
Defeasible argumentation over relational databases
Abstract
Defeasible argumentation has been applied successfully in several real-world domains in which it is necessary to handle incomplete and contradictory information. In recent years, there have been interesting attempts to carry out argumentation processes supported by massive repositories developing argumentative reasoning applications. One of such efforts builds arguments by retrieving information from relational databases using the DBI-DeLP framework; this article presents eDBI-DeLP, which extends the original DBI-DeLP framework by providing two novel aspects which refine the interaction between DeLP programs and relational databases. First, we expand the expressiveness of dbi-delp programs by providing ways of controlling how the information in databases is recovered; this is done by introducing filters that enable an improved fine-grained control on the argumentation processes which become useful in applications, providing the semantics and the implementation of such filters. Second, we introduce an argument comparison criterion which can be adjusted at the level of literals to model particular features such as credibility and topic expertise, among others. These new tools can be particularly useful in environments such as medical diagnosis expert systems, decision support systems, or recommender systems based on argumentation, where datasets are often provided in the form of relational databases.
1.Introduction
Argumentation represents a sophisticated mechanism for the formalization of commonsense reasoning, which has found application and proven its importance in different areas of Artificial Intelligence (AI) such as legal systems, multi-agent systems, and decision support systems among others (see [4,21,26,30]). Intuitively, an argument is a coherent set of statements that supports a claim; the acceptance of this claim will depend on a dialectical analysis (formalized through an inference procedure) of the arguments in support of the claim and considering those arguments against that support [30].
In the literature, a particular kind of argumentation systems can be identified, namely Rule Based Argumentation Systems (RBAS) [2,14,18,28]. In RBAS, arguments are built from a specific knowledge base of rules and facts, which in many cases represents an important drawback, as all the available information needs to be explicitly encoded in such rules and facts; this may be an obstacle for their application to real world situations where often there is an enormous amount of data to be included, and encoding explicitly such data would make the RBAS highly impractical [10]. Because of this problem, recently there has been an increasing interest in connecting argumentation approaches with massive data repositories, such as relational databases or the Web [7,13,22,29,36].
The research presented here is related to those works focused on enabling argumentation over massive repositories but following a different direction. Our goals are not only to provide means of interaction between the argumentation mechanisms and relational databases, but also to introduce means of controlling the interaction itself and how it affects the proof procedure used to warrant claims through the argumentation process. To achieve this, we will take as the basis for our work the DBI-DeLP (Database Integration for Defeasible Logic Programming) framework developed in [13], revising and expanding several parts in it to achieve the mentioned goals. In particular, a key aspect to be considered for this is that different information sources can have attached different epistemic importance (whether it reflects credibility, weight, probability, etc.); thus, it is important which particular source is providing the support for literals in arguments. Moreover, such epistemic importance may vary as the topic changes, and then we argue that it is not advisable to simply establish an order among databases, but rather we have also to consider literals themselves in the equation.
To model this, we will introduce the notion of authority, which represents the topic expertise associated with a specific database regarding the particular predicate it gives support to; using this concept we introduce eDBI-DeLP (extended DBI-DeLP), an extension of framework developed in [13], whose main contribution will be twofold. On the one hand, we introduce a mechanism to control how the data supporting an argument is to be retrieved from databases; this is achieved by using filters, which provide the user with a way to restrict the databases in which the data should be searched. These filters can take different forms; for instance, we can restrict the search to those databases with a maximal authority for the given predicate, or ask to retrieve those results which have more consensus on the set of available databases. On the other hand, we provide an argument comparison criterion tailored for our scenario of obtaining data to build arguments from databases. Such comparison criterion will be based on the use of an argument valuation function that considers both the inherent strength associated with rules in the program and the authority assigned to the databases that provide the data that enables the use of these rules. In this way, the dialectical process outcome becomes influenced by the authority of the repositories used to construct arguments, a feature which can be of great benefit in different application domains by focusing the process on the pertinent data. For instance, in a medical setting we can have databases corresponding to different hospitals, attaching higher authority to those pieces of information coming from hospitals specialized in various areas of expertise (e.g., burn and skin injuries, cancer treatments, etc.), rather than plainly adopt a general ranking among all hospitals. This approach can help to identify which arguments should prevail in different situations (e.g., a good argument concerning how to treat skin cancer should combine high-quality information from the skin-specialized hospital and the cancer-specialized hospital).
The remainder of the paper is organized as follow: in Section 2, we review DeLP, the formalism that supports eDBI-DeLP; in Section 3, we outline a possible structure that allows the realization of argumentation processes over information stored in databases, focusing on how to control the interaction between the rules in the program and relational databases, and how such interaction influences the dialectical process used to warrant arguments; in Section 4, we present a complete structure that enables the objectives of this paper. Finally, in Section 5, we introduce the main conclusions obtained and discuss the pertinent related works, identifying lines for future research work as well.
2.Preliminaries
We will begin by giving a brief summary of Defeasible Logic Programming (DeLP) [18], a formalism that combines results from Logic Programming and Defeasible Argumentation providing the possibility of representing information as rules in a declarative manner, and a defeasible argumentation inference mechanism for warranting the entailed conclusions. These rules are the key element for introducing defeasibility and they are used to represent a relation between pieces of knowledge that could be defeated after all things are considered.
Assuming certain familiarity with Logic Programming, the language of DeLP can be succinctly described as follows. A term is either (a) a constant, (b) a variable, or (c) if f is a functor and
Strict and defeasible rules are ground, nevertheless, following the usual practice in logic programming [23], we use schematic rules with (meta-)variables in them, that stand for all possible grounded instances of such rules. To distinguish these variables from other elements in a schematic rule, we adopt the notation of logic programming, where variable names begin with uppercase letters, and where constant and predicate names begin with lowercase letters. For example, actor(Person) ← performs_in(Movie, Person) represents a strict rule; and good_movie(Movie)
A defeasible rule with an empty body is called a presumption. Presumptions are assumed to be true if nothing could be posed against them. In [18,25] an extension to DeLP that includes presumptions is presented, where an extended delp is a set of facts, strict rules, defeasible rules and presumptions.
From a DeLP program it is possible to infer tentative information and these inferences are called defeasible derivations, and are computed by backward chaining applying the usual SLD inference procedure used in logic programming. Strong negation can appear in facts and presumptions, or generally in the head and body of strict and defeasible rules; therefore, it is important to note that from a program it is possible to obtain contradictory literals; but, the set Π used to represent non-defeasible information is non-contradictory, i.e., Π is such that no pair of contradictory literals can be derived from Π. This last restriction is methodological since from an inconsistent Π all the language can be obtained.
An argument for a literal L, denoted
It seems natural that in a setting where arguments are supported by information extracted from databases, the characteristics of such databases, e.g., the credibility associated with them should influence the preference of an argument over another. Moreover, we argue that those characteristics should take into account the topics considered as well, since a database could be reliable for a particular topic but be completely inadequate for another; for instance, a database with movie information provided by users can be a good resource when we try to find out by looking at the ratings provided by the users whether a movie is good or not, but it may not be reliable when trying to find out the salaries earned by the actors who participated in the film and, on the other hand, a database provided by the Internal Revenue Service should be a good fit for the latter topic, but not for the former. To model this, we introduce the concept of authority, denoted
3.Defeasible argumentation over databases
DeLP enables query resolution by an argumentative process which deals with incomplete and potentially contradictory information. Several real-world applications have been proposed on the basis of DeLP, such as recommender and decision-support systems [27], multi-agent systems [35], agreement technologies [6], etc. However, many of these real-world environments require massive repositories of data; thus, DeLP requires additional features to handle such data, since this cannot be achieved by including new data as a static part of the program. The DBI-DeLP framework [13] is an extension of DeLP that uses relational databases as the source of the information on which arguments are based. This framework has been proven useful in the definition of new architectures for argumentation-based applications which have the above mentioned requirements [9]. In what follows, we will add new components to the framework presented in [13], and redefine others in such a way they suit our objectives. The extended DBI-DeLP framework will be called eDBI-DeLP.
