web Conference ISWC 2004, Hiroshima Prince Hotel, Hiroshima, Japan, 7th November 2004, Y. Sure, Ó. Corcho, J. Euzenat and T. Hughes, eds, CEUR Workshop Proceedings, Vol. 128: , CEUR-WS.org, (2004) . http://ceur-ws.org/Vol-128/EON2004_EXP_Euzenat.pdf. |
[73] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, New York, (2013) , pp. 399–461, Chapter 13. ISBN 978-3-642-38720-3. doi:10.1007/978-3-642-38721-0_13. |
[74] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, New York, (2013) , pp. 73–84, Chapter 4. ISBN 978-3-642-38720-3. doi:10.1007/978-3-642-38721-0_4. |
[75] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, New York, (2013) , p. vii–xiii, Chapter Preface. ISBN 978-3-642-38720-3. |
[76] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, New York, (2013) , pp. 25–54, Chapter 2. ISBN 978-3-642-38720-3. doi:10.1007/978-3-642-38721-0_2. |
[77] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, New York, (2013) , pp. 149–197, Chapter 7. ISBN 978-3-642-38720-3. doi:10.1007/978-3-642-38721-0_7. |
[78] | M. Fahad, DKP-AOM: Results for OAEI 2015, in: Proceedings of the 10th International Workshop on Ontology Matching Collocated with the 14th International Semantic Web Conference (ISWC 2015), Bethlehem, PA, USA, October 12, 2015, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 1545: , CEUR-WS.org, (2015) , pp. 136–144. http://ceur-ws.org/Vol-1545/oaei15_paper4.pdf. |
[79] | M. Fahad, DKP-AOM: Results for OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 166–171. http://ceur-ws.org/Vol-1766/oaei16_paper6.pdf. |
[80] | O. Fallatah, Z. Zhang and F. Hopfgartner, A gold standard dataset for large knowledge graphs matching, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 24–35. http://ceur-ws.org/Vol-2788/om2020_LTpaper3.pdf. |
[81] | O. Fallatah, Z. Zhang and F. Hopfgartner, KGMatcher results for OAEI 2021, in: Proceedings of the 16th International Workshop on Ontology Matching Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 25, 2021, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 3063: , CEUR-WS.org, (2021) , pp. 160–166. http://ceur-ws.org/Vol-3063/oaei21_paper8.pdf. |
[82] | A. Fang, N. Hong, S. Wu, J. Zheng and Q. Qian, An integrated biomedical ontology mapping strategy based on multiple mapping methods, in: Web Information Systems Engineering – WISE 2013 Workshops – WISE 2013 International Workshops BigWebData, MBC, PCS, STeH, QUAT, SCEH, and STSC 2013, Nanjing, China, October 13–15, 2013, Revised Selected Papers, Z. Huang, C. Liu, J. He and G. Huang, eds, Lecture Notes in Computer Science, Vol. 8182: , Springer, (2013) , pp. 373–386. doi:10.1007/978-3-642-54370-8_32. |
[83] | D. Faria, B.S. Balasubramani, V.R. Shivaprabhu, I. Mott, C. Pesquita, F.M. Couto and I.F. Cruz, Results of AML in OAEI 2017, in: Proceedings of the 12th International Workshop on Ontology Matching Co-Located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 21, 2017, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2032: , CEUR-WS.org, (2017) , pp. 122–128. http://ceur-ws.org/Vol-2032/oaei17_paper2.pdf. |
[84] | D. Faria, B. Lima, M.C. Silva, F.M. Couto and C. Pesquita, AML and AMLC results for OAEI 2021, in: Proceedings of the 16th International Workshop on Ontology Matching Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 25, 2021, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 3063: , CEUR-WS.org, (2021) , pp. 131–136. http://ceur-ws.org/Vol-3063/oaei21_paper4.pdf. |
[85] | D. Faria, C. Martins, A. Nanavaty, A. Taheri, C. Pesquita, E. Santos, I.F. Cruz and F.M. Couto, AgreementMakerLight results for OAEI 2014, in: Proceedings of the 9th International Workshop on Ontology Matching Collocated with the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Trentino, Italy, October 20, 2014, P. Shvaiko, J. Euzenat, M. Mao, E. Jiménez-Ruiz, J. Li and A. Ngonga, eds, CEUR Workshop Proceedings, Vol. 1317: , CEUR-WS.org, (2014) , pp. 105–112. http://ceur-ws.org/Vol-1317/oaei14_paper1.pdf. |
[86] | D. Faria, C. Pesquita, B.S. Balasubramani, C. Martins, J. Cardoso, H. Curado, F.M. Couto and I.F. Cruz, OAEI 2016 results of AML, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 138–145. http://ceur-ws.org/Vol-1766/oaei16_paper2.pdf. |
[87] | D. Faria, C. Pesquita, I. Mott, C. Martins, F.M. Couto and I.F. Cruz, Tackling the challenges of matching biomedical ontologies, J. Biomed. Semant. 9: (1) ((2018) ), 4:1–4:19. doi:10.1186/s13326-017-0170-9. |
[88] | D. Faria, C. Pesquita, E. Santos, I.F. Cruz and F.M. Couto, AgreementMakerLight results for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 101–108. http://ceur-ws.org/Vol-1111/oaei13_paper1.pdf. |
[89] | D. Faria, C. Pesquita, E. Santos, I.F. Cruz and F.M. Couto, Automatic background knowledge selection for matching biomedical ontologies, PloS one 9: (11) ((2014) ). https://www.doi.org/10.1371/journal.pone.0111226. |
[90] | D. Faria, C. Pesquita, E. Santos, M. Palmonari, I.F. Cruz and F.M. Couto, The AgreementMakerLight ontology matching system, in: On the Move to Meaningful Internet Systems: OTM 2013 Conferences – Confederated International Conferences: CoopIS, DOA-Trusted Cloud, and ODBASE 2013, Graz, Austria, September 9–13, 2013, Proceedings, R. Meersman, H. Panetto, T.S. Dillon, J. Eder, Z. Bellahsene, N. Ritter, P.D. Leenheer and D. Dou, eds, Lecture Notes in Computer Science, Vol. 8185: , Springer, (2013) , pp. 527–541. doi:10.1007/978-3-642-41030-7_38. |
[91] | H. Fatemi, M. Sayyadi and H. Abolhassani, Using background knowledge and context knowledge in ontology mapping, in: Formal Ontologies Meet Industry, Proceedings of the 3th Workshop FOMI 2008, Torino, Italy, June 5–6, 2008, S. Borgo and L. Lesmo, eds, Frontiers in Artificial Intelligence and Applications, Vol. 174: , IOS Press, (2008) , pp. 56–64. http://www.booksonline.iospress.nl/Content/View.aspx?piid=8891. |
[92] | C. Fellbaum (ed.), WordNet: An Electronic Lexical Database, Language, Speech, and Communication, MIT Press, Cambridge, Massachusetts, (1998) . ISBN 978-0-262-06197-1. |
[93] | S. Fernández, I. Marsá-Maestre and J.R. Velasco, Performing ontology alignment via a fuzzy-logic multi-layer architecture, in: Knowledge Discovery, Knowledge Engineering and Knowledge Management – 4th International Joint Conference, IC3K 2012, Barcelona, Spain, October 4–7, 2012, Revised Selected Papers, A.L.N. Fred, J.L.G. Dietz, K. Liu and J. Filipe, eds, Communications in Computer and Information Science, Vol. 415: , Springer, (2012) , pp. 194–210. doi:10.1007/978-3-642-54105-6_13. |
[94] | S. Fernández, J.R. Velasco and M.A. López-Carmona, A fuzzy rule-based system for ontology mapping, in: Principles of Practice in Multi-Agent Systems, 12th International Conference, PRIMA 2009, Nagoya, Japan, December 14–16, 2009, Proceedings, J. Yang, M. Yokoo, T. Ito, Z. Jin and P. Scerri, eds, Lecture Notes in Computer Science, Vol. 5925: , Springer, (2009) , pp. 500–507. doi:10.1007/978-3-642-11161-7_35. |
[95] | S. Fernández, J.R. Velasco, I. Marsá-Maestre and M.A. López-Carmona, FuzzyAlign – A fuzzy method for ontology alignment, in: KEOD 2012 – Proceedings of the International Conference on Knowledge Engineering and Ontology Development, Barcelona, Spain, 4–7 October, 2012, J. Filipe and J.L.G. Dietz, eds, SciTePress, (2012) , pp. 98–107. |
[96] | M.L. Forcada, M. Ginestí-Rosell, J. Nordfalk, J. O’Regan, S. Ortiz-Rojas, J.A. Pérez-Ortiz, F. Sánchez-Martínez, G. Ramírez-Sánchez and F.M. Tyers, Apertium: A free/open-source platform for rule-based machine translation, Mach. Transl. 25: (2) ((2011) ), 127–144. doi:10.1007/s10590-011-9090-0. |
[97] | R. Forsati and M. Shamsfard, Symbiosis of evolutionary and combinatorial ontology mapping approaches, Inf. Sci. 342: ((2016) ), 53–80. doi:10.1016/j.ins.2016.01.025. |
[98] | B. Fu, R. Brennan and D. O’Sullivan, Cross-lingual ontology mapping – An investigation of the impact of machine translation, in: The Semantic Web, Fourth Asian Conference, ASWC 2009, Shanghai, China, December 6–9, 2009, Proceedings, A. Gómez-Pérez, Y. Yu and Y. Ding, eds, Lecture Notes in Computer Science, Vol. 5926: , Springer, (2009) , pp. 1–15. doi:10.1007/978-3-642-10871-6_1. |
[99] | B. Fu, R. Brennan and D. O’Sullivan, Cross-lingual ontology mapping and its use on the multilingual semantic web, in: Proceedings of the 1st International Workshop on the Multilingual Semantic Web, Raleigh, North Carolina, USA, April 27th, 2010, P. Buitelaar, P. Cimiano and E. Montiel-Ponsoda, eds, CEUR Workshop Proceedings, Vol. 571: , CEUR-WS.org, (2010) , pp. 13–20. http://ceur-ws.org/Vol-571/paper3.pdf. |
[100] | B. Fu, R. Brennan and D. O’Sullivan, Using pseudo feedback to improve cross-lingual ontology mapping, in: The Semantic Web: Research and Applications – 8th Extended Semantic Web Conference, ESWC 2011, Heraklion, Crete, Greece, May 29–June 2, 2011, Proceedings, Part I, G. Antoniou, M. Grobelnik, E.P.B. Simperl, B. Parsia, D. Plexousakis, P.D. Leenheer and J.Z. Pan, eds, Lecture Notes in Computer Science, Vol. 6643: , Springer, (2011) , pp. 336–351. doi:10.1007/978-3-642-21034-1_23. |
[101] | B. Fu, R. Brennan and D. O’Sullivan, A configurable translation-based cross-lingual ontology mapping system to adjust mapping outcomes, J. Web Semant. 15: ((2012) ), 15–36. doi:10.1016/j.websem.2012.06.001. |
[102] | A. Gangemi, N. Guarino, C. Masolo, A. Oltramari and L. Schneider, Sweetening ontologies with DOLCE, in: Knowledge Engineering and Knowledge Management. Ontologies and the Semantic Web, 13th International Conference, EKAW 2002, Siguenza, Spain, October 1–4, 2002, Proceedings, A. Gómez-Pérez and V.R. Benjamins, eds, Lecture Notes in Computer Science, Vol. 2473: , Springer, (2002) , pp. 166–181. doi:10.1007/3-540-45810-7_18. |
[103] | R. García-Castro, M. Esteban-Gutiérrez and A. Gómez-Pérez, Towards an infrastructure for the evaluation of semantic technologies, in: eChallenges e-2010 Conference, IEEE, (2010) , pp. 1–7. |
[104] | A. Ghazvinian, N.F. Noy, C. Jonquet, N.H. Shah and M.A. Musen, What four million mappings can tell you about two hundred ontologies, in: The Semantic Web – ISWC 2009, 8th International Semantic Web Conference, ISWC 2009, Chantilly, VA, USA, October 25–29, 2009, Proceedings A. Bernstein, D.R. Karger, T. Heath, L. Feigenbaum, D. Maynard, E. Motta and K. Thirunarayan, eds, Lecture Notes in Computer Science, Vol. 5823: , Springer, (2009) , pp. 229–242. doi:10.1007/978-3-642-04930-9_15. |
[105] | S. Gherbi and M.T. Khadir, ONTMAT: Results for OAEI 2017, in: Proceedings of the 12th International Workshop on Ontology Matching Co-Located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 21, 2017, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2032: , CEUR-WS.org, (2017) , pp. 166–170. http://ceur-ws.org/Vol-2032/oaei17_paper9.pdf. |
[106] | S. Gherbi and M.T. Khadir, ONTMAT1: Results for OAEI 2019, in: Proceedings of the 14th International Workshop on Ontology Matching Co-Located with the 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, October 26, 2019, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2536: , CEUR-WS.org, (2019) , pp. 164–168. http://ceur-ws.org/Vol-2536/oaei19_paper12.pdf. |
[107] | R. Gligorov, W. ten Kate, Z. Aleksovski and F. van Harmelen, Using Google distance to weight approximate ontology matches, in: Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff, Alberta, Canada, May 8–12, 2007, C.L. Williamson, M.E. Zurko, P.F. Patel-Schneider and P.J. Shenoy, eds, ACM, (2007) , pp. 767–776. doi:10.1145/1242572.1242676. |
[108] | J. Gracia and K. Asooja, Monolingual and cross-lingual ontology matching with CIDER-CL: Evaluation report for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 109–116. http://ceur-ws.org/Vol-1111/oaei13_paper2.pdf. |
[109] | J. Gracia, J. Bernad and E. Mena, Ontology matching with CIDER: Evaluation report for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper3.pdf. |
