
Prediction of adverse biological effects of chemicals using knowledge graph embeddings
Abstract
We have created a knowledge graph based on major data sources used in ecotoxicological risk assessment. We have applied this knowledge graph to an important task in risk assessment, namely chemical effect prediction. We have evaluated nine knowledge graph embedding models from a selection of geometric, decomposition, and convolutional models on this prediction task. We show that using knowledge graph embeddings can increase the accuracy of effect prediction with neural networks. Furthermore, we have implemented a fine-tuning architecture which adapts the knowledge graph embeddings to the effect prediction task and leads to a better performance. Finally, we evaluate certain characteristics of the knowledge graph embedding models to shed light on the individual model performance.
1.Introduction
Ecotoxicology is a multidisciplinary field that studies the potentially adverse toxicological effects of chemicals on organisms, starting at molecular level to individuals, sub-populations, communities and ecosystems. One major societal contribution of ecotoxicology is ecological risk assessments, which compare environmental concentrations of chemicals with existing laboratory effect data to evaluate the ecosystem health status. While laboratory experiments are thus crucial, they are both labour intensive and result in a high number of animal testing. Therefore, the development of modelling techniques for extrapolating from existing laboratory effect data is a major effort in the field of ecotoxicology.
A very important challenge in ecotoxicology risk assessment is the interoperability of the disparate data sources, formats and vocabularies. The use of Semantic Web technologies and (RDF-based) knowledge graphs [6] can address this challenge and facilitate the orchestration of these datasets. Hence, extrapolation or prediction models can benefit from an integrated view of the data and the background knowledge provided by a knowledge graph. The use of knowledge graphs also enables the use of the available infrastructure to perform automated reasoning, explore the data via semantic queries, and compute semantic embeddings for machine learning prediction.
In this work we have created the Toxicological Effect and Risk Assessment Knowledge Graph (TERA) and implemented a prediction model over this knowledge graph to extrapolate adverse biological effects of chemicals on organisms. Here, we limit ourselves to binary effect prediction of mortality (shortened to effect prediction), i.e., where there is a chance that a chemical can affect a species in a lethal way. The work and evaluation conducted in this paper is driven by the following research question: does the use of contextual information in the form of knowledge graph embeddings brings added value in the prediction of adverse biological effects?
Our contributions can be summarized as follows:
(i) TERA aims at consolidating the relevant information to the ecological risk assessment domain. TERA integrates several disparate datasets and enables a unified (semantic) access. The formats of these data sources vary from tabular, to RDF files and SPARQL endpoints over public linked data. We have exploited external resources (e.g., Wikidata [76]) and ontology alignment methods (e.g., LogMap [33]) to discover equivalences between the data sources.
(ii) We have designed and implemented a model tailored to binary lethal chemical effect prediction. This model relies on TERA and builds upon existing knowledge graph embedding models. Moreover, it supplies the knowledge graph embedding models with additional information. This is used to tailor the embeddings to this specific task.
(iii) We have evaluated nine knowledge graph embedding (KGE) models, together with a naive baseline on the binary chemical effect prediction task. This evaluation includes four data sampling strategies which highlight the different settings of chemical effect prediction (i.e., the test data contains unseen chemical-organism pairs where: (a) the chemical and the organism may be known (but not in previously seen pairs), (b) the chemical is unknown, (c) the organism is unknown, and (d) both the chemical and the organism are unknown).
This paper extends our preliminary work presented in the In-Use Track of the 18th International Semantic Web Conference [51]. We have (i) extended TERA with new sources (Encyclopedia of Life (EOL), MeSH, and a larger part of ChEMBL) and provided detailed steps about its creation; (ii) created a more robust prediction model with nine (up from three) embedding algorithms supported and a task-specific embedding fine-tuning strategy; and (iii) conducted a more comprehensive evaluation with all combinations of KGE models and sampling strategies totalling 648 data points (324 for each prediction model).
The rest of the paper is organized as follows. Section 2 introduces essential concepts to the subsequent sections. Section 3 introduces the use case where the knowledge graph and prediction models are applied. Section 4 introduces related work. The creation of the knowledge graph is described in Section 5. Section 6 introduces the prediction models, while Section 7 presents the evaluation of these models. Section 8 elaborates on the contributions and discusses future directions of research. Finally, the Appendix gives an overview of the knowledge graph embedding models used in this work.
2.Preliminaries
In this section we introduce important background concepts that will be used throughout the paper. Table 1 contain the most important symbols.
Table 1
Key symbols and acronyms used throughout the paper
| Symbol | Definition |
| RDF | Resource Description Framework |
| OWL | Web Ontology Language |
| SPARQL | SPARQL Protocol and RDF Query Language |
| KG | Knowledge graph |
| KGE | Knowledge graph embedding |
| t | A triple |
| The subject of a triple | |
| The object of a triple | |
| p, r | The predicate/relation of a triple |
| e | A KG entity |
| The set of KG triples | |
| The set of KG entities | |
| The set of KG relations | |
| The set of literal values | |
| e | The vector representation of an entity or relation |
| k | The dimension of a vector |
| The scoring function of a KGE model | |
| Pre-trained KGE-based model | |
| Fine-tuning KGE-based model | |
| s | A species |
| c | A chemical |
| S | Refers to species |
| C | Refers to chemicals |
| κ | Chemical concentration |
2.1.Ecotoxicological terminology
Taxonomy in this work refers to a species classification hierarchy. Any node in a taxonomy is called a taxon. Species is a taxon which is also a leaf node in the taxonomy. An Organism denotes an individual living organism which is an instance of a species. Chemicals or compounds are unique isotopes of substances consisting of two or more atoms. Effect, used in this work as short form for chemical effect, refers to the response of an organism (or population) to a chemical at a specific concentration. Endpoint11 denotes a measured effect on the test population at a certain time; e.g., lethal concentration to 50% of test population (LC50) measured at 48 hours. Note that, an experiment can have several endpoints, e.g., LC50 at 48 hours and LC100 at 96 hours (lethal concentration for all test organisms). See Table 2 for the most common endpoints.
2.2.Ontology-enhanced knowledge graphs
In this work we consider the most broadly accepted notion of knowledge graph within the Semantic Web: an ontology enhanced RDF-based knowledge graph (KG) [32]. This kind of knowledge graph enables the use of the available Semantic Web infrastructure, including SPARQL engines and OWL reasoners.22 Thus, in our setting, KGs are composed by RDF triples in the form of
An (ontology-enhanced) KG can be split into a TBox (terminology) and an ABox (assertions). The TBox is composed by triples using RDF Schema (RDFS) constructors like class subsumptions and property domain and range; and OWL constructors like disjointness, equivalence and property inverses.44 The ABox contains assertions among instances, including OWL equality and inequality, and semantic type definitions. Table 5 shows several examples of TBox and ABox triples.
2.3.Ontology alignment
Ontology alignment is the process of finding mappings or correspondences between a source and a target ontology or knowledge graph [23,66]. These mappings typically represent equivalences or broader/narrower relationships among the entities of the input ontologies. In the ontology matching community [61], mappings are exchanged using the RDF Alignment format [18]; but they can also be interpreted as standard OWL axioms (e.g., [24,35]). In this work we treat ontology alignments as OWL axioms (e.g., triple
2.4.Embedding models
Knowledge graph embedding (KGE) [63,78] plays a key role in link prediction problems where it is applied to knowledge graphs to resolve missing facts in largely connected knowledge graphs, such as DBpedia [44]. Biomedical link prediction is another area where embedding models have been applied successfully (e.g., [1,5]).
The embeddings of the entities in a KG are commonly learned by (i) defining a scoring function over a triple, which is typically proportional to the probability of the existence of that triple in the KG,55 i.e.,
Several knowledge graph embedding models have been proposed. In this work, we used models of three major categories: decomposition models, geometric models, and convolutional models.66 The decomposition models represent the triples of the KG into a one-hot 3-order tensor and apply matrix decomposition to learn entity vectors. Geometric models, also known as translational, try to learn embeddings by defining a scoring function where the predicate in the triple act as a geometric translation (e.g., rotation) from subject to object. Convolutional models, unlike previous models, learn entity embedding with non-linear scoring functions via convolutional layers.
3.Ecotoxicological risk assessment and adverse biological effect prediction
The task of ecotoxicological risk assessment is to study the potential hazardous effects of chemicals on organisms from individuals to ecosystems. In this context, risk is the result of the intrinsic hazards of a substance on species, populations or ecosystems, combined with an estimate of the environmental exposure, i.e., the product of exposure and effect (hazard).
Fig. 1.
Simplified ecological risk assessment pipeline.
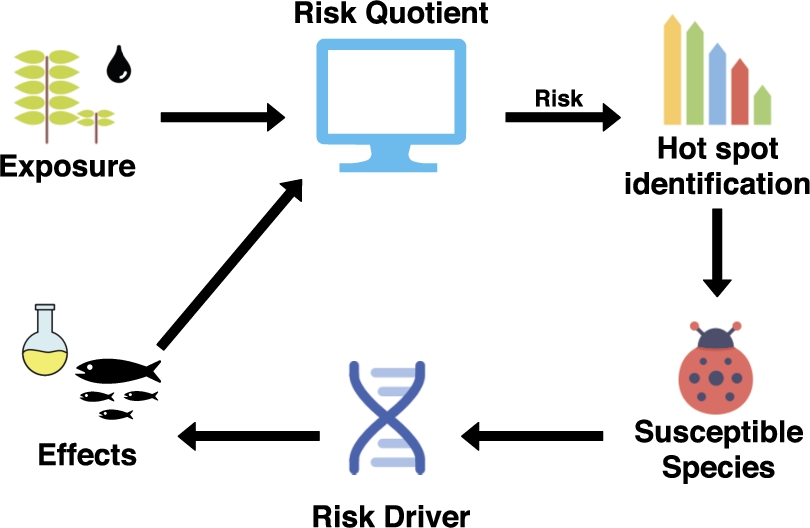
Figure 1 shows a simplified risk assessment pipeline. Exposure data is gathered from analysis of environmental concentrations of one or more chemicals, while effects (hazards) are characterized for a number of species in the laboratory as a proxy for more ecologically relevant organisms. These two data sources are used to calculate the so-called risk quotient (RQ; ratio between exposure and effects). The RQ for one chemical or the mixture of many chemicals is used to identify chemicals with the highest RQs (risk drivers), identify relevant modes of action77 (MoA) and characterize detailed toxicity mechanisms for one or more species (or taxa). Results from these predictions can generate a number of new hypotheses that can be investigated in the laboratory or studied in the environment. Note that, this risk assessment pipeline is a simplified version of the one in use at the Norwegian Institute for Water Research,88 however, similar methodologies are used across regulatory risk assessment pipelines.
Table 2
The most frequent endpoints in ECOTOX [74] chemical effect data
| Endpoint | Frequency | Description |
| NR | 0.21 | Not reported |
| NOEL | 0.17 | No-observable-effect-level |
| LC50 | 0.16 | Lethal concentration for |
| LOEL | 0.14 | Lowest-observable-effect-level |
| NOEC | 0.05 | No-observable-effect-concentration |
| EC50 | 0.05 | Effective concentration for |
| LOEC | 0.04 | Lowest observable effect concentration |
| BCF | 0.03 | Bioconcentration factor |
| NR-LETH | 0.02 | Lethal to |
| LD50 | 0.02 | Lethal dose for |
| Other | 0.11 |
The chemical effect data is gathered during laboratory experiments, where a sub-population of a single species is exposed to an increasing concentration of a toxic chemical. The endpoints of the experiments are recorded at chemical concentrations and time after exposure. These endpoints are categorized into several categories, e.g., lethality rate of test population (see Table 2).
Ecological risk assessment methods require a large amount of these experimental data to give an accurate depiction of the long term risk to an ecosystem. The data must cover the relevant chemicals and species present in the ecosystem, e.g., an ecological risk assessment of agricultural runoff in Norway will mostly concern pesticides and waterflees, copepods, and frogs, among other species [42]. Just with a few relevant chemicals and species the search space becomes immense and performing laboratory experiments becomes unfeasible. Thus, it is essential to develop in silico methods to extrapolate new chemical-species effects from known combinations. We differentiate among two types complementary strategies: (i) highly specialized (restricted in chemical and species domains) models to predict chemical concentrations that will have an effect on a test species, and (ii) models that produce rankings of highly representative chemical-species pair hypothesis which can be used by a laboratory to perform targeted experiments. In this paper we focus on the latter strategy, using a method based on knowledge graph embeddings. Methods that fall into the first strategy are introduced in Section 4.1.
4.Related work
This section will cover related work from ecotoxicology and knowledge graph based prediction.
4.1.Toxicity extrapolation
There are two main research areas in toxicology to extrapolate chemical effects, i.e., Quantitative Structure-Activity Relationship (QSAR) and read-across. QSAR modelling try to find a relationship between the structure of a chemical and the chemical’s biological activity (cf. reviews [22,26]). This relationship is described using derived chemical features. Some features are simple, e.g., octanol-water partition coefficient or logP, others concern the entire chemical, e.g., chemical fingerprints. The basis of the QSAR relationship is usually modeled as polynomial equations. Parthasarathi and Dhawan [59] take this further by using the logarithm of chemical concentration to achieve a polynomial relationship:
The read-across methods try to mitigate these drawbacks, mainly by considering extrapolation of the effect at the chemical and species levels. Similar to QSAR models, read-across of chemicals use the chemical features to create similarity measures between chemicals to justify the read-across of chemical effects. The read-across in the species domain is harder. Species do not tend to have easily derived features. Therefore, genetic similarity has emerged as a viable option. Sequence Alignment to Predict Across Species Susceptibility (SeqAPASS), developed by the United States Environmental Protection Agency (U.S. EPA), is an example of such an approach [20,41]. SeqAPASS uses a large amount of data available for humans, mice, rats, and zebrafish to extrapolate to areas with lower coverage.
4.2.Embedding models
In this work, we use nine KGE models across three categories of models. Here, we will give a brief introduction to the models, while a more extended explanation of the models is found in the Appendix. The interested reader please refer to [63] for a comprehensive survey.
The three categories of models are decomposition, geometric, and convolutional [63]. The decomposition models are DistMult, ComplEx, and HolE. DistMult models the score of a triple as the vector multiplication of the representation of each subject, predicate and object [83]. ComplEx uses the same scoring function as DistMult, however, in a complex vector space, such that it can handle inverse relations [73]. HolE is based on holographic embeddings [56], however, it has been shown that HolE is equivalent to ComplEx [30].
The geometric models are TransE, RotatE, pRotatE, and HAKE. TransE is the base of a whole family of models and scores triples based on the translation from subject to object using the representation of the predicate [10]. RotatE is similar to TransE, however, the translation using the predicate is done by rotating it (via Euler’s identity) [70]. Furthermore, pRotatE is a baseline for RotatE where the modulus in Euler’s identity is ignored [70]. Finally, the hierarchical-aware model, HAKE, where entities at each level in the hierarchy is at equal distance from the origin and relations at a level is modeled as rotation [86].
The convolutional models take a deep learning approach to the task of KGE. We use ConvKB [55] and ConvE [19], which are similar with slightly different architectures. They have shown good performance given the relative small number of parameters.
Although quite a few KGE models have been proposed, the adopted ones are either classic models or can achieve state-of-the-art performance in some benchmarks. They are representative of mainstream techniques, and have been widely adopted in KGE research and applications [63]. Thus, the benefits and shortcomings of the KGE models analysed in this study provide good evidence of the general performance of this type of models in a complex prediction task, i.e., adverse biological effect of chemicals on organisms.