3.1.Representing knowledge in the framework: Interaction between rules and databases
The eDBI-DeLP framework will enable argumentation supported by information stored in relational databases. In what follows, we will describe how this can be achieved, introducing ways of representing the information stored in the databases in the context of a DeLP-like program. First, we will introduce an annotated form of literals extending the notation with additional information regarding the information the literals represent; this extra information may take diverse forms, e.g., describe conditions that must be met for the literal to hold, or provide information about which sources we shall use to support the literals. Then, an annotated literal is defined as follows:
Definition 1
Definition 1(Annotated literal).
Given an atom
The extra information is called
ϵ filter: indicates that the literal is supported from databases; thus, if a literal with this filter is included in a rule it is unnecessary to look into the facts in the program to prove the literal.
max filter: indicates that we should retrieve only tuples from databases that have the maximal authority value for the predicate that the filter is annotating; for instance,
maj filter: states that we should use a majority approach when retrieving information. That is, we should retrieve information that is replicated in most databases; for instance,
source filter: establishes which databases we will search for support for the annotated literal; e.g.,
excluded_source filter: prohibits some source to be used as support for the literal; for instance,
Definition 2
Definition 2(Strict rules and defeasible rules).
Given a literal L, i.e., a ground atom or a negated ground atom, and a finite, non empty, set
A strict rule is an ordered pair “
A defeasible rule is an ordered pair “
To properly represent information coming from relational databases the eDBI-DeLP framework adopts the notion of presumptions [18] for representing “defeasible” facts, thus avoiding inconsistencies in the strict knowledge as required in DeLP. Given a database D, their operative presumptions (OPs) are those tentative facts associated with the information stored in D. Such tentative facts are represented by means of annotated literals, and then they contain information of the filters used in the retrieval of tuples from databases (if any). In addition, in this work we will attach to every presumption which is supported by tuples in a relational database (i.e., to every OP) additional information regarding the authority of the sources that gives support to the operative presumption. Formally, these presumptions are defined as follows:
Definition 3
Definition 3(Annotated operative presumption).
Let X be a set of predicates, pred the predicate name for some predicate
Given an operative presumption
The set of all OPs for given sets of predicates X and set of databases
Example 1.
Suppose that we have the predicate 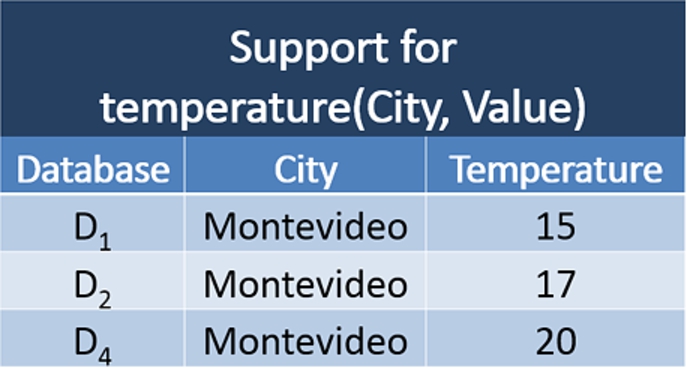
Then, we can build the OP
To see how filters affect the way OPs are built consider now the case where we have
In this manner, operative presumptions are used to represent the information available in the databases so they could be used to build arguments. Nevertheless, given that in this work we use annotated operative presumptions which are different from the presumptions used in [18], then we could not simply reuse the standard derivation in DeLP used in that work. Then, we present now a modified version of derivation, tailored to our particular setting.
Definition 4
Definition 4(DB-based defeasible derivation).
Let Π be a set of strict rules and facts, Δ be a set of defeasible rules, X the set of every predicate in the rules of
(a)
(b)
(c) there exists a rule
if
if
When there is some operative presumption or defeasible rule in a derivation we call such derivation a defeasible derivation.
As a remark note that here we use the same notational practice adopted from Programming Logic for DeLP regarding schematic rules. That is, in eDBI-DeLP all strict and defeasible rules are grounded, but for notational simplicity we will present them using meta-variables that represent all the grounded instances of them. Nevertheless, if we were to use variables in the programs then we could apply a substitution schema such as the one introduced by Capobianco et al., [10].
Arguments in eDBI-DeLP are obtained in the same way explained previously for DeLP, but using the derivation procedure stated in Definition 4.
Definition 5
Definition 5(Arguments in eDBI-DeLP).
Let Π be a set of strict rules and facts, Δ be a set of defeasible rules, X the set of every predicate in the rules of
(1) there exists a defeasible derivation for Q from
(2)
(3)
Given an argument
For the sake of simplicity through the rest of the paper we will often omit the claim in an argument, i.e., we will refer to
An eDBI-DeLP program (edbi-delp) accounts for a DeLP program (as defined in Section 2) along with a set Σ of operative presumptions, associated with a number of available databases
Definition 6
Definition 6(eDBI-DeLP program).
Let
Now we describe the process used to answer queries from an edbi-delp. In Definition 4 we have outlined how eDBI-DeLP constructs arguments to solve queries by a backward chaining process. That is, when eDBI-DeLP is searching for an argument in support of a literal L, the argument construction might involve a strict or defeasible rule having L in the head; then, DeLP tries to prove the literals in the body of this rule. These literals in the body are called Target Goals
Definition 7
Definition 7(Target goals).
Let Π be a set of facts and strict rules, and Δ a set of defeasible rules. Given some strict rule
The TGs are a key element in eDBI-DeLP, as they are the connection between the rules in the program and the records in databases. As such, since they emerge from rules then TGs clearly depend on the particular sets of strict and defeasible rules being considereng in an edbi-delp. Every TG will be analyzed following the traditional SLD procedure, using all the rules, facts and presumptions in the edbi-delp. For the purpose of this work, we focus on how presumptions can be obtained from the available databases. To do so, a search for operative presumptions is launched to retrieve from the databases information offering support to the literal (if any). For this, we begin by identifying the data sources; i.e., the databases, and the tables and fields in it, that are expected to have useful data for the TG. The triplet [database, table, field] in the data source is called a Parameter Source (PS), formally,
Definition 8
Definition 8(Parameter source).
Given a set
Each potential data source of useful information for a given TG is linked to the corresponding TG through a Pertinence Relation. Moreover, in this relation we find the information regarding the authority assigned to a database with respect to a particular predicate. It is important to remark that authority is information extra that is attached to the pertinence relation for further use in the warranting of arguments, but does not affect whether or not a data source is pertinent for a TG.
Definition 9
Definition 9(Pertinence relation).
Given a set D of available databases
We assume that the Pertinence Relation is given as an input to the system; in Section 4.3 we show how this relation is implemented through a particular structure.
Intuitively, if a data source is pertinent for a TG then we can use that data source to support that TG, i.e., we can obtain the necessary tuples (and, in turn, built the necessary OPs) from this source. Once we know which data sources are pertinent, we have to retrieve from them the data and make it available to the DeLP core which builds answers to the query using this data, along with the rest of the edbi-delp. This retrieval is made by the application of the Presumption Retrieval Function (PRF).
