
Addressing disorder in scholarly communication: Strategies from NISO Plus 2021
Abstract
Open science and preprints have invited a larger audience of readers, especially during the pandemic. Consequently, communicating the limitations and uncertainties of research to a broader public has become important over the entire information lifecycle. This paper brings together reports from the NISO Plus 2021 conference session “Misinformation and truth: from fake news to retractions to preprints”. We discuss the validation and verification of scientific information at the preprint stage in order to support sound and open science standards, at the publication stage in order to limit the spread of retracted research, and after publication, to fight fake news about health-related research by mining open access content.
1.Introduction
The COVID-19 pandemic has placed renewed emphasis on the centrality and integrity of open research and the broadened role of the public in science-based policy. This emphasis builds upon pre-existent trends, but also highlights the vulnerabilities of research communications to information disorder [1]. The recent UNESCO Open Science Recommendations [2] and the U.S. National Academies of Science & Engineering’s Open Science by Design [3], build upon long-standing movements to move citizens closer to science and to encourage (1) greater transparency in the production and use of science and (2) the broad dissemination of scientific information and data. In doing so they reshape how science is both communicated and evaluated in the scholarly communications ecosystem. While the pace of scientific discovery and its dissemination are enhanced by open research practices, such as open access to published research and data without paid subscriptions, public trust in science is required for these gains to be made actionable, and for scientists and policy makers to engage in effective public collaboration. Yet greater public attention to the production and dissemination of scientific data and information also focuses attention on the uncertainties involved in scientific research. We see this presented in sharp relief by the important role preprints have played in the communication of science during the pandemic and the growing need for trusted mechanisms to evaluate scientific evidence in transparent and public ways. While we see a growing awareness of the need for broader conversations about the role of science in public deliberation and the evaluation of scientific evidence, the role of preprints and retractions in the pandemic presents many lessons and lost opportunities. Indeed, the growing importance of “viral misinformation” linked to invalidated research highlights how the public accessibility of science makes it more urgent to solve problems such as:
Transparency in research reporting.
Open access to scientific data and literature.
The quality of scientific information employed in public policy.
Trusted public platforms for the evaluation of evidence.
As we reach the end of 2021, we are in a pandemic age with more research in the scholarly communication ecosystem than ever before and with more eyeballs and input from a lay audience. In some ways, the publication and spread of misinformation could be a recipe for disaster and perpetuate distrust for science, but it can also mean the opposite. With more peer-reviewed content, expanding trends to publish additional research output, and advanced technological infrastructures to support it, there are more opportunities than ever to make the scholarly communications machine more transparent. As the old saying goes, “sunlight is the best disinfectant;” by increasing transparency and collaboration among stakeholders, and introducing more (and more openly-accessible) research artifacts into the ecosystem, we can create a more informed, connected, and trustworthy scholarly communication network. Each stakeholder within this network is motivated by the shared goal of trust. Trust leads to adoption, generates citations, increases downloads, bolsters subscriptions, and grows revenue.
This paper reports on the NISO Plus conference Session “Misinformation and truth: from fake news to retractions to preprints” [4]. We focus on the validation and verification of scientific information in three different stages of the information lifecycle: (1) at the preprint stage, (2) once the research is published, and (3) at the dissemination stage. Communicating the limitations and uncertainties of research to a broader public has become important because open science and preprints invite a broader readership. The public needs more support in filtering information when “bad science” gets through, compared to what is needed by those explicitly trained to read and communicate research.
We paired the topics in this paper because they speak to opportunities and strategies to address information disorder in the context of the pandemic and beyond. In particular we discuss:
Workflows in which stakeholders are investing. Platforms need to be good at communicating not only research, but also the publisher’s mission.
Investment in solving the issue of the continued circulation of retracted or invalidated research.
The continued salience and influence of open access, research, and data, particularly in shaping conversations about transparency and the evaluation of research and scientific evidence.
2.Supporting sound and open science standards at the preprint stage
The literary biographer Marchette Chute said, “Nothing can so quickly blur and distort the facts as desire – the wish to use the facts for some purpose of your own – and nothing can so surely destroy the truth” [5]. The wisdom of this statement has resonated repeatedly since the very first communications about the novel coronavirus, SARS-CoV-2, began to make their way from preprint servers to press releases, sometimes making an appearance in journals along the way. The sense of urgency felt by journalists sometimes meant that new layers of confusion were added to the interpretation of necessarily hasty research articles. Information was moving at a blindingly fast pace in those early weeks and months, presenting novel challenges to researchers, journalists, and platforms such as Research Square (see https://www.researchsquare.com), which hosts preprints – the early outputs that have so often been the first source of the information.
There is a misconception that preprint platforms are “anything goes” platforms. While some servers may characterize themselves as repositories and only perform the most rudimentary screens on incoming submissions, most preprint servers have well-defined submission criteria and employ the judgement of qualified experts to block submissions that are clearly pseudoscientific, ethically dubious, or potentially dangerous [6,7]. However, preprint servers generally do not consider methodological rigor, completeness of reporting, or tenability of conclusions as screening criteria. This means that methodologically flawed, poorly written, and/or inadequately reasoned studies can and do get posted on preprint servers. As preprints become more widely-adopted, there will likely be an increased demand for platforms to play a more active role in providing information to help readers contextualize and properly interpret preprints that may be seriously flawed or prone to misinterpretation.
