
Towards fully-fledged archiving for RDF datasets
Abstract
The dynamicity of RDF data has motivated the development of solutions for archiving, i.e., the task of storing and querying previous versions of an RDF dataset. Querying the history of a dataset finds applications in data maintenance and analytics. Notwithstanding the value of RDF archiving, the state of the art in this field is under-developed: (i) most existing systems are neither scalable nor easy to use, (ii) there is no standard way to query RDF archives, and (iii) solutions do not exploit the evolution patterns of real RDF data. On these grounds, this paper surveys the existing works in RDF archiving in order to characterize the gap between the state of the art and a fully-fledged solution. It also provides RDFev, a framework to study the dynamicity of RDF data. We use RDFev to study the evolution of YAGO, DBpedia, and Wikidata, three dynamic and prominent datasets on the Semantic Web. These insights set the ground for the sketch of a fully-fledged archiving solution for RDF data.
1.Introduction
The amount of RDF data has steadily grown since the conception of the Semantic Web in 2001 [13], as more and more organizations opt for RDF [66] as the format to publish and manage semantic data [39,41]. For example, by July 2009 the Linked Open Data (LOD) cloud counted a few more than 90 RDF datasets adding up to almost 6.7B triples [14]. By 2020, these numbers have catapulted to 1200+ datasets11 and at least 28B triples,22 although estimates based on LODStats [22] suggest more than 10K datasets and 150B+ triples if we consider the datasets with errors omitted by the LOD Cloud [58]. This boom does not only owe credit to the increasing number of data providers and availability of Open Government Data [6,24,63], but also to the constant evolution of the datasets in the LOD cloud. This phenomenon is especially true for community-driven initiatives such as DBpedia [9], YAGO [74], or Wikidata [23], and also applies to automatically ever-growing projects such as NELL [17].
Storing and querying the entire edition history of an RDF dataset, a task we call RDF archiving, has plenty of applications for data producers. For instance, RDF archives can serve as a backend for fine-grained version control in collaborative projects [5,8,29,33,49,79]. They also allow data providers to study the evolution of the data [27] and track errors for debugging purposes. Likewise, they can be of use to RDF streaming applications that rely on a structured history of the data [16,40]. But archives are also of great value for consumer applications such as data analytics, e.g., mining correction patterns [60,61] or historical trend analysis [42].
For all the aforementioned reasons, a significant body of literature has started to tackle the problem of RDF archiving. The current state of the art ranges from systems to store and query RDF archives [7,8,19,31,33,54,64,73,75,79,81], to benchmarks to evaluate such engines [27,48], as well as temporal extensions for SPARQL [12,28,32,62]. Diverse in architecture and aim, all these works respond to particular use cases. Examples are solutions such as R&Wbase [79], R43ples [33], and Quit Store [8] that provide data maintainers with distributed version control management in the spirit of Git. Conversely, other works [31,62] target data consumers who need to answer time-aware queries such as “obtain the list of house members who sponsored a bill from 2008”. In this case the metadata associated to the actual triples is used to answer domain-specific requirements.
Despite this plethora of work, there is currently no available fully-fledged solution for the management of large and dynamic RDF datasets. This situation originates from multiple factors such as (i) the performance and functionality limitations of RDF engines to handle metadata, (ii) the absence of a standard for querying RDF archives, and (iii) a disregard of the actual evolution of real RDF data. This paper elaborates on factors (i) and (ii) through a survey of the state of the art that sheds light on what aspects have not yet been explored. Factor (iii) is addressed by means of a framework to study the evolution of RDF data applied to three large and ever-changing RDF datasets, namely DBpedia, YAGO, and Wikidata. The idea is to identify the most challenging settings and derive a set of design lessons for fully-fledged RDF archive management. We therefore summarize our contributions as follows:
1. RDFev, a metric-based framework to analyze the evolution of RDF datasets;
2. A study of the evolution of DBpedia, YAGO, and Wikidata using RDFev;
3. A detailed survey of existing work on RDF archive management systems and SPARQL temporal extensions;
4. An evaluation of Ostrich [75] on the history of DBpedia, YAGO, and Wikidata. This was the only system that could be tested on the experimental datasets;
5. The sketch of a fully-fledged RDF archiving system that can satisfy the needs not addressed in the literature, as well as a discussion about the challenges in the design and implementation of such a system.
This paper is organized as follows. In Section 2 we introduce preliminary concepts. Then, Section 3 presents RDFev, addressing contribution (1). Contribution (2) is elaborated in Section 4. In the light of the evolution of real-world RDF data, we then survey the strengths and weaknesses of the different state-of-the-art solutions in Section 5 (contribution 3). Section 6 addresses contribution (4). The insights from the previous sections are then used to drive the sketch of an optimal RDF archiving system in Section 7, which addresses contribution (5). Section 8 concludes the paper.
2.Preliminaries
This section introduces the basic concepts in RDF archive storage and querying, and proposes some formalizations for the design of RDF archives.
Table 1
Notation related to RDF graphs
| triple and 4-tuple: subject, predicate, object, graph revision | |
| G | an RDF graph |
| g | a graph label |
| the i-th version or revision of graph G | |
| an RDF graph archive | |
| an update or changeset with sets of added and deleted triples. | |
| the changeset between graph revisions i and j ( | |
| revision number of graph revision ρ | |
| commit time of graph revision ρ | |
| labels of graph revision ρ and graph G |
2.1.RDF graphs
We define an RDF graph G as a set of triples
2.2.RDF graph archives
Intuitively, an RDF graph archive is a temporally-ordered collection of all the states an RDF graph has gone through since its creation. More formally, a graph archive
Fig. 1.
Two revisions

We remark that a graph archive can also be modeled as a collection of 4-tuples
2.3.RDF dataset archives
In contrast to an RDF graph archive, an RDF dataset is a set
Table 2
Notation related to RDF datasets
| a 5-tuple subject, predicate, object, graph revision, and dataset revision | |
| an RDF dataset | |
| an RDF dataset archive | |
| the j-th version or revision of dataset D | |
| the i-th revision of the k-th graph in a dataset archive | |
| a graph changeset with sets of added and deleted graphs | |
| a dataset update or changeset consisting of a graph changeset | |
| the addition/deletion changes of U: | |
| the dataset changeset between dataset revisions i and j ( | |
| revision number of dataset revision ζ | |
| commit time of dataset revision ζ | |
| the set of terms (IRIs, literals, and blank nodes) present in a graph G, dataset D, changeset u, and dataset changeset U. |
Most of the existing solutions for RDF archiving can handle the history of a single graph. However, scenarios such as data warehousing [20,21,30,35,36,43–45,47] may require to keep track of the common evolution of an RDF dataset, for example, by storing the addition and removal timestamps of the different RDF graphs in the dataset. Analogously to the definition of graph archives, we define a dataset archive
Figure 2 illustrates an example of a dataset archive with two revisions
As proposed by some RDF engines [57,77], we define the master graph
Fig. 2.
A dataset archive
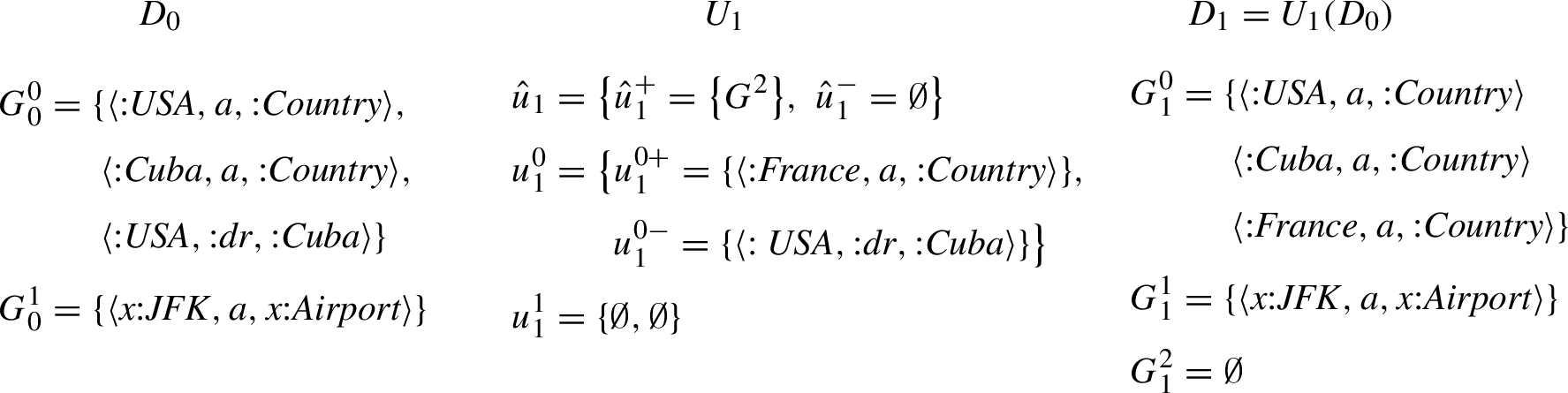
2.4.SPARQL
SPARQL 1.1 is the W3C standard language to query RDF data [71]. For the sake of brevity, we do not provide a rigorous definition of the syntax and semantics of SPARQL queries; instead we briefly introduce the syntax of a subset of SELECT queries and refer the reader to the official specification [71]. SPARQL is a graph-based language whose building blocks are triple patterns. A triple pattern
When no named graph is specified, the SPARQL standard assumes that the BGP is matched against the default graph in the RDF dataset. Otherwise, for matches against specific graphs, SPARQL supports the syntax GRAPH
2.5.Queries on archives
Queries on graph/dataset archives may combine results coming from different revisions in the history of the data collection in order to answer an information need. The literature defines five types of queries on RDF archives [27,75]. We illustrate them by means of our example graph archive from Fig. 1.
– Version Materialization. VM queries are standard queries run against a single revision, such as what was the list of countries according to the UN at revision j?
– Delta Materialization. DM queries are standard queries defined on a changeset
– Version. V queries ask for the revisions where a particular query yields results. An example of a V query is: in which revisions j did USA and Cuba have diplomatic relationships?
– Cross-version. CV queries result from the combination (e.g., via joins, unions, aggregations, differences, etc.) of the information from multiple revisions, e.g., which of the current countries was not in the original list of UN members?
– Cross-delta. CD queries result from the combination of the information from multiple sets of changes, e.g., what are the revisions j with the largest number of UN member adhesions?
