
Applying artificial intelligence in the science & technology cycle
Abstract
The science and technology (S&T) cycle starts with Congress identifying areas that demand scientific advancements. The cycle continues with funding agencies distributing funds to researchers to investigate and advance these areas. These novel advancements are then reported in scholarly publications. Scientific advancements are ultimately expected to be converted into wealth, promoting economic activity, and benefiting society. It is not, however, guaranteed that the desired advances targeted by Congress are met. Scholarly publications encompass valuable knowledge about many aspects of the S&T cycle and may retain the key to many unanswered questions and support multiple, yet unoffered, services to users. Because of the data deluge, it has become necessary to rely on automated decision-making agents based on artificial intelligence (AI) methods to make decisions. This article introduces AI and proposes to relieve highly-specialized human experts from the position of decision makers and shift them to become managers of automated decision-making agents that can handle the data volume. This article will lay out research directions, technical challenges, and the benefits of applying AI in various steps of the S&T cycle.
1.Introduction
This article proposes to examine the Science and Technology (S&T) cycle as a cycle of humans, users, money, data, and opportunities. It proposes artificial intelligence (AI) methods to create automated agents that convert the data in the S&T cycle into services to meet several needs of the cycle users.
Currently, there are isolated efforts harnessing the S&T cycle’s data that may not be exploring the full potential or synergies that the cycle affords. Other efforts seek profits without the responsibility of the regulated scientific industry. This article argues for coordinated and responsible efforts through explainable AI (XAI).
Humans are the main decision makers in the S&T cycle. The history of computational support is marked by the use of databases to absorb data that is produced through natural and artificial processes. In the S&T cycle, organizational processes produce two types of data. Structured data is organized in valued fields and is easily stored in databases. Unstructured data is in form of text and is either unused or poorly used. For example, texts can be stored in a database and most frequent words are used as metadata. This is ineffective as most frequent words do not convey the actual meaning in texts. The structured data is processed within databases to produce information. Information are facts that are interpretable by humans; they are facts that humans can consume.
Humans use information available about situations to make decisions. Decisions are needed when there are problems to be solved. Information describes facets of the problem, its constraints and specificities. Fig. 1 shows a simplified model of decision making proposed by Huber [1]. Intelligence is when humans gather information about a problem. Design is when humans use their knowledge and intelligence to think of strategies to solve a problem. Choice is when the decision is made, which is the decision of which strategy to adopt to solve the problem. Humans can then take action based on the decision to solve the problem and implement the decision, and then monitor it to guarantee success.
![Decision-making and problem-solving model proposed by Huber [1].](https://content.iospress.com:443/media/isu/2019/39-4/isu-39-4-isu190062/isu-39-isu190062-g001.jpg)
Consider that we are witnessing a paradigm shift. The volume of data that is being currently produced surpasses the most ambitious predictions. There are accounts comparing data produced in hours with all the data stored in the library of congress [2], that 90% of all data has been generated in the last two years, and that it would take a person 181 million years to download all the data from the internet [3]. This shift impacts decision making because although database technologies are robust enough to handle all data, there are not enough humans or enough hours in a day for humans to look into the processed information to make decisions. This is now the era of automated decision agents.
Automated decision agents are the main product of AI technologies. Automated agents execute complex tasks such as planning and classification to make decisions. We describe the field of AI through its three waves. The recent advancements in AI technologies are making possible for agents to execute tasks with high levels of competence, even surpassing humans in natural language tasks [4]. We propose Third Wave AI applications to offer services to users in the S&T cycle because they are transparent and interpretable, hence users and automated agents can collaborate as partners, giving humans the opportunity to supervise and guide automated agents that can absorb the data deluge.
Section 2 discusses the S&T cycle, its problems, and opportunities. Section 3 presents the three waves of AI. Section 4 proposes several AI applications. A discussion section follows with benefits and challenges. Section 6 concludes the discussion.
2.The science & technology cycle
This article examines the S&T cycle with respect to four main players, namely, society, funding agencies, researchers and educators, and scientific publishers. S&T is meant to better society. This is one of the important roles of governments as they allocate funds collected from taxpayers. Legislators are elected to represent the people and communicate to central governmental boards such as Congress what people’s needs are. The government bodies react by allocating funds to better areas of demand. This is the idea in democratic countries like the United States, and we limit this discussion to this federal context. In the United States, Congress distributes funds to funding agencies to realize the advances that will address societal needs, such as cure diseases, decrease pollution, fight inequality, etc.
Fig. 2.
The main components of the S&T cycle.
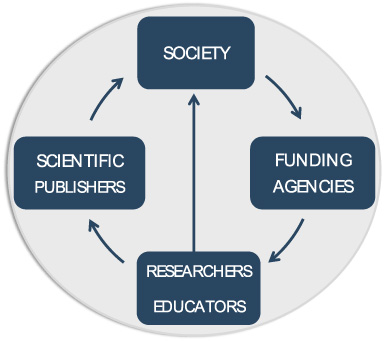
Funding agencies hire highly-specialized experts to create and manage the infrastructure to distribute funds allocated by the government. These funds are distributed in form of grants to scientists, engineers, and humanists (henceforth referred to generically as researchers) who conduct scientific research projects targeting the societal demands identified by Congress. These funds are extraordinarily crucial because they promote the betterment of society at the same time that they promote education. Most of these researchers, the ones from academia, are also instructors in courses in higher education where they disseminate their scientific findings and the findings of others. This way they foster the education and quality of the future generation of the workforce. These researchers hire doctoral students who support these research projects as they learn to become the next generation of researchers. The findings in these research projects that represent new knowledge learned are described in peer-reviewed publications. Researchers transfer their copyrights on their publications to scientific publishers in exchange for exposure in peer-reviewed publications. The scientific publishers create and support the infrastructure for peer reviews and are compensated by being given the copyrights to the publications.