Before introducing the PRF, however, we will introduce the Tuple To Presumption Function (TPF), as a previous step to formally define the filters that we will consider through the paper. As its name suggests, the TPF is a function that takes a set of tuples (possibly with some other parameters) and built presumptions that can be used by the argumentative process presented in the paper. Formally, a TPF is as follows.
Definition 10
Definition 10(Tuple to presumption function).
Let
A Tuple To Presumption Function
Clearly, the TPF models a family of functions that transform tuples (along with additional information) into operative presumptions, rather than a particular constructive function. In this work we call filters to the particular instances of the TPF that we will use when operative presumptions are built.
So, filters are functions that focus on certain subsets of the whole set of presumptions that could be retrieved from the databases to support certain literals. We have already intuitively introduced the set of filters that we will use in this work. Now we will look more deeply into how such filters behave, that is, we will introduce the particularizations of the TPF that we will use through this paper. In what follows let
The ϵ filter simply builds the presumptions based on the tuples received and the authority for the pair (
Definition 11
Definition 11(ϵ filter).
Given
․ there exists
The max filter only returns those presumptions built based on tuples retrieved from databases with the maximal authority for the given TG.
Definition 12
Definition 12(max filter).
Given
there exists
there does not exist
The maj filter returns presumptions supported in the greater number of databases, assigning as the authority for the presumption the maximal authority among the ones assigned for the databases containing the tuple and the given target goal.
Definition 13
Definition 13(maj filter).
Given
there exists
there does not exist
The source filter builds the presumptions based on the tuples received and the authority for the pair (TG, DB) under consideration, filtering out those based on tuples retrieved from databases that are not listed on its parameter.
Definition 14
Definition 14(sources filter).
Given
there exists
The excluded_source filter builds the presumptions based on the tuples received and the authority for the pair (TG, DB) under consideration, filtering out those based on tuples retrieved from databases listed on its parameter.
Definition 15
Definition 15(excluded_sources filter).
Given
there exists
The set of filters introduced is the particular one that we will consider in the present work, but clearly could be expanded to suit other application environment needs if necessary. We can show that the filters max, maj, source and excluded_source are proper instances of TPF (that is, the ϵ filter).
Proposition 1.
Let
Then, for any
Proof.
Let
We begin with the analysis of the
From (1) and Definition 11 it follows that there exists
We omit the proofs for filters
Now that we outlined all filters that will be considered in the paper, we are ready to introduce the Presumption Retrieval Function. The goal of the PRF is to feed the argumentation process with relevant data obtained from the pertinent data sources, along with information regarding the authority assigned to such datasources for the topic addressed by the particular literal that is trying to support.
Definition 16
Definition 16(Presumption retrieval function).
Let
The Presumption Retrieval Function
for every
there exists
Therefore, the PRF function retrieves database tuples from pertinent data sources with values equal to the corresponding constant values. Notice how the PRF function formalizes the effects of the different filters available by conditioning the retrieval of tuples. Clearly, Definition 16 is flexible enough to allow an easy expansion of the set of filters proposed.
To see an example of how the PRF works, consider a database  unifying the non grounded parameter (i.e., schematic variable) Actor with both stallone and snipes with an assigned authority of 0.9. As we can see, (performs_in(rambo, stallone), 0.9) is not in S as the tuple (rambo, stallone) does not match the value required for the grounded parameter.
unifying the non grounded parameter (i.e., schematic variable) Actor with both stallone and snipes with an assigned authority of 0.9. As we can see, (performs_in(rambo, stallone), 0.9) is not in S as the tuple (rambo, stallone) does not match the value required for the grounded parameter.
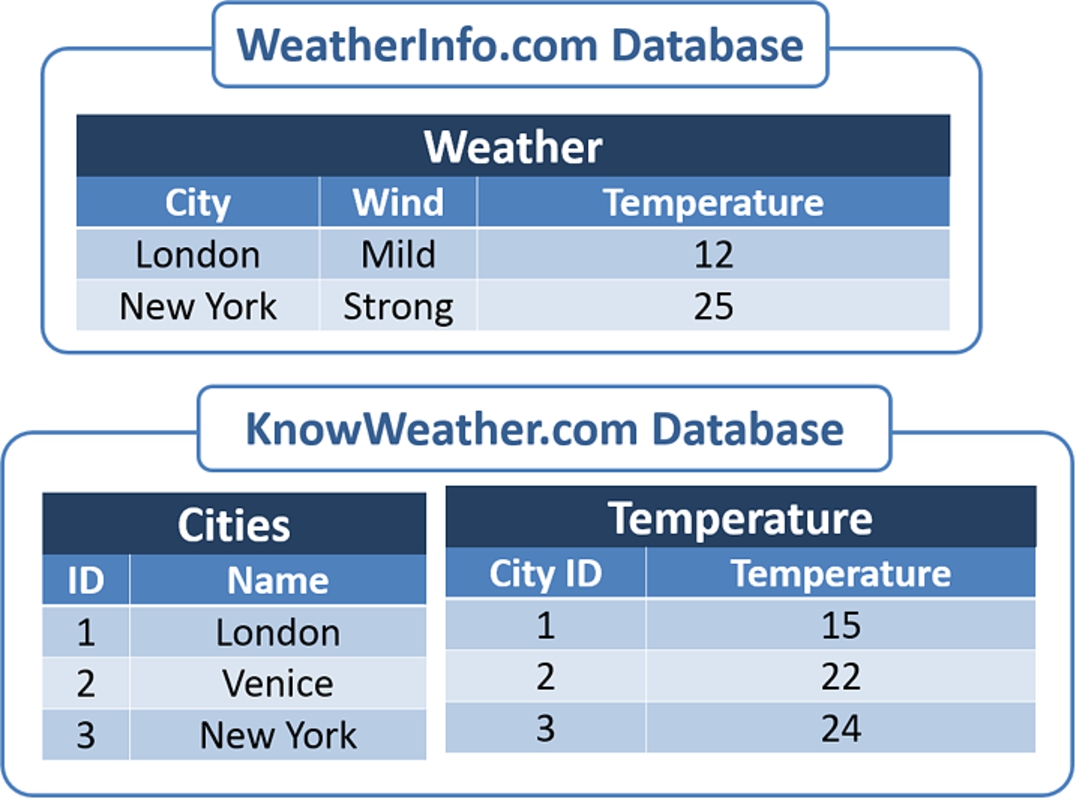
Now, to see an example of how filters are applied consider the following situation. Suppose that we have the databases depicted in Fig. 1, and the TG 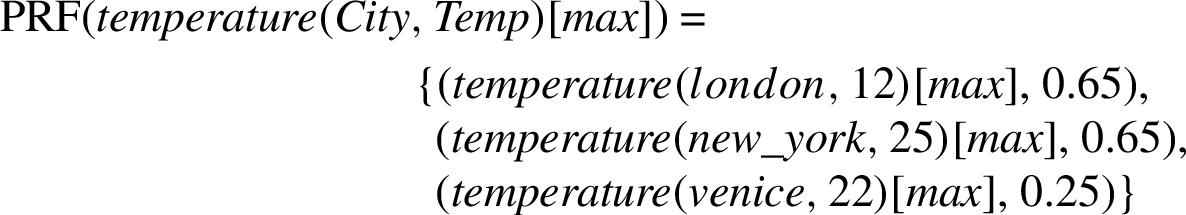
Fig. 1.
Weather databases.
