
Rhetorical strategies in German argumentative dialogs
Abstract
An important factor of argument mining in dialog or multilog data is the framing with which interlocutors put forth their arguments. By using rhetorical devices such as hedging or reference to the Common Ground, speakers relate themselves to their interlocutors, their arguments, and the ongoing discourse. Capitalizing on theoretical linguistic insights into the semantics and pragmatics of discourse particles in German, we propose a categorization of rhetorical information that is highly relevant in natural transcribed speech. In order to shed light on the rhetorical strategies of different interlocutors in large amounts of real mediation data, we use a method from Visual Analytics which allows for an exploration of the rhetorical patterns via an interactive visual interface. With this innovative combination of theoretical linguistics, argument mining and information visualization, we offer a novel way of analyzing framing strategies in large amounts of multi-party argumentative discourse in German.
1.Introduction
With the increasing availability of large amounts of real, natural language and multi-party discourse data, the breadth and complexity of questions that can be answered with automatic methods are expanding. In this type of data, argument mining should not only involve the analysis of the propositional content of the discourse; it should also take into account the framing, i.e., the pragmatic packaging that is used to enrich the propositional content. Research in pragmatics has a history of looking at individual phenomena such as hedging or notions such as the Common Ground; however a systematic categorization of rhetorical devices that have an impact on the way arguments are framed in a discourse is lacking to date. This information regarding the relation between interlocutors, their arguments, and the ongoing discourse is thereby missed out on. A second issue resides in uncovering the rhetorical strategies that individual speakers or groups employ. This is a particularly pressing issue when dealing with argumentation in large amounts of real, multi-party dialog data.
In this paper, we focus on German discourse particles as a way of illustrating our general approach towards an automatic analysis of natural language argumentation. We make crucial use of the VisArgue pipeline [2,12,15], a linguistically motivated, high-quality parsing pipeline that automatically identifies, disambiguates and annotates discourse information in transcribed natural speech, among them information coming from discourse particles.
Discourse particles represent a linguistic category that is highly frequent in natural speech but not confined to it. These particles steer the discourse and express speaker stance towards uttered propositions – subtle pragmatic devices that are highly effective in natural communication. For an illustration of the effects of particles in arguments, see the example in (1): A proposition (‘We have a massive change to through stations in the centers.’) is followed by a premise (‘And because that’s the case, [...]’). Without a discourse particle in the premise, as in (1a), the speaker neutrally refers to the proposition that there is a massive change to through stations. Using the discourse particle ja ‘yes’ in (1b), however, the speaker signals that they consider the premise and the preceding proposition as already being part of the Common Ground shared by the interlocutors and is simply reminding the discourse partner that this fact is already shared and acknowledged as being true by the interlocutors. That is, the speaker wants to make the proposition about the nature of the train stations an uncontroversial fact at the time of the utterance [22,24,29,51].

Using the particle halt ‘stop’ in (1c) has yet another effect: It conveys speaker stance in that the speaker shows resigned acceptance for the fact that more and more train stations are being converted to through stations. Interestingly, particles can also render a speech act infelicitous: The hedging particle wohl ‘possibly’ in (1d) reduces the speaker’s responsibility for the truth of the premise, thereby defeating the pragmatic inference of the preceding proposition that the information about the through stations is true.
A consistent and meaningful manifestation of the dimensions of rhetorical devices is challenging, exacerbated by the fact that it ultimately needs to be valid across languages. In this paper, we make a first attempt at devising such a categorization by capitalizing on theoretical linguistic insights on the semantics and pragmatics of a comprehensive set of German particles. We operationalize these theoretical insights in a way that they can be used in an automatic discourse processing pipeline, which allows us to mine the arguments and the rhetorical patterns triggered by these particles. In order to shed light on the rhetorical strategies that are pursued in a large corpus of German multi-party argumentative discourse, we use a method from Information Visualization which allows us to see these strategies at-a-glance. This interdisciplinary combination of theoretical linguistics, argument mining and Information Visualization allows us to shed light on the pragmatic structuring of natural language argumentation.
The paper proceeds as follows: We first lay out the necessary background concerning the theoretical linguistic insights on discourse particles (Section 2) and then provide quantitative evidence as to the relevance of discourse particles in German natural speech arguments (Section 3). Section 4 provides the classification of rhetorical information triggered by these particles. In Section 5 we first present the discourse processing pipeline and then propose an Information Visualization approach that provides a visual interface to analyzing the usage of these particles and the accompanying rhetorical strategies in large amounts of German multilog data. Section 6 discusses the findings and concludes the paper.
2.Discourse particles and their pragmatic contribution
In linguistic theory, German modal or discourse particles have been a long-standing issue [7,21,22,28,48]. Overall, they are considered to not contribute to the at-issue content of an utterance but to its expressive content [25,29,51, inter alia]. Analyses range from considering them as contributing conventional implicatures [10], adding felicity conditions [29], being modifiers of illocutionary operators [22,32] or being a modifier of sentence types [51]. Despite the breadth of analyses, discourse particles are generally considered as conveying a speaker’s stance towards an utterance and situating the utterance in the web of information that comprises the discourse, including the Common Ground held by the discourse participants [17,45] and the question under discussion [40]. It is this property that we claim we can capitalize on for mining arguments in dialogical data.
Discourse particles are found across languages, as shown in (2) for English. Here, the particle like does not change the descriptive content of the utterance, i.e., it does not change the fact that someone is a representative of their clan. Instead, like indicates that the speaker is not quite sure of how to say what they mean [42]. In contrast, (3) illustrates the verbal usage of like where it contributes to the proposition of the utterance.

For German, consider the example in (4) with two particles eben ‘lit. even’ and immerhin ‘at least’. The discourse particle eben ‘lit. even’ expresses the (resigned) acceptance of an immutable constraint [14], i.e., the speaker accepts the premise that travel times are reduced, although he or she might not like the fact. In contrast, with the concessive immerhin ‘at least’, the speaker signals that they agree with the premise that the tunnels reduce travel times. However, they do not agree with other reasons why the tunnels are crucially important, implying some conversational back-and-forth [14], while eben ‘even’ seeks to end the discussion on this point.

For some particles such as doch ‘indeed’, multiple interpretations exist depending on whether the particle is used in the unstressed or the stressed version [11,18,25,30,51, inter alia]. In (5), the stressed doch ‘indeed’ signals the rejection of the Common Ground [11,51], i.e., the speaker rejects an opinion uttered in the previous discourse that the tunnels do not reduce travel times. The unstressed doch ‘indeed’ is predominantly found as a means to re-check a fact [25], thereby activating the Common Ground between the interlocutors.

Since we employ methods from natural language processing, we will not deal with these ambiguous cases, where the meaning of the particle can only be resolved by taking into account prosodic information. Instead, we focus on those particles which are amenable for automatic text analysis.
Before we provide a classification of the rhetorical information that is contributed by a comprehensive set of German discourse particles, we briefly show that discourse particles in German are highly frequent in natural language arguments and are therefore worth exploiting for argumentation mining purposes.
3.Relevance of particles for argumentation mining in German
For the investigation we employ three different corpora: We first use the transcripts of Stuttgart 21 (S21) (10,000 utterances, ∼500,000 tokens), a public arbitration in the German city of Stuttgart, where a new railway and urban development plan caused a massive public conflict in 2010.11 We further use the transcripts of experimentally controlled discussions on whether or not to allow fracking in Germany (2,000 utterances, ∼282,000 tokens) and on establishing a hypothetical African government (3670 utterances, ∼363,000 tokens).22
For the investigation we take the 20 most frequent particles (plus their combinations) in the three corpora (among them ja ‘yes’, halt ‘stop’, doch ‘indeed’, eben ‘even’, wohl ‘probably’ – for an overview see Table 4) and calculate their relative frequency in premises, conclusions, contrasts, concessions and conditions – units that constitute core building blocks of argumentative discourse in our type of data. These argumentative units are marked explicitly by the 38 discourse connectives given in Table 1 which are taken from the Potsdam Commentary Corpus [46], complemented with our own curated list of items.33 To extract the information from the dialogs, we use the VisArgue pipeline, a parsing pipeline that reliably annotates the spans triggered by discourse connectives and several rhetorical devices [2,12,15, for more details on the annotation of argumentative units and the performance of the system see Section 5.1].