3.Framework for the evolution of RDF data
This section proposes RDFev, a framework to understand the evolution of RDF data. The framework consists of a set of metrics and a software tool to calculate those metrics throughout the history of the data. The metrics quantify the changes between two revisions of an RDF graph or dataset and can be categorized into two families: metrics for low-level changes, and metrics for high-level changes. Existing benchmarks, such as BEAR [27], focus on low-level changes, that is, additions and deletions of triples. This, however, may be of limited use to data maintainers, who may need to know the semantics of those changes, for instance, to understand whether additions are creating new entities or editing existing ones. On these grounds, we propose to quantify changes at the level of entities and object values, which we call high-level.
RDFev takes each version of an RDF dataset as an RDF dump in N-triples format (our implementation does not support multi-graph datasets and quads for the time being). The files must be provided in chronological order. RDFev then computes the different metrics for each consecutive pair of revisions. The tool is implemented in C++ and Python and uses the RocksBD33 key-value store as storage and indexing backend. All metrics are originally defined for RDF graphs in the state of the art [27], and have been ported to RDF datasets in this paper. RDFev’s source code is available at our project website.44
3.1.Low-level changes
Low-level changes are changes at the triple level. Indicators for low-level changes focus on additions and deletions of triples and vocabulary elements. The vocabulary
Change ratio The authors of BEAR [27] define the change ratio between two revisions i and j of an RDF graph G as
We now adapt these metrics for RDF datasets. For this purpose, we define the size of a dataset D as
Here,
Vocabulary dynamicity The vocabulary dynamicity for two revisions i and j of an RDF graph is defined as [27]:
Growth ratio The grow ratio is the ratio between the number of triples in two revisions i, j. It is calculated as follows for graphs and datasets:
3.2.High-level changes
A high-level change confers semantics to a changeset. For example, if an update consists of the addition of triples about an unseen subject, we can interpret the triples as the addition of an entity to the dataset. High-level changes provide deeper insights about the development of an RDF dataset than low-level changes. In addition, they can be domain-dependent. Some approaches [59,69] have proposed vocabularies to describe changesets in RDF data as high-level changes. Since our approach is oblivious to the domain of the data, we propose a set of metrics on domain-agnostic high-level changes.
Entity changes RDF datasets describe real-world entities s by means of triples
We also propose the triple-to-entity-change score, that is, the average number of triples that constitute a single entity change. It can be calculated as follows for RDF graphs:
Object updates and orphan object additions/deletions An object update in a changeset
Table 3 summarizes all the metrics defined by RDFev.
Table 3
RDFev’s metrics
| Low-level changes | Change ratio |
| Insertion and deletion ratios | |
| Vocabulary dynamicity | |
| Growth ratio | |
| High-level changes | Entity changes |
| Triple-to-entity-change score | |
| Object updates | |
| Orphan object additions and deletions |
4.Evolution analysis of RDF datasets
Having introduced RDFev, we use it to conduct an analysis of the revision history of three large and publicly available RDF knowledge bases, namely YAGO, DBpedia, and Wikidata. The analysis resorts to the metrics defined in Sections 3.1 and 3.2 for every pair of consecutive revisions.
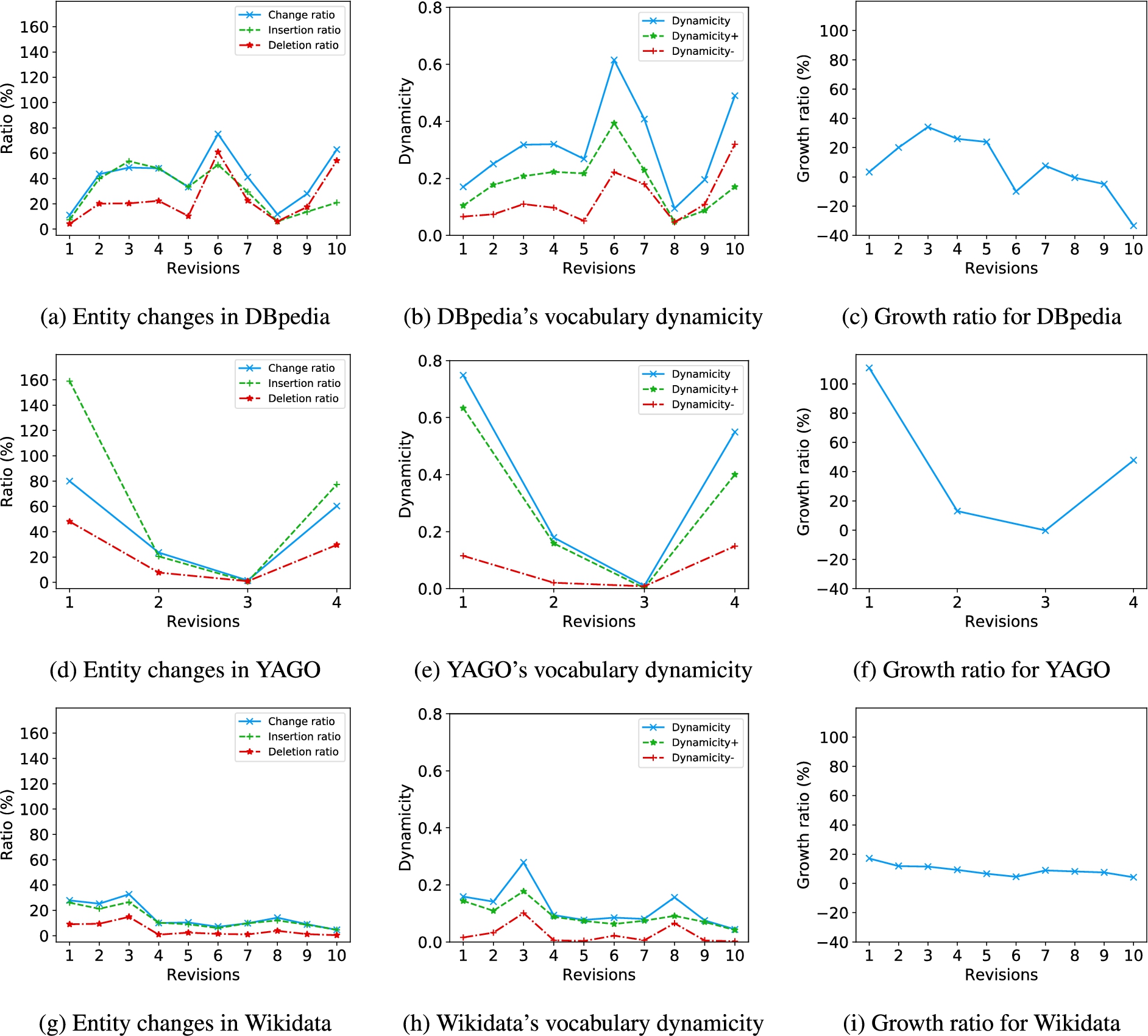
Fig. 3.
Change ratio, vocabulary dynamicity, and growth ratio.
4.1.Data
We chose the YAGO [74], DBpedia [9], and Wikidata [23] knowledge bases for our analysis, because of their large size, dynamicity, and central role in the Linked Open Data initiative. We build an RDF graph archive by considering each release of the knowledge base as a revision. None of the datasets is provided as a monolithic file, instead they are divided into themes. These are subsets of triples of the same nature, e.g., triples with literal objects extracted with certain extraction methods. We thus focus on the most popular themes. For DBpedia we use the mapping-based objects and mapping-based literals themes, which are available from version 3.5 (2015) onwards. Additionally, we include the instance-types theme as well as the ontology. For YAGO, we use the knowledge base’s core, namely, the themes facts, meta facts, literal facts, date facts, and labels available from version 2 (v.1.0 was not published in RDF). As for Wikidata, we use the simple-statements of the RDF Exports [68] in the period from 2014-05 to 2016-08. These dumps provide a clean subset of the dataset useful for applications that rely mainly on Wikidata’s encyclopedic knowledge. All datasets are available for download in the RDFev’s website https://relweb.cs.aau.dk/rdfev. Table 4 maps revision numbers to releases for the sake of conciseness in the evolution analysis.
Table 4
Datasets revision mapping
| Revision | DBpedia | YAGO | Wikidata |
| 0 | 3.5 | 2 s | 2014-05-26 |
| 1 | 3.5.1 | 3.0.0 | 2014-08-04 |
| 2 | 3.6 | 3.0.1 | 2014-11-10 |
| 3 | 3.7 | 3.0.2 | 2015-02-23 |
| 4 | 3.8 | 3.1 | 2015-06-01 |
| 5 | 3.9 | 2015-08-17 | |
| 6 | 2015-04 | 2015-10-12 | |
| 7 | 2015-10 | 2015-12-28 | |
| 8 | 2016-04 | 2016-03-28 | |
| 9 | 2016-10 | 2016-06-21 | |
| 10 | 2019-08 | 2016-08-01 |
4.2.Low-level evolution analysis
Change ratio Figures 3(a), 3(d) and 3(g) depict the evolution of the change, insertion, and deletion ratios for our experimental datasets. Up to the release 3.9 (rev. 5), DBpedia exhibits a steady growth with significantly more insertions than deletions. Minor releases such as 3.5.1 (rev. 1) are indeed minor in terms of low-level changes. Release 2015-04 (rev. 6) is an inflexion point not only in terms of naming scheme (see Table 4): the deletion rate exceeds the insertion rate and subsequent revisions exhibit a tight difference between the rates. This suggests a major design shift in the construction of DBpedia from revision 6.
As for YAGO, the evolution reflects a different release cycle. There is a clear distinction between major releases (3.0.0 and 3.1, i.e., rev. 1 and 4) and minor releases (3.0.1 and 3.0.2, i.e., rev. 2 and 3). The magnitude of the changes in major releases is significantly higher for YAGO than for any DBpedia release. Minor versions seem to be mostly focused on corrections, with a low number of changes.
Contrary to the other datasets, Wikidata shows a slowly decreasing change ratio that fluctuates between 5% (rev. 10) and 33% (rev. 3) within the studied period of 2 years.
Vocabulary dynamicity As shown in Figs 3(b), 3(e), and 3(h), the vocabulary dynamicity is, not surprisingly, correlated with the change ratio. Nevertheless, the vocabulary dynamicity between releases 3.9 and 2015-14 (rev. 5 and 6) in DBpedia did not decrease. This suggests that DBpedia 2015-04 contained more entities, but fewer – presumably noisy – triples about those entities. The major releases of YAGO (rev. 1 and 4) show a notably higher vocabulary dynamicity than the minor releases. As for Wikidata, slight spikes in dynamicity can be observed at revisions 4 and 9, however this metric remains relatively low in Wikidata compared to the others bases.
