
Complexity of logic-based argumentation in Post's framework†
Abstract
Many proposals for logic-based formalisations of argumentation consider an argument as a pair (Φ,α), where the support Φ is understood as a minimal consistent subset of a given knowledge base which has to entail the claim α. In case the arguments are given in the full language of classical propositional logic reasoning in such frameworks becomes a computationally costly task. For instance, the problem of deciding whether there exists a support for a given claim has been shown to be
1.Introduction
Argumentation is nowadays a main research topic within the area of Artificial Intelligence (Bench-Capon and Dunne 2007; Besnard and Hunter 2008; Rahwan and Simari 2009) aiming to formally analyse the pros and cons of statements within a certain scenario in order to understand implicit conflicts and to support decision-making. The overall process of formal argumentation can be considered as a sequence of the following steps; see, for instance, the work by Caminada and Amgoud (2007) or Gorogiannis and Hunter (2011): Given a knowledge base Δ, in the first step arguments are formed, and then conflicts between the arguments are identified. Next, one abstracts from the concrete contents of the arguments and uses certain semantics to find acceptable subsets of arguments by analysing solely the graph obtained from the arguments and conflicts; this particular step was first proposed by Dung (1995) who invented the concept of abstract argumentation frameworks. Finally, by inspecting selected arguments certain conclusions can be made. Towards practicably efficient realisations, a good understanding of the computational complexity of all these single steps is thus of high importance.
We focus here on the first step of this process, i.e. forming valid and plausible arguments from a given set of formulæ. This step is also sometimes referred to as logic-based argumentation (Chesñevar, Maguitman, and Loui 2000; Prakken and Vreeswijk 2002; Besnard and Hunter 2008; Amgoud and Besnard 2010) in order to separate it from the abstraction as used in Dung's frameworks. One goal in logic-based argumentation is thus to find a concrete formal representation of an argument and then to define – on top of this concept – notions such as counterarguments, rebuttals or undercuts (see Besnard and Hunter 2001). Many proposals consider an argument as a pair
Computing the support for an argument underlies many reasoning problems in logic-based argumentation, for instance, the computation of argument trees as proposed by Besnard and Hunter (2001). Since the basic task of finding a support is already computationally involved, it is indispensable to understand its sources of complexity and to identify fragments for which that problem becomes tractable. In this paper, we contribute to this line of research by restricting the formulæ involved (i.e. formulæ in the knowledge base and thus in the support, as well as the formula used as the claim). In fact, we restrict formulæ to use only connectives from a given set B of Boolean functions and study the decision problems of existence, validity, relevance, and respectively, dispensability, which are defined as follows:
• Arg (Argumentation): given Δ, α, does there exist a support
• Arg-Check (Argument Checking): given a pair
• Arg-Rel (Argument Relevance): given Δ, α, ϕ, is there an argument
• Arg-Disp (Argument Dispensability): given Δ, α, ϕ, is there an argument
• #Arg (Argument Counting): given Δ, α, how many arguments
• Enum-Arg (Argument Enumeration): given Δ, α, output all arguments
It can be seen that the minimality condition is only important for the decision problems Arg-Check and Arg-Rel (for instance, in case of Arg-Disp, there exists a support Φ without ϕ for α exactly if there exists a minimal such support; we will make this more precise in Section 2.3) as well as for #Arg and Enum-Arg. For the Enum-Arg problem, we will provide a general scheme to compute all arguments making use of decision procedures for Arg-Check, Arg-Rel and Arg-Disp. This also indicates the practical relevance of the decision problems we study, since enumerating all arguments is the central task in the overall process discussed above. However, also counting the number of arguments is of importance. Consider two different formulæ α, β, it might be of interest to know whether more arguments of form
A major tool when analysing the complexity of problems parameterised by a given set B of Boolean connectives is Post's lattice: a lattice showing the inclusion relations between all existing sets of Boolean functions that are closed under superposition (that is, roughly speaking, closed under arbitrary composition, see Section 2.2 for a formal definition). Several complexity classifications have already been obtained in this so-called Post's framework, such as the classical satisfiability problem (Lewis 1979), equivalence and implication problems (Reith 2003; Beyersdorff, Meier, Thomas, and Vollmer 2009a), satisfiability and model checking in modal and temporal logics (Bauland, Hemaspaandra, Schnoor, and Schnoor 2006; Bauland, Schneider, Schnoor, Schnoor, and Vollmer 2008), default logic (Beyersdorff, Meier, Thomas, and Vollmer 2009b), circumscription (Thomas 2009) and abduction (Creignou, Schmidt, and Thomas 2010).