4.3.Using KGE for prediction
Our focus to use KGE models is to predict if a chemical has a lethal effect on an organism. KGE models have been explored in the biomedical domain to solve similar predictions tasks (e.g., finding relationships between diseases, drugs, genes, and treatments). Several works have shown improvements in results by using KGE models for prediction, e.g., [1,5,46]. Chen et al. [15] used random walks over networks to perform drug-target predictions. The ChEMBL and DrugBank KGs have also been used to predict chemical mode of action (MoA) of anticancer drugs with high performance on benchmark datasets [82].
Opa2vec [68] and Blagec et al. [8] have developed embedding models to improve similarity-based prediction in the biomedical domain, while OpenBioLink [12] has created a framework for evaluating models in the biomedical domain.
EL Embeddings [40] and opa2vec [68] present new semantic embedding methods for KGs with expressive logic expressions (i.e., OWL ontologies) to predict protein interaction. The former utilizes complex geometric structures to model the logic relationships between entities, while the later learns a language model from a corpus extracted from the ontology. OWL2Vec* [13] also learns a language model from an ontology and applies the computed embeddings into two prediction tasks: class subsumption and class membership. OWL2Vec* has also been used to predict the plausibility of ontology alignments [14].
To the best of our knowledge there is no work using link prediction or KGE models to support ecotoxicological effect prediction. This study will give novel insights and empirical results of KGE models in this new domain.
5.TERA knowledge graph
One major challenge in ecological risk assessment processes is the interoperability of data. In this section, we introduce the Toxicological Effect and Risk Assessment (TERA), an ontology-enhanced RDF-based knowledge graph that aims at providing an integrated view of the relevant data sources for risk assessment.1010
The initial inspiration for TERA was the aid of ecotoxicological effect prediction where access to disparate resources was required (see Section 5.3). However, by integrating these sources into a KG, we were also able to directly apply TERA into the prediction process by leveraging knowledge graph embedding models (see Section 5.4).
The data sources integrated into TERA vary from tabular and RDF files to SPARQL endpoints over public linked data. The sources currently integrated into TERA are: (i) biological: NCBI Taxonomy, Encyclopedia of Life, and Wikidata mappings (∼500k species); (ii) chemical: PubChem, ChEMBL, MeSH, and Wikidata mappings (∼110M compounds); and (iii) biological effects: ECOTOXicology Knowledgebase (∼1M results, ∼12k compounds, ∼13k species), and system-generated mappings. These three distinct parts make up the sub-KGs of TERA, i.e., (i) the Taxonomy sub-KG (
Fig. 2.
Data sources and processes to create the TERA knowledge graph.
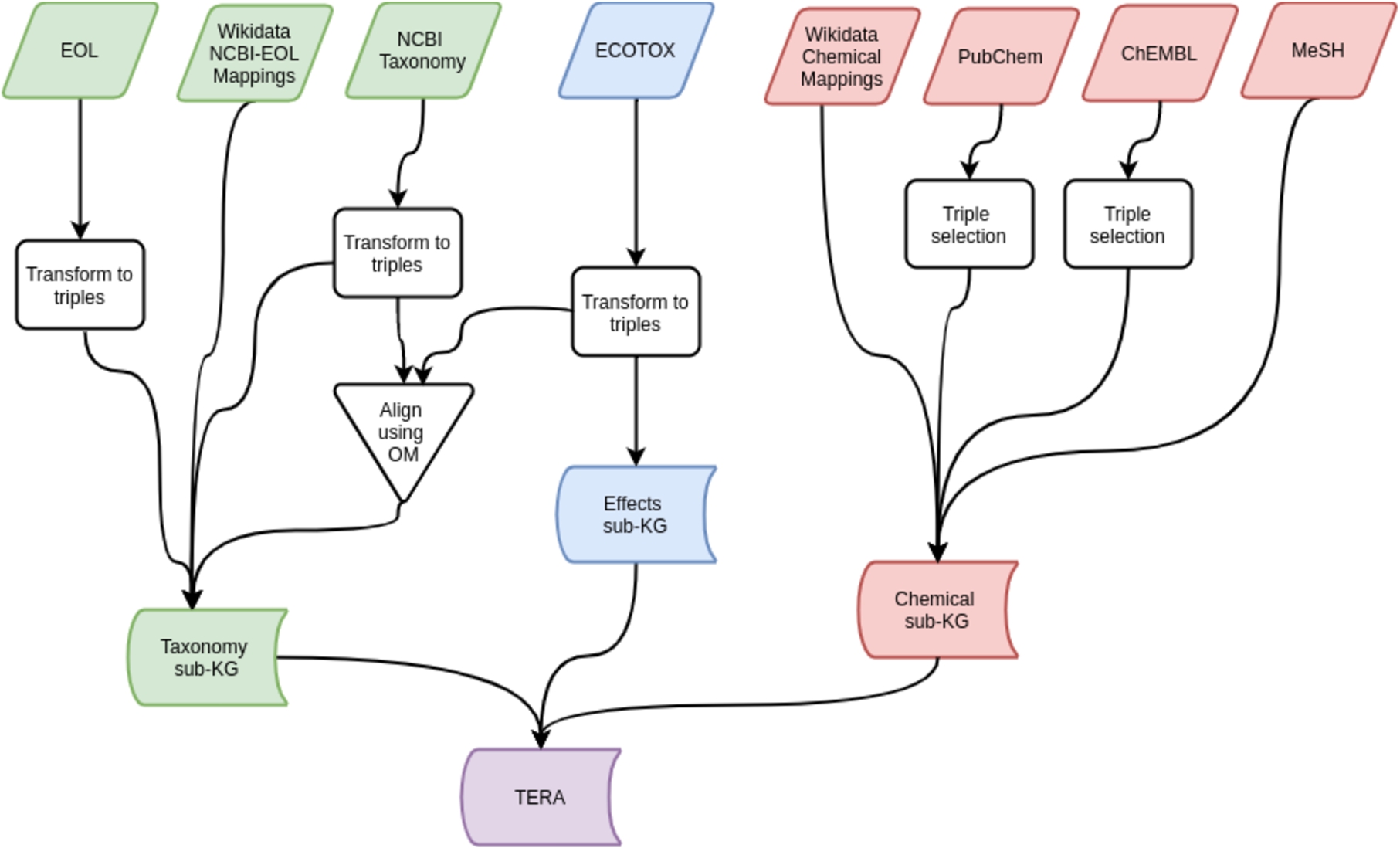
A snapshot of TERA is available on Zenodo [53], where licenses permit.1111 PubChem and ChEMBL are not included in the snapshot due to size constraints; these can be downloaded from the National Institutes of Health1212 and European Bioinformatics Institute,1313 respectively. The subgraph of TERA used for prediction is available alongside the chemical effect prediction models in our GitHub repository.1414 Table 5 shows several examples of RDF triples from TERA.1515
5.1.Dataset overview
TERA, as mentioned above, is constructed by gathering a number of sources about chemicals, species and chemical toxicity, with a diverse set of formats including tabular data, RDF dumps and SPARQL endpoints.
Biological effect data of chemicals. The largest publicly available repository of effect data is the ECOTOXicology knowledgebase (ECOTOX) developed by the US Environmental Protection Agency [74]. This data is gathered from published toxicological studies and limited internal experiments. The dataset consists of
Table 3
ECOTOX database tests example
| test_id | reference_number | test_cas | species_number | organism_habitat |
| 1147366 | 12448 | 134623 (diethyltoluamide) | 1 (Pimephales promelas) | Water |
Table 4
ECOTOX database results example
| result_id | test_id | endpoint | effect | conc1_mean | conc1_unit |
| 102570 | 1147366 | LC50 | MOR | 110000 | μg/L |
Tables 3 and 4 contain an excerpt of the ECOTOX database. ECOTOX includes information about the chemicals and species used in the tests. This information, however, is limited and additional (external) resources are required to complement ECOTOX.
Chemicals. The ECOTOX database uses an identifier called CAS Registry Number assigned by the Chemical Abstracts Service to identify chemicals. The CAS numbers are proprietary, however, Wikidata [76] (indirectly) encodes mappings between CAS numbers and open identifiers like InChIKey, a 27-character hash of the International Chemical Identifier (InChI) which encodes chemical information uniquely [31].1717 Wikidata also provides mappings to well known databases like PubChem, ChEMBL and MeSH, which include relevant chemical information such as chemical structure, structural classification and functional classification.
Taxonomy. ECOTOX contains a taxonomy1818 (of species), however, this only considers the species represented in the ECOTOX effect data. Hence, to enable extrapolation of effects across a larger taxonomic domain, we include the NCBI Taxonomy [64]. This taxonomy data source consists of a number of database dump files, which contains a hierarchy for all sequenced species, which equates to around
Species traits. As an analog to chemical features, we use species traits to expand the coverage of the knowledge graph. Apart from taxonomic classifications, traits are the most important information to identify species and will be of great importance when predicting the effect on the species.
The traits we have included in the knowledge graph are the habitat, endemic regions, and presence (and classifications of these). This data is gathered from the Encyclopedia of Life (EOL) [57], which is available as a property graph. Moreover, EOL uses external definitions of certain concepts, and mappings to these sources are available as glossary files. In addition to traits, researchers may be interested in species that have different conservation statuses, e.g., if the population is stable or declining, etc. This data can also be extracted from EOL.
5.2.Dataset preprocessing
In this section we present the different steps to extract, transform and integrate the source datasets into the main TERA components and sub-KGs. All data is transformed using custom mappings (scripts) from the sources to RDF triples. Table 5 shows an excerpt of the triples in TERA.
Table 5
Example triples from the TERA knowledge graph. For space reasons, we have added the full id or label for some of the entities using footnote marks where 1inchikey:MMOXZBCLCQITDF-UHFFFAOYSA-N, 2Pimephales, 3Cyprinidae, 4Headwater, 5Benzamides, 6Insect Repellents, 7CHRNA3, 8CHRNB4, 9DETA-20, 10DETA Epichlorohydrin, 11Has component, 12Triclocarban, 13Trichlorocarbanilide-containing product, 14Similar to, 153-Chloromethyl-N,N-diethylbenzamide
| # | subject | predicate | object |
| Effects sub-KG | |||
| et:test/1147366 | et:compound | et:chemical/134623 | |
| et:test/1147366 | et:species | et:taxon/1 | |
| et:test/1147366 | et:hasResult | et:result/102570 | |
| et:result/102570 | et:endpoint | et:endpoint/LC50 | |
| et:result/102570 | et:effect | et:effect/Mortality | |
| et:taxon/1 | rdf:type | et:taxon/Pimephales | |
| et:taxon/Pimephales | rdfs:subClassOf | et:taxon/Cyprinidae | |
| et:taxon/1 | et:latinName | “Pimephales promelas” | |
| et:taxon/1 | et:commonName | “Fathead Minnow” | |
| et:taxon/1 | et:speciesGroup | et:group/Fish | |
| et:taxon/1 | et:rank | et:rank/species | |
| et:chemical/134623 | rdfs:label | “diethyltoluamide” | |
| Entity Mappings | |||
| et:taxon/1 | owl:sameAs | ncbi:taxon/90988 | |
| ncbi:taxon/90988 | owl:sameAs | wd:Q2700010 | |
| wd:Q2700010 | owl:sameAs | eol:211492 | |
| et:chemical/134623 | owl:sameAs | wd:Q408389 | |
| wd:Q408389 | owl:sameAs | chembl_m:CHEMBL1453317 | |
| wd:Q408389 | owl:sameAs | compound:CID4284 | |
| wd:Q408389 | owl:sameAs | mesh:D003671 | |
| wd:Q408389 | owl:sameAs | inchikey:MMOXZBCLC…1 | |
| Taxonomy sub-KG | |||
| ncbi:taxon/90988 | rdf:type | ncbi:taxon/511372 | |
| ncbi:taxon/90988 | rdf:type | ncbi:division/10 | |
| ncbi:taxon/90988 | ncbi:scientific_name | “Pimephales promelas” | |
| ncbi:taxon/90988 | ncbi:rank | ncbi:species | |
| ncbi:taxon/51137 | rdfs:subClassOf | ncbi:taxon/79533 | |
| ncbi:division/10 | rdfs:label | “Vertebrates” | |
| ncbi:division/10 | owl:disjointWith | ncbi:division/1 | |
| ncbi:division/1 | rdfs:label | “Invertebrates” | |
| eol:211492 | eol:habitat | envo:000001534 | |
| Chemical sub-KG | |||
| mesh:D003671 | mesh:broaderDescriptor | mesh:D0015495 | |
| mesh:D003671 | mesh:pharmacologicalAction | mesh:D0073026 | |
| chembl_m:CHEMBL1453317 | chembl:hasTarget | chembl_t:CHEMBL19075947 | |
| chembl_t:CHEMBL1907594 | chembl:relSubsetOf | chembl_t:CHEMBL31372738 | |
| compound:CID898457699 | vocab:hasParentCompound | compound:CID4284 | |
| compound:CID13172106910 | cheminf:CHEMINF_00047811 | compound:CID4284 | |
| compound:CID131721069 | rdf:type | bp:SmallMolecule | |
| compound:CID754712 | vocab:is_active_ingredient_of | snomedct:41134600913 | |
| compound:CID131721069 | cheminf:CHEMINF_00048014 | compound:CID1075169115 | |
Fig. 3.
Example of an ECOTOX test and related triples.
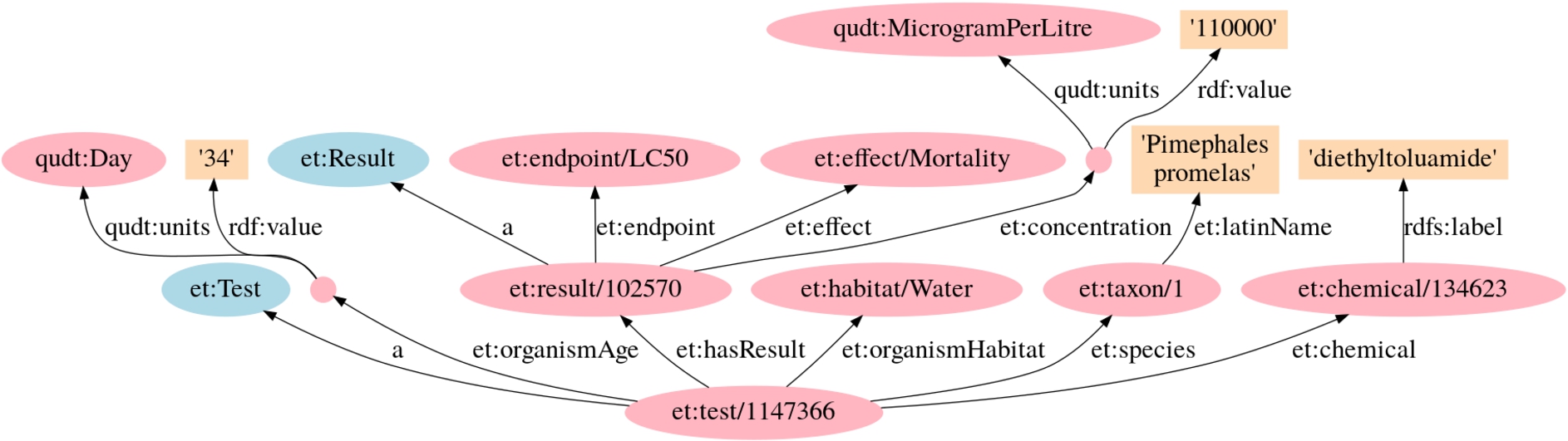
5.2.1.Effects sub-KG construction
The effect data in ECOTOX consist of two parts, i.e., test definitions and results associated with the test definitions (see Tables 3 and 4, respectively). The important columns of a test are the chemical and the species used. Other columns include metadata, but these are optional and often empty. Each result is composed by an endpoint, an effect, and a concentration (with a unit) at which the endpoint and effect are recorded.