2.1.A tale of 3 preprints
During the COVID-19 pandemic, the Research Square preprint platform has received thousands of pandemic-related submissions. Some of these studies experienced “viral” success on social media for various non-intellectual reasons ranging from poor understanding to bad faith. By way of example, three of them will be described here.
The first example preprint, “the misunderstood”, was submitted to the Research Square platform in June of 2020. Its posting coincided with the posting of similar work on other preprint servers. The study described the phenomenon of T-cell immunity to SARS-CoV-2, which the authors observed in 81% of patients, and is thought to be derived from the patients’ past exposures to coronaviruses that cause the common cold. Social media users immediately seized upon the complex immunological story, drawing the false impression that most people are already immune to the SARS-CoV-2 virus. The preprint was touted as evidence that the COVID-19 pandemic is a hoax or that herd immunity has already been achieved and thus the preventative measures being enforced by world governments were misguided. This false narrative was repeated on Twitter and elsewhere – using this preprint and others like it in its defense. These conspiratorial tweets were the dominant contributors to the astonishing usage metrics that the preprint accumulated. However, by all accounts, the study was considered sound, and it was ultimately published in Nature Immunology [8]. The published journal article continues to garner attention from conspiracy theorists. In an interview with Al Letson for National Public Radio’s Reveal podcast [9], the author expressed her own surprise at discovering how the study was being misinterpreted.
The second example, “the over-interpreted”, is a preprint that reported the results of a targeted questionnaire about the effects of mask wearing on children. The goal of the survey was to collect feedback from children and their caregivers regarding their mask-related complaints. Although the preprint did not explicitly suggest a causal relationship between mask wearing and various mild symptoms in children, such as headache and irritability, the implied connection was enough to stir up a groundswell of anti-mask sentiment on social media. The efficacy of masks in controlling the spread of COVID-19 and government mandates around mask wearing both became increasingly contentious and hyper-politicized topics throughout the pandemic. The level of attention and persistent over-interpretation of this study reflected this. Indeed, the preprint collected over two hundred thousand views and was downloaded nearly seven thousand times. As of this writing, however, the work has not been published in a journal. Its flawed methodology, particularly with respect to multiple forms of bias, was critiqued by a number of scientists online, including in a long-form review conducted by the medical fact-checking group Health Feedback (see: https://www.healthfeedback.org). Due to the level of misguided attention the preprint received, Research Square also issued an Editorial Note to help readers interpret the work.
The final example is “the convenient truth”. This preprint describes the observed negative correlation between vitamin D levels and COVID severity in a European population. The (generally weak) association had been found by a number of research groups, and this particular preprint ultimately underwent some revision before getting published in a journal. However, both the preprint and the journal article were cited in support of fringe theories suggesting that various political bodies were obfuscating important information about the strong prophylactic effects of vitamin D in order to garner support for lockdowns. The study was also perversely used to suggest that the large disparities in COVID infection and outcomes between people of different races could be adequately attributed to their differential levels of vitamin D. Though this specific claim is both unsubstantiated by the evidence and highly tenuous, the fact that it has some basis in reality (people with darker skin tones do have lower levels of Vitamin D), became convenient fodder for narratives that seek to minimize differential outcomes based on practical inequities.
2.2.The role of preprints in preventing the spread of misinformation
These stories are highlighted to emphasize that much of the focus on misinformation originating with preprints is simply due to the abrupt surge in preprints as the earliest medium for emergent research during the pandemic. Indeed, two of the three examples provided were ultimately published in peer reviewed journals without major substantive changes to their conclusions, and the misinformation campaigns attached to them continued unabated after their publication. The problem of misinformation and misinterpretation is not unique to preprints, but because they are positioned early in the publication process, these platforms are uniquely positioned to address such problems in enduring and meaningful ways.
As one of the leading preprint servers, and one being fed incoming content from a large number of journals, Research Square has seen the pandemic reinforce the importance of filtering out highly contentious and alarming studies and ensuring that disclaimers indicating preprint status are made prominent on the preprints that are posted (Fig. 1).
Fig. 1.
Example of a disclaimer on the Research Square platform.

But once the most egregious content is screened out, preprint servers have an opportunity to encourage community behaviors that ultimately benefit the general public, other researchers, and science as an institution. By recommending and providing access to both automated tools and human-led assessments at the preprint stage, these platforms can lead in the support of open science and reproducibility initiatives. For example, preprint servers can integrate with automated tools that assess methodological and open science reporting quality, detect issues with language clarity, and analyze references for retracted or corrected publications. On posted preprints, platforms can provide automated fact checking, supply context-specific citation information, and pull in relevant information from preprint review platforms and those investigating misconduct. Independent lay summaries may also play a critical role in ensuring that readers come away with the correct message.
Adherence to important standards can be signaled to readers by way of badges or other notation and standards to enable and simplify the effective assessment of these papers. Together, these features can create an ecosystem of context and validation around a preprint, offering readers important contextual clues regarding the rigor and reproducibility of the work, while fostering a culture of unprecedented accessibility and transparency.