The main contribution of this paper is a systematic complexity classification for the six aforementioned problems in terms of all possible sets of Boolean connectives.
• Concerning the four decision problems, we show that, depending on the chosen set of connectives, the problems range from inside P up to the second level of the polynomial hierarchy, and we identify those fragments complete for NP, coNP, and also for DP, the class of differences of problems in NP. We also show that unless the polynomial hierarchy collapses there exist particular sets of Boolean connectives such that: (i) deciding the existence of an argument is easier than verifying a given one; (ii) deciding the dispensability of a formula for some argument is easier than deciding its relevance.
• We provide a general schema for enumerating all arguments. For the fragments which have their decision problems in P, we also obtain positive results in terms of enumeration by showing that either each solution is computed with at most polynomial delay (for the fragments where the number of arguments might be exponential) or that all solutions can be computed in polynomial time (which obviously is only possible for fragments where the number of arguments is bounded polynomially in the size of the knowledge base and the claim). Finally, we complement our picture by considering the problem of counting the number of arguments in terms of all possible sets of Boolean connectives.
The paper is structured as follows. Section 2 contains the necessary background on complexity theory (Section 2.1) and on Post's lattice (Section 2.2). Moreover, we define the studied framework of argumentation and relevant problems in Section 2.3. We then turn to our main results which are given in Sections 3 and 4. More specifically, the complexity of the decision problems is classified in Sections 3.2–3.4, enumeration is studied in Section 4.1 and counting complexity is dealt with in Section 4.2. We summarise our results and discuss their relation to similar work (as e.g. in the area of abduction) in a dedicated Section 5. Finally, Section 6 concludes with a brief recapitulation of the achieved results as well as future research directions.
2.Background
We assume familiarity with propositional logic. The set of all propositional formulæ is denoted by ℒ. A model for a formula ϕ is a truth assignment to the set of its variables that satisfies ϕ. Further, we denote by
For a given formula ϕ, we denote by
A literal l is a variable x or its negation ¬ x. A positive literal is a variable x, a negative literal is the negation of a variable ¬ x. Given a set of variables V, Lits(V) denotes the set of all literals formed upon the variables in V, i.e.
2.1Complexity theory
We require standard notions of the complexity theory. For the decision problems, the arising complexity degrees encompass the classes Logspace, P, NP, coNP, DP and
When analysing an enumeration algorithm, polynomial time complexity is not a suitable yardstick of efficiency since the output size is usually exponential in the size of the input. We consider an enumeration algorithm to be efficient, when it runs in polynomial delay, i.e. if the delay until the first solution is output, thereafter the delay between any two consecutive solutions, and the delay between the last solution and termination is bounded by a polynomial p(n) in the input size n. This notion of efficiency for enumeration has first been introduced by Johnson, Papadimitriou, and Yannakakis (1988). We denote the corresponding complexity class by DelayP.
A counting problem is represented using a witness function w, which for every input x returns a finite set of witnesses. This witness function gives rise to the following counting problem: given an instance x, find the cardinality
For more background information on complexity theory, the reader is referred to Papadimitriou (1994).
2.2Post's lattice
A Boolean function is an n-ary function
• f is c-reproducing if
• f is monotonic if
• f is c-separating of degree k if for all
• f is c-separating if f is c-separating of degree | f−1(c)|. The implication
• f is self-dual if
• f is affine if
• the clone of all Boolean functions
• the monotonic clones
• the affine clones
• the disjunctive clones
• the conjunctive clones
• the c-reproducing clones
• the implication clone
• the negated-implication clone
• the dual clones
• the clones
•
•
•
Figure 1.
Post's lattice showing the complexity of the decision problems studied herein.
