
Semantic clause types and modality as features for argument analysis1
Abstract
This work investigates the role of semantic clause types and modality in argumentative texts. We annotate argumentative microtexts with situation entity (SE) classes and additionally label the segments that contain modal verbs with their modal senses. We analyse the correlation both of SE classes and of modal verbs and senses with components of argument structures (such as premises and conclusions) and their functions (such as support and rebuttal). We find interesting tendencies in the correlations between both argument components and argumentative functions with SE types.
We also see interesting differences in the distributions of modal verbs and senses within different argumentative components and functions, as well as evidence that modal senses can be helpful to distinguish conclusions and premises. We conclude that both semantic clause types and modal senses can be deployed for automatic recognition and fine-grained classification of argumentative text passages.
1.Introduction
Argumentation mining has recently gained attention as a novel task in automatic discourse analysis which is of high relevance, for instance in the analysis of opinions in social media. Argumentation analysis aims at automatically identifying and structuring arguments in natural language texts. Informally, an argument can be understood as a discussion – or a monological debate – in which reasons (so-called premises) are advanced for or against some controversial issue, proposition or proposal (often called the conclusion) [18].
The aim of this study is to better understand linguistic features of argument components in argumentative texts. We take an analytical approach, investigating the roles of both modality and semantic clause types in an annotated corpus of argumentative microtexts [24].
In previous work [3], we have annotated the 112 microtexts in this corpus with semantic clause types in the form of situation entities [8].22 In this prior work, we observed striking differences in the distribution of semantic clause types in argumentative texts, as compared to other textual genres. In the present work we extend these annotations by labeling the same texts with modal verbs and senses, which we also found to show characteristic properties in argumentative texts. We present the results of our investigation of the correlations between (1) clause types and various argument components and functions and (2) modal verbs and senses and various argument components and functions. Specifically, we are asking the following questions:
Do particular semantic clause types correlate with specific argument components (i.e. conclusion, proponent premise, or opponent premise)?
Do particular semantic clause types correlate with specific argumentative functions (i.e. support, rebuttal, and undercut)?
Do particular modal verbs or modal senses correlate with particular argument components?
Do particular modal verbs or modal senses correlate with particular functions of argument components?
In the following, we first, in Section 2, present the microtext corpus [24] on which we base our analysis. In Section 3 we introduce the annotation categories for situation entities and modal senses, which have both been established and annotated in prior work, for genres other than argumentative texts [8,10,16]. Section 4 analyzes the distributional properties of semantic clause types in the argumentative microtexts and their correlation with specific argument structure components. Section 5 performs a similar analysis for modal verbs and senses. In Section 6 we summarize our observations and draw conclusions on the contribution of semantic annotation categories for the linguistic characterization of arguments and argument components.
2.Data
The argumentative microtexts are a collection of short written texts (of usually 5 sentences) elicited in response to a trigger question, such as (1).33 The texts were written in German and translated to English; our analysis addresses the original German texts.
(1) Sollten Videospiele in den Reigen der Olympischen Disziplinen aufgenommen werden?
Should video games be made olympic?
Figure 1 shows one complete microtext (b036), written in response to the trigger question above.
Fig. 1.
Argumentation graph of a microtext.
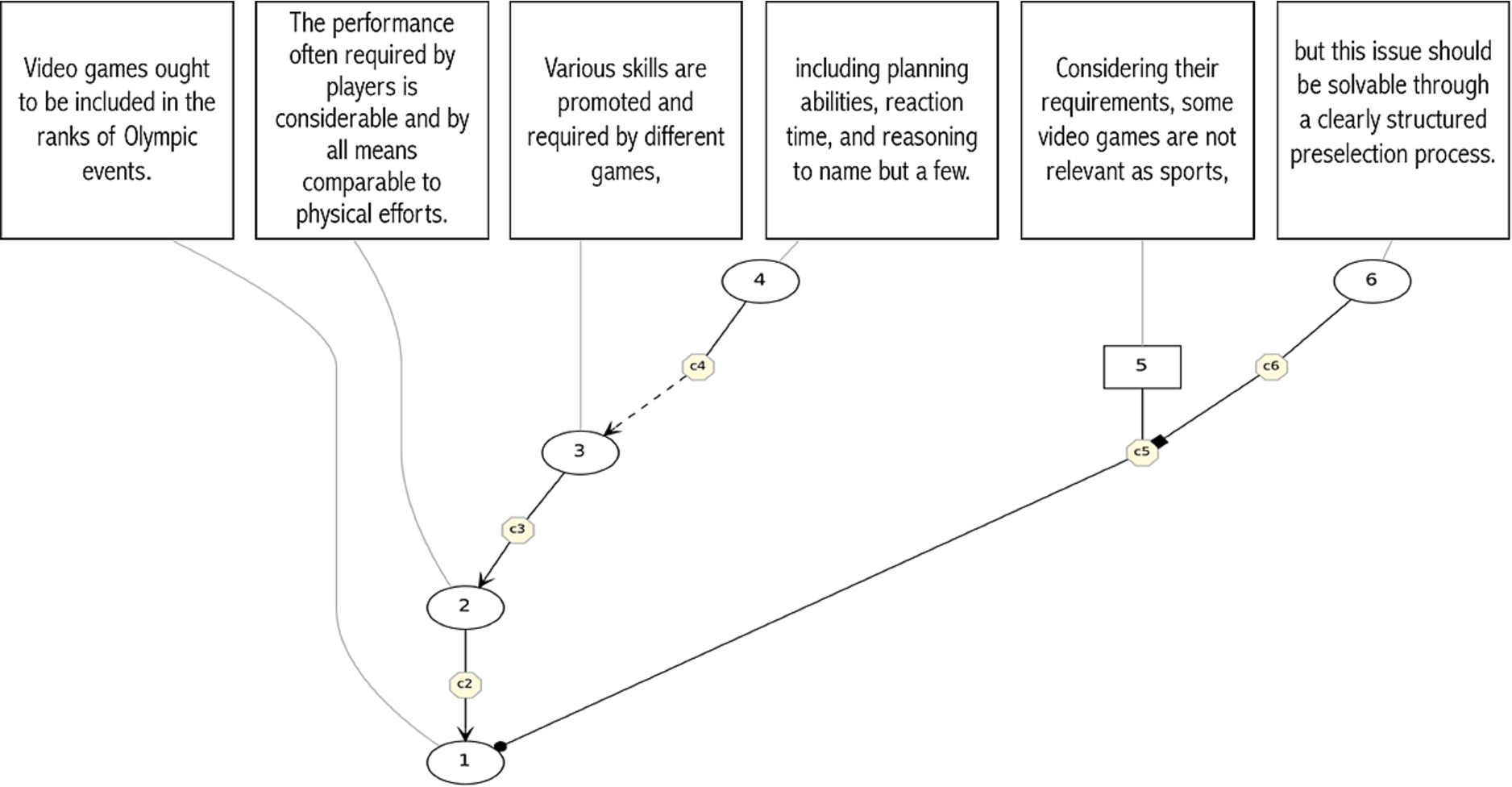
The microtexts are dense argumentative texts; each segment contributes to the argument. Each text contains one segment stating the conclusion, or the main claim of the proponent. In Fig. 1, this is the first sentence (Video games ought to be included in the ranks of Olympic events). The other segments in the text are premises either supporting the conclusion or presenting the view of a potential opponent. Premises are related to the conclusion or to other premises via the argumentative functions of (a) support; (b) rebuttal, in which a premise directly challenges a conclusion or premise; or (c) undercut, in which a premise challenges the acceptability of an inference between two other segments (two premises, or one premise and one conclusion). Again in Fig. 1, the second sentence (The performance often required by players is considerable and by all means comparable to physical efforts) supports the conclusion, while the fifth segment (Considering their requirements, some video games are not relevant as sports) attacks the conclusion and is therefore a opponent premise (represented as a square node). This fifth segment is in turn being undercut by the last segment (but this issue should be solvable through a clearly structured preselection process), which represents a proponent premise.
3.Annotations
3.1.Situation entity types
To investigate the semantic types of clauses found in argumentative text passages, we use the inventory developed by [30] and extended in later work [8,22]. Situation entity (SE) types describe the semantic types of situations (including states, events, generics, habituals, questions, and imperatives) evoked in discourse by individual clauses of text. As such, they concern the manner of presentation of content along with the conveyed information.
