
Answer-set programming encodings for argumentation frameworks
Abstract
Answer-set programming (ASP) has emerged as a declarative programming paradigm where problems are encoded as logic programs, such that the so-called answer sets of theses programs represent the solutions of the encoded problem. The efficiency of the latest ASP solvers reached a state that makes them applicable for problems of practical importance. Consequently, problems from many different areas, including diagnosis, data integration, and graph theory, have been successfully tackled via ASP. In this work, we present such ASP-encodings for problems associated to abstract argumentation frameworks (AFs) and generalisations thereof. Our encodings are formulated as fixed queries, such that the input is the only part depending on the actual AF to process. We illustrate the functioning of this approach, which is underlying a new argumentation system called ASPARTIX in detail and show its adequacy in terms of computational complexity.
1.Motivation
In Artificial Intelligence (AI), the area of argumentation (the survey by Bench-Capon and Dunne (2007) gives an excellent overview) has become one of the central issues during the last decade. Argumentation provides a formal treatment for reasoning problems arising in a number of applications fields, including Multi-Agent Systems and Law Research. In a nutshell, the so-called abstract argumentation frameworks (AFs) formalise statements together with a relation denoting rebuttals between them, such that the semantics gives an abstract handle to solve the inherent conflicts between statements by selecting admissible subsets of them. The reasoning underlying such AFs turned out to be a very general principle capturing many other important formalisms from the areas of AI and knowledge representation.
The increasing interest in argumentation led to numerous proposals for formalisations of argumentation. These approaches differ in many aspects. First, there are several ways as to how “admissibility” of a subset of statements can be defined; second, the notion of rebuttal has different meanings (or even additional relationships between statements are taken into account); finally, statements are augmented with priorities, such that the semantics yields those admissible sets which contain statements of higher priority. Thus, in order to compare these different proposals, it is desirable to have a system at hand, which is capable of dealing with a large number of argumentation semantics.
Argumentation problems are, in general, intractable; for instance, deciding if an argument is contained in some preferred extension is known to be NP-complete. Therefore, developing dedicated algorithms for the different reasoning problems is non-trivial. A promising way to implement such systems is to use a reduction method, where the given problem is translated into another language, for which sophisticated systems already exist.
In this work, we present an approach which meets these challenges, i.e. we describe a system which, on the one hand, implements numerous approaches for abstract argumentation, and, on the other hand, gains its efficiency by exploiting highly sophisticated solvers to which we can map the problems in question. The declarative programming paradigm of Answer-Set Programming (ASP) (Niemelä 1999; Leone et al. 2006) is especially well suited for this purpose due to the following three characteristics.
• The prototypical language of ASP (i.e. logic programming under the answer-set semantics (Gelfond and Lifschitz 1991), also known as stable logic programming or A-Prolog) is very expressible and allows to formulate queries (in an extended datalog fashion) over databases, such that multiple results can be obtained. In our context, queries thus can be employed to obtain multiple extensions for AFs, where the actual AF to process is just given as an input database.
• Advanced ASP-solvers such as Smodels, DLV, GnT, Cmodels, Clasp, or ASSAT are nowadays able to deal with large problem instances, see, e.g. (Gebser et al. 2007). Thus, using our proposed reduction method delegates the burden of optimisation to these systems.
• Depending on the syntactical structure of a given ASP query, the complexity of evaluating that query on input databases (i.e. the data complexity of ASP) varies from classes P, NP, coNP up to
The main aim of this paper is to present ASP queries for reasoning problems within different types of AFs. To be more specific, we give queries for the most important types of extensions (i.e. admissible, preferred, stable, semi-stable, complete, and grounded (Dung 1995; Caminada 2006)) in terms of Dung's original abstract framework, the preference-based AF by Amgoud and Cayrol (2002), the value-based argumentation framework (VAF) by Bench-Capon (2003), and the bipolar argumentation framework (BAF) (Cayrol and Lagasquie-Schiex 2005; Amgoud, Cayrol, Lagasquie-Schiex, and Livet 2008).
We have implemented these queries in a system called ASPARTIX, which makes use of the prominent answer set solver DLV (Leone et al. 2006). All necessary programs to run ASPARTIX and some illustrating examples are available at
www.dbai.tuwien.ac.at/research/project/argumentation/systempage/
We believe that our system is a useful tool for researchers in the argumentation community to compare different argumentation semantics on concrete examples within a uniform setting. In fact, investigating the relationship between different argumentation semantics has received increasing interest lately (Baroni and Giacomin 2008b).
Earlier work already proposed reductions from argumentation problems to certain target formalisms. Most notably are encodings in terms of (quantified) propositional logic (Besnard and Doutre 2004; Egly and Woltran 2006; Besnard, Hunter, and Woltran 2009) and logic programs (Nieves, Osorio, and Cortés 2008; Nieves, Osorio, and Zepeda 2009; Osorio, Zepeda, Nieves, and Cortés 2005; Wakaki and Nitta 2008; we will come back to the earlier work on reductions to logic programs, which is indeed most closely related to ours, in the discussion section at the end of this article).
The main difference of this earlier work compared with our approach is the necessity of compiling (at least, for some of the semantics) each problem instance into a different instance of the target formalism (e.g. into a different logic program).
In our approach, all semantics are encoded within a fixed query (independent from the concrete AF to process). Thus, we are more in the tradition of a classical implementation because we construct an interpreter in ASP which takes an AF given as input. Although there is no advantage of the interpreter approach from a theoretical point of view (as long as the reductions are polynomial-time computable), there are several practical ones. The interpreter is easier to understand, easier to debug, and easier to extend. Additionally, proving properties like correspondence between answer sets and extensions is simpler. Moreover, the input AF can be changed easily and dynamically without translating the whole formula. This indeed simplifies the answering of questions like “What happens if I add this new argument?”.