Table 1
Discourse markers signaling argumentative units (alphabetically sorted)
| Type | Discourse markers |
| Causal | da ‘since/as’, denn ‘since/as’, weil ‘because’ |
| Consecutive | also ‘therefore’, dadurch ‘thus’, daher ‘hence’, darum ‘therefore’, deshalb ‘hence/therefore’, deswegen ‘therefore’, drum ‘therefore’ |
| Adversative | anstatt ‘instead of’, anderenfalls ‘otherwise’, andererseits ‘on the other hand’, einerseits ‘on the one hand’, hingegen ‘however’, jedoch ‘however’, sondern ‘but’, statt ‘instead of’, stattdessen ‘instead’, vielmehr ‘on the contrary’, wiederum ‘however’, zum einen ‘on the one hand’, zum anderen ‘on the other hand’ |
| Concessive | allerdings ‘however’, dennoch ‘nevertheless’, gleichwohl ‘nevertheless’, nichtsdestotrotz ‘nonetheless’, nichtsdestoweniger ‘nevertheless’, obschon ‘although’, obwohl ‘although’, trotzdem ‘nevertheless’, wenngleich ‘though’, wobei ‘whereas’, zwar ‘indeed’ |
| Conditional | falls ‘if’, ob ‘if’, sofern ‘as far as’, wenn ‘if’ |
The relative frequencies of argumentative units that contain one or more particles are shown in Table 2.44 Overall, Table 2 shows that particles are used frequently across corpora and across those discourse relations that signal argumentative structures: Conclusions rate highest, with particles contained in 32% to 46% of cases, followed by premises where particles occur in 28% to 40% of cases. Contrasts and conditions range in the middle, concessions contain the least number of particles (8% to 15% of cases).
Table 2
Relative frequencies of explicit argument relations containing discourse particles
| Premise | Conclusion | Contrast | Concession | Condition | |
| Stuttgart21 | 0.28 | 0.32 | 0.20 | 0.08 | 0.23 |
| Fracking | 0.39 | 0.46 | 0.30 | 0.10 | 0.34 |
| Africa | 0.40 | 0.43 | 0.23 | 0.15 | 0.29 |
In sum, the results indicate that particles are worth taking into account when mining arguments in German dialogs: They are frequently employed in natural language arguments and carry pragmatic information that conveys important information on how arguments and speakers relate to the discourse and frame their arguments. However, these particles are not the only means for pragmatically enriching and rhetorically packaging information, other devices for instance include the usage of pre-emptive arguments, assertions, typecasting, or metaphors ([43], inter alia). In order to situate discourse particles and their contribution in a larger framework of framing, the following section offers a categorization of the rhetorical effects of individual discourse particles and their combinations.
4.Categorization
Our long-term goal is to create a language-independent scheme of framing in natural language discourse. This paper concentrates on an integration of German discourse particles. Based on ongoing research in theoretical linguistics, we determine how to operationalize the current state of knowledge within theoretical linguistics. In this, we face two challenges: First, the chosen categories need to be general enough to allow for a meaningful comparison, but they also need to be fine-grained enough to allow for meaningful pragmatic interpretation. The second challenge resides in the nature of the discourse particles: The pragmatic information they carry is subtle and therefore hard to pin down. This is also due to the fact that the majority of them can be used as “regular” lexical items such as verbs or adverbs. In the following, we present the dimensions of framing we determined with respect to the set of discourse particles under investigation (Section 4.1). We then evaluate the classification via an inter-annotator agreement study (Section 4.2) before giving an overview of all particles and their rhetorical effects in Section 4.3.
4.1.Dimensions
Based on a comprehensive set of 27 German discourse particles (for an alphabetically-ordered list see Table 4 in Section 4.3), our classification proposes five major dimensions of rhetorical information triggered by discourse particles in the three German corpora discussed in Section 3 along with illustrative examples. Table 3 gives an overview of the classification.55
Table 3
Categorization of rhetorical information
| Dimension | Subdimension | Example |
| Common ground | Refer to cg | ja ‘yes’ |
| Reject cg | doch wohl ‘lit. indeed probably’ | |
| Update cg | doch mal ‘lit. indeed sometime’ | |
| Constraint | Immutable constraint | halt ‘stop’, eben ‘even’ |
| External constraint | mal ‘sometime’ | |
| Accommodation | Consensus | ja ‘yes’ |
| Consensus-willing | nicht wahr ‘lit. not true’ = ‘right’ | |
| Concession | immerhin ‘at least’ | |
| Question under discussion (qud) | Move to higher qud | überhaupt ‘lit. anyway’ |
| Move to other qud | eigentlich ‘actually’ | |
| Hedging | Attenuation | möglicherweise ‘possibly’ |
| Reinforcement | jedenfalls ‘anyway’ |
4.1.1.Common ground
The first dimension and one in which particles have lately been analyzed as triggering conventional implicatures (ci) is concerned with the Common Ground, i.e., the knowledge shared between the interlocutors. With respect to the discourse particle ja ‘yes’, [30,47,50–52, inter alia] show that it is used to refer to the Common Ground, i.e., the speaker wants the hearer to know that the utterance refers to content that was previously under discussion and had previously been accepted into the Common Ground. It is therefore a means for framing information as being considered to be uncontroversial at the time of the utterance [25]. This double-layeredness is shown in the conclusion featuring ja ‘yes’ in (6b): The speaker provides facts with the different tracks and their capacity in (6a), which lead to the conclusion that is in the Common Ground of the interlocutors (‘the through station can be built’). Here, ja ‘yes’ signals that the conclusion should be uncontroversial.

Other Common Ground particles, for instance doch mal ‘indeed’, frame an argument as indicating an update of the Common Ground. Here, the speaker deliberately puts information into the Common Ground of the hearers and expects it to be present in the continuing dialog, thereby extending the knowledge shared in the discussion. In (7b), the speaker updates the Common Ground of the hearer with the fact that the quality of traveling should be taken into account in the subsequent discussion about transfer times between trains.

Thirdly, the Common Ground can be rejected, i.e., information that is shared among a group of hearers is objected to explicitly by the speaker, i.e., the speaker expresses a different opinion than the other interlocutors. This rhetorical information is for instance triggered by the particle combination doch wohl ‘lit. indeed probably’, illustrated in (8b) with the context provided in (8a).66 
4.1.2.Constraint
This dimension subsumes a rhetorical contribution that conveys either an immutable or an external constraint. With respect to the former, for instance, triggered by halt ‘stop’, the speaker signals that an argument is based on a fact and is resignedly accepted as immutable, be it out of their own accord or imposed from outside. This is shown in (9), where the number of trains in the utterance in (9b) is being put forth as a fact that is indisputable.

In another example, for instance, triggered by mal ‘lit. sometime’, the speaker signals that they are subjected to an external constraint, either imposed by a hearer or by a fact under discussion. In (10b), the speaker concludes that the process will take four to five years, a circumstance based on the nature of the federal agency, an external factor (although theoretically, there is still a possibility that the process may take a shorter period of time). 
4.1.3.Accommodation
While full consensus is generally signaled by ja or jawohl ‘yes’, some particles have concessive meaning. Using for instance immerhin or zumindest ‘at least’, the speaker signals partial consent to information that was previously under discussion. This is illustrated in (11b), where the speaker argues for one feature of the train and although they are still skeptical regarding other features, they agree on one factor, namely the utility of the buffer times.

