
A fuzzy control system for fitness service based on genetic algorithm during COVID-19 pandemic
Abstract
During the COVID-19 epidemic period, it is essential to strengthen physical exercise and improve the health of the whole people. In this paper, based on genetic algorithm, a fuzzy control system is proposed to dynamically adjust the exercise ability of the bodybuilders under the comprehensive consideration of parameters. Through experiments and data processing, the system obtains bioelectric information related to heart rate, heart rate variability and muscle fatigue of the fitness people in the three states of not fatigue, moderate fatigue and extreme fatigue, establishes fuzzy membership function, and thus establishes personalized fitness information feedback control strategy to maintain moderate fitness intensity. By narrowing the gap between the predicted RPE value based on objective information and the measured RPE, the method provides a unified subjective and objective exercise intensity for the bodybuilders, effectively expands the time of aerobic exercise, and enhances the effect of aerobic exercise. In addition, in order to expand the scope of application of the exercise intensity control model, the service-oriented transformation is carried out to enable it to provide fitness content combinations of interest to fitness practitioners and instructors.
1Introduction
At present, new virus pneumonia of COVID-19 is abusing the world, which has a serious impact on the production and life of people around the world, especially a serious threat to the health of the people. Therefore, while focusing on strengthening epidemic prevention work, we must attach importance to the construction of sports health service projects and continuously improve the weight of people’s physical fitness [1].
Service Technology (Service Engineering, SE) refers to the technical support link for Services Sciences (Management, and Engineering, SSME) [2]. The concept was first proposed by IBM, which refers to the combination of computer science, industrial engineering, management science and other disciplines to create a service area to develop and implement technology applications to help service providers improve the current service engineering. Service technology involves a systematic development and design service process, which refers to the use of appropriate models and tools to design a comprehensive service system for customer satisfaction and produce customer satisfaction [3]. As service engineering is increasingly used in various fields such as finance, logistics, and IT industries, this concept has also been introduced in the sports industry. However, because ordinary fitness people cannot be like professional athletes, they can achieve their training goals through fully equipped physiological and biochemical instruments and professional trainers. They can only open and disseminate to the public through targeted personalized fitness prescription methods and service sharing.
Domestic research on fitness service technology mainly focuses on providing services such as physical fitness evaluation, exercise prescription, fitness monitoring, fitness effect evaluation and fitness nutrition guidance [4, 5]. It mainly includes: three levels of system: decision-making system, command system and implementation of operating system. The development of sports health service technology can be based on a reference model, which should be able to support the planning and monitoring of the entire project. Using service engineering in sports fitness service research can reduce the blindness of development, and has good scalability and compatibility [6].
However, so far, there are still many theoretical and application issues concerning the guidance of sports and fitness services. For example, there are three prominent main problems in the field of sports fatigue. First, there is still a lack of information about sports fatigue information acquisition and intelligent processing. At present, sports fatigue information is too professional, and a lot of information needs to be interpreted by professionals, which hinders the effective promotion of mass fitness. Secondly, problems such as the formulation of reasonable exercise intensity and intelligent feedback processing and control in the process of sports fitness have not received attention. The third is the lack of effective guidance on the sports fitness guidance service implementation model [7].
In response to the above problems, a scientific method is needed to deal with it. In scientific research and practice, the use of genetic algorithms is a commonly adopted method. It establishes a model to study the entire system and structure. The parameters to be determined in the model need to be determined by some measured values. This process of reverse solution (parameter identification), that is, inverse problem solving, widely exists in many fields such as engineering design, biological signal processing, and physics [8–11].
In this regard, this article is based on genetic algorithms, sports fitness services based on physiological fatigue assessment methods and service engineering theory based on physiology, according to the personalized sports requirements of fitness people, reduce the demand and dependence on fitness service guidance professionals to improve Research on the goal of scientific fitness and moderate fatigue.
2Theoretical basis and parameter setting
2.1Measurement index
Reasonable exercise intensity can improve people’s fitness level, which is also the key to exercise prescription. However, the current fitness prescription is basically a “dogma” guidance type, that is, to formulate items such as the form, intensity and time of sports through a certain sports item for a certain type of object. This prescription does not distinguish the specific physical qualities of individuals in detail. The set exercise intensity and other requirements cannot meet the personalized fitness needs of modern people [12–14]. The lack of effective means of obtaining and processing personal physiological information is the reason why personalized exercise prescriptions cannot develop.
