
Creating value through data collaboratives
Abstract
Driven by the technological capabilities that ICTs offer, data enable new ways to generate value for both society and the parties that own or offer the data. This article looks at the idea of data collaboratives as a form of cross-sector partnership to exchange and integrate data and data use to generate public value. The concept thereby bridges data-driven value creation and collaboration, both current themes in the field. To understand how data collaboratives can add value in a public governance context, we exploratively studied the qualitative longitudinal case of an infomobility platform. We investigated the ability of a data collaborative to produce results while facing significant challenges and tensions between the goals of parties, each having the conflicting objectives of simultaneously retaining control whilst allowing for generativity. Taken together, the literature and case study findings help us to understand the emergence and viability of data collaboratives. Although limited by this study’s explorative nature, we find that conditions such as prior history of collaboration and supportive rules of the game are key to the emergence of collaboration. Positive feedback between trust and the collaboration process can institutionalise the collaborative, which helps it survive if conditions change for the worse.
1.Introduction
Over the past decade there has been an increasing focus on the role of data in public value creation. Government and semi-government agencies are, for example, opening up datasets for others to use. Their hope in doing so is that wider use and re-use of data may spur data-based innovations, enhance transparency and boost economic growth by enabling new digital services and applications (Estermann et al., 2018; Meijer, 2015, 2017; Zuiderwijk & Janssen, 2014). These developments are driven by advancements in big, open and linked dat (Janssen & Kuk, 2016). Yet, the promise of data-driven innovations goes beyond the availability and use of data. Governments are working on strategies to facilitate a data-driven economy that creates new value through data sharing (Klievink et al., 2017). Data-driven innovations can be a powerful instrument in modern public governance, which is increasingly focused on the value of inclusive approaches and collaboration in horizontal ‘networked’ settings (Ansell & Gash, 2007; Bryson et al., 2006; De Bruijn & Ten Heuvelhof, 2018; Mcguire et al., 2010; Stoker, 2006). Recently, the collaborative aspect of data-driven innovation began attracting attention, the idea being that real added value can be achieved from combining data from various sources and integrating them to create new value-added functionalities (Klievink et al., 2016; Susha et al., 2017a). New York University’s GovLab has even dedicated a programme to what it calls ‘data collaboratives’ (Verhulst & Sangokoya, 2015). Data collaboratives are a form of partnership in which a variety of parties, such as government, operators, companies and others, collaborate to exchange and integrate data in order to help solve public problems or create public value (Susha et al., 2017a; Verhulst & Sangokoya, 2015). We argue that the concept of data collaboratives represents a combination of data-driven innovations and the central notion that modern public governance benefits from including and collaborating with non-government actors (Ansell & Gash, 2017; Janssen & Estevez, 2013; Klievink et al., 2016).
Although the concept of data collaboratives can thus act as a bridge between data-driven value creation and collaboration, it is also a rather new concept, and empirical work on data collaboratives is scarce. What does exist focuses, for example, on statistics (e.g., Robin et al., 2016; Susha et al., 2017b). Although insightful, this is a domain where private sector organisations already provide – and indeed are required to provide – lots of data to government for certain collective purposes. More challenging are data collaboratives that use the tremendous growth in real-time data availability to generate new services, products or other value. However, the openness that such generativity provides can be a source of uncertainty or vulnerability, real or perceived (Eaton et al., 2015). Different values, incentives and goals of actors in a data collaborative may clash, yet are also a source of innovation (a known problem in collaborative forms of governance, see, e.g., Vangen & Huxham, 2011). This, and other potential obstacles, might inhibit innovations based on data collaboratives from living up to the high expectations proponents have of them.
To shed more light on how data collaboratives can add value in a public governance context, we exploratively studied the following question: what factors contribute to value creation through data sharing in a data collaborative? Employing a qualitative longitudinal analysis of an infomobility platform, we investigated the ability of a data collaborative to produce valuable results. We specifically focused on two paradoxes: the goals paradox (Vangen & Huxham, 2011) and the paradox of simultaneous control and generativity (Eaton et al., 2015). Section two explains these paradoxes in more detail. There, we construct an analytical lens based on the literature on data collaboratives, collaborative governance and trust. Our case study then employs the lens to explain the outcomes of a data collaborative and reflect on the contributive factors that emerged from the literature. Section three presents the case study approach. Section four describes the case study subject, while section five presents the analysis. The conclusions, as well as limitations and suggestions for further research, are discussed in section six.
2.Theoretical background
The idea of data collaboratives, especially those aimed at addressing societal issues, is related to the broader rise of openness, transparency and inclusion of actors in public governance. The networked society calls for new forms of governance, while also offering opportunities to co-create solutions to public problems (De Bruijn & Ten Heuvelhof, 2018; Dunleavy et al., 2006; Hartley et al., 2013; Klievink et al., 2016; Provan & Kenis, 2008). In a variety of ways, a network governance approach, featuring collaboration between government, semi-government and private parties, is seen as a way to improve operations and delivery of public tasks and services (Fountain, 2001; Heinrich et al., 2010; Kettl, 2006; Mcguire et al., 2010; Milward et al., 2010; Salamon, 2002; Stoker, 2006). Indeed, collaboration is deemed key in modern governance.
Data collaboratives leverage the availability of data with collaborative approaches to modern governance to enable generation of value that single actors cannot produce alone. However, this situation is rife with potential conflict that needs to be overcome or avoided to realise the co-creation of public value.
2.1Data collaboratives
The term ‘data collaboratives’ is relatively new, though the phenomenon is not necessarily novel. We use the definition of data collaboratives provided by Susha et al. (2017a, p. 2691): “cross-sector (and public-private) collaboration initiatives aimed at data collection, sharing, or processing for the purpose of addressing a societal challenge”. This definition puts data collaboratives at the interface between (a) data-driven innovations; (b) inter-organisational information exchange and collaboration between organisations (government and others) (Gil-garcia et al., 2007); and (c) collaborative forms of governance, via partnerships or collaborations (Klievink et al., 2016; Lowndes & Skelcher, 1998) or via other forms of networked governance (Ansell & Gash, 2007; Mcguire et al., 2010). As a mode of data-related innovation, the collaborative nature of these initiatives also links them to the paradigm of inclusive innovation approaches, which we will briefly touch on later in this section.
At the core, data collaboratives are about combining data and collaboration to enable creation of new value, beyond the immediate goals, capabilities and logics of each of the participating actors. In that sense, the interests of data collaboratives are much wider than merely data standards and interoperability, though those are clearly important. As a field of study, data collaboratives is relatively new, with most existing research largely conceptual or illustrative.
Following our definition, data collaboratives are initiatives related to the goal-directed collection, sharing or processing of data. The data come from somewhere, but can be of various types (e.g., on people or phenomena) and in different forms (e.g., in words or transactions); it can be specific or not, structured or unstructured (Susha et al., 2017a). Often, open government datasets are quite specific and structured, as they come from specific administrative departments or levels and originate from specific administrative processes, activities or sources. The less specific or structured a dataset is, the harder it is to provide the necessary metadata and to create a useful dataset (Zuiderwijk, 2015). As data collaboratives are initiatives in which data is collected, processed and shared by various organisations, even from different sectors, the data they use can be quite diverse. As Susha et al. (2017a) observed, this also implies a significant diversity in data providers, which collaboratives must take into account, given the inherent multiplicity of interests and incentives to join and share data within a data collaborative (Klievink et al., 2016). This diversity of data and actors is precisely what makes data collaboratives valuable. By combining their different capacities for data generation, analysis and processing, the data, goals and expertise of the various partners in the collaborative are brought together to create something none of the individual parties could create alone. Or, a problem might be addressed that none of the individual parties could tackle alone.
2.2Tensions that seem inherent to data collaboratives
Our above conceptualisation of data collaboratives shows that our view on data collaboratives is one of a collaboration and innovation phenomenon rather than a data phenomenon, at least for the purpose of this article. As such, the challenge of setting up such a collaborative is more of an organisational and incentivisation nature than it is about data standardisation or processing. In the literature, two ‘paradoxes’ can be found that illustrate the complexity of the interactions among partners in a data collaborative. These are the aforementioned goals paradox and paradox of simultaneous control and generativity.
