
Acquiring knowledge from expert agents in a structured argumentation setting
Abstract
Information-seeking interactions in multi-agent systems are required for situations in which there exists an expert agent that has vast knowledge about some topic, and there are other agents (questioners or clients) that lack and need information regarding that topic. In this work, we propose a strategy for automatic knowledge acquisition in an information-seeking setting in which agents use a structured argumentation formalism for knowledge representation and reasoning. In our approach, the client conceives the other agent as an expert in a particular domain and is committed to believe in the expert’s qualified opinion about a given query. The client’s goal is to ask questions and acquire knowledge until it is able to conclude the same as the expert about the initial query. On the other hand, the expert’s goal is to provide just the necessary information to help the client understand its opinion. Since the client could have previous knowledge in conflict with the information acquired from the expert agent, and given that its goal is to accept the expert’s position, the client may need to adapt its previous knowledge. The operational semantics for the client-expert interaction will be defined in terms of a transition system. This semantics will be used to formally prove that, once the client-expert interaction finishes, the client will have the same assessment the expert has about the performed query.
1.Introduction
In multi-agent systems, agents can have different aims and goals, and it is normal to assume that there is no central control over their behaviour. One of the advantages of these systems is that the information is decentralised. Hence, the agents have to interact in order to obtain the information they need, or to share part of their knowledge.
In this work, we propose a strategy for automatic knowledge acquisition which involves two different kinds of agents: one agent that has expertise in a particular domain or field of knowledge and a client agent that lacks that quality. In our approach, the client agent will initially make a query to the expert agent in order to acquire some knowledge about a topic it does not know about or partially knows about. Since the client conceives the other agent as an expert, it will be committed to believe in the answer for its query. Unlike other approaches in the literature, we consider that the client may have previous strict knowledge that is in contradiction with the information the expert knows about the consulted topic. Hence, the client may require to ask further questions and adapt its previous knowledge in order to be aligned with what the expert says.
A naive solution to the proposed problem would be for the expert to send its whole knowledge base to the client. However, this is not a sensible nor feasible solution for several reasons. First, depending on the application domain, the expert could have private information that is sensitive and should not be shared. Second, its knowledge base could be very extensive and merging it with the client’s could be computationally impracticable in a real-time and dynamic environment. Finally, the merged knowledge bases would probably have many contradictions whose relevance is outside of the domain of the query. Ignoring these inconsistencies would lead to undesired results and conclusions, but solving them would be time-consuming and irrelevant for the query. Another solution would be for the client to revise its initial knowledge base to believe in the expert’s opinion in a single step. However, as will be shown in the following sections, this may imply the unnecessary removal of pieces of information that, from the expert’s perspective, are valid.
In [47], the concept of information-seeking dialogues was introduced, in which one participant is an expert in a particular domain or field of knowledge and the other is not. By asking questions, the non-expert participant elicits the expert’s opinion (advice) on a matter in which the questioner itself lacks direct knowledge. The questioner’s goal is to accept the expert’s opinion while the expert’s goal is to provide just the necessary information to help the questioner understand its opinion about the consulted topic. In this particular type of dialogue, the questioner can arrive at a presumptive conclusion which gives a plausible expert-based answer to its question. Information-seeking has already been addressed in literature when defining dialogue frameworks for agents. However, some of these approaches do not consider that the questioner may have previous strict knowledge in contradiction to the expert’s [31], while others, which consider such a possibility, simply disregard conflicting interactions [17–19].
Differently from existing approaches, our proposal not only considers that agents may have previous strict knowledge in contradiction, but also focuses on a strategy which guarantees that the information-seeking goals are always achieved. That is, once a client-expert interaction finishes, the client agent will believe the same as the expert agent about the initial query. Since the client conceives the other agent as an expert, whenever a contradiction between their knowledge arises the client will always prefer the expert’s opinion. However, in order to avoid the unnecessary removal of pieces of information that – from the expert’s perspective – are valid, the client will keep asking questions to the expert until the goal is achieved.
In order to provide a dialogue protocol specification that satisfies the aforementioned goals, one of the main contributions of our proposal is a definition of the operational semantics in terms of a transition system. Although we will formalise a two-agent interaction, this strategy can be applied in a multi-agent environment in which an expert agent could have several simultaneous interactions with different clients – each one in a separate session.
The research on the use of argumentation to model agent interactions is a very active field, including argumentation-based negotiation approaches [3,26,27,36], persuasion [6,12,32,33], general dialogue formalizations [17], strategic argumentation [12,43,44], among others. In our proposal, agents will be equipped with the structured argumentation reasoning mechanism of DeLP (Defeasible Logic Programming) [22]. DeLP allows the involved agents to represent tentative or weak information in a declarative manner. Such information is used to build arguments, which are sets of coherent information supporting claims. The acceptance of a claim will depend on an exhaustive dialectical analysis (formalised through a proof procedure) of the arguments in favour of and against it. This procedure provides agents with an inference mechanism for warranting their entailed conclusions. We will use the structured argumentation formalism DeLP for knowledge representation and reasoning since the purpose of this paper is to show how to solve the problems associated to the agents’ argument structures in an information-seeking setting. In particular, DeLP has been used to successfully implement inquiries [1,42,45], another type of dialogue defined by [47]. In contrast to other approaches that use argumentation as a tool for deciding among dialogue moves, similarly to [4,8] we use structured argumentation just as the underlying representation formalism for the involved agents.
There is plenty of work on revision of argumentation frameworks (AFs) [11,13,14,30,38] which, regardless of their individual goals, end up adding or removing arguments or attacks and returning a new AF or set of AFs as output. Our proposal differs from all those approaches in that the client agent will not just revise its “initial framework” in order to warrant the expert’s opinion. Instead, the client will keep asking questions and acquiring knowledge from the expert agent (that is relevant to the initial query) in order to avoid removing from its knowledge base pieces of information that, from the expert’s perspective, are valid. As will be explained in detail in the following sections, in order to be able to believe in the expert’s qualified opinion, the client will only revise its previous knowledge if it is in contradiction with the expert’s. In other words, our proposal differs from other approaches in that unnecessary modifications are avoided by maintaining the communication with the expert, with the additional benefit of acquiring more relevant knowledge and making informed changes considering a qualified opinion.
It has been recognised in the literature [22,37] that the argumentation mechanism provides a natural way of reasoning with conflicting information while retaining much of the process a human being would apply in such situations. Thus, defeasible argumentation provides an attractive paradigm for conceptualising common-sense reasoning, and its importance has been shown in different areas of Artificial Intelligence such as multi-agent systems [10], recommender systems [5], decision support systems [23], legal systems [34], agent internal reasoning [2], multi-agent argumentation [42,45], agent dialogues [7,8], among others (see [37]). In particular, DeLP has been used to equip agents with a qualitative reasoning mechanism to infer recommendations in expert and recommender systems [9,24,41]. Below, we introduce an example to motivate the main ideas of our proposal.
Example 1
Example 1(Motivating example).
Consider an agent called
It is important to note that, in the example above, the expert
A strategy for information-seeking in an argumentative setting – defined in terms of a transition system – in which agents use DeLP for knowledge representation and reasoning.
Results that formally prove that the agents always achieve the information-seeking goals.
Two different approaches which the expert can take to minimise – under some assumption – or reduce – using the client’s previous knowledge – the information exchange.
An extension to the operational semantics, which allows the client to reject the expert’s qualified opinion, hence relaxing the assumption that the client is committed to believe in the expert.
The rest of this work is organised as follows. In Section 2 we introduce the background related to the agents’ knowledge representation and reasoning formalism. Then, in Section 3, we explain the client-expert interaction in detail, and we define the operational semantics of the proposed strategy using transition rules. Next, in Section 4, we define some operators that the expert can use to minimise or reduce the information exchange with the client. Section 5 follows with an extension to the operational semantics that allows the client to reject the expert’s opinion, relaxing the assumption of commitment. Then, in Section 6 we discuss on some design choices of our formalism. Next, in Section 7, related work is included. Finally, in Section 8, we present conclusions and comment on future lines of work. At the end of the paper we include an Appendix with the proofs for the formal results of our approach.
2.Knowledge representation and reasoning
In this section, the background related to the agents’ knowledge representation and reasoning is included. In our approach, both the expert and the client represent their knowledge using DeLP, a language that combines results of Logic Programming and Defeasible Argumentation [21]. As in Logic Programming, DeLP allows to represent information declaratively using facts and rules. A DeLP program consists of a finite set of facts and defeasible rules. Facts are used for the representation of irrefutable evidence, and are denoted with ground literals: that is, either atomic information (e.g.,
Example 2.