This tabular data in ECOTOX is transformed into triples that form the effects sub-KG in TERA (
ECOTOX contains metadata about the species and chemicals used in the experiments. This metadata is also included in TERA to facilitate the alignment with other resources (see Section 5.2.2).
(i) The ECOTOX metadata file species.txt includes common and Latin names, along with a (species) ECOTOX group (see triples
(ii) The full hierarchical lineage1919 is also available in the metadata file species.txt. Each column represents a taxonomic level, e.g., genus or family. If a column is empty, we construct an intermediate classification; for example, Daphnia magna has no genus classification in the data, then its classification is set to Daphniidae genus (family name + genus, actually called Daphnia). We construct these classifications to ensure the number of levels in the taxonomy is consistent (see triples
(iii) The ECOTOX source file chemicals.txt includes chemical metadata and it is handled similarly to species.txt. The file includes chemical name (see
For the units in the effect data, e.g., chemical concentrations (mg/L, mol/L, mg/kg, etc.), we reuse the QUDT 1.12020 ontologies. When an unit such as mg/L is not defined, we define it according to Listing 1.
Listing 1.
Unit definition of mg/L using QUDT

5.2.2.Alignment with state-of-the-art tools
ECOTOX database provides proprietary chemical identifiers (i.e., CAS numbers) and internal ECOTOX ids for species. In order to extrapolate effects across a larger set of chemicals and species than those available in ECOTOX, TERA integrates taxonomy and trait data from NCBI and EOL, and chemical data from PubChem, ChEMBL and MeSH.
Alignment between ECOTOX and the NCBI Taxonomy. There does not exist a complete and public alignment between the 23,439 ECOTOX species and the 1,830,312 the NCBI Taxonomy species.2121 We have used three methods, two state-of-art ontology alignments systems and a baseline, to align ECOTOX and the NCBI Taxonomy: (i) LogMap [33,34], (ii) AgreementMakerLight (AML) [25], and (iii) a string matching algorithm based on Levenshtein distance [45]. LogMap and AML were chosen since they have performed well across many datasets in the Ontology Alignment Evaluation Initiative (e.g., [2,3,61]). Most mappings in our setting are expected to be lexical, therefore, we also selected a purely lexical matcher to evaluate if more sophisticated systems like LogMap and AML bring an additional value.
Due to the large size of the NCBI Taxonomy, we needed to split NCBI into manageable chunks to enable the use of ontology alignment systems. Fortunately, this can be easily done by considering the species division, e.g., mammal or invertebrate. This divides the NCBI Taxonomy into 11 distinct parts, which can be aligned to the taxonomy in ECOTOX.
Table 6
Alignment results for ECOTOX-NCBI. #M: number of mappings (at instance level), R: Recall,
| Method | 1-to-1 mappings | ||
| #M | R | ||
| LogMap | 20,585 | 0.81 | 0.87 |
| AML | 14,148 | 0.77 | 0.94 |
| String similarity ( | 20,423 | 0.76 | 0.87 |
| Consensus ( | 12,740 | 0.76 | 0.98 |
| 21,145 | 0.83 | 0.86 | |
Note that it is expected an entity from ECOTOX to match to a single entity in the NCBI Taxonomy, and vice-versa. Hence, 1-to-N and N-to-1 alignments were filtered according to the system computed confidence. A partial mapping curated by experts can be obtained through the ECOTOX Web.2222 We have gathered a total of 2,321 mappings for validation purposes. Table 6 shows the alignment results over the ground truth samples for the 1-to-1 (filtered) system mappings. We report number of mappings (#M), Recall (R) and estimated precision (
We have selected the union of the 1-to-1 equivalence2323 mappings computed by AML and LogMap to be integrated within TERA, as they represent the mapping set with the best recall with a reasonable estimated precision. This choice was made by considering the large uncertainty of downstream applications (effect prediction and risk assessment), where we prefer a larger coverage of the domain. See triple
Listing 2.
Construct taxon mapping between Wikidata and, NCBI and EOL. wd:Q16521 is the class of all taxa, while wdt:P31, wdt:P685 and wdt:P830 are the relations instance of, NCBI Taxonomy ID and Encyclopedia of Life ID, respectively
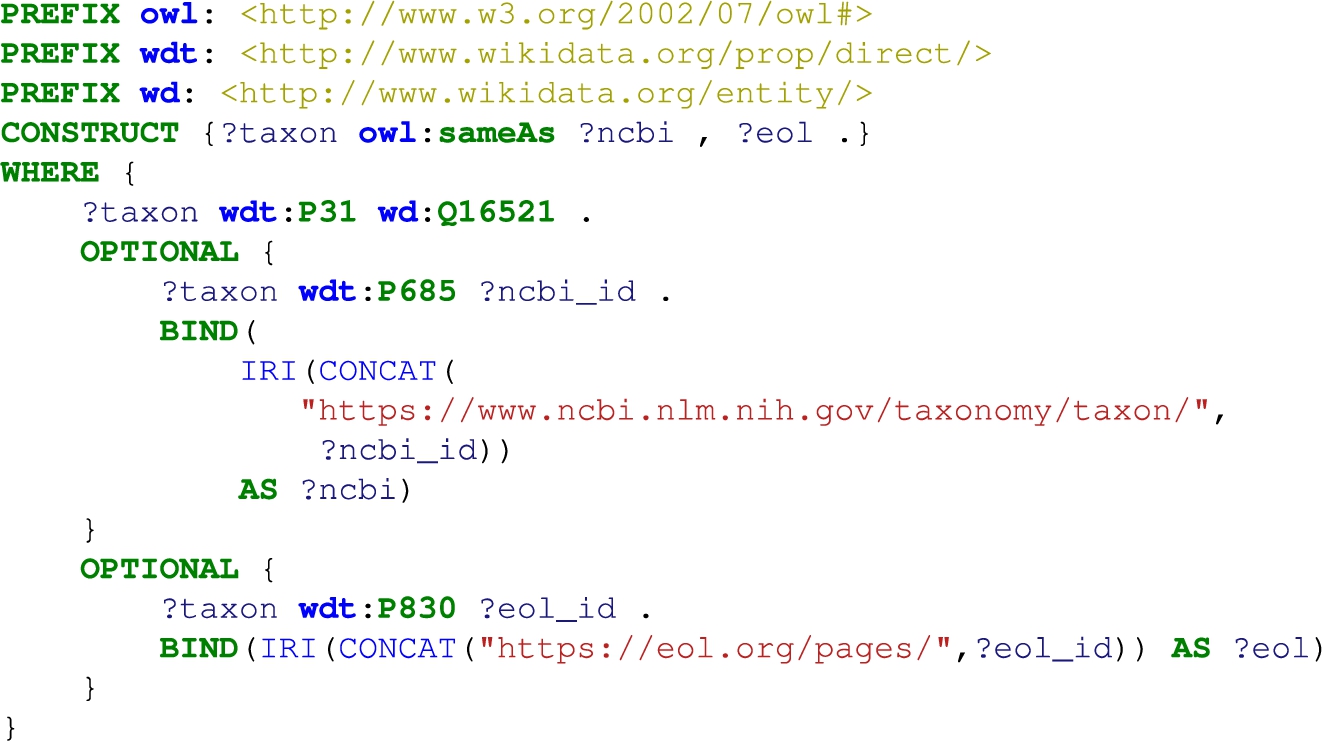
We use Wikidata as source of alignments between the NCBI Taxonomy and EOL, and among the used chemical datasets. Alignments are extracted via Wikidata’s query interface (i.e., SPARQL endpoint).2424 The data in Wikidata concerning species and chemicals are in large parts manually curated [77] and will have a low error rate, comparatively to using the automated ontology alignment systems.
Alignment between the NCBI Taxonomy and EOL. In order to include in TERA trait data from EOL, we need to establish an alignment between EOL and the NCBI Taxonomy. We have constructed equivalence triples between the NCBI Taxonomy and EOL identifiers using Wikidata. The species identifiers are available as literals in Wikidata. Therefore, we concatenate them with the appropriate namespace. Listing 2 represents the SPARQL CONSTRUCT query used against the Wikidata endpoint. Here, we query Wikidata for instances of taxa, thereafter adding optional triple patterns for NCBI Taxonomy and EOL identifiers which are added as owl:sameAs triples to TERA.
Examples of resulting mapping triples are shown in
Alignment between chemical entities. The mapping between ECOTOX chemical identifiers (CAS Registry Numbers) to Wikidata entities enables the alignment to a vast set of chemical datasets, e.g., PubChem, ChEBI, KEGG, ChemSpider, MeSH, UMLS, to name a few. The construction of equivalence triples between CAS, ChEMBL, MeSH, PubChem and Wikidata identifiers is shown in Listing 3. As for the case of species identifiers, the literal representing a chemical identifier is concatenated with the corresponding namespace. For the CAS Registry Numbers we also remove the hyphens to match ECOTOX notation. Examples of resulting mapping triples are shown in
Listing 3.
Construct chemical mapping between Wikidata and ECOTOX, ChEMBL, MeSH and PubChem. wdt:P31 is the predicate for instance of and wd:Q11173 is the class of all chemical compounds. wdt:P231, wdt:P592, wdt:P486, wdt:P662 and wdt:P235 are the relations for CAS Registry Number, ChEMBL ID, MeSH ID, PubChem CID and InChIKey, respectively

These mappings are not complete, but for some the coverage is large. Out of the chemicals used in ECOTOX,
5.2.3.Taxonomy sub-KG construction
The Taxonomy sub-KG (
(i) We load the hierarchical structure included in the NCBI Taxonomy file nodes.dmp. The columns of interest are the taxon identifiers of the child and parent taxon, along with the rank of the child taxon and the division where the taxon belongs. We use this to create triples like
(ii) To aid alignment between the NCBI Taxonomy and the ECOTOX identifiers, we add the synonyms found in names.dmp. Here, the taxon identifier, its name and name type are used to create triples like
(iii) Finally, we add the labels of the divisions found in divisions.dmp (see triples
We use the TraitBank from EOL [58] to add species traits to TERA. The TraitBank is modeled as a property graph and can be accessed as a neo4j database or via a set of tabular files. To integrate the TraitBank into TERA we validate the identifiers used in EOL and convert to URIs. If an identifier is not a valid URI, we replace invalid symbols. A trait example is shown as triple
5.2.4.Chemical sub-KG construction
The Chemical sub-KG (
The chemical subset of PubChem is used since information about chemicals is standardized in PubChem, while information about substances is not. In this subset we use: (i) component information, i.e., what are the building blocks of the chemical or parts of a mixture; (ii) type assertions, which either link to ChEBI or describe the type of molecule, e.g., small or large; (iii) role assertions, which describe additional attributes or relationships of the chemical, e.g., FDAApprovedDrug; and (iv) drug products, which link to the clinical data in SNOMED CT [7]. Examples of these can be seen in triples
Parent chemical data in PubChem is limited to permutations e.g., bonds, polarity, and part of mixtures axioms (triple
ChEMBL contains facts about bioactivity of chemicals. This contributes in assessing the danger of a chemical. In TERA, we use the mode of action (MoA) and target (receptor targeted by MoA; triple
We use the entire MeSH dataset in TERA. MeSH is organised as several hierarchies. The most prominent classifications are based on chemical groups and the intended use of the chemicals. Triples
Listing 4.
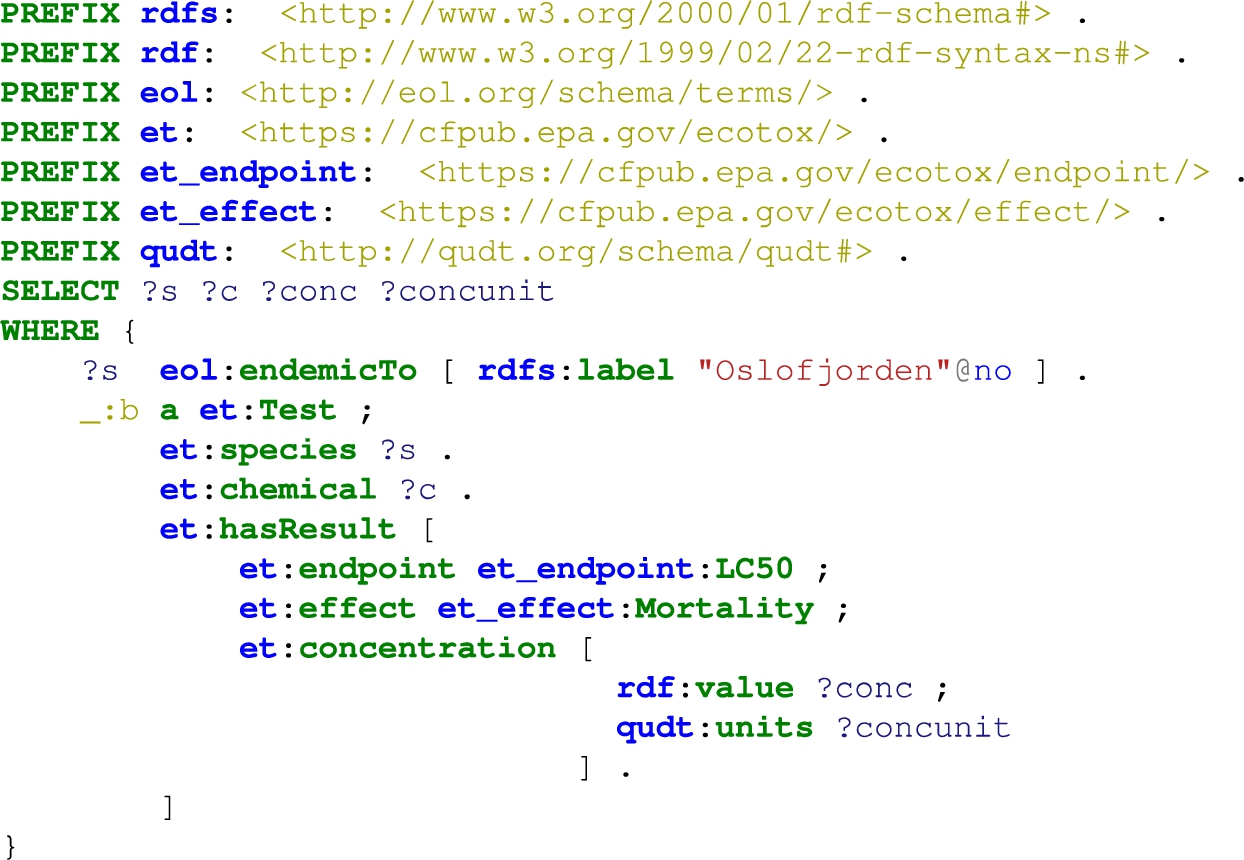
Query to select all species, chemicals, concentrations and units, where the species is endemic to the Oslofjord
5.3.TERA for data access
TERA covers knowledge and data relevant to the ecotoxicological domain and enables an integrated semantic access across data sets. In addition, the adoption of an RDF-based knowledge graph enables the use of an extensive range of Semantic Web infrastructure (e.g., reasoning engines, ontology alignment systems, SPARQL query engines).
The data integration efforts and the construction of TERA go in line with the vision in the computational risk assessment communities (e.g., Norwegian Institute for Water Research’s Computational Toxicology Program (NCTP)), where increasing the availability and accessibility of knowledge enables optimal decision making.