First, the goals paradox refers to the fact that the involvement of diverse actors is a source of both value and conflict (Vangen & Huxham, 2011). Data collaboratives bring together a certain breadth of parties. Indeed, this serves to make the collaboration valuable, as each has different pieces of information, different perspectives, complementary expertise, involvement or targeting of different user groups and access to other sources. Yet, having a more diverse set of actors involved also increases the range of goals in relation to the collaboration, in turn increasing the potential for conflicts between those goals (Vangen & Huxham, 2011). Goals can be public or commercial and related to various products or services. Some parties may join a collaboration to get a seat at the table; others might seek to explore new business models or to cut costs by bringing others on board. Also, a collaborative approach to innovation can be a goal in itself, or it can represent an attempt to gain legitimacy for an endeavour by engaging other stakeholders. Whatever the goals or incentives, the more there are, the greater the risk of a clash.
Second, and related to this, is the control and generativity challenge. This comes down to the fact that the actors control assets that are used in a process that they don’t fully control and that leads to new uses, products or services which they don’t control and which may even be opposed to their interests. This is our version of a tension that is well documented in the literature on digital platforms and inter-organisational systems (Eaton, 2012; Markus & Bui, 2012). The collaboration (not necessarily the data) needs to be relatively open to novel, potentially unforeseen, value creation. That ‘generativity’ can lead to the innovations with the highest impact. However, information and information systems are both an object of and tool for control by organisations, and control is tightly linked to autonomy and competitive advantage (Gawer & Cusumano, 2013; Johnston & Vitale, 1988; Tilson et al., 2010; Tiwana et al., 2010). Data are a key organisational asset, and opening up data to new uses, potentially by others, means giving up some control over that asset and relinquishing some autonomy to the collaborative. Fear over what others might do with the data could be a disincentive to collaboration.
This all leads to perceived vulnerabilities, especially if it is unclear whether data may be used for purposes, or by users or groups, other than those identified beforehand. Working with real time and raw data is more challenging than with data that was pre-processed, altered or specifically selected (Tan et al., 2011). Government can act as a facilitator and create a neutral or ‘safe’ environment to get a collaboration going. Yet, next to the competitive concerns of private partners, government partners also face challenges in sharing, for example, related to public values or statutory roles. A government role can, furthermore, bring additional challenges, such as fear among private partners that data may be ‘misused’ by government. For example, real-time data on arrival times of trains and buses is great for customers and operations, yet may reflect negatively on the provider when the time comes to renew a concession (Klievink et al., 2018).
It is therefore key to determine potential and novel uses of data and to instil trust in others so that all can feel comfortable opening up data as part of a collaboration (Thomson & Perry, 2006). To arrive at our analytical model for studying what factors contribute to value creation by data collaboratives, we explore the literature on how to mitigate these challenges. We start with a focus on trust relations within a collaborative. We then move to the role of government.
2.3Trust relations within data collaboratives
The topic of trust has been well-researched in several institutional contexts. Trust is said to facilitate interaction among actors by lowering transaction costs (Ring & Van de Ven, 1994). Without trust, more formal arrangements would be needed to anticipate and cover risks. This idea suggests that risk and trust are intertwined. Trust implies vulnerability (Newell & Swan, 2000; Seppänen et al., 2007). In data collaboratives, this vulnerability – or risk – is that others will opportunistically use the available data, to the detriment of one’s own goals within or beyond the collaboration. Much of the literature on trust relates to hierarchical relations in an organisation (Nooteboom, 1996; Norman, 2002; Six, 2007). Relationships within data collaboratives are typically mixed, ranging from horizontal to, indeed, control relations. Still, within this setting harm can be done, for example, in market relations if sensitive data are made available to competitors, or in power relationships if data are used to reinforce uneven power positions.
The role of trust in fuelling interaction seems conditional, however, as it is only wise to accept vulnerability if the other actors are trustworthy. Yet, collaborators’ assessments of ‘trustworthiness’ are inherently subjective and beyond calculation (Möllering, 2014). Trust represents a ‘leap of faith’ in regard to others’ commitment to shared values, good conduct and the sought-after outcomes (Nooteboom, 1999; Ring & Van de Ven, 1994; Van der Voort, 2017). The more complex relationships are, the more difficult it will be to assess these elements and the causal associations between them.
These assessments are easier if actors already know each other through a previous interaction. Interaction provides actors feedback on each other’s behaviour. If feedback is positive, trust increases (Nooteboom, 2002; Six, 2007). Thus, collaboration and trust are mutually reinforcing. They feed each other in processes of interaction. However, this makes it hard to just start with one and hope the other will appear. Without a history with the other actors, there are just too many unknowns to take that ‘leap of faith’. For example, if a data collaborative or a specific use of data is part of a continuing collaboration, then parties will typically be more willing to provide their data; or at least, there will be existing channels of communication and coordination to discuss and resolve any potential hurdles (Hart & Saunders, 1997). If the collaboration is ad hoc or it is a first attempt to set up a collaborative, these experiences will need to be acquired first, for example, through piloting (Klievink & Lucassen, 2013). Bachman and Inkpen (2011) suggested the importance of institutions to ease this first step. They identified three roles of institutions in a trust relationship. Institutions such as laws, contracts and informal ‘rules of the game’ provide meaning to the context of a relationship, they structure an interaction process among actors, and they serve as a trustworthy intermediary themselves.
Applied to data collaboratives, the literature informs us that trust and collaboration are mutually dependent. The positive feedbacks between trust and collaboration suggest the possibility of a catalyst effect, with collaboration feeding trust, feeding collaboration, et cetera. This process is bounded and facilitated by institutions (Van der Voort, 2017). In other words, antecedents of collaboration have a volatile part – trust and cooperation fuelling each other – and a more stable, facilitative part – institutions shaping this volatile process.
2.4Government and collaborative governance
Data collaboratives are here presented as a tool of modern public governance. The focus on the active involvement of non-government actors puts these initiatives in the area of collaborative governance and co-creation (Ansell & Gash, 2007, 2017; Mcguire et al., 2010; Voorberg et al., 2015). One of the conceptual models discussed in the literature, and the one we use here, is that provided by Ansell and Gash (2007). It is well-cited and offers useful concepts for the present study, though these authors emphasised that their model concerns general organisational logic, and is not confined to information technology (Ansell & Gash, 2017).
The core of the model is a collaborative process that can be likened to our notion of trust in that it is an iterative process in which trust facilitates commitment, which helps in developing a shared understanding (of the problem or goal), leading to joint outcomes and dialogue, which again reinforce trust. This iterative, collaborative process is affected by three main factors: starting conditions, institutional design and facilitative leadership (Ansell & Gash, 2007). These factors provide key components relevant to our understanding of how data collaboratives may be effective. We discuss each of them in turn.
2.4.1Starting conditions
As starting conditions, Ansell and Gash (2007) referred to an initial trust level, resource asymmetries and incentives for participation. Applied to data collaboratives, this entails that they require continuity to counter uncertainty and safeguard against opportunistic behaviour, which is known to inhibit inter-organisational IT endeavours (Premkumar et al., 2005). This is closely related to the type and level of control that partners can exert over the data they provide to the collaborative and what may be done with it. For example, in earlier research we found that for some pivotal parties, fear of data potentially being used for purposes other than the primary purpose led them to demand strict governance and contractual arrangements, which then dragged down the collaborative process hindering it from thriving. The more the data is core and central to a party (i.e., to their primary products or processes), the more it will be integral to their power and competitive position, and the harder it will be for those parties to give up full control over the data for a use they cannot oversee now and which might come back at a cost later (Homburg, 2000; Klein, 1996). Note that this need not reflect an actual vulnerability of parties; a perceived vulnerability can be just as inhibiting to collaboration (Hart & Saunders, 1997). At the same time, openness to future opportunities to realise collaborative or public value based on the data is or should be important to data collaboratives, as specifying a public problem in advance is difficult. In summary, starting conditions such as existing relationships, prior collaboration, incentives and pressures (e.g., from peers or government) affect the collaborative process and the trust-feedback loop therein.