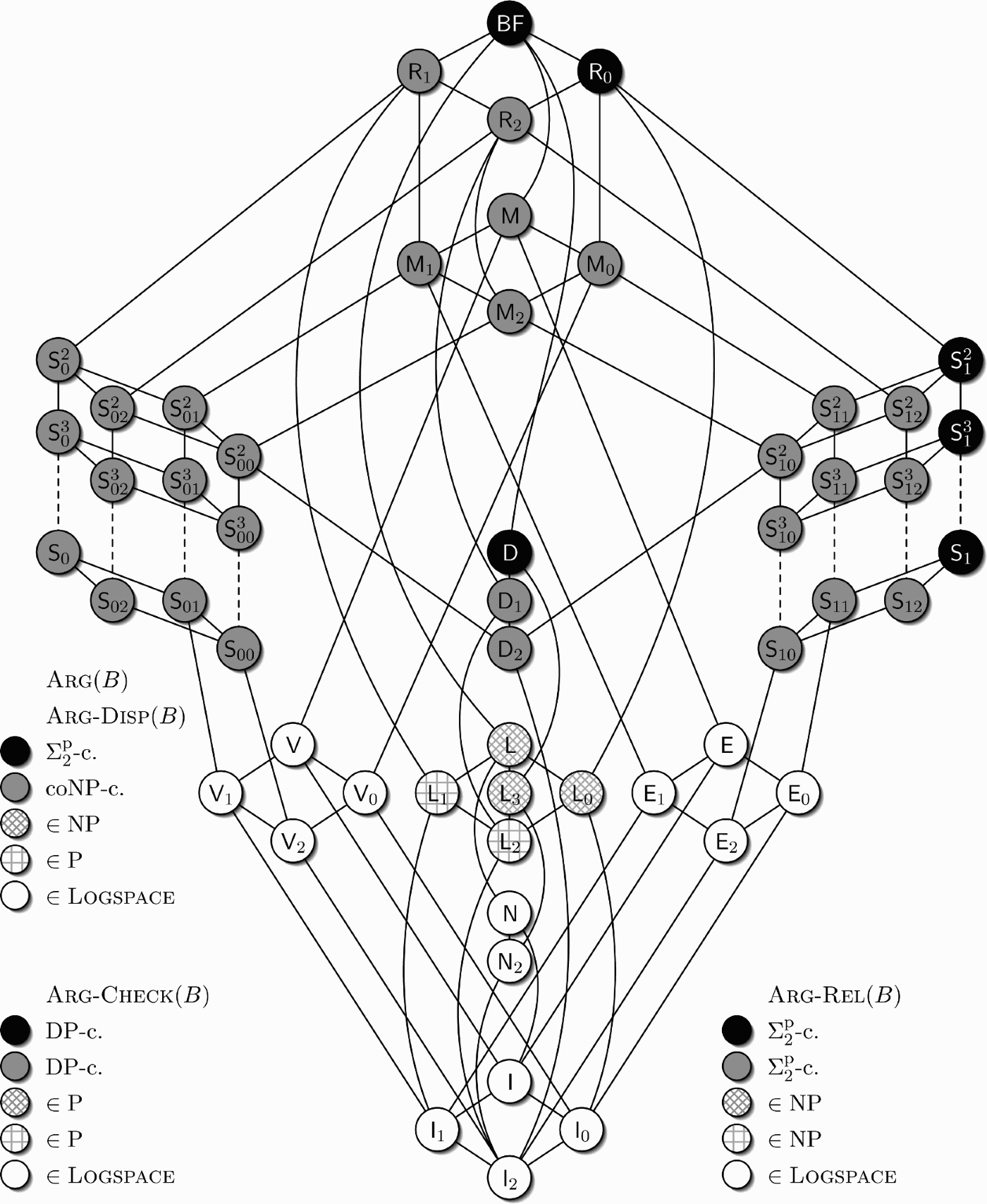
Table 1.
The list of all Boolean clones with definitions and bases, where
| Name | Definition | Base |
|
| All Boolean functions |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
For an example on how these identities will be useful, see Section 3.1, in particular at the end.
A propositional formula using only functions from B as connectives is called a
B-formula. The set of all B-formulæ is denoted by
Let f be an n-ary Boolean function. A B-formula ϕ is called
B-representation of f if
Example 2.1
Example 2.1Exponential blow up
Let
2.3Logic-based argumentation
Throughout the paper, Δ is assumed to be a given finite set of formulæ (the knowledge base) representing a large depositary of information, from which arguments can be constructed for arbitrary claims.