The remainder of the article is organised as follows. In the next section, we recall the necessary concepts of ASP and AFs. Furthermore we give some illustrative examples and recall the respective complexity results. In Section 3, we gradually introduce the encodings for the particular semantics and in Section 4, we adapt these encodings for some generalisations of AFs. Finally, in Section 5, we give an overview of related approaches and discuss future work.
2.Preliminaries
2.1.Answer-set programming
We first give a brief overview of the syntax and semantics of the ASP-formalism we consider, i.e. disjunctive datalog under the answer-set semantics (Gelfond and Lifschitz 1991). Then, we illustrate useful programming techniques on some simple examples. Finally, we briefly recall some important complexity results for disjunctive datalog. We refer to Eiter, Gottlob, and Mannila (1997) and Leone et al. (2006) for a broader exposition on all of these topics.
In what follows, we fix a countable set 𝒰 of (domain) elements, also called constants and suppose a total order < over these elements. An atom is an expression p(t1, …,tn), where p is a predicate symbol of arity n≥0 and each ti is either a variable or an element from 𝒰. An atom is ground if it is free of variables.
A (disjunctive) rule r is of the form
The head of r is the set H(r) =
A program is a finite set of safe (disjunctive) rules. Employing database notation, we call a finite set of facts also an input database and a set of non-ground rules a query. For a query Π and an input database D, we often write Π(D), instead of the program D∪Π, in order to indicate that D serves as input for query Π.
A normal program Π is called stratified if no atom a depends by recursion through negation on itself (Apt, Blair, and Walker 1988). More formally, Π is stratified if there exists an assignment
(i) in the positive body of r, then
(ii) in the negative body of r, then
For the program
For any program Π, let
Let the set of all ground atoms over 𝒰 be denoted by
Let us discuss some typical concepts of ASP which are important for the implementation later on by providing queries for some graph problems (see Leone et al. (2006) for a more detailed discussion of similar examples). First, consider the problem of reachability in directed graphs. We assume that an input graph G is given as a set of facts
Before we give some further examples, let us introduce the concept of splitting sets (Lifschitz and Turner 1994). Given a program Π, a set S of predicate symbols is a splitting set for Π, iff, for every rule r∈Π, it holds that if some atom with predicate symbol from S occurs in the head of r, then each atom in r has its predicate symbol from S as well. Any splitting set S for program Π divides Π in two parts. The top of Π (with respect to S), in symbols
Proposition 2.1
Let S be a splitting set of a program Π, and let
We next illustrate a typical use of default negation. We consider here the problem of 3-colourability of an (undirected) graph. Suppose a graph's vertices are defined via the predicate
The three rules of
Now let use consider
Actually, instead of the rules (1)–(3), we could have used disjunction to guess a colour for each vertex. As we shall see next, disjunction is a more expressive concept than default negation. While with default negation, one is able to formulate an exclusive guess (as we did in the above example), disjunction can be additionally employed for a certain saturation technique, which allows for representing even more complex problems. The term “saturation” indicates that all atoms which are subject to a guess can also be jointly contained in an interpretation. To saturate a guess, it is however necessary that the checking part of a program interacts with the guessing part.
As a very simple example, let us compare the following two programs:
To have a slightly more meaningful application of this saturation technique, let us now reduce also the non-3-colourability problem to the problem of deciding whether an answer set exists. Therefore, we adapt the encoding
We conclude this section by recalling some central complexity results for ASP. Credulous and skeptical reasoning in terms of programs are defined as follows. Given a program Π and a set A of ground atoms, we denote by
Since we will deal with fixed programs, we focus on results for data complexity. Recall that data complexity in our context addresses the problem
Table 1.
Data complexity for datalog (all results are completeness results).
| Stratified programs | Normal programs | General case | |
| P | NP | ||
| P | coNP |
2.2.Basic argumentation frameworks
In this section, we recall the most important semantics for the basic version of abstract AFs and highlight complexity results for typical decision problems. Later, in Section 4, we will introduce some generalisations of AFs.
In order to relate frameworks to programs, we use the universe 𝒰 of domain elements (introduced in the previous subsection) also in the following basic definition.
Definition 2.2
An AF is a pair F=(A, R) where
An AF can be naturally represented as a directed graph.
Example 2.3
Let F=(A, R) be an AF with

In order to be able to reason about such frameworks, it is necessary to group arguments with special properties to extensions. One of the basic properties is the absence of conflicts between arguments contained in the same extension.
Definition 2.4
Let F=(A, R) be an AF. A set S⊆ A is said to be conflict-free in F, if there are no a, b∈S, such that (a, b)∈R. We denote the collection of sets which are conflict-free in F by cf(F).
For our framework F=(A, R) from Example 2.3, we have
Definition 2.5
Let F=(A, R) be an AF. A set S is a stable extension of F, if
The framework F from Example 2.3 has a single stable extension {a, d}. Indeed, {a, d} is conflict-free, and each further element b, c, e is defeated by either a or d. In turn, {a, c} for instance is not contained in
Stable semantics in terms of argumentation are considered to be quite restricted. Moreover, it is not guaranteed that a framework possesses at least one stable extension (consider, e.g. the simple cyclic framework
Definition 2.6
Let F=(A, R) be an AF. A set S is an admissible extension of F (or S is admissible in F), if
For the framework F from Example 2.3, we obtain
Definition 2.7
Let F=(A, R) be an AF. A set S is a preferred extension of F, if
Obviously, the preferred extensions of the framework F from Example 2.3 are {a, c} and {a, d}. We note that each stable extension is also preferred, but the converse does not hold, as witnessed by this example.