Growth ratio Figures 3(c), 3(f), and 3(i) depict the growth ratio of our experimental datasets. In all cases, this metric is mainly positive with low values for minor revisions. As pointed out by the change ratio, the 2015-04 release in DBpedia is remarkable as the dataset shrank and was succeeded by more conservative growth ratios. This may suggest that recent DBpedia releases are more curated. We observe that YAGO’s growth ratio is significantly larger for major versions. This is especially true for the 3.0.0 (rev. 1) release that doubled the size of the knowledge base.
4.3.High-level evolution analysis
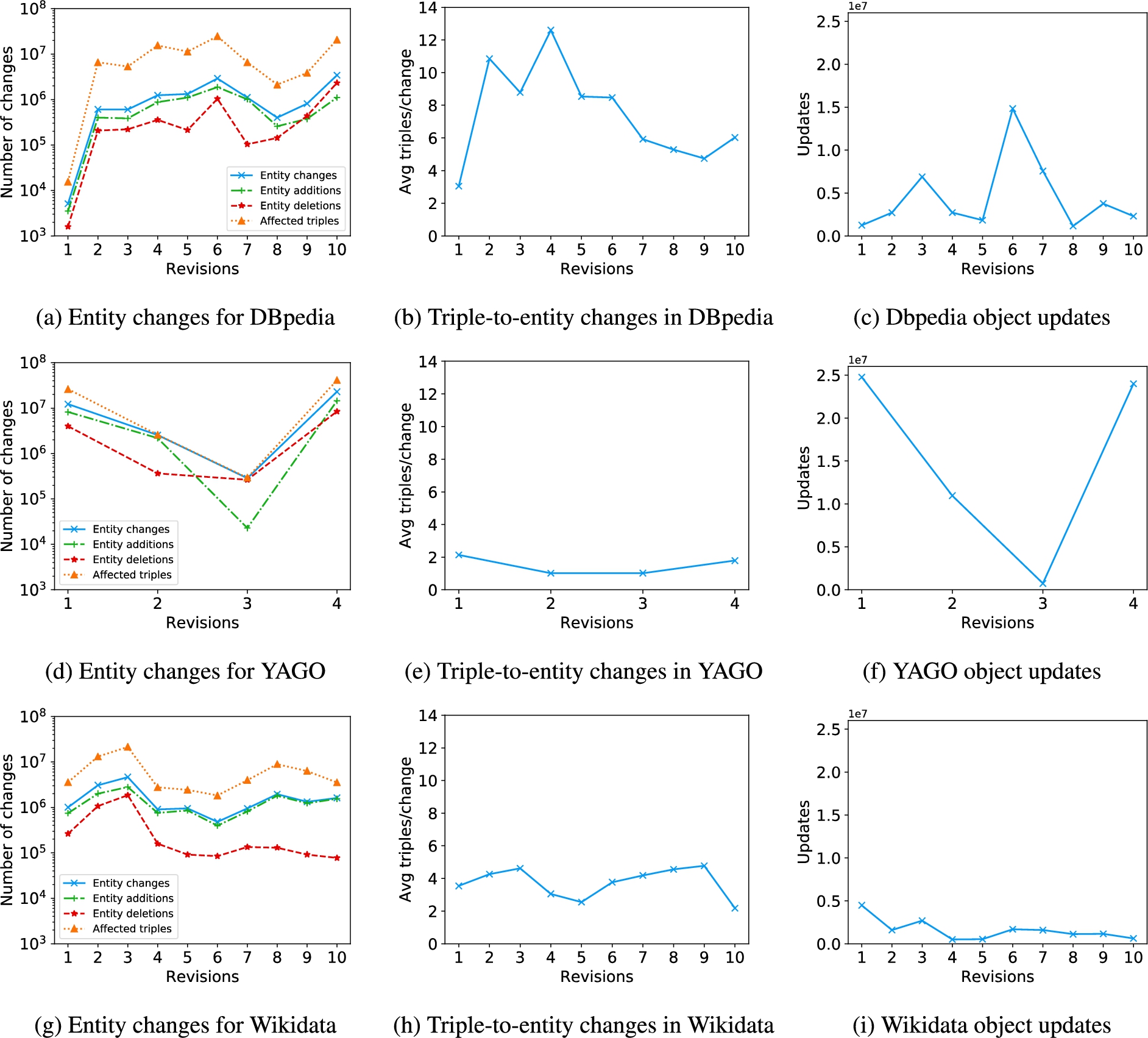
Fig. 4.
Entity changes and object updates.
4.3.1.Entity changes
Figures 4(a), 4(d), and 4(g) illustrate the evolution of the entity changes, additions, and deletions for DBpedia, YAGO and Wikidata. We also show the number of triples used to define these high-level changes (labeled as affected triples). We observe a stable behavior for these metrics in DBpedia except for the minor release 3.5.1 (rev. 1). Entity changes in Wikidata also display a monotonic behavior, even though the deletion rate tends to decrease from rev. 4. In YAGO, the number of entity changes peaks for the major revisions (rev. 1 and 4), and is one order of magnitude larger than for minor revisions. The minor release 3.0.2 (rev. 3) shows the lowest number of additions, whereas deletions remain stable w.r.t release 3.0.1 (rev. 2). This suggests that these two minor revisions focused on improving the information extraction process, which removed a large number of noisy entities.
Figure 4(b) shows the triple-to-entity-change score in DBpedia. Before the 2015-14 release, this metric fluctuates between 2 and 12 triples without any apparent pattern. Conversely subsequent releases show a decline, which suggests a change in the extraction strategies for the descriptions of entities. The same cannot be said about YAGO and Wikidata (Figs 4(e) and 4(h)), where values for this metric are significantly lower than for DBpedia, and remain almost constant. This suggests that minor releases in YAGO improved the strategy to extract entities, but did not change much the amount of extracted triples per entity.
4.3.2.Object updates and orphan object additions/deletions
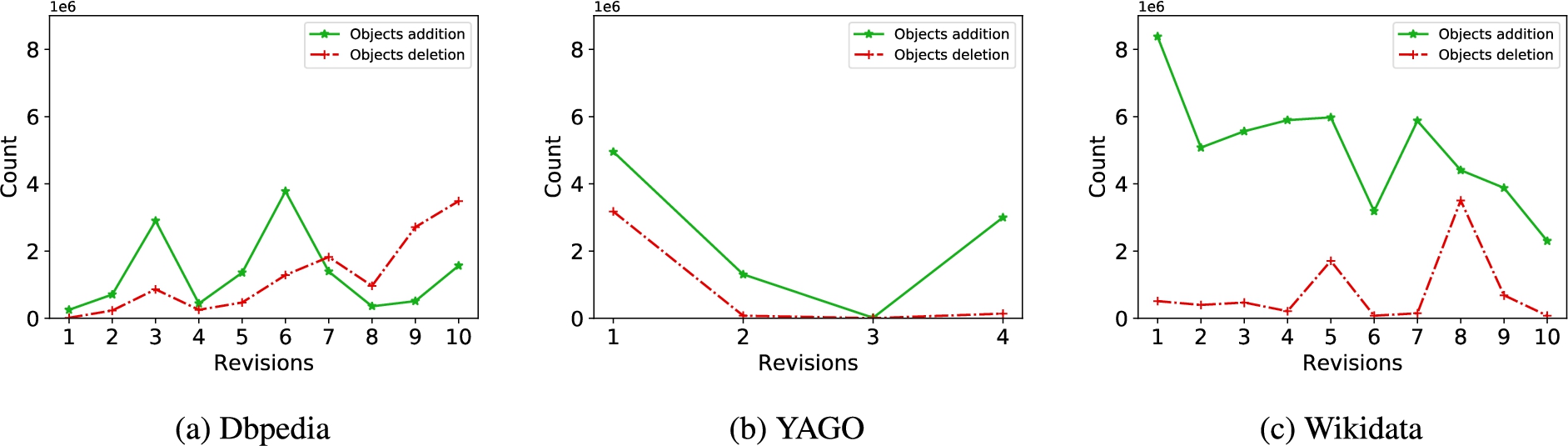
Fig. 5.
Orphan object additions and deletions.
We present the evolution of the number of object updates for our experimental datasets in Figs 4(c), 4(f), and 4(i). For DBpedia, the curve is consistent with the change ratio (Fig. 3(a)). In addition to a drop in size, the 2015-04 release also shows the highest number of object updates, which corroborates the presence of a drastic redesign of the dataset.
The results for YAGO are depicted in Fig. 4(f), where we see larger numbers of object updates compared to major releases in DBpedia. This is consistent with the previous results that show that YAGO goes through bigger changes between releases. The same trends are observed for the number of orphan object additions and deletions in Figs 5(a) and 5(b). Compared to the other two datasets, Wikidata’s number of object updates, shown in Fig. 4(i), is much lower and constant throughout the stream of revisions.
Finally, we remark that in YAGO and DBpedia, object updates are 4.8 and 1.8 times more frequent than orphan additions and deletions. This entails that the bulk of editions in these knowledge bases aims at updating existing object values. This behavior contrasts with Wikidata, where orphan object updates are 3.7 times more common than proper object updates. As depicted in Fig. 5(c), Wikidata exhibits many more orphan object updates than the other knowledge bases. Moreover, orphan object additions are 19 times more common than orphan object deletions.
4.4.Conclusion
In this section we have conducted a study of the evolution of three large RDF knowledge bases using our proposed framework RDFev, which resorts to a domain-agnostic analysis from two perspectives: At the low-level it studies the dynamics of triples and vocabulary terms across different versions of an RDF dataset, whereas at the high-level it measures how those low-level changes translate into updates to the entities described in the experimental datasets. All in all, we have identified different patterns of evolution. On the one hand, Wikidata exhibits a stable release cycle in the studied period, as our metrics did not exhibit big fluctuations from release to release. On the other hand, YAGO and DBpedia have a release cycle that distinguishes between minor and major releases. Major releases are characterized by a large number of updates in the knowledge base and may not necessarily increase its size. Conversely, minor releases incur in at least one order of magnitude fewer changes than major releases and seem to focus on improving the quality of the knowledge base, for instance, by being more conservative in the number of triple and entity additions. Unlike YAGO, DBpedia has shown decreases in size across releases. We argue that an effective solution for large-scale RDF archiving should be able to adapt to different patterns of evolution.
5.Survey of RDF archiving solutions
We structure this section in three parts. Section 5.1 surveys the existing engines for RDF archiving and discusses their strengths and weaknesses. Section 5.2 presents the languages and SPARQL extensions to express queries on RDF archives. Finally, Section 5.3 introduces various endeavors on analysis and benchmarking of RDF archives.