3.2.Argument preference in database-supported argumentation processes
So far we have introduced a retrieval mechanism to obtain data to support the construction of arguments from databases together with other information associated that can be used to measure the value of such information. As explained in Section 2, to find out whether a literal is warranted, a dialectical process is carried out, looking to find an argument for that literal that is not defeated under an established defeat relation. Even when it is possible to abstract from the way in which the defeat relation is obtained, usually in practice it is better to be able to calculate the relation by taking advantage of the particular meaning of the domain [17]. A key component to obtain a defeat relation is the argument comparison criterion, which is used to decide whether or not an argument is preferred to another. In this section we will introduce a comparison criterion that we will use in eDBI-DeLP. Such comparison criterion makes full use of the authority assigned to a database regarding its specific topic (i.e., the different predicates) to model topic expertise.
Next we define the rule in an argument that is used to infer the corresponding claim supported by that argument. Formally:
Definition 17
Definition 17(Claim inferring rule).
Let
r is a strict rule with
We will now establish how the value of an argument is obtained in eDBI-DeLP, i.e., how the authority assigned to presumptions and the valuation in rules is combined to calculate a final value for an argument. Formally, the argument valuation in eDBI-DeLP proceeds as follows.
Definition 18
Definition 18(Argument valuation function).
Given an edbi-delp
Intuitively, the valuation of an argument is made by combining the intrinsic valuation of its claiming rule with the valuations of its subarguments. To do so, we take the product of the less-valued element in the body of the rule and the numerical valuation of the rule, following a cautious approach similar to the propagation of necessity degrees in P-DeLP (Possibilistic Defeasible Logic Programming) [1]. Nevertheless, it is clear that this approach can be modified as needed to suit the particular requirements of the different application environments, e.g., we could use an average of the values obtained for the elements in the body.
In eDBI-DeLP the argument valuation function will be used as the argument comparison criterion. First, however, we will formally introduce the notion of counter-argument. Intuitively, an argument counter-argues another when a contradiction arise when considering both arguments along with the strict information in the program. Formally this is as follows.
Definition 19
Definition 19(Counterargument).
Given
Therefore, using this notion of counter-argument and the argument valuation in eDBI-DeLP, we will formalize the notion of defeater in our framework.
Definition 20
Definition 20(Defeat).
Given
(a)
(b)
Example 2.
To see how the argument valuation and the comparison criterion work, let’s consider the following situation. Suppose that in our program we have the rules 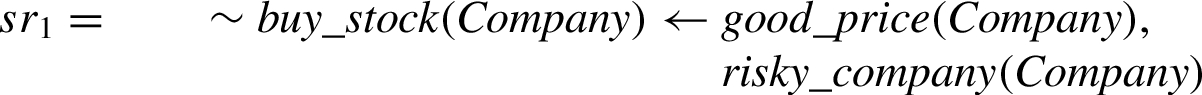 and
and 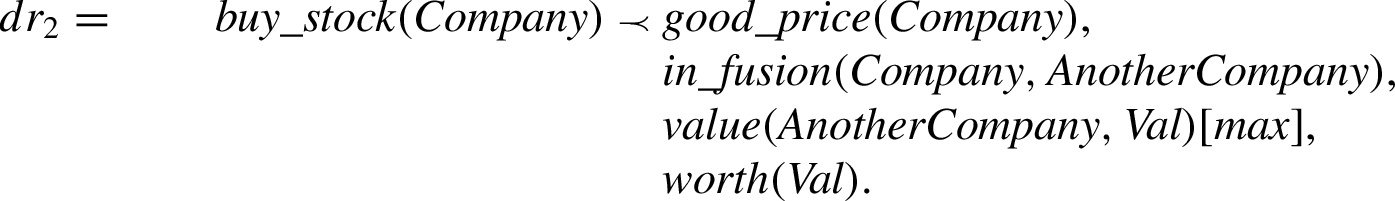 where the valuations for the rules are
where the valuations for the rules are
Now, assume that we have the argument: 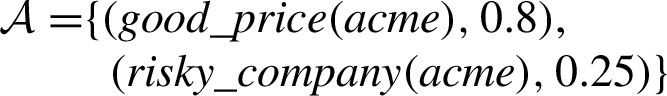 which uses
which uses
On the other hand, assume that we build argument  for
for
In addition, note that
4.Components of the framework
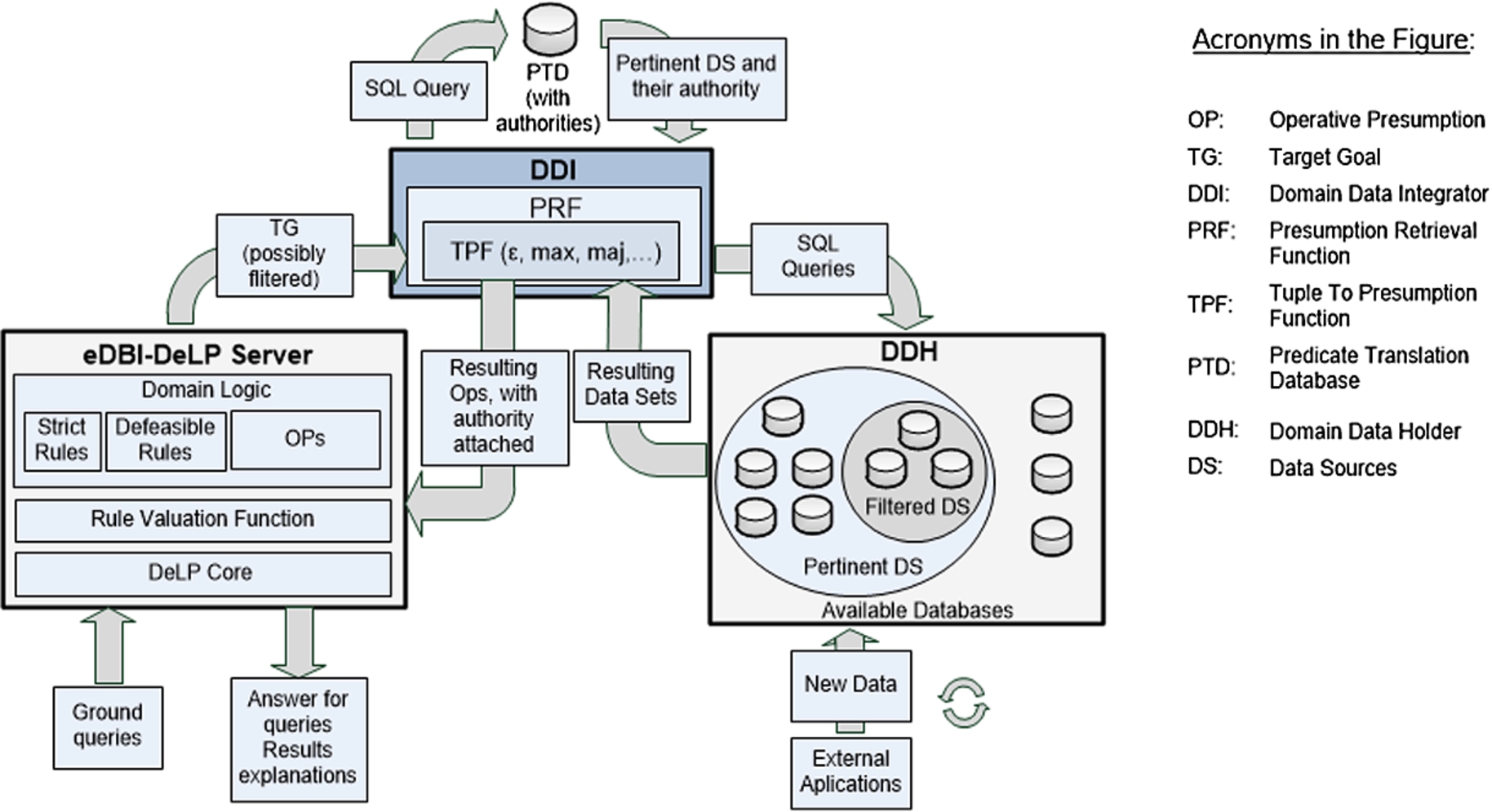
In order to integrate DeLP with a database system we need to identify which databases can be used during the argumentation process. We assume that our database system may involve several databases, which are accessed asynchronously. At runtime, new databases could be added or existing databases could be removed from the system. To formalize this setting in a seamless way, we must maintain compatibility with external systems, so that both the DeLP inference mechanism and the databases schemas can remain unchanged. To achieve this we establish a translation layer between the argumentation process and the databases, where the architecture is based on the following three components.