The last step in the S&T cycle is when the new knowledge learned by researchers and described in scientific publications is converted into wealth as it is transformed into products, services, and behaviors that meet societal needs or at least attenuate their problems. In this step are included the creation of patents and trade publications.
2.1.The problems in the science & technology cycle
This section examines problems in the S&T cycle of varied nature. They are all problems that one could recognize as societal demands. These may not be the demands that directly impact all society members, but indirectly these problems impact us all because they make the cycle inefficient and ineffective, which leads to wastage of funds that were meant to be used for societal benefit.
In the first step of the S&T cycle, between society and funding agencies, investments are transferred for funding agencies to address societal problems. The main problem in this step is that no one knows how much science advancements cost. This means that neither Congress nor funding agencies can predict or at least produce an informed estimation of how much would be needed to fund a desired impact in societal demands. Every other industry invests fortunes to track investments and create financial analysis to evaluate its effectiveness and efficacy. Entire fields such as microeconomics and financial management are dedicated to study investments and return. This is not the case for investments in science and technology. It is consensual that better methods and tools are urgently needed [5]. Statistics indicators and economic models use expenditures to make inferences, but do not help with decision-making [6]. The Organization for Economic Co-operation and Development (OECD) [7] studies and tracks how science and technology compares against foreign countries and the only metric ever used is that of expenditures - outcomes are not considered.
The second problem we propose refers to the structure of funding agencies. Selecting which researchers to fund in order to conduct scientific endeavors is no small task. It is a highly-specialized challenge that requires highly specialized experts. It is not a task that can be fully standardized, which leads to a process that is nearly impossible to evaluate. The main problem is how many researchers this task borrows from actual research projects that will actually better society. It is not only the experts hired by the funding agencies on a permanent basis, but it also includes a large number of researchers who are asked on an ad hoc basis to participate in review panels. The result is that none of these researchers are addressing societal problems. The process is inconsistent and is hardly ever evaluated - making it difficult to improve.
The problems for researchers start with the fact they lack proper supporting tools to do their job competently. The levels of reproducible scientific research are minimal [8]. The rush into publishing to meet requirements affects even the most successful researchers. In 2010, a Nobel laureate retracted two articles published in Science and Nature from earlier years claiming inability to repeat the published findings [9]. There are no means to produce an exhaustive literature review that can guarantee that an author is not committing unintentional plagiarism. It is important to point out that any form of omission of existing related work does not only impact the omitted author, it denies readers the chance to learn about existing work, which leads to duplication [10]. No one can tell how many research projects are redundant. A clinical trial misinformed by an incomplete review has caused the death of a human subject [11]. Nobody knows how much of the produced findings are promoted by the funds distributed by funding agencies.
These same researchers are asked to volunteer to help review proposals for funding and are the ones who actually delivered peer reviews. A similar lack of support is for researchers dealing with data and processing. This is studied as e-science [12], cyberinfrastructure [13], or e-Infrastructure [14]. The main efforts to ease this problem have been in the development of scientific workflows [15]. There is still a lot to be done until the cyberinfrastructure is such that it has made researchers’ work efficient and effective.
The problems with education can (and have) been the topic of multiple books (e.g., [16]). We mention here problems that could be neutralized with proper use of data and that impact the productivity of researchers in the S&T cycle. Curriculum analysis is one of the main problems. In academia, because educators are researchers who keep up-to-date with cutting edge advancements in their fields, they are tasked with analyzing and updating curricula. The problem is one of coverage given that educators can only keep up with the advancements of a narrow sub-field that their research projects focus on. The burden is placed on educators to adjust and adapt curricula and predict the contents necessary to equip students for successful careers.
Another problem in education that directly impacts educators is one that also impacts scientific publishers – it is that of producing educational materials. Scientific publications are used by educators to create course contents, supporting materials, and exams. Unsurprisingly, these same publications end up being published in textbooks. There is no synergy in this process, at least not in general. The educators, who are also researchers, are also the ones who prepare those materials and compose the textbooks. There are no processes to make these tasks synergistic. The copyrights of textbooks are also transferred to the scientific publishers who have to fund the infrastructure to offer and distribute textbooks. In fields that advance quickly, textbooks are often obsolete when published, and yet they still carry a high price tag for students. It is not hard to recognize how inefficient the production and dissemination of scientific knowledge is today.
The scientific publishers hold the copyrights of scientific publications and textbooks so they can be remunerated for their efforts with commercial sales. As stated earlier, the world has changed. This change has modified how decisions are made and how the economy works. This is impacting businesses of all kinds. Today, any company has to be a data company, or it may simply cease to exist. Scientific publishers are at risk of losing their niche market to the Big Tech giants (e.g., Microsoft, Amazon, etc.). Scientific publishers are a regulated industry because of their role in the S&T cycle. Their current situation is a serious problem for everyone.
The last step of the cycle is where scientific publications are to be converted into wealth to meet societal needs. This is yet another problem in the cycle. Studies in individual segments such as pharmaceuticals show how scientific advancements lead to wealth. These studies are isolated and cover several years. But because of the lack of clarity in the rest of the cycle, this last step is even more obscure.