At present, some of the main indicators for assessing individual exercise are: heart rate, blood pressure, maximum oxygen uptake, and human blood metabolites, such as lactic acid. These biochemical indicators require expensive instruments to measure, and some are invasive tests, so they are not widely used in actual real-time testing. There is a big difference between individual sports. It is necessary to evaluate the individual’s physical condition during exercise to determine the appropriate amount of exercise in real time, but the control of the exercise intensity of individual exercise intensity has always been a difficult problem to solve. The use of genetic algorithms can provide the possibility of dynamically assessing human sports fatigue during exercise. In addition, as a subjective fatigue evaluation, the RPE scale can also be widely used in sports.
2.2Sports fitness intensity model
In general, we have obtained the main objective parameters for evaluating the fatigue level of human beings during the fitness exercise of a specific group of people: the amplitude index RMS of the surface EMG signal, the frequency domain index MPF, the heart rate HR, the low frequency component LF, and the high frequency component HF [15]. In each exercise, the time during the aerobic exercise phase is extended as much as possible, so as to improve the tolerance of the body of the fitness person. In addition, the subjective fatigue scale is also an important factor to evaluate fatigue. The intensity control of the exercise process can actually be attributed to the optimization problem of the genetic algorithm. On the premise of satisfying the physical fitness constraints of the bodybuilder, in each exercise, the time during the aerobic exercise phase is extended as much as possible, thereby improving the fitness capacity of the bodybuilder.
However, the difference from the traditional optimization problem is that due to the complexity of the human body and the redundancy of physiological information, human fatigue reflected by surface EMG and ECG information is a process that cannot be described with a deterministic mathematical model. Therefore, it cannot be established using the modeling process of “physical model-conceptual model-mathematical model” followed in the traditional method.
Therefore, for this model system with typical nonlinear input-output characteristics, we usually use the method of fuzzy neural network to simulate the structure and function of the human brain, and then form a processing method similar to human brain behavior.
3Research on fuzzy control of sports fitness load
3.1Load incremental fuzzy control
The bioelectric signal parameters of load incremental fuzzy control are mainly completed by the processing of bioelectric signals, the fuzzy reasoning of control parameters and the control of sports fitness load. Sensors are used to process the bioelectrical signals during exercise. It is a continuous signal. After filtering, noise removal and other processing, the selected indicators are evaluated respectively for fatigue. When performing signal analysis, we process it through frame analysis and divide the signal into several data segments. In the specific calculation, we can set z to represent the signal of the first frame, use IV to represent the number of sampled samples in each frame, and use EMG to represent the samples of surface EMG signals. In order to ensure the accuracy of data processing, when we divide the frame, we can define the data repetition rate of each frame as 0.5. Regarding signal processing and statistical analysis, under Matlab2008 environment, it is processed with its signal processing toolbox, statistical toolbox and index calculation tool written in conjunction with the special needs of this article. In sports and fitness, the pedal power bike collects surface EMG signals and ECG once every 5 revolutions. Obviously, such a frame signal includes 5 cycles of surface EMG signals, and calculates the RMS and MPF values of each frame, Using the Pcason simple correlation coefficient method to calculate the correlation coefficient of the RMS and MPF two sets of variables, the formula is
(1)
For the power load required by exercisers during exercise, the following load increment methods are designed:
(2)
In the formula: the workload at the mth frame adjusts the increment of exercise intensity through a recursive call process, and its positive and negative states are divided according to whether the exercise is in a fatigue state:
ΔWL is the increase in exercise intensity, and its value needs to be set according to the personal condition of the fitness person. The continuous power of the general population to maintain aerobic exercise on power bikes is generally below 250 w, and ΔWL can be set to 5–20 w/min. It should be noted that this increase in exercise intensity has an exact physical meaning and is related to the fitness of the bodybuilder. Therefore, when controlling the load increase of exercise intensity, it must be noted that the load cannot make the bodybuilder exceed its maximum heart rate. Otherwise, on the one hand, it may cause damage to the cardiovascular system of the fitness person; on the other hand, the increase cannot play a substantial regulatory role in the fitness process.