2.4.2Institutions and context
A second factor in the model, institutional design, refers to the context of innovative collaborative governance. For innovation systems, institutions are particularly important as they “reduce uncertainty by providing information, manage conflicts and cooperation, and provide incentives for innovation” (Hekkert et al., 2007, p. 418, citing Edquist and Johnson, 1997). Furthermore, provision of incentives is key for companies to engage in innovative work. At the same time, some guidance is needed in the direction in which actors deploy and resource their efforts (Hekkert et al., 2007). Government can play a facilitator role here (this is linked to facilitative leadership, as we will discuss later). For example, government might provide datasets that are key to an innovation. Or, it could ensure a stable environment for innovation, or even create or stimulate markets for uptake of an innovation. Institutional design can help in managing interfaces; in stimulating debate; in preventing lock-in; in identifying, facilitating and protecting prime or first movers; and in ensuring that relevant parties are involved (Hekkert et al., 2007; Smits & Kuhlmann, 2004). The more these institutional arrangements are in place, the easier it is to iteratively develop data uses and allow trust to emerge.
2.4.3Government and leadership
As for leadership, government is commonly seen as a key facilitator of collaboration. Government or a trusted intermediary may be crucial in establishing the rules of the game, building initial trust and exploring a collaborative advantage (Ansell & Gash, 2007; Huxham & Vangen, 2000). However, the role of government as leader in data collaboratives can be complicated, due to the tensions discussed earlier.
Government organisations have multiple roles and interests. Data collaboratives are a means to realise value or objectives that government cannot (or cannot efficiently) achieve on its own. As a consequence, government in principle has an interest in supporting and facilitating these collaboratives. Government may act as a facilitative leader to resolve potential conflicts between the private partners involved in a collaborative and create a level playing field and clear rules of the game. This provides a safe environment for others to enter the collaboration and start sharing data and finding common ground. At the same time, government is also a party in the collaborative, in which it must safeguard public values and push for its own interests. Data collaboratives are not just about enabling private sector innovation; they are about the simultaneous realisation of multiple public and private goals. For this, government needs to contribute data and perhaps infrastructure to the collaboration and potentially may end up with a leading role. For example, it might fund a data platform or sustain a collaborative as a social practice or institution. Relating the idea of data collaboratives to the literature on collaborative governance, we argue, helps us to further conceptualise the institutional context for the collaboration and the role of the government as a facilitator.
2.5Analytical lens
In the introduction, we asked what factors contribute to value creation through data sharing in a data collaborative. This section has explored the literature on data collaboratives, trust and collaborative governance. This literature provides us a lens to identify contributive factors and to understand the collaborative process as a setting in which value creation, control and trust are balanced and iteratively lead to a result.
Based on the tensions discussed, it is not hard to fathom why data collaboratives are so hard to set up, why their initial coverage seems quite limited and why so much effort goes into discussions on their governance, covering questions like who should have access to a data platform, how, when and who decides (Klievink et al., 2012; Susha et al., 2017a).
The literature discussed suggests that trust can counterbalance the dynamics and challenges raised in this section and catalyse successful collaboration. A positive feedback loop between trust and collaboration can foster a collaborative process with shared, intermediate gains that become self-reinforcing, gradually strengthening the collaborative’s capacity to cope with greater potential threats, like opportunistic behaviour, and to generate new value creation. Over time, parties will also have invested in the collaborative and face costs (financial, reputational and operational) if they withdraw from it.
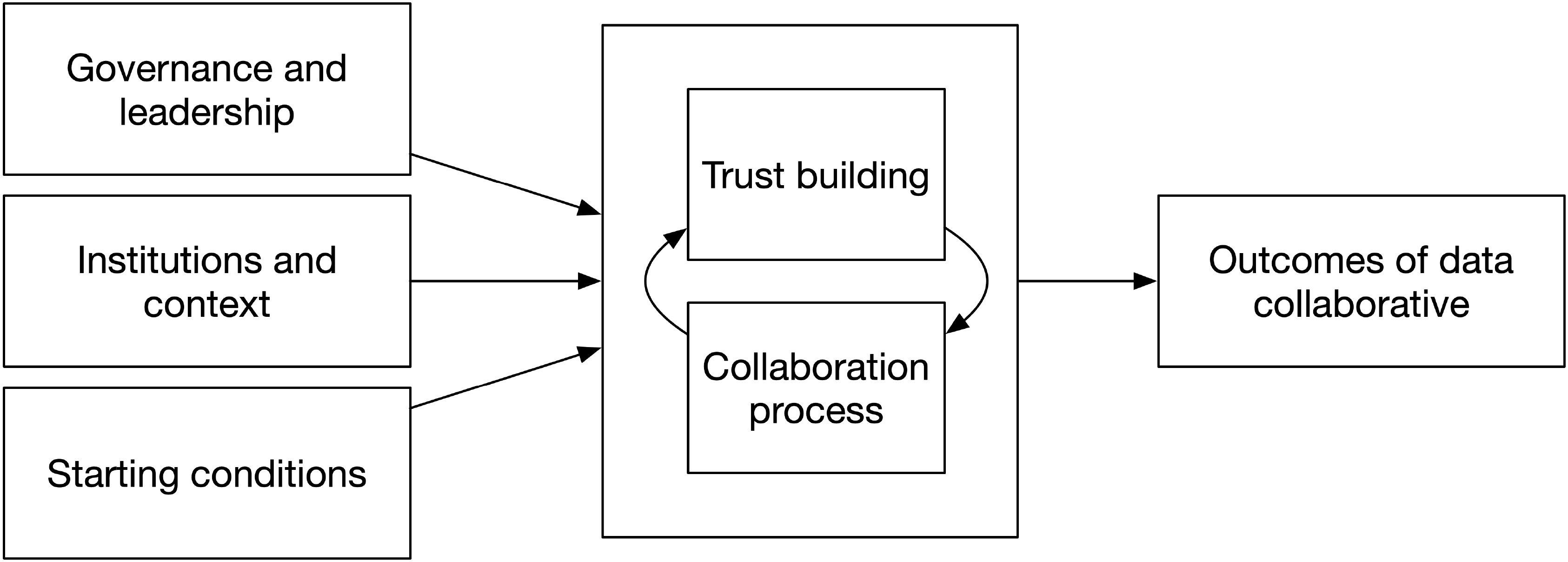
Summarising this literature, we build our lens on four components to understand the data collaborative process. Each of these four components are domains of the aforementioned struggle between the capacity to produce new value in innovative and unforeseen ways, and individual actors’ need for control over their data and data-related activities, goals and interests. Figure 1 presents the analytical model (inspired by Ansell & Gash, 2007).
The main components, based on this section, can be summarised as follows:
• Trust and collaboration (§2.3), entailing the dynamics between trust and collaboration and the positive feedback loop between them;
• Starting conditions (§2.4.1), entailing existing relationships, incentives, pressure (e.g., from peers or government), prior collaboration and other informal factors;
• Institutions and context (§2.4.2), which facilitate and constrain the interaction between trust and collaboration, with institutions helping to make the context of a collaboration more stable and predictable;
• Government and leadership (§2.4.3), entailing formal and informal mechanisms for coordination and governance (e.g., of data sharing, of a joint platform or of the collaboration at a non-technical level) and the roles of stakeholders and leadership in the collaborative process, especially the roles of government.
3.Approach and case selection
The idea of collaboratively generating value from sharing data and then using the shared data for new purposes is not new. Practice shows earlier examples. Yet, the term ‘data collaborative’ is of recent origin. Moreover, recent data collaboratives are typically much more enabled or even triggered by the tremendous growth in data and communication available in real time or near real time. Indeed, nowadays organisations collect and store whatever data they can, sometimes without even a clear goal or purpose. The idea is that the data might come in handy at some point, at which time it can easily be made available.
Figure 1.
Analytical lens.
As our goal is to understand what makes data collaboratives work, and given our broad analytical model, we considered an explorative and longitudinal case study a suitable approach to examine the phenomenon in-depth and in context. The number of long-running cases fully complying with our current definition of data collaboratives is limited. Confinement to these would thus have unnecessarily limited our ability to understand the data collaborative development process. We therefore selected a case that was not originally called a data collaborative, but matches the core characteristics of one, while also allowing us to study development over time. The insights such a long-running case can provide were considered particularly valuable, given our research objective and the explorative nature of our study.