Another subdimension is termed ‘consensus-willing’ – here we consider particle instances which signal that the speaker wants to achieve a consensus between the interlocutors, without necessarily being successful. For instance, the multiword particle nicht wahr ‘lit. not true’ was used extensively in one of the corpora as a tag question to signal the overall aim of the speaker to come to an agreement, calling on the hearers to follow suit. An example is shown in (12b), with the context provided in (12a). 
4.1.4.Question under discussion
The dimension of the question under discussion (qud) is an area in pragmatics that has been vibrant for some time, with qud referring to the immediate topic of discussion [37]. The assumption is that a conversation addresses a number of (explicit or implicit) questions that concern sub-aspects of a higher-level question. The answers to these quds are part of the conversation. In German, a set of particles can serve as triggers that relate a proposition to the qud: For example, the particle überhaupt ‘lit. anyway’ signals a move to a higher-level qud [40], i.e., when a speaker wants to doubt the validity of a larger question in the discourse or wants to resolve it. An example is shown in (13b), with the context provided in (13a): The qud in (13a) is whether the train station can compete with the runway or not. The higher qud, mentioned earlier in the discussion and which the question in (13b) refers to, is whether one wants to compete with the runway at all. Using überhaupt ‘lit. anyway’ in (13b), the speaker moves to the higher-level qud and away from the lower-level qud in (13a).

In contrast, a particle such as eigentlich ‘actually’ signals a move to a different qud that is on the same level as the present qud in the immediate context. An example is shown in (14b), with the context provided in (14a): The qud in the first sentence is what facts are relevant for the terminal station. In (14b) the speaker signals the intention to get back to the qud about the terminal station, which was previously dealt with in the discourse and which is also part of the higher qud about which type of terminal is more effective. 
4.1.5.Hedging
Coined by [31], hedging is treated as a rhetorical strategy for avoiding commitment to an assumption or reducing the force and truth of an utterance. Despite hedging being mainly considered as a strategy to attenuate an utterance [5,6,13,35] which serves as an important face saving device for the speaker as well of the addressee, [4] also consider the reinforcement of a commitment as a type of hedging, i.e., the strengthening of facts or the confirmation of the commitment of the speaker. This type of hedging is considered as an attack on the addressee by imposing constraints on their actions. In this paper, we pursue an inclusive view of hedging where both dimensions, namely the attenuation and the reinforcement strategy, fall under the category of hedging. Regarding the former, however, we do not distinguish between further subtypes, as opposed to the theoretical literature. This keeps our dimensions clear-cut and usable from a computational perspective.
Example (15) illustrates the attenuating function of vielleicht ‘maybe’, which here reduces the commitment of the speaker to the utterance, i.e., to get the speaker to refer to the view of the population. In the Politeness Theory of [4], this type of attenuation is a quantity hedge that redresses the impact of a complaint or a request and allows both speaker and hearer to save their face in a discussion.

In contrast, the use of jedenfalls ‘in any case’ in (16) reinforces the speakers’ attitude against the statement of his interlocutor, i.e., that the problem was specific to the new train station. Using this reinforcement strategy, the speaker threatens the face of the interlocutors by openly challenging their views.

The following evaluation shows that our classification is indeed valid and that the discourse particles can be reliably annotated with the proposed dimensions.
4.2.Inter-annotator agreement
In order to evaluate our classification of rhetorical information, we conducted an experiment on the inter-annotator agreement, using the five highest-frequent particles. For the dimension ‘Common Ground’, we selected ja ‘yes’, for ‘Constraint’ we selected halt ‘stop’ and for ‘Consensus’ we used immerhin ‘at least’. We also included doch ‘yes’ as its pragmatic contribution varies with intonation (see Section 2), which was expected to create disambiguation problems for the annotators, as well as mal ‘sometime’ whose particle meaning can be hard to differentiate from its literal usages depending on the context. The task for the annotators was to differentiate the particle meaning from the literal meaning, and, in the case of ja ‘yes’ and doch ‘indeed’, pick the correct particle reading.
The data to be annotated consisted of a total of 100 sentences which were randomly chosen from the S21 corpus, each containing one of the five particles. The task for each of the four annotators (undergraduates of linguistics) was to assign one dimension to each of the sentences. Across all particles and all annotators, kappa was κ = 0.66 (“substantial agreement”). Filtering out the least accurate annotator (who turned out to be a non-native speaker of German) increased κ to κ = 0.85 (“almost perfect agreement”). A closer investigation of the results showed that doch ‘indeed’ was the most problematic particle due to the effects of the intonation on the pragmatic contribution. Here, the agreement between annotators was significantly lower, leading us to the decision that we would not include doch ‘indeed’ in our annotation pipeline. In all other cases, the annotators were able to assign the right annotations to the data, showing that the proposed classification scheme is systematic and well-defined.
4.3.Summary
Overall, the classification of the individual particles and the associated rhetorical information is a necessary first step in operationalizing the information for argumentation mining. Table 4 provides an alphabetical list of all 27 particles under investigation and their contribution to one of the five rhetorical dimensions.77 The categorization broadly reflects results in ongoing theoretical linguistic research in syntax, semantics, and pragmatics, but has been operationalized for our computational purposes, and offers a way for making these insights available to automatic processing. Almost all particles also have literal usages as verbs, adverbs or conjunctions etc., the list only provides their pragmatic contribution.88
Table 4
Alphabetical list of all particles and their contribution
| Particle | Contribution |
| aber ‘but’ | update cg |
| bloß ‘only’ | attenuation |
| denn ‘since’ | update cg |
| doch noch ‘lit. indeed still’ | reject cg |
| durchaus noch ‘lit. indeed still’ | reject cg |
| eben ‘even’ | immutable constraint |
| eigentlich ‘actually’ | move to higher qud |
| erst recht ‘all the more’ | reinforcement |
| gar nicht erst ‘lit. very not just’ | reinforcement |
| halt ‘stop’ | immutable constraint |
| immerhin ‘even so’ | concession |
| ja ‘yes’ | consensus/cg |
| ja doch ‘lit. yes indeed’ | reject cg |
| ja wohl ‘lit. yes probably’ | reject cg |
| jedenfalls ‘anyway’ | reinforcement |
| mal ‘sometime’ | external constraint |
| möglicherweise ‘possibly’ | attenuation |
| nicht wahr ‘lit. not true’ | consensus-willing |
| nun mal ‘now sometime’ | immutable constraint |
| ruhig ‘quiet’ | attenuation |
| schon ‘already’ | update cg |
| sehr wohl ‘very probably’ | reject cg |
| sogar ‘even’ | reinforcement |
| überhaupt ‘anyway’ | move to higher qud |
| vielleicht ‘maybe’ | attenuation |
| wahrscheinlich ‘probably’ | attenuation |
| wohl ‘probably’ | attenuation |
5.Fingerprinting rhetorical strategies
In this section, we take the operationalization of rhetorical information in Table 4 and use an interdisciplinary approach between computational linguistics and Information Visualization to shed light on rhetorical strategies in real, multi-party argumentation. For that, we automatically extract explicit arguments and the particles contained in them and represent the patterns via an interactive visual interface. This allows us to fingerprint argumentative strategies of individual interlocutors as well as whole speaker parties. In the following, we present the computational linguistic component of the system (Section 5.1) and our method for Information Visualization (Section 5.2). We conclude the section with a case study on the strategies pursued in the S21 corpus (Section 5.3).
5.1.Computational linguistic analysis
Due to the fact that we deal with noisy transcribed natural speech, our computational processing pipeline has to be designed in a specific way, with the overall aim of providing a high-quality and linguistically-motivated annotation of argumentative units and the rhetorical information contributed by the set of discourse particles under investigation. For this, we devise our own set of hand-crafted rules that deal with the identification and disambiguation of explicit linguistic markers and the annotation of spans and relations in the text [12].