Consider the motivating example introduced above. The DeLP program
In the set
We will briefly include below some concepts related to the argumentation inference mechanism of DeLP. We refer to [21] for the details. In a valid DeLP program the set Π must be non-contradictory. Since in this proposal Π is a set of facts, this means that Π cannot have a pair of contradictory literals, and this should be considered every time the client adopts new knowledge from the expert. In DeLP a ground literal L will have a defeasible derivation from a program
Definition 1
Definition 1(Argument).
Let h be a literal, and
(1)
(2) there exists a defeasible derivation for h from
(3)
(4)
Given
Definition 2
Definition 2(Evidence).
Let
The evidence of
In this paper, agents will be characterised by three elements: (
Definition 3
Definition 3(Proper Defeater, Blocking Defeater).
Let
Continuing with Example 2, for the agent
In DeLP, in order to determine whether a query h can be accepted as warranted from a program
Given a dialectical tree
Definition 4
Definition 4(Acceptable Argumentation Line).
Let
(1) Λ is a finite sequence, and
(2) no argument
(3) for every i such that the argument
(4) both the set
Note that, given an acceptable dialectical tree, all the leaves of the tree are undefeated arguments. Therefore, to determine if
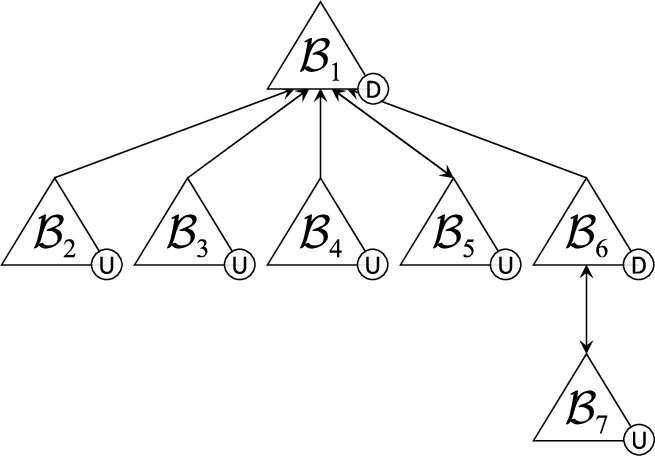
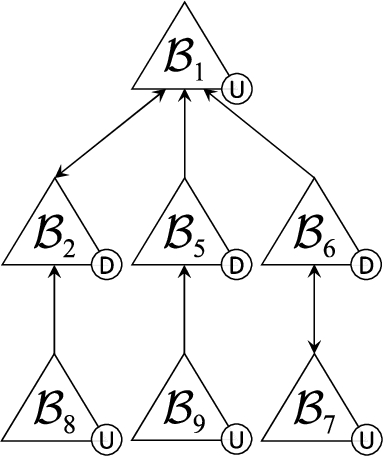
Figure 1 (left) shows the marked dialectical tree
Example 3.
Consider the DeLP program
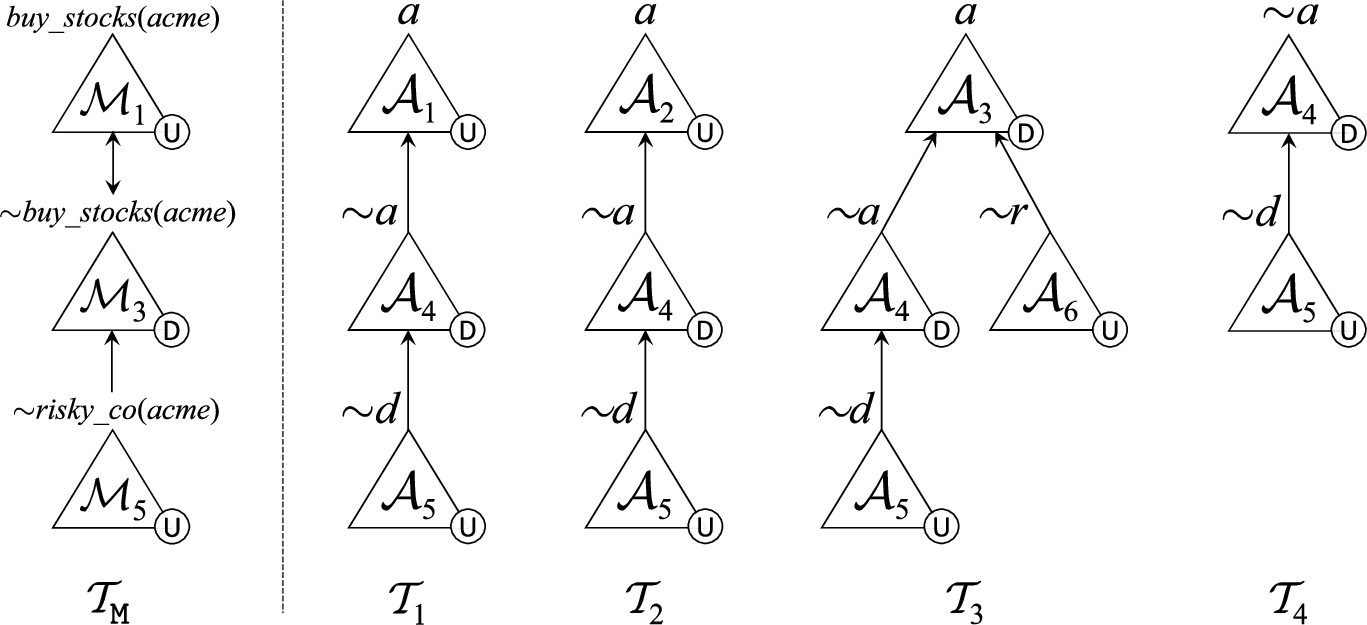
In Fig. 1 we show four marked dialectical trees that can be constructed from
We say that a literal q (respectively an argument
Given a DeLP program
3.Client-expert interaction
The whole interaction between both agents is called a session, which starts with a query and finishes when the client believes in the expert’s position. We assume that the expert’s knowledge does not change during a session and that the client does not simultaneously maintain more than one session. If the client has specific personal information that represents a context for its query and would affect the expert’s answer, then this contextual information is sent before the session starts.
Once a new session has started, its current state will be determined by a session state. Intuitively, a session state is a structure that keeps track of all the elements that both agents had already communicated, and also other elements that the client needs to ask about and remain pending. As will be explained in detail below, those pending elements will allow the client to acquire the knowledge that it needs to understand the expert’s position while avoiding unnecessary loss of information. In the rest of the paper, we will distinguish the client agent with
Definition 5
Definition 5(Session State).
Let
When there is no ambiguity, session states will be simply referred to as “states”, and the query subscript q will be omitted. The first component in a state’s 5-tuple is the client agent
Note that once a query q is posed to an expert agent, one of the following three alternatives could occur: (1) the expert believes in q (i.e. q is warranted by
Fig. 2.
Session evolution outline.