3.Limiting the spread of retracted research: Cross-industry perspectives
3.1.RISRS: Reducing the Inadvertent Spread of Retracted Science
Reducing the Inadvertent Spread of Retracted Science (RISRS) aims to develop an actionable agenda for reducing the inadvertent spread of retracted science. Our work, funded by the Alfred P. Sloan Foundation, started with four motivating questions:
What is the actual harm associated with retracted research?
What are the intervention points for stopping the spread of retraction? Which gatekeepers can intervene and/or disseminate retraction status?
What are the classes of retracted papers? (What classes of retracted papers can be considered citable, and in what context?)
What are the impediments to open access dissemination of retraction statuses and retraction notices?
The project developed recommendations through a series of interviews with stakeholders in the scholarly publishing ecosystem, and a three-part online workshop. In the workshop stakeholders interacted in real-time to discuss: (1) the problem retractions pose and possible solutions; (2) a citation analysis of retracted research [10]; and (3) and a literature review of empirical research about retraction. Stakeholders represented a variety of roles: members of the publishing industry, such as publishers and editors; researchers and librarians, including those with experience in handling retractions; research integrity officers in a variety of institutions; stakeholders working in standards setting organizations; and a variety of “webbing” or infrastructure roles, such as technical services, metadata, reference management software, and platform services.
The RISRS recommendations are [11]:
Develop a systematic cross-industry approach to ensure the public availability of consistent, standardized, interoperable, and timely information about retractions.
Recommend a taxonomy of retraction categories/classifications and corresponding retraction metadata that can be adopted by all stakeholders.
Develop best practices for coordinating the retraction process to enable timely, fair, and unbiased outcomes.
Educate stakeholders about publication correction processes including retraction and about pre- and post-publication stewardship of the scholarly record.
At NISO Plus, three stakeholders presented their perspectives about the problems retractions and their ongoing citation pose, from the point of view of a non-profit publisher, a librarian, and a platform provider.
3.2.A non-profit publisher’s perspective from Randy Townsend, Director, Journal Operations at American Geophysical Union
Today, we are quick to build connections and establish relationships, whether it’s a conversation on Twitter or the association of data to a manuscript that connects an author to their ORCID and links to other related published content. New researchers build on previous research to further our understanding. But, when one link in the chain is compromised, whether it is because an analysis was incorrect, an instrument was not properly calibrated, or somebody intentionally falsified the numbers to produce results to sell a product, it jeopardizes trust, and we move further away from the truth.
Taboos surrounding retracted research tend to evoke feelings of anger, frustration, and failure. For the author, a retraction damages their credibility and puts into question the validity of any previous or future publications. It has been a falsely-accepted belief that retractions are career-ending, and retracted authors were often shamed and disgraced. In one of the most drastic reports that highlight the angst surrounding retractions, in 2014, Yoshiki Sasai committed suicide after a paper about stem cell research he coauthored was retracted in Nature [12].
A real truism is that a retracted manuscript does not necessarily mean that the entire manuscript held no scientific value. For example, in the Earth and Space Science sector, territories that are disputed between two or more countries are being captured in maps, and phrased in ways that could infer innuendos that legitimize one country’s claim to ownership of that region over another country. Although guidance says that authors must follow the United Nations’ guidelines for the naming of territories, we continue to see inappropriate names in manuscript submissions that contribute no scientific value to the research. A common map we see inflaming tensions is related to China’s unsubstantiated claim of territory over the South China Sea, illustrated by a Nine-Dash Line. These maps imply that islands in that region, such as Brunei, Indonesia, Malaysia, Singapore, Thailand, and Vietnam, belong to China [13]. In these instances, the maps reflect one minor element of the manuscript primarily used to add context to the research.
The American Geophysical Union (AGU) peer reviews thousands of papers a year across our twenty-two scholarly journals, and it is easy for referees to overlook something as seemingly miniscule as a dashed line in one map. However, if we are unable to reach an agreement with the authors to make a correction and replace an inappropriate image, AGU generally retracts the entire article to remain unbiased in a territorial dispute between conflicting governments, proverbially throwing the baby out with the bathwater. Our preference is to replace the image, and in most cases, authors prioritize the value of the research over the political implications of the publishing element.
3.3.A Librarian’s perspective from Caitlin Bakker, Medical School Librarian and Research Services Coordinator, Health Sciences Library, University of Minnesota
Retracted research may not be clearly communicated as such and these materials have the potential for reuse, both in practice and in research, without the user’s knowledge. Within the health sciences, the number of retracted publications is growing, although it remains a very small fraction of the overall corpus [14]. While the rates of retraction are growing, potentially due to increased interest in retractions and for research transparency writ large, retraction alone is insufficient. Information users may expect that a paper found fundamentally-flawed is subsequently retracted, and that science and scholarship would be corrected. Although the paper may be retracted, that retraction may not be clearly communicated, both within the journal and via all other points of access.
That the scholarly record is not fully-corrected with retraction can be seen in the subsequent use of those retracted publications. As evidence of this, we can consider the use of retracted publications in systematic reviews. A systematic review is a research method that identifies, critically appraises, and summarizes all available evidence on a particular topic with the goal of definitively answering a precise question. In the words of Ben Goldacre, it constitutes “looking at the totality of the evidence [and] is quietly one of the most important innovations in medicine over the past 30 years” [15]. While this method first developed popularity in health sciences, its use is now becoming commonplace across a range of disciplines, including psychology, education, social work, and food and environmental sciences. For both researchers and practitioners in these fields, a systematic review can provide a powerful means of answering pressing questions in a timely manner. However, the incorporation of retracted studies into systematic reviews undermines the potential rigor and value of these studies.