Following Besnard and Hunter (2001), an argument is a pair
(1) Φ is consistent,
(2)
(3) Φ is minimal with this last property, i.e. no proper subset of Φ entails α.
(C1) Φ is satisfiable,
(C2)
(C3) for all
Let B be a finite set of Boolean functions. Then the argument existence problem for B-formulæ is defined as
Problem: Arg(B).
Instance:
Question: Does there exist Φ such that
Besides the decision problem for the existence of an argument, we are interested in the decision problems for B-formulæ for validity, relevance and dispensability. They are defined as follows and deal with formulæ in
Problem: Arg-Check(B).
Instance:
Question: Is
Problem: Arg-Rel(B).
Instance:
Question: Does there exist an argument
Problem: Arg-Disp(B).
Instance:
Question: Does there exist an argument
Observe that the minimality of the support is only relevant to the problems Arg-Check and Arg-Rel. For Arg and Arg-Disp, the existence of a consistent subset Φ of the knowledge base Δ that entails the claim α (and does not contain some formula ϕ) implies a consistent
Other interesting tasks are to enumerate all solutions or to count them.
Problem: Enum-Arg(B).
Instance:
Output: Generate all arguments
Problem: #Arg(B).
Instance:
Output: Number of arguments
Obviously, for both Enum-Arg(B) and #Arg(B), minimality of the support plays a crucial role, as well.
3.Decision problems
3.1Tools and methods
Observe that if B1 and B2 are two sets of Boolean functions such that
When we show hardness-results for Arg(B) for some B such that
The following lemmas show that we can often suppose that our considered B contains the constant 1. This will reduce the number of cases to study.
Lemma 3.1
Let
Arg-
Proof
Let ℐ be the given instance. We map ℐ to the instance ℐ′ obtained by replacing each formula ψ occurring in ℐ by
In addition on this, one can also eliminate the constant 1 for the problems Arg(B) and Arg-Rel(B) when
Lemma 3.2
Let B be a finite set of Boolean functions such that
Proof
Let
Let Φ be an argument for α in Δ. Consider
Conversely, with similar arguments, it is easy to see that if Φ′ is an argument for α′ in Δ′, then
This proves a correctness of the reduction from Arg
Remark 1
Observe that this reduction does not work for Arg-Check: one would have to decide whether to map Φ to Φ′ or to
Let us show in an example how one can use these lemmas. Suppose, we want to show hardness results for Arg-Rel(B) in the case where
We will henceforth give less details when applying Lemmas 3.1 and 3.2.
3.2The complexity of verification
We commence our study of the introduced argumentation problems with the argument verification problem. This problem is in DP. Indeed, it is readily observed, as there are languages A, B with A∈NP and B∈coNP such that Arg-Check =
The next two results will cover all cases where we have a matching lower bound, i.e. we provide those clones for which DP-hardness holds.
Proposition 3.3
Let
Proof
To prove DP-hardness, we establish a reduction from Critical-Sat. Let
Since x∨ y and
Suppose now that ψ ∈ Critical-Sat, i.e. ψ is unsatisfiable and ψk is satisfiable for all
It remains to prove that Φ is minimal. Since for each
Conversely suppose that
We finally transform
Proposition 3.4
Let B be a finite set of Boolean functions such that
Proof
We give a reduction from Critical-Sat similar to Proposition 3.3. For
(a)
(b)
We map ψ to
Obviously α and the formulæ in Φ are
Note that if
(i)
(ii) (u, v)=(0, 0):
It remains to prove that Φ is minimal. Since
Conversely suppose that
Finally, we transform
The full picture for Arg-Check(B) is given in the forthcoming theorem, where we also provide the results for the ‘easier’ clones.
Theorem 3.5
Let B be a finite set of Boolean functions. Then the argument validity problem for propositional B-formulæ, Arg – Check (B), is
(1) DP-complete if
(2) in P if
(3) in Logspace if
Proof
For DP-completeness, according to Propositions 3.3 and 3.4, it remains only to deal with the case
In the case
3.3The complexity of existence and dispensability
We next consider the problems Arg(B) and Arg-Disp(B). For the membership part of the forthcoming results, we can make use of the results from the previous subsection.