SE types are recognizable (and distinguishable) through a combination of linguistic features of the clause and its main verb, and it was found that the distribution of SE types in text passages correlates to some extent with whether the text passage is (e.g.) narrative, informative, or argumentative [3,17,21].
The use of linguistic features for distinguishing text passages is closely related to Argumentative Zoning [20,32], where linguistic features are used to distinguish genre-specific types of text passages in scientific texts. In this manner, those texts are segmented into types of text passages such as Methods or Results. Notions related to SE type have been widely studied in theoretical linguistics [1,4,6,29,33,34] and have seen growing interest in computational linguistics [5,11,12,19,25,28,35].
Annotation categories. The inventory of SE types considered in our analysis starts with states and events (cf. Table 1 and Fig. 2 for examples from the microtexts).
(2) State (S): Armin has brown eyes.
(3) Event (EV): Bonnie ate three tacos.
(4) Report (R): The agency said applications had increased.
Modality, negation, future tense, and conditionals, when coupled with an Event-type clause, cause a coercion to State. In these constructions, reference is made to actual or potential states of the world rather than to actual events that have occurred. Several examples appear below; note that no coercion happens for State clauses.
(5) Carlo got the job. (EV) → Carlo should get the job. (S)
(6) Georg has blue eyes. (S) → Georg could have blue eyes. (S)
(7) Darya answered. (EV) → Darya did not answer. (S)
(8) Reza is short. (S) → Reza is not short. (S)
(9) He won the race. (EV) → If he wins the race, … (S)
(10) It is warm today. (S) → If it is warm tomorrow, … (S)
The other two frequently-occurring SE categories in argumentative texts are generic sentences and generalizing sentences, the latter sometimes referred to as habituals. While the former predicate over classes or kinds, the latter describe regularly-occurring events, such as habits of individuals.
(11) Generic Sentence (GEN):
Birds can fly.
Scientists make arguments.
(12) Generalizing Sentence (GS):
Fei travels to India every year.
Generic sentences express the most general knowledge: attributes of classes,
States often introduce facts held to be generally true, and
Generalizing sentences talk about “what usually happens”.
The next category of SE types is broadly referred to as Abstract Entities. This type of clause presents semantic content in a manner that draws attention to its epistemic status. We focus primarily on a small subset of constructions – factive and propositional predicates with clausal complements. Of course a wide range of linguistic constructions can be used to convey such information, and to address them all would require a comprehensive treatment of subjective language. In the examples below, the matrix clause is in both cases a State, and the embedded clause (in italics) is both an Event and either a Fact, Proposition, or Resemblance-type situation entity. Note that in the Resemblance case, it is unclear whether or not the embedded event took place.
(13) Fact (F): Georg knows that Reza won the competition.
(14) Proposition (P): Georg thinks that Reza won the competition.
(15) Resemblance (RES): Reza looks like he won the competition.
Finally, the labels Question and Imperative are added to allow complete annotation of texts.
(16) Question (Q): Why do you torment me so?
(17) Imperative (IMP): Listen to this.
Annotators had access to the full inventory of ten SE types described above, but only four of them occur often enough in the microtext corpus to allow for meaningful analysis (see Section 4 for details).
3.2.Modal verbs and modal senses
Modal verbs convey extra-propositional meaning of clauses, encoding information about possibility, necessity, obligation, permission, wishes, or requests [13]. Features of the verb such as modal auxiliaries, tense, and mood have been widely used in previous work for classifying argumentative vs. non-argumentative sentences [7,18]. For example, [18] include verb lemmas and modal auxiliaries as features, and [7] find that, for Greek web texts related to public policy issues, tense and mood features of the verbal constructions are helpful for determining the role of the sentences within argumentative structures. Classifiers that automatically distinguish modal senses in context have been developed by [26] and improved in subsequent work [15,16,36].
We annotate all modal verb occurrences in the microtexts with their modal sense, following the inventory of modal senses and annotation guidelines from [36]. They distinguish three senses: epistemic (ep), indicating possibility/necessity, deontic/bouletic (de), indicating permission/request/wish, and dynamic (dy), indicating ability. Different types of modalities express different types of extrapropositional meaning: dynamic modality captures knowledge about specific capacities of certain entities or types of entities, while epistemic modality expresses knowledge about how likely a certain proposition is. Deontic modality expresses wishes or requests that are desired or undesired, and that may be possible or counterfactual. We illustrate these modal senses below with sentences taken from the microtext corpus:
(18) DYNAMIC (DY):
Außerdem können sich nur große Unternehmen die zusätzlichen Personalkosten leisten.
In addition, only large companies can afford the additional personnel costs. (Ability)
(19) EPISTEMIC (EP):
Eine ungewollte Schwangerschaft kann sowohl für die Eltern als auch das Kind eine schwere Belastung für den Rest des Lebens darstellen.
An unwanted pregnancy can be a heavy burden for the rest of life for both the parents and the child. (Possibility)
(20) DEONTIC (DE):
Die Krankenkassen sollten Behandlungen beim Natur-oder Heilpraktiker nicht zahlen.
Health insurance companies should not cover treatment in complementary medicine. (Obligation)
(21) DEONTIC (DE):
Zwar wollen die Vermieter möglichst viel verdienen […]
The landlords want to earn as much as possible […] (Wish)
(22) DEONTIC (DE):
Der Staat darf ein medizinisches Produkt bzw. eine medizinische Behandlung nicht aus moralischen Gruenden einschränken.
The state may not restrict a medical product or medical treatment for moral reasons. (Permission)
It is important to mention that the interpretation of modal verbs can vary with their context. [36] find that specific sense ambiguities such as dynamic vs. deontic readings of can, epistemic vs. dynamic readings of could, or epistemic vs. deontic readings of should are difficult to discriminate. Likewise, senses can be expressed through different modal verbs. In the following example, a possibility (epistemic sense) is expressed by two different German modal verbs (mögen and können):
(23) EPISTEMIC (EP):
Manche mögen das Konzept der Schul-Uniform anachronistisch finden.
Some may find the concept of school uniform anachronistic. (Possibility)
(24) EPISTEMIC (EP):
Obwohl die Geschäftszahlen von IBM in letzter Zeit nicht umwerfend waren und die Stimmung an der Börse insgesamt besser sein könnte, solltest du IBM Aktien kaufen.
Although IBM’s numbers haven’t been staggering recently, and the mood in the stock market could (können) be better on the whole, you should (sollen) buy IBM shares. (Possibility)
3.3.Extending argumentative annotations of microtexts to SE types and modal senses
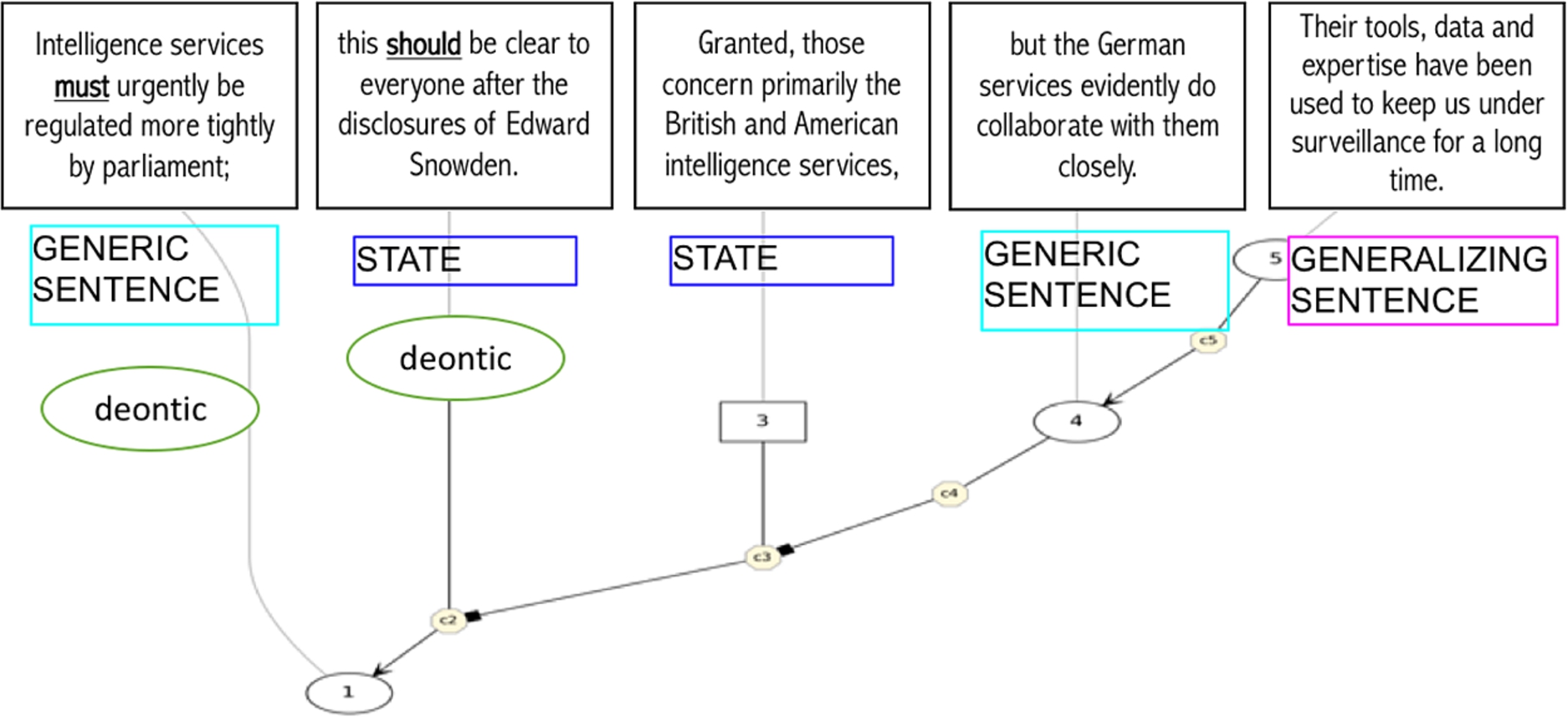
We annotate all segments with their situation entity types, and those containing modal verbs, with their modal senses. Annotation examples are illustrated in Table 1 and Fig. 2 which also give examples of both SE types and modal verbs and their senses in argumentative texts. The premise Sure, other people have to work in the shops on the weekend (Table 1) is an example for a Generic Sentence, while the premise This should be clear to everyone after the disclosures of Edward Snowden in Fig. 2 is a State and the last segment in Fig. 2 (Their tools, data and expertise have been used to keep us under surveillance for a long time) a Generalizing Sentence.