In a recent project considering the use of retracted research in systematic reviews in the pharmaceutical literature, a sample of one thousand three hundred and ninety-six retracted publications was identified using data from the Center for Scientific Integrity’s Retraction Watch Database. Of these one thousand three hundred and ninety-six retracted publications, two hundred and eighty-three had been cited one thousand and ninety-six times in systematic reviews. Approximately one-third of those systematic reviews were published more than six months after the original article had been officially retracted [16]. These findings are supported by additional research indicating that retraction due to scientific misconduct does not impact the subsequent number of citations received when compared to their citation prior to retraction [17].
Citation alone may not be problematic, as discussion of a retracted publication and refutation of its findings would require citing that work. However, if individuals are incorporating retracted publications into their research and practice without knowledge of their retracted status, there is potential to undermine research and practice. Unfortunately, there is also some evidence that citations to retracted publications may be more supportive and positive than negative or contradictory. Looking at a sample of six hundred and eighty-five publications that cited retracted articles in the field of dentistry, it was found that only 5.4% of the citations acknowledged the retracted status of the paper or refuted the paper’s findings [18].
Although it is not possible to identify the precise reasons individuals are continuing to use retracted publications, it is important to note the inconsistency with which retracted publications are being displayed across different platforms and journals. In one study focused on retracted publications in mental health, one hundred and forty-four retracted publications were examined across seven different platforms. Approximately 40% of the records reviewed did not indicate that the paper had been retracted. Of the one hundred and forty-four papers, only ten were noted to be retracted across all platforms through which they were available and, while 83% of the platforms included a separate retraction notice, the majority of these notices were not linked to the original article or indexed to ensure discoverability [19]. Although guidance is available from the Committee on Publication Ethics (COPE) [20] and the International Committee of Medical Journal Editors (ICMJE) [21], this guidance may not be consistently employed. ICMJE has established seven recommendations for retracting articles. In one study of one hundred and fifty retracted publications, only 47% of the articles met all ICMJE recommendations [22,23].
3.4.A publishing platform provider’s perspective from Hannah Heckner, Director of Product Strategy, Silverchair
As a critical partner to publishers and an integral player in the scholarly communication ecosystem, it’s important to consider the roles and responsibilities of the publishing platform in the discussion surrounding retracted research and its dissemination.
At its core, the primary job of the platform is to act as a container for content. The platform should disseminate information with clarity, thoroughness, and a thought to the end-user, which in 2021 pertains to human- and machine-readers alike. In addition to communicating research content, the platform should also be a “lowercase p” platform for the publisher to interface directly with their user, building trust and loyalty while also collecting information about their users and their content. As the main home for content, the platform should also serve (1) as a hub for information about the content; (2) as a possessor of canonical URLs and versions of record and; (3) as a downstream distributor and a source of truth.
In regards to retractions, one can think of the platform as functioning as a palimpsest, which is defined by Dictionary.com [24] as “something that has a new layer, aspect, or appearance that builds on its past and allows us to see or perceive parts of this past”. Instead of a well-used piece of parchment, the publishing platform can simultaneously communicate: the first research artifact, subsequent corrections on the research artifact, and valuable information about the creative process on the whole.
In this way, the platform should be the source of truth for the original research and any ensuing retractions or corrections. It should clearly display and make accessible retractions according to publisher specifications and should also link to the related content that also lives on the platform. The platform should also create and maintain links between the original content, the retracted content, and the wider scholarly and general audience communication ecosystem.
In the straight-forward arena of display, the publishing platform should work with its partners to communicate retraction status through:
Watermarked PDFs.
Reciprocal links between and notices upon retraction notices and their original research.
Access to updated supplementary material, if applicable, that demonstrates the areas involved in the retraction.
Given scholarly workflows, however, updates to the original publication platform in the event of retractions only do part of the work to alert readers and re-users of this news. Having your platform serve as a conduit to third parties to deliver content and updates to content downstream is imperative. These third parties include services and infrastructure providers such as Crossref, PubMed, Scopus, Google Scholar, Web of Science, and others. So much of this valuable information sent downstream and exposed to crawling is “invisible” to the end human user, so it is important that the platform serve as a collaborative partner to publishers as well as a stakeholder in industry discussions on this topic to ensure that standards and best practices are being upheld.
There is certainly room for growth in the current state of publishing platforms helping to stop the spread of retracted research, as well as the scholarly communications community overall. Areas primed for improvement include:
Inconsistencies between publishers and platforms in metadata and display standards.
Differing practices and standards to decide what behavior requires a retraction, and varying interpretations of the different types of retractions.
Gaps in the metadata ecosystem to effectively map retractions. Addressing these gaps is of utmost importance given the current trends pointing towards increased research readership by the general audience. Today there are far more general audiences consuming research content, requiring a greater emphasis on clarity for these artifacts.
And finally, the stigma tied to retractions can mean that some authors or publishers may pause before deciding to retract content, or do “silent” retractions, which leads to extensive problems down the line.