Theorem 3.6
Let B be a finite set of Boolean functions. Then the argument existence problem for propositional B -formulæ, Arg(B), is
(1)
(2) coNP-complete if
(3) in NP if
(4) in P if
(5) in Logspace if
Proof
The general argumentation problem has been shown to be
As
For
For
In all other cases, Logspace-membership follows from the fact that both problems, satisfiability and entailment, are contained in Logspace (see Beyersdorff et al. 2009a) for B-formulæ.
Finally, observe that we have Arg-Disp
3.4The complexity of relevance
The remaining decision problem to analyse is Arg-Rel(B) which turns out to be the most difficult in terms of complexity.
Proposition 3.7
Let B be a finite set of Boolean functions such that
Proof
To see that Arg-Rel(B) is contained in
To prove
We show that
For the converse direction, let Φ be a support for α such that u∈Φ. Since
It remains to transform
Proposition 3.8
Let B be a finite set of Boolean functions such that
Proof
We assume the representation of

Algorithm 1 can be implemented using only a logarithmic amount of space if we do not construct Δx entirely, but rather check the condition in line 3 directly:
To prove correctness, notice that Algorithm 1 accepts only if there exists a
Next, consider Arg-Rel(B) for
Finally Arg-Rel(B) for
We obtain the following complexity classification for Arg-Rel.
Theorem 3.9
Let B be a finite set of Boolean functions. Then the argument relevance problem for propositional B -formulæ, Arg-Rel(B), is
(1)
(2) in NP if
(3) in Logspace if
4.Enumeration and counting problems
4.1Enumeration
A general procedure to enumerate all supports in Δ for a given claim α is given in Algorithm 2. The initial call has to be done by Enum

The correctness of the procedure is based on the deduction theorem, which says that
Note that the only cases in which we can hope to obtain polynomial delay enumeration algorithms are those for which the decision problem Arg(B) is tractable, i.e. the cases
Proposition 4.1
Let B be a finite set of Boolean functions. If
Proof
If
If
4.2Counting
The argument counting problem #Arg(B) belongs to
Proposition 4.2
Let B be a finite set of Boolean functions such that either
Proof
We show
Let
Since
Proposition 4.3
Let B be a finite set of Boolean functions such that
Proof
Since the reductions in Lemmas 3.1 and 3.2 are parsimonious, analogously to Theorem 3.9, it suffices to show hardness for the case
We prove #P;-hardness by giving a parsimonious reduction from the following #P;-hard problem: count the number of models of a positive 2-CNF-formula. Let
It remains to show that α can be transformed in polynomial time into a B-formula for all B such that
Proposition 4.4
Let B be a finite set of Boolean functions such that
Proof
Membership in #P; follows from the fact that Arg
To prove #P;-hardness, we establish a parsimonious reduction from the same #P;-hard problem as in the previous proposition. So let
By minimality every support
It remains to transform α and the formulæ in Δ into B-formulæ. We can insert parentheses in each term in order to represent it as a binary ∧-tree of logarithmic depth. Then it suffices to replace the ∧-connective by its B-representation which exists since
Theorem 4.5
Let B be a finite set of Boolean functions. Then the argument counting problem for propositional B -formulæ, #Arg (B), is
(1)
(2) in
(3) in #P; if
(4) #P;-complete if
(5) in FP if
Proof
Items (1), (2) and (4) follow directly from the above three propositions. Item (3) follows from the fact that Arg
Let us conclude this section by pointing out that for the case where
5.Discussion of results
Complexity classifications along the lines of Boolean clones have already been carried out for AI formalisms as circumscription (Thomas 2009) and abduction (Creignou et al. 2010). In particular, the latter work is closely related to the contents of this paper. To make this more precise, let us consider the positive abduction problem
(1) if ∧∈[B], i.e. if
(2) if
It turns out that Arg and Arg-Disp have the same complexity classification as positive abduction. This is due to the fact that minimality of the argument plays no role in Arg and Arg-Disp. However, for Arg-Rel the situation is different but we expect similarly harder complexity for the relevance problem in abduction with respect to subset-minimal explanations (see Eiter and Gottlob 1995 for the definitions) which has not been analysed by Creignou et al. (2010). In other words, the results provided in the present paper can be used to obtain novel results for certain variants of abduction, which have not been classified yet.
