
Color recognition of design object of manual decoration element based on convolution neural network under the impact of COVID-19
Abstract
The popularity of covid-19 has led to the introduction of the policy of controlling the flow of personnel, which has a certain impact on the color recognition of the design objects of hand decorative elements. In the past, the research on convolution neural network design and color recognition is still in the traditional method, and the field of computer vision is not really combined with the traditional decorative fabric. This paper proposes a solution based on deep learning. Color learning and main color recognition can be processed as a whole. By introducing convolution neural network, the scheme can learn color features directly from the image itself, and the process of artificial design features is omitted. While simplifying the process of model building and training, the potential information association can be obtained, so as to obtain better recognition effect. In addition, due to the deep depth of the network, this paper uses the initial optimization module to avoid the performance degradation and over fitting in the training process. This method has an important reference value for the color design of modern hand decoration, and can promote the development of hand decoration during the popularity of covid-19.
1Introduction
Nearly 150 billion won (about 880 million yuan) has been lost in the field of culture and art due to the COVID-19 epidemic, according to a report released on the 15th by the Korean Institute of culture and tourism. According to the report, in the first half of this year, the loss of sales in the field of performing arts was 82.3 billion won, and that in the field of visual arts was 66.6 billion won, a total loss of 148.9 billion won. In the first half of the year, 6457 performances and 1525 exhibitions were cancelled. According to the data from the public performance art comprehensive computer network and the art market survey, the average sales volume of each performance and exhibition is 20.3 million won and 43.7 million won, and then multiplied by the number of cancellations to obtain the loss amount. The report also quoted data from the service industry survey and labor force survey to calculate the results of employment losses caused by the new crown epidemic in the first half of the year.
In the first half of the year, the labor costs in the performing arts and visual arts fields decreased by 30.5 billion won and 3.4 billion won respectively, a total decrease of about 33.9 billion won. At the same time, compared with the employment of enterprises, the proportion of artists who become freelancers through the contract of art projects is higher. Based on this, an additional analysis of the employment losses of these people was carried out, and the results showed that the scale of the employment loss of the freelancers was 24.4 billion to 57.2 billion won. Earlier, the survey results released by the General Federation of Korean cultural and art groups in March showed that 2511 cultural and art activities cancelled due to the new crown epidemic situation lost 52.3 billion won. According to the survey data released by the Ministry of culture, sports and tourism in April, 87.4% of the artists had to cancel or postpone art activities.
The World Health Organization said on June 19 that the new corona virus is still spreading rapidly around the world, and countries should prevent new epidemic peaks. The world is at a new dangerous stage. Although many people are tired of staying at home to avoid the epidemic, and countries are eager to open up in social and economic activities, it still calls on all countries and people to maintain a high degree of vigilance and social distance. The COVID-19 epidemic has led to the introduction of policies to control the flow of people, which has a certain impact on color recognition of design object of manual decoration element.
As an interior design element, decorative fabric is not the product of modern material civilization and the great development of urban civilization, but has existed in ancient times, and its unique ingenuity is not inferior to that of contemporary people. As an ancient civilized country, the history of applying decorative fabrics to interior decoration dates back to the Yin and Shang Dynasties thousands of years ago [1, 2]. At that time, due to the emergence of the state and class, decorative fabrics began to evolve into cultural symbols symbolizing power, class and class. A large number of exquisite hand-made decorative fabrics were applied to the palace or noble rooms. Noble people also laid beautiful and gorgeous decorative fabrics Glory in things. The differentiation of this special cultural significance of decorative fabrics was strengthened in the feudal dynasties of the later several thousand years until the peak. The imperial palace of Ming and Qing Dynasties is a model of hand-made decorative fabrics used to decorate interior decoration, such as dragon and Phoenix drapery, golden and blue curtains, vanilla and orchid embellishment masks, as well as beautiful upholstery screens [3]. These gorgeous decorative fabrics complement each other with the open court space and the scattered layout, making the imperial palace a real art palace [4, 5]. It can be seen that the perfect combination of decorative fabric and interior decoration [6–8], with its own cultural symbolic significance and overflowing cultural taste, plays a significant role in promoting the style of living environment, enhancing and highlighting the owner’s life taste and aesthetic sentiment [9].