4.1.EDBI-DeLP server:
This component takes care of the argumentation process; that is, it receives a DeLP ground query, and then builds arguments and counter-arguments based on an edbi-delp, providing answers and explanations on how they were built. This component plays a central role in the framework, carrying out the valuation for rules and applying the comparison criterion for argument-based decision making. The component includes two modules to separate knowledge storage issues from the actual usage of such knowledge: Domain Logic and DeLP Core. Finally, the Rule Valuation Function is a component used to provide valuations for rules in the program.
– Domain Logic: is the knowledge of the domain that the system has. It is expressed as (part of) an eDBI-DeLP program. Thus, this component comprises strict rules and facts, defeasible rules, and also operative presumptions.
– DeLP Core: The argumentation process is carried out by the DeLP core. It receives a query from a client and tries to build arguments for and against it, and finally gives the obtained answer. Clearly, this is a key component in terms of the goal of our work, which is establishing how preference between arguments can be obtained by analyzing the different sources used. Note that this component will effectively apply the preference criteria for argument-based decision making. However, no major modifications need to be done to it, since the use of argument preference criteria in DeLP is modular [18], and thus we can directly change the comparison criterion, adapting it for its use when contrasting database-supported arguments.
– Rule Valuation Function: This component is used by the user to provide the υ relation in an edbi-delp; thus, it maintains the valuation for every rule in the Domain Logic.
4.2.Domain data Holder (DDH):
This component represents the set of databases that can be accessed to support arguments.
4.3.Domain data integrator (DDI):
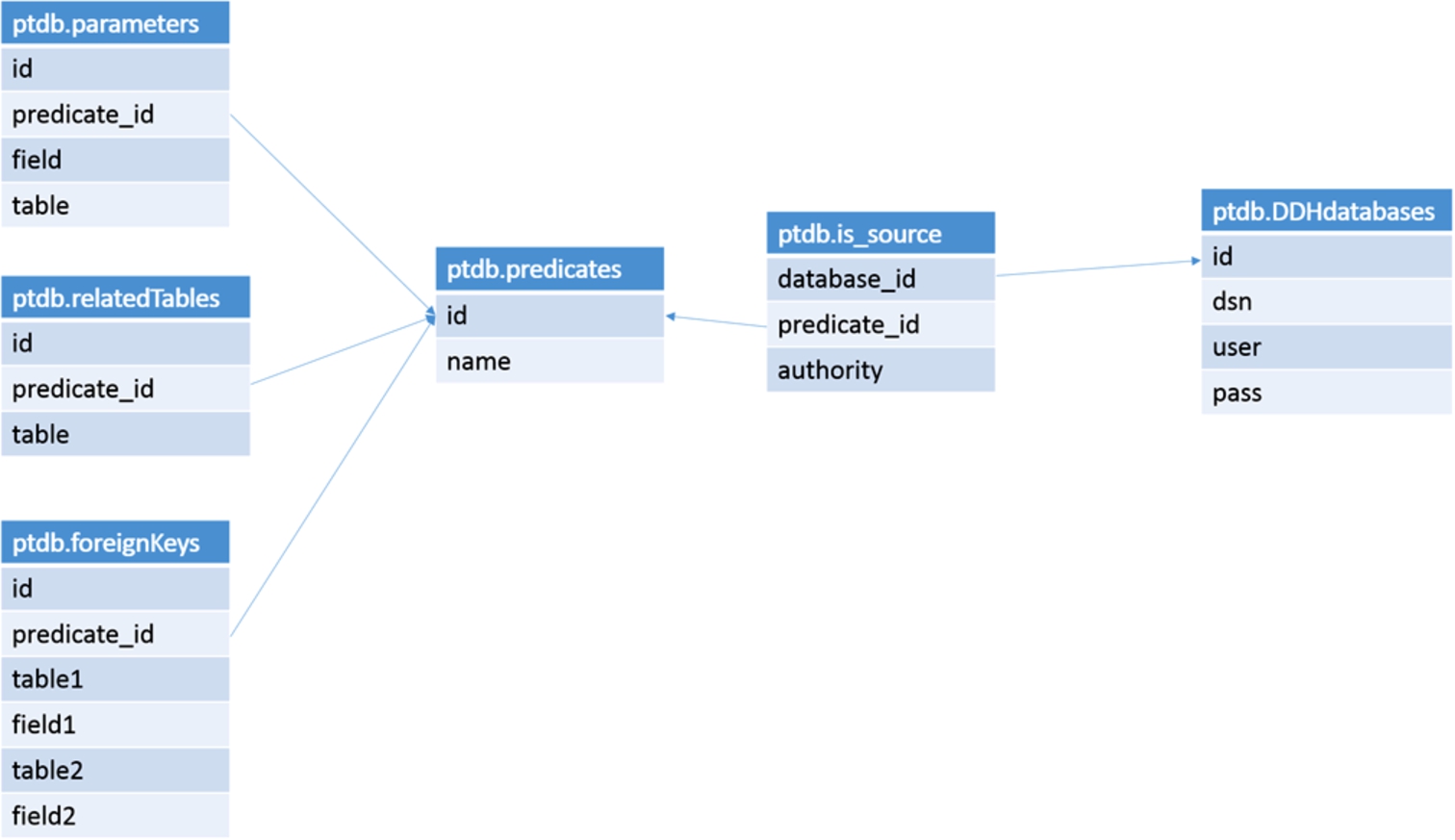
The DDI retrieves the necessary information from the DDH and feeds it to the DeLP Core so it can be used in the argumentation process. The information needed by the DDI to perform this translation is provided by the Predicate Translation Database (PTD). Thus, this database is used to implement Definition 9 into the framework; that is, PTD maintains information about relations between predicates and data sources which enable the information retrieval from that sources that the user indicate as potential support sources. In addition the PTD can store additional information regarding some characteristics (e.g., quality or credibility) associated with the database in the matters of the particular predicate, for every predicate that can be supported with information in a database in the DDH. For example, we want to store that for the predicate
– Predicates table: it has information about predicate’s functors in the program that are able to be supported by some databases in the DDH.
– DDH databases table: stores the information needed to connect with every database available in the DDH.
– Is_source database: indicates when certain databases can be used to support a given predicate; it also stores information to be used by arguments’ preference criteria, i.e., the authority given to the database to support the predicate.
– Parameters table: it maintains the equivalence between a predicate’s parameter and a pair (table, field).