Preprocessing. In a preprocessing step, we divide all speaker turns into sentences and then discourse units in order to work with a more fine-grained structure of the text. Although there is no consensus in the literature on what exactly discourse units have to comprise, it is generally assumed that each describes a single event [34]. We approximate the assumption made by [34] by inserting a boundary at every punctuation mark and every clausal connector (conjunctions, complementizers). Following [8], we term these units elementary discourse units (edus). The annotation is performed on the level of these edus, therefore relations that span multiple units are marked individually at each unit. Due to the type of data, we are not able to use an off the shelf parser for German. For instance, an initial experiment using the German Stanford Dependency parser [36] showed that 60% of parses are incorrect due to filled pauses (‘hm’, ‘ah’), reduplications, interruptions, speech repairs and multiple embeddings. We therefore only use the morphological and pos information from dmor [41].
Disambiguation. Based on this preprocessing, we devise rules for the disambiguation and annotation of linguistic cues. With respect to argumentative units (premises, conclusions, contrasts, concessions, conditions and consequences), we rely on the discourse markers in Table 1. For the annotation of rhetorical information, we use the operationalization in Table 4. The pipeline also takes into account information coming from other linguistic cues such as speech acts (verbs of agreement, disagreement, arguing, bargaining and information giving/seeking/refusing), event modality (modal verbs and adverbs signaling obligation, permission, volition, reluctance or alternative) or epistemic modality (modal expressions conveying certainty, probability, possibility and impossibility).
Due to the fact that many of the linguistic markers are ambiguous, we propose a set of rules built on heuristics, which take into account a number of factors in the clause in order to perform disambiguation. Important features include the position in the clause (for instance for discourse markers which can be signalers of argumentative units at the beginning of an edu, but not at the end, and vice versa) or the pos of other lexical items in the surrounding context. For instance, causal markers like da, denn, darum and daher ‘because/thus’ have a number of different senses and the results of [9] indicate that pos tagging alone does not help in disambiguating the causal usages from the other functions, particularly not for our data type which includes much noise and exceptional constructions that are not present in written corpora. We, therefore, devise our own set of rules. To illustrate the underlying procedure for disambiguation in the VisArgue pipeline, (17) schematizes part of the disambiguation rule for the German causal connector da ‘since’, taken from [2]. Overall, the pipeline features 20 disambiguation rules.

Annotation. After disambiguation is complete, a second set of rules annotates the spans and the relations that the lexical items trigger. We only analyze units within a single utterance of a speaker, i.e., spans of text that are expressed in a sequence of clauses which a speaker utters without interference from another speaker. As a consequence, the annotation system does not take into account argumentative and rhetorical units that are split up between utterances of one speaker or utterances of different speakers. Nevertheless, they can extend over multiple edus/sentences. This means that not only units which contain a discourse connector are annotated, for instance the premise and conclusion of a causal marker, but preceding/following units that are part of the causal relation also have to be marked. This involves deep linguistic knowledge about the cues that delimit or license relations, information which is encoded in a set of heuristics that feed the annotation rules and mark the relevant units. An example for a (simplified) argumentative unit annotation is given in (18).

The rhetorical information of the particles is annotated in a similar style, although in this case we only mark those discourse units with the pragmatic information which contain the particle.
Evaluation. In order to evaluate the performance of the VisArgue pipeline, we use the Stuttgart 21 corpus as the development set and the Africa corpus as a test set. As shown in [2] for causal markers, we extracted 60 utterances with an average length of 71 words from the Africa corpus, each containing at least two causal markers. For the creation of the gold standard, this test set was annotated by two linguistic experts. We then evaluated the system against this test set. For evaluating the annotation of the rhetorical information from the discourse particles, we randomly extracted 55 sentences from the Africa corpus with an average sentence length of 27 tokens. Each sentence contained at least one particle. Again, two linguistic experts created a gold standard which we use for comparison with the results of the VisArgue pipeline. The results of the evaluation in Table 5 show that the annotation system allows for a consistent and correct disambiguation and annotation of the different particle usages.
Table 5
Evaluation of performance against gold standard from the Africa corpus
| Precision | Recall | F-score | |
| Causal markers | 0.84 | 0.84 | 0.84 |
| Particles | 0.98 | 0.95 | 0.97 |
With the VisArgue pipeline providing us with a high-quality, linguistically motivated annotation of argumentative units and rhetorical information, we create the basis for looking at the framing of arguments in large amounts of data. Using an innovative approach by employing a method from Information Visualization, we now visually encode the patterns and thereby pave the way for the analysis of framing strategies in multi-party, natural language argumentation.
5.2.Information visualization
In the research fields of Information Visualization and Visual Analytics, as described by [26], the main objective is to tightly integrate visual and automatic data analysis methods for information exploration and scalable decision support. This allows an analyst to identify interesting patterns and to detect anomalies in the data. Through interacting with the visualization, the user then continues the investigation process by getting details on demand, such as the values of a visual parameter or the actual underlying data. Especially when designing visualizations based on textual data, such detail views are essential to allow close-reading [23] and hypothesis verification. In the present paper, we rely on a Visual Analytics approach to analyze the outcome of the VisArgue processing pipeline, with the design of the visualization tailored to the task of shedding light on rhetorical strategies in multi-party discourse.
For this enterprise, we propose a visual, glyph-based fingerprint of utterances based on the operationalization of discourse particles described in Table 3 and the different types of argumentative units. Every glyph consists of two components, a star-coordinate plot as the central component and a high-level feature fingerprint as a controller (bar with colored dimensions on the bottom), as shown in Fig. 1. Star-coordinate plots [3] are a visualization technique that is widely used for comparing different manifestations of the same attribute dimensions in comparable datasets. They rely on the intuition of the human distinction of shapes. By mapping the normalized value of a particular attribute on the polar coordinates and connecting neighboring points, a shape is generated. This shape can then be used to visually compare the characteristics of the different glyphs. In our case, the glyphs encode sets of utterances, dynamically computed based on the underlying data and normalized according to the division of the utterances in mutually exclusive sets. For example, one glyph can represent a single utterance of one speaker, but it can also be chosen to represent an aggregate of all utterances belonging to the same topic or to the same speaker (for the latter see Fig. 2).
Fig. 1.
Glyph design.
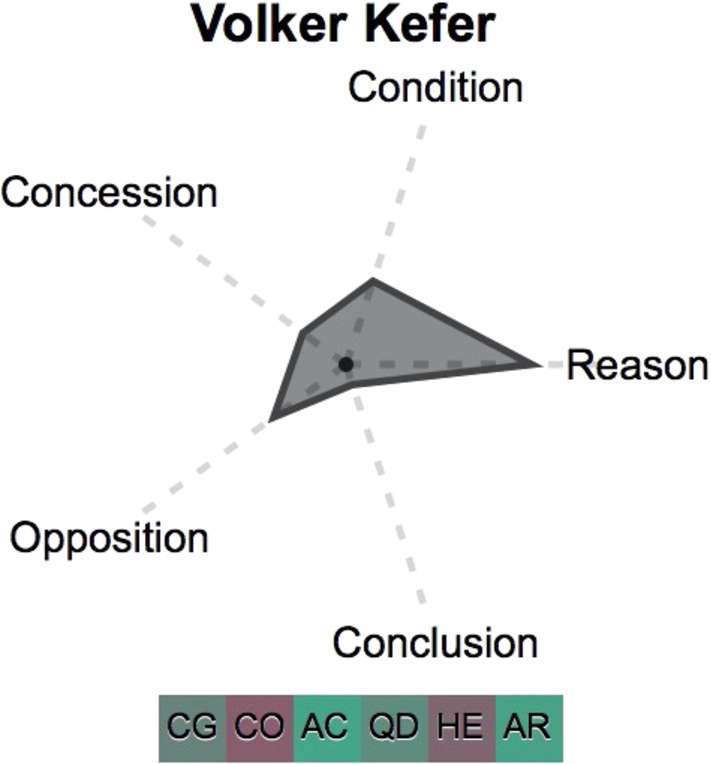
Fig. 2.
Overview of individual speaker glyphs sorted according to the number of utterances.