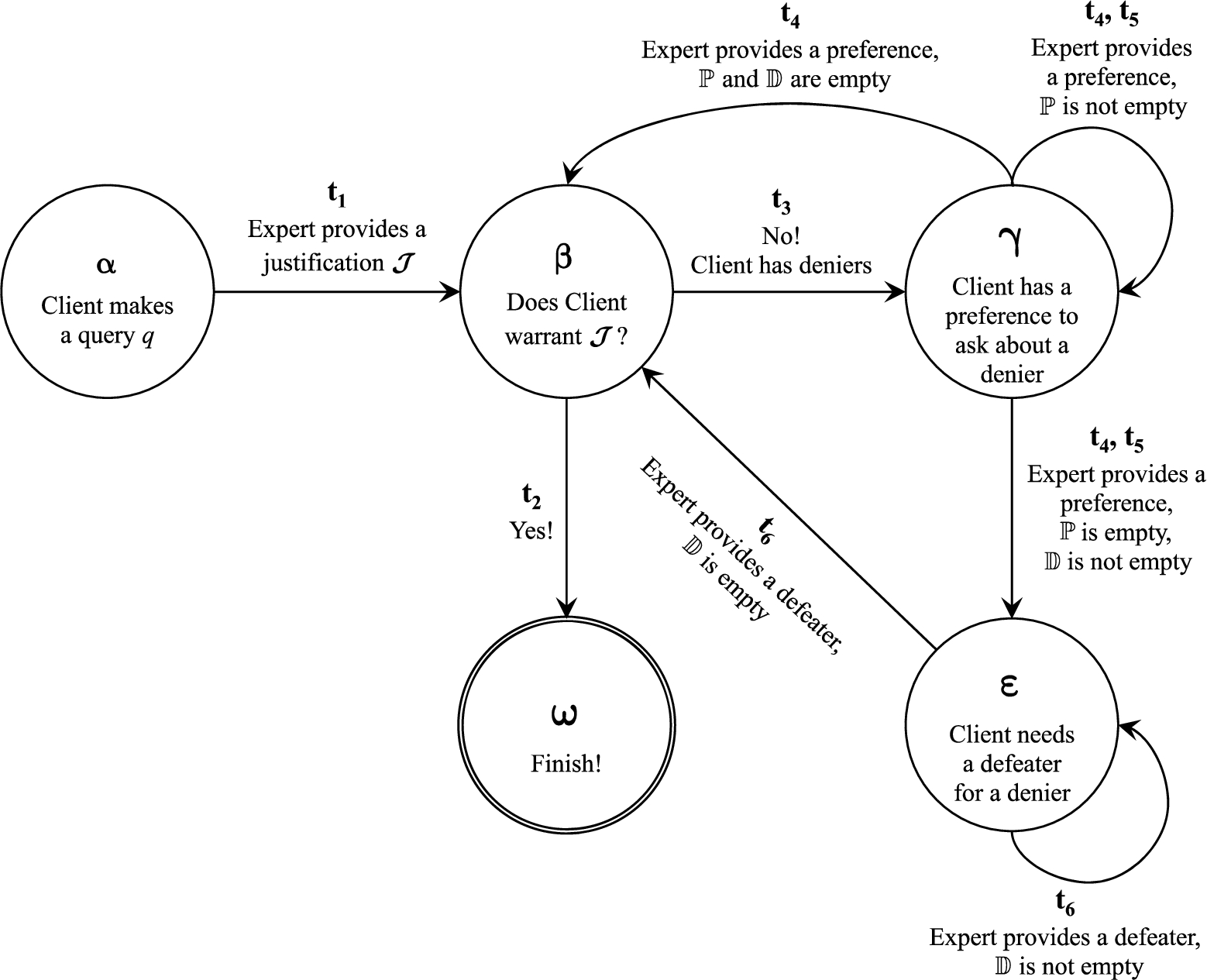
Figure 2 shows a directed graph that outlines how session states could evolve during a client-expert interaction. In that graph, nodes – identified with Greek letters – represent different session states of the interaction, while the directed arcs represent transitions among session states. All these transitions will be formally specified with transition rules during the rest of this section. For instance, the transition rule
First, two special session states will be distinguished: the initial state and the final state. Observe that a session starts (see α in Fig. 2) when a client agent
A final session state (see ω in Fig. 2) will have at least one interaction element in the tuple’s second component, and the last three components will be empty (i.e. all the pending issues will have been solved). The final state’s first component (
Once a session has started, the expert has to consider the initial query q made by the client and send one argument
Definition 6
Definition 6(Expert Justification).
Let
Example 4.
Consider the expert agent
As was explained above, the client’s goal is to accept the expert’s opinion, and hence, when the interaction is finished the client should believe the same as the expert about the submitted query. Therefore, when the client
Definition 7
Definition 7(Argument Adoption).
Given a client agent
Consider a client agent
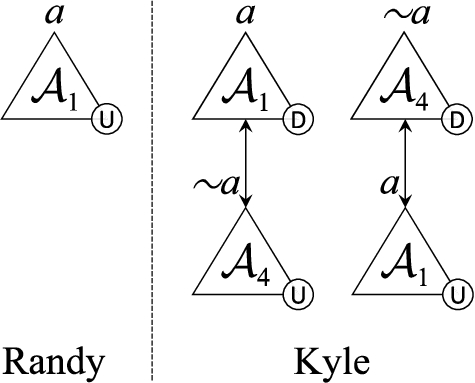
Example 5.
Consider an agent Kyle, characterised by
Example 6.
Consider an agent Randy, characterised by
The following proposition shows that, whenever the client agent adopts an argument from the expert agent, it is guaranteed that the client will be able to construct that argument. The proofs of all the formal results are in the Appendix section at the end of the paper.
Fig. 3.
Client agent Kyle before and after adopting
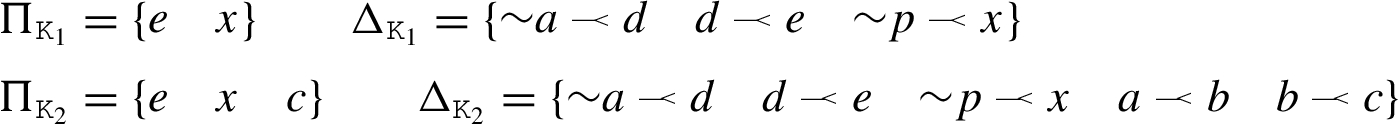
Fig. 4.
Client agent Randy before and after adopting
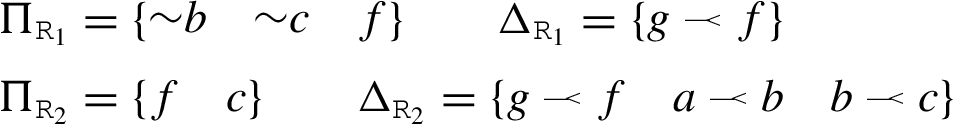
Proposition 1.
Let
As it will be explained below, the justification
Proposition 2.
Let
In order to formally define our strategy and then prove its properties, the operational semantics of the interaction will be defined in terms of a transition system. A transition system is a set of transition rules for deriving transitions. In addition, a transition is a transformation of one session state into another. A transition rule has the form
When the transition rule
Recall that, in our approach, the client conceives the other agent as an expert and its goal is to believe in the expert’s qualified opinion. Since the client may have previous knowledge that can be in conflict with the information acquired from the expert agent (e.g. it could build a defeater for
Definition 8
Definition 8(Introspection).
Given a client agent
Note that introspections check the mark of an argument in a particular dialectical tree. As we mentioned above, the client is only interested in the mark of that argument in the dialectical tree whose root is the justification
If the client makes an introspection to check the mark of the justification
Recall that the first element in a session state’s second component is always the expert’s justification. If the transition rule
Example 7.
Consider again the client agent Randy
In contrast to Example 7, the following example shows a scenario in which the client has a denier for the received justification. Hence, the result of the introspection would be Ⓓ and the session would not be able to end immediately. The client-expert interaction will continue with the client’s goal of having a warrant for the received justification.
Example 8.
Consider again the client agent Kyle
A denier (as
Definition 9
Definition 9(Preference Questions).
Given a client agent
For instance, since in Example 8
Proposition 3.
Let
We mentioned above that the justification for the initial query may not be the only argument that the client will need to adopt during the session. As we will explain in detail below, other arguments – also in favour of the claim of the justification (called “pro arguments”) – can be received. Then, if the client makes an introspection to check the mark of the justification (see β in Fig. 2) and does not result in ⓤ, it means that some of these pro arguments are marked as Ⓓ. In this case, the client agent will proceed to ask preference questions for one of the furthest deniers from the root (see γ in Fig. 2). When this pro argument becomes marked as ⓤ later in the session, the pro argument marked as Ⓓ above in the same argumentation line may also become marked as ⓤ and so on, like a cascade effect. This behaviour is reflected in the following transition rule:

The transition rule
Example 9.
Consider a new scenario in which a client agent
Whenever a set of preference questions
Definition 10
Definition 10(Expert Preference).
Let
When the client receives from the expert a preference between two arguments, it will adjust its own preferences accordingly. Similarly to an argument adoption, in a preference adoption the client respects the expert’s opinion. The adoption of a preference is determined by the operator
Definition 11
Definition 11(Preference Adoption).
Given a client agent
Note that the adoption of new preferences may require to withdraw from
The transition rules

Recall that, given a preference question
Consider again the Example 8 in which the transition rule
Example 10.
Let us suppose that the client agent
Whenever a set of denier questions
Apart from the defeater, the expert will also send the type of the defeater (proper or blocking) so that the client can adjust the preference between that argument and the corresponding denier in advance. The defeater sent by the expert agent for a denier is determined by the operator
Definition 12
Definition 12(Expert Defeater).
Given two arguments 
Whenever the client receives from the expert a defeater
Definition 13
Definition 13(Defeater Adoption).
Given a client agent
For each denier question
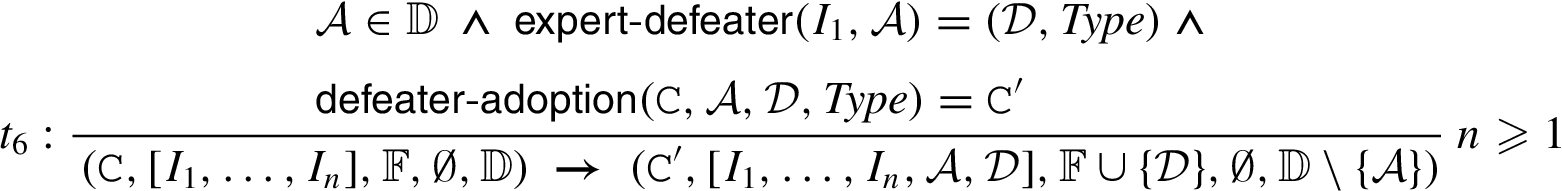
The transition rule
Example 11.