The next semantics we consider is the semi-stable semantics, recently introduced by Caminada (2006) and investigated also in (Dunne and Caminada 2008). Semi-stable semantics are located in-between stable and preferred semantics, in the sense that each stable extension of an AF F is also a semi-stable extension of F, and each semi-stable extension of F is a preferred extension of F. However, in general, both inclusions do not hold in the opposite direction. In contrast to the stable semantics, semi-stability guarantees that there exists at least one extension (in case of finite AFs). We use the definition given by Dunne and Caminada (2008).
Definition 2.8
Let F=(A, R) be an AF, and for a set S⊆ A, let S+Rbe defined as
For our example framework (A, R), the only semi-stable extension coincides with the stable extension T={a, d}. In contrast, S={a, c} is not semi-stable because
Finally, we introduce complete and grounded extensions which Dung considered as skeptical counterparts of admissible and preferred extensions, respectively.
Definition 2.9
Let F=(A, R) be an AF. A set S is a complete extension of F, if
The complete extensions of framework F from Example 2.3 are {a, c}, {a, d}, and {a}, with the last being also the grounded extension of F.
This concludes our collection of argumentation semantics that we consider in this paper. The relations between the semantics are depicted in Figure 1, where an arrow from e to f indicates that each e-extension is also an f-extension.
Figure 1.
Overview of argumentation semantics and their relations.
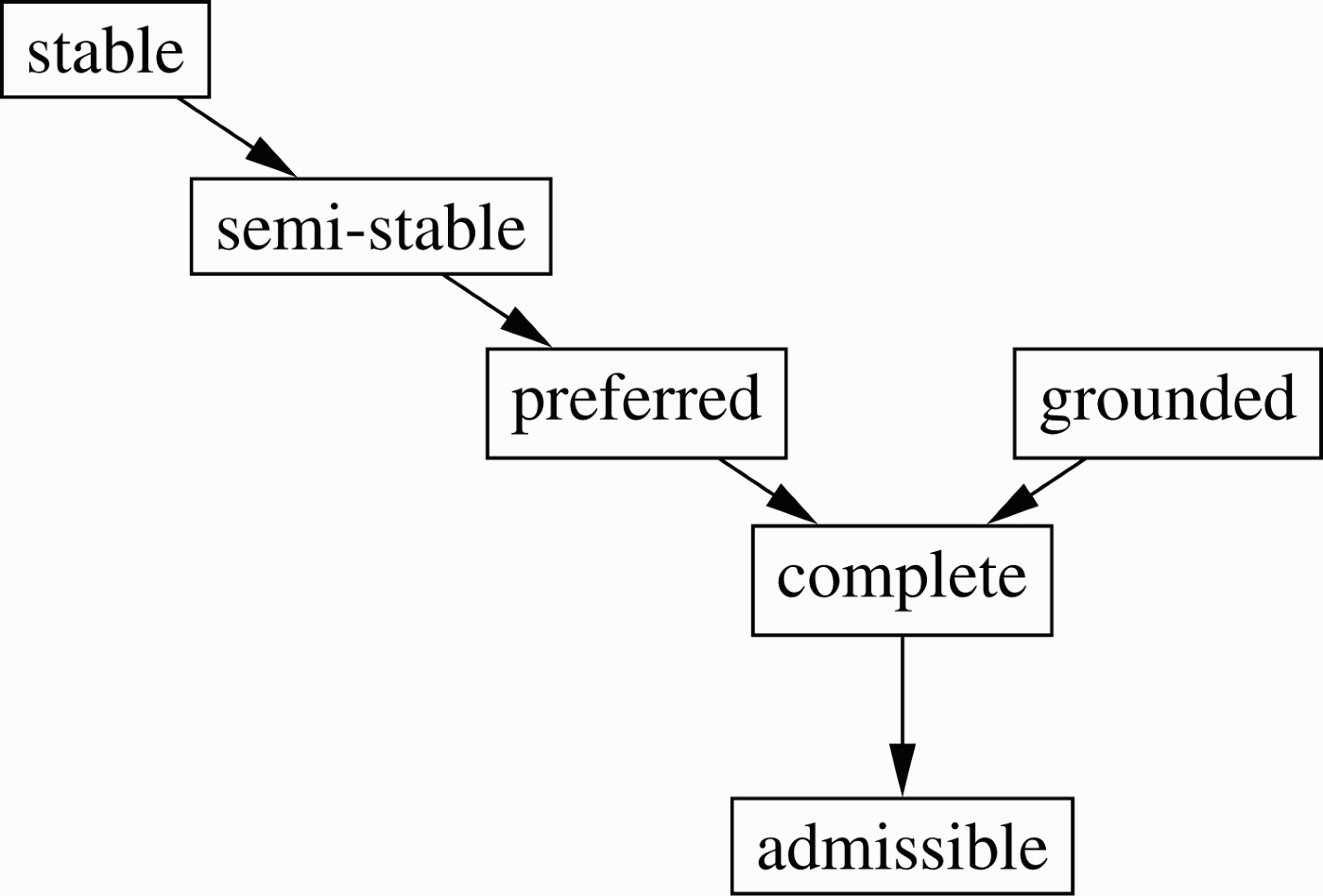
We briefly review the complexity of reasoning in AFs. To this end, we define the following decision problems for
• Crede: Given AF F=(A, R) and a∈A. Is a contained in some S∈e(F)?
• Skepte: Given AF F=(A, R) and a∈A. Is a contained in all S∈e(F)?