The large-scale production of modern decorative fabrics is caused by the large-scale machinery industry. Although the streamlined modern decorative fabrics retain some basic features of decorative fabrics, such as color, pattern and practical functions, compared with the hand-made decorative fabrics, the visual effect of color, the vividness of drawings and texture of materials are greatly reduced. Traditional hand-made decorative fabrics have two key elements: one is “tradition”, which embodies national or local characteristics and is recognized by the collective under the common cultural and emotional background, such as dragon and Phoenix elements of Chinese nation, patterns of Islamic style in Western Asia, etc.; the other is “manual”, which means hand-made, abandoning mass production of machines and hand-made decorative fabrics Things are often delicate, concave and convex, good texture, strong comfort. Because of these differences and the advantages of modern decorative fabrics produced by machines, the traditional and hand sewn decorative fabrics can highlight the exquisite elegance of interior decoration and the high-end life taste and aesthetic pursuit of the owner in the era of pursuing high-quality life. Color is one of the most intuitive properties for people to perceive the world and describe objects. Different from the wavelength of light in the physical sense or the inherent characteristics of matter, the color discussed in this paper refers to the visual effects people feel through the activities of eyes and brain. The definition of “red” and “blue” has been widely studied in visual psychology, anthropology and linguistics.
In the field of computer vision, the target of object color recognition is to give a picture of an object, so that the computer can determine what color (name) human will use to describe it, which is equivalent to detecting the main color of the image and classifying it. With the development of content-based image retrieval technology, color, texture, shape and other information are widely studied as the most basic description features, but there are relatively few researches focusing on color recognition. On the one hand, the pattern of the problem itself is small, on the other hand, because the amount of data on the Internet before is small, the text description of the context has been able to roughly meet the needs of people. However, with the continuous development of the Internet, especially the proliferation of multimedia data and the improvement of mobile Internet, people’s search needs are increasingly refined [10, 11]. Therefore, for the traditional manual decorative elements, people often add color requirements in the design process. Only by accurately identifying the color of the design object of the manual decorative elements, can it play a better role in the auxiliary design.
2Convolution architecture for object color recognition
As mentioned before, CNN has made a considerable success in the field of computer vision. In order to enhance the performance of deep neural network, the most intuitive way is to increase its scale, including increasing the number of hidden layers and the number of neurons in each layer. However, with the increase of scale, the calculation time is also increasing rapidly, and it is easy to lead to over fitting. Arora pointed out that in traditional CNN, the full connection layer almost accounts for 90% of the parameters of the whole model, and changing it to sparse connection layer can effectively reduce the computational complexity; in addition, the computational efficiency of unbalanced sparse data is not high at present, aykanat proposed that multiple sparse matrices can be combined into related dense submatrix to improve the computational efficiency. In this paper, we refer to the CNN architecture googlenet used by the champion team of item recognition in ILSVRC-2014 competition, and introduce a separate convolution layer called Inception module to optimize, and remove the top-level full connection layer, so that the model can be guaranteed in both depth and efficiency.
2.1Inception module
The main idea of the concept module is to find a local sparse structure in the convolutional vision network and replace it with an approximate dense structure to improve the computational efficiency. Assuming that translation invariance means that the final network is composed of several convolution modules, then for the optimization work, we need to find an improved local structure, and then simply repeat it in space. Based on the Hebbian principle, Arora proposes a layer by layer construction method: in the last layer, analyze the node correlation, and aggregate the high correlation into a group, which will form the nodes of the next layer and connect with the nodes of the previous layer. It is assumed that each node in the front layer of the network always corresponds to some areas of the original image, and these nodes are integrated into a filter bank. Then the lower layer (close to the original data) will focus on the local area, which means that there will be many node groups only connected to a single area, which can be covered by 1 * 1 convolution in the later layer. Of course, the number of groups can be reduced by increasing the image area covered by the node group. In order to avoid too complex size alignment of feature map (or for the convenience of construction), only 1 * 1, 3 * 3 and 5 * 5 filters are selected in this paper. These layers with different specifications and their output filter banks will be connected to the same output vector to form the input of the latter layer. In addition, in view of the important role of pooling layer in current CNN, it should be beneficial to add another pooling part to the module, so Fig. 1 is obtained. A new convolution network can be obtained by concatenating such modules layer by layer (instead of each layer of the original CNN). It can be predicted that with the increase of network layers, the convolution ratios of 3 * 3 and 5 * 5 will increase, and the spatial constraints corresponding to the original image will be less, which is equivalent to that the learned features will be more abstract.
Fig. 1
The simple Inception.