The knowledge in TERA can be accessed via predefined queries2626 (e.g., classification, sibling, and name queries, and fuzzy queries over the species names) and arbitrary SPARQL queries. The (final) output is flexible to the task, and can be given either as a graph or in tabular format. Listing 4 shows an example query to extract the chemicals and concentrations, at which, the species in the Oslofjord experience lethal effects.
5.4.TERA for effect prediction
TERA is used as background knowledge in combination with machine learning models for chemical effect prediction. TERA’s sub-KGs play different roles in effect prediction. The rich semantics of the species and chemical entities in the Taxonomy sub-KG (
Table 7
Densities and entropies of benchmark datasets. TERA
| Dataset | RD | ED | RE | EE | AD |
| TERA | 5.5 | 3.0 | 24 | ||
| TERA | 5.1 | 2.7 | 23 | ||
| TERA | 8.6 | 2.3 | 17 | ||
| TERA | 15 | 2.3 | 14 | ||
| YAGO3-10 | 18 | 2.0 | 20 | ||
| FB15k-237 | 43 | 4.5 | 16 | ||
| WN18 | 7.4 | 2.1 | 16 | ||
| WN18RR | 4.5 | 1.5 | 19 |
Table 7 shows the sparsity-related measures of common benchmark datasets2727 and TERA’s
In addition, we calculate the absolute density of the graph, which is
High RD and low RE typically lead to a worse performance, while high ED and low EE often lead to better link prediction performance (e.g., [19]). In Table 7 we can see that the density and entropy values are in between those for YAGO3-10 and FB15k-237, which typically lead to worse and better predictive performance, respectively [19]. This shows that TERA is a suitable background knowledge to extrapolate effect data and, at the same time, an interesting dataset to benchmark state-of-the-art knowledge graph embedding models. Note that using the full TERA (i.e.,
6.Adverse biological effect prediction
The aim of chemical effect prediction is to extrapolate exiting data to new combinations of (possibly unknown) chemicals and species. In this section we present three classification models used to predict the adverse biological effect of chemicals on species: (i) a multilayer perceptron (MLP) model (our baseline), (ii) the baseline model fed with pre-trained KG embeddings, (iii) a model that simultaneously trains the baseline model and the KGE models (i.e., it fine-tunes the KG embeddings). A MLP was chosen as baseline as it is a basic model where additional components and penalties can be easily added and assessed as we do in our third model (see Section 6.3).
The models have three inputs, namely a chemical c, a species s, and a chemical concentration κ (denoted
Notation. Throughout this section we use bold lower case letters to denote vectors while matrices are denoted as bold upper case letters. The vector representation of an entity and a relation are noted as
6.1.Baseline model
Our baseline prediction model is a multilayer perceptron (MLP) with multiple hidden layers.
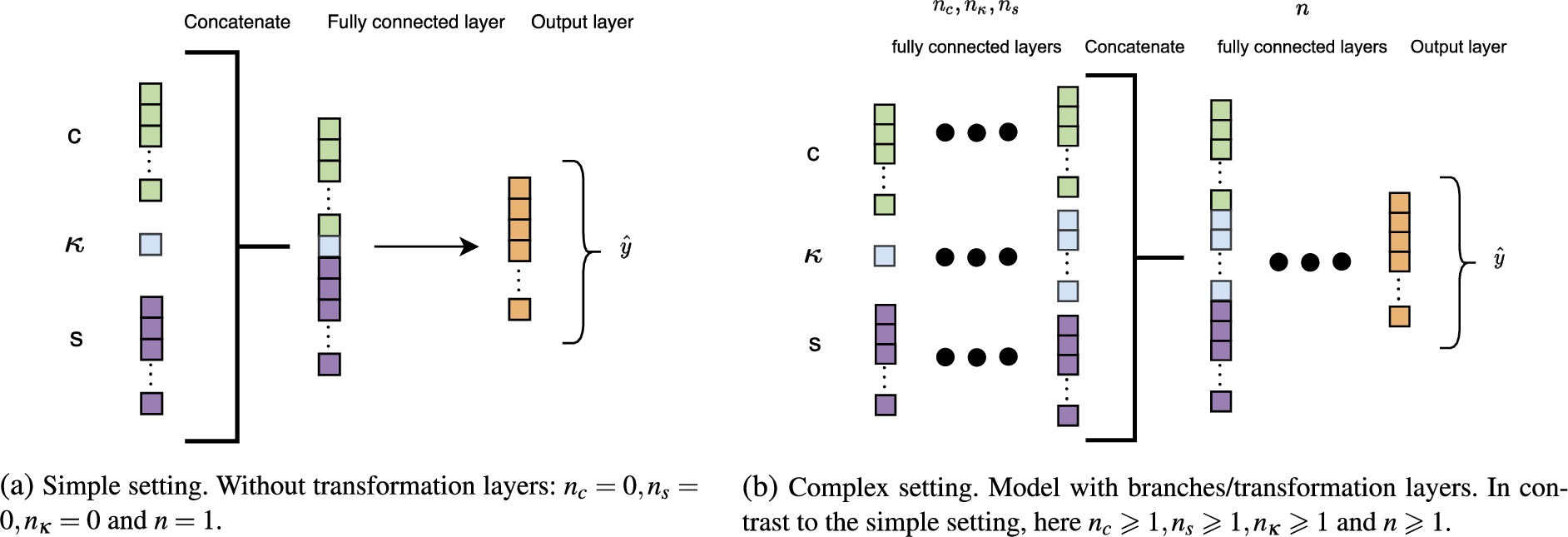
We differentiate between two settings of the baseline model (see Fig. 4):
(i) Simple setting. Figure 4a shows the model without embedding transformation layers, i.e.,
(ii) Complex setting. The complex model shown in Fig. 4b introduces transformation layers on the embeddings and chemical concentration input. These transformations aim at extracting the important information in the inputs and disregard the redundant information based on the output.
In the experiments we refer to the baseline models as Simple one-hot and Complex one-hot, depending on the selected MLP setting.
6.2.Baseline model with pre-trained KG embeddings
This models relies on pre-trained embeddings of chemicals and species computed using state-of-the-art KGE models (see Section 4.2 and the Appendix for an overview). A (different) KGE model is applied to the chemicals
These pre-trained KG embeddings are then given as input instead of the one-hot encoding vectors in the baseline model. We replace the trainable matrices
In the experiments we refer to these models as Simple PT
6.3.Fine-tuning optimization model
This model improves upon the pre-trained KG embeddings with fine-tuning based on the effect prediction data. This is done by simultaneously training the (selected) KGE models and the MLP-based baseline model. Such that the
Fig. 5.
Fine-tuning optimization model. In addition to variables described in Figs 4a and 4b,
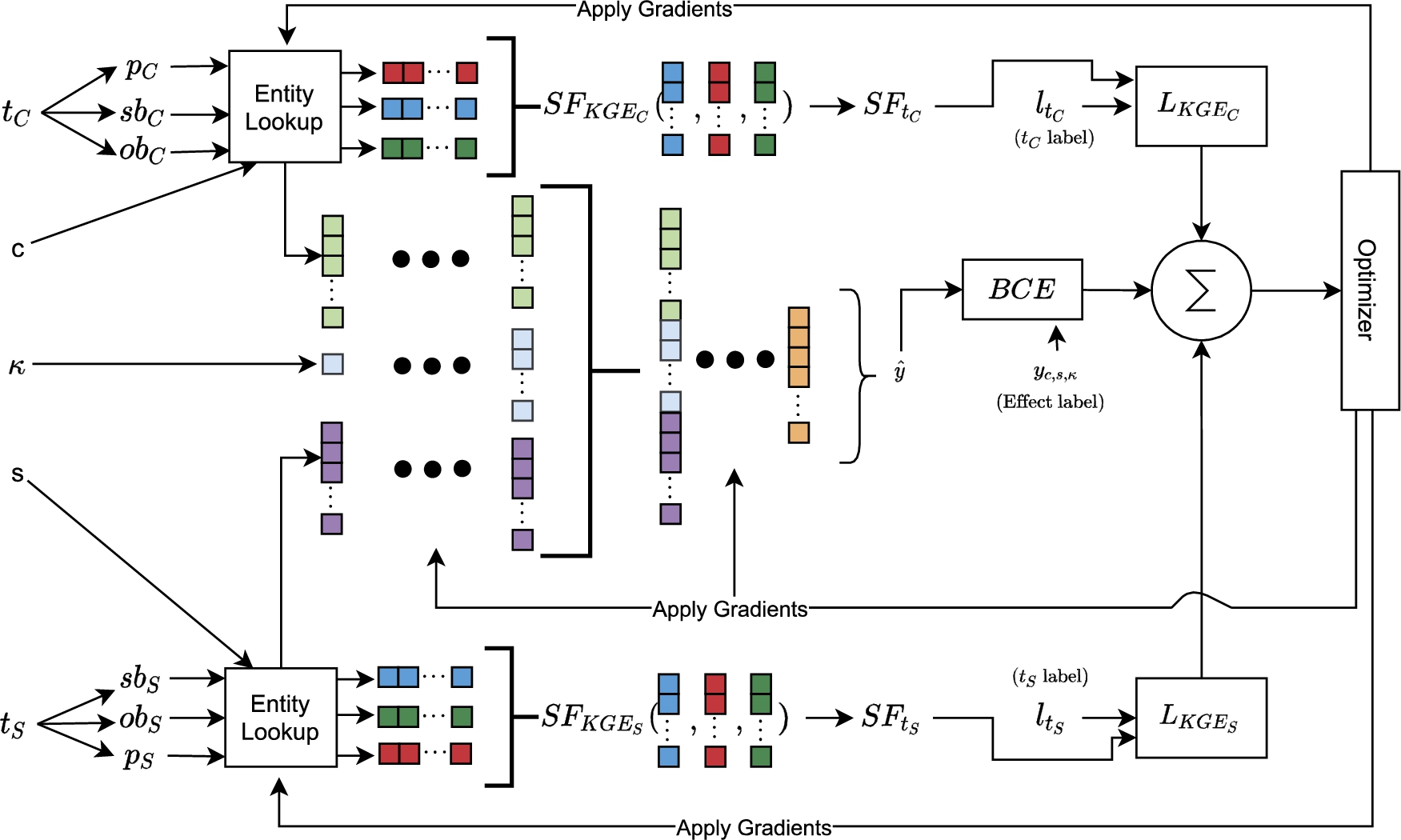
The model architecture is shown in Fig. 5 and the overall loss to minimize is
Figure 5 shows the full simultaneous fine-tuning model and the optimization process. The initial state of the entity lookups is the pre-trained embeddings. The full training procedure is summarised as follows:
1. Select N triples from
2. Generate negative knowledge graph triples (see Appendix A.5 for details) from the extracted subsets of triples from
3. Feed-forward the input through the model and calculate loss for each model component and combine according the loss weights.
4. Optimize the KG entity and relation embeddings, and the MLP layers.
In the experiments we refer to these models as Simple FT
7.Results
7.1.Experimental setup
All models are implemented using Keras [16] and the model codes are available in our GitHub repository, alongside all data preparation and analysis scripts.3232
7.1.1.Preparation of TERA for prediction
As shown earlier, TERA consists of three sub-KGs. These are the basis for the chemical effect prediction.3333 We process the sub-KGs further to limit their size by removing irrelevant triples for prediction. This is necessary to scale up the training of the KGE models. The reduction of TERA’s sub-KGs is performed according to the following steps:
(i) Effect data. For prediction purposes, the effect data in
(ii)
(iii)
These steps reduce
The transformation from TERA’s
7.1.2.Sampling
We use four sampling strategies of the effect data to analyze how the proposed classification models behave by varying the data parts that are used for training and testing. Note that, we only consider effect data where the chemical and species have mappings to external sources (e.g., NCBI Taxonomy and Wikidata, cf. Section 5.2.2) so that there is additional contextual information that can be used by the KGE models. For each of the strategies, the validation and test sets contain unseen chemical-organism pairs with respect to the training set. The strategies, however, differ with respect to the individual organism and chemical as follows:
Strategy (i) Random
Strategy (ii) Training/validation/test split where there is no overlap between chemicals in the three sets (i.e., the chemicals in the validation and test sets are unknown). This resulted on a
Strategy (iii) Training/validation/test split where there is no overlap between species in the three sets (i.e., the species in the validation and test sets are unknown). This resulted on a
Strategy (iv) Training/validation/test split with no chemicals or species overlap in the three sets (i.e., both the chemicals and the organisms in the validation and test sets are unknown). This resulted on a
There were originally 57,560 samples, however, this includes experiment duplicates, i.e., same chemical, species, and endpoint, with different chemical concentrations. This is down to large discrepancies in laboratory testing variance, therefore, we use the median concentration across the duplicates. The prior probability is approximately
Table 8
Hyper-parameter choices for the models. Please refer to the Equations (9)–(15) in Section 6.1 for the prediction hyper-parameters
| KGE hyper-parameters | Search space |
| Loss function | |
| Margin (only hinge loss) | |
| Bias (only geometric models) | |
| Embedding dimension | |
| Negative samples |
| Prediction hyper-parameters | Search space |
| # units (10), (11), (14) | |
| # units (12) |
Table 9
Best hyper-parameters for KGE models. The two values before and after / are for the embeddings of
| Model | Loss function | Margin | Bias | Embedding dimension | Negative samples |
| DistMult | – / 2 | – | 143 / 383 | 28 / 43 | |
| ComplEx | – / 4 | – | 163 / 372 | 27 / 42 | |
| HolE | 6 / – | – | 188 / 376 | 30 / 100 | |
| TransE | 4 / 7 | 14 / 20 | 226 / 196 | 23 / 57 | |
| RotatE | 5 / 2 | 16 / 6 | 271 / 398 | 75 / 22 | |
| pRotatE | – / – | 14 / 16 | 164 / 210 | 34 / 82 | |
| HAKE | – / – | 12 / 10 | 108 / 359 | 56 / 13 | |
| ConvKB | – / 5 | – | 248 / 276 | 18 / 90 | |
| ConvE | 7 / 3 | – | 228 / 196 | 68 / 40 |
7.1.3.Hyper-parameters
To optimize the hyper-parameters for the KGE and classification models we use random search over the parameter ranges. We conduct 20 trials per model. Tables 8 and 9 contain the best hyper-parameters and can be used to reproduce the top performing models.
To find the best hyper-parameters for the KGE models, we use the loss as a proxy for performance, normalized by the initial loss,
We use validation loss to select the best hyper-parameter setting for the classification models presented in Section 6. The best prediction models are refitted and evaluated 10 times to reduce the influence of initial conditions on the metrics. The average and standard deviation of the metrics are presented in Section 7.2.
The hyper-parameter ranges for the KGE models are shown in Table 8 based on common values used in the literature. We conduct 20 trials of random hyper-parameters choices and validate over the validation data. In Table 9 we show the best hyper-parameters.
