
The future of access: How a mosaic of next-gen solutions will deliver more convenient access to more users
Abstract
Rogue services such as SciHub deliver a clear message that users demand fast, convenient access to content. This paper discusses how the landscape of user access to content is being defined by RA21, CASA and LibKey. The reach and limitation of each approach is reviewed, discussing how the future of user experience will be a mosaic of services, that while different, all share core attributes.
Since the OpenURL framework was designed in the late 1990’s1, link resolvers based on this mechanism have become the standard gateway for linking library subscribed indexes to library subscribed content. At that point in time, IP access was the norm and libraries were quickly subscribing to more and more online content in increasingly complex subscription arrangements necessitating the creation of this technology in order to provide as seamless a linking route for users as possible.
Since then, the world of information services has become even more complex with the massive amount of scholarly information available online, new and powerful commercial discovery tools as well as freely available ones on the web such as Google Scholar, the rise of numerous open access models, sophisticated aggregated package schemes, and numerous flavors of remote authentication technology.
Through all of this the link resolver has persisted as the standard mechanism of linking users to content, even though it is most prominently used to connect library services to library content.

In 2011, the site Sci-hub was launched2 providing nearly all subscribed articles from the major scholarly publishers online for free. The success of this project had two important impacts:
Publishers suddenly had a thief of their content of large proportions whose mission was and is to make scholarly material available to all.
It was quickly realized that many of the significant users of Sci-Hub actually have full text access to that same material via their institutional subscriptions3.
If many users have access to content that they instead use Sci-Hub to retrieve, one logical conclusion would be that the mechanisms required to utilize this access has too many steps or is too complicated or too confusing for many users, driving them to piracy.
In response to this assertion, a number of different technologies have emerged in recent years to address different facets of this problem with novel solutions. As these technologies mature into the market, it is likely that users will benefit from one or more of these technologies in order to improve the overall user experience of authorized content retrieval.
At Third Iron4, we began tackling this problem in 2011 when designing the product that would eventually become BrowZine, now used by over seven hundred and twenty-five libraries worldwide. While the purpose of that product was to create a platform to browse, read and monitor the scholarly journals provided by the reader’s institution, the overall ethos was to create a platform with all of the simplicity of print but with all the advantages of digital technology.
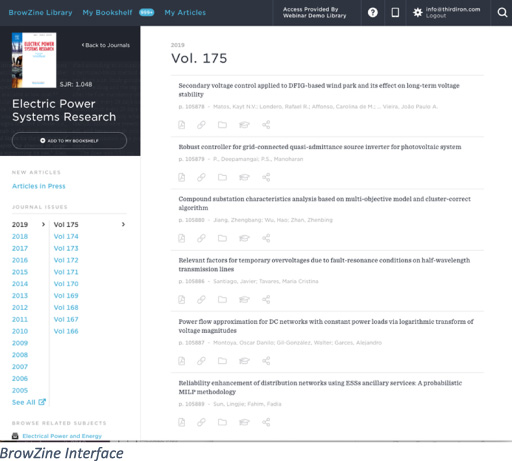
Since BrowZine at its root is an index, we needed to figure out a way to go from an article that a user at an entitled institution is interested in reading to the full text document. While we explored the common practice of integrating with the institution’s link resolver, we were not satisfied by the speed or the reliability of this experience, nor the number of potentially confusing clicks that it could potentially introduce. In essence, we were being frustrated by the same elements driving scholars otherwise entitled to content to Sci-Hub. While we did not want to attempt to “replace” the link resolver and all of its functions, for the simple act of getting to a known item as fast as possible, we decided to develop a new technology.
This technology eventually found its way into the API-driven technology known today in 2019 as LibKey5. LibKey is capable of emulating the “Sci-Hub experience” of one click access to the PDF document via the institution’s authentication mechanism utilizing only an identifier (DOI/PMID) and an understanding of the user’s affiliation. This technology could then be used in a number of different contexts to assist users in connecting to content from numerous different starting points.
However, Third Iron was not the only company trying to improve the ability to easily authenticate a user and to do so from “non-library” starting points which represented traditionally the biggest point of failure. If a user were to start in a library portal, the links and authentication mechanism would typically be designed to guide the user on a fairly streamlined path to their content goal.
Others working on this issue included Google with their Google CASA project as well as the RA21 initiative6.