The controller maps the aggregated value of the six high-level dimensions (the five rhetorical dimensions determined by the particles plus one argumentation dimension) using the pixel icons  . The dimensions are abbreviated to ensure their recognition and are ordered as follows:
. The dimensions are abbreviated to ensure their recognition and are ordered as follows:  Common Ground,
Common Ground,  Constraint,
Constraint,  Accommodation,
Accommodation,  Question under Discussion,
Question under Discussion,  Hedging, and
Hedging, and  Argumentation. The aggregated average values for every dimension are normalized and mapped to a bi-polar colormap going from magenta over black to cyan, representing the values from
Argumentation. The aggregated average values for every dimension are normalized and mapped to a bi-polar colormap going from magenta over black to cyan, representing the values from  to
to
In our glyph design, we map the subdimension (of the selected dimension from the controller) to the coordinates and highlight the concrete values when hovering over a dimension. For instance, in Figs. 1 and 2 the selected dimension is Argumentation and all five of its subdimensions (Reason, Conclusion, Opposition, Concession, Condition) are shown in the central plot. The dimensions are ordered according to their mutual correlation score, starting with the most frequent feature. Additionally, the color of the shape of the central plot encodes the concatenated length of the represented utterances, mapping larger values to a darker color. In order to get a first overview of the different argumentation patterns in the S21 corpus, Fig. 2 gives an overview of the aggregated individual speaker glyphs (one glyph for all utterances of one speaker) for the 24 speakers with the largest number of utterances, starting with Heiner Geißler (top left) with 2279 utterances and ending with Josef-Walter Kirchberg (bottom right) with 31 utterances.
5.3.Case study
The data underlying the case study is the corpus of the S21 mediation (described in further detail in Section 3). The case study is comprised of two parts and decreases in the level of aggregation: First, we investigate the framing strategies of the different parties in the mediation, namely proponents, opponents, experts and the mediator (Section 5.3.1). We then explore the strategies of individual speakers (Section 5.3.2). This investigation of the data allows for a higher-level analysis of framing strategies as well as an exploration of individual speaker behavior.
5.3.1.Group strategies
Figure 3 shows the aggregated glyphs of the four parties in the mediation, namely the mediator (neutral), the group of proponents for the through station (pro), the group of opponents (contra) and the consultants (expert). All utterances by all speakers of one party are aggregated to one glyph.
Fig. 3.
Glyphs aggregated for speaker positions.
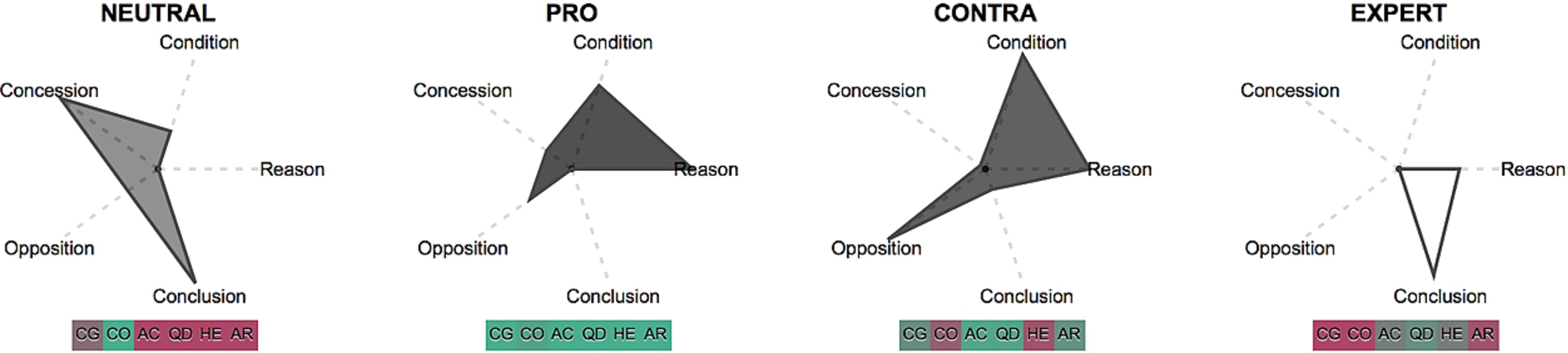
Overall, the pro and contra party have the longest utterances in the corpus, followed by the mediator (neutral) and the experts (expert). Concerning the argumentative patterns, the neutral glyph of the mediator (leftmost glyph in Fig. 3) shows that he has a low degree of argumentation in comparison to the other parties  , those argumentative units that he contributes are, in a decreasing order, concluding, concessive and conditional. His framing strategy is characterized by a high degree of mentioning constraints
, those argumentative units that he contributes are, in a decreasing order, concluding, concessive and conditional. His framing strategy is characterized by a high degree of mentioning constraints  and a low degree of hedging, accommodation and referring to the question under discussion
and a low degree of hedging, accommodation and referring to the question under discussion  . Together with the argumentative patterns, these results are verified by looking into the actual data and the role the mediator plays in the debate: He draws conclusions from the information that is provided in the ongoing discourse and uses concessive statements to bring the conflicting parties together. He brings his points across in a straightforward manner (low degree of hedging) and by explicitly mentioning the circumstances that influence the decision-making process (high degree of constraint mentioning).
. Together with the argumentative patterns, these results are verified by looking into the actual data and the role the mediator plays in the debate: He draws conclusions from the information that is provided in the ongoing discourse and uses concessive statements to bring the conflicting parties together. He brings his points across in a straightforward manner (low degree of hedging) and by explicitly mentioning the circumstances that influence the decision-making process (high degree of constraint mentioning).
The glyphs for the proponents (pro) and the opponents (contra) (two middle glyphs in Fig. 3) exhibit a very different pattern: Both sides have a comparatively high amount of argumentation ( and
and  , respectively) and most frequently use reasons in their argumentation. The pro glyphs show a moderate degree of conditions, oppositions and concessions, whereas the opponents (contra) use a high degree of opposing arguments and conditions. Concerning the rhetoric devices, the pro side uses more of them, in particular with respect to hedging and referring to constraints (see pro’s
, respectively) and most frequently use reasons in their argumentation. The pro glyphs show a moderate degree of conditions, oppositions and concessions, whereas the opponents (contra) use a high degree of opposing arguments and conditions. Concerning the rhetoric devices, the pro side uses more of them, in particular with respect to hedging and referring to constraints (see pro’s  and
and  versus contra’s
versus contra’s  and
and  ). However, both sides show a high degree of referring to the question under discussion and a moderate degree of mentioning the Common Ground between the discussion partners (pro’s
). However, both sides show a high degree of referring to the question under discussion and a moderate degree of mentioning the Common Ground between the discussion partners (pro’s  versus contra’s
versus contra’s  ). Taken together, the results for both parties can be explained based on their role in the mediation: Their high degree of argumentation is expected as both parties want to convince the other side. The strategy of the proponents is to make many concessive statements, attenuating their utterances and referring to constraints, whereas the contra side exhibits a high level of opposing argumentation without attenuation. Nevertheless, both parties refer to the questions under discussion and the knowledge shared between discussion partners. In sum, the opposing parties employ rhetorical strategies that are diametrically opposed to the strategy of the mediator – as expected in this type of dialog.
). Taken together, the results for both parties can be explained based on their role in the mediation: Their high degree of argumentation is expected as both parties want to convince the other side. The strategy of the proponents is to make many concessive statements, attenuating their utterances and referring to constraints, whereas the contra side exhibits a high level of opposing argumentation without attenuation. Nevertheless, both parties refer to the questions under discussion and the knowledge shared between discussion partners. In sum, the opposing parties employ rhetorical strategies that are diametrically opposed to the strategy of the mediator – as expected in this type of dialog.