2.2.The opportunities in the science & technology cycle
Referring back to Fig. 1, the main players in the S&T cycle are the people in government, in funding agencies, in education, in research and development (R&D) institutions, in the scientific publishing industry, which includes the industry regulators, and in the organizations that manufacture and distribute new products and services. These organizations are all comprised of people. The changes in our world and economy have made people opportunities (Fig. 3) because they are users of electronic software and services. As argued by Holmen [17], the reason big technology giants are big is because they own the users, not services or products. So a cycle that has so many users, is a cycle of opportunities, as these users are under-served considering the problems discussed above. The opportunity is to serve these users and own them.
Fig. 3.
A cycle of people is a cycle of users and opportunities.
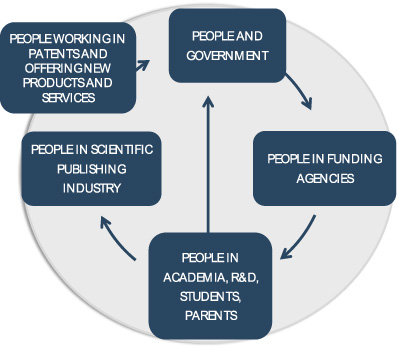
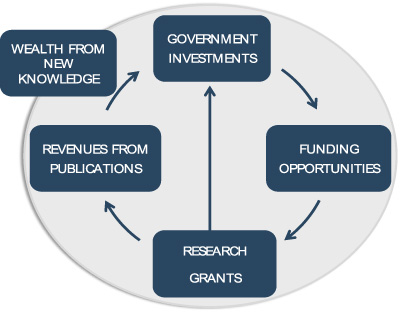
There are other ways to view the S&T cycle. The way we described the cycle starting from the government identifying demands, and then allocating funds to meet said demands, it starts as a cycle of money. When visualizing this as a cycle of money (Fig. 4), it has a new component that comes from the economic leveraging resultant from the new scientific knowledge that affords new products, services, and modifications that open new niches and produce new jobs. Even if the evidence for this wealth may be scarce [5], this is the general gist of the money flow. Because it is a cycle of money, it can be better understood through the volume of money that flows in its different stages. The opportunity is that it can be budgeted.
Fig. 4.
The S&T cycle is a cycle of money.
There is still one other valuable asset populating the entire S&T cycle: it is data. The OPEN Government Data Act refers to the Open Data Policy (M13-13) [18] that mandates federal agencies to publish all their information as open data. Notwithstanding politics and other obstacles, in the United States, the people earned this right. Fortunately, the majority of funding agencies are federal, so there are open data for the two first players. Not all universities are public, but information about all funded research is also open. Their products, however, are not all freely-accessible. When scientific publishers are the players, then data is mostly proprietary. As we move into patents, data is also available. The S&T cycle is indeed a cycle of data (Fig. 5), even if not all of the data is publicly-accessible. This is the greatest opportunity anyone can ever expect now that the world has changed. The data is there and the methods to convert them into user services through automated decision agents are described in the next section.
Fig. 5.
The vision is a Third Wave AI approach to support for users engaged in conducting literature reviews through interpretable citation recommender that leads to trust.

3.The three waves of artificial intelligence
As earlier introduced, when making decisions, entities (i.e., human or artificial agents) design alternative strategies and then choose the one to take into action. Decision-making entities utilize some form of content that allows them to align feasible strategies with a problem and also to make the decision that they believe will produce the best results for solving it. This content is knowledge, it is a contextual-justified belief that enables an entity to take action [19–22].
There is a clear relationship between the definition of knowledge, decision making, and AI [22]. AI is a field of study focused on the design, development, evaluation, and deployment of artificial agents that make rational decisions [23]. Unique to AI agents is the way on which they make decisions, which is through the execution of a complex task such as classification, planning, design, etc. This means that each agent typically executes only one complex task. For example, the popular app Waze executes route planning every time a user enters a destination. Automated agents used for loan applications execute classification. They consider the information entered by an applicant and classify that applicant as a member of either the approved or the rejected class. An industrial application executes design by indicating the order of steps to be taken to assemble a part.
The Defense Advanced Research Projects Agency (DARPA) groups AI methods in three waves. The first wave is labeled describe. This wave was driven by a vision for the field proposed in the 1956 workshop when the name of the field artificial intelligence was coined. The vision was that any aspect of learning or intelligence could be described in such a way that it could be simulated [24].
The First Wave produced all methods used in AI today. Some of these methods were substantially revised. These methods are rule-based reasoning, search algorithms, neural networks, decision trees, case-based reasoning, fuzzy logic, ontologies, constraint satisfaction, and multiple methods for natural language. Some of these methods follow principles of logic, some attempt to represent and reason with knowledge, and those focused on learning rely on data. These methods were the basis of multiple AI applications such as expert systems, intelligent tutoring systems, route planning, automated design, machine translation, question-answering, credit underwriting, natural language interfaces, among others. These applications produced decisions based on the execution of complex tasks such as planning, classification, diagnosis, configuration, design, prescription, interpretation, configuration, scheduling, and so on.
The applications in the first wave have produced several results and were adopted in multiple industries. End-users were not typically aware when there was an AI agent executing a task. It was when the world changed that AI changed. The data deluge offered new challenges and new opportunities for AI methods. The methods focused on learning, usually labeled machine learning, made an exponential leap as big data became available. The large volumes of data also favored statistical learning. This is now the Second Wave of AI.
Machine learning methods excel in executing classification and categorization. The second wave of AI is labeled categorize. In this wave decision agents become ubiquitous. Advances in neural networks enable learning in deep networks and the new sub-field deep learning is born. Image classification becomes more accurate and new vision-related tasks are created such as object segmentation, image style transfer, image reconstruction, image resolution, and even image synthesis. Deep networks and the methods conceived for their training also advance natural language, speech recognition, and speech synthesis. The advances in natural language understanding allow computers to learn analogies from vast amounts of unstructured data without the systems being presented with any examples. A computer program beats humans in the game Jeopardy [25]. Electric cars are computers on wheels that can overtake other cars on crowded roads. This is the Second Wave of AI.