5.1.RDF archiving systems
There are plenty of systems to store and query the history of an RDF dataset. Except for a few approaches [7,8,33,81], most available systems support archiving of a single RDF graph. Ostrich [75], for instance, manages quads of the form
– Storage paradigm. The storage paradigm is probably the most important feature as it shapes the system’s architecture. We identify three main paradigms in the literature [27], namely independent copies (IC), change-based (CB), and timestamp-based (TB). Some systems [75] may fall within multiple categories, whereas Quit Store [8] implements a fragment-based (FB) paradigm.
– Data model. It can be quads or 5-tuples with different semantics for the fourth and fifth component.
– Full BGPs. This feature determines whether the system supports BGPs with a single triple pattern or full BGPs with an unbounded number of triple patterns and filter conditions.
– Query types. This criterion lists the types of queries on RDF archives (see Section 2.5) natively supported by the solution.
– Branch & tags. It defines whether the system supports branching and tagging as in classical version control systems.
– Multi-graph. This feature determines if the system supports archiving of the history of multi-graph RDF datasets.
– Concurrent updates. This criterion determines whether the system supports concurrent updates. This is defined regardless of whether conflict management is done manually or automatically.
– Source available. We also specify whether the system’s source code is available for download and is usable, that is, whether it can be compiled and run in modern platforms.
Table 5
Existing RDF archiving systems
| Storage paradigm | Data model | Full BGPs | Queries | Branch & tags | Multi-graph | Concurrent Updates | Source available | |
| Dydra [7] | TB | 5-tuples | + | all | – | + | – | – |
| Ostrich [75] | IC/CB/TB | quads | +d | VM, DM, V | – | – | – | + |
| QuitStore [8] | FB | 5-tuples | + | all | + | + | + | + |
| RDF-TX [31] | TB | quads | + | all | – | – | – | – |
| R43ples [33] | CB | 5-tuplesc | + | all | + | + | + | +a |
| R&WBase [79] | CB | quads | + | all | + | – | + | + |
| RBDMS [46] | CB | quads | + | all | + | – | + | – |
| SemVersion [81] | IC | 5-tuplesc | – | VM, DM | + | – | + | – |
| Stardog [73] | CB | 5-tuples | + | all | tags | + | – | – |
| v-RDFCSA [19] | TB | quads | – | VM, DM, V | – | – | – | – |
| x-RDF-3X [54] | TB | quads | + | VM, V | – | – | – | +b |
aIt needs modifications to have the console client running and working.
bOld source code.
bGraph local revisions.
cFull BGP support is possible via integration with the Comunica query engine.
In the following, we discuss further details of the state-of-the-art systems, grouped by their storage paradigms.
5.1.1.Independent copies systems
In an IC-like approach, each revision
5.1.2.Change-based systems
Solutions based on the CB paradigm store a subset
R&WBase [79] is an archiving system that provides Git-like distributed version control with support for merging, branching, tagging, and concurrent updates with manual conflict resolution on top of a classical SPARQL endpoint. R&WBase supports all types of archive queries on full BGPs. The system uses the PROV-Ontology (PROV-O) [78] to model the metadata (e.g., timestamps, parent branches) about the updates of a single RDF graph. An update
Stardog [73] is a commercial RDF data store with support for dataset snapshots, tags, and full SPARQL support. Unlike R43ples, Stardog keeps track of the global history of a dataset, hence its logical model consists of 5-tuples of the form
5.1.3.Timestamp-based systems
TB solutions store triples with their temporal metadata, such as domain temporal validity intervals or insertion/deletion timestamps. Like in CB solutions, revisions must be materialized at a high cost for VM and CV queries. V queries are usually better supported, whereas the efficiency of materializing deltas depends on the system’s indexing strategies.
x-RDF-3X [54] is a system based on the RDF-3X [53] engine. Logically x-RDF-3X supports quads of the form
Dydra [7] is a TB archiving system that supports archiving of multi-graph datasets. Logically, Dydra stores 5-tuples of the form
RDF-TX [31] supports single RDF graphs and uses a multiversion B-tree (MVBT) to index triples and their time metadata (insertion and deletion timestamps). An MVBT is actually a forest where each tree indexes the triples that were inserted within a time interval. RDF-TX implements an efficient compression scheme for MVBTs, and proposes SPARQL-T, a SPARQL extension that adds a fourth component
v-RDFCSA [19] is a lightweight and storage-efficient TB approach that relies on suffix-array encoding [15] for efficient storage with basic retrieval capabilities (much in the spirit of HDT [25]). Each triple is associated to a bitsequence of length equals the number of revisions in the archive. That is, v-RDFCSA logically stores quads of the form
5.1.4.Hybrid and fragment-based systems
Some approaches can combine the strengths of the different storage paradigms. One example is Ostrich [75], which borrows inspirations from IC, CB, and TB systems. Logically, Ostrich supports quads of the form
Like R43ples [33], Quit Store [8] provides collaborative Git-like version control for multi-graph RDF datasets, and uses PROV-O for metadata management. Unlike R43ples, Quit Store provides a global view of the evolution of a dataset, i.e., each commit to a graph generates a new dataset revision. The latest revision is always materialized in an in-memory quad store. QuitStore is implemented in Python with RDFlib and provides full support for SPARQL 1.1. The dataset history (RDF graphs, commit tree, etc.) is physically stored in text files (i.e. N-quads files resp. N-triples files in the latest implementation) and is accessible via a SPARQL endpoint on a set of virtual graphs. However, the system only stores snapshots of the modified files in the spirit of fragment-based storage. Quit Store is tailored for collaborative construction of RDF datasets, but its high memory requirements make it unsuitable as an archiving backend. As discussed in Section 7, fully-fledged RDF archiving can provide a backend for this type of applications.
5.2.Languages to query RDF archives
Multiple research endeavors have proposed alternatives to succinctly formulate queries on RDF archives. The BEAR benchmark [27] uses AnQL to express the query types described in Section 2.5. AnQL [82] is a SPARQL extension based on quad patterns

T-SPARQL [32] is a SPARQL extension inspired by the query language TSQL2 [72]. T-SPARQL allows for the annotation of groups of triple patterns with constraints on temporal validity and commit time, i.e., it supports both time-intervals and timestamps as time objects. T-SPARQL defines several comparison operators between time objects, namely equality, precedes, overlaps, meets, and contains. Similar extensions [12,62] also offer support for geo-spatial data.
SPARQ-LTL [28] is a SPARQL extension that makes two assumptions, namely that (i) triples are annotated with revision numbers, and (ii) revisions are accessible as named graphs. When no revision is specified, BGPs are iteratively matched against every revision. A set of clauses on BGPs can instruct the SPARQL engine to match a BGP against other revisions at each iteration. For instance the clause PAST in the expression PAST{ q } MINUS { q } with
5.3.Benchmarks and tools for RDF archives
BEAR [27] is the state-of-the-art benchmark for RDF archive solutions. The benchmark provides three real-world RDF graphs (called BEAR-A, BEAR-B, and BEAR-C) with their corresponding history, as well as a set of VM, DM, and V queries on those histories. In addition, BEAR allows system designers to compare their solutions with baseline systems based on different storage strategies (IC, CB, TB, and hybrids TB/CB, IC/CB) and platforms (Jena TDB and HDT). Despite its multiple functionalities and its dominant position in the domain, BEAR has some limitations: (i) It assumes single-graph RDF datasets; (ii) it does not support CV and CD queries, moreover VM, DM, and V queries are defined on single triple patterns; and (iii) it cannot simulate datasets of arbitrary size and query workloads.
EvoGen [48] tackles the latter limitation by extending the Lehigh University Benchmark (LUBM) [34] to a setting where both the schema and the data evolve. Users cannot only control the size and frequency of that evolution, but can also define customized query workloads. EvoGen supports all the types of queries on archives presented in Section 2.5 on multiple triple patterns.
A recent approach [76] proposes to use FCA (Formal Concept Analysis) and several data fusion techniques to produce summaries of the evolution of entities across different revisions of an RDF archive. A summary can, for instance, describe groups of subjects with common properties that change over time. Such summaries are of great interest for data maintainers as they convey edition patterns in RDF data through time.
6.Evaluation of the related work
In this section, we conduct an evaluation of the state-of-the-art RDF archiving engines. We first provide a global analysis of the systems’ functionalities in Section 6.1. Section 6.2 then provides a performance evaluation of Ostrich (the only testable solution) on our experimental RDF archives from Table 4. This evaluation is complementary to the Ostrich’s evaluation on BEAR (available in [75]), as it shows the performance of the system in three real-world large RDF datasets.
6.1.Functionality analysis
As depicted in Table 5, existing RDF archiving solutions differ greatly in design and functionality. The first works [18,54,81] offered mostly storage of old revisions and support for basic VM queries. Consequently, subsequent efforts focused on extending the query capabilities and allowing for concurrent updates as in standard version control systems [8,33,46,79]. Such solutions are attractive for data maintainers in collaborative projects, however they still lack scalability, e.g., they cannot handle large datasets and changesets, besides conflict management is still delegated to users. More recent works [19,75] have therefore focused on improving storage and querying performance, alas, at the expense of features. For example, Ostrich [75] is limited to a single snapshot and delta chain. In addition to the limitations in functionality, Table 5 shows that most of the existing systems are not available because their source code is not published. While this still leaves us with Ostrich [75], Quit Store [8], R&WBase [79], R43ples [33] and x-RDF-3X as testable solutions, only [75] was able to run on our experimental datasets. To carry out a fair comparison with the other systems, we tried Quit Store in the persistence mode, which ingests the data graphs into main memory at startup – allowing us to measure ingestion times. Unfortunately, the system crashes for all our experimental datasets.77 We also tested Quit Store in its default lazy loading mode, which loads the data into main memory at query time. This option throws a Python MemoryError for our experimental queries. In regards to R43ples, we had to modify its source code to handle large files.88 Despite this change, the system could not ingest a single revision of DBpedia after four days of execution. R&WBase, on the other hand, accepts updates only through a SPARQL endpoint, which cannot handle the millions of update statements required to ingest the changesets. Finally, x-RDF-3X’s source code does not compile out of the box in modern platforms, and even after successful compilation, it is unable to ingest one DBpedia changeset.
6.2.Performance analysis
We evaluate the performance of Ostrich on our experimental datasets in terms of storage space, ingestion time – the time to generate a new revision from an input changeset – and query response time. The changesets were computed with RDFev from the different versions of DBpedia, YAGO, and Wikidata (Table 4). All the experiments were run on a server with a 4-core CPU (Intel Xeon E5-2680 [email protected] GHz) and 64 GB of RAM.