Generally speaking, the fuzzy membership function is a function that represents the degree to which an object u belongs to the set A. It is usually written that fuzzy logic is based on fuzzy sets as operations and inferences. With the help of membership function, the transformation from ordinary set to fuzzy set can be realized. Common membership function forms include triangle and trapezoid. In this paper, the definition method is divided into sections, and the triangular period is adopted for the fatigue period.
(3)
Since fitness exercise is a dynamic process, the data obtained is also dynamic changes, which can be represented by an infinite triangle distribution. In the process of the subject’s incremental load movement, its heart rate continues to rise, and the correlation index gradually transitions from a positive value to a negative value area. Therefore, we can easily divide the pedaling fitness process into three stages: unfatigue period, moderate fatigue period and over-fatigue period.
Since fitness exercise is a dynamic process, the data obtained is also dynamic changes, which can be represented by an infinite triangle distribution. In the process of the subject’s incremental load movement, its heart rate continues to rise, and the correlation index gradually transitions from a positive value to a negative value area. Therefore, we can easily divide the pedaling fitness process into three stages: unfatigue period, moderate fatigue period and over-fatigue period.
When considering that n samples are divided into c categories, the criterion adopts the smallest sum of squared errors between each sample and the mean of its class, assuming {xi, i = 1, 2,..., N) is a set consisting of n samples; c is the number of categories; {ml, i = 1, 2,..., C) is the center of each cluster; uj(xi) is the membership function of the fth sample to the Jth class, then the clustering loss function is:
(4)
(5)
(6)
3.2Research on the method of predicting RPE based on genetic algorithm optimized neural network
Artificial neural network is an artificial intelligence information processing method that imitates the brain to process information. By designing a reasonable multi-layer network, it can handle strong nonlinear problems between complex multi-variables. However, the traditional BP algorithm (Back Propagation, BP) is difficult to converge to the global best, and the multi-layer network training results are unstable, and the execution efficiency is poor. By constructing a suitable genetic operator, the neural network can be optimized to simulate and predict the RPE value of bodybuilders’ subjective fatigue. In this regard, this paper proposes a method based on genetic algorithm to optimize neural network to predict RPE in sports fitness. Through the extraction and training of objective information, the prediction output RPE expectation and subjective RPE error are reduced, thereby improving fitness quality.
In fact, the working process of genetic algorithm is essentially to simulate the evolution of organisms. The principle of automatically generating verification vectors based on genetic algorithm and coverage-driven is to use genetic algorithm to automatically search for a solution that meets the requirements in the solution space. That is, the gene coding method and algorithm parameters are selected according to the DUT (design under test) functional coverage model, and individuals with higher “adaptability” are selected based on the feedback coverage information to combine and breed the next generation. This algorithm is completely in line with the principle of survival of the fittest in nature, and at the same time, combining the excellent genes between different individuals to produce the next generation more adaptable to the environment, so the algorithm is called the genetic algorithm. The process of generating verification vectors based on GA is shown in Fig. 1. First, the verification vectors generated by GA need to be combined (verification vector combiner) and then handed over to drv (verification vector driver). d “Driving the verification vectors into the DUT for simulation according to the DUT interface timing. Finally, the coverage information will be Feedback back to GA, GA regenerates a new verification vector with higher adaptability to the DUT according to the coverage information until the coverage reaches the predetermined requirements. The most critical technology in this process is GA, which is the most important advantage of this algorithm for verification That is, the verifier only needs to build a DUT function coverage model, and does not need to care about how these coverage points are covered.
Fig. 1
Improved fuzzy C-means clustering process.
Chromosome coding can use both binary coding of 0 and l, or real coding, and express the solution data into a data structure of genotype strings through coding, so as to seek the solution of the original problem in the genetic space, and finally convert it back to the original Solution space to explain. In this paper, the real number coding method is used. Since the input node of the designed neural network is 5, the number of nodes in the output layer is 1, and the number of nodes in the hidden layer is determined to 20 by empirical formula, so it constitutes a “5.20.1” network structure. The chromosome coding length L under this structure is:
In this paper, the target position of each step is regarded as an individual, and many different positions and directions constitute the population. The initial population is some running directions and positions generated by random numbers before the algorithm starts to operate. The population needs to contain enough random factors (that is, there are many different running directions and positions), so it must be large enough to adapt to the application requirements of genetic algorithms. This paper generates 200 in codes as the initial population. The values of these individuals are composed of random numbers, and the number is sufficient. Therefore, genetic algorithm operations can be performed on them.