Humans are not comfortable handing over decision-making power to others. Imagine an administrative office where the boss is replaced. It takes time until employees can trust the new boss. Humans like to observe decision makers to trust them. This poses a problem for the Second Wave of AI. This challenge is the precursor of the Third Wave of AI. The Third Wave is labeled explain because this is what humans need from automated decision-making agents. They want agents to explain themselves, to justify the reasons for their decisions, to explain why they did not decide something different, to explain which factors were prioritize, to explain which data was used, to guarantee that the decision was unbiased, that it was not prejudicial, and that it conforms to human accepted norms and principles [26].
In the Third Wave of AI, agents and humans are partners in decision-making. The automated agent is the one to absorb the data deluge and propose decisions. Humans are the ones who take action (Fig. 1). The world has changed. In the past humans were the ones who made the decisions and took action. Humans now need to learn to collaborate with AI agents who, in turn, need to become interpretable, transparent, accountable, and ethical. The automated decision agents of the Third Wave have to be capable of adapting to the context of a situation and be capable of explaining how the context was used. This is a model where agents make decisions and humans supervise them to guarantee that they are making the right decisions, and following the right principles, just as an expert leads an apprentice who needs supervision. Humans entered the AI equation in the Third Wave of AI. It is no longer acceptable for AI agents to simply execute complex tasks. They have to make decisions like humans. They also need to leverage organizational, contextual, experiential, and scientific knowledge. The field of explainable AI (XAI) (e.g., [27–31]) is the core of the Third Wave.
4.Artificial intelligence applications in the science & technology cycle
This section proposes third wave AI applications for the opportunities offered in the S&T cycle. We start with applying AI to the wealthy source of scientific publications.
We propose a vision of automated analysis of scientific literature. This is not novel, as multiple authors have been pursuing various approaches with the same vision (e.g., [22,32–34]). The vision we propose is direct, accurate, and exhaustive access to literature related to a topic so that anyone considering a doctoral degree could first read about open research questions in a given field and access literature reviews based on different perspectives of the topic; e.g., in a personalized fashion to the student’s interests.
4.1.Third wave of AI for literature reviews
Efforts towards automating literature reviews have been proposed since 1999 [35], and continue to be explored (e.g., [36,37]). Despite having been around for so many years, we do not see these implementations yet available in the mainstream digital libraries that are currently offered to researchers and students. We may conjecture about multiple reasons for this, but the last section suggests the reason is lack of transparency, which prevents users from the opportunity to learn about these systems enough to trust them [30,31]. Consequently, we propose an approach for improving support to users conducting literature reviews based on the Third Wave of AI [38,39].
First, we propose a personalized citation recommender as the central model to search for relevant related research similar to that proposed in Bhagavatula et al. [40] that uses different deep-learning steps to separately address recall and precision. Second, we recommend that this tool relies on state-of-the-art (SOA) contextual embeddings given their exceptional quality (e.g., [4,41]). The personalization in citation recommenders is realized through multiple sentences that users enter as a query that describe the fields of interest better than a few keywords.
For interpretability, we propose that citations are augmented by the class of citation type that would characterize the citation if the user chooses to take action and accept the decision of the recommender and cite it in their work. Given previous work investigating mental models of users of information retrieval systems (e.g., [42,43]), we recommend aligning the explanation with those studies and also present sentences from the query text entered by the user and the publication being recommended demonstrating how they match.
When deployed, these systems will be partnering with humans to increase the aggregated understanding of scientific literature. These systems, in combination with methods for extraction of claims [44] and other crucial elements of scientific discourse [22], will support the proposed vision. Some of the services that the resultant technologies would be able to provide with high degrees of accuracy include answers to questions such as, “What are the open questions in this field? Which scientific contributions are redundant? Which scientific contributions are contradictory?”
4.2.Third wave of AI for funding agencies
Placing a program officer from a funding agency as supervisor of multiple automated decision agents that can deal with big data and a high level of understanding of the scientific literature can decrease the volume of highly-qualified experts allocated to the agency. This allows more highly qualified researchers to do their job, which is to produce novel scientific findings for the betterment of society.
A widely-studied problem related to allocating federal funds is the evaluation of researcher quality [45]. The limitations of the Second Wave to automate some of its decisions has contributed to the creation of the Leiden Manifesto [46], which dictates ten principles to be followed when assessing research quality. Not surprisingly, one of them makes it a requirement that methods are transparent, presenting adequate explanations that justify assessments. One AI methodology conceived in the First Wave, case-based reasoning (CBR) [47], affords explanations with high levels of transparency, and was hence the methodology proposed in [45] to assess researcher quality and meet Leiden Manifesto’s principles. The initial version [45] does not yet include explanations, but already meets other principles [ibid].
Still considering the work of funding agencies with respect to researchers, one application that has been vastly studied is that of expert locator systems. Researchers are located today and assessed based on their profiles in applications such as Google Scholar. These profiles are semi-automatically populated and are incomplete. Furthermore, they are partially self-populated, which has its own sets of limitations. The better understanding of the scientific literature can also help with this task. One idea that has been proposed [48] is to characterize researchers based upon their most recent contributions to the scientific literature [ibid]. This would eliminate the limitations of both automatic- and self-populated expert locators. Advancements such as those from [44] to extract crucial passages from scientific discourse and the development of a representation structure for scientific contributions such as the one in [22] can be used for an interpretable expert locator system.