[110] | A. Groß, M. Hartung, T. Kirsten and E. Rahm, Mapping composition for matching large life science ontologies, in: Proceedings of the 2nd International Conference on Biomedical Ontology, Buffalo, NY, USA, July 26–30, 2011, O. Bodenreider, M.E. Martone and A. Ruttenberg, eds, CEUR Workshop Proceedings, Vol. 833: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-833/paper15.pdf. |
[111] | A. Groß, M. Hartung, T. Kirsten and E. Rahm, GOMMA results for OAEI 2012, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/oaei12_paper3.pdf. |
[112] | T.R. Gruber, A translation approach to portable ontology specifications, Knowledge acquisition 5: (2) ((1993) ), 199–220. doi:10.1006/knac.1993.1008. |
[113] | T. Grütze, C. Böhm and F. Naumann, Holistic and scalable ontology alignment for linked open data, in: WWW2012 Workshop on Linked Data on the Web, Lyon, France, 16 April, 2012, C. Bizer, T. Heath, T. Berners-Lee and M. Hausenblas, eds, CEUR Workshop Proceedings, Vol. 937: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-937/ldow2012-paper-08.pdf. |
[114] | M. Gulic, I. Magdalenic and B. Vrdoljak, Ontology matching using TF/IDF measure with synonym recognition, in: Information and Software Technologies – 19th International Conference, ICIST 2013, Kaunas, Lithuania, October 2013, Proceedings, T. Skersys, R. Butleris and R. Butkiene, eds, Communications in Computer and Information Science, Vol. 403: , Springer, (2013) , pp. 22–33. doi:10.1007/978-3-642-41947-8_3. |
[115] | M. Gulic, B. Vrdoljak and M. Banek, CroMatcher results for OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 153–160. http://ceur-ws.org/Vol-1766/oaei16_paper4.pdf. |
[116] | M.A. Haendel, J.P. Balhoff, F.B. Bastian, D.C. Blackburn, J.A. Blake, Y.M. Bradford, A. Comte, W.M. Dahdul, T. Dececchi, R.E. Druzinsky, T.F. Hayamizu, N. Ibrahim, S.E. Lewis, P.M. Mabee, A. Niknejad, M. Robinson-Rechavi, P.C. Sereno and C.J. Mungall, Unification of multi-species vertebrate anatomy ontologies for comparative biology in Uberon, J. Biomed. Semant. 5: ((2014) ), 21. doi:10.1186/2041-1480-5-21. |
[117] | A.Y. Halevy, Information integration, in: Encyclopedia of Database Systems, L. Liu and M.T. Özsu, eds, Springer US, (2009) , pp. 1490–1496. doi:10.1007/978-0-387-39940-9_1069. |
[118] | B. Hamp and H. Feldweg, Germanet-a lexical-semantic net for German, in: Automatic Information Extraction and Building of Lexical Semantic Resources for NLP Applications, (1997) . |
[119] | J. Hao, C. Lei, V. Efthymiou, A. Quamar, F. Özcan, Y. Sun and W. Wang, MEDTO: Medical data to ontology matching using hybrid graph neural networks, in: KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, August 14–18, 2021, F. Zhu, B.C. Ooi and C. Miao, eds, ACM, (2021) , pp. 2946–2954. doi:10.1145/3447548.3467138. |
[120] | I. Harrow, E. Jiménez-Ruiz, A. Splendiani, M. Romacker, P. Woollard, S. Markel, Y. Alam-Faruque, M. Koch, J. Malone and A. Waaler, Matching disease and phenotype ontologies in the ontology alignment evaluation initiative, J. Biomed. Semant. 8: (1) ((2017) ), 55:1–55:13. doi:10.1186/s13326-017-0162-9. |
[121] | I. Harrow, T. Liener and E. Jiménez-Ruiz, Ontology matching for the laboratory analytics domain, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 237–238. http://ceur-ws.org/Vol-2788/om2020_poster3.pdf. |
[122] | M. Hartung, A. Groß, T. Kirsten and E. Rahm, Effective composition of mappings for matching biomedical ontologies, in: The Semantic Web: ESWC 2012 Satellite Events – ESWC 2012 Satellite Events, Heraklion, Crete, Greece, May 27–31, 2012, Revised Selected Papers, E. Simperl, B. Norton, D. Mladenic, E.D. Valle, I. Fundulaki, A. Passant and R. Troncy, eds, Lecture Notes in Computer Science, Vol. 7540: , Springer, (2012) , pp. 176–190. doi:10.1007/978-3-662-46641-4_13. |
[123] | W. Hassen, MEDLEY results for OAEI 2012, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/oaei12_paper8.pdf. |
[124] | Y. He, X. Xue and S. Zhang, Using artificial bee colony algorithm for optimizing ontology alignment, J. Inf. Hiding Multim. Signal Process. 8: (4) ((2017) ), 766–773. http://bit.kuas.edu.tw/%7Ejihmsp/2017/vol8/JIH-MSP-2017-04-002.pdf. |
[125] | M.A. Helou, M. Palmonari and M. Jarrar, Effectiveness of automatic translations for cross-lingual ontology mapping, J. Artif. Intell. Res. 55: ((2016) ), 165–208. doi:10.1613/jair.4789. |
[126] | S. Hertling and H. Paulheim, WikiMatch results for OEAI 2012, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/oaei12_paper15.pdf. |
[127] | S. Hertling and H. Paulheim, WebIsALOD: Providing hypernymy relations extracted from the web as linked open data, in: The Semantic Web – ISWC 2017–16th International Semantic Web Conference, Vienna, Austria, October 21–25, 2017, Proceedings, Part II, C. d’Amato, M. Fernández, V.A.M. Tamma, F. Lécué, P. Cudré-Mauroux, J.F. Sequeda, C. Lange and J. Heflin, eds, Lecture Notes in Computer Science, Vol. 10588: , Springer, (2017) , pp. 111–119. doi:10.1007/978-3-319-68204-4_11. |
[128] | S. Hertling and H. Paulheim, DBkWik: A consolidated knowledge graph from thousands of Wikis, in: 2018 IEEE International Conference on Big Knowledge, ICBK 2018, Singapore, November 17–18, 2018, X. Wu, Y. Ong, C.C. Aggarwal and H. Chen, eds, IEEE Computer Society, (2018) , pp. 17–24. doi:10.1109/ICBK.2018.00011. |
[129] | S. Hertling and H. Paulheim, DOME results for OAEI 2018, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 144–151. http://ceur-ws.org/Vol-2288/oaei18_paper5.pdf. |
[130] | S. Hertling and H. Paulheim, The knowledge graph track at OAEI – Gold standards, baselines, and the golden hammer bias, in: The Semantic Web – 17th International Conference, ESWC 2020, Heraklion, Crete, Greece, May 31–June 4, 2020, Proceedings, A. Harth, S. Kirrane, A.N. Ngomo, H. Paulheim, A. Rula, A.L. Gentile, P. Haase and M. Cochez, eds, Lecture Notes in Computer Science, Vol. 12123: , Springer, (2020) , pp. 343–359. doi:10.1007/978-3-030-49461-2_20. |
[131] | S. Hertling, J. Portisch and H. Paulheim, MELT – Matching EvaLuation Toolkit, in: Semantic Systems. The Power of AI and Knowledge Graphs – 15th International Conference, SEMANTiCS 2019, Karlsruhe, Germany, September 9–12, 2019, Proceedings, M. Acosta, P. Cudré-Mauroux, M. Maleshkova, T. Pellegrini, H. Sack and Y. Sure-Vetter, eds, Lecture Notes in Computer Science, Vol. 11702: , Springer, (2019) , pp. 231–245. doi:10.1007/978-3-030-33220-4_17. |
[132] | S. Hertling, J. Portisch and H. Paulheim, Supervised ontology and instance matching with MELT, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 60–71. http://ceur-ws.org/Vol-2788/om2020_LTpaper6.pdf. |
[133] | G.N. Hess, C. Iochpe and S. Castano, Geographic ontology matching with iG-match, in: Advances in Spatial and Temporal Databases, 10th International Symposium, SSTD 2007, Boston, MA, USA, July 16–18, 2007, Proceedings, D. Papadias, D. Zhang and G. Kollios, eds, Lecture Notes in Computer Science, Vol. 4605: , Springer, (2007) , pp. 185–202. doi:10.1007/978-3-540-73540-3_11. |
[134] | B. Hnatkowska, A. Kozierkiewicz and M. Pietranik, Fuzzy based approach to ontology relations alignment, in: 30th IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2021, Luxembourg, July 11–14, 2021, IEEE, (2021) , pp. 1–7. doi:10.1109/FUZZ45933.2021.9494564. |
[135] | A. Hofmann, S. Perchani, J. Portisch, S. Hertling and H. Paulheim, DBkWik: Towards knowledge graph creation from thousands of Wikis, in: Proceedings of the ISWC 2017 Posters & Demonstrations and Industry Tracks Co-Located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 23rd – to – 25th, 2017, N. Nikitina, D. Song, A. Fokoue and P. Haase, eds, CEUR Workshop Proceedings, Vol. 1963: , CEUR-WS.org, (2017) . http://ceur-ws.org/Vol-1963/paper540.pdf. |
[136] | Y. Hu, S. Bai, S. Zou and P. Wang, Lily results for OAEI 2020, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 194–200. http://ceur-ws.org/Vol-2788/oaei20_paper9.pdf. |
[137] | S. Ibrahim, S. Fathalla, J. Lehmann and H. Jabeen, Multilingual ontology merging using cross-lingual matching, in: IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, WI/IAT 2020, Melbourne, Australia, December 14–17, 2020, J. He, H. Purohit, G. Huang, X. Gao and K. Deng, eds, IEEE, (2020) , pp. 113–120. doi:10.1109/WIIAT50758.2020.00020. |
[138] | R. Ichise, Machine learning approach for ontology mapping using multiple concept similarity measures, in: 7th IEEE/ACIS International Conference on Computer and Information Science, IEEE/ACIS ICIS 2008, Portland, Oregon, USA, 14–16 May 2008, R.Y. Lee, ed., IEEE Computer Society, (2008) , pp. 340–346. doi:10.1109/ICIS.2008.51. |
[139] | R. Idoudi, K.S. Ettabaâ, B. Solaiman and K. Hamrouni, Ontology knowledge mining for ontology alignment, Int. J. Comput. Intell. Syst. 9: (5) ((2016) ), 876–887. doi:10.1080/18756891.2016.1237187. |
[140] | V. Iyer, A. Agarwal and H. Kumar, VeeAlign: A supervised deep learning approach to ontology alignment, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 216–224. http://ceur-ws.org/Vol-2788/oaei20_paper13.pdf. |
[141] | P. Jaiboonlue, S. Nitsuwat, W.N. Chai, P. Luekhong, T. Ruangrajitpakorn and T. Supnithi, A framework of automatic alignment of concept in ontology with confidence score based on inner concept information, in: Workshop and Poster Proceedings of the 4th Joint International Semantic Technology Conference, JIST 2014, Chiang Mai, Thailand, November 9–11, 2014, T. Supnithi, T. Yamaguchi and M. Buranarach, eds, CEUR Workshop Proceedings, Vol. 1312: , CEUR-WS.org, (2014) , pp. 54–68. http://ceur-ws.org/Vol-1312/ldop2014_preface.pdf. |
[142] | P. Jain, P. Hitzler, A.P. Sheth, K. Verma and P.Z. Yeh, Ontology alignment for linked open data, in: The Semantic Web – ISWC 2010–9th International Semantic Web Conference, ISWC 2010, Shanghai, China, November 7–11, 2010, Revised Selected Papers, Part I, P.F. Patel-Schneider, Y. Pan, P. Hitzler, P. Mika, L. Zhang, J.Z. Pan, I. Horrocks and B. Glimm, eds, Lecture Notes in Computer Science, Vol. 6496: , Springer, (2010) , pp. 402–417. doi:10.1007/978-3-642-17746-0_26. |
[143] | P. Jain, P.Z. Yeh, K. Verma, R.G. Vasquez, M. Damova, P. Hitzler and A.P. Sheth, Contextual ontology alignment of LOD with an upper ontology: A case study with proton, in: The Semantic Web: Research and Applications – 8th Extended Semantic Web Conference, ESWC 2011, Heraklion, Crete, Greece, May 29–June 2, 2011, Proceedings, Part I, G. Antoniou, M. Grobelnik, E.P.B. Simperl, B. Parsia, D. Plexousakis, P.D. Leenheer and J.Z. Pan, eds, Lecture Notes in Computer Science, Vol. 6643: , Springer, (2011) , pp. 80–92. doi:10.1007/978-3-642-21034-1_6. |
[144] | S. Jan, M. Li, H.S. Al-Raweshidy, A. Mousavi and M. Qi, Dealing with uncertain entities in ontology alignment using rough sets, IEEE Trans. Syst. Man Cybern. Part C 42: (6) ((2012) ), 1600–1612. doi:10.1109/TSMCC.2012.2209869. |
[145] | S. Jan, M. Li, G. Al-Sultany and H.S. Al-Raweshidy, Ontology alignment using rough sets, in: Eighth International Conference on Fuzzy Systems and Knowledge Discovery, FSKD 2011, Shanghai, China, 26–28 July 2011, IEEE, (2011) , pp. 2683–2686. doi:10.1109/FSKD.2011.6020069. |
[146] | Y.R. Jean-Mary and M.R. Kabuka, ASMOV results for OAEI 2007, in: Proceedings of the 2nd International Workshop on Ontology Matching (OM-2007) Collocated with the 6th International Semantic Web Conference (ISWC-2007) and the 2nd Asian Semantic Web Conference (ASWC-2007), Busan, Korea, November 11, 2007, P. Shvaiko, J. Euzenat, F. Giunchiglia and B. He, eds, CEUR Workshop Proceedings, Vol. 304: , CEUR-WS.org, (2007) . http://ceur-ws.org/Vol-304/paper12.pdf. |
[147] | J.J. Jiang and D.W. Conrath, Semantic similarity based on corpus statistics and lexical taxonomy, in: Proceedings of the 10th Research on Computational Linguistics International Conference, ROCLING 1997, Taipei, Taiwan, August 1997, K. Chen, C. Huang and R. Sproat, eds, The Association for Computational Linguistics and Chinese Language Processing (ACLCLP), (1997) , pp. 19–33. https://aclanthology.org/O97-1002/. |
