
Artificial intelligence in scholarly communications: An elsevier case study
Abstract
This paper is an adaptation of presentation given by the author at the NFAIS Conference on Artificial Intelligence that was held in Alexandria, VA from May 15–16, 2019. It provides an overview on the need for increased Artificial Intelligence (AI) usage in scholarly communications for both information providers and the research community. It also includes an introduction to how Elsevier transitioned from print to electronic to information solutions (P – E – S) and how some of its tools employ AI. In addition, it covers two case studies showcasing how Elsevier incorporated Machine Learning (ML) and Natural Language Processing (NLP) to create two technological and data-based solutions for researchers, as well as a summary of the solutions’ positive outcomes.
1.Introduction
Andrew Ng, Stanford computer science professor and co-founder of Coursera, once said, “I have a hard time thinking of an industry that I don’t think AI will transform in the next several years [1]”.
The scholarly publishing and information industries are no exception. Smart publishers are beginning to embrace AI, weaving it into the core of their business - to help them enter new markets or source new content, to inform and improve existing content, and for new product development - which otherwise might have required significant investment and business risk. Publishers are also using AI to reduce costs in their editorial processes. Many use Natural Language Processing (NLP) to provide sematic enrichment and content recommendations for users.
Today, the need for academic publishers to adopt AI has become undeniable. There are several reasons for this, the most obvious of which is that scholarly output across the world has tripled in the last two decades. As the number of articles, journals, and publishers grows, it’s reasonable to assume that the value of this content will decline.
Additionally, while global research spend is growing quickly every year - $2 trillion today, which is nearly triple the spending in 2000 [2] - we’re hearing from researchers that they still lack effective tools. A number of recent studies show that a large proportion of scientific research asks the wrong questions, or when the research is completed, it cannot be reproduced.
On the health side, the median cost of developing a drug is now $2.6 billion [3]; yet the success rate is only one in twenty. Furthermore, alongside heart disease and cancer, the third largest cause of death is medical error.
There is a huge opportunity in these spaces for publishers to leverage AI, to curate and enhance content, and ro help researchers and medical professionals find what they are looking for more quickly and accurately.

2.Elsevier’s P – E – S transition
That’s why Elsevier employs more than one thousand technologists today, who are rapidly developing new capabilities in ML and NLP. But before I go into more detail on what we are doing today, it might be useful to go back in time and review how we got here in the first place.
Elsevier’s history as a publisher of physical books and journals goes back hundreds of years, but when the Internet started to become mainstream in the 1990s, our core products suddenly seemed outdated. In fact, in 1995, Forbes even released an article predicting that we would be the “Internet’s first victim” [4]. We did survive the digital revolution, however, because of our willingness to embrace technological innovation. As industry leaders, we realized that we had to transform ourselves from being a traditional print content publisher to a provider of e-content and information solutions.
In the print environment, Elsevier published and sold raw content in fixed quantities, without really knowing how it was being used. Then, in the internet era of the 1990s, we pivoted to electronic distribution. This enabled us to consolidate all of our content into a digital repository (ScienceDirect), where library and research customers could easily search and pick out what they needed.
This shift from print to electronic was momentous, but it was only the beginning. Once we had all our content digitized, we started to understand that we had even more value on our hands than we’d originally thought - and this is where the topic of data analytics and AI comes in. With all of this digital content, we realized that Elsevier had the world’s largest, highest-quality source of machine-readable STM data and metadata. With the right analytics, this data could be leveraged to create a suite of AI and ML-powered solutions. For instance, we provide tools to help doctors in making the right diagnosis, exploratory drillers in finding oil efficiently, pharmaceutical drug companies in bringing new drugs to market, scholars in tracking the most important research in their field, universities in benchmarking their performance, and much more.
In other words, Elsevier’s trajectory was one of “P – E – S”; we started off as a print publisher (P), became a digital publisher of electronic content (E), and ultimately evolved into a data-based solutions (S) provider. Today, print sales account for less than 10% of Elsevier’s revenue - the vast majority now coming from data-based solutions that help turn static information into actionable knowledge.