– RelatedTables table: it keeps information about the tables that take part in the SQL JOINS needed to obtain information about a particular predicate.
– ForeignKeys table: it maintains a list of the pairs (primaryKey, foreignKey) on which the SQL JOINS have to be made.
Fig. 2.
The predicate translation database schema.
With the introduced architecture it is possible to carry out argumentation processes capable of relying on information from relational databases to provide argument support. The interaction among the components in the framework when solving a query is depicted in Fig. 3. The process is executed each time the eDBI-DeLP Server receives a query.
Remark 1.
The process of answering a query is considered as part of a closed transaction in the sense of database theory. This is because the available databases (i.e., their current state) are part of the edbi-delp. Thus, if we change some database then we are modifying the program as well, but since queries are posed to particular programs then they are solved with the information available when the query arrives.
Fig. 3.
The eDBI-DeLP argumentation process.
The Obtain Instantiated Parameters function receives a list of parameters from a function objective and returns those that are ground. For example, for the predicate director(Movie, tarantino) the function returns the list [tarantino], while for the predicate film
The Obtain Instantiated Fields function takes a list of fields and a list of parameters and returns those fields corresponding to instantiated parameters. For example, if the function receives [[table.field1, table.field2], [Movie, tarantino]] then it returns [table.field2].
The Generate Operative Presumptions function receives a functor’s name, a list of values and an authority
After outlining the auxiliary functions for the algorithm, we show in Algorithm 1 the implementation for the process used by eDBI-DeLP to obtain Operative Presumptions for a TG, i.e., the Presumption Retrieval function. We also present the implementation of the filters previously introduced in the paper, which will help Algorithm 1 to achieve its goal.
Algorithm 1
Presumption retrieval function

Now that we have presented the algorithms used to retrieve argument supporting information from the databases we will briefly look into their computational complexity aspects. In [13] it was shown that the non-filtered version of the PRF has a complexity of
Algorithm 2
Tuples to presumptions function

Algorithm 3
Max filter function

Algorithm 4
Maj filter function

Algorithm 5
Sources filter function

Algorithm 6
Excluded sources filter function

5.Conclusions and related work
We have shown an approach to combine defeasible argumentation with relational database technologies, where the latter is used to obtain information that enables the construction of arguments to support claims. In particular, in this work we focused on providing more control on how such information is obtained by using methods that state how the developer expects that certain literal in a rule is to be supported. For providing such control we presented a filtering mechanism. Rather than being tailored for particular scenarios, this fine-grained control is versatile enough to be useful in different application domains. Moreover, even when we have presented a particular set of filters, to expand such set only involves altering Definition 16 providing the semantics for the new filters (and perhaps modifications of the PTD, if new information regarding the sources is required for the filters). This makes the framework flexible enough to handle dynamic environments where new requirements can arise: such requirements may involve new needs that may be better captured by modifying the argument support mechanism adding new filters rather than modifying the rules in the program to capture said needs.
We were also concerned about how the characteristics of the databases involved in the argument construction process influence the dialectical analysis performed by the argumentation system. Since different sources can have a different level of expertise in the different aspects involved in the argumentation, instead of using a preference order between the different databases, we claim that it is also important to consider which literal the process is trying to support; for instance, we can have a greater confidence in a database storing tax income information when trying to support a literal regarding the salary of certain person rather than using a database with information regarding the films that person likes.
To model the topic expertise we have chosen to associate a pair (predicate, database) with a value representing the authority assigned to the database for the particular topic the predicate is about. Then, when trying to establish the defeat relation between arguments we combine this authority with the value associated with the rules in each argument. This provides a valuation for these arguments which can be used to compare them to adjudicate the defeat of one over the other. This combination is used in a cautious approach where we combine the valuation of the rule that infers the claim of the argument with the least valued element in the body of such rule; nevertheless, even when we presented a particular valuation function, to modify such behavior only involves the modification of Definition 18 to accommodate it to the particular needs of the application domain. For instance, to be less cautious, we can consider the average between the values in the elements of the body of the rule instead of the minimal value. Moreover, if we prefer to follow a credulous approach, we can consider the maximal value in elements instead. As it was explained, to include such modifications in the framework is straightforward, and will not affect how the rest of the framework works, only affecting final answers to queries.
Recently, the research community has developed an interest in integrating relational database technologies with defeasible argumentation systems. In particular, although this paper builds on [13], here we have extended that work in several novel aspects. The main focus of [13] was to formally support the construction of arguments using information coming from relational databases; however, in that paper no further control on how to interact with such databases was provided. Here, we extended and adapted the method to retrieve information from the databases to introduce the notion of filters. In contrast with [13], this extension provides a tool to modify how tuples from databases should be retrieved, and along with filters we also introduced the use of authority.
In [13], no particular comparison criterion was introduced, and the use of databases did not influence the dialectical process itself, even when they did influence the argument building process. Here, we acknowledge such influence providing means to control how the use of particular sources of information results on different answers to queries. We also provide a definition of argument valuation that accounts for the particular characteristics of the databases that support the argument along with a comparison criterion tailored for such valuation. Finally, we have extended and revised other aspects of the framework presented in [13] such as the derivation mechanism, the Predicate Translation Database, and the algorithm used to retrieve Operative Presumptions (among others) to achieve the above mentioned goals.
In [36], Wardeh et al. introduced a protocol called PADUA to support two agents debating a classification by offering arguments based on association rules mined from individual datasets. In contrast with our approach, this research connects databases with argumentation from a machine learning perspective, including as well a large scale evaluation designed to test the effectiveness of using PADUA to detect misclassified examples, and to provide a comparison with other classification systems. In [3] the problem of using defeasible reasoning in a massive data repository was addressed, but instead of using databases to look for information to support conclusions its repository is the Web, more specifically the Semantic Web. Recently, several large-scale domain-dependent datasets have been released, providing additional motivation for the development of the framework proposed in that paper. Thus, using databases we probably will have access to the same repositories that those accessed by the system in [3], and even more.
Regarding databases, there is research related to the use of non-monotonic reasoning to resolve inconsistencies in databases by means of database repairs [32]. Although this approach can resolve inconsistencies in databases allowing reasoning on data stored in them, database repair is conducted by the explicit addition, modification or suppression of tuples in databases. Instead, our approach is based on a conflict resolution strategy using argumentation, avoiding thus any modification of the actual information stored in the database. Other approaches to deal with the issue of inconsistent databases are presented in [5,11], where instead of repairing the databases, modifications to queries are made to provide consistent answers to them. In eDBI-DeLP we always obtain consistent answers as inconsistency will be managed automatically by the DeLP Core and the proof procedure using the domain information. In addition, in eDBI-DeLP the filtering mechanism provides tools to discard potentially contradictory information, as we have shown in Example 1 where the max filter is used to retrieve only one temperature value of a given city (the one in the database with the maximum authority).
Another approach that uses databases as the basis of a reasoning process is presented in [12]. The aim of the reasoning mechanism is to address the different conflicts that may arise when merging several databases. Nevertheless, the databases used in that work are deductive databases, i.e., databases that are made of an extensional part – a set of positive or negative ground literals – and an intensional part, i.e., a set of first order function-free clauses. Deductive databases have some known drawbacks that are not present in eDBI-DeLP, such as the need to define criteria for using a rule included in the database as a deduction rule or a coherence rule; in eDBI-DeLP this does not happen because rules are only used to build arguments. Another well-known drawback of deductive databases is that they have the possibility of falling in infinite loops in the deduction process; this is also avoided in eDBI-DeLP using constraints over the argumentation lines [18].