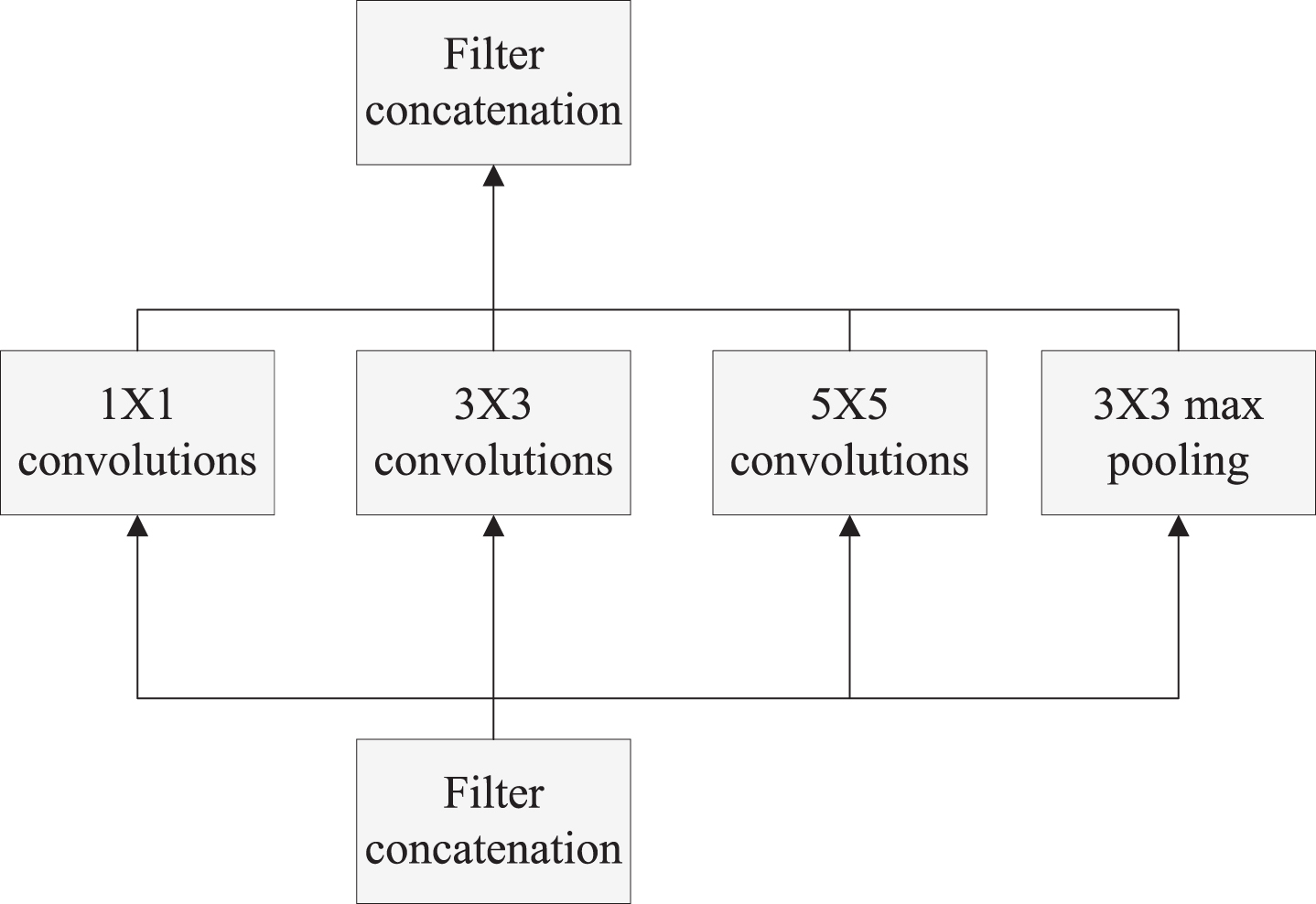
However, such a simple improvement module will quickly lead to the collapse of computing efficiency. Because, even if the number of 5 * 5 convolutions is minimized, more filtering operations than traditional models will consume computing resources quickly. Moreover, when connected to the pooling layer, the output of the optical pooling is equal to the number of the input characteristic maps of the previous layer, which will inevitably lead to the output dimension disaster when connected with other convolution layers in parallel. Although the sparse structure of the original network is optimized, the rapidly increasing computational cost after several layers will completely offset this part of the benefits.
And the actual improvement idea is also very intuitive: add appropriate dimension reduction to all places that need a lot of calculation. The success of the embedding method proves that even low-dimensional embedding can cover the information of relatively large image area. In order to meet the experimental requirements, we hope that the embedded expression is sparse in most places, and only starts to be dense when the signal is uniformly concentrated. Therefore, 1 * 1 convolution is introduced before the 3 * 3 and 5 * 5 convolutions with large amount of calculation, and the original neurons are fully connected with the newly added neurons of 1 * 1 convolution. In this way, the number of connections is reduced from the number of original feature graphs to the number of (controllable) 1 * 1 convolutions. As shown in Fig. 2, if the original architecture is Fig. 2(a), the number of input characteristic graphs is m, and the number of 3 * 3 convolution filters is n, then the number of parameters is n (3 * 3 * m + 1); if 1 * 1 convolution filter is added in the middle during the improvement, then the number of parameters becomes l (m + 1) + n (3 * 3 * l + 1), and the number of parameters can be reduced by simply monotonic integer l < m, thus the number of connections and calculation amount can be reduced. At the same time, the added 1 * 1 convolution layer also increases the nonlinearity of the network, which makes the model more discriminative. The final Inception module is shown in Fig. 3.