Table 10
Number of units in the hidden layers in the (complex) one-hot model and the top-1 prediction models with pre-trained KG embeddings. The same parameters are used for the fine-tuning models. Organized as follows:
| Model | Sampling | # units |
| Complex one-hot | (i) | |
| (ii) | ||
| (iii) | ||
| (iv) | ||
| Complex PT DistMult-HAKE (top-1 in (i)) | (i) | |
| Complex PT HolE-ConvKB (top-1 in (ii)) | (ii) | |
| Complex PT HAKE-DistMult (top-1 in (iii), (iv)) | (iii) | |
| (iv) |
We can see in Table 9 that the decomposition models have similar hyper-parameters for
The fine-tuning optimization model (Section 6.3), in order to save on intensive computation, reuses the same hyper-parameters found for the KGE models. Depending on the optimizer choice, the choice of loss weights,
7.1.4.Initialization of the fine-tuning optimization models
As presented in Section 6.3, we simultaneously train the KGE models and the MLP-based baseline model. This is done by initializing the model with (i) the weights learned in the correspondent baseline model with pre-trained embeddings, and (ii) the KG embeddings learned with the respective KGE models. For example, the Complex FT DistMult-HAKE model is initialized with the learned weights with the Complex PT DistMult-HAKE model and the pre-trained KG embeddings using DistMult and HAKE models. Then the model is further trained with a small learning rate. We found that reducing the learning rate by a factor of 100 worked well. Using this learning rate we optimize the model until convergence.
7.1.5.Simple and complex settings
As presented in Section 6.1, we use two settings in our classification models: simple and complex. This will help us isolate the effects of the KG embeddings versus the power of the MLP model. The simple setting uses no branching layers, i.e.,
Looking at the increasing complexity of the layer configuration of the one-hot models in Table 10 we can see a correlation from the simplest sampling strategy (i.e., (i)) through the most challenging one (i.e., (iv)). The same can be seen for PT HAKE-DisMult from strategy (iii) to (iv), where the number of layers increase. Overall we can see that the layer configurations of the chemical branch is more complex than for the species branch. This indicates that the KGE models are better at representing
7.2.Prediction results
In this section we present a summary of the conducted chemical effect prediction evaluation. Complete results are available at the project repository.3535 The default decision threshold is set to 0.5. That is, if a model predicts
We use several metrics to compare the different prediction models. These are Sensitivity (i.e., recall), Specificity, and Youden’s index (
Sensitivity and Specificity are defined as
In our setting, sensitivity is a measure on how well the models identify harmful chemicals while specificity measures models’ ability to identify non-harmful chemicals. Youden’s index is used to capture the usefulness of a diagnostic test (or in our case, a toxicity test). A useless test will have
Table 11
Prediction results (mean and standard deviation over 10 runs) for sampling strategy (i). Bold denotes best mean result and underline denotes within one standard deviation of best result. PT prefix denotes pre-trained and FT denotes fine-tuning. Simple denotes
| Model | Sensitivity | Specificity | YI | ||
| Simple one-hot | |||||
| Simple PT HAKE-HAKE | |||||
| Simple PT pRotatE-HAKE | |||||
| Simple PT ConvE-HAKE | |||||
| Simple PT pRotatE-ConvE | |||||
| Simple PT RotatE-ConvE | |||||
| Simple FT HAKE-HAKE | |||||
| Simple FT pRotatE-HAKE | |||||
| Simple FT ConvE-HAKE | |||||
| Simple FT pRotatE-ConvE | |||||
| Simple FT RotatE-ConvE | |||||
| Complex one-hot | |||||
| Complex PT DistMult-HAKE | |||||
| Complex PT HAKE-ConvKB | |||||
| Complex PT HolE-ConvKB | |||||
| Complex PT ComplEx-DistMult | |||||
| Complex PT HolE-pRotatE | |||||
| Complex FT DistMult-HAKE | |||||
| Complex FT HAKE-ConvKB | |||||
| Complex FT HolE-ConvKB | |||||
| Complex FT ComplEx-DistMult | |||||
| Complex FT HolE-pRotatE |
Table 12
Prediction results for sampling strategy (ii). Same notation as Table 11
| Model | Sensitivity | Specificity | YI | ||
| Simple one-hot | |||||
| Simple PT HAKE-ConvKB | |||||
| Simple PT HAKE-HAKE | |||||
| Simple PT pRotatE-HAKE | |||||
| Simple PT RotatE-ConvKB | |||||
| Simple PT RotatE-ConvE | |||||
| Simple FT HAKE-ConvKB | |||||
| Simple FT HAKE-HAKE | |||||
| Simple FT pRotatE-HAKE | |||||
| Simple FT RotatE-ConvKB | |||||
| Simple FT RotatE-ConvE | |||||
| Complex one-hot | |||||
| Complex PT HolE-ConvKB | |||||
| Complex PT pRotatE-ConvKB | |||||
| Complex PT TransE-ConvKB | |||||
| Complex PT ComplEx-ConvE | |||||
| Complex PT ConvKB-pRotatE | |||||
| Complex FT HolE-ConvKB | |||||
| Complex FT pRotatE-ConvKB | |||||
| Complex FT TransE-ConvKB | |||||
| Complex FT ComplEx-ConvE | |||||
| Complex FT ConvKB-pRotatE |
Table 13
Prediction results for sampling strategy (iii). Same notation as Table 11
| Model | Sensitivity | Specificity | YI | ||
| Simple one-hot | |||||
| Simple PT ConvKB-DistMult | |||||
| Simple PT HAKE-DistMult | |||||
| Simple PT ConvKB-TransE | |||||
| Simple PT ConvE-RotatE | |||||
| Simple PT HolE-HAKE | |||||
| Simple FT ConvKB-DistMult | |||||
| Simple FT HAKE-DistMult | |||||
| Simple FT ConvKB-TransE | |||||
| Simple FT ConvE-RotatE | |||||
| Simple FT HolE-HAKE | |||||
| Complex one-hot | |||||
| Complex PT HAKE-DistMult | |||||
| Complex PT pRotatE-ComplEx | |||||
| Complex PT ConvKB-DistMult | |||||
| Complex PT ComplEx-HolE | |||||
| Complex PT ComplEx-HAKE | |||||
| Complex FT HAKE-DistMult | |||||
| Complex FT pRotatE-ComplEx | |||||
| Complex FT ConvKB-DistMult | |||||
| Complex FT ComplEx-HolE | |||||
| Complex FT ComplEx-HAKE |
Table 14
Prediction results sampling strategy (iv). Same notation as Table 11
| Model | Sensitivity | Specificity | YI | ||
| Simple one-hot | |||||
| Simple PT HAKE-ComplEx | |||||
| Simple PT pRotatE-ComplEx | |||||
| Simple PT HolE-ComplEx | |||||
| Simple PT pRotatE-RotatE | |||||
| Simple PT HAKE-HAKE | |||||
| Simple FT HAKE-ComplEx | |||||
| Simple FT pRotatE-ComplEx | |||||
| Simple FT HolE-ComplEx | |||||
| Simple FT pRotatE-RotatE | |||||
| Simple FT HAKE-HAKE | |||||
| Complex one-hot | |||||
| Complex PT HAKE-DistMult | |||||
| Complex PT HolE-DistMult | |||||
| Complex PT ConvKB-DistMult | |||||
| Complex PT HolE-RotatE | |||||
| Complex PT TransE-HAKE | |||||
| Complex FT HAKE-DistMult | |||||
| Complex FT HolE-DistMult | |||||
| Complex FT ConvKB-DistMult | |||||
| Complex FT HolE-RotatE | |||||
| Complex FT TransE-HAKE |
Tables 11–14 show the results for each of the data sampling strategies (i)–(iv), respectively. The tables include the three best models (based on
Overall, models with the complex setting and fine-tuning are needed as the data sampling strategies become more challenging. Moreover, all models favour sensitivity over specificity at default decision threshold (0.5). This is down to the imbalance in the data. We can see the imbalance by
For settings (iii) and (iv) the performance drops and the standard deviation increases compared to the other strategies. This large standard deviation leads to large overlaps in quantiles among top-3 models in all categories, such that, by chance, one of these models could perform best in one individual evaluation.
7.2.1.One-hot baseline models
For the sampling strategy (i) the one-hot baseline models perform well, especially, with the complex one-hot model. This complex model is equivalent in terms of
7.2.2.Baseline with pre-trained KG embeddings
We can see that the PT-based models do not lead to an important improvement with respect to
The results with the strategy (ii) are similar to strategy (i), the delta in
In the sampling strategy (iii) we can observe that the improvement of the PT-based models over the one-hot models increases. The increase is up to
Finally, the impact of using a PT-based models is strengthen in strategy (iv). The delta between the one-hot and PT-based models is up to
7.2.3.Fine-tuning optimization model
The FT-based models, with some exceptions, improve the results over the PT-based models, most notably in sampling strategies (iii) and (iv). For example, the FT-based models Complex FT HolE-DistMult and Simple FT HolE-ComplEx are the best models in terms of
7.3.KG embedding analysis
In this section we look at correlations between KGE model choices and prediction performance. KGE models are designed to capture certain structures in the data, and this can give some explanation of which parts of the KGs are important for prediction.
First, in Table 15 we show how many times a KGE model is used when regarding the top 10 performing combinations (out of the total 81 possible combinations). We focus on the choices when using the simple MLP setting to reduce the influence of the non-linear transforms on the embeddings.
Table 15
Usage of KGE models for each sampling strategy in simple MLP setting in top-10 performing combinations. Note that, there is one model for the
| KGE model | # uses (i) | # uses (ii) | # uses (iii) | # uses (iv) |
| DistMult | ||||
| ComplEx | ||||
| HolE | ||||
| Total decomposition | ||||
| TransE | ||||
| RotatE | ||||
| pRotatE | ||||
| HAKE | ||||
| Total geometric | ||||
| ConvKB | ||||
| ConvE | ||||
| Total convolutional |
Looking at Table 15 we can see that the KGE models used to embed the chemicals
The use of the decomposition models increase in strategies (iii) and (iv) for the embedding of
7.3.1.Explained variance
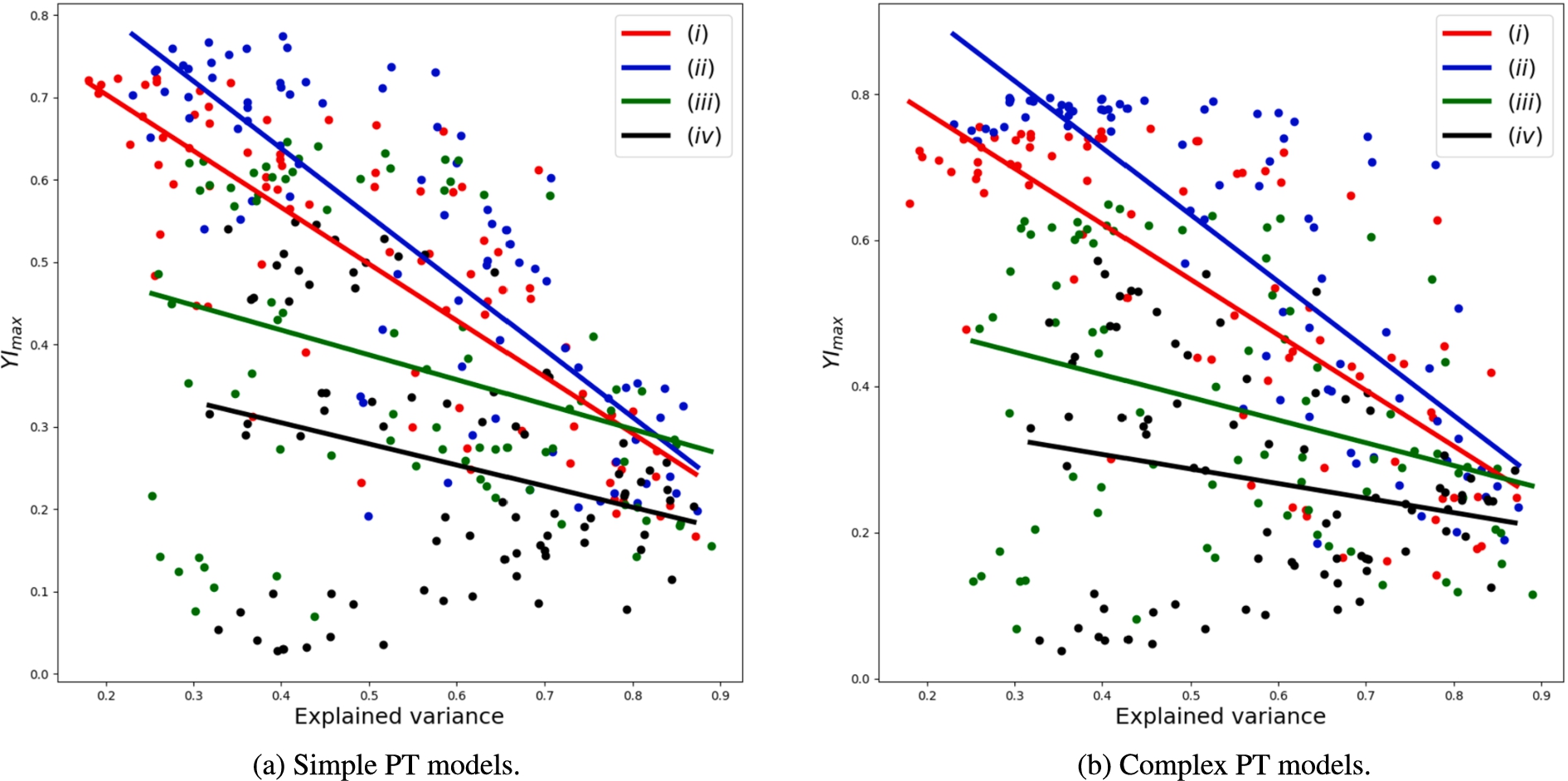
Explained variance is a measure of how many principal components are required to describe all components.3838 In Fig. 6, we present how the
Fig. 6.
Relation between explained variance using 10 principal components and model performance represented as
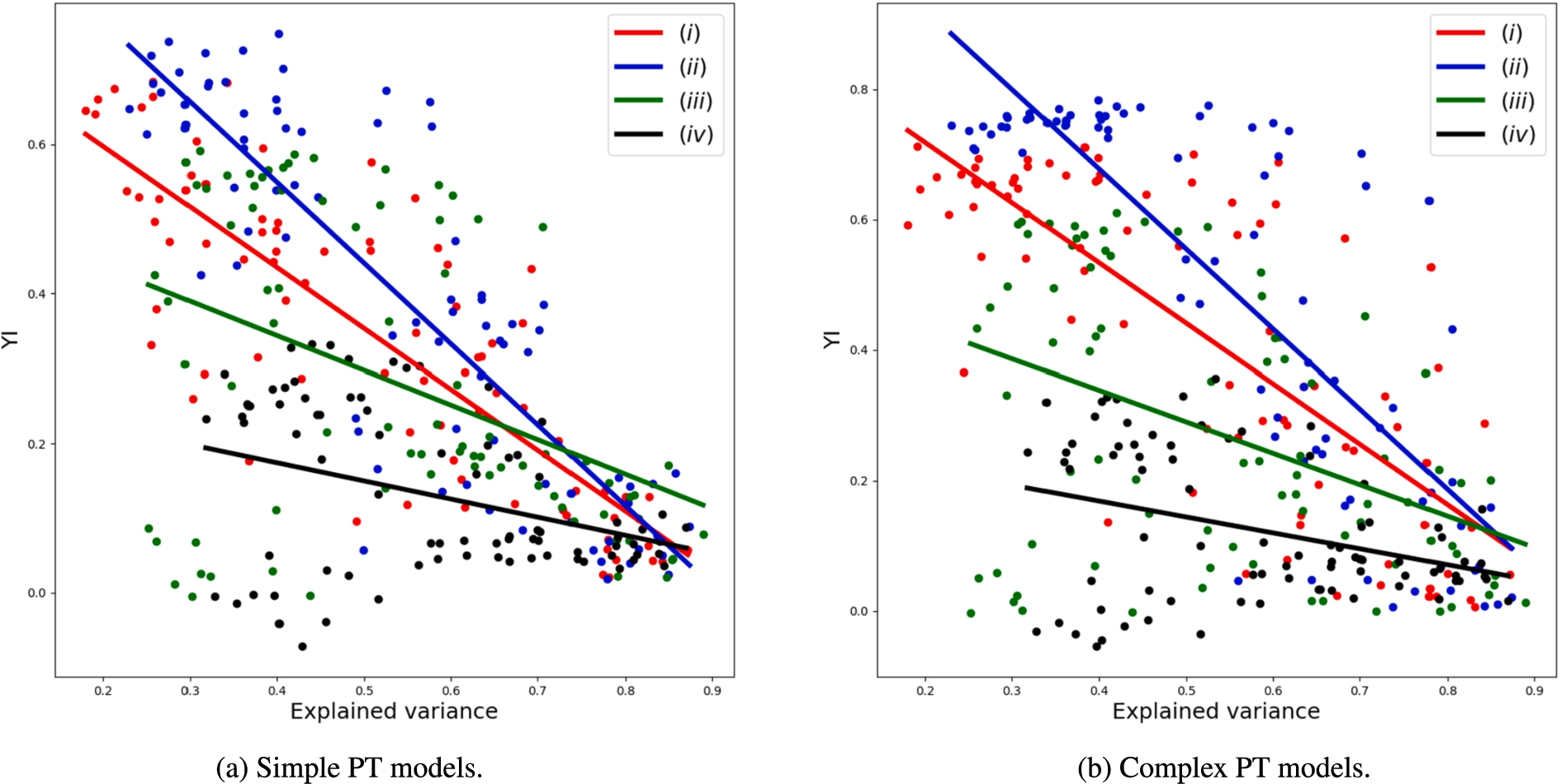
Fig. 7.