There is a plethora of applications that can be developed in support of processes in funding agencies that include the summarization and the drafting of documents. These all can benefit from the better understanding of the scientific literature such as identifying gaps and making correlations to societal demands, which become possibly achievable goals.
Another set of applications in support of funding agencies includes those based on data analytics using open governmental data. One such application is the budgeting of scientific advances, which can help answer questions about the cost of science. The investigations needed for this budgeting are beyond the scope of this article.
4.3.Third wave of AI for education
Third Wave AI applications for education target partnerships with pedagogists and educators. These applications require both extensive data analytics and the advanced representation of scientific knowledge discussed above. They encompass services for curriculum creation and maintenance, course contents, and course materials.
Curriculum creation requires a combination of data analytics to help us predict the placement of students in the workforce. Barbosky [49] stated how the demand for data analysts is larger than the market can fill. Note, however, that the big data revolution has been observed in the scientific literature [50] since 2000. This means that if educators who are tasked to create, maintain, and adapt curricula were supported by the proper knowledge of scientific facts, they would have realized that the curricula had to account for this labor demand. We propose applications where curricula experts would be supervising multiple automated decision agents that would constantly and continuously adapt curricula to markets’ needs. This reality would render obsolete course contents at ever academic year or semester.
To meet the new demands of agile curricula management, Third Wave AI applications would need to use a representation framework [22] to prepare course contents, textbook materials, presentations, videos, and assignments [34]. An initial strategy for such applications is given in [ibid].
4.4.Third wave of AI for scientific content creation
In this section, we discuss Third Wave AI applications for scientific content creation, as opposed to the previous section where we discussed educational content creation. These applications are needed in support of researchers as they deliver scientific projects to learn new scientific findings.
Scientific workflows [15] make experimental repeatability possible through implementing steps to deliver scientific discovery. When representing experiments, they enable reproducible contributions, decreasing the chance of error in manual handling and increasing the quality of experiments. There are various systems for managing workflows such as taverna.org.uk and pegasus.isi.edu. These systems provide a window into the future of the automation of the production of knowledge. To select an existing workflow, researchers do not have to know how to write code. They merely need to understand if that operation is what they need. Once researchers begin using a workflow system, they benefit from features such as statistical analyses, visualizations, etc.
The vision we propose for Third Wave AI support for scientific content creation connects scientific workflows with a representation framework [22], working as metadata for scientific workflows. Consider how much easier it would be to manage scientific conferences with semi-standardized conference submissions. Consider, for example, a visualization procedure such as the ROC chart method for comparison of discrete classifiers [51]: (see also: Receiver Operating Characteristic at https://www.semanticscholar.org/paper/ROC-Graphs%3A-Notes-and-Practical-Considerations-for-Fawcett/44bb1605c4ab8a8ce2764fa20424f6a148101ca4). Now consider that every author of a conference paper that uses the code that creates a ROC chart has to include a couple of sentences describing it with a citation. What we are proposing is that the draft of the conference paper be automatically prepared including the sentences explaining what a ROC chart is and why it is advantageous over other methods, its required references, and the citations populated in the reference list. This kind of application would be an ideal set of requirements for a Third Wave AI conference management system.
This same approach for semi-automation of conference papers can be used for preparation of journal manuscripts. Besides the methodology section as mentioned above, other parts of a manuscript can be drafted with the literature review and motivation being the lowest hanging opportunities. Based on recent efforts in automating literature reviews to create summaries of these reviews, summaries of publications with specific foci may be ideal for this application. Once accepting a citation recommended to incorporate into a manuscript, the citation recommender personalization may be able to offer capabilities beyond those proposed above and produce the drafts of the description of how the recommended article is relevant to the user-entered query draft.
The development of automated drafting is a consequence of the better understanding of a representation framework for scientific knowledge and the automated analysis of scientific literature. Sections like results can utilize metadata from scientific workflows and a draft of a discussion section can explore meta discussions learned from other publications.
5.Benefits and challenges
5.1.Benefits
Applying AI to automated decision making to provide users of the S&T cycle with answers to many unanswered questions has multiple benefits. The most immediate is greater understanding of the cycle itself, which shall directly lead to better decisions. This responds to the challenges posed by Lane and Bertuzzi [52] to create a system to capture, analyze, distribute, and represent scientific data in support of adequate measurement, budgeting, and economic analyses. These needed tasks will make the S&T cycle transparent to its players, but furthermore they are business opportunities that can be undertaken by the publishing industry, which has plenty of room to grow.
The most significant result from making the S&T cycle transparent would likely be the automated analysis of scientific literature. Being able to automatically, and with high degrees of accuracy, identify research gaps and redundant works would increase efficiency of an industry that, in 2018, was estimated at $1.3 trillion dollars [53]. Another potential realization from the automated analysis of scientific literature is to enable easy access to scientific facts. Consider that easier access to scientific facts can be a crucial weapon against ignorance and the use of fallacies by advertisers and politicians, enhancing the education of society. Better access to scientific facts is also a weapon against crimes such as those categorized as confidence crimes and fake news. Another result would be the understanding of which disciplines generate wealth and which do not, at least in the short term. This would encourage private investments and allow governments to invest in the fields that would not be supported by for-profit segments.
Third Wave AI methods are deployed in partnerships with human users. This new paradigm will afford further discoveries about computer support for automated decision making in the cycle. For example, Third Wave AI support for literature reviews will lead to further developments in automated analysis of scientific literature because users will supervise the results and provide the needed understanding for automated systems that may be lacking today.