Table 1
Sample microtext (micro_b015), German and English versions, with SE labels, proponent/opponent status, and argumentative functions (support, undercut, rebuttal, addition)
| Arg | German/English + (SE-Labels) & [Modal Senses] |
| Concl. | Also, ich als Arbeitnehmer fände es sehr praktisch, (State) |
| Well, I as an employee find it very practical | |
| zumindest an Wochenenden einkaufen zu können [dynamic]. (Generic Sentence) | |
| to be able to shop at least on weekends. | |
| Prem. Opp:Reb | Klar müssen [deontic] dann auch Leute am Wochenende in den Läden arbeiten, (Generic Sentence) |
| Sure, other people have to work in the shops on the weekend, | |
| Prem. Pro:Und | aber die haben dann eben innerhalb der Woche frei (Generic Sentence) |
| but they can have days off during the week | |
| und können [dynamic] in Ruhe Termine wahrnehmen, (Generic Sentence) | |
| and run errands at their leisure | |
| während ich im Büro sitze. (Generalizing Sentence) | |
| while I’m stuck in the office. | |
| Prem. Pro:Supp | Ausserdem will [deontic] doch der Staat, (State) |
| Plus, the state wants me | |
| dass ich mein Geld ausgebe, (Event) | |
| to spend my money, | |
| Prem. Pro:Add | und wie soll [deontic] ich dass machen, (Question) |
| and how am I supposed to do that | |
| wenn die Geschäfte nicht offen sind, (Generic Sentence) | |
| when the shops aren’t open | |
| wenn ich frei habe? (Generalizing Sentence) | |
| when I’m off work? |
Modal verbs and their senses are marked in boldface;
Segmentation. Before annotating the microtexts, we first segment them into clauses (cf. [3]). As seen in Table 1, an argumentative component can in fact consist of several SE segments. The granularity of situation-evoking clauses is different from that of argument components, requiring that the texts be re-segmented prior to SE annotation. For segmentation we use DiscourseSegmenter [27], a Python package offering both rule-based and machine-learning based discourse segmenters.44 After preprocessing texts with the Mate Tools,55 we use DiscourseSegmenter’s rule-based segmenter (edseg), which employs German-specific rules to determine the boundaries of elementary discourse units in texts. Because DiscourseSegmenter occasionally oversplit segments, we did a small amount of post-processing. On average, one argument component contains 1.16 clauses.66 These clauses are then annotated with SE types and modal verbs and senses.
Fig. 2.
Argumentation graph with clause type and modal sense annotations.
Agreement statistics. We train two student annotators with backgrounds in linguistics for labeling texts with both SE types and modal senses. The two annotators then label the microtexts independently. We compute agreement both for SE types and for modal senses and gain an inter-annotator agreement of 0.40 for the former and 0.75 for the latter, both reported as Cohen’s Kappa. As reported by several studies [23], the annotation of argumentative texts is a difficult task for humans. The agreement statistics reported above suggest that this is also the case for the task of labeling argumentative texts with SE types. The SE-labels that caused most disagreement among the annotators are State vs. Generic Sentence (39% of all disagreements), followed by State vs. Generalizing Sentence (22%). For modal verbs, most disagreements are caused by the labels dynamic vs. epistemic (60% of all disagreements), followed by epistemic vs. deontic (24%). We then produce a gold standard annotation by re-annotating all segments for which the two student annotators disagreed about the SE type and/or the modal sense. This third annotation is done by an expert annotator (one of the authors), and we use the adjudicated annotations for our analysis.
4.Analysis of semantic clause types
4.1.Distributions of SE types within different genres
We find that the most important SE types within the microtexts are State, Event, Generic Sentence, and Generalizing Sentence, while the remaining six types occurred not at all or infrequently: Question (10 segments), Proposition (2 segments), Resemblance (2 segments), Fact (0 segments), Report (0 segments), and Imperative (0 segments). Thus, our further analysis will focus only on the four most frequent SE types State, Event, Generic Sentence, and Generalizing Sentence.
In order to investigate whether argumentative texts can be distinguished from non-argumentative texts with respect to the distribution of SE types (cf. [30]), we compare the distribution of States, Events, Generic Sentences, and Generalizing Sentences in the microtext subcorpus to those of other text genres. Therefore, we first segment and then annotate a small corpus with texts of different genres with SE types. This corpus includes the following genres: fiction (47 segments), reports (42 segments), TED talks (50 segments) and commentary (127 segments).
The microtexts, which can be described as “purely” argumentative texts, are characterized by a high proportion of Generic Sentences and Generalizing Sentences and very few Events, while reports and talks, for example, contain a high proportion of States. This is displayed in Fig. 3. Fiction is characterized by a high number of Events. The commentary genre, which contains many argumentative passages but is not as purely argumentative as the microtexts, is most likely to be comparable to the microtexts. This finding suggests that SE types could be helpful for modeling argumentative regions of text.
Fig. 3.
Distribution of SE types within different genres.