Fig. 2
Dimension reduction of cascaded 1 * 1 convolution.
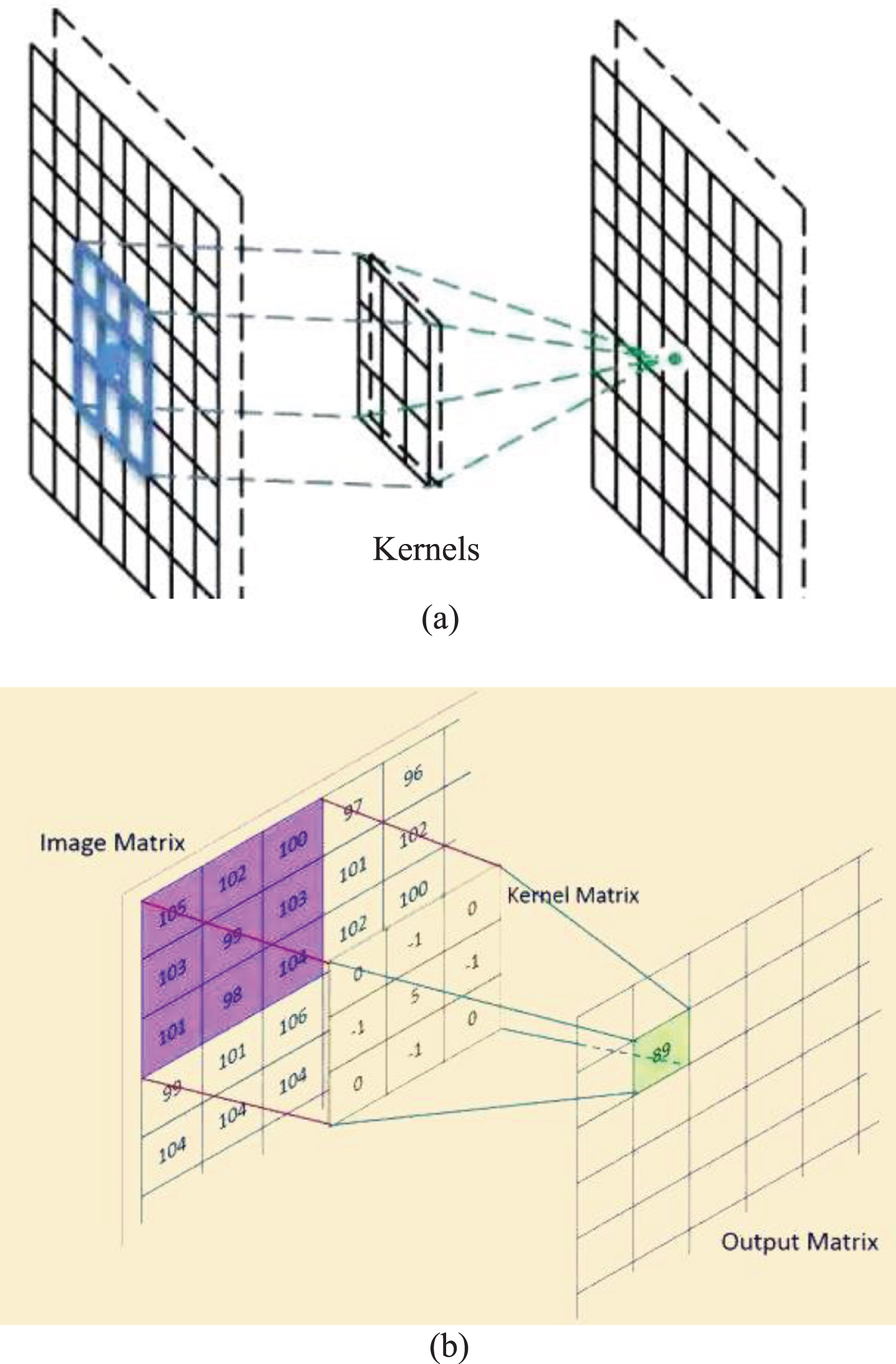
Fig. 3
Improved Inception.