In addition to direct decisions stemming from AI applications, the benefits of proposed AI applications are expected to impact organizations from the cycle. Consider how funding agencies rely on so many highly-specialized experts that could be directly working on addressing societal improvements. Organizations that prioritize their own processes rather than their final goal are infected by a form of bureaucratic disease. Relieving scientists from the process and freeing them to work in research projects will attenuate this unwanted phenomenon.
The further development of Third Wave AI applications for the S&T cycle by federally-funded researchers promotes advances in the fields of XAI, applied AI, and domain areas such as Science of Science. These advances will lead to the development of applications that follow standards for information services thus guaranteeing access to knowledge to all readers.
Agile creation of curriculum and course contents will enable the reduction of time from the moment that a new scientific advance is learned to the time that it reaches educators and students and the marketplace. This may also make the connection between the scientific publishers and creation of wealth faster because today there is a gap from the moment that a patent is filed to the point where organizations can have an educated and trained workforce to deliver the new knowledge. Agile curricula and course contents would benefit this step of the S&T cycle.
Benefits of automating content creation will facilitate the work of researchers and scientific publishers. Today, the publishing industry is investing in tools to streamline the infrastructure needed in support of peer-reviewed publications [54]. One example is the use of automated proof editing and plagiarism detection. Publishers claim a lot of time is wasted using volunteer reviewers who often dismiss manuscripts due to their low presentation quality. Consider how this problem would be attenuated with semi-automated drafting of manuscripts that would eliminate ambiguity in the composition of a manuscript.
5.2.Challenges
There are many challenges to the realization of so many benefits. The challenges that pose the most risk to the realization of the vision in this article are, not surprisingly, of economic nature. The social challenges are mostly in earning user trust and in humans learning to adapt to a new paradigm interacting with automated agents. There are also some technical challenges.
Researchers do not have access to the full text of all scientific publications. It is quite unusual to find a scientific article that manages to get authorization from scientific publishers to use full texts. One example used 15 million full-text articles [55]. In the same year this academic work was published, a news article disclosed that Microsoft had 176 million articles in their academic graph [56]. Google Scholar had 160 million articles in 2014 [57]. This challenge is multifold. First, scientific publishers do not want to lose what may be the last source of revenue they have as technology giants like Microsoft, Facebook, Apple and Amazon own the users and are taking over this market [17]. Second, scientific publishers are only preventing themselves and researchers from producing alternatives that can actually stand a chance in competing against technology giants. These two challenges have multiple consequences and need to be better explained.
Technology giants are powerful, and they are already offering services to users from the S&T cycle, namely, Google Scholar. They do not yet solve the problem, but the challenge is that they will propose solutions that will shrink our knowledge base because they are not regulated and have no obligation to follow the standards that guarantee readers access to scientific knowledge. They are only committed to remunerating their shareholders. Furthermore, their processes are not transparent, and it is easy to manipulate citation counting [58].
Scientific publishers are utilizing and offering services with limited data, and their efforts may be described as timid in comparison to technology giants because they either do not use full text or only use their own copyrighted publications, or just have a small number of alliances that allow them to use copyrighted materials from their competitors. Consider, for example, a tool to detect plagiarism [54] that uses full-text data from just a handful of publishers. This tool will miss out on detecting plagiarism unless it uses all scientific publications. The same problem occurs with recommender systems. TrendMD [59] provides recommendation of articles based on articles a user reads or retrieves. TrendMD reported having about 300 partnerships [ibid], but they still only use abstracts and not full text.
Earning the trust of users is the main goal of XAI [26,29,30]. This body of research is moving in this direction. Although this may still be considered a challenge, it is only a matter of time until automated agents built with high technical standards are distinguishable by users and they are the ones that will be trusted.
Another social challenge refers to the shift in the nature of work. Humans need to adapt to a new paradigm to become supervisors of automated agents. This is also a challenge that XAI will contribute to overcome.
6.Concluding remarks
This article proposes that the S&T cycle is a cycle of opportunities because it is full of problems and users starving for answers. The opportunities are ready to be seized because the S&T cycle is also a cycle of data, and the Third Wave of AI is poised to be fully-developed to use the cycle’s data to create automated decision agents. Automated decision agents have finally reached a high level of competence in several tasks (e.g., [4]).
The S&T cycle is a cycle of data and of users thirsty for services. It is imperative that the publishing industry form strong alliances between its own players, with academia, and with the government to guarantee that the services that are offered to users of the S&T cycle meet the highest standards proposed by institutions such as the National Information Standards Organization.
The S&T cycle is also a cycle of opportunities. The publishing industry has a great opportunity to disrupt and take ownership of all users in the S&T cycle. Publishers can provide service to the federal government helping them to better identify underserved fields of scientific knowledge and helping them budget, predict, and control their investments. The publishing industry can provide services to funding agencies, helping them create needed programs, better distribute their funds, learn from their data, and predict their impact, among others. The publishing industry can provide multiple services to the education sector from agile curriculum management, to the agile generation of course contents and course materials, including for assessment. This is all possible with the combination of Third Wave AI applications and the richest and most valuable source of knowledge: the proprietary data in scientific publications. Let us create alliances, develop XAI further, earn users and their trust, and have a transparent, efficient, and effective S&T cycle. These achievements will guarantee a better future where scientific knowledge meets needs and promotes a health and educated society.
About the Author
With an international and multidisciplinary background in engineering and management, Rosina Weber, associate professor, department of Information Science, College of Computing & Informatics, Drexel University, has twenty years of experience, more than a hundred publications and two books on artificial intelligence (Weber co-authored the first textbook in English in case-based reasoning).