[148] | Y. Jiang, X. Wang and H. Zheng, A semantic similarity measure based on information distance for ontology alignment, Inf. Sci. 278: ((2014) ), 76–87. doi:10.1016/j.ins.2014.03.021. |
[149] | E. Jiménez-Ruiz, LogMap family participation in the OAEI 2020, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 201–203. http://ceur-ws.org/Vol-2788/oaei20_paper10.pdf. |
[150] | E. Jiménez-Ruiz, LogMap family participation in the OAEI 2021, in: Proceedings of the 16th International Workshop on Ontology Matching Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 25, 2021, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 3063: , CEUR-WS.org, (2021) , pp. 175–177. http://ceur-ws.org/Vol-3063/oaei21_paper10.pdf. |
[151] | E. Jiménez-Ruiz and B.C. Grau, LogMap: Logic-based and scalable ontology matching, in: The Semantic Web – ISWC 2011 – 10th International Semantic Web Conference, Bonn, Germany, October 23–27, 2011, Proceedings, Part I, L. Aroyo, C. Welty, H. Alani, J. Taylor, A. Bernstein, L. Kagal, N.F. Noy and E. Blomqvist, eds, Lecture Notes in Computer Science, Vol. 7031: , Springer, (2011) , pp. 273–288. doi:10.1007/978-3-642-25073-6_18. |
[152] | E. Jiménez-Ruiz, B.C. Grau and V. Cross, LogMap family participation in the OAEI 2017, in: Proceedings of the 12th International Workshop on Ontology Matching Co-Located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 21, 2017, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2032: , CEUR-WS.org, (2017) , pp. 153–157. http://ceur-ws.org/Vol-2032/oaei17_paper7.pdf. |
[153] | E. Jiménez-Ruiz, B.C. Grau and V. Cross, LogMap family participation in the OAEI 2018, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 187–191. http://ceur-ws.org/Vol-2288/oaei18_paper11.pdf. |
[154] | E. Jiménez-Ruiz, B.C. Grau and V.V. Cross, LogMap family participation in the OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 185–189. http://ceur-ws.org/Vol-1766/oaei16_paper9.pdf. |
[155] | E. Jiménez-Ruiz, B.C. Grau, A. Solimando and V.V. Cross, LogMap family results for OAEI 2015, in: Proceedings of the 10th International Workshop on Ontology Matching Collocated with the 14th International Semantic Web Conference (ISWC 2015), Bethlehem, PA, USA, October 12, 2015, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 1545: , CEUR-WS.org, (2015) , pp. 171–175. http://ceur-ws.org/Vol-1545/oaei15_paper10.pdf. |
[156] | E. Jiménez-Ruiz, B.C. Grau, W. Xia, A. Solimando, X. Chen, V.V. Cross, Y. Gong, S. Zhang and A. Chennai-Thiagarajan, LogMap family results for OAEI 2014, in: Proceedings of the 9th International Workshop on Ontology Matching Collocated with the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Trentino, Italy, October 20, 2014, P. Shvaiko, J. Euzenat, M. Mao, E. Jiménez-Ruiz, J. Li and A. Ngonga, eds, CEUR Workshop Proceedings, Vol. 1317: , CEUR-WS.org, (2014) , pp. 126–134. http://ceur-ws.org/Vol-1317/oaei14_paper4.pdf. |
[157] | E. Jiménez-Ruiz, O. Hassanzadeh, V. Efthymiou, J. Chen and K. Srinivas, SemTab 2019: Resources to benchmark tabular data to knowledge graph matching systems, in: The Semantic Web – 17th International Conference, ESWC 2020, Heraklion, Crete, Greece, May 31–June 4, 2020, Proceedings, A. Harth, S. Kirrane, A.N. Ngomo, H. Paulheim, A. Rula, A.L. Gentile, P. Haase and M. Cochez, eds, Lecture Notes in Computer Science, Vol. 12123: , Springer, (2020) , pp. 514–530. doi:10.1007/978-3-030-49461-2_30. |
[158] | E. Jiménez-Ruiz, A. Morant and B.C. Grau, LogMap results for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper8.pdf. |
[159] | T. Jin, Y. Fu, X. Lin, Q. Liu and Z. Cui, A method of ontology mapping based on instance, in: 3rd International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP 2007), Kaohsiung, Taiwan, 26–28 November 2007, Proceedings, B. Liao, J. Pan, L.C. Jain, M. Liao, H. Noda and A.T.S. Ho, eds, IEEE Computer Society, (2007) , pp. 145–148. doi:10.1109/IIH-MSP.2007.31. |
[160] | T. Jin, Y. Fu, X. Ling, Q. Liu and Z. Cui, A method of ontology mapping based on subtree kernel, in: Proceedings of the Workshop on Intelligent Information Technology Application, IITA 2007, Zhang Jiajie, China, December 2–3, 2007, F. Yu, R. Li and G. Liao, eds, IEEE Computer Society, (2007) , pp. 70–73. doi:10.1109/IITA.2007.25. |
[161] | V. Jirkovský and R. Ichise, MAPSOM: User involvement in ontology matching, in: Semantic Technology – Third Joint International Conference, JIST 2013, Seoul, South Korea, November 28–30, 2013, Revised Selected Papers, W. Kim, Y. Ding and H. Kim, eds, Lecture Notes in Computer Science, Vol. 8388: , Springer, (2013) , pp. 348–363. doi:10.1007/978-3-319-06826-8_26. |
[162] | M. Kachroudi, G. Diallo and S.B. Yahia, OAEI 2017 results of KEPLER, in: Proceedings of the 12th International Workshop on Ontology Matching Co-Located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 21, 2017, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2032: , CEUR-WS.org, (2017) , pp. 138–145. http://ceur-ws.org/Vol-2032/oaei17_paper5.pdf. |
[163] | M. Kachroudi, E.B. Moussa, S. Zghal and S.B. Yahia, LDOA results for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper6.pdf. |
[164] | M. Kachroudi and S.B. Yahia, Dealing with direct and indirect ontology alignment, J. Data Semant. 7: (4) ((2018) ), 237–252. doi:10.1007/s13740-018-0098-y. |
[165] | M. Kachroudi, S. Zghal and S.B. Yahia, Bridging the multilingualism gap in ontology alignment, Int. J. Metadata Semant. Ontologies 9: (3) ((2014) ), 252–262. doi:10.1504/IJMSO.2014.063139. |
[166] | Y. Kalfoglou and B. Hu, CROSI mapping system (CMS) – Result of the 2005 ontology alignment contest, in: Integrating Ontologies ’05, Proceedings of the K-CAP 2005 Workshop on Integrating Ontologies, Banff, Canada, October 2, 2005, B. Ashpole, M. Ehrig, J. Euzenat and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 156: , CEUR-WS.org, (2005) . http://ceur-ws.org/Vol-156/paper12.pdf. |
[167] | A. Kammoun and G. Diallo, ServOMap results for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 169–176. http://ceur-ws.org/Vol-1111/oaei13_paper10.pdf. |
[168] | N. Karam, A. Khiat, A. Algergawy, M. Sattler, C. Weiland and M. Schmidt, Matching biodiversity and ecology ontologies: Challenges and evaluation results, Knowl. Eng. Rev. 35: ((2020) ), e9. doi:10.1017/S0269888920000132. |
[169] | S. Kaza and H. Chen, Evaluating ontology mapping techniques: An experiment in public safety information sharing, Decis. Support Syst. 45: (4) ((2008) ), 714–728. doi:10.1016/j.dss.2007.12.007. |
[170] | W.A. Khan, M.B. Amin, A.M. Khattak, M. Hussain and S. Lee, System for Parallel Heterogeneity Resolution (SPHeRe) results for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 184–189. http://ceur-ws.org/Vol-1111/oaei13_paper12.pdf. |
[171] | N. Kheder and G. Diallo, ServOMBI at OAEI 2015, in: Proceedings of the 10th International Workshop on Ontology Matching Collocated with the 14th International Semantic Web Conference (ISWC 2015), Bethlehem, PA, USA, October 12, 2015, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 1545: , CEUR-WS.org, (2015) , pp. 200–207. http://ceur-ws.org/Vol-1545/oaei15_paper15.pdf. |
[172] | A. Khiat, CroLOM: Cross-lingual ontology matching system results for OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 146–152. http://ceur-ws.org/Vol-1766/oaei16_paper3.pdf. |
[173] | A. Khiat and M. Benaissa, AOT / AOTL results for OAEI 2014, in: Proceedings of the 9th International Workshop on Ontology Matching Collocated with the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Trentino, Italy, October 20, 2014, P. Shvaiko, J. Euzenat, M. Mao, E. Jiménez-Ruiz, J. Li and A. Ngonga, eds, CEUR Workshop Proceedings, Vol. 1317: , CEUR-WS.org, (2014) , pp. 113–119. http://ceur-ws.org/Vol-1317/oaei14_paper2.pdf. |
[174] | A. Khiat and M. Benaissa, InsMT / InsMTL results for OAEI 2014 instance matching, in: Proceedings of the 9th International Workshop on Ontology Matching Collocated with the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Trentino, Italy, October 20, 2014, P. Shvaiko, J. Euzenat, M. Mao, E. Jiménez-Ruiz, J. Li and A. Ngonga, eds, CEUR Workshop Proceedings, Vol. 1317: , CEUR-WS.org, (2014) , pp. 120–125. http://ceur-ws.org/Vol-1317/oaei14_paper3.pdf. |
[175] | A. Khiat and M. Mackeprang, I-Match and OntoIdea results for OAEI 2017, in: Proceedings of the 12th International Workshop on Ontology Matching Co-Located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 21, 2017, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2032: , CEUR-WS.org, (2017) , pp. 135–137. http://ceur-ws.org/Vol-2032/oaei17_paper4.pdf. |
[176] | A. Khiat, E.A. Ouhiba, M.A. Belfedhal and C.E. Zoua, SimCat results for OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 217–221. http://ceur-ws.org/Vol-1766/oaei16_paper14.pdf. |
[177] | J. Kim, M. Jang, Y. Ha, J. Sohn and S. Lee, MoA: OWL ontology merging and alignment tool for the semantic web, in: Innovations in Applied Artificial Intelligence, 18th International Conference on Industrial and Engineering Applications of Artificial Intelligence and Expert Systems, IEA/AIE 2005, Bari, Italy, June 22–24, 2005, Proceedings, M. Ali and F. Esposito, eds, Lecture Notes in Computer Science, Vol. 3533: , Springer, (2005) , pp. 722–731. doi:10.1007/11504894_100. |
[178] | W. Kim, S. Park, S. Bang and S. Lee, An ontology mapping algorithm between heterogeneous product classification taxonomies, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper24.pdf. |
[179] | T. Kiren and M. Shoaib, A novel ontology matching approach using key concepts, Aslib J. Inf. Manag. 68: (1) ((2015) ), 99–111. doi:10.1108/AJIM-04-2015-0054. |
[180] | C. Kiu and C. Lee, Ontology mapping and merging through OntoDNA for learning object reusability, J. Educ. Technol. Soc. 9: (3) ((2006) ), 27–42. http://www.ifets.info/abstract.php?art_id=651. |
[181] | L. Knorr and J. Portisch, Fine-TOM matcher results for OAEI 2021, in: Proceedings of the 16th International Workshop on Ontology Matching Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 25, 2021, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 3063: , CEUR-WS.org. (2021) , pp. 144–151. http://ceur-ws.org/Vol-3063/oaei21_paper6.pdf. |
[182] | P. Kolyvakis, A. Kalousis and D. Kiritsis, DeepAlignment: Unsupervised ontology matching with refined word vectors, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1–6, 2018, Volume 1 (Long Papers), M.A. Walker, H. Ji and A. Stent, eds, Association for Computational Linguistics, (2018) , pp. 787–798. doi:10.18653/v1/n18-1072. |
[183] | P. Kolyvakis, A. Kalousis, B. Smith and D. Kiritsis, Biomedical ontology alignment: An approach based on representation learning, J. Biomed. Semant. 9: (1) ((2018) ), 21:1–21:20. doi:10.1186/s13326-018-0187-8. |
[184] | D. Kossack, N. Borg, L. Knorr and J. Portisch, TOM matcher results for OAEI 2021, in: Proceedings of the 16th International Workshop on Ontology Matching Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 25, 2021, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 3063: , CEUR-WS.org, (2021) , pp. 193–198. http://ceur-ws.org/Vol-3063/oaei21_paper13.pdf. |
[185] | K. Kotis, A. Katasonov and J. Leino, AUTOMSv2 results for OAEI 2012, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/oaei12_paper2.pdf. |
[186] | K. Kotis, A.G. Valarakos and G.A. Vouros, AUTOMS: Automated ontology mapping through synthesis of methods, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper8.pdf. |