3.4.1.Suggestions for moving forward
While there is a lot of room for growth, it’s also important to keep in mind the promise of the future. As indicated in this paper, there is already incredible momentum in cross-industry collaboration – while the stakeholders within publishing do not necessarily agree on all topics, fixing this is something we can all agree upon. It will also be beneficial to deeply engage with all the parties within the communications ecosystem on areas for leveraging current activities and developing others in the areas of improved XML standards, machine readability, and the overall busting of information silos. In thinking of the STM article-sharing framework and what it is doing to highlight reuse information from licenses, thinking of Google Scholar’s lookup links and metatags, and also the initial thoughts behind Crossref’s distributed usage logging projects (now paused: see https://www.crossref.org/community/project-dul), there is a lot of promise here to apply some of those approaches to fleshing out the metadata landscape so that retraction updates, and article updates in general, will become more visible and easily shared. Presentations on COPE’s new taxonomy project at the 2021 meeting of the Society for Scholarly Publishing focused on terminology to describe article statuses are also harbingers of positive change [25]. The adoption of these taxonomies by publishers and their ingestion into platforms, allowing for downstream delivery and incorporation into the metadata landscape, will be a boon for discoverability and organization.
4.Mining open access content to fight fake news about health-related research
4.1.Motivation
The subject of fake news is very topical. With social networks and the advance of Artificial Intelligence (AI), the creation and circulation of fake news is accelerating. Health and science are particularly vulnerable topics for fake news. The current context of the COVID-19 pandemic has made this crisis in the scientific information ecosystem even more obvious [26].
In this work, we want to illustrate that the development of open access scholarly publishing, combined with automatic analysis enabled by the latest AI technologies, in particular in the domain of Natural Language Processing (NLP), offers new ways to tackle fact-checking for the general public.
Building on the results that were presented at the Open Science Conference 2020 [27], a prototype that automatically analyzes open access research articles to help verify scientific claims was built.
The main objectives of this prototype are threefold:
Demonstrate that we can use open access scientific articles to help people verify whether a claim is true or false.
Educate people regarding the large body of scientific studies, emphasizing that usually, no one study can settle the debate. The general public would benefit from a greater understanding of how science progresses – through the gradual process of publication, peer review, and replication.
Provide a useful tool that helps people navigate the scientific literature, search for information, identify the consensus or the lack thereof, and finally become better informed on a specific topic.
This prototype takes a claim such as “Coffee causes cancer” as an input and builds three indicators to evaluate the truth behind this claim. The first indicator assesses whether or not claim has been extensively studied. The second indicator is based on an NLP pipeline and analyzes whether the articles generally agree or disagree with the claim. The third indicator is based on the retrieval and analysis of numerical values from the pertinent articles.
In this section, we present our methodology, discuss the results that we have obtained, and extend the discussion to the role that open access scholarly literature can play to fight false scientific claims and to help inform the public.
4.2.General approach
The team at Opscidia developed a prototype of an automatic fact-checking system, based on the automatic analysis of a corpus of open access articles retrieved from Europe PubMed Central. The developed application can be accessed at science-checker.opscidia.com.
The prototype is of the following form: the user enters a statement, such as “does Agent X cure, cause, prevent or increase Disease Y?” Based on data that we collect from Europe PubMed Central, our system assesses whether scientific literature backs or contradicts the claim of the user.
In order to achieve this objective, the developed prototype retrieves from Europe PubMed Central the scientific articles which are related to the topic of the user’s claim and provides three indicators to the user:
Timeline of the sources: a graph that indicates how much research has been done on the user’s topic of interest and when this research was done.
Semantic analysis of the sources: a Machine Learning pipeline that classifies the position of the retrieved articles with respect to the user’s claim (as backing, contradicting, or neutral).
Numerical conclusions retrieval: a rule-based system that retrieves important numerical conclusions of epidemiological studies, the relative risk, and its confidence interval.
We discuss each of these in turn.
4.3.Indicator 1: timeline of the sources
The first indicator that we provide is a graph of the timeline of the relevant articles retrieved from Europe PubMed Central. While very simple and easy to build, this indicator is quite standard for fighting fake news outside of the scientific world because it is usually much easier to trace where information comes from rather than to directly decide whether it is true or not.
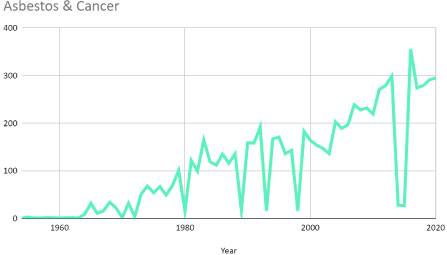
In the general case, this indicator helps the user understand the context of the research that has been performed on their topic of interest. It also helps people discover whether or not there are many articles on the topic, whether the topic is still actively discussed, and how long it has been studied. It helps people know whether researchers’ interest in the topic is increasing or, on the contrary, whether it is falling out of fashion. For example, Fig. 2 shows that the topic of asbestos and cancer has been growing slowly and regularly since the mid-1960’s.
Fig. 2.
Number of research articles in PubMed on the topic of asbestos and cancer. Notice that interest has been growing slowly and regularly since the mid-1960’s.