Another work that is related to ours is the one in [8]. In that work the authors introduce a framework to allow for reasoning on heterogeneous sources by combining arbitrary monotonic and non-monotonic logics. To do this the authors exploit bridge rules to infer knowledge on the different contexts in play (i.e., the different logics and the belief bases obtained from them), where the bridge rules in one context are used to augment belief bases in other contexts. Based on this last feature the authors present how to achieve a certain equilibrium among the contexts, which represent acceptable belief states a system may adopt. Thus, our work can be modelled as a particular instance of Brewka and Eiter’s framework, as there are certain parallels even when the aims of the works are clearly different. It can be argued that in our work we have two different contexts in play (a non-monotonic one – DeLP – and a monotonic one – SQL), and some “one-way” bridge rules can be obtained that augment the belief base in one context (DeLP) with information obtained from the other context (the databases). In our work such bridge rules are represented through the use of the Pertinence Relation and the Presumption Retrieval Function. Nevertheless, note that there will be some differences between a “pure” multi-context system and our approach. For instance, to properly adequate our work to Brewka and Eiter’s we will have to retrieve all tuples related to each annotated literal in the program and build every operative presumption at first (i.e., we need to apply all applicable bridge rules), and then use those necessary to the dialectical process. Instead, for the sake of efficiency in our work we have chosen to only retrieve tuples and build Operative Presumptions when needed by such dialectical proof procedure.
As for future work, there are several lines of research that we are following. First, as we have discussed, the set of filters presented in this work can be easily expanded to accommodate the system to new requirements. As a future line of work we plan to tackle different application domains and develop new filters inspired in the detected needs. Moreover, in the present work we can have certain combination between filters (v.g., by using them sequentially for the same predicate in a rule); nevertheless, we want to further increase the expressiveness in our framework by providing ways to use more refined combinations (e.g., in the same annotated literal) that adhere to the original semantics of the filters combined as much as possible.
Also, several interesting questions and lines of work arise from our use of the notion of authority. For instance, in this work we have followed a cautious approach when considering how authority in operative presumptions affects the valuation of arguments, but it may be interesting to explore how less cautious approaches behave. Also, we acknowledge that in any dynamic environment a concept such as authority cannot be static. In this first approach we were not concerned with how authority may change, but we plan to integrate in the framework automatic mechanisms to update it, inspired by similar efforts in areas like Belief Revision and Trust in multiagent systems, e.g., [16,24,31,33,34,37].
It is interesting to study how to enhance this framework with semantic information about predicates allowing to automatically obtain information about the different possible data sources; e.g., one way this could be done is by using ontologies with semantic definitions for every parameter in a predicate. In this way, such ontologies may help us to identify and recognize the structure of the different data sources, allowing the definition of processes that could automatically fill the PTD. Additionally, this can help to add new capabilities, e.g., data alignment among heterogeneous databases. Notice that the presented structure of the PTD is adequate to maintain the information relating predicates and data sources provided by such processes, making the addition and modification of data sources easier. Also, the proposed framework is flexible enough to allow the automatic generation of the necessary SQL queries; thus, every modification in the PTD is reflected in the formed queries directly, because they are constructed on the fly.
We also plan to tackle on the implementation of the framework introduced in this work. As expected, for such implementation we will take as basis the one presented in [13]. Once we have implemented the new features of eDBI-DeLP we plan to perform empirical evaluations to asses the impact of such new features in the overall efficiency of the framework. As explained before, the use of filtering does not increase complexity for the PRF, but clearly execution times could be different than if no filtering is made at all. It is our intuition, however, that the impact of filtering in execution times for the PRF should not be noticeable, and that the most time-consuming task will still be the dialectical process, with little negative impact of the filtering process. Moreover, we believe that in certain situations filters will improve performance, e.g., when we use the
Finally, another line of research we are currently following is the dynamics in the knowledge in our scenario. This involves at least two different aspects. On the one hand, we want to explore how changes in the set of available databases affect the query solving process in our framework. In our current version of the paper the set of available databases is included in the edbi-delp, and thus when posing a query to a program the set of databases is fixed for that query. Indeed, if the set of databases changes then the program change, but we still should consider the previous state of the databases for queries already being solved, since they were posed to the previous state of the program. For the future we plan to allow that the databases change in a program while considering these changes for queries being solved. This poses some interesting challenges, both regarding how we treat arguments in dialectical trees supported by information no longer available, and how it affects the credibility and trust assigned to the databases (i.e., how authority reflects changes, changing in turn the defeat relation and thus the query resolution).
On the other hand, we can tackle the update of the rules in the program based on the analysis of the information stored in the DDH. In particular, as supporting information is searched in the databases, counterexamples to already known rules may arise. We plan to take advantage of such counterexamples to further refine the available knowledge. While searching for support for some TG the set of rules may be revised when data with values different to those expected are found; for example, strict rules may be weakened to defeasible ones, or new refined defeasible rules may be formed by analyzing the characteristics of the newly found data [15]. To do this, we can exploit mechanisms already developed for DeLP to make the knowledge base updates; for instance, we can take advantage of the addition and removal of elements of knowledge from a DeLP program provided by contextual queries proposed in [20].
Acknowledgements
This work has been partially supported by EU H2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No. 690974 for the project MIREL: MIning and REasoning with Legal texts, the project “Representación de conocimiento y razonamiento argumentativo: Herramientas inteligentes para la web y las bases de conocimiento”, PGI 24/N040 funded by the Universidad Nacional del Sur, and PID UNER 7042 funded by the Universidad Nacional de Entre Ríos (UNER). This work is also funded by the Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET), from Argentina.