Fig. 6.
Ostrich’s performance on multiple revisions of DBpedia and YAGO.
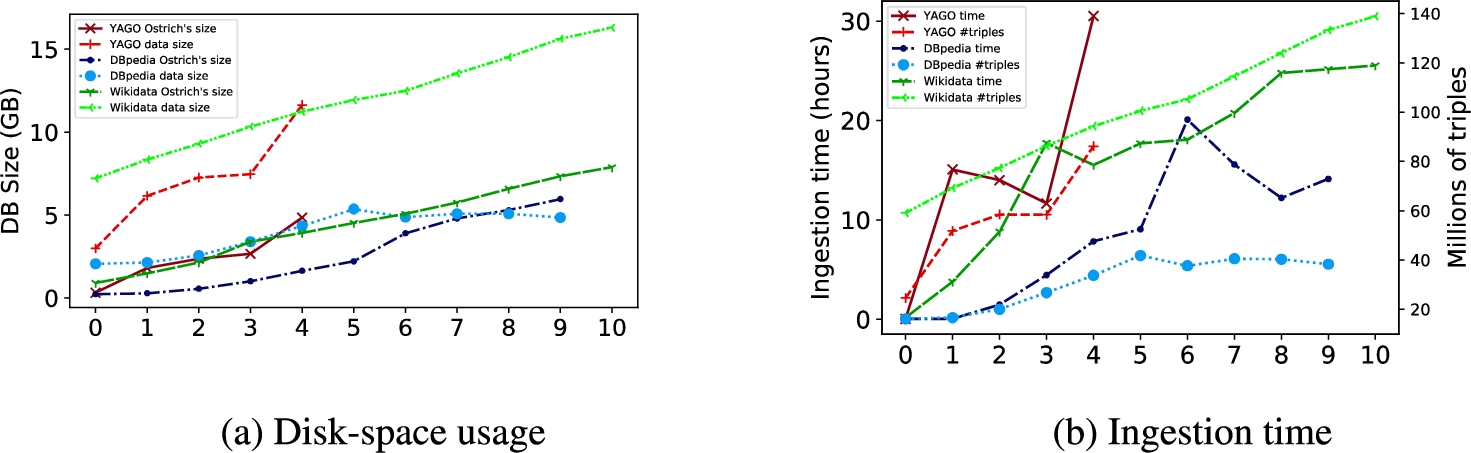
Table 6
Ostrich’s query performance in seconds
| DBpedia | YAGO | Wikidata | |||||||
| Triple Patterns | VM | V | DM | VM | V | DM | VM | V | DM |
| ? p ? | 92.81 (0) | 118.64 (0) | 91.78 (0) | 2.9 (3) | – (5) | 1.82 (3) | 281.41 (0) | 302.26 (0) | 303.73 (0) |
| ? <top p> o | 112.81 (0) | 283.59 (0) | 130.88 (0) | 35.08 (2) | 69.65 (4) | 137.16 (4) | 347.06 (0) | 499.77 (0) | 285.02 (0) |
| ? p o | 96.74 (0) | 92.04 (0) | 91.93 (0) | 2.38 (4) | 2.35 (4) | 2.35 (2) | 282.12 (0) | 281.63 (0) | 281.45 (0) |
| s p ? | 94.99 (0) | 91.67 (0) | 92.81 (0) | 2.42 (2) | 2.36 (3) | 2.41 (1) | 284.74 (0) | 281.4 (0) | 281.2 (0) |
Storage space Figure 6(a) shows the amount of storage space (in GB) used by Ostrich for the selected revisions of our experimental datasets. We provide the raw sizes of the RDF dumps of each revision for reference. Storing each version of YAGO separately requires 36 GB, while Ostrich uses only 4.84 GB. For DBpedia compression goes from 39 GB to 5.96 GB. As for Wikidata, it takes 131 GB to stores the raw files, but only 7.88 GB with Ostrich. This yields a compression rate of 87% for YAGO, 84% for DBpedia and 94% for Wikidata. This space efficiency is the result of using HDT [25] for snapshot storage, as well as compression for the delta chains.
Ingestion time Figure 6(b) shows Ostrich’s ingestion times. We also provide the number of triples of each revision as reference. The results suggest that this measure depends both on the changeset size, and the length of the delta chain. However, the latter factor becomes more prominent as the length of the delta chain increases. For example, we can observe that Ostrich requires ∼22 hours to ingest revision 9 of DBpedia (2.43M added and 2.46M deleted triples) while it takes only ∼14 hours to ingest revision 5 (12.85M added and 5.95M deleted triples). This confirms the trends observed in [75] where ingestion time increases linearly with the number of revisions. This is explained by the fact that Ostrich stores the i-th revision of an archive as a changeset of the form
Query runtime We run Ostrich on 100 randomly generated VM, V, and DM queries on our experimental datasets. Ostrich does not support queries on full BGPs natively, thus the queries consisted of single triple patterns of the most common forms, namely ⟨ ?, p, ? ⟩, ⟨ s, p, ? ⟩, and ⟨ ?, p, o ⟩ in equal numbers. We also considered queries ⟨ ?, <top p>, o ⟩, where <top p> corresponds to the top 5 most common predicates in the dataset. Revision numbers for all queries were also randomly generated. Table 6 shows Ostrich’s average runtime in seconds for the different types of queries. We set a timeout of 1 hour for each query, and show the number of timeouts in parentheses next to the runtime, which excludes queries that timed out. We observe that Ostrich is roughly one order of magnitude faster on YAGO than on DBpedia and Wikidata. To further understand the factors that impact Ostrich’s runtime, we computed the Spearman correlation score between Ostrich’s query runtime and a set of features relevant to query execution. These features include the length of the delta chain, the average size of the relevant changesets, the size of the initial revision, the average number of deleted and added triples in the changesets, and the number of query results. The results show that the most correlated features are the length of the delta chain, the standard deviation of the changeset size, and the average number of deleted triples. This suggests that Ostrich’s runtime performance will degrade as the history of the archive grows and that massive deletions actually aggravate that phenomenon. Finally, we observe some timeouts in YAGO in contrast to DBpedia and Wikidata. We believe this is mainly caused by the sizes of the changesets, which are on average of 3.72GB for YAGO, versus 2.09GB for DBpedia and 1.86GB for Wikidata. YAGO’s changesets at revisions 1 and 4 are very large as shown in Section 4.
7.Towards fully-fledged RDF archiving
We now build upon the findings from previous sections to derive a set of lessons towards the design of a scalable fully-fledged solution for archiving of large RDF datasets. We structure this section in two parts. Section 7.1 discusses the most important functionalities that such a solution may offer, whereas Sect. 7.2 discusses the algorithmic and design challenges of providing those functionalities.
7.1.Functionalities
Global and local history Our survey in Section 5.1 shows that R43ples [33] and Quit Store [8] are the only available solutions that support both archiving of the local and joint (global) history of multiple RDF graphs. We argue that such a feature is vital for proper RDF archiving: It is not only of great value for distributed version control in collaborative projects, but can also be useful for the users and maintainers of data warehouses. Conversely, existing solutions are strictly focused on distributed version control and their Git-based architectures make them unsuitable to archive the releases of large datasets such as YAGO, DBpedia, or Wikidata as explained in Section 6. From an engineering and algorithmic perspective, this implies to redesign RDF solutions to work with 5-tuples instead of triples. We discuss the technical challenges of such requirement in Section 7.2.
Fig. 7.
Two logical models to handle metadata in RDF archives. The namespace prov: corresponds to the PROV-O namespace.
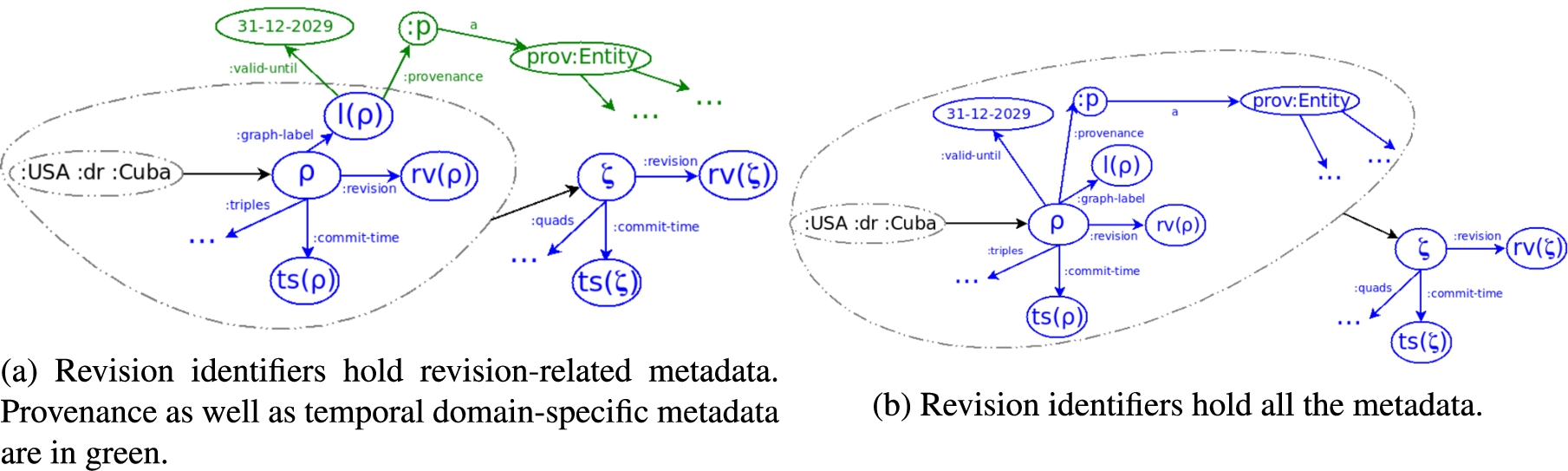
Temporal domain-specific vs. revision metadata Systems and language extensions for queries with time constraints [31,32], treat both domain-specific metadata (e.g., triple validity intervals) and revision-related annotations (e.g., revision numbers) in the same way. We highlight, however, that revision metadata is immutable and should therefore be logically placed at a different level. In this line of thought we propose to associate revision metadata for graphs and datasets, e.g., commit time, revision numbers, or branching & tagging information, to the local and global revision identifiers ρ and ζ, whereas depending on the application, domain-specific time objects could be modeled either as statements about the revisions or as statements about the graph labels
Provenance Revision metadata is part of the history of a triple within a dataset. Instead, its complete history is given by its workflow provenance. The W3C offers the PROV-O ontology [78] to model the history of a triple from its sources to its current state in an RDF dataset. Pretty much like temporal domain-specific metadata, provenance metadata can be logically linked to either the (local or global) revision identifiers or to the graph labels (Fig. 7). This depends on whether we want to define provenance for changesets because the triples added to an RDF graph may have different provenance workflows. A hybrid approach could associate a default provenance history to a graph and use the revision identifiers to override or extend that default history for new triples. Moreover, the global revision identifier ζ provides an additional level of metadata that allow us to model the provenance of a dataset changeset.