Relation between explained variance using 10 principal components and model performance represented as sensitivity.
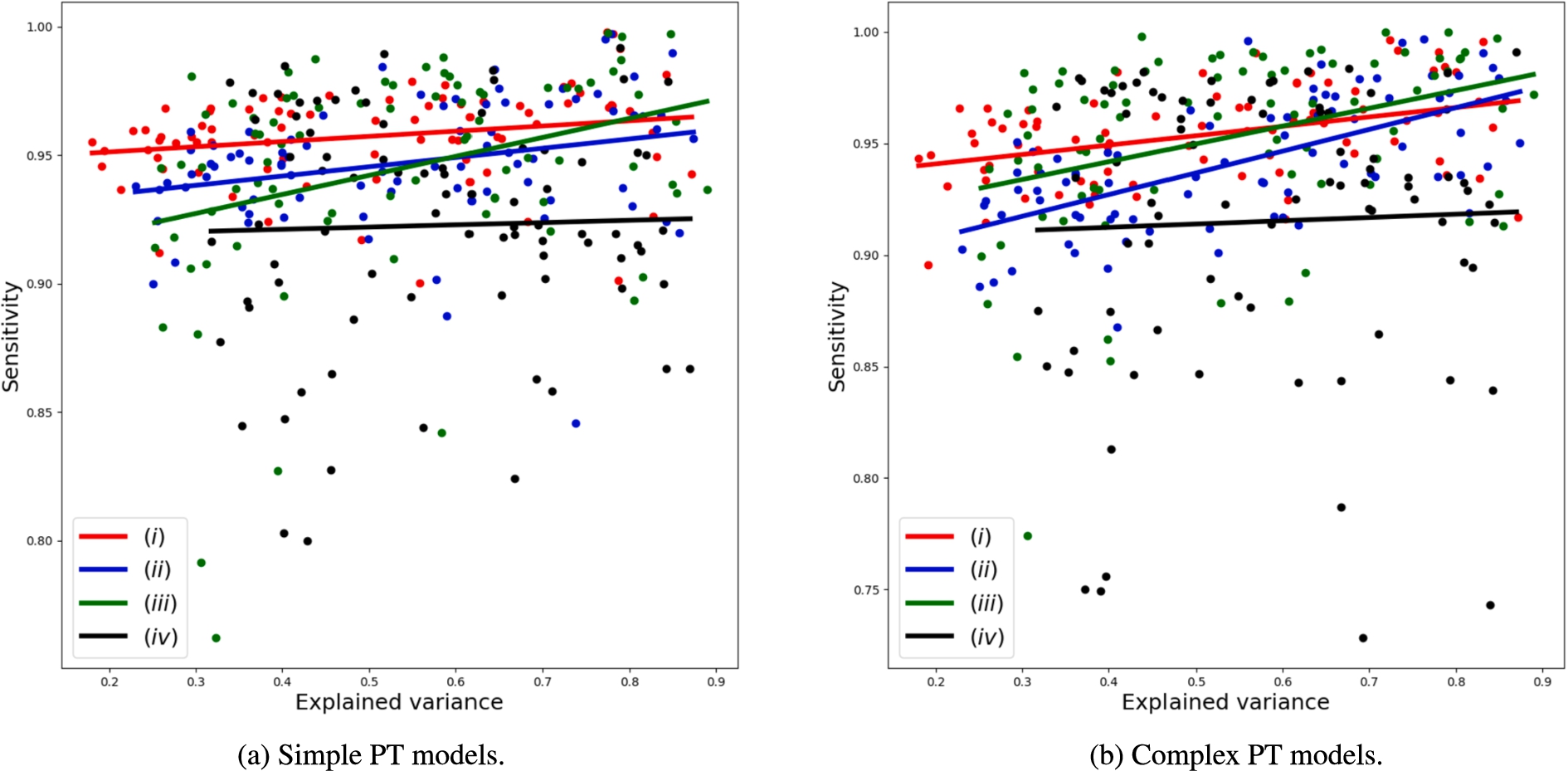
Figure 7 represents the explained variance against sensitivity. We can see that the trend is flat for strategy (iv), but positive for strategies (i)-(iii). This means that the trends in Fig. 6 are explained by specificity rather than sensitivity. By balancing sensitivity and specificity, i.e.,
Fig. 8.
Relation between explained variance using 10 principal components and model performance represented as
7.4.Example predictions
Table 16 shows a few examples of correct (TP and TN) and incorrect predictions (FN and FP).
Table 16
Example predictions by complex FT HolE-DistMult (best model) for sampling strategy (iv)
| Chemical | Species | Predicted | Lethal | Classification | |
| D001556 (hexachlorocyclohexane) | 59899 (walking catfish) | −3.4 | 0.97 | 1 (yes) | TP |
| C037925 (benthiocarb) | 7965 (sea urchins) | 0.9 | 0.2 | 0 (no) | TN |
| D026023 (permethrin) | 378420 (bivalves) | 0.7 | 0.96 | 1 (yes) | TP |
| D011189 (potassium chloride) | 938113 (megacyclops viridis) | 6.7 | 0.27 | 1 (yes) | FN |
| C427526 (carfentrazone-ethyl) | 208866 (eudicots) | −0.9 | 0.82 | 0 (no) | FP |
| D010278 (parathion) | 201691 (green sunfish) | −0.9 | 0.86 | 0 (no) | FP |
Benthiocarb and permethrin are both biocides with different targets: benthiocarb is a herbicide and permethrin is an insecticide. It is therefore not surprising that benthiocarb has a low predicted effect on sea urchins, while permethrin has a severe effect on bivalves.
There are several possible explanations for the failed predictions. A wrong prediction of potassium chloride toxicity to a marine copepod (Megacyclops viridis) could be due to the prediction model not being accurate enough for metal salts, or the copepod species being particularly sensitive to changes in osmolarity due to salt content. The wrong prediction of lack of herbicide toxicity (i.e., carfentrazone-ethyl) to a flower (i.e., eudicots) could be due to the fact that flowers, and plants in general, are severely underrepresented in the available effect prediction data.
8.Discussion
We have introduced the Toxicological Effect and Risk Assessment (TERA) knowledge graph and shown how we can directly use it in chemical effect prediction. The use of TERA improves the PT-based prediction models over the one-hot baselines. In the most challenging data sampling strategies, we have also seen the benefits of creating tailored (i.e., fine-tuned) KG embeddings in the FT-based prediction models.
8.1.TERA knowledge graph
The constructed knowledge graph consists of several sources from the ecotoxicological domain. There are three major parts in TERA: the effects data, the chemical data, and the species taxonomic data. Integrating each part has different challenges. The chemical and pharmacological communities have come a long way in annotating their data as knowledge graphs and ontologies. Here, selecting the correct subsets to work with the chemical effect prediction data was a major challenge. This had to be done based on mappings between effect data and chemical data that were extracted from Wikidata. We selected a relatively small subset of the chemical sub-KG to facilitate faster model training, however, still larger than the extracted fragment from the species sub-KG. The species sub-KG was created from tabular data and cleaned by removing several annotation labels with redundant information. This sub-KG was aligned using ontology alignment systems to the species taxonomy in the effects sub-KG. This required pre-processing of the KG, where it was divided into smaller parts such that the selected systems could perform the alignment. We used several standard ontologies to facilitate the transformation of the effect data into a knowledge graph. This involved not only automatic processes, but also an important amount of manual work.
Integrating more data into TERA involves the creation of mappings to the existing data. This is possible for a large amount of chemical datasets as Wikidata links multiple datasets, e.g., the chemical compound diethyltoluamide (wd:Q408389) has
The additional integrated data will give larger coverage of the domain, and thereby, improve model performance. However, adding more data will also increase the memory and time requirements of KGE models. This was bypassed in this work by reducing TERA to only relevant parts.
Adding additional domain knowledge is also critical in other applications, such as using TERA for data access.
8.2.Performance of prediction models
We have shown that the ability to embed some structure types of different KGE models largely impact the prediction models. We see that some KGE models fail to capture the semantics of the chemicals and the species, which leads to similar performance to the one-hot baselines. Moreover, in a few isolated cases the performance is reduced further which leads us to believe that the embeddings collapse in one or some dimensions, making it impossible to distinguish among entities.
We suspect that the even distribution of KGE models to embed
9.Conclusions and future work
TERA is a novel knowledge graph which includes large amounts of data required by ecological risk assessment. We have conducted an extensive evaluation of KGE embedding models in a novel and very challenging application domain. Moreover, we have shown the value of using TERA in an ecotoxicological effect prediction task. The fine-tuning optimization model architecture to adapt the KG embeddings to the prediction task has, to our knowledge, not been applied elsewhere.
9.1.Value for the ecotoxicology community
The creation of TERA is of great importance to future effect modelling and computational risk assessment approaches within ecotoxicology. Where the strategic goal is designing and developing prediction models to assess the hazard and risks of chemicals and their mixtures where traditional laboratory data cannot easily be acquired.
A great effort in the hazard and risk assessment of chemicals is the reduction of regulatory-mandated animal testing. Wide-scale predictive approaches, as described here, answer a direct and current need for generalized prediction frameworks. These can aid in identifying especially sensitive species and toxic chemicals. At the Norwegian Institute for Water Research (NIVA), TERA will be used in this regard and will support several research projects.
In environmental risk assessment it is often unfeasible to assess the hazard and risk a chemical poses to a local species in the environment. These species may not be suitable for lab testing, or may even be endangered and thus are protected by national or international legislation. The currently presented work provides an in silico approach to predict the hazard to such species based on the taxonomic position of the species within the tree of life.
From an economic perspective, TERA and the prediction models are useful tools to evaluate new industrial chemicals during the synthetic in silico stage. Candidate chemicals can be evaluated for their potential environmental hazard, which is in line with the Green Chemistry initiatives by authorities such as the European Parliament or the US Environmental Protection Agency.
The effect prediction using TERA is also in line with a larger shift in ecological risk assessment towards the use of artificial intelligence [80]. We also believe the development of TERA contributes to a methodological change in the community, and encourages others to make their data interoperable.
9.2.TERA as background knowledge
As mentioned, in this work we use TERA directly in prediction models. However, TERA could be used as background knowledge to improve many emerging techniques for toxicity prediction (e.g., [65]). These methods often use chemical features, images, fingerprints and so on as input, and machine learning methods such as Convolutional Neural Networks and Random Forests as prediction models [81,84]. These models are often uninterpretable, and the predictions lack domain explanations. TERA can also provide context for machine learning tasks such as pre-processing, feature extraction, transfer and zero/few-shot learning. Furthermore, the knowledge graph is a possible source for the (semantic) explanation of the predictions (e.g., [43]).
9.3.Benchmarking KG embedding models
We have shown that embedding TERA brings new challenges to state-of-the-art KGE models with respect to capturing the semantics of the chemicals and the species. Furthermore, as shown in Section 5.4 the sparsity-related measures indicate that TERA represent an interesting KG. KGE models could be benchmarked in a standard KG completion task or in a specific task such as the chemical effect prediction.
9.4.Value to the ontology alignment community
As mentioned in Section 5.2, there does not exist a complete and public alignment between ECOTOX species and the NCBI Taxonomy. Therefore the computed mappings can also be seen as a very relevant resource to the ecotoxicology community. The used alignment techniques achieve high scores for recall over the available (incomplete) reference mappings. However, aligning such large and challenging datasets requires preprocessing before ontology alignment systems can cope with them. We removed all nodes which did not share a word (or shared only a stop word) in labels across the two taxonomies. This quartered the size of ECOTOX and reduced NCBI Taxonomy 50 fold. However, the possible alignment between entities without labels is lost when reducing the dataset size. Thus, the alignment of ECOTOX and NCBI Taxonomy has the potential of becoming a new track of the Ontology Alignment Evaluation Initiative (OAEI) [52] to push the limits of large scale ontology alignment tools. Furthermore, the output of the different OAEI participants could be merged into a rich consensus alignment (e.g., as done in the phenotype-disease domain [28]) that could become the reference alignment to integrate ECOTOX and NCBI Taxonomy.
9.5.Future work
We plan to extend TERA to include a larger part of ChEBI (which ChEMBL is a part of). ChEBI includes relevant data on the interaction between chemicals and species at a cellular level, which may be very important for chemical effect prediction. In this work we only consider effect data from ECOTOX as this is the largest data set available, however, the inclusion of e.g., TOXCAST [75] is in our interest. New sources will always bring more coverage of the domain and will improve TERA for prediction, as background knowledge, and for data access.
We plan to evaluate the effect prediction under different parts of TERA, i.e., which sources in TERA provide value and which do not contribute in terms of the effect prediction. A similar effort in exploring different KG crawling techniques has been explored in [67]. In a similar vain, we plan to evaluate how materialization, via OWL reasoning, of TERA’s implicit triples affects prediction performance.
Finally, as mentioned already, some KGE models cannot deal with parts of the structure of TERA. An in-depth analysis of this is an interesting direction for future research. This could be solved by embedding the hierarchy separately, e.g., [50], or imposing restrictions on the embeddings, such as a minimum distance constraint.
9.6.Resources
We encourage feedback from domain researchers on extensions to TERA and associated tools.
A snapshot of TERA is available at
This snapshot does not include data that is impractical to re-share (i.e., partialAll the material related to this project is available at
Source codes to create TERA are available in the TERA GitHub repository. The prediction models and data used for prediction can be found in the KGs_and_Effect_Prediction_2020 GitHub repository. The prediction models require the implementation of the KGE models from the KGE-Keras GitHub repository.
Notes
1 Not to be confused with SPARQL endpoint.
2 RDF, RDFS, OWL and SPARQL are standards defined by the W3C: https://www.w3.org/standards/semanticweb/.
3
4 Note that the Web Ontology Language (OWL) [27] also enables the creation of complex axioms that are translated/serialized into more than one triple: https://www.w3.org/TR/owl2-mapping-to-rdf/.