References
[1] | T. Alsinet, C.I. Chesñevar, L. Godo and G.R. Simari, A logic programming framework for possibilistic argumentation: Formalization and logical properties, Fuzzy Sets and Systems 159: (10) ((2008) ), 1208–1228. doi:10.1016/j.fss.2007.12.013. |
[2] | L. Amgoud and S. Kaci, An argumentation framework for merging conflicting knowledge bases: The prioritized case, in: Proc. of the Ecsqaru-2005 Conf., Lnai 3571, Springer, (2005) , pp. 527–538. |
[3] | N. Bassiliades, G. Antoniou and I.P. Vlahavas, A defeasible logic reasoner for the semantic web, Int. J. Semantic Web Inf. Syst. 2: (1) ((2006) ), 1–41. doi:10.4018/jswis.2006010101. |
[4] | T.J.M. Bench-Capon and P.E. Dunne, Argumentation in artificial intelligence, Artif. Intell. 171: ((2007) ), 619–641. doi:10.1016/j.artint.2007.05.001. |
[5] | L.E. Bertossi, Consistent query answering in databases, Sigmod Record 35: (2) ((2006) ), 68–76. doi:10.1145/1147376.1147391. |
[6] | F. Bex, I. Bratko, C.I. Chesñevar, W. Dvorak, M.A. Falappa, S.A. Gaggl, A.J. García, M.P. González, T. Gordon, J. Leite, M. Možina, C. Reed, G.R. Simari, S. Szeider, P. Torroni and S. Woltran, Agreeement technology handbook, S. Modgil and F. Toni, eds, Springer Verlag, Law, Governance and Technology Series, (2012) , Chap. Argumentation in Agreement Technologies. |
[7] | F. Bex, J. Lawrence, M. Snaith and C. Reed, Implementing the argument web, Communications of the Acm 56: (10) ((2013) ), 66–73. doi:10.1145/2500891. |
[8] | G. Brewka and T. Eiter, Equilibria in heterogeneous nonmonotonic multi-context systems, in: AAAI, Vol. 7: , (2007) , pp. 385–390. |
[9] | C.E. Briguez, M.C. Budán, C.A.D. Deagustini, A.G. Maguitman, M. Capobianco and G.R. Simari, Argument-based mixed recommenders and their application to movie suggestion, Expert Syst. Appl. 41: (14) ((2014) ), 6467–6482. doi:10.1016/j.eswa.2014.03.046. |
[10] | M. Capobianco, C.I. Chesñevar and G.R. Simari, Argumentation and the dynamics of warranted beliefs in changing environments, Autonomous Agents and Multi-Agent Systems 11: (2) ((2005) ), 127–151. doi:10.1007/s10458-005-1354-8. |
[11] | A. Celle and L.E. Bertossi, Querying inconsistent databases: Algorithms and implementation, in: Computational Logic, (2000) , pp. 942–956. |
[12] | L. Cholvy and C. Garion, Answering queries addressed to several databases according to a majority merging approach, J. Intell. Inf. Syst. 22: ((2004) ), 175–201. doi:10.1023/B:JIIS.0000012469.11873.bb. |
[13] | C.A.D. Deagustini, S.E.F. Dalibón, S. Gottifredi, M.A. Falappa, C.I. Chesñevar and G.R. Simari, Relational databases as a massive information source for defeasible argumentation, Knowl.-Based Syst. 51: ((2013) ), 93–109. doi:10.1016/j.knosys.2013.07.010. |
[14] | P.M. Dung, R.A. Kowalski and F. Toni, Dialectic proof procedures for assumption-based, admissible argumentation, Artificial Intelligence 170: (2) ((2006) ), 114–159. doi:10.1016/j.artint.2005.07.002. |
[15] | M.A. Falappa, G. Kern-Isberner and G.R. Simari, Explanations, belief revision and defeasible reasoning, Artif. Intell. 141: (1/2) ((2002) ), 1–28. doi:10.1016/S0004-3702(02)00258-8. |
[16] | R. Falcone and C. Castelfranchi, Trust dynamics: How trust is influenced by direct experiences and by trust itself, in: Proceedings of the Third International Joint Conference on Autonomous Agents and Multiagent Systems-Volume 2, IEEE Computer Society, (2004) , pp. 740–747. |
[17] | E. Ferretti, M.L. Errecalde, A.J. García and G.R. Simari, Decision rules and arguments in defeasible decision making, in: Proceedings of the 2008 Conference on Computational Models of Argument: Proceedings of Comma 2008, IOS Press, (2008) , pp. 171–182. |
[18] | A.J. García and G.R. Simari, Defeasible logic programming an argumentative approach, Tplp ((2004) ), 95–138. |
[19] | A.J. García and G.R. Simari, Defeasible logic programming: Delp-servers, contextual queries, and explanations for answers, Argument & Computation 5: (1) ((2014) ), 63–88. doi:10.1080/19462166.2013.869767. |
[20] | S. Gottifredi, A.J. García and G.R. Simari, Query-based argumentation in agent programming, in: 12th Ibero-American Conference on Ai (Iberamia 2010), (2010) , pp. 284–295. |
[21] | N.K. Janjua, F.K. Hussain and O.K. Hussain, Semantic information and knowledge integration through argumentative reasoning to support intelligent decision making, Information Systems Frontiers 15: (2) ((2013) ), 167–192. doi:10.1007/s10796-012-9365-x. |
[22] | J. Lawrence, F. Bex, C. Reed and M. Snaith, Aifdb: Infrastructure for the argument web, in: Comma, (2012) , pp. 515–516. |
[23] | V. Lifschitz, Foundations of logic programming, Principles of Knowledge Representation 3: ((1996) ), 69–127. |
[24] | J. Ma and M.A. Orgun, Trust management and trust theory revision, Trans. Sys. Man Cyber. Part A 36: (3) ((2006) ), 451–460. doi:10.1109/TSMCA.2006.871628. |
[25] | M.V. Martinez, A.J. García and G.R. Simari, On the use of presumptions in structured defeasible reasoning, in: Computational Models of Argument – Proceedings of COMMA 2012, Vienna, Austria, September 10–12, 2012, B. Verheij, S. Szeider and S. Woltran, eds, Frontiers in Artificial Intelligence and Applications, Vol. 245: , IOS Press, (2012) , pp. 185–196. |
[26] | S. Modgil, F. Toni, F. Bex, I. Bratko, C.I. Chesñevar, W. Dvŏrák, M.A. Falappa, X. Fan, S.A. Gaggl, A.J. García, M.P. González, T.F. Gordon, J.A. Leite, M. Moz˘ina, C. Reed, G.R. Simari, S. Szeider, P. Torroni and S. Woltran, The added value of argumentation: Examples and challenges in agreement technologies, S. Ossowski ed., in: Law, Governance and Technology, Vol. 8: , Springer, New York, (2013) , pp. 357–403, Chap. 21. ISBN 978-94-007-5583-3 (eBook). |
[27] | C.I. Chesñevar, A. Maguitman and M. González, Argumentation in artificial intelligence, Springer Verlag, (2009) , pp. 403–422, Chap. Empowering Recommendation Technologies Through Argumentation. |
[28] | H. Prakken and G. Sartor, Argument-based extended logic programming with defeasible priorities, Journal of Applied Non-Classical Logics 7: (1) ((1997) ). |
[29] | I. Rahwan, Mass argumentation and the semantic web, J. Web Sem. 6: (1) ((2008) ), 29–37. doi:10.1016/j.websem.2007.11.007. |
[30] | I. Rahwan and G.R. Simari, Argumentation in Artificial Intelligence, Springer, (2009) . doi:10.1007/978-0-387-98197-0. |
[31] | J. Sabater and C. Sierra, Review on computational trust and reputation models, Artificial Intelligence Review 24: (1) ((2005) ), 33–60. doi:10.1007/s10462-004-0041-5. |
[32] | E. Santos, J.P. Martins and H. Galhardas, An argumentation-based approach to database repair, in: 19th European Conference on Artificial Intelligence (ECAI), (2010) , pp. 125–130. |
[33] | L.H. Tamargo, A.J. García, M.A. Falappa and G.R. Simari, On the revision of informant credibility orders, Artif. Intell. 212: ((2014) ), 36–58. doi:10.1016/j.artint.2014.03.006. |
[34] | L.H. Tamargo, S. Gottifredi, A.J. García and G.R. Simari, Sharing beliefs among agents with different degrees of credibility, Knowl. Inf. Syst. 50: (3) ((2017) ), 999–1031. doi:10.1007/s10115-016-0964-6. |
[35] | M. Thimm, Realizing argumentation in multi-agent systems using defeasible logic programming, in: Argmas, P. McBurney, I. Rahwan, S. Parsons and N. Maudet, eds, Lecture Notes in Computer Science, Vol. 6057: , Springer, (2009) , pp. 175–194. ISBN 978-3-642-12804-2. |
[36] | M. Wardeh, T.J.M. Bench-Capon and F. Coenen, Padua: A protocol for argumentation dialogue using association rules, Artif. Intell. Law 17: (3) ((2009) ), 183–215. doi:10.1007/s10506-009-9078-8. |
[37] | F.M. Zahedi and J. Song, Dynamics of trust revision: Using health infomediaries, Journal of Management Information Systems 24: (4) ((2008) ), 225–248. doi:10.2753/MIS0742-1222240409. |