Consider the last session state shown in Example 10
The previous example illustrates a scenario in which the justification is marked as ⓤ after the client adopted the necessary defeaters (new pro arguments) for two deniers. However, as will be shown in Example 12, the client may have undefeated counter-arguments against any of the recently adopted defeaters. These counter-arguments are new deniers, which means that there is still at least one argument marked as Ⓓ in
Example 12.
Consider again the session between the client Kyle
Recall from the transition rule
Before concluding this section, a detailed example will be included to show the complete interaction between the client
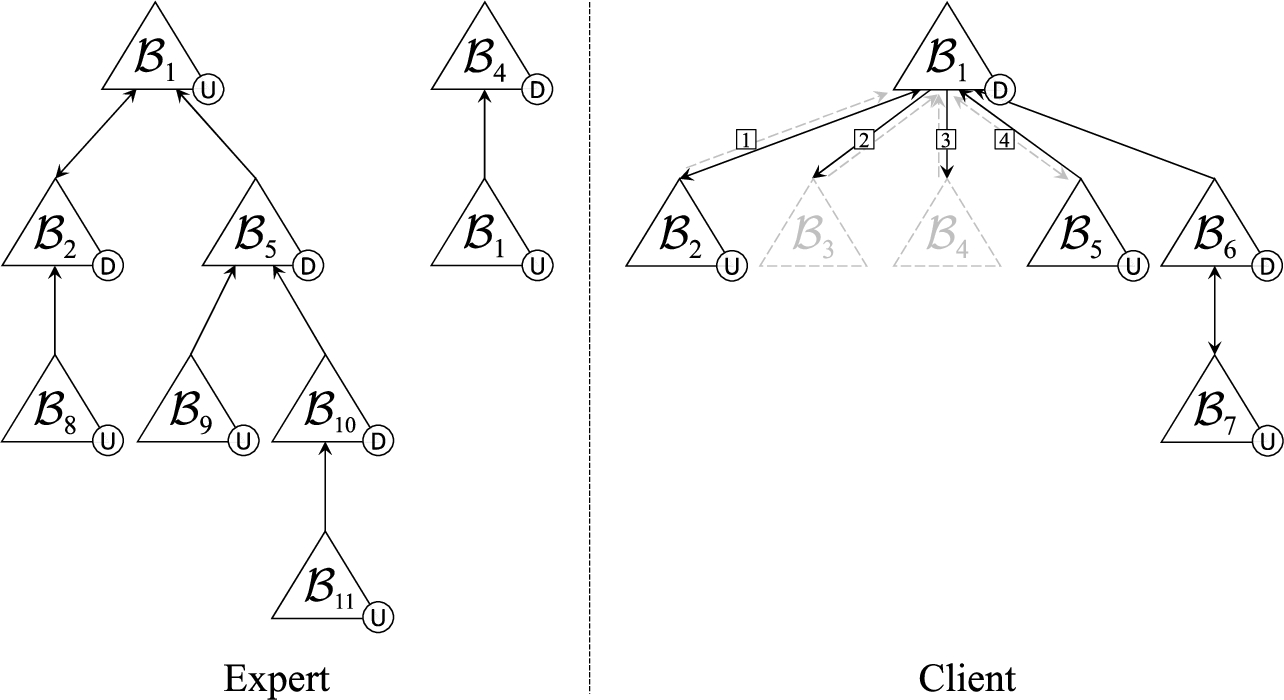
Example 13.
Consider the initial knowledge of the client agent
Consider again the expert agent
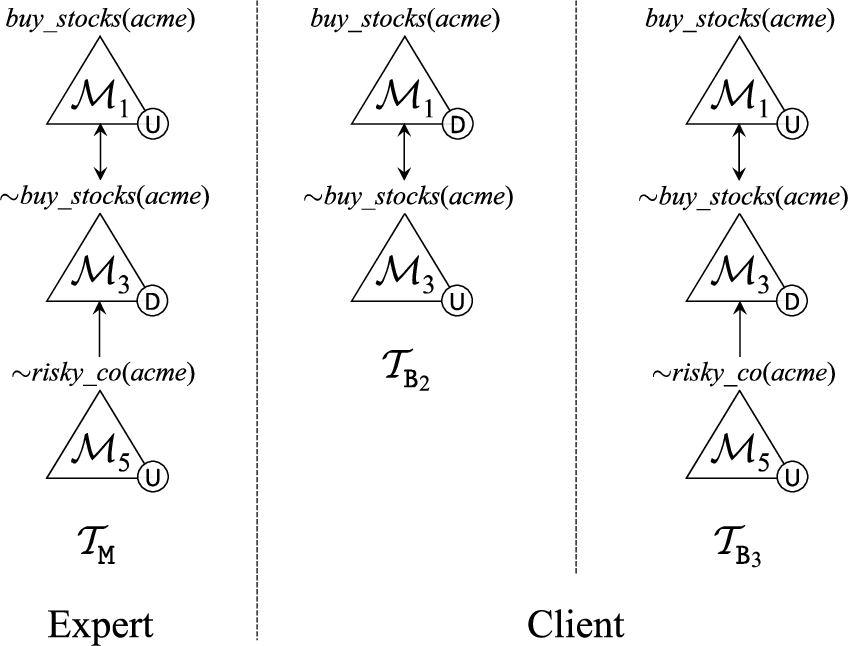
Figure 9 (left) depicts
The client (
Then, the client asks the preference question
Next, the client asks the denier question
Finally, given that there are no pending preference or denier questions, the client makes an introspection to check the mark of the justification, which results in
We will end this section showing some results which prove that our strategy behaves as expected. The following lemma shows that from any reachable session state (except a final one) there is always a single applicable transition rule. Recall that all the proofs are included in the Appendix at the end of the paper.
Lemma 1.
Let
Lemma 1 is important because it is used to prove that, given an initial state in which a client agent has made a query to an expert, there always exists a sequence of transitions that leads to the final state. That is, every session will terminate in a finite amount of time and when that occurs the client will have no open issues about the received knowledge. We will also show that, when a session arrives to a final state, the client has a warrant for the claim of the expert’s justification and, therefore, it will have adopted the expert’s position about that query.
Theorem 1.
Let
The following corollary is a direct consequence of Theorem 1 and states that the sequence of transitions that leads to the final state is unique. Hence, a session will never loop infinitely.
Corollary 1.
Let
Finally, the following result shows that in any final session state the client warrants the claim of the justification sent by the expert.
Theorem 2.
Let
From the results given above, we can conclude that, for any session, the goal of our proposal will always be achieved: the expert provides just the necessary information to help the client understand its opinion about the query, and the client agent acquires relevant information regarding the topic of the query to be able to warrant the claim of the received justification.
4.Implementing the expert’s selection operators
In this section, we will propose two alternatives for implementing the operators
We will define
The size of the client’s resulting dialectical tree is bounded to which con arguments from
In the worst-case scenario, the client will have enough knowledge to be able to construct every con argument in
Intuitively, if the expert wants to minimise the size of the client’s resulting dialectical tree,
Definition 14 details how to assign a worst-case scenario selection value (WCSSV) to an argument in a dialectical tree. In the case of a pro argument
Definition 14
Definition 14(Worst-Case Scenario Selection Value).