3.Case study 1: ScienceDirect topic pages
NLP (the “machine” used to turn natural language into structured semantic text that is machine-readable and parse-able) and ML enable truly Smart Content. We are currently seeing a gradual, industry-wide migration from manual processes and flat text to using highly-automated means to derive greater semantic meaning from content.
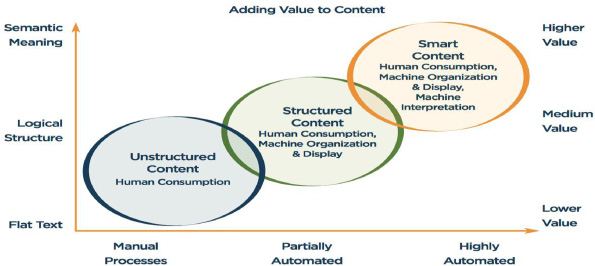
Elsevier uses NLP and semantic technologies extensively in all of its solutions. For example, we can transform the source text to noun phrases, apply eleven domain-specific thesauri and structured vocabularies, extract concepts, and create fingerprints from any text – such as an abstract or a grant description. We’ve recently added a Chemistry thesaurus with hundreds of thousands of compound names.
So, let’s take a look at how these NLP and semantic technologies are being applied in Elsevier tools. I’d like to focus on one example from our online database of scientific and medical research, ScienceDirect, which will also serve as a concrete demonstration of our shift from electronic content to solutions.
Below is an illustrative example in the field of Earth Sciences of what types of compositional content we might seek to extract from previously static text.

While the text in this article may be the most obvious form of extractable data, there are also many other data points in different formats: namely, tables, equations, graphs, figures, maps seismic profiles, and stratigraphic columns.
Here I think it would be appropriate to quote David Smith (Head of Product Solutions at the Institution of Engineering and Technology), in his Scholarly Kitchen article on AI and scholarly communications:
“The research article, frankly, isn’t a very good “raw material” as things currently stand. It’s not written to be consumed by a machine. Its components can’t be easily decoupled and utilized; they lack enough context and description and organization to collect at scale and, oh yeah, often times the data is wrong… Because research is a journey involving scholars trying to become slightly less uncertain about the worlds they are trying to understand” [5].
However, adding further structure to the content in an article - which would otherwise have remained trapped in a PDF - enables it to be leveraged for use cases that enhance research productivity.
For instance, if researchers reading an article were to stumble across a term with which they were not familiar, our research showed that they would stop reading and search the term on other internet sources (e.g. Wikipedia) to get definitions and background information about the concept. The problem is that information from sources like Wikipedia is not always authoritative - which is why we decided to deploy AI to help our end-users understand articles better and more efficiently.
Our objective was to create an automated, scalable model for extracting and highlighting definitions and concepts at the point of use, so that we could give researchers the trusted and citable information they needed when they needed it. So how did we accomplish this?
Creating a viable solution was not easy, and there were several serious roadblocks we had to overcome before we could proceed. For example, we have a massive corpus of data; and within this corpus, most sentences are not definitions and many scientific concepts are ambiguous. Therefore, we sought to develop strong predictive models, including incorporating human feedback to ensure that all concept definitions were sound.
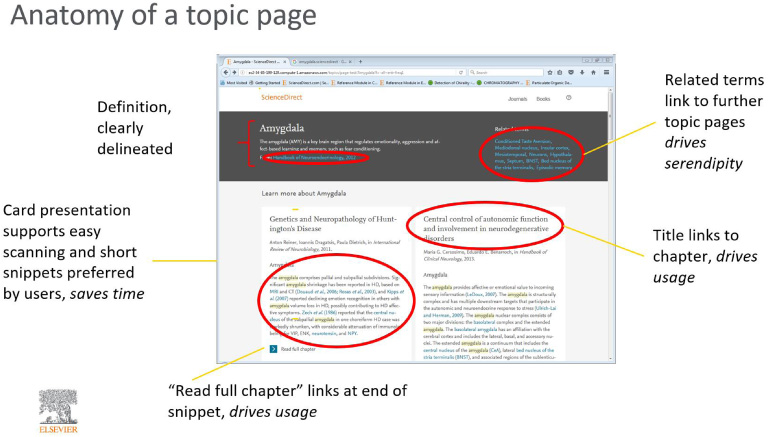
What finally emerged from the end-user need to understand the article was a feature on ScienceDirect (SD) called “Topic Pages” as shown in the following figure

Concise definitions for terms help to orient users to a subject quickly. Relevant excerpts are highlighted across all literature, and we meet researchers where they are - we list Topic Pages in journal articles as well as in search engine results, and they are all freely-accessible.