Our case study concerns an ‘infomobility platform’, that is, a data platform that creates value for the parties involved and for society at large by leveraging mobility data to support both collective goals and individual travellers’ demands. Mobility is a particularly relevant domain for data sharing for joint value creation. Urban areas face major problems of congestion, accessibility, liveability, air quality and traffic safety. Infomobility platforms seek to solve or minimise these by using ICT advancements for sustainable transportation development. Typically, this requires various private and public transport service providers, infrastructure managers, transport authorities, regulators and other organisations to cooperate, share and use data that these various parties have. Indeed, in a European project in which we compared 13 infomobility platforms (Veeneman et al., 2018), we found that in most cases private parties gathered a great deal of highly relevant data, though they lacked a clear incentive to share it openly and consistently. They often perceived a risk that others – competitors and regulatory bodies – might use the data they shared against their interests. Transport authorities generally pursue public value, but often focus narrowly on a particular region or mode of transport (car, bicycle, bus), which limits their agency in this increasingly global and integrated field. In addition, management of data in regard to mobility is often overseen in a changing institutional context, for example, under contracts with transport service operators or new regulatory frameworks. Therefore, authorities pushing for data sharing between operators and across the public-private barrier often find themselves playing catch up in unhelpful institutional and contractual environments.
At its core, an infomobility platform seeks to bring together mobility-related data from multiple sources, both public and private, to create value-added services. There is often an absence of formal authority. Contributing data to the collaboration is more or less voluntary – or at least, consent is required to use the data, especially for purposes other than those for which the data were originally shared. An infomobility platform can be considered a data collaborative, as the parties involved exchange and integrate their data to address a public problem or demand whilst also doing so for their own sake. This sets it apart from other business-government information exchanges, which are often geared towards formal reporting to government by businesses. This puts a lot of pressure on the collaborative process and governance, as most of the parties involved have incentives to do more with the data of others than what others would like, thus providing a disincentive for the others to share.
The specific case studied here is the Dutch ‘9292’. This is a public-private collaborative that brokers and shares public transport data in the Netherlands. The collaborative fuels most travel planners and real-time travel information systems in the country. Currently, 9292 emphasises open data for public goals. It has progressed over time to get where it is now. Our case study covers the entire process from the inception of the collaborative in 1992 (9-2-92) up to the time of this writing.
To collect data, we used a combination of participant observation and interviews, supported by document analysis. The participant observation stemmed from one of the authors’ involvement in the policy processes surrounding the platform for roughly a decade, in the capacity of an academic observer and advisor. Specifically, he was involved in the working group on data sharing. Our case study sought a deep longitudinal understanding, rather than a systematic comparison with other cases (Stake, 1995). We approached the case as an inductive analysis of the rich set of factors driving the success of infomobility platforms, to provide a basis for more targeted and comparative studies later. This fits the explorative nature of the study, yet meant that our findings could be construed as representing our view of events, which might be influenced by confirmation bias. To counter this risk, we included nine extensive interviews, many of which spanned multiple sessions. For reasons of anonymity, we cannot disclose names and roles of the interviewees, but only describe their coverage. These nine interviews were with people from seven key stakeholders in the collaborative: transport operators, government authorities, the Dutch travellers’ association and the data platform under study. In the interviews, we discussed where the platform was at the time of the interview and what process led it there, generally focusing on the governance of the collaboration, as well as on the technical factors that have affected its governance.
4.Case description: 9292 as a data collaborative
The case of 9292 is revelatory in that it was initiated jointly by Dutch transport operators, and they started the initiative long before web-based information platforms became popular. It can be considered a success story, too, in terms of coverage and use. For that reason, we selected it to learn how such a diverse set of actors can set up a data-sharing platform and continue to manage it for decades, creating value for the parties involved, for travellers, for government and for the wider public.
In the 9292 case, all public transport operators in the Netherlands collaborate and exchange data. Initially the data concerned mainly public transport schedules, though this evolved over time into provision of real-time data on public transport operations. All of the operators have benefitted from enhanced travel planning beyond any individual operator, as knowledge of each other’s connections and arrival times has enabled them to serve customers better. Yet, local operators perceive they have less to gain from the cooperation, as their travellers are less likely to have complex travel chains. As part of 9292, we also considered the national public transport database, or ‘NDOV’. Both 9292 and NDOV are managed by the REISinformatiegroep. Together they represent a central platform wherein all public transport information in the Netherlands is publicly shared. This information spans planned and real-time operations, prices and other data. The REISinformatiegroep is funded through advertisement income, earnings from their telephone information line (legacy), sales of their travel information API, and development of dynamic travel information systems. Although currently ‘NDOV’ refers to the database and ‘9292’ to the services of the REISinformatiegroep, this article uses 9292 as an umbrella term for the collaboration in its entirety (the group, the transport providers and the platform with its database, interfaces and the joint services based on them).
The key parties that pushed for 9292 were the largest public transport providers in the Netherlands: the passenger rail service operator, public transport operators in the country’s three biggest cities, and a public transport operator covering more outlying areas in the country. Each was, at the time, a near monopolist in their transport modality and geographical area. The parties operated independently, albeit under government contracts and with public guidance. Upon initiating 9292, they were not in competition with each other and were seeking to create a travel information system with national coverage. Their main incentive was the belief that better travel information would increase traveller numbers, helping to realise public transport goals. The income of these initiators was dependent on the numbers of passengers they carried.
Transportation authorities at the municipal and national levels played no role in the process, and the lack of direct competition between the transport providers at that time implied few disincentives for parties to join. Compared to similar platforms elsewhere, this one was unusual in that it was owned and operated by the public transport companies with no role played by government authorities. Also, technically it was relatively easy to set up, as the largest of them – the national rail operator – was already working to develop its own data for a travel planner. Moreover, the other public transport operators all bought planning software from the same commercial provider, which meant they used uniform data types. This allowed use of a single interface to get information into the new platform. The fact that they all used the same planning software thus greatly reduced complexity. In many similar platforms, much more effort has to be put into standardising interfaces and establishing messaging and data standards.
At first, the public side of the platform was a phone-based information line that travellers could call to get travel advice. Soon, they developed a website and later apps. Thanks to its coverage of the entire country and all modes of public transportation (rail, metro, tram, bus), 9292 became widely popular. It also benefitted from open interfaces, primarily because many cities installed dynamic traveller information systems in the form of electronic signs providing real-time information on arrival and departure times.
The open character of these information systems also meant that transportation providers could use information from other providers. For example, in its own apps, the national rail operator also included information on other transport modalities and providers, such as timetables and real-time scheduling information. The parties put a lot of effort into data quality and integrity; concerns about access were secondary. This led to a situation in which timetables for every route and real-time data on virtually every train, bus, metro and tram (including raw data on GPS locations) were available through open interfaces.
A major test for this data sharing came in 2002, when the government started to put the transportation services up for tender, de facto formalising the relation between authorities and operators. In that process, the transport operators that had founded the platform suddenly became potential competitors, and regional public transport authorities, which had no role in the platform, gained relevance as formal clients of the operators.
Another test came when authorities developed the know-how to use the data for their supervision tasks. This led to a situation in which data sharing, as initiated and institutionalised by the operators, allowed for a different, unforeseen and potentially adverse type of use. A delay in arrival times was no longer just handy for the traveller to know, but at an aggregate level could alert authorities to a punctuality problem – and low performance could trigger fines for the operators.
Both events changed the incentives to collaborate in a highly negative way. One might have expected the collaborative to become unstable and falter. However, the collaboration did not end. Apart from the scientific question we posed in this study, it is also interesting from a practical perspective to examine why the partners in the collaborative invested in opening up their data to each other, and continued to be open, even when there no longer seemed to be a direct incentive for this. In fact, incentives to openly provide data turned for the worse. Below we analyse how this discrepancy between expected and actual behaviour can be understood.
5.Analysis and discussion
5.1Starting conditions
The starting situation was potentially challenging, as much of the data were in the hands of private or semi-public transport operators and there was no clear party in charge with the power, be it regulatory, financial or otherwise, to enforce ‘data collaboration’.
Yet, the starting conditions were apparently conducive to the innovation. Even though there was no meaningful prior collaboration, the situation was generally non-competitive, not just in terms of the use of data but also in terms of the parties’ core processes. There was also enthusiasm to do more with the data that the operators increasingly had. Most parties had similar incentives; that is, the idea that sharing would benefit public transport in general. This made it relatively easy to start a conversation on what they, as public transport operators, could collaboratively do. This could be considered a form of peer pressure, in which the collaborative incentive prevailed over the lack of individual incentives among some of the partners. As the platform started to work and parties found themselves in a situation without the materialisation of risks to their core services, trust developed, which mitigated perceived vulnerabilities. The actors did not feel a strong need for control over their activities and data. Within a decade, this led to real-time sharing of even raw data, not just with their customers, but also with each other.