[187] | A. Koukourikos, P. Karampiperis and G. Stoitsis, Cross-language ontology alignment utilizing machine translation models, in: Metadata and Semantics Research – 7th Research Conference, MTSR 2013, Thessaloniki, Greece, November 19–22, 2013, Proceedings, E. Garoufallou and J. Greenberg, eds, Communications in Computer and Information Science, Vol. 390: , Springer, (2013) , pp. 75–86. doi:10.1007/978-3-319-03437-9_9. |
[188] | A. Koukourikos, G.A. Vouros and V. Karkaletsis, SYNTHESIS: Results for the ontology alignment evaluation initiative (OAEI) 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 190–196. http://ceur-ws.org/Vol-1111/oaei13_paper13.pdf. |
[189] | S.K. Kumar and J.A. Harding, Ontology mapping using description logic and bridging axioms, Comput. Ind. 64: (1) ((2013) ), 19–28. doi:10.1016/j.compind.2012.09.004. |
[190] | A. Laadhar, F. Ghozzi, I. Megdiche, F. Ravat, O. Teste and F. Gargouri, POMap results for OAEI 2017, in: Proceedings of the 12th International Workshop on Ontology Matching Co-Located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 21, 2017, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2032: , CEUR-WS.org, (2017) , pp. 171–177. http://ceur-ws.org/Vol-2032/oaei17_paper10.pdf. |
[191] | F.A. Lachtim, A.M. de Carvalho Moura and M.C. Cavalcanti, Ontology matching for dynamic publication in semantic portals, J. Braz. Comput. Soc. 15: (1) ((2009) ), 27–43. doi:10.1590/S0104-65002009000100004. |
[192] | O. Lassila and D. McGuinness, The role of frame-based representation on the semantic web, Linköping Electronic Articles in Computer and Information Science 6: (5) ((2001) ). |
[193] | B.T. Le, R. Dieng-Kuntz and F. Gandon, On ontology matching problems – for building a corporate semantic web in a multi-communities organization, in: ICEIS 2004, Proceedings of the 6th International Conference on Enterprise Information Systems, Porto, Portugal, April 14–17, 2004, (2004) , pp. 236–243. |
[194] | J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C.H. So and J. Kang, BioBERT: A pre-trained biomedical language representation model for biomedical text mining, Bioinform. 36: (4) ((2020) ), 1234–1240. doi:10.1093/bioinformatics/btz682. |
[195] | J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P.N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer and C. Bizer, DBpedia – A large-scale, multilingual knowledge base extracted from Wikipedia, Semantic Web 6: (2) ((2015) ), 167–195. doi:10.3233/SW-140134. |
[196] | D. Lenat and R. Guha, Building Large Knowledge-Based Systems: Representation and Inference in the Cyc Project, Addison-Wesley Pub. Co, Reading, Mass, (1989) . ISBN 0201517523. |
[197] | I. Lera, C. Juiz and R. Puigjaner, Quick ontology mapping algorithm for distributed environments, in: Proceedings of the 2008 International Conference on Semantic Web & Web Services, SWWS 2008, Las Vegas, Nevada, USA, July 14–17, 2008, H.R. Arabnia and A. Marsh, eds, CSREA Press, (2008) , pp. 107–113. |
[198] | G. Li, Improving biomedical ontology matching using domain-specific word embeddings, in: CSAE 2020: The 4th International Conference on Computer Science and Application Engineering, Sanya, China, October 20–22, 2020, A. Emrouznejad and J.R. Chou, eds, ACM, (2020) , pp. 120:1–120:5. doi:10.1145/3424978.3425102. |
[199] | S. Li, H. Hu and X. Hu, An ontology mapping method based on tree structure, in: 2006 International Conference on Semantics, Knowledge and Grid (SKG 2006), Guilin, China, 1–3 November 2006, IEEE Computer Society, (2006) , p. 87. doi:10.1109/SKG.2006.26. |
[200] | Y. Li, J. Li, D. Zhang and J. Tang, Result of ontology alignment with RiMOM at OAEI’06, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper17.pdf. |
[201] | Y. Li, Q. Zhong, J. Li and J. Tang, Result of ontology alignment with RiMOM at OAEI’07, in: Proceedings of the 2nd International Workshop on Ontology Matching (OM-2007) Collocated with the 6th International Semantic Web Conference (ISWC-2007) and the 2nd Asian Semantic Web Conference (ASWC-2007), Busan, Korea, November 11, 2007, P. Shvaiko, J. Euzenat, F. Giunchiglia and B. He, eds, CEUR Workshop Proceedings, Vol. 304: , CEUR-WS.org, (2007) . http://ceur-ws.org/Vol-304/paper20.pdf. |
[202] | J. Liao, X. Liu, X. Zhu, T. Xu, J. Wang and H. Sun, Ontology alignment by combining lexical analysis with consequences from reasoners, in: 2012 IEEE 19th International Conference on Web Services, Honolulu, HI, USA, June 24–29, 2012, C.A. Goble, P.P. Chen and J. Zhang, eds, IEEE Computer Society, (2012) , pp. 288–294. doi:10.1109/ICWS.2012.57. |
[203] | B. Lima, D. Faria, F.M. Couto, I.F. Cruz and C. Pesquita, OAEI 2020 results for AML and AMLC, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 154–160. http://ceur-ws.org/Vol-2788/oaei20_paper3.pdf. |
[204] | D. Lin, An information-theoretic definition of similarity, in: Proceedings of the Fifteenth International Conference on Machine Learning (ICML 1998), Madison, Wisconsin, USA, July 24–27, 1998, J.W. Shavlik, ed., Morgan Kaufmann, (1998) , pp. 296–304. |
[205] | F. Lin and A. Krizhanovsky, Multilingual ontology matching based on Wiktionary data accessible via SPARQL endpoint, in: Proceedings of the 13th All-Russian Scientific Conference “Digital Libraries: Advanced Methods and Technologies, Digital Collections”, RCDL 2011, Voronezh, Russia, October 19–22, 2011, L.A. Kalinichenko, A. Sychev and S.A. Stupnikov, eds, CEUR Workshop Proceedings, Vol. 803: , CEUR-WS.org, (2011) , pp. 1–8. http://ceur-ws.org/Vol-803/paper1.pdf. |
[206] | F. Lin and K. Sandkuhl, A survey of exploiting WordNet in ontology matching, in: Artificial Intelligence in Theory and Practice II, IFIP 20th World Computer Congress, TC 12: IFIP AI 2008 Stream, Milano, Italy, September 7–10, 2008, M. Bramer, ed., IFIP, Vol. 276: , Springer, (2008) , pp. 341–350. doi:10.1007/978-0-387-09695-7_33. |
[207] | W. Lin, C. Hu, Y. Li and X. Cheng, Similarity-based ontology mapping in material science domain, in: WEBIST 2013 – Proceedings of the 9th International Conference on Web Information Systems and Technologies, Aachen, Germany, 8–10 May, 2013, K. Krempels and A. Stocker, eds, SciTePress, (2013) , pp. 265–269. |
[208] | D.A. Lindberg, B.L. Humphreys and A.T. McCray, The unified medical language system, Yearbook of Medical Informatics 2: (01) ((1993) ), 41–51. doi:10.1055/s-0038-1637976. |
[209] | J. Liu, B. Zheng, L. Luo, J. Zhou, Y. Zhang and Z. Yu, Ontology representation and mapping of common fuzzy knowledge, Neurocomputing 215: ((2016) ), 184–195. doi:10.1016/j.neucom.2016.01.114. |
[210] | L. Liu, F. Yang, P. Zhang, J. Wu and L. Hu, SVM-based ontology matching approach, Int. J. Autom. Comput. 9: (3) ((2012) ), 306–314. doi:10.1007/s11633-012-0649-x. |
[211] | X. Liu, B. Cheng, J. Liao, P.M. Barnaghi, L. Wan and J. Wang, OMI-DL: An ontology matching framework, IEEE Trans. Serv. Comput. 9: (4) ((2016) ), 580–593. doi:10.1109/TSC.2015.2410794. |
[212] | S. Löbner, Semantik: Eine Einführung, De Gruyter, Berlin, Germany Boston, Massachusetts, (2015) , pp. 48–70, Chapter 3. ISBN 978-3-11-034815-6. doi:10.1515/9783110350906-004. |
[213] | A. Locoro, J. David and J. Euzenat, Context-based matching: Design of a flexible framework and experiment, J. Data Semant. 3: (1) ((2014) ), 25–46. doi:10.1007/s13740-013-0019-z. |
[214] | Z. Lu, ontoMATCH: A probabilistic architecture for ontology matching, in: Proceedings of the 3rd International Conference on Information Sciences and Interaction Sciences (ICIS 2010), Chengdu, China, June 23–25, 2010, Y. Peng, G. Kou, F.I.S. Ko, Y. Zeng and K. Kwack, eds, IEEE, (2010) , pp. 174–180. doi:10.1109/ICICIS.2010.5534737. |
[215] | Q. Lv, C. Jiang and H. Li, Solving ontology meta-matching problem through an evolutionary algorithm with approximate evaluation indicators and adaptive selection pressure, IEEE Access 9: ((2021) ), 3046–3064. doi:10.1109/ACCESS.2020.3047875. |
[216] | M. Mao, Y. Peng and M. Spring, Ontology mapping: As a binary classification problem, Concurr. Comput. Pract. Exp. 23: (9) ((2011) ), 1010–1025. doi:10.1002/cpe.1633. |
[217] | V. Mascardi, A. Locoro and P. Rosso, Automatic ontology matching via upper ontologies: A systematic evaluation, IEEE Trans. Knowl. Data Eng. 22: (5) ((2010) ), 609–623. doi:10.1109/TKDE.2009.154. |
[218] | C. Meilicke, R. Garcia-Castro, F. Freitas, W.R. van Hage, E. Montiel-Ponsoda, R.R. de Azevedo, H. Stuckenschmidt, O. Sváb-Zamazal, V. Svátek, A. Tamilin, C.T. dos Santos and S. Wang, MultiFarm: A benchmark for multilingual ontology matching, J. Web Semant. 15: ((2012) ), 62–68. doi:10.1016/j.websem.2012.04.001. |
[219] | M. Mohammadi, W. Hofman and Y. Tan, in: SANOM Results for OAEI 2018, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 205–209. http://ceur-ws.org/Vol-2288/oaei18_paper14.pdf. |
[220] | M. Mongiello and R. Totaro, Automatic ontology mapping for agent communication in an e-commerce environment, in: E-Commerce and Web Technologies: 6th International Conference, EC-Web 2005, Copenhagen, Denmark, August 23–26, 2005, Proceedings, K. Bauknecht, B. Pröll and H. Werthner, eds, Lecture Notes in Computer Science, Vol. 3590: , Springer, (2005) , pp. 21–30. doi:10.1007/11545163_3. |
[221] | M. Monych, J. Portisch, M. Hladik and H. Paulheim, DESKMatcher, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 181–186. http://ceur-ws.org/Vol-2788/oaei20_paper7.pdf. |
[222] | I. Mountasser, B. Ouhbi and B. Frikh, Hybrid large-scale ontology matching strategy on big data environment, in: Proceedings of the 18th International Conference on Information Integration and Web-Based Applications and Services, IiWAS 2016, Singapore, November 28–30, 2016, G. Anderst-Kotsis, ed., ACM, (2016) , pp. 282–287. doi:10.1145/3011141.3011185. |
[223] | L. Mukkala, J. Arvo, T. Lehtonen, T. Knuutila et al., Current state of ontology matching, A Survey of Ontology and Schema Matching. University of Turku Technical Reports 4: ((2015) ). |
[224] | C.J. Mungall, C. Torniai, G.V. Gkoutos, S.E. Lewis and M.A. Haendel, Uberon, an integrative multi-species anatomy ontology, Genome Biology 13: (1) ((2012) ), 1–20. doi:10.1186/gb-2012-13-1-r5. |
[225] | L. Murphy, Semantic Relations and the Lexicon: Antonymy, Synonymy, and Other Paradigms, Cambridge University Press, Cambridge, UK New York, (2003) , pp. 216–236, Chapter 6. ISBN 978-0-511-48649-4. doi:10.1017/CBO9780511486494. |
[226] | M. Nagy, M. Vargas-Vera and E. Motta, DSSim-ontology mapping with uncertainty, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper10.pdf. |
[227] | M. Nagy, M. Vargas-Vera and E. Motta, Uncertainty handling in the context of ontology mapping for question-answering, in: Semantic Web for Collaborative Knowledge Acquisition, Papers from the 2006 AAAI Fall Symposium, Washington, DC, USA, October 13–15, 2006, V.G. Honavar and T. Finin, eds, AAAI Technical Report, Vol. FS-06-06: , AAAI Press, (2006) , pp. 48–55. https://www.aaai.org/Library/Symposia/Fall/2006/fs06-06-007.php. |
[228] | R. Navigli and S.P. Ponzetto, BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network, Artif. Intell. 193: ((2012) ), 217–250. doi:10.1016/j.artint.2012.07.001. |
[229] | S. Neutel and M.H.T. de Boer, Towards automatic ontology alignment using BERT, in: Proceedings of the AAAI 2021 Spring Symposium on Combining Machine Learning and Knowledge Engineering (AAAI-MAKE 2021), Stanford University, Palo Alto, California, USA, March 22–24, 2021, A. Martin, K. Hinkelmann, H. Fill, A. Gerber, D. Lenat, R. Stolle and F. van Harmelen, eds, CEUR Workshop Proceedings, Vol. 2846: , CEUR-WS.org, (2021) . http://ceur-ws.org/Vol-2846/paper28.pdf. |
[230] | D. Ngo and Z. Bellahsene, YAM++ results for OAEI 2012, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/oaei12_paper16.pdf. |
[231] | D. Ngo, Z. Bellahsene and R. Coletta, YAM++ results for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper17.pdf. |
[232] | A.-C.N. Ngomo and M. Röder, HOBBIT: Holistic benchmarking for big linked data, Ercim News 2016: (105) ((2016) ). |