The complexity results are depicted in Table 2 (many of them follow implicitly from Dimopoulos and Torres (1996); for the remaining results and discussions, see (Dunne and Bench-Capon 2002, 2004; Coste-Marquis, Devred, and Marquis 2005; Dunne and Caminada 2008; Dvořák and Woltran 2009)). In the table, “𝒞-c” refers to a problem which is complete for class 𝒞, while “in 𝒞” is assigned to problems for which a tight lower complexity bound is not known. A few further comments are in order. We already mentioned that skeptical reasoning over admissible extensions always is trivially false. Moreover, we note that credulous reasoning over preferred extensions is easier than skeptical reasoning. This is due to the fact that the additional maximality criterion only comes into play for the latter task. Indeed, for credulous reasoning the following simple observation makes clear why there is no increase in complexity compared with credulous reasoning over admissible extensions: a is contained in some
Table 2.
Complexity for decision problems in AFs.
| stable | adm | pref | semi | comp | ground | |
| Crede | NP-c | NP-c | NP-c | NP-c | in P | |
| Skepte | coNP-c | (trivial) | in P | in P |
Proposition 2.10
The grounded extension of an AF F=(A, R) is given by the least fixed point of ΓF, where the operator
3.ASP-encodings for abstract argumentation frameworks
We now provide fixed queries πe for each extension of type e introduced in the previous section, in such a way that the AF F is given as an input database [Fcirc] and the answer sets of the combined program
Definition 3.1
Let
Note that
Let F=(A, R) be an AF. The following program fragment guesses, when augmented by [Fcirc], any subset S⊆ A and then checks whether the guess is conflict-free in F:
For our framework F from Example 2.3, we have as input
Moreover, using [Fcirc] together with πcf, we obtain
Proposition 3.2
For any AF F,
Proof
Let F=(A, R) and
This shows that I satisfies
Now suppose
3.1.Stable extensions
We are now prepared to present our first encoding. Two additional rules for the stability test are required and we define
Note that we can use the Splitting Theorem (Section 2.1) as follows. The splitting set
In fact, using our calculations from the previous subsection, we obtain
If we now apply the constraint
In general, our encoding for stable extensions satisfies the following correspondence result.
Proposition 3.3
For any AF F,
Proof
First, let us formally describe the application of the Splitting Theorem (Proposition 2.1) as sketched above with the splitting set
Let now
3.2.Admissible extensions
We next give the rules for the admissibility test:
For our example framework, we start from a collections 𝒞 of sets as above but now we check which sets violate the new constraint
(1) Sb contains in(b) and
(2) for
Proposition 3.4
For any AF F,
The proof is similar to the one of Proposition 3.3.
3.3.Complete extensions
We proceed with the encoding for complete extensions. We define
Proposition 3.5
For any AF F,
The proof is similar to the one of Proposition 3.3.
3.4.Grounded extension
Computing the grounded extension of a given AF could also be done by the “Guess & Check” method we used in the previous encodings. But since reasoning via the grounded extension is tractable (Table 2), we aim to find an encoding in a tractable subclass of datalog (the encodings we used so far are not contained in such a tractable subclass). Inspecting Table 1 shows that stratified programs are the appropriate candidate. However, as discussed in Section 2.1, stratified negation is too weak to formalise guesses as we did in the encodings above. Instead, a suitable encoding of the operator ΓF as introduced in Proposition 2.10 is possible. Therefore, we recursively derive
Note that π< is indeed stratified and constraint-free. Hence,
We now define the required predicate
For illustration, we compute the answer set for
In the “first round” of computation, we have no
Proposition 3.6
For any AF F,
Proof
Let F=(A, R) and let [Fcirc]< be the answer set of
Using the one-step provability operator for logic programs (see e.g. van Emden and Kowalski (1976) for details on that operator), it can be shown that for every AF F=(A, R), the answer set of the program
Therefore, let
We now show, given an AF F=(A, R), that
Induction base
Suppose i=0 and let
Induction step
Let i>0, and suppose Relation (30) holds for all 0≤j<i; in particular, we can assume that
Obviously, we could have used the
3.5.Preferred extensions
To compute the preferred extensions of an AF, we will use the saturation technique described in Section 2.1 as follows: Having computed an admissible extension S (characterised via predicates
Let us for the moment also assume that predicates eq (rule (33)) and
• eq is derived if the guess S via
•
In what follows, we discuss the functioning of
The task of the rules (33)–(35) is to check whether the new guess T is a proper superset of S and characterises an admissible extension of the given AF F. If this is not the case, we derive the predicate fail. More specifically, rule (33) checks whether S=T, and in case this holds we derive fail; rule (34) checks whether T is not conflict-free in F, and in case this holds we derive fail; rule (35) checks whether T contains an argument not defended by T in F, and in case this holds we derive fail. In other words, we have not derived fail if T⊃ S and T is admissible in F. By definition, S then cannot be a preferred extension of F.
The remaining rules (36)–(38) saturate the guess in case fail was derived, and finally ensure that fail has to be in an answer set. We already discussed the underlying idea of such rules for the program
Let us illustrate now the behaviour of
Now suppose the first guess S (via predicates
We still have to define the rules for the predicates eq and
Proposition 3.7
For any AF F,
To illustrate how πpref applies to our example framework, note that a step-by-step evaluation as used before is no longer possible. In particular, the sub-program
The situation is different for set
3.6.Semi-stable extensions
We conclude our encodings for the different types of extensions with a query for the semi-stable semantics. The basic intuition for the forthcoming encoding is the same as for the preferred semantics. The main difference lies in the fact that, given an admissible extension S for an AF F=(A, R), we now have to test whether no
We reuse the modules πadm, π<, as well as
We define
Proposition 3.8
For any AF F,
3.7.Summary and combinations of encodings
We summarise the results from this section.
Theorem 3.9
For any AF F and
We note that our encodings are adequate in the sense that the data complexity of the encodings mirrors the complexity of the encoded task. In fact, depending on the chosen reasoning task, the queries which have to be used are depicted in Table 3. Recall that credulous reasoning over preferred extensions reduces to credulous reasoning over admissible extensions and skeptical reasoning over complete extensions reduces to reasoning over the single grounded extension. The only proper disjunctive programs involved are πpref and πsemi; all other encodings are disjunction-free. Moreover,
Table 3.