5.2Trust and collaboration
The literature presented in section two on the dynamics between trust and collaboration suggests the existence of a positive feedback loop between them. In our case study, some reciprocity in the data-sharing relationship might have existed but was limited because the parties differed significantly in size and stakes. The passenger rail service company operated nation-wide, whereas most of the other transport operators served a smaller region only. A comparison with similar platforms in other countries covered in a project of which this case study was part (Veeneman et al., 2018) shows that it is not uncommon for a similar set of parties to fail to share such data. This is even the case when a transport authority forcefully pushes for data exchange. Our analytical lens suggests that 9292 succeeded here because of trust, based on prior collaboration. The collaborative process reinforced trust, leading to expansion of the platform. The starting conditions were conducive to a situation in which trust could develop between the parties bringing data to the collaborative platform.
When advanced traveller information systems entered the scene, a need arose to share real-time information, which helped to further institutionalise 9292. The incentive here was initially primarily of the ‘nice to have’ variety; undoubtedly, it was nice to have the electronic signs announcing the up to the minute arrival times of the various transport options, and no real competitive costs seemed to be involved. This happened at about the same time as the first competitive tendering procedures began. But at that time the transport authorities did not yet have the desire or know-how to use the 9292 data for contract supervision, and such use of the real-time data was not yet included in the public transport contracts – though this changed later.
Further institutionalisation of the platform and formalisation of 9292 as a collaborative, combined with the popularity of the joint value-added services and absence of trouble between the partners, led to a positive feedback loop as described in the literature.
5.3Institutions and context
Institutions facilitate and constrain the interaction between trust and collaboration by making the context more stable. In our case, we could argue that the collaboration itself, and its formalisation, became an institution that mitigated the risk of opportunistic behaviour, persisting even when the threat of data use beyond the envisaged goals substantially increased over time.
The collaboration’s perseverance can be explained, first, by the absence of disincentives and absence of noteworthy transaction costs, due to the coincidental use of the same systems. However, the introduction of competitive tendering did provide for disincentives, at least for some of the parties. Still, this system change occurred almost ten years after the collaboration started – an aeon in ICT development terms. By the time it became clear that authorities could use the data for supervision purposes, the parties were so invested in the collaboration and in the platform that backing out could come only at great cost. In other words, the trust and collaboration process began an institutionalisation process that was hard to stop. The entity 9292 was too well-established in the routines of travellers and transport operators to be stymied by changes in context.
This might also explain why in other countries a push by authorities has been much less effective than the collaborative process was in this case. The collaboration started relatively small and quickly grew into a national system. A look at other countries shows us that elsewhere government involvement has been less of an enabler than the push to exchange data with Google’s Transit (as the latter forced operators to adopt GTFS as a data standard). Compare that to the case at hand, in which 9292 became the source of the data and Google a user.
5.4Government and leadership
Consciously or not, government played a vital role in establishment of the platform. Government was responsible for the initial incentive structure in which public transport providers were not direct competitors. This created fertile grounds for collaboration. At this meta-level, government was a main facilitator of 9292. Once government introduced tendering, the collaboration process was already too institutionalised to be harmed. Also, the potential for the transport authorities to use the data for control produced little conflict. As an institution with a clear governance structure and strong leadership, 9292 had over time become strong enough to keep parties on board in the collaborative, even though the contracts eventually stated that they must open up the data to government organisations for supervision. The data collaborative had thus gained sufficient independence from its sponsors and members to start playing a role not in the interests of those same parties. The platform evolved into an important instrument for satisfying travellers’ information demands, and the transport operators would not want that real-time information to disappear, for instance, from the electronic information signs announcing the arrival times of public transportation virtually everywhere.
The governance of the mobility data platform was captured in the governance of the association, composed of key data providers and data users. It helped, too, that open data sharing had become so ‘common’ over the years. Indeed, today a widely-supported idea in the Netherlands is that data generated directly or indirectly by publicly funded activities should also be public. This ‘open data culture’ has become an important incentive for the parties to sustain the collaborative in the near future.
6.Conclusions and discussion
Infomobility platforms can be considered data collaboratives. Technological developments and the real-time availability of (big) data enable them to develop tools that optimise both the individual journey of a traveller and the collective interest and the system as a whole. That they work, however, is not guaranteed. Ministries, local governments, transport authorities, a host of transport providers, interest organisations and many others all have their own stakes. Some of these will be threatened by a new data platform, at least to some extent. A data collaborative can help bridge differences in capabilities and catalyse standardisation of transit and transport data. Yet, there are many practical and fundamental hurdles. These range from standardising data formats to dealing with information and power asymmetries. What is more, parties create additional dependencies through the platform, for example, because their image (at least the part related to information provisioning) begins to depend, in part, on the performance of the platform, over which they do not have control. In this final section, we present the conclusions we draw from our study and discuss limitations and ideas for further research.
6.1Conclusions
We started out with two paradoxes that illustrate the complexity of the interactions among partners in a data collaborative: the goals paradox and the paradox of simultaneous control and generativity. Theoretically these represent major challenges. Data collaboratives rely on parties opening up their data in or through the collaborative. Yet, the participating parties may find it difficult to disclose, for example, real-time information gained through channels that they own themselves. They may additionally fear that competitors could gain early or advanced access to sensitive information. And it does not help that the government could potentially use the data to assess the performance of transport operators.
We explored the literature on how these tensions could be mitigated. Academic work on trust and on collaborative governance formed the basis of our analytical lens, featuring trust and collaboration as a mutually reinforcing process, with starting conditions, institutions and leadership as antecedents. All these features were present in some form in the case.
We found four types of antecedents of collaboration and collaborative innovation that both confirm and complement those found in the literature:
• Collaborative antecedents, associated with concepts from collaborative governance, the information systems literature (e.g., depth of use for collaborative advantage) and the innovation systems literature (e.g., infrastructure for learning). In general, we can conclude that the idea of open innovation based on what shared data allow the parties to accomplish is similar to the idea of generativity in digital platforms. As in those platforms, value comes from novel usages that are enabled by the data in the collaborative, without that usage being the intention or under control of one of the collaborators.
• Information system antecedents, related to electronic data-sharing, as found in the (inter-organisational) information systems literature (for an overview see Robey et al., 2008). Our case suggests that peer pressure (direct or indirect), expected benefits, compatibility of systems and uses, and frankly, an absence of reasons not to share, were the main antecedents at work here.
• Prior experience and culture of open data, particularly collaboration and strategies for finding shared problems that collaboration could help resolve. In 9292, prior experiences were derived from the collaboration on the telephone information line. The resulting platform was then used for exchanging data and collaboratively generating value from it.
• Rules of the game or playing field, entailing power and resource positions and the rules governing the data collaborative, or the absence of such rules. In our case, we found power asymmetry, but in the absence of competition, the power imbalance posed no threat to the collaboration. When a competitive situation did emerge, the collaborative was already in a position of power itself and able to set some of the rules.
Next to these antecedents, we found the context of a data collaborative makes a difference. Context factors include, for example, institutional and governance frameworks, cultures of inclusiveness or transparency, the interest demonstrated by government in data collaboratives, and the means by which collaboration is legitimised as a strategy for governance or innovation. Changes in the context may significantly affect the incentives and goals of the actors and threaten the collaborative process. However, in our case such changes did not harm the collaboration.
In our case, the reinforcement process between collaboration and trust, as found in the literature, resulted in institutionalisation of the collaboration itself. The collaboration was recognised by the public, by clients and by authorities. This recognition provided positive incentives to pursue collaboration. We therefore propose that the collaboration process and the institutionalisation process are also potentially mutually reinforcing. Our case suggests that these positive feedbacks can result in such strong collaboration that it continues even if the original incentives to collaborate change or disappear.
As a conclusion, Fig. 2 presents a model (loosely based on the models of Ansell & Gash, 2007; Robey et al., 2008) of the factors found in the literature and their relationships as found in our case. It is a further specification of the analytical model summarised in Fig. 1.