References
[1] | G.P. Huber, Managerial Decision Making. Scott, Foresman, Glenview, IL, (1980) . |
[2] | B. Smyth, Small sensors. Big Data. Presentation. https://www.slideshare.net/bsmyth, accessed September 10, 2019. |
[3] | Big Data Statistics 2019. March 22, 2019. Available at: https://techjury.net/stats-about/big-data-statistics/, accessed September 10, 2019. |
[4] | J. Devlin, C. Ming-Wei, K. Lee and K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint https://arxiv.org/abs/1810.04805 (2018), accessed September 10, 2019. |
[5] | C. Macilwain, Science economics: What science is really worth, Nature News 465: (7299) ((2010) ), 682–684. |
[6] | J. Lane, Assessing the impact of science funding, Science 324: (5932) ((2009) ), 1273. |
[7] | B. Godin, Measurement and Statistics on Science and Technology: 1920 to the Present. Routledge, London, (2005) . |
[8] | M. Baker and D. Penny, Is there a reproducibility crisis?, Nature 533: (7604) ((2016) ), 452–454, ISSN: 14764687. |
[9] | NY Times 2010, Nobel laureate retracts two papers unrelated to her prize. www.nytimes.com/2010/09/24/science/24retraction.html?_r=1_emc=eta1. |
[10] | E. Garfield, From citation amnesia to bibliographic plagiarism, Essays of an Information Scientist 4: : ((1980) ), 503–507. |
[11] | J. Savulescu and M. Spriggs, The hexamethonium asthma study and the death of a normal volunteer in research, Journal of Medical Ethics 28: (1) 3–4. |
[12] | T. Hey and A.E. Trefethen, The UK e-science core programme and the grid, Future Generation Computer Systems 18: : ((2002) ), 1017–1031. |
[13] | D.E. Atkins, K.K. Droegemeier, S.I. Feldman, H. Garcia-Molina, M.L. Klein, D.G. Messerschmitt, P. Messina, J.P. Ostriker and M.H. Wright, Final Report of the NSF Blue Ribbon Advisory Panel on Cyberinfrastructure: Revolutionizing Science and Engineering through Cyberinfrastructure, 2003, https://www.nsf.gov/cise/sci/reports/atkins.pdf, accessed September 10, 2019. |
[14] | M. Jirotka, C.P. Lee and G.M. Olson, Supporting scientific collaboration: methods, tools and concepts, Computer Supported Cooperative Work (CSCW) 22: (4-6) ((2013) ), 667–715. |
[15] | Y. Gil, E. Deelman, M. Ellisman, T. Fahringer, G. Fox, D. Gannon and J. Myers, Examining the challenges of scientific workflows, IEEE Computer 40: (12) ((2007) ), 24–32. |
[16] | R.E. Floden, Policy Tools for Improving Education. SAGE Publications, (2003) . |
[17] | M. Holmen, Blockchain and scholarly publishing could be best friends, Information Services & Use 38: : ((2018) ), 131–140. |
[18] | Open Government Data Act. Data Coalition. https://www.datacoalition.org/open-government-data-act/, accessed 8/3/2019. |
[19] | G.P. Huber, Organizational learning: the contributing processes and the literatures, Organization Science 2: (1) ((1991) ), 88–115. |
[20] | I. Nonaka, A dynamic theory of organizational knowledge creation, Organization Science 5: (1) ((1994) ), 14–37. |
[21] | M. Alavi and D.E. Leidner, Knowledge management and knowledge management systems: conceptual foundations and research issues, MIS Quarterly 25: (1) ((2001) ), 107–136. |
[22] | R.O. Weber, Objectivistic knowledge artifacts, Data Technologies and Applications (Formerly published as Program) 52: (1) ((2017) ), 105–129. |
[23] | S. Russell and P. Norvig, Artificial Intelligence: A Modern Approach. Prentice-Hall, (2009) . |
[24] | J. Moor, The Dartmouth College artificial intelligence conference: the next fifty years, Ai Magazine 27: (4) ((2006) ), 87. |
[25] | D. Ferrucci, A. Levas, S. Bagchi, D. Gondek and E.T. Mueller, Watson: Beyond Jeopardy, Artificial Intelligence 199: : ((2013) ), 93–105. |
[26] | P. Langley, Explainable, normative, and justified agency, in: Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence. AAAI Press, Honolulu, HI, (2019) . |
[27] | A. Adadi and M. Berrada, Peeking inside the black-box: a survey on Explainable Artificial Intelligence (XAI), IEEE Access 6: ((2018) ). |
[28] | R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, D. Pedreschi and F. Giannotti, A survey of methods for explaining black box models, ACM Computing Surveys (CSUR) 51: (5) ((2018) ), 93. |
[29] | R.R. Hoffman, S.T. Mueller, G. Klein and J. Litman, Metrics for Ex-plainable AI: Challenges and Prospects. arXiv preprint arXiv:1812.04608. |
[30] | T. Miller, Explanation in artificial intelligence: insights from the social sciences, Artificial Intelligence 267: : ((2019) ), 1–38. |
[31] | S.T. Mueller, R.R. Hoffman, W. Clancey, A. Emrey and G. Klein, Explanation in Human-AI Systems: A Literature Meta-Review, Synopsis of Key Ideas and Publications, and Bibliography for Explaina-ble AI. arXiv preprint, arXiv:1902.01876. |
[32] | A. Cohan, W. Ammar, M. van Zuylen and F. Cady, Structural Scaffolds for Citation Intent Classification in Scientific Publications. arXiv preprint arXiv:1904.01608, 2019. |
[33] | C. Chen and M. Song, Representing Scientific Knowledge. Springer, (2017) . |
[34] | R. Weber and S. Gunawardena, Representing Scientific Knowledge. Cognition and Exploratory Learning in the Digital Age. Rio de Janeiro, Brazil, (2011) . |