Distance function d from the final target point, the distance d between the current position (xn, yn) and the end point (x, y) is [16, 17]:
(7)
Record the distance between the position point (xn, yn) of each step and the starting point of this step (x n - 1, y n - 1) as l, and accumulate each l to be the run the distance function L.
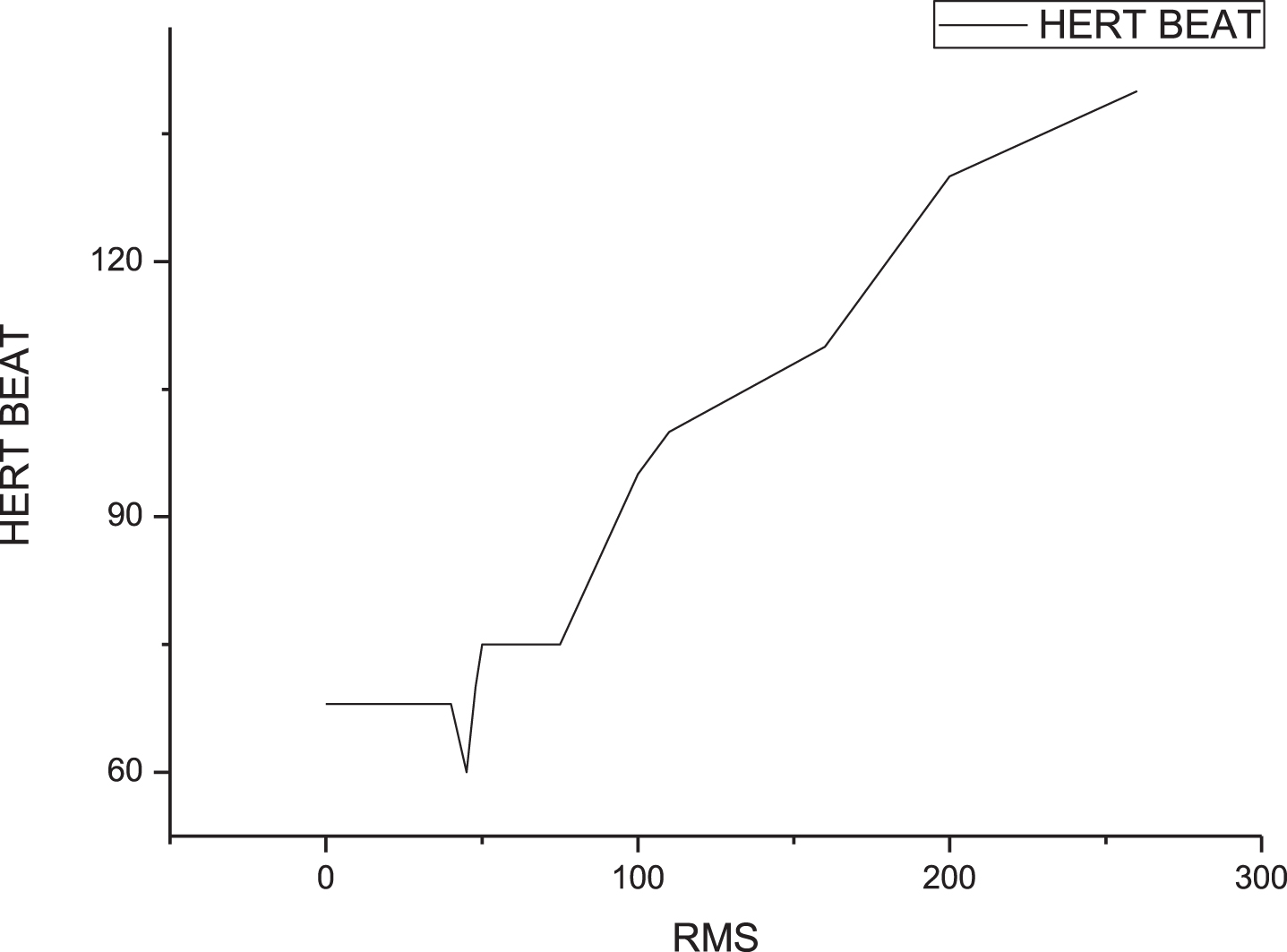
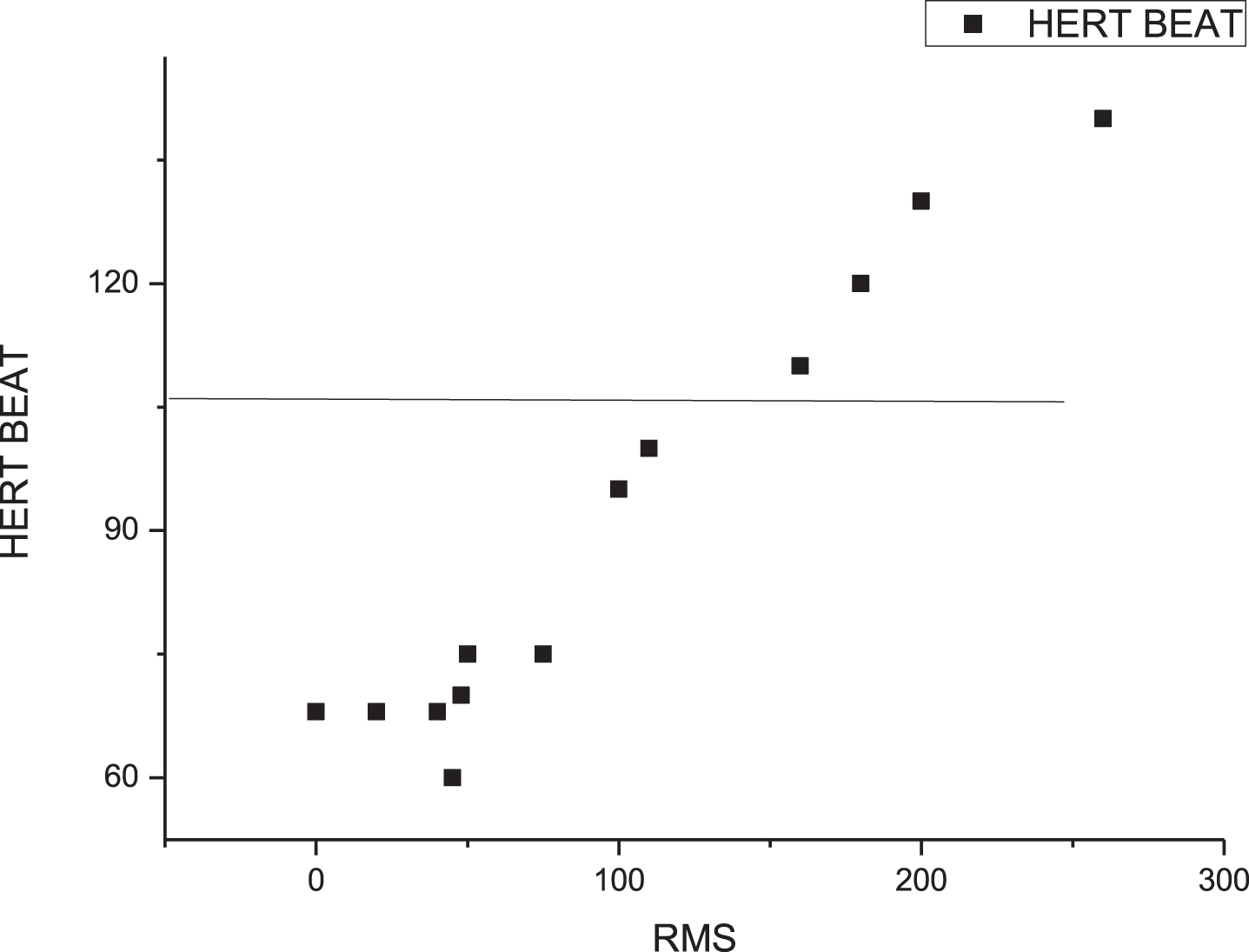
We can get the time-varying situation of γRMS-MPF during exercise. Because heart rate can be used as a rough indicator of exercise intensity to a certain extent, there is a clear correlation with each other. With the gradual increase of the exercise center rate, the correlation coefficient of RMS and MPF, γRMS-MPF gradually transitions from a positive value to a negative value. Intensity control near the target heart rate. γRMS-MPF fluctuates in the region of zero value, so combined with the change of heart rate and x, the intensity of exercise can be controlled within a certain range to avoid the phenomenon of fatigue during exercise.