Given a dialectical tree
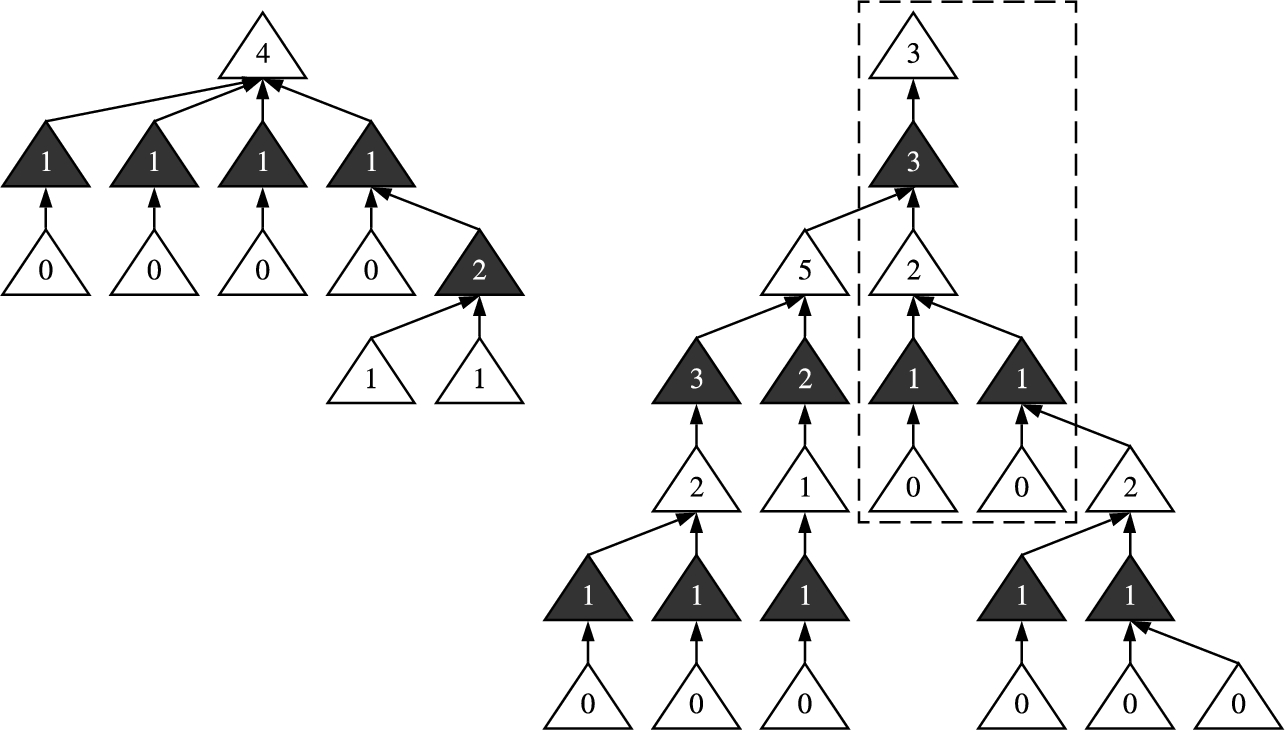
The operator’s first and second cases assign the corresponding WCSSV to all the dialectical tree’s leaves. The operator’s third case represents the fact that, whenever the client asks a denier question, the expert can choose the defeater that will cause the lowest number of con arguments becoming new deniers for the client. The operator’s fourth case represents the fact that – in the worst-case scenario – the client will be able to construct every con argument below that pro argument. Figure 10 depicts two dialectical trees and their corresponding WCSSVs.
Fig. 10.
Two dialectical trees whose arguments contain their WCSSV. Undefeated arguments are coloured in white while defeated arguments are coloured in black.
Next, we define the operators
Definition 15
Definition 15(Dialectical Tree Selection using Worst-Case Scenario Criterion).
Given a non-empty set of dialectical trees
Consider an expert agent that, given a query, constructs the dialectical trees depicted in Fig. 10. In this case, the operator
Definition 16
Definition 16(Defeater Selection using Worst-Case Scenario Criterion).
Given a dialectical tree
Consider the selected dialectical tree from Fig. 10. The expert will initially send to the client the argument coloured in white with a WCSSV of 3 (i.e., [white; 3]) as the justification. Then, if the client can construct the argument [black; 3] and eventually asks the corresponding denier question, the expert has two defeaters to choose from: [white; 5] and [white; 2]. In this case, the operator
Assuming the client has enough knowledge to construct every con argument from the expert may not be realistic depending on the application domain. However, it is clear that unless the client sends in advance all its knowledge, it is impossible for the expert to predict which con arguments the client will be able to build. Hence, given that minimising the size of the client’s resulting dialectical tree without making assumptions is not feasible, we will take another approach and define the selection operators to help the expert reduce it considering the query’s context and the previous knowledge that the client exposed during the session.
As we mentioned in Section 3, before the session starts the client sends to the expert any specific personal information that represents a context for its query and would affect the expert’s answer. As proposed in [22], such contextual information can be temporarily considered by the expert to generate the dialectical trees for the client’s query without changing its own knowledge. Once the session has finished, the received context will disappear from the expert’s knowledge base and will not be used for answering queries from other clients. We refer the interested reader to [22] for the details of how different operators for temporarily integrating knowledge can be defined.
Following the aforementioned approach, the query’s context will be represented by a DeLP program
Even though it is impossible to predict which con arguments the client will be able to build, the expert can use the client’s previous knowledge to select the dialectical tree and the defeaters based on the con arguments that the client is more likely to be able to build. In particular, a constructibility ratio can be calculated for each con argument, corresponding to the number of elements from that argument (facts and defeasible rules) that are present in the client’s previous knowledge over the total number of elements. However, when calculating a constructibility ratio, the expert should not only consider the information the client knows at the moment, but also the information the client will certainly know if it interacts with that particular con argument later in the session. This information consists of all the evidence and defeasible rules of the arguments that are above the con argument in consideration in the corresponding argumentation line, as defined next:
Definition 17
Definition 17(Ancestral Elements).
Given a dialectical tree
Then, an argument’s constructibility ratio can be calculated by considering both the client’s previous knowledge and the argument’s ancestral elements, as defined next:
Definition 18
Definition 18(Constructibility Ratio).
Let
Following a similar strategy to the WCSSV, the expert can use the constructibility ratio to assign a constructibility selection value (CSV) to the arguments in a dialectical tree. In the case of a pro argument
Definition 19
Definition 19(Constructibility Selection Value).
Given a dialectical tree
Con arguments increase the total CSV by the value corresponding to their constructibility ratio, instead of increasing it by 1 as in the operator
Definition 20
Definition 20(Dialectical Tree Selection using Constructibility Criterion).
Given a non-empty set of dialectical trees
Definition 21
Definition 21(Defeater Selection using Constructibility Criterion).
Given a dialectical tree
Since Definitions 20 and 21 use the operator
5.Rejecting the expert’s opinion
As we have stated in Section 1, we focus on a proposal in which the client’s goal is to ask questions to an expert in order to acquire knowledge until it believes in the expert’s qualified opinion. As explained, we assume that the client conceives the other agent as an expert on the matter and it will be committed to believe in the answer for its query. Therefore, the client will adopt all the information received from the expert and, in case of a contradiction with its previous knowledge, it will prefer the expert’s opinion.
Although our approach was developed for application domains in which committing to the expert’s opinion is the best alternative, there can be situations in which it is better not to do so. Clearly, the client is the one that has the responsibility of deciding whether to accept the expert’s opinion. For an excellent analysis of this matter see [46], where critical questions are proposed to guide such decision. If the assumption of commitment that we have adopted is relaxed, then the client could argue (with itself or with other agents) about whether to accept the expert’s opinion.
Next, we will introduce three additional transition rules which can be included in the operational semantics in order to relax such assumption. With these transition rules, the client can opt to reject an argument or a preference sent by the expert agent, causing the session to end immediately.
With
With
With
Note that after any of these transition rules is executed the session evolves into a final state. The reason is that, if the client rejects an expert’s argument or preference, it cannot be guaranteed that the client will be able to believe in the claim of the justification any more.
The reader should note that, if any of these transitions rules is added to the system, Theorem 2 will not hold anymore. In addition,
6.Discussion
Throughout this paper different design choices were made to tackle the issues that our approach addresses. In this section we will discuss some of those decisions, and for some of them possible alternatives will be commented.
As we explained in the previous sections, the goal of the client agent after adopting the justification
In addition, consider the expert’s justification
Example 14.