[35] | H. Nanba and M. Okumura, Towards multi-paper summarization using reference information, in: Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence (1999) , pp. 926–931. |
[36] | V. Qazvinian, D.R. Radev, S. Mohammad, B.J. Dorr, D.M. Zajic, M. Whidby and T. Moon, Generating extractive summaries of scientific paradigms, Journal of Artificial Intelligence Research (JAIR) 46: : 165–201. |
[37] | G. Tsafnat, P. Glasziou, M.K. Choong, A. Dunn, F. Galgani and E. Coiera, Systematic review automation technologies, Systematic Reviews 3: (1) ((2014) ), 1. |
[38] | R.O. Weber, A.J. Johs, J. Li and K. Huang, Investigating textual case-based XAI, in: Case-Based Reasoning Research and Development, M.T. Cox, P. Funk and S. Begum (eds),Lecture Notes in Computer Science, Vol. 11156: , Springer, (2018) . |
[39] | R.O. Weber, H. Haolin and G. Prateek, Explaining Citation Recommendations: Abstracts or Full Texts? In IJCAI 2019 Explainable AI Workshop. https://sites.google.com/view/xai2019/home. |
[40] | C. Bhagavatula, F. Sergey, P. Russell and A. Waleed, Content-Based Citation Recommendation. NAACL, HLT, (2018) . |
[41] | Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov and Q.V. Le, XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237, 2019. |
[42] | A. Thatcher and S. Mlilo, Changes in users’ men-tal models of Web search engines after ten years, Ergo-nomics SA: Journal of the Ergonomics Society of South Africa 26: (2) ((2014) ), 50–66. |
[43] | T. Gossen, H. Juliane and N. Andreas, A comparative study about children’s and adults’ per-ception of targeted web search engines, in: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. ACM, (2014) , pp. 1821–1824. |
[44] | T. Achakulvisut, C. Bhagavatula, D. Acuna and K. Kording, Claim Extraction in Biomedical Publications using Deep Discourse Model and Transfer Learning. arXiv preprint arXiv:1907.00962, 2019. |
[45] | K. Duarte, R.O. Weber and R.C.S. Pacheco, Purpose-oriented metrics to assess researcher quality, in: Proceedings of the 21st International Conference on Science and Technology Indicators (STI2016) (2016) , pp. 1310–1314. |
[46] | D. Hicks, P. Wouters, L. Waltman, S. De Rijcke and I. Rafols, Bibliometrics: the Leiden Manifesto for research metrics, Nature 520: (7548) ((2015) ), 429–431. |
[47] | M.M. Richter and R.O. Weber, Case-Based Reasoning: a Textbook. Springer-Verlag, Berlin, (2013) . |
[48] | R.O. Weber and S. Gunawardena, Designing multifunctional knowledge management systems, in: Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS-41), Jan. 2008 (2008) , pp. 368–368. |
[49] | C. Barbosky, AI Fuel: High quality data and human expertise in the development of machine learning, in: Talk at the NFAIS Conference on Artificial Intelligence: Finding Its Place in Research. Discovery and Scholarly Publishing, Alexandria, VA, (2019) . |
[50] | S.H. Koslow, Should the neuroscience community make a paradigm shift to sharing primary data?, Nature Neuroscience 3: (9) ((2000) ), 863. |
[51] | T. Fawcett, ROC graphs: Notes and practical considerations for researchers. Tech Report HPL-2003-4, HP Laboratories, 2003. |
[52] | J. Lane and S. Bertuzzi, Measuring the results of science investments, Science 331: (11) ((2011) ), 678–680. |
[53] | Science. March 23, 2018. Trump, Congress approve largest U.S. research spending increase in a decade. Retrieved from https://www.sciencemag.org/news/2018/03/updated-us-spending-deal-contains-largest-research-spending-increase-decade, accessed September 8, 2019. |
[54] | G. Kloiber, Using AI to improve manuscript quality and speed up the evaluation process, in: Talk at the NFAIS Conference on Artificial Intelligence: Finding Its Place in Research. Discovery and Scholarly Publishing, Alexandria, VA, (2019) . |
[55] | D. Westergaard, S. Hans-Henrik, T. Christian, J. Lars Juhl and B. Søren, A comprehensive and quantitative comparison of text-mining in 15 million full-text articles versus their corresponding abstracts, PLoS Computational Biology 14: (2) ((2018) ), e1005962. |
[56] | InfoDocket, 2018, Microsoft Academic Graph Now Contains Over 176 Million Articles, Announces Improved Patent Coverage. Available online: https://www.infodocket.com/2018/08/07/microsoft-academic-graph-now-contains-over-176-million-articles-announces-improved-patent-coverage/, accessed September 10, 2019. |
[57] | Science. Sep. 30, 2014. Just how big is Google Scholar? Ummm … Available online: https://www.sciencemag.org/news/2014/09/just-how-big-google-scholar-ummm, accessed September 10, 2019. |
[58] | E. Delgado López-Cózar, N. Robinson-García and D. Torres-Salinas, The Google scholar experiment: How to index false papers and manipulate bibliometric indicators, Journal of the Association for Information Science and Technology 65: (3) ((2014) ), 446–454. |
[59] | B. Carelli, Using AI to enhance discovery and achieve publisher goals, in: Presentation at the NFAIS Conference on Artificial Intelligence: Finding its Place in Research. Discovery and Scholarly Publishing, Alexandria, VA, (2019) . |