[233] | T.T.A. Nguyen and S. Conrad, Ontology matching using multiple similarity measures, in: KDIR 2015 – Proceedings of the International Conference on Knowledge Discovery and Information Retrieval, Part of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015), Vol. 1: , Lisbon, Portugal, November 12–14, 2015, A.L.N. Fred, J.L.G. Dietz, D. Aveiro, K. Liu and J. Filipe, eds, SciTePress, (2015) , pp. 603–611. doi:10.5220/0005615606030611. |
[234] | S. Niedbala, OWL-CtxMatch in the OAEI 2006 Alignment Contest, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper15.pdf. |
[235] | I. Niles and A. Pease, Towards a standard upper ontology, in: 2nd International Conference on Formal Ontology in Information Systems, FOIS 2001, Ogunquit, Maine, USA, October 17–19, 2001, Proceedings, ACM, (2001) , pp. 2–9. doi:10.1145/505168.505170. |
[236] | P. Ochieng and S. Kyanda, A statistically-based ontology matching tool, Distributed Parallel Databases 36: (1) ((2018) ), 195–217. doi:10.1007/s10619-017-7206-0. |
[237] | I. Osman, S.B. Yahia and G. Diallo, Ontology integration: Approaches and challenging issues, Inf. Fusion 71: ((2021) ), 38–63. doi:10.1016/j.inffus.2021.01.007. |
[238] | L. Otero-Cerdeira, F.J. Rodríguez-Martínez and A. Gómez-Rodríguez, Ontology matching: A literature review, Expert Syst. Appl. 42: (2) ((2015) ), 949–971. doi:10.1016/j.eswa.2014.08.032. |
[239] | R. Pan, Z. Ding, Y. Yu and Y. Peng, A Bayesian network approach to ontology mapping, in: The Semantic Web – ISWC 2005, 4th International Semantic Web Conference, ISWC 2005, Galway, Ireland, November 6–10, 2005, Proceedings, Y. Gil, E. Motta, V.R. Benjamins and M.A. Musen, eds, Lecture Notes in Computer Science, Vol. 3729: , Springer, (2005) , pp. 563–577. doi:10.1007/11574620_41. |
[240] | S. Park and W. Kim, Ontology mapping between heterogeneous product taxonomies in an electronic commerce environment, Int. J. Electron. Commer. 12: (2) ((2007) ), 69–87. doi:10.2753/JEC1086-4415120203. |
[241] | S. Park, W. Kim, S. Lee and S. Bang, Product matching through ontology mapping in comparison shopping, in: iiWAS’2006 – The Eighth International Conference on Information Integration and Web-Based Applications Services, Yogyakarta, Indonesia, 4–6 December 2006, G. Kotsis, D. Taniar, E. Pardede and I.K. Ibrahim, eds, [email protected], Vol. 214: , Austrian Computer Society, (2006) , pp. 39–49. |
[242] | H. Paulheim, Ontology-Based Application Integration, Springer Science & Business Media, (2011) . doi:10.1007/978-1-4614-1430-8. |
[243] | H. Paulheim, WeSeE-match results for OEAI 2012, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/oaei12_paper14.pdf. |
[244] | H. Paulheim, Knowledge graph refinement: A survey of approaches and evaluation methods, Semantic Web 8: (3) ((2017) ), 489–508. doi:10.3233/SW-160218. |
[245] | H. Paulheim and S. Hertling, WeSeE-match results for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 197–202. http://ceur-ws.org/Vol-1111/oaei13_paper14.pdf. |
[246] | E. Pavlick, P. Rastogi, J. Ganitkevitch, B.V. Durme and C. Callison-Burch, PPDB 2.0: Better paraphrase ranking, fine-grained entailment relations, word embeddings, and style classification, in: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, ACL 2015, Beijing, China, July 26–31, 2015, Volume 2: Short Papers, The Association for Computer Linguistics, (2015) , pp. 425–430. doi:10.3115/v1/p15-2070. |
[247] | P. Petrov, M. Krachunov and D. Vassilev, A semi-automated approach for anatomical ontology mapping, J. Integr. Bioinform. 10: (2) ((2013) ). doi:10.1515/jib-2013-221. |
[248] | G. Pirrò, M. Ruffolo and D. Talia, An algorithm for discovering ontology mappings in P2P systems, in: Knowledge-Based Intelligent Information and Engineering Systems, 12th International Conference, KES 2008, Zagreb, Croatia, September 3–5, 2008, Proceedings, Part II, I. Lovrek, R.J. Howlett and L.C. Jain, eds, Lecture Notes in Computer Science, Vol. 5178: , Springer, (2008) , pp. 631–641. doi:10.1007/978-3-540-85565-1_78. |
[249] | G. Pirrò and D. Talia, UFOme: A user friendly ontology mapping environment, in: Proceedings of the 4th Italian Semantic Web Workshop, Dipartimento di Informatica – Universita’ degli Studi di Bari – Italy, 18–20 December, 2007, G. Semeraro, E.D. Sciascio, C. Morbidoni and H. Stoermer, eds, CEUR Workshop Proceedings, Vol. 314: , CEUR-WS.org, (2007) . http://ceur-ws.org/Vol-314/22.pdf. |
[250] | J. Portisch, Towards matching of domain-specific schemas using general-purpose external background knowledge, in: The Semantic Web: ESWC 2020 Satellite Events – ESWC 2020 Satellite Events, Heraklion, Crete, Greece, May 31–June 4, 2020, Revised Selected Papers, A. Harth, V. Presutti, R. Troncy, M. Acosta, A. Polleres, J.D. Fernández, J.X. Parreira, O. Hartig, K. Hose and M. Cochez, eds, Lecture Notes in Computer Science, Vol. 12124: , Springer, (2020) , pp. 270–279. doi:10.1007/978-3-030-62327-2_42. |
[251] | J. Portisch, S. Hertling and H. Paulheim, Visual analysis of ontology matching results with the MELT dashboard, in: The Semantic Web: ESWC 2020 Satellite Events – ESWC 2020 Satellite Events, Heraklion, Crete, Greece, May 31–June 4, 2020, Revised Selected Papers, A. Harth, V. Presutti, R. Troncy, M. Acosta, A. Polleres, J.D. Fernández, J.X. Parreira, O. Hartig, K. Hose and M. Cochez, eds, Lecture Notes in Computer Science, Vol. 12124: , Springer, (2020) , pp. 186–190. doi:10.1007/978-3-030-62327-2_32. |
[252] | J. Portisch, M. Hladik and H. Paulheim, Wiktionary matcher, in: Proceedings of the 14th International Workshop on Ontology Matching Co-Located with the 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, October 26, 2019, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2536: , CEUR-WS.org, (2019) , pp. 181–188. http://ceur-ws.org/Vol-2536/oaei19_paper15.pdf. |
[253] | J. Portisch, M. Hladik and H. Paulheim, Evaluating ontology matchers on real-world financial services data models, in: Proceedings of the Posters and Demo Track of the 15th International Conference on Semantic Systems Co-Located with 15th International Conference on Semantic Systems (SEMANTiCS 2019), Karlsruhe, Germany, September 9th – to – 12th, 2019, M. Alam, R. Usbeck, T. Pellegrini, H. Sack and Y. Sure-Vetter, eds, CEUR Workshop Proceedings, Vol. 2451: , CEUR-WS.org, (2019) . http://ceur-ws.org/Vol-2451/paper-22.pdf. |
[254] | J. Portisch, M. Hladik and H. Paulheim, KGvec2go – Knowledge graph embeddings as a service, in: Proceedings of the 12th Language Resources and Evaluation Conference, LREC 2020, Marseille, France, May 11–16, 2020, N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk and S. Piperidis, eds, European Language Resources Association, (2020) , pp. 5641–5647. https://aclanthology.org/2020.lrec-1.692/. |
[255] | J. Portisch, M. Hladik and H. Paulheim, ALOD2Vec matcher results for OAEI 2020, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 147–153. http://ceur-ws.org/Vol-2788/oaei20_paper2.pdf. |
[256] | J. Portisch and H. Paulheim, ALOD2Vec matcher, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 132–137. http://ceur-ws.org/Vol-2288/oaei18_paper3.pdf. |
[257] | J. Portisch and H. Paulheim, Wiktionary matcher results for OAEI 2020, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 225–232. http://ceur-ws.org/Vol-2788/oaei20_paper14.pdf. |
[258] | J. Portisch and H. Paulheim, Wiktionary matcher results for OAEI 2021, in: Proceedings of the 16th International Workshop on Ontology Matching Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 25, 2021, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 3063: , CEUR-WS.org, (2021) , pp. 199–206. http://ceur-ws.org/Vol-3063/oaei21_paper14.pdf. |
[259] | J.P. Portisch, Automatic schema matching utilizing hypernymy relations extracted from the web, 2018. https://madoc.bib.uni-mannheim.de/52029/1/thesis.pdf. |
[260] | K. Purvis, Fachwörterbuch Versicherungswirtschaft und Recht: Englisch / Deutsch – Deutsch / Englisch, C.H. Beck & Vahlen, Heidelberg, Germany, (2021) . ISBN 978-3-406-72353-7. |
[261] | C. Quix, A. Gal, T. Sagi and D. Kensche, An integrated matching system GeRoMeSuite and SMB: Results for OAEI 2010, in: Proceedings of the 5th International Workshop on Ontology Matching (OM-2010), Shanghai, China, November 7, 2010, P. Shvaiko, J. Euzenat, F. Giunchiglia, H. Stuckenschmidt, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 689: , CEUR-WS.org, (2010) . http://ceur-ws.org/Vol-689/oaei10_paper7.pdf. |
[262] | C. Quix, S. Geisler, D. Kensche and X. Li, Results of GeRoMeSuite for OAEI 2008, in: Proceedings of the 3rd International Workshop on Ontology Matching (OM-2008) Collocated with the 7th International Semantic Web Conference (ISWC-2008), Karlsruhe, Germany, October 26, 2008, P. Shvaiko, J. Euzenat, F. Giunchiglia and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 431: , CEUR-WS.org, (2008) . http://ceur-ws.org/Vol-431/oaei08_paper6.pdf. |
[263] | C. Quix, S. Geisler, D. Kensche and X. Li, Results of GeRoMeSuite for OAEI 2009, in: Proceedings of the 4th International Workshop on Ontology Matching (OM-2009) Collocated with the 8th International Semantic Web Conference (ISWC-2009), Chantilly, USA, October 25, 2009, P. Shvaiko, J. Euzenat, F. Giunchiglia, H. Stuckenschmidt, N.F. Noy and A. Rosenthal, eds, CEUR Workshop Proceedings, Vol. 551: , CEUR-WS.org, (2009) . http://ceur-ws.org/Vol-551/oaei09_paper6.pdf. |
[264] | C. Quix, P. Roy and D. Kensche, Automatic selection of background knowledge for ontology matching, in: Proceedings of the International Workshop on Semantic Web Information Management, SWIM 2011, Athens, Greece, June 12, 2011, R.D. Virgilio, F. Giunchiglia and L. Tanca, eds, ACM, (2011) , p. 5. doi:10.1145/1999299.1999304. |
[265] | E. Rahm and P.A. Bernstein, A survey of approaches to automatic schema matching, VLDB J. 10: (4) ((2001) ), 334–350. doi:10.1007/s007780100057. |
[266] | V. Rajeswari, M. Kavitha and D.K. Varughese, A weighted graph-oriented ontology matching algorithm for enhancing ontology mapping and alignment in Semantic Web, Soft Comput. 23: (18) ((2019) ), 8661–8676. doi:10.1007/s00500-019-04148-3. |
[267] | F.J.Q. Real, G. Bella, F. McNeill and A. Bundy, Using domain lexicon and grammar for ontology matching, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 1–12. http://ceur-ws.org/Vol-2788/om2020_LTpaper1.pdf. |
[268] | M. Rebstock, J. Fengel and H. Paulheim, Ontologies-Based Business Integration, Springer, (2008) . doi:10.1007/978-3-540-75230-1. |
[269] | A. Refoufi and A. Benarab, A robust approach to the ontology matching problem, in: Proceedings of the 2nd Mediterranean Conference on Pattern Recognition and Artificial Intelligence, MedPRAI 2018, Rabat, Morocco, March 27–28, 2018, M.E.Y.E. Kettani, C. Djeddi, I. Siddiqi, Y. Hannad and S.K. Pal, eds, ACM, (2018) , pp. 76–83. doi:10.1145/3177148.3180086. |
[270] | N. Reimers and I. Gurevych, Sentence-BERT: Sentence embeddings using Siamese BERT-networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3–7, 2019, K. Inui, J. Jiang, V. Ng and X. Wan, eds, Association for Computational Linguistics, (2019) , pp. 3980–3990. doi:10.18653/v1/D19-1410. |
[271] | P. Resnik, Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language, J. Artif. Intell. Res. 11: ((1999) ), 95–130. doi:10.1613/jair.514. |
[272] | C. Reynaud and B. Safar, When usual structural alignment techniques don’t apply, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper18.pdf. |
[273] | P. Ristoski, J. Rosati, T.D. Noia, R.D. Leone and H. Paulheim, RDF2Vec: RDF graph embeddings and their applications, Semantic Web 10: (4) ((2019) ), 721–752. doi:10.3233/SW-180317. |
[274] | P. Roussille, I. Megdiche, O. Teste and C. Trojahn, Boosting holistic ontology matching: Generating graph clique-based relaxed reference alignments for holistic evaluation, in: Knowledge Engineering and Knowledge Management – 21st International Conference, EKAW 2018, Nancy, France, November 12–16, 2018, Proceedings, C. Faron-Zucker, C. Ghidini, A. Napoli and Y. Toussaint, eds, Lecture Notes in Computer Science, Vol. 11313: , Springer, (2018) , pp. 355–369. doi:10.1007/978-3-030-03667-6_23. |