Overview of the encodings of the reasoning tasks for AF F=(A, R) and a∈A.
| stable | adm | pref | semi | comp | ground | |
| (trivial) |
We are now able to encode more involved decision problems using our queries. As a first example, consider the
Corollary 3.10
The coherence problem for an AF F holds iff the program
As a second example, we give a program which decides, for a given AF F, whether the semi-stable and the preferred extension of F coincide. Dunne and Caminada (2008) have shown
Again, we can decide this problem by reusing some of the modules from previous encodings. In this particular case, however, we need to separate some of the atoms which are used in common by πpref and πsemi. For this reason, we require new atoms
Corollary 3.11
Given an AF F, it holds that
Roughly speaking, we combine here the program which computes the preferred extensions with a program which checks whether the input is not semi-stable. The latter test can be accomplished via constraints (instead of the saturation technique used above), since it is sufficient here to just get rid off candidates which already have been checked to be preferred but are not semi-stable.
4.Encodings for generalisations of argumentation frameworks
In this section, we again show the flexibility of our approach by reusing the queries from the previous section in the context of generalisations of abstract AFs.
4.1.Value-based argumentation frameworks
As a first example for generalising basic AFs, we deal with value-based AFs (VAFs) (Bench-Capon 2003) which themselves generalise the preference-based AFs (Amgoud and Cayrol 2002). Again we give the definition w.r.t. the universe 𝒰.
Definition 4.1
A VAF is a 5-tuple F=(A, R, Σ, σ, <) where
Example 4.2
Consider the following VAF F=(A, R, Σ, σ, <). Let A={a, b, c},

Using this notion of defeat, we say in accordance with Definition 2.2 that a set S⊆ A of arguments defeats b in F, if there is an a∈S which defeats b.
An argument a∈A is defended by S ⊆ A in F iff, for each b∈A, it holds that, if b defeats a in F, then S defeats b in F. Using these notions of defeat and defence, the definitions in Bench-Capon (2003) for conflict-free sets, admissible extensions, and preferred extensions are exactly along the lines of Definitions 2.4, 2.6, and 2.7, respectively.
In order to compute these extensions for VAFs, we thus only need to slightly adapt the modules introduced in Section 3.
In fact, we now use, for a VAF F,
Theorem 4.3
For any VAF F and
For the other notions of extensions, we can employ our encodings from Section 3 in a similar way. The concrete composition of the modules however depends on the exact definitions, and whether they make use of the notion of a defeat in a uniform way.
In (Bench-Capon 2002), for instance, stable extensions for a VAF F are defined as those conflict-free subsets S of arguments, such that each argument not in S is attacked (rather than defeated) by S. Still, we can obtain a suitable encoding quite easily using the following redefined module:
Theorem 4.4
For any VAF F,
The coherence problem for VAFs thus can be decided as follows.
Corollary 4.5
The coherence problem for a VAF F holds iff the program
4.2.Bipolar argumentation frameworks
Bipolar AFs (BAFs) (Cayrol and Lagasquie-Schiex 2005) augment basic AFs by a second relation between arguments which indicates supports independent from defeats.
Definition 4.6
A BAF is a tuple
An argument a defeats an argument b in F if there exists a sequence
•
•
A BAF can be represented by a directed graph called the bipolar interaction graph. In order to distinguish between the two relations, two kinds of edges are used. For two arguments a and b, (a, b)∈Rd is represented by
Example 4.7
Consider the following
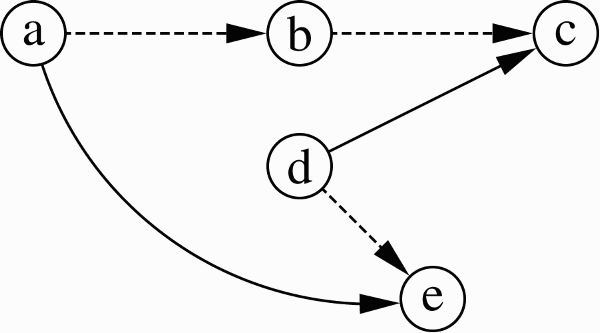
As before, we say that a set S⊆ A defeats an argument b in F if some a∈S defeats b. An argument a∈A is defended by S ⊆ A in F iff, for each b∈A, it holds that, if b defeats a in F, then S defeats b in F.
Again, we just need to adapt the input database and incorporate the new defeat-relation. Other modules from Section 3 can then be reused. In fact, we define for a given BAF
Theorem 4.8
For any BAF F and
More specific variants of admissible extensions from Cayrol and Lagasquie-Schiex (2005) are obtained by replacing the notion of a conflict-free set by other concepts.
Definition 4.9
Let
Note that for a BAF F, each safe set in F is conflict-free in F. We also remark that a set S of arguments is closed under Rs iff S is closed under the transitive closure of Rs.
Definition 4.10
Let
We define now further programs as follows:
The two constraints in πcadm rule out, according to the definition of closed sets, all answer sets where (a, b)∈Rs but either a∈S and b¬∈S or a¬∈S and b∈S (note that the relation support is not symmetric).
Finally, one defines s-preferred (resp., c-preferred) extensions as maximal (w.r.t. set-inclusion) s-admissible (resp., c-admissible) extensions.
Definition 4.11
Let
For the framework F from Example 4.7, we obtain
Again, we can reuse parts of the program πpref from Section 3. The only addition necessary is to saturate in case the additional requirements are violated.