Figure 2.
Conceptual model for data collaboratives.
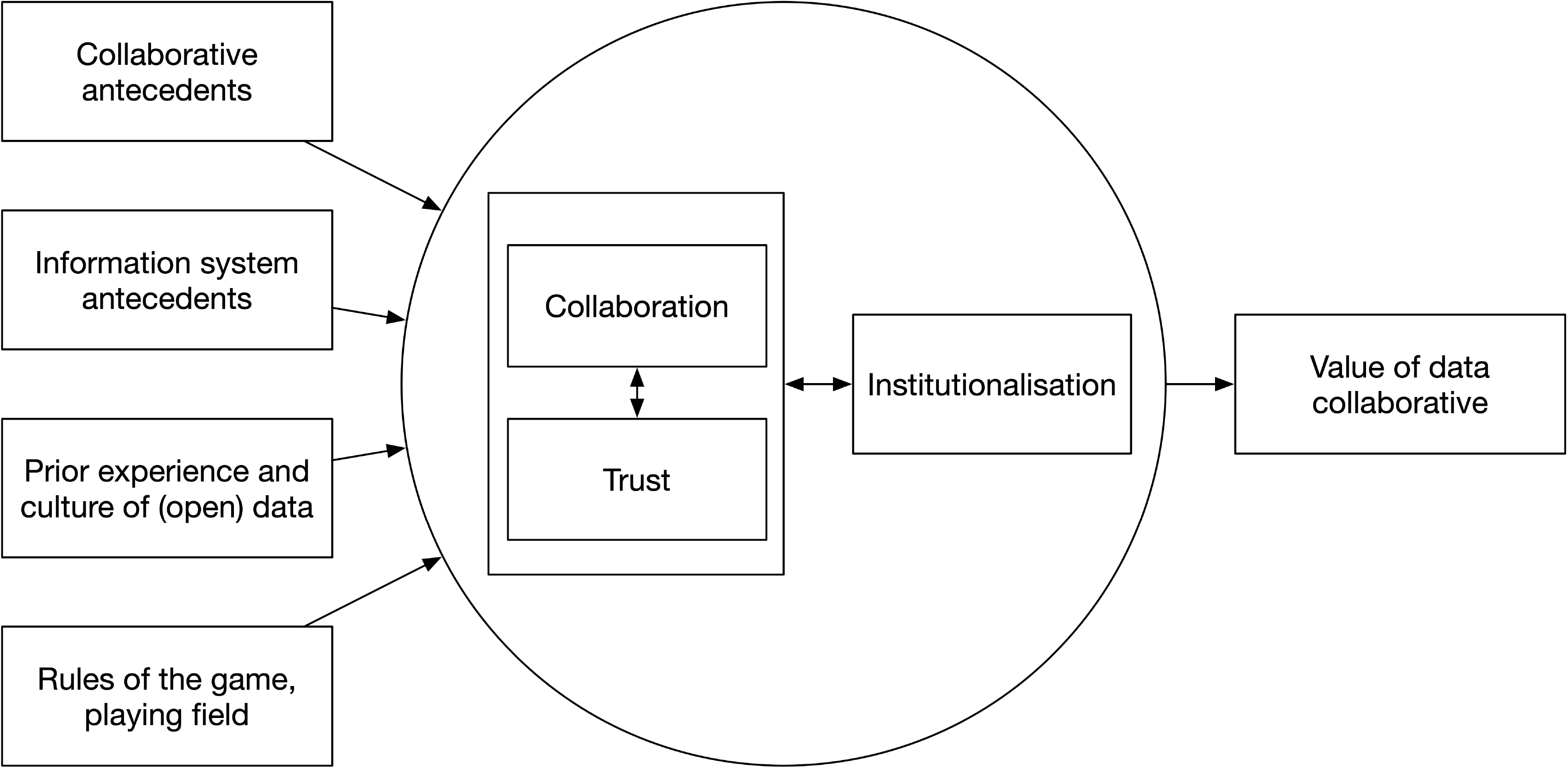
Our findings suggest that next to the constellation of actors involved, timing is key. The model implies at least two time-related factors that contribute to collaboratives’ ability to create value. First, the collaborative is more likely to take off if the antecedents are favourable. In our case, the rules of the game (the low competition level) and the information systems (actors used the same systems) were especially favourable to collaboration. Second, once collaboration has commenced, the favourable conditions need to remain until a degree of institutionalisation has taken place. In the Netherlands, 9292 was strongly institutionalised, partly because for many years it was the only multi-modal infomobility data service. If the collaboration had not been institutionalised, for instance, because there were multiple infomobility data services, it would have been more vulnerable to changing conditions.
Summarising the findings and conclusions, there are at least three key ideas to take away from our study:
• Data collaboratives offer gains at both the individual and collective level. A data collaborative can help bridge differences in capabilities and catalyse standardisation of data. Yet, there are many practical and fundamental hurdles. They present risks and vulnerabilities to individual collaborators. When the starting conditions and existing institutions are favourable and provide basic levels of trust, that level of trust can be reinforced through the collaboration, which then gains from the increased level of trust.
• The positive feedback loop represented by trust and collaboration leads to the institutionalisation of trust, which is further strengthened by ongoing collaboration. Institutionalised trust makes the data collaborative less vulnerable to changes in the collaborative or in the competitive context and conditions, and it puts a higher price on opportunistic behaviour. These positive feedbacks can result in such strong collaboration that it continues even if the original incentives to collaborate change or disappear.
• Such institutionalisation is required for successful collaboratives, as much value comes from novel and even unanticipated use of data, enabled by the collaborative, without it being under control of any one of the collaborators. The data collaborative in our study gained sufficient independence from its sponsors and members to start playing a role not in the interests of those same parties.
6.2Discussion, limitations and future research
Our case spanned 25 years of development and evolution. Hence, data collaboratives may be seen here as ‘merely’ a new lens on a long-established phenomenon. As pointed out, cases labelled data collaboratives in the literature might be relatively ‘easy’ cases built on datasets already being shared in some form, and just being put to a new use. Yet, we think it is worthwhile to attempt to identify established data collaboratives as well. Established ones may already have had significant impact on policy or public governance but may not have been studied from the perspective of how the data enabled those practices and their impacts. New data collaboratives can tell us more about what is possible today, as incredibly large sets of data are becoming available, with unprecedented degrees of interconnectedness and strong personal, public and commercial motivations to make use of the data. Studying new and emerging collaboratives may help to inform existing practises, to gain more from the institutions and trust already in place to share and re-use data for new value creation.
Still, to really enable the use of data collaboratives as a tool for public governance, there are many challenges that need to be solved in situations that are rendered much more difficult because of differences in goals, fear of opportunistic behaviour and lack of incentives to join the collaborative. Our case suggests the importance of organising the process and context in such a way that perceived vulnerabilities and fear of misuse are dealt with.
The right choices in the design of the technology and governance of the data collaborative depend highly on the perspective and position of the actors. Which parties should be involved? In what capacity? By whom? These seem to be the million-dollar questions for data collaboratives. Regarding infomobility platforms, regional views will likely differ from local views, and public and private views will differ as well. Service provider and service consumer perspectives will not be the same, and data contributors and data users will have different perspectives. Further, we must consider all the others, ranging from technology providers through to local politicians, visitors of a metropolitan area and many more. To make a mobility platform work, some or most of those actors will have to be connected to the data collaborative in some way, though perhaps not be active in it. Such a platform will be highly dependent on the contributions of these actors. If data providers don’t provide data, if no one funds the platform, if travellers don’t use the services on offer, the platform can create no value. If one of those actors have blocking power and an incentive to use it, it may not fly at all.
We aim and hope to have offered insights relevant to the emerging practice of data collaboratives, yet our study is limited in several ways. This article covered just one case. We cannot make any broader inferences based on this research, and the model in Fig. 2 should be considered an exploratory and relatively broad attempt at identifying what makes data collaboratives work. The emerging nature of the phenomenon and the explorative character of this study severely limit the contribution of this research at the current stage. The case featured here was studied inductively, and the lack of research rigour further adds to the validity problems this research presents. The contribution of this article is therefore largely conceptual, and the proposed conceptual model is proposed as a subject for further testing and verification. Further research is required employing more rigorous designs in both quantitative and qualitative follow-up. Qualitative designs will aid in further refining the model and in gaining a more in-depth understanding of the questions and paradoxes raised here, across multiple cases and domains. Quantitative research could test and verify those findings. This research is a first step towards describing and understanding this phenomenon by looking at potential tensions and paradoxes. The analytical lens presented, bringing together insights from collaborative governance, trust and data collaboratives, could be further expanded with other literatures, such as that on inter-organisational information systems and innovation systems – both of which we only touched upon here. We aim to further develop and refine the analytical model and commit a comparative and in-depth study of other data collaboratives, including those with different degrees of complexity, generativity and success.