Furthermore, in some specific cases, this indicator can give very strong indications about the fake character of the information. For example, in the very well-known case of an hypothetical link between Measles, Mumps, and Rubella (MMR) vaccine and autism, that was discussed intensely (and clearly proven false) at the beginning of the 2000’s, we can see that the interest in that topic increased in a very sudden manner in 1998, just after the publication of the famously retracted MMR study by Andrew Wakefield in The Lancet (see Fig. 3).
Fig. 3.
Number of research articles in PubMed on the topic of vaccine and autism. Notice that interest starts suddenly booming, just after the publication of the hugely controversial and ultimately retracted Wakefield’s study.
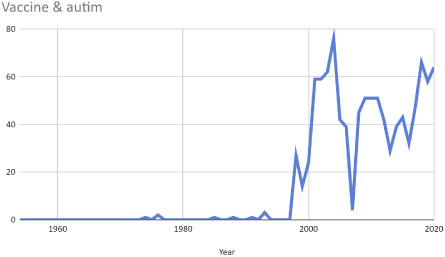
Hence, in this particular case, this indicator shows that the interest in the subject was spurred by an article which was later retracted, which is very important information to know and gives a strong indication that the claim is false.
4.4.Indicator 2: semantic analysis
This second indicator aims at building a response to the question: “Does the retrieved research article support or contradict the claim formulated by the user?”
To achieve this objective, we use the following routine:
For each article retrieved from Europe PubMed Central, an AI-based pipeline classifies the article as supporting, neutral, contradicting the user’s statement.
The number of articles in each category is given to the user and a tentative answer is formulated.
Although the classification of the article as supporting, neutral, or contradictory with respect to the claim is a difficult (and still open) information retrieval problem, recent advances in NLP have significantly improved the performance of such classification pipelines. In particular, the development of language models [28] allowed strong improvements in question-answering [29]. Furthermore, the aggregation of the classification over several articles makes the complete pipeline less sensitive to individual article classification errors, hence, making this strategy viable. We have already built, trained, and evaluated several classification pipelines against standard question-answering datasets. The most successful approach was based on an extractive question-answering pipeline combined with a three-outputs-classifier, as described in work under review [30].
4.5.Indicator 3: evaluating the numerical conclusions
An alternative way to evaluate whether or not an article supports or contradicts the user’s claim is to analyze whether or not the numerical conclusion seems to support the claim. In particular, in the special case of epidemiology, the relative risk and its confidence intervals are enough to determine whether an article supports or contradicts the user’s claim.
The relative risk is the ratio of the probability of the disease in a group exposed to the agent X to the probability of the disease in an unexposed group. Hence, if the confidence interval of the relative risk does not contain 1, then the study is conclusive (a correlation was found). Inversely, if the confidence interval of the relative risk includes 1, then the study failed to find any correlation between agent X and disease Y.
Hence, in the context of this project, a pipeline for the retrieval of confidence intervals in epidemiologic studies has been developed. This pipeline is based on a simple rule-based approach with three steps:
The relevant scientific literature is retrieved from Europe PubMed Central.
The sentences that mention agent X and disease Y are collected.
Within these phrases, the confidence intervals are selected through a set of rules.
The main advantage of this pipeline is its speed, enabling its inclusion in an online tool.
Our focus is providing a proof-of-concept and the performance of this pipeline has not been formally evaluated, nevertheless, it is expected to have two drawbacks:
• It does not take negation into account, i.e. it gives the same result for “sleep is correlated with anxiety,” and “lack of sleep is correlated with anxiety;” hence, it has to be manually-verified.
• Since the set of rules has been set to minimize false positives, we expect many false negatives.
This simple set of rules proved the feasibility of such an approach and allows the retrieval of confidence intervals. Its integration into our platform, together with the result of the semantic analysis, illustrate the interest of collecting this value as a complement to semantic analysis.
In future work, more advanced models could be used to build more precise pipelines. For example, Grobid quantities, which retrieve all the numerical information from an article [31], could be used.
As a conclusion, the prototype of Science-checker, an online platform for scientific fact-checking has been built and is accessible at http://science-checker.opscidia.com. Using Europe PubMed’s open access repository of three million articles, Science-checker enables the user to verify a health-related scientific claim of the form “Does agent X cure/cause/prevent/increase disease Y?” It is built on three indicators: a timeline of results, a semantic analysis of the pertinent articles, and the retrieval of numerical values. The aim of this tool is to help fact-checkers verify more thoroughly the literature, to help explore the scientific literature on a given topic, and to show how the development of open access scientific publishing could be used to fight fake news and to increase the scientific information for the general public.
5.Synthetic discussion
Science is an iterative process, and its findings and presentation must be continually verified and re-verified. This article describes opportunities and challenges around the verification of scientific information at multiple stages of the information life cycle: at initial discovery in the preprint stage, at the point of publication and dissemination, and post-publication when being synthesized by a broad audience. The evolving scholarly communication landscape introduces new opportunities to facilitate this verification process, but also surfaces new challenges.
Methods of addressing flawed information were developed and are grounded in the print-based environment. As the amount of available information has increased and methods of distribution and discovery have emerged, strategies for dealing with flawed information must adjust.
Open access of scientific articles, as well as their underlying data, allow for independent replication of results, ensuring the validity and rigor of the research. Preprint servers create opportunities to accelerate this dissemination and replication. Beyond the ability to access the paper, end users – whether researchers, policy makers or members of the public – must be able to trust the article and its findings. Streamlined solutions that allow for a consistent experience for users across journals, publishers and platforms are essential to facilitating information use.