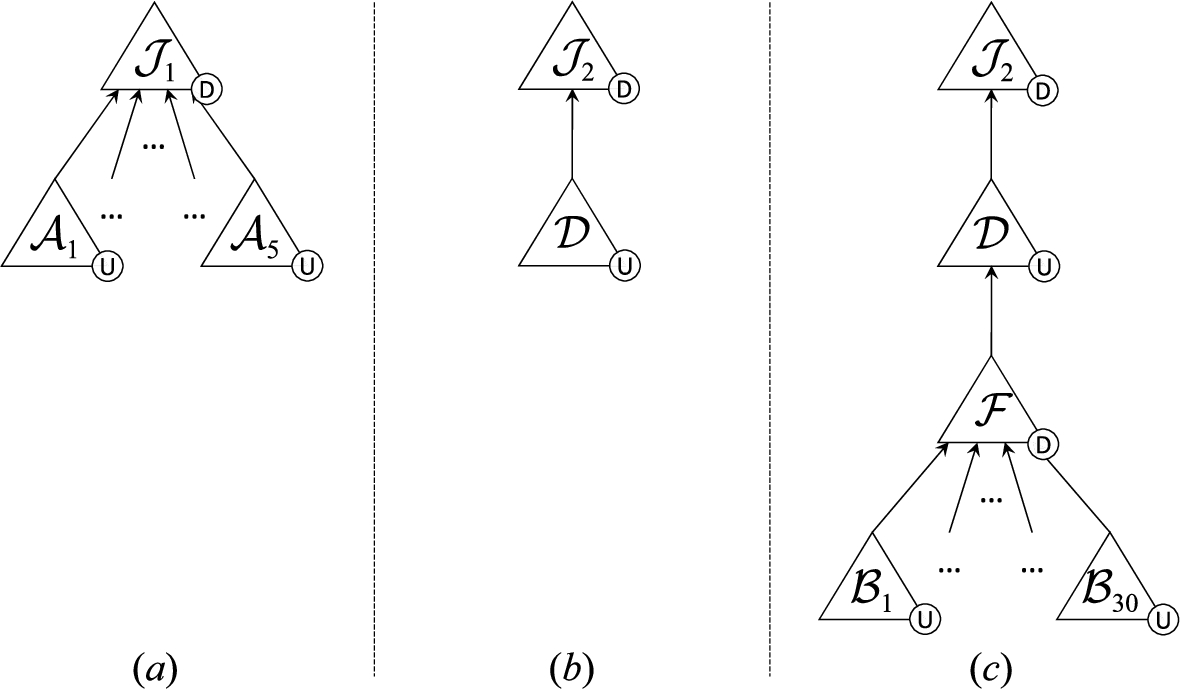
Consider the expert
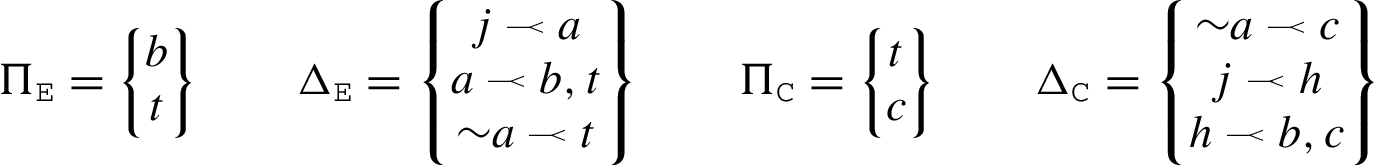
Recall the operator
Example 15.
Consider a client agent
When Definition 9 was introduced, we mentioned that we opted to use preference questions in order to abstract away from the details of how the client’s criterion would be modified. Although we could have formalized our approach with a particular family of preference criteria similarly to [7,8], we aimed for a high level formalization that allows to be instantiated with any argument comparison criterion from any family. As we will show next, any comparison criterion can be applied to our approach by making some changes in the operators
7.Related work
In [47], the authors define dialogue as a normative framework comprising exchange of arguments between two participants reasoning together to achieve a collective goal. During a dialogue, the participants take turns to make “moves” and have individual goals and strategies in making such moves. A move is a sequence of locutions provided by a participant at a particular point in the sequence of dialogue. In addition, the authors define four kinds of rules which characterise different types of dialogue: locution rules that define the permissible locutions – like statements, questions, inferences, and so on; structural rules that define the order in which moves can be made by each participant; commitment rules that define the insertion and deletion of propositions from a participant’s commitment store – as a consequence of its moves; and win-loss rules that determine the conditions under which a player wins or loses the game.
Regarding to the different types of dialogues, the authors particularly define information-seeking dialogue in which one participant has some knowledge and the other party lacks and needs that information. This type of dialogue’s goal is to share that knowledge. Expert consultation is a subtype of the information-seeking dialogue in which one participant is an expert in a particular domain or field of knowledge, and the other is not. By asking questions, the non-expert participant (in [47], the layman) tries to elicit the expert’s opinion (advice) on a matter which the questioner itself lacks direct knowledge. In this kind of dialogue, the questioner can arrive at a presumptive conclusion which gives a plausible expert-based answer to its question. Our proposal clearly fits the information-seeking and expert consultation concepts. Furthermore, we could instance every element in the definition of dialogue with elements of our strategy to make a match. For instance, there are strong similarities between the “locution rules” and the operators used by the agents (e.g.
In [31], the authors present a framework for argumentation-based dialogues between agents. They define a set of locutions by which agents can trade arguments, a set of agent attitudes which relate what arguments an agent can build and what locutions it can make, and a set of protocols by which dialogues can be carried out. Regarding to the assertion attitudes, an agent may be either confident, if it can assert any proposition p for which it can construct an argument
Based on the typology of [47], the authors of [31] also define information-seeking dialogues in which one agent A seeks the answer to some question from another agent B, which is believed by the first to know the answer. In the protocol which they provide for an information-seeking dialogue about a proposition p, first A asks a
In [17 –19], the authors model information-seeking dialogues using Assumption-Based-Argumentation (ABA) [16]. In such proposal, a questioner agent α proposes a topic χ and an answerer agent β utters information of relevance to χ. They assume that the questioner contributes no information apart from initiating the dialogue and that the answerer is interested in conveying information for χ, but not against. Strategy-move functions are used to help the agents identify suitable utterances that advance the information-seeking dialogue towards its goal while fulfilling the participants’ aims. The authors also define two subtypes of dialogues: IS-Type I, in which the answerer agent conveys all arguments for χ, and IS-Type II, in which the answerer agent conveys only one argument for χ. Unlike that approach, in our work we consider that the client agent may have previous knowledge in conflict with the information acquired from the expert agent. Given that the client agent is committed to believe in the justification for the query sent by the expert, the client will need to adapt its previous knowledge losing as little information as possible. This may either imply the removal of facts contradicting an unchallengeable information acquired from the expert, the addition of new knowledge that allows the construction of arguments provided by the expert, or even further interactions with the expert.
A framework for representing inquiry dialogues that uses Defeasible Logic Programming as the underlying representation formalism is presented in [7,8] and its implementation is reported in [35]. Their approach, unlike us, does not deal with information-seeking dialogues or expert consultations. Instead, their focus is on inquiry dialogues [47], in which the initial situation, the main goal, the participant’s aims, and the side benefits are different from the ones in information-seeking. Inquiry dialogues are defined as arising from an initial situation of “general ignorance” and as having the main goal to achieve the “growth of knowledge and agreement”, while each individual participating aims to “find a ‘proof’ or destroy one”. As explained in [47], in inquiry dialogues there is a common problem to be solved between the participants while in information-seeking dialogues there in not. In the later, the knowledge is already there, and the problem is to communicate it from one party to the other.
The authors define and give the necessary details to generate two subtypes of inquiry dialogues. Argument inquiry dialogues allow two agents to share beliefs to jointly construct arguments for a specific claim that neither of them may construct from their own personal beliefs alone. For instance, an agent that wants to construct an argument for ϕ can open an argument inquiry dialogue with the defeasible rule
The main contribution of [7,8] is a protocol and strategy sufficient to generate sound and complete warrant inquiry dialogues. To prove this, the authors compare the outcome of their dialogues with the outcome that would be arrived at by a single agent that has as its beliefs the union of both the agents participating in the dialogue’s beliefs. This is, in a sense, the “ideal” situation in which there are clearly no constraints on the sharing of beliefs. However, this union of both agents’ beliefs is only possible because it is assumed that the agents use defeasible facts instead of strict facts. Therefore, in contrast with our approach, no contradictions can arise from both agents’ joint beliefs. In addition, the authors assume a global preference ordering across all knowledge, from which a global preference ordering across arguments is derived. Hence, an exchange of opinion on the participants’ arguments’ preferences is unnecessary, differently from our proposal.
The author of [46] explains appeal to expert opinion, a form of argument based on the assumption that the source is alleged to be in a position to know about a subject because he or she has expert knowledge of that subject. In addition, the author mentions that there is a natural tendency to respect experts and treat them as infallible, which is a dangerous approach since they can be wrong. For this reason, an informal argumentation scheme for deciding whether to accept an expert’s opinion is introduced. The author mentions that it is vital to see appeal to expert opinion as defeasible, as open to the following critical questions: (1) How credible is E as an expert source? (2) Is E an expert in the field that A (the proposition) is in? (3) What did E assert that implies A? (4) Is E personally reliable as a source? (5) Is A consistent with what other experts assert? (6) Is E’s assertion based on evidence? Regarding question 5, the consistency question, the author mentions that one can compare A with other known evidence, particularly with what other experts on the field say.