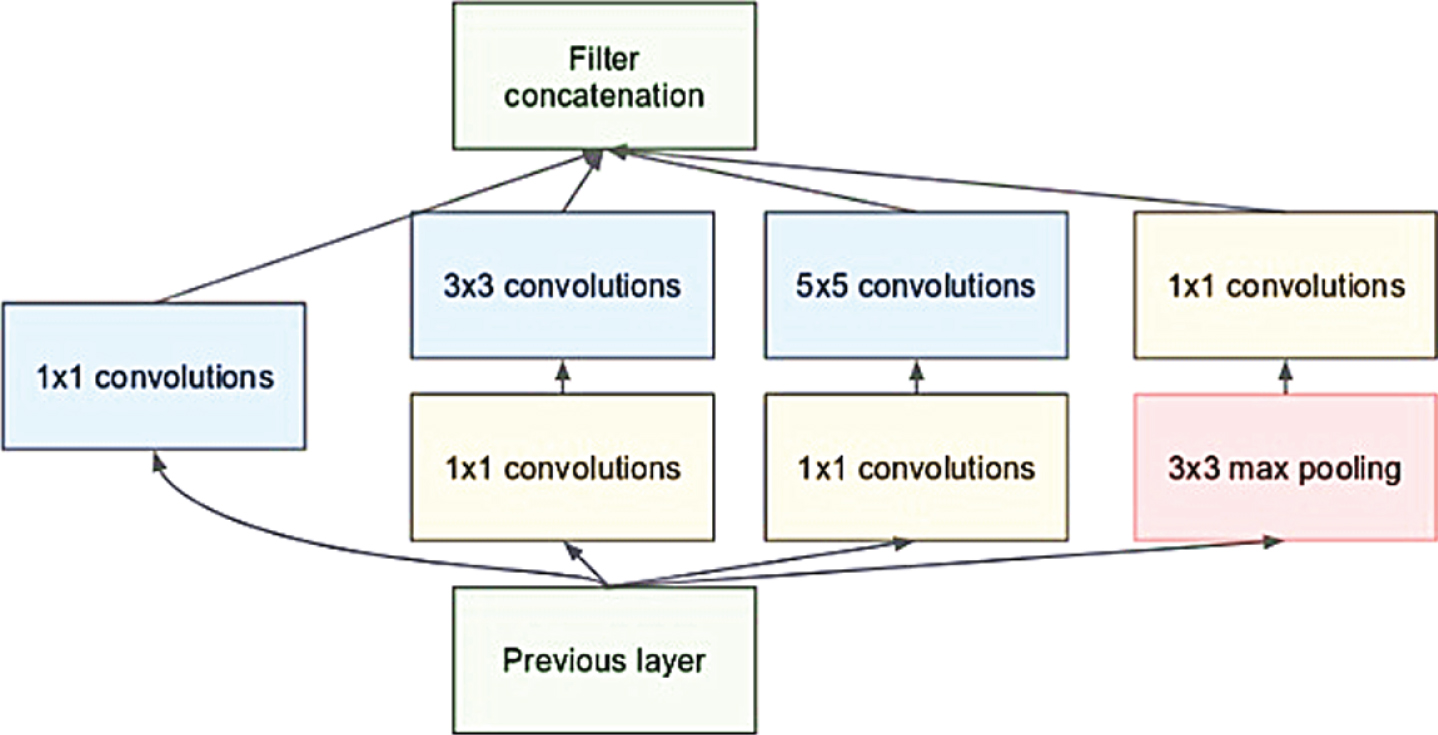
By stacking Inception module and the conventional pooling layer described above (halving the size of the feature map), a CNN like learning network can be obtained. The Google team suggests using Inception only at the higher level, while keeping the traditional convolution layer at the lower level, which can guarantee the computing performance.
It is easy to see that the use of Inception to form a network can avoid the unlimited increase of computational complexity while increasing the number of nodes in each layer. The ubiquitous 1 * 1 in the module has been dimensionally reduced before the actual convolution operation, reducing the huge amount of input in the previous stage to the acceptable amount in the later layer. At the same time, this structure is also in line with the intuitive cognition that visual information should be processed on different scales, which together constitute the source of high-level abstraction.
2.2Schematic diagram of architecture
The CNN architecture used in this paper is shown in Fig. 3, where each “Inception” block represents a cascade module similar to Fig. 1. It is shown in Table 1 that specific convolution kernel size and other parameter settings, named colornet.