Acknowledgments
This work was part of the research project “Governing Public-Private Information Infrastructures”, financed by the Netherlands Organisation for Scientific Research (NWO) as Veni grant 451-13-020.
References
[1] | Ansell, C., & Gash, A. ((2007) ). Collaborative Governance in Theory and Practice. Journal of Public Administration Research and Theory, 18: (4), 543-571. https://doi.org/10.1093/jopart/mum032 |
[2] | Ansell, C., & Gash, A. ((2017) ). Collaborative Platforms as a Governance Strategy. Journal of Public Administration Research and Theory, (November), 1-17. https://doi.org/10.1093/jopart/mux030 |
[3] | Bachmann, R., & Inkpen, A. C. ((2011) ). Understanding institutional-based trust building processes in inter-organizational relationships. Organization Studies, 32: (2), 281-301. https://doi.org/10.1177/0170840610397477 |
[4] | Bryson, J. M., Crosby, B. C., & Stone, M. M. ((2006) ). The Design and Implementation of Cross-Sector Collaboration: Propositions from the Literature. Public Administration Review, (December), 44-55. |
[5] | De Bruijn, H., & Ten Heuvelhof, E. F. ((2018) ). Management in Networks (2nd ed.). Routledge. |
[6] | Dunleavy, P., Margetts, H., Bastow, S., & Tinkler, J. ((2006) ). New Public Management Is Dead – Long Live Digital-Era Governance. Journal of Public Administration Research and Theory, 16: (3), 467-494. https://doi.org/10.1093/jopart/mui057 |
[7] | Eaton, B. D. ((2012) ). The Dynamics of Digital Platform Innovation: Unfolding the Paradox of Control and Generativity in Apple’s iOS. LSE. |
[8] | Eaton, B. D., Elaluf-Calderwood, S., Sørensen, C., & Yoo, Y. ((2015) ). Distributed Tuning Of Boundary Resources – The Case Of Apple’s iOS Service System. MIS Quarterly, 39: (1), 217-243. |
[9] | Estermann, B., Fraefel, M., Neuroni, A. C., & Vogel, J. ((2018) ). Conceptualizing a national data infrastructure for Switzerland. Information Polity, 23: (1), 43-65. https://doi.org/10.3233/IP-170033 |
[10] | Fountain, J. E. ((2001) ). Building the Virtual State: Information Technology and Institutional Change. Washington, D.C.: Brookings Institution Press. |
[11] | Gawer, A., & Cusumano, M. A. ((2013) ). Industry Platforms and Ecosystem Innovation. Journal of Product Innovation Management, 31: (3). https://doi.org/10.1111/jpim.12105aaa(000)Gil-garcia, J. R., Chengalur-Smith, I., & Duchessi, P. (2007). Collaborative E-Government: Impediments and Benefits of Information-Sharing Projects in the Public Sector. European Journal of Information Systems, 16(2), 121-133. https://doi.org/10.1057/palgrave.ejis.3000673 aaa(000)Hart, P., & Saunders, C. (1997). Power and trust: Critical factors in the adoption and use of electronic data interchange. Organization Science, 8(1), 23-42. aaa(000)Hartley, J., Sørensen, E., & Torfing, J. (2013). Collaborative Innovation: A Viable Alternative to Market Competition. Public Administration Review, 73(6), 821-830. https://doi.org/10.1111/puar.12136 aaa(000)Heinrich, C. J., Lynn, L. E., & Milward, H. B. (2010). A state of agents? Sharpening the debate and evidence over the extent and impact of the transformation of governance. Journal of Public Administration Research and Theory, 20(Suppl 1), 3-19. https://doi.org/10.1093/jopart/mup032 aaa(000)Hekkert, M. P., Suurs, R. A. A., Negro, S. O., Kuhlmann, S., & Smits, R. E. H. M. (2007). Functions of innovation systems: A new approach for analysing technological change. Technological Forecasting and Social Change, 74(4), 413-432. https://doi.org/10.1016/j.techfore.2006.03.002 aaa(000)Homburg, V. M. F. (2000). The political economy of information exchange politics and property rights in the development and use of interorganizational information systems. Knowledge, Technology and Policy, 13(3), 49-66. https://doi.org/10.1007/s12130-000-1020-z aaa(000)Huxham, C., & Vangen, S. (2000). What makes partnerships work? In S. Osborne (Ed.), Public-Private Partnerships: theory and practice in international perspective (pp. 293-310). London: Routledge. aaa(000)Janssen, M., & Estevez, E. (2013). Lean government and platform-based governance – Doing more with less. Government Information Quarterly, 30(S1), S1-S8. aaa(000)Janssen, M., & Kuk, G. (2016). Big and Open Linked Data (BOLD) in research, policy, and practice. Journal of Organizational Computing and Electronic Commerce, 26(1-2), 3-13. https://doi.org/10.1080/10919392.2015.1124005 aaa(000)Johnston, H. R., & Vitale, M. R. (1988). Creating competitive advantage with interorganizational information systems. Mis Quarterly, 12(2), 152-165. aaa(000)Kettl, D. F. (2006). Managing Boundaries in American Administration: The Collaboration Imperative. Public Administration Review, 66(s1), 10-19. Retrieved from http://www.jstor.org/stable/4096566 aaa(000)Klein, S. (1996). The configuration of inter-organizational relations. European Journal of Information Systems, 5(2), 92-102. aaa(000)Klievink, B., Bharosa, N., & Tan, Y.-H. (2016). The collaborative realization of public values and business goals: Governance and infrastructure of public-private information platforms. Government Information Quarterly, 33(1), 67-79. https://doi.org/10.1016/j.giq.2015.12.002 aaa(000)Klievink, B., Janssen, M., & Tan, Y.-H. (2012). A Stakeholder Analysis of Business-to-Government Information Sharing: the Governance of a Public-Private Platform. International Journal of Electronic Government Research, 8(4), 54. https://doi.org/10.4018/jegr.2012100104 aaa(000)Klievink, B., Janssen, M., Van der Voort, H., & van Engelenburg, S. (2018). Regulatory compliance and over-compliant information sharing – changes in the B2G landscape. In Electronic Government. EGOV 2018. Lecture Notes in Computer Science. Cham: Springer. https://doi.org/10.1007/978-3-319-98690-6_21 aaa(000)Klievink, B., & Lucassen, I. (2013). Facilitating adoption of international information infrastructures: a Living Labs approach. In M. A. Wimmer, M. Janssen, & H. J. Scholl (Eds.), Electronic Government. EGOV 2013. Lecture Notes in Computer Science (Vol. 8074). Berlin, Heidelberg: Springer. https://doi.org/10.1007/978-3-642-40358-3_21 aaa(000)Klievink, B., Neuroni, A., Fraefel, M., & Zuiderwijk, A. (2017). Digital Strategies in Action – a Comparative Analysis of National Data Infrastructure Development. In Proceedings of the 18th Annual International Conference on Digital Government Research (pp. 129-138). ACM. https://doi.org/10.1145/3085228.3085270 aaa(000)Lowndes, V., & Skelcher, C. (1998). The Dynamics of Multi-Organizational Partnerships: An Analysis of Changing Modes of Governance. Public Administration, 76(2), 313-333. aaa(000)Markus, M. L., & Bui, Q. “Neo”. (2012). Going Concerns: The Governance of Interorganizational Coordination Hubs. Journal of Management Information Systems, 28(4), 163-197. https://doi.org/10.2753/MIS0742-1222280407 aaa(000)Mcguire, M., Agranoff, R., & Silvia, C. (2010). Collaborative Public Administration. Public Administration Review, 1(c), 1-35. aaa(000)Meijer, A. (2015). Government Transparency in Historical Perspective: From the Ancient Regime to Open Data in The Netherlands. International Journal of Public Administration, 38(March), 189-199. https://doi.org/10.1080/01900692.2014. 934837 aaa(000)Meijer, A. (2017). Datapolis: A Public Governance Perspective on “Smart Cities” Perspectives on Public Management and Governance, (December), 1-12. https://doi.org/10.1093/ppmgov/gvx017 |