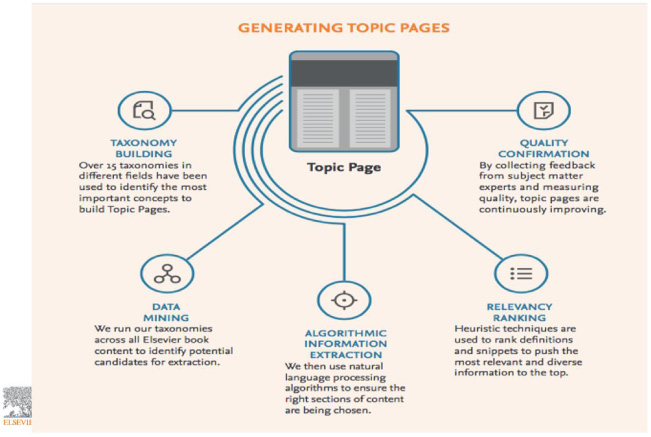
Using ML, we have generated more than one hundred thousand Topic Pages from reference content on ScienceDirect. Over one million articles are being enriched with links to Topic Pages, and we are planning to expand to more domains.
This achievement would not have been possible without the right technology, including:
Taxonomy building: Over fifteen taxonomies in different fields have been used to identify the most important concepts to build Topic Pages.
Data mining: We run our taxonomies across all Elsevier book content to identify potential candidates for extraction.
Algorithmic information extraction: We then use NLP to ensure that the right sections of content are being chosen.
Relevancy ranking: We use heuristic techniques to rank definitions and snippets to push the most relevant and diverse information to the top.
Quality confirmation: By collecting feedback from subject matter experts, measuring quality, and testing the User Experience (UX), Topic Pages are continuously improving.
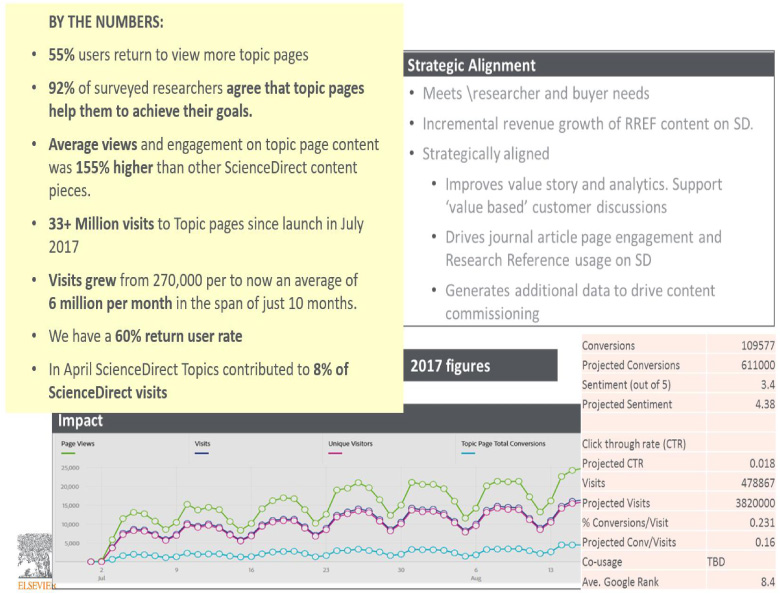
The response within the research community and across the broader public has been astounding. Since its launch in 2017, Topic Pages have received more than thirty-three million visits, which in less than one year grew from two hundred and seventy thousand per page to an average of six million per month. We have a 60% return rate among users, and 55% of users return to view more pages. 92% of surveyed researchers agree that Topic Pages have helped them to achieve their goals.