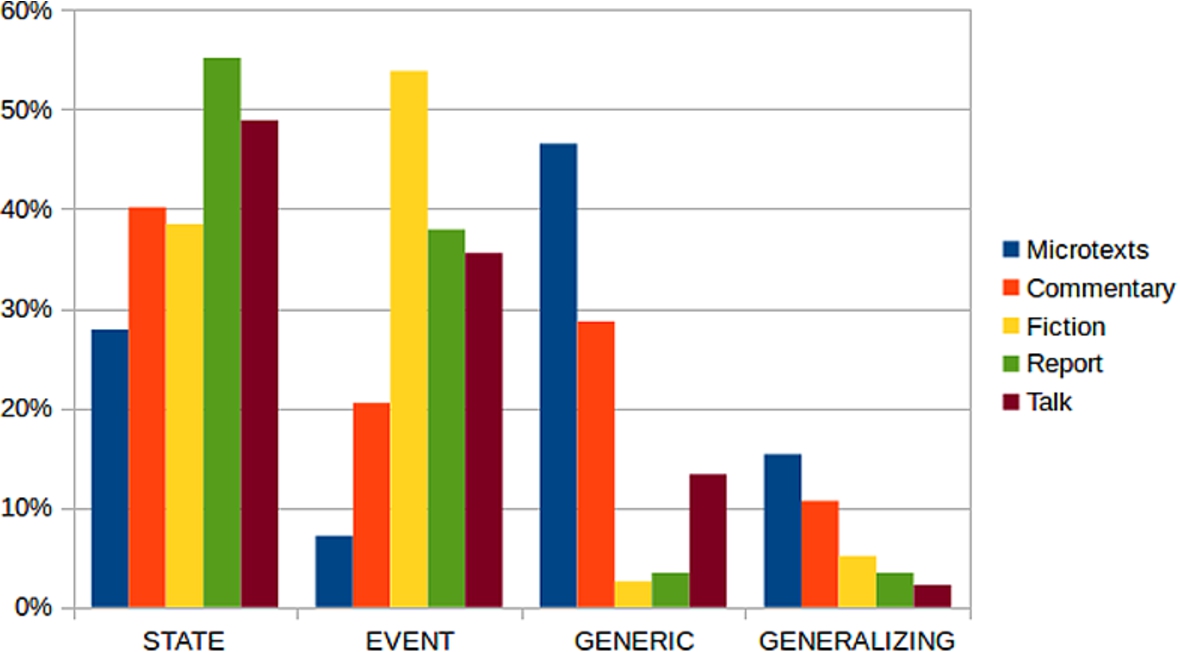
Table 2
Distributions of SE types for argument components and functions, along with absolute number of each type of segment in the microtext corpus (in brackets: subset without coerced cases)
| All segments | Premises only | Functions | |||||
| Conclusions | Prem-All | Prem-Pro | Prem-Opp | Supp | Rebut | Undercut | |
| # | 112 | 464 | 339 | 125 | 263 | 108 | 63 |
| GEN | 0.48 (0.48) | 0.49 (0.49) | 0.52 (0.52) | 0.42 (0.42) | 0.51 (0.51) | 0.42 (0.42) | 0.56 (0.56) |
| GS | 0.05 (0.05) | 0.12 (0.12) | 0.08 (0.08) | 0.13 (0.13) | 0.12 (0.12) | 0.13 (0.13) | 0.11 (0.11) |
| S | 0.44 (0.17) | 0.29 (0.17) | 0.29 (0.18) | 0.31 (0.18) | 0.29 (0.19) | 0.32 (0.17) | 0.24 (0.08) |
| EV | 0.03 (0.30) | 0.10 (0.22) | 0.11 (0.22) | 0.14 (0.27) | 0.08 (0.18) | 0.13 (0.28) | 0.09 (0.25) |
GEN: Generic Sentence; GS: Generalizing Sentence; S: State; E: Event.
4.2.Correlations between SE types and argument components
Generic Sentences are the most frequent type overall, distinguishing argumentative texts from other genres, in which Generic Sentences occur quite infrequently [8]. In the microtexts, conclusions are almost exclusively Generic Sentence or State, while premises, next to a majority of Generic Sentence, include a higher proportion of Generalizing Sentences and Events (cf. Table 2 and Fig. 4(a)). This is in line with the role of the conclusion in the argument – it should concisely state the supported position, which is more likely to be a statement about a class of things (e.g. Not everyone should be obliged to pay TV license) or a condition or attribute of the world (e.g. Raising the retirement age on the basis of physical fitness of the average citizen is fair) rather than reference to an episodic event.
Looking at premises only, Generic Sentences are extremely frequent for proponent premises (52%) and less so for opponent premises (42%) (cf. Fig. 4(b)).
Fig. 4.
SE types and argument components and propositions.
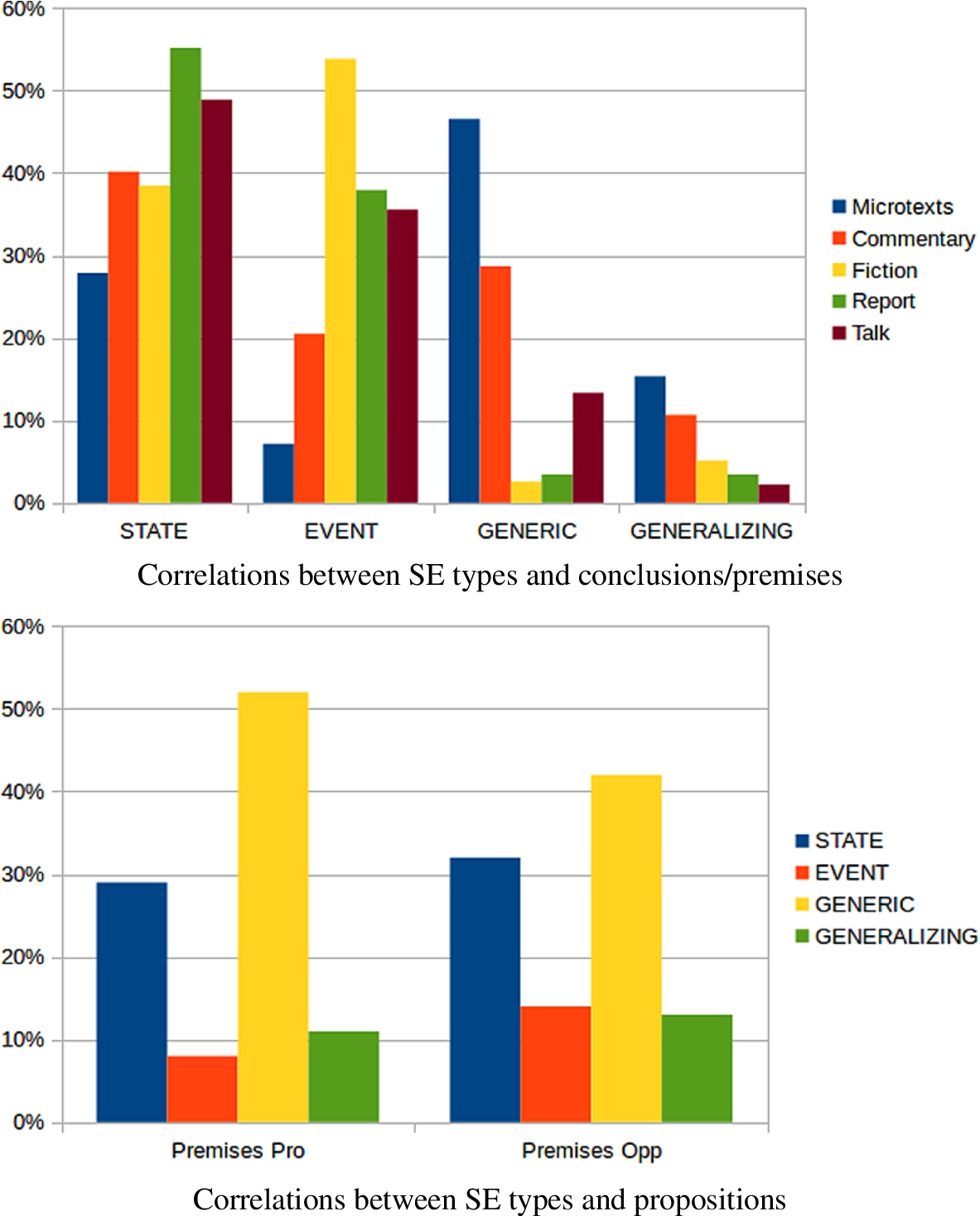
Table 2 shows the distributions over the four major SE types for the various types of argument components in the microtext corpus.
4.3.Correlations between SE types and argumentative functions
Turning to correlations between SE types and argumentative functions of premises, we focus on the three most frequent functions: support, rebuttal, and undercut (Table 2, rightmost section, and Fig. 5). Supporting premises have a SE type distribution very similar to that of proponent premises overall. This is not surprising given that most microtexts contain only a single opponent premise. Undercutting premises show an even higher frequency of Generic Sentences (56%), with the caveat that undercuts occur less frequently than the other types. Finally, rebutting premises show a lower frequency of Generic Sentences (only 42%) and a fairly high occurrence of States (32%). This tendency can be illustrated with the following example, where a State (bold face) rebuts the conclusion (in italics).
(25) Die Krankenkassen sollten Behandlungen beim Natur-oder Heilpraktiker nicht zahlen, (Generic Sentence) es sei denn der versprochene Effekt und dessen medizinischer Nutzen sind handfest nachgewiesen. (State)
Health insurance companies should not cover treatment in complementary medicine unless the promised effect and its medical benefit have been concretely proven.
Fig. 5.
Correlations between SE types and argumentative functions.