3.3Neural network training
The general nonlinear fitting approximation problem can be solved by constructing a three-layer neural network. In the network structure shown in Fig. 3, the neural network predicts the subjective fatigue value of RPE. In order to speed up the convergence speed, the input and output values are normalized, the value range is controlled within [0.1], and each node is input. The frame information collected in the experiment is used as the input. Among them, after the load power is increased and the load is calculated by MARLAB, the load change data is input to the car through the communication port of the Monark power bicycle and the computer, and the weights of the hidden layer of the neural network are dynamically trained during the exercise of the bodybuilder. Record the subjective RPE value of the fitness person at intervals and compare with the prediction result of the neural network. If the difference is too large, it means that there is a big difference between the current exercise intensity and the degree of subjective perception. This information is fed back to the fuzzy control structure, and then the appropriate load and load increment coefficient are adjusted.
The open white dots indicate the function points that need to be covered. The solid ellipse indicates the current verification vector. The number of points surrounded by the ellipse indicates the functional points that can be covered by the vector. The number of points surrounded by the ellipse is used to select the vector that covers more functional points to “breed” the offspring. The dotted ellipse indicates that the generated next generation covers more function points. This rule continues to evolve and eventually covers all functional points. C in Fig. 2 is generated by A, B, and D, and c covers some new coverage points, and finally, through the accumulation of test case coverage, a higher coverage rate will be obtained.
Fig. 2
Comparison between HR and RMS.
It can be seen from the traditional genetic algorithm that the main idea is to select individuals with higher fitness for hybridization and mutation to produce a better next generation. We know that there is also a phenomenon in nature, such as bubbles in water. When two bubbles collide with each other, they will form larger bubbles. That is to say, when the areas covered by two individuals are adjacent or intersect, you can they fuse together to form more powerful individuals. The next-generation verification vectors generated according to this rule can at least cover the sum of the areas covered by the previous-generation verification vectors. Therefore, according to this idea, the traditional genetic algorithm has been improved as follows, and named the growth algorithm. Of course, the coverage in the verification is not a spatial arrangement, but we can define interconnected and continuous functional coverage points from the DUT behavior, and map these interconnected functional coverage points to the spatial arrangement. On this basis, there is the concept that the coverage area can be adjacent and intersect. This concept is a prerequisite for our growth algorithm. The coverage points of the growth algorithm are shown in Fig. 3.
Fig. 3
The coverage points of the growth algorithm.
3.3Convergence analysis
The mutation operator generates a new individual by changing one or some genes in the individual, which is helpful to maintain the diversity of the population. Population 1 randomly determines a locus for mutation operation, and population 2 randomly determines N genes for mutation operation. The specific formula for:
(8)
Each verification vector generated by the genetic algorithm needs to make the DUT complete a complete job, and the growth algorithm only requires it to complete part of the work, that is, to cover some functional coverage points. The genetic algorithm is to cross two individuals with the same number of chromosomes, and then form a new individual with the same number of chromosomes after mutation, and the growth algorithm merges the two chromosomes on the basis that the two chromosomes do not coincide with each other., Which can ensure that the generated next-generation verification vector can cover all the functional points that the previous generation can cover. To avoid repeatedly generating individuals with similar coverage rates, accelerating the evolution of genetic algorithm will always lead to some difficult to detect coverage points (blind spots) that cannot be covered. The growth algorithm selects the verification vectors that are adjacent to the coverage area to merge, just like the “carpet” search avoids the problem that the blind spots cannot be covered. The improved algorithm and the genetic algorithm are also performed on the verification platform of the LCD-Controller module. In the simulation, the verification vectors generated by the two algorithms are 650, the simulation time is 1, and the crossover rate is 0,85, and the mutation rate is 0,2. The simulation results are shown in Figs. 4–6.
Fig. 4
The simulation results.
Fig. 5
The simulation results.