Last year, ScienceDirect Topic Pages was even a CODiE Award finalist for the category of “Best Artificial Intelligence/Machine Learning Solution”.
4.Case study 2: Topics of prominence
The idea of modelling science using computers and citation linkages is not a new idea. Eugene Garfield and Henry Small took this approach back in the 1980s, and their pioneer work played a role in the development of what is now known as “Topic Prominence”.
Back in 1985, it took eight weeks to analyze 2% of the citation base in order to come up with a list of hot research topics - namely, those in the Top 1%. Now, we use the entire corpus of literature to create a comprehensive view of the roughly one hundred thousand global research topics currently extant.

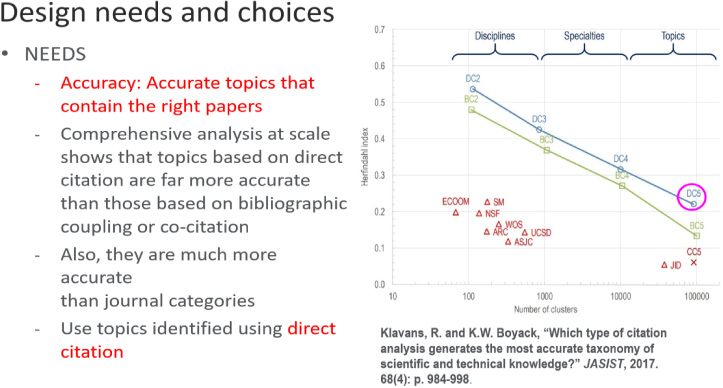
When we think about modeling research, there are a few key design principles to consider: full coverage, the right level of topic granularity, accuracy of topics that contain the right papers, and the stability of topics over time.
Based on researcher needs and aimed at portfolio analysis, we chose to identify roughly one hundred thousand topics in science using direct citation on citation linkages (including those to cited non-indexed items) in the full Scopus database.
As I mentioned previously, it is important to use the full corpus of literature when modeling. Elsevier’s Topics of Prominence (TOP) tool does this. I won’t go into too much detail here, but the following figure should give you an idea of the level of calculation required for such an analysis - calculation of over half a billion cited-citing pairs - to yield around ninety-seven thousand specific research topics (topic clusters) across every field of research, from basic science to highly applied fields related to manufacturing and commercial technologies.
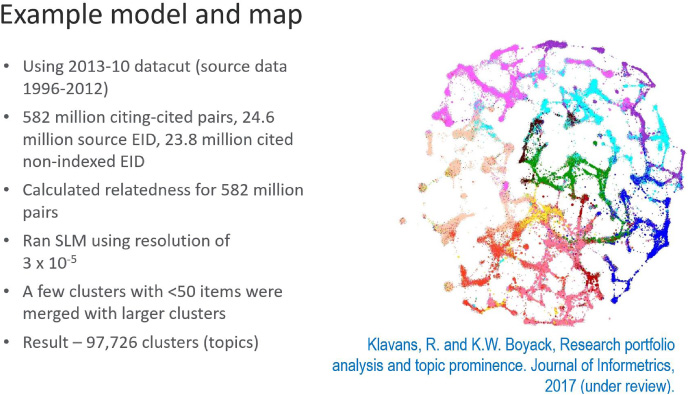
To determine the right level of granularity, prior research and expert interviews were used to look at the approximate size of scientific research questions.

Perhaps one of the most important elements in any model is how accurately that model captures scientific activity. Using direct citation analysis, we have a higher accuracy at 105 scale than most of the current classification schema have using around one hundred to three hundred categories. No pre-existing categories are assumed, unlike journal-based classification schema, and the clusters are calculated from the bottom up. These clusters are small enough so that we can see manufacturing-oriented research in specific geographies, and multiple topics around a single larger specialty or discipline. This also captures interdisciplinary research in a fundamentally different way.