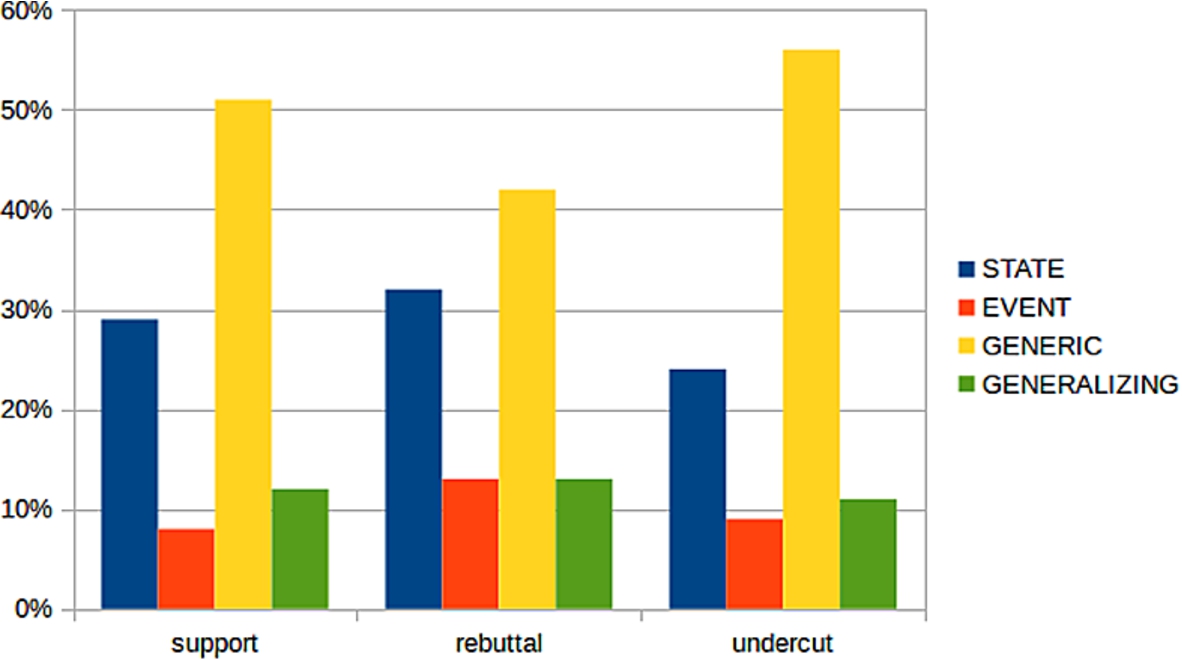
These results suggest that situation entity types could be helpful even for a finer-grained analysis of argumentative functions.
Of course, our annotated corpus is very small, and the phenomena we observe can be interpreted solely as tendencies. Nevertheless, we hypothesize that the prevalence of the Generic Sentence and Generalizing Sentence labels, as well as the absence (or rareness) of the Event label are indicators not only of argumentative text passages, but in particular of conclusions and proponent argument components.
4.4.Analysis on the dataset without considering coercions
As mentioned above, linguistic features such as modality, negation, future tense or conditionals cause a coercion from Event-type to State. We find 84 such coercions in our dataset, 30 within conclusions and 54 within premises.
To better understand the effect of these coercions on our analyses, we reiterated our analyses on the same dataset, but undoing these coercions. This means that we use a version of the dataset in which what ordinarily would be treated as cases of coercion are instead labeled with the SE type that holds prior to coercion. Example (26) e.g. would be labeled as Event instead of as State:
(26) Deshalb sollte Deutschland die Todesstrafe nicht einführen!
That’s why Germany should not introduce capital punishment!
The distributions of SE types within the dataset with and without coercions can be found in Table 2 (version without coercions in brackets) and are visualized in Fig. 6.77 Since coercion affects the proportion of State- and Event-types, we of course find a smaller number of States and a higher number of Events in this analysis. As Fig. 6 shows, the relation between States and Events changes the most for conclusions. Instead of only 3% Events (when applying coercion), we find 30% Events (without coercion), i.e., a difference of 27 percentage points (for premises, the difference is only 12 percentage points). Moreover, while in the analysis considering coercions we find a higher percentage of States compared to Events, in the analysis ignoring coercion the reverse is true. Here we find more Events than States for all categories (argument components as well as argumentative functions) – except in supporting premises, where we find 19% States and only 18% Events.
Fig. 6.
Distributions of SE types within argument components and argumentative functions, with and without coercions.
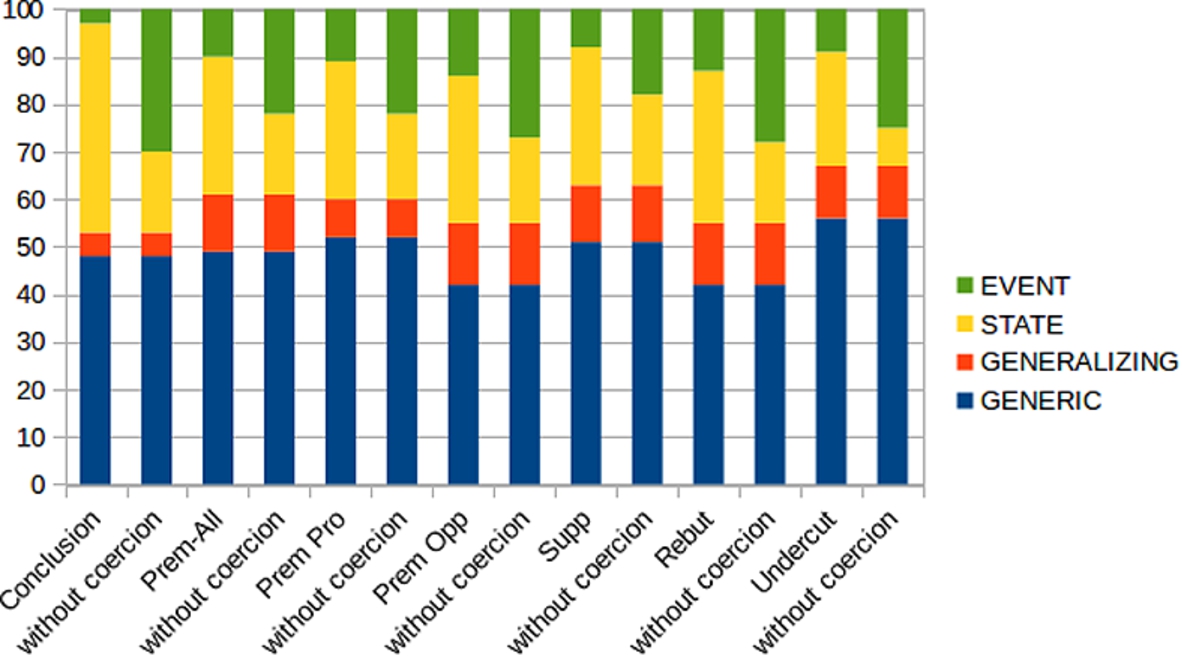
This supports the assumption that episodic events are dispreferred for supporting a conclusion or a premise, but preferred for attacking a conclusion or another premise. This second claim is supported by the high proportion of Events within rebutting and undercutting premises (28% and 25%). In other words, anecdotal reference to events occurs more often for attacking than for supporting. This can be illustrated with the following example, where a generic premise (in italics) is rebutted by a negated and modalized premise which is accordingly coerced from Event to State:
(27) Befürworter der Todesstrafe setzen auf die abschreckende Wirkung sowie die endgültige Eliminierung einer potentiellen Gefahr. (Generic Sentence) Offensichtlich kann aber auch die drohende Todesstrafe in entsprechenden Ländern nicht verhindern, dass es Mord und Gewaltverbrechen gibt. (Event → State)
Proponents of the death penalty count on its deterring effect as well as the ultimate elimination of any potential threat. However also the threat of the death penalty in the respective countries apparently cannot prevent murder and violent crime.
Our motivation of comparing the datasets with and without coercions was to learn more about the effect that modals and other linguistic features which cause coercions may have on the distribution of SE types within argumentative texts. We find that indeed there is a considerable effect: as reported above, we naturally find fewer Events within the dataset without coercions – a distributional effect that one can possibly exploit in an automatic system. What we also find is that 59 of the 84 coercions (70%) in our data are due to modal verbs. We thus complement our study of SE types with an investigation of the role of modal verbs and their senses within argumentative texts.