We define
Theorem 4.12
For any BAF F and
Slightly different semantics for BAFs occur in Amgoud et al. (2008), where the notion of defence is based on Rd, while the notion of conflict remains evaluated with respect to the more general concept of defeat as given in Definition 4.6. However, also such variants can be encoded within our system by a suitable composition of the concepts introduced so far.
Again, we note that we can put together encodings for complete and grounded extensions for BAFs, which, to the best of our knowledge, have not been studied in the literature yet.
5.Discussion
In this work we provided ASP-encodings for computing different types of extensions in Dung's AF as well as in some recent extensions of it. Our system ASPARTIX, together with some illustrating examples, is available at www.dbai.tuwien.ac.at/research/project/argumentation/systempage/
Besides the types of extensions discussed in this paper, the current version of ASPARTIX also implements the recently proposed concept of ideal semantics (Dung, Mancarella, and Toni 2007). For the respective encoding for ideal semantics, we refer to the paper by Faber and Woltran (2009).
To the best of our knowledge, so far no system is available which supports such a broad range of different semantics, although nowadays a reasonable number of different implementations exists. (See http://wyner.info/LanguageLogicLawSoftware/index.php/software/ for an overview.) In short, one can divide these systems into two categories: graphical representation of AFs and computation of acceptable arguments. The first category contains systems like Argunet (http://www.argunet.org/debates/) and Araucaria (Reed and Rowe 2004). To the second category belong systems like:
• ArgKit (South, Vreeswijk, and Fox 2008), a Java reasoner capable of reasoning with grounded and preferred extensions which can be integrated in Araucaria.
• A system by Verheij (2007) which computes grounded, preferred, stable and semi-stable semantics via labelings.
• The epistemic and practical reasoner by Visser (2008) which is an implementation of an argument-based practical reasoning system. From a given belief base of formulas (in a propositional modal logic with a single modality D standing for desire) and a query formula, one selects between different argument games including one for grounded semantics and one for credulous reasoning over admissible extensions.
• PARMENIDES (Cartwright and Atkinson 2008), a system for e-democracy that makes use of argumentation tools including VAFs.
• CASAPI (Gaertner and Toni 2007), a Prolog implementation for credulous and sceptical argumentation based upon the computation of dispute derivations for grounded, admissible and ideal beliefs for the generalised assumption-based frameworks.
• An implementation of a query-answering algorithm due to Vreeswijk (2006) for grounded and admissible semantics. Compared with the other systems, this algorithm computes the so-called defence sets around the queried argument rather than the entire collection of extensions.
• An implementation (Efstathiou and Hunter 2008) for logic-based formalisations of argumentation (Besnard and Hunter 2001), which constructs arguments using connection graphs.
The work which is related closest to ours is by Nieves et al. (2008, 2009) who also suggested to use ASP for computing extensions of AFs. One aspect in their work is to use a fixed encoding schema to represent AFs as logic programs, and then show how different semantics for logic programs can be used to compute different forms of extensions using this particular schema. Most notably, they showed that in their setting the stable semantics (for logic programs) captures stable extensions of AFs, the well-founded semantics captures the grounded extension of AFs, and a novel stratification semantics (Nieves et al. 2009) captures the CF2 semantics due to Baroni, Giacomin and Guida (2005). Osorio et al. (2005) present an algorithm for computing preferred extensions (based on abductive logic programming) using a fixed logic program to characterise the admissible sets in the same manner we have used here. In Nieves et al. (2008), a different approach to compute preferred extensions by means of logic programs has been proposed. However, this work requires a recompilation of the encoding for each particular AF. Similarly, Wakaki and Nitta (2008) also provide ASP encodings for different semantics. In contrast to our work, their encodings for complete and stable semantics are based on labellings, whereas for grounded, preferred and semi-stable semantics they use a meta-programming technique by applying additional translations for each AF into normal logic programs. We recall that in our system, fixed disjunctive queries which require the actual instance just as an input database are used for all these semantics. We believe that our approach is thus more reliable and easily extendible to further formalisms.
Future work includes a comparison of the efficiency of different implementations. Preliminary tests show that our approach is able to deal with more than 100 arguments for all considered semantics in Dung's abstract framework. Another direction of future work is to extend our system by incorporating further recent notions of semantics. In particular, it is planned to implement the resolution-based semantics due to Baroni and Giacomin (2008a), semantics based on decomposition into strongly connected components (like, for instance, the CF2 semantics) due to Baroni et al. (2005), novel approaches to preferential semantics due to Amgoud and Vesic (2009), and semantics based on meta-attacks as introduced by Modgil (2009).
Acknowledgements
The authors thank the anonymous referees for valuable comments which helped in improving the paper. This work was supported by the Austrian Science Fund (FWF) under the grant P20704-N18 and the Vienna Science and Technology Fund (WWTF) under the grant ICT08-028. A short version of this article was presented at the Proceedings of the ICLP’08 Workshop Answer-Set Programming and Other Computing Paradigms (ASPOCP).