[275] | M. Rybinski, M. del Mar Roldán García, J. García-Nieto and J.F.A. Montes, DisMatch results for OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 161–165. http://ceur-ws.org/Vol-1766/oaei16_paper5.pdf. |
[276] | M. Sabou, M. d’Aquin and E. Motta, Exploring the semantic web as background knowledge for ontology matching, J. Data Semant. 11: ((2008) ), 156–190. doi:10.1007/978-3-540-92148-6_6. |
[277] | M. Sabou and J. Gracia, Spider: Bringing non-equivalence mappings to OAEI, in: Proceedings of the 3rd International Workshop on Ontology Matching (OM-2008) Collocated with the 7th International Semantic Web Conference (ISWC-2008), Karlsruhe, Germany, October 26, 2008, P. Shvaiko, J. Euzenat, F. Giunchiglia and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 431: , CEUR-WS.org, (2008) . http://ceur-ws.org/Vol-431/oaei08_paper11.pdf. |
[278] | M. Sabou, J. Gracia, S. Angeletou, M. d’Aquin and E. Motta, Evaluating the semantic web: A task-based approach, in: The Semantic Web, 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, November 11–15, 2007, K. Aberer, K. Choi, N.F. Noy, D. Allemang, K. Lee, L.J.B. Nixon, J. Golbeck, P. Mika, D. Maynard, R. Mizoguchi, G. Schreiber and P. Cudré-Mauroux, eds, Lecture Notes in Computer Science, Vol. 4825: , Springer, (2007) , pp. 423–437. doi:10.1007/978-3-540-76298-0_31. |
[279] | F.C. Schadd and N. Roos, MaasMatch results for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper9.pdf. |
[280] | F.C. Schadd and N. Roos, Coupling of WordNet entries for ontology mapping using virtual documents, in: Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946/om2012_Tpaper3.pdf. |
[281] | F.C. Schadd and N. Roos, A feature selection approach for anchor evaluation in ontology mapping, in: Knowledge Engineering and the Semantic Web – 5th International Conference, KESW 2014, Kazan, Russia, September 29–October 1, 2014, Proceedings, P. Klinov and D. Mouromtsev, eds, Communications in Computer and Information Science, Vol. 468: , Springer, (2014) , pp. 160–174. doi:10.1007/978-3-319-11716-4_14. |
[282] | F.C. Schadd and N. Roos, Word-sense disambiguation for ontology mapping: Concept disambiguation using virtual documents and information retrieval techniques, J. Data Semant. 4: (3) ((2015) ), 167–186. doi:10.1007/s13740-014-0045-5. |
[283] | L.M. Schriml, C. Arze, S. Nadendla, Y.W. Chang, M. Mazaitis, V. Felix, G. Feng and W.A. Kibbe, Disease ontology: A backbone for disease semantic integration, Nucleic Acids Res. 40: (Database-Issue) ((2012) ), 940–946. doi:10.1093/nar/gkr972. |
[284] | J. Seitner, C. Bizer, K. Eckert, S. Faralli, R. Meusel, H. Paulheim and S.P. Ponzetto, A large DataBase of hypernymy relations extracted from the web, in: Proceedings of the Tenth International Conference on Language Resources and Evaluation LREC 2016, Portorož, Slovenia, May 23–28, 2016, N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk and S. Piperidis, eds, European Language Resources Association (ELRA), (2016) . http://www.lrec-conf.org/proceedings/lrec2016/summaries/204.html. |
[285] | S. Sen, D. Fernandes and N.L. Sarda, Optimal learning of ontology mappings from human interactions, in: On the Move to Meaningful Internet Systems 2007: CoopIS, DOA, ODBASE, GADA, and IS, OTM Confederated International Conferences CoopIS, DOA, ODBASE, GADA, and IS 2007, Vilamoura, Portugal, November 25–30, 2007, Proceedings, Part I, R. Meersman and Z. Tari, eds, Lecture Notes in Computer Science, Vol. 4803: , Springer, (2007) , pp. 1025–1033. doi:10.1007/978-3-540-76848-7_67. |
[286] | S. Sen, S. Somavarapu and N.L. Sarda, Class structures and lexical similarities of class names for ontology matching, in: Ontologies-Based Databases and Information Systems, First and Second VLDB Workshops, ODBIS 2005/2006, Trondheim, Norway, September 2–3, 2005, Seoul, Korea, September 11, 2006, Revised Papers, M. Collard, ed., Lecture Notes in Computer Science, Vol. 4623: , Springer, (2006) , pp. 18–36. doi:10.1007/978-3-540-75474-9_2. |
[287] | G. Sérasset, DBnary: Wiktionary as a Lemon-based multilingual lexical resource in RDF, Semantic Web 6: (4) ((2015) ), 355–361. doi:10.3233/SW-140147. |
[288] | H.M. Sergieh and R. Unland, IROM: Information retrieval-based ontology matching, in: Semantic Multimedia – 5th International Conference on Semantic and Digital Media Technologies, SAMT 2010, Saarbrücken, Germany, December 1–3, 2010, Revised Selected Papers, T. Declerck, M. Granitzer, M. Grzegorzek, M. Romanelli, S.M. Rüger and M. Sintek, eds, Lecture Notes in Computer Science, Vol. 6725: , Springer, (2010) , pp. 127–142. doi:10.1007/978-3-642-23017-2_9. |
[289] | G. Shen, L. Jin, Z. Zhao, Z. Jia, W. He and Z. Huang, OMReasoner: Using reasoner for ontology matching: Results for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org (2011) . http://ceur-ws.org/Vol-814/oaei11_paper13.pdf. |
[290] | P. Shvaiko and J. Euzenat, A survey of schema-based matching approaches, J. Data Semant. ((2005) ), 146–171. doi:10.1007/11603412_5. |
[291] | P. Shvaiko and J. Euzenat, Ten challenges for ontology matching, in: On the Move to Meaningful Internet Systems: OTM 2008, OTM 2008 Confederated International Conferences CoopIS, DOA, GADA, IS, and ODBASE 2008, Monterrey, Mexico, November 9–14, 2008, Proceedings, Part II, R. Meersman and Z. Tari, eds, Lecture Notes in Computer Science, Vol. 5332: , Springer, (2008) , pp. 1164–1182. doi:10.1007/978-3-540-88873-4_18. |
[292] | P. Shvaiko, J. Euzenat, F. Giunchiglia and B. He (eds), Proceedings of the 2nd International Workshop on Ontology Matching (OM-2007) Collocated with the 6th International Semantic Web Conference (ISWC-2007) and the 2nd Asian Semantic Web Conference (ASWC-2007), Busan, Korea, November 11, 2007, CEUR Workshop Proceedings, Vol. 304: , CEUR-WS.org (2007) . http://ceur-ws.org/Vol-304. |
[293] | P. Shvaiko, J. Euzenat, F. Giunchiglia and H. Stuckenschmidt (eds), Proceedings of the 3rd International Workshop on Ontology Matching (OM-2008) Collocated with the 7th International Semantic Web Conference (ISWC-2008), Karlsruhe, Germany, October 26, 2008, CEUR Workshop Proceedings, Vol. 431: , CEUR-WS.org, (2008) . http://ceur-ws.org/Vol-431. |
[294] | P. Shvaiko, J. Euzenat, F. Giunchiglia, H. Stuckenschmidt, M. Mao and I.F. Cruz (eds), Proceedings of the 5th International Workshop on Ontology Matching (OM-2010), Shanghai, China, November 7, 2010, CEUR Workshop Proceedings, Vol. 689: , CEUR-WS.org, (2010) . http://ceur-ws.org/Vol-689. |
[295] | P. Shvaiko, J. Euzenat, F. Giunchiglia, H. Stuckenschmidt, N.F. Noy and A. Rosenthal (eds), Proceedings of the 4th International Workshop on Ontology Matching (OM-2009) Collocated with the 8th International Semantic Web Conference (ISWC-2009), Chantilly, USA, October 25, 2009, CEUR Workshop Proceedings, Vol. 551: , CEUR-WS.org, (2009) . http://ceur-ws.org/Vol-551. |
[296] | P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz (eds), Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814. |
[297] | P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh (eds), Proceedings of the 10th International Workshop on Ontology Matching Collocated with the 14th International Semantic Web Conference (ISWC 2015), Bethlehem, PA, USA, October 12, 2015, CEUR Workshop Proceedings, Vol. 1545: , CEUR-WS.org, (2015) . http://ceur-ws.org/Vol-1545. |
[298] | P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh (eds), Proceedings of the 12th International Workshop on Ontology Matching Co-Located with the 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 21, 2017, CEUR Workshop Proceedings, Vol. 2032: , CEUR-WS.org, (2017) . http://ceur-ws.org/Vol-2032. |
[299] | P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh (eds), Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) . http://ceur-ws.org/Vol-2288. |
[300] | P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise (eds), Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) . http://ceur-ws.org/Vol-1766. |
[301] | P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn (eds), Proceedings of the 14th International Workshop on Ontology Matching Co-Located with the 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, October 26, 2019, CEUR Workshop Proceedings, Vol. 2536: , CEUR-WS.org, (2020) . http://ceur-ws.org/Vol-2536. |
[302] | P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn (eds), Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference (Originally Planned to Be in Athens, Greece), November 2, 2020, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) . http://ceur-ws.org/Vol-2788. |
[303] | P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn (eds), Proceedings of the 16th International Workshop on Ontology Matching Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Conference, October 25, 2021, CEUR Workshop Proceedings, Vol. 3063: , CEUR-WS.org, (2022) . http://ceur-ws.org/Vol-3063. |
[304] | P. Shvaiko, J. Euzenat, A. Kementsietsidis, M. Mao, N.F. Noy and H. Stuckenschmidt (eds), Proceedings of the 7th International Workshop on Ontology Matching, Boston, MA, USA, November 11, 2012, CEUR Workshop Proceedings, Vol. 946: , CEUR-WS.org, (2012) . http://ceur-ws.org/Vol-946. |
[305] | P. Shvaiko, J. Euzenat, M. Mao, E. Jiménez-Ruiz, J. Li and A. Ngonga (eds), Proceedings of the 9th International Workshop on Ontology Matching Collocated with the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Trentino, Italy, October 20, 2014, CEUR Workshop Proceedings, Vol. 1317: , CEUR-WS.org, (2014) . http://ceur-ws.org/Vol-1317. |
[306] | P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold (eds), Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006 CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225. |
[307] | P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz (eds), Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) . http://ceur-ws.org/Vol-1111. |
[308] | J.W. Son, S. Park and S. Park, An ontology alignment based on parse tree kernel for combining structural and semantic information without explicit enumeration of features, in: 2008 IEEE / WIC / ACM International Conference on Web Intelligence, WI 2008, Sydney, NSW, Australia, 9–12 December 2008, Main Conference Proceedings, IEEE Computer Society, (2008) , pp. 468–474. doi:10.1109/WIIAT.2008.239. |
[309] | F. Song, G. Zacharewicz and D. Chen, Multi-strategies ontology alignment aggregated by AHP, in: Advances in Knowledge-Based and Intelligent Information and Engineering Systems – 16th Annual KES Conference, San Sebastian, Spain, 10–12 September 2012, M. Graña, C. Toro, J. Posada, R.J. Howlett and L.C. Jain, eds, Frontiers in Artificial Intelligence and Applications, Vol. 243: , IOS Press, (2012) , pp. 1583–1592. http://www.booksonline.iospress.nl/Content/View.aspx?piid=32098. |
[310] | R. Speer, J. Chin and C. Havasi, ConceptNet 5.5: An open multilingual graph of general knowledge, in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, California, USA, February 4–9, 2017, S.P. Singh and S. Markovitch, eds, AAAI Press, (2017) , pp. 4444–4451. http://aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14972. |
[311] | V. Spiliopoulos, A.G. Valarakos, G.A. Vouros and V. Karkaletsis, SEMA: Results for the ontology alignment contest OAEI 2007, in: Proceedings of the 2nd International Workshop on Ontology Matching (OM-2007) Collocated with the 6th International Semantic Web Conference (ISWC-2007) and the 2nd Asian Semantic Web Conference (ASWC-2007), Busan, Korea, November 11, 2007, P. Shvaiko, J. Euzenat, F. Giunchiglia and B. He, eds, CEUR Workshop Proceedings, Vol. 304: , CEUR-WS.org, (2007) . http://ceur-ws.org/Vol-304/paper22.pdf. |