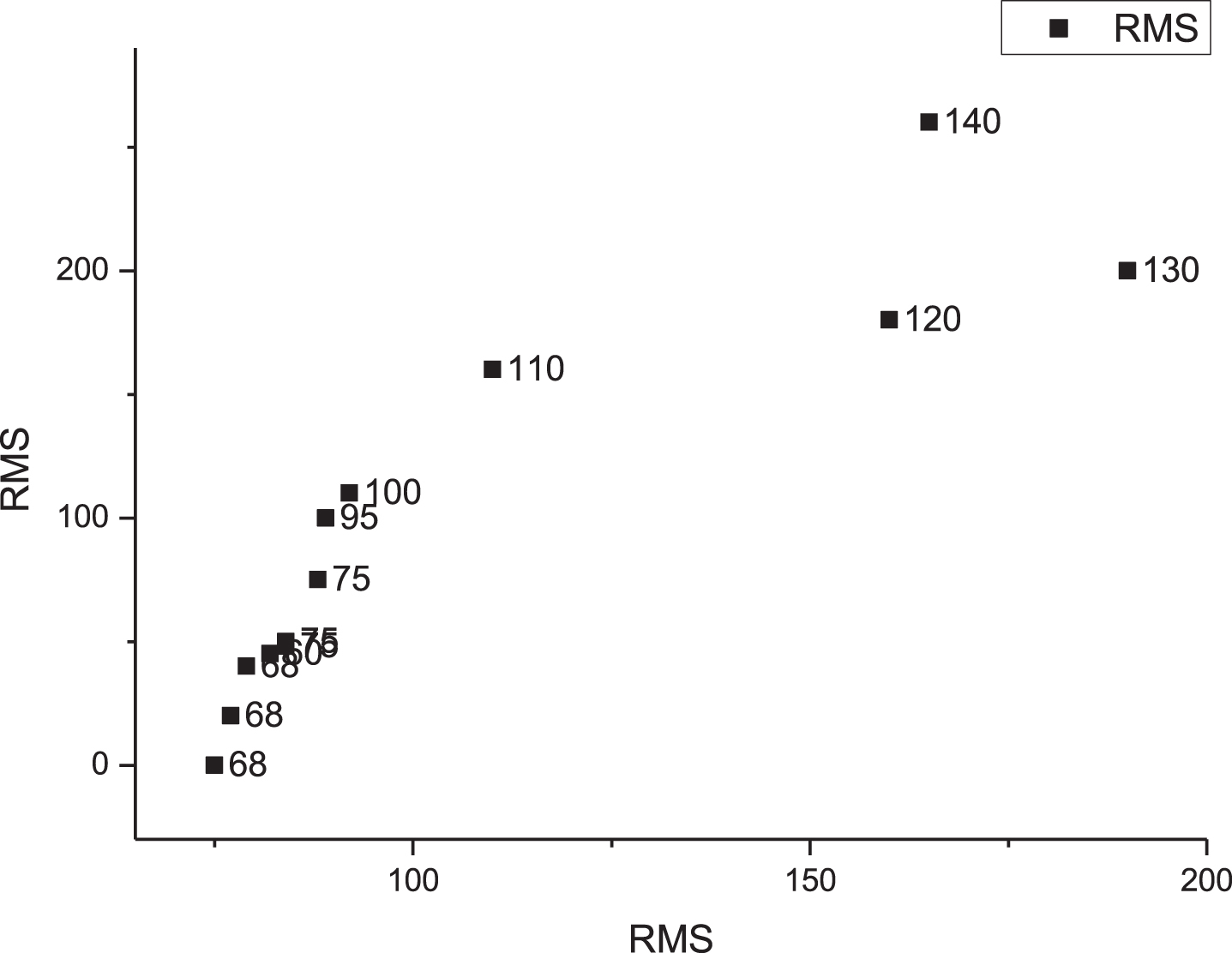
Fig. 6
The simulation results.
The structure of the fuzzy controller adopts a two-dimensional fuzzy controller, and the input variable is the deviation E and the change rate E c of the domain of the argument is [–6, 6], and the domain of the output variable U is selected [1–3, 3], Since the shape of the membership function has little effect on the controller, the membership function selects a uniformly distributed triangle with full overlap. Use M am d an fuzzy reasoning method, and use weighted average method for clarity. The parameter optimization process and simulation experiment curve of the improved fuzzy controller are shown in Fig. 1. The improved two-population genetic algorithm obtains the optimal solution in the 34th generation.