Table 2 gives an overview of the results for the studied argumentation problems. The small numbers on the right side in the table cells refer to the corresponding theorem/proposition/remark.
Table 2.
The complexity of the argumentation problems.
|
|
|
|
|
|
| |
| Arg-Check | ∈L, 3.5 | ∈L, 3.5 | ∈P, 3.5 ∈P, 3.5 | DP-c, 3.3, 3.4 | DP-c, 3.3, 3.4 | |
| Arg, Arg-Disp | ∈L, 3.6 | ∈L, 3.6 | ∈P, 3.6 | ∈NP, 3.6 | ||
| Arg-Rel | ∈L, 3.8 | ∈L, 3.8 | ∈NP, 3.9 | ∈NP, 3.9 | ||
| Enum-Arg | ∈FP, 4.1 | Unknown | Unknown | coNP-h, 3.6 | ||
| #Arg | ∈FP, 4.5 | #P;-c, 4.4 | ∈#P;, 4.5 | ∈#P;, 4.5 |
Note: The *-subscripts on clones denote all valid completions, L abbreviates Logspace, and ‘-c’ and ‘-h’ indicate, respectively, completeness and hardness.
Our results show, for instance, that when the knowledge base's formulæ are restricted to be represented as positive clauses or single literals (column
Notably are the sets B of Boolean connectives where
The results obtained for the
6.Conclusion and future work
To summarise, we took in this paper first steps to understanding the complexity of logic-based argumentation. We provided a classification of the complexity of four important decision tasks (Figure 1), as well as a classification of the complexity of enumeration and counting, for all possible restrictions on the set of allowed connectives.
The interpretation of our results is twofold: first, we have shown that the high complexity (i.e.
The complexity of the problems studied in this paper is also a computational core for evaluating more complex argumentation problems, for instance, the warranted formula problem (WFP) on argument trees, which has recently been shown to be PSPACE-complete by Hirsch and Gorogiannis (2011). We expect that fragments studied here also lower the complexity of WFP, but leave details for future work. Another problem which is amenable to the kind of complexity analysis we did in this paper is the identification of conflicts between two arguments (different notions for conflicts between arguments based on classical logic exist, see e.g. Gorogiannis and Hunter 2011) which is an intractable problem itself; however, since most conflicts are identified via the implication problem, we expect results similar to the one derived by Beyersdorff et al. (2009a). A complexity analysis in that direction has already been undertaken by Wooldridge, Dunne, and Parsons (2006). In that paper, the authors studied problems as, for instance, equivalence of arguments. Further future work also concerns studying the complexity of all the problems investigated here in the popular Schaefer's framework in which formulas are in generalised conjunctive normal form (see Creignou and Zanuttini (2006), Nordh and Zanuttini (2008) for complexity classifications of abduction in this framework, and Creignou and Vollmer (2008) for a survey of results obtained for various non-monotonic logics).
Notes
1 We note that the complexity of the corresponding fragments remained unclassified also for circumscription and positive abduction.
Acknowledgements
Supported by ANR ENUM 07-BLAN-0327-04, WWTF grant ICT 08-028, FWF grant P20704-N18, ÖAD grant Amadée 17/2011/EGIDE PHC Amadeus project 24908NM, and DFG grant VO 630/6-2.