5 For the embedding process, we focus on triples where
6 The interested reader please refer to [63] for a comprehensive survey.
7 The mode of action describes the molecular pathway by which a chemical causes physiological change in an organism.
8 NIVA: https://www.niva.no/en.
9 Measure of the absence of attraction to water.
10 Resources to create and access TERA: https://github.com/NIVA-Knowledge-Graph/TERA.
11 EOL: Various Creative commons (CC), NCBI: Creative Commons CC0 1.0 Universal (CC0 1.0), ECOTOX: No restrictions, PubChem: Open Data Commons Open Database License, ChEMBL: CC Attribution, MeSH: Open, Courtesy of the U.S. National Library of Medicine, Wikidata: CC0 1.0.
15 Prefixes associated to the URI namespaces of entities in TERA: et: (ECOTOXicology knowledgebase), ncbi: (NCBI taxonomy), eol: (Encyclopedia of Life), mesh: (Medical Subject Heading), compound: (PubChem compound), descr: (PubChem descriptors), vocab: (PubChem vocabulary), inchikey: (InChIKey identifiers), envo: (Environment Ontology) cheminf: (Chemical information ontology), chembl: (ChEMBL), chembl_m: (ChEMBL molecule subset), chembl_t: (ChEMBL target subset), wd: (WikiData entities), wdt: (Wikidata properties), qudt: (Quantities, Units, Dimensions and Types Catalog), snomedct: (SNOMED CT ontology), and bp: (Biological PAthway eXchange ontology). owl:, rdfs:, rdf: and xsd: are prefixes referring to W3C standard vocabularies.
16 Version dated Sep. 15, 2020.
17 While InChI is unique, InChiKey is not, and collisions have greater than zero probability [79].
18 In the context of the paper “taxonomy” typically refers to a classification of organisms.
19 As defined by U.S. EPA. Note that species hierarchies are contested among researchers.
20 QUDT 1.1: http://linkedmodel.org/catalog/qudt/1.1/
21 There are a total of 27,133 and 2,246,074 taxa in ECOTOX and NCBI, respectively. However, we focus on species, i.e., instances.
22 ECOTOX interface: https://cfpub.epa.gov/ecotox/search.cfm.
23 There is no need for more complex mappings in this use case.
24 Wikidata endpoint: https://query.wikidata.org/sparql.
25 Default value used in PubChem [37].
26 Predefined queries are typically abstractions of SPARQL queries.
28 If effect is mortality (e.g., see Table 4).
29
30 Appendix A.5 introduces the used loss-functions in this work. The selection of the loss function for a KGE model will be via a hyper-parameter.
31 Section 7.1 describes how the known effect data extracted from ECOTOX is split into training, validation and test sets.
33 All data used to create TERA was downloaded on the 14th of May 2020.
34
36 We set the decision threshold
37 Note that we only consider the best mean result and not the standard deviation in both directions.
Acknowledgements
This work is supported by the grant 272414 from the Research Council of Norway (RCN), the MixRisk project (Research Council of Norway, project 268294), SIRIUS Centre for Scalable Data Access (Research Council of Norway, project 237889), Samsung Research UK, Siemens AG, and the EPSRC projects AnaLOG (EP/P025943/1), OASIS (EP/S032347/1), UK FIRES (EP/S019111/1) and the AIDA project (Alan Turing Institute).
Appendices
Appendix
AppendixKnowledge graph embedding models
In this work, we use 9 KGE models of three major categories: decomposition models, geometric models, and convolutional models. The interested reader please refer to [63] for a comprehensive survey.
A.1.Notation
Throughout this section we use bold letters to denote vectors while matrices are denoted as M. Common notation for all KGE models are,
The vector representation of an entity and a relation are noted as
A.2.Decomposition models
DistMult. Developed by [83] and shown to have state-of-the-art performance on link prediction tasks under optimal hyper-parameters [36]. This model represent the score of a triple as an Hadaman product (dot product) of the vectors representing the subject, predicate, and object of a triple.
ComplEx. This model use the same scoring function as DistMult [73]. However, the entity vector representation are in the complex space (
HolE. The Holographic embedding model is described in [56], and use a circular correlation scoring function
A.3.Geometric models
TransE. The translational model has the scoring function [10]
RotatE. This model is inspired by Euler’s identity (
pRotatE. This model is described as a baseline for RotatE enabling comparison when including modulus information in the model versus limiting to phase information only [70]. pRotatE has the scoring function
HAKE. The hierarchy-aware model use the modulus and the phase part of the embedding vectors [86]. Such that entities at the same level in the hierarchy is modelled using rotation, i.e., phase, and the entities at different levels are modelled using the distance from the origin, i.e., modulus. Therefore, the scoring function of HAKE is modelled in two parts
A.4.Convolutional models
The final set of models used in this work are convolutional models. We denote convolutions between an image X and filters ω is denoted as
ConvKB. The scoring function of ConvKB [55] use a single convolutional layer and a single dense layer
ConvE. In contrast to ConvKB, ConvE [19] only perform convolution over the subject and predicate image (concatenated and reshaped) and multiples the output dense layer with the object vector as such
A.5.Loss functions
Work on KGE models usually define loss functions specific to the models. However, as show in [49,54] the choice of loss function has a huge impact on model performance. In this work we use four loss functions. We experimented with other loss functions, e.g., absolute/square error, however, these did not materialize in improved results.
To optimize a loss function we need to generate negative examples. Under the local closed world assumption we replace the object of each true triple with all entities and sample negative examples from this set [21], i.e., we sample from
Pointwize hinge. The objective of pointwize losses minimize the scores of negative triples and maximize the score of positive triples.
Pointwize logistic. In contrast to hinge loss, logistic loss applies a larger non-linear loss to predictions that are further away from the true label.
Pairwise logistic. Akin to the move from pointwize to pairwize hinge, pairwize logistic maximizes the distance between positive and negative triples, however, in a non-linear way
A.6.Implementation
We have implemented the KGE models in Keras [16] and the model codes are available at https://github.com/NIVA-Knowledge-Graph/KGE-Keras. This enables us to easily use the KGE models as components in other models as described in Section 6.
References
[1] | A. Agibetov and M. Samwald, Benchmarking neural embeddings for link prediction in knowledge graphs under semantic and structural changes, J. Web Semant. 64: ((2020) ), 100590. doi:10.1016/j.websem.2020.100590. |
[2] | A. Algergawy, M. Cheatham, D. Faria, A. Ferrara, I. Fundulaki, I. Harrow, S. Hertling, E. Jiménez-Ruiz, N. Karam, A. Khiat, P. Lambrix, H. Li, S. Montanelli, H. Paulheim, C. Pesquita, T. Saveta, D. Schmidt, P. Shvaiko, A. Splendiani, É. Thiéblin, C. Trojahn, J. Vatascinová, O. Zamazal and L. Zhou, Results of the ontology alignment evaluation initiative 2018, in: Proceedings of the 13th International Workshop on Ontology Matching Co-Located with the 17th International Semantic Web Conference, OM@ISWC 2018, Monterey, CA, USA, October 8, 2018, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, M. Cheatham and O. Hassanzadeh, eds, CEUR Workshop Proceedings, Vol. 2288: , CEUR-WS.org, (2018) , pp. 76–116. |
[3] | A. Algergawy, D. Faria, A. Ferrara, I. Fundulaki, I. Harrow, S. Hertling, E. Jiménez-Ruiz, N. Karam, A. Khiat, P. Lambrix, H. Li, S. Montanelli, H. Paulheim, C. Pesquita, T. Saveta, P. Shvaiko, A. Splendiani, É. Thiéblin, C. Trojahn, J. Vatascinová, O. Zamazal and L. Zhou, Results of the ontology alignment evaluation initiative 2019, in: Proceedings of the 14th International Workshop on Ontology Matching Co-Located with the 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, October 26, 2019, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2536: , CEUR-WS.org, (2019) , pp. 46–85. |
[4] | M. Ali, M. Berrendorf, C.T. Hoyt, L. Vermue, M. Galkin, S. Sharifzadeh, A. Fischer, V. Tresp and J. Lehmann, Bringing light into the dark: A large-scale evaluation of knowledge graph embedding models under a unified framework, CoRR, 2020. arXiv:2006.13365. |
[5] | M. Alshahrani, M.A. Khan, O. Maddouri, A.R. Kinjo, N. Queralt-Rosinach and R. Hoehndorf, Neuro-symbolic representation learning on biological knowledge graphs, Bioinform. 33: (17) ((2017) ), 2723–2730. doi:10.1093/bioinformatics/btx275. |
[6] | H. Arnaout and S. Elbassuoni, Effective searching of rdf knowledge graphs, Journal of Web Semantics 48: ((2018) ), 66–84. doi:10.1016/j.websem.2017.12.001. |
[7] | T. Benson, Principles of Health Interoperability HL7 and SNOMED, Health Information Technology Standards, Springer, London, (2012) . |
[8] | K. Blagec, H. Xu, A. Agibetov and M. Samwald, Neural sentence embedding models for semantic similarity estimation in the biomedical domain, BMC Bioinformatics 20: (1) ((2019) ), 178. doi:10.1186/s12859-019-2789-2. |
[9] | K. Bollacker, C. Evans, P. Paritosh, T. Sturge and J.T. Freebase, A collaboratively created graph database for structuring human knowledge, in: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, SIGMOD ’08, Association for Computing Machinery, New York, NY, USA, (2008) , pp. 1247–1250. doi:10.1145/1376616.1376746. |
[10] | A. Bordes, N. Usunier, A. García-Durán, J. Weston and O. Yakhnenko, Translating embeddings for modeling multi-relational data, in: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Proceedings of a meeting held December 5–8, 2013, Lake Tahoe, Nevada, United States, C.J.C. Burges, L. Bottou, Z. Ghahramani and K.Q. Weinberger, eds, (2013) , pp. 2787–2795. |
[11] | P. Branco, L. Torgo and R.P. Ribeiro, A survey of predictive modeling on imbalanced domains, ACM Comput. Surv. 49: (2) ((2016) ), 31:1–31:50. doi:10.1145/2907070. |
[12] | A. Breit, S. Ott, A. Agibetov and M. Samwald, Openbiolink: A benchmarking framework for large-scale biomedical link prediction, Bioinformatics 36: (13) ((2020) ), 4097–4098. doi:10.1093/bioinformatics/btaa274. |
[13] | J. Chen, P. Hu, E. Jiménez-Ruiz, O.M. Holter, D. Antonyrajah and I. Horrocks, OWL2Vec*: Embedding of OWL ontologies, Mach. Learn. 110: (7) ((2021) ), 1813–1845. doi:10.1007/s10994-021-05997-6. |
[14] | J. Chen, E. Jiménez-Ruiz, I. Horrocks, D. Antonyrajah, A. Hadian and J. Lee, Augmenting ontology alignment by semantic embedding and distant supervision, in: European Semantic Web Conference (ESWC), (2021) , pp. 392–408. |
[15] | X. Chen, M.-X. Liu and G.-Y. Yan, Drug–target interaction prediction by random walk on the heterogeneous network, Mol. BioSyst. 8: ((2012) ), 1970–1978. doi:10.1039/c2mb00002d. |
[16] | F. Chollet et al., Keras, 2015. https://github.com/fchollet/keras. |
[17] | T.F. Coleman and J.J. Moré, Estimation of sparse Jacobian matrices and graph coloring blems, SIAM Journal on Numerical Analysis 20: (1) ((1983) ), 187–209. doi:10.1137/0720013. |
[18] | J. David, J. Euzenat F. Scharffe and C.T. dos Santos The alignment API 4.0, Semantic Web 2: (1) ((2011) ), 3–10. doi:10.3233/SW-2011-0028. |
[19] | T. Dettmers, P. Minervini, P. Stenetorp and S. Riedel, Convolutional 2d knowledge graph embeddings, in: Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2–7, 2018, S.A. McIlraith and K.Q. Weinberger, eds, AAAI Press, (2018) , pp. 1811–1818. |
[20] | J.A. Doering, S. Lee, K. Kristiansen, L. Evenseth, M.G. Barron, I. Sylte and C.A. LaLone, In silico site-directed mutagenesis informs species-specific predictions of chemical susceptibility derived from the sequence alignment to predict across species susceptibility (SeqAPASS) tool, Toxicological Sciences 166: (1) ((2018) ), 131–145. |
[21] | X. Dong, E. Gabrilovich, G. Heitz, W. Horn, N. Lao, K. Murphy, T. Strohmann, S. Sun and W. Zhang, Knowledge vault: A web-scale approach to probabilistic knowledge fusion, in: The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA, August 24–27, 2014, S.A. Macskassy, C. Perlich, J. Leskovec, W. Wang and R. Ghani, eds, ACM, (2014) , pp. 601–610. doi:10.1145/2623330.2623623. |
[22] | A.Z. Dudek, T. Arodz and J. Gálvez, Computational methods in developing quantitative structure-activity relationships (QSAR): A review, Combinatorial Chemistry & High Throughput Screening 9: (3) ((2006) ), 213–228. doi:10.2174/138620706776055539. |
[23] | J. Euzenat and P. Shvaiko, Ontology Matching, 2nd edn, Springer, (2013) . |
[24] | D. Faria, E. Jiménez-Ruiz, C. Pesquita, E. Santos and F.M. Couto, Towards annotating potential incoherences in bioportal mappings, in: Proceedings, Part II, The Semantic Web – ISWC 2014 – 13th International Semantic Web Conference, Riva del Garda, Italy, October 19–23, 2014, Proceedings, Part II, P. Mika, T. Tudorache, A. Bernstein, C. Welty, C.A. Knoblock, D. Vrandecic, P. Groth, N.F. Noy, K. Janowicz and C.A. Goble, eds, Lecture Notes in Computer Science, Vol. 8797: , Springer, (2014) , pp. 17–32. |
[25] | D. Faria, C. Pesquita, E. Santos, M. Palmonari, I.F. Cruz and F.M. Couto, The AgreementMakerLight ontology matching system, in: On the Move to Meaningful Internet Systems: OTM 2013 Conferences – Confederated International Conferences: CoopIS, DOA-Trusted Cloud, and ODBASE 2013, Graz, Austria, September 9–13, 2013, Proceedings, (2013) , pp. 527–541. |
[26] | J. Fukuchi, A. Kitazawa, K. Hirabayashi and M. Honma, A practice of expert review by read-across using QSAR toolbox, Mutagenesis 34: (1) ((2019) ), 49–54. doi:10.1093/mutage/gey046. |