Concurrent updates & modularity We can group the existing state-of-the-art solutions in three categories regarding their support for concurrent updates, namely (i) solutions with limited or no support for concurrent updates [7,19,31,64,75], (ii) solutions inspired by version control systems such as Git [8,33,46,79,81], and (iii) approaches with full support for highly concurrent updates [54]. Git-like solutions are particularly interesting for collaborative efforts such as DBpedia, because it is feasible to delegate users the task of conflict management. Conversely, fully automatically constructed KBs such as NELL [17] or data-intensive (e.g., streaming) applications may need the features of solutions such as x-RDF-3X [54]. Consequently, we propose a modular design that separates the concurrency layer from the storage backend. Such a middleware could take care of enforcing a consistency model for concurrent commits either automatically or via user-based conflict management. The layer could also manage the additional metadata for features such as branching and tagging. In that light, collaborative version control systems for RDF [8,33,79] become an application of fully-fledged RDF archiving.
Formats for publication and querying A fully functional archiving solution should support the most popular RDF serialization formats for data ingestion and dumping. For metadata enhanced RDF, this should include support for N-quads, singleton properties, and RDF-star. Among those, RDF-star [37] is the only one that can natively support multiple levels of metadata (still in a very verbose fashion). For example RDF-star could serialize the tuple ⟨:USA, :dr, :Cuba,
<<<:USA :dr :Cuba> :gl :UN> :ts “2020-07-09”ˆˆxsd:date>
The authors of [37] propose this serialization as part of the Turtle-star format. Moreover, they propose SPARQL-star that allows for nested triple patterns. While SPARQL-star enables the definition of metadata constraints at different levels, a fully archive-compliant language could offer further syntactic sugar such as the clauses REVISION [7,33] or DELTA to bind the variables of a BGP to the data in particular revisions or deltas. We propose to build such an archive-compliant language upon SPARQL-star.
Support for different types of archive queries Most of the studied archiving systems can answer all the query types defined in the literature of RDF archives [27,75]. That said, more complex queries such as CD and CV queries, or queries on full BGPs are sometimes supported via query middlewares and external libraries [8,75]. We endorse this design philosophy because it eases modularity. Existing applications in mining archives [42,60,61] already benefit from support for V, VM, and DM queries on single triple patterns. By guaranteeing scalable runtime for such queries, we can indirectly improve the runtime of more complex queries. Further optimizations can be achieved by proper query planning.
7.2.Challenges
Trade-offs on storage, query runtime, and ingestion time RDF archiving differs from standard RDF management in an even more imperative need for scalability, in particular storage efficiency. As shown by Taelman et al. [75], the existing storage paradigms shine at different types of queries. Hence, supporting arbitrary queries while being storage-efficient requires the best from the IC, CB, FB, and TB philosophies. A hybrid approach, however, will inevitably be more complex and introduce further parameters and trade-offs. The authors of Ostrich [75], for instance, chose to benefit faster version materialization via redundant deltas at the expense of larger ingestion times. Users requiring shorter ingestion times could, on the other hand, opt for non-redundant changesets, or lazy non-asynchronous ingestion (at the expense of data availability). We argue that the most crucial algorithmic challenge for a CB archiving solution is to decide when to store a revision as a snapshot or as a delta, which is tantamount to trading disk space for faster VM queries. This could be formulated as an (multi-objective) minimization problem whose objective might be a function of response time for triple patterns in VM, CV and V queries with constraints on available disk space and average ingestion time. When high concurrency is imperative, the objective function could also take query throughput into account. In the same vibe, a TB solution could trigger the construction of further indexes (e.g., new combinations of components, incremental indexes in the concurrent setting) based on a careful consideration of disk consumption and runtime gain. Such scenarios would not only require the conception of a novel cost model for query runtime in the archiving setting, but also the development of approximation algorithms for the underlying optimization problems, which are likely NP-Hard. Finally, since fresh data is likely to be queried more often than stale data, we believe that fetch time complexity99 on the most recent(s) version(s) of the dataset should not depend on the size of the archive history. Hence, and depending on the host available main memory, an RDF archiving system could keep the latest revision(s) of a dataset (or parts of it) in main memory or in optimized disk-based stores for faster query response time (as done by QuitStore [8]). Hence, main memory consumption could also be part of the optimization objective.
Internal serialization Archiving multi-graph datasets requires the serialization of 5-tuples, which complexifies the trade-offs between space (i.e., disk and main memory consumption) and runtime efficiency (i.e., response time, ingestion time). For example, dealing with more columns increases the number of possible index combinations. Also, it leads to more data redundancy, since a triple can be associated to multiple values for the fourth and fifth component. Classical solutions for metadata in RDF include reification [67], singleton properties [55], and named graphs [66]. Reification assigns each RDF statement (triple or quad) an identifier
Accounting for evolution patterns As our study in Section 4 shows, the evolution patterns of RDF archives can change throughout time leading even, to decreases in dataset size. With that in mind, we envision an adaptive data-oriented system that adjusts its parameters according to the archive’s evolution for the sake of efficient resource comsumption. Parameter tuning could rely on the metrics proposed in Section 3. Nonetheless, these desiderata translate into some design and engineering considerations. For example, we saw in Section 6 that a large number of deletions can negatively impact Ostrich’s query runtime, hence, such an event could trigger the construction of a complete snapshot of the dataset in order to speed-up VM queries (assuming the existence of a cost model for query runtime). In the same spirit and assuming some sort of dictionary encoding, an increase in the vocabulary dynamicity could increase the number of bits used to encode the identifiers of RDF terms in the dictionary. Those changes could be automatically carried out by the archiving engine, but could also be manually set up by the system administrator after an analysis with RDFev. A design philosophy that we envision to explore divides the history of each graph in the dataset in intervals such that each interval is associated to a block file. This file contains a full snapshot plus all the changesets in the interval. It follows that the application of a new changeset may update the latest block file or create a new one (old blocks could be merged into snapshots to save disk space). This action could be automatically executed by the engine or triggered by the system administrator. For instance, if the archive is the backend of a version control system, new branches may always trigger the creation of snapshots. This base architecture should be enhanced with additional indexes to speed up V queries and adapted compression for the dictionary and the triples.
Finally as we expect long dataset histories, it is vital for solutions to improve their ingestion time complexity, which should depend on the size of the changesets rather than on history size—contrary to what we observed in Section 6 for Ostrich. This constraint could be taken into account by the storage policy for the creation of storage structures such as deltas, snapshots, or indexes (e.g., by reducing the length of delta chains for redundant changesets). Nevertheless, very large changesets may still be challenging, specially in the concurrent scenario. This may justify the creation of temporary incremental (in-memory) indexes and data structures optimized for asynchronous batch updates as proposed in x-RDF-3X [54].
8.Conclusions
In this paper we have discussed the importance of RDF archiving for both maintainers and consumers of RDF data. Besides, we have discussed the importance of evolution patterns in the design of a fully-fledged RDF archiving solution. On these grounds, we have proposed a metric-based framework to characterize the evolution of RDF data, and we have applied our framework to study the history of three challenging RDF datasets, namely DBpedia, YAGO, and Wikidata. This study has allowed us to characterize the history of these datasets in terms of changes at the level of triples, vocabulary terms, and entities. It has also allowed us to identify design shifts in their release history. Those insights can be used to optimize the allocation of resources for archiving, for example, by triggering the creation of a new snapshot as a response to a large changeset.
In other matters, our survey and study of the existing solutions and benchmarks for RDF archiving has shown that only a few solutions are available for download and use, and that among those, only Ostrich can store the release history of very large RDF datasets. Nonetheless, its design still does not scale to long histories and does not exploit the data evolution patterns. R43ples [33], R&WBase [79], Quit Store [8], and x-RDF-3X [54] are also available, however they are still far from tackling the major challenges of this task, mainly because, they are conceived for collaborative version control, which is an application of RDF archiving in itself. Our survey also reveals that the state of the art lacks a standard to query RDF archives. We think that a promising solution is to use SPARQL-star combined with additional syntactic sugar as proposed by some approaches [7,28,33]
Finally, we have used all these observations to derive a set of design lessons in order to overcome the gap between the literature and a fully functional solution for large RDF archives. All in all, we believe that such a solution should (i) support global histories for RDF datasets, (i) resort to a modular architecture that decouples the storage from the application layers, (iii) handle provenance and domain-specific temporal metadata, (iv) implement a SPARQL extension to query archives, (v) use a metric-based approach to monitor the data evolution and adapt resource consumption accordingly, and (vi) provide a performance that does not depend on the length of the history. The major algorithmic challenges in the field lie in how to handle the inherent trade-offs between disk usage, ingestion time, and query runtime. With this detailed study and the derived guidelines, we aim at paving the way towards an ultimate solution for this problem. In this sense, we envision archiving solutions to not only serve as standalone single server systems but also as components of the RDF ecosystem on the Web in all its flavors covering federated [1,52,65,70] and client-server architectures [2,10,11,38,50,51,80] as well as peer-to-peer [3,4] solutions.
Notes
7 The Python interpreter reports a UnboundLocalError.
8 The code creates an array that exceeds the maximal array size in Java.
9 For single triple patterns on VM queries.
Acknowledgements
This research was partially funded by the Danish Council for Independent Research (DFF) under grant agreement no. DFF-8048-00051B and the Poul Due Jensen Foundation.