4Conclusions
During the COVID-19 epidemic period, it is essential to strengthen physical exercise and improve the health of the whole people. Therefore, while focusing on strengthening epidemic prevention work, we must attach importance to the construction of sports health service projects and continuously improve the weight of people’s physical fitness.
In the fuzzy control load increment mode, the exercise intensity of bodybuilders changes. It can be seen from the figure that the subjective fatigue value RPE predicted by the neural network established by A’s objective information and load and load increments fluctuates with the adjustment of the load, and its value is between 10.13, which is too small; The measured subjective value RPE also fluctuates, with a value between 10 and 14; the RPE is lagging in time compared to the measured RPE. This may be related to the samples and training time of the neural network training. The influence of the hidden layer weights of the neural network on the final output requires long-term training to form an accurate non-linear mapping of the objective information data for individual fitness people and the subjective fatigue feeling. By collecting and updating the data of the fitness process, the weights of the neural network are gradually modified personally, and the error between the predicted RPE and the measured RPE will tend to be smaller. This neural network structure helps to design a personalized fitness program and optimal load control, that is, a personalized fitness prescription.
References
[1] | Linlin L. , Bin Y. , Xiaolin Z. , Zhiqiang Z. , Research on VMI of multi-supplier and multi-retailer based on cultural genetic algorithm, Modern Manufacturing Engineering 2017: (2). |
[2] | Yue J. , Mengtian C. , Jiang W. , Wenrong T. , Gene expression programming algorithm based on conditional cloud, Application Research of Computers 2015: 153–155. |
[3] | Liangliang J. , Chaoyong Z. , Xinyu S. , Research on integrated process planning and scheduling based on cultural genetic algorithm, Journal of Huazhong University of Science and Technology (Natural Science Edition) 2017: (3). |
[4] | Wei L. , Image segmentation algorithm based on genetic algorithm, Western Leather 2017: (8). |
[5] | Changsheng M. , Network traffic feature selection based on mutual information and cultural genetic algorithms, Journal of Northeastern University: Natural Science Edition 2014: (35), 1534. |
[6] | Shuiwang G. , Baohong W. , Gang J. , Mingsheng S. , Infrared image contour extraction based on gene expression coding algorithm, Infrared Technology 2013: (01), 42–45. |
[7] | Xiaoping G. , Aijun Z. , Research on the decision problem of winning bidding in combination auction based on cultural genetic algorithm, Value Engineering 2013: (31), 251–252. |
[8] | Yongquan W. , Na J. , Duoqian M. , A gene selection algorithm based on splitting, Computer Science 2012: (01), 234–239. |
[9] | Li L. , Analysis of disease gene prediction algorithm based on network method, Journal of Baoji University of Arts and Sciences (Natural Science Edition) 2017: (1). |
[10] | Qian L. , Tao Z. , Advancement learning algorithm based on gene expression programming, Computer Technology and Development 2013: (02), 171–175. |
[11] | Baohong W. , Hongsheng L. , Zhen L. , Gang J. , Research on image segmentation based on genetic evolution branch tree algorithm[J], Laser and Infrared 2013: (08), 99–102. |
[12] | Jinjin T. , Ming Y. , Lina G. , Map Reduce-based improved algorithm for locating gene reads, Computer Science 2015: (08), 88–91. |
[13] | Jinjin T. , Ming Y. , Lina G. , Map Reduce-based genetic data density hierarchical clustering algorithm, Journal of University of Science and Technology of China 2014: (7), 537–543. |
[14] | Zheng L. , Liming Z. , Multi-objective differential evolution algorithm based on jumping genes, Computer Engineering 2016: (4), 168–172, 5 pages. |
[15] | Cheng W. , Wenlong X. , Yufei G. , Calculation of JWL equation of state parameters based on genetic algorithm and γ-law state equation, Journal of Ordnance Engineering 2017: (S1), 172–178. |
[16] | Xiuming Y. , Research and application ofworkshop scheduling for an enterprise based on cultural genetic algorithm, Wuhan University of Technology (2016). |
[17] | Wei Y. , Ruoshui L. , Design of test signals for system identification based on genetic algorithm, Henan Science 2014: , 154–160. |