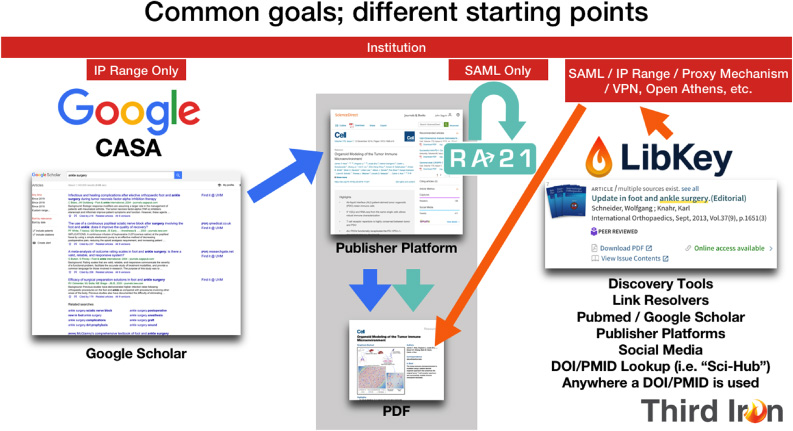
As the illustration above notes, ultimately each of these technologies was looking at the issue of getting users to the publisher PDF from different starting points. Google is largely interested in improving the utility of the Google Scholar service by working with publishers to allow the Google cookie to let a publisher know that the user has recently been within an allowed IP range thus allowing the publisher to read that cookie rather than use the user’s IP range at that moment to gate access to their content. Thus, a user could be working perhaps physically in the library during the week, and then from their apartment off campus on the weekend using Google Scholar and still get automatic access to their favorite content providers.
This of course requires a lot of cooperation by the publishers and the user needs to be interfacing (routinely) with Google products. And because it’s somewhat of an “invisible” technology it’s a little ambiguous how to intentionally get started. Finally, it is rooted in IP authentication which may not be available at all institutions.
RA21 is focused on the issue of streamlining the experience of using SAML-based authentication to log directly into publisher sites utilizing a recommended WAYF workflow and aesthetic to present commonalities between many publishers. This is a great initiative, but its benefit is limited by publisher participation and adoption as well as the number of institutions who have the capability to use SAML authentication.
Finally, LibKey works in numerous different environments as shown to provide one-click access to content. It does so by understanding all the key elements needed to create the appropriate signpost link in these various interfaces:
• It understands and works with the institution’s existing authentication mechanism
• It understands the entitlements by working with the library’s knowledgebase and thus can present accurate results of entitlement before a user is asked to authenticate
• It understands access rights, including subscribed content and open access
• If content is not available by open access or subscription, LibKey integrates with a library’s preferred fulfillment mechanism whether by ILL, Document Delivery or another mechanism
• It utilizes advanced metadata schemes to in all cases to route a user as close to a PDF document as possible - often times in a single click
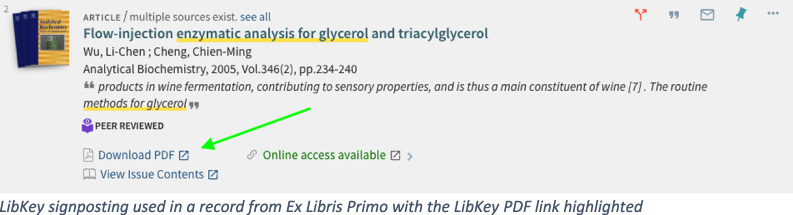
The net result is a high-performance API solution providing instant “signposting” of direct download links within numerous environments, including Discovery Tools7 like Primo, Summon and EDS, Link resolvers, PubMed8, Google Scholar9, Publisher Pages, Wikipedia and more. The limiting factor is not adoption by publishers (of which thousands are already supported) but rather by the number of institutional subscribers.
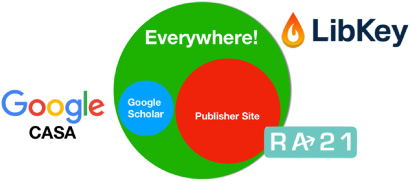
The great news for users is that whether they use Google frequently, are at an institution with SAML capability or their institution subscribes to LibKey, it is likely that they will benefit from one or more of the technologies to accelerate and simplify their access to content.
Because these technologies overlap in numerous ways but do not compete with each other, users can easily utilize the technologies best for them to simplify their access journey.
About the Author
John Seguin has over fifteen years of experience in the library industry, first as an academic librarian at the Missouri University of Science & Technology where we he worked in Electronic Resources and helped to build the Scholars’ Mine, the MS&T Institutional Repository. After this he moved to the private sector as an Account Executive for ProQuest, selling their products into academic institutions across the Midwest. At Third Iron, John heads up the product management and development and is engaged in strategic sales efforts. John has a Master of Library Science as well as Bachelor of Music from the University of Illinois, Champaign-Urbana. Email Address: [email protected].
Notes
1 http://www.dlib.org/dlib/may06/apps/05apps.html, Accessed June 16, 2019.
2 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5832410/, Accessed June 16, 2019.
3 https://www.sciencemag.org/news/2016/04/whos-downloading-pirated-papers-everyone, Accessed June 16, 2019.
4 https://thirdiron.com, Accessed June 16, 2019.
5 https://bit.ly/2wJmf40, Accessed June 16, 2019.
6 https://ra21.org/, Accessed June 16, 2019.
7 https://thirdiron.com/libkey-discovery/, Accessed June 16, 2019.
8 https://thirdiron.com/libkey-link/, Accessed June 16, 2019.
9 https://thirdiron.com/libkey-nomad/, Accessed June 16, 2019.