References
1 | Amgoud, L. and Besnard, P. A Formal Analysis of Logic-based Argumentation Systems. Proceedings of the 4th International Conference on Scalable Uncertainty Management (SUM’10, Toulouse, France). Edited by: Deshpande, A. and Hunter, A. pp. 42–55. Springer Verlag. Vol. 6379 of Lecture Notes in Computer Science |
2 | Amgoud, L. and Cayrol, C. (2002) . A Reasoning Model Based on the Production of Acceptable Arguments. Annals of Mathematics and Artificial Intelligence, 34: : 197–215. |
3 | Baroni, P., Dunne, P. and Giacomin, M. On Extension Counting Problems in Argumentation Frameworks. Proceedings of the 3rd International Conference on Computational Models of Argument (COMMA 2010, Desenzano del Garda, Italy). Edited by: Baroni, P., Cerutti, F., Giacomin, M. and Simari, G. pp. 63–74. IOS Press. Vol. 216 of Frontiers in Artificial Intelligence and Applications |
4 | Bauland, M., Hemaspaandra, E., Schnoor, H. and Schnoor, I. Generalized Modal Satisfiability. Proceedings of the 23rd Annual Symposium on Theoretical Aspects of Computer Science (STACS 2006, Marseille, France). Edited by: Durand, B. and Thomas, W. pp. 500–511. Springer Verlag. Vol. 3884 of Lecture Notes in Computer Science |
5 | Bauland, M., Schneider, T., Schnoor, H., Schnoor, I. and Vollmer, H. (2008) . The Complexity of Generalized Satisfiability for Linear Temporal Logic. Logical Methods in Computer Science, : 5 |
6 | Bench-Capon, T. and Dunne, P. (2007) . Argumentation in Artificial Intelligence. Artificial Intelligence, 171: : 619–641. |
7 | Besnard, P. and Hunter, A. (2001) . A Logic-based Theory of Deductive Arguments. Artificial Intelligence, 128: : 203–235. |
8 | Besnard, P. and Hunter, A. (2008) . Elements of Argumentation, MIT Press. |
9 | Beyersdorff, O., Meier, A., Thomas, M. and Vollmer, H. (2009) a. The Complexity of Propositional Implication. Information Processing Letters, 109: : 1071–1077. |
10 | Beyersdorff, O., Meier, A., Thomas, M. and Vollmer, H. The Complexity of Reasoning for Fragments of Default Logic. Proceedings of the 12th International Conference on Theory and Applications of Satisfiability Testing (SAT 2009, Swansea, UK). Edited by: Kullmann, O. pp. 51–64. Springer Verlag. Vol. 5584 of Lecture Notes in Computer Science |
11 | Caminada, M. and Amgoud, L. (2007) . On the Evaluation of Argumentation Formalisms. Artificial Intelligence, 171: : 286–310. |
12 | Cayrol, C. On the Relation between Argumentation and Non-monotonic Coherence-based Entailment. Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI 1995, Montréal, Canada). pp. 1443–1448. Morgan Kaufmann. |
13 | Chesñevar, C., Maguitman, A. and Loui, R. (2000) . Logical Models of Argument. ACM Compututing Surveys, 32: : 337–383. |
14 | Creignou, N., Schmidt, J. and Thomas, M. Complexity of Propositional Abduction for Restricted Sets of Boolean Functions. Proceedings of the 12th International Conference on Principles of Knowledge Representation and Reasoning (KR 2010, Toronto, Canada). Edited by: Lin, F., Sattler, U. and Truszczynski, M. pp. 8–16. AAAI Press. (full review to appear in Journal of Logic and Computation 2011) |
15 | Creignou, N. and Vollmer, H. Boolean Constraint Satisfaction Problems: When Does Post's Lattice Help?. Complexity of Constraints – An Overview of Current Research Themes. Edited by: Creignou, N., Kolaitis, P. G. and Vollmer, H. pp. 3–37. Springer. Vol. 5250 of Lecture Notes in Computer Science |
16 | Creignou, N. and Zanuttini, B. (2006) . A Complete Classification of the Complexity of Propositional Abduction. SIAM Journal on Computing, 36: : 207–229. |
17 | Dung, P., Kowalski, R. and Toni, F. (2006) . Dialectical Proof Procedures for Assumption-based Admissible Argumentation. Artificial Intelligence, 170: : 114–159. |
18 | Dung, P. M. (1995) . On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games. Artificial Intelligence, 77: : 321–358. |