[34] | Milward, H. B., Provan, K. G., Fish, A., Isett, K. R., & Huang, K. ((2010) ). Governance and Collaboration: An Evolutionary Study of Two Mental Health Networks. Journal of Public Administration Research and Theory, 20: (Supplement 1), i125-i141. https://doi.org/10.1093/jopart/mup033 |
[35] | Möllering, G. ((2014) ). Trust, calculativeness, and relationships: A special issue 20 years after Williamson’s warning. Journal of Trust Research, 4: (1), 1-21. https://doi.org/10.1080/21515581.2014.891316 |
[36] | Newell, S., & Swan, J. ((2000) ). Trust and inter-organizational networking. Human Relations, 53: (10), 1287-1328. https://doi.org/10.1177/a014106 |
[37] | Nooteboom, B. ((1996) ). Trust, opportunism and governance: A process and control model. Organization Studies, 17: (6), 985-1010. https://doi.org/10.1177/017084069601700605 |
[38] | Nooteboom, B. ((1999) ). The Triangle: Roles of the Go-Between. In R. T. A. J. Leenders & S. M. Gabbay (Eds.), Corporate Social Capital and Liability (pp. 341-355). Boston, MA: Springer US. https://doi.org/10.1007/978-1-4615-5027-3_19 |
[39] | Nooteboom, B. ((2002) ). Trust: Forms, Foundations, Functions, Failures and Figures. Cheltenham: Edward Elgar. |
[40] | Norman, P. M. ((2002) ). Protecting knowledge in strategic alliances: Resource and relational characteristics. The Journal of High Technology Management Research, 13: (2), 177-202. https://doi.org/10.1016/S1047-8310(02)00050-0 |
[41] | Premkumar, G., Ramamurthy, K., & Saunders, C. S. ((2005) ). Information Processing View of Organizations: an Exploratory Examination of Fit in the Context of Interorganizational Relationships. Journal of Management Information Systems, 22: (1), 257-294. |
[42] | Provan, K. G., & Kenis, P. ((2008) ). Modes of network governance: Structure, management, and effectiveness. Journal of Public Administration Research and Theory, 18: (2), 229-252. https://doi.org/10.1093/jopart/mum015 |
[43] | Ring, P. S., & Van de Ven, A. H. ((1994) ). Developmental Processes of Cooperative Interorganizational Relationships. Academy of Management Review, 19: (1), 90-118. https://doi.org/10.5465/AMR.1994.9410122009 |
[44] | Robey, D., Im, G., & Wareham, J. D. ((2008) ). Theoretical Foundations of Empirical Research on Interorganizational Systems: Assessing Past Contributions and Guiding Future Directions. Journal of the Association for Information Systems, 9: (9), 497-518. |
[45] | Robin, N., Klein, T., & Jutting, J. ((2016) ). Public-Private Partnerships for Statistics: Lessons Learned , Future Steps: A focus on the use of non-official data sources for national statistics. OECD Development Co-Operation, (February). Retrieved from http://dx.doi.org/10.1787/5jm3nqp1g8wf-en%5CnOECD |
[46] | Salamon, L. M. ((2002) ). The Tools of Government: A Guide to the New Governance. Oxford. |
[47] | Seppänen, R., Blomqvist, K., & Sundqvist, S. ((2007) ). Measuring inter-organizational trust-a critical review of the empirical research in 1990–2003. Industrial Marketing Management, 36: (2), 249-265. https://doi.org/10.1016/j.indmarman.2005.09.003 |
[48] | Six, F. E. ((2007) ). Building interpersonal trust within organizations: A relational signalling perspective. Journal of Management and Governance, 11: (3), 285-309. https://doi.org/10.1007/s10997-007-9030-9 |
[49] | Smits, R., & Kuhlmann, S. ((2004) ). The rise of systemic instruments in innovation policy. Int J Foresight Innov Policy 1:4-32. International Journal of Foresight and Innovation Policy (Vol. 1). https://doi.org/10.1504/IJFIP.2004.004621 |
[50] | Stake, R. E. ((1995) ). The art of case study research. Thousand Oaks: Sage Publications. |
[51] | Stoker, G. ((2006) ). Public Value Management: A New Narrative for Networked Governance? The American Review of Public Administration, 36: (1), 41-57. https://doi.org/10.1177/0275074005282583 |
[52] | Susha, I., Janssen, M., & Verhulst, S. ((2017) a). Data Collaboratives as a New Frontier of Cross-Sector Partnerships in the Age of Open Data: Taxonomy Development. Proceedings of the 50th Hawaii International Conference on System Sciences, 2691-2700. Retrieved from http://hdl.handle.net/10125/41480 |
[53] | Susha, I., Janssen, M., & Verhulst, S. ((2017) b). Data collaboratives as “bazaars”? A review of coordination problems and mechanisms to match demand for data with supply. Transforming Government: People, Process and Policy, 11: . https://doi.org/10.1108/TG-08-2013-0026 |
[54] | Tan, Y.-H., Bjørn-Andersen, N., Klein, S., & Rukanova, B. ((2011) ). Accelerating Global Supply Chains with IT-Innovation. ITAIDE Tools and Methods. Berlin: Springer. |
[55] | Thomson, A. M., & Perry, J. L. ((2006) ). Collaboration Processes: Inside the Black Box. Public Administration Review, 66: (December), 20-32. https://doi.org/10.1111/j.1540-6210.2006.00663.x |
[56] | Tilson, D., Lyytinen, K., & Sørensen, C. ((2010) ). Digital Infrastructures: The Missing IS Research Agenda. Information Systems Research, 21: (4), 748-759. https://doi.org/10.1287/isre.1100.0318 |
[57] | Tiwana, A., Konsynski, B., & Bush, A. A. ((2010) ). Research Commentary – Platform Evolution: Coevolution of Platform Architecture, Governance, and Environmental Dynamics. Information Systems Research, 21: (4), 675-687. https://doi.org/10.1287/isre.1100.0323 |
[58] | Van Der Voort, H. ((2017) ). Trust and cooperation over the public-private divide: an empirical study on trust evolving in co-regulation. In F. E. Six & K. Verhoest (Eds.), Trust in Regulatory Regimes (pp. 181-204). Cheltenham: Edward Elgar. https://doi.org/10.4337/9781785365577 |
[59] | Vangen, S., & Huxham, C. ((2011) ). The Tangled Web: Unraveling the Principle of Common Goals in Collaborations. Journal of Public Administration Research and Theory, 22: (4), 731-760. https://doi.org/10.1093/jopart/mur065 |
[60] | Veeneman, W., Van der Voort, H., Hirschhorn, F., Steenhuisen, B., & Klievink, B. ((2018) ). PETRA: Governance as a key success factor for big data solutions in mobility. Research in Transportation Economics, forthcoming. https://doi.org/10.1016/j.retrec.2018.07.003 |
[61] | Verhulst, S., & Sangokoya, D. ((2015) ). Data Collaboratives: Exchanging Data to Improve People’s Lives. Retrieved from https://medium.com/@sverhulst/data-collaboratives-exchanging-data-to-improve-people-s-lives-d0fcfc1bdd9a |
[62] | Voorberg, W. H., Bekkers, V. J. J. M., & Tummers, L. G. ((2015) ). A Systematic Review of Co-Creation and Co-Produc-tion? Embarking on the social innovation journey. Public Management Review, 17: (9), 1333-1357. https://doi.org/10.1080/14719037.2014.930505 |
[63] | Zuiderwijk, A. ((2015) ). Open Data Infrastructures – the design of an infrastructure to enhance the coordination of open data use. Delft University of Technology, Delft. https://doi.org/10.4233/UUID:9B9E60BC-1EDD-449A-84C6-7485D9BDE012 |
[64] | Zuiderwijk, A., & Janssen, M. ((2014) ). Open data policies, their implementation and impact: A framework for comparison. Government Information Quarterly, 31: (1), 17-29. https://doi.org/10.1016/j.giq.2013.04.003 |