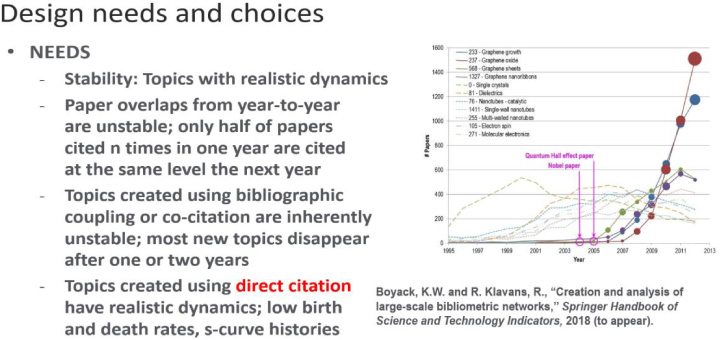
Finally, the topics need to be stable year-to-year for long-term trend analysis. The model also meets this criterion. Only about five hundred new clusters per year are born, and older ones persist. Indeed, we can see the growth dynamics of specific topics as they develop. Below are four topics related to graphene, and one can trace the inflection points to papers by Andre Geim and his colleagues at the University of Manchester.
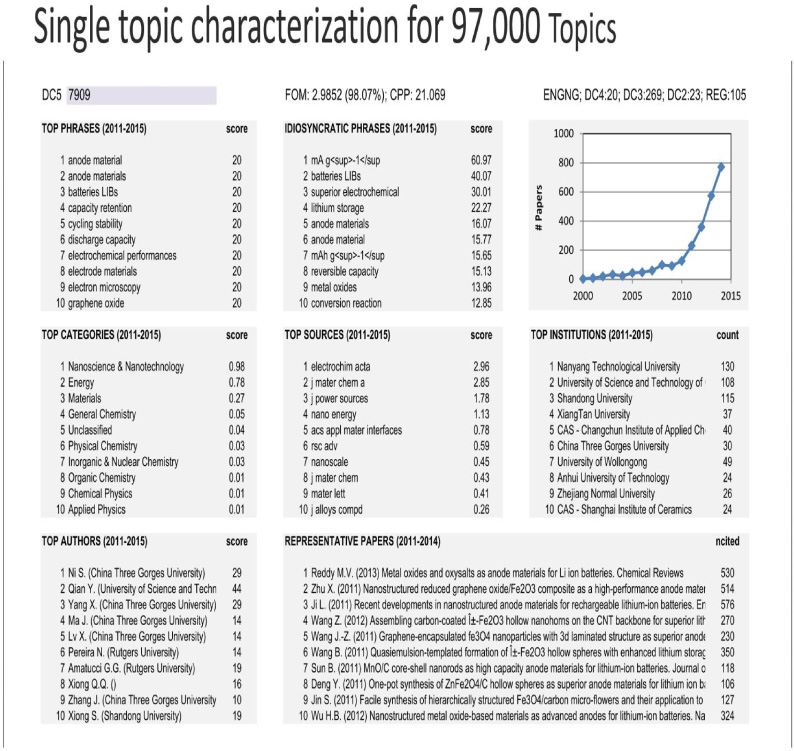
Another primary benefit to this approach is the richness of detail per topic. Leading authors, institutions, semantic terms, journals, and representative papers are generated for one hundred and five topics. We see the top idiosyncratic phrases, top authors, leading institutions, and the different fields from which this particular interdisciplinary topic is drawn. Using semantic analysis, we can even identify the most representative papers for this topic.
To give a quick flavor of how this works, let’s look at the U.S. Elsevier’s SciVal tracks over eight thousand institutions and countries, including major corporates that publish R&D, government labs such as Los Alamos or CNRS, and over seven thousand universities.
Below is 2012–2016 data from the U.S. Looking at the U.S.’ output as a country, we can see that it conducts research in every field and has strengths across the board, although it has a higher proportion of biochemistry, genetics, and biomedical research as a percentage of all output than do most other countries.