[27] | B.C. Grau, I. Horrocks, B. Motik, B. Parsia, P.F. Patel-Schneider and U. Sattler, OWL 2: The next step for OWL, J. Web Semant. 6: (4) ((2008) ), 309–322. doi:10.1016/j.websem.2008.05.001. |
[28] | I. Harrow, E. Jiménez-Ruiz, A. Splendiani, M. Romacker, P. Woollard, S. Markel, Y. Alam-Faruque, M. Koch, J. Malone and A. Waaler, Matching disease and phenotype ontologies in the ontology alignment evaluation initiative, J. Biomed. Semant. 8: (1) ((2017) ), 55:1–55:13. doi:10.1186/s13326-017-0162-9. |
[29] | J. Hastings, G. Owen, A. Dekker, M. Ennis, N. Kale, V. Muthukrishnan, S. Turner, N. Swainston, P. Mendes and C. Steinbeck, ChEBI in 2016: Improved services and an expanding collection of metabolites, Nucleic acids research 44: (D1) ((2016) ), 214–219. |
[30] | K. Hayashi and M. Shimbo, On the equivalence of holographic and complex embeddings for link prediction, in: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, Canada, July 2017, Association for Computational Linguistics, (2017) , pp. 554–559. doi:10.18653/v1/P17-2088. |
[31] | S.R. Heller, A. McNaught, I.V. Pletnev, S. Stein and D. Tchekhovskoi, Inchi, the IUPAC international chemical identifier, J. Cheminformatics 7: ((2015) ), 23. doi:10.1186/s13321-015-0068-4. |
[32] | A. Hogan, E. Blomqvist, M. Cochez, C. d’Amato, G. de Melo, C. Gutiérrez, S. Kirrane, J.E.L. Gayo, R. Navigli, S. Neumaier, A.N. Ngomo, A. Polleres, S.M. Rashid, A. Rula, L. Schmelzeisen, J.F. Sequeda, S. Staab and A. Zimmermann, Knowledge graphs, ACM Comput. Surv. 54: (4) ((2021) ), 71:1–71:37. |
[33] | E. Jiménez-Ruiz, B. Cuenca Grau, Y. Zhou and I. Horrocks, Large-scale interactive ontology matching: Algorithms and implementation, in: 20th European Conference on Artificial Intelligence (ECAI), (2012) , pp. 444–449. |
[34] | E. Jiménez-Ruiz and B. Cuenca Grau, LogMap: Logic-based and scalable ontology matching, in: 10th International Semantic Web Conference (ISWC), (2011) , pp. 273–288. |
[35] | E. Jiménez-Ruiz, B.C. Grau, I. Horrocks and R.B. Llavori, Logic-based assessment of the compatibility of UMLS ontology sources, J. Biomed. Semant. 2: (S-1) ((2011) ), S2. |
[36] | R. Kadlec, O. Bajgar and J. Kleindienst, Knowledge base completion: Baselines strike back, in: Proceedings of the 2nd Workshop on Representation Learning for NLP, Rep4NLP@ACL 2017, Vancouver, Canada, August 3, 2017, P. Blunsom, A. Bordes, K. Cho, S.B. Cohen, C. Dyer, E. Grefenstette, K.M. Hermann, L. Rimell, J. Weston and S. Yih, eds, Association for Computational Linguistics, (2017) , pp. 69–74. |
[37] | S. Kim, E.E. Bolton and S.H. Bryant, Similar compounds versus similar conformers: Complementarity between PubChem 2-D and 3-D neighboring sets, Journal of Cheminformatics 8: (1) ((2016) ), 62. doi:10.1186/s13321-016-0163-1. |
[38] | S. Kim, J. Chen, T. Cheng, A. Gindulyte, J. He, S. He, Q. Li, B.A. Shoemaker, P.A. Thiessen, B. Yu, L. Zaslavsky, J. Zhang and E.E. Bolton, PubChem 2019 update: Improved access to chemical data, Nucleic Acids Research 47: (D1) ((2018) ), D1102–D1109. |
[39] | D.P. Kingma and J.B. Adam, A method for stochastic optimization, in: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Y. Bengio and Y. LeCun, eds, Conference Track Proceedings, (2015) . |
[40] | M. Kulmanov, W. Liu-Wei, Y. Yan and R. Hoehndorf, EL embeddings: Geometric construction of models for the description logic EL++, in: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10–16, 2019, S. Kraus, ed., ijcai.org, (2019) , pp. 6103–6109. |
[41] | C. LaLone, D. Villeneuve, H. Helgen and G. Ankley, Sequence alignment to predict across-species susceptibility, in: SETAC Europe, Basel, Switzerland, May 11–15, (2014) . |
[42] | M. Lare, (Skolelaboratoriet i realfag ved Universitetet i Bergen). Smỵr i ferskvann. Accessed 11.06.2020. |
[43] | F. Lécué and J. Wu, Semantic explanations of predictions, CoRR, 2018. arXiv:1805.10587. |
[44] | J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P.N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer and C. Bizer, Dbpedia – A large-scale, multilingual knowledge base extracted from Wikipedia, Semantic Web 6: (2) ((2015) ), 167–195. doi:10.3233/SW-140134. |
[45] | V.I. Levenshtein, Binary codes capable of correcting deletions, insertions and reversals, Soviet Physics Doklady 10: ((1966) ), 707. |
[46] | X. Liang, D. Li, M. Song, A. Madden, Y. Ding and Y. Bu, Predicting biomedical relationships using the knowledge and graph embedding cascade model, PLOS ONE 14: (6) ((2019) ), 1–23. |
[47] | NLM. Medical Subject Headings (MeSH) RDF, 2020. https://id.nlm.nih.gov/mesh/. |
[48] | G.A. Miller, Wordnet: A lexical database for English, Commun. ACM 38: (11) ((1995) ), 39–41. doi:10.1145/219717.219748. |
[49] | S.K. Mohamed, V. Novácek, P. Vandenbussche and E. Muñoz, Loss functions in knowledge graph embedding models, in: Proceedings of the Workshop on Deep Learning for Knowledge Graphs (DL4KG2019) Co-Located with the 16th Extended Semantic Web Conference 2019 (ESWC 2019), M. Alam, D. Buscaldi, M. Cochez, F. Osborne, D.R. Recupero and H. Sack, eds, CEUR Workshop Proceedings, Vol. 2377: , CEUR-WS.org, (2019) , pp. 1–10. |
[50] | S. Mumtaz and M. Giese, Hierarchy-based semantic embeddings for single-valued & multi-valued categorical variable, Journal of Intelligent Information Systems (2021) (in press). |
[51] | E.B. Myklebust, E. Jimenez-Ruiz, J. Chen, R. Wolf and K.E. Tollefsen, Knowledge graph embedding for ecotoxicological effect prediction, The Semantic Web – ISWC 2019: ((2019) ), 490–506. |
[52] | E.B. Myklebust, E. Jiménez-Ruiz, J. Chen, R. Wolf and K.E. Tollefsen, Ontology alignment in ecotoxicological effect prediction, in: 15th International Workshop on Ontology Matching, (2020) . |
[53] | E.B. Myklebust, E. Jimenez-Ruiz, C. Jiaoyan, R. Wolf and K.E. Tollefsen, Toxicological Effect and Risk Assessment (TERA) Knowledge Graph, 2020, (Version 1.1.0) [Data set]. Zenodo. doi:10.5281/zenodo.4244313. |
[54] | M. Nayyeri, C. Xu, Y. Yaghoobzadeh, H.S. Yazdi and J. Lehmann, Toward understanding the effect of loss function on then performance of knowledge graph embedding, 2019. |
[55] | D.Q. Nguyen, T.D. Nguyen, D.Q. Nguyen and D.Q. Phung, A novel embedding model for knowledge base completion based on convolutional neural network, in: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, M.A. Walker, H. Ji and A. Stent, eds, (2018) , pp. 327–333. |
[56] | M. Nickel, L. Rosasco and T.A. Poggio, Holographic embeddings of knowledge graphs, in: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, USA, February 12–17, 2016, D. Schuurmans and M.P. Wellman, eds, AAAI Press, (2016) , pp. 1955–1961. |
[57] | C.S. Parr, N. Wilson, P. Leary, K. Schulz, K. Lans, L. Walley, J. Hammock, A. Goddard, J. Rice and M. Studer, The encyclopedia of life v2: Providing global access to knowledge about life on earth, 2014. |
[58] | C.S. Parr, N. Wilson, P. Leary, K.S. Schulz, K. Lans, L. Walley, J.A. Hammock, A. Goddard, J. Rice, M. Studer, J.T.G. Holmes and J.R.J. Corrigan, The encyclopedia of life v2: Providing global access to knowledge about life on Earth, Biodiversity Data Journal 2: ((2014) ), e1079. |
[59] | R. Parthasarathi and A. Dhawan, Chapter 5 – In silico approaches for predictive toxicology, in: In Vitro Toxicology, A. Dhawan and S. Kwon, eds, Academic Press, (2018) , pp. 91–109. doi:10.1016/B978-0-12-804667-8.00005-5. |
[60] | F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot and E. Duchesnay, Scikit-learn: Machine learning in Python, Journal of Machine Learning Research 12: ((2011) ), 2825–2830. |
[61] | M.A.N. Pour, A. Algergawy, R. Amini, D. Faria, I. Fundulaki, I. Harrow, S. Hertling, E. Jiménez-Ruiz, C. Jonquet, N. Karam, A. Khiat, A. Laadhar, P. Lambrix, H. Li, Y. Li, P. Hitzler, H. Paulheim, C. Pesquita, T. Saveta, P. Shvaiko, A. Splendiani, É. Thiéblin, C. Trojahn, J. Vatascinová, B. Yaman, O. Zamazal and L. Zhou, Results of the ontology alignment evaluation initiative 2020, in: Proceedings of the 15th International Workshop on Ontology Matching Co-Located with the 19th International Semantic Web Conference (ISWC 2020), Virtual conference (originally planned to be in Athens, Greece), November 2, 2020, P. Shvaiko, J. Euzenat, E. Jiménez-Ruiz, O. Hassanzadeh and C. Trojahn, eds, CEUR Workshop Proceedings, Vol. 2788: , CEUR-WS.org, (2020) , pp. 92–138. |
[62] | J. Pujara, E. Augustine and L. Getoor, Sparsity and noise: Where knowledge graph embeddings fall short, in: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, Sept. 2017, Association for Computational Linguistics, (2017) , pp. 1751–1756. |
[63] | A. Rossi, D. Barbosa, D. Firmani, A. Matinata and P. Merialdo, Knowledge graph embedding for link prediction: A comparative analysis, ACM Trans. Knowl. Discov. Data 15: (2) ((2021) ), 14:1–14:49. |
[64] | E.W. Sayers, T. Barrett, D.A. Benson, S.H. Bryant, K. Canese, V. Chetvernin, D.M. Church, M. DiCuccio, R. Edgar, S. Federhen, M. Feolo, L.Y. Geer, W. Helmberg, Y. Kapustin, D. Landsman, D.J. Lipman, T.L. Madden, D.R. Maglott, V. Miller, I. Mizrachi, J. Ostell, K.D. Pruitt, G.D. Schuler, E. Sequeira, S.T. Sherry, M. Shumway, K. Sirotkin, A. Souvorov, G. Starchenko, T.A. Tatusova, L. Wagner, E. Yaschenko and J. Ye, Database resources of the National Center for Biotechnology Information, Nucleic Acids Research 37: (suppl_1) ((2008) ), D5–D15. |
[65] | A.K. Sharma, G.N. Srivastava, A. Roy and V.K. Sharma, Toxim: A toxicity prediction tool for small molecules developed using machine learning and chemoinformatics approaches, Frontiers in pharmacology 8: ((2017) ), 880. doi:10.3389/fphar.2017.00880. |
[66] | P. Shvaiko and J. Euzenat, Ontology matching: State of the art and future challenges, IEEE Trans. Knowl. Data Eng. 25: (1) ((2013) ), 158–176. doi:10.1109/TKDE.2011.253. |
[67] | N.P.O. Skrindebakke, Understanding the Role of Background Knowledge in Predictions, Master’s thesis, 2020. |
[68] | F.Z. Smaili, X. Gao and R. Hoehndorf, Opa2vec: Combining formal and informal content of biomedical ontologies to improve similarity-based prediction, Bioinform. 35: (12) ((2019) ), 2133–2140. doi:10.1093/bioinformatics/bty933. |
[69] | F.M. Suchanek, G. Kasneci and G. Weikum, Yago: A core of semantic knowledge, in: Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff, Alberta, Canada, May 8–12, 2007, C.L. Williamson, M.E. Zurko, P.F. Patel-Schneider and P.J. Shenoy, eds, ACM, (2007) , pp. 697–706. doi:10.1145/1242572.1242667. |
[70] | Z. Sun, Z. Deng, J. Nie and J.T. Rotate, Knowledge graph embedding by relational rotation in complex space, in: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6–9, 2019, OpenReview.net, (2019) . |
[71] | M. Swain et al., PubChemPy: Python wrapper for the pubchem pug rest api, 2014. [Online; accessed 15.08.2019]. |
[72] | M.E. Tipping and C.M. Bishop, Probabilistic principal component analysis, Journal of the Royal Statistical Society. Series B (Statistical Methodology) 61: (3) ((1999) ), 611–622. doi:10.1111/1467-9868.00196. |
[73] | T. Trouillon, J. Welbl, S. Riedel, É. Gaussier and G. Bouchard, Complex embeddings for simple link prediction, CoRR, 2016. arXiv:1606.06357. |
[74] | U.S. Environmental Protection Agency. Ecotox user guide: Ecotoxicology knowledgebase system, version 5.3, 2020. |
[75] | U.S. Environmental Protection Agency. ToxCast & Tox21 Summary Files from invitrodb_v3, 2020. |
[76] | D. Vrandecic and M. Krötzsch, Wikidata: A free collaborative knowledgebase, Commun. ACM 57: (10) ((2014) ), 78–85. doi:10.1145/2629489. |
[77] | A. Waagmeester, G. Stupp, S. Burgstaller, B. Good, M. Griffith, O. Griffith, K. Hanspers, H. Hermjakob, T. Hudson, K. Hybiske, S. Keating, M. Manske, M. Mayers, D. Mietchen, E. Mitraka, A. Pico, T. Putman, A. Riutta, N. Queralt-Rosinach and A. Su, Wikidata as a knowledge graph for the life sciences, eLife 9: ((2020) ), e52614. |
[78] | Q. Wang, Z. Mao, B. Wang and L. Guo, Knowledge graph embedding: A survey of approaches and applications, IEEE Trans. Knowl. Data Eng. 29: (12) ((2017) ), 2724–2743. doi:10.1109/TKDE.2017.2754499. |
[79] | E. Willighagen, InChIKey collision: The DIY copy/pastables, 2011. |
[80] | C. Wittwehr, P. Blomstedt, J.P. Gosling, T. Peltola, B. Raffael, A.-N. Richarz, M. Sienkiewicz, P. Whaley, A. Worth and M. Whelan, Artificial intelligence for chemical risk assessment, Computational Toxicology 13: ((2019) ), 100114. |
[81] | Y. Wu and G. Wang, Machine learning based toxicity prediction: From chemical structural description to transcriptome analysis, International Journal of Molecular Sciences 19: ((2018) ), 2358. doi:10.18483/ijSci.1625. |
[82] | Z. Wu, W. Lu, D. Wu, A. Luo, H. Bian, J. Li, W. Li, G. Liu, J. Huang, F. Cheng and Y. Tang, In silico prediction of chemical mechanism of action via an improved network-based inference method, British Journal of Pharmacology 173: (23) ((2016) ), 3372–3385. doi:10.1111/bph.13629. |
[83] | B. Yang, W. Yih, X. He, J. Gao and L. Deng, Embedding entities and relations for learning and inference in knowledge bases, in: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Y. Bengio and Y. LeCun, eds, Conference Track Proceedings, (2015) . |
[84] | H. Yang, L. Sun, W. Li, G. Liu and Y. Tang, In silico prediction of chemical toxicity for drug design using machine learning methods and structural alerts, Frontiers in chemistry 6: ((2018) ), 30. doi:10.3389/fchem.2018.00030. |
[85] | W.J. Youden, Index for rating diagnostic tests, Cancer 3: (1) ((1950) ), 32–35. doi:10.1002/1097-0142(1950)3:1<32::AID-CNCR2820030106>3.0.CO;2-3. |
[86] | Z. Zhang, J. Cai, Y. Zhang and J. Wang, Learning hierarchy-aware knowledge graph embeddings for link prediction, in: The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI Press, (2020) , pp. 3065–3072. |