The consistency question from [46] together with the proposal of [25,39,40] could be used in our formalism to add an implementation for the operator
We will end this section with a comment on the differences between our proposal and borth belief revision and revision of argument frameworks (AFs). Recall that, whenever the client agent receives an argument from the expert agent (either the justification or a defeater for a con argument) the operator
Since changing preferences alters how arguments defeat each other, our proposal may resemble existing work on revision of argumentation frameworks [11,13,14,30,38]. These approaches, regardless of their individual goals, end up adding or removing arguments or attacks and returning a new AF or set of AFs as output. Especially, [11,13] revise AFs by modifying the sets of extensions and then modifying the attack graph accordingly to the newly obtained extensions, while [14] focuses on updating the extensions. However, our proposal differs both conceptually and methodologically: we do not want the client agent to mark the expert’s justification as ⓤ in a single step by changing its preferences or previous knowledge without further information. Instead, we want the client to maintain the communication with the expert in order to ask questions to keep acquiring relevant knowledge (arguments and preferences) and make informed changes considering a qualified opinion.
8.Conclusions and future work
In this work, we have presented a strategy that involves two agents: an expert agent which has expertise in a particular domain or field of knowledge and a client agent which lacks that quality. The inexpert client or questioner initially makes a query to the expert in order to acquire knowledge about a topic in which the client itself lacks expertise. The client agent is committed to believe in the answer of the query and, unlike other approaches, we consider that the client may have previous knowledge in conflict with the information acquired from the expert agent. Thus, the client could need to adapt its previous knowledge without making unnecessary changes in order to accept what the expert says.
A naive solution to the proposed problem would be for the expert to send all of its knowledge to the client, but this is not feasible because, depending on the domain, the expert may have private information or its knowledge could be very extensive. Furthermore, the joined knowledge bases of both agents would probably have contradictions which are completely unnecessary to solve because their relevance is outside of the domain or field of knowledge of the query. For instance, consider a simple scenario in which the expert believes in
All interactions between both agents occur during a session which will start only if the expert has a warrant for the literal of the query or its complement, i.e., it must be certain about the topic of the client agent’s query. In this case, the expert will select one of its undefeated arguments to send to the client as justification. Whenever the client acquires new knowledge from the expert, it may have to withdraw some of its previous contradictory knowledge (which is inaccurate from the expert’s position).
The goal of this strategy is for the client to be able to mark the justification as ⓤ (that is, it manages to believe in the claim of the justification) without making unnecessary changes to its previous knowledge. However, after adopting the justification, the client may have denier arguments for it, some of which may be acknowledged or not by the expert. In this case, the client will have to ask preference and denier questions to the expert from which it will acquire new preferences and arguments. The session will continue until the goal is finally achieved. We proved that every session eventually finishes and, when this happens, the client agent will believe in the claim of the expert’s justification. This means that the goal of this strategy is always achieved. Another conclusion we can draw is that the fewer pieces of information (facts and rules) the client previously has about the topic of the query, the shorter will be the session. This property holds because the client will have fewer denier arguments against the justification, and it will be easier to mark it as ⓤ. Ultimately, it could occur that the client knows absolutely nothing, and the goal of the session would be simply achieved by adopting the justification from the expert.
DeLP was used as the underlying knowledge representation and reasoning mechanism in order to show how to solve the problems associated to the agents’ argument structures in an information-seeking setting. Conceptually, our proposal can be divided into three different levels: First, a level corresponding to the outline illustrated in Fig. 2, which abstracts away from the argumentative reasoning mechanism used by the agents. Second, a level corresponding to the actual transition rules whose conditions are defined by different operators. Third, a level corresponding to the implementation of those operators. In particular, the transition rules and the operators were defined considering the particular characteristics of DeLP. Even though the separation of these three conceptual levels provides some modularity to our approach, the second level would need some modifications in order to be able to adapt the formalism to another structured argumentation formalism (e.g., ASPIC+ [29]). The transition rules should be more abstractly defined to allow different operators – regardless of how they are implemented – as long as they satisfy certain conditions. The modularization of the transition system is left as future work.
Future work has multiple directions. Although DeLP allows the use of strict rules (besides defeasible rules), we have not considered them in our proposal. We plan to adapt the operational semantics of our formalism to allow agents to have strict rules in their knowledges bases. Hence, in order to guarantee that the client will always be able to believe in the expert’s justification, different belief revision operators will be necessary to insightfully adapt the client’s knowledge during the session. In addition, we are interested in adapting our strategy to the didactic dialogues proposed in [47], in which the purpose of the expert agent is not just to satisfy the doubts of the client agent, but also to turn it into an expert itself. To provide a strategy for didactic dialogues, our expert agent would deliberatively need to decide how to share all its knowledge about its field of expertise to the client. This could also imply an effort from the client to show the expert how deep is its knowledge regarding the topic at hand. Finally, we would like to further analyze the selection operators defined in Section 4 to formally define minimal information exchange in the context of a session between a client and an expert.
Notes
1 This may resemble the argumentation game of Dung’s [15] grounded semantics. However, they differ since DeLP does not allow arguments to be repeated within an argumentation line, whereas the grounded semantics only prevents pro arguments from being repeated. In this sense, the grounded semantics are more skeptical than DeLP’s dialectical process.
Acknowledgements
This work has been partially supported by PGI-UNS (grants 24/ZN32, 24/N046).
Appendices
Appendix
Proposition 1.
Let
Proof.
Let
(1) By Definition 7, every defeasible rule
(2) By hypothesis there is a defeasible derivation for h from
(3) By Definition 7, every literal
(4) Given that
Proposition 2.
Let
Proof.
Let
(1) There is no defeasible derivation for b from
(a) a defeasible rule
(b) a literal
i.
ii.
iii.
(2) the set
(3)
Condition (a) is not possible because defeasible rules are never removed during an argument adoption. Condition (i) is not possible because, given that
Proposition 3.
Let
Proof.
Let us suppose that
Lemma 1.
Let
Proof.
For this proof – starting from the initial state – we will analyse the conditions under which the transition rules are applicable and lead to all the possible session states.
From the initial state
From the state
From the state
From the state
Theorem 1.
Let
Proof.
Let us suppose that there does not exist a sequence of transitions that leads to
(1) The session evolved to a state
(2) The session can never evolve from the state
(a) Agent
(b)
By Lemma 1, condition (1) does not hold. Condition (a) is not possible: If the session is in the state
Corollary 1.
Let
Proof.
According to Theorem 1 the sequence of transitions that leads from
Theorem 2.
Let
Proof.