5.Overall research performance: United States country – output (2012–2016)
| Publications: | 3,210,189 |
| Citations: | 24,767,636 |
| Authors: | 2,560,062 |
| Citation/Publication: | 7.7 |
| Field-weighted Citation Impact: | 1.47 |
| Research Disciplines: | |
| Medicine: 21.9% | Chemistry: 3.4% |
| Biochem, Genetics, Mol. Biology: 8.7% | Arts & Humanities: 3.3% |
| Engineering: 8.3% | Mathematics: 3.2% |
| Social Science: 6.7% | Environmental Science: 2.8% |
| Physics & Astronomy: 5.8% | Earth & Planetary Sciences: 2.8% |
| Computer Science: 5.6% | Psychology: 2.5% |
| Agriculture & Biological Science: 4.4% | Neuroscience: 2.2% |
| Material Science: 4.1% | Other: 14.5% |
Looking at a few of the U.S.’ most prominent topics, we can see that these correlate with areas of research strength. Many topics can easily be linked with specific technologies and even manufacturing capabilities, such as graphene growth and solar cell heterojunctions. Between 2012 and 2017, the U.S. contributed to more than ninety thousand of the approximately ninety-seven thousand topics pursued globally.
6.United States: Researchers in the USA have contributed to 90,988 topics between 2012 to 2017
| Topic | Scholarly | Publication | Field-weighted | Prominence |
| output | share | citation impact | percentile | |
| (in the US) | worldwide | |||
| Analgesics, Opioids, | 1,989 | 69.59% | 2.53 | 99.762 |
| Prescriptions (T.248) | ||||
| Brain, Magnetic | 1,689 | 47.19% | 2.97 | 99.940 |
| Resonance Imaging | ||||
| (T.219) | ||||
| Genome, RNA (T.456) | 1,829 | 45.49% | 5.94 | 99.998 |
| Planet (T.131) | 1,545 | 62.15% | 2.8 | 99.740 |
Again, we see the striking correlation between research activity in a topic and its successful commercial application. The U.S. is almost entirely dominant in this area of applied geology.
7.U.S. topics of prominence - shale; hydraulic fracturing
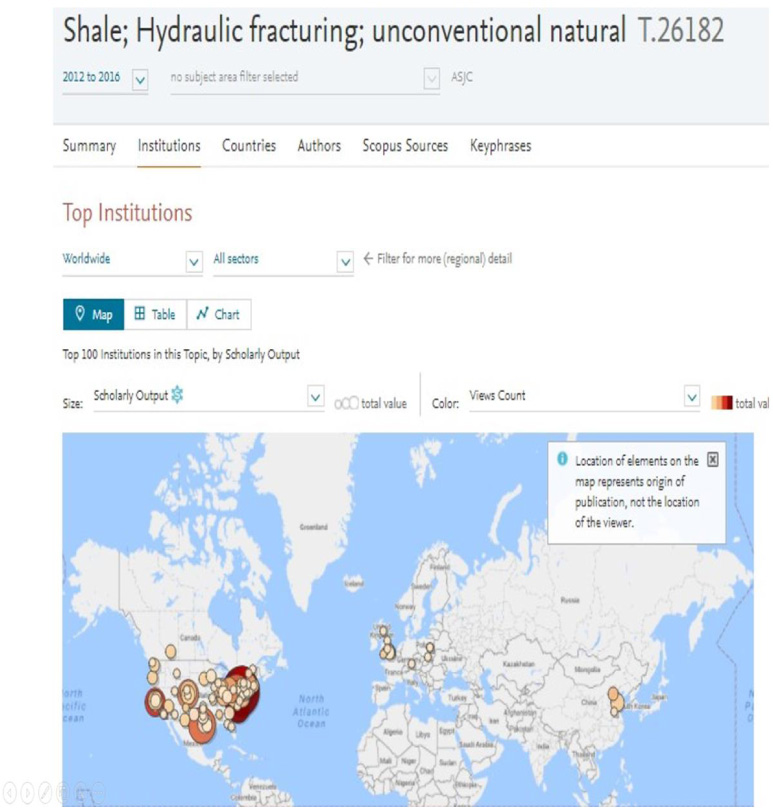
It should be noted that not all topics dominated by the U.S. are basic science topics or removed from commercial applications.
To summarize, we have accurately modeled approximately one hundred thousand topics in all areas of science and social science, calculated an indicator that measures the current growth momentum of a topic and correlates it with funding, and can help institutions make more informed decisions about their investments in research.