[312] | D. Spohr, L. Hollink and P. Cimiano, A machine learning approach to multilingual and cross-lingual ontology matching, in: The Semantic Web – ISWC 2011–10th International Semantic Web Conference, Bonn, Germany, October 23–27, 2011, Proceedings, Part I, L. Aroyo, C. Welty, H. Alani, J. Taylor, A. Bernstein, L. Kagal, N.F. Noy and E. Blomqvist, eds, Lecture Notes in Computer Science, Vol. 7031: , Springer, (2011) , pp. 665–680. doi:10.1007/978-3-642-25073-6_42. |
[313] | U. Straccia and R. Troncy, oMAP: Results of the ontology alignment contest, in: Integrating Ontologies ’05, Proceedings of the K-CAP 2005 Workshop on Integrating Ontologies, Banff, Canada, October 2, 2005, B. Ashpole, M. Ehrig, J. Euzenat and H. Stuckenschmidt, eds, CEUR Workshop Proceedings, Vol. 156: , CEUR-WS.org, (2005) . http://ceur-ws.org/Vol-156/paper14.pdf. |
[314] | J.N. Stuart, W.D. Johnston and B.L. Humphreys, Relationships in Medical Subject Headings, Relationships in the Organization of Knowledge, Kluwer Academic Publishers, New York, (2001) , pp. 171–184. doi:10.1007/978-94-015-9696-1_11. |
[315] | X. Su and J.A. Gulla, An information retrieval approach to ontology mapping, Data Knowl. Eng. 58: (1) ((2006) ), 47–69. doi:10.1016/j.datak.2005.05.012. |
[316] | F.M. Suchanek, G. Kasneci and G. Weikum, Yago: A core of semantic knowledge, in: Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff, Alberta, Canada, May 8–12, 2007, C.L. Williamson, M.E. Zurko, P.F. Patel-Schneider and P.J. Shenoy, eds, ACM, (2007) , pp. 697–706. doi:10.1145/1242572.1242667. |
[317] | Y. Sure, Ó. Corcho, J. Euzenat and T. Hughes (eds), EON 2004, Evaluation of Ontology-Based Tools, Proceedings of the 3rd International Workshop on Evaluation of Ontology-Based Tools Held at the 3rd International Semantic Web Conference ISWC 2004, 7th November 2004, Hiroshima Prince Hotel, Hiroshima, Japan, CEUR Workshop Proceedings, Vol. 128: , CEUR-WS.org, (2005) . http://ceur-ws.org/Vol-128. |
[318] | E. Sutanta, R. Wardoyo, K. Mustofa and E. Winarko, Survey: Models and prototypes of schema matching, International Journal of Electrical & Computer Engineering (2088-8708) 6: (3) ((2016) ). doi:10.11591/ijece.v6i3.pp1011-1022. |
[319] | H. Tan and P. Lambrix, SAMBO results for the ontology alignment evaluation initiative 2007, in: Proceedings of the 2nd International Workshop on Ontology Matching (OM-2007) Collocated with the 6th International Semantic Web Conference (ISWC-2007) and the 2nd Asian Semantic Web Conference (ASWC-2007), Busan, Korea, November 11, 2007, P. Shvaiko, J. Euzenat, F. Giunchiglia and B. He, eds, CEUR Workshop Proceedings, Vol. 304: , CEUR-WS.org, (2007) . http://ceur-ws.org/Vol-304/paper21.pdf. |
[320] | H. Tan and P. Lambrix, A method for recommending ontology alignment strategies, in: The Semantic Web, 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, November 11–15, 2007, K. Aberer, K. Choi, N.F. Noy, D. Allemang, K. Lee, L.J.B. Nixon, J. Golbeck, P. Mika, D. Maynard, R. Mizoguchi, G. Schreiber and P. Cudré-Mauroux, eds, Lecture Notes in Computer Science, Vol. 4825: , Springer, (2007) , pp. 494–507. doi:10.1007/978-3-540-76298-0_36. |
[321] | J. Tang, J. Li, B. Liang, X. Huang, Y. Li and K. Wang, Using Bayesian decision for ontology mapping, J. Web Semant. 4: (4) ((2006) ), 243–262. doi:10.1016/j.websem.2006.06.001. |
[322] | J. Tang, B. Liang, J. Li and K. Wang, Risk minimization based ontology mapping, in: Content Computing, Advanced Workshop on Content Computing, AWCC 2004, ZhenJiang, JiangSu, China, November 15–17, 2004, Proceedings, C. Chi and K. Lam, eds, Lecture Notes in Computer Science, Vol. 3309: , Springer, (2004) , pp. 469–480. doi:10.1007/978-3-540-30483-8_58. |
[323] | Y. Tang, P. Wang, Z. Pan and H. Liu, Lily results for OAEI 2018, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 179–186. http://ceur-ws.org/Vol-2288/oaei18_paper10.pdf. |
[324] | H. Tardieu, A. Rochfeld and R. Coletti, La méthode MERISE, Principes et outils, Revue du SCOM anc Bulletin O. et M. Organisation, Méthodes et Automatisation dans les Services Publics Paris (1983). |
[325] | U. Thayasivam and P. Doshi, Optima results for OAEI 2011, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper14.pdf. |
[326] | U. Thayasivam and P. Doshi, On the utility of WordNet for ontology alignment: Is it really worth it? in: Proceedings of the 5th IEEE International Conference on Semantic Computing (ICSC 2011), Palo Alto, CA, USA, September 18–21, 2011, IEEE Computer Society, (2011) , pp. 267–274. doi:10.1109/ICSC.2011.28. |
[327] | É. Thiéblin, O. Haemmerlé, N. Hernandez and C. Trojahn, Survey on complex ontology matching, Semantic Web 11: (4) ((2020) ), 689–727. doi:10.3233/SW-190366. |
[328] | É. Thiéblin, O. Haemmerlé and C. Trojahn, Automatic evaluation of complex alignments: An instance-based approach, Semantic Web 12: (5) ((2021) ), 767–787. doi:10.3233/SW-210437. |
[329] | A.N. Tigrine, Z. Bellahsene and K. Todorov, LYAM++ results for OAEI 2015, in: Proceedings of the 10th International Workshop on Ontology Matching Collocated with the 14th International Semantic Web Conference (ISWC 2015), Bethlehem, PA, USA, October 12, 2015, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 1545: , CEUR-WS.org, (2015) , pp. 176–180. http://ceur-ws.org/Vol-1545/oaei15_paper11.pdf. |
[330] | A.N. Tigrine, Z. Bellahsene and K. Todorov, Selecting optimal background knowledge sources for the ontology matching task, in: Knowledge Engineering and Knowledge Management – 20th International Conference, EKAW 2016, Bologna, Italy, November 19–23, 2016, Proceedings, E. Blomqvist, P. Ciancarini, F. Poggi and F. Vitali, eds, Lecture Notes in Computer Science, Vol. 10024: , (2016) , pp. 651–665. doi:10.1007/978-3-319-49004-5_42. |
[331] | A.N. Tigrine, Z. Bellahsene and K. Todorov, LYAM++ results for OAEI 2016, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 196–200. http://ceur-ws.org/Vol-1766/oaei16_paper11.pdf. |
[332] | K. Todorov, C. Hudelot and P. Geibel, Fuzzy and cross-lingual ontology matching mediated by background knowledge, in: Uncertainty Reasoning for the Semantic Web III – ISWC International Workshops, URSW 2011–2013, Revised Selected Papers, F. Bobillo, R.N. Carvalho, P.C.G. da Costa, C. d’Amato, N. Fanizzi, K.B. Laskey, K.J. Laskey, T. Lukasiewicz, M. Nickles and M. Pool, eds, Lecture Notes in Computer Science, Vol. 8816: , Springer, (2014) , pp. 142–162. doi:10.1007/978-3-319-13413-0_8. |
[333] | Q. Tran, R. Ichise and B. Ho, Cluster-based similarity aggregation for ontology matching, in: Proceedings of the 6th International Workshop on Ontology Matching, Bonn, Germany, October 24, 2011, P. Shvaiko, J. Euzenat, T. Heath, C. Quix, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 814: , CEUR-WS.org, (2011) . http://ceur-ws.org/Vol-814/oaei11_paper5.pdf. |
[334] | C. Trojahn, R. Vieira, D. Schmidt, A. Pease and G. Guizzardi, Foundational ontologies meet ontology matching: A survey, Semantic Web ((2021) ), 1–20. doi:10.3233/SW-210447. |
[335] | M. Uschold and M. Grüninger, Ontologies and semantics for seamless connectivity, SIGMOD Rec. 33: (4) ((2004) ), 58–64. doi:10.1145/1041410.1041420. |
[336] | L. Vaccari, P. Shvaiko, J. Pane, P. Besana and M. Marchese, An evaluation of ontology matching in geo-service applications, GeoInformatica 16: (1) ((2012) ), 31–66. doi:10.1007/s10707-011-0125-8. |
[337] | W.R. van Hage, S. Katrenko and G. Schreiber, A method to combine linguistic ontology-mapping techniques, in: The Semantic Web – ISWC 2005, 4th International Semantic Web Conference, ISWC 2005, Galway, Ireland, November 6–10, 2005, Proceedings, Y. Gil, E. Motta, V.R. Benjamins and M.A. Musen, eds, Lecture Notes in Computer Science, Vol. 3729: , Springer, (2005) , pp. 732–744. doi:10.1007/11574620_52. |
[338] | R. Vazquez and N. Swoboda, Combining the semantic web with the web as background knowledge for ontology mapping, in: On the Move to Meaningful Internet Systems 2007: CoopIS, DOA, ODBASE, GADA, and IS, OTM Confederated International Conferences CoopIS, DOA, ODBASE, GADA, and IS 2007, Vilamoura, Portugal, November 25–30, 2007, Proceedings, Part I, R. Meersman and Z. Tari, eds, Lecture Notes in Computer Science, Vol. 4803: , Springer, (2007) , pp. 814–831. doi:10.1007/978-3-540-76848-7_55. |
[339] | A. Vennesland and T. Aalberg, False-positive reduction in ontology matching based on concepts’ domain similarity, in: Digital Libraries for Open Knowledge, 22nd International Conference on Theory and Practice of Digital Libraries, TPDL 2018, Porto, Portugal, September 10–13, 2018, Proceedings, E. Méndez, F. Crestani, C. Ribeiro, G. David and J.C. Lopes, eds, Lecture Notes in Computer Science, Vol. 11057: , Springer, (2018) , pp. 344–348. doi:10.1007/978-3-030-00066-0_37. |
[340] | A. Vennesland, J. Gorman, S. Wilson, B. Neumayr and C.G. Schuetz, Automated compliance verification in ATM using principles from ontology matching, in: Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2018, Volume 2: KEOD, Seville, Spain, September 18–20, 2018, D. Aveiro, J.L.G. Dietz and J. Filipe, eds, SciTePress, (2018) , pp. 39–50. doi:10.5220/0006924000390050. |
[341] | P.R. Visser, D.M. Jones, T.J. Bench-Capon and M. Shave, An analysis of ontology mismatches; heterogeneity versus interoperability, in: AAAI 1997 Spring Symposium on Ontological Engineering, Stanford CA, USA, (1997) , pp. 164–172. |
[342] | L.L. Wang, C. Bhagavatula, M. Neumann, K. Lo, C. Wilhelm and W. Ammar, Ontology alignment in the biomedical domain using entity definitions and context, in: Proceedings of the BioNLP 2018 Workshop, Melbourne, Australia, July 19, 2018, D. Demner-Fushman, K.B. Cohen, S. Ananiadou and J. Tsujii, eds, Association for Computational Linguistics, (2018) , pp. 47–55. doi:10.18653/v1/W18-2306. |
[343] | S. Wang, G. Wang and X. Liu, Results of NBJLM for OAEI 2010, in: Proceedings of the 5th International Workshop on Ontology Matching (OM-2010), Shanghai, China, November 7, 2010, P. Shvaiko, J. Euzenat, F. Giunchiglia, H. Stuckenschmidt, M. Mao and I.F. Cruz, eds, CEUR Workshop Proceedings, Vol. 689: , CEUR-WS.org, (2010) . http://ceur-ws.org/Vol-689/oaei10_paper10.pdf. |
[344] | X. Wang, L.M. Haas and A. Meliou, Explaining data integration, IEEE Data Eng. Bull. 41: (2) ((2018) ), 47–58, http://sites.computer.org/debull/A18june/p47.pdf. |
[345] | Y. Wang, ProbLog program based ontology matching, in: Knowledge Science, Engineering and Management – 8th International Conference, KSEM 2015, Chongqing, China, October 28–30, 2015, Proceedings, S. Zhang, M. Wirsing and Z. Zhang, eds, Lecture Notes in Computer Science, Vol. 9403: , Springer, (2015) , pp. 778–783. doi:10.1007/978-3-319-25159-2_72. |
[346] | Y. Wang, J. Gong, Z. Wang, Y. Liang and N. Lu, Combining two strategies for ontology mapping, in: WEBIST 2006, Proceedings of the Second International Conference on Web Information Systems and Technologies: Internet Technology / Web Interface and Applications, Setúbal, Portugal, April 11–13, 2006, J.A.M. Cordeiro, V. Pedrosa, B. Encarnação and J. Filipe, eds, INSTICC Press, (2006) , pp. 381–386. |
[347] | Y. Wang, J. Gong, Z. Wang and C. Zhou, A composite approach for ontology mapping, in: Flexible and Efficient Information Handling, 23rd British National Conference on Databases, BNCOD 23, Belfast, Northern Ireland, UK, July 18–20, 2006, Proceedings, D.A. Bell and J. Hong, eds, Lecture Notes in Computer Science, Vol. 4042: , Springer, (2006) , pp. 282–285. doi:10.1007/11788911_31. |
[348] | Y. Wang, W. Liu and D.A. Bell, A concept hierarchy based ontology mapping approach, in: Knowledge Science, Engineering and Management, 4th International Conference, KSEM 2010, Belfast, Northern Ireland, UK, September 1–3, 2010, Proceedings, Y. Bi and M. Williams, eds, Lecture Notes in Computer Science, Vol. 6291: , Springer, (2010) , pp. 101–113. doi:10.1007/978-3-642-15280-1_12. |