References
1 | Amgoud, L. and Cayrol, C. (2002) . A Reasoning Model Based on the Production of Acceptable Arguments. Annals of Mathematics and Artificial Intelligence, 34: : 197–215. |
2 | Amgoud, L. and Vesic, S. Repairing Preference-Based Argumentation Frameworks. Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI 2009). pp. 665–670. |
3 | Amgoud, L., Cayrol, C., Lagasquie-Schiex, M.C. and Livet, P. (2008) . On Bipolarity in Argumentation Frameworks. International Journal of Intelligent Systems, 23: : 1–32. |
4 | Apt, K.R., Blair, H.A. and Walker, A. (1988) . “Towards a Theory of Declarative Knowledge”. In Foundations of Deductive Databases and Logic Programming, Edited by: Minker, J. 89–148. Morgan Kaufmann Publishers, Inc. |
5 | Baroni, P. and Giacomin, M. Resolution-based Argumentation Semantics. Proceedings of the 2nd Conference on Computational Models of Argument (COMMA 2008). Edited by: Besnard, P., Doutre, S. and Hunter, A. pp. 25–36. Toulouse: IOS Press. Vol. 172 of Frontiers in Artificial Intelligence and Applications |
6 | Baroni, P. and Giacomin, M. A Systematic Classification of Argumentation Frameworks Where Semantics Agree. Proceedings of the 2nd Conference on Computational Models of Argument (COMMA 2008). Edited by: Besnard, P., Doutre, S. and Hunter, A. pp. 37–48. Toulouse: IOS Press. Vol. 172 of Frontiers in Artificial Intelligence and Applications |
7 | Baroni, P., Giacomin, M. and Guida, G. (2005) . SCC-Recursiveness: A General Schema for Argumentation Semantics. Artificial Intelligence, 168: : 162–210. |
8 | Bench-Capon, T.J.M. Value-based Argumentation Frameworks. Proceedings of the 9th International Workshop on Non-Monotonic Reasoning (NMR 2002). Edited by: Benferhat, S. and Giunchiglia, E. pp. 443–454. Toulouse |
9 | Bench-Capon, T.J.M. (2003) . Persuasion in Practical Argument Using Value-based Argumentation Frameworks. Journal of Logic and Computation, 13: : 429–448. |
10 | Bench-Capon, T.J.M. and Dunne, P.E. (2007) . Argumentation in Artificial Intelligence. Artificial Intelligence, 171: : 619–641. |
11 | Besnard, P. and Doutre, S. Checking the Acceptability of a Set of Arguments. Proceedings of the 10th International Workshop on Non-Monotonic Reasoning (NMR 2004). Edited by: Delgrande, J.P. and Schaub, T. pp. 59–64. Whistler |
12 | Besnard, P. and Hunter, A. (2001) . A Logic-based Theory of Deductive Arguments. Artificial Intelligence, 128: : 203–235. |
13 | Besnard, P., Hunter, A. and Woltran, S. (2009) . Encoding Deductive Argumentation in Quantified Boolean Formulae. Artificial Intelligence, 173: : 1406–1423. |
14 | Caminada, M. Semi-Stable Semantics. Proceedings of the 1st Conference on Computational Models of Argument (COMMA 2006). Edited by: Dunne, P.E. and Bench-Capon, T.J.M. pp. 121–130. Liverpool: IOS Press. Vol. 144 of Frontiers in Artificial Intelligence and Applications |
15 | Cartwright, D. and Atkinson, K. Political Engagement Through Tools for Argumentation. Proceedings of the 2nd Conference on Computational Models of Argument (COMMA 2008). Edited by: Besnard, P., Doutre, S. and Hunter, A. pp. 116–127. Toulouse: IOS Press. Vol. 172 of Frontiers in Artificial Intelligence and Applications |
16 | Cayrol, C. and Lagasquie-Schiex, M.C. On the Acceptability of Arguments in Bipolar Argumentation Frameworks. Proceedings of the 8th European Conference on Symbolic and Quantitative Approaches to Reasoning with Uncertainty (ECSQARU 2005). Edited by: Godo, L. pp. 378–389. Barcelona: Springer. Vol. 3571 of LNCS |
17 | Coste-Marquis, S., Devred, C. and Marquis, P. Symmetric Argumentation Frameworks. Proceedings of the 8th European Conference on Symbolic and Quantitative Approaches to Reasoning with Uncertainty (ECSQARU 2005). Edited by: Godo, L. pp. 317–328. Barcelona: Springer. Vol. 3571 of LNCS |
18 | Dantsin, E., Eiter, T., Gottlob, G. and Voronkov, A. (2001) . Complexity and Expressive Power of Logic Programming. ACM Computing Surveys, 33: : 374–425. |
19 | Dimopoulos, Y. and Torres, A. (1996) . Graph Theoretical Structures in Logic Programs and Default Theories. Theoretical Computer Science, 170: : 209–244. |
20 | Dung, P.M. (1995) . On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games. Artificial Intelligence, 77: : 321–358. |
21 | Dung, P.M., Mancarella, P. and Toni, F. (2007) . Computing Ideal Sceptical Argumentation. Artificial Intelligence, 171: : 642–674. |
22 | Dunne, P.E. and Bench-Capon, T.J.M. (2002) . Coherence in Finite Argument Systems. Artificial Intelligence, 141: : 187–203. |
23 | Dunne, P.E. and Bench-Capon, T.J.M. Complexity in Value-Based Argument Systems. Proceedings of the 9th European Conference on Logics in Artificial Intelligence (JELIA 2004). Edited by: Alferes, J.J. and Leite, J.A. pp. 360–371. Lisbon: Springer. Vol. 3229 of LNCS |
24 | Dunne, P.E. and Caminada, M. Computational Complexity of Semi-Stable Semantics in Abstract Argumentation Frameworks. Proceedings of the 11th European Conference on Logics in Artificial Intelligence (JELIA 2008). Edited by: Hölldobler, S., Lutz, C. and Wansing, H. pp. 153–165. Dresden: Springer. Vol. 5293 of LNCS |
25 | Dvořák, W. and Woltran, S. (2009) . Technical Note: Complexity of Stage Semantics in Argumentation Frameworks. Technical Report DBAI-TR-2009-66, Technische Universität Wien, Database and Artificial Intelligence Group |