5.Analysis of modal verbs and senses
5.1.Modal verbs within argumentative and non-argumentative texts
In our annotation we found that modal verbs constitute a high-frequency linguistic phenomenon in the microtexts. The overall 188 modal verbs included in the microtexts occur in 31% of all argumentative segments (57% of conclusions and 26% of premises) and are thus at least partly responsible for the high number of States, due to the coercion of Events to States when embedded under a modal verb. In comparison, only 5% of the segments of the mixed-genre subcorpus introduced in Section 4, including genres such as fiction, report, commentary and TED talks (see [3]), contain modal verbs. Due to this coercion, the contribution of modality indicators is orthogonal to SE types. We thus complement the analysis of SE types with a deeper investigation of modality-indicating expressions, here modal verbs.
Table 3 shows the German modal verbs and their available senses. Note that wollen is not a modal verb, but was included because mögen (may/want to) is ambiguous, and thus we included the synonymous wollen and tagged this sense as deontic (wish).
Our analysis looks closely at distributions of both modal verbs and modal senses and is performed on a subset of the segments from the SE type analysis, as we are concerned only with segments containing modal verbs (cf. first row in Table 4).
Table 3
German modal verbs with English translations and available modal senses (ep = epistemic; de = deontic; dy = dynamic), as well as number of occurrences in the data
| Verb | Occ. | Translation | Senses |
| sollen | 81 | shall/should | ep, de |
| können | 45 | can/could | ep, de, dy |
| müssen | 36 | must/have to | ep, de |
| dürfen | 9 | may/might | ep, de |
| mögen | 7 | may/want to | ep, de |
| wollen | 10 | want to | de |
Table 4
Distributions of modal verbs and modal senses for various argument components and functions, plus absolute number of modal-verb-containing segments in the microtext corpus
| All segments | Premises only | Functions | |||||
| Conclusions | Prem-All | Prem-Pro | Prem-Opp | Support | Rebut | Undercut | |
| # | 68 | 120 | 85 | 35 | 60 | 30 | 17 |
| Deontic | 0.97 | 0.61 | 0.64 | 0.53 | 0.62 | 0.50 | 0.76 |
| Dynamic | 0.015 | 0.15 | 16 | 0.15 | 0.18 | 0.11 | 0.12 |
| Epistemic | 0.015 | 0.24 | 0.20 | 0.32 | 0.20 | 0.39 | 0.12 |
| sollen | 0.86 | 0.19 | 0.21 | 0.14 | 0.18 | 0.10 | 0.40 |
| können | 0.03 | 0.36 | 0.38 | 0.31 | 0.42 | 0.30 | 0.24 |
| müssen | 0.07 | 0.25 | 0.22 | 0.31 | 0.25 | 0.33 | 0.24 |
| dürfen | 0.02 | 0.07 | 0.08 | 0.04 | 0.06 | 0.03 | 0.06 |
| mögen | – | 0.06 | 0.03 | 0.14 | 0.02 | 0.17 | 0.06 |
| wollen | 0.02 | 0.07 | 0.08 | 0.06 | 0.07 | 0.07 | – |
5.2.Correlations between modal verbs/senses and argument components
Overall, the most frequent modal verb in the microtexts is sollen (121 occurrences, 41% of modal verbs), and the most frequent sense across all modal verbs is deontic (133 occurrences, 75%).
Fig. 7.
Modal senses and argument components and propositions.
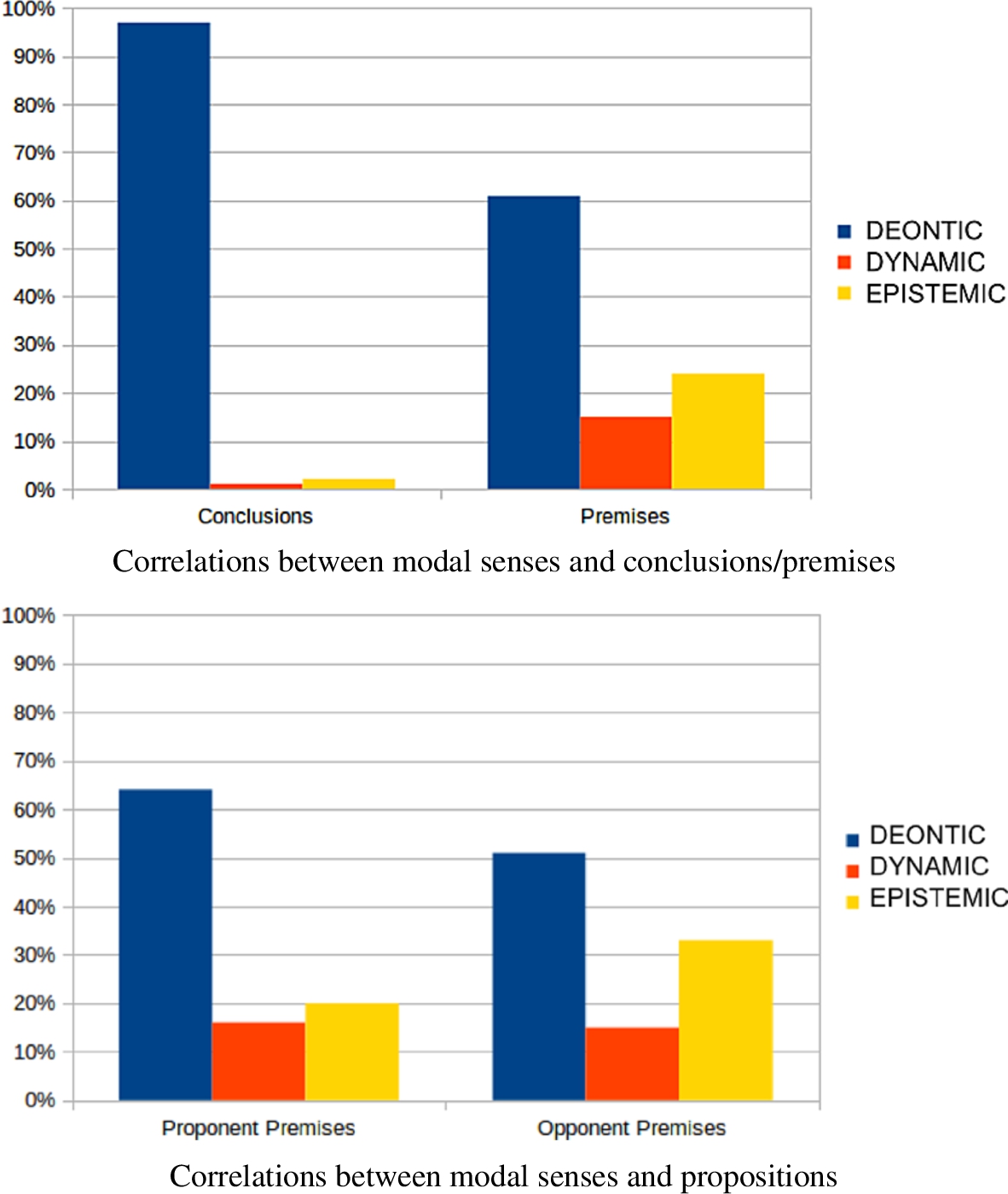
Of the conclusions that contain a modal verb, an overwhelming 97% (62/64) are deontic; compare this to premises that contain modal verbs, for which only 61% (71/117) are deontic (Fig. 7(a)).
The prevalence of sollen within conclusions (86%) warrants a caveat: most of the trigger questions contain some form of sollen, and so it is possible that the predominance of sollen, particularly in conclusions (86%), is a result of the form of the trigger questions.88 However, the distributions of modal verbs within the subset of microtexts not associated with a trigger question are very similar to the overall distributions (among conclusions: sollen = 77%, können = 8%, müssen = 15%). This suggests that the observed distributions are not overly influenced by the trigger questions.
The other nearly 40% of premises are epistemic and dynamic senses of MVs, which occur in conclusions with a combined frequency of only 3%. The prevalence of these two senses is reflected in the high frequency of können, which frequently occurs as dynamic or epistemic. As is generally the case, müssen in epistemic sense is rather rare. The tendencies can be seen clearly in the upper part of Table 4, which displays the modal sense distributions.
In premises, the most frequent modal verb is können, at 36%, followed by müssen with 25%. These again stand in stark contrast to conclusions, where these two verbs occur with frequencies of 3% and 7%, respectively. A similar observation concerns proponent and opponent premises (Fig. 7(b)). Here, 64% of proponent components with a modal verb are deontic, while this is true only for 53% of opponent components with modal verbs. Instead, we find a relatively high proportion of epistemic senses (32%) for opponent premises, and a similarly high proportion for epistemic sense is found with rebutting premises.