With respect to the expert group (rightmost glyph in Fig. 3), the following patterns emerge: Their degree of argumentation  lies below the one of the opposing parties, but still above the level of the mediator. The glyph shows a clear focus on reason- and conclusion-giving, rhetorically characterized by making reference to the question under discussion
lies below the one of the opposing parties, but still above the level of the mediator. The glyph shows a clear focus on reason- and conclusion-giving, rhetorically characterized by making reference to the question under discussion  , but not employing a strategy of mentioning constraints and the knowledge shared between discussion partners
, but not employing a strategy of mentioning constraints and the knowledge shared between discussion partners  . Their use of hedging and accommodation lies below those of the opposing parties (
. Their use of hedging and accommodation lies below those of the opposing parties ( and
and  , respectively). In sum, the experts use the strategy of providing information rather than arguing for or against a point, with a rhetorical focus on staying factive (no hedging) and to the point (referring to the question under discussion). This strategy differs to those of the other parties and can be explained by their function in the mediation.
, respectively). In sum, the experts use the strategy of providing information rather than arguing for or against a point, with a rhetorical focus on staying factive (no hedging) and to the point (referring to the question under discussion). This strategy differs to those of the other parties and can be explained by their function in the mediation.
In the following, we will explore the framing strategies of individual speakers and compare them to the group strategies discussed above.
5.3.2.Individual speaker strategies
In order to have a meaningful comparison, we look more closely at two speakers in the S21 mediation who both have a high amount of contributions and come from the opposing parties. In particular, we investigate the strategies of Volker Kefer from the proponents (pro) and Boris Palmer from the opponents (contra) (replicated below in Fig. 4 from the overview in Fig. 2).
Fig. 4.
Individual speaker glyphs for Volker Kefer (pro) (left) and Boris Palmer (contra) (right).
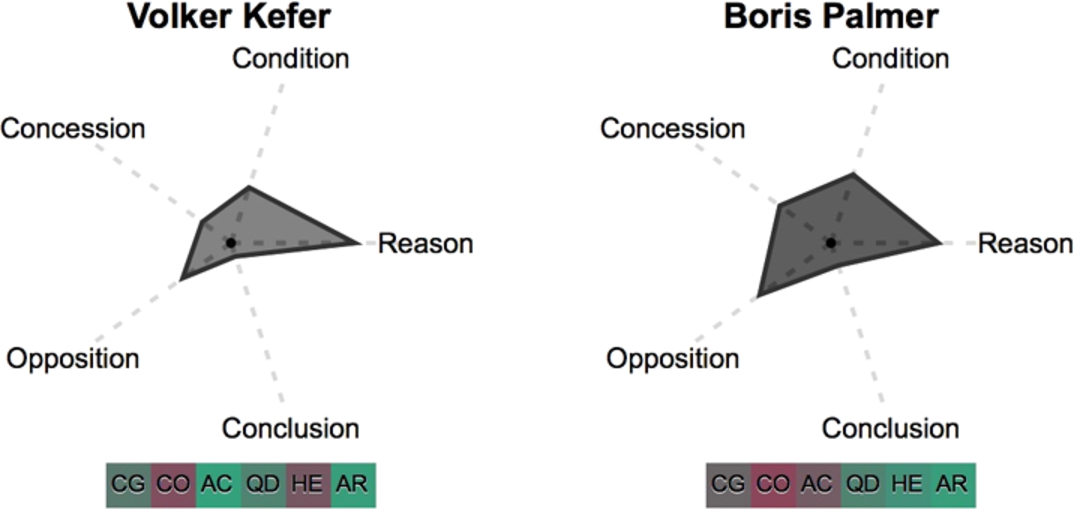
In comparison to the aggregated pro glyph in Fig. 3, the individual speaker glyph of Volker Kefer shows that he follows the argumentative strategy of the overall proponent party: He has a high level of argumentation  , mostly reason-giving, followed by conditions, oppositions and concessions (in descending order). However, his framing strategy differs with respect to the strategy of his group: Whereas the proponents are overall characterized as heavily drawing on rhetorical devices, Volker Kefer acts differently, in particular with respect to hedges and references to constraints (see pros
, mostly reason-giving, followed by conditions, oppositions and concessions (in descending order). However, his framing strategy differs with respect to the strategy of his group: Whereas the proponents are overall characterized as heavily drawing on rhetorical devices, Volker Kefer acts differently, in particular with respect to hedges and references to constraints (see pros  versus Kefer’s
versus Kefer’s  ). His degree of mentioning the Common Ground and the question under discussion is also lower than that of the proponents in general (pro:
). His degree of mentioning the Common Ground and the question under discussion is also lower than that of the proponents in general (pro:  , Kefer:
, Kefer:  ). Only his level of accommodation devices is comparable with that of the group (pro:
). Only his level of accommodation devices is comparable with that of the group (pro:  , Kefer:
, Kefer:  ).
).
Looking at the glyph of Boris Palmer (contra) on the right-hand side of Fig. 4 we see that he has longer utterances than Volker Kefer, represented by the darker color of the plot. His argumentation resembles the one of Volker Kefer with a comparatively high degree of argumentation overall  and a focus on reason-giving. However, he uses more oppositions, conditions and concessions than Kefer. Rhetorically, he differs from Volker Kefer in that he has a higher level of hedging (Palmer:
and a focus on reason-giving. However, he uses more oppositions, conditions and concessions than Kefer. Rhetorically, he differs from Volker Kefer in that he has a higher level of hedging (Palmer:  , Kefer:
, Kefer:  ) and a lower level of accommodation (Palmer:
) and a lower level of accommodation (Palmer:  , Kefer:
, Kefer:  ). Both speakers have a moderate level of referring to the question under discussion (Palmer:
). Both speakers have a moderate level of referring to the question under discussion (Palmer:  , Kefer:
, Kefer:  ). When comparing Boris Palmer with his party (contra), his argumentative strategy is different in that he has a higher level of concession-making and a lower level of opposing arguments. On the framing level, he has in common that he does not use a high level of reference to constraints (Palmer:
). When comparing Boris Palmer with his party (contra), his argumentative strategy is different in that he has a higher level of concession-making and a lower level of opposing arguments. On the framing level, he has in common that he does not use a high level of reference to constraints (Palmer:  , contra:
, contra:  ). In contrast to his party, he intensely uses hedging as a framing strategy (Palmer:
). In contrast to his party, he intensely uses hedging as a framing strategy (Palmer:  , contra:
, contra:  ), despite not making many accommodation efforts (Palmer:
), despite not making many accommodation efforts (Palmer:  , contra:
, contra:  ).
).
Overall, we can conclude that the two speakers show striking commonalities with respect to their argumentative patterns, despite using different particles to frame their points. The comparison of the individual strategies with those of the overall parties shows that the speakers are representative of their party in some aspects of the argumentation, but should not be treated as prototypical representatives.
6.Discussion and conclusion
In analyzing the rhetorical strategies with which speakers and groups put forth their arguments in the Stuttgart 21 mediation corpus, we use an innovative interdisciplinary approach that combines theoretical linguistic insights with argument computation and Information Visualization. Based on results of ongoing work in the fields of semantics and pragmatics, we arrive at a workable classification of rhetorical information triggered by a comprehensive set of 27 discourse particles in German. This classification can be used for the computational analysis of the framing of argumentation in multi-party natural language discourse. Our novel interactive visualization interface shows at a glance that speakers and speaker parties use different framing strategies to bring forth their arguments – a method for analysis that offers a potential for interpreting a range of layers of information relevant in natural language argumentation.