[349] | Y. Wang, X. Liu and J. Chen, A multi-stage strategy for ontology mapping resolution, in: Proceedings of the IEEE International Conference on Information Reuse and Integration, IRI 2008, Las Vegas, Nevada, USA, 13–15 July 2008, IEEE Systems, Man, and Cybernetics Society, (2008) , pp. 345–350. doi:10.1109/IRI.2008.4583055. |
[350] | Z. Wang, Y. Wang and T. Du, Ontology mapping approach based on parsing graph, in: Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, October 8–11, 2006, IEEE, (2006) , pp. 5309–5313. doi:10.1109/ICSMC.2006.385152. |
[351] | Z. Wang, Y. Wang, S. Zhang, G. Shen and T. Du, Effective large scale ontology mapping, in: Knowledge Science, Engineering and Management, First International Conference, KSEM 2006, Guilin, China, August 5–8, 2006, Proceedings, J. Lang, F. Lin and J. Wang, eds, Lecture Notes in Computer Science, Vol. 4092: , Springer, (2006) , pp. 454–465. doi:10.1007/11811220_38. |
[352] | P.L. Whetzel, N.F. Noy, N.H. Shah, P.R. Alexander, C. Nyulas, T. Tudorache and M.A. Musen, BioPortal: Enhanced functionality via new web services from the national center for biomedical ontology to access and use ontologies in software applications, Nucleic Acids Res. 39: (Web-Server-Issue) ((2011) ), 541–545. doi:10.1093/nar/gkr469. |
[353] | S.N. Wrigley, R. Garcia-Castro and L.J.B. Nixon, Semantic evaluation at large scale (SEALS), in: Proceedings of the 21st World Wide Web Conference, WWW 2012, Lyon, France, April 16–20, 2012, Companion Volume, A. Mille, F. Gandon, J. Misselis, M. Rabinovich and S. Staab, eds, ACM, (2012) , pp. 299–302. doi:10.1145/2187980.2188033. |
[354] | J. Wu and Y. Wang, IAOM: An integrated automatic ontology mapping approach towards knowledge integration, in: Bio-Inspired Computational Intelligence and Applications, International Conference on Life System Modeling and Simulation, LSMS 2007, Shanghai, China, September 14–17, 2007, Proceedings, K. Li, M. Fei, G.W. Irwin and S. Ma, eds, Lecture Notes in Computer Science, Vol. 4688: , Springer, (2007) , pp. 502–509. doi:10.1007/978-3-540-74769-7_54. |
[355] | Z. Wu and M.S. Palmer, Verb semantics and lexical selection, in: 32nd Annual Meeting of the Association for Computational Linguistics, New Mexico State University, Las Cruces, New Mexico, USA, 27–30 June 1994, Proceedings J. Pustejovsky, ed., Morgan Kaufmann Publishers / ACL, (1994) , pp. 133–138. https://aclanthology.org/P94-1019/. doi:10.3115/981732.981751. |
[356] | H. Xia, X. Zheng, X. Hu and Y. Tian, Multi-strategy ontology mapping based on stacking method, in: Sixth International Conference on Fuzzy Systems and Knowledge Discovery, FSKD 2009, Tianjin, China, 14–16 August 2009, 6 Volumes, Y. Chen, H. Deng, D. Zhang and Y. Xiao, eds, IEEE Computer Society, (2009) , pp. 262–269. doi:10.1109/FSKD.2009.103. |
[357] | C. Xie, M.W. Chekol, B. Spahiu and H. Cai, Leveraging structural information in ontology matching, in: 30th IEEE International Conference on Advanced Information Networking and Applications, AINA 2016, Crans-Montana, Switzerland, 23–25 March, 2016, L. Barolli, M. Takizawa, T. Enokido, A.J. Jara and Y. Bocchi, eds, IEEE Computer Society, (2016) , pp. 1108–1115. doi:10.1109/AINA.2016.64. |
[358] | X. Xue, Optimizing ontology alignments through NSGA-II using an aggregation strategy and a mapping extraction approach, in: 2015 International Conference on Intelligent Information Hiding and Multimedia Signal Processing, IIH-MSP 2015, Adelaide, Australia, September 23–25, 2015, J. Pan, I. Lee, H. Huang and C. Yang, eds, IEEE, (2015) , pp. 349–352. doi:10.1109/IIH-MSP.2015.100. |
[359] | X. Xue, Efficient ontology meta-matching using alignment prescreening approach and Gaussian random field model assisted NSGA-II, J. Inf. Hiding Multim. Signal Process. 8: (5) ((2017) ), 1062–1068, http://bit.kuas.edu.tw/%7Ejihmsp/2017/vol8/JIH-MSP-2017-05-010.pdf. |
[360] | X. Xue and J. Chen, Optimizing ontology alignment through hybrid population-based incremental learning algorithm, Memetic Comput. 11: (2) ((2019) ), 209–217. doi:10.1007/s12293-018-0255-8. |
[361] | X. Xue and J. Chen, Optimizing sensor ontology alignment through compact co-firefly algorithm, Sensors 20: (7) ((2020) ), 2056. doi:10.3390/s20072056. |
[362] | X. Xue and J. Liu, Collaborative ontology matching based on compact interactive evolutionary algorithm, Knowl. Based Syst. 137: ((2017) ), 94–103. doi:10.1016/j.knosys.2017.09.017. |
[363] | X. Xue, J. Liu, P. Tsai, X. Zhan and A. Ren, Optimizing ontology alignment by using compact genetic algorithm, in: 11th International Conference on Computational Intelligence and Security, CIS 2015, Shenzhen, China, December 19–20, 2015, IEEE Computer Society, (2015) , pp. 231–234. doi:10.1109/CIS.2015.64. |
[364] | X. Xue and J. Pan, A segment-based approach for large-scale ontology matching, Knowl. Inf. Syst. 52: (2) ((2017) ), 467–484. doi:10.1007/s10115-016-1018-9. |
[365] | X. Xue, P. Tsai and L. Zhang, Using parallel compact evolutionary algorithm for optimizing ontology alignment, in: Genetic and Evolutionary Computing – Proceedings of the Tenth International Conference on Genetic and Evolutionary Computing, ICGEC 2016, Fuzhou City, Fujian Province, China, November 7–9, 2016, J. Pan, J.C. Lin, C. Wang and X.H. Jiang, eds, Advances in Intelligent Systems and Computing, Vol. 536: , (2016) , pp. 157–165. doi:10.1007/978-3-319-48490-7_19. |
[366] | X. Xue and Y. Wang, Optimizing ontology alignments through a memetic algorithm using both MatchFmeasure and unanimous improvement ratio, Artif. Intell. 223: ((2015) ), 65–81. doi:10.1016/j.artint.2015.03.001. |
[367] | X. Xue and Y. Wang, Ontology alignment based on instance using NSGA-II, J. Inf. Sci. 41: (1) ((2015) ), 58–70. doi:10.1177/0165551514550142. |
[368] | X. Xue, Y. Wang and W. Hao, Using MOEA/D for optimizing ontology alignments, Soft Comput. 18: (8) ((2014) ), 1589–1601. doi:10.1007/s00500-013-1165-9. |
[369] | X. Xue, Y. Wang and W. Hao, Optimizing ontology alignments by using NSGA-II, Int. Arab J. Inf. Technol. 12: (2) ((2015) ), 175–181. http://iajit.org/index.php?option=com_content&task=blogcategory&id=97&Itemid=373. |
[370] | X. Xue, Y. Wang, W. Hao and J. Hou, Optimizing ontology alignments through NSGA-II without using reference alignment, Comput. Informatics 33: (4) ((2014) ), 857–876, http://www.cai.sk/ojs/index.php/cai/article/view/1159. |
[371] | X. Xue, Y. Wang and A. Ren, Optimizing ontology alignment through memetic algorithm based on partial reference alignment, Expert Syst. Appl. 41: (7) ((2014) ), 3213–3222. doi:10.1016/j.eswa.2013.11.021. |
[372] | X. Xue, C. Yang, C. Jiang, P. Tsai, G. Mao and H. Zhu, Optimizing ontology alignment through linkage learning on entity correspondences, Complex. 2021: ((2021) ), 5574732:1–5574732:12. doi:10.1155/2021/5574732. |
[373] | F. Yang, Variable weight semantic graph-based ontology mapping method, Expert Syst. J. Knowl. Eng. 36: (5) ((2019) ). doi:10.1111/exsy.12337. |
[374] | Y. Yang, D. Cer, A. Ahmad, M. Guo, J. Law, N. Constant, G.H. Ábrego, S. Yuan, C. Tar, Y. Sung, B. Strope and R. Kurzweil, Multilingual universal sentence encoder for semantic retrieval, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, ACL 2020, Online, July 5–10, 2020, A. Celikyilmaz and T. Wen, eds, Association for Computational Linguistics, (2020) , pp. 87–94. doi:10.18653/v1/2020.acl-demos.12. |
[375] | A. Zaveri and M. Dumontier, Ontology mapping for life science linked data, in: Proceedings of the First International Workshop on Biomedical Data Integration and Discovery (BMDID 2016) Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 17, 2016, C. Tao, G. Jiang, D. Song, J. Heflin and F. Schilder, eds, CEUR Workshop Proceedings, Vol. 1709: , CEUR-WS.org, (2016) . http://ceur-ws.org/Vol-1709/BMDID_2016_paper_11.pdf. |
[376] | L. Zhang, S. Ding and S. Tang, An applicable approach to ontology mapping based on knowledge base, in: First IITA International Joint Conference on Artificial Intelligence, Hainan Island, China, 25–26 April 2009, IEEE Computer Society, (2009) , pp. 211–214. doi:10.1109/JCAI.2009.29. |
[377] | L. Zhang, J. Ren and X. Li, OIM-SM: A method for ontology integration based on semantic mapping, J. Intell. Fuzzy Syst. 32: (3) ((2017) ), 1983–1995. doi:10.3233/JIFS-161553. |
[378] | M. Zhang, Z. Duan and C. Zhao, Semi-automatically annotating data semantics to web services using ontology mapping, in: Proceedings of the 12th International Conference on CSCW in Design, CSCWD 2008, Nanyang Hotel, Xi’an Jiaotong University, Xi’an, China, April 16–18, 2008, IEEE, (2008) , pp. 470–475. doi:10.1109/CSCWD.2008.4537024. |
[379] | S. Zhang and O. Bodenreider, NLM anatomical ontology alignment system. Results of the 2006 ontology alignment contest, in: Proceedings of the 1st International Workshop on Ontology Matching (OM-2006) Collocated with the 5th International Semantic Web Conference (ISWC-2006), Athens, Georgia, USA, November 5, 2006, P. Shvaiko, J. Euzenat, N.F. Noy, H. Stuckenschmidt, V.R. Benjamins and M. Uschold, eds, CEUR Workshop Proceedings, Vol. 225: , CEUR-WS.org, (2006) . http://ceur-ws.org/Vol-225/paper14.pdf. |
[380] | S. Zhang and O. Bodenreider, Hybrid alignment strategy for anatomical ontologies: Results of the 2007 ontology alignment contest, in: Proceedings of the 2nd International Workshop on Ontology Matching (OM-2007) Collocated with the 6th International Semantic Web Conference (ISWC-2007) and the 2nd Asian Semantic Web Conference (ASWC-2007), Busan, Korea, November 11, 2007 P. Shvaiko, J. Euzenat, F. Giunchiglia and B. He, eds, CEUR Workshop Proceedings, Vol. 304: , CEUR-WS.org, (2007) . http://ceur-ws.org/Vol-304/paper11.pdf. |
[381] | Y. Zhang, A.V. Panangadan and V.K. Prasanna, UFOM: Unified fuzzy ontology matching, in: Proceedings of the 15th IEEE International Conference on Information Reuse and Integration, IRI 2014, Redwood City, CA, USA, August 13–15, 2014, J. Joshi, E. Bertino, B.M. Thuraisingham and L. Liu, eds, IEEE Computer Society, (2014) , pp. 787–794. doi:10.1109/IRI.2014.7051969. |
[382] | Y. Zhang, X. Wang, S. Lai, S. He, K. Liu, J. Zhao and X. Lv, Ontology matching with word embeddings, in: Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data – 13th China National Conference, CCL 2014, and Second International Symposium, NLP-NABD 2014, Wuhan, China, October 18–19, 2014, Proceedings, M. Sun, Y. Liu and J. Zhao, eds, Lecture Notes in Computer Science, Vol. 8801: , Springer, (2014) , pp. 34–45. doi:10.1007/978-3-319-12277-9_4. |
[383] | M. Zhao and S. Zhang, Identifying and validating ontology mappings by formal concept analysis, in: Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, October 18, 2016, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham, O. Hassanzadeh and R. Ichise, eds, CEUR Workshop Proceedings, Vol. 1766: , CEUR-WS.org, (2016) , pp. 61–72. http://ceur-ws.org/Vol-1766/om2016_Tpaper6.pdf. |
[384] | Q. Zheng, C. Shao, J. Li, Z. Wang and L. Hu, RiMOM2013 results for OAEI 2013, in: Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 21, 2013, P. Shvaiko, J. Euzenat, K. Srinivas, M. Mao and E. Jiménez-Ruiz, eds, CEUR Workshop Proceedings, Vol. 1111: , CEUR-WS.org, (2013) , pp. 161–168. http://ceur-ws.org/Vol-1111/oaei13_paper9.pdf. |
[385] | Q. Zhong, H. Li, J. Li, G.T. Xie, J. Tang, L. Zhou and Y. Pan, A Gauss function based approach for unbalanced ontology matching, in: Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2009, Providence, Rhode Island, USA, June 29–July 2, 2009, U. Çetintemel, S.B. Zdonik, D. Kossmann and N. Tatbul, eds, ACM, (2009) , pp. 669–680. doi:10.1145/1559845.1559915. |
[386] | H. Zhu, X. Xue, C. Jiang and H. Ren, Multiobjective sensor ontology matching technique with user preference metrics, Wirel. Commun. Mob. Comput. 2021: ((2021) ), 5594553:1–5594553:9. doi:10.1155/2021/5594553. |