8.Conclusion
Despite all the progress academic publishers and information providers have made, it is important to note two things: first, that there is a long way to go before we reach a point where AI has certain abilities that are still uniquely human, such as the ability to generate a research hypothesis; and there is no conclusive evidence on whether or not AI will either wholly benefit or wholly harm humans. According to Ray Kurzweil, thanks to AI, by 2045 “we will have multiplied the human intelligence of our civilization a billion-fold” [6]. But according to Stephen Hawking, “The development of full AI could spell the end of the human race” [7].
The second is that as in any industry, there has to be more discussion about how to create the necessary checks and balances to ensure that new AI-based technologies are built with representative datasets and with as little bias as possible. By allowing these technologies to develop without agreeing on a guiding philosophy now, we risk a world in which humans cannot understand how AI draws its conclusions, or set limits on the technology’s power.
There is still a lot of work to be done, and it is important for researchers and research solutions providers alike to monitor and analyze emerging AI scholarship - which will ultimately help us predict trends and preempt potential problems. For more information on the state of global AI research, I encourage you to explore Elsevier’s recent AI report [8] - which explains the terminology around, and brings clarity to, the global AI research landscape. For more information on Elsevier’s research and health solutions, please visit us at https://www.elsevier.com/.
About the Author
Ann Gabriel, Senior Vice President, Global Strategic Networks at Elsevier, along with Elsevier’s global team, engages with key stakeholders across the research enterprise to establish strategic collaborations and to use analytics and data to address societal challenges in the area of sustainability, diversity and inclusion, and open science. Prior to her current role, she held a variety of positions at the forefront of scholarly communication - most recently as Elsevier’s Publishing Director for journals in Computer Science and Engineering, as well as electronic product development for Elsevier’s ScienceDirect platform. She was previously with Cambridge University Press. Ann represents Elsevier on several STM (Scientific, Technical & Medical) industry committees, including the CHORUS Board and RA21 (Resource Access for the 21st Century), each of which has a mission to enhance access to scientific data and publication. Ann holds a master’s degree in communications from the University of Pennsylvania, Philadelphia, PA, USA.
References
[1] | S. Lynch, Andrew Ng: Why AI is the new electricity, Insights by Stanford Business, March 11, 2017, available at: https://www.gsb.stanford.edu/insights/andrew-ng-why-ai-new-electricity, accessed September 28, 2019. |
[2] | Congressional Research Service, Global Research and Development Expenditures: Fact Sheet, September 19, 2019, available at: https://fas.org/sgp/crs/misc/R44283.pdf, accessed September 28, 2019. |
[3] | T. Sullivan, A tough road: Cost to develop one new drug is $2.6 billion; approval rate for drugs entering clinical development is less than 12%, Policy \& Medicine ((2019) ), available at: https://www.policymed.com/2014/12/a-tough-road-cost-to-develop-one-new-drug-is-26-billion-approval-rate-for-drugs-entering-clinical-de.html, accessed September 28, 2019. |
[4] | J. Doebele, Another Look, Forbes, December 14, 1998, available at: https://www.forbes.com/global/1998/1214/0119009a.html#16d29a8bb560, accessed September 28, 2019. |
[5] | A. Michael, AI and scholarly communications, Scholarly Kitchen, available at: https://scholarlykitchen.sspnet.org/2019/04/25/ask-chefs-ai-scholarly-communications/, accessed September 28, 2019. |
[6] | C. Reedy, Kurzweil claims that the singularity will happen by 2045: Get ready for humanity 2.0, Futurism ((2017) ), available at: https://futurism.com/kurzweil-claims-that-the-singularity-will-happen-by-2045, accessed September 28, 2019. |
[7] | Stephen Hawking warns artificial intelligence may supersede humans, disrupt economy, AIReligion, available at: https://aireligion.org/?p=368, accessed September 28, 2019. |
[8] | ArtificiaI Intelligence: How knowledge is created, transferred, and used Trends in China, Europe, and the United States, available at: https://www.elsevier.com/research-intelligence/resource-library/ai-report, accessed September 28, 2019. |