5.3.Correlations between modal verbs/senses and argumentative functions
Epistemic modals refer to alternative, often counterfactual worlds, and as such they are well suited for rebutting preceding or hypothesized arguments or premises (Fig. 8). An example of this from our data is given in example (28), where bold face marks a rebutting premise:
(28) Obwohl die Geschäftszahlen von IBM in letzter Zeit nicht umwerfend waren und die Stimmung an der Börse insgesamt besser sein könnte, solltest du IBM Aktien kaufen.
Although IBM’s numbers haven’t been staggering recently, and the mood in the stock market could (können) be better on the whole, you should (sollen) buy IBM shares.
Fig. 8.
Correlations between modal senses and argumentative functions.
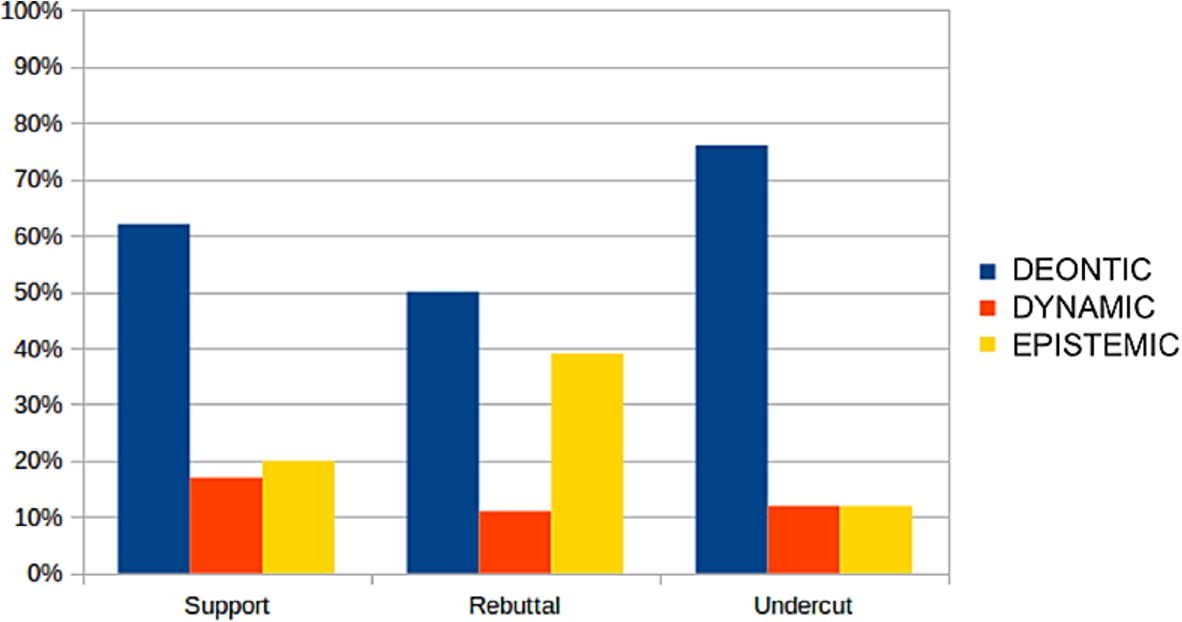
Turning to dynamic sense, we find it more strongly associated with supporting function. We typically find this sense realized with können, bringing forth abilities or capabilities of entities, presented as options and chances, in support of a premise (29).
(29) Bereits heute dominieren Supermärkte und grosse Einkaufszentren den Markt. So können auch kleinere Geschäfte von der zusätzlichen Freiheit profitieren, da die Kunden am Sonntag im Durchschnitt entspannter einkaufen.
Supermarkets and large shopping centres dominate the market today already. Thus smaller shops could (können) benefit from the additional freedom, as customers are on average more laid-back on Sunday.
Finally, even though deontic is the most frequent modal sense within all of the microtexts, it is especially frequent within undercuts: 76% of the undercuts that contain modal verbs have the modal sense deontic (obligation).
As an example, we find (30):99
(30) Man sollte einem langjährigen Eigentümer nicht die Chance auf Angleichung seiner Rendite auf Marktniveau verwehren.
One should not deny a longtime owner the opportunity to approximate his return to market level.
In rebuttals with modal verbs (30 occurrences) we count only 50% deontic and 39% epistemic modal senses, see (31) for a deontic rebuttal.
(31) Dennoch sollten Frauen vor der Einnahme über die Risiken aufgeklärt werden und gynäkologisch untersucht werden.
However, women should be educated about the risks and gynecological studies before taking them.
6.Conclusion
This study extends our understanding of linguistic features of argumentative texts by investigating the utility of SE types and modal verb senses for modeling regions of argumentative texts. Although the microtext corpus is small and the observed phenomena can be interpreted only as tendencies, our analyses show that both semantic clause types and modal senses can be useful features for automated argumentation analysis – not as stand-alone features, but as part of a larger system. Table 51010 summarizes our findings and gives an overview of the features we believe can be deployed to improve systems for automated argumentation analysis.
Table 5
Clause types and modality as features for argumentation mining: Summary
| Linguistic phenomena | Useful as features for… |
| Clause types | |
| High frequency of Generic + Generalizing Sentences | Identifying argumentative text passages |
| High proportion of Generic Sentences + rareness of Events | Distinguishing conclusions from premises |
| High proportion of Generic Sentences | Distinguishing proponent from opponent premises |
| High proportion of Events + States | Identifying rebuttals |
| Modality | |
| High frequency of modal verbs | Identifying argumentative text passages |
| High frequency of sollen | Distinguishing conclusions from premises |
| High proportion of deontic modal sense | Identifying conclusions and proponent premises |
| High proportion of epistemic modal sense | Identifying rebuttals and opponent premises |
Our analyses revealed some clear-cut distinctions as well as weaker tendencies. First, SE types, especially Generic Sentences, allow for a clear distinction between argumentative and non-argumentative text passages. Similar to SE types, a high proportion of modal verbs was found to be a characteristic feature of argumentative texts as opposed to other text genres.
The high frequency of Generic Sentences and the rareness of Events within conclusions compared to premises can be helpful to identify conclusions and premises within argumentative texts.
Proponent premises were found to be characterized by a high proportion of Generic Sentences and very few Events, whereas a higher amount of Events are found within rebutting premises and opposing premises when controlling for coercions. This finding supports the assumption that references to episodic events are suitable to rebut against conclusions or other premises.
Modal verbs and senses can be used to distinguish conclusions from premises since conclusions show a strong tendency to be deontic. Modal senses can also be helpful for classifying proponent and opponent premises, since the former show a higher proportion of deontic sense.
Finally, we found rebutting premises to contain more epistemic modal verbs than supporting or undercutting premises.
Moving forward, we will extend our analysis to longer texts with both argumentative and non-argumentative passages. With more data, we will be able to consider finer distinctions in the usage of modal senses, for example investigating the sense distributions for particular modal verbs in particular components of argumentative structures. We also consider broadening the scope of modality-indicating expressions to modal adjectives (possible) and adverbials (probably) or attitudinal expressions (to be expected).
Using automatic classifiers to assign situation entity [9] and modal sense labels [15,16], the contribution of these phenomena to argument structure parsing can be examined on a broader scale.
Notes
2 See Section 4 for details on situation entities. The argumentative microtext corpus with pre-annotated argumentative functions comes from [24], while we added annotations of SE types and modality as new layers of annotation. For details of the dataset and the annotation process please refer to [3].
3 23 of the 112 texts were written by one of the authors of the microtext corpus as teaching tools and were used mainly in teaching and testing the students’ argumentative analysis, thus not associated with trigger questions.
6 [31] annotated the microtext corpus additionally with two alternative approaches to discourse structure, Rhetorical Structure Theory (RST, [14]) and Segmented Discourse Representation Theory (SDRT, [1]). The authors make similar observations to ours regarding the granularity of SE segments and argument components, finding that argument components may consist of several elementary discourse units (EDUs) as used in RST and SDRT.
7 Please note that all other figures in this paper report results on the original dataset, with coercions.
8 The frequency of certain modal verbs could also be a feature of a specific type or subclass of argumentative texts: While most of the microtexts can be characterized as persuasive/suggestive towards certain future actions, argumentative texts may also be of an epistemic nature (e.g. arguments in scientific discourse). Therefore, our observations of features of argumentative texts first of all hold for the subclass of argumentative texts as represented in the microtext corpus, while we leave the analysis of features of other subclasses as future work.