A session can only evolve into the state
References
[1] | R.A. Agis, S. Gottifredi and A.J. García, An approach for distributed discussion and collaborative knowledge sharing: Theoretical and empirical analysis, Expert Systems with Applications 116: ((2019) ), 377–395. doi:10.1016/j.eswa.2018.09.016. |
[2] | L. Amgoud, C. Devred and M. Lagasquie-Schiex, Generating possible intentions with constrained argumentation systems, Int. J. Approx. Reasoning 52: (9) ((2011) ), 1363–1391. doi:10.1016/j.ijar.2011.07.005. |
[3] | L. Amgoud, Y. Dimopoulos and P. Moraitis, A general framework for argumentation-based negotiation, in: Argumentation in Multi-Agent Systems, 4th International Workshop, ArgMAS 2007, Honolulu, HI, USA, May 15, 2007, Revised Selected and Invited Papers, (2007) , pp. 1–17. |
[4] | K. Atkinson, T.J.M. Bench-Capon and P. McBurney, A dialogue game protocol for multi-agent argument over proposals for action, Autonomous Agents and Multi-Agent Systems 11: (2) ((2005) ), 153–171. doi:10.1007/s10458-005-1166-x. |
[5] | P. Bedi and P.B. Vashisth, Empowering recommender systems using trust and argumentation, Inf. Sci. 279: ((2014) ), 569–586. doi:10.1016/j.ins.2014.04.012. |
[6] | T.J.M. Bench-Capon, Persuasion in practical argument using value-based argumentation frameworks, J. Log. Comput. 13: (3) ((2003) ), 429–448. doi:10.1093/logcom/13.3.429. |
[7] | E. Black and A. Hunter, A generative inquiry dialogue system, in: 6th International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS 2007), Honolulu, Hawaii, USA, May 14–18, (2007) , p. 241. |
[8] | E. Black and A. Hunter, An inquiry dialogue system, Autonomous Agents and Multi-Agent Systems 19: (2) ((2009) ), 173–209. doi:10.1007/s10458-008-9074-5. |
[9] | C.E. Briguez, M.C. Budán, C.A.D. Deagustini, A.G. Maguitman, M. Capobianco and G.R. Simari, Argument-based mixed recommenders and their application to movie suggestion, Expert Syst. Appl. 41: (14) ((2014) ), 6467–6482. doi:10.1016/j.eswa.2014.03.046. |
[10] | Á. Carrera and C.A. Iglesias, A systematic review of argumentation techniques for multi-agent systems research, Artif. Intell. Rev. 44: (4) ((2015) ), 509–535. doi:10.1007/s10462-015-9435-9. |
[11] | S. Coste-Marquis, S. Konieczny, J.-G. Mailly and P. Marquis, On the revision of argumentation systems: Minimal change of arguments statuses, in: Fourteenth International Conference on the Principles of Knowledge Representation and Reasoning, (2014) . |
[12] | J. Devereux and C. Reed, Strategic argumentation in rigorous persuasion dialogue, in: Argumentation in Multi-Agent Systems, 6th International Workshop, ArgMAS 2009, Budapest, Hungary, May 12, 2009, Revised Selected and Invited Papers, (2009) , pp. 94–113. |
[13] | M. Diller, A. Haret, T. Linsbichler, S. Rümmele and S. Woltran, An extension-based approach to belief revision in abstract argumentation, International Journal of Approximate Reasoning 93: ((2018) ), 395–423. doi:10.1016/j.ijar.2017.11.013. |
[14] | S. Doutre, A. Herzig and L. Perrussel, A dynamic logic framework for abstract argumentation, in: Fourteenth International Conference on the Principles of Knowledge Representation and Reasoning, (2014) . |
[15] | P.M. Dung, On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games, Artificial intelligence 77: (2) ((1995) ), 321–357. doi:10.1016/0004-3702(94)00041-X. |
[16] | P.M. Dung, R.A. Kowalski and F. Toni, Assumption-based argumentation, in: Argumentation in Artificial Intelligence, Springer, (2009) , pp. 199–218. doi:10.1007/978-0-387-98197-0_10. |
[17] | X. Fan and F. Toni, Assumption-based argumentation dialogues, in: IJCAI 2011, Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, July 16–22, (2011) , pp. 198–203. |
[18] | X. Fan and F. Toni, Agent strategies for ABA-based information-seeking and inquiry dialogues, in: ECAI 2012 – 20th European Conference on Artificial Intelligence. Including Prestigious Applications of Artificial Intelligence (PAIS-2012) System Demonstrations Track, Montpellier, France, August 27–31, (2012) , pp. 324–329. |
[19] | X. Fan and F. Toni, Mechanism design for argumentation-based information-seeking and inquiry, in: International Conference on Principles and Practice of Multi-Agent Systems, Springer, (2015) , pp. 519–527. |
[20] | E. Ferretti, M. Errecalde, A.J. García and G.R. Simari, Decision rules and arguments in defeasible decision making, in: Computational Models of Argument: Proceedings of COMMA 2008, Toulouse, France, May 28–30, (2008) , pp. 171–182. |
[21] | A.J. García and G.R. Simari, Defeasible logic programming: An argumentative approach, TPLP 4: (1–2) ((2004) ), 95–138. |
[22] | A.J. García and G.R. Simari, Defeasible logic programming: DeLP-servers, contextual queries, and explanations for answers, Argument & Computation 5: (1) ((2014) ), 63–88. |
[23] | S.A. Gómez, C.I. Chesñevar and G.R. Simari, ONTOarg: A decision support framework for ontology integration based on argumentation, Expert Syst. Appl. 40: (5) ((2013) ), 1858–1870. doi:10.1016/j.eswa.2012.10.025. |
[24] | S.A. Gómez, A. Goron, A. Groza and I.A. Letia, Assuring safety in air traffic control systems with argumentation and model checking, Expert Syst. Appl. 44: ((2016) ), 367–385. doi:10.1016/j.eswa.2015.09.027. |
[25] | S. Gottifredi, L.H. Tamargo, A.J. García and G.R. Simari, Arguing about informant credibility in open multi-agent systems, Artif. Intell. 259: ((2018) ), 91–109. doi:10.1016/j.artint.2018.03.001. |
[26] | N.C. Karunatillake, N.R. Jennings, I. Rahwan and T.J. Norman, Argument-based negotiation in a social context, in: 4th International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS 2005), Utrecht, The Netherlands, July 25–29, (2005) , pp. 1331–1332. |
[27] | S. Kraus, Negotiation and cooperation in multi-agent environments, Artif. Intell. 94: (1–2) ((1997) ), 79–97. doi:10.1016/S0004-3702(97)00025-8. |
[28] | V. Lifschitz, Foundations of logic programs, in: Principles of Knowledge Representation, G. Brewka, ed., CSLI Pub., (1996) , pp. 69–128. |
[29] | S. Modgil and H. Prakken, The ASPIC+ framework for structured argumentation: A tutorial, Argument & Computation 5: (1) ((2014) ), 31–62. doi:10.1080/19462166.2013.869766. |
[30] | M.O. Moguillansky, N.D. Rotstein, M.A. Falappa, A.J. García and G.R. Simari, Argument theory change through defeater activation, in: COMMA, (2010) , pp. 359–366. |
[31] | S. Parsons, M. Wooldridge and L. Amgoud, An analysis of formal inter-agent dialogues, in: Proceedings of the First International Joint Conference on Autonomous Agents and Multiagent Systems: Part 1, ACM, (2002) , pp. 394–401. doi:10.1145/544741.544835. |
[32] | L. Perrussel, S. Doutre, J. Thévenin and P. McBurney, A persuasion dialog for gaining access to information, in: Argumentation in Multi-Agent Systems, 4th International Workshop, ArgMAS 2007, Honolulu, HI, USA, May 15, 2007, Revised Selected and Invited Papers, (2007) , pp. 63–79. |
[33] | H. Prakken, Formal systems for persuasion dialogue, Knowledge Eng. Review 21: (2) ((2006) ), 163–188. doi:10.1017/S0269888906000865. |
[34] | H. Prakken, A.Z. Wyner, T.J.M. Bench-Capon and K. Atkinson, A formalization of argumentation schemes for legal case-based reasoning in ASPIC+, J. Log. Comput. 25: (5) ((2015) ), 1141–1166. doi:10.1093/logcom/ext010. |
[35] | L. Riley, K. Atkinson, T.R. Payne and E. Black, An implemented dialogue system for inquiry and persuasion, in: Theorie and Applications of Formal Argumentation – First International Workshop, TAFA 2011, Barcelona, Spain, July 16–17, 2011, Revised Selected Papers, (2011) , pp. 67–84. |
[36] | S.V. Rueda, A.J. García and G.R. Simari, Argument-based negotiation among BDI agents, Journal of Computer Science & Technology 2: ((2002) ). |
[37] | G.R. Simari and I. Rahwan (eds), Argumentation in Artificial Intelligence, Springer, (2009) . |
[38] | M. Snaith and C. Reed, Argument revision, Journal of Logic and Computation 27: (7) ((2016) ), 2089–2134. |
[39] | L.H. Tamargo, A.J. García, M.A. Falappa and G.R. Simari, On the revision of informant credibility orders, Artif. Intell. 212: ((2014) ), 36–58. doi:10.1016/j.artint.2014.03.006. |
[40] | L.H. Tamargo, S. Gottifredi, A.J. García and G.R. Simari, Sharing beliefs among agents with different degrees of credibility, Knowl. Inf. Syst. 50: (3) ((2017) ), 999–1031. doi:10.1007/s10115-016-0964-6. |
[41] | J.C. Teze, S. Gottifredi, A.J. García and G.R. Simari, Improving argumentation-based recommender systems through context-adaptable selection criteria, Expert Syst. Appl. 42: (21) ((2015) ), 8243–8258. doi:10.1016/j.eswa.2015.06.048. |
[42] | M. Thimm, Realizing argumentation in multi-agent systems using defeasible logic programming, in: Argumentation in Multi-Agent Systems, 6th International Workshop, ArgMAS 2009, Budapest, Hungary, May 12, 2009, Revised Selected and Invited Papers, (2009) , pp. 175–194. |
[43] | M. Thimm, Strategic argumentation in multi-agent systems, KI 28: (3) ((2014) ), 159–168. |
[44] | M. Thimm and A.J. García, On strategic argument selection in structured argumentation systems, in: International Workshop on Argumentation in Multi-Agent Systems, (2010) , pp. 286–305. |
[45] | M. Thimm, A.J. Garcia, G. Kern-Isberner and G.R. Simari, Using collaborations for distributed argumentation with defeasible logic programming, in: Proceedings of the 12th International Workshop on Non-Monotonic Reasoning (NMR’08), (2008) , pp. 179–188. |
[46] | D. Walton, Appeal to Expert Opinion: Arguments from Authority, Penn State Press, (2010) . |
[47] | D. Walton and E.C. Krabbe, Commitment in Dialogue: Basic Concepts of Interpersonal Reasoning, SUNY Press, (1995) . |