While a standard of practice may appear to be an easily attainable goal, the large number of scientific articles and their diversity makes it challenging to develop verification solutions that scale and address flaws in a manner that is consistent, fair, and allows for sufficient nuance.
Scholarly communication will continue to evolve. The methods in which people will discover information will look as different ten years from now as they did ten years ago. Coupled with the understanding that truth is a moving target, strategies that allow creators, distributors, and users of information to engage with information effectively must be similarly evolving. These solutions will likely be iterative, needing to grow and expand to include previously unrepresented voices and perspectives and to address new challenges.
Acknowledgements
Kudos to the NISO Plus 2021 Team for anticipating the synergies of these topics! RISRS funding: Alfred P. Sloan Foundation G-2020-12623. Thanks to Katherine Howell for reference wrangling.
About the corresponding author
Jodi Schneider is an assistant professor at the School of Information Sciences, University of Illinois Urbana-Champaign (UIUC). She studies the science of science through the lens of arguments, evidence, and persuasion. She is developing Linked Data (ontologies, metadata, Semantic Web) approaches to manage scientific evidence. Schneider holds degrees in informatics (Ph.D., National University of Ireland, Galway), library & information science (M.S., UIUC), mathematics (M.A., University of Texas Austin), and liberal arts (B.A., Great Books, St. John’s College). She has worked as an actuarial analyst for a Fortune 500 insurance company, as the gift buyer for a small independent bookstore, and in academic science and web libraries. She has held research positions across the U.S. as well as in Ireland, England, France, and Chile. Email: [email protected], [email protected].
References
[1] | C. Wardle and H. Derakhshan, Information disorder: Toward an interdisciplinary framework for research and policy making, [Internet]. 2017, Report No.: DGI (2017)09. Available from: https://rm.coe.int/information-disorder-toward-an-interdisciplinary-framework-for-researc/168076277c, accessed July 18, 2021. |
[2] | UNESCO, UNESCO recommendation on open science [Internet]. 2020, Available from: https://en.unesco.org/science-sustainable-future/open-science/recommendation, accessed July 18, 2021. |
[3] | National Academies of Sciences, Engineering, and Medicine, Open Science by Design: Realizing a Vision for 21st Century Research, [Internet]. Washington, D.C., The National Academies Press, 2018, Available from: 10.17226/25116, accessed July 17, 2021. |
[4] | C.J. Bakker, J. Schneider, R. Townsend, M. Avissar-Whiting, H. Heckner and C. Letaillieur, Misinformation and truth: From fake news to retractions to preprints. in: NISO Plus 2021 (2021) , [Internet]. Available from: https://nisoplus21.sched.com/event/fMnP/misinformation-and-truth-from-fake-news-to-retractions-to-preprints; https://nisoplus.figshare.com/, accessed July 18, 2021. |
[5] | M. Chute, Available from: https://todayinsci.com/C/Chute_Marchette/ChuteMarchette-Quotations.htm. |
[6] | D. Kwon, How swamped preprint servers are blocking bad coronavirus research, Nature 581: (7807) ((2020) ), 130–131. doi:10.1038/d41586-020-01394-6. |
[7] | M. Malicki, A. Jeroncic, G. ter Riet, L.M. Bouter, J.P.A. Ioannidis, S.N. Goodman , Preprint servers’ policies, submission requirements, and transparency in reporting and research integrity recommendations, JAMA 3 24: (18) ((2020) ), 1901, [Internet]. Available from: 10.1001/jama.2020.17195, accessed July 18, 2021. |
[8] | A. Nelde, T. Bilich, J.S. Heitmann, Y. Maringer, H.R. Salih, M. Roerden , SARS-CoV-2-derived peptides define heterologous and COVID-19-induced T cell recognition, Nature Immunology 22: (1) ((2021) ), 74–85, [Internet]. Available from: 10.1038/s41590-020-00808-x, accessed July 18, 2021. |
[9] | A. Letson, How the pandemic changed us, [Internet], KALW Local Public Radio; 2021. (Reveal). Available from: http://revealnews.org/podcast/how-the-pandemic-changed-us/, accessed July 18, 2021. |
[10] | T.-K. Hsiao and J. Schneider, Continued use of retracted papers: Temporal trends in citations and (lack of) awareness of retractions shown in citation contexts in biomedicine, [Internet]. 2021. Accepted to Quantitative Science Studies. Preprint available from: https://osf.io/4jexb/, accessed September 14, 2021. |
[11] | J. Schneider, N.D. Woods, R. Proescholdt and Y. Fu, The RISRS Team. Reducing the inadvertent spread of retracted science: Shaping a research and implementation agenda, MetaArXiv Preprints. Available from: 10.31222/osf.io/ms579 , accessed September 14, 2021. |
[12] | A. Martin, Japanese stem-cell scientist Yoshiki Sasai commits suicide, Wall Street Journal, https://online.wsj.com/articles/japanese-stem-cell-scientist-yoshiki-sasai-is-dead-1407206857, accessed July 18, 2021. |