9 Note that the English translation does not render the deontic sense of müssen in the German original.
10 Note that the results for SE types are based on the original dataset, cf. Section 4.4.
Acknowledgements
We want to thank Michael Staniek for building the annotation tool and preprocessing the texts. Sabrina Effenberger and Rebekka Sons we thank for realizing the annotations and for their helpful feedback on the annotation manual. We also would like to thank the reviewers for their insightful comments and suggestions on the paper. This research is funded by the Leibniz Science-Campus “Empirical Linguistics and Computational Language Modeling”, supported by Leibniz Association grant no. SAS-2015-IDS-LWC and by the Ministry of Science, Research, and Art of Baden-Württemberg.
References
[1] | N. Asher, Reference to Abstract Objects in Discourse, Kluwer, Alphen aan den Rijn, The Netherlands, (1993) . doi:10.1007/978-94-011-1715-9. |
[2] | M. Becker, A. Palmer and A. Frank, Clause types and modality in argumentative microtexts, in: Workshop on Foundations of the Language of Argumentation (in Conjunction with COMMA 2016), Potsdam, Germany, (2016) , pp. 1–9, http://www.ling.uni-potsdam.de/comma2016/pdf/FLA16-proceedings.pdf. |
[3] | M. Becker, A. Palmer and A. Frank, Clause types and argumentative texts, in: Proceedings of the 3rd Workshop on Argument Mining, Berlin, Germany, (2016) , pp. 21–30. |
[4] | G.N. Carlson and F.J. Pelletier, eds, The Generic Book, University of Chicago Press, Chicago, IL. |
[5] | F. Costa and A. Branco, Aspectual type and temporal relation classification, in: Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, (2012) , pp. 266–275. |
[6] | D. Dowty, Word Meaning and Montague Grammar, Reidel, Dordrecht, (1979) . doi:10.1007/978-94-009-9473-7. |
[7] | E. Florou, S. Konstantopoulos, A. Kukurikos and P. Karampiperis, Argument extraction for supporting public policy formulation, in: Proceedings of the 7th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, Sofia, Bulgaria, (2013) , pp. 49–54. |
[8] | A. Friedrich and A. Palmer, Situation entity annotation, in: Proceedings of the Linguistic Annotation Workshop VIII, Dublin, Ireland, (2014) , pp. 149–158. |
[9] | A. Friedrich, A. Palmer and M. Pinkal, Situation entity types: Automatic classification of clause-level aspect, in: Proceedings of the Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, (2016) , pp. 1757–1768. |
[10] | A. Friedrich, A. Palmer, M.P. Sørensen and M. Pinkal, Annotating genericity: A survey, a scheme, and a corpus, in: The 9th Linguistic Annotation Workshop Held in Conjuncion with NAACL 2015, Denver, CO, USA, (2015) , pp. 21–29. |
[11] | A. Friedrich and M. Pinkal, Discourse-sensitive automatic identification of generic expressions, in: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, Beijing, China, (2015) , pp. 1272–1281. |
[12] | A. Herbelot and A. Copestake, Annotating genericity: How do humans decide? (A case study in ontology extraction), Studies in Generative Grammar 101: ((2009) ), 103–107. |
[13] | A. Kratzer, The notional category of modality, in: Words, Worlds, and Contexts: New Approaches in Word Semantics, H.J. Eikmeyer and H. Rieser, eds, de Gruyter, (1981) , pp. 38–74. |
[14] | W. Mann and S. Thompson, Rhetorical structure theory: Towards a functional theory of text organization, Text – Interdisciplinary Journal for the Study of Discourse, 8: ((1988) ), 243–281. |
[15] | A. Marasović and A. Frank, Multilingual modal sense classification using a convolutional neural network, in: Proceedings of the 1st Workshop on Representation Learning for NLP, Berlin, Germany, (2016) , pp. 111–120. |
[16] | A. Marasović, M. Zhou, A. Palmer and A. Frank, Modal sense classification at large: Paraphrase-driven sense projection, semantically enriched classification models and cross-genre evaluations, Linguistic Issues in Language Technology 14: (2) ((2016) ), 1–58. |
[17] | K.-I. Mavridou, A. Friedrich, M. Sorensen, A. Palmer and M. Pinkal, Linking discourse modes and situation entities in a cross-linguistic corpus study, in: Proceedings of the EMNLP Workshop LSDSem: Linking Models of Lexical, Sentential and Discourse-Level Semantics, Lisbon, Portugal, (2015) , pp. 12–21. |
[18] | M.-F. Moens, E. Boiy, R.M. Palau and C. Reed, Automatic detection of arguments in legal texts, in: Proceedings of ICAIL, Stanford, CA, USA, (2007) , pp. 225–230. |
[19] | A. Nedoluzhko, Generic noun phrases and annotation of coreference and bridging relations in the Prague Dependency Treebank, in: Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Sofia, Bulgaria, (2013) , pp. 103–111. |
[20] | D. O’Seaghdha and S. Teufel, Unsupervised learning of rhetorical structure with un-topic models, in: Proceedings of COLING, Dublin, Ireland, (2014) , pp. 2–13. |
[21] | A. Palmer and A. Friedrich, Genre distinctions and discourse modes: Text types differ in their situation type distributions, in: Proceedings of the Symposium on Frontiers and Connections Between Argumentation Mining and Natural Language Processing, Bertinoro, Italy, (2014) . |
[22] | A. Palmer, E. Ponvert, J. Baldridge and C. Smith, A sequencing model for situation entity classification, in: Proceedings of ACL, Prague, Czech Republic, (2007) , pp. 896–903. |
[23] | A. Peldszus and M. Stede, Ranking the annotators: An agreement study on argumentation structure, in: Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Sofia, Bulgaria, (2013) , pp. 196–204, http://www.aclweb.org/anthology/W13-2324. |
[24] | A. Peldszus and M. Stede, An annotated corpus of argumentative microtexts, in: Proceedings of the First European Conference on Argumentation: Argumentation and Reasoned Action, London, UK, (2016) , pp. 801–815. |
[25] | N. Reiter and A. Frank, Identifying generic noun phrases, in: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, (2010) , pp. 40–49. |
[26] | J. Ruppenhofer and I. Rehbein, Yes we can!? Annotating the senses of English modal verbs, in: Proceedings of LREC, Paris, France, (2012) , pp. 1538–1545. |
[27] | U. Sidarenka, A. Peldszus and M. Stede, Discourse segmentation of German texts, Journal for Language Technology and Computational Linguistics 30: (1) ((2015) ), 71–98. |
[28] | E.V. Siegel and K.R. McKeown, Learning methods to combine linguistic indicators: Improving aspectual classification and revealing linguistic insights, Computational Linguistics 26: (4) ((2000) ), 595–628, http://www.aclweb.org/anthology/J00-4004. doi:10.1162/089120100750105957. |
[29] | C.S. Smith, The Parameter of Aspect, Kluwer, Alphen aan den Rijn, The Netherlands, (1991) . doi:10.1007/978-94-015-7911-7. |
[30] | C.S. Smith, Modes of Discourse: The Local Structure of Texts, Vol. 103: , Cambridge University Press, Cambridge, (2003) . doi:10.1017/CBO9780511615108. |
[31] | M. Stede, S. Afantenos, A. Peldszus, N. Asher and J. Perret, Parallel discourse annotations on a corpus of short texts, in: Proceedings of LREC, Portorož, Slovenia, (2016) , pp. 1051–1058. ISBN 978-2-9517408-9-1. |
[32] | S. Teufel, Argumentative zoning: Information extraction from scientific text, PhD thesis, University of Edinburgh, 2000. |
[33] | Z. Vendler, Verbs and times, The Philosophical Review 66: (2) ((1957) ), 143–160. |
[34] | H.J. Verkuyl, On the Compositional Nature of the Aspects, Reidel, Dordrecht, (1972) . doi:10.1007/978-94-017-2478-4. |
[35] | A. Zarcone and A. Lenci, Computational models of event type classification in context, in: Proceedings of LREC, Marrakech, Morocco, (2008) , pp. 1232–1238. |
[36] | M. Zhou, A. Frank, A. Friedrich and A. Palmer, Semantically enriched models for modal sense classification, in: Workshop on Linking Models of Lexical, Sentential and Discourse-Level Semantics, Lisbon, Portugal, (2015) , pp. 44–53, http://www.aclweb.org/anthology/W/W15/W15-2705.pdf. |