The input picture is limited to 224 * 224, RGB24 bit bitmap; the output corresponds to 11 kinds of colors (black, white, gray, red, orange, yellow, green, blue, brown, purple, pink). All neurons selected relu as the excitation function (f (x) = max (0, x)). For the Inceptiont row in the table,¬=3×3 reduce,¬=5×5 reduce, and the poor proj column represent the number of convolution filters used for dimension reduction respectively. The number of parameters of each layer (interval) can be calculated according to the method of CNN. For the Inception module, take the Inception (3a) layer as an example, and its composition is detailed as shown in Table 2:
Table 1
The detailed description of parameters of Inception (3a) layer
| Cell layer type | Number of parameters |
| 64 #1*1 | 64*(192 + 1) |
| 96 #1*1 cascade 128 #3*3 | 96*(192 + 1) + 128*(3*3*96 + 1) |
| 16 #1*1 cascade 32 #5*5 | 16*(192 + 1) + 32*(5*5*16 + 1) |
| 3*3Cascade of pool filter 32 #1*1 | 192*2 + 32*(192 + 1) |
| Total | 164080 |
Table 2
CNN settings
| Layer type | Core size / span | Output dimension | #1*1 | #3*3 reduce | #3*3 | #5*5 reduce | #5*5 | pool Proj | Parameter quantity |
| Conv | 7*7/2 | 112*112*64 | 9.2K | ||||||
| max pool | 3*3/2 | 56*56*64 | |||||||
| Conv | 3*3/1 | 56*56*192 | 64 | 192 | U4K | ||||
| max pool | 3*3/2 | 28*28*192 | |||||||
| inception] 3a) | 28*28*256 | 64 | 96 | 128 | 16 | 32 | 160K | ||
| inception(3b) | 28*28*480 | 128 | 128 | 192 | 32 | ’96 | 380K | ||
| max pool | 3*3/2 | 14*14*480 | |||||||
| inception (4a) | 14*14*512 | 192 | 96 | 208 | 16 | 48 | 64 | 364K | |
| inception(4b) | 14*14*512 | 160 | 112 | 224 | 24 | 64 | 64 | 437K | |
| inception(4c) | 14*14*512 | 128 | 128 | 256 | 24 | 64 | 64 | 463k | |
| inception(4d) | 14*14*528 | 112 | 144 | 288 | 32 | 64 | 64 | 550K | |
| inception(4e) | 14*14*823 | 256 | 160 | 320 | 32 | 128 | 128 | 840K | |
| max pool | 3*3/2 | 7*7*823 | |||||||
| Conv | 1*1/1 | 7*7*1024 | 824K | ||||||
| avg pool | 7*7/1 | 1*1*1024 | |||||||
| dropout (40%) | 1*1*1024 | ||||||||
| full connect | 1*1*11 | 12K | |||||||
| softmax | 1*1*11 |
Near the top of the network, avg pool is added to the model instead of the direct full connection layer, which reduces the dimension and reduces the number of parameters to be trained. However, in order to avoid over fitting, dropout operation is added in the end.
In addition, it is also recommended by GoogleNet to add a softmax exit above the Inception (4a) layer in Table 2.
Because of its deep network, it is not easy to converge. In layer by layer training, we can use labeled data at the middle exit to carry out a back propagation, adjust the front network, and continue to train backward after convergence, which is equivalent to giving a better initial value to the lower layer. The specific settings are shown in Table 3 below:
Table 3
The middle outlet setting
| Layer type | Convolution kernel size / span | Output dimension | Parameter quantity |
| 14*14*512 | |||
| avg pool | 5*5/3 | 4*4*512 | |
| Conv | 1*1/1 | 4*4*128 | 256 |
| full connect | 1*1*1024 | 1.6K | |
| drop (40%) | 1*1*1024 | ||
| full connect | 1*1*11 | 17.4K | |
| softmax | 1*1*11 |
3Collocation and application of traditional manual decorative fabrics in interior furnishings
The fundamental difference between traditional handmade decorative fabrics and machine-made decorative fabrics lies in the “tradition” of color and pattern and the special texture caused by handmade. Therefore, the collocation and application of traditional hand-made decorative fabrics in the interior furnishings described in this paper is also based on its color attributes, pattern attributes and other aspects.