References
[1] | M. Acosta, M.-E. Vidal, T. Lampo, J. Castillo and E. Ruckhaus, ANAPSID: An adaptive query processing engine for SPARQL endpoints, in: The Semantic Web – ISWC 2011–10th International Semantic Web Conference, Bonn, Germany, October 23–27, 2011, (2011) , pp. 18–34. doi:10.1007/978-3-642-25073-6_2. |
[2] | C. Aebeloe, I. Keles, G. Montoya and K. Hose, Star Pattern Fragments: Accessing Knowledge Graphs through Star Patterns, 2020, CoRR, https://arxiv.org/abs/2002.09172 abs/2002.09172. |
[3] | C. Aebeloe, G. Montoya and K. Hose, A decentralized architecture for sharing and querying semantic data, in: ESWC, Vol. 11503: , Springer, (2019) , pp. 3–18. doi:10.1007/978-3-030-21348-0_1. |
[4] | C. Aebeloe, G. Montoya and K. Hose, Decentralized indexing over a network of RDF peers, in: ISWC, Vol. 11778: , Springer, (2019) , pp. 3–20. doi:10.1007/978-3-030-30793-6_1. |
[5] | C. Aebeloe, G. Montoya and K. Hose, ColChain: Collaborative linked data networks, in: WWW’21: The Web Conference 2021. ACM / IW3C2, (2021) , to appear. |
[6] | A.B. Andersen, N. Gür, K. Hose, K.A. Jakobsen and T. Bach Pedersen, Publishing Danish agricultural government data as semantic web data, in: Semantic Technology – 4th Joint International Conference, JIST 2014, Chiang Mai, Thailand, November 9–11, 2024, Springer, (2014) , pp. 178–186. doi:10.1007/978-3-319-15615-6_13. |
[7] | J. Anderson and A. Bendiken, Transaction-time queries in Dydra, in: MEPDaW/LDQ@ESWC, CEUR Workshop Proceedings, Vol. 1585: , CEUR-WS.org, (2016) , pp. 11–19. |
[8] | N. Arndt, P. Naumann, N. Radtke, M. Martin and E. Marx, Decentralized collaborative knowledge management using git, Journal of Web Semantics 54: ((2019) ), 29–47, http://www.sciencedirect.com/science/article/pii/S1570826818300416. doi:10.1016/j.websem.2018.08.002. |
[9] | S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak and Z. Ives, DBpedia: A nucleus for a web of open data, in: The Semantic Web, (2007) , pp. 722–735. doi:10.1007/978-3-540-76298-0_52. |
[10] | A. Azzam, C. Aebeloe, G. Montoya, I. Keles, A. Polleres and K. Hose, WiseKG: Balanced access to web knowledge graphs, in: WWW’21: The Web Conference 2021. ACM / IW3C2, (2021) , to appear. |
[11] | A. Azzam, J.D. Fernández, M. Acosta, M. Beno and A. Polleres, SMART-KG: Hybrid shipping for SPARQL querying on the web, in: WWW’20: The Web Conference 2020, ACM/IW3C2, (2020) , pp. 984–994. doi:10.1145/3366423.3380177. |
[12] | K. Bereta, P. Smeros and M. Koubarakis, Representation and querying of valid time of triples in linked geospatial data, in: Extended Semantic Web Conference, (2013) , pp. 259–274. doi:10.1007/978-3-642-38288-8_18. |
[13] | T. Berners-Lee, J. Hendler, O. Lassila et al., The Semantic Web. Scientific American 284: (5) ((2001) ), 28–37. doi:10.1007/978-0-387-30440-3_478. |
[14] | C. Bizer, The emerging web of linked data, IEEE Intelligent Systems 24: (5) ((2009) ), 87–92. doi:10.1109/MIS.2009.102. |
[15] | N.R. Brisaboa, A. Cerdeira-Pena, A. Fariña and G. Navarro, A compact RDF store using suffix arrays, in: String Processing and Information Retrieval, (2015) , pp. 103–115. doi:10.1007/978-3-319-23826-5_11. |
[16] | J. Brunsmann, Archiving pushed inferences from sensor data streams, in: Proceedings of the International Workshop on Semantic Sensor Web, INSTICC, (2010) , pp. 38–46. doi:10.5220/0003116000380046. |
[17] | A. Carlson, J. Betteridge, B. Kisiel, B. Settles, E.R. Hruschka Jr. and T.M. Mitchell, Toward an architecture for never-ending language learning, in: Proceedings of the Twenty-Fourth Conference on Artificial Intelligence, (2010) . doi:10.5555/2898607.2898816. |
[18] | S. Cassidy and J. Ballantine, Version control for RDF triple stores, ICSOFT (ISDM/EHST/DC) 7: ((2007) ), 5–12. doi:10.1142/S0218194012500040. |
[19] | A. Cerdeira-Pena, A. Fariña, J.D. Fernández and M.A. Martínez-Prieto, Self-indexing RDF archives, in: DCC, IEEE, (2016) , pp. 526–535. doi:10.1109/DCC.2016.40. |
[20] | R.P. Deb Nath, K. Hose, T. Bach Pedersen and O. Romero, SETL: A programmable semantic extract-transform-load framework for semantic data warehouses, Inf. Syst. 68: ((2017) ), 17–43. doi:10.1016/j.is.2017.01.005. |
[21] | R.P. Deb Nath, K. Hose and T. Bach Pedersen, O. Romero and A. Bhattacharjee, SETLBI: An integrated platform for semantic business intelligence, in: Proceedings of the 2020 World Wide Web Conference, (2020) . doi:10.1145/3366424.3383533. |
[22] | I. Ermilov, J. Lehmann, M. Martin and S. Auer, LODStats: The data web census dataset, in: Proceedings of 15th International Semantic Web Conference – Resources Track, (2016) , http://svn.aksw.org/papers/2016/ISWC_LODStats_Resource_Description/public.pdf. |
[23] | F. Erxleben, M. Günther, M. Krötzsch, J. Mendez and D. Vrandečić, Introducing wikidata to the linked data web, in: International Semantic Web Conference, (2014) , pp. 50–65. doi:10.1007/978-3-319-11964-9_4. |
[24] | European Open Data Portal. https://data.europa.eu/data/. Accessed: 2020-06-09. |
[25] | J.D. Fernández, M.A. Martínez-Prieto, C. Gutiérrez, A. Polleres and M. Arias, Binary RDF representation for publication and exchange (HDT), Web Semantics: Science, Services and Agents on the World Wide Web 19: ((2013) ), 22–41. doi:10.1016/j.websem.2013.01.002. |
[26] | J.D. Fernández, M.A. Martínez-Prieto, A. Polleres and J. Reindorf, HDTQ: Managing RDF datasets in compressed space, in: The Semantic Web, (2018) , pp. 191–208. doi:10.1007/978-3-319-93417-4_13. |
[27] | J.D. Fernández, J. Umbrich, A. Polleres and M. Knuth, Evaluating query and storage strategies for RDF archives, in: Proceedings of the 12th International Conference on Semantic Systems, (2016) , pp. 41–48. doi:10.1145/2993318.2993333. |
[28] | V. Fionda, M. Wudage Chekol and G. Pirrò, Gize a time warp in the web of data, in: International Semantic Web Conference (Posters & Demos), Vol. 1690: , (2016) . |
[29] | J. Frey, M. Hofer, D. Obraczka, J. Lehmann and S. Hellmann, DBpedia: FlexiFusion the best of Wikipedia > wikidata > your data, in: The Semantic Web – ISWC 2019, (2019) , pp. 96–112. doi:10.1007/978-3-030-30796-7_7. |
[30] | L. Galárraga, K. Ahlstrøm, K. Hose and T. Bach Pedersen, Answering provenance-aware queries on RDF data cubes under memory budgets, in: The Semantic Web – ISWC 2018, (2018) , pp. 547–565. doi:10.1007/978-3-030-00671-6_32. |
[31] | S. Gao J. Gu and C. Zaniolo, RDF-TX: A fast, user-friendly system for querying the history of RDF knowledge bases, in: Proceedings of the Extended Semantic Web Conference, (2016) , pp. 269–280. doi:10.1016/j.ic.2017.08.012. |
[32] | F. Grandi, T-SPARQL: A TSQL2-like temporal query language for RDF, in: Local Proceedings of the Fourteenth East-European Conference on Advances in Databases and Information Systems, (2010) , pp. 21–30. doi:10.1145/3180374.3181338. |
[33] | M. Graube, S. Hensel and L. Leon, R43ples: Revisions for triples, in: Proceedings of the 1st Workshop on Linked Data Quality Co-Located with 10th International Conference on Semantic Systems (SEMANTiCS), (2014) . |
[34] | Y. Guo, Z. Pan and J. Heflin, LUBM: A benchmark for OWL knowledge base systems, Journal of Web Semantics 3: (2) ((2005) ), 158–182. doi:10.1016/j.websem.2005.06.005. |
[35] | N. Gür, T. Bach Pedersen, E. Zimányi and K. Hose, A foundation for spatial data warehouses on the semantic web, Semantic Web 9: (5) ((2018) ), 557–587. doi:10.3233/SW-170281. |
[36] | N. Gür, J. Nielsen, K. Hose and T. Bach Pedersen, GeoSemOLAP: Geospatial OLAP on the semantic web made easy, in: Proceedings of the 26th International Conference on World Wide Web Companion, ACM, (2017) , pp. 213–217. doi:10.1145/3041021.3054731. |
[37] | O. Hartig, Foundations of RDF⋆ and SPARQL⋆: An alternative approach to statement-level metadata in RDF, in: Proc. of the 11th Alberto Mendelzon International Workshop on Foundations of Data Management, AMW, (2017) . |
[38] | O. Hartig and C.B. Aranda, Bindings-restricted triple pattern fragments, in: On the Move to Meaningful Internet Systems: OTM 2016 Conferences – Confederated International Conferences: CoopIS, C&TC, and ODBASE 2016, (2016) , pp. 762–779. doi:10.1007/978-3-319-48472-3_48. |
[39] | O. Hartig, K. Hose and J.F. Sequeda, Linked data management, in: Encyclopedia of Big Data Technologies, S. Sakr and A.Y. Zomaya, eds, Springer, (2019) . doi:10.1007/978-3-319-63962-8_76-1. |
[40] | I. Horrocks, T. Hubauer, E. Jiménez-Ruiz, E. Kharlamov, M. Koubarakis, R. Möller, K. Bereta, C. Neuenstadt, Ö. Özçep, M. Roshchin and P. Smeros, D. Zheleznyakov, Addressing streaming and historical data in OBDA systems: Optique’s approach (statement of interest), in: Workshop on Knowledge Discovery and Data Mining Meets Linked Open Data (Know@LOD), (2013) . |