[13] | S. Shukla, What is nine-dash line? The basis of China’s claim to sovereignty over South China Sea. ThePrint, [Internet]. 2020 Jul 28, Available from: https://theprint.in/theprint-essential/what-is-nine-dash-line-the-basis-of-chinas-claim-to-sovereignty-over-south-china-sea/469403/, accessed July 18, 2021. |
[14] | M.L. Grieneisen and M. Zhang, A comprehensive survey of retracted articles from the scholarly literature, PLoS ONE 7: (10) ((2012) ), e44118. doi:10.1371/journal.pone.0044118. |
[15] | B. Goldacre, I. Chalmers and P. Glasziou, Foreword. in: Testing Treatments: Better Research for Better Healthcare, H. Thornton (ed.), 2nd ed. Pinter \& Martin, London, (2011) , ISBN: 9781905177493 [Internet]. Available from: http://www.ncbi.nlm.nih.gov/books/NBK66204/, accessed July 18, 2021 . |
[16] | S.J. Brown, C.J. Bakker and N.R. Theis-Mahon, Retracted publications in pharmacy systematic reviews, [manuscript]. |
[17] | N.R. Theis-Mahon and C.J. Bakker, The continued citation of retracted publications in dentistry, Journal of the Medical Library Association 108: (3) ((2020) ), 389–397, [Internet]. Available from: 10.5195/jmla.2020.824, accessed July 18, 2021. |
[18] | C. Candal-Pedreira, A. Ruano-Ravina, E. Fernández, J. Ramos, I. Campos-Varela and M. Pérez-Ríos, Does retraction after misconduct have an impact on citations? A pre–post study, BMJ Global Health 5: (11) ((2020) ), e003719. doi:10.1136/bmjgh-2020-003719 . Available from: 10.1136/bmjgh-2020-003719, accessed September 14, 2021. |
[19] | C. Bakker and A. Riegelman, Retracted publications in mental health literature: Discovery across bibliographic platforms, Journal of Librarianship and Scholarly Communication 6: (1) ((2018) ) . Available from 10.7710/2162-3309.2199, accessed September 14, 2021. |
[20] | COPE Council. Retraction guidelines [Internet]. 2019 Nov., Available from: 10.24318/cope.2019.1.4, accessed July 18, 2021. |
[21] | International Committee of Medical Journal Editors, “Corrections, retractions, republications and version control,” [Internet]. ICMJE. 2019, Available from: http://www.icmje.org/recommendations/browse/publishing-and-editorial-issues/corrections-and-version-control.html, accessed July 18, 2021. |
[22] | E.M. Suelzer, J. Deal and K.L. Hanus, Challenges in discovering the retracted status of an article, [manuscript] [Internet]. Discussion paper for Reducing the Inadvertent Spread of Retracted Science: Shaping a Research and Implementation Agenda; 2020, Available from: http://hdl.handle.net/2142/108367, accessed July 18, 2021. |
[23] | E.M. Suelzer, J. Deal, K. Hanus, B.E. Ruggeri and E. Witkowski, Challenges in identifying the retracted status of an article, JAMA Network Open 4: (6) ((2021) ), e2115648. doi:10.1001/jamanetworkopen.2021.15648. |
[24] | Dictionary.com, Palimpsest, In: Dictionary.com [Internet], Available from: https://www.dictionary.com/browse/palimpsest, accessed July 18, 2021. |
[25] | A. Flanagin, H. Heckner, D. Poff, J. Seguin and J. Schneider, A cross-industry discussion on retracted research: Connecting the dots for shared responsibility, In 2021, Available from: https://43ssp.cd.pathable.com/meetings/virtual/kCxnm2KPiqBY8prKs, accessed July 18, 2021. |
[26] | K.T. Gradoń, J.A. Hołyst, W.R. Moy, J. Sienkiewicz and K. Suchecki, Countering misinformation: A multidisciplinary approach, Big Data and Society 8: (1) ((2021) ), 20539517211013850. [Internet]. Available from: 10.1177/20539517211013848, accessed July 18, 2021. |
[27] | S. Massip and C. Letaillieur, Leveraging Open Access publishing to fight fake news, [Internet]. Open Science Conference 2020; 2020 Apr 30, Germany. Available from: 10.5281/zenodo.3776797, accessed July 18, 2021. |
[28] | J. Devlin, M.-W. Chang, K. Lee and K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding. in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, (2019) , pp. 4171–4186. doi:10.18653/v1/N19-1423. Available from: https://aclanthology.org/N19-1423. |
[29] | R. Puri, R. Spring, M. Shoeybi, M. Patwary and B. Catanzaro, Training question answering models from synthetic data. in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, (2020) , pp. 5811–5826. doi:10.18653/v1/2020.emnlp-main.468. Available from: https://aclanthology.org/2020.emnlp-main.468. |
[30] | L. Rakotoson, C. Letaillieur, S. Massip and F. Laleye, Science Checker: An extractive summary-based pipeline for scientific question answering, [manuscript], 2021. |
[31] | L. Foppiano, L. Romary, M. Ishii and M. Tanifuji, Automatic identification and normalisation of physical measurements in scientific literature. in: Proceedings of the ACM Symposium on Document Engineering 2019 (DocEng'19). Association for Computing Machinery, New York, NY, USA, (2019) , pp. 1–4. [Internet]. Available from: 10.1145/3342558.3345411, accessed July 18, 2021. |