We put our focus on particles because we believe they are a good test case for investigating framing strategies: (1) they are frequent in natural language arguments and (2) offer information on the if and how of relations between propositions and more abstract notions: For instance, they allow us to tie arguments to the Common Ground of the dialog participants, i.e., the knowledge shared between discussion partners. Using the pragmatic information contributed by the particle, we cannot only connect individual propositions (or arguments), we can also relate them to a larger set of propositions that constitute the Common Ground, as well as determine the type of the relation. For instance, if a premise contains a reference to the Common Ground, the speaker indicates that they base their conclusion on information that they believe is known among the debate participants. Conversely, if the conclusion implies a rejection of the Common Ground, the speaker signals that the inference rejects information that is known among the participants. For argument mining, this information yields more detailed insights into how dialogs differ in the way participants relate their arguments and themselves to the shared knowledge of the discussion – enriching the relations between arguments and the propositions that constitute them. We can hereby complement other work in argumentation mining that takes into account pragmatic information, for instance, based on speech act theory [44]. This complementation also opens up the possibility of devising a new set of argumentation schemes based on the notion of the Common Ground, complementing those previously proposed by [27,49] and many others.
Regarding our dimensions of constraint and consensus, the discourse particles that instantiate these dimensions rather offer information on the intention of the speaker and the stance/attitude of the speaker towards the current utterance and the arguments put forward previously. For instance, if an immutable constraint particle is used in a premise, the speaker implies that the conclusion results from a constraint that cannot be avoided. Speakers can indicate that they are willing to make concessions or are seeking consensus, they can also use them to strengthen the force of their argument by invoking the idea of an immutable constraint that is governing their argumentation. With respect to hedging, those particles serve an important function of saving one’s own or the interlocutor’s face by attenuating the force or truth of an argument. The reinforcing particles make an argument stronger in that the interlocutors have less room for conversational maneuvering, a strategy that can help pushing through the speaker’s own agenda.
From the point of information visualization, the challenge lies in representing the complexity of the interaction between the different levels that shape argumentation. In the glyph visualization proposed in this paper, we only deal with two levels of analysis, argumentation, and framing. But even with the current design and the possibilities for interaction, namely the different levels of aggregation, the party- and speaker-aggregated glyphs offer interesting insights into the rhetorical aspects of real, natural language argumentation in German.
Overall, this type of work shows that investigating the linguistic properties of argumentation more closely has direct benefits for argumentation computation and analysis. But the paper also shows that a range of avenues remains for further work: Besides discourse particles, natural language contains a variety of further strategies for structuring the discourse and for expressing pragmatic information that contributes to rhetorical structuring. Prominent examples are tag questions and rhetorical questions – linguistic phenomena that are found across languages and are well-known means to structure a discourse. Investigating rhetorical structuring on a larger scale will, therefore, have benefits for argumentation mining as well as discourse processing in general. Given the vibrant field of Visual Analytics in linguistics [15,16,19,20,33,38,39], this area will come up with new ways of presenting a more holistic view of single arguments as well as the process of argumentation in large amounts of high-dimensional data. Taken together, we arrive at a much richer and more detailed interpretation of the discourse and the web of information that comprises natural language argumentation.
Notes
1 Until October 2014 the transcripts were publicly available for download at http://stuttgart21.wikiwam.de/Schlichtungsprotokolle. A new, edited version of the minutes can be found here: http://www.schlichtung-s21.de/dokumente.html. For the annotated unofficial transcripts, please contact the corresponding author.
2 These experimentally controlled discussions were done as part of our eHumanities VisArgue project, which represented a collaboration between computer science, linguistics and political science at the University of Konstanz. The experiments were conducted by our political science partners.
3 We refrain from annotating aber ‘but’, a highly frequent discourse connector, due to its ambiguity between signaling contrast and concession.
4 The total number of discourse relations ranges from 107 concessions in the Fracking corpus to 3075 conclusions in the S21 corpus (across corpora, mean: 1746, median: 1798).
5 All examples in this section come from the S21 mediation corpus.
6 The particle doch ‘indeed’ by itself is actually ambiguous between rejection and activation of Common Ground, see [52] for more discussion.
7 One reviewer notes that the particle aber ‘but’ can also have concessive meaning in some contexts. While this is clearly the case with conjunctive uses of aber ‘but’, we did not find these uses in our corpora. Artificial examples suggest that there is a shade of surprise in using aber ‘but’ as a particle, but we still treat it as contradicting a previous point and updating the Common Ground of the interlocutors.
8 The particle denn ‘since’ is also an interrogative particle, its syntactic and semantic properties for instance discussed in [1]. We only consider the modal particle usage here.
Acknowledgements
The research carried out in this paper was supported by the Bundesministerium für Bildung und Forschung (BMBF) under grant no. 01461246 (eHumanities VisArgue project).
References
[1] | J. Bayer, From modal particle to interrogative marker: A study of German denn, in: Functional Heads, L. Brugè, A. Cardinaletti, G. Giusti, N. Munaro and C. Poletto, eds, Oxford University Press, Oxford, (2012) , pp. 13–28. doi:10.1093/acprof:oso/9780199746736.003.0001. |
[2] | T. Bögel, A. Hautli-Janisz, S. Sulger and M. Butt, Automatic detection of causal relations in German multilogs, in: Proceedings of the EACL 2014 Workshop on Computational Approaches to Causality in Language (CAtoCL), Association for Computational Linguistics, Gothenburg, Sweden, (2014) , pp. 20–27. URL http://www.aclweb.org/anthology/W14-0703. doi:10.3115/v1/W14-0703. |
[3] | R. Borgo, J. Kehrer, D.H. Chung, E. Maguire, R.S. Laramee, H. Hauser, M. Ward and M. Chen, Glyph-based visualization: Foundations, design guidelines, techniques and applications, Eurographics State of the Art Reports (2013), 39–63. URL https://www.cg.tuwien.ac.at/research/publications/2013/borgo-2013-gly/. |
[4] | P. Brown and S.C. Levinson, Politeness. Some Universals in Language Usage, Cambridge University Press, Cambridge, (1978) . |
[5] | C. Caffi, On mitigation, Journal of Pragmatics 31: ((1999) ), 881–900. doi:10.1016/S0378-2166(98)00098-8. |
[6] | C. Caffi, Mitigation, Elsevier, Amsterdam, (2007) . |
[7] | M. Coniglio, Die Syntax der Deutschen Modalpartikeln: Ihre Distribution und Lizenzierung in Haupt- und Nebensätzen, Akademie Verlag, Berlin, (2011) . |
[8] | D. Marcu, The Theory and Practice of Discourse Parsing and Summarization, MIT Press, Cambridge, MA, (2000) . |