26 | Efstathiou, V. and Hunter, A. Algorithms for Effective Argumentation in Classical Propositional Logic: A Connection Graph Approach. Proceedings of the 5th International Symposium on Foundations of Information and Knowledge Systems, (FoIKS 2008). Edited by: Hartmann, S. and Kern-Isberner, G. pp. 272–290. Pisa: Springer. February, Vol. 4932 of Lecture Notes in Computer Science |
27 | Egly, U. and Woltran, S. Reasoning in Argumentation Frameworks Using Quantified Boolean Formulas. Proceedings of the 1st Conference on Computational Models of Argument (COMMA 2006). Edited by: Dunne, P.E. and Bench-Capon, T.J.M. pp. 133–144. Liverpool: IOS Press. Vol. 144 of Frontiers in Artificial Intelligence and Applications |
28 | Eiter, T. and Polleres, A. (2006) . Towards Automated Integration of Guess and Check Programs in Answer Set Programming: A Meta-Interpreter and Applications. Theory and Practice of Logic Programming, 6: : 23–60. |
29 | Eiter, T., Gottlob, G. and Mannila, H. (1997) . Disjunctive Datalog. ACM Transactions on Database Systems, 22: : 364–418. |
30 | Faber, W. and Woltran, S. Manifold Answer-Set Programs for Meta-Reasoning. Proceedings of the 10th International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR 2009). Edited by: Erdem, E., Lin, F. and Schaub, T. pp. 115–128. Potsdam: Springer. Vol. 5753 of LNCS |
31 | Gaertner, D. and Toni, F. CaSAPI – A System for Credulous and Sceptical Argumentation. Proceedings of the First International Workshop on Argumentation and Nonmonotonic Reasoning (ArgNMR 2007). Edited by: Simari, G.R. and Torroni, P. pp. 80–95. May, Arizona |
32 | Gebser, M., Liu, L., Namasivayam, G., Neumann, A., Schaub, T. and Truszczyński, M. The First Answer Set Programming System Competition. Proceedings of the 9th International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR 2007). Edited by: Baral, C., Brewka, G. and Schlipf, J.S. pp. 3–17. Tempe, AZ, , USA: Springer. Vol. 4483 of LNCS |
33 | Gelfond, M. and Lifschitz, V. (1991) . Classical Negation in Logic Programs and Disjunctive Databases. New Generation Computing, 9: : 365–386. |
34 | Leone, N., Pfeifer, G., Faber, W., Eiter, T., Gottlob, G., Perri, S. and Scarcello, F. (2006) . The DLV System for Knowledge Representation and Reasoning. ACM Transactions on Computational Logic, 7: : 499–562. |
35 | Lifschitz, V. and Turner, H. Splitting a Logic Program. Proceedings of the 11th International Conference on Logic Programming (ICLP’94). pp. 23–37. Santa Margherita Ligure: MIT Press. |
36 | Modgil, S. (2009) . Reasoning about Preferences in Argumentation Frameworks. Artificial Intelligence, 173: : 901–934. |
37 | Niemelä, I. (1999) . Logic Programming with Stable Model Semantics as a Constraint Programming Paradigm. Annals of Mathematics and Artificial Intelligence, 25: : 241–273. |
38 | Nieves, J.C., Osorio, M. and Cortés, U. (2008) . Preferred Extensions as Stable Models. Theory and Practice of Logic Programming, 8: : 527–543. |
39 | Nieves, J.C., Osorio, M. and Zepeda, C. Expressing Extension-Based Semantics Based on Stratified Minimal Models. Proceedings of the 16th International Workshop on Logic, Language, Information and Computation, (WoLLIC 2009). Edited by: Ono, H., Kanazawa, M. and de Queiroz, R.J.G.B. pp. 305–319. Tokyo: Springer. Vol. 5514 of LNCS |
40 | Osorio, M., Zepeda, C., Nieves, J.C. and Cortés, U. Inferring Acceptable Arguments with Answer Set Programming. Proceedings of the 6th Mexican International Conference on Computer Science (ENC 2005). pp. 198–205. Puebla: IEEE Computer Society. |
41 | Reed, C. and Rowe, G. (2004) . Araucaria: Software for Argument Analysis, Diagramming and Representation. International Journal on Artificial Intelligence Tools (IJAIT), 13: : 961–979. |
42 | South, M., Vreeswijk, G. and Fox, J. Dungine: A Java Dung Reasoner. Proceedings of the 2nd Conference on Computational Models of Argument (COMMA 2008). Edited by: Besnard, P., Doutre, S. and Hunter, A. pp. 360–368. Toulouse: IOS Press. Vol. 172 of Frontiers in Artificial Intelligence and Applications |
43 | van Emden, M. and Kowalski, R. (1976) . The Semantics of Predicate Logic as a Programming Language. Journal of the ACM, 23: : 733–742. |
44 | Verheij, B. A Labeling Approach to the Computation of Credulous Acceptance in Argumentation. Proceedings of the 20th International Joint Conference on Artificial Intelligence (IJCAI 2007). Edited by: Veloso, M.M. pp. 623–628. Hyderabad: AAAI Press. |
45 | Visser, W. (2008) . “Implementation of Argument-Based Practical Reasoning”. Master's thesis, Utrecht University |
46 | Vreeswijk, G. An Algorithm to Compute Minimally Grounded and Admissible Defence Sets in Argument Systems. Proceedings of the 1st Conference on Computational Models of Argument (COMMA 2006). Edited by: Dunne, P.E. and Bench-Capon, T.J.M. pp. 109–120. Liverpool: IOS Press. Vol. 144 of Frontiers in Artificial Intelligence and Applications |
47 | Wakaki, T. and Nitta, K. Computing Argumentation Semantics in Answer Set Programming. New Frontiers in Artificial Intelligence (JSAI 2008), Conference and Workshops. Edited by: Hattori, H., Kawamura, T., Idé, T., Yokoo, M. and Murakami, Y. pp. 254–269. Asahikawa: Springer. Vol. 5447 of LNCS |