3.1The application of color attribute of traditional hand decorated fabric
Because of the intuitive visual experience, color has become the most important and priority element in the interior furnishing collocation, and because of its rich and variable colors and the sense of hierarchy brought by the collocation, the designers also pay special attention to decorative fabrics, especially the large area coverage of fabrics will often play a supporting role in controlling the main color of the interior, so the selection of fabric color and the collocation of interior furnishings It must be considered in the initial stage to avoid the influence of color deviation on the overall indoor environment trend. Compared with modern decorative fabrics, traditional hand-made decorative fabrics are more limited when they are matched with furnishings, but the space for designers to play is still large. Decorative fabrics cover curtains, household masks, floor laying, indoor furnishings and bedding, etc., while the traditional fabric colors are no more than five categories of red, yellow, blue, green and black, and some colors derived from them, light or deep. However, it must be realized that the traditional decorative fabrics often permeate the residents’ certain cultural feelings and aesthetic tastes, such as Huai The old generation or traditional people tend to prefer traditional colors, and their interior furnishings often exude or classical or solemn atmosphere, so when matching with this kind of furnishings, it is necessary to realize the organic blending with the hue of this kind of furnishings. For example, the fabric under the antique vase can be the dark yellow of the totem color of the Chinese nation; for the indoor furnishings with many characters and paintings, the curtains can choose multi-level light color landscape patterns; for the rooms with ancient wood furniture as the main furnishing layout, the carpet color can be mostly dark. The use of traditional decorative fabrics often reflects the appreciation of classical culture and the pursuit of refined and solemn spiritual interest of the owner of the room. Therefore, for traditional furnishings, the color selection should be as close as possible to the breath contained in them, in order to achieve mutual benefit.
3.2Pattern attribute application of traditional hand decorated fabric
The pattern of decorative fabric is the best carrier to show the regional cultural characteristics. In this regard, the traditional hand-made decorative fabric has the most advantages. For example, Persian carpet is full of rich Islamic customs, Japanese Zen cultural ornaments, and the blankets of Maya civilization in central and South America, all of which contain regional culture, national customs and even national totem, which is also a wonderful carrier for adding indoor exotic customs and highlighting inclusive culture. If the lamp shade or curtain in the study is decorated with a Japanese Zen like pattern, it can not only express the owner’s desire for peace, but also make people inadvertently look at the Japanese wooden house with the clear and crisp bagpipes. For another example, if Persian carpets are laid in the reception hall, the living room will be greatly enhanced immediately. In a word, the fabric pattern containing regional culture will set off the indoor atmosphere in an instant because of its intuitive visual impact and some kind of cultural atmosphere emitted by the pattern, so as to show the spiritual interest and aesthetic level of the host.
In addition, the material attribute is also an element that traditional hand-made decorative fabrics pay more attention to in the application of interior furnishings, especially the hand-made fabrics, whose texture and comfort are often more prominent. Of course, because of the wisdom and hard work of the stitcher, the price and the status symbol along with it are more obvious.
4Experiment and analysis
4.1Data acquisition and preprocessing
For the convenience of comparison, 11 colors of black, white, gray, red, orange, yellow, green, blue, brown, purple and pink were selected as the classification labels in this paper. In order to make the model close to reality and avoid tedious manual annotation, we choose to directly grab pictures from Google and other network suppliers as the training data set. The data sources used in the experiment are as follows:
1. Car data: get from Google Images, search with the keyword of “English color name + car” and grab the results with crawlers, about 800 for each category.
2. Clothing data dress; obtained from Ebay, also search under the clothing top classification with “English color name” and use reptiles to grab, about 2000 pieces for each category.
3. Integrated data misc: grab from Google Images, search and crawl the results with “English color name + color”, about 200 for each category.
All of the above data have been screened by simple manual method, and the part of obvious color inconformity has been removed.
The test data set uses the Ebay product picture set provided by PLSA-ind, including four kinds of products, including cars, dresses, shoes and pottery products. Each product has 11 kinds of colors and 12 pictures of each kind of colors, and each picture has a corresponding mask file to mark the main color area of the image (as shown in Fig. 4). In addition, the dress comp atlas contains more than 120 pictures with more than one label, that is, one garment has two distinct colors.
Fig. 4
Schematic diagram of Ebay atlas for test.

Naturally, we assume that the main body of the picture always appears in the middle, so for all pictures, we scale to the minimum side length of 256px, and then cut out the central 224 * 224 area as the actual input data.
When CNN model is implemented, cuda-convent is used to write the corresponding architecture configuration and run, and GPU operation is turned on at the same time; for PLSA-ind, Matlab code provided in the paper is used directly.
When the trained model is used for prediction, since the softmax layer outputs a probability vector, the category corresponding to the largest component is the judgment result (arg max k = 1,... kok). At the same time, in the remaining components, if any value exceeds 70% of the maximum component, it will also be returned as part of the multi tag determination. PLSA-ind has the same method for multi label determination.
4.2CNN network architecture comparison
In order to find the optimal network structure for object color recognition, this paper attempts to use CNN models of different depths, including the original 9 Inception modules and 22 layer architecture of GoogLeNet, the shallow layer network directly truncated at the middle exit of this model, and the avg pool of the last layer of ColorNet in this paper is replaced by the traditional full connect layer. Input car and dress data sets respectively for training, and then the results on the corresponding test set of Ebay are shown in Table 4.