19 | Durand, A., Hermann, M. and Kolaitis, P. G. (2005) . Subtractive Deductions and Complete Problems for Counting Complexity Classes. Theoretical Computer Science, 340: : 496–513. |
20 | Durand, A. and Hermann, M. (2008) . On the Counting Complexity of Propositional Circumscription. Information Processing Letters, 106: : 164–170. |
21 | Eiter, T. and Gottlob, G. (1995) . The Complexity of Logic-based Abduction. Journal of the ACM, 42: : 3–42. |
22 | García, A. and Simari, G. (2004) . Defeasible Logic Programming: An Argumentative Approach. Theory and Practice of Logic Programming, 4: : 95–138. |
23 | Gorogiannis, N. and Hunter, A. (2011) . Instantiating Abstract Argumentation with Classical Logic Arguments: Postulates and Properties. Artificial Intelligence, 175: : 1479–1497. |
24 | Hemaspaandra, L. and Vollmer, H. (1995) . The Satanic Notations: Counting Classes Beyond #P and Other Definitional Adventures. Complexity Theory Column 8, ACM-SIGACT News, 26: : 2–13. |
25 | Hermann, M. and Pichler, R. (2010) . Counting Complexity of Propositional Abduction. Journal of Computer and System Sciences, 76: : 634–649. |
26 | Hirsch, R. and Gorogiannis, N. (2010) . The Complexity of the Warranted Formula Problem in Propositional Argumentation. Journal of Logic and Computation, 20: : 481–499. |
27 | Johnson, D., Papadimitriou, C. and Yannakakis, M. (1988) . On Generating All Maximal Independent Sets. Information Processing Letters, 27: : 119–123. |
28 | Karchmer, M. and Wigderson, A. Monotone Circuits for Connectivity Require Super-logarithmic Depth. Proceedings of the 20th Annual ACM Symposium on Theory of Computing (STOC 1988, Chicago, Illinois, USA). Edited by: Simon, J. pp. 539–550. ACM. |
29 | Lewis, H. (1979) . Satisfiability Problems for Propositional Calculi. Mathematical Systems Theory, 13: : 45–53. |
30 | Nordh, G. and Zanuttini, B. (2008) . What Makes Propositional Abduction Tractable. Artificial Intelligence, 172: : 1245–1284. |
31 | Papadimitriou, C. (1994) . Computational Complexity, Addison-Wesley. |
32 | Papadimitriou, C. and Wolfe, D. (1988) . The Complexity of Facets Resolved. Journal of Computer and System Sciences, 37: : 2–13. |
33 | Parsons, S., Wooldridge, M. and Amgoud, L. (2003) . Properties and Complexity of Some Formal Inter-agent Dialogues. Journal of Logic and Computation, 13: : 347–376. |
34 | Post, E. (1941) . The Two-valued Iterative Systems of Mathematical Logic. Annals of Mathematics Studies, 5: : 1–122. |
35 | Prakken, H. and Vreeswijk, G. (2002) . “Logical Systems for Defeasible Argumentation”. In Handbook of Philosophical Logic, Edited by: Gabbay, D. Kluwer. |
36 | Rahwan, I. and Simari, G. (2009) . Argumentation in Artificial Intelligence, Edited by: Rahwan, I. and Simari, G. Springer Verlag. |
37 | Reith, S. On the Complexity of some Equivalence Problems for Propositional Calculi. Proceedings of the 28th International Symposium on Mathematical Foundations of Computer Science (MFCS 2003, Bratislava, Slovakia). Edited by: Rovan, B. and Vojtás, P. pp. 632–641. Springer Verlag. Vol. 2747 of Lecture Notes in Computer Science |
38 | Schnoor, H. (2005) . The Complexity of the Boolean Formula Value Problem, University of Hannover. Technical Report, Theoretical Computer Science |
39 | Spira, P.M. (1971), ‘On Time-hardware Complexity Tradeoffs for Boolean Functions’, Proceedings of the 4th Hawaii International Symposium on System Sciences, pp. 525–527 |
40 | Thomas, M. The Complexity of Circumscriptive Inference in Post's Lattice. Proceedings of the 10th International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR 2009, Potsdam, Germany). Edited by: Erdem, E., Lin, F. and Schaub, T. pp. 290–302. Springer Verlag. Vol. 5753 of Lecture Notes in Computer Science |
41 | Wooldridge, M., Dunne, P. and Parsons, S. On the Complexity of Linking Deductive and Abstract Argument Systems. Proceedings of the 21st National Conference on Artificial Intelligence (AAAI 2006, Boston, Massachusetts, USA). pp. 299–304. MIT Press. |