[41] | K. Hose and R. Schenkel, RDF stores, in: Encyclopedia of Database Systems, L. Liu and M. Tamer Özsu, eds, 2nd edn, Springer, (2018) . doi:10.1007/978-1-4614-8265-9_80676. |
[42] | T. Huet, J. Biega and F.M. Suchanek, Mining history with le monde, in: Proceedings of the Workshop on Automated Knowledge Base Construction, (2013) , pp. 49–54. doi:10.1145/2509558.2509567. |
[43] | D. Ibragimov, K. Hose, T. Bach Pedersen and E. Zimányi, Towards exploratory OLAP over linked open data – a case study, in: Enabling Real-Time Business Intelligence – International Workshops, BIRTE 2013, Vol. 206: , Springer, (2014) , pp. 114–132. doi:10.1007/978-3-662-46839-5_8. |
[44] | D. Ibragimov, K. Hose, T. Bach Pedersen and E. Zimányi, Processing aggregate queries in a federation of SPARQL endpoints, in: Proceedings, the Semantic Web. Latest Advances and New Domains – 12th European Semantic Web Conference, ESWC 2015, Portoroz, Slovenia May 31–June 4, Vol. 9088: , Springer, (2015) , pp. 269–285. doi:10.1007/978-3-319-18818-8_17. |
[45] | D. Ibragimov, K. Hose, T. Bach Pedersen and E. Zimányi, Optimizing aggregate SPARQL queries using materialized RDF views, in: Proceedings, Part I, The Semantic Web – ISWC 2016 – 15th International Semantic Web Conference, Kobe, Japan, October 17–21, 2016, (2016) , pp. 341–359. doi:10.1007/978-3-319-46523-4_21. |
[46] | D.H. Im, S.W. Lee and H.J. Kim, A version management framework for RDF triple stores, International Journal of Software Engineering and Knowledge Engineering 22: ((2012) ), 04. doi:10.1142/S0218194012400141. |
[47] | K.A. Jakobsen, A.B. Andersen, K. Hose and T. Bach Pedersen, Optimizing RDF data cubes for efficient processing of analytical queries, in: International Workshop on Consuming Linked Data, (COLD) Co-Located with 14th International Semantic Web Conference (ISWC 2105), Vol. 1426: , CEUR-WS.org, (2015) . http://ceur-ws.org/Vol-1426/paper-02.pdf. |
[48] | M. Meimaris, EvoGen: A generator for synthetic versioned RDF, in: Proceedings of the Workshops of the EDBT/ICDT 2016 Joint Conference, EDBT/ICDT Workshops 2016, Vol. 1558: , (2016) , http://ceur-ws.org/Vol-1558/paper9.pdf. |
[49] | S. Metzger, K. Hose and R. Schenkel, Colledge: A vision of collaborative knowledge networks, in: Proceedings of the 2nd International Workshop on Semantic Search over the Web, ACM, (2012) , pp. 1–8. doi:10.1145/2494068.2494069. |
[50] | T. Minier, H. Skaf-Molli and P. Molli, SaGe: Web preemption for public SPARQL query services, in: The World Wide Web Conference, WWW 2019, ACM, (2019) , pp. 1268–1278. doi:10.1145/3308558.3313652. |
[51] | G. Montoya, C. Aebeloe and K. Hose, Towards efficient query processing over heterogeneous RDF interfaces, in: Proceedings of the 2nd Workshop on Decentralizing the Semantic Web Co-Located with the 17th International Semantic Web Conference, DeSemWeb@ISWC, CEUR Workshop Proceedings Vol. 2165: , CEUR-WS.org, (2018) . http://ceur-ws.org/Vol-2165/paper4.pdf. |
[52] | G. Montoya, H. Skaf-Molli and K. Hose, The odyssey approach for optimizing federated SPARQL queries, in: International Semantic Web Conference, Vol. 10587: , Springer, (2017) , pp. 471–489. doi:10.1007/978-3-319-68288-4_28. |
[53] | T. Neumann and G. Weikum, RDF-3X: A RISC-style engine for RDF, Proceedings of the VLDB Endowment 1: (1) ((2008) ), 647–659. doi:10.14778/1453856.1453927. |
[54] | T. Neumann and G. Weikum, x-rdf-3x: Fast querying, high update rates, and consistency for rdf databases, Proceedings of the VLDB Endowment 3: (1–2) ((2010) ), 256–263. doi:10.14778/1920841.1920877. |
[55] | V. Nguyen, O. Bodenreider and A. Sheth, Don’t like RDF reification?: Making statements about statements using singleton property, in: Proceedings of the 23rd International Conference on World Wide Web, (2014) , pp. 759–770. doi:10.1145/2566486.2567973. |
[56] | N. Noy and M. Musen, Ontology Versioning in an Ontology Management Framework, Intelligent Systems, IEEE (2004), 19:6–13, 08. doi:10.1109/MIS.2004.33. |
[57] | OpenLink Software. OpenLink Virtuoso. http://virtuoso.openlinksw.com. |
[58] | G. Papadakis, K. Bereta, T. Palpanas and M. Koubarakis, Multi-core meta-blocking for big linked data, in: Proceedings of the 13th International Conference on Semantic Systems, (2017) , pp. 33–40. doi:10.1145/3132218.3132230. |
[59] | V. Papavassiliou, G. Flouris, I. Fundulaki, D. Kotzinos and V. Christophides, On detecting high-level changes in RDF/S KBs, in: International Semantic Web Conference (ISWC), (2009) , pp. 473–488. doi:10.1007/978-3-642-04930-9_30. |
[60] | T. Pellissier Tanon, C. Bourgaux and F. Suchanek, Learning how to correct a knowledge base from the edit history, in: The World Wide Web Conference, (2019) , pp. 1465–1475. doi:10.1145/3308558.3313584. |
[61] | T. Pellissier Tanon and F.M. Suchanek, Querying the edit history of wikidata, in: Extended Semantic Web Conference, (2019) . doi:10.1007/978-3-030-32327-1_32. |
[62] | M. Perry, P. Jain and A.P. Sheth, SPARQL-ST: Extending SPARQL to support spatio-temporal queries, in: Geospatial Semantics and the Semantic Web, Vol. 12: , (2011) , pp. 61–86. doi:10.1007/978-1-4419-9446-2_3. |
[63] | USA Data Gov. portal. https://www.data.gov/. Accessed: 2020-06-09. |
[64] | M. Psaraki and Y. Tzitzikas, CPOI: A Compact Method to Archive Versioned RDF Triple-Sets, (2019) , arXiv:1902.04129. |
[65] | B. Quilitz and U. Leser, Querying distributed RDF data sources with SPARQL, in: The Semantic Web: Research and Applications, 5th European Semantic Web Conference, ESWC 2008, Proceedings, Tenerife, Canary Islands Spain, June 1–5, 2008, (2008) , pp. 524–538. doi:10.1007/978-3-540-68234-9_39. |
[66] | Y. Raimond and G. Schreiber, RDF 1.1 primer. W3C recommendation, 2014. http://www.w3.org/TR/2014/NOTE-rdf11-primer-20140624/. |
[67] | Y. Raimond and G. Schreiber, RDF 1.1 Semantics. W3C recommendation, 2014. http://www.w3.org/TR/2014/REC-rdf11-mt-20140225/. |
[68] | RDF Exports from Wikidata. Available at tools.wmflabs.org/wikidata-exports/rdf/index.html. |
[69] | Y. Roussakis, I. Chrysakis, K. Stefanidis, G. Flouris and Y. Stavrakas, A flexible framework for understanding the dynamics of evolving RDF datasets, in: International Semantic Web Conference (ISWC), (2015) . doi:10.1007/978-3-319-25007-6_29. |
[70] | A. Schwarte, P. Haase, K. Hose, R. Schenkel and M. Schmidt, FedX: Optimization techniques for federated query processing on linked data, in: International Semantic Web Conference, Vol. 7031: , Springer, (2011) , pp. 601–616. doi:10.1007/978-3-642-25073-6_38. |
[71] | A. Seaborne and S. Harris, SPARQL 1.1 query language. W3C recommendation, W3C, 2013. http://www.w3.org/TR/2013/REC-sparql11-query-20130321/. |
[72] | R.T. Snodgrass, I. Ahn, G. Ariav, D.S. Batory, J. Clifford, C.E. Dyreson, R. Elmasri, F. Grandi, C.S. Jensen, W. Käfer, N. Kline, K.G. Kulkarni, T.Y. Cliff Leung, N.A. Lorentzos, J.F. Roddick, A. Segev, M.D. Soo and S.M. Sripada, TSQL2 language specification, SIGMOD Record 23: (1) ((1994) ), 65–86. doi:10.1145/181550.181562. |
[73] | Stardog. http://stardog.com. Accessed: 2020-06-09. |
[74] | F.M. Suchanek, G. Kasneci and G. Weikum, Yago: A large ontology from Wikipedia and wordnet, Web Semantics: Science, Services and Agents on the World Wide Web 6: (3) ((2008) ), 203–217. doi:10.1016/j.websem.2008.06.001. |
[75] | R. Taelman, M. Vander Sande and R. Verborgh, OSTRICH: Versioned random-access triple store, in: Companion of the Web Conference 2018, WWW, (2018) , pp. 127–130. doi:10.1145/3184558.3186960. |
[76] | M. Tasnim, D. Collarana, D. Graux, F. Orlandi and M.-E. Vidal, Summarizing entity temporal evolution in knowledge graphs, in: Companion Proceedings of the 2019 World Wide Web Conference, (2019) , pp. 961–965. doi:10.1145/3308560.3316521. |
[77] | The Apache Software Foundation. Apache Jena Semantic Web Framework. jena.apache.org. |
[78] | The World Wide Web Consortium. PROV-O: The PROV Ontology. http://www.w3.org/TR/prov-o, 2013. |
[79] | M. Vander Sande, P. Colpaert, R. Verborgh, S. Coppens, E. Mannens and R. Van de Walle, R&Wbase: Git for Triples. Linked Data on the Web Workshop, (2013) . |
[80] | R. Verborgh, M. Vander Sande, O. Hartig, J. Van Herwegen, L. De Vocht, B. De Meester, G. Haesendonck and P. Colpaert, Triple pattern fragments: A low-cost knowledge graph interface for the web, J. Web Semant. 37–38: ((2016) ), 184–206. doi:10.1016/j.websem.2016.03.003. |
[81] | M. Volkel, W. Winkler, Y. Sure, S.R. Kruk and M. Synak, SemVersion: A Versioning System for RDF and Ontologies. Second European Semantic Web Conference, (2005) . |
[82] | A. Zimmermann, N. Lopes, A. Polleres and U. Straccia, A general framework for representing, reasoning and querying with annotated semantic web data, Web Semantics 11: ((2012) ), 72–95. doi:10.1016/j.websem.2011.08.006. |