Table 4
Test error rate of CNN in different layers
| Model∖test data set | Car | Dress | Dress-comp |
| ColorNet | 9.09% | 7.58% | 25.0% |
| ColorNet+Full links | 13.6% | 9.09% | 31.3% |
| ColorNet(Inception) | 14.4% | 11.4% | 41.7% |
| GoogLeNet | 8.33% | 7.58% | 18.8% |
From lines 1 and 2, we can see that using avg pool instead of full connection layer can achieve better results on the test set, which shows that it has better universality.
Comparing 1 and 3 lines, we can see that the recognition accuracy of three Inception cascaded networks is not as good as several deeper models due to their shallow layers.
Compared with 1 and 4 lines, the deeper Inception network can get better results, but in actual operation, it is found that GoogLeNet needs more convergence time than ColorNet. On NVIDIA Titan and 24 G ram tester, the convergence time of ColorNet is about 16 hours, while that of GoogLeNet is about 25 hours. Considering the improvement of its accuracy, this paper chooses the existing structure with fewer layers.
5Conclusions
The COVID-19 epidemic has led to the introduction of policies to control the flow of people, which has a certain impact on color recognition of design object of manual decoration element. In this paper, the definition of object color recognition task and current related algorithms are introduced in detail. Traditional color recognition methods either focus on the extraction of the main color of the image, or focus on the mapping of the pixel color value and the color name of human concept, but lack of a scheme that can combine the two aspects.
In this paper, a CNN based solution is designed to enable the system to recognize color terms and distinguish the main color of the image in an overall form. CNN is one of the commonly used models of deep learning. Because its hierarchical structure is consistent with human visual cognitive process, it has been widely used in the field of computer vision. The actual research and the final experiment also prove that the CNN model (named ColorNet) designed in this paper has a high accuracy in solving the problem of object color recognition.
Due to the deep layer of ColorNet model designed in this paper, in order to deal with the dimension disaster in training, a new concept multi-layer convolution cascade architecture is introduced in the model, which increases the nonlinearity of the system while reducing the dimension; in addition, the traditional CNN top layer full connection layer is replaced by an avg pool layer, which simplifies the operation and avoids the model over fitting. Finally, the convergence of training and prediction efficiency of the model have reached an acceptable level.
Acknowledgments
The study was supported by “Study on the development of intangible cultural heritage industry in Dyeing Art Gansu Province from the perspective of new culture and innovation”.
References
[1] | Berens C. , Visual Acuity and Color Recognition Test for Children, American Journal of Ophthalmology 46: (2) ((1958) ), 219. |
[2] | Zimmer J. , Knipp D. , Amorphous silicon-based unipolar detector for color recognition, IEEE Transactions on Electron Devices 46: (5) ((1999) ), 884–891. |
[3] | Caulfield H.J. , Mueller P.F. , Direct Optical Computation Of Linear Discriminants For Color Recognition, Optical Engineering 23: (1) ((1984) ), 16–19. |
[4] | Bombardier V. , Schmitt R. , Fuzzy rule classifier: Capability for generalization in wood color recognition, Engineering Applications of Artificial Intelligence 23: (6) ((2010) ), 978–988. |
[5] | Lee S.D. , Tzeng C.Y. , Kehr Y.Z. , et al., Autopilot System Based on Color Recognition Algorithm and Internal Model Control Scheme for Controlling Approaching Maneuvers of a Small Boat, IEEE Journal of Oceanic Engineering 35: (2) ((2010) ), 376–387. |
[6] | Chen P. , Bai X. , Liu W. , Vehicle Color Recognition on Urban Road by Feature Context, Intelligent Transportation Systems, IEEE Transactions on 15: (5) ((2014) ), 2340–2346. |
[7] | Benítez-Díaz D. , Modular architecture for custom-built systems oriented to real-time computer vision: Application to color recognition, Journal of Systems Architecture 42: (9-10) ((1997) ), 709–723. |
[8] | Nakamura K. , Okajima O. , Nishio Y. , et al., New Color Vision Tests to Evaluate Faulty Color Recognition, Japanese Journal of Ophthalmology 46: (6) ((2002) ), 601–606. |
[9] | Cheong C. , Bowman G. , Han T.D. , Unsupervised clustering approaches to color classification for color-based image code recognition, Applied Optics 47: (13) ((2008) ), 2326–2345. |
[10] | Paschos G. , Fast color texture recognition using chromaticity moments, Pattern Recognition Letters 21: (9) ((2000) ), 837–841. |
[11] | Zhang J. , Pan R. , Gao W. , et al., Automatic recognition of the color effect of yarn-dyed fabric by the smallest repeat unit recognition algorithm, Textile Research Journal 85: (4) ((2015) ), 432–446. |