[9] | S. Dipper and M. Stede, Disambiguating potential connectives, in: Proceedings of KONVENS’06 (Conference on Natural Language Processing), Konstanz, (2006) , pp. 167–173. |
[10] | M. Doherty, Epistemische Bedeutung, Studia Grammatica, Vol. 23: , Akademie Verlag, Berlin, (1985) . |
[11] | M. Egg, A unified account of the semantics of discourse particles, in: Proceedings of SIGDIAL 2010, (2010) , pp. 132–138. |
[12] | M. El-Assady, A. Hautli-Janisz, V. Gold, M. Butt, K. Holzinger and D. Keim, Interactive visual analysis of transcribed multi-party discourse, in: Proceedings of ACL 2017 (Demo paper), Association for Computational Linguistics, August accepted. |
[13] | B. Fraser, Hedged performatives, in: Sytax and Semantics, P. Cole and J.L. Morgan, eds, Speech Acts, Vol. 3: , Academic Press, New York, (1975) , pp. 187–210. |
[14] | H.-M. Gärtner, Root infinitivals and modal particles. An interim report, in: Discourse Particles: Formal Approaches to Their Syntax and Semantics, J. Bayer and V. Struckmeier, eds, Mouton de Gruyter, Berlin/Boston, (2017) , pp. 115–143. |
[15] | V. Gold, M. El-Assady, T. Bögel, C. Rohrdantz, M. Butt, K. Holzinger and D. Keim, Visual linguistic analysis of political discussions: Measuring deliberative quality, Digital Scholarship in the Humanities 32: (1) ((2017) ), 141–158. doi:10.1093/llc/fqv033. |
[16] | V. Gold, C. Rohrdantz and M. El-Assady, Exploratory text analysis using lexical episode plots, in: Eurographics Conference on Visualization (EuroVis) – Short Papers, E. Bertini, J. Kennedy and E. Puppo, eds, The Eurographics Association, (2015) . doi:10.2312/eurovisshort.20151130. |
[17] | C. Gunglogson, Declarative questions, in: Proceedings from Semantics and Linguistic Theory (SALT XII), Cornell University, Ithaca, NY, (2002) , pp. 124–143. |
[18] | D. Gutzmann, Betonte Modalpartikeln und Verumfokus, in: 40 Jahre Partikelforschung, E. Heuschel and T. Harden, eds, Stauffenberg, Tübingen, (2010) , pp. 119–138. |
[19] | A. Hautli-Janisz and V. Lyding (eds), Proceedings of VisLR: Visualization as Added Value in the Development, Use and Evaluation of Language Resources (LREC’14), (2014) . |
[20] | A. Hautli-Janisz and V. Lyding (eds), Proceedings of VisLR: Visualization as Added Value in the Development, Use and Evaluation of Language Resources (LREC’16), (2016) . |
[21] | J. Jacobs, Fokus und Skalen: Zur Syntax und Semantik der Gradpartikeln im Deutschen, Niemeyer, Tübingen, (1983) . |
[22] | J. Jacobs, On the semantics of modal particles, in: Discourse Particles, W. Abraham, ed., Benjamins, Amsterdam, (1991) , pp. 141–162. doi:10.1075/pbns.12.06jac. |
[23] | S. Jänicke, G. Franzini, M.F. Cheema and G. Scheuermann, On close and distant reading in digital humanities: A survey and future challenges, in: Proc. of EuroVis – STARs, (2015) , pp. 83–103. |
[24] | E. Karagjosova, Modal Particles and the Common Ground: Meaning and Functions of German ja, doch, eben/halt and auch, in: Perspectives on Dialogue in the New Millennium, Vol. 114: , P. Kühnlein, H. Rieser and H. Zeevat, eds, John Benjamins, Amsterdam, (2003) , pp. 335–349. doi:10.1075/pbns.114.19kar. |
[25] | E. Karagjosova, The Meaning and Function of German Modal Particles, PhD thesis, Universität des Saarlandes, 2004. |
[26] | D.A. Keim, F. Mansmann, A. Stoffel and H. Ziegler, Visual analytics, in: Encyclopedia of Database Systems, Springer, (2009) . |
[27] | M. Kienpointner, Alltagslogik: Struktur und Funktion Von Argumentationsmustern, Fromman-Holzboog, Stuttgart, (1992) . |
[28] | E. König, Zur Bedeutung von Modalpartikeln im Deutschen: Ein Neuansatz im Rahmen der Relevanztheorie, Germanistische Linguistik 136: ((1997) ), 57–75. |
[29] | A. Kratzer, Beyond “oops” and “ouch”: How descriptive and expressive meaning interact, in: Cornell Conference on Theories of Context Dependency, Vol. 26: , (1999) . |
[30] | A. Kratzer and L. Matthewson, Anatomy of two discourse particles, Handout, SULA 5 (2009). |
[31] | G. Lakoff, Hedges: A study in meaning criteria and the logic of fuzzy concepts, Journal of Philosophical Logic 2: ((1973) ), 458–508. |
[32] | K. Lindner, ‘Wir sind ja doch alte Bekannte’ – the use of German ja and doch as modal particles, in: Discourse Particles: Descriptive and Theoretical Investigations on the Logical, Syntactic and Pragmatic Properties of Discourse Particles in German, Vol. 12: , W. Abraham, ed., John Benjamins, Amsterdam, (1991) , pp. 163–201. doi:10.1075/pbns.12.07lin. |
[33] | T. Mayer and C. Rohrdantz, PhonMatrix: Visualizing co-occurrence constraints in sounds, in: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics: System Demonstrations, (2013) , pp. 73–78. |
[34] | L. Polanyi, C. Culy, M. van den Berg, G.L. Thione and D. Ahn, Sentential structure and discourse parsing, in: Proceedings of the 2004 ACL Workshop on Discourse Annotation, (2004) , pp. 80–87. doi:10.3115/1608938.1608949. |
[35] | E.F. Prince, J. Frader and C. Bosk, On hedging in physician-physician discourse, in: Linguistics and the Professions: Proceedings of the Second Annual Delaware Symposium on Language Studies, R.J. Di Pietro, ed., Ablex, Norwood, NJ, (1982) , pp. 83–97. |
[36] | A.N. Rafferty and C.D. Manning, Parsing three German treebanks: Lexicalized and unlexicalized baselines, in: Proceedings of the ACL’08 Workshop on Parsing German, (2008) , pp. 40–46. doi:10.3115/1621401.1621407. |
[37] | C. Roberts, Information sructure in discourse: Towards an integrated formal theory of pragmatics, Semantics & Pragmatics 5: ((2012) ), Article no. 6. doi:10.3765/sp.5.6. |
[38] | C. Rohrdantz, A. Hautli, T. Mayer, M. Butt, D.A. Keim and F. Plank, Towards tracking semantic change by visual analytics, in: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-HLT’11): Short papers, Vol. 2: , Association for Computational Linguistics, Portland, Oregon, (2011) , pp. 305–310. |
[39] | C. Rohrdantz, A. Niekler, A. Hautli, M. Butt and D. Keim, Lexical semantics and distribution of suffixes – A visual analysis, in: Proceedings of the EACL 2012 Joint Workshop of LINGVIS and UNCLH, (2012) , pp. 7–15. |
[40] | T. Rojas-Esponda, A discourse model for überhaupt, Semantics and Pragmatics 7: (1) ((2014) ), 1–45. |
[41] | A. Schiller, Dmor – User’s guide, Technical report, Universität Stuttgart, Institut für maschinelle Sprachverarbeitung, 1994. |
[42] | L. Schourup, Common Discourse Particles, Garland, New York, (1991) . |
[43] | B. Scott, Framing an argument, Technical report, DiploFoundation, 2013. |
[44] | J. Searle and D. Vanderveken, Foundations of Illocutionary Logic, Cambridge University Press, Cambridge, (1985) . |
[45] | R. Stalnaker, Common ground, Linguistics and Philosophy 25: (5) ((2002) ), 701–721. doi:10.1023/A:1020867916902. |
[46] | M. Stede and A. Neumann, Potsdam commentary corpus 2.0: Annotation for discourse research, in: Proceedings of LREC 2014, (2014) , pp. 925–929. |
[47] | Y. Viesel, Discourse structure and syntactic embedding: The German discourse particle ‘ja’, in: Proceedings of the 20th Amsterdam Colloquium, F. Roelofson, T. Brochhagen and N. Theiler, eds, (2015) , pp. 418–428. |
[48] | G. von der Gabelentz, Die Sprachwissenschaft, ihre Aufgaben und Methoden, Narr, Tübingen, (1891) . |
[49] | D.N. Walton, Argumentation Schemes for Presumptive Reasoning, Lawrence Erlbaum Associates, Mahwah, NJ, (1996) . |
[50] | H. Zeevat, Particles: Presupposition triggers, contet markers or speech act markers, in: Optimality Theory and Pragmatics, R. Blutner and H. Zeevat, eds, Palgrave Macmillan, Basingstoke, (2004) , pp. 91–111. doi:10.1057/9780230501409. |
[51] | M. Zimmermann, Discourse particles, in: Semantics. (= Handbücher zur Sprach- und Kommunikationswissenschaft HSK 33.2), Vol. 2: , K. von Heusinger, C. Maienborn and P. Portner, eds, De Gruyter, Berlin, (2011) , pp. 2011–2038. |
[52] | M.-M. Zymla, M. Müller and M. Butt, Modeling the common ground for discourse particles, in: The 20th International Lexical Functional Grammar Conference (LFG15), M. Butt and T.H. King, eds, CSLI Publications, Stanford, (2015) , pp. 420–440. URL http://nbn-resolving.de/urn:nbn:de:bsz:352-0-323879. |


